Parametrización Avanzada
|
|
|
- Raquel Prado Peña
- hace 8 años
- Vistas:
Transcripción
1 Parametrización Avanzada Por lo general, cualquier acción ejecutada sobre la base de datos, resultará en alguna actividad de acceso de E/S. Este tipo de acceso puede ser lógico (en memoria) ó físico (a disco). Es muy importante formarse una perspectiva de rendimiento al momento de querer mejorar estos tipos de accesos. En este capítulo veremos la importancia del ajuste de rendimientos, orientado al servidor y a los accesos de E/S. Las mediciones que se puedan realizar en este ámbito también recaerán en la consulta de vistas dinámicas de rendimiento (V$) y en vistas del diccionario de datos (DBA), como así también en las salidas de los reportes de STATSPACK.
. Esta clasificación sugiere diferentes momentos de lectura, estudio y revisión, entre los contenidos de este currículo y el Material del Estudiante (Kit).")
2 5.1 - Uso Eficiente de los Bloques de la Base de Datos En la figura se presenta una clasificación de los contenidos tratados en esta subunidad, teniendo en cuenta, la relación de los mismos con el Material del Estudiante (kit). Esta clasificación sugiere diferentes momentos de lectura, estudio y revisión, entre los contenidos de este currículo y el Material del Estudiante (Kit). Según esta clasificación los contenidos pueden ser de: Lectura Previa: Se sugiere la lectura de estos contenidos antes de abordar los subtemas, temas o unidades asociados al Material del Estudiante (Kit). Lectura Complementaria: Se sugiere la lectura de estos contenidos como complemento a los subtemas, temas o unidades asociados al Material del Estudiante (Kit). Lectura Adicional: Se sugiere la lectura posterior de estos contenidos, como material adicional a los tratados en el Material del Estudiante (Kit). Prácticas : Actividades de laboratorios e interactivas incluidas como práctica adicional al Material del Estudiante (Kit).
3 5.1 Uso Eficiente de los Bloques de la Base de Datos Objetivos En el presente subcapítulo nos interesa que aprenda a utilizar la gestión automática de los segmentos, que pueda gestionarlos en forma manual, y que sepa desfragmentar el espacio de estos. También nos importa que usted comprenda la utilización de los bloques de Oracle y que pueda detectar y describir el encadenamiento y la migración de los mismos. Por último, aspiramos a que usted se encuentre posibilitado de reorganizar índices.

4 5.1 Uso Eficiente de los Bloques de la Base de Datos Cuestionario de Iniciación LECTURA PREVIA - Coloque el cursor sobre los botones numerados que aparecen a la izquierda para visualizar las preguntas de iniciación. Si desea, puede desplegar su respuesta.

5 5.1 Uso Eficiente de los Bloques de la Base de Datos Jerarquía de Almacenamiento LECTURA COMPLEMENTARIA En Oracle 9i hay dos tamaños de bloques que se deben considerar, los referidos al Bloque Primario y los referidos al Bloque Local. El Bloque Primario, es el tamaño definido al momento de crear la base de datos, es determinado por el parámetro DB_BLOCK_SIZE y será el tamaño de bloque que utilizarán los tablespaces SYSTEM y TEMP; la única manera de cambiar este tamaño, es volviendo a crear la base de datos. En cuanto al Bloque Local podemos decir que está asociado a un tablespace individual. Cuando se crea un tablespace, es posible asignarle un tamaño de bloque mayor ó menor al tamaño del Bloque Primario utilizando la opción BLOCKSIZE, teniendo en cuenta que este valor debe coincidir con alguno de los parámetros DB_nk_CACHE_SIZE. De esta manera, cualquier segmento almacenado en ese tablespace utilizará un tamaño de bloque igual al tamaño Local para almacenar los datos. Si se omite la opción BLOCKSIZE al momento de crear el tablespace, éste utilizará el tamaño del bloque primario. Es posible determinar el tamaño de bloque de cada tablespace consultando la columna BLOCK_SIZE de la vista del diccionario de datos DBA_TABLESPACES. Por cuestiones de rendimiento, los tamaños de Bloque Brimario y de Local, deberían ser múltiplos del tamaño de bloque del sistema operativo y no mayor que el tamaño máximo de E/S del sistema operativo.

6
.")
7 5.1 Uso Eficiente de los Bloques de la Base de Datos Administración de Extensiones Una extensión es una colección de bloques de Oracle contiguos. Cuando se crea un segmento, éste es asignado al menos a una extensión llamada Extensión Inicial (Initial Extent). Cuando un segmento es eliminado, sus extensiones son marcadas para que sean utilizadas por otro segmento del tablespace. La Figura crea una tabla que conceptualmente se ve en la Figura y muestra la relación que hay entre la tabla EMPLOYEE; su extensión inicial de 250KB; el tablespace al que pertenece (APPL_DATA); y los Archivos de Datos asociados, llamados appl_data01.dbf y appl_data02.dbf. El primer bloque de la Extensión Inicial llamado bloque de cabecera (Header Block) contiene un mapa con las ubicaciones del resto de los bloques de la extensión. La Figura muestra una vista conceptual de un bloque de estos, suponiendo que tiene 32 bloques la extensión inicial de 250k.

8
9 5.1 Uso Eficiente de los Bloques de la Base de Datos La Marca de Agua (Water Mark) Cuando se está hablando del ajuste de rendimiento de una base de datos a nivel de bloque, hay que tener muy en cuenta el concepto de Marca de Agua ó Límite Superior (High WaterMark). Como los segmentos utilizan los bloques de la base de datos asociados en extensiones, Oracle Server mantiene un rastreo del mayor identificador de bloques que ese segmento ha utilizado para almacenar datos en su tiempo de vida. Este código de bloque es el denominado Marca de Agua ó Límite Superior (HWM). La Figura muestra este mecanismo. La Marca de Agua es importante ya que un Proceso de Servidor de Usuario lee todos los bloques del segmento, hasta esta marca, cuando realiza una lectura completa de una tabla (FULL TABLE SCAN). Como se observa en la figura, la Marca de Agua (HWM) no se mueve cuando los registros son eliminados del segmento. De esta manera, muchos bloques podrían llagar a ser leídos durante la lectura completa del segmento por más que no contengan datos. Adicionalmente, si el segmento es estático (no se espera que se agreguen más registros al segmento) el espacio sobre la marca de agua se malgastará. Luego de utilizar el comando ANALYZE la columna EMPTY_BLOCKS de la vista DBA_TABLES, mostrará la cantidad de bloques que el segmento tiene sobre su Marca de Agua. Este espacio inutilizado puede ser reutilizable para el tablespace con el comando ALTER TABLE nom_tabla DEALLOCATE UNUSED. Adicionalmente, el espacio inutilizado sobre la Marca de Agua se puede determinar utilizando el procedimiento UNUSED_SPACE del paquete PL/SQL dedbms_space. La columna BLOCKS de la vista DBA_TABLES muestra la cantidad de bloques que pertenecen al segmento por debajo de su Marca de Agua, teniendo en cuenta que estos bloques pueden ó no contener datos. Para poder estimar qué cantidad de bloques pertenecientes a un segmento y por debajo de la marca de agua realmente tienen datos, se podría armar una consulta, como se ve en la Figura, donde se muestra que de los bloques pertenecientes al segmento por debajo de la Marca de Agua, aproximadamente bloques son usados realmente (contienen datos) para almacenar los datos de la tabla. De esta información se puede deducir que existen unos 262 bloques vacíos debajo de la Marca de Agua. Mejorar la ubicación de la Marca de Agua puede resultar también en una mejora en el rendimiento de aquellas consultas que realizan lecturas completas de tablas. Esto se puede hacer aplicando dos técnicas posibles; una es exportar la tabla, eliminarla ó trucarla y luego volver a importar la tabla y la otra manera es utilizar el comando ALTER TABLE MOVE para reconstruir la tabla.
10 5.1 Uso Eficiente de los Bloques de la Base de Datos Espacio de Recuperación Cuando todas las extensiones disponibles asignadas a un segmento se llenan, el próximo insert que se realice sobre esa tabla causará que el segmento deba adquirir una nueva extensión. En aquellas tablas de rápido crecimiento que almacenan las extensiones con el método tradicional de tablespaces gestionados por el diccionario de datos, esta asignación dinámica incurre en un procesamiento adicional de E/S. Una manera de evitar este procesamiento innecesario es almacenando todas las tablas de la aplicación y sus índices en tablespaces gestionados localmente. Ya que este tipo de tablespaces utilizan mapas de bits (bitmaps), en los encabezados de los Archivos de Datos, para definir el espacio libre en lugar del diccionario de datos. La asignación dinámica de extensiones en un tablespace gestionado localmente incurre en un consumo muy bajo de E/S. En lugar de esto, Oracle simplemente cambia los valores del mapa de bits para indicar el estado del bloque dentro del propio Archivo de Datos. Otra forma de evitar la asignación dinámica de extensiones es identificando las tablas e índices que están cercanas a requerir nuevas extensiones para luego asignar proactivamente nuevas extensiones en forma manual en un momento de baja producción. La consulta que se muestra en la Figura muestra cómo es posible hacer esta identificación basándose en aquellos segmentos que están utilizando el 95% de los bloques asignados a su segmento. En este ejemplo se ve que la tabla SALES se encuentra utilizando actualmente el 100% de los bloques de su segmento; esto significa que la tabla SALES crecerá una extensión más la próxima vez que se inserte un registro en esa tabla. Si se espera que esto ocurra, el DBA puede utilizar el siguiente comando para pre-asignar una extensión adicional al segmento de la tabla SALES: SQL> ALTER TABLE sales ALLOCATE EXTENT; Asignar esta extensión evitará la asignación dinámica que podría haber ocurrido durante el próximo insert. Por cuestiones de rendimiento, Oracle recomienda que la cantidad máxima de extensiones para un segmento que pertenece a un tablespace gestionado por el diccionario de datos, no debería exceder las extensiones. En cambio, los segmentos en un tablespace gestionado localmente pueden tener varios miles de extensiones, sin tener impacto en el rendimiento.
11 5.1.7 Tamaño de Bloque de la BD Íntimamente relacionado con la asignación dinámica de extensiones es justamente el tamaño de cada una de las extensiones en sí. Una extensión de gran tamaño suele ofrecer mejor rendimiento que las extensiones pequeñas ya que la frecuencia de creación será menor y además pueden tener todas las ubicaciones de los bloques identificadas desde un solo bloque almacenado en el encabezado de la extensión del segmento. Las desventajas de las extensiones grandes son las pérdidas de espacio libre potenciales en el tablespace, y la posibilidad de fragmentación de las extensiones. Como es sabido, las extensiones están compuestas por bloques contiguos y un bloque de la base de datos está íntimamente relacionado con el rendimiento de E/S. El tamaño de bloque apropiado para un sistema dependerá del tipo de aplicación; de las especificaciones de l sistema operativo y del hardware disponible. Generalmente, los sistemas OLTP utilizan un tamaño de bloque menor por las siguientes razones: Los bloques pequeños proveen mejor rendimiento para los accesos aleatorios (naturaleza de los sistemas OLTP). Los bloques pequeños reducen la contención de los bloques, ya que cada bloque de datos contiene pocos registros. Los bloques pequeños son mejores para el almacenado de registros pequeños, los cuales son comunes en ambientes OLTP. De todas maneras, los tamaños de bloque pequeños agregan un procesamiento adicional al Buffer Cache de la SGA, ya que por lo general se deben acceder a una cantidad mayor de bloques debido a que cada uno de ellos contiene pocos registros. Consecuentemente, los sistemas de soporte a decisiones (DSS) suelen rendir mejor con tamaños de bloques mayores, por las siguientes razones: Los bloques grandes almacenan una mayor cantidad de datos ó índices en cada bloque..los bloques grandes favorecen la lectura secuencial de bloques (naturaleza de los sistemas DSS). Las desventajas de los bloques grandes son por un lado la contención de los bloques y por el otro, el hecho de que además requieren un mayor tamaño definido para el Buffer Cache, para poder asignar todos los buffers requeridos para alcanzar los requerimientos de los indicadores de esta estructura de memoria (Buffer Hit Ratio). El tamaño del bloque tiene dos mecanismos a ajustar que son importantes al momento de mejorar el rendimiento; estos son el encadenamiento de registros y la migración. Temas que se explicarán en las lecturas siguientes.

12 5.1.8 Migración de Filas de Bloque El tamaño del bloque también es altamente importante al momento de realizar ajustes de rendimiento, teniendo en cuenta la técnica de Oracle para realizar el encadenamiento y la migración de registros. Encadenamiento de Registros Row Chaining. Cuando un registro que es insertado en una tabla excede el tamaño de bloque de la base de datos, el registro se dividirá en dos ó más bloques. Entonces, cuando un registro se almacena a través de varios bloques, está ocurriendo un encadenamiento del registro. Este encadenamiento es malo para el rendimiento ya que múltiples bloques son requeridos para obtener un solo registro. La única forma de solucionar el problema del encadenamiento de registros es aumentar el tamaño del bloque que almacena estos registros ó disminuir el tamaño de los registros insertados. La Migración de Registros Row Migration ocurre cuando un registro previamente insertado es actualizado (mediante una operación DML Update). Si la modificación de este registro causa que el mismo registro crezca a un tamaño mayor al que puede albergar el bloque donde está almacenado, (especificado por el parámetro PCTFREE) Oracle mueve (migra) el registro a un nuevo bloque. Cuando ocurre una migración, Oracle deja un puntero a ese registro (que ahora se encuentra en un bloque nuevo), en la ubicación original. De esta forma podemos ver que la migración de registros también es mala para el rendimiento, ya que Oracle debe realizar al menos dos accesos de E/S: uno para el bloque original, donde lee el puntero, y otro para el bloque donde realmente está almacenado el registro para obtener un solo registro. La migración de registros puede ser minimizada definiendo el parámetro PCTFREE a un valor apropiado, de modo que la actualización de un registro tenga suficiente espacio en el mismo bloque para almacenar la nueva información. Existen dos técnicas para determinar si están ocurriendo migraciones de registros ó encadenamientos: Examinando la columna CHAIN_CNT de la vista del diccionario de datos DBA_TABLES. La presencia de un registro llamado table fetch continued row en la vista dinámica de rendimiento V$SYSSTAT.

13

14 5.1 Uso Eficiente de los Bloques de la Base de Datos Reorganización de Índices A diferencia de los bloques de datos, cuando se realiza un insert en un bloque de índice, Oracle Server ordena los registros secuencialmente, ya que los valores deben estar en el bloque correspondiente junto a los otros registros del rango al que pertenecen. De esta manera, las tablas que tienen datos muy volátiles son propensas a tener problemas de rendimiento si tienen algún índice asociado. Para poder conocer la actividad de un índice, por ejemplo el índice llamado CUST_PK del esquema OE, puede utilizar el comando: SQL> EXECUTE dbms_stats.gather_index_stats( OE, CUST_PK ) Una vez finalizado, sólo queda consultar la vista INDEX_STATS (que contiene información sobre el último índice analizado) para conocer los valores obtenidos, como se ve en la Figura. La tabla de la Figura muestra una descripción de las columnas de esta vista. Hay dos técnicas que se pueden aplicar para solucionar el problema de los bloques libres en un índice, fusionándolos ó reconstruyéndolos. Para terminar de decidir si es realmente necesario reconstruir ó fusionar un índice, nos basamos en la tabla que muestra la Figura El indicador para la reconstrucción de un índice es: si supera el 20% de las entradas eliminadas. La Figura muestra las sentencias para implementar estas dos soluciones.

15 5.1 Uso Eficiente de los Bloques de la Base de Datos Monitoreo de Índices Oracle brinda tres técnicas para controlar el uso del índice: Utilizando el procedimiento GATHER_INDEX_STATS del paquete DBMS_STATS, como se vio en el tema anterior. Al momento de crear el índice, agregando al final de la sentencia la cláusula COMPUTE STATISTICS. Al reconstruir un índice incluyendo también la opción COMPUTE STATISTICS. Adicionalmente, es posible determinar si un índice se ha utilizado ó no, una vez creado, con una opción de monitoreo que brinda Oracle: SQL> ALTER INDEX cust_ok MONITORING USAGE; De esta manera, Oracle comienza a monitorear la utilización de este índice hasta que se le ejecute el comando: SQL> ALTER INDEX cust_ok NOMONITORING USAGE. Para ver los resultados obtenidos se debe consultar la vista dinámica de rendimiento V$OBJECT_USAGE. De esta manera, si esta vista no presenta registros, indica que el índice nunca fue utilizado y por lo tanto, puede ser eliminado. La tabla de la Figura muestra una descripción de las columnas de esta vista.
 y PCTUSED (porcentaje utilizado)")
16 5.1 Uso Eficiente de los Bloques de la Base de Datos Lectura Adicional: Bloque de la Base de Datos Como se ha visto en lecturas anteriores, el bloque de la base de datos se divide en las siguientes secciones: Área del encabezado del bloque Espacio reservado Espacio Libre Estas áreas, utilizadas en conjunto con los parámetros PCTFREE (porcentaje libre) y PCTUSED (porcentaje utilizado) ayudan al DBA a determinar cómo están siendo utilizados los bloques para almacenar los datos. Encabezado del Bloque (Header). Cada bloque de un segmento utiliza parte de su espacio definido para almacenar información sobre su contenido. Esta información de encabezado incluye las transacciones realizadas sobre los registros que son almacenadas en un espacio de esta cabecera, determinado por el parámetro INITRANS al momento de crear la tabla; un directorio de los registros que contiene en la sección de datos; e información general necesaria para la gestión del contenido. El tamaño que suele utilizar esta sección varía entre 50 y 200 bytes del tamaño total del bloque. Espacio Reservado ó de Datos. El parámetro PCTFREE le avisa a Oracle qué cantidad de espacio debe reservar un bloque para almacenar los posibles crecimientos de los registros por actualizaciones. Este valor es definido como porcentaje sobre el tamaño total del bloque. Por ejemplo, si una tabla se crea con un PCTFREE del 20%, entonces el 20% del espacio del bloque se reservará para almacenar información de las actualizaciones de los registros. Una vez que el bloque se llena con datos hasta el nivel de PCTFREE (el 80%), el bloque no aceptará más inserts, dejando el espacio libre remanente para las actualizaciones de los registros existentes. El proceso de eliminar un bloque de la lista de bloques disponibles es realizado por la lista de Bloques Libres de la tabla (Free List). La lista de bloques libres se la puede pensar como una cartelera que contiene la lista de los ID de bloque que pertenecen a un determinado segmento. Cuando un Proceso de Servidor de un Usuario quiere insertar un nuevo registro en un segmento, el Proceso de Servidor consulta a la Lista de Bloques Libres para encontrar el próximo ID de bloque que se encuentra disponible para aceptar un insert. Si el insert subsecuente causa que el bloque se llene sobre el tamaño determinado por PCTFREE, entonces el bloque es eliminado de la lista de bloques libres y no permitirá que se inserten nuevos registros en ese bloque. Este bloque permanecerá fuera de la lista de bloques libres hasta que se eliminen datos del bloque y su tamaño quede por debajo del valor especificado en el parámetro PCTUSED. Cuando esto ocurre, el bloque volverá a aparecer al inicio de la lista de bloques libres del segmento para que pueda volver a ser utilizado para almacenar nuevos inserts. El valor por defecto de PCTFREE y PCTUSED es el 10% y 40% respectivamente. Espacio Libre. El espacio que queda en el bloque entre el encabezado y la zona de datos, es justamente espacio libre que es utilizado para almacenar los datos del registro para el segmento. La cantidad de registros que almacenará en cada bloque dependerá del tamaño del bloque y del tamaño promedio del registro a almacenar.
17 5.1 Uso Eficiente de los Bloques de la Base de Datos EI: Marca de Agua Determinar la Marca de Agua (High Water Mark) en función de los siguientes datos: - Se tiene un tamaño de bloque de 64KB - Al momento de crear la tabla, se especificó la siguiente cláusula: STORAGE(initial 256k next 1024k pctincrease 0) - Se han insertado 4096KB en registros - Se han eliminado la totalidad de los registros truncando la tabla En qué tamaño quedará la Marca de agua?
18 5.1 Uso Eficiente de los Bloques de la Base de Datos TP: Migración y Encadenamiento de Registros TP: Migración y Encadenamiento de Registros. Duración Estimada: 40 min.
19 5.1 Uso Eficiente de los Bloques de la Base de Datos Síntesis Los segmentos de Oracle (por ejemplo las tablas ó índices) almacenan sus datos en tablespaces, los cuales se encuentran formados por uno ó más Archivos de Datos. Cada Archivo de Datos está formado por bloques individuales de la Base de Datos. Estos bloques almacenan concretamente los datos de cada segmento, representando la menor unidad de almacenamiento que tiene una base de datos Oracle. Cuando un segmento es creado, se asignan un conjunto de bloques contiguos llamado extensión el cual es asociado a un Archivo de Datos que a su vez está asociado con un tablespace. La siguiente es una representación de la jerarquía de Oracle: Una base de datos se compone de uno ó más Tablespaces. Un Tablespace utiliza Archivos de Datos para almacenar Segmentos. Los Segmentos están hechos de una ó más extensiones. Una extensión está compuesta de un conjunto contiguo de bloques de la Base de Datos. Los bloques de Oracle están compuestos de bloques contiguos al sistema operativo. En este subcapitulo se analizaron las distintas posibilidades para ajustar el rendimiento de la base de datos desde el punto de vista de los segmentos y los bloques, teniendo en cuenta la forma en que se almacenan los datos y cómo solucionar el encadenamiento de registros y la migración de registros.

20 5.1 Uso Eficiente de los Bloques de la Base de Datos EInt: Uso Eficiente de los Bloques de la Base de Datos A continuación le proponemos un ejercicio que pondrá a prueba sus conocimientos acerca de la totalidad de este subcapítulo.
. Esta clasificación sugiere diferentes momentos de lectura, estudio y revisión, entre los contenidos de este currículo y el Material del Estudiante (Kit).")
21 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente En la figura se presenta una clasificación de los contenidos tratados en esta subunidad, teniendo en cuenta, la relación de los mismos con el Material del Estudiante (kit). Esta clasificación sugiere diferentes momentos de lectura, estudio y revisión, entre los contenidos de este currículo y el Material del Estudiante (Kit). Según esta clasificación los contenidos pueden ser de: Lectura Previa: Se sugiere la lectura de estos contenidos antes de abordar los subtemas, temas o unidades asociados al Material del Estudiante (Kit). Lectura Complementaria: Se sugiere la lectura de estos contenidos como complemento a los subtemas, temas o unidades asociados al Material del Estudiante (Kit). Lectura Adicional: Se sugiere la lectura posterior de estos contenidos, como material adicional a los tratados en el Material del Estudiante (Kit). Prácticas : Actividades de laboratorios e interactivas incluidas como práctica adicional al Material del Estudiante (Kit).
22 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Objetivos En este subcapítulo queremos que usted conozca las diferentes estructuras de almacenamiento. Además nuestro objetivo es que aprenda a examinar diferentes modos de acceso a datos y a implementar modos de particionamiento.

23 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Cuestionario de Iniciación Coloque el cursor sobre los botones numerados que aparecen a la izquierda para visualizar las preguntas de iniciación. Si desea, puede desplegar su respuesta.
24 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Estructuras de Almacenamiento La utilización de Bosquejos Almacenados (Stoded Outlines) y Vistas Materializadas (Tema que se verá en capítulos posteriores) son procedimientos que apuntan al mejoramiento del rendimiento de las aplicaciones, ayudando al optimizador a tomar una decisión correcta al momento de crear el Plan de Ejecución. En este capítulo trataremos con otro aspecto que completa la ecuación al momento de ejecutar un plan de ejecución, que es el acceso al medio físico. Uno de los métodos más efectivos para reducir el tiempo que le toma a Oracle Server encontrar y obtener los registros solicitados, es la utilización de la estructura de almacenamiento correcta, utilizando índices, particiones y agrupamientos (clusters).
25 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Métodos de Acceso Es sabido que los índices mejoran el rendimiento de las consultas, ya que eliminan la necesidad de hacer una búsqueda completa de la tabla (Full Scan), dándole a Oracle la ubicación precisa de los registros solicitados. Esto reduce drásticamente la cantidad total de bloques de datos que deben ser leídos para satisfacer una consulta. Un segundo mecanismo para mejorar el rendimiento, minimizando el acceso E/S, puede ser la utilización de Agrupamientos ó Clusters. Un Agrupamiento es un conjunto de una ó más tablas, donde sus datos son almacenados juntos en los mismos bloques de datos. De esta manera, las consultas que utilizan este tipo de tablas a través de una unión, no tienen que leer dos juegos de bloques de datos para obtener los resultados, simplemente Oracle Server tiene que leer un solo bloque. Existen dos tipos de agrupamientos disponibles en Oracle 9i: los agrupamientos por Índice y la Comprobación Aleatoria (Hash Clusters).
26
27
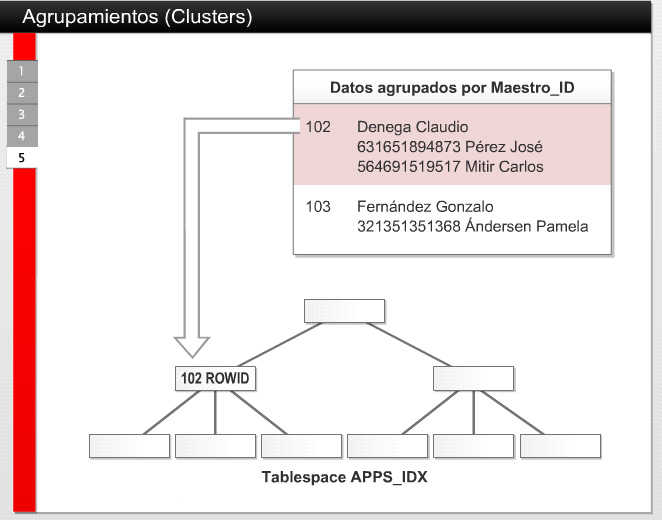
28 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Agrupamientos (Clusters) Los Agrupamientos por Índices (Index Clusters) son utilizados para almacenar una ó más tablas físicamente, en los mismos bloques de Oracle. La ventaja de utilizar esta técnica de agrupamiento se limita a una serie de situaciones. En general, las tablas agrupadas deberían tener los siguientes atributos: Siempre deben ser consultadas juntas (con una unión de tablas) y casi nunca en forma individual. Tener poca ó ninguna actividad DML una vez que pasaron la carga inicial. La cantidad de registros hijos por cada padre tiene que ser lo más equitativa posible. Si se tienen tablas que cumplen con estos criterios, el DBA podría considerar la creación de estas tablas agrupadas para el almacenamiento de los datos. Cabe destacar que de cara al usuario, el comportamiento de las tablas agrupadas es el mismo que las tablas comunes, con la diferencia que el espacio de almacenamiento es tomado no desde un tablespace, sino desde un Cluster, el cual es un segmento almacenado en un tablespace. El agrupamiento es accedido a través de un índice que contiene entradas que apuntan a una clave específica en donde las tablas se encuentran unidas. Suponiendo que se tienen dos tablas MAESTROS y ALUMNOS, las cuales contienen la información mostrada en la Figura 1. Como se puede ver, rara vez se crea un maestro sin que se le asignen alumnos. Si la distribución de alumnos por maestro es uniforme, el DBA podría decidir agrupar estas tablas para que se almacenen en los mismos bloques de datos. La Figura 2 muestra un ejemplo de creación del agrupamiento, llamado MAEST_ALUMN, junto a un índice (agrupado) llamado MAEST_ALUMN_IDX. De esta manera se crea el agrupamiento que especifica que la columna MAESTRO_ID será la clave del agrupamiento de las tablas MAESTROS y EMPLEADOS. La opción SIZE especifica cuántas claves agrupadas se espera que tenga cada bloque de Oracle. Seguidamente debemos crear el índice, como se ve en la Figura 3, notando que la columna no se especifica al momento de la creación. El índice se crea automáticamente sobre la clave del agrupamiento, que en este caso es MAESTRO_ID. Una vez que se ha creado el agrupamiento, es cuando se debe crear el resto de las tablas que formarán parte de este clustering, como se ve en la Figura 4. Cabe destacar que en la creación de las tablas no se ha especificado un tablespace para su almacenamiento. Esto no es porque se quiera utilizar el tablespace por defecto del usuario sino porque el agrupamiento será quien defina el almacenamiento en sí. De esta manera, todos los datos insertados en las tablas MAESTROS y ALUMNOS se almacenarán en los mismos bloques de datos (los bloques del segmento de agrupamiento). La Figura 5 muestra la relación entre dos tablas agrupadas, el agrupamiento en sí, el índice del agrupamiento y el tablespace al que pertenece.

29 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Agrupamiento de Comprobación Aleatoria (Hash Cluster) Los Agrupamientos por Comprobación Aleatoria ó Hash Clusters son utilizados actualmente en lugar de los agrupamientos por índices tradicionales. De la misma manera, para poder utilizar un agrupamiento de este tipo, se deben cumplir ciertas reglas previas: Tener una muy baja (o ninguna) actividad DML luego de la carga inicial. Contar con una distribución uniforme de los valores indexados. Los valores de los datos que se indexarán deben ser predecibles. Utilizar consultas SQL que solamente usen el operador de comparación de igualdad (=) contra las columnas indexadas en la cláusula WHERE. A diferencia de examinar un índice para luego obtener los registros de una tabla, los datos de un agrupamiento hash se almacenan de una manera que el agrupamiento puede utilizar un algoritmo del tipo Hash para determinar directamente dónde se encuentra almacenado el registro en una intervención de un índice. Para poder comparar este algoritmo de comprobación aleatoria (hash) con un índice de una tabla que no está agrupada, se debería hacer una consulta como se muestra en la Figura. Continuando con el ejemplo de la Figura 1, si la tabla EMPLOYEES fuese creada con un índice NO hash, la consulta hubiera sido resuelta de la siguiente manera: Encontrar el valor EMP_ID en el índice de la columna. Utilizar el ROWID almacenado en el índice para ubicar el registro en la tabla. Leer el registro de la tabla y devolvérselo al usuario. Esta operación requiere al menos dos lecturas para obtener la información del registro del índice y de la tabla. Por el contrario, si la tabla se hubiese creado agrupada por un algoritmo de comprobación aleatoria (hash), entonces, la consulta hubiera involucrado las siguientes operaciones: El valor en la cláusula WHERE (100) es pasado hacia el algoritmo de comprobación aleatoria que fue el mismo para hacer el insert. Este proceso ocurre en memoria, sin requerir acceso a disco. El valor obtenido por el algoritmo apunta directamente a la ubicación del registro en la tabla. El registro es obtenido de la tabla y devuelto al usuario. De esta manera se ha necesitado sólo una lectura a disco en lugar de dos.

30 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Método de Particionado Otra técnica para reducir la cantidad de acceso a disco, es dividiendo la tabla en sub tablas menores llamadas Particiones. Esta técnica debe ser producida durante la ejecución de una consulta SQL. Una tabla de gran tamaño que se encuentra correctamente particionada, indexada y analizada se beneficiará mucho al utilizar CBO, ya que puede llegar a eliminar particiones que no utiliza ó no tienen información relevante. Adicionalmente, las operaciones de mantenimiento de estas tablas se pueden realizar a nivel de partición. De esta manera es que Oracle 9i ofrece cuatro métodos de particionado de tablas. Antes que una tabla pueda ser particionada, se debe seleccionar un método de partición acorde a las necesidades que se tengan. La opción de un método en particular va a depender principalmente de la manera en que se almacenarán los datos de la clave primaria. Por ejemplo, suponiendo que Ud. es el DBA de una gran Universidad. Como parte de una iniciativa de implementación de un DataWarehouse el equipo de desarrollo de la Universidad le solicita indicaciones para construir una gran tabla con la información histórica de los alumnos (de más de cinco años). Por cuestiones de simplicidad, se asumirá que la tabla tiene sólo cuatro campos y se crea con la definición de la Figura 1. Este ejemplo de tabla será el utilizado para la demostración de los cuatro tipos de particionado que ofrece Oracle 9i: Partición por rango (Range Partition) Partición de Lista (List Partition) Partición por Comprobación Aleatoria (Hash Partition) Partición Compuesta (Composite Partition)
31
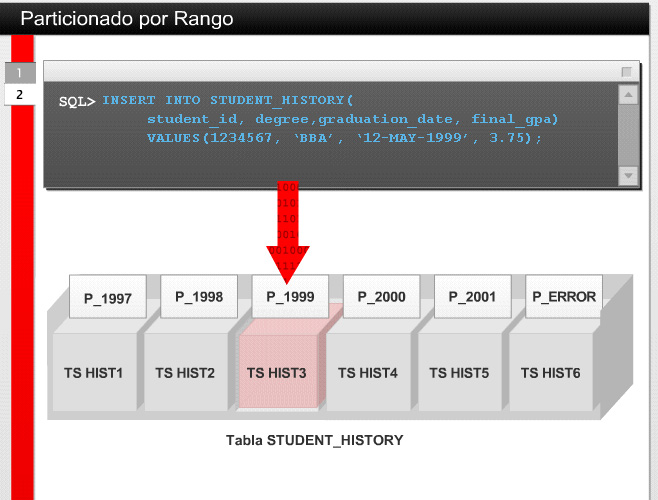
32 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Particionado por Rango Las Particiones por Rango ó Range Partitioning representan una opción de subdivisión de los contenidos de la tabla STUDENT_HISTORY, comentada en el ítem anterior. Las particiones por rango de valores de columna determinan cómo se insertarán los registros en esa tabla. Suponiéndose que se decide utilizar un rango de partición sobre la columna GRADUATION_DATE, con lo que el script de creación quedaría formado como se ve en la Figura 1. En este ejemplo se creará una tabla con seis particiones llamadas de P-1997 a P_2001 y P_ERROR. Por cuestiones de rendimiento, cada una de estas particiones se almacena físicamente en un tablespace independiente (HIST01 a HIST06). Cada registro insertado en esta tabla se ubicará en el tablespace apropiado, basándose en la fecha de graduación. La Figura 2 ilustra estos pasos en forma conceptual. Al considerar una estructura de este tipo, se deben considerar ciertos lineamientos para llevar a cabo la tarea de particionado por rangos: La clave de la partición puede ser compuesta hasta por 16 columnas. Una tabla puede tener hasta particiones. Cualquier registro insertado fuera del rango especificado en las particiones se insertará en la partición P_ERROR. Las tablas particionadas no pueden tener tipos de datos LONG, LONG RAW. Las actualizaciones que podrían causar que un registro se mueva de una partición a otra no están permitidas a menos que se especifique la cláusula ENABLE ROW MOVEMENT al momento de crear la tabla. Sin esta cláusula, los intentos de modificación de este tipo no se permitirán. La selección del campo GRADUATION_DATE como la clave de partición, puede llegar a ser inefectivo si la cantidad de estudiantes que se graduaron varían considerablemente de una partición a otra (de un año a otro). Si este es el caso, entonces la cantidad de registros almacenados en cada partición será muy desparejo, dando resultados dispares en cuanto al rendimiento de las consultas. Si este es el caso, entonces es recomendable utilizar la técnica de comprobación aleatoria (hash) en la partición. Tema que se verá más adelante.

33 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Particionado por Lista La Partición por Lista ó List Partitioning es similar a la Partición por Rango, con la diferencia de que las Particiones por Lista son basadas en un juego específico de valores, en lugar de utilizar un rango. Por ejemplo, continuando con el escenario anterior, si se decide hacer una partición por lista en la columna DEGREE para particionar la tabla STUDENT_HISTORY, se debería implementar utilizando el script de la Figura 1. De esta manera se creará una tabla con tres particiones llamadas P_UNDERGRAD, P_GRADUATE y P_DOCTORATE. Por cuestiones de rendimiento, cada una de estas particiones se almacenará en un tablespace distinto (HIST01 as HIST03). Cada registro insertado en esta tabla será ubicado en la partición apropiada, basándose en el código de graduación (el campo DEGREE). La Figura 2 muestra un esquema de este funcionamiento. Al examinar la estructura de la Figura 2, sale que sólo una regla relacionada al particionado por lista se debe tener en cuenta: Los valores que no cumplan con ninguna de las condiciones de clave de partición darán un error : ORA A diferencia de las particiones por rango, Oracle 9i Release 1 no soporta la opción MAXVALUE para eliminar este problema. A partir de Oracle 9i Release 2, es posible utilizar la opción DEFAULT para aquellos valores que están fuera de las listas de partición.

34 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Particionado Hash Las Particiones por Comprobación Aleatoria ó Hash Partitions utilizan un algoritmo de comprobación aleatoria (hash algorithm) para insertar los registros en las particiones. Esto produce un efecto de repartir los registros entre las particiones de manera relativamente pareja, mejorando de esta manera el rendimiento de las operaciones en paralelo como consultas en paralelo ó DML Paralelo. Por ejemplo, suponiendo que el DBA decidió utilizar una partición por comprobación aleatoria en la columna STUDENT_ID en lugar de una partición por rango para la tabla STUDENT_HISTORY. Como se puede ver en la Figura 1, la clave de partición será STUDENT_ID. De esta forma se crea una tabla con seis particiones, con los nombres generados por el sistema. Cuando se inserta un registro en esta tabla, Oracle pasará el valor de STUDENT_ID por el algoritmo de comprobación aleatoria, y utilizará el resultado para determinar en qué partición será almacenado. La Figura 2 ilustra este concepto. De esta estructura se determinan las reglas que se deben seguir para implementar un particionado de estas características: La clave de partición debería ser de una muy alta cardinalidad (ser clave única ó tener muy pocos valores duplicados). Estas tablas trabajan mejor cuando las consultas obtienen registros de una tabla particionada a través de una clave única. Las búsquedas por rango en particiones por comprobación aleatoria no derivan en ningún beneficio de la técnica de particionado. Cuando este tipo de tablas se encuentran correctamente indexadas, el rendimiento de uniones entre tablas particionadas se mejora significativamente. Las actualizaciones a registros que pudiesen causar un movimiento de una partición a otra no están permitidas. En cada partición se puede crear un índice de comprobación aleatoria (hash index) en forma local. Oracle recomienda que la cantidad total de particiones sea una potencia de dos para ayudar a mejorar la eficacia del algoritmo de comprobación aleatoria.

35 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Particionado Compuesto Como su nombre lo indica, el Particionado Compuesto ó Composite Partitioning representa una combinación del particionado por rango y el particionado por comprobación aleatoria. Este tipo de particiones son útiles cuando se desea utilizar una partición por rango, pero la cantidad de valores para cada partición no se encuentra distribuido normalmente. Las particiones compuestas crean una partición por rango que luego se subdivide en particiones por comprobación aleatoria. El algoritmo de creación se muestra en la Figura 1. De esta manera se crea la tabla con seis particiones por rango llamados de P_1997 a P_2001. Cada una de estas particiones se subdividirá en cuatro particiones por comprobación aleatoria con un nombre generado por el sistema, como se ve en la Figura 2. Al ver la estructura de funcionamiento, se observan las siguientes consideraciones para la construcción de una partición combinada: las particiones con estructuras lógicas solamente. Los datos de la tabla son almacenados físicamente a nivel de subpartición. Las particiones combinadas son útiles para datos históricos ó consultas por fechas a nivel de partición. También son útiles para operaciones en paralelo (consultas y DML) a nivel de subpartición. No se permite la creación de índices locales. Cabe destacar que la misma técnica puede utilizarse para particiones por rango como partición principal y particiones por lista, como partición secundaria, teniendo la misma sintaxis de creación.

36
37 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Particionado de Indices Una vez que se ha creado una tabla particionada por rango, por lista, por comprobación aleatoria ó combinado, se debería crear un índice para maximizar la ventaja de las tablas particionadas. Un indexado correcto de las tablas particionadas también brindará una mejor administración de los mismos. Existen dos métodos para la creación de índices particionados: Local y Global. La diferencia en estos tipos de índice radica en el macheo ó no de las entradas del índice con las particiones de la tabla. Índices de Partición Local. Este tipo de índices son locales debido a que la cantidad de particiones en el índice coincide con las particiones de la tabla. De esta manera, si la tabla tiene cuatro particiones, el índice local sobre esa tabla debería tener cuatro particiones también, cada una de ellas indexando a cada partición de la tabla. La Figura 1 muestra la relación entre este tipo de índices y la tabla asociada. Teniendo en cuenta esta estructura, se observan los lineamientos para la creación de índices de este tipo: Pueden ser utilizados por cualquier tipo de particionado (rango, lista, comprobación aleatoria ó combinado). Oracle mantiene la relación entre las particiones de la tabla y las particiones del índice en forma automática. Si una partición de la tabla es fusionada, dividida ó eliminada, la partición correspondiente al índice tendrá el mismo comportamiento. Cualquier índice BitMap construido en una tabla particionada debe ser un índice de tipo Local. Índices de Partición Global. Los índices de partición son global cuando la cantidad de particiones en el índice no coinciden con la cantidad de particiones de la tabla. De esta manera, cada partición del índice puede contener más de una partición de tabla. La Figura 2 muestra la relación entre un índice particionado globalmente y su tabla particionada. Para poder realizar la implementación de este tipo de índices, se deben tener en cuenta los siguientes lineamientos: A pesar que los índices de partición global pueden ser construidos en una tabla particionada por rango, lista, comprobación aleatoria ó combinada, el índice en sí debe ser siempre particionado por rango. La partición mayor de un índice global, debe definirse (al igual que para las tablas particionadas por rango) con el parámetro MAXVALUE. La realización de operaciones de mantenimiento en tablas particionadas puede causar que los índices globales asociados, se pongan en un estado inválido. Estos índices deben ser reconstruidos antes que los usuarios puedan accederlos. Para evitar este posible comportamiento de la invalidación del índice, Oracle recomienda la utilización de índices locales en lugar de los índices globales.

38 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Indices con y sin Prefijo Otra forma de clasificar los índices particionados es con los índices con prefijo y sin prefijo, en relación a aquellos índices particionados que contienen la clave de partición y la ubicación donde está la estructura del índice. Índices Particionados con Prefijo ó Prefixed Partitioned Indexes. Se dice que estos tipos de índices son con prefijo cuando la primer columna del índice es la misma que la clave de partición de la tabla. Por ejemplo, si la tabla STUDENT_HISTORY estuviese particionada por la columna GRADUATION_DATE, un índice con prefijo debería utilizar la columna GRADUATION_DATE como la primer columna en la definición del índice. Índices Particionados sin Prefijo ó Non-Prefixed Partitioned Indexes. Estos tipos de índices, son aquellos en los que la primer columna del índice no es la misma que la clave de partición de la tabla particionada. Continuando con el ejemplo anterior, un índice particionado sin prefijo se crearía con cualquier otra columna de la tabla particionada que no sea GRADUATION_DATE. Hay que destacar que los índices particionados sin prefijo sólo se pueden crear cuando la clave de partición del índice es un subconjunto de la clave del índice. La tabla de la Figura 1 muestra la forma en que se pueden combinar los índices con ó sin prefijo con los índices globales ó locales.

39 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Obteniendo Información de Objetos Particionados Existen unas 15 vistas del diccionario de datos que contienen información relacionada con las tablas e índices particionados. La tabla de la Figura 1 muestra los nombres y descripciones de estas vistas.
 la decisión de cómo utilizar estas particiones en forma efectiva al momento de armar el plan de ejecución para una consulta.")
40 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Lectura Adicional: Particiones y el Optimizador Una vez que se han creado las tablas e índices particionados, depende del optimizador basado por costos (CBO) la decisión de cómo utilizar estas particiones en forma efectiva al momento de armar el plan de ejecución para una consulta. A partir de Oracle 9i, se dice que el CBO es dependiente de las particiones, con lo que podría eliminar las particiones que no forman parte de los resultados de la consulta. Por ejemplo, si se ejecuta la consulta que se ve en la Figura 1, donde se usa una tabla particionada por rango y la clave de partición es GRADUATION_DATE, debido a la presencia de una tabla particionada y de un índice particionado, el CBO sabrá que sólo una partición (P_1997) necesitará acceder para satisfacer la consulta, con lo que ninguna otra partición de esa tabla se considerará. Esta rápida eliminación de particiones inutilizadas mejora implícitamente el rendimiento de la consulta. Esta acción es conocida como el Podado de Particiones ó Partition Prunning. El CBO no puede podar las particiones de una tabla si la consulta aplica funciones a la columna que es clave de partición, al igual que para las particiones de los índices particionados. Las tablas e índices particionados también ayudan al CBO a desarrollar planes de ejecución efectivos, al influenciarlo en la forma en que debe realizar las uniones (joins) entre dos ó más tablas particionadas. Cuando se está utilizando una consulta en paralelo (Parallel Query), hay dos formas de unir las tablas; Las Uniones Basadas en la Partición, que ocurren siempre que las dos tablas son unidas por su clave de partición y las Uniones Basadas en Particiones Parciales, en donde para las tablas unidas sólo una de ellas utiliza una clave de partición. Como se ha discutido anteriormente, la acumulación de estadísticas de tabla e índices son vitales para un uso eficiente del rendimiento del CBO. El procedimiento GATHER _TABLE_STATS del paquete DBMS_STATS puede ser utilizado para obtener estadísticas globales de tablas particionadas. Estas estadísticas pueden obtenerse a nivel de segmento, partición ó subpartición. El ejemplo de la Figura 2 muestra cómo se obtienen estadísticas para la partición P_1998 de la tabla STUDENT_HISTORY. De la misma manera, en la Figura 3 se ve cómo se obtienen estadísticas para la partición P_200n del índice STUDENT_HISTORY_GP_IDX.
 son FECHA_CREDITO y MONTO_FINAL. Se sabe por un análisis previo que su distribución de datos será normal en función de la línea de crédito.")
41 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente EI: Tablas Particionadas Se desea crear una tabla para una aplicación de un banco, la cual almacenará los datos de los préstamos hipotecarios históricos. Los campos (reducidos para esta práctica) son FECHA_CREDITO y MONTO_FINAL. Se sabe por un análisis previo que su distribución de datos será normal en función de la línea de crédito. Sabiendo esta información, escribir la consulta.
42 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente TP: Indexado de Particiones Laboratorio TP: Indexación de Particiones. Duración Estimada: 40 min.
43 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Síntesis La utilización de particiones para las tablas es la clave del soporte para aquellas tablas e índices de gran tamaño, permitiendo a la base de datos descomponerlas en piezas más pequeñas y manejables llamadas particiones. Una vez que se ha definido una partición, las sentencias SQL pueden acceder y manipular las particiones como así también las entradas de los índices. Las particiones son especialmente útiles para aplicaciones de almacenamiento masivo de datos históricos ó DataWareHousing. Hay cuatro métodos de particionado: Particionado por Rango, en donde las particiones de datos se dividen de acuerdo a un rango de valores. Particionado por Lista, en donde las particiones de datos se dividen de acuerdo a valores específicos. Particionado por Comprobación Aleatoria, en donde las particiones de datos se dividen de acuerdo a un algoritmo de Comprobación Aleatoria ó HASH. Particionado Compuesto, donde se utiliza una combinación del particionado por rango ó lista como partición principal y luego se subdivide utilizando el particionado por comprobación aleatoria. Cada partición se almacena en un segmento individual ó cada subpartición para el caso de una partición compuesta (las particiones de una partición compuesta son estructuras lógicas solamente, no ocupan segmento ya que de esto se encargan las subparticiones). Opcionalmente se puede almacenar las particiones (ó subparticiones) en tablespaces diferentes, brindando las siguientes ventajas: Minimiza el impacto de una corrupción de datos. Es posible resguardar ó recuperar cada partición por separado en forma independiente. Es posible ubicar físicamente las particiones en discos distintos para balancear la carga de E/S.

44 5.2 Utilizando las Estructuras de Almacenamiento Eficientemente Eint: Utilizando las Estructuras de Almacenamiento Eficientemente A continuación le proponemos un ejercicio que pondrá a prueba sus conocimientos acerca de la totalidad de este subcapítulo.
.")
45 5.3 Tuning de Aplicaciones En la figura se presenta una clasificación de los contenidos tratados en esta subunidad, teniendo en cuenta, la relación de los mismos con el Material del Estudiante (kit). Esta clasificación sugiere diferentes momentos de lectura, estudio y revisión, entre los contenidos de este currículo y el Material del Estudiante (Kit). Según esta clasificación los contenidos pueden ser de: Lectura Previa: Se sugiere la lectura de estos contenidos antes de abordar los subtemas, temas o unidades asociados al Material del Estudiante (Kit). Lectura Complementaria: Se sugiere la lectura de estos contenidos como complemento a los subtemas, temas o unidades asociados al Material del Estudiante (Kit). Lectura Adicional: Se sugiere la lectura posterior de estos contenidos, como material adicional a los tratados en el Material del Estudiante (Kit). Prácticas : Actividades de laboratorios e interactivas incluidas como práctica adicional al Material del Estudiante (Kit).
46 5.3 Tuning de Aplicaciones Objetivos En el presente subcapítulo aspiramos a que usted conozca cuál es el rol del DBA frente al ajuste de aplicaciones. También nos interesa que sea capaz de crear diferentes tipos de tablas y tablas gestionadas por índices; además de que sepa mover objetos tipo tabla y redefinir una tabla. Por último con los contenidos tratados en este subcapítulo pretendemos que usted adquiera los conocimientos necesarios para saber explicar los sistemas OLTP, DSS y sistemas híbridos.

47 5.3 Tuning de Aplicaciones Cuestionario de Iniciación Coloque el cursor sobre los botones numerados que aparecen a la izquierda para visualizar las preguntas de iniciación. Si desea, puede desplegar su respuesta.

48 5.3 Tuning de Aplicaciones El Rol del DBA Los problemas de bajo rendimiento de las aplicaciones pueden ser debidos a las sentencias SQL mal estructuradas ó a un diseño ineficiente de la base de datos. A causa de esto, Oracle provee al DBA una serie de herramientas que le ayudan a identificar y solucionar aquellas aplicaciones SQL de bajo rendimiento. Estas herramientas pueden llegar a ser muy valiosas para los sistemas en desarrollo, donde el código de aplicación se encuentra aún en etapa de refinamiento. De todas formas, por más que un sistema se encuentre en producción, es posible utilizar este tipo de herramientas aplicando los principios de ajuste que requieren intervención del DBA, como por ejemplo agregar un índice para mejorar el rendimiento de una consulta SQL muy grande. Las modificaciones de ajuste de este tipo requieren que el DBA comprenda todas las opciones disponibles, desde el uso de las tablas organizadas por índices a las sugerencias ó Hints. También debe considerar cuáles son las herramientas apropiadas para el sistema que se va a evaluar. Por ejemplo, un sistema OLTP tiene una escritura de las sentencias SQL y un diseño diferentes a un sistema de soporte a decisión (DSS).

49 5.3 Tuning de Aplicaciones Gestión de Tablas Una técnica con que cuenta el DBA a nivel de administración y organización de objetos de la base de datos, es el movimiento de tablas entre tablespaces. Por ejemplo, esta tarea suele ser frecuente al momento de trabajar en una mejora de la gestión de una aplicación, donde se toma como objetivo el mejoramiento del rendimiento de acceso a datos y como solución de diseño, se opta por la división del tablespace de la aplicación en varios tablespaces independientes. De esta manera se crea un tablespace para las tablas de alto nivel transaccional y otro para almacenar aquellas tablas que forman parte del histórico. Una vez creados los tablespaces, sólo queda pasar las tablas que se encuentran todas juntas a sus respectivos tablespaces. Esta tarea se puede realizar: Utilizando una exportación e importación, con la desventaja que la tabla quedará no disponible durante este proceso. Utilizando el comando CREATE TABLE AS SELECT Se creará la nueva tabla con la misma estructura y los mismos datos, pero no se crearán en ella, ni las restricciones y ni los disparadores asociados. Utilizando el comando ALTER TABLE MOVE con las siguientes posibilidades: Movimiento de la tabla. Mantenimiento de las restricciones asociadas y los disparadores. Soporte a la operación en paralelo. La Figura 1 muestra un ejemplo de la escritura de esta sentencia, donde se mueve la tabla SALES del esquema HR al tablespace USERS. Otra técnica para hacer el movimiento de tablas es con la reorganización OnLine. Este proceso permite modificar la definición de almacenamiento de la tabla, y por lo tanto, moverla a otro tablespace. También permite agregarle soporte para consultas paralelas ó particionado. Esta reorganización se realiza con el paquete DBMS_REDEFINITION; de esta forma se redefinirá esta tabla sin ponerla OFFLINE, salvo durante un breve tiempo de procesamiento que no tiene que ver con el tamaño de la tabla. Cabe destacar que este movimiento de tablespace independientemente del método que se utilice, reducirá la fragmentación al reorganizar las extensiones.
50
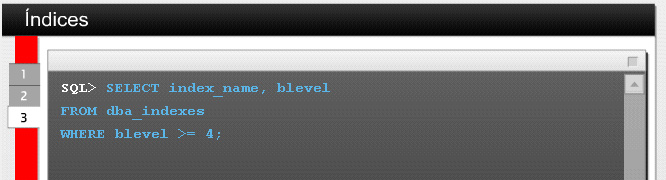
51 5.3 Tuning de Aplicaciones Indices El uso apropiado de los índices es probablemente la forma más efectiva de ajuste dentro de las técnicas disponibles del DBA para la mejora del rendimiento. Esto es así porque los índices simplifican significativamente el acceso a disco innecesario en tablas de gran tamaño, contribuyendo de esta manera con el tiempo de respuesta de la consulta. Existen seis tipos de índices disponibles en Oracle 9i: Índice en árbol B ó B-Tree. Índice B-tree comprimido Índices basados en funciones. Índice de clave reversa. Tablas organizadas por índices. Cada uno de estos temas serán explicados a continuación. Índices en Árbol B. Los índices Balanceados ó en Árbol B (B-Tree) son los índices más comunes que se encuentran en un ambiente transaccional relacional. Los índices B-tree acomodan en forma ascendente a los datos de la ó las columna(s) que forman parte de la clave del índice, junto al ROWID correspondiente al registro que hace referencia cada clave del índice. El nombre de este índice se corresponde con la forma de almacenamiento, esto es, en forma de árbol. Por ejemplo, si se tiene una tabla llamada EMPLOYEES y examinando los archivos de rastreo de los planes de ejecución, el DBA determina que la utilización de un índice B-Tree sobre la columna LAST_NAME de la tabla podría ayudar al rendimiento de la consulta, se crea un índice mostrando su estructura, tal como se puede ver en la Figura 1. De esta manera se crea un índice B-Tree que almacenará los valores de la columna LAST_NAME junto al ROWID de cada registro al que pertenece, formando el árbol como se muestra en la Figura 2. Este tipo de índices son muy útiles cuando se ejecutan consultas que retornan sólo una pequeña cantidad de registros de la tabla. Oracle recomienda que se considere la utilización de un índice de este tipo cuando una consulta retorne menos del 5% del total de registros de la tabla. Las columnas que son mejores candidatas a indexar, son aquellas que tienen una alta cardinalidad y que suelen encontrarse frecuentemente en la selección (el where) del bloque de consulta SQL. Por definición de su diseño (y como se ve en la Figura 2), este tipo de índices se encuentran siempre balanceados, esto se debe a que Oracle Server continuamente divide los bloques de estos índices a medida que se llenan con nuevos valores. La actividad DML que ocurra sobre la tabla asociada al índice afecta también a la organización del índice degradando el rendimiento que pudiera tener la consulta. Para esto, el DBA puede determinar la profundidad de un índice al analizarlo a través de la vista DBA_INDEXES, como se ve en la Figura 3. Esta consulta mostrará aquellos índices que tienen una profundidad mayor a cuatro niveles desde el nodo raíz hasta sus últimas hojas. De esta manera se determina también que estos índices son buenos candidatos para su reorganización. La reorganización ó reindexación producirá que se reduzcan los niveles mejorando el rendimiento del mismo.

52
53 5.3 Tuning de Aplicaciones Reconstrucción Una vez determinados los índices que necesitan una reorganización para mejorar el rendimiento de acceso, se puede optar por alguna de las siguientes técnicas: Eliminar y volver a crear el índice. La eliminación y vuelta a crear del índice es la técnica de reconstrucción que más tiempo de procesamiento y ocupación de recursos consume. Hay que tener en cuenta que esta era la única técnica disponible en versiones previas a Oracle 7.3. Comando ALTER INDEX REBUILD. Este comando junto a la opción REBUILD es una forma efectiva de reconstruir el índice en forma rápida, ya que son utilizadas las mismas entradas en los bloques del índice para crear el nuevo índice. Adicionalmente se puede especificar la opción ONLINE para minimizar los bloqueos producidos por operaciones DML al momento de la reconstrucción. El resultado de esta operación es tener dos índices, el viejo fragmentado y el nuevo reconstruido. Es por esto que se debe contar con el espacio en disco necesario para almacenar ambos índices. Luego de la reconstrucción, Oracle Server eliminará el índice viejo. Cabe destacar que la opción REBUILD da la posibilidad de mover el índice a otro tablespace, brindando otra funcionalidad adicional de gestión de los objetos de la base de datos. Comando ALTER INDEX COALESCE. Usando este comando con la opción COALESCE es otra forma efectiva de reconstruir un índice. Para esta opción en particular fusionará los bloques hoja de la misma rama para ese índice. Esto minimiza el bloqueo potencial asociado al proceso de recreación. De todas formas, la opción COALESCE no puede ser utilizada para mover el índice a otro tablespace. Indices B-Tree Comprimidos. Cuando un índice B-Tree es construido sobre una tabla muy grande, particularmente en un sistema de datos históricos ó DataWareHouse ó un sistema de soporte a decisiones (Data Decision Support), estos índices pueden consumir una gran cantidad de espacio de almacenamiento. Los índices B-Tree comprimidos son índices utilizados para reducir la cantidad de espacio utilizado por ciertos tipos de índices B-Tree. Cuando un índice de estas características es comprimido, las ocurrencias duplicadas del índice son eliminadas reduciendo el espacio requerido para el almacenamiento. La Figura 1 muestra una comparación de un índice B-Tree comprimido y uno sin compresión, donde se toma como clave del índice el apellido y se sabe que una gran cantidad de estos valores son, por ejemplo, PEREZ. De esta manera, para cada ocurrencia del valor PEREZ almacenará este valor junto a su ROWID correspondiente. Para el caso del índice comprimido solamente almacenará una vez el valor PEREZ y junto a esta cadena almacenará todos los posibles valores de ROWID que coincidan con este valor. La Figura 2 muestra la sentencia de creación de un índice comprimido. Si la decisión de comprimir el índice es tomada una vez que el índice propiamente ya fue creado sin comprimir, el DBA puede modificar el índice para que cambie su comportamiento y pase a ser un índice comprimido; esto es, utilizando el comando ALTER INDEX, como se muestra en la Figura 3.

54

55 5.3 Tuning de Aplicaciones Indices BITMAP Los índices del tipo B-Tree trabajan mejor en columnas de alta cardinalidad. Para aquellas columnas que no cumplan este requisito, se podría utilizar un índice del tipo BitMap como solución más efectiva de indexado. A diferencia de los índices B-Tree, los índices BitMap crean un mapa de bits de los registros de la tabla y lo almacena en los bloques del índice. Esto significa que el índice resultante requerirá un almacenamiento significativamente menor para almacenar sus entradas. Este tipo de índices son útiles para columnas con muchos valores pero con baja actividad DML y muy alta cardinalidad. Por ejemplo, si se decide crear un índice sobre la columna SEXO de la tabla de EMPLEADOS, la utilización de un índice BitMap sería la mejor solución, ya que cumple con las características antes mencionadas. La Figura 1 muestra la sintaxis de creación del índice BitMap. El índice BitMap almacenará los valores posibles junto al mapa binario de cada uno de estos valores. De esta manera, aquel bit que se encuentre en 1 indicará que ese ROWID contiene el valor buscado y de lo contrario no. La Figura 2 muestra una ilustración de esta actividad. Las consultas subsecuentes sobre la tabla EMPLEADOS que incluya una selección basada en la columna SEXO podrá ubicar el ROWID a través del índice. Adicionalmente, las consultas que utilicen el operador AND ú OR en este tipo de índices lo harán con una velocidad muy alta, ya que la comprobación será a nivel de bits, es decir, con una operación binaria. Cabe destacar que las operaciones DML sobre tablas que tienen índices BitMap son muy costosas en términos de rendimiento, ya que causan un bloqueo a nivel de mapa de bits y esto requiere un bloqueo consecuente del segmento completo para cada operación. Al momento de utilizar este tipo de índices, hay que tener en cuenta cierta parametrización de la SGA para mejorar la velocidad de su creación y gestión. Estos parámetros están descritos en la tabla de la Figura 3.
56
57 5.3 Tuning de Aplicaciones Indices Reversos Cuando se aplica una función a una columna indexada en una sentencia SQL, cualquier índice creado sobre esa columna será ignorado durante el armado del plan de ejecución. Por ejemplo, si se construye un índice sobre la columna NOMBRE de la tabla de EMPLEADOS, el mismo no será utilizado por el optimizador en la sentencia SQL que se muestra en la Figura 1, debido a que utiliza una función de fila para hacer la comparación. De esta manera, el plan de ejecución resultante incluirá una búsqueda completa de la tabla (FULL SCAN) para poder aplicar la función a cada registro y luego seleccionar, por más que exista un índice sobre esa columna. Este comportamiento ocurre cada vez que una función es aplicada en una columna indexada. Los Índices Basados en Funciones resuelven este problema incorporando la función propiamente en el índice al momento de la creación. Tanto los índices B-Tree y los BitMap puede contener una función de fila para almacenar la clave. La forma de crear este tipo de índices es muy sencilla y queda demostrado en la sentencia de la Figura 2. Así, cuando se vuelva a ejecutar una consulta con esta función, el optimizador considerará el uso de este índice evitando la búsqueda secuencial de la tabla. Cabe destacar que para poder utilizar los índices basados en funciones se debe definir el parámetro QUERY_REWRITE_ENABLED en True. Los Índices de Clave Reversa ó Reverse key Index (RKI) son un tipo especial de índices. Los RKI son útiles cuando son construidos sobre una columna que contiene números secuenciales. Si se construye un índice tradicional B-Tree sobre una columna que tiene estos tipos de datos, el índice tiende a generar muchos niveles. Es sabido que si supera los cuatro niveles de profundidad, el rendimiento decaerá. Es por esto que un RKI es más recomendable para estas situaciones. El principio de funcionamiento de estos índices es almacenar los bytes de la columna clave pero en forma reversa. De esta manera los valores secuenciales de la columna pasan a tener una forma de distribución más uniforme. Entonces sólo queda indexar estos valores modificados, con el método habitual. Por ejemplo, si se decide crear un índice sobre el campo EMP_ID de la tabla EMPLOYEES, sería útil utilizar un índice de clave reversa (RKI) dado su conocido comportamiento secuencial. La Figura 3 muestra un ensayo sobre esta creación. De la misma manera, es posible crear un índice de clave reversa a partir de un índice normal con el comando ALTER INDEX y la opción REVERSE, como se ve en la Figura 4. La Figura 5 muestra un ejemplo de cómo un RKI en el campo EMP_ID de la tabla EMPLOYEES trabajaría internamente. De esta imagen se desprende que el índice de clave reversa es transparente a la aplicación ó al usuario, es decir, no requieren sintaxis adicional para utilizar este tipo de índices en las consultas. Los índices de clave reversas (RKI) sólo son útiles para búsquedas de igualdad ó no igualdad. Aquellas consultas que realicen búsquedas por rango (BETWEEN, > ó <) en columnas que tienen un RKI, omitirán el uso del índice terminando con una búsqueda completa de la tabla (FULL SCAN)

58
59 5.3 Tuning de Aplicaciones Tablas Organizadas por Indices La ganancia de rendimiento obtenida por el uso del índice B-Tre, BitMap, basado en funciones ó de clave reversa resalta en que el hecho es que las entradas en estos índices apuntan directamente al ROWID del registro correspondiente, en la tabla a la que el índice hace referencia. Entonces, esta es una forma efectiva de obtener registros de una tabla en donde los registros no se encuentran almacenados en ningún orden en particular. Este tipo de tablas son conocidas con el nombre de Tabla Apilada (Heap Table) en donde Oracle almacena los datos de los registros en forma amontonada a medida que se insertan. El resultado es un almacenamiento aleatorio de las claves de la tabla, debido a que Oracle no considera el contenido del registro al momento de almacenarlo, sino que lo almacena en el primer bloque libre que encuentra de la lista de bloques libres. Si se decide almacenar los datos de la tabla en un orden específico, entonces no es posible crear una tabla apilada. Para esto Oracle provee la posibilidad de crear una Tabla Organizada por Índice (Oracle Index Table OIT). A diferencia de las tablas apiladas, el índice no almacena el ROWID apuntando al resto del registro, sino que directamente el registro completo es quien es almacenado en el índice. Esto tiene dos implicaciones: Los registros de la tabla son almacenados en orden. Si accede a una tabla IOT utilizando su clave primaria, retornará los registros más rápido que una tabla tradicional. Es requerido un procesamiento y E/S adicional tanto para la tabla como para el índice. La Figura 1 muestra la sintaxis de creación de una tabla de estas características. Cabe destacar que una tabla de este tipo debe tener definida una clave primaria, para este caso, EMP_ID. Otra cosa para tener en cuenta es que una IOT no puede tener restricciones de claves únicas ó agrupamientos. La tabla de la Figura 2 indica las opciones utilizadas en la sintaxis de la Figura 1. Una vez creada la tabla e insertados los registros, se puede ver su estructura a nivel de segmento, tal como lo muestra la Figura 3. Nótese que el registro que corresponde al empleado Nro. 107 puede almacenar su registro completo en el índice, pero el empleado 102 tiene una descripción cargada que supera a la capacidad definida por PCTTHRESHOLD y por lo tanto rompe en FIRST_NAME y los datos remanentes son almacenados en el segmento contenido en el tablespace APPL_OF.
60 5.3 Tuning de Aplicaciones Tablas Mapeadas Los índices BitMap pueden ser construidos tanto en una tabla apilada como en una tabla organizada por índices (IOT). Cuando se crea un índice BitMap en una tabla apilada, el índice almacena los mapas de bits a lo largo de los posibles ROWID s para ubicar los registros que cumplan con el valor de la clave. Pero para el caso de las tablas organizadas por índice, se debe hacer uso de una tabla mapeada (Mapping Table) para ubicar los registros indexados en la tabla. El funcionamiento de esta tabla mapeada es vincular el índice físico del ROWID al correspondiente índice lógico, utilizado por la tabla organizada por índice. Entonces, una IOT utiliza un ROWID lógico para gestionar el acceso al índice, ya que el ROWID físico puede llegar a cambiar si se insertan ó eliminan registros de la IOT. Este comportamiento ocurre debido a que los nodos hoja se tienen que dividir a medida que se llenan (al igual que los índices B-Tree), y por esto, si en esta tabla de mapeo hay un nodo hoja dividido en una IOT, debería cambiar el ROWID físico dejando el índice BitMap inutilizable. Gracias a la utilización de una tabla intermedia, como la tabla de mapeo, las entradas del índice BitMap no requieren reflejar el mapeo entre los ROWID lógicos y físicos en la IOT. De lo contrario esto reduciría la efectividad del índice. Es posible ver si este mapeo está sincronizado con el índice BitMap utilizando el script de la Figura 1. Sólo las tablas IOT tendrán valores no nulos de PCT_DIRECT_ACCESS. Cualquier índice que exceda este valor en 30% debería tener su índice de Mapa de Bits reconstruido para mantener el rendimiento. Cabe destacar que sólo se debe mantener una tabla mapeada por IOT por más que ésta tenga múltiples índices BitMap en esa tabla.

61 5.3 Tuning de Aplicaciones Lectura Adicional: Reconstrucción de Indices En temas anteriores hemos visto que una forma de determinar qué índices son buenos candidatos para su reconstrucción es consultando la vista del diccionario de datos DBA_INDEXES y verificando aquellos índices que superan una profundidad de cuatro niveles. Otra forma de contar con un indicador de índices candidatos a la reconstrucción es cuando se detecta que los registros eliminados en el índice (a través de la eliminación del registro completo en la tabla a la que hace referencia) representan el 20% de la cantidad total de registros. Cuando esto ocurre, el índice utiliza mayor espacio del que necesita para almacenar las entradas, (ordenadas) incrementando innecesariamente el espacio en disco y su acceso. La Figura 1 muestra el comando que se debe utilizar para identificar los índices con esta característica. La opción VALIDATE STRUCTURE del comando ANALYZE genera información para la vista del diccionario de datos INDEX_STATS. De esta manera, se puede consultar esta vista para ver el gasto del espacio para el índice, como se ve en la Figura 2. Los resultados de esta consulta indican que el 34% del espacio en los bloques del índice está mal gastado, ya que es espacio que quedó de la eliminación de registros. Cuando se debe reconstruir un índice, se puede utilizar alguna de las siguientes técnicas: * Eliminar y recrear el índice, * Utilizar el comando ALTER INDEX...REBUILD * Utilizar el comando ALTER INDEX...COALESCE Estas técnicas se han comentado en temas anteriores.

62 5.3 Tuning de Aplicaciones EI: B-Tree vs BitMap Identificar las características que son propias de cada modelo de índice.
63 5.3 Tuning de Aplicaciones TP: Indices Desbalanceados Laboratorio TP: Indices Desbalanceados. Duración Estimada: 40 min.

64 5.3 Tuning de Aplicaciones Síntesis Se han visto una gran variedad de métodos que brinda Oracle para mejorar el rendimiento de las aplicaciones a través de las consultas SQL desde el punto de vista de la utilización de los mecanismos de acceso rápido a datos como por ejemplo los índices. Estos métodos incluyen los índices de árbol en B (B-Tree) ó balanceados, índices de mapas de bits (BitMap), índices basados en funciones, índices comprimidos, índices de clave reversa y tablas basadas en índices. El uso apropiado de estos índices dependerá del tipo de sistema que se esté utilizando, como ser un sistema transaccional (OLTP) ó un sistema de soporte a la toma de decisiones (DSS) ó de almacenamiento de datos histórico (DataWareHouse). Como parte de la gestión del índice, hemos visto los mecanismos con que cuenta el DBA para poder identificar aquellos índices que no cumplen con las características óptimas de funcionamiento para ser pasados por un proceso de reconstrucción. Finalmente, se cuenta con un laboratorio en el cual se puede poner en práctica un procedimiento PL/SQL para automatizar esta tarea de reconstrucción de índices desbalanceados.

65 5.3 Tuning de Aplicaciones Eint: Tuning de Aplicaciones A continuación le proponemos un ejercicio que pondrá a prueba sus conocimientos acerca de la totalidad de este subcapítulo.
Estructura de una BD Oracle. datafiles redo log controlfiles tablespace objetos Estructura lógica. Tablespaces tablespace SYSTEM
 Estructura de una BD Oracle. Una BD Oracle tiene una estructura física y una estructura lógica que se mantienen separadamente. La estructura física se corresponde a los ficheros del sistema operativo:
Estructura de una BD Oracle. Una BD Oracle tiene una estructura física y una estructura lógica que se mantienen separadamente. La estructura física se corresponde a los ficheros del sistema operativo:
6.0 Funcionalidades Adicionales
 6.0 Funcionalidades Adicionales Oracle Server provee dos maneras de resguardar su base de datos. La primera es el backup físico, el que consiste en la copia y restauración de los archivos necesarios de
6.0 Funcionalidades Adicionales Oracle Server provee dos maneras de resguardar su base de datos. La primera es el backup físico, el que consiste en la copia y restauración de los archivos necesarios de
Capítulo 12: Indexación y asociación
 Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Clase 2: Estructuras Lógicas y Físicas(I)
") Clase 2: Estructuras Lógicas y Físicas(I) Introducción a Segmentos, Extents y bloques de datos Bloque de datos Inittrans, Maxtrans Extents Segmentos Cláusula Storage Introducción tablespaces, datafiles
Clase 2: Estructuras Lógicas y Físicas(I) Introducción a Segmentos, Extents y bloques de datos Bloque de datos Inittrans, Maxtrans Extents Segmentos Cláusula Storage Introducción tablespaces, datafiles
Universidad Nacional de Costa Rica Administración de Bases de Datos
 Universidad Nacional de Costa Rica Administración de Bases de Datos Mantenimiento de tablespaces e índices Para más información visite: http://www.slinfo.una.ac.cr Autor: Steven Brenes Chavarria Email:
Universidad Nacional de Costa Rica Administración de Bases de Datos Mantenimiento de tablespaces e índices Para más información visite: http://www.slinfo.una.ac.cr Autor: Steven Brenes Chavarria Email:
3 Consultas y subconsultas
 3 Consultas y subconsultas En SQL, la sentencia SELECT permite escribir una consulta o requerimiento de acceso a datos almacenados en una base de datos relacional. Dichas consultas SQL van desde una operación
3 Consultas y subconsultas En SQL, la sentencia SELECT permite escribir una consulta o requerimiento de acceso a datos almacenados en una base de datos relacional. Dichas consultas SQL van desde una operación
Base de datos en Excel
 Base de datos en Excel Una base datos es un conjunto de información que ha sido organizado bajo un mismo contexto y se encuentra almacenada y lista para ser utilizada en cualquier momento. Las bases de
Base de datos en Excel Una base datos es un conjunto de información que ha sido organizado bajo un mismo contexto y se encuentra almacenada y lista para ser utilizada en cualquier momento. Las bases de
CAPÍTULO 4. EL EXPLORADOR DE WINDOWS XP
 CAPÍTULO 4. EL EXPLORADOR DE WINDOWS XP Características del Explorador de Windows El Explorador de Windows es una de las aplicaciones más importantes con las que cuenta Windows. Es una herramienta indispensable
CAPÍTULO 4. EL EXPLORADOR DE WINDOWS XP Características del Explorador de Windows El Explorador de Windows es una de las aplicaciones más importantes con las que cuenta Windows. Es una herramienta indispensable
Modificación y parametrización del modulo de Solicitudes (Request) en el ERP/CRM Compiere.
 en el ERP/CRM Compiere.") UNIVERSIDAD DE CARABOBO FACULTAD DE CIENCIA Y TECNOLOGÍA DIRECCION DE EXTENSION COORDINACION DE PASANTIAS Modificación y parametrización del modulo de Solicitudes (Request) en el ERP/CRM Compiere. Pasante:
UNIVERSIDAD DE CARABOBO FACULTAD DE CIENCIA Y TECNOLOGÍA DIRECCION DE EXTENSION COORDINACION DE PASANTIAS Modificación y parametrización del modulo de Solicitudes (Request) en el ERP/CRM Compiere. Pasante:
Base de datos relacional
 Base de datos relacional Una base de datos relacional es una base de datos que cumple con el modelo relacional, el cual es el modelo más utilizado en la actualidad para modelar problemas reales y administrar
Base de datos relacional Una base de datos relacional es una base de datos que cumple con el modelo relacional, el cual es el modelo más utilizado en la actualidad para modelar problemas reales y administrar
Estas visiones de la información, denominadas vistas, se pueden identificar de varias formas.
 El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
Adelacu Ltda. www.adelacu.com Fono +562-218-4749. Graballo+ Agosto de 2007. Graballo+ - Descripción funcional - 1 -
 Graballo+ Agosto de 2007-1 - Índice Índice...2 Introducción...3 Características...4 DESCRIPCIÓN GENERAL...4 COMPONENTES Y CARACTERÍSTICAS DE LA SOLUCIÓN...5 Recepción de requerimientos...5 Atención de
Graballo+ Agosto de 2007-1 - Índice Índice...2 Introducción...3 Características...4 DESCRIPCIÓN GENERAL...4 COMPONENTES Y CARACTERÍSTICAS DE LA SOLUCIÓN...5 Recepción de requerimientos...5 Atención de
- Bases de Datos - - Diseño Físico - Luis D. García
 - Diseño Físico - Luis D. García Abril de 2006 Introducción El diseño de una base de datos está compuesto por tres etapas, el Diseño Conceptual, en el cual se descubren la semántica de los datos, definiendo
- Diseño Físico - Luis D. García Abril de 2006 Introducción El diseño de una base de datos está compuesto por tres etapas, el Diseño Conceptual, en el cual se descubren la semántica de los datos, definiendo
En cualquier caso, tampoco es demasiado importante el significado de la "B", si es que lo tiene, lo interesante realmente es el algoritmo.
 Arboles-B Características Los árboles-b son árboles de búsqueda. La "B" probablemente se debe a que el algoritmo fue desarrollado por "Rudolf Bayer" y "Eduard M. McCreight", que trabajan para la empresa
Arboles-B Características Los árboles-b son árboles de búsqueda. La "B" probablemente se debe a que el algoritmo fue desarrollado por "Rudolf Bayer" y "Eduard M. McCreight", que trabajan para la empresa
Funcionalidades Software PROYECTOS GotelGest.Net Software para la gestión de Proyectos GotelGest.Net
 2012 Funcionalidades Software PROYECTOS GotelGest.Net Software para la gestión de Proyectos GotelGest.Net Servinet Sistemas y Comunicación S.L. www.softwaregestionproyectos.com Última Revisión: Febrero
2012 Funcionalidades Software PROYECTOS GotelGest.Net Software para la gestión de Proyectos GotelGest.Net Servinet Sistemas y Comunicación S.L. www.softwaregestionproyectos.com Última Revisión: Febrero
Toda base de datos relacional se basa en dos objetos
 1. INTRODUCCIÓN Toda base de datos relacional se basa en dos objetos fundamentales: las tablas y las relaciones. Sin embargo, en SQL Server, una base de datos puede contener otros objetos también importantes.
1. INTRODUCCIÓN Toda base de datos relacional se basa en dos objetos fundamentales: las tablas y las relaciones. Sin embargo, en SQL Server, una base de datos puede contener otros objetos también importantes.
WINDOWS 2008 7: COPIAS DE SEGURIDAD
 1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final
![Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final](/thumbs/27/10370366.jpg "Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final") Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final INTRODUCCION En principio surgió la idea de un buscador que brinde los resultados en agrupaciones de
Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final INTRODUCCION En principio surgió la idea de un buscador que brinde los resultados en agrupaciones de
Ingeniería del Software I Clase de Testing Funcional 2do. Cuatrimestre de 2007
 Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER
 LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER GUÍA DE LABORATORIO Nº 1O Actividad de Proyecto No. 12: ESTABLECER PLANES DE RESGUARDO, RESTAURACION Y CONTINGENCIA. Estructura de contenidos.
LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER GUÍA DE LABORATORIO Nº 1O Actividad de Proyecto No. 12: ESTABLECER PLANES DE RESGUARDO, RESTAURACION Y CONTINGENCIA. Estructura de contenidos.
GENERACIÓN DE ANTICIPOS DE CRÉDITO
 GENERACIÓN DE ANTICIPOS DE CRÉDITO 1 INFORMACIÓN BÁSICA La aplicación de generación de ficheros de anticipos de crédito permite generar fácilmente órdenes para que la Caja anticipe el cobro de créditos
GENERACIÓN DE ANTICIPOS DE CRÉDITO 1 INFORMACIÓN BÁSICA La aplicación de generación de ficheros de anticipos de crédito permite generar fácilmente órdenes para que la Caja anticipe el cobro de créditos
Consultas con combinaciones
 UNIDAD 1.- PARTE 2 MANIPULACIÓN AVANZADA DE DATOS CON SQL. BASES DE DATOS PARA APLICACIONES Xochitl Clemente Parra Armando Méndez Morales Consultas con combinaciones Usando combinaciones (joins), se pueden
UNIDAD 1.- PARTE 2 MANIPULACIÓN AVANZADA DE DATOS CON SQL. BASES DE DATOS PARA APLICACIONES Xochitl Clemente Parra Armando Méndez Morales Consultas con combinaciones Usando combinaciones (joins), se pueden
Manual de rol gestor de GAV para moodle 2.5
 Manual de rol gestor de GAV para moodle 2.5 Consultas LDAP-GAUR... 2 Buscar en LDAP datos de un usuario... 2 Docentes... 3 Buscar en GAUR datos de un docente... 3 Buscar en GAUR la docencia de un docente
Manual de rol gestor de GAV para moodle 2.5 Consultas LDAP-GAUR... 2 Buscar en LDAP datos de un usuario... 2 Docentes... 3 Buscar en GAUR datos de un docente... 3 Buscar en GAUR la docencia de un docente
Operación Microsoft Access 97
 Trabajar con Controles Características de los controles Un control es un objeto gráfico, como por ejemplo un cuadro de texto, un botón de comando o un rectángulo que se coloca en un formulario o informe
Trabajar con Controles Características de los controles Un control es un objeto gráfico, como por ejemplo un cuadro de texto, un botón de comando o un rectángulo que se coloca en un formulario o informe
Fórmulas. Objetivos y Definición. Definir fórmulas nos brinda una forma clave de compartir conocimiento y obtener código generado optimizado
 97 Objetivos y Definición Definir fórmulas nos brinda una forma clave de compartir conocimiento y obtener código generado optimizado Cuando el valor de un atributo o variable puede calcularse a partir
97 Objetivos y Definición Definir fórmulas nos brinda una forma clave de compartir conocimiento y obtener código generado optimizado Cuando el valor de un atributo o variable puede calcularse a partir
Sesión No. 4. Contextualización INFORMÁTICA 1. Nombre: Procesador de Texto
 INFORMÁTICA INFORMÁTICA 1 Sesión No. 4 Nombre: Procesador de Texto Contextualización La semana anterior revisamos los comandos que ofrece Word para el formato del texto, la configuración de la página,
INFORMÁTICA INFORMÁTICA 1 Sesión No. 4 Nombre: Procesador de Texto Contextualización La semana anterior revisamos los comandos que ofrece Word para el formato del texto, la configuración de la página,
GESTIÓN DOCUMENTAL PARA EL SISTEMA DE CALIDAD
 GESTIÓN DOCUMENTAL PARA EL SISTEMA DE CALIDAD Manual de usuario 1 - ÍNDICE 1 - ÍNDICE... 2 2 - INTRODUCCIÓN... 3 3 - SELECCIÓN CARPETA TRABAJO... 4 3.1 CÓMO CAMBIAR DE EMPRESA O DE CARPETA DE TRABAJO?...
GESTIÓN DOCUMENTAL PARA EL SISTEMA DE CALIDAD Manual de usuario 1 - ÍNDICE 1 - ÍNDICE... 2 2 - INTRODUCCIÓN... 3 3 - SELECCIÓN CARPETA TRABAJO... 4 3.1 CÓMO CAMBIAR DE EMPRESA O DE CARPETA DE TRABAJO?...
1.1.- Objetivos de los sistemas de bases de datos 1.2.- Administración de los datos y administración de bases de datos 1.3.- Niveles de Arquitectura
 1. Conceptos Generales 2. Modelo Entidad / Relación 3. Modelo Relacional 4. Integridad de datos relacional 5. Diseño de bases de datos relacionales 6. Lenguaje de consulta estructurado (SQL) 1.1.- Objetivos
1. Conceptos Generales 2. Modelo Entidad / Relación 3. Modelo Relacional 4. Integridad de datos relacional 5. Diseño de bases de datos relacionales 6. Lenguaje de consulta estructurado (SQL) 1.1.- Objetivos
CASO PRÁCTICO. ANÁLISIS DE DATOS EN TABLAS DINÁMICAS
 CASO PRÁCTICO. ANÁLISIS DE DATOS EN TABLAS DINÁMICAS Nuestra empresa es una pequeña editorial que maneja habitualmente su lista de ventas en una hoja de cálculo y desea poder realizar un análisis de sus
CASO PRÁCTICO. ANÁLISIS DE DATOS EN TABLAS DINÁMICAS Nuestra empresa es una pequeña editorial que maneja habitualmente su lista de ventas en una hoja de cálculo y desea poder realizar un análisis de sus
CAPÍTULO 3 Servidor de Modelo de Usuario
 CAPÍTULO 3 Servidor de Modelo de Usuario Para el desarrollo del modelado del estudiante se utilizó el servidor de modelo de usuario desarrollado en la Universidad de las Américas Puebla por Rosa G. Paredes
CAPÍTULO 3 Servidor de Modelo de Usuario Para el desarrollo del modelado del estudiante se utilizó el servidor de modelo de usuario desarrollado en la Universidad de las Américas Puebla por Rosa G. Paredes
Soporte y mantenimiento de base de datos y aplicativos
 Soporte y mantenimiento de base de datos y aplicativos Las bases de datos constituyen la fuente de información primaria a todos los servicios que el centro de información virtual ofrece a sus usuarios,
Soporte y mantenimiento de base de datos y aplicativos Las bases de datos constituyen la fuente de información primaria a todos los servicios que el centro de información virtual ofrece a sus usuarios,
Centro de Capacitación en Informática
 Fórmulas y Funciones Las fórmulas constituyen el núcleo de cualquier hoja de cálculo, y por tanto de Excel. Mediante fórmulas, se llevan a cabo todos los cálculos que se necesitan en una hoja de cálculo.
Fórmulas y Funciones Las fórmulas constituyen el núcleo de cualquier hoja de cálculo, y por tanto de Excel. Mediante fórmulas, se llevan a cabo todos los cálculos que se necesitan en una hoja de cálculo.
Análisis de los datos
 Universidad Complutense de Madrid CURSOS DE FORMACIÓN EN INFORMÁTICA Análisis de los datos Hojas de cálculo Tema 6 Análisis de los datos Una de las capacidades más interesantes de Excel es la actualización
Universidad Complutense de Madrid CURSOS DE FORMACIÓN EN INFORMÁTICA Análisis de los datos Hojas de cálculo Tema 6 Análisis de los datos Una de las capacidades más interesantes de Excel es la actualización
Internet Information Server
 Internet Information Server Internet Information Server (IIS) es el servidor de páginas web avanzado de la plataforma Windows. Se distribuye gratuitamente junto con las versiones de Windows basadas en
Internet Information Server Internet Information Server (IIS) es el servidor de páginas web avanzado de la plataforma Windows. Se distribuye gratuitamente junto con las versiones de Windows basadas en
Elementos requeridos para crearlos (ejemplo: el compilador)
") Generalidades A lo largo del ciclo de vida del proceso de software, los productos de software evolucionan. Desde la concepción del producto y la captura de requisitos inicial hasta la puesta en producción
Generalidades A lo largo del ciclo de vida del proceso de software, los productos de software evolucionan. Desde la concepción del producto y la captura de requisitos inicial hasta la puesta en producción
Utilidades de la base de datos
 Utilidades de la base de datos Desde esta opcion del menú de Access, podemos realizar las siguientes operaciones: Convertir Base de datos Compactar y reparar base de datos Administrador de tablas vinculadas
Utilidades de la base de datos Desde esta opcion del menú de Access, podemos realizar las siguientes operaciones: Convertir Base de datos Compactar y reparar base de datos Administrador de tablas vinculadas
e-mailing Solution La forma más efectiva de llegar a sus clientes.
 e-mailing Solution La forma más efectiva de llegar a sus clientes. e-mailing Solution Es muy grato para nosotros presentarles e-mailing Solution, nuestra solución de e-mail Marketing para su empresa. E-Mailing
e-mailing Solution La forma más efectiva de llegar a sus clientes. e-mailing Solution Es muy grato para nosotros presentarles e-mailing Solution, nuestra solución de e-mail Marketing para su empresa. E-Mailing
Módulo I Unidad Didáctica 2
 Módulo I Unidad Didáctica 2 Introducción Tal como un periódico, por ejemplo, no es sólo una colección de artículos, un sitio Web no puede ser simplemente una colección de páginas. Qué se busca al diseñar
Módulo I Unidad Didáctica 2 Introducción Tal como un periódico, por ejemplo, no es sólo una colección de artículos, un sitio Web no puede ser simplemente una colección de páginas. Qué se busca al diseñar
UNLaM REDES Y SUBREDES DIRECCIONES IP Y CLASES DE REDES:
 DIRECCIONES IP Y CLASES DE REDES: La dirección IP de un dispositivo, es una dirección de 32 bits escritos en forma de cuatro octetos. Cada posición dentro del octeto representa una potencia de dos diferente.
DIRECCIONES IP Y CLASES DE REDES: La dirección IP de un dispositivo, es una dirección de 32 bits escritos en forma de cuatro octetos. Cada posición dentro del octeto representa una potencia de dos diferente.
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología
 Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
MANUAL DE LA APLICACIÓN HELP DESK
 CASAMOTOR MANUAL DE LA APLICACIÓN HELP DESK Desarrollado por: NOVIEMBRE, 2012 BOGOTÁ D.C. - COLOMBIA INTRODUCCIÓN Este documento es el manual de la aplicación de Help Desk de Casamotor, producto desarrollado
CASAMOTOR MANUAL DE LA APLICACIÓN HELP DESK Desarrollado por: NOVIEMBRE, 2012 BOGOTÁ D.C. - COLOMBIA INTRODUCCIÓN Este documento es el manual de la aplicación de Help Desk de Casamotor, producto desarrollado
Indice I. INTRODUCCIÓN SEGURIDAD DE ACCESO REGISTRO DEL VALOR FLETE CONSULTAS V. GRÁFICAS. MANUAL GENERADORES DE CARGA RNDC Noviembre 2015 Versión 2
 MANUAL GENERADORES DE CARGA RNDC Noviembre 2015 Versión 2 Indice I. INTRODUCCIÓN II. SEGURIDAD DE ACCESO III. REGISTRO DEL VALOR FLETE IV. CONSULTAS V. GRÁFICAS Ministerio de Transporte - Manual generadores
MANUAL GENERADORES DE CARGA RNDC Noviembre 2015 Versión 2 Indice I. INTRODUCCIÓN II. SEGURIDAD DE ACCESO III. REGISTRO DEL VALOR FLETE IV. CONSULTAS V. GRÁFICAS Ministerio de Transporte - Manual generadores
La ventana de Microsoft Excel
 Actividad N 1 Conceptos básicos de Planilla de Cálculo La ventana del Microsoft Excel y sus partes. Movimiento del cursor. Tipos de datos. Metodología de trabajo con planillas. La ventana de Microsoft
Actividad N 1 Conceptos básicos de Planilla de Cálculo La ventana del Microsoft Excel y sus partes. Movimiento del cursor. Tipos de datos. Metodología de trabajo con planillas. La ventana de Microsoft
BANCO NACIONAL DE PANAMÁ, BANCO DE DESARROLLO AGROPECUARIO Y BANCO HIPOTECARIO NACIONAL
 BANCO NACIONAL DE PANAMÁ, BANCO DE DESARROLLO AGROPECUARIO Y BANCO HIPOTECARIO NACIONAL LICITACION ABREVIADA POR PONDERACIÓN Nº 2010-7-01-0-08-AV-000001 MANUAL DE SEGURIDAD TABLA DE CONTENIDO I. INTRODUCCIÓN
BANCO NACIONAL DE PANAMÁ, BANCO DE DESARROLLO AGROPECUARIO Y BANCO HIPOTECARIO NACIONAL LICITACION ABREVIADA POR PONDERACIÓN Nº 2010-7-01-0-08-AV-000001 MANUAL DE SEGURIDAD TABLA DE CONTENIDO I. INTRODUCCIÓN
GENERACIÓN DE TRANSFERENCIAS
 GENERACIÓN DE TRANSFERENCIAS 1 INFORMACIÓN BÁSICA La aplicación de generación de ficheros de transferencias permite generar fácilmente órdenes para que la Caja efectúe transferencias, creando una base
GENERACIÓN DE TRANSFERENCIAS 1 INFORMACIÓN BÁSICA La aplicación de generación de ficheros de transferencias permite generar fácilmente órdenes para que la Caja efectúe transferencias, creando una base
Sub consultas avanzadas
 Sub consultas avanzadas Objetivo Después de completar este capítulo conocerá lo siguiente: Escribir una consulta de múltiples columnas Describir y explicar el comportamiento de las sub consultas cuando
Sub consultas avanzadas Objetivo Después de completar este capítulo conocerá lo siguiente: Escribir una consulta de múltiples columnas Describir y explicar el comportamiento de las sub consultas cuando
Introducción. Ciclo de vida de los Sistemas de Información. Diseño Conceptual
 Introducción Algunas de las personas que trabajan con SGBD relacionales parecen preguntarse porqué deberían preocuparse del diseño de las bases de datos que utilizan. Después de todo, la mayoría de los
Introducción Algunas de las personas que trabajan con SGBD relacionales parecen preguntarse porqué deberían preocuparse del diseño de las bases de datos que utilizan. Después de todo, la mayoría de los
Acronis License Server. Guía del usuario
 Acronis License Server Guía del usuario TABLA DE CONTENIDO 1. INTRODUCCIÓN... 3 1.1 Generalidades... 3 1.2 Política de licencias... 3 2. SISTEMAS OPERATIVOS COMPATIBLES... 4 3. INSTALACIÓN DE ACRONIS LICENSE
Acronis License Server Guía del usuario TABLA DE CONTENIDO 1. INTRODUCCIÓN... 3 1.1 Generalidades... 3 1.2 Política de licencias... 3 2. SISTEMAS OPERATIVOS COMPATIBLES... 4 3. INSTALACIÓN DE ACRONIS LICENSE
port@firmas V.2.3.1 Manual de Portafirmas V.2.3.1
 Manual de Portafirmas V.2.3.1 1 1.- Introducción 2.- Acceso 3.- Interfaz 4.- Bandejas de peticiones 5.- Etiquetas 6.- Búsquedas 7.- Petición de firma 8.- Redactar petición 9.- Firma 10.- Devolución de
Manual de Portafirmas V.2.3.1 1 1.- Introducción 2.- Acceso 3.- Interfaz 4.- Bandejas de peticiones 5.- Etiquetas 6.- Búsquedas 7.- Petición de firma 8.- Redactar petición 9.- Firma 10.- Devolución de
Selección de los puntos de montaje
 PARTICIONES PARA LINUX Selección de los puntos de montaje Tanto para aquellos que vayan a instalar ahora, como para quienes quieran cambiar el tamaño de una partición o formatear este apunte (resumen de
PARTICIONES PARA LINUX Selección de los puntos de montaje Tanto para aquellos que vayan a instalar ahora, como para quienes quieran cambiar el tamaño de una partición o formatear este apunte (resumen de
Introducción a la Firma Electrónica en MIDAS
 Introducción a la Firma Electrónica en MIDAS Firma Digital Introducción. El Módulo para la Integración de Documentos y Acceso a los Sistemas(MIDAS) emplea la firma digital como método de aseguramiento
Introducción a la Firma Electrónica en MIDAS Firma Digital Introducción. El Módulo para la Integración de Documentos y Acceso a los Sistemas(MIDAS) emplea la firma digital como método de aseguramiento
UAM MANUAL DE EMPRESA. Universidad Autónoma de Madrid
 MANUAL DE EMPRESA Modo de entrar en ÍCARO Para comenzar a subir una oferta de empleo, el acceso es a través del siguiente enlace: http://icaro.uam.es A continuación, aparecerá la página de inicio de la
MANUAL DE EMPRESA Modo de entrar en ÍCARO Para comenzar a subir una oferta de empleo, el acceso es a través del siguiente enlace: http://icaro.uam.es A continuación, aparecerá la página de inicio de la
Autor: Microsoft Licencia: Cita Fuente: Ayuda de Windows
 Qué es Recuperación? Recuperación del Panel de control proporciona varias opciones que pueden ayudarle a recuperar el equipo de un error grave. Nota Antes de usar Recuperación, puede probar primero uno
Qué es Recuperación? Recuperación del Panel de control proporciona varias opciones que pueden ayudarle a recuperar el equipo de un error grave. Nota Antes de usar Recuperación, puede probar primero uno
Guías _SGO. Gestione administradores, usuarios y grupos de su empresa. Sistema de Gestión Online
 Guías _SGO Gestione administradores, usuarios y grupos de su empresa Sistema de Gestión Online Índice General 1. Parámetros Generales... 4 1.1 Qué es?... 4 1.2 Consumo por Cuentas... 6 1.3 Días Feriados...
Guías _SGO Gestione administradores, usuarios y grupos de su empresa Sistema de Gestión Online Índice General 1. Parámetros Generales... 4 1.1 Qué es?... 4 1.2 Consumo por Cuentas... 6 1.3 Días Feriados...
MANUAL DE USUARIO CMS- PLONE www.trabajo.gob.hn
 MANUAL DE USUARIO CMS- PLONE www.trabajo.gob.hn Tegucigalpa M. D. C., Junio de 2009 Que es un CMS Un sistema de administración de contenido (CMS por sus siglas en ingles) es un programa para organizar
MANUAL DE USUARIO CMS- PLONE www.trabajo.gob.hn Tegucigalpa M. D. C., Junio de 2009 Que es un CMS Un sistema de administración de contenido (CMS por sus siglas en ingles) es un programa para organizar
O C T U B R E 2 0 1 3 SOPORTE CLIENTE. Manual de Usuario Versión 1. VERSIÓN 1 P á g i n a 1
 SOPORTE CLIENTE Manual de Usuario Versión 1 VERSIÓN 1 P á g i n a 1 Contenido Contenido... 2 INTRODUCCIÓN... 3 DESCRIPCIÓN ACTIVIDADES... 4 1. INICIO... 4 2. REGISTRAR NUEVO CLIENTE... 5 1.1 INGRESO DE
SOPORTE CLIENTE Manual de Usuario Versión 1 VERSIÓN 1 P á g i n a 1 Contenido Contenido... 2 INTRODUCCIÓN... 3 DESCRIPCIÓN ACTIVIDADES... 4 1. INICIO... 4 2. REGISTRAR NUEVO CLIENTE... 5 1.1 INGRESO DE
GENERALIDADES DE BASES DE DATOS
 GENERALIDADES DE BASES DE DATOS A fin de evitar que idénticos datos se encuentren repetidos en múltiples archivos, parece necesario que los comunes se almacenen en un archivo único y que este archivo sea
GENERALIDADES DE BASES DE DATOS A fin de evitar que idénticos datos se encuentren repetidos en múltiples archivos, parece necesario que los comunes se almacenen en un archivo único y que este archivo sea
MANUAL DE USUARIO APLICACIÓN SYSACTIVOS
 MANUAL DE USUARIO APLICACIÓN SYSACTIVOS Autor Edwar Orlando Amaya Diaz Analista de Desarrollo y Soporte Produce Sistemas y Soluciones Integradas S.A.S Versión 1.0 Fecha de Publicación 19 Diciembre 2014
MANUAL DE USUARIO APLICACIÓN SYSACTIVOS Autor Edwar Orlando Amaya Diaz Analista de Desarrollo y Soporte Produce Sistemas y Soluciones Integradas S.A.S Versión 1.0 Fecha de Publicación 19 Diciembre 2014
TEMA 20 EXP. WINDOWS PROC. DE TEXTOS (1ª PARTE)
") 1. Introducción. TEMA 20 EXP. WINDOWS PROC. DE TEXTOS (1ª PARTE) El Explorador es una herramienta indispensable en un Sistema Operativo ya que con ella se puede organizar y controlar los contenidos (archivos
1. Introducción. TEMA 20 EXP. WINDOWS PROC. DE TEXTOS (1ª PARTE) El Explorador es una herramienta indispensable en un Sistema Operativo ya que con ella se puede organizar y controlar los contenidos (archivos
Metadatos en Plataformas ECM
 Metadatos en Plataformas ECM understanding documents Ofrece tu sistema soporte para tipos documentales en bases de datos? Por qué debería importarte? Marzo, 2013 Basado en: Manejo de metadatos en plataformas
Metadatos en Plataformas ECM understanding documents Ofrece tu sistema soporte para tipos documentales en bases de datos? Por qué debería importarte? Marzo, 2013 Basado en: Manejo de metadatos en plataformas
Seminario de Informática
 Unidad II: Operaciones Básicas de Sistemas Operativos sobre base Windows 11. Herramientas del Sistema INTRODUCCION Este apunte está basado en Windows XP por ser el que estamos utilizando en el gabinete
Unidad II: Operaciones Básicas de Sistemas Operativos sobre base Windows 11. Herramientas del Sistema INTRODUCCION Este apunte está basado en Windows XP por ser el que estamos utilizando en el gabinete
Unidad III: Lenguaje de manipulación de datos (DML) 3.1 Inserción, eliminación y modificación de registros
 3.1 Inserción, eliminación y modificación de registros") Unidad III: Lenguaje de manipulación de datos (DML) 3.1 Inserción, eliminación y modificación de registros La sentencia INSERT permite agregar nuevas filas de datos a las tablas existentes. Está sentencia
Unidad III: Lenguaje de manipulación de datos (DML) 3.1 Inserción, eliminación y modificación de registros La sentencia INSERT permite agregar nuevas filas de datos a las tablas existentes. Está sentencia
Manual de uso de la plataforma para monitores. CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES -bilib
 Manual de uso de la plataforma para monitores CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES -bilib [Manual de uso de la plataforma para monitores] 1. Licencia Autor del documento: Centro de Apoyo Tecnológico
Manual de uso de la plataforma para monitores CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES -bilib [Manual de uso de la plataforma para monitores] 1. Licencia Autor del documento: Centro de Apoyo Tecnológico
AGREGAR COMPONENTES ADICIONALES DE WINDOWS
 INSTALACIÓN DE IIS EN WINDOWS XP El sistema está desarrollado para ejecutarse bajo la plataforma IIS de Windows XP. Por esta razón, incluimos la instalación de IIS (Servidor de Web) para la correcta ejecución
INSTALACIÓN DE IIS EN WINDOWS XP El sistema está desarrollado para ejecutarse bajo la plataforma IIS de Windows XP. Por esta razón, incluimos la instalación de IIS (Servidor de Web) para la correcta ejecución
CREACIÓN O MIGRACIÓN DEL CORREO POP A IMAP PARA MOZILLA THUNDERBIRD
 CREACIÓN O MIGRACIÓN DEL CORREO POP A IMAP PARA MOZILLA THUNDERBIRD Realización de copia de seguridad del correo actual... 2 Creación y configuración de la cuenta IMAP... 6 Migración de carpetas de POP
CREACIÓN O MIGRACIÓN DEL CORREO POP A IMAP PARA MOZILLA THUNDERBIRD Realización de copia de seguridad del correo actual... 2 Creación y configuración de la cuenta IMAP... 6 Migración de carpetas de POP
Capítulo 9. Archivos de sintaxis
 Capítulo 9 Archivos de sintaxis El SPSS permite generar y editar archivos de texto con sintaxis SPSS, es decir, archivos de texto con instrucciones de programación en un lenguaje propio del SPSS. Esta
Capítulo 9 Archivos de sintaxis El SPSS permite generar y editar archivos de texto con sintaxis SPSS, es decir, archivos de texto con instrucciones de programación en un lenguaje propio del SPSS. Esta
Plataforma e-ducativa Aragonesa. Manual de Administración. Bitácora
 Plataforma e-ducativa Aragonesa Manual de Administración Bitácora ÍNDICE Acceso a la administración de la Bitácora...3 Interfaz Gráfica...3 Publicaciones...4 Cómo Agregar una Publicación...4 Cómo Modificar
Plataforma e-ducativa Aragonesa Manual de Administración Bitácora ÍNDICE Acceso a la administración de la Bitácora...3 Interfaz Gráfica...3 Publicaciones...4 Cómo Agregar una Publicación...4 Cómo Modificar
Manual para la obtención del certificado del sello digital. Manual para la obtención del certificado del sello digital
 Manual para la obtención del certificado del sello digital Manual para la obtención del certificado del sello digital. 1. Introducción 1.1. Objetivo. El objetivo de este documento es proporcionarle al
Manual para la obtención del certificado del sello digital Manual para la obtención del certificado del sello digital. 1. Introducción 1.1. Objetivo. El objetivo de este documento es proporcionarle al
ARQUITECTURA DE DISTRIBUCIÓN DE DATOS
 4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
CONVERSOR LIBROS DE REGISTRO (IVA IGIC) Agencia Tributaria DEPARTAMENTO DE INFORMÁTICA TRIBUTARIA
 Agencia Tributaria DEPARTAMENTO DE INFORMÁTICA TRIBUTARIA") CONVERSOR LIBROS DE REGISTRO (IVA IGIC) Agencia Tributaria DEPARTAMENTO DE INFORMÁTICA TRIBUTARIA ÍNDICE DEL DOCUMENTO 1. INTRODUCCIÓN...2 1.1. REQUISITOS TÉCNICOS...2 2. DECLARACIONES...3 2.1. CREAR UNA
CONVERSOR LIBROS DE REGISTRO (IVA IGIC) Agencia Tributaria DEPARTAMENTO DE INFORMÁTICA TRIBUTARIA ÍNDICE DEL DOCUMENTO 1. INTRODUCCIÓN...2 1.1. REQUISITOS TÉCNICOS...2 2. DECLARACIONES...3 2.1. CREAR UNA
COMANDOS DE SQL, OPERADORES, CLAUSULAS Y CONSULTAS SIMPLES DE SELECCIÓN
 COMANDOS DE SQL, OPERADORES, CLAUSULAS Y CONSULTAS SIMPLES DE SELECCIÓN Tipos de datos SQL admite una variada gama de tipos de datos para el tratamiento de la información contenida en las tablas, los tipos
COMANDOS DE SQL, OPERADORES, CLAUSULAS Y CONSULTAS SIMPLES DE SELECCIÓN Tipos de datos SQL admite una variada gama de tipos de datos para el tratamiento de la información contenida en las tablas, los tipos
Sistema para el control y tramitación de documentos SITA MSc. María de la Caridad Robledo Gómez y Ernesto García Fernández.
 Sistema para el control y tramitación de documentos SITA MSc. María de la Caridad Robledo Gómez y Ernesto García Fernández. CITMATEL Ave 47 e/18 A y 20, Playa, Ciudad de La habana, CP 10300 Cuba. E mail:
Sistema para el control y tramitación de documentos SITA MSc. María de la Caridad Robledo Gómez y Ernesto García Fernández. CITMATEL Ave 47 e/18 A y 20, Playa, Ciudad de La habana, CP 10300 Cuba. E mail:
Guía de instalación de la carpeta Datos de IslaWin
 Guía de instalación de la carpeta Datos de IslaWin Para IslaWin Gestión CS, Classic o Pyme a partir de la revisión 7.00 (Revisión: 10/11/2011) Contenido Introducción... 3 Acerca de este documento... 3
Guía de instalación de la carpeta Datos de IslaWin Para IslaWin Gestión CS, Classic o Pyme a partir de la revisión 7.00 (Revisión: 10/11/2011) Contenido Introducción... 3 Acerca de este documento... 3
GESTINLIB GESTIÓN PARA LIBRERÍAS, PAPELERÍAS Y KIOSCOS DESCRIPCIÓN DEL MÓDULO DE KIOSCOS
 GESTINLIB GESTIÓN PARA LIBRERÍAS, PAPELERÍAS Y KIOSCOS DESCRIPCIÓN DEL MÓDULO DE KIOSCOS 1.- PLANTILLA DE PUBLICACIONES En este maestro crearemos la publicación base sobre la cual el programa generará
GESTINLIB GESTIÓN PARA LIBRERÍAS, PAPELERÍAS Y KIOSCOS DESCRIPCIÓN DEL MÓDULO DE KIOSCOS 1.- PLANTILLA DE PUBLICACIONES En este maestro crearemos la publicación base sobre la cual el programa generará
Un nombre de usuario de 30 caracteres o menos, sin caracteres especiales y que inicie con una letra.
 Unidad IV: Seguridad 4.1 Tipos de usuario El objetivo de la creación de usuarios es establecer una cuenta segura y útil, que tenga los privilegios adecuados y los valores por defecto apropiados Para acceder
Unidad IV: Seguridad 4.1 Tipos de usuario El objetivo de la creación de usuarios es establecer una cuenta segura y útil, que tenga los privilegios adecuados y los valores por defecto apropiados Para acceder
PANEL DE CONTROL (Zona de Administración) MANUAL DE USO Por conexanet. Revisión 1.1 Fecha 2006-08
 MANUAL DE USO Por conexanet. Revisión 1.1 Fecha 2006-08") PANEL DE CONTROL (Zona de Administración) MANUAL DE USO Por conexanet Revisión 1.1 Fecha 2006-08 Índice 1. Acceder 2. Menú 3. Gestión Básica 3.1 Añadir 3.2 Editar 3.3 Eliminar 3.4 Eliminación de registros
PANEL DE CONTROL (Zona de Administración) MANUAL DE USO Por conexanet Revisión 1.1 Fecha 2006-08 Índice 1. Acceder 2. Menú 3. Gestión Básica 3.1 Añadir 3.2 Editar 3.3 Eliminar 3.4 Eliminación de registros
MANUAL COPIAS DE SEGURIDAD
 MANUAL COPIAS DE SEGURIDAD Índice de contenido Ventajas del nuevo sistema de copia de seguridad...2 Actualización de la configuración...2 Pantalla de configuración...3 Configuración de las rutas...4 Carpeta
MANUAL COPIAS DE SEGURIDAD Índice de contenido Ventajas del nuevo sistema de copia de seguridad...2 Actualización de la configuración...2 Pantalla de configuración...3 Configuración de las rutas...4 Carpeta
COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA
 COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA Autor: Carlos Javier Martín González. Licenciado en Física Teórica por la Universidad Autónoma de Madrid. Analista programador y funcional. Desarrollador
COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA Autor: Carlos Javier Martín González. Licenciado en Física Teórica por la Universidad Autónoma de Madrid. Analista programador y funcional. Desarrollador
Manual para la utilización de PrestaShop
 Manual para la utilización de PrestaShop En este manual mostraremos de forma sencilla y práctica la utilización del Gestor de su Tienda Online mediante Prestashop 1.6, explicaremos todo lo necesario para
Manual para la utilización de PrestaShop En este manual mostraremos de forma sencilla y práctica la utilización del Gestor de su Tienda Online mediante Prestashop 1.6, explicaremos todo lo necesario para
2_trabajar con calc I
 Al igual que en las Tablas vistas en el procesador de texto, la interseccción de una columna y una fila se denomina Celda. Dentro de una celda, podemos encontrar diferentes tipos de datos: textos, números,
Al igual que en las Tablas vistas en el procesador de texto, la interseccción de una columna y una fila se denomina Celda. Dentro de una celda, podemos encontrar diferentes tipos de datos: textos, números,
SISTEMA InfoSGA Manual de Actualización Mensajeros Radio Worldwide C.A Código Postal 1060
 SISTEMA InfoSGA Manual de Actualización Mensajeros Radio Worldwide C.A Código Postal 1060 Elaborado por: Departamento de Informática Febrero 2012 SISTEMA InfoSGA _ Manual de Actualización 16/02/2012 ÍNDICE
SISTEMA InfoSGA Manual de Actualización Mensajeros Radio Worldwide C.A Código Postal 1060 Elaborado por: Departamento de Informática Febrero 2012 SISTEMA InfoSGA _ Manual de Actualización 16/02/2012 ÍNDICE
PROYECTOS, FORMULACIÓN Y CRITERIOS DE EVALUACIÓN
 PROYECTOS, FORMULACIÓN Y CRITERIOS DE EVALUACIÓN GESTIÓN DE PROYECTOS CON PLANNER AVC APOYO VIRTUAL PARA EL CONOCIMIENTO GESTIÓN DE PROYECTOS CON PLANNER Planner es una poderosa herramienta de software
PROYECTOS, FORMULACIÓN Y CRITERIOS DE EVALUACIÓN GESTIÓN DE PROYECTOS CON PLANNER AVC APOYO VIRTUAL PARA EL CONOCIMIENTO GESTIÓN DE PROYECTOS CON PLANNER Planner es una poderosa herramienta de software
Construcción de Escenarios
 Construcción de Escenarios Consiste en observar los diferentes resultados de un modelo, cuando se introducen diferentes valores en las variables de entrada. Por ejemplo: Ventas, crecimiento de ventas,
Construcción de Escenarios Consiste en observar los diferentes resultados de un modelo, cuando se introducen diferentes valores en las variables de entrada. Por ejemplo: Ventas, crecimiento de ventas,
LiLa Portal Guía para profesores
 Library of Labs Lecturer s Guide LiLa Portal Guía para profesores Se espera que los profesores se encarguen de gestionar el aprendizaje de los alumnos, por lo que su objetivo es seleccionar de la lista
Library of Labs Lecturer s Guide LiLa Portal Guía para profesores Se espera que los profesores se encarguen de gestionar el aprendizaje de los alumnos, por lo que su objetivo es seleccionar de la lista
INVENTARIO INTRODUCCIÓN RESUMEN DE PASOS
 INVENTARIO INTRODUCCIÓN Es habitual que en las empresas realicen a final de año un Inventario. Con este proceso se pretende controlar el nivel de stock existente, para iniciar el nuevo ejercicio, conociendo
INVENTARIO INTRODUCCIÓN Es habitual que en las empresas realicen a final de año un Inventario. Con este proceso se pretende controlar el nivel de stock existente, para iniciar el nuevo ejercicio, conociendo
CRM Gestión de Oportunidades Documento de Construcción Bizagi Process Modeler
 Bizagi Process Modeler Copyright 2011 - Bizagi Tabla de Contenido CRM- Gestión de Oportunidades de Venta... 4 Descripción... 4 Principales Factores en la Construcción del Proceso... 5 Modelo de Datos...
Bizagi Process Modeler Copyright 2011 - Bizagi Tabla de Contenido CRM- Gestión de Oportunidades de Venta... 4 Descripción... 4 Principales Factores en la Construcción del Proceso... 5 Modelo de Datos...
Prototipo de un sistema. interactivo de soporte y ayuda a los compradores de un centro. comercial de equipamiento del hogar
 Prototipo de un sistema interactivo de soporte y ayuda a los compradores de un centro comercial de equipamiento del hogar Chema Lizano Lacasa. Miguel Ancho Morlans. IPO1-5 INDICE 1.- Descripción general....3
Prototipo de un sistema interactivo de soporte y ayuda a los compradores de un centro comercial de equipamiento del hogar Chema Lizano Lacasa. Miguel Ancho Morlans. IPO1-5 INDICE 1.- Descripción general....3
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
CAPITULO V. SIMULACION DEL SISTEMA 5.1 DISEÑO DEL MODELO
 CAPITULO V. SIMULACION DEL SISTEMA 5.1 DISEÑO DEL MODELO En base a las variables mencionadas anteriormente se describirán las relaciones que existen entre cada una de ellas, y como se afectan. Dichas variables
CAPITULO V. SIMULACION DEL SISTEMA 5.1 DISEÑO DEL MODELO En base a las variables mencionadas anteriormente se describirán las relaciones que existen entre cada una de ellas, y como se afectan. Dichas variables
Manual de Usuario Comprador. Módulo Administración de Presupuesto. www.iconstruye.com. Iconstruy e S.A. Serv icio de Atención Telefónica: 486 11 11
 Manual de Usuario Comprador www.iconstruye.com Módulo Administración de Presupuesto Iconstruy e S.A. Serv icio de Atención Telefónica: 486 11 11 Índice ÍNDICE...1 DESCRIPCIÓN GENERAL...2 CONFIGURACIÓN...3
Manual de Usuario Comprador www.iconstruye.com Módulo Administración de Presupuesto Iconstruy e S.A. Serv icio de Atención Telefónica: 486 11 11 Índice ÍNDICE...1 DESCRIPCIÓN GENERAL...2 CONFIGURACIÓN...3
BASE DE DATOS RELACIONALES
 BASE DE DATOS RELACIONALES Una base de datos relacional es una base de datos que cumple con el modelo relacional, el cual es el modelo más utilizado en la actualidad para implementar bases de datos ya
BASE DE DATOS RELACIONALES Una base de datos relacional es una base de datos que cumple con el modelo relacional, el cual es el modelo más utilizado en la actualidad para implementar bases de datos ya
Guía de instalación de la carpeta Datos de ContaWin
 Guía de instalación de la carpeta Datos de ContaWin Para ContaWin CS, Classic o Pyme a partir de la revisión 12.10 (Revisión: 29/06/2011) Contenido Introducción... 3 Acerca de este documento... 3 Dónde
Guía de instalación de la carpeta Datos de ContaWin Para ContaWin CS, Classic o Pyme a partir de la revisión 12.10 (Revisión: 29/06/2011) Contenido Introducción... 3 Acerca de este documento... 3 Dónde
Mantenimiento Limpieza
 Mantenimiento Limpieza El programa nos permite decidir qué tipo de limpieza queremos hacer. Si queremos una limpieza diaria, tipo Hotel, en el que se realizan todos los servicios en la habitación cada
Mantenimiento Limpieza El programa nos permite decidir qué tipo de limpieza queremos hacer. Si queremos una limpieza diaria, tipo Hotel, en el que se realizan todos los servicios en la habitación cada
Bienvenido al sistema de Curriculum Digital CVDigital
 CVDigital 1 Bienvenido al sistema de Curriculum Digital CVDigital Este programa se ha desarrollado con el fin de llevar a cabo Certificaciones y Recertificaciones de los profesionales a partir del ingreso
CVDigital 1 Bienvenido al sistema de Curriculum Digital CVDigital Este programa se ha desarrollado con el fin de llevar a cabo Certificaciones y Recertificaciones de los profesionales a partir del ingreso
En términos generales, un foro es un espacio de debate donde pueden expresarse ideas o comentarios sobre uno o varios temas.
 1 de 18 Inicio Qué es un foro En términos generales, un foro es un espacio de debate donde pueden expresarse ideas o comentarios sobre uno o varios temas. En el campus virtual, el foro es una herramienta
1 de 18 Inicio Qué es un foro En términos generales, un foro es un espacio de debate donde pueden expresarse ideas o comentarios sobre uno o varios temas. En el campus virtual, el foro es una herramienta
Hi-Spins. Hi-Spins - Novedades v.10.2.0 10.2.2
 Hi-Spins Hi-Spins - Novedades 10.2.2 Tabla de contenido Hi-Spins Consulta Renovación de la presentación gráfica................................... 3 Visualización compacta de dimensiones en ventana de
Hi-Spins Hi-Spins - Novedades 10.2.2 Tabla de contenido Hi-Spins Consulta Renovación de la presentación gráfica................................... 3 Visualización compacta de dimensiones en ventana de
MANUAL DE USUARIOS DEL SISTEMA MESA DE SOPORTE PARA SOLICITAR SERVICIOS A GERENCIA DE INFORMATICA
 MANUAL DE USUARIOS DEL SISTEMA MESA DE SOPORTE PARA SOLICITAR SERVICIOS A Usuario Propietario: Gerencia de Informática Usuario Cliente: Todos los usuarios de ANDA Elaborada por: Gerencia de Informática,
MANUAL DE USUARIOS DEL SISTEMA MESA DE SOPORTE PARA SOLICITAR SERVICIOS A Usuario Propietario: Gerencia de Informática Usuario Cliente: Todos los usuarios de ANDA Elaborada por: Gerencia de Informática,
Access Control. Manual de Usuario
 Access Control Manual de Usuario Contenido Login... 3 Pantalla Principal... 3 Registro de Acceso... 4 Catálogos... 5 Empleados... 5 Departamentos... 8 Puestos... 9 Perfiles... 9 Usuarios... 11 Horarios...
Access Control Manual de Usuario Contenido Login... 3 Pantalla Principal... 3 Registro de Acceso... 4 Catálogos... 5 Empleados... 5 Departamentos... 8 Puestos... 9 Perfiles... 9 Usuarios... 11 Horarios...
 Introducción En los años 60 s y 70 s cuando se comenzaron a utilizar recursos de tecnología de información, no existía la computación personal, sino que en grandes centros de cómputo se realizaban todas
Introducción En los años 60 s y 70 s cuando se comenzaron a utilizar recursos de tecnología de información, no existía la computación personal, sino que en grandes centros de cómputo se realizaban todas
QUERCUS PRESUPUESTOS MANUAL DEL USO
 QUERCUS PRESUPUESTOS MANUAL DEL USO 2 Tabla de Contenido 1 Introducción 1 1.1 General 1 1.1.1 Que es Quercus Presupuestos? 1 1.1.2 Interfaz 1 1.1.3 Árbol de Navegación 2 1.1.4 Estructura de Datos de un
QUERCUS PRESUPUESTOS MANUAL DEL USO 2 Tabla de Contenido 1 Introducción 1 1.1 General 1 1.1.1 Que es Quercus Presupuestos? 1 1.1.2 Interfaz 1 1.1.3 Árbol de Navegación 2 1.1.4 Estructura de Datos de un