DESARROLLO DE APLICACIONES EN CUDA
|
|
|
- Ana Belmonte Velázquez
- hace 7 años
- Vistas:
Transcripción

1 DESARROLLO DE APLICACIONES EN CUDA Curso 2014 / 15 Procesadores Gráficos y Aplicaciones en Tiempo Real Alberto Sánchez GMRV /30

2 Contenidos Introducción Debugging Profiling Streams Diseño de aplicaciones CUDA 2/30

3 CPU vs GPU CPU Orientado a Latencia GPU Orientado a Throughput 3/30

4 CPU vs GPU CPUs pueden ser 10+X más rápidas que GPUs para código secuencial Caches grandes Control sofisticado. Predicción de saltos, pipeline ALU poderosa GPUs pueden 10+X más rápidas que CPUs para código paralelo Caches pequeñas Control sencillo Múltiples ALUs eficientes energéticamente 4/30

5 Anatomía de una aplicación CUDA Código serie se ejecuta en un thread en CPU Código paralelo se ejecuta en treads GPUs 5/30

6 Aplicación CUDA 6/30
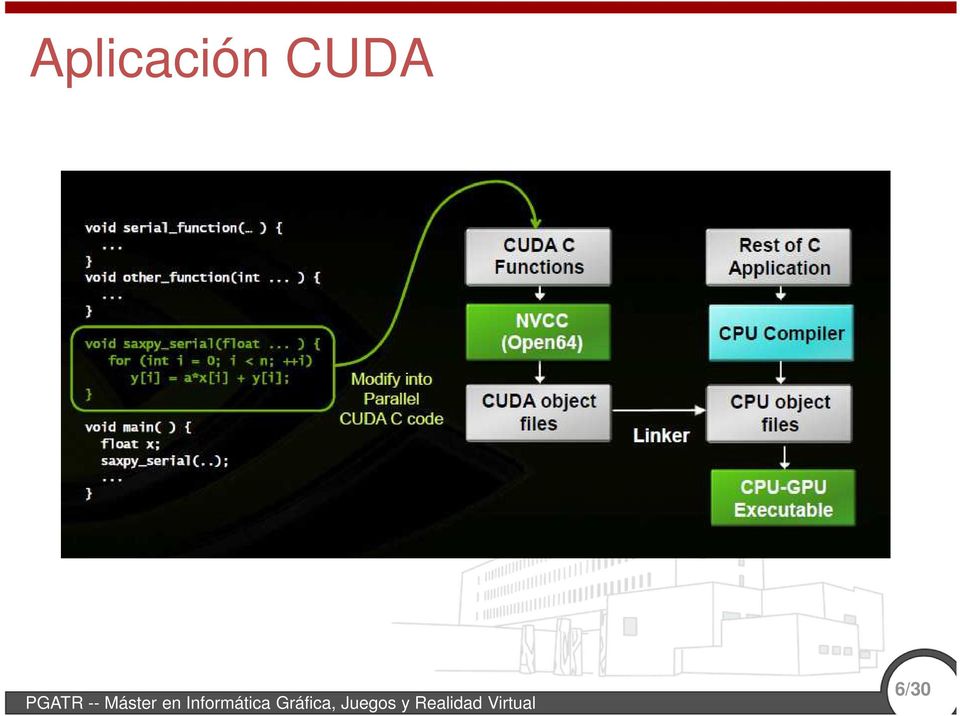
7 Aplicación CUDA Kernel: función llamada desde CPU que ejecuta en GPU como un array de threads en paralelo Solo puede acceder a memoria en GPU Todos los threads ejecutan el mismo código, aunque pueden tomar diferentes caminos Cada thread tiene un identificador (threadidx.x, blockidx.x, ) Permite seleccionar datos de entrada Decisiones de control Funciones se deben declarar: global : funcion kernel en GPU lanzada desde CPU. Debe devolver void device : funciones en GPU host : (por defecto) funciones en GPU 7/30
 Permite seleccionar datos de entrada Decisiones de control Funciones se deben declarar: global : funcion kernel en GPU")
8 Aplicación CUDA Threads esta agrupados en bloques (blockidx.x, ) La dimensión del bloque se puede conocer con blockdim Los bloques están agrupados en un grid y pueden ejecutar en cualquier orden, concurrentemente o secuencialmente Un kernel es ejecutado como un grid de bloques de threads 8/30

9 Jerarquia de memoria memoria compartida: shared int a[size]; Accesible por cada thread del bloque Elevado ancho de banda Memoria global Visible desde reserva hasta liberación de memoria en código cudamalloc(void ** pointer, size_tnbytes) cudamemset(void * pointer, int value, size_tcount) cudafree(void* pointer) Accesible por todos los threads Menor ancho de banda 9/30
 cudafree(void* pointer) Accesible por todos los threads Menor ancho de")

10 Aplicación CUDA 10/30

11 Condiciones de carrera Varios threads en ejecución Comparten datos El acceso concurrente a esos datos puede llevar a resultados erróneos: Ejemplo: Suma de 1 millón de threads, divididos en bloques. Cada uno de ellos suma en una posición del array correspondiente a su bloque b cuentagm[b] 11/30

12 Condiciones de carrera cuentamg[b]++ para thread0: register1 = cuentamg[b] register1 = register1 + 1 cuentamg[b] = register1 cuentamg[b]++ para thread1: register2 = cuentamg[b] register2 = register2 + 1 cuentamg[b] = register2 Supongamos que cuentamg[b] vale 5. Puede suceder que ambos threads lleguen a la instrucción que modifica cuentamg[b] y se ejecute lo siguiente: T0: register1 = cuentamg[b] {register1 = 5} T0: register1 = register1 + 1 {register1 = 6} T1: register2 = cuentamg[b] {register2 = 5} T1: register2 = register2 + 1 {register2 = 6} T0: cuentamg[b] = register1 {cuenta = 6 } T1: cuentamg[b] = register2 {cuenta = 6} Se ha llegado al valor de cuentamg[b] = 6 en memoria global (MG) que es incorrecto. 12/30
![Puede suceder que ambos threads lleguen a la instrucción que modifica cuentamg[b] y se ejecute lo siguiente: T0: register1 = cuentamg[b] {register1 = 5} T0: register1 = register1 +](/docs-images/49/19225088/images/page_12.jpg "1 {register1 = 6} T1: register2 = cuentamg[b] {register2 = 5} T1: register2 = register2 + 1 {register2 = 6} T0: cuentamg[b] = register1 {cuenta = 6 } T1: cuentamg[b] = register2")
13 Condiciones de carrera Esto sucede por permitir que ambos threads manipulen variables compartidas al mismo tiempo Cuando varios threads acceden a los mismos datos de forma concurrente y el resultado de la ejecución depende del orden concreto en que se realicen los accesos, se dice que hay una condición de carrera. Necesitamos mecanismos para tratar estas situaciones. Ej: atomicadd 13/30

14 Debugging Se requiere la instalación de CUDA Toolkit Actualmente v7.0 Se han extendido las herramientas de depuración tradicionales: cuda-gdb. Necesario compilar con el flag G nvcc g G code.cu o executable ddd. Más visual cuda-memcheck Nsight: Visual Studio (Windows) Eclipse (Linux/Mac) 14/30
 Eclipse")
15 Debugging Devices cuya versión es superior a 2.0 permiten depurar dentro de la tarjeta. Sencillez: Utilizando librería estandar printf #include " stdio.h" global kernel(){. printf("[%d][%d][%d] = %f\n",r,c,k,output);... } Depuración con Nsight dentro del propio kernel. Se pueden establecer breakpoints condicionales (ej. indicando el id del thread (threadidx.x == id)) 15/30
![printf("[%d][%d][%d] = %f\n",r,c,k,output);... } Depuración con Nsight dentro del propio kernel.](/docs-images/49/19225088/images/page_15.jpg "Se pueden establecer breakpoints condicionales (ej. indicando el id del thread (threadidx.")
16 Debugging Devices 1.0 y 1.1 no permiten depuración dentro de la tarjeta. Se puede hacer de forma más compleja: Librería cuprintf: imprime a través de la memoria de texturas #include "cuprintf.cuh" #include "cuprintf.cu" cudaprintfinit(); kernel<<<nblocks,nthreads>>>(); cudaprintfdisplay(stderr, true); cudaprintfend(); global kernel(){. cuprintf("[%d][%d][%d] = %f\n",r,c,k,output);... } 16/30
; kernel<<<nblocks,nthreads>>>(); cudaprintfdisplay(stderr, true);")
17 Compilación Para simplificar el proceso de compilación lo habitual es hacer un fichero Makefile en el mismo directorio donde estén los fuentes Posible definición de variables: CFLAGS=-I<path1> -I<path2>... CC=nvcc Ordenados en forma de reglas: objetivo: dependencias comandos Reglas virtuales: sin dependencias clean : rm *.o *~ Reglas implicitas: programa : programa.o programa.o : programa.c Reglas patrón: %.o : %.c $(CC) $(CFLAGS) $< -o $@ $< primera dependencia de la regla $@ primer objetivo de la regla Posibilidad de utilizar cmake Permite crear ficheros Makefile, Permite adaptación a IDE de programación: Visual Studio, Eclipse, Xcode, 17/30
 $(CFLAGS) $< -o $@ $< primera dependencia de la regla $@ primer objetivo de la regla Posibilidad de utilizar cmake Permite crear ficheros Makefile,")
18 Profiling Factores que limitan el rendimiento: Ancho de banda de memoria Ancho de banda de instrucciones Latencia Herramientas de Profiling Nvidia Visual Profiler: Herramienta propia: nvvp Integrado en Nsight nvprof: línea de comandos 18/30

19 Profiling Las herramientas de profiling en CUDA no requieren cambios en las aplicaciones Pero algunas modificaciones simples mejoran la utilidad y eficacia Anotaciones: Reducen el volumen de los datos a analizar Mejoran la usabilidad Mejoran la precisión del análisis 19/30

20 Profiling Limitar profiling a una región de interés: cuda_profiler_api.h cudaprofilerstart() cudaprofilerstop() nvprof --profile-from-start off para deshabilitar profiling al comienzo de la aplicación Desabilitar Start execution with profiling enabled en nvpp o Nsight 20/30

21 Profiling Que nos permite profiling Permite ver cuando cada thread de la CPU invoca funciones de CUDA (TimeView) Comprender las interacciones de la CPU / GPU Comprobar si se está aprovechando tanto CPU cómo GPU Saber si está la CPU esperando por la GPU o viceversa Buscar oportunidades de concurrencia Solapar transferencias (memcpy()) y kernels Solapar kernels concurrentes. Ojo con las condiciones de carrera 21/30
22 Streams Algunos dispositivos CUDA permiten solapar la ejecución de kernels con las copias entre host y device mediante el uso de streams int dev_count; cudadeviceprop prop; cudagetdevicecount (&dev_count); for (int i= 0; i<dev_count; i++) { cudagetdeviceproperties(&prop,i); if (prop.deviceoverlap) Cada stream es una cola FIFO de tareas (kernels y copias (memcpy). El driver asegura que las tareas de una cola se procesan de forma ordenada Las tareas que ejecutan en diferentes streams pueden ejecutar en paralelo permitiendo Task Paralellism Los eventos en CUDA permiten a la CPU sincronizar los diferentes streams 22/30
23 Streams Para poder solapar las transferencias de datos es necesario realizarlas de forma asíncrona cudastream_t stream0; cudastream_t stream1; cudamemcpyasync(h, d, size,, stream0); cudamemcpyasync(h, d, size,, stream1); kernel0<<<size/numthreads, numthreads, 0, stream0>>>(d,...); kernel1<<<size/numthreads, numthreads, 0, stream1>>>(d,...); cudamemcpyasync(h, d, size,, stream0); cudamemcpyasync(h, d, size,, stream1); 23/30
24 Streams Para sincronizar streams se utiliza cudastreamsynchronize (stream_id); Espera hasta que todas las tareas del stream han finalizado Para esperar por todos los streams se hace mediante: cudadevicesynchronize(); Además de los streams se pueden tener diferentes GPUs en funcionamiento. La CPU siempre tiene en contexto una GPU. Para cambiar de contexto se utiliza cudasetdevice(i) cudamalloc(&d[i], size); //Para provocar un cambio de contexto Se pueden gestionar cada una de las GPUs en paralelo mediante el uso de streams La memoria unificada (UVA) existente en CUDA en las últimas versiones del toolkit posibilita un único espacio de direcciones de memoria para GPUs y CPU que se puede utilizar para copias directas entre los diferentes dispositivos 24/30
25 Streams La versión 6 de CUDA toolkit elimina la necesidad de hacer copias CPU-GPU 25/30

26 Cuda 6 en adelante 26/30
27 Cuda 6 en adelante Elimina la necesidad de realizar múltiples copias 27/30
28 Cuda 6 en adelante Elimina la necesidad de realizar múltiples copias 28/30
29 Diseño de aplicaciones CUDA Tres reglas básicas basadas en la arquitectura: 1. Poner los datos en la GPU y mantenerlos allí 2. Dar a la GPU suficiente trabajo que hacer 3. Centrarse en la reutilización de datos en la GPU: evita limitaciones de ancho de banda de memoria 29/30
30 Diseño de aplicaciones CUDA Las transferencias de datos entre CPU- GPU son muy costosas Reducir en la medida de lo posible Cuando cudamemcpy() copia un array, se implementa como una transferencia de DMA La dirección se traduce y se comprueba que la página existe en memoria al principio de cada transferencia de DMA sin volver a traducir El sistema operativo podría accidentalmente paginar otra página de memoria virtual en la misma ubicación física 30/30
31 Diseño de aplicaciones CUDA Pinned memory son páginas de memoria marcadas para que no puedan expulsarse de memoria principal cudahostalloc(): indicando cudahostallocdefault cudafreehost() Si el origen o destino de cudamemcpy() no está en pinned memory, hay que copiarlo cudamemcpy() es aproximadamente 2 veces más rápido con pinned memory Pinned memory es un recurso limitado. Si se sobreexplota puede llevar a hiperpáginación 31/30
32 Diseño de aplicaciones CUDA Conveniencia de colocar los datos alineados en memoria para que los accesos sean coalescentes Primer factor para conseguir eficiencia Capacidad de la arquitectura para obtener 16 palabras de memoria simultáneamente (en un único acceso). Una para cada thread del half-warp (16) Tamaños de bloque múltiplo de 16 facilitan el acceso a memoria En cualquier caso, para no desperdiciar recursos, el tamaño de bloque debería ser múltiplo del tamaño de warp (32) Aprovecha la localidad espacial en memoria Se consigue bajo ciertos patrones de acceso 32/30
33 Diseño de aplicaciones CUDA Aprovechar al máximo los recursos de la GPU Tratar de minimizar la divergencia de warps Thread Level Parallelism: Lanzar suficientes threads para maximizar throughtput Ocupancia: número de warps ejecutando concurrentemente por ciclo en un multiprocesador dividido por el máximo número de warps que pueden estar en un SM Una elevada ocupancia implica que el planificador en cada SM tiene bastantes warps para elegir ocultando latencias de ALU y memoria. Conviene especificar múltiples bloques por SM (múltiplo del ńumero de SM) para ejecutar concurrentemente dentro del mismo Si es posible, especificar un gran número de bloques por grid 33/30
34 Diseño de aplicaciones CUDA Instruction Level Parallelism: Alta ocupancia no tiene porque traducirse en elevado rendimiento Usar menos threads posibilita tener mas registros por thread y más memoria compartida para cada uno de ellos Se puede intentar procesar varios elementos por thread Si las operaciones son independientes se pueden ocultar latencias de ALU, por lo que se pueden beneficiar problemas aritméticamente intensivos Más difícil para ocultar latencias de memoria 34/30
35 Diseño de aplicaciones CUDA Acceso a memoria global muy costoso La memoria compartida (16KB-48KB por MP) es muchísimo más rápida Cada bloque de threads copia su parte de datos de trabajo (tile) a memoria compartida ( shared ) El tamaño de los datos puede ser dinámico: extern shared int data[]; kernel<<<nblocks,nthreads,tilesize>>>; Se comparte la información del tile entre los threads del bloque y se trabaja sobre memoria compartida El resultado final se copia a global para su actualización Necesario rediseñar algoritmos 35/30
Primeros pasos con CUDA. Clase 1
 Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
CUDA: MODELO DE PROGRAMACIÓN
 CUDA: MODELO DE PROGRAMACIÓN Autor: Andrés Rondán Tema: GPUGP: nvidia CUDA. Introducción En Noviembre de 2006, NVIDIA crea CUDA, una arquitectura de procesamiento paralelo de propósito general, con un
CUDA: MODELO DE PROGRAMACIÓN Autor: Andrés Rondán Tema: GPUGP: nvidia CUDA. Introducción En Noviembre de 2006, NVIDIA crea CUDA, una arquitectura de procesamiento paralelo de propósito general, con un
Introducción a Cómputo Paralelo con CUDA C/C++
 UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO Facultad de Ingeniería Introducción a Cómputo Paralelo con CUDA C/C++ Laboratorio de Intel y Cómputo de alto desempeño Elaboran: Revisión: Ing. Laura Sandoval Montaño
UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO Facultad de Ingeniería Introducción a Cómputo Paralelo con CUDA C/C++ Laboratorio de Intel y Cómputo de alto desempeño Elaboran: Revisión: Ing. Laura Sandoval Montaño
INTRODUCCIÓN A LA PROGRAMACIÓN DE GPUS CON CUDA
 INTRODUCCIÓN A LA PROGRAMACIÓN DE GPUS CON CUDA Francisco Igual Peña León, 10 de mayo de 2011 PLANIFICACIÓN 1. Miércoles: Conceptos introductorios 1. Breve presentación de conceptos básicos 2. Ejercicios
INTRODUCCIÓN A LA PROGRAMACIÓN DE GPUS CON CUDA Francisco Igual Peña León, 10 de mayo de 2011 PLANIFICACIÓN 1. Miércoles: Conceptos introductorios 1. Breve presentación de conceptos básicos 2. Ejercicios
Introducción a la Arquitectura y Plataforma de Programación de Cómputo Paralelo CUDA (36 hrs) Instructor M. en C. Cristhian Alejandro Ávila-Sánchez
 Instructor M. en C. Cristhian Alejandro Ávila-Sánchez") Introducción a la Arquitectura y Plataforma de Programación de Cómputo Paralelo CUDA (36 hrs) I Presentación: Instructor M. en C. Cristhian Alejandro Ávila-Sánchez CUDA (Compute Unified Device Architecture)
Introducción a la Arquitectura y Plataforma de Programación de Cómputo Paralelo CUDA (36 hrs) I Presentación: Instructor M. en C. Cristhian Alejandro Ávila-Sánchez CUDA (Compute Unified Device Architecture)
CUDA 5.5 y Visual Studio Express 2012 para Escritorio. Primeros pasos.
 CUDA 5.5 y Visual Studio Express 2012 para Escritorio. Primeros pasos. La nueva versión de CUDA 5.5 es completamente compatible con la plataforma de desarrollo Visual Studio Express 2012 para escritorio
CUDA 5.5 y Visual Studio Express 2012 para Escritorio. Primeros pasos. La nueva versión de CUDA 5.5 es completamente compatible con la plataforma de desarrollo Visual Studio Express 2012 para escritorio
GPGPU ( GENERAL PURPOSE COMPUTING ON GRAPHICS PROCESSING UNITS)
") 26 GPGPU ( GENERAL PURPOSE COMPUTING ON GRAPHICS PROCESSING UNITS) Técnica GPGPU consiste en el uso de las GPU para resolver problemas computacionales de todo tipo aparte de los relacionados con el procesamiento
26 GPGPU ( GENERAL PURPOSE COMPUTING ON GRAPHICS PROCESSING UNITS) Técnica GPGPU consiste en el uso de las GPU para resolver problemas computacionales de todo tipo aparte de los relacionados con el procesamiento
Alejandro Molina Zarca
 Compute Unified Device Architecture (CUDA) Que es CUDA? Por qué CUDA? Dónde se usa CUDA? El Modelo CUDA Escalabilidad Modelo de programación Programación Heterogenea Memoria Compartida Alejandro Molina
Compute Unified Device Architecture (CUDA) Que es CUDA? Por qué CUDA? Dónde se usa CUDA? El Modelo CUDA Escalabilidad Modelo de programación Programación Heterogenea Memoria Compartida Alejandro Molina
Francisco J. Hernández López
 Francisco J. Hernández López fcoj23@cimat.mx 2 Procesadores flexibles de procesamiento general Se pueden resolver problemas de diversas áreas: Finanzas, Gráficos, Procesamiento de Imágenes y Video, Algebra
Francisco J. Hernández López fcoj23@cimat.mx 2 Procesadores flexibles de procesamiento general Se pueden resolver problemas de diversas áreas: Finanzas, Gráficos, Procesamiento de Imágenes y Video, Algebra
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Alvaro Cuno 23/01/2010 1 CUDA Arquitectura de computación paralela de propósito general La programación para la arquitectura CUDA puede hacerse usando lenguaje
CUDA (Compute Unified Device Architecture) Alvaro Cuno 23/01/2010 1 CUDA Arquitectura de computación paralela de propósito general La programación para la arquitectura CUDA puede hacerse usando lenguaje
INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA. Francisco Javier Hernández López
 INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA Francisco Javier Hernández López http://www.cimat.mx/~fcoj23 Guanajuato, Gto. Noviembre de 2012 Introducción a la Programación en CUDA 2 Qué es el Cómputo Paralelo
INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA Francisco Javier Hernández López http://www.cimat.mx/~fcoj23 Guanajuato, Gto. Noviembre de 2012 Introducción a la Programación en CUDA 2 Qué es el Cómputo Paralelo
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Arquitecturas GPU v. 2015
 v. 2015 http://en.wikipedia.org/wiki/graphics_processing_unit http://en.wikipedia.org/wiki/stream_processing http://en.wikipedia.org/wiki/general-purpose_computing_on_graphics_processing_ units http://www.nvidia.com/object/what-is-gpu-computing.html
v. 2015 http://en.wikipedia.org/wiki/graphics_processing_unit http://en.wikipedia.org/wiki/stream_processing http://en.wikipedia.org/wiki/general-purpose_computing_on_graphics_processing_ units http://www.nvidia.com/object/what-is-gpu-computing.html
GPU-Ejemplo CUDA. Carlos García Sánchez
 Carlos García Sánchez 1 2 Contenidos Motivación GPU vs. CPU GPU vs. Vectoriales CUDA Sintaxis Ejemplo 2 3 Motivación Computación altas prestaciones: www.top500.org 1º: Titan (300mil AMD-Opteron + 19mil
Carlos García Sánchez 1 2 Contenidos Motivación GPU vs. CPU GPU vs. Vectoriales CUDA Sintaxis Ejemplo 2 3 Motivación Computación altas prestaciones: www.top500.org 1º: Titan (300mil AMD-Opteron + 19mil
Comunicación y múltiples GPU
 Escuela de Computación de Alto Rendimiento 2014 Comunicación y múltiples GPU Carlos Bederián IFEG CONICET GPGPU Computing Group FaMAF UNC Streams - Motivación La GPU queda muy lejos del resto del sistema
Escuela de Computación de Alto Rendimiento 2014 Comunicación y múltiples GPU Carlos Bederián IFEG CONICET GPGPU Computing Group FaMAF UNC Streams - Motivación La GPU queda muy lejos del resto del sistema
Sistemas Operativos. Procesos
 Sistemas Operativos Procesos Agenda Proceso. Definición de proceso. Contador de programa. Memoria de los procesos. Estados de los procesos. Transiciones entre los estados. Bloque descriptor de proceso
Sistemas Operativos Procesos Agenda Proceso. Definición de proceso. Contador de programa. Memoria de los procesos. Estados de los procesos. Transiciones entre los estados. Bloque descriptor de proceso
Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas]
![Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas]](/thumbs/68/58196775.jpg "Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas]") Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas] RIO 2014 Río Cuarto (Argentina), 20 de Febrero, 2014 1. 2. 3. 4. 5. 6. Balanceo dinámico de la carga. [2] Mejorando el paralelismo
Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas] RIO 2014 Río Cuarto (Argentina), 20 de Febrero, 2014 1. 2. 3. 4. 5. 6. Balanceo dinámico de la carga. [2] Mejorando el paralelismo
Francisco Javier Hernández López
 Francisco Javier Hernández López fcoj23@cimat.mx http://www.cimat.mx/~fcoj23 Ejecución de más de un cómputo (cálculo) al mismo tiempo o en paralelo, utilizando más de un procesador. Arquitecturas que hay
Francisco Javier Hernández López fcoj23@cimat.mx http://www.cimat.mx/~fcoj23 Ejecución de más de un cómputo (cálculo) al mismo tiempo o en paralelo, utilizando más de un procesador. Arquitecturas que hay
V. OPTIMIZACIÓN PARA COMPUTACIÓN GPU EN CUDA
 V. OPTIMIZACIÓN PARA COMPUTACIÓN GPU EN CUDA La arquitectura de una GPU es básicamente distinta a la de una CPU. Las GPUs están estructuradas de manera paralela y disponen de un acceso a memoria interna
V. OPTIMIZACIÓN PARA COMPUTACIÓN GPU EN CUDA La arquitectura de una GPU es básicamente distinta a la de una CPU. Las GPUs están estructuradas de manera paralela y disponen de un acceso a memoria interna
Procesos y Threads Procesos y Threads. Concurrencia Concurrencia Ventajas Ventajas. Rendimiento Rendimiento (paralelismo) (paralelismo)
 (paralelismo)") Procesos y Threads Procesos y Threads Procesos Procesos Threads Threads Concurrencia Concurrencia Ventajas Ventajas Modelos Modelos Información Información adicional () adicional () Preparado Preparado
Procesos y Threads Procesos y Threads Procesos Procesos Threads Threads Concurrencia Concurrencia Ventajas Ventajas Modelos Modelos Información Información adicional () adicional () Preparado Preparado
Programación de una GPU con CUDA
 Programación de una GPU con CUDA Programación de Arquitecturas Multinúcleo Universidad de Murcia. Contenidos Introducción Arquitectura y programación de CUDA Optimización y depuración de código Librerías
Programación de una GPU con CUDA Programación de Arquitecturas Multinúcleo Universidad de Murcia. Contenidos Introducción Arquitectura y programación de CUDA Optimización y depuración de código Librerías
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Preparación y Adaptación de Códigos Científicos para su Ejecución Paralela TICAL 2018
 Preparación y Adaptación de Códigos Científicos para su Ejecución Paralela TICAL 2018 Gilberto Díaz gilberto.diaz@uis.edu.co Universidad Industrial de Santander Centro de Súper Computación y Cálculo Científico
Preparación y Adaptación de Códigos Científicos para su Ejecución Paralela TICAL 2018 Gilberto Díaz gilberto.diaz@uis.edu.co Universidad Industrial de Santander Centro de Súper Computación y Cálculo Científico
Plan 95 Adecuado DEPARTAMENTO: ELECTRÓNICA CLASE: ELECTIVA DE ESPECIALIDAD ÁREA: TÉCNICAS DIGITALES HORAS SEM.: 4 HS. HORAS / AÑO: 64 HS.
 Plan 95 Adecuado ASIGNATURA: COMPUTACIÓN PARALELA CON PROCESADORES GRÁFICOS CODIGO: 95-0409 DEPARTAMENTO: ELECTRÓNICA CLASE: ELECTIVA DE ESPECIALIDAD ÁREA: TÉCNICAS DIGITALES HORAS SEM.: 4 HS. HORAS /
Plan 95 Adecuado ASIGNATURA: COMPUTACIÓN PARALELA CON PROCESADORES GRÁFICOS CODIGO: 95-0409 DEPARTAMENTO: ELECTRÓNICA CLASE: ELECTIVA DE ESPECIALIDAD ÁREA: TÉCNICAS DIGITALES HORAS SEM.: 4 HS. HORAS /
Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]
![Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]](/thumbs/27/10261315.jpg "Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]") Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
Computación en procesadores gráficos
 Programación con CUDA Ejercicio 8 José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos
Programación con CUDA Ejercicio 8 José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU. Clase 5 Programación Avanzada y Optimización
 Computación de Propósito General en Unidades de Procesamiento Gráfico () P. Ezzatti, M. Pedemontey E. Dufrechou Clase 5 Programación Avanzada y Optimización Contenido Memoria compartida Conflicto de bancos
Computación de Propósito General en Unidades de Procesamiento Gráfico () P. Ezzatti, M. Pedemontey E. Dufrechou Clase 5 Programación Avanzada y Optimización Contenido Memoria compartida Conflicto de bancos
Sistema Operativo. Repaso de Estructura de Computadores. Componentes Hardware. Elementos Básicos
 Sistema Operativo Repaso de Estructura de Computadores Capítulo 1 Explota los recursos hardware de uno o más procesadores Proporciona un conjunto de servicios a los usuarios del sistema Gestiona la memoria
Sistema Operativo Repaso de Estructura de Computadores Capítulo 1 Explota los recursos hardware de uno o más procesadores Proporciona un conjunto de servicios a los usuarios del sistema Gestiona la memoria
Introducción a los Sistemas Operativos
 Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
Sistemas Operativos Tema 5. Procesos. 1998-2012 José Miguel Santos Alexis Quesada Francisco Santana
 Sistemas Operativos Tema 5. Procesos 1998-2012 José Miguel Santos Alexis Quesada Francisco Santana 1 Contenidos Concepto de proceso Estructuras de datos: BCP y colas de procesos Niveles de planificación
Sistemas Operativos Tema 5. Procesos 1998-2012 José Miguel Santos Alexis Quesada Francisco Santana 1 Contenidos Concepto de proceso Estructuras de datos: BCP y colas de procesos Niveles de planificación
Guillermo Román Díez
 Concurrencia Creación de Procesos en Java Guillermo Román Díez groman@fi.upm.es Universidad Politécnica de Madrid Curso 2016-2017 Guillermo Román, UPM CC: Creación de Procesos en Java 1/18 Concurrencia
Concurrencia Creación de Procesos en Java Guillermo Román Díez groman@fi.upm.es Universidad Politécnica de Madrid Curso 2016-2017 Guillermo Román, UPM CC: Creación de Procesos en Java 1/18 Concurrencia
Mapa de memoria. memoria CACHÉ
 Mapa de memoria memoria CACHÉ Miguel Ángel Asensio Hernández, Profesor de Electrónica de Comunicaciones. Departamento de Electrónica, I.E.S. Emérita Augusta. 06800 MÉRIDA. Segmentación de la memoria Estructuración
Mapa de memoria memoria CACHÉ Miguel Ángel Asensio Hernández, Profesor de Electrónica de Comunicaciones. Departamento de Electrónica, I.E.S. Emérita Augusta. 06800 MÉRIDA. Segmentación de la memoria Estructuración
Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)
![Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)](/thumbs/36/17576386.jpg "Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)") Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
CDI Arquitecturas que soportan la concurrencia. granularidad
 granularidad Se suele distinguir concurrencia de grano fino es decir, se aprovecha de la ejecución de operaciones concurrentes a nivel del procesador (hardware) a grano grueso es decir, se aprovecha de
granularidad Se suele distinguir concurrencia de grano fino es decir, se aprovecha de la ejecución de operaciones concurrentes a nivel del procesador (hardware) a grano grueso es decir, se aprovecha de
Concurrencia. Concurrencia
 Concurrencia Procesos y hebras Concurrencia Programación concurrente Por qué usar hebras y procesos? Ejecución de procesos Ejecución de hebras Hebras vs. Procesos Creación y ejecución de hebras La prioridad
Concurrencia Procesos y hebras Concurrencia Programación concurrente Por qué usar hebras y procesos? Ejecución de procesos Ejecución de hebras Hebras vs. Procesos Creación y ejecución de hebras La prioridad
Arquitecturas y programación de procesadores gráficos. Nicolás Guil Mata Dpto. de Arquitectura de Computadores Universidad de Málaga
 Arquitecturas y programación de procesadores gráficos Dpto. de Arquitectura de Computadores Universidad de Málaga Indice Arquitectura de las GPUs Arquitectura unificada Nvidia: GT200 Diagrama de bloques
Arquitecturas y programación de procesadores gráficos Dpto. de Arquitectura de Computadores Universidad de Málaga Indice Arquitectura de las GPUs Arquitectura unificada Nvidia: GT200 Diagrama de bloques
Computación en procesadores gráficos
 Programación con CUDA José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos Modelo de programación
Programación con CUDA José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos Modelo de programación
Arquitecturas GPU v. 2013
 v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
Iniciación a la Programación de GPU
 Iniciación a la Programación de GPU Domingo Giménez Básicamente a partir del seminario de Juan Fernández Peinador en el curso de Computación Científica en Clusters Algoritmos y Programación Paralela, curso
Iniciación a la Programación de GPU Domingo Giménez Básicamente a partir del seminario de Juan Fernández Peinador en el curso de Computación Científica en Clusters Algoritmos y Programación Paralela, curso
CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS
 CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS Leopoldo N. Gaxiola, Juan J. Tapia Centro de Investigación y Desarrollo de Tecnología Digital Instituto Politécnico Nacional Avenida
CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS Leopoldo N. Gaxiola, Juan J. Tapia Centro de Investigación y Desarrollo de Tecnología Digital Instituto Politécnico Nacional Avenida
Memorias, opciones del compilador y otras yerbas. Clase 3
 Memorias, opciones del compilador y otras yerbas Clase 3 Memorias en CUDA Grid CUDA ofrece distintas memorias con distintas características. Block (0, 0) Shared Memory Block (1, 0) Shared Memory registros
Memorias, opciones del compilador y otras yerbas Clase 3 Memorias en CUDA Grid CUDA ofrece distintas memorias con distintas características. Block (0, 0) Shared Memory Block (1, 0) Shared Memory registros
Segunda Parte: TECNOLOGÍA CUDA
 Segunda Parte: (compute unified device architecture) 12 I. CUDA CUDA es una arquitectura de cálculo paralelo de NVIDIA que aprovecha la potencia de la GPU (unidad de procesamiento gráfico) para proporcionar
Segunda Parte: (compute unified device architecture) 12 I. CUDA CUDA es una arquitectura de cálculo paralelo de NVIDIA que aprovecha la potencia de la GPU (unidad de procesamiento gráfico) para proporcionar
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS
 INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano sorts@dtic.ua.es Vicente Morell Giménez vmorell@dccia.ua.es Universidad de Alicante Departamento de tecnología informática y computación
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano sorts@dtic.ua.es Vicente Morell Giménez vmorell@dccia.ua.es Universidad de Alicante Departamento de tecnología informática y computación
TAREA 1. INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS.
 1 TAREA 1. INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS. 1- Cuáles son las principales funciones de un sistema operativo? Los Sistemas Operativos tienen como objetivos o funciones principales lo siguiente; Comodidad;
1 TAREA 1. INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS. 1- Cuáles son las principales funciones de un sistema operativo? Los Sistemas Operativos tienen como objetivos o funciones principales lo siguiente; Comodidad;
Bloque IV. Prácticas de programación en CUDA. David Miraut Marcos García Ricardo Suárez
 Bloque IV Prácticas de programación en CUDA David Miraut Marcos García Ricardo Suárez Control de flujo Situaciones no tratadas Claves con tamaños diferentes. Cada Wrap debería acceder a claves del mismo
Bloque IV Prácticas de programación en CUDA David Miraut Marcos García Ricardo Suárez Control de flujo Situaciones no tratadas Claves con tamaños diferentes. Cada Wrap debería acceder a claves del mismo
GESTION DE LA MEMORIA
 GESTION DE LA MEMORIA SISTEMAS OPERATIVOS Generalidades La memoria es una amplia tabla de datos, cada uno de los cuales con su propia dirección Tanto el tamaño de la tabla (memoria), como el de los datos
GESTION DE LA MEMORIA SISTEMAS OPERATIVOS Generalidades La memoria es una amplia tabla de datos, cada uno de los cuales con su propia dirección Tanto el tamaño de la tabla (memoria), como el de los datos
CUDA Overview and Programming model
 Departamento de Ciencias de la computación Universidad de Chile Modelado en 3D y sus Aplicaciones en Realidad Virtual CC68W CUDA Overview and Programming model Student: Juan Silva Professor: Dr. Wolfram
Departamento de Ciencias de la computación Universidad de Chile Modelado en 3D y sus Aplicaciones en Realidad Virtual CC68W CUDA Overview and Programming model Student: Juan Silva Professor: Dr. Wolfram
Concurrencia de Procesos
 Concurrencia de Procesos Dos o mas procesos, se dice que son concurrentes o paralelos, cuando se ejecutan al mismo tiempo. Esta concurrencia puede darse en un sistema con un solo procesador (pseudo paralelismo)
Concurrencia de Procesos Dos o mas procesos, se dice que son concurrentes o paralelos, cuando se ejecutan al mismo tiempo. Esta concurrencia puede darse en un sistema con un solo procesador (pseudo paralelismo)
Procesamiento Paralelo
 Procesamiento Paralelo OpenCL - Introducción Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar
Procesamiento Paralelo OpenCL - Introducción Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar
Programando con memoria unificada. Contenidos [15 diapositivas] Aportaciones de la memoria unificada. I. Descripción
![Programando con memoria unificada. Contenidos [15 diapositivas] Aportaciones de la memoria unificada. I. Descripción](/thumbs/27/11245443.jpg "Programando con memoria unificada. Contenidos [15 diapositivas] Aportaciones de la memoria unificada. I. Descripción") Programando con memoria unificada IX Curso de Verano de la UMA Programación de GPUs con CUDA Contenidos [15 diapositivas] Málaga, del 15 al 24 de Julio, 2015 1. Descripción [5] 2. Ejemplos [8] 3. Observaciones
Programando con memoria unificada IX Curso de Verano de la UMA Programación de GPUs con CUDA Contenidos [15 diapositivas] Málaga, del 15 al 24 de Julio, 2015 1. Descripción [5] 2. Ejemplos [8] 3. Observaciones
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
reactivision en CUDA:
 reactivision en CUDA: Aprovechando las capacidades de la computación paralela en GPU Daniel García Rodríguez Proyecto Final de Carrera Director: Sergi Jordà i Puig 17 de Junio de 2010 Ingeniería Informática
reactivision en CUDA: Aprovechando las capacidades de la computación paralela en GPU Daniel García Rodríguez Proyecto Final de Carrera Director: Sergi Jordà i Puig 17 de Junio de 2010 Ingeniería Informática
UNIVERSIDAD DE BURGOS Área de Tecnología Electrónica INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA
 UNIVERSIDAD DE BURGOS Área de Tecnología Electrónica INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA César Represa Pérez José María Cámara Nebreda Pedro Luis Sánchez Ortega Introducción a la programación en CUDA
UNIVERSIDAD DE BURGOS Área de Tecnología Electrónica INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA César Represa Pérez José María Cámara Nebreda Pedro Luis Sánchez Ortega Introducción a la programación en CUDA
Aspectos avanzados de arquitectura de computadoras Multiprocesadores (I) Facultad de Ingeniería - Universidad de la República Curso 2017
 Facultad de Ingeniería - Universidad de la República Curso 2017") Aspectos avanzados de arquitectura de computadoras Multiprocesadores (I) Facultad de Ingeniería - Universidad de la República Curso 2017 Motivación Explotación de ILP estancada desde 2005 (aproximadamente)
Aspectos avanzados de arquitectura de computadoras Multiprocesadores (I) Facultad de Ingeniería - Universidad de la República Curso 2017 Motivación Explotación de ILP estancada desde 2005 (aproximadamente)
Programación Concurrente y Paralela. Unidad 1 Introducción
 Programación Concurrente y Paralela Unidad 1 Introducción Contenido 1.1 Concepto de Concurrencia 1.2 Exclusión Mutua y Sincronización 1.3 Corrección en Sistemas Concurrentes 1.4 Consideraciones sobre el
Programación Concurrente y Paralela Unidad 1 Introducción Contenido 1.1 Concepto de Concurrencia 1.2 Exclusión Mutua y Sincronización 1.3 Corrección en Sistemas Concurrentes 1.4 Consideraciones sobre el
Organización de Computadoras. Pipeline Continuación
 Organización de Computadoras Pipeline Continuación Extensión del pipeline para manejar operaciones multiciclo (unpipelined) Extensión del pipeline para manejar operaciones multiciclo El pipeline del MIPS
Organización de Computadoras Pipeline Continuación Extensión del pipeline para manejar operaciones multiciclo (unpipelined) Extensión del pipeline para manejar operaciones multiciclo El pipeline del MIPS
PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS
 Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Aspectos avanzados de arquitectura de computadoras Superescalares I. Facultad de Ingeniería - Universidad de la República Curso 2017
 Aspectos avanzados de arquitectura de computadoras Superescalares I Facultad de Ingeniería - Universidad de la República Curso 2017 Instruction Level Parallelism Propiedad de un programa. Indica qué tanto
Aspectos avanzados de arquitectura de computadoras Superescalares I Facultad de Ingeniería - Universidad de la República Curso 2017 Instruction Level Parallelism Propiedad de un programa. Indica qué tanto
*** SOLUCIONES *** SISTEMAS OPERATIVOS Examen Parcial 24 de Abril de 2010
 Calificación SISTEMAS OPERATIVOS Examen Parcial 24 de Abril de 2010 1 2 3 4 Nombre *** SOLUCIONES *** Titulación Dispone de tres horas para realizar el examen 1 (5 puntos) Test. En cada uno de los siguientes
Calificación SISTEMAS OPERATIVOS Examen Parcial 24 de Abril de 2010 1 2 3 4 Nombre *** SOLUCIONES *** Titulación Dispone de tres horas para realizar el examen 1 (5 puntos) Test. En cada uno de los siguientes
ENTRADA-SALIDA. 2. Dispositivos de Carácter: Envía o recibe un flujo de caracteres No es direccionable, no tiene operación de búsqueda
 Tipos de Dispositivos ENTRADA-SALIDA 1. Dispositivos de Bloque: Almacena información en bloques de tamaño fijo (512b hasta 32Kb) Se puede leer o escribir un bloque en forma independiente 2. Dispositivos
Tipos de Dispositivos ENTRADA-SALIDA 1. Dispositivos de Bloque: Almacena información en bloques de tamaño fijo (512b hasta 32Kb) Se puede leer o escribir un bloque en forma independiente 2. Dispositivos
Tema 12: El sistema operativo y los procesos
 Tema 12: El sistema operativo y los procesos Solicitado: Tarea 06 Arquitecturas de una computadora y el funcionamiento del software M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com edfrancom@ipn.mx
Tema 12: El sistema operativo y los procesos Solicitado: Tarea 06 Arquitecturas de una computadora y el funcionamiento del software M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com edfrancom@ipn.mx
Introducción a los Sistemas Operativos
 Introducción a los Sistemas Operativos Indice Conceptos sobre ordenadores Concepto de Sistema Operativo Historia de los SO Multiprogramación Administración CPU Memoria Entrada/Salida Estados de un proceso
Introducción a los Sistemas Operativos Indice Conceptos sobre ordenadores Concepto de Sistema Operativo Historia de los SO Multiprogramación Administración CPU Memoria Entrada/Salida Estados de un proceso
GPGPU Avanzado. Sistemas Complejos en Máquinas Paralelas. Esteban E. Mocskos (emocskos@dc.uba.ar) 5/6/2012
 5/6/2012") Sistemas Complejos en Máquinas Paralelas GPGPU Avanzado Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales, UBA CONICET 5/6/2012 E. Mocskos (UBA CONICET) GPGPU Avanzado 5/6/2012
Sistemas Complejos en Máquinas Paralelas GPGPU Avanzado Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales, UBA CONICET 5/6/2012 E. Mocskos (UBA CONICET) GPGPU Avanzado 5/6/2012
SISTEMAS PARALELOS Y DISTRIBUIDOS. 3º GIC. PRÁCTICA 3. PLANIFICACIÓN ESTÁTICA AVANZADA. TMS320C6713
 SISTEMAS PARALELOS Y DISTRIBUIDOS. 3º GIC. PRÁCTICA 3. PLANIFICACIÓN ESTÁTICA AVANZADA. TMS320C6713 OBJETIVOS. En esta práctica se trata de estudiar dos de las técnicas de planificación estática más importantes:
SISTEMAS PARALELOS Y DISTRIBUIDOS. 3º GIC. PRÁCTICA 3. PLANIFICACIÓN ESTÁTICA AVANZADA. TMS320C6713 OBJETIVOS. En esta práctica se trata de estudiar dos de las técnicas de planificación estática más importantes:
Computación matricial dispersa con GPUs y su aplicación en Tomografía Electrónica
 con GPUs y su aplicación en Tomografía Electrónica F. Vázquez, J. A. Martínez, E. M. Garzón, J. J. Fernández Portada Universidad de Almería Contenidos Computación matricial dispersa Introducción a SpMV
con GPUs y su aplicación en Tomografía Electrónica F. Vázquez, J. A. Martínez, E. M. Garzón, J. J. Fernández Portada Universidad de Almería Contenidos Computación matricial dispersa Introducción a SpMV
Taxonomía de las arquitecturas
 Taxonomía de las arquitecturas 1 INTRODUCCIÓN 2 2 CLASIFICACIÓN DE FLYNN 3 2.1 SISD (SINGLE INSTRUCTION STREAM, SINGLE DATA STREAM) 3 2.2 SIMD (SINGLE INSTRUCTION STREAM, MULTIPLE DATA STREAM) 4 2.2.1
Taxonomía de las arquitecturas 1 INTRODUCCIÓN 2 2 CLASIFICACIÓN DE FLYNN 3 2.1 SISD (SINGLE INSTRUCTION STREAM, SINGLE DATA STREAM) 3 2.2 SIMD (SINGLE INSTRUCTION STREAM, MULTIPLE DATA STREAM) 4 2.2.1
Con estas consideraciones, Flynn clasifica los sistemas en cuatro categorías:
 Taxonomía de las arquitecturas 1 Introducción Introducción En este trabajo se explican en detalle las dos clasificaciones de computadores más conocidas en la actualidad. La primera clasificación, es la
Taxonomía de las arquitecturas 1 Introducción Introducción En este trabajo se explican en detalle las dos clasificaciones de computadores más conocidas en la actualidad. La primera clasificación, es la
Arquitectura de Computadores II Clase #3
 Arquitectura de Computadores II Clase #3 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Registros Repertorio de instrucciones Modos de direccionamiento El
Arquitectura de Computadores II Clase #3 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Registros Repertorio de instrucciones Modos de direccionamiento El
Inside Kepler. I. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes ( )
![Inside Kepler. I. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes ( )](/thumbs/70/62983111.jpg "Inside Kepler. I. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes ( )") Índice de contenidos [25 diapositivas] Inside Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3 diapositivas] 2. Los cores
Índice de contenidos [25 diapositivas] Inside Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3 diapositivas] 2. Los cores
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Procesamiento Paralelo
 Procesamiento Paralelo OpenCL - Introducción Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina http://www.frbb.utn.edu.ar/hpc/
Procesamiento Paralelo OpenCL - Introducción Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina http://www.frbb.utn.edu.ar/hpc/
Aspectos avanzados de arquitectura de computadoras Multithreading. Facultad de Ingeniería - Universidad de la República Curso 2017
 Aspectos avanzados de arquitectura de computadoras Multithreading Facultad de Ingeniería - Universidad de la República Curso 2017 Introducción En este capítulo se explorará la posibilidad de ejecutar múltiples
Aspectos avanzados de arquitectura de computadoras Multithreading Facultad de Ingeniería - Universidad de la República Curso 2017 Introducción En este capítulo se explorará la posibilidad de ejecutar múltiples
SOLUCIONES. DURACIÓN: Dispone de dos horas para realizar el examen. Lea las instrucciones para el test en la hoja correspondiente.
 1 2 3 test extra NOTA Fundamentos de los Sistemas Operativos Examen parcial 10 de abril de 2015 Nombre y apellidos SOLUCIONES DURACIÓN: Dispone de dos horas para realizar el examen. Lea las instrucciones
1 2 3 test extra NOTA Fundamentos de los Sistemas Operativos Examen parcial 10 de abril de 2015 Nombre y apellidos SOLUCIONES DURACIÓN: Dispone de dos horas para realizar el examen. Lea las instrucciones
Descubriendo Kepler. 1. Presentación de la arquitectura. Agradecimientos. Indice de contenidos [46 diapositivas]
![Descubriendo Kepler. 1. Presentación de la arquitectura. Agradecimientos. Indice de contenidos [46 diapositivas]](/thumbs/28/12635433.jpg "Descubriendo Kepler. 1. Presentación de la arquitectura. Agradecimientos. Indice de contenidos [46 diapositivas]") Agradecimientos Descubriendo Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga A los ingenieros de Nvidia, por compartir ideas, material, diagramas, presentaciones,...
Agradecimientos Descubriendo Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga A los ingenieros de Nvidia, por compartir ideas, material, diagramas, presentaciones,...
Aspectos avanzados de arquitectura de computadoras Pipeline. Facultad de Ingeniería - Universidad de la República Curso 2017
 Aspectos avanzados de arquitectura de computadoras Pipeline Facultad de Ingeniería - Universidad de la República Curso 2017 Objetivo Mejorar el rendimiento Incrementar frecuencia de reloj? Ancho de los
Aspectos avanzados de arquitectura de computadoras Pipeline Facultad de Ingeniería - Universidad de la República Curso 2017 Objetivo Mejorar el rendimiento Incrementar frecuencia de reloj? Ancho de los
Sistemas Operativos Distribuidos
 Contenidos del Tema Gestión de procesos Modelos de sistema Asignación de procesadores Estrategias dinámicas Estrategias estáticas Ejecución remota de procesos Modelos de sistema Organización de los procesadores
Contenidos del Tema Gestión de procesos Modelos de sistema Asignación de procesadores Estrategias dinámicas Estrategias estáticas Ejecución remota de procesos Modelos de sistema Organización de los procesadores
Sistemas Operativos. Curso 2014 Estructura de los sistemas operativos
 Sistemas Operativos Curso 2014 Estructura de los sistemas operativos Agenda Componentes de un sistema operativo. Servicios del sistema operativo (system services). Llamados a sistema (system calls). Estructura
Sistemas Operativos Curso 2014 Estructura de los sistemas operativos Agenda Componentes de un sistema operativo. Servicios del sistema operativo (system services). Llamados a sistema (system calls). Estructura
Tema 1: PROCESADORES SEGMENTADOS
 Tema 1: PROCESADORES SEGMENTADOS 1.1. Procesadores RISC frente a procesadores CISC. 1.2. Clasificación de las arquitecturas paralelas. 1.3. Evaluación y mejora del rendimiento de un computador. 1.4. Características
Tema 1: PROCESADORES SEGMENTADOS 1.1. Procesadores RISC frente a procesadores CISC. 1.2. Clasificación de las arquitecturas paralelas. 1.3. Evaluación y mejora del rendimiento de un computador. 1.4. Características
Diseño de los servicios del sistema
 Diseño de los servicios del sistema Marisa Gil (marisa@ac.upc.es) Ernest Artiaga (ernest@ac.upc.es) ENtornos Operativos para la Gestión de Recursos de Aplicaciones Paralelas CURSO 1.998-99 Situación de
Diseño de los servicios del sistema Marisa Gil (marisa@ac.upc.es) Ernest Artiaga (ernest@ac.upc.es) ENtornos Operativos para la Gestión de Recursos de Aplicaciones Paralelas CURSO 1.998-99 Situación de
48 ContactoS 84, (2012)
") 48 ContactoS 84, 47 55 (2012) Recibido: 31 de enero de 2012. Aceptado: 03 de mayo de 2012. Resumen En los últimos años la tecnología de las unidades de procesamiento de gráficos (GPU-Graphics Processsing
48 ContactoS 84, 47 55 (2012) Recibido: 31 de enero de 2012. Aceptado: 03 de mayo de 2012. Resumen En los últimos años la tecnología de las unidades de procesamiento de gráficos (GPU-Graphics Processsing
Tema III. Multihilo. Desarrollo de Aplicaciones para Internet Curso 12 13
 Tema III. Multihilo Desarrollo de Aplicaciones para Internet Curso 12 13 Índice 1.Introducción 2.Tipos de Concurrencia 3.Hilos en Java 4.Implementación de un SNB i. Sin Hilos ii. Con Hilos iii.con Pool
Tema III. Multihilo Desarrollo de Aplicaciones para Internet Curso 12 13 Índice 1.Introducción 2.Tipos de Concurrencia 3.Hilos en Java 4.Implementación de un SNB i. Sin Hilos ii. Con Hilos iii.con Pool
PARTE II PROGRAMACION CON THREADS EN C
 PARTE II PROGRAMACION CON THREADS EN C II.1 INTRODUCCION Una librería o paquete de threads permite escribir programas con varios puntos simultáneos de ejecución, sincronizados a través de memoria compartida.
PARTE II PROGRAMACION CON THREADS EN C II.1 INTRODUCCION Una librería o paquete de threads permite escribir programas con varios puntos simultáneos de ejecución, sincronizados a través de memoria compartida.
Apartado Puntuación. No Presentado
 Apartado 1 2 3 4 5 6 7 Puntuación No Presentado EXAMEN DE SISTEMAS OPERATIVOS (Grado en Ing. Informática), Julio 2015. APELLIDOS Y NOMBRE:....................................................... Justificar
Apartado 1 2 3 4 5 6 7 Puntuación No Presentado EXAMEN DE SISTEMAS OPERATIVOS (Grado en Ing. Informática), Julio 2015. APELLIDOS Y NOMBRE:....................................................... Justificar
SUMA de Vectores: Hands-on
 SUMA de Vectores: Hands-on Clase X http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Algunas preguntas practicas (1) Que pasa si los vectores a sumar son muy grandes? (2) Como saber en que
SUMA de Vectores: Hands-on Clase X http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Algunas preguntas practicas (1) Que pasa si los vectores a sumar son muy grandes? (2) Como saber en que
Universisdad de Los Andes Facultad de Ingeniería Escuela de Sistemas
 Universisdad de Los Andes Facultad de Ingeniería Escuela de Sistemas Introducción y Conceptos Básicos Prof. Gilberto Díaz gilberto@ula.ve Departamento de Computación, Escuela de Sistemas, Facultad de Ingeniería
Universisdad de Los Andes Facultad de Ingeniería Escuela de Sistemas Introducción y Conceptos Básicos Prof. Gilberto Díaz gilberto@ula.ve Departamento de Computación, Escuela de Sistemas, Facultad de Ingeniería
Nombre alumno: Ventajas: Inconvenientes:
 Preguntas cortas (justifica todas las respuestas) (2 puntos) 1. Define qué es la buffer cache, qué tipo de información encontramos y cuál es su objetivo 2. Explica qué ventajas e inconvenientes tendría
Preguntas cortas (justifica todas las respuestas) (2 puntos) 1. Define qué es la buffer cache, qué tipo de información encontramos y cuál es su objetivo 2. Explica qué ventajas e inconvenientes tendría
Fundamentos de los Sistemas Operativos. Tema 2. Procesos José Miguel Santos Alexis Quesada Francisco Santana
 Fundamentos de los Sistemas Operativos Tema 2. Procesos 1998-2015 José Miguel Santos Alexis Quesada Francisco Santana Contenidos del Tema 2 Qué es un proceso Estructuras de datos para gestionar procesos
Fundamentos de los Sistemas Operativos Tema 2. Procesos 1998-2015 José Miguel Santos Alexis Quesada Francisco Santana Contenidos del Tema 2 Qué es un proceso Estructuras de datos para gestionar procesos
Unidad 4 - Procesamiento paralelo. Arquitectura de computadoras. D o c e n t e : E r n e s t o L e a l. E q u i p o : J e s s i c a F i e r r o
 Unidad 4 - Procesamiento paralelo. D o c e n t e : E r n e s t o L e a l E q u i p o : J e s s i c a F i e r r o L u i s N a v e j a s Arquitectura de computadoras Introducción Cuestionario Conclusiones
Unidad 4 - Procesamiento paralelo. D o c e n t e : E r n e s t o L e a l E q u i p o : J e s s i c a F i e r r o L u i s N a v e j a s Arquitectura de computadoras Introducción Cuestionario Conclusiones
Entornos de programación paralela basados en modelos/paradigmas
 Program. paralela/distribuida Entornos de programación paralela basados en modelos/paradigmas Sobre la programación paralela 1 Índice Reflexiones sobre la programación paralela MapReduce Propuesta original
Program. paralela/distribuida Entornos de programación paralela basados en modelos/paradigmas Sobre la programación paralela 1 Índice Reflexiones sobre la programación paralela MapReduce Propuesta original
TEMA 3. CONCEPTOS FUNDAMENTALES DEL NIVEL DEL SISTEMA OPERATIVO. Definición y objetivos de un S.O
 TEMA 3. CONCEPTOS FUNDAMENTALES DEL NIVEL DEL SISTEMA OPERATIVO Definición y objetivos de un S.O Definición y objetivos del sistema operativo Estructura, componentes y servicios de un S.O Llamadas al sistema
TEMA 3. CONCEPTOS FUNDAMENTALES DEL NIVEL DEL SISTEMA OPERATIVO Definición y objetivos de un S.O Definición y objetivos del sistema operativo Estructura, componentes y servicios de un S.O Llamadas al sistema
Sistemas Operativos. Revisión del Sistema del Cómputador. John A. Sanabria Cali, Colombia
 Sistemas Operativos Revisión del Sistema del Cómputador John A. Sanabria john.sanabria@gmail.com Cali, Colombia Sistema Operativos - Febrero-Junio 2015 Sanabria (Cali, Colombia) Sistemas Operativos Febrero-Junio
Sistemas Operativos Revisión del Sistema del Cómputador John A. Sanabria john.sanabria@gmail.com Cali, Colombia Sistema Operativos - Febrero-Junio 2015 Sanabria (Cali, Colombia) Sistemas Operativos Febrero-Junio
Seminario II: Introducción a la Computación GPU
 Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
Uso de recursos compartidos
 Uso de recursos compartidos Cada proceso o hebra se ejecuta de forma independiente. Sin embargo, cuando varias hebras (o procesos) han de acceder a un mismo recurso, se ha de coordinar el acceso a ese
Uso de recursos compartidos Cada proceso o hebra se ejecuta de forma independiente. Sin embargo, cuando varias hebras (o procesos) han de acceder a un mismo recurso, se ha de coordinar el acceso a ese
T5-multithreading. Indice
 T5-multithreading 1.1 Indice Proceso vs. Flujos Librerías de flujos Comunicación mediante memoria compartida Condición de carrera Sección Crítica Acceso en exclusión mutua Problemas Abrazos mortales 1.2
T5-multithreading 1.1 Indice Proceso vs. Flujos Librerías de flujos Comunicación mediante memoria compartida Condición de carrera Sección Crítica Acceso en exclusión mutua Problemas Abrazos mortales 1.2
Primer Semestre Laboratorio de Electrónica Universidad de San Carlos de Guatemala. Electrónica 5. Aux. Marie Chantelle Cruz.
 Laboratorio de Electrónica Universidad de San Carlos de Guatemala Primer Semestre 2017 Overview 1 Cortex La más usada para dispositivos móviles Encoding por 32 bits, excepto Thumb y Thumb-2 15x32bits registros
Laboratorio de Electrónica Universidad de San Carlos de Guatemala Primer Semestre 2017 Overview 1 Cortex La más usada para dispositivos móviles Encoding por 32 bits, excepto Thumb y Thumb-2 15x32bits registros
Diseño de algoritmos paralelos
 PROGRAMACIÓN CONCURRENTE TEMA 7 Diseño de algoritmos paralelos ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN DISEÑO DE ALGORITMOS PARALELOS - TEMA 7.2 Algoritmos
PROGRAMACIÓN CONCURRENTE TEMA 7 Diseño de algoritmos paralelos ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN DISEÑO DE ALGORITMOS PARALELOS - TEMA 7.2 Algoritmos
Fac. de Informática / Escuela Univ. Informática SISTEMAS OPERATIVOS Examen Primer Parcial 5 de mayo de 2007
 Calificación Fac. de Informática / Escuela Univ. Informática SISTEMAS OPERATIVOS Examen Primer Parcial 5 de mayo de 2007 1 2 3 4 Nombr SOLUCIONES Titulació Dispone de tres horas para realizar el examen
Calificación Fac. de Informática / Escuela Univ. Informática SISTEMAS OPERATIVOS Examen Primer Parcial 5 de mayo de 2007 1 2 3 4 Nombr SOLUCIONES Titulació Dispone de tres horas para realizar el examen
Arquitectura de Computadoras
 Arquitectura de Computadoras Clase 7 Memoria Sistema de Memoria Los programadores desean acceder a cantidades ilimitadas de memoria rápida!! Solución práctica: Jerarquía de memoria organizada en niveles
Arquitectura de Computadoras Clase 7 Memoria Sistema de Memoria Los programadores desean acceder a cantidades ilimitadas de memoria rápida!! Solución práctica: Jerarquía de memoria organizada en niveles