Arquitecturas GPU v. 2013
|
|
|
- Ángel Vidal Rojo
- hace 8 años
- Vistas:
Transcripción
1 v. 2013

2 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image, video and digital signal processing) pero no para procesamiento de propósitos generales con acceso a los datos aleatorio (randomized data access) como por ejemplo bases de datos. El modelo es adecuado para aplicaciones que presentan las siguientes características: Cómputo intensivo, el número de operaciones aritméticas por I/O o referencia a memoria debe ser elevado. En muchas aplicaciones de procesamiento de señales actuales dicha razón está bien por encima de 50:1 y se incrementa con la complejidad del algoritmo. Parallelismo en los Datos, está presente si la misma función se aplica a todos los elementos de un stream y un cierto número de elementos puede ser procesado simultaneamente sin esperar los resultados de operaciones anteriores. Localidad en los Datos, es una forma específica de localidad temporal, común en procesamiento multimedia y de señales, donde los datos se producen una vez, son utilizados una o dos veces en la aplicación, y nunca más son utilizados. DATAFLOW PROGRAMMING

3 GPU (Unidad de procesamiento gráfico) Coprocesador con su propio repertorio de instrucciones y memoria propia (aunque no siempre). Se accede como cualquier otro dispositivo de I/O (comandos o DMA). Para el software es otro núcleo al cual se le envían datos y rutinas para procesar. Marcas actuales: - Sony/Toshiba/IBM Cell Broadband Engine - NVIDIA family of GPUs. GeForce (games), Quadro (workstation) y Tesla (supercomputing). - ATI (AMD) family, Fusion APU accelerated processing unit (CPU+GPU) DirectX (Microsoft propietario) vs. OpenGL (Open Graphics Library): API multilenguaje y multiplataforma para gráficos 2D y 3D (250+ funciones).
 family, Fusion APU accelerated processing unit (CPU+GPU) DirectX (Microsoft propietario) vs.")
4 Organización

5 Prestaciones Tres aspectos clave: Procesadores: 30 multiprocesadores, cada uno con 8 procesadores de hebras que ejecutan el mismo programa sincrónicamente (ejecutan la misma instrucción al mismo tiempo). Memoria: hasta 4GB actualmente, bastante lenta como en CPU. Cache, pero principalmente ejecución por hebras. Interconexión: gran ancho de banda. DESACTUALIZADO

6 GP-GPU Los chips gráficos empezaron como procesadores gráficos de funciones fijas, pero se hicieron cada vez más programables y potentes desde el punto de vista computacional, lo que permitió a NVIDIA introducir la primera GPU. Entre los años 1999 y 2000, científicos del sector informático y de otras disciplinas empezaron a utilizar las GPU para acelerar diversas aplicaciones científicas. Fue el nacimiento de un nuevo concepto denominado GP-GPU o GPU de propósito general. Aunque los usuarios conseguían un rendimiento sin igual (por encima de 100x con respecto a las GPU en algunos casos), el problema era que las GP-GPU requerían el uso de APIs de programación de gráficos como OpenGL al programar para las GPU. Eso limitaba el acceso a la enorme capacidad de las GPU en el campo científico. NVIDIA CUDA (Compute Unified Device Architecture) SDK, incluye un compilador con extensiones para C. Aún implica reescritura y reestructuración del programa y el código no es ejecutable en x86.
, el problema era que las GP-GPU requerían el uso de APIs de programación de")
 de 32 cores CUDA.")

7 NVIDIA Fermi 16x32= SM (streaming multiprocessor) de 32 cores CUDA. Los 32 cores ejecutan el mismo kernel sobre 32 threads diferentes. Los 16 SM pueden ejecutar diferentes kernels (multicore)

8 APU (accelerated processing unit) CPU multinúcleo + GPU + Bus de interconexión + Controlador de memoria

9 Herramientas de programación Actualmente: NVIDIA's CUDA AMD's Brook+ OpenCL: Open standard language, portable entre diferentes GPU y otros systemas paralelos (FPGA) Requieren reestructurar el programa de aplicación en dos partes: la sección host y la sección acelerador, que debe ser expresada como funciones tipo kernel. HOST: manage device memory allocation, data movement, and kernel invocation. KERNEL: optimizado para GPU (unrolling loops and orchestrating device memory fetches and stores). Si bien se ha avanzado mucho, tanto CUDA como OpenCL están lejos de ser una herramienta de utilización inmediata (curva de aprendizaje).
.")

10 - Programación Plataforma NVIDIA-CUDA La plataforma de cálculo paralelo CUDA proporciona extensiones de C y C++ que permiten implementar paralelismo en el procesamiento de tareas y procesos con diferentes niveles de granularidad. El programador puede expresar ese paralelismo mediante diferentes lenguajes de alto nivel como C, C++ y Fortran o mediante estándares abiertos como las directivas del modelo OpenACC.

11 - Programación OpenCL Open Computing Language permite crear aplicaciones con paralelismo a nivel de datos y de tareas que pueden ejecutarse en diferentes plataformas (CPU, GPU, FPGA). El lenguaje está basado en C, eliminando cierta funcionalidad y extendiéndolo con operaciones que permiten la especificación de paralelismo. Apple creó la especificación original y fue desarrollada en conjunto con AMD, IBM, Intel y NVIDIA. Apple la propuso al Grupo Khronos para convertirla en un estándar abierto y libre de derechos.

12 Tendencias en arquitecturas paralelas reprogramables
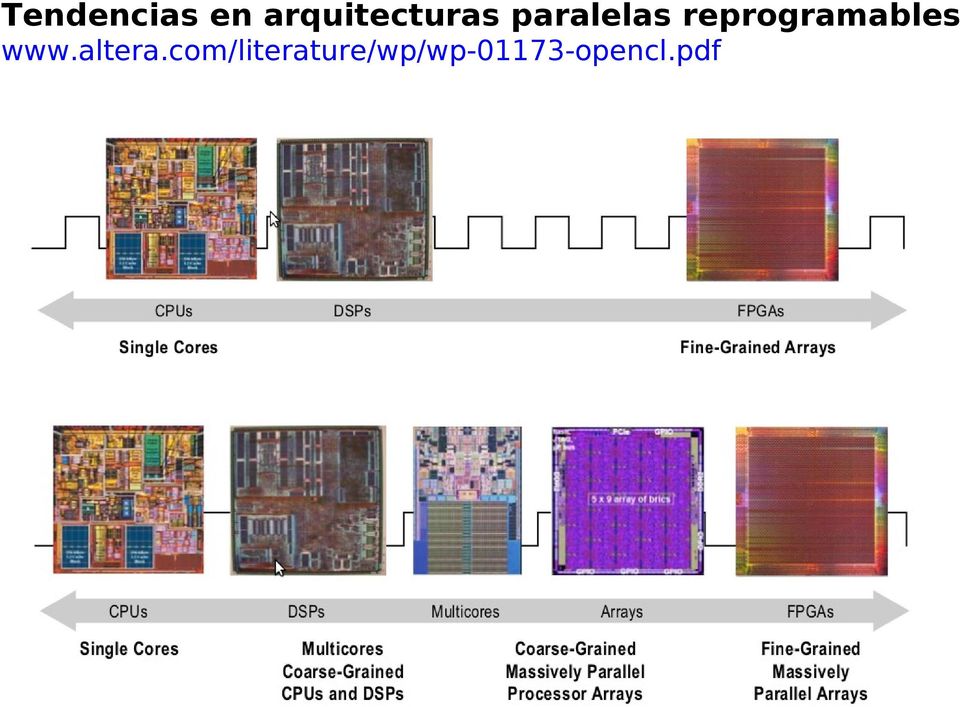
13 Tendencias OpenCL en FPGA...
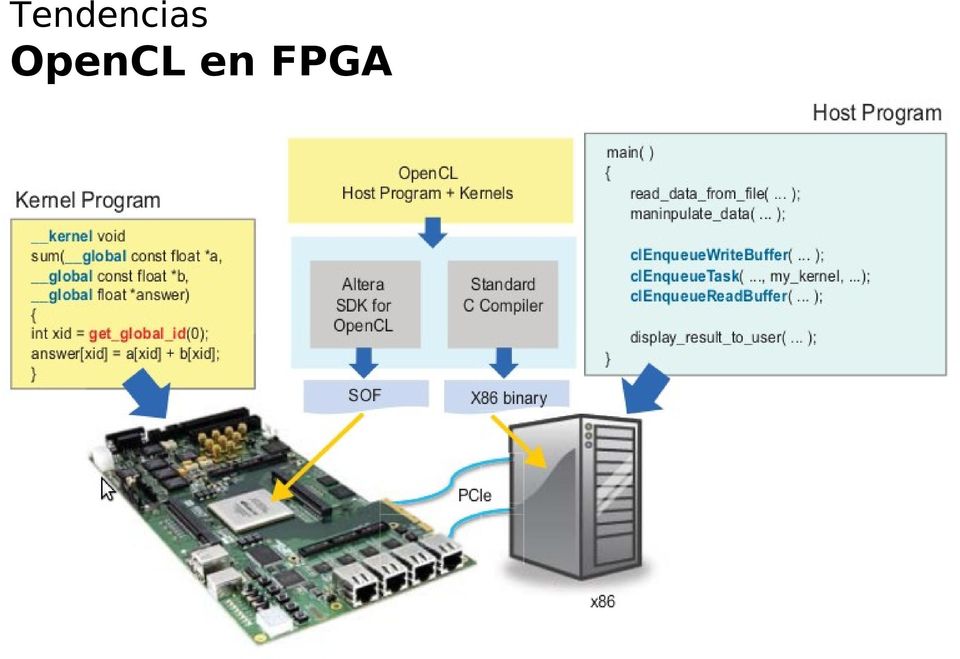


14 Tendencias OpenCL en FPGA

15 Tendencias AMD Bulldozer microarchitecture Ver procesadores FX

Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Seminario II: Introducción a la Computación GPU
 Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS
 GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
Arquitecturas GPU v. 2015
 v. 2015 http://en.wikipedia.org/wiki/graphics_processing_unit http://en.wikipedia.org/wiki/stream_processing http://en.wikipedia.org/wiki/general-purpose_computing_on_graphics_processing_ units http://www.nvidia.com/object/what-is-gpu-computing.html
v. 2015 http://en.wikipedia.org/wiki/graphics_processing_unit http://en.wikipedia.org/wiki/stream_processing http://en.wikipedia.org/wiki/general-purpose_computing_on_graphics_processing_ units http://www.nvidia.com/object/what-is-gpu-computing.html
TEMA 4. Unidades Funcionales del Computador
 TEMA 4 Unidades Funcionales del Computador Álvarez, S., Bravo, S., Departamento de Informática y automática Universidad de Salamanca Introducción El elemento físico, electrónico o hardware de un sistema
TEMA 4 Unidades Funcionales del Computador Álvarez, S., Bravo, S., Departamento de Informática y automática Universidad de Salamanca Introducción El elemento físico, electrónico o hardware de un sistema
Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)
![Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)](/thumbs/36/17576386.jpg "Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)") Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
UNA NUEVA GENERACIÓN: HÍBRIDOS CPU/GPU. Microprocesadores para Comunicaciones. Paloma Monzón Rodríguez 42217126M
 UNA NUEVA GENERACIÓN: HÍBRIDOS CPU/GPU Microprocesadores para Comunicaciones 2010 Paloma Monzón Rodríguez 42217126M Índice 1. Introducción... 3 2. Unidad Central de Procesamiento (CPU)... 4 Arquitectura
UNA NUEVA GENERACIÓN: HÍBRIDOS CPU/GPU Microprocesadores para Comunicaciones 2010 Paloma Monzón Rodríguez 42217126M Índice 1. Introducción... 3 2. Unidad Central de Procesamiento (CPU)... 4 Arquitectura
ACTIVIDADES TEMA 1. EL LENGUAJE DE LOS ORDENADORES. 4º E.S.O- SOLUCIONES.
 1.- a) Explica qué es un bit de información. Qué es el lenguaje binario? Bit es la abreviatura de Binary digit. (Dígito binario). Un bit es un dígito del lenguaje binario que es el lenguaje universal usado
1.- a) Explica qué es un bit de información. Qué es el lenguaje binario? Bit es la abreviatura de Binary digit. (Dígito binario). Un bit es un dígito del lenguaje binario que es el lenguaje universal usado
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () R. Bayá, E. Dufrechou, P. Ezzattiy M. Pedemonte Clase 1 Introducción Contenido Un poco de historia El pipeline gráfico Tarjetas
Computación de Propósito General en Unidades de Procesamiento Gráfico () R. Bayá, E. Dufrechou, P. Ezzattiy M. Pedemonte Clase 1 Introducción Contenido Un poco de historia El pipeline gráfico Tarjetas
Procesador Intel Core 2 Extreme de 4 núcleos Traducción de Textos Curso 2007/2008
 Procesador Intel Core 2 Traducción de Textos Curso 2007/2008 Versión Cambio 0.9RC Revisión del texto 0.8 Traducido el octavo párrafo 0.7 Traducido el séptimo párrafo Autor: Rubén Paje del Pino i010328
Procesador Intel Core 2 Traducción de Textos Curso 2007/2008 Versión Cambio 0.9RC Revisión del texto 0.8 Traducido el octavo párrafo 0.7 Traducido el séptimo párrafo Autor: Rubén Paje del Pino i010328
High Performance Computing and Architectures Group
 HPCA Group 1 High Performance Computing and Architectures Group http://www.hpca.uji.es Universidad Jaime I de Castellón ANACAP, noviembre de 2008 HPCA Group 2 Generalidades Creado en 1991, al mismo tiempo
HPCA Group 1 High Performance Computing and Architectures Group http://www.hpca.uji.es Universidad Jaime I de Castellón ANACAP, noviembre de 2008 HPCA Group 2 Generalidades Creado en 1991, al mismo tiempo
Procesadores Gráficos: OpenCL para programadores de CUDA
 Procesadores Gráficos: para programadores de CUDA Curso 2011/12 David Miraut david.miraut@urjc.es Universidad Rey Juan Carlos April 24, 2013 Indice Estándar Modelo de de El lenguaje programa de Inicialización
Procesadores Gráficos: para programadores de CUDA Curso 2011/12 David Miraut david.miraut@urjc.es Universidad Rey Juan Carlos April 24, 2013 Indice Estándar Modelo de de El lenguaje programa de Inicialización
Tarjetas gráficas para acelerar el cómputo complejo
 LA TECNOLOGÍA Y EL CÓMPUTO AVANZADO Tarjetas gráficas para acelerar el cómputo complejo Tarjetas gráficas para acelerar el cómputo complejo Jorge Echevarría * La búsqueda de mayor rendimiento A lo largo
LA TECNOLOGÍA Y EL CÓMPUTO AVANZADO Tarjetas gráficas para acelerar el cómputo complejo Tarjetas gráficas para acelerar el cómputo complejo Jorge Echevarría * La búsqueda de mayor rendimiento A lo largo
ITT-327-T Microprocesadores
 ITT-327-T Microprocesadores Introducción al Microprocesador y al Microcomputador. al Microcomputador. Profesor Julio Ferreira. Sistema Microcomputador. Un Sistema Microcomputador tiene dos componentes
ITT-327-T Microprocesadores Introducción al Microprocesador y al Microcomputador. al Microcomputador. Profesor Julio Ferreira. Sistema Microcomputador. Un Sistema Microcomputador tiene dos componentes
PVM Parallel Virtual Machine. Autor: Alejandro Gutiérrez Muñoz
 PVM Parallel Virtual Machine Autor: Alejandro Gutiérrez Muñoz PVM Qué es PVM? Consiste en un software y un conjunto de librerías, que permiten establecer una colección de uno o mas sistemas de computación,
PVM Parallel Virtual Machine Autor: Alejandro Gutiérrez Muñoz PVM Qué es PVM? Consiste en un software y un conjunto de librerías, que permiten establecer una colección de uno o mas sistemas de computación,
Talleres CLCAR. CUDA para principiantes. Título. Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.
 a CUDA para principiantes Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.com Tener un primer encuentro práctico con la programación en CUDA para personas
a CUDA para principiantes Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.com Tener un primer encuentro práctico con la programación en CUDA para personas
picojava TM Características
 picojava TM Introducción El principal objetivo de Sun al introducir Java era poder intercambiar programas ejecutables Java entre computadoras de Internet y ejecutarlos sin modificación. Para poder transportar
picojava TM Introducción El principal objetivo de Sun al introducir Java era poder intercambiar programas ejecutables Java entre computadoras de Internet y ejecutarlos sin modificación. Para poder transportar
Generalidades Computacionales
 Capítulo 2 Generalidades Computacionales 2.1. Introducción a los Computadores Definición: Un computador es un dispositivo electrónico que puede transmitir, almacenar, recuperar y procesar información (datos).
Capítulo 2 Generalidades Computacionales 2.1. Introducción a los Computadores Definición: Un computador es un dispositivo electrónico que puede transmitir, almacenar, recuperar y procesar información (datos).
Qué es una Tarjetas Madre? El Procesador. Partes de una tarjeta madre. Tarjetas madres
 Tarjetas madres 1. Qué es una Tarjetas Madre? 2. El Procesador 3. Partes de una tarjeta madre 4. Modelo de tarjeta madre, fabricante, características generales e imagen Qué es una Tarjetas Madre? Una tarjeta
Tarjetas madres 1. Qué es una Tarjetas Madre? 2. El Procesador 3. Partes de una tarjeta madre 4. Modelo de tarjeta madre, fabricante, características generales e imagen Qué es una Tarjetas Madre? Una tarjeta
Electrónica Digital II
 Electrónica Digital II M. C. Felipe Santiago Espinosa Aplicaciones de los FPLDs Octubre / 2014 Aplicaciones de los FPLDs Los primeros FPLDs se usaron para hacer partes de diseños que no correspondían a
Electrónica Digital II M. C. Felipe Santiago Espinosa Aplicaciones de los FPLDs Octubre / 2014 Aplicaciones de los FPLDs Los primeros FPLDs se usaron para hacer partes de diseños que no correspondían a
La nueva arquitectura del paquete AMORE (A MORE Flexible Neural Network)
") La nueva arquitectura del paquete AMORE (A MORE Flexible Neural Network) III Jornadas de Usuarios de R Javier Alfonso Cendón, Manuel Castejón Limas, Joaquín Ordieres Mere, Camino Fernández Llamas Índice
La nueva arquitectura del paquete AMORE (A MORE Flexible Neural Network) III Jornadas de Usuarios de R Javier Alfonso Cendón, Manuel Castejón Limas, Joaquín Ordieres Mere, Camino Fernández Llamas Índice
Sistemas Operativos Windows 2000
 Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Procesador Pentium II 450 MHz Procesador Pentium II 400 MHz Procesador Pentium II 350 MHz Procesador Pentium II 333 MHz Procesador Pentium II 300 MHz
 PENTIUM El procesador Pentium es un miembro de la familia Intel de procesadores de propósito general de 32 bits. Al igual que los miembros de esta familia, el 386 y el 486, su rango de direcciones es de
PENTIUM El procesador Pentium es un miembro de la familia Intel de procesadores de propósito general de 32 bits. Al igual que los miembros de esta familia, el 386 y el 486, su rango de direcciones es de
La interoperabilidad se consigue mediante la adopción de estándares abiertos. Las organizaciones OASIS y W3C son los comités responsables de la
 Servicios web Introducción Un servicio web es un conjunto de protocolos y estándares que sirven para intercambiar datos entre aplicaciones. Distintas aplicaciones de software desarrolladas en lenguajes
Servicios web Introducción Un servicio web es un conjunto de protocolos y estándares que sirven para intercambiar datos entre aplicaciones. Distintas aplicaciones de software desarrolladas en lenguajes
Introducción a las redes de computadores
 Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Unidad 1: Conceptos generales de Sistemas Operativos.
 Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los sistemas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejecución de instrucciones e interrupciones
Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los sistemas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejecución de instrucciones e interrupciones
Tema 1 Introducción. Arquitectura básica y Sistemas Operativos. Fundamentos de Informática
 Tema 1 Introducción. Arquitectura básica y Sistemas Operativos Fundamentos de Informática Índice Descripción de un ordenador Concepto básico de Sistema Operativo Codificación de la información 2 1 Descripción
Tema 1 Introducción. Arquitectura básica y Sistemas Operativos Fundamentos de Informática Índice Descripción de un ordenador Concepto básico de Sistema Operativo Codificación de la información 2 1 Descripción
Sistema Operativo Linux
 Fundación Colegio Aplicación Toico Palo Gordo. Municipio Cárdenas. Cátedra: Informática Objetivo N. 2 (SISTEMA OPERATIVO LINUX) Segundo Año. Secciones: A y B. Prof. Dayana Meléndez Sistema Operativo Linux
Fundación Colegio Aplicación Toico Palo Gordo. Municipio Cárdenas. Cátedra: Informática Objetivo N. 2 (SISTEMA OPERATIVO LINUX) Segundo Año. Secciones: A y B. Prof. Dayana Meléndez Sistema Operativo Linux
270150 - TGA - Tarjetas Gráficas y Aceleradores
 Unidad responsable: 270 - FIB - Facultad de Informática de Barcelona Unidad que imparte: 701 - AC - Departamento de Arquitectura de Computadores Curso: Titulación: 2014 GRADO EN INGENIERÍA INFORMÁTICA
Unidad responsable: 270 - FIB - Facultad de Informática de Barcelona Unidad que imparte: 701 - AC - Departamento de Arquitectura de Computadores Curso: Titulación: 2014 GRADO EN INGENIERÍA INFORMÁTICA
Desarrollo de apps para móviles Android. Introducción a Android
 Desarrollo de apps para móviles Android Introducción a Android Qué es Android? I Es una plataforma de desarrollo libre y de código abierto. Ofrece gran cantidad de servicios: bases de datos, servicios
Desarrollo de apps para móviles Android Introducción a Android Qué es Android? I Es una plataforma de desarrollo libre y de código abierto. Ofrece gran cantidad de servicios: bases de datos, servicios
MICROSOFT MOVIE MAKER: CREACIÓN DE PELÍCULAS DOMÉSTICAS CON VÍDEOS O FOTOGRAFÍAS DIGITALES
 MICROSOFT MOVIE MAKER: CREACIÓN DE PELÍCULAS DOMÉSTICAS CON VÍDEOS O FOTOGRAFÍAS DIGITALES Microsoft Movie Maker es una aplicación que se proporciona con el sistema operativo Windows XP Home Edition o
MICROSOFT MOVIE MAKER: CREACIÓN DE PELÍCULAS DOMÉSTICAS CON VÍDEOS O FOTOGRAFÍAS DIGITALES Microsoft Movie Maker es una aplicación que se proporciona con el sistema operativo Windows XP Home Edition o
Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011
 Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Figura 1.4. Elementos que integran a la Tecnología de Información.
 1.5. Organización, estructura y arquitectura de computadoras La Gráfica siguiente muestra la descomposición de la tecnología de información en los elementos que la conforman: Figura 1.4. Elementos que
1.5. Organización, estructura y arquitectura de computadoras La Gráfica siguiente muestra la descomposición de la tecnología de información en los elementos que la conforman: Figura 1.4. Elementos que
UNIVERSIDAD CARLOS III DE MADRID
 : Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas A R C O S I V E R S ID A D U N III I D R D A M D E I C A R L O S II UNIVERSIDAD CARLOS III DE MADRID Grupo de Arquitectura de Computadores,
: Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas A R C O S I V E R S ID A D U N III I D R D A M D E I C A R L O S II UNIVERSIDAD CARLOS III DE MADRID Grupo de Arquitectura de Computadores,
Una mirada práctica a los Micro-Kernels y los Virtual Machine Monitors François Armand, Michel Gien INFORMATICA III
 Una mirada práctica a los Micro-Kernels y los Virtual Machine Monitors François Armand, Michel Gien INFORMATICA III DI PIETRO, Franco RODRIGUEZ, Matías VICARIO, Luciano Introducción En este papper se muestran
Una mirada práctica a los Micro-Kernels y los Virtual Machine Monitors François Armand, Michel Gien INFORMATICA III DI PIETRO, Franco RODRIGUEZ, Matías VICARIO, Luciano Introducción En este papper se muestran
INFORMACIÓN TÉCNICA ACERCA DE TOSHIBA Y LA TECNOLOGÍA MÓVIL. Toshiba y la tecnología móvil Intel Centrino Duo para empresas
 Toshiba y la tecnología móvil Intel Centrino Duo para empresas En el mundo empresarial actual, el ordenador portátil es la herramienta móvil esencial tanto para la productividad como para las comunicaciones.
Toshiba y la tecnología móvil Intel Centrino Duo para empresas En el mundo empresarial actual, el ordenador portátil es la herramienta móvil esencial tanto para la productividad como para las comunicaciones.
Capítulo 5. Cliente-Servidor.
 Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Estrategia de Cómputo en la Nube. Servicios en la Nube
 Estrategia de Cómputo en la Nube Servicios en la Nube Computación para la Nube? Tecnología informática por la que se proporcionan software y servicios a través de la Internet. El nombre Cloud Computing
Estrategia de Cómputo en la Nube Servicios en la Nube Computación para la Nube? Tecnología informática por la que se proporcionan software y servicios a través de la Internet. El nombre Cloud Computing
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570
 Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
Estructura y Tecnología de Computadores (ITIG) Luis Rincón Córcoles Ángel Serrano Sánchez de León
 Luis Rincón Córcoles Ángel Serrano Sánchez de León") Estructura y Tecnología de Computadores (ITIG) Luis Rincón Córcoles Ángel Serrano Sánchez de León Programa. Introducción. 2. Elementos de almacenamiento. 3. Elementos de proceso. 4. Elementos de interconexión.
Estructura y Tecnología de Computadores (ITIG) Luis Rincón Córcoles Ángel Serrano Sánchez de León Programa. Introducción. 2. Elementos de almacenamiento. 3. Elementos de proceso. 4. Elementos de interconexión.
1.2 Análisis de los Componentes. Arquitectura de Computadoras Rafael Vazquez Perez
 1.2 Análisis de los Componentes. Arquitectura de Computadoras Rafael Vazquez Perez 1.2.1 CPU 1 Arquitecturas. 2 Tipos. 3 Características. 4 Funcionamiento(ALU, unidad de control, Registros y buses internos)
1.2 Análisis de los Componentes. Arquitectura de Computadoras Rafael Vazquez Perez 1.2.1 CPU 1 Arquitecturas. 2 Tipos. 3 Características. 4 Funcionamiento(ALU, unidad de control, Registros y buses internos)
TEMA 1. Introducción
 TEMA 1 Introducción LO QUE ABORDAREMOS Qué es Android? Qué lo hace interesante? Arquitectura del sistema Entorno de desarrollo 2 QUÉ ES ANDROID? Sistema operativo para móviles Desarrollado inicialmente
TEMA 1 Introducción LO QUE ABORDAREMOS Qué es Android? Qué lo hace interesante? Arquitectura del sistema Entorno de desarrollo 2 QUÉ ES ANDROID? Sistema operativo para móviles Desarrollado inicialmente
Estado actual de los procesadores
 Estado actual de los procesadores José Domingo Muñoz Rafael Luengo Fundamentos de Hardware Noviembre 2012 Procesadores actuales de Intel Procesadores actuales de Intel Procesadores actuales de Intel Procesadores
Estado actual de los procesadores José Domingo Muñoz Rafael Luengo Fundamentos de Hardware Noviembre 2012 Procesadores actuales de Intel Procesadores actuales de Intel Procesadores actuales de Intel Procesadores
Entre los más conocidos editores con interfaz de desarrollo tenemos:
 Herramientas de programación Para poder programar en ensamblador se precisa de algunas herramientas básicas, como un editor para introducir el código, un ensamblador para traducir el código a lenguaje
Herramientas de programación Para poder programar en ensamblador se precisa de algunas herramientas básicas, como un editor para introducir el código, un ensamblador para traducir el código a lenguaje
servicios. El API es definido al nivel de código fuente y proporciona el nivel de
 GLOSARIO API Application Program -ming- Interface Es la interfaz por la cual una aplicación accede al sistema operativo u a otros servicios. El API es definido al nivel de código fuente y proporciona el
GLOSARIO API Application Program -ming- Interface Es la interfaz por la cual una aplicación accede al sistema operativo u a otros servicios. El API es definido al nivel de código fuente y proporciona el
Tema: Historia de los Microprocesadores
 Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Historia de los Microprocesadores 1 Contenidos La década de los
Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Historia de los Microprocesadores 1 Contenidos La década de los
Tipos de Dispositivos Controladores
 Tipos de Dispositivos Controladores PLC Allen Bradley Siemens Schneider OMRON PC & Software LabView Matlab Visual.NET (C++, C#) FPGAS Xilinx Altera Híbridos Procesador + FPGA (altas prestaciones) µcontrolador
Tipos de Dispositivos Controladores PLC Allen Bradley Siemens Schneider OMRON PC & Software LabView Matlab Visual.NET (C++, C#) FPGAS Xilinx Altera Híbridos Procesador + FPGA (altas prestaciones) µcontrolador
Arquitecturas de computadoras
 Arquitecturas de computadoras Colaboratorio Nacional de Computación Avanzada (CNCA) 2014 Contenidos 1 Computadoras 2 Estación de Trabajo 3 Servidor 4 Cluster 5 Malla 6 Nube 7 Conclusiones Computadoras
Arquitecturas de computadoras Colaboratorio Nacional de Computación Avanzada (CNCA) 2014 Contenidos 1 Computadoras 2 Estación de Trabajo 3 Servidor 4 Cluster 5 Malla 6 Nube 7 Conclusiones Computadoras
Guía de selección de hardware Windows MultiPoint Server 2010
 Guía de selección de hardware Windows MultiPoint Server 2010 Versión de documento 1.0 Publicado en marzo del 2010 Información sobre los derechos de reproducción Este documento se proporciona como está.
Guía de selección de hardware Windows MultiPoint Server 2010 Versión de documento 1.0 Publicado en marzo del 2010 Información sobre los derechos de reproducción Este documento se proporciona como está.
BASES DE DATOS OFIMÁTICAS
 BASES DE DATOS OFIMÁTICAS Qué es una Bases de Datos Ofimática?. En el entorno de trabajo de cualquier tipo de oficina ha sido habitual tener un archivo con gran parte de la información necesaria para el
BASES DE DATOS OFIMÁTICAS Qué es una Bases de Datos Ofimática?. En el entorno de trabajo de cualquier tipo de oficina ha sido habitual tener un archivo con gran parte de la información necesaria para el
Procesamiento de imágenes en GPUs mediante CUDA. I. Introducción. Indice de contenidos
 Procesamiento de imágenes en GPUs mediante CUDA Manuel Ujaldón Martínez Nvidia CUDA Fellow Departamento de Arquitectura de Computadores Universidad de Málaga Indice de contenidos 1. Introducción. [2] 2.
Procesamiento de imágenes en GPUs mediante CUDA Manuel Ujaldón Martínez Nvidia CUDA Fellow Departamento de Arquitectura de Computadores Universidad de Málaga Indice de contenidos 1. Introducción. [2] 2.
OBJETIVOS DE LA MATERIA... 4 PROGRAMA ANALÍTICO. CONTENIDOS TEÓRICOS Y PRÁCTICOS... 5 BIBLIOGRAFIA... 7
 UNIVERSIDAD NACIONAL DE LA MATANZA DEPARTAMENTO DE INGENIERIA E INVESTIGACIONES TECNOLOGICAS INGENIERIA EN INFORMATICA ARQUITECTURA DE COMPUTADORAS (1109) Profesor Titular: Ing. Fernando I. Szklanny PLANIFICACIÓN
UNIVERSIDAD NACIONAL DE LA MATANZA DEPARTAMENTO DE INGENIERIA E INVESTIGACIONES TECNOLOGICAS INGENIERIA EN INFORMATICA ARQUITECTURA DE COMPUTADORAS (1109) Profesor Titular: Ing. Fernando I. Szklanny PLANIFICACIÓN
Software Computacional y su clasificación
 Software Computacional y su clasificación Capítulo 5 El software En modo sencillo el software permite que las personas puedan contarle a la computadora cierto tipo de problemas y que ésta a su vez le ofrezca
Software Computacional y su clasificación Capítulo 5 El software En modo sencillo el software permite que las personas puedan contarle a la computadora cierto tipo de problemas y que ésta a su vez le ofrezca
UT04 01 Máquinas virtuales (introducción)
") UT04 01 Máquinas virtuales (introducción) n) Módulo: Sistemas Informáticos Virtualización Qué es una máquina m virtual? Terminología Características, ventajas e inconvenientes de las MVs Productos: VMWare,
UT04 01 Máquinas virtuales (introducción) n) Módulo: Sistemas Informáticos Virtualización Qué es una máquina m virtual? Terminología Características, ventajas e inconvenientes de las MVs Productos: VMWare,
La Arquitectura de las Máquinas Virtuales.
 La Arquitectura de las Máquinas Virtuales. La virtualización se ha convertido en una importante herramienta en el diseño de sistemas de computación, las máquinas virtuales (VMs) son usadas en varias subdiciplinas,
La Arquitectura de las Máquinas Virtuales. La virtualización se ha convertido en una importante herramienta en el diseño de sistemas de computación, las máquinas virtuales (VMs) son usadas en varias subdiciplinas,
Clase 20: Arquitectura Von Neuman
 http://computacion.cs.cinvestav.mx/~efranco @efranco_escom efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco) 1 Contenido Arquitectura de una computadora Elementos básicos de una
http://computacion.cs.cinvestav.mx/~efranco @efranco_escom efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco) 1 Contenido Arquitectura de una computadora Elementos básicos de una
Windows Server 2003. Windows Server 2003
 Windows Server 2003 Windows Server 2003 Es un sistema operativo de la familia Windows de la marca Microsoft para servidores que salió al mercado en el año 2003. Está basada en tecnología NT y su versión
Windows Server 2003 Windows Server 2003 Es un sistema operativo de la familia Windows de la marca Microsoft para servidores que salió al mercado en el año 2003. Está basada en tecnología NT y su versión
2. Requerimientos Técnicos
 2. Requerimientos Técnicos La solución SIR-LA (Sistema Integral RECO de Logística Aduanera) fue diseñada para operar como una plataforma centralizada, es decir, un sistema único para una Agencia o grupo
2. Requerimientos Técnicos La solución SIR-LA (Sistema Integral RECO de Logística Aduanera) fue diseñada para operar como una plataforma centralizada, es decir, un sistema único para una Agencia o grupo
ING. YURI RODRIGUEZ ALVA
 Historia y evolución de las Aplicaciones. Acerca de Cloud Computing o Computación para la Nube. Tipos de Aplicaciones para la Nube. Ventajas y desventajas de Cloud Computing Uso y Aplicaciones de Cloud
Historia y evolución de las Aplicaciones. Acerca de Cloud Computing o Computación para la Nube. Tipos de Aplicaciones para la Nube. Ventajas y desventajas de Cloud Computing Uso y Aplicaciones de Cloud
(Integrated Development Environment) Herramienta de soporte para el desarrollo de sotfware: Editor (escribir y editar programas); un
 Herramienta de soporte para el desarrollo de sotfware: Editor (escribir y editar programas); un") (Integrated Development Environment) Herramienta de soporte para el desarrollo de sotfware: Editor (escribir y editar programas); un compilador/intérprete y un depurador (localización de errores lógicos).
(Integrated Development Environment) Herramienta de soporte para el desarrollo de sotfware: Editor (escribir y editar programas); un compilador/intérprete y un depurador (localización de errores lógicos).
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators
 Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Maribel Castillo, Francisco D. Igual, Rafael Mayo, Gregorio Quintana-Ortí, Enrique S. Quintana-Ortí, Robert van de Geijn Grupo
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Maribel Castillo, Francisco D. Igual, Rafael Mayo, Gregorio Quintana-Ortí, Enrique S. Quintana-Ortí, Robert van de Geijn Grupo
Capitulo 1. Introducción a Objetos de Aprendizaje Móvil
 Capitulo 1. Introducción a Objetos de Aprendizaje Móvil En la actualidad está surgiendo, día a día, nueva tecnología con el objetivo de mejorar y facilitar la vida diaria. Una tecnología en específico
Capitulo 1. Introducción a Objetos de Aprendizaje Móvil En la actualidad está surgiendo, día a día, nueva tecnología con el objetivo de mejorar y facilitar la vida diaria. Una tecnología en específico
1.1 Definición del problema
 Capítulo 1. Introducción 1.1 Definición del problema Cuando el famoso juego Doom apareció, no solamente nos asombró el grandioso juego, sino que también trajo y popularizo un nuevo modelo de programación
Capítulo 1. Introducción 1.1 Definición del problema Cuando el famoso juego Doom apareció, no solamente nos asombró el grandioso juego, sino que también trajo y popularizo un nuevo modelo de programación
Tema 3 GPUs: Introducción
 Tema 3 GPUs: Introducción Alberto Ros Bardisa Tema 3 GPUs Alberto Ros Bardisa 1 / 15 Agenda 1 GPUs: Introducción 2 GP-GPU 3 Ejemplos comerciales 4 Conclusiones Tema 3 GPUs Alberto Ros Bardisa 2 / 15 Agenda
Tema 3 GPUs: Introducción Alberto Ros Bardisa Tema 3 GPUs Alberto Ros Bardisa 1 / 15 Agenda 1 GPUs: Introducción 2 GP-GPU 3 Ejemplos comerciales 4 Conclusiones Tema 3 GPUs Alberto Ros Bardisa 2 / 15 Agenda
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
Software de sistema: Programas genéricos que permiten gestionar los recursos del ordenador.
 PRINCIPALES TIPOS DE SOFTWARE Software de sistema: Programas genéricos que permiten gestionar los recursos del ordenador. Software de aplicación: Son programas escritos para realizar funciones específicas
PRINCIPALES TIPOS DE SOFTWARE Software de sistema: Programas genéricos que permiten gestionar los recursos del ordenador. Software de aplicación: Son programas escritos para realizar funciones específicas
Trabajo TP6 Sistemas Legados
 Trabajo TP6 Sistemas Legados VIRTUALIZACIÓN DE SISTEMAS A TRAVÉS DE APLICACIONES DE PAGO Diego Gálvez - 649892 Diego Grande - 594100 Qué es la virtualización? Técnica empleada sobre las características
Trabajo TP6 Sistemas Legados VIRTUALIZACIÓN DE SISTEMAS A TRAVÉS DE APLICACIONES DE PAGO Diego Gálvez - 649892 Diego Grande - 594100 Qué es la virtualización? Técnica empleada sobre las características
MANUAL DE USUARIO Joomla 2.5
 MANUAL DE USUARIO Joomla 2.5 Introducción Página 1 de 7 Tabla de contenido Cómo usar el manual de usuario... 3 Introducción a la herramienta... 4 Precondiciones a tener en cuenta... 4 Descripción y condiciones
MANUAL DE USUARIO Joomla 2.5 Introducción Página 1 de 7 Tabla de contenido Cómo usar el manual de usuario... 3 Introducción a la herramienta... 4 Precondiciones a tener en cuenta... 4 Descripción y condiciones
INTRODUCCIÓN. Que es un sistema operativo? - Es un programa. - Funciona como intermediario entre el usuario y los programas y el hardware
 INTRODUCCIÓN Que es un sistema operativo? - Es un programa. - Funciona como intermediario entre el usuario y los programas y el hardware INTRODUCCIÓN METAS: Brindar un entorno para que los usuarios puedan
INTRODUCCIÓN Que es un sistema operativo? - Es un programa. - Funciona como intermediario entre el usuario y los programas y el hardware INTRODUCCIÓN METAS: Brindar un entorno para que los usuarios puedan
I NTRODUCCIÓN 1. ORDENADOR E INFORMÁTICA
 I. INTRODUCCIÓN 1. ORDENADOR E INFORMÁTICA 1.1. Informática Informática (Información Automática) es la ciencia y la técnica del tratamiento automatizado de la información mediante el uso de ordenadores.
I. INTRODUCCIÓN 1. ORDENADOR E INFORMÁTICA 1.1. Informática Informática (Información Automática) es la ciencia y la técnica del tratamiento automatizado de la información mediante el uso de ordenadores.
Palabras Clave: Vídeo en FPGA, Procesamiento en Tiempo Real RESUMEN
 Procesamiento de Vídeo en Tiempo Real Utilizando FPGA J. G. Velásquez-Aguilar, A. Zamudio-Lara Centro de Investigación en Ingeniería y Ciencias Aplicadas, Universidad Autónoma del Estado de Morelos, Cuernavaca,
Procesamiento de Vídeo en Tiempo Real Utilizando FPGA J. G. Velásquez-Aguilar, A. Zamudio-Lara Centro de Investigación en Ingeniería y Ciencias Aplicadas, Universidad Autónoma del Estado de Morelos, Cuernavaca,
Informática Electrónica Interfaces para los programas de aplicación (APIs)
") Informática Electrónica Interfaces para los programas de aplicación (APIs) DSI- EIE FCEIA 2015 Que es un API? Application Program Interface (interface para programas aplicativos) es el mecanismo mediante
Informática Electrónica Interfaces para los programas de aplicación (APIs) DSI- EIE FCEIA 2015 Que es un API? Application Program Interface (interface para programas aplicativos) es el mecanismo mediante
GLOSARIO. Arquitectura: Funcionamiento, estructura y diseño de una plataforma de desarrollo.
 GLOSARIO Actor: Un actor es un usuario del sistema. Esto incluye usuarios humanos y otros sistemas computacionales. Un actor usa un Caso de Uso para ejecutar una porción de trabajo de valor para el negocio.
GLOSARIO Actor: Un actor es un usuario del sistema. Esto incluye usuarios humanos y otros sistemas computacionales. Un actor usa un Caso de Uso para ejecutar una porción de trabajo de valor para el negocio.
UNIVERSIDAD DE LOS ANDES FACULTAD DE CIENCIAS ECONOMICAS Y SOCIALES. PROF. ISRAEL J. RAMIREZ israel@ula.ve
 UNIVERSIDAD DE LOS ANDES FACULTAD DE CIENCIAS ECONOMICAS Y SOCIALES PROF. ISRAEL J. RAMIREZ israel@ula.ve UNIVERSIDAD DE LOS ANDES FACULTAD DE CIENCIAS ECONOMICAS Y SOCIALES LOS SISTEMAS OPERATIVOS 1.-
UNIVERSIDAD DE LOS ANDES FACULTAD DE CIENCIAS ECONOMICAS Y SOCIALES PROF. ISRAEL J. RAMIREZ israel@ula.ve UNIVERSIDAD DE LOS ANDES FACULTAD DE CIENCIAS ECONOMICAS Y SOCIALES LOS SISTEMAS OPERATIVOS 1.-
Desarrollo de Aplicaciones Web Por César Bustamante Gutiérrez. Módulo I: Conceptos Básicos Tema 1: Concepto iniciales. www.librosdigitales.
 1 Arquitectura de una Aplicación Android Para empezar con el desarrollo de aplicaciones en Android es importante conocer cómo está estructurado este sistema operativo. A esto le llamamos arquitectura y
1 Arquitectura de una Aplicación Android Para empezar con el desarrollo de aplicaciones en Android es importante conocer cómo está estructurado este sistema operativo. A esto le llamamos arquitectura y
Análisis de aplicación: Virtual Machine Manager
 Análisis de aplicación: Virtual Machine Manager Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla
Análisis de aplicación: Virtual Machine Manager Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla
Familia de Windows Server 2003
 Familia de Windows Server 2003 Windows Server 2003 está disponible en cuatro ediciones. Cada edición se ha desarrollado para una función de servidor específica, como se describe en la tabla siguiente:
Familia de Windows Server 2003 Windows Server 2003 está disponible en cuatro ediciones. Cada edición se ha desarrollado para una función de servidor específica, como se describe en la tabla siguiente:
Arquitecturas de Computadoras II. Febrero 2013
 Arquitecturas de Computadoras II Febrero 2013 1 Sabes... 1. Cuál es la Arquitectura Von Neumann? 2. Qué es Programación? 3. Qué es un algoritmo? 4. Qué es un programa? 5. Qué es un sistema? 6. Materias
Arquitecturas de Computadoras II Febrero 2013 1 Sabes... 1. Cuál es la Arquitectura Von Neumann? 2. Qué es Programación? 3. Qué es un algoritmo? 4. Qué es un programa? 5. Qué es un sistema? 6. Materias
Ingº CIP Fabian Guerrero Medina Master Web Developer-MWD
 1 Java es un lenguaje de programación de Sun Microsystems originalmente llamado "Oak. James Gosling Bill Joy 2 Oak nació para programar pequeños dispositivos electrodomésticos, como los asistentes personales
1 Java es un lenguaje de programación de Sun Microsystems originalmente llamado "Oak. James Gosling Bill Joy 2 Oak nació para programar pequeños dispositivos electrodomésticos, como los asistentes personales
ESCUELA NORMAL PROFESOR CARLOS A. CARRILLO
 ESCUELA NORMAL PROFESOR CARLOS A. CARRILLO Primer Semestre Licenciatura en Educación Primaria Profesor: Cruz Jorge Fernández Alumna: Sandra Carina Villalobos Olivas Unidad II ACTIVIDAD 3 Software Se conoce
ESCUELA NORMAL PROFESOR CARLOS A. CARRILLO Primer Semestre Licenciatura en Educación Primaria Profesor: Cruz Jorge Fernández Alumna: Sandra Carina Villalobos Olivas Unidad II ACTIVIDAD 3 Software Se conoce
TEMA 2: CAPACIDAD: Diseño del Servicio TI Anexo II: Amazon EC2
 CIMSI Configuración, Implementación y Mantenimiento de Sistemas Informáticos TEMA 2: CAPACIDAD: Diseño del Servicio TI Anexo II: Amazon EC2 Daniel Cascado Caballero Rosa Yáñez Gómez Mª José Morón Fernández
CIMSI Configuración, Implementación y Mantenimiento de Sistemas Informáticos TEMA 2: CAPACIDAD: Diseño del Servicio TI Anexo II: Amazon EC2 Daniel Cascado Caballero Rosa Yáñez Gómez Mª José Morón Fernández
UNIVERSIDAD AUTÓNOMA DEL CARIBE
 Página: 1/5 UNIVERSIDAD AUTÓNOMA DEL CARIBE SOPORTE DE PLATAFORMA GESTIÓN INFORMÁTICA Página: 2/5 1. OBJETO El objeto del procedimiento es garantizar una plataforma tecnológica y un sistema de comunicación
Página: 1/5 UNIVERSIDAD AUTÓNOMA DEL CARIBE SOPORTE DE PLATAFORMA GESTIÓN INFORMÁTICA Página: 2/5 1. OBJETO El objeto del procedimiento es garantizar una plataforma tecnológica y un sistema de comunicación
Laboratorio de Herramientas Computacionales
 Laboratorio de Herramientas Computacionales Tema 1.1 Componentes físicos de la computadora UNIVERSIDAD MICHOACANA DE SAN NICOLÁS DE HIDALGO FACULTAD DE INGENIERIA ELECTRICA M.I. ROSALÍA MORA JUÁREZ Antecedentes
Laboratorio de Herramientas Computacionales Tema 1.1 Componentes físicos de la computadora UNIVERSIDAD MICHOACANA DE SAN NICOLÁS DE HIDALGO FACULTAD DE INGENIERIA ELECTRICA M.I. ROSALÍA MORA JUÁREZ Antecedentes
Global File System (GFS)...
...") Global File System (GFS)... Diferente a los sistemas de ficheros en red que hemos visto, ya que permite que todos los nodos tengan acceso concurrente a los bloques de almacenamiento compartido (a través
Global File System (GFS)... Diferente a los sistemas de ficheros en red que hemos visto, ya que permite que todos los nodos tengan acceso concurrente a los bloques de almacenamiento compartido (a través
Toshiba e Intel: emocionante entretenimiento digital portátil
 Información técnica Toshiba e Intel Toshiba e Intel: emocionante entretenimiento digital portátil Gracias a la tecnología móvil Intel Centrino Duo, Toshiba ha desarrollado nuevos portátiles para ofrecer
Información técnica Toshiba e Intel Toshiba e Intel: emocionante entretenimiento digital portátil Gracias a la tecnología móvil Intel Centrino Duo, Toshiba ha desarrollado nuevos portátiles para ofrecer
Introducción. Por último se presentarán las conclusiones y recomendaciones pertinentes.
 Introducción En el presente documento se explicarán las consideraciones realizadas para implementar la convolución bidimensional en la arquitectura CUDA. En general se discutirá la metodología seguida
Introducción En el presente documento se explicarán las consideraciones realizadas para implementar la convolución bidimensional en la arquitectura CUDA. En general se discutirá la metodología seguida
Arquitecturas basadas en computación gráfica (GPU)
") Arquitecturas basadas en computación gráfica (GPU) Francesc Guim Ivan Rodero PID_00184818 CC-BY-NC-ND PID_00184818 Arquitecturas basadas en computación gráfica (GPU) Los textos e imágenes publicados en
Arquitecturas basadas en computación gráfica (GPU) Francesc Guim Ivan Rodero PID_00184818 CC-BY-NC-ND PID_00184818 Arquitecturas basadas en computación gráfica (GPU) Los textos e imágenes publicados en
Capítulo 1 Introducción a la Computación
 Capítulo 1 Introducción a la Computación 1 MEMORIA PRINCIPAL (RAM) DISPOSITIVOS DE ENTRADA (Teclado, Ratón, etc) C P U DISPOSITIVOS DE SALIDA (Monitor, Impresora, etc.) ALMACENAMIENTO (Memoria Secundaria:
Capítulo 1 Introducción a la Computación 1 MEMORIA PRINCIPAL (RAM) DISPOSITIVOS DE ENTRADA (Teclado, Ratón, etc) C P U DISPOSITIVOS DE SALIDA (Monitor, Impresora, etc.) ALMACENAMIENTO (Memoria Secundaria:
Dr.-Ing. Paola Vega Castillo
 EL-3310 DISEÑO O DE SISTEMAS DIGITALES Dr.-Ing. Paola Vega Castillo Información n General Curso: Diseño de Sistemas Digitales Código: EL-3310 Tipo de curso: Teórico Créditos/Horas por semana: 4/4 Requisito:
EL-3310 DISEÑO O DE SISTEMAS DIGITALES Dr.-Ing. Paola Vega Castillo Información n General Curso: Diseño de Sistemas Digitales Código: EL-3310 Tipo de curso: Teórico Créditos/Horas por semana: 4/4 Requisito:
Intel XeonPhi Workshop
 Intel XeonPhi Workshop Elena Núñez-González Unidad Informática Científica - CIEMAT Madrid, 11 de Febrero de 2015 Evento Lugar, Fecha Índice Introducción MIC Intel Xeon Phi Arquitectura Intel Xeon Phi Entorno
Intel XeonPhi Workshop Elena Núñez-González Unidad Informática Científica - CIEMAT Madrid, 11 de Febrero de 2015 Evento Lugar, Fecha Índice Introducción MIC Intel Xeon Phi Arquitectura Intel Xeon Phi Entorno
Métricas de Rendimiento
 Métricas de Rendimiento DISEÑO DE SISTEMAS DIGITALES EL-3310 I SEMESTRE 2008 6. RENDIMIENTO DE SISTEMAS COMPUTACIONALES (1 SEMANA) 6.1 Definición de rendimiento en términos computacionales 6.2 Medición
Métricas de Rendimiento DISEÑO DE SISTEMAS DIGITALES EL-3310 I SEMESTRE 2008 6. RENDIMIENTO DE SISTEMAS COMPUTACIONALES (1 SEMANA) 6.1 Definición de rendimiento en términos computacionales 6.2 Medición
Introducción a Computación
 Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
Unidad I. Introducción a la programación de Dispositivos Móviles
 Clase:002 1 Unidad I Introducción a la programación de Dispositivos Móviles Tomado de : Programación Multimedia y Dispositivos Móviles 2012 Paredes Velasco, Maximiliano / Santacruz Valencia, Liliana 2
Clase:002 1 Unidad I Introducción a la programación de Dispositivos Móviles Tomado de : Programación Multimedia y Dispositivos Móviles 2012 Paredes Velasco, Maximiliano / Santacruz Valencia, Liliana 2
WEB APP VS APP NATIVA
 WEB APP VS APP NATIVA Agosto 2013 Por Jesús Demetrio Velázquez 1 Ya decidió hacer su aplicación en Web App o App Nativa? Debido a que surgieron varias preguntas relacionadas con nuestro artículo Yo Mobile,
WEB APP VS APP NATIVA Agosto 2013 Por Jesús Demetrio Velázquez 1 Ya decidió hacer su aplicación en Web App o App Nativa? Debido a que surgieron varias preguntas relacionadas con nuestro artículo Yo Mobile,
Unidad CPE/VPN cpe@redescomm.com www.redescomm.com. RedesComm, c.a.
 Unidad CPE/VPN cpe@redescomm.com www.redescomm.com RedesComm, c.a. Qué es ASTC*MM? Es un Sistema Integral de Telefonía IP de fácil uso y totalmente e Código Abierto (software libre) capaz de cubrir en
Unidad CPE/VPN cpe@redescomm.com www.redescomm.com RedesComm, c.a. Qué es ASTC*MM? Es un Sistema Integral de Telefonía IP de fácil uso y totalmente e Código Abierto (software libre) capaz de cubrir en
WebSphere es una familia de productos de software propietario de IBM
 WEBSPHERE MQ WebSphere es una familia de productos de software propietario de IBM WebSphere MQ (anteriormente MQSeries), el punto central de la familia MQ, proporciona conectividad de aplicaciones. Puede
WEBSPHERE MQ WebSphere es una familia de productos de software propietario de IBM WebSphere MQ (anteriormente MQSeries), el punto central de la familia MQ, proporciona conectividad de aplicaciones. Puede
El computador. Miquel Albert Orenga Gerard Enrique Manonellas PID_00177070
 El computador Miquel Albert Orenga Gerard Enrique Manonellas PID_00177070 CC-BY-SA PID_00177070 El computador Los textos e imágenes publicados en esta obra están sujetos excepto que se indique lo contrario
El computador Miquel Albert Orenga Gerard Enrique Manonellas PID_00177070 CC-BY-SA PID_00177070 El computador Los textos e imágenes publicados en esta obra están sujetos excepto que se indique lo contrario
Programación en LabVIEW para Ambientes Multinúcleo
 Programación en LabVIEW para Ambientes Multinúcleo Agenda Introducción al Multithreading en LabVIEW Técnicas de Programación en Paralelo Consideraciones de Tiempo Real Recursos Evolución de la Instrumentación
Programación en LabVIEW para Ambientes Multinúcleo Agenda Introducción al Multithreading en LabVIEW Técnicas de Programación en Paralelo Consideraciones de Tiempo Real Recursos Evolución de la Instrumentación
BUSES GRUPO 8 Miguel París Dehesa Ricardo Sánchez Arroyo
 BUSES GRUPO 8 Miguel París Dehesa Ricardo Sánchez Arroyo - Trabajo de ampliación. BUSES. - 1 INDICE 1. Introducción 2. Integrated Drive Electronics (IDE) (1986) 3. Universal Serial Bus (USB) (1996) 4.
BUSES GRUPO 8 Miguel París Dehesa Ricardo Sánchez Arroyo - Trabajo de ampliación. BUSES. - 1 INDICE 1. Introducción 2. Integrated Drive Electronics (IDE) (1986) 3. Universal Serial Bus (USB) (1996) 4.