Mineración de Textos Científicos
|
|
|
- Francisco Carmona Santos
- hace 8 años
- Vistas:
Transcripción
1 Mineración de Textos Científicos Sheila Maricela Pinto Cáceres Universidade Estadual de Campinas IC - UNICAMP

2 Índice Introducción Colección Preprocesamiento Pasos a seguir Clusterización Resultados Conclusiones

3 Introducción Gran crecimiento de información, mayor cantidad de documentos en formato digital. Procesar estos datos y agruparlos automáticamente se torna en una tarea realmente necesaria. En este trabajo se describe el proceso para agrupar textos en una colección considerablemente grande dando énfasis a la parte de preprocesamiento de la colección.

4 Colección Artículos ACM Idioma Inglés Numero de documentos artículos

5 Pasos 1. Documento -> palabras

6 Estandarización de la colección Se analiza la data, verificando que los datos sean representativos y que no estén dañados o faltantes. Se observo que de los paper: 2875 de estos artículos no tienen abstract. Total Formatos no usables requieren ser convertidos a texto plano. Se extrajo cada abstract de la colección desde el portal de la ACM (html txt). Minusculas.

7 Pasos Pasos 1. Documento -> palabras 2. Palabras -> raíz (stemming) Ej: walk, walking, walks walk
 Ej: walk,")
8 Stemmización Extracción de las raíces de palabras. El proceso de stemmización esta basado en el algoritmo propuesto por Porter que anteriormente ha sido adaptado para Ingles, Español y portugues.

9 Recuperación de Texto (Review) Pasos 1. Documento -> palabras 2. Palabras -> raíz (stemming) Ej: walk, walking, walks walk 3. Stop List: Palabras comunes son eliminadas Ej: El, un, etc.

10 Ejemplo: Representation, detection and learning are the main issues that need to be tackled in designing a visual system for recognizing object. categories

11 Ejemplo: represent detect learn Representation, detection and learning are the main issue tackle design main issues that need to be tackled in designing visual system recognize category a visual system for recognizing object categories.

12 Pasos Pasos 1. Documento -> palabras 2. Palabras -> raíz (stemming) Ej: walk, walking, walks walk 3. Stop List: Palabras comunes son eliminadas Ej: El, un, etc. 4. Creación del bag of words. Cada palabra -> identificador único Word represent ID 1 detect learn 2 3.

13 Pasos Pasos 1. Documento -> palabras 2. Palabras -> raíz (stemming) Ej: walk, walking, walks walk 3. Stop List: Palabras comunes son eliminadas Ej: El, un, etc. 4. Creación del bag of words. Cada palabra -> identificador único 5. Cada documento-> Vector de k componentes

14 Frecuencia Se hicieron pruebas con tres tipos de frecuencias en una palabra a ser utilizadas sobre la matriz de datos: 1. Booleano: Si el atributo aparece o no en el texto. 2. Frecuencia: cantidad de veces que un atributo aparece en un texto. 3. Frecuencia relativizada: utilizando term frequency - inverse document frequency.

15 Documento ->k-vector de f(palabra) Vocabulario de K palabras. Documento -> vector de k componentes Documento V d =(t 1,,t i,,t k ) (0,0, 3, 4,. 5, 0,0) Estándar Weighting Term frecuency Inverse document frecuency tf-idf Word Frecuency Inverse Document Frecuency n id : numero de ocurrencias de la palabra i en documento d n d : numero de palabras en el documento d n i : numero de ocurrencias del termino i en la bd N: numero de documentos en la bd

16 Selección de atributos A pesar de la stemmización y el empleo de stop list, quedaron palabras (dimensiones) Como primera prueba o primer escenario se uso el conjunto total de dimensiones, tomando 8 horas de processamiento para generar una matriz de 14 GB de texto. Para la reducción de dimensionalidades se usaron los cortes de Luhn[6] Se establecen dos puntos de corte para los atributos de acuerdo con la frecuencia de los términos en un determinado documento mediante un histograma de frecuencias ordenado e forma descendente. Adoptando como puntos de corte los dos puntos de inflexión de la curva.(puntos no exactos)
![Para la reducción de dimensionalidades se usaron los cortes de Luhn[6] Se establecen dos puntos de corte para los atributos de acuerdo con la frecuencia de](/docs-images/44/7077104/images/page_16.jpg "los términos en un determinado documento mediante un histograma de frecuencias ordenado e forma descendente.")
17 Mineración Clusterización jerarquica: construye una jerarquia o un árbol de clusters conocido como dendograma mostrando como son agrupados los documentos. Cada cluster en el árbol contiene diferentes clusteres hijos permitiendo diferente numero de clusters

18 Experimentos y Resultados Fueron montados 8 escenarios diferentes. Todos los escenarios fueron analisados de acordo com a similaridade interna e a similaridade externa dos clusters. Para aplicar algoritmos de clusterización en 3D se uso la herramienta gcluto. Cada pico es uma curva gaussiana y es uma estimativa de la distribucion de los datos de cada cluster. A altura de cada pico similaridad interna de cada cluster. volume cantidad de documentos. Color del pico Proporcional al desviación interna del cluster. Se describen tambien los siguientes datos. Size: N umero de textos no cluster ISim: Similaridade interna ESim: Similaridade externa

19
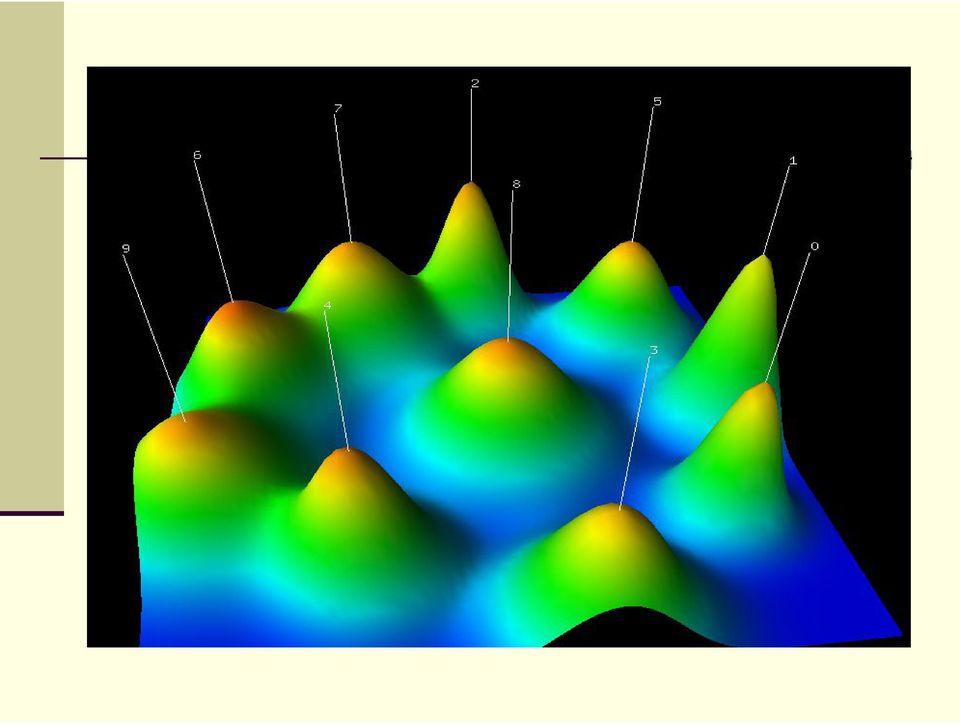
20 Experimentos y Resultados Cluster 0, Size: 3212, ISim: 0.033, ESim: approxim, polynomial, linear, matrix, equat, curv Cluster 1, Size: 4589, ISim: 0.040, ESim: equat numer, equat numer discret, equat boundari, equat numer differenti, equat nonlinear Cluster 2, Size: 4582, ISim: 0.036, ESim: memori parallel, processor hardwar, benchmark, processor instruct, memori cach Cluster 3, Size: 7496, ISim: 0.029, ESim: prove, bound give, polynomial, vertic edg, theorem Cluster 4, Size: 5242, ISim: 0.031, ESim: product, decis, busi, organ, market price Cluster 5, Size: 6537, ISim: 0.027, ESim: circuit, low, voltag current, circuit gate, circuit delai Cluster 6, Size: 7489, ISim: 0.026, ESim: semant, defin, express, logic, extens Cluster 7, Size: 10699, ISim: 0.029, ESim: protocol, traffic, packet, internet, wireless Cluster 8, Size: 10699, ISim: 0.027, ESim: extract, retriev, databas, classif classifi, train Cluster 9, Size: 12234, ISim: 0.025, ESim: student, interfac, project, collabor, creat

21 Experimentos y Resultados Hierarchical Tree Size XSim Gain 18 [72779, 2.09e-11, +1.84e-02] [15297, 6.34e-10, +3.71e-02] [ 7496, 0.00e+00, +0.00e+00] [ 7801, 3.09e-09, +4.56e-02] ---0 [ 3212, 0.00e+00, +0.00e+00] ---1 [ 4589, 0.00e+00, +0.00e+00] -17 [57482, 3.21e-11, +2.50e-02] -16 [21818, 2.59e-10, +2.59e-02] [ 6537, 0.00e+00, +0.00e+00] -15 [15281, 5.72e-10, +2.80e-02] [ 4582, 0.00e+00, +0.00e+00] [10699, 0.00e+00, +0.00e+00] [35664, 1.32e-10, +3.53e-02] [24965, 2.98e-10, +3.90e-02] [ 7489, 0.00e+00, +0.00e+00] -11 [17476, 6.54e-10, +4.19e-02] [ 5242, 0.00e+00, +0.00e+00] [12234, 0.00e+00, +0.00e+00] [10699, 0.00e+00, +0.00e+00]
22 Escenario 6 con 10 clusters
23 Conclusiones La selección de atributos tuvo un papel trascendental antes de aplicar los métodos de clusterización sobre los datos directamente, ya que de tener todos los datos las funciones o hiperplanos de separación de los planos nos podrían llevar a un overfitting. Los cortes de Luhn sirvieron eficientemente en la reduccion de dimensionalidad. La clusterizacoin de todos los artículos demostro que una colección de esta magnitud envuelve una mayor dificultad en la definicion de los clusters, no entanto con un conjunto menor de articulos estos fueron mejor definidos despues de aplicar el algoritmo de clusterizacion La eleccion del numero de clusters deseados demostró tambien tener un papel importante en la clasificación de cada cluster.
24 Trabajos Futuros Adicionar Key-words, autor o titulo en la información del documento. Usar bigramas y/o trigramas
25 Referencias [1] A. Asuncion and D. Newman. UCI machine learning repository, [2] S. Banerjee and T. Pedersen. The design, implementation, and use of the ngram statis- tics package. In A. F. Gelbukh, editor, CICLing, volume 2588 of Lecture Notes in Computer Science, pages Springer, [3] I. Dhillon, J. Kogan, and C. Nicholas. Feature selection and document clustering. In M. W. Berry, editor, Survey of Text Mining, pages Springer, [4] L. Liu, J. Kang, J. Yu, and Z. Wang. A comparative study on unsupervised feature selection methods for text clustering. Natural Language Processing and Knowledge Engineering, IEEE NLP-KE 05. Proceedings of 2005 IEEE International Conference on, pages , 30 Oct.-1 Nov [5] Ding, C., He, X., Zha, H., Gu, M., and Simon, H. (2001). Spectral minmax cut for graph partitioning and data clustering. In Proc. 1st IEEE International Conference on Data Mining, pages [6] Luhn, H. P. (1958). The automatic creation of literature abstracts. IBM Journal of Research and Development, 2(2). [7] Porter, M. F. (1980). An algorithm for suffix stripping. Program, 14(3):
26 Gracias
Procesamiento de Texto y Modelo Vectorial
 Felipe Bravo Márquez 6 de noviembre de 2013 Motivación Cómo recupera un buscador como Google o Yahoo! documentos relevantes a partir de una consulta enviada? Cómo puede procesar una empresa los reclamos
Felipe Bravo Márquez 6 de noviembre de 2013 Motivación Cómo recupera un buscador como Google o Yahoo! documentos relevantes a partir de una consulta enviada? Cómo puede procesar una empresa los reclamos
Los futuros desafíos de la Inteligencia de Negocios. Richard Weber Departamento de Ingeniería Industrial Universidad de Chile rweber@dii.uchile.
 Los futuros desafíos de la Inteligencia de Negocios Richard Weber Departamento de Ingeniería Industrial Universidad de Chile rweber@dii.uchile.cl El Vértigo de la Inteligencia de Negocios CRM: Customer
Los futuros desafíos de la Inteligencia de Negocios Richard Weber Departamento de Ingeniería Industrial Universidad de Chile rweber@dii.uchile.cl El Vértigo de la Inteligencia de Negocios CRM: Customer
Clasificación Bayesiana de textos y páginas web
 Clasificación Bayesiana de textos y páginas web Curso de doctorado: Ingeniería Lingüística aplicada al Procesamiento de Documentos Víctor Fresno Fernández Introducción Enorme cantidad de información en
Clasificación Bayesiana de textos y páginas web Curso de doctorado: Ingeniería Lingüística aplicada al Procesamiento de Documentos Víctor Fresno Fernández Introducción Enorme cantidad de información en
Introducción a selección de. Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012
 Introducción a selección de atributos usando WEKA Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012 Contenido 1 Introducción a WEKA El origen Interfaces
Introducción a selección de atributos usando WEKA Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012 Contenido 1 Introducción a WEKA El origen Interfaces
Análisis Estadístico de Datos Climáticos
 Análisis Estadístico de Datos Climáticos Análisis de agrupamiento (o clusters) (Wilks, Cap. 14) Facultad de Ciencias Facultad de Ingeniería 2013 Objetivo Idear una clasificación o esquema de agrupación
Análisis Estadístico de Datos Climáticos Análisis de agrupamiento (o clusters) (Wilks, Cap. 14) Facultad de Ciencias Facultad de Ingeniería 2013 Objetivo Idear una clasificación o esquema de agrupación
MINERIA DE DATOS Y Descubrimiento del Conocimiento
 MINERIA DE DATOS Y Descubrimiento del Conocimiento UNA APLICACIÓN EN DATOS AGROPECUARIOS INTA EEA Corrientes Maximiliano Silva La información Herramienta estratégica para el desarrollo de: Sociedad de
MINERIA DE DATOS Y Descubrimiento del Conocimiento UNA APLICACIÓN EN DATOS AGROPECUARIOS INTA EEA Corrientes Maximiliano Silva La información Herramienta estratégica para el desarrollo de: Sociedad de
Un Sistema Inteligente para Asistir la Búsqueda Personalizada de Objetos de Aprendizaje
 Un Sistema Inteligente para Asistir la Búsqueda Personalizada de Objetos de Aprendizaje Ana Casali 1, Claudia Deco, Cristina Bender y Valeria Gerling, Universidad Nacional de Rosario, Facultad de Ciencias
Un Sistema Inteligente para Asistir la Búsqueda Personalizada de Objetos de Aprendizaje Ana Casali 1, Claudia Deco, Cristina Bender y Valeria Gerling, Universidad Nacional de Rosario, Facultad de Ciencias
Base de datos II Facultad de Ingeniería. Escuela de computación.
 Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Minería de Datos Web. 1 er Cuatrimestre 2015. Página Web. Prof. Dra. Daniela Godoy. http://www.exa.unicen.edu.ar/catedras/ageinweb/
 Minería de Datos Web 1 er Cuatrimestre 2015 Página Web http://www.exa.unicen.edu.ar/catedras/ageinweb/ Prof. Dra. Daniela Godoy ISISTAN Research Institute UNICEN University Tandil, Bs. As., Argentina http://www.exa.unicen.edu.ar/~dgodoy
Minería de Datos Web 1 er Cuatrimestre 2015 Página Web http://www.exa.unicen.edu.ar/catedras/ageinweb/ Prof. Dra. Daniela Godoy ISISTAN Research Institute UNICEN University Tandil, Bs. As., Argentina http://www.exa.unicen.edu.ar/~dgodoy
Aprendizaje Automático y Data Mining. Bloque IV DATA MINING
 Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
Integrando Información de Fuentes Relevantes para un Sistema Recomendador
 Integrando Información de Fuentes Relevantes para un Sistema Recomendador Silvana Aciar, Josefina López Herrera and Javier Guzmán Obando Agents Research Laboratory University of Girona {saciar, jguzmano}@eia.udg.es,
Integrando Información de Fuentes Relevantes para un Sistema Recomendador Silvana Aciar, Josefina López Herrera and Javier Guzmán Obando Agents Research Laboratory University of Girona {saciar, jguzmano}@eia.udg.es,
Information Retrieval:
 Information Retrieval: Consiste en encontrar información, mayormente en la forma de documentos, pero que se encuentran en una forma no estructurada. Estos datos satisfacen las necesidades de grandes repositorios
Information Retrieval: Consiste en encontrar información, mayormente en la forma de documentos, pero que se encuentran en una forma no estructurada. Estos datos satisfacen las necesidades de grandes repositorios
CLUSTERING MAPAS AUTOORGANIZATIVOS (KOHONEN) (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN)
 (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN)") CLASIFICACIÓN NO SUPERVISADA CLUSTERING Y MAPAS AUTOORGANIZATIVOS (KOHONEN) (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN) info@clustering.50webs.com Indice INTRODUCCIÓN 3 RESUMEN DEL CONTENIDO 3 APRENDIZAJE
CLASIFICACIÓN NO SUPERVISADA CLUSTERING Y MAPAS AUTOORGANIZATIVOS (KOHONEN) (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN) info@clustering.50webs.com Indice INTRODUCCIÓN 3 RESUMEN DEL CONTENIDO 3 APRENDIZAJE
Data Mining Técnicas y herramientas
 Data Mining Técnicas y herramientas Introducción POR QUÉ? Empresas necesitan aprender de sus datos para crear una relación one-toone con sus clientes. Recogen datos de todos lo procesos. Datos recogidos
Data Mining Técnicas y herramientas Introducción POR QUÉ? Empresas necesitan aprender de sus datos para crear una relación one-toone con sus clientes. Recogen datos de todos lo procesos. Datos recogidos
Aplicaci n de los Mapas Autoorganizativos al campo de la Documentaci n
 Aplicaci n de los Mapas Autoorganizativos al campo de la Documentaci n SRP Carlos Carrascosa Casamayor Vicente J. Julián Inglada Introducci n Objetivo: Cubrir necesidades de: Organizar, explorar y buscar
Aplicaci n de los Mapas Autoorganizativos al campo de la Documentaci n SRP Carlos Carrascosa Casamayor Vicente J. Julián Inglada Introducci n Objetivo: Cubrir necesidades de: Organizar, explorar y buscar
TÉCNICAS DE MINERÍA DE DATOS Y TEXTO APLICADAS A LA SEGURIDAD AEROPORTUARIA
 TÉCNICAS DE MINERÍA DE DATOS Y TEXTO APLICADAS A LA SEGURIDAD AEROPORTUARIA MSC ZOILA RUIZ VERA Empresa Cubana de Aeropuertos y Servicios Aeronáuticos Abril 2010 ANTECEDENTES El proyecto Seguridad es una
TÉCNICAS DE MINERÍA DE DATOS Y TEXTO APLICADAS A LA SEGURIDAD AEROPORTUARIA MSC ZOILA RUIZ VERA Empresa Cubana de Aeropuertos y Servicios Aeronáuticos Abril 2010 ANTECEDENTES El proyecto Seguridad es una
PROCESO EDITORIAL DE UNA REVISTA CIENTÍFICA.
 PROCESO EDITORIAL DE UNA REVISTA CIENTÍFICA. Seminario: Publicaciones Científicas. Asamblea Nacional de Rectores 26-27 de marzo del 2012. Ing. Fernando Ardito Jefe de Publicaciones Científicas de la Universidad
PROCESO EDITORIAL DE UNA REVISTA CIENTÍFICA. Seminario: Publicaciones Científicas. Asamblea Nacional de Rectores 26-27 de marzo del 2012. Ing. Fernando Ardito Jefe de Publicaciones Científicas de la Universidad
Aprendizaje Computacional. Eduardo Morales y Jesús González
 Aprendizaje Computacional Eduardo Morales y Jesús González Objetivo General La capacidad de aprender se considera como una de los atributos distintivos del ser humano y ha sido una de las principales áreas
Aprendizaje Computacional Eduardo Morales y Jesús González Objetivo General La capacidad de aprender se considera como una de los atributos distintivos del ser humano y ha sido una de las principales áreas
Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final
![Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final](/thumbs/27/10370366.jpg "Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final") Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final INTRODUCCION En principio surgió la idea de un buscador que brinde los resultados en agrupaciones de
Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final INTRODUCCION En principio surgió la idea de un buscador que brinde los resultados en agrupaciones de
Costos Estándar. Mtra. Alejandra Salas Ramírez
 Costos Estándar Mtra. Alejandra Salas Ramírez Nov-2013 Costos Históricos O Reales Costos predeterminados estimados estandar Costos Históricos O Reales Son aquellos que se obtienen después, de que el producto
Costos Estándar Mtra. Alejandra Salas Ramírez Nov-2013 Costos Históricos O Reales Costos predeterminados estimados estandar Costos Históricos O Reales Son aquellos que se obtienen después, de que el producto
Área Académica: Sistemas Computacionales. Tema: Introducción a almacén de datos. Profesor: Mtro Felipe de Jesús Núñez Cárdenas
 Área Académica: Sistemas Computacionales Tema: Introducción a almacén de datos Profesor: Mtro Felipe de Jesús Núñez Cárdenas Periodo: Agosto Noviembre 2011 Keywords Almacén de Datos, Datawarehouse, Arquitectura
Área Académica: Sistemas Computacionales Tema: Introducción a almacén de datos Profesor: Mtro Felipe de Jesús Núñez Cárdenas Periodo: Agosto Noviembre 2011 Keywords Almacén de Datos, Datawarehouse, Arquitectura
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos. - Sesión 2 -
 Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 2 - Juan Alfonso Lara Torralbo 1 Índice de contenidos (I) Introducción a Data Mining Actividad. Tipos
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 2 - Juan Alfonso Lara Torralbo 1 Índice de contenidos (I) Introducción a Data Mining Actividad. Tipos
Decisión: Indican puntos en que se toman decisiones: sí o no, o se verifica una actividad del flujo grama.
 Diagrama de Flujo La presentación gráfica de un sistema es una forma ampliamente utilizada como herramienta de análisis, ya que permite identificar aspectos relevantes de una manera rápida y simple. El
Diagrama de Flujo La presentación gráfica de un sistema es una forma ampliamente utilizada como herramienta de análisis, ya que permite identificar aspectos relevantes de una manera rápida y simple. El
Notas. Modelo conceptual para el diseño e implementación del sitio web de un museo regional * Resumen. 1. Introducción y formulación del problema
 Notas Modelo conceptual para el diseño e implementación del sitio web de un museo regional * Resumen El presente artículo propone el modelo conceptual para la creación de un sitio Web de un museo regional
Notas Modelo conceptual para el diseño e implementación del sitio web de un museo regional * Resumen El presente artículo propone el modelo conceptual para la creación de un sitio Web de un museo regional
Recuperación de información Bases de Datos Documentales Licenciatura en Documentación Curso 2011/2012
 Bases de Datos Documentales Curso 2011/2012 Miguel Ángel Rodríguez Luaces Laboratorio de Bases de Datos Universidade da Coruña Introducción Hemos dedicado la primera mitad del curso a diseñar e implementar
Bases de Datos Documentales Curso 2011/2012 Miguel Ángel Rodríguez Luaces Laboratorio de Bases de Datos Universidade da Coruña Introducción Hemos dedicado la primera mitad del curso a diseñar e implementar
http://swoogle.umbc.edu/
 Sistemas de Representación y Procesamiento Automático del Conocimiento http://swoogle.umbc.edu/ ://swoogle.umbc.edu Consuelo Barberá Mercé Millet Emiliano Torres Valencia, 22 de mayo de 2006 Qué es? Un
Sistemas de Representación y Procesamiento Automático del Conocimiento http://swoogle.umbc.edu/ ://swoogle.umbc.edu Consuelo Barberá Mercé Millet Emiliano Torres Valencia, 22 de mayo de 2006 Qué es? Un
Cómo publicar en. International Journal of Gastronomy and Food Science. Guía para autores
 Cómo publicar en International Journal of Gastronomy and Food Science Guía para autores Por qué publicar Si tienes información que permita avanzar en el campo de la gastronomía y la ciencia de los alimentos,
Cómo publicar en International Journal of Gastronomy and Food Science Guía para autores Por qué publicar Si tienes información que permita avanzar en el campo de la gastronomía y la ciencia de los alimentos,
Parte I: Introducción
 Parte I: Introducción Introducción al Data Mining: su Aplicación a la Empresa Cursada 2007 POR QUÉ? Las empresas de todos los tamaños necesitan aprender de sus datos para crear una relación one-to-one
Parte I: Introducción Introducción al Data Mining: su Aplicación a la Empresa Cursada 2007 POR QUÉ? Las empresas de todos los tamaños necesitan aprender de sus datos para crear una relación one-to-one
CLASIFICACIÓN NO SUPERVISADA
 CLASIFICACIÓN NO SUPERVISADA CLASIFICACION IMPORTANCIA PROPÓSITO METODOLOGÍAS EXTRACTORES DE CARACTERÍSTICAS TIPOS DE CLASIFICACIÓN IMPORTANCIA CLASIFICAR HA SIDO, Y ES HOY DÍA, UN PROBLEMA FUNDAMENTAL
CLASIFICACIÓN NO SUPERVISADA CLASIFICACION IMPORTANCIA PROPÓSITO METODOLOGÍAS EXTRACTORES DE CARACTERÍSTICAS TIPOS DE CLASIFICACIÓN IMPORTANCIA CLASIFICAR HA SIDO, Y ES HOY DÍA, UN PROBLEMA FUNDAMENTAL
PREGUNTAS FRECUENTES DEL SISTEMA DE FONDOS
 PREGUNTAS FRECUENTES DEL SISTEMA DE FONDOS 1. EL SISTEMA NO ME PERMITE INGRESAR CON MI USUARIO Y CONTRASEÑA... 2 2. CÓMO ACCEDO A MI SOLICITUD?... 9 3. PARA QUÉ SIRVEN LAS LUPAS?...15 4. EXISTEN LIMITANTES
PREGUNTAS FRECUENTES DEL SISTEMA DE FONDOS 1. EL SISTEMA NO ME PERMITE INGRESAR CON MI USUARIO Y CONTRASEÑA... 2 2. CÓMO ACCEDO A MI SOLICITUD?... 9 3. PARA QUÉ SIRVEN LAS LUPAS?...15 4. EXISTEN LIMITANTES
CURSO/GUÍA PRÁCTICA GESTIÓN EMPRESARIAL DE LA INFORMACIÓN.
 SISTEMA EDUCATIVO inmoley.com DE FORMACIÓN CONTINUA PARA PROFESIONALES INMOBILIARIOS. CURSO/GUÍA PRÁCTICA GESTIÓN EMPRESARIAL DE LA INFORMACIÓN. Business Intelligence. Data Mining. PARTE PRIMERA Qué es
SISTEMA EDUCATIVO inmoley.com DE FORMACIÓN CONTINUA PARA PROFESIONALES INMOBILIARIOS. CURSO/GUÍA PRÁCTICA GESTIÓN EMPRESARIAL DE LA INFORMACIÓN. Business Intelligence. Data Mining. PARTE PRIMERA Qué es
Taller práctico: Crear y visualizar nuevo conocimiento extraído de un corpus documental mediante
 Taller práctico: Crear y visualizar nuevo conocimiento extraído de un corpus documental mediante TextMining Análisis estratégico de la investigación en Información y documentación ambiental, según ISOC
Taller práctico: Crear y visualizar nuevo conocimiento extraído de un corpus documental mediante TextMining Análisis estratégico de la investigación en Información y documentación ambiental, según ISOC
Análisis de Datos. Práctica de métodos predicción de en WEKA
 SOLUCION 1. Características de los datos y filtros Una vez cargados los datos, aparece un cuadro resumen, Current relation, con el nombre de la relación que se indica en el fichero (en la línea @relation
SOLUCION 1. Características de los datos y filtros Una vez cargados los datos, aparece un cuadro resumen, Current relation, con el nombre de la relación que se indica en el fichero (en la línea @relation
Análisis textual con el programa de concordancias Antconc
 Análisis textual con el programa de concordancias Antconc 1. Para empezar Para abrir el programa, en el interfaz de Google, escribe antcon y selecciona la versión correspondiente a Windows: AntConc 3.2.1
Análisis textual con el programa de concordancias Antconc 1. Para empezar Para abrir el programa, en el interfaz de Google, escribe antcon y selecciona la versión correspondiente a Windows: AntConc 3.2.1
Novedades de software/new softwares
 REVISTA INVESTIGACIÓN OPERACIONAL VOL., 3, No. 3, 275-28, 2 Novedades de software/new softwares ALGORITMO PARA LA GENERACIÓN ALEATORIA DE MATRICES BOOLEANAS INVERSIBLES P. Freyre*, N. Díaz*, E. R. Morgado**
REVISTA INVESTIGACIÓN OPERACIONAL VOL., 3, No. 3, 275-28, 2 Novedades de software/new softwares ALGORITMO PARA LA GENERACIÓN ALEATORIA DE MATRICES BOOLEANAS INVERSIBLES P. Freyre*, N. Díaz*, E. R. Morgado**
Big Data & Machine Learning. MSc. Ing. Máximo Gurméndez Universidad de Montevideo
 Big Data & Machine Learning MSc. Ing. Máximo Gurméndez Universidad de Montevideo Qué es Big Data? Qué es Machine Learning? Qué es Data Science? Ejemplo: Predecir origen de artículos QUÉ DIARIO LO ESCRIBIÓ?
Big Data & Machine Learning MSc. Ing. Máximo Gurméndez Universidad de Montevideo Qué es Big Data? Qué es Machine Learning? Qué es Data Science? Ejemplo: Predecir origen de artículos QUÉ DIARIO LO ESCRIBIÓ?
www.gtbi.net soluciones en Fotogrametría Digital El software de análisis más potente basado en objetos de datos geoespaciales. Fotogrametría Digital
 soluciones en Fotogrametría Digital El software de análisis más potente basado en objetos de datos geoespaciales. Fotogrametría Digital www.gtbi.net LA MANERA DE ENTENDER EL MUNDO ESTÁ CAMBIANDO El usuario
soluciones en Fotogrametría Digital El software de análisis más potente basado en objetos de datos geoespaciales. Fotogrametría Digital www.gtbi.net LA MANERA DE ENTENDER EL MUNDO ESTÁ CAMBIANDO El usuario
FILTRADO DE CONTENIDOS WEB EN ESPAÑOL DENTRO DEL PROYECTO POESIA
 FILTRADO DE CONTENIDOS WEB EN ESPAÑOL DENTRO DEL PROYECTO POESIA Enrique Puertas epuertas@uem.es Francisco Carrero fcarrero@uem.es José María Gómez Hidalgo jmgomez@uem.es Manuel de Buenaga buenga@uem.es
FILTRADO DE CONTENIDOS WEB EN ESPAÑOL DENTRO DEL PROYECTO POESIA Enrique Puertas epuertas@uem.es Francisco Carrero fcarrero@uem.es José María Gómez Hidalgo jmgomez@uem.es Manuel de Buenaga buenga@uem.es
ESCUELA POLITÉCNICA SUPERIOR
 UNIVERSIDAD DE CÓRDOBA ESCUELA POLITÉCNICA SUPERIOR INGENIERÍA TÉCNICA EN INFORMÁTICA DE GESTIÓN PETICIÓN DE TEMA PARA PROYECTO FIN DE CARRERA: TÍTULO Herramienta para la preparación de conjuntos de aprendizaje
UNIVERSIDAD DE CÓRDOBA ESCUELA POLITÉCNICA SUPERIOR INGENIERÍA TÉCNICA EN INFORMÁTICA DE GESTIÓN PETICIÓN DE TEMA PARA PROYECTO FIN DE CARRERA: TÍTULO Herramienta para la preparación de conjuntos de aprendizaje
EL ANÁLISIS DE CONGLOMERADOS EN LOS ESTUDIOS DE MERCADO
 EL ANÁLISIS DE CONGLOMERADOS EN LOS ESTUDIOS DE MERCADO I. INTRODUCCIÓN Beatriz Meneses A. de Sesma * En los estudios de mercado intervienen muchas variables que son importantes para el cliente, sin embargo,
EL ANÁLISIS DE CONGLOMERADOS EN LOS ESTUDIOS DE MERCADO I. INTRODUCCIÓN Beatriz Meneses A. de Sesma * En los estudios de mercado intervienen muchas variables que son importantes para el cliente, sin embargo,
LICEO BRICEÑO MÉNDEZ S0120D0320 DEPARTAMENTO DE CONTROL Y EVALUACIÓN CATEDRA: FISICA PROF.
 LICEO BRICEÑO MÉNDEZ S0120D0320 CATEDRA: FISICA PROF. _vwéa gxâw á atätá GRUPO # 4to Cs PRACTICA DE LABORATORIO #2 CALCULADORA CIENTIFICA OBJETIVO GENERAL: Comprender la importancia del cálculo haciendo
LICEO BRICEÑO MÉNDEZ S0120D0320 CATEDRA: FISICA PROF. _vwéa gxâw á atätá GRUPO # 4to Cs PRACTICA DE LABORATORIO #2 CALCULADORA CIENTIFICA OBJETIVO GENERAL: Comprender la importancia del cálculo haciendo
BASE DE DATOS UNIVERSIDAD DE LOS ANDES FACULTAD DE MEDICINA T.S.U. EN ESTADISTICA DE SALUD CATEDRA DE COMPUTACIÓN II. Comenzar presentación
 UNIVERSIDAD DE LOS ANDES FACULTAD DE MEDICINA T.S.U. EN ESTADISTICA DE SALUD CATEDRA DE COMPUTACIÓN II BASE DE DATOS Comenzar presentación Base de datos Una base de datos (BD) o banco de datos es un conjunto
UNIVERSIDAD DE LOS ANDES FACULTAD DE MEDICINA T.S.U. EN ESTADISTICA DE SALUD CATEDRA DE COMPUTACIÓN II BASE DE DATOS Comenzar presentación Base de datos Una base de datos (BD) o banco de datos es un conjunto
Arboles AA. Kenneth Sanchez y Tamara Moscoso 8 de octubre del 2015
 Arboles AA Kenneth Sanchez y Tamara Moscoso 8 de octubre del 2015 Abstract En la industria comercial, durante mucho tiempo se han pasado por alto metodos de ordenamiento con una eficiencia buena y en su
Arboles AA Kenneth Sanchez y Tamara Moscoso 8 de octubre del 2015 Abstract En la industria comercial, durante mucho tiempo se han pasado por alto metodos de ordenamiento con una eficiencia buena y en su
UNIDAD 2: Abstracción del Mundo real Al Paradigma Orientado a Objetos
 2.1. Principios básicos del Modelado de Objetos UNIDAD 2: Abstracción del Mundo real Al Paradigma Orientado a Objetos Hoy en día muchos de los procesos que intervienen en un negocio o empresa y que resuelven
2.1. Principios básicos del Modelado de Objetos UNIDAD 2: Abstracción del Mundo real Al Paradigma Orientado a Objetos Hoy en día muchos de los procesos que intervienen en un negocio o empresa y que resuelven
Metodologías de diseño de hardware
 Capítulo 2 Metodologías de diseño de hardware Las metodologías de diseño de hardware denominadas Top-Down, basadas en la utilización de lenguajes de descripción de hardware, han posibilitado la reducción
Capítulo 2 Metodologías de diseño de hardware Las metodologías de diseño de hardware denominadas Top-Down, basadas en la utilización de lenguajes de descripción de hardware, han posibilitado la reducción
Plataformas paralelas
 Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
5. DISTRIBUCIONES DE PROBABILIDADES
 5. DISTRIBUCIONES DE PROBABILIDADES Dr. http://academic.uprm.edu/eacunaf UNIVERSIDAD DE PUERTO RICO RECINTO UNIVERSITARIO DE MAYAGUEZ DISTRIBUCIONES DE PROBABILIDADES Se introducirá el concepto de variable
5. DISTRIBUCIONES DE PROBABILIDADES Dr. http://academic.uprm.edu/eacunaf UNIVERSIDAD DE PUERTO RICO RECINTO UNIVERSITARIO DE MAYAGUEZ DISTRIBUCIONES DE PROBABILIDADES Se introducirá el concepto de variable
Método Supervisado orientado a la clasificación automática de documentos. Caso Historias Clínicas
 Método Supervisado orientado a la clasificación automática de documentos. Caso Historias Clínicas Roque E. López Condori 1 Dennis Barreda Morales 2 Javier Tejada Cárcamo 2 Luis Alfaro Casas 1 1 Universidad
Método Supervisado orientado a la clasificación automática de documentos. Caso Historias Clínicas Roque E. López Condori 1 Dennis Barreda Morales 2 Javier Tejada Cárcamo 2 Luis Alfaro Casas 1 1 Universidad
1) Descargar gvsig 1.11 con prerrequisitos de instalación:
 Descargar gvsig 1.11 con prerrequisitos de instalación:") Programa Nacional Mapa Educativo Curso de capacitación Introducción a los Sistemas de Información Geográfica CLASE 1 Instructivo de instalación de gvsig 1.11 Original: Norberto Yacante Mapa Educativo de
Programa Nacional Mapa Educativo Curso de capacitación Introducción a los Sistemas de Información Geográfica CLASE 1 Instructivo de instalación de gvsig 1.11 Original: Norberto Yacante Mapa Educativo de
Tabla de contenidos. Tabla de contenidos. Índice de tablas. Índice de figuras. Resumen. Abstract. Agradecimientos
 Tabla de contenidos Tabla de contenidos Índice de tablas Índice de figuras Resumen Abstract Agradecimientos VII XI XII XV XVII XIX 1. Introducción 1 1.1. Planteamiento del problema... 1 1.2. Objetivos
Tabla de contenidos Tabla de contenidos Índice de tablas Índice de figuras Resumen Abstract Agradecimientos VII XI XII XV XVII XIX 1. Introducción 1 1.1. Planteamiento del problema... 1 1.2. Objetivos
Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322
 Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322 Nicole García Gómez 2830047-6 Diego Riquelme Adriasola 2621044-5 RESUMEN.- La minería de datos corresponde a la extracción
Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322 Nicole García Gómez 2830047-6 Diego Riquelme Adriasola 2621044-5 RESUMEN.- La minería de datos corresponde a la extracción
Área Académica: Sistemas Computacionales. Tema: Arquitectura de un sistema de almacén de datos. Profesor: Mtro Felipe de Jesús Núñez Cárdenas
 Área Académica: Sistemas Computacionales Tema: Arquitectura de un sistema de almacén de datos Profesor: Mtro Felipe de Jesús Núñez Cárdenas Periodo: Agosto Noviembre 2011 Keywords Almacen de Datos, Datawarehouse,
Área Académica: Sistemas Computacionales Tema: Arquitectura de un sistema de almacén de datos Profesor: Mtro Felipe de Jesús Núñez Cárdenas Periodo: Agosto Noviembre 2011 Keywords Almacen de Datos, Datawarehouse,
En nuestro capitulo final, daremos las conclusiones y las aplicaciones a futuro
 Capitulo 6 Conclusiones y Aplicaciones a Futuro. En nuestro capitulo final, daremos las conclusiones y las aplicaciones a futuro para nuestro sistema. Se darán las conclusiones para cada aspecto del sistema,
Capitulo 6 Conclusiones y Aplicaciones a Futuro. En nuestro capitulo final, daremos las conclusiones y las aplicaciones a futuro para nuestro sistema. Se darán las conclusiones para cada aspecto del sistema,
Trabajo final de Ingeniería
 UNIVERSIDAD ABIERTA INTERAMERICANA Trabajo final de Ingeniería Weka Data Mining Jofré Nicolás 12/10/2011 WEKA (Data Mining) Concepto de Data Mining La minería de datos (Data Mining) consiste en la extracción
UNIVERSIDAD ABIERTA INTERAMERICANA Trabajo final de Ingeniería Weka Data Mining Jofré Nicolás 12/10/2011 WEKA (Data Mining) Concepto de Data Mining La minería de datos (Data Mining) consiste en la extracción
Servicio de Apoyo a la Investigación. Tutorial EndNoteWeb
 Servicio de Apoyo a la Investigación Tutorial EndNoteWeb I AÑADIR REFERENCIAS. LA PESTAÑA COLLECT Collect es la pestaña que se utiliza para añadir referencias a nuestra biblioteca. Se pueden añadir hasta
Servicio de Apoyo a la Investigación Tutorial EndNoteWeb I AÑADIR REFERENCIAS. LA PESTAÑA COLLECT Collect es la pestaña que se utiliza para añadir referencias a nuestra biblioteca. Se pueden añadir hasta
La calidad de los datos ha mejorado, se ha avanzado en la construcción de reglas de integridad.
 MINERIA DE DATOS PREPROCESAMIENTO: LIMPIEZA Y TRANSFORMACIÓN El éxito de un proceso de minería de datos depende no sólo de tener todos los datos necesarios (una buena recopilación) sino de que éstos estén
MINERIA DE DATOS PREPROCESAMIENTO: LIMPIEZA Y TRANSFORMACIÓN El éxito de un proceso de minería de datos depende no sólo de tener todos los datos necesarios (una buena recopilación) sino de que éstos estén
DIVISION DE ESTUDIOS DE POSGRADO E INVESTIGACION DOCTORADO EN CIENCIAS EN COMPUTACION SEDE: INSTITUTO TECNOLOGICO DE TIJUANA No 002206
 DIVISION DE ESTUDIOS DE POSGRADO E INVESTIGACION DOCTORADO EN CIENCIAS EN COMPUTACION SEDE: INSTITUTO TECNOLOGICO DE TIJUANA No 002206 MEDIOS DE VERIFICACION 4. Infraestructura del Programa Criterio 9.
DIVISION DE ESTUDIOS DE POSGRADO E INVESTIGACION DOCTORADO EN CIENCIAS EN COMPUTACION SEDE: INSTITUTO TECNOLOGICO DE TIJUANA No 002206 MEDIOS DE VERIFICACION 4. Infraestructura del Programa Criterio 9.
PREPROCESADO DE DATOS PARA MINERIA DE DATOS
 Ó 10.1007/978-3-319-02738-8-2. PREPROCESADO DE DATOS PARA MINERIA DE DATOS Miguel Cárdenas-Montes Frecuentemente las actividades de minería de datos suelen prestar poca atención a las actividades de procesado
Ó 10.1007/978-3-319-02738-8-2. PREPROCESADO DE DATOS PARA MINERIA DE DATOS Miguel Cárdenas-Montes Frecuentemente las actividades de minería de datos suelen prestar poca atención a las actividades de procesado
RECONOCIMIENTO E IDENTIFICACIÓN DE LOGOTIPOS EN IMÁGENES CON TRANSFORMADA SIFT
 UNIVERSIDAD CARLOS III DE MADRID ESCUELA POLITÉCNICA SUPERIOR INGENIERÍA TÉCNICA DE TELECOMUNICACIÓN (ESPECIALIDAD EN SONIDO E IMAGEN) PROYECTO FIN DE CARRERA RECONOCIMIENTO E IDENTIFICACIÓN DE LOGOTIPOS
UNIVERSIDAD CARLOS III DE MADRID ESCUELA POLITÉCNICA SUPERIOR INGENIERÍA TÉCNICA DE TELECOMUNICACIÓN (ESPECIALIDAD EN SONIDO E IMAGEN) PROYECTO FIN DE CARRERA RECONOCIMIENTO E IDENTIFICACIÓN DE LOGOTIPOS
ALGUNOS RESULTADOS EXPERIMENTALES DE LA INTEGRACIÓN DE AGRUPAMIENTO E INDUCCIÓN COMO MÉTODO DE DESCUBRIMIENTO DE CONOCIMIENTO
 ALGUNOS RESULTADOS EXPERIMENTALES DE LA INTEGRACIÓN DE AGRUPAMIENTO E INDUCCIÓN COMO MÉTODO DE DESCUBRIMIENTO DE CONOCIMIENTO Kogan, A. 1, Rancan, C. 2,3, Britos, P. 3,1, Pesado, P. 2,4, García-Martínez,
ALGUNOS RESULTADOS EXPERIMENTALES DE LA INTEGRACIÓN DE AGRUPAMIENTO E INDUCCIÓN COMO MÉTODO DE DESCUBRIMIENTO DE CONOCIMIENTO Kogan, A. 1, Rancan, C. 2,3, Britos, P. 3,1, Pesado, P. 2,4, García-Martínez,
Similaridad y Clustering
 Similaridad y Clustering 1 web results motivación Problema 1: ambigüedad de consultas Problema 2: construcción manual de jerarquías de tópicos y taxonomías Problema 3: acelerar búsqueda por similaridad
Similaridad y Clustering 1 web results motivación Problema 1: ambigüedad de consultas Problema 2: construcción manual de jerarquías de tópicos y taxonomías Problema 3: acelerar búsqueda por similaridad
ARREGLOS DEFINICION GENERAL DE ARREGLO
 ARREGLOS DEFINICION GENERAL DE ARREGLO Conjunto de cantidades o valores homogéneos, que por su naturaleza se comportan de idéntica forma y deben de ser tratados en forma similar. Se les debe de dar un
ARREGLOS DEFINICION GENERAL DE ARREGLO Conjunto de cantidades o valores homogéneos, que por su naturaleza se comportan de idéntica forma y deben de ser tratados en forma similar. Se les debe de dar un
Estimación de Tamaño de Software: Puntos Funcionales. Grupo de Construcción de Software Facultad de Ingeniería Universidad de los Andes
 Estimación de Tamaño de Software: Puntos Funcionales Grupo de Construcción de Software Facultad de Ingeniería Universidad de los Andes Puntos de Función Métrica para cuantificar la funcionalidad de un
Estimación de Tamaño de Software: Puntos Funcionales Grupo de Construcción de Software Facultad de Ingeniería Universidad de los Andes Puntos de Función Métrica para cuantificar la funcionalidad de un
Esteban Tlelo Cuautle
 .. Taller de Autores Esteban Tlelo Cuautle etlelo@inaoep.mx www.inaoep.mx Agosto 1 de 2014 1 / 40 . Contents.1 12 pasos para escribir un artículo en revista Organice la información y seleccione la revista
.. Taller de Autores Esteban Tlelo Cuautle etlelo@inaoep.mx www.inaoep.mx Agosto 1 de 2014 1 / 40 . Contents.1 12 pasos para escribir un artículo en revista Organice la información y seleccione la revista
Árboles AVL. Laboratorio de Programación II
 Árboles AVL Laboratorio de Programación II Definición Un árbol AVL es un árbol binario de búsqueda que cumple con la condición de que la diferencia entre las alturas de los subárboles de cada uno de sus
Árboles AVL Laboratorio de Programación II Definición Un árbol AVL es un árbol binario de búsqueda que cumple con la condición de que la diferencia entre las alturas de los subárboles de cada uno de sus
Sistemas de Recuperación de Información
 Sistemas de Recuperación de Información Los SRI permiten el almacenamiento óptimo de grandes volúmenes de información y la recuperación eficiente de la información ante las consultas de los usuarios. La
Sistemas de Recuperación de Información Los SRI permiten el almacenamiento óptimo de grandes volúmenes de información y la recuperación eficiente de la información ante las consultas de los usuarios. La
CASO PRÁCTICO Nº 04. El desarrollo del Caso Práctico Nº 04 busca lograr los siguientes objetivos en el participante:
 CASO PRÁCTICO Nº 04 1. OBJETIVO El desarrollo del Caso Práctico Nº 04 busca lograr los siguientes objetivos en el participante: - Crear la Línea Base del Proyecto. - Emitir Informes en el MS Project. 2.
CASO PRÁCTICO Nº 04 1. OBJETIVO El desarrollo del Caso Práctico Nº 04 busca lograr los siguientes objetivos en el participante: - Crear la Línea Base del Proyecto. - Emitir Informes en el MS Project. 2.
MANUAL PORTAL DE SERVICIOS STUDY IN MEXICO INSTITUCIONES SOCIAS
 MANUAL PORTAL DE SERVICIOS STUDY IN MEXICO INSTITUCIONES SOCIAS INTRODUCCIÓN En el siguiente documento se encuentra la guía para conocer el portal de servicio a instituciones socias. Revisaremos la función
MANUAL PORTAL DE SERVICIOS STUDY IN MEXICO INSTITUCIONES SOCIAS INTRODUCCIÓN En el siguiente documento se encuentra la guía para conocer el portal de servicio a instituciones socias. Revisaremos la función
Un Protocolo de Caracterización Empírica de Dominios para Uso en Explotación de Información
 Un Protocolo de aracterización Empírica de Dominios para Uso en Explotación de Información Lopez-Nocera, M., Pollo-attaneo, F., Britos, P., García-Martínez, R. Grupo Investigación en Sistemas de Información.
Un Protocolo de aracterización Empírica de Dominios para Uso en Explotación de Información Lopez-Nocera, M., Pollo-attaneo, F., Britos, P., García-Martínez, R. Grupo Investigación en Sistemas de Información.
3. Selección y Extracción de características. Selección: Extracción: -PCA -NMF
 3. Selección y Extracción de características Selección: - óptimos y subóptimos Extracción: -PCA - LDA - ICA -NMF 1 Selección de Características Objetivo: Seleccionar un conjunto de p variables a partir
3. Selección y Extracción de características Selección: - óptimos y subóptimos Extracción: -PCA - LDA - ICA -NMF 1 Selección de Características Objetivo: Seleccionar un conjunto de p variables a partir
Gestión de Proyectos en Bibliotecas Universitarias bajo el Enfoque de Marco Lógico. Alejandra M. Nardi anardi@eco.unc.edu.ar
 Gestión de Proyectos en Bibliotecas Universitarias bajo el Enfoque de Marco Lógico Alejandra M. Nardi anardi@eco.unc.edu.ar Qué es el Marco Lógico? Es una herramienta para facilitar el proceso de conceptualización,
Gestión de Proyectos en Bibliotecas Universitarias bajo el Enfoque de Marco Lógico Alejandra M. Nardi anardi@eco.unc.edu.ar Qué es el Marco Lógico? Es una herramienta para facilitar el proceso de conceptualización,
Tema: Maquetación Web y CSS
 Diseño Digital V. Guía 4 1 Tema: Maquetación Web y CSS Facultad: Ciencias y Humanidades Escuela: Diseño Gráfico Asignatura: Diseño Digital V Objetivos Contenidos A través del desarrollo de la guía el estudiante
Diseño Digital V. Guía 4 1 Tema: Maquetación Web y CSS Facultad: Ciencias y Humanidades Escuela: Diseño Gráfico Asignatura: Diseño Digital V Objetivos Contenidos A través del desarrollo de la guía el estudiante
Alumna: Adriana Elizabeth Mendoza Martínez. Grupo: 303. P.S.P. Miriam De La Rosa Díaz. Carrera: PTB. en Informática 3er Semestre.
 Alumna: Adriana Elizabeth Mendoza Martínez. Grupo: 303. P.S.P. Miriam De La Rosa Díaz. Carrera: PTB. en Informática 3er Semestre. Tema: Sistemas Subtema: Base de Datos. Materia: Manejo de aplicaciones
Alumna: Adriana Elizabeth Mendoza Martínez. Grupo: 303. P.S.P. Miriam De La Rosa Díaz. Carrera: PTB. en Informática 3er Semestre. Tema: Sistemas Subtema: Base de Datos. Materia: Manejo de aplicaciones
Hi-Spins. Hi-Spins - Novedades v.10.2.0 10.2.2
 Hi-Spins Hi-Spins - Novedades 10.2.2 Tabla de contenido Hi-Spins Consulta Renovación de la presentación gráfica................................... 3 Visualización compacta de dimensiones en ventana de
Hi-Spins Hi-Spins - Novedades 10.2.2 Tabla de contenido Hi-Spins Consulta Renovación de la presentación gráfica................................... 3 Visualización compacta de dimensiones en ventana de
Tema 11 Bases de datos. Fundamentos de Informática
 Tema 11 Bases de datos Fundamentos de Informática Índice Evolución Tipos de modelos de datos y SGBD El modelo relacional y el Diseño de una Base de Datos Operaciones básicas: consulta, inserción y borrado.
Tema 11 Bases de datos Fundamentos de Informática Índice Evolución Tipos de modelos de datos y SGBD El modelo relacional y el Diseño de una Base de Datos Operaciones básicas: consulta, inserción y borrado.
MANUAL DE USO PORTAL B2B PROCESO OPERATIVO- DESPACHOS
 MANUAL DE USO PORTAL B2B PROCESO OPERATIVO- DESPACHOS MANUAL USO PORTAL B2B. Estimado proveedor. Le invitamos a que revise el actual manual de proveedores, este manual le será de gran ayuda al momento
MANUAL DE USO PORTAL B2B PROCESO OPERATIVO- DESPACHOS MANUAL USO PORTAL B2B. Estimado proveedor. Le invitamos a que revise el actual manual de proveedores, este manual le será de gran ayuda al momento
Capítulo 12: Indexación y asociación
 Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Contenido 1 INTRODUCCIÓN. Universidad Pablo de Olavide, de Sevilla Vicerrectorado de TIC, Calidad e Innovación
 GUÍA PARA INICIAR UN TRÁMITE ELECTRÓNICO Contenido 1 INTRODUCCIÓN... 1 2 PRESENTACIÓN DEL TRÁMITE ELECTRÓNICO... 2 2.1 Requisitos Técnicos... 3 2.2 Iniciación... 3 2.3 Firmar un documento... 9 2.4 Adjuntar
GUÍA PARA INICIAR UN TRÁMITE ELECTRÓNICO Contenido 1 INTRODUCCIÓN... 1 2 PRESENTACIÓN DEL TRÁMITE ELECTRÓNICO... 2 2.1 Requisitos Técnicos... 3 2.2 Iniciación... 3 2.3 Firmar un documento... 9 2.4 Adjuntar
Introducción al Data Mining Clases 5. Cluster Analysis. Ricardo Fraiman Centro de Matemática, Udelar y Universidad de San Andrés, Argentina
 Introducción al Data Mining Clases 5 Cluster Analysis Ricardo Fraiman Centro de Matemática, Udelar y Universidad de San Andrés, Argentina Cluster Análisis 1 El término cluster analysis (usado por primera
Introducción al Data Mining Clases 5 Cluster Analysis Ricardo Fraiman Centro de Matemática, Udelar y Universidad de San Andrés, Argentina Cluster Análisis 1 El término cluster analysis (usado por primera
Proyecto final "Sistema de instrumentación virtual"
 "Sistema de instrumentación virtual" M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com @efranco_escom edfrancom@ipn.mx 1 Contenido Introducción Objetivos Actividades Observaciones Reporte
"Sistema de instrumentación virtual" M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com @efranco_escom edfrancom@ipn.mx 1 Contenido Introducción Objetivos Actividades Observaciones Reporte
CONVERTIDORES DIGITAL ANALÓGICO Y ANALÓGICO - DIGITAL
 CONVERTIDORES DIGITAL ANALÓGICO Y ANALÓGICO - DIGITAL CONVERTIDORES DIGITAL ANALÓGICO Las dos operaciones E/S relativas al proceso de mayor importancia son la conversión de digital a analógico D/A y la
CONVERTIDORES DIGITAL ANALÓGICO Y ANALÓGICO - DIGITAL CONVERTIDORES DIGITAL ANALÓGICO Las dos operaciones E/S relativas al proceso de mayor importancia son la conversión de digital a analógico D/A y la
Estándares Web: XHTML y CSS - Usabilidad - Accesibilidad. Desarrollo de Sitios Web de Calidad, Usables, Seguros, Válidos y Accesibles
 Estándares Web: XHTML y CSS - Usabilidad - Accesibilidad Desarrollo de Sitios Web de Calidad, Usables, Seguros, Válidos y Accesibles Versión actualizada en http://www.usabilidadweb.com.ar/cursos_esp.php
Estándares Web: XHTML y CSS - Usabilidad - Accesibilidad Desarrollo de Sitios Web de Calidad, Usables, Seguros, Válidos y Accesibles Versión actualizada en http://www.usabilidadweb.com.ar/cursos_esp.php
Recuperación de Datos: Data Carving y Archivos Fragmentados
 Data Carving y Archivos Fragmentados Daniel A. Torres Falkonert datorres@poligran.edu.co Johany A. Carreño Gamboa jcarreno@poligran.edu.co Motivación Recuperación de Datos en Sistemas de Archivos 1. Recuperación
Data Carving y Archivos Fragmentados Daniel A. Torres Falkonert datorres@poligran.edu.co Johany A. Carreño Gamboa jcarreno@poligran.edu.co Motivación Recuperación de Datos en Sistemas de Archivos 1. Recuperación
KNime. KoNstanz Information MinEr. KNime - Introducción. KNime - Introducción. Partes de la Herramienta. Editor Window. Repositorio de Nodos
 KNime - Introducción KNime Significa KoNstanz Information MinEr. Se pronuncia [naim]. Fue desarrollado en la Universidad de Konstanz (Alemania). Esta escrito en Java y su entorno grafico esta desarrollado
KNime - Introducción KNime Significa KoNstanz Information MinEr. Se pronuncia [naim]. Fue desarrollado en la Universidad de Konstanz (Alemania). Esta escrito en Java y su entorno grafico esta desarrollado
Elaboración de Mapas Conceptuales
 UNIVERSIDAD PEDAGOGICA LIBERTADOR INSTITUTO PEDAGÓGICO DE CARACAS. DEPARTAMENTO DE PEDAGOGIA. SOCIOLOGIA DE LA EDUCACIÓN (PHB-104) Prof. Robert Rodríguez Raga PAGINA WEB http://sociologiaeducacion.tripod.com
UNIVERSIDAD PEDAGOGICA LIBERTADOR INSTITUTO PEDAGÓGICO DE CARACAS. DEPARTAMENTO DE PEDAGOGIA. SOCIOLOGIA DE LA EDUCACIÓN (PHB-104) Prof. Robert Rodríguez Raga PAGINA WEB http://sociologiaeducacion.tripod.com
MÁQUINA DE VECTORES DE SOPORTE
 MÁQUINA DE VECTORES DE SOPORTE La teoría de las (SVM por su nombre en inglés Support Vector Machine) fue desarrollada por Vapnik basado en la idea de minimización del riesgo estructural (SRM). Algunas
MÁQUINA DE VECTORES DE SOPORTE La teoría de las (SVM por su nombre en inglés Support Vector Machine) fue desarrollada por Vapnik basado en la idea de minimización del riesgo estructural (SRM). Algunas
UNA PROPUESTA DIDÁCTICA PARA LA COMPRENSIÓN DEL CONCEPTO MASA EN LA EDUCACIÓN MEDIA
 UNA PROPUESTA DIDÁCTICA PARA LA COMPRENSIÓN DEL CONCEPTO MASA EN LA EDUCACIÓN MEDIA ANGÉLICA ARISTIZÁBAL OBANDO angelica8120@yahoo.es DAVID BERMÚDEZ POVEDA daber82@hotmail.com RESUMÉN Se dará a conocer
UNA PROPUESTA DIDÁCTICA PARA LA COMPRENSIÓN DEL CONCEPTO MASA EN LA EDUCACIÓN MEDIA ANGÉLICA ARISTIZÁBAL OBANDO angelica8120@yahoo.es DAVID BERMÚDEZ POVEDA daber82@hotmail.com RESUMÉN Se dará a conocer
Registro (record): es la unidad básica de acceso y manipulación de la base de datos.
: es la unidad básica de acceso y manipulación de la base de datos.") UNIDAD II 1. Modelos de Bases de Datos. Modelo de Red. Representan las entidades en forma de nodos de un grafo y las asociaciones o interrelaciones entre estas, mediante los arcos que unen a dichos nodos.
UNIDAD II 1. Modelos de Bases de Datos. Modelo de Red. Representan las entidades en forma de nodos de un grafo y las asociaciones o interrelaciones entre estas, mediante los arcos que unen a dichos nodos.
Visión global del KDD
 Visión global del KDD Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Introducción Desarrollo tecnológico Almacenamiento masivo de información Aprovechamiento
Visión global del KDD Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Introducción Desarrollo tecnológico Almacenamiento masivo de información Aprovechamiento
Naive Bayes Multinomial para Clasificación de Texto Usando un Esquema de Pesado por Clases
 Naive Bayes Multinomial para Clasificación de Texto Usando un Esquema de Pesado por Clases Emmanuel Anguiano-Hernández Abril 29, 2009 Abstract Tratando de mejorar el desempeño de un clasificador Naive
Naive Bayes Multinomial para Clasificación de Texto Usando un Esquema de Pesado por Clases Emmanuel Anguiano-Hernández Abril 29, 2009 Abstract Tratando de mejorar el desempeño de un clasificador Naive
Sistema categorizador de ofertas de empleo informáticas
 Diego Expósito Gil diegoexpositogil@hotmail.com Manuel Fidalgo Sicilia Manuel_fidalgo@hotmail.com Diego Peces de Lucas pecesdelucas@hotmail.com Sistema categorizador de ofertas de empleo informáticas 1.
Diego Expósito Gil diegoexpositogil@hotmail.com Manuel Fidalgo Sicilia Manuel_fidalgo@hotmail.com Diego Peces de Lucas pecesdelucas@hotmail.com Sistema categorizador de ofertas de empleo informáticas 1.
Área Académica: Ingeniería en Computación. Profesor: M. en C. Evangelina Lezama León
 Área Académica: Ingeniería en Computación Tema: Datos Profesor: M. en C. Evangelina Lezama León Periodo: Enero-Junio 2012 Tema: Abstract The data are the base of computer. In this paper we study concepts,
Área Académica: Ingeniería en Computación Tema: Datos Profesor: M. en C. Evangelina Lezama León Periodo: Enero-Junio 2012 Tema: Abstract The data are the base of computer. In this paper we study concepts,
GENERALIDADES DE BASES DE DATOS
 GENERALIDADES DE BASES DE DATOS A fin de evitar que idénticos datos se encuentren repetidos en múltiples archivos, parece necesario que los comunes se almacenen en un archivo único y que este archivo sea
GENERALIDADES DE BASES DE DATOS A fin de evitar que idénticos datos se encuentren repetidos en múltiples archivos, parece necesario que los comunes se almacenen en un archivo único y que este archivo sea
Implementación de la transformada wavelet discreta para imágenes en un FPGA
 Implementación de la transformada wavelet discreta para imágenes en un FPGA Madeleine León 1, Carlos A. Murgas 1, Lorena Vargas 2, Leiner Barba 2, Cesar Torres 2 1 Estudiantes de pregrado de la Universidad
Implementación de la transformada wavelet discreta para imágenes en un FPGA Madeleine León 1, Carlos A. Murgas 1, Lorena Vargas 2, Leiner Barba 2, Cesar Torres 2 1 Estudiantes de pregrado de la Universidad
PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación. II MODELOS y HERRAMIENTAS UML. II.1 UML: Introducción
 PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación II MODELOS y HERRAMIENTAS UML 1 1 Técnica de modelado de objetos (I) El modelado orientado a objetos es una técnica de especificación semiformal para
PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación II MODELOS y HERRAMIENTAS UML 1 1 Técnica de modelado de objetos (I) El modelado orientado a objetos es una técnica de especificación semiformal para
Acerca de esté Catálogo
 Catálogo de Cursos 2015 Acerca de esté Catálogo En el presente documento podrá obtenerse la información necesaria sobre la oferta de cursos que Manar Technologies S.A.S. y su línea de educación Campus
Catálogo de Cursos 2015 Acerca de esté Catálogo En el presente documento podrá obtenerse la información necesaria sobre la oferta de cursos que Manar Technologies S.A.S. y su línea de educación Campus
Google: Una oportunidad para la evolución de las Bibliotecas
 Google: Una oportunidad para la evolución de las Bibliotecas Elizabeth Cañón Acosta elizadavaes@gmail.com Universidad de la Salle Resumen El uso generalizado de Google como herramienta de búsqueda de información
Google: Una oportunidad para la evolución de las Bibliotecas Elizabeth Cañón Acosta elizadavaes@gmail.com Universidad de la Salle Resumen El uso generalizado de Google como herramienta de búsqueda de información
Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones.
 Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones. 2.1 Revisión sistema reconocimiento caracteres [9]: Un sistema de reconocimiento típicamente esta conformado por
Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones. 2.1 Revisión sistema reconocimiento caracteres [9]: Un sistema de reconocimiento típicamente esta conformado por
Manual de Integrador.NET
 Manual de Integrador.NET viafirma platform v3.5 ÍNDICE 1. INTRODUCCIÓN... 5 1.1. Objetivos... 5 1.2. Referencia... 5 2. GUÍA RÁPIDA... 5 2.1. Añadir las dependencias necesarias... 5 2.2. Página de acceso
Manual de Integrador.NET viafirma platform v3.5 ÍNDICE 1. INTRODUCCIÓN... 5 1.1. Objetivos... 5 1.2. Referencia... 5 2. GUÍA RÁPIDA... 5 2.1. Añadir las dependencias necesarias... 5 2.2. Página de acceso
SISTEMAS INTELIGENTES
 SISTEMAS INTELIGENTES T11: Métodos Kernel: Máquinas de vectores soporte {jdiez, juanjo} @ aic.uniovi.es Índice Funciones y métodos kernel Concepto: representación de datos Características y ventajas Funciones
SISTEMAS INTELIGENTES T11: Métodos Kernel: Máquinas de vectores soporte {jdiez, juanjo} @ aic.uniovi.es Índice Funciones y métodos kernel Concepto: representación de datos Características y ventajas Funciones