CURSO: DESARROLLADOR PARA APACHE HADOOP
|
|
|
- Alba Olivera Lucero
- hace 8 años
- Vistas:
Transcripción

1 CURSO: DESARROLLADOR PARA APACHE HADOOP CAPÍTULO 3: HADOOP CONCEPTOS BÁSICOS


2 Índice 1 Introducción a Hadoop 1.1 Proyecto Hadoop 1.2 Conceptos de Hadoop 2 Cluster Hadoop 2.1 Demonios Hdfs 2.2 Demonios Hdfs y MapReduce V1 2.3 Demonios Hdfs y MapReduce V2 3 Características de Hadoop Distributed File System (HDFS) 4 Conceptos de MapReduce 4.1 MapReduce 2

3 Índice 5 6 Funcionamiento de un cluster Hadoop 5.1 Ejecución de un Job 5.2 Procesamiento de los datos Otros proyectos del ecosistema Hadoop 6.1. Hive 6.2. Pig 6.2. Impala 6.4. Flume y Sqoop 6.5. Oozie 6.6 Hbase 6.7 Spark 6.8 Hue 3

4 ÍNDICE Introducción a Hadoop

5 1.1 Proyecto Hadoop Hadoop es un proyecto open-source supervisado por Apache Software Fundation. Originalmente Hadoop está basado en los 'papers' publicados por Google en 2003 y 2004: Paper #1: [2003] The Google File System Paper #2: [2004] MapReduce: Simplified Data Processing on Large Cluster Los commiters de Hadoop trabajan en diferentes organizaciones: Incluyendo Cloudera, Yahoo, Facebook, Linkedln, HortonWorks, Twitter, ebay... 5

6 1.2 Conceptos de Hadoop El Core de Hadoop se divide en 2 componentes: 1. Hadoop Distributed File System (HDFS). 2. MapReduce. 6



7 1.2 Conceptos de Hadoop Hay muchos otros proyectos que se basan en el Core de Hadoop (esto es a lo que nos referimos como ecosistema de Hadoop). Algunos de estos proyectos son: Pig, Hive, Hbase, Flume, Oozie, Sqoop, Impala, etc (más adelante en el curso veremos varios de ellos en detalle). 7


8 1.2 Conceptos de Hadoop Si lo que necesitamos es realizar procesamiento de datos a gran escala, necesitaremos dos cosas: Un lugar para almacenar grandes cantidades de datos y un sistema para el procesamiento de la misma. HDFS proporciona el almacenamiento y MapReduce ofrece una manera de procesarlo. Un conjunto de máquinas que ejecutan HDFS y MapReduce se conoce como cluster Hadoop. Un cluster puede contener desde de 1 nodo hasta una gran cantidad de nodos. En la siguiente imagen, vemos la composición de un cluster Hadoop con los demonios de la versión 1 de MapReduce. Esta versión es la recomendada para la distribución CDH4. En la distribución CDH5 la versión recomendada de MapReduce es la versión 2 (YARN). Como podemos observar, un cluster Hadoop se compone como mínimo de un nodo Maestro y un nodo Esclavo. 8
.")
9 ÍNDICE Cluster Hadoop

10 Demonios perteneciente a HDFS: - NameNode: Mantiene los metadatos del sistema de ficheros HDFS. - Secondary NameNode: Realiza funciones de mantenimiento del NameNode. No hace funciones de backup del NameNode. - DataNode : Almacena los bloques de datos del HDFS. Demonios pertenecientes a MapReduce V1: - JobTracker: Administra los jobs MapReduce y distribuye las tareas individuales a los nodos. - TaskTracker : Crea una instancia y supervisa la tarea individual Map o Reduce. Demonios pertenecientes a MapReduce V2 (YARN): - ResourceManager: Inicia las aplicaciones (Jobs) y gestiona los recursos. Uno por cluster. - ApplicationMaster: Se encarga de ejecutar las aplicaciones iniciadas por el ResourceManager. Uno por aplicación (Job). - NodeManager: Ejecuta las tareas Map o Reduce de cada una de las aplicaciones. Uno por nodo esclavo. - JobHistory: Se encarga de almacenar las estadísticas y los metadatos. Uno por cluster. Un cluster únicamente puede tener en ejecución una de las dos versiones de MapReduce. En ningún caso es posible tener las dos versiones de MapReduce en ejecución al mismo tiempo. 10

11 2.1 Demonios Hdfs Demonios HDFS: Existen dos formas de tener configurado nuestro cluster Hadoop: Sin alta disponiblidad (3 demonios): - NameNode (maestro) - Secondary NameNode (maestro) - DataNode (en cada uno de los esclavos) Con alta disponiblidad (2 demonios): - NameNode (maestro y otro NameNode en standby en otro maestro) - DataNode(en cada uno de los esclavos) 11
 - DataNode(en cada uno de los")
12 2.1 Demonios Hdfs Demonio NameNode (maestro): El NameNode es el encargado de almacenar los metadatos del cluster Hadoop: - Información de la localización de los ficheros del HDFS - Información de permisos y usuarios - Nombre de los bloques - Localización de los bloques Los metadatos son almacenados en el disco y son cargados en memoria cuando el NameNode arranca por primera vez: - Se almacenan en el fichero fsimage (los nombres del bloque no son almacenados en el fichero) - Los cambios realizados en los metadatos son almacenados en memoria y en el fichero edits. 12
 - Los cambios realizados en los metadatos son almacenados en memoria y en el fichero")
13 2.1 Demonios Hdfs Demonio DataNode (esclavo): El DataNode es el encargado de acceder a los bloques almacenados en cada uno de los nodos esclavos: - El nombre de los bloques es: blk_xxxxxxxxx - En los nodos esclavo únicamente se almacenan los datos, no se almacena ningún tipo de información referente al bloque (nombre, parte de.., etc). Cada uno de los bloques es almacenado en varios nodos dependiendo de la configuración de la replicación Cada uno de los esclavos debe tener el demonio DataNode para poder comunicarse con el NameNode y poder acceder a los datos 13

14 2.1 Demonios Hdfs Demonio Secondary NameNode (master): El Secondary NameNode no es un NameNode en standby. El Secondary NameNode se encarga de operaciones de mantenimiento: - El NameNode escribe las modificaciones de los metadatos en el fichero edits. - El Secondary NameNode periódicamente obtiene el fichero edits del NameNode y lo une con el fichero fsimage y envía el nuevo snapshot al NameNode. El Secondary NameNode se debe poner en otro nodo maestro en un cluster de un tamaño considerable. Checkpointing Secondary NameNode: Cada hora o cada de transacciones (por defecto) el Secondary NameNode realiza el checkpoint de los metadatos: 1. Llama al NameNode para obtener el fichero edits 2. Obtiene los ficheros fsimage y edits del NameNode 3. Carga el fichero fsimage en memory y agrega los cambios del fichero edits 4. Crea el nuevo fichero consolidado de fsimage 5. Envía el nuevo fichero consolidado al NameNode 6. El NameNode reemplaza el antiguo fsimage por el nuevo 14

15 2.2 Demonios Hdfs y MapReduce V1 Cada demonio se ejecuta en su propia máquina virtual Java (JVM). En un cluster real no deben ejecutarse los 5 demonios en la misma máquina. En un entorno pseudodistribuido tendremos los 5 demonios en la misma máquina (este entorno es el que se suele utilizar para la programación y testeo de aplicaciones MapReduce). Los demonios deben ir situados de la siguiente manera: - Nodo Maestro (Master): Ejecuta el NameNode, Secondary NameNode y JobTracker. Sólo puede ejecutarse una instancia de cada demonio en el cluster. - Nodo Esclavo (Slave): Ejecuta el DataNode y TaskTracker. En cada slave del cluster se ejecuta una instancia de los demonios. En casi todos los cluster pequeños, se suelen ejecutar en la misma máquina los 3 demonios (NameNode, Secondary NameNode y JobTracker). A partir de de un cluster con Nodos esclavos, se ejecutan en máquinas diferentes. 15
: Ejecuta el DataNode y TaskTracker. En cada slave del cluster se ejecuta una instancia de los demonios.")
16 2.2 Demonios Hdfs y MapReduce V1 16

17 2.3 Demonios Hdfs y MapReduce V2 En un cluster real no deben ejecutarse los 7 demonios en la misma máquina. En un entorno pseudodistribuido tendremos los 7 demonios en la misma máquina (este entorno es el que se suele utilizar para la programación y testeo de aplicaciones MapReduce). Los demonios deben ir situados de la siguiente manera: - Nodo Maestro (Master): Ejecuta el NameNode, Secondary NameNode y ResourceManager. - Nodo Esclavo (Slave): Ejecuta el DataNode, NodeManager y ApplicationMaster. - Nodo History : Ejecuta el JobHistory, encargado de almacenar las métricas. En casi todos los cluster pequeños, se suelen ejecutar en la misma máquina los 3 demonios (NameNode, Secondary NameNode y ResourceManager). A partir de de un cluster con Nodos esclavos, se ejecutan en máquinas diferentes. 17
: Ejecuta el DataNode, NodeManager y ApplicationMaster. - Nodo History : Ejecuta el JobHistory, encargado de almacenar las métricas.")
18 2.3 Demonios Hdfs y MapReduce V2 18


19 ÍNDICE Características de Hadoop Distributed File System (HDFS)

20 El HDFS es el responsable del almacenamiento de los datos en el cluster. Los datos se dividen en bloques y son almacenados en varios nodos del cluster. El tamaño por defecto del bloque es de 64Mb, pero Cloudera recomienda 128Mb. Siempre que sea posible los bloques son replicados varias veces en diferentes nodos. La replicación por defecto de la distribución de Cloudera es de 3. Dicha replicación aumenta la fiabilidad (debido a que hay varias copias), la disponibilidad (debido a que estas copias se distribuyen a diferentes máquinas) y el rendimiento (debido a que más copias significan más oportunidades para "llevar la computación a los datos", principal objetivo de un sistema Hadoop). El sistema de ficheros de Hadoop (HDFS) está optimizado para la lectura de grandes cantidades de datos con el fin de reducir al mínimo el impacto global del rendimiento (latencia). En la imagen podemos observar el almacenamiento de 1 ficheros en HDFS. En este caso la replicación es de 3, con lo que cada uno de los bloques del fichero es almacenado en los diferentes nodos del cluster. 20
, la disponibilidad (debido a que estas copias se distribuyen a diferentes máquinas) y el rendimiento (debido a que más copias")
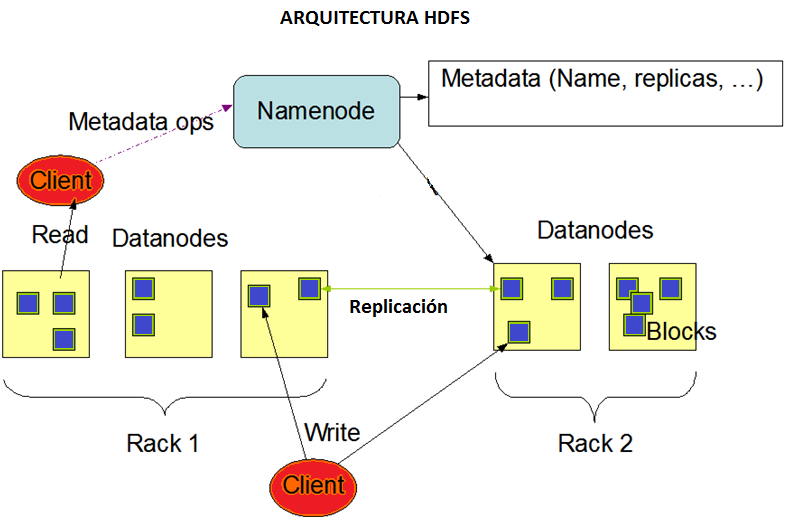
21 21
22 Procedimiento de escritura de un fichero en HDFS: 1. El cliente conecta con el NameNode 2. El NameNode busca en sus metadatos y devuelve al cliente el nombre del bloque y la lista de los DataNode 3. El cliente conecta con el primer DataNode de la lista y empieza el envío de los datos 4. Se conecta con el segundo DataNode para realizar el envío 5. Idem con el tercer DataNode 6. Finaliza el envío 7. El cliente indica al NameNode donde se ha realizado la escritura del bloque Procedimiento de lectura de un fichero en HDFS: 1. El cliente conecta con el NameNode 2. El NameNode devuelve una lista con los DataNode que contienen ese bloque 3. El cliente conecta con el primero de los DataNode y comienza la lectura del bloque 22
23 Fiabilidad y recuperación del HDFS: Los DataNode envían heartbeats al NameNode cada 3 segundos para indicar su estado Si pasado un tiempo (por defecto 5 minutos) el NameNode no recibe el heartbeat de alguno de los nodos, da por perdido ese nodo: - El NameNode averigua que bloques había en el nodo perdido - El NameNode busca otros DataNode donde realizar la copia de los bloques perdidos y así mantener el número de replicación. Los DataNode serán los encargados de realizarse la copia de los bloques perdidos En caso de recuperar el nodo perdido, el sistema automáticamente decidirá que bloques eliminar para mantener el número de replicación de bloques. Web UI del NameNode: A través de la web UI del NameNode seremos capaces de ver el estado de nuestro cluster: - Espacio total del HDFS - Espacio ocupado del HDFS - Espacio disponible del HDFS - Estado de los Nodos - Navegación por el sistema de ficheros Por defecto se encuentra en el puerto
24 Web UI del NameNode: 24
25 Acceso al HDFS a través de la línea de comandos: Nuestro sistema de fichero es muy similar a un sistema de ficheros tradicional, por lo que podemos acceder a el a través de la línea de comandos con el cliente hadoop fs hadoop fs permite casi todos los comandos típicos de nuestro sistema de ficheros tradicional: - hadoop fs -cat /file.txt - hadoop fs -mkdir /repos - hadoop fs -put file.txt /repos - hadoop fs -get /repos/file.txt /tmp - hadoop fs -ls /repos - hadoop fs -ls -R /repos - hadoop fs -rm /repos/file.txt 25
26 ÍNDICE Conceptos de MapReduce
27 MapReduce no es un lenguaje de programación o incluso un marco específico, sino que con mayor precisión se podría describir como un "modelo de programación". Originalmente fue implementado por Google internamente, aunque posteriormente fue convertido a código abierto por Apache Hadoop. Hay otras implementaciones MapReduce (tales como Disco y Phoenix), pero la mayoría son de propiedad o proyectos de "juguete". Hadoop es de lejos la aplicación más utilizada de MapReduce. 27
28 4.1 MapReduce MapReduce es el sistema utilizado para procesar los datos en el cluster Hadoop. Se compone de 2 fases: Map y Reduce. Entre las dos fases se produce la fase de shuffle and sort. Cada tarea Map opera con una parte de los datos, normalmente, un bloque HDFS de los datos. Una vez finalizadas todas las tareas Map, el sistema MapReduce distribuye todos los datos intermedios de los nodos para realizar la fase de Reduce. Como podemos observar en la imagen siguiente, dado un fichero es dividido en varios input split de entrada, estos son enviados a diferentes tareas Map. Una vez finalizadas todas las tareas Map se realiza la fase de shuffle and short, donde los datos son ordenados para posteriormente ser enviado a los nodos para realizar la fase Reduce. La fase Reduce no empieza hasta que han finalizado TODAS las tareas Map del Job correspondiente. En el ejemplo nos encontramos con 4 tareas Reduce, una por cada tipo de dato. El resultado final son varios ficheros, uno por cada tarea reduce ejecutada. 28

29 4.1 MapReduce 29
30 ÍNDICE Funcionamiento de un cluster Hadoop
31 5.1 Ejecución de un Job En este apartado vamos a ver una primera introducción del funcionamiento de un cluster Hadoop al ejecutar un Job y el funcionamiento del procesamiento de los datos por dicho Job. Ya que el curso está enfocado para realizar la certificación de Cloudera (CCDH) y está certificación se basa en la distribución CDH4, los ejemplos se van a realizar con la versión 1 de MapReduce. Esto debe ser independiente para un desarrollador, ya que es el cluster el que se encarga de ejecutar de una manera u otra dependiendo de la versión de MapReduce que tenga configurada. Cuando un cliente envía un trabajo, la información de configuración es empaquetada en un fichero xml. El fichero xml junto con el.jar que contiene el código del programa es enviado al JobTracker. El jobtracker será el encargado de enviar la solicitud al TaskTracker que crea oportuno para ejecutar la tarea. Una vez el TaskTraker recibe la solicitud de ejecutar una tarea, instancia una JVM para esa tarea. El TaskTracker puede configurarse para ejecutar diferentes tareas al mismo tiempo. Para realizar esto, habrá que tener en cuenta que disponemos de suficiente procesador y memoria. 31
32 5.2 Procesamiento de los datos Los datos intermedios producidos por una tarea son almacenados en el disco local de la máquina donde se ha ejecutado. Puede resultar un poco extraño, pero es debido a que al ser datos temporales, si fueran almacenados en HDFS con su correspondiente replicación, aumentaríamos el problema de nuestro cuello de botella ( la red ), ya que el sistema se dispondría a replicar los datos y con ello generar tráfico en la red. Los datos intermedios serán borrados una vez el Job se ha ejecutado completamente. Nunca serán borrados antes, aunque una de las tareas del job finalice, no serán borrados hasta que finalicen el resto de tareas y con ello el job. En la fase de start up del Reduce los datos intermedios son distribuidos a través de la red a los Reducers. Los Reducers almacenan su salida en el sistema de ficheros HDFS. 32
33 5.2 Procesamiento de los datos Fases de una aplicación MapReduce: 1 En la primera fase los datos son divididos en tantos splits como fuera necesario. Cada split genera un Map para ser procesado. 2 En la segunda fase, los datos (splits) son procesados por su Map correspondiente. 3 Una vez procesados los datos por el Mapper, los datos intermedios son almacenados en el sistema de ficheros local a la espera de ser enviados a su correspondiente Reduce. Cuando se inicia la transferencia de los datos intermedios al Reduce, se realiza la tarea de shuffle and short, donde los datos son ordenados por sus correspondientes llaves para que todas las llaves sean procesadas por el mismo Reduce. 4 Se realiza el procesamiento de los datos con su Reduce. 5 La salida de cada uno de los Reducer es almacenada en el sistema de ficheros HDFS realizando la replicación correspondiente. 33
34 ÍNDICE Otros proyectos del ecosistema Hadoop
35 Existen muchos otros proyectos que utilizan Hadoop core o ayudan a utilizarlo, como puede ser el caso de Sqoop, Flume o Oozie. La mayoría de los proyectos son ahora proyectos de Apache o proyectos de incubadora de Apache. Estar en la incubadora de Apache no significa que el proyecto es inestable o inseguro para su uso en producción, sólo significa que es un proyecto relativamente nuevo en Apache y todavía se está creando la comunidad que lo rodea. A continuación veremos una breve explicación de cada uno de los proyectos. Durante el curso veremos con mucho más detenimiento muchos de estos proyectos del ecosistema Hadoop. 35
36 6.1 Hive Hive es una abstracción en la parte superior de MapReduce. Permite a los usuarios poder consultar los datos del cluster Hadoop sin necesidad de saber java o MapReduce utilizando el lenguaje HiveQL. Dicho lenguaje es muy similar al SQL. Hive se ejecuta en la máquina cliente convirtiendo la consulta HiveQL en programas MapReduce los cuales son enviados al cluster Hadoop para ser ejecutados. Ejemplo de query HiveQL: SELECT stock.producto FROM stock JOIN ventas ON (stock.id = ventas.id); Más información en: 36
37 6.2 Pig Pig es una alternativa de abstracción para realizar programas MapReduce. Usa un lenguaje de scripting llamado PigLatin. El interprete de Pig es ejecutado en la máquina cliente transformando el código en programas MapReduce para posteriormente enviarlos al cluster Hadoop para su ejecución. Ejemplo de un programa Pig: A = LOAD 'data' AS (f1,f2,f3); B = FOREACH A GENERATE f1 + 5; C = FOREACH A generate f1 + f2; Más información en: 37

38 6.3 Impala Impala es un proyecto open-source creado por Cloudera. Su finalidad es facilitar la consulta en tiempo real de los datos almacenados en HDFS. Impala no usa MapReduce, es un demonio que es ejecutado en los nodos esclavos utilizando un lenguaje muy parecido al HiveQL. Impala es mucho más rápido que Hive. Puede llegar a realizar consultas 40 veces más rápido que Hive aprovechando sus mismos metadatos. Más información en: 38
39 6.4 Flume y Sqoop Flume y Sqoop son dos productos totalmente diferentes con una cosa en común: Ambos ayudan a obtener datos en el clúster Hadoop. Flume permite integrar los datos directamente en el clúster en tiempo real. Como su nombre lo indica, se utiliza con mayor frecuencia para los registros del servidor (servidor web, servidor de correo electrónico, Syslog, UNIX, etc), pero se pueden adaptar para leer datos de otras fuentes, como veremos más adelante en el curso. Más información en: Sqoop puede ser recordado como una contracción de "SQL a Hadoop" ya que es una herramienta para traer datos de una base de datos relacional al cluster Hadoop para su procesamiento o análisis, o para la exportación de datos que ya tienes en el cluster Hadoop a una base de datos externa para su posterior procesamiento o análisis. Más información en: 39
40 6.5 Oozie Como se verá más adelante en este curso, en realidad es una práctica bastante común tener como entrada de un trabajo MapReduce una salida de otro trabajo MapReduce. Oozie es una herramienta que le ayudará a definir este tipo de flujo de trabajo para un cluster Hadoop, encargándose de la ejecución de los trabajos en el orden correcto, especificando la ubicación de la entrada y la salida, permitiendo definir lo que se desea realizar cuando el trabajo se completa correctamente o cuando se encuentra un error. Más información en: 40
41 6.6 Hbase Hbase es la base de datos de Hadoop. Es una base de datos NoSql que realiza almacenamiento masivo de datos ( Gigabytes, terabytes, petabytes de datos en una misma tabla). Hbase escala a una velocidad muy alta, ciento de miles de inserciones por segundo. Las tablas pueden tener miles de columnas aunque la mayoría de ellas estén vacías para una fila dada. Uno de los inconvenientes de Hbase es que tiene un modelo de acceso muy limitado. Sus acciones mas comunes son de inserción de una fila, recuperación de una fila, escaneo completo o parcial de la tabla. En Hbase sólo una columna está indexada (row key). Más información en: 41
42 6.7 Spark Spark es un programa de computación en paralelo que puede operar a través de cualquier fuente de entrada Hadoop: HDFS, HBase, Amazon S3, Avro, etc. Spark es un proyecto de código abierto creado por UC Berkeley AMPLab y en sus propias palabras, Spark inicialmente fue desarrollado para dos aplicaciones en las que es de gran ayuda almacenar los datos en memoria: algoritmos iterativos, que son comunes en el aprendizaje automático y minería de datos interactiva. En este curso únicamente veremos las posibilidades que nos ofrece Spark una vez integrado en nuestro cluster Hadoop. En Formación Hadoop ofrecemos un curso avanzado para aprender a realizar nuestras propias aplicaciones de procesamientos de datos con Spark. Más información en: 42

43 6.8 Hue Hue es un proyecto open source que a través de una interfaz Web nos permitirá acceder a los componentes más comunes de nuestro cluster Hadoop. Será posible otorgar diferentes privilegios a cada uno de los usuarios dependiendo del rol que ocupen en el sistema. Más información en: 43


44 Contacto TWITTER Twitter.com/formacionhadoop FACEBOOK Facebook.com/formacionhadoop LINKEDIN linkedin.com/company/formación-hadoop 44
Hadoop. Cómo vender un cluster Hadoop?
 Hadoop Cómo vender un cluster Hadoop? ÍNDICE Problema Big Data Qué es Hadoop? Descripción HDSF Map Reduce Componentes de Hadoop Hardware Software 3 EL PROBLEMA BIG DATA ANTES Los datos los generaban las
Hadoop Cómo vender un cluster Hadoop? ÍNDICE Problema Big Data Qué es Hadoop? Descripción HDSF Map Reduce Componentes de Hadoop Hardware Software 3 EL PROBLEMA BIG DATA ANTES Los datos los generaban las
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK. www.formacionhadoop.com
 CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
APACHE HADOOP. Daniel Portela Paz Javier Villarreal García Luis Barroso Vázquez Álvaro Guzmán López
 APACHE HADOOP Daniel Portela Paz Javier Villarreal García Luis Barroso Vázquez Álvaro Guzmán López Objetivos 1. Qué es Apache Hadoop? 2. Funcionalidad 2.1. Map/Reduce 2.2. HDFS 3. Casos prácticos 4. Hadoop
APACHE HADOOP Daniel Portela Paz Javier Villarreal García Luis Barroso Vázquez Álvaro Guzmán López Objetivos 1. Qué es Apache Hadoop? 2. Funcionalidad 2.1. Map/Reduce 2.2. HDFS 3. Casos prácticos 4. Hadoop
MÁSTER: MÁSTER EXPERTO BIG DATA
 MÁSTER: MÁSTER EXPERTO BIG DATA Información detallada del máster www.formacionhadoop.com Este máster online está enfocado a los ingenieros que quieran aprender el despliegue y configuración de un cluster
MÁSTER: MÁSTER EXPERTO BIG DATA Información detallada del máster www.formacionhadoop.com Este máster online está enfocado a los ingenieros que quieran aprender el despliegue y configuración de un cluster
Alessandro Chacón 05-38019. Ernesto Level 05-38402. Ricardo Santana 05-38928
 Alessandro Chacón 05-38019 Ernesto Level 05-38402 Ricardo Santana 05-38928 CONTENIDO Universo Digital Hadoop HDFS: Hadoop Distributed File System MapReduce UNIVERSO DIGITAL 161 EB 2006 Fuente: International
Alessandro Chacón 05-38019 Ernesto Level 05-38402 Ricardo Santana 05-38928 CONTENIDO Universo Digital Hadoop HDFS: Hadoop Distributed File System MapReduce UNIVERSO DIGITAL 161 EB 2006 Fuente: International
CURSO: DESARROLLADOR PARA APACHE HADOOP
 CURSO: DESARROLLADOR PARA APACHE HADOOP CAPÍTULO 1: INTRODUCCIÓN www.formacionhadoop.com Índice 1 Por qué realizar el curso de desarrollador para Apache Hadoop? 2 Requisitos previos del curso 3 Bloques
CURSO: DESARROLLADOR PARA APACHE HADOOP CAPÍTULO 1: INTRODUCCIÓN www.formacionhadoop.com Índice 1 Por qué realizar el curso de desarrollador para Apache Hadoop? 2 Requisitos previos del curso 3 Bloques
CURSO PRESENCIAL: ADMINISTRADOR HADOOP
 CURSO PRESENCIAL: ADMINISTRADOR HADOOP Información detallada del curso www.formacionhadoop.com El curso se desarrolla a lo largo de 4 semanas seguidas. Se trata de un curso formato ejecutivo que permite
CURSO PRESENCIAL: ADMINISTRADOR HADOOP Información detallada del curso www.formacionhadoop.com El curso se desarrolla a lo largo de 4 semanas seguidas. Se trata de un curso formato ejecutivo que permite
CURSO PRESENCIAL: DESARROLLADOR BIG DATA
 CURSO PRESENCIAL: DESARROLLADOR BIG DATA Información detallada del curso www.formacionhadoop.com El curso se desarrolla durante 3 semanas de Lunes a Jueves. Se trata de un curso formato ejecutivo que permite
CURSO PRESENCIAL: DESARROLLADOR BIG DATA Información detallada del curso www.formacionhadoop.com El curso se desarrolla durante 3 semanas de Lunes a Jueves. Se trata de un curso formato ejecutivo que permite
BIG DATA. Jorge Mercado. Software Quality Engineer
 BIG DATA Jorge Mercado Software Quality Engineer Agenda Big Data - Introducción Big Data - Estructura Big Data - Soluciones Conclusiones Q&A Big Data - Introducción Que es Big Data? Big data es el termino
BIG DATA Jorge Mercado Software Quality Engineer Agenda Big Data - Introducción Big Data - Estructura Big Data - Soluciones Conclusiones Q&A Big Data - Introducción Que es Big Data? Big data es el termino
MÁSTER: MÁSTER DESARROLLADOR BIG DATA
 MÁSTER: MÁSTER DESARROLLADOR BIG DATA Información detallada del máster www.formacionhadoop.com Este máster online está enfocado a los desarrolladores que quieran aprender a construir potentes aplicaciones
MÁSTER: MÁSTER DESARROLLADOR BIG DATA Información detallada del máster www.formacionhadoop.com Este máster online está enfocado a los desarrolladores que quieran aprender a construir potentes aplicaciones
Instalación Hadoop. Guía para Debian y derivados
 Instalación Hadoop Guía para Debian y derivados Índice Instalación Hadoop Hadoop Distributed File System a. NameNode b. DataNode. Requisitos Diferentes modos de configuración Instalación Java Instalación
Instalación Hadoop Guía para Debian y derivados Índice Instalación Hadoop Hadoop Distributed File System a. NameNode b. DataNode. Requisitos Diferentes modos de configuración Instalación Java Instalación
MANUAL COPIAS DE SEGURIDAD
 MANUAL COPIAS DE SEGURIDAD Índice de contenido Ventajas del nuevo sistema de copia de seguridad...2 Actualización de la configuración...2 Pantalla de configuración...3 Configuración de las rutas...4 Carpeta
MANUAL COPIAS DE SEGURIDAD Índice de contenido Ventajas del nuevo sistema de copia de seguridad...2 Actualización de la configuración...2 Pantalla de configuración...3 Configuración de las rutas...4 Carpeta
Guía de uso del Cloud Datacenter de acens
 guíasdeuso Guía de uso del Cloud Datacenter de Calle San Rafael, 14 28108 Alcobendas (Madrid) 902 90 10 20 www..com Introducción Un Data Center o centro de datos físico es un espacio utilizado para alojar
guíasdeuso Guía de uso del Cloud Datacenter de Calle San Rafael, 14 28108 Alcobendas (Madrid) 902 90 10 20 www..com Introducción Un Data Center o centro de datos físico es un espacio utilizado para alojar
Conectores Pentaho Big Data Community VS Enterprise
 Conectores Pentaho Big Data Community VS Enterprise Agosto 2014 Stratebi Business Solutions www.stratebi.com info@stratebi.com Índice 1. Resumen... 3 2. Introducción... 4 3. Objetivo... 4 4. Pentaho Community
Conectores Pentaho Big Data Community VS Enterprise Agosto 2014 Stratebi Business Solutions www.stratebi.com info@stratebi.com Índice 1. Resumen... 3 2. Introducción... 4 3. Objetivo... 4 4. Pentaho Community
ARQUITECTURA DE DISTRIBUCIÓN DE DATOS
 4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
Introducción a las redes de computadores
 Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Big data A través de una implementación
 Big data A través de una implementación Lic. Diego Krauthamer Profesor Adjunto Interino del Área Base de Datos Universidad Abierta Interamericana Facultad de Tecnología Informática Buenos Aires. Argentina
Big data A través de una implementación Lic. Diego Krauthamer Profesor Adjunto Interino del Área Base de Datos Universidad Abierta Interamericana Facultad de Tecnología Informática Buenos Aires. Argentina
Base de datos en Excel
 Base de datos en Excel Una base datos es un conjunto de información que ha sido organizado bajo un mismo contexto y se encuentra almacenada y lista para ser utilizada en cualquier momento. Las bases de
Base de datos en Excel Una base datos es un conjunto de información que ha sido organizado bajo un mismo contexto y se encuentra almacenada y lista para ser utilizada en cualquier momento. Las bases de
Proyecto Fin de Carrera OpenNebula y Hadoop: Cloud Computing con herramientas Open Source
 Proyecto Fin de Carrera OpenNebula y Hadoop: Cloud Computing con herramientas Open Source Francisco Magaz Villaverde Consultor: Víctor Carceler Hontoria Junio 2012 Contenido Introducción Qué es Cloud Compu5ng?
Proyecto Fin de Carrera OpenNebula y Hadoop: Cloud Computing con herramientas Open Source Francisco Magaz Villaverde Consultor: Víctor Carceler Hontoria Junio 2012 Contenido Introducción Qué es Cloud Compu5ng?
Big Data y BAM con WSO2
 Mayo 2014 Big Data y BAM con Leonardo Torres Centro Experto en SOA/BPM en atsistemas ofrece una completa suite de productos Open Source SOA y son contribuidores de muchos de los productos de Apache, como
Mayo 2014 Big Data y BAM con Leonardo Torres Centro Experto en SOA/BPM en atsistemas ofrece una completa suite de productos Open Source SOA y son contribuidores de muchos de los productos de Apache, como
PROGRAMA FORMATIVO Analista de Datos Big Data Cloudera Apache Hadoop
 PROGRAMA FORMATIVO Analista de Datos Big Data Cloudera Apache Hadoop Julio 2015 DATOS GENERALES DE LA ESPECIALIDAD 1. Familia Profesional: INFORMÁTICA Y COMUNICACIONES (IFC) Área Profesional: SISTEMAS
PROGRAMA FORMATIVO Analista de Datos Big Data Cloudera Apache Hadoop Julio 2015 DATOS GENERALES DE LA ESPECIALIDAD 1. Familia Profesional: INFORMÁTICA Y COMUNICACIONES (IFC) Área Profesional: SISTEMAS
CURSO: CURSO ADMINISTRADOR HADOOP
 CURSO: CURSO ADMINISTRADOR HADOOP Información detallada del curso www.formacionhadoop.com Este curso online está enfocado a administradores de sistemas que quieran aprender a realizar el despliegue y mantenimiento
CURSO: CURSO ADMINISTRADOR HADOOP Información detallada del curso www.formacionhadoop.com Este curso online está enfocado a administradores de sistemas que quieran aprender a realizar el despliegue y mantenimiento
Big Data con nombres propios
 Febrero 2014 Big Data con Al hablar de tecnología Big Data se está obligado, sin duda alguna, a hablar de programación paralela y procesamiento distribuido, ya que éstas serán las características que permitirán
Febrero 2014 Big Data con Al hablar de tecnología Big Data se está obligado, sin duda alguna, a hablar de programación paralela y procesamiento distribuido, ya que éstas serán las características que permitirán
GESTIÓN DOCUMENTAL PARA EL SISTEMA DE CALIDAD
 GESTIÓN DOCUMENTAL PARA EL SISTEMA DE CALIDAD Manual de usuario 1 - ÍNDICE 1 - ÍNDICE... 2 2 - INTRODUCCIÓN... 3 3 - SELECCIÓN CARPETA TRABAJO... 4 3.1 CÓMO CAMBIAR DE EMPRESA O DE CARPETA DE TRABAJO?...
GESTIÓN DOCUMENTAL PARA EL SISTEMA DE CALIDAD Manual de usuario 1 - ÍNDICE 1 - ÍNDICE... 2 2 - INTRODUCCIÓN... 3 3 - SELECCIÓN CARPETA TRABAJO... 4 3.1 CÓMO CAMBIAR DE EMPRESA O DE CARPETA DE TRABAJO?...
CURSO: CURSO DESARROLLADOR HADOOP
 CURSO: CURSO DESARROLLADOR HADOOP Información detallada del curso www.formacionhadoop.com Este curso online está enfocado a los desarrolladores que quieran aprender a construir potentes aplicaciones de
CURSO: CURSO DESARROLLADOR HADOOP Información detallada del curso www.formacionhadoop.com Este curso online está enfocado a los desarrolladores que quieran aprender a construir potentes aplicaciones de
Arquitectura de sistema de alta disponibilidad
 Mysql Introducción MySQL Cluster esta diseñado para tener una arquitectura distribuida de nodos sin punto único de fallo. MySQL Cluster consiste en 3 tipos de nodos: 1. Nodos de almacenamiento, son los
Mysql Introducción MySQL Cluster esta diseñado para tener una arquitectura distribuida de nodos sin punto único de fallo. MySQL Cluster consiste en 3 tipos de nodos: 1. Nodos de almacenamiento, son los
Toda base de datos relacional se basa en dos objetos
 1. INTRODUCCIÓN Toda base de datos relacional se basa en dos objetos fundamentales: las tablas y las relaciones. Sin embargo, en SQL Server, una base de datos puede contener otros objetos también importantes.
1. INTRODUCCIÓN Toda base de datos relacional se basa en dos objetos fundamentales: las tablas y las relaciones. Sin embargo, en SQL Server, una base de datos puede contener otros objetos también importantes.
CAPITULO 9. Diseño de una Base de Datos Relacional Distribuida
 9.1 Operaciones CAPITULO 9 Diseño de una Base de Datos Relacional Distribuida Las consultas distribuidas obtienen acceso a datos de varios orígenes de datos homogéneos o heterogéneos. Estos orígenes de
9.1 Operaciones CAPITULO 9 Diseño de una Base de Datos Relacional Distribuida Las consultas distribuidas obtienen acceso a datos de varios orígenes de datos homogéneos o heterogéneos. Estos orígenes de
App para realizar consultas al Sistema de Información Estadística de Castilla y León
 App para realizar consultas al Sistema de Información Estadística de Castilla y León Jesús M. Rodríguez Rodríguez rodrodje@jcyl.es Dirección General de Presupuestos y Estadística Consejería de Hacienda
App para realizar consultas al Sistema de Información Estadística de Castilla y León Jesús M. Rodríguez Rodríguez rodrodje@jcyl.es Dirección General de Presupuestos y Estadística Consejería de Hacienda
Manual de uso de la plataforma para monitores. CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES -bilib
 Manual de uso de la plataforma para monitores CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES -bilib [Manual de uso de la plataforma para monitores] 1. Licencia Autor del documento: Centro de Apoyo Tecnológico
Manual de uso de la plataforma para monitores CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES -bilib [Manual de uso de la plataforma para monitores] 1. Licencia Autor del documento: Centro de Apoyo Tecnológico
Hostaliawhitepapers. Las ventajas de los Servidores dedicados. www.hostalia.com. Cardenal Gardoki, 1 48008 BILBAO (Vizcaya) Teléfono: 902 012 199
 Teléfono: 902 012 199") Las ventajas de los Servidores dedicados Cardenal Gardoki, 1 48008 BILBAO (Vizcaya) Teléfono: 902 012 199 www.hostalia.com A la hora de poner en marcha una aplicación web debemos contratar un servicio
Las ventajas de los Servidores dedicados Cardenal Gardoki, 1 48008 BILBAO (Vizcaya) Teléfono: 902 012 199 www.hostalia.com A la hora de poner en marcha una aplicación web debemos contratar un servicio
WINDOWS 2008 5: TERMINAL SERVER
 WINDOWS 2008 5: TERMINAL SERVER 1.- INTRODUCCION: Terminal Server proporciona una interfaz de usuario gráfica de Windows a equipos remotos a través de conexiones en una red local o a través de Internet.
WINDOWS 2008 5: TERMINAL SERVER 1.- INTRODUCCION: Terminal Server proporciona una interfaz de usuario gráfica de Windows a equipos remotos a través de conexiones en una red local o a través de Internet.
Gestión de Oportunidades
 Gestión de Oportunidades Bizagi Suite Gestión de Oportunidades 1 Tabla de Contenido CRM Gestión de Oportunidades de Negocio... 4 Elementos del Proceso... 5 Registrar Oportunidad... 5 Habilitar Alarma y
Gestión de Oportunidades Bizagi Suite Gestión de Oportunidades 1 Tabla de Contenido CRM Gestión de Oportunidades de Negocio... 4 Elementos del Proceso... 5 Registrar Oportunidad... 5 Habilitar Alarma y
Oficina Online. Manual del administrador
 Oficina Online Manual del administrador 2/31 ÍNDICE El administrador 3 Consola de Administración 3 Administración 6 Usuarios 6 Ordenar listado de usuarios 6 Cambio de clave del Administrador Principal
Oficina Online Manual del administrador 2/31 ÍNDICE El administrador 3 Consola de Administración 3 Administración 6 Usuarios 6 Ordenar listado de usuarios 6 Cambio de clave del Administrador Principal
Global File System (GFS)...
...") Global File System (GFS)... Diferente a los sistemas de ficheros en red que hemos visto, ya que permite que todos los nodos tengan acceso concurrente a los bloques de almacenamiento compartido (a través
Global File System (GFS)... Diferente a los sistemas de ficheros en red que hemos visto, ya que permite que todos los nodos tengan acceso concurrente a los bloques de almacenamiento compartido (a través
Plataforma e-ducativa Aragonesa. Manual de Administración. Bitácora
 Plataforma e-ducativa Aragonesa Manual de Administración Bitácora ÍNDICE Acceso a la administración de la Bitácora...3 Interfaz Gráfica...3 Publicaciones...4 Cómo Agregar una Publicación...4 Cómo Modificar
Plataforma e-ducativa Aragonesa Manual de Administración Bitácora ÍNDICE Acceso a la administración de la Bitácora...3 Interfaz Gráfica...3 Publicaciones...4 Cómo Agregar una Publicación...4 Cómo Modificar
Ventajas, Características y Aplicaciones de los SGBD Distribuidos.
 Ventajas, Características y Aplicaciones de los SGBD Distribuidos. Definición Un SBD Distribuido se compone de un conjunto de sitios, conectados entre sí mediante algún tipo de red de comunicaciones, en
Ventajas, Características y Aplicaciones de los SGBD Distribuidos. Definición Un SBD Distribuido se compone de un conjunto de sitios, conectados entre sí mediante algún tipo de red de comunicaciones, en
Base de datos en la Enseñanza. Open Office
 1 Ministerio de Educación Base de datos en la Enseñanza. Open Office Módulo 1: Introducción Instituto de Tecnologías Educativas 2011 Introducción Pero qué es una base de datos? Simplificando mucho, podemos
1 Ministerio de Educación Base de datos en la Enseñanza. Open Office Módulo 1: Introducción Instituto de Tecnologías Educativas 2011 Introducción Pero qué es una base de datos? Simplificando mucho, podemos
BIG DATA & SEGURIDAD UN MATRIMONIO DE FUTURO
 BIG DATA & SEGURIDAD UN MATRIMONIO DE FUTURO PRESENTACIÓN ANTONIO GONZÁLEZ CASTRO IT SECURITY DIRECTOR EN PRAGSIS TECHNOLOGIES agcastro@pragsis.com antoniogonzalezcastro.es @agonzaca linkedin.com/in/agonzaca
BIG DATA & SEGURIDAD UN MATRIMONIO DE FUTURO PRESENTACIÓN ANTONIO GONZÁLEZ CASTRO IT SECURITY DIRECTOR EN PRAGSIS TECHNOLOGIES agcastro@pragsis.com antoniogonzalezcastro.es @agonzaca linkedin.com/in/agonzaca
Capítulo 3 Diseño del Sistema de Administración de Información de Bajo Costo para un Negocio Franquiciable
 Capítulo 3 Diseño del Sistema de Administración de Información de Bajo Costo para un Negocio Franquiciable 1. Introducción. El Sistema de Administración de Información de un Negocio Franquiciable (SAINF)
Capítulo 3 Diseño del Sistema de Administración de Información de Bajo Costo para un Negocio Franquiciable 1. Introducción. El Sistema de Administración de Información de un Negocio Franquiciable (SAINF)
Accede a su DISCO Virtual del mismo modo como lo Hace a su disco duro, a través de:
 Gemelo Backup Online DESKTOP Manual DISCO VIRTUAL Es un Disco que se encuentra en su PC junto a las unidades de discos locales. La información aquí existente es la misma que usted ha respaldado con su
Gemelo Backup Online DESKTOP Manual DISCO VIRTUAL Es un Disco que se encuentra en su PC junto a las unidades de discos locales. La información aquí existente es la misma que usted ha respaldado con su
PINOT. La ingestión near real time desde Kafka complementado por la ingestión batch desde herramientas como Hadoop.
 PINOT Stratebi Paper (2015 info@stratebi.com www.stratebi.com) Pinot es la herramienta de análisis en tiempo real desarrollada por LinkedIn que la compañía ha liberado su código bajo licencia Apache 2.0,
PINOT Stratebi Paper (2015 info@stratebi.com www.stratebi.com) Pinot es la herramienta de análisis en tiempo real desarrollada por LinkedIn que la compañía ha liberado su código bajo licencia Apache 2.0,
Novedades en Q-flow 3.02
 Novedades en Q-flow 3.02 Introducción Uno de los objetivos principales de Q-flow 3.02 es adecuarse a las necesidades de grandes organizaciones. Por eso Q-flow 3.02 tiene una versión Enterprise que incluye
Novedades en Q-flow 3.02 Introducción Uno de los objetivos principales de Q-flow 3.02 es adecuarse a las necesidades de grandes organizaciones. Por eso Q-flow 3.02 tiene una versión Enterprise que incluye
Introducción a la Firma Electrónica en MIDAS
 Introducción a la Firma Electrónica en MIDAS Firma Digital Introducción. El Módulo para la Integración de Documentos y Acceso a los Sistemas(MIDAS) emplea la firma digital como método de aseguramiento
Introducción a la Firma Electrónica en MIDAS Firma Digital Introducción. El Módulo para la Integración de Documentos y Acceso a los Sistemas(MIDAS) emplea la firma digital como método de aseguramiento
Autor: Microsoft Licencia: Cita Fuente: Ayuda de Windows
 Qué es Recuperación? Recuperación del Panel de control proporciona varias opciones que pueden ayudarle a recuperar el equipo de un error grave. Nota Antes de usar Recuperación, puede probar primero uno
Qué es Recuperación? Recuperación del Panel de control proporciona varias opciones que pueden ayudarle a recuperar el equipo de un error grave. Nota Antes de usar Recuperación, puede probar primero uno
QUE ES COMLINE MENSAJES? QUE TIPO DE MENSAJES PROCESA COMLINE MENSAJES?
 QUE ES COMLINE MENSAJES? Comline Mensajes es una plataforma flexible, ágil y oportuna, que permite el envío MASIVO de MENSAJES DE TEXTO (SMS). Comline Mensajes integra su tecnología a los centros de recepción
QUE ES COMLINE MENSAJES? Comline Mensajes es una plataforma flexible, ágil y oportuna, que permite el envío MASIVO de MENSAJES DE TEXTO (SMS). Comline Mensajes integra su tecnología a los centros de recepción
COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX
 COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX En este manual se presenta el proceso de configuración de una Maquina Virtual en VirtualBox, que será utilizada para instalar un Servidor
COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX En este manual se presenta el proceso de configuración de una Maquina Virtual en VirtualBox, que será utilizada para instalar un Servidor
Manual de uso básico de la aplicación
 Manual de uso básico de la aplicación Autor del documento Centro de Apoyo Tecnológico a Emprendedores, Fundación Parque Científico y Tecnológico de Albacete Datos de contacto E-Mail: bilib@bilib.es Página
Manual de uso básico de la aplicación Autor del documento Centro de Apoyo Tecnológico a Emprendedores, Fundación Parque Científico y Tecnológico de Albacete Datos de contacto E-Mail: bilib@bilib.es Página
Creación y administración de grupos de dominio
 Creación y administración de grupos de dominio Contenido Descripción general 1 a los grupos de Windows 2000 2 Tipos y ámbitos de los grupos 5 Grupos integrados y predefinidos en un dominio 7 Estrategia
Creación y administración de grupos de dominio Contenido Descripción general 1 a los grupos de Windows 2000 2 Tipos y ámbitos de los grupos 5 Grupos integrados y predefinidos en un dominio 7 Estrategia
Sitios remotos. Configurar un Sitio Remoto
 Sitios remotos Definir un sitio remoto significa establecer una configuración de modo que Dreamweaver sea capaz de comunicarse directamente con un servidor en Internet (por eso se llama remoto) y así poder
Sitios remotos Definir un sitio remoto significa establecer una configuración de modo que Dreamweaver sea capaz de comunicarse directamente con un servidor en Internet (por eso se llama remoto) y así poder
Manual de iniciación a
 DOCUMENTACIÓN Picasa y otras nubes Manual de iniciación a DROPBOX 1 Últimamente se ha hablado mucho de la nube y de cómo es el futuro de la Web. También se han presentado servicios y aplicaciones que ya
DOCUMENTACIÓN Picasa y otras nubes Manual de iniciación a DROPBOX 1 Últimamente se ha hablado mucho de la nube y de cómo es el futuro de la Web. También se han presentado servicios y aplicaciones que ya
Adelacu Ltda. www.adelacu.com Fono +562-218-4749. Graballo+ Agosto de 2007. Graballo+ - Descripción funcional - 1 -
 Graballo+ Agosto de 2007-1 - Índice Índice...2 Introducción...3 Características...4 DESCRIPCIÓN GENERAL...4 COMPONENTES Y CARACTERÍSTICAS DE LA SOLUCIÓN...5 Recepción de requerimientos...5 Atención de
Graballo+ Agosto de 2007-1 - Índice Índice...2 Introducción...3 Características...4 DESCRIPCIÓN GENERAL...4 COMPONENTES Y CARACTERÍSTICAS DE LA SOLUCIÓN...5 Recepción de requerimientos...5 Atención de
D.T.Informática S.L. [Sistema hada] hilo Administrador Desarrollo Activo
![D.T.Informática S.L. [Sistema hada] hilo Administrador Desarrollo Activo](/thumbs/24/3309215.jpg "D.T.Informática S.L. [Sistema hada] hilo Administrador Desarrollo Activo") 2010 D.T.Informática S.L. [Sistema hada] hilo Administrador Desarrollo Activo INDICE: 1- Introducción 2- El Servicio hada 3- Copias de Seguridad ( Backups ) 4- Actualizaciones DAF Win 5- Cuentas Comunicación
2010 D.T.Informática S.L. [Sistema hada] hilo Administrador Desarrollo Activo INDICE: 1- Introducción 2- El Servicio hada 3- Copias de Seguridad ( Backups ) 4- Actualizaciones DAF Win 5- Cuentas Comunicación
Técnicas para mejorar nuestro Posicionamiento
 Para aumentar nuestras ganancias deberíamos: 1. Llegar a mayor cantidad de público. 2. Aumentar el valor percibido de nuestro producto (lo que nos permite subir el precio de venta). 3. Aumentar la tasa
Para aumentar nuestras ganancias deberíamos: 1. Llegar a mayor cantidad de público. 2. Aumentar el valor percibido de nuestro producto (lo que nos permite subir el precio de venta). 3. Aumentar la tasa
Internet Information Server
 Internet Information Server Internet Information Server (IIS) es el servidor de páginas web avanzado de la plataforma Windows. Se distribuye gratuitamente junto con las versiones de Windows basadas en
Internet Information Server Internet Information Server (IIS) es el servidor de páginas web avanzado de la plataforma Windows. Se distribuye gratuitamente junto con las versiones de Windows basadas en
Sistema de SaaS (Software as a Service) para centros educativos
 para centros educativos") Sistema de SaaS (Software as a Service) para centros educativos Definiciones preliminares: Qué es SaaS? SaaS (1) es un modelo de distribución del software que permite a los usuarios el acceso al mismo
Sistema de SaaS (Software as a Service) para centros educativos Definiciones preliminares: Qué es SaaS? SaaS (1) es un modelo de distribución del software que permite a los usuarios el acceso al mismo
LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER
 LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER GUÍA DE LABORATORIO Nº 1O Actividad de Proyecto No. 12: ESTABLECER PLANES DE RESGUARDO, RESTAURACION Y CONTINGENCIA. Estructura de contenidos.
LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER GUÍA DE LABORATORIO Nº 1O Actividad de Proyecto No. 12: ESTABLECER PLANES DE RESGUARDO, RESTAURACION Y CONTINGENCIA. Estructura de contenidos.
WINDOWS 2008 7: COPIAS DE SEGURIDAD
 1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
Servicio de Email Marketing
 Servicio de Email Marketing Cuando hablamos de Email marketing, es un envío Masivo de correos con permisos realizado por herramientas tecnológicas de correo electrónico, mediante el cual su anuncio estará
Servicio de Email Marketing Cuando hablamos de Email marketing, es un envío Masivo de correos con permisos realizado por herramientas tecnológicas de correo electrónico, mediante el cual su anuncio estará
CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES, BILIB RECETA TECNOLÓGICA REALIZACIÓN DE COPIAS DE SEGURIDAD CON GSYNC
 CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES, BILIB RECETA TECNOLÓGICA REALIZACIÓN DE COPIAS DE SEGURIDAD CON GSYNC Fecha: 11 de Abril de 2012 Licencia Autor del documento: Centro de Apoyo Tecnológico a
CENTRO DE APOYO TECNOLÓGICO A EMPRENDEDORES, BILIB RECETA TECNOLÓGICA REALIZACIÓN DE COPIAS DE SEGURIDAD CON GSYNC Fecha: 11 de Abril de 2012 Licencia Autor del documento: Centro de Apoyo Tecnológico a
Manual para la utilización de PrestaShop
 Manual para la utilización de PrestaShop En este manual mostraremos de forma sencilla y práctica la utilización del Gestor de su Tienda Online mediante Prestashop 1.6, explicaremos todo lo necesario para
Manual para la utilización de PrestaShop En este manual mostraremos de forma sencilla y práctica la utilización del Gestor de su Tienda Online mediante Prestashop 1.6, explicaremos todo lo necesario para
SISTEMA DE REGISTRO DE TRANSACCIONES BURSATILES BAGSA MANUAL DE USUARIO
 SISTEMA DE REGISTRO DE TRANSACCIONES BURSATILES BAGSA MANUAL DE USUARIO Consideraciones Iniciales I. El sistema está desarrollado bajo un entorno web por lo que puede ser accedido desde cualquier cliente
SISTEMA DE REGISTRO DE TRANSACCIONES BURSATILES BAGSA MANUAL DE USUARIO Consideraciones Iniciales I. El sistema está desarrollado bajo un entorno web por lo que puede ser accedido desde cualquier cliente
Google Drive y Almacenamiento en Nubes Virtuales
 Google Drive y Almacenamiento en Nubes Virtuales Integrantes: Nicolás Cienfuegos Tábata Larenas Deyanira Torres Ramo: Redes de Computadoras I (ELO-322) Profesor: Agustín Gonzalez Fecha: 6 de Septiembre
Google Drive y Almacenamiento en Nubes Virtuales Integrantes: Nicolás Cienfuegos Tábata Larenas Deyanira Torres Ramo: Redes de Computadoras I (ELO-322) Profesor: Agustín Gonzalez Fecha: 6 de Septiembre
GlusterFS. Una visión rápida a uno de los más innovadores sistema de archivos distribuido
 GlusterFS Una visión rápida a uno de los más innovadores sistema de archivos distribuido Qué es GlusterFS? Es un sistema de archivos de alta disponibilidad y escalabilidad que puede brindar almacenamiento
GlusterFS Una visión rápida a uno de los más innovadores sistema de archivos distribuido Qué es GlusterFS? Es un sistema de archivos de alta disponibilidad y escalabilidad que puede brindar almacenamiento
GENERACIÓN DE TRANSFERENCIAS
 GENERACIÓN DE TRANSFERENCIAS 1 INFORMACIÓN BÁSICA La aplicación de generación de ficheros de transferencias permite generar fácilmente órdenes para que la Caja efectúe transferencias, creando una base
GENERACIÓN DE TRANSFERENCIAS 1 INFORMACIÓN BÁSICA La aplicación de generación de ficheros de transferencias permite generar fácilmente órdenes para que la Caja efectúe transferencias, creando una base
Manual de uso básico de la aplicación
 Manual de uso básico de la aplicación Autor del documento Centro de Apoyo Tecnológico a Emprendedores, Fundación Parque Científico y Tecnológico de Albacete Datos de contacto E-Mail: bilib@bilib.es Página
Manual de uso básico de la aplicación Autor del documento Centro de Apoyo Tecnológico a Emprendedores, Fundación Parque Científico y Tecnológico de Albacete Datos de contacto E-Mail: bilib@bilib.es Página
Propuesta de Portal de la Red de Laboratorios Virtuales y Remotos de CEA
 Propuesta de Portal de la Red de Laboratorios Virtuales y Remotos de CEA Documento de trabajo elaborado para la Red Temática DocenWeb: Red Temática de Docencia en Control mediante Web (DPI2002-11505-E)
Propuesta de Portal de la Red de Laboratorios Virtuales y Remotos de CEA Documento de trabajo elaborado para la Red Temática DocenWeb: Red Temática de Docencia en Control mediante Web (DPI2002-11505-E)
Capítulo VI. Estudio de Caso de Aplicación del Integrador de Información Desarrollado
 Capítulo VI Estudio de Caso de Aplicación del Integrador de Información Desarrollado 6.1 Organización elegida La Organización elegida para el caso de aplicación, es la empresa CTM Tours del grupo Costamar,
Capítulo VI Estudio de Caso de Aplicación del Integrador de Información Desarrollado 6.1 Organización elegida La Organización elegida para el caso de aplicación, es la empresa CTM Tours del grupo Costamar,
No se requiere que los discos sean del mismo tamaño ya que el objetivo es solamente adjuntar discos.
 RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
CATÁLOGO CATÁLOGO CATÁLOGO CATÁLOGO CATÁLOGO
 CATÁLOGO MANUAL DE USUARIO CATÁLOGO MANUAL DE USUARIO CATÁLOGO MANUAL DE USUARIO 1. CATÁLOGO MANUAL DE USUARIO CATÁLOGO AHORA CATÁLOGO MANUAL DE USUARIO 1 1. Introducción AHORA Catálogo es una aplicación
CATÁLOGO MANUAL DE USUARIO CATÁLOGO MANUAL DE USUARIO CATÁLOGO MANUAL DE USUARIO 1. CATÁLOGO MANUAL DE USUARIO CATÁLOGO AHORA CATÁLOGO MANUAL DE USUARIO 1 1. Introducción AHORA Catálogo es una aplicación
Adaptación al NPGC. Introducción. NPGC.doc. Qué cambios hay en el NPGC? Telf.: 93.410.92.92 Fax.: 93.419.86.49 e-mail:atcliente@websie.
 Adaptación al NPGC Introducción Nexus 620, ya recoge el Nuevo Plan General Contable, que entrará en vigor el 1 de Enero de 2008. Este documento mostrará que debemos hacer a partir de esa fecha, según nuestra
Adaptación al NPGC Introducción Nexus 620, ya recoge el Nuevo Plan General Contable, que entrará en vigor el 1 de Enero de 2008. Este documento mostrará que debemos hacer a partir de esa fecha, según nuestra
Instantáneas o Shadow Copy
 Instantáneas o Shadow Copy Las instantáneas o en ingles shadow copy, es una utilidad del sistema operativo que realiza copias de seguridad de los ficheros y carpetas de una partición determinada cada cierto
Instantáneas o Shadow Copy Las instantáneas o en ingles shadow copy, es una utilidad del sistema operativo que realiza copias de seguridad de los ficheros y carpetas de una partición determinada cada cierto
COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA
 COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA Autor: Carlos Javier Martín González. Licenciado en Física Teórica por la Universidad Autónoma de Madrid. Analista programador y funcional. Desarrollador
COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA Autor: Carlos Javier Martín González. Licenciado en Física Teórica por la Universidad Autónoma de Madrid. Analista programador y funcional. Desarrollador
Capitulo V Administración de memoria
 Capitulo V Administración de memoria Introducción. Una de las tareas más importantes y complejas de un sistema operativo es la gestión de memoria. La gestión de memoria implica tratar la memoria principal
Capitulo V Administración de memoria Introducción. Una de las tareas más importantes y complejas de un sistema operativo es la gestión de memoria. La gestión de memoria implica tratar la memoria principal
Tema: INSTALACIÓN Y PARTICIONAMIENTO DE DISCOS DUROS.
 1 Facultad: Ingeniería Escuela: Electrónica Asignatura: Arquitectura de computadoras Lugar de ejecución: Lab. de arquitectura de computadoras, edif. de electrónica. Tema: INSTALACIÓN Y PARTICIONAMIENTO
1 Facultad: Ingeniería Escuela: Electrónica Asignatura: Arquitectura de computadoras Lugar de ejecución: Lab. de arquitectura de computadoras, edif. de electrónica. Tema: INSTALACIÓN Y PARTICIONAMIENTO
REGISTRO DE PEDIDOS DE CLIENTES MÓDULO DE TOMA DE PEDIDOS E INTEGRACIÓN CON ERP
 REGISTRO DE PEDIDOS DE CLIENTES MÓDULO DE TOMA DE PEDIDOS E INTEGRACIÓN CON ERP Visual Sale posee módulos especializados para el método de ventas transaccional, donde el pedido de parte de un nuevo cliente
REGISTRO DE PEDIDOS DE CLIENTES MÓDULO DE TOMA DE PEDIDOS E INTEGRACIÓN CON ERP Visual Sale posee módulos especializados para el método de ventas transaccional, donde el pedido de parte de un nuevo cliente
Autenticación Centralizada
 Autenticación Centralizada Ing. Carlos Rojas Castro Herramientas de Gestión de Redes Introducción En el mundo actual, pero en especial las organizaciones actuales, los usuarios deben dar pruebas de quiénes
Autenticación Centralizada Ing. Carlos Rojas Castro Herramientas de Gestión de Redes Introducción En el mundo actual, pero en especial las organizaciones actuales, los usuarios deben dar pruebas de quiénes
REDES DE ÁREA LOCAL. APLICACIONES Y SERVICIOS EN WINDOWS
 REDES DE ÁREA LOCAL. APLICACIONES Y SERVICIOS EN WINDOWS Servicio DNS - 1 - Servicio DNS...- 3 - Definición... - 3 - Instalación... - 5 - Configuración del Servidor DNS...- 10 - - 2 - Servicio DNS Definición
REDES DE ÁREA LOCAL. APLICACIONES Y SERVICIOS EN WINDOWS Servicio DNS - 1 - Servicio DNS...- 3 - Definición... - 3 - Instalación... - 5 - Configuración del Servidor DNS...- 10 - - 2 - Servicio DNS Definición
DISCOS RAID. Se considera que todos los discos físicos tienen la misma capacidad, y de no ser así, en el que sea mayor se desperdicia la diferencia.
 DISCOS RAID Raid: redundant array of independent disks, quiere decir conjunto redundante de discos independientes. Es un sistema de almacenamiento de datos que utiliza varias unidades físicas para guardar
DISCOS RAID Raid: redundant array of independent disks, quiere decir conjunto redundante de discos independientes. Es un sistema de almacenamiento de datos que utiliza varias unidades físicas para guardar
Capítulo 5. Cliente-Servidor.
 Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
MANUAL DE AYUDA HERRAMIENTA DE APROVISIONAMIENTO
 MANUAL DE AYUDA HERRAMIENTA DE APROVISIONAMIENTO Fecha última revisión: Junio 2011 INDICE DE CONTENIDOS HERRAMIENTA DE APROVISIONAMIENTO... 3 1. QUÉ ES LA HERRAMIENTA DE APROVISIONAMIENTO... 3 HERRAMIENTA
MANUAL DE AYUDA HERRAMIENTA DE APROVISIONAMIENTO Fecha última revisión: Junio 2011 INDICE DE CONTENIDOS HERRAMIENTA DE APROVISIONAMIENTO... 3 1. QUÉ ES LA HERRAMIENTA DE APROVISIONAMIENTO... 3 HERRAMIENTA
Microsoft SQL Server Conceptos.
 Microsoft Conceptos. Microsoft 2005 es una plataforma de base de datos a gran escala de procesamiento de transacciones en línea (OLTP) y de procesamiento analítico en línea (OLAP). La siguiente tabla muestra
Microsoft Conceptos. Microsoft 2005 es una plataforma de base de datos a gran escala de procesamiento de transacciones en línea (OLTP) y de procesamiento analítico en línea (OLAP). La siguiente tabla muestra
ADMINISTRACIÓN DE BASES DE DATOS DISTRIBUIDAS
 5 ADMINISTRACIÓN DE BASES DE DATOS DISTRIBUIDAS Contenido: 5.1 Conceptos Generales Administración de Bases de Datos Distribuidas 5.1.1 Administración la Estructura de la Base de Datos 5.1.2 Administración
5 ADMINISTRACIÓN DE BASES DE DATOS DISTRIBUIDAS Contenido: 5.1 Conceptos Generales Administración de Bases de Datos Distribuidas 5.1.1 Administración la Estructura de la Base de Datos 5.1.2 Administración
Acronis License Server. Guía del usuario
 Acronis License Server Guía del usuario TABLA DE CONTENIDO 1. INTRODUCCIÓN... 3 1.1 Generalidades... 3 1.2 Política de licencias... 3 2. SISTEMAS OPERATIVOS COMPATIBLES... 4 3. INSTALACIÓN DE ACRONIS LICENSE
Acronis License Server Guía del usuario TABLA DE CONTENIDO 1. INTRODUCCIÓN... 3 1.1 Generalidades... 3 1.2 Política de licencias... 3 2. SISTEMAS OPERATIVOS COMPATIBLES... 4 3. INSTALACIÓN DE ACRONIS LICENSE
Capítulo I. Definición del problema y objetivos de la tesis. En la actualidad Internet se ha convertido en una herramienta necesaria para todas
 Capítulo I Definición del problema y objetivos de la tesis 1.1 Introducción En la actualidad Internet se ha convertido en una herramienta necesaria para todas las personas ya que nos permite realizar diferentes
Capítulo I Definición del problema y objetivos de la tesis 1.1 Introducción En la actualidad Internet se ha convertido en una herramienta necesaria para todas las personas ya que nos permite realizar diferentes
Guía Rápida de Inicio
 Guía Rápida de Inicio 1. Acerca de esta Guía Esta guía le ayudará a instalar y dar los primeros pasos con BitDefender Security for SharePoint. Para disponer de instrucciones detalladas, por favor, diríjase
Guía Rápida de Inicio 1. Acerca de esta Guía Esta guía le ayudará a instalar y dar los primeros pasos con BitDefender Security for SharePoint. Para disponer de instrucciones detalladas, por favor, diríjase
Manual de usuario de Solmicro BI. Página 1
 Manual de usuario de Solmicro BI Página 1 Índice 1. Estructura general del sistema, 2. Estructura de presentación de la información, 3. Acceso a Solmicro BI y los diferentes cuadros de mando, 4. Partes
Manual de usuario de Solmicro BI Página 1 Índice 1. Estructura general del sistema, 2. Estructura de presentación de la información, 3. Acceso a Solmicro BI y los diferentes cuadros de mando, 4. Partes
Creación paso a paso de Formularios con Google (Parte I) (AKA: no corrijo nunca más!)
 (AKA: no corrijo nunca más!)") Creación paso a paso de Formularios con Google (Parte I) (AKA: no corrijo nunca más!) por Rodrigo Martínez Gazoni La idea de este tutorial es meternos en una de los servicios que ofrece Google en forma
Creación paso a paso de Formularios con Google (Parte I) (AKA: no corrijo nunca más!) por Rodrigo Martínez Gazoni La idea de este tutorial es meternos en una de los servicios que ofrece Google en forma
Tutorial: Primeros Pasos con Subversion
 Tutorial: Primeros Pasos con Subversion Introducción Subversion es un sistema de control de versiones open source. Corre en distintos sistemas operativos y su principal interfaz con el usuario es a través
Tutorial: Primeros Pasos con Subversion Introducción Subversion es un sistema de control de versiones open source. Corre en distintos sistemas operativos y su principal interfaz con el usuario es a través
Optimizar base de datos WordPress
 Optimizar base de datos WordPress Cardenal Gardoki, 1 48008 BILBAO (Vizcaya) Teléfono: 902 012 199 www.hostalia.com WordPress se ha convertido en uno de los CMS más utilizados en todo el mundo. Su robustez,
Optimizar base de datos WordPress Cardenal Gardoki, 1 48008 BILBAO (Vizcaya) Teléfono: 902 012 199 www.hostalia.com WordPress se ha convertido en uno de los CMS más utilizados en todo el mundo. Su robustez,
GESTOR DE DESCARGAS. Índice de contenido
 GESTOR DE DESCARGAS Índice de contenido 1. Qué es DocumentosOnLine.net?...2 2. Qué es el Gestor de Descargas?...3 3.Instalación / Configuración...5 4.Descarga de Documentos...9 5.Búsqueda / Consulta de
GESTOR DE DESCARGAS Índice de contenido 1. Qué es DocumentosOnLine.net?...2 2. Qué es el Gestor de Descargas?...3 3.Instalación / Configuración...5 4.Descarga de Documentos...9 5.Búsqueda / Consulta de
GUÍA RÁPIDA DE TRABAJOS CON ARCHIVOS.
 GUÍA RÁPIDA DE TRABAJOS CON ARCHIVOS. 1 Direcciones o Ubicaciones, Carpetas y Archivos Botones de navegación. El botón Atrás permite volver a carpetas que hemos examinado anteriormente. El botón Arriba
GUÍA RÁPIDA DE TRABAJOS CON ARCHIVOS. 1 Direcciones o Ubicaciones, Carpetas y Archivos Botones de navegación. El botón Atrás permite volver a carpetas que hemos examinado anteriormente. El botón Arriba
Motores de Búsqueda Web Tarea Tema 2
 Motores de Búsqueda Web Tarea Tema 2 71454586A Motores de Búsqueda Web Máster en Lenguajes y Sistemas Informáticos - Tecnologías del Lenguaje en la Web UNED 30/01/2011 Tarea Tema 2 Enunciado del ejercicio
Motores de Búsqueda Web Tarea Tema 2 71454586A Motores de Búsqueda Web Máster en Lenguajes y Sistemas Informáticos - Tecnologías del Lenguaje en la Web UNED 30/01/2011 Tarea Tema 2 Enunciado del ejercicio
Servicios de impresión y de archivos (Windows 2008) www.adminso.es
 www.adminso.es") Servicios de y de archivos (Windows 2008) www.adminso.es Servicios de y archivos (w2k8) COMPARTIR ARCHIVOS E IMPRESORAS Servicios de y archivos (w2k8) Los servicios de y de archivos permiten compartir
Servicios de y de archivos (Windows 2008) www.adminso.es Servicios de y archivos (w2k8) COMPARTIR ARCHIVOS E IMPRESORAS Servicios de y archivos (w2k8) Los servicios de y de archivos permiten compartir
Capitulo 3. Desarrollo del Software
 Capitulo 3 Desarrollo del Software 3.1 Análisis del sistema 3.1.1 Organización de la autopista virtual Para el presente proyecto se requiere de simular una autopista para que sirva de prueba. Dicha autopista
Capitulo 3 Desarrollo del Software 3.1 Análisis del sistema 3.1.1 Organización de la autopista virtual Para el presente proyecto se requiere de simular una autopista para que sirva de prueba. Dicha autopista
MANUAL DE AYUDA TAREA PROGRAMADA COPIAS DE SEGURIDAD
 MANUAL DE AYUDA TAREA PROGRAMADA COPIAS DE SEGURIDAD Fecha última revisión: Diciembre 2010 Tareas Programadas TAREAS PROGRAMADAS... 3 LAS TAREAS PROGRAMADAS EN GOTELGEST.NET... 4 A) DAR DE ALTA UN USUARIO...
MANUAL DE AYUDA TAREA PROGRAMADA COPIAS DE SEGURIDAD Fecha última revisión: Diciembre 2010 Tareas Programadas TAREAS PROGRAMADAS... 3 LAS TAREAS PROGRAMADAS EN GOTELGEST.NET... 4 A) DAR DE ALTA UN USUARIO...
Gestión de Retales WhitePaper Noviembre de 2009
 Gestión de Retales WhitePaper Noviembre de 2009 Contenidos 1. Introducción 3 2. Almacén de retales 4 3. Propiedades de los materiales 6 4. Alta de retales 8 5. Utilización de retales en un lote de producción
Gestión de Retales WhitePaper Noviembre de 2009 Contenidos 1. Introducción 3 2. Almacén de retales 4 3. Propiedades de los materiales 6 4. Alta de retales 8 5. Utilización de retales en un lote de producción
Manual de NetBeans y XAMPP
 Three Headed Monkey Manual de NetBeans y XAMPP Versión 1.0 Guillermo Montoro Delgado Raúl Nadal Burgos Juan María Ruiz Tinas Lunes, 22 de marzo de 2010 Contenido NetBeans... 2 Qué es NetBeans?... 2 Instalación
Three Headed Monkey Manual de NetBeans y XAMPP Versión 1.0 Guillermo Montoro Delgado Raúl Nadal Burgos Juan María Ruiz Tinas Lunes, 22 de marzo de 2010 Contenido NetBeans... 2 Qué es NetBeans?... 2 Instalación
Posicionamiento WEB POSICIONAMIENTO WEB GARANTIZADO
 Posicionamiento WEB 1 Tipos de Posicionamiento Web Posicionamiento Orgánico o Natural (SEO): es el posicionamiento que se consigue en los motores de búsqueda para las palabras clave seleccionadas. Este
Posicionamiento WEB 1 Tipos de Posicionamiento Web Posicionamiento Orgánico o Natural (SEO): es el posicionamiento que se consigue en los motores de búsqueda para las palabras clave seleccionadas. Este
Windows Server 2012 Manejabilidad y automatización. Module 3: Adaptación del Administrador de servidores a sus necesidades
 Windows Server 2012 Manejabilidad y automatización Module 3: Adaptación del Administrador de servidores a sus necesidades Fecha de publicación: 4 de septiembre de 2012 La información contenida en este
Windows Server 2012 Manejabilidad y automatización Module 3: Adaptación del Administrador de servidores a sus necesidades Fecha de publicación: 4 de septiembre de 2012 La información contenida en este