Utilización de la programación paralela en procesadores gráficos para el cálculo científico.
|
|
|
- Lucía Lucero Vázquez
- hace 8 años
- Vistas:
Transcripción
1 Utilización de la programación paralela en procesadores gráficos para el cálculo científico. EMNO 2013

2 Rolando E. Rodríguez Fernández Medicina Computacional, Instituto de Nefrología. y Facultad de Física, Universidad de la Habana. rerodriguez@infomed.sld.cu

3 Medicina Computacional que cosa es eso? La Medicina Computacional es un campo de aplicaciones científicas, definido como la aplicación de las ciencias naturales y exactas a la medicina, utilizando como puente los modelos computacionales que han servido de manera clásica para explicar en la naturaleza y la sociedad, los fenómenos químicos, físicos, biológicos, matemáticos, psicológicos y hasta económicos y sociales. La Medicina Computacional utiliza a la Clínica y la Epidemiología como fundamentos esenciales para tener al paciente en la perspectiva directa de trabajo. La versión de la Bioinformática en el contexto médico

4 J. Endocrinol. Aug 2012

5 La enfermedad renal poliquística una condición genética producida por el mal funcionamiento de un sistema de señales mediado de manera primaria por un canal de calcio

6 La enfermedad renal poliquística mecanismos involucrados Ca, camp, TSC2, MAP kinasas (regulación primaria por receptores de GABA y canales de Ca L P y Q) EGFR inh

7

8

9

10 Simulación en la Membrana Celular Receptor de GABA, DM en solución salina isotónica [ átomos]

11 Un problema grande Cálculo del movimiento y la energía en un sistema molecular (Dinámica molecular) E total = E enlazante + E no-enlazante E enlazante = E enlace + E tangular + E tdihedrica E no-enlazante = E electrostatica + E van der Waals Poisson s Eq

12 Un problema grande Cálculo del movimiento y la energía en un sistema molecular (Dinámica molecular) Descomposición de dominio: Descomposición funcional: Cada átomo se puede calcular por separado Lista de átomos enlazados Interacciones enlazantes Energía vibracional Energía rotacional Lista de átomos vecinos Generación del enrejado Interacciones no enlazantes Potencial Electrostático Potencial de van der Waals Puentes de Hidrógeno Posición y velocidad Conservación de la Energía Parte no Paralela (serial): Cálculo de la energía total del sistema Temperatura y Volumen
: Cálculo de la energía total del sistema Temperatura y")
13
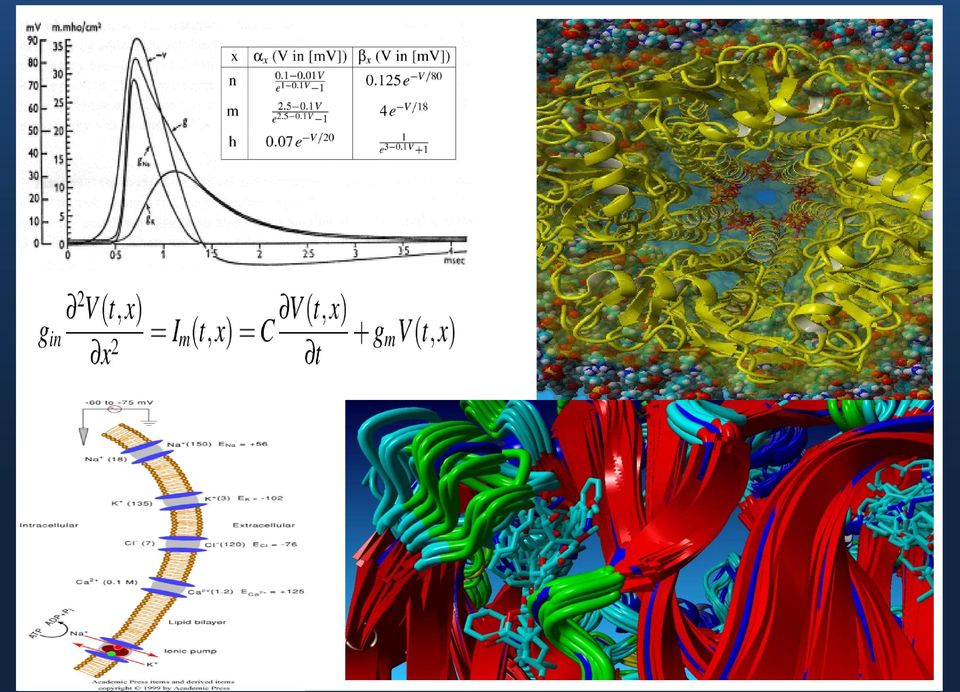
14 Un problema Enorme La simulación del acoplamiento molecular buscando posibles ligandos Superficie de interacción en el sitio activo del receptor Topología de la interacción

15 Un problema Enorme La simulación del acoplamiento molecular buscando posibles ligandos Enrejado para el cálculo de energía El experimento!! ( Compuestos)

16

17 La programación en paralelo es un concepto bastante antiguo Existe una demanda continua de potencia de cálculo en las computadoras siempre mayor que la que encontramos disponible. Desde el principio de la existencia de las computadoras hemos aprendido a dividir el problema en partes que deben ser ejecutadas en varios sistemas de computación y luego combinadas para obtener el resultado final. Esta estrategia se conoce como programación paralela o en paralelo. Gill (1958) Parallel Programming, The computer Journal, Vol 1, April, pp

18 Hace falta un sistema computacional grande Vamos a construir un clúster de computadoras Nicholas Metropolis formuló por primera vez el dilema eterno en el que ponemos a nuestros jefes.. Esta máquina (la ENIAC) no es suficiente potente para resolver nuestros problemas Y así obtuvo el dinero para armar una mas potente (MANIAC) que podía hasta jugar ajedrez.. En la MANIAC hizo el programa con el que George Gamow elucidó el código genético, que publicaron juntos en 1954
 que podía hasta jugar ajedrez.")
19 Hace falta un sistema computacional grande La evolución de los sistemas distribuidos hoy nos podemos construir el clúster en el laboratorio.. antes no s

20

21 Sistema de Cálculo Científico 152 CPUs, 4352 GPUs (9.8 TFlops), 380GB RAM, 80+ TB HDD 3 unidades de cálculo 4 estaciones gráficas 3D 6 estaciones gráficas 24 CPUs (2x Opteron 12 core), 64GB RAM, 6TB HDD 48 CPUs (4x Opteron 12 core), 128 GB RAM, 6TB HDD 24 CPUs (2x Opteron 12 core), 64GB RAM 1024 GPUs (2x NVIDIA M2075, 12GB GDDR6, 2TFlops) 3TB UHSHDD 8 CPUs (Opteron 8 core), 16GB RAM, 1TB HDD, 256 GPUs (Nvidia Quadro 4000, 2GB GDDR5, 1 TFlop) 4 CPUs (Opteron 4 core), 8GB RAM, 1TB HDD, 192 GPUs (Nvidia GTX, 1GB GDDR5, 0.4 TFlop) 7 u de control 2 CPUs (Atom 2 core), 4GB RAM, no HDD, vsphere 1 unidad SAN 1x Promise 32TB dual iscsi SAN
22 Sistema de cálculo y procesamiento gráfico la tendencia actual es la arquitectura híbrida
23 Sistemas computacionales las arquitecturas actuales mas comunes Programación en sistemas ccnuma 1. Hasta 16 núcleos 2. Registros multipropósito en los núcleos 3. Interfaz rápida de los 16 núcleos con su memoria x vector pipeline, una instrucción se puede ejecutar simultáneamente en los 64 registros multipropósito de cada núcleo (SIMD) Multicomputadora de paso de mensajes y memoria compartida (ccnuma)
24 Sistemas computacionales La evolución de los procesadores gráficos independientes (la línea de desarrollo de nvidia) Kepler 7B trans RIVA 128 3M trans GeForce M trans GeForce 3 60M trans GeForce FX 125M trans GeForce M trans Fermi 3B trans
25 Sistemas computacionales Los procesadores gráficos, el camino (pipeline) de los gráficos
26 Sistemas computacionales La evolución de los procesadores gráficos Vertex Raster Pixel Raster Vertex Pixel 0 Pixel 1 Pixel 2 Blend Blend Pixel 3 Vrtx 1 Vrtx 0 Vrtx 2
27 Sistemas computacionales La evolución de los procesadores gráficos Control Control Control Control Control Control ALU ALU ALU ALU ALU ALU Control ALU ALU ALU ALU ALU ALU
28 Sistemas computacionales Los procesadores gráficos son bastante baratos
29 Sistemas computacionales AMD y nvidia tenían hasta ahora rendimientos similares (ej. Cálculo del orbital molecular del C 60 )
30 Sistemas computacionales La evolución de los procesadores gráficos, un clúster dentro del chip (nvidia Kepler K110 GF)
31 Sistemas computacionales La evolución de los procesadores gráficos, el multiprocesador de streaming
32 Sistemas computacionales un programa muy simple que si hace algo /* * Copyright NVIDIA Corporation. All rights reserved. * Modified by Rolando, rolando@cmbi.ru.nl */ #include <cuda.h> #include <stdio.h> global void add( int a, int b, int *c ) { *c = a + b; } int main( void ) { int c; int *dev_c; } cudamalloc( (void**)&dev_c, sizeof(int) ); add <<<1,1>>> ( 2, 7, dev_c ); cudamemcpy( &c, dev_c, sizeof( int ),cudamemcpydevicetohost ); printf( "2 + 7 = %d\n", c ); cudafree( dev_c ); return 0;
33 Sistemas computacionales Vamos a programar un procesador gráfico de nvidia con CUDA Cada kernel de CUDA es ejecutado por un arreglo de hilos - Cada hilo corre el mismo código (SIMD) - Cada hilo tiene un ID que se puede usar para calcular las direcciones de memoria y realizar decisiones de control threadid float x = input[threadid]; float y = func(x); output[threadid] = y;
34 Sistemas computacionales Vamos a programar un procesador gráfico de nvidia con CUDA El arreglo de hilos se distribuye en bloques - Los hilos dentro del bloque cooperan a través de memoria compartida, operaciones atómicas y sincronización de barrera - Los hilos de bloques diferentes no pueden cooperar entre si. Thread Block 0 Thread Block 1 Thread Block N - 1 threadid float x = input[threadid]; float y = func(x); output[threadid] = y; float x = input[threadid]; float y = func(x); output[threadid] = y; float x = input[threadid]; float y = func(x); output[threadid] = y;
35 Sistemas computacionales Vamos a programar un procesador gráfico de nvidia con CUDA Cada instancia tiene un ID - Block ID: 1D, 2D y ahora hasta 3D - Thread ID: 1D, 2D o 3D Host Kernel 1 Device Grid 1 Block (0, 0) Block (1, 0) Block (0, 1) Block (1, 1) Grid 2 Kernel 2 Block (1, 1) (0,0,1) (1,0,1) (2,0,1) (3,0,1) Thread (0,0,0) Thread (0,1,0) Thread Thread Thread (1,0,0) (2,0,0) (3,0,0) Thread Thread Thread (1,1,0) (2,1,0) (3,1,0)
36 Sistemas computacionales Vamos a programar un procesador gráfico de nvidia con CUDA Grid Bloque (0, 0) Bloque (1, 0) Memoria Compartida Memoria Compartida Registros Registros Registros Registros Hilo (0, 0) Hilo (1, 0) Hilo (0, 0) Hilo (1, 0) Host Memoria Global Memoria de Constantes Tipos de memoria
37 Sistemas computacionales Vamos a programar en paralelo Mi algoritmo puede ser paralelizable? Bueno yo no se, al final de todo es su algoritmo Puedo programar mi problema en paralelo? Generalmente si... Los métodos numéricos SI son paralelizables! Se están paralelizando para GPU la mayoría de los paquetes de cálculo numérico.
38 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto
39 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto
40 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto
41 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto
42 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto
43 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto
44 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto
45 Bibliotecas numéricas en el GPU un buen comienzo para su proyecto Factorización de Cholesky utilizando MAGMA
46 Conclusiones o algo parecido Los procesadores gráficos son una buena alternativa a los clústeres de computadoras, en prestaciones y coste. El código para los procesadores gráficos no es igual a los que se utilizan en los clústeres, pero no es difícil de portar una vez que ya se ha paralelizado. Existen numerosas bibliotecas numéricas disponibles para los procesadores gráficos que sustituyen directamente las funciones anteriormente existentes. El incremento de la velocidad de ejecución es siempre mas del doble sin mucho esfuerzo y puede llegar a miles de veces.
47 En todo el mundo.. Hay mas de 200 universidades que enseñan Programación Gráfica, Mas de artículos en la literatura, mas de desarrolladores
48 Mejoramiento de la conectividad ETECSA/CUBADATA, Empalme FO hasta Panorama
49 Muchas Gracias
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS
 GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)
![Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)](/thumbs/36/17576386.jpg "Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)") Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Arquitecturas GPU v. 2013
 v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
Arquitecturas de computadoras
 Arquitecturas de computadoras Colaboratorio Nacional de Computación Avanzada (CNCA) 2014 Contenidos 1 Computadoras 2 Estación de Trabajo 3 Servidor 4 Cluster 5 Malla 6 Nube 7 Conclusiones Computadoras
Arquitecturas de computadoras Colaboratorio Nacional de Computación Avanzada (CNCA) 2014 Contenidos 1 Computadoras 2 Estación de Trabajo 3 Servidor 4 Cluster 5 Malla 6 Nube 7 Conclusiones Computadoras
PRACTICA NO.24: CLUSTER
 PRACTICA NO.24: CLUSTER Jose Arturo Beltre Castro 2013-1734 ING. JOSE DOÑE Sistemas Operativos III Cluster El término clúster se aplica a los conjuntos o conglomerados de computadoras construidos mediante
PRACTICA NO.24: CLUSTER Jose Arturo Beltre Castro 2013-1734 ING. JOSE DOÑE Sistemas Operativos III Cluster El término clúster se aplica a los conjuntos o conglomerados de computadoras construidos mediante
Programando con memoria unificada. Contenidos [15 diapositivas] Aportaciones de la memoria unificada. I. Descripción
![Programando con memoria unificada. Contenidos [15 diapositivas] Aportaciones de la memoria unificada. I. Descripción](/thumbs/27/11245443.jpg "Programando con memoria unificada. Contenidos [15 diapositivas] Aportaciones de la memoria unificada. I. Descripción") Programando con memoria unificada IX Curso de Verano de la UMA Programación de GPUs con CUDA Contenidos [15 diapositivas] Málaga, del 15 al 24 de Julio, 2015 1. Descripción [5] 2. Ejemplos [8] 3. Observaciones
Programando con memoria unificada IX Curso de Verano de la UMA Programación de GPUs con CUDA Contenidos [15 diapositivas] Málaga, del 15 al 24 de Julio, 2015 1. Descripción [5] 2. Ejemplos [8] 3. Observaciones
Vielka Mari Utate Tineo 2013-1518. Instituto Tecnológico de las Américas ITLA. Profesor José Doñé PRATICA NO. 24, CLUSTER
 Vielka Mari Utate Tineo 2013-1518 Instituto Tecnológico de las Américas ITLA Profesor José Doñé PRATICA NO. 24, CLUSTER CREAR UN HOWTO CON EL PROCEDIMIENTO NECESARIO PARA LA IMPLEMENTACION DE CLUSTER DE
Vielka Mari Utate Tineo 2013-1518 Instituto Tecnológico de las Américas ITLA Profesor José Doñé PRATICA NO. 24, CLUSTER CREAR UN HOWTO CON EL PROCEDIMIENTO NECESARIO PARA LA IMPLEMENTACION DE CLUSTER DE
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Actividades de Divulgación del Centro Atómico Bariloche. Qué hay detrás de un programa de computadora? Daniela Arnica Pablo E. Argañaras.
 Actividades de Divulgación del Centro Atómico Bariloche Qué hay detrás de un programa de computadora? Expositores: Daniela Arnica Pablo E. Argañaras División Mecánica Computacional Gerencia de Investigación
Actividades de Divulgación del Centro Atómico Bariloche Qué hay detrás de un programa de computadora? Expositores: Daniela Arnica Pablo E. Argañaras División Mecánica Computacional Gerencia de Investigación
Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]
![Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]](/thumbs/27/10261315.jpg "Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]") Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
CLASIFICACION DE LAS COMPUTADORAS
 CLASIFICACION DE LAS COMPUTADORAS Tipos de Computadoras Dentro de la evolución de las computadoras, han surgido diferentes equipos con diferentes tamaños y características según su tipo de labor. Los computadores
CLASIFICACION DE LAS COMPUTADORAS Tipos de Computadoras Dentro de la evolución de las computadoras, han surgido diferentes equipos con diferentes tamaños y características según su tipo de labor. Los computadores
Nuevas tendencias: Virtualización de computadores / servidores
 Nuevas tendencias: Virtualización de computadores / servidores Expositor: Ing. José Wu Chong Laboratorio de Internetworking FIA DATA Agenda Qué es un servidor? Qué servicios hay en la red? Qué es Virtualización?
Nuevas tendencias: Virtualización de computadores / servidores Expositor: Ing. José Wu Chong Laboratorio de Internetworking FIA DATA Agenda Qué es un servidor? Qué servicios hay en la red? Qué es Virtualización?
Capítulo 5. Cliente-Servidor.
 Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
NTRODUCCION. "Tipos de Computadoras" Tipos de Computadoras
 NTRODUCCION Con el paso del tiempo y el avance de la tecnología se ha podido definir los tipos de computadoras que se usan actualmente, en este trabajo estudiaremos sus tipos y sus características, con
NTRODUCCION Con el paso del tiempo y el avance de la tecnología se ha podido definir los tipos de computadoras que se usan actualmente, en este trabajo estudiaremos sus tipos y sus características, con
CLUSTER FING: ARQUITECTURA Y APLICACIONES
 CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
CUDA Overview and Programming model
 Departamento de Ciencias de la computación Universidad de Chile Modelado en 3D y sus Aplicaciones en Realidad Virtual CC68W CUDA Overview and Programming model Student: Juan Silva Professor: Dr. Wolfram
Departamento de Ciencias de la computación Universidad de Chile Modelado en 3D y sus Aplicaciones en Realidad Virtual CC68W CUDA Overview and Programming model Student: Juan Silva Professor: Dr. Wolfram
UAEM 2015, Estado de México
 CONSTRUCCIÓN DE CLUSTERS Fernando Robles Morales Ins/tuto Nacional de Medicina Genómica Enrique Cruz Mar
CONSTRUCCIÓN DE CLUSTERS Fernando Robles Morales Ins/tuto Nacional de Medicina Genómica Enrique Cruz Mar
Proyecto Human Brain
 Proyecto Human Brain 2013 Human Brain Project Laboratorio Cajal de Circuitos Corticales (UPM-CSIC) Universidad Politécnica de Madrid El SP11 representa el primer paso hacia la consecución de los ambiciosos
Proyecto Human Brain 2013 Human Brain Project Laboratorio Cajal de Circuitos Corticales (UPM-CSIC) Universidad Politécnica de Madrid El SP11 representa el primer paso hacia la consecución de los ambiciosos
GANETEC SOLUTIONS HPC Farmacéuticas
 GANETEC SOLUTIONS HPC Farmacéuticas La integración de tecnologías HPC en el sector Farmacéutico y de la Bioinformática ha permitido grandes avances en diversos campos. NUESTRA VISIÓN Estas nuevas posibilidades
GANETEC SOLUTIONS HPC Farmacéuticas La integración de tecnologías HPC en el sector Farmacéutico y de la Bioinformática ha permitido grandes avances en diversos campos. NUESTRA VISIÓN Estas nuevas posibilidades
15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores.
 UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
Introducción Componentes Básicos Concurrencia y Paralelismo Ejemplos Síntesis Lecturas Recomendadas. Arquitectura de Computadoras
 Arquitectura de Computadoras Contenidos 1 Introducción Computadora Arquitectura Partes de una arquitectura 2 Componentes Básicos CPU Jerarquía de Memoria 3 Concurrencia y Paralelismo Arquitecturas concurrentes
Arquitectura de Computadoras Contenidos 1 Introducción Computadora Arquitectura Partes de una arquitectura 2 Componentes Básicos CPU Jerarquía de Memoria 3 Concurrencia y Paralelismo Arquitecturas concurrentes
Preliminares. Tipos de variables y Expresiones
 Preliminares. Tipos de variables y Expresiones Felipe Osorio Instituto de Estadística Pontificia Universidad Católica de Valparaíso Marzo 5, 2015 1 / 20 Preliminares Computadoras desarrollan tareas a un
Preliminares. Tipos de variables y Expresiones Felipe Osorio Instituto de Estadística Pontificia Universidad Católica de Valparaíso Marzo 5, 2015 1 / 20 Preliminares Computadoras desarrollan tareas a un
Análisis de aplicación: Moon Secure AV
 Análisis de aplicación: Moon Secure AV Este documento ha sido elaborado por el Centro de excelencia de software libre de Castilla La Mancha (Ceslcam, http://ceslcam.com). Copyright 2010, Junta de Comunidades
Análisis de aplicación: Moon Secure AV Este documento ha sido elaborado por el Centro de excelencia de software libre de Castilla La Mancha (Ceslcam, http://ceslcam.com). Copyright 2010, Junta de Comunidades
Software de Simulación aplicado a entornos de e-learning
 Software de Simulación aplicado a entornos de e-learning 2009 Laboratorio de Investigación de Software Universidad Tecnológica Nacional Facultad Regional Córdoba Titulo del Proyecto Software de Simulación
Software de Simulación aplicado a entornos de e-learning 2009 Laboratorio de Investigación de Software Universidad Tecnológica Nacional Facultad Regional Córdoba Titulo del Proyecto Software de Simulación
Análisis de aplicación: Scribus
 Análisis de aplicación: Scribus Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este
Análisis de aplicación: Scribus Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este
Procesador Intel Core 2 Extreme de 4 núcleos Traducción de Textos Curso 2007/2008
 Procesador Intel Core 2 Traducción de Textos Curso 2007/2008 Versión Cambio 0.9RC Revisión del texto 0.8 Traducido el octavo párrafo 0.7 Traducido el séptimo párrafo Autor: Rubén Paje del Pino i010328
Procesador Intel Core 2 Traducción de Textos Curso 2007/2008 Versión Cambio 0.9RC Revisión del texto 0.8 Traducido el octavo párrafo 0.7 Traducido el séptimo párrafo Autor: Rubén Paje del Pino i010328
Análisis de aplicación: Xen
 Análisis de aplicación: Xen Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este documento
Análisis de aplicación: Xen Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este documento
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA
 CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
Análisis de aplicación: Virtual Machine Manager
 Análisis de aplicación: Virtual Machine Manager Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla
Análisis de aplicación: Virtual Machine Manager Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla
Análisis de aplicación: TightVNC
 Análisis de aplicación: TightVNC Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este
Análisis de aplicación: TightVNC Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este
Supercómputo. Oscar Rafael García Regis Enrique Cruz Martínez
 Supercómputo Oscar Rafael García Regis Enrique Cruz Martínez 2003-I Oscar Rafael García Regis Laboratorio de Dinámica No Lineal Facultad de Ciencias, UNAM Enrique Cruz Martínez Dirección General de Servicios
Supercómputo Oscar Rafael García Regis Enrique Cruz Martínez 2003-I Oscar Rafael García Regis Laboratorio de Dinámica No Lineal Facultad de Ciencias, UNAM Enrique Cruz Martínez Dirección General de Servicios
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK. www.formacionhadoop.com
 CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
INTRODUCCIÓN: LA FÍSICA Y SU LENGUAJE, LAS MATEMÁTICAS
 INTRODUCCIÓN: LA FÍSICA Y SU LENGUAJE, LAS MATEMÁTICAS La física es la más fundamental de las ciencias que tratan de estudiar la naturaleza. Esta ciencia estudia aspectos tan básicos como el movimiento,
INTRODUCCIÓN: LA FÍSICA Y SU LENGUAJE, LAS MATEMÁTICAS La física es la más fundamental de las ciencias que tratan de estudiar la naturaleza. Esta ciencia estudia aspectos tan básicos como el movimiento,
Análisis de aplicación: Vinagre
 Análisis de aplicación: Vinagre Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este
Análisis de aplicación: Vinagre Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla La Mancha. Este
SEMINARIO PRÁCTICO Cómo elegir el sistema de cálculo científico ideal para mi investigación. Raúl Díaz rdiaz@sie.es
 ORGANIZA SEMINARIO PRÁCTICO Cómo elegir el sistema de cálculo científico ideal para mi investigación Raúl Díaz rdiaz@sie.es 1ª CUESTIÓN Necesito un sistema HPC? Si mi cálculo supera las 8 horas, un equipo
ORGANIZA SEMINARIO PRÁCTICO Cómo elegir el sistema de cálculo científico ideal para mi investigación Raúl Díaz rdiaz@sie.es 1ª CUESTIÓN Necesito un sistema HPC? Si mi cálculo supera las 8 horas, un equipo
Descomposición de dominios
 Descomposición de dominios Miguel Vargas 27/10/10 1/29 Contenido Contenido Solución de ecuaciones diferenciales con descomposición de dominios Dominios sin traslape, complemento de Schur Método alternante
Descomposición de dominios Miguel Vargas 27/10/10 1/29 Contenido Contenido Solución de ecuaciones diferenciales con descomposición de dominios Dominios sin traslape, complemento de Schur Método alternante
Tipos de computadoras
 Tipos de computadoras Tú necesitas saber la estructura física que posee cada computadora Los componentes esenciales de una computadora Qué vas a aprender en este módulo: Las distintas clasificaciones bajo
Tipos de computadoras Tú necesitas saber la estructura física que posee cada computadora Los componentes esenciales de una computadora Qué vas a aprender en este módulo: Las distintas clasificaciones bajo
Interoperabilidad de Fieldbus
 2002 Emerson Process Management. Todos los derechos reservados. Vea este y otros cursos en línea en www.plantwebuniversity.com. Fieldbus 201 Interoperabilidad de Fieldbus Generalidades Qué es interoperabilidad?
2002 Emerson Process Management. Todos los derechos reservados. Vea este y otros cursos en línea en www.plantwebuniversity.com. Fieldbus 201 Interoperabilidad de Fieldbus Generalidades Qué es interoperabilidad?
computadoras que tienen este servicio instalado se pueden publicar páginas web tanto local como remotamente.
 Investigar Qué es un IIS? Internet Information Services o IIS es un servidor web y un conjunto de servicios para el sistema operativo Microsoft Windows. Originalmente era parte del Option Pack para Windows
Investigar Qué es un IIS? Internet Information Services o IIS es un servidor web y un conjunto de servicios para el sistema operativo Microsoft Windows. Originalmente era parte del Option Pack para Windows
Mineria de Grafos en Redes Sociales usando MapReduce
 Mineria de Grafos en Redes Sociales usando MapReduce Jose Gamez 1 and Jorge Pilozo 1 Carrera de Ingeniería en Sistemas Computacionales Universidad de Guayaquil 1. Introduccion a la Problematica Recordemos
Mineria de Grafos en Redes Sociales usando MapReduce Jose Gamez 1 and Jorge Pilozo 1 Carrera de Ingeniería en Sistemas Computacionales Universidad de Guayaquil 1. Introduccion a la Problematica Recordemos
COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX
 COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX En este manual se presenta el proceso de configuración de una Maquina Virtual en VirtualBox, que será utilizada para instalar un Servidor
COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX En este manual se presenta el proceso de configuración de una Maquina Virtual en VirtualBox, que será utilizada para instalar un Servidor
Soluciones para entornos HPC
 Dr.. IT Manager / Project Leader @ CETA-Ciemat abelfrancisco.paz@ciemat.es V Jornadas de Supercomputación y Avances en Tecnología INDICE 1 2 3 4 HPC Qué? Cómo?..................... Computación (GPGPU,
Dr.. IT Manager / Project Leader @ CETA-Ciemat abelfrancisco.paz@ciemat.es V Jornadas de Supercomputación y Avances en Tecnología INDICE 1 2 3 4 HPC Qué? Cómo?..................... Computación (GPGPU,
High Performance Computing and Architectures Group
 HPCA Group 1 High Performance Computing and Architectures Group http://www.hpca.uji.es Universidad Jaime I de Castellón ANACAP, noviembre de 2008 HPCA Group 2 Generalidades Creado en 1991, al mismo tiempo
HPCA Group 1 High Performance Computing and Architectures Group http://www.hpca.uji.es Universidad Jaime I de Castellón ANACAP, noviembre de 2008 HPCA Group 2 Generalidades Creado en 1991, al mismo tiempo
Entender el funcionamiento de los relojes permitiría lidiar con ciertas patologías en humanos. 28 ACTUALIDAD EN I+D RIA / Vol. 41 / N.
 28 ACTUALIDAD EN I+D RIA / Vol. 41 / N.º 1 Entender el funcionamiento de los relojes permitiría lidiar con ciertas patologías en humanos Abril 2015, Argentina 29 Relojes biológicos en plantas Ajustar el
28 ACTUALIDAD EN I+D RIA / Vol. 41 / N.º 1 Entender el funcionamiento de los relojes permitiría lidiar con ciertas patologías en humanos Abril 2015, Argentina 29 Relojes biológicos en plantas Ajustar el
Práctica de laboratorio: Construcción de una topología lógica e identificar Patrón de comunicación Unicast y Broadcast
 CCNA Discovery Networking para el hogar y pequeñas empresas Práctica de laboratorio: Construcción de una topología lógica e identificar Patrón de comunicación Unicast y Broadcast Objetivos Construir una
CCNA Discovery Networking para el hogar y pequeñas empresas Práctica de laboratorio: Construcción de una topología lógica e identificar Patrón de comunicación Unicast y Broadcast Objetivos Construir una
Benemérita Universidad Autónoma del Estado de Puebla
 Benemérita Universidad Autónoma del Estado de Puebla Facultad de Cs. De la Computación Programación Concurrente y Paralela Práctica de Laboratorio No. 4 Profr: María del Carmen Cerón Garnica Alumno: Roberto
Benemérita Universidad Autónoma del Estado de Puebla Facultad de Cs. De la Computación Programación Concurrente y Paralela Práctica de Laboratorio No. 4 Profr: María del Carmen Cerón Garnica Alumno: Roberto
Aprendiendo con las redes sociales
 DHTIC Aprendiendo con las redes sociales Benemérita Universidad Autónoma de Puebla Silvia Arellano Romero [Seleccione la fecha] Índice Introducción La educación es la formación destinada a desarrollar
DHTIC Aprendiendo con las redes sociales Benemérita Universidad Autónoma de Puebla Silvia Arellano Romero [Seleccione la fecha] Índice Introducción La educación es la formación destinada a desarrollar
Análisis y evaluación del sistema de separación y recuperación de gas y condensados amargos del CPTG Atasta
 Foro Consultivo Científico y Tecnológico 3º Seminario Regional sobre Desarrollo de la Competitividad con base en el Conocimiento Región Sur-Sureste Análisis y evaluación del sistema de separación y recuperación
Foro Consultivo Científico y Tecnológico 3º Seminario Regional sobre Desarrollo de la Competitividad con base en el Conocimiento Región Sur-Sureste Análisis y evaluación del sistema de separación y recuperación
UNIVERSIDAD DE ORIENTE FACULTAD DE ICIENCIAS ECONOMICAS LAS REDES I. Licda. Consuelo Eleticia Sandoval
 UNIVERSIDAD DE ORIENTE FACULTAD DE ICIENCIAS ECONOMICAS LAS REDES I Licda. Consuelo Eleticia Sandoval OBJETIVO: ANALIZAR LAS VENTAJAS Y DESVENTAJAS DE LAS REDES DE COMPUTADORAS. Que es una red de computadoras?
UNIVERSIDAD DE ORIENTE FACULTAD DE ICIENCIAS ECONOMICAS LAS REDES I Licda. Consuelo Eleticia Sandoval OBJETIVO: ANALIZAR LAS VENTAJAS Y DESVENTAJAS DE LAS REDES DE COMPUTADORAS. Que es una red de computadoras?
Manual instalación Windows 8. Instalar Windows 8 paso a paso
 Manual instalación Windows 8. Instalar Windows 8 paso a paso Windows 8 es el nuevo sistema operativo de Microsoft, en el cual se han incluido más de 100.000 cambios en el código del sistema operativo,
Manual instalación Windows 8. Instalar Windows 8 paso a paso Windows 8 es el nuevo sistema operativo de Microsoft, en el cual se han incluido más de 100.000 cambios en el código del sistema operativo,
UNIDAD 1. LOS NÚMEROS ENTEROS.
 UNIDAD 1. LOS NÚMEROS ENTEROS. Al final deberás haber aprendido... Interpretar y expresar números enteros. Representar números enteros en la recta numérica. Comparar y ordenar números enteros. Realizar
UNIDAD 1. LOS NÚMEROS ENTEROS. Al final deberás haber aprendido... Interpretar y expresar números enteros. Representar números enteros en la recta numérica. Comparar y ordenar números enteros. Realizar
CLASIFICACIÓN DE LAS COMPUTADORAS. Ing. Erlinda Gutierrez Poma
 CLASIFICACIÓN DE LAS COMPUTADORAS Ing. Erlinda Gutierrez Poma Tipos de Computadoras Dentro de la evolución de las computadoras, han surgido diferentes equipos con diferentes tamaños y características según
CLASIFICACIÓN DE LAS COMPUTADORAS Ing. Erlinda Gutierrez Poma Tipos de Computadoras Dentro de la evolución de las computadoras, han surgido diferentes equipos con diferentes tamaños y características según
Benemérita Universidad Autónoma del Estado de Puebla
 Benemérita Universidad Autónoma del Estado de Puebla Facultad de Cs. De la Computación Programación Concurrente y Paralela Práctica de Laboratorio No. 5 Profr: María del Carmen Cerón Garnica Alumno: Roberto
Benemérita Universidad Autónoma del Estado de Puebla Facultad de Cs. De la Computación Programación Concurrente y Paralela Práctica de Laboratorio No. 5 Profr: María del Carmen Cerón Garnica Alumno: Roberto
Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011
 Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Heterogénea y Jerárquica
 Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
SIMULACIÓN SIMULACIÓN DE UN JUEGO DE VOLADOS
 UNIVERSIDAD NACIONAL DE INGENIERIA RECINTO UNIVERSITARIO SIMON BOLIVAR FACULTAD DE ELECTROTECNIA Y COMPUTACIÓN INGENIERIA EN COMPUTACIÓN SIMULACIÓN SIMULACIÓN DE UN JUEGO DE VOLADOS Integrantes: Walter
UNIVERSIDAD NACIONAL DE INGENIERIA RECINTO UNIVERSITARIO SIMON BOLIVAR FACULTAD DE ELECTROTECNIA Y COMPUTACIÓN INGENIERIA EN COMPUTACIÓN SIMULACIÓN SIMULACIÓN DE UN JUEGO DE VOLADOS Integrantes: Walter
Nuevos Servicios WAP
 Nuevos Servicios WAP WAP es un protocolo basado en los estándares de Internet que ha sido desarrollado para permitir a teléfonos celulares navegar a través de Internet. Con la tecnología WAP se pretende
Nuevos Servicios WAP WAP es un protocolo basado en los estándares de Internet que ha sido desarrollado para permitir a teléfonos celulares navegar a través de Internet. Con la tecnología WAP se pretende
Orbitales híbridos. Cajón de Ciencias
 Orbitales híbridos Cajón de Ciencias Los orbitales híbridos son aquellos que se forman por la fusión de otros orbitales. Estudiarlos es un paso básico para entender la geometría y la estructura de las
Orbitales híbridos Cajón de Ciencias Los orbitales híbridos son aquellos que se forman por la fusión de otros orbitales. Estudiarlos es un paso básico para entender la geometría y la estructura de las
Almacenamiento virtual de sitios web HOSTS VIRTUALES
 Almacenamiento virtual de sitios web HOSTS VIRTUALES El término Hosting Virtual se refiere a hacer funcionar más de un sitio web (tales como www.company1.com y www.company2.com) en una sola máquina. Los
Almacenamiento virtual de sitios web HOSTS VIRTUALES El término Hosting Virtual se refiere a hacer funcionar más de un sitio web (tales como www.company1.com y www.company2.com) en una sola máquina. Los
1. INTRODUCCIÓN 1.1 INGENIERÍA
 1. INTRODUCCIÓN 1.1 INGENIERÍA Es difícil dar una explicación de ingeniería en pocas palabras, pues se puede decir que la ingeniería comenzó con el hombre mismo, pero se puede intentar dar un bosquejo
1. INTRODUCCIÓN 1.1 INGENIERÍA Es difícil dar una explicación de ingeniería en pocas palabras, pues se puede decir que la ingeniería comenzó con el hombre mismo, pero se puede intentar dar un bosquejo
Plataformas paralelas
 Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
LAS TIC. Cintyha Lizbeth Gómez Salazar. Lic. Cruz Jorge Fernández Aramburo. 0 1 / 0 8 / 2 0 1 3
 LAS TIC. Cintyha Lizbeth Gómez Salazar. Lic. Cruz Jorge Fernández Aramburo. PREESCOLAR. 0 1 / 0 8 / 2 0 1 3 INTRODUCCIÓN. Actualmente curso la Lic. En preescolar en la escuela normal Carlos A. Carrillo
LAS TIC. Cintyha Lizbeth Gómez Salazar. Lic. Cruz Jorge Fernández Aramburo. PREESCOLAR. 0 1 / 0 8 / 2 0 1 3 INTRODUCCIÓN. Actualmente curso la Lic. En preescolar en la escuela normal Carlos A. Carrillo
Lab 05: Redes Inalámbricas
 UNIVERSIDAD NACIONAL DE SAN ANTONIO ABAD DEL CUSCO Departamento Académico de Informática REDES Y TELECOMUNICACIONES I Lab 05: Redes Inalámbricas Ingº Manuel Peñaloza Figueroa Dime y lo olvidaré. Muéstrame
UNIVERSIDAD NACIONAL DE SAN ANTONIO ABAD DEL CUSCO Departamento Académico de Informática REDES Y TELECOMUNICACIONES I Lab 05: Redes Inalámbricas Ingº Manuel Peñaloza Figueroa Dime y lo olvidaré. Muéstrame
SEDO: SOFTWARE EDUCATIVO DE MATEMÁTICA NUMÉRICA. Lic. Maikel León Espinosa. mle@uclv.edu.cu
 EDU082 Resumen SEDO: SOFTWARE EDUCATIVO DE MATEMÁTICA NUMÉRICA Lic. Maikel León Espinosa mle@uclv.edu.cu Departamento de Ciencia de la Computación Universidad Central Marta Abreu de Las Villas Carretera
EDU082 Resumen SEDO: SOFTWARE EDUCATIVO DE MATEMÁTICA NUMÉRICA Lic. Maikel León Espinosa mle@uclv.edu.cu Departamento de Ciencia de la Computación Universidad Central Marta Abreu de Las Villas Carretera
El universo en la palma de tu mano. www.dialogaquilt.com. El software de gestión para organizaciones políticas e instituciones
 El universo en la palma de tu mano www.dialogaquilt.com El software de gestión para organizaciones políticas e instituciones Quiénes somos? Dialoga es una empresa constituida por un equipo humano con un
El universo en la palma de tu mano www.dialogaquilt.com El software de gestión para organizaciones políticas e instituciones Quiénes somos? Dialoga es una empresa constituida por un equipo humano con un
Procesadores Gráficos: OpenCL para programadores de CUDA
 Procesadores Gráficos: para programadores de CUDA Curso 2011/12 David Miraut david.miraut@urjc.es Universidad Rey Juan Carlos April 24, 2013 Indice Estándar Modelo de de El lenguaje programa de Inicialización
Procesadores Gráficos: para programadores de CUDA Curso 2011/12 David Miraut david.miraut@urjc.es Universidad Rey Juan Carlos April 24, 2013 Indice Estándar Modelo de de El lenguaje programa de Inicialización
Direcciones IP y máscaras de red
 También en este nivel tenemos una serie de protocolos que se encargan de la resolución de direcciones: ARP (Address Resolution Protocol): cuando una maquina desea ponerse en contacto con otra conoce su
También en este nivel tenemos una serie de protocolos que se encargan de la resolución de direcciones: ARP (Address Resolution Protocol): cuando una maquina desea ponerse en contacto con otra conoce su
Asignación de Procesadores
 INTEGRANTES: Asignación de Procesadores Un sistema distribuido consta de varios procesadores. Estos se pueden organizar como colección de estaciones de trabajo personales, una pila pública de procesadores
INTEGRANTES: Asignación de Procesadores Un sistema distribuido consta de varios procesadores. Estos se pueden organizar como colección de estaciones de trabajo personales, una pila pública de procesadores
Seminario II: Introducción a la Computación GPU
 Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
Workflows? Sí, cuántos quiere?
 Workflows? Sí, cuántos quiere? 12.11.2006 Servicios Profesionales Danysoft Son notables los beneficios que una organización puede obtener gracias al soporte de procesos de negocios que requieran la intervención
Workflows? Sí, cuántos quiere? 12.11.2006 Servicios Profesionales Danysoft Son notables los beneficios que una organización puede obtener gracias al soporte de procesos de negocios que requieran la intervención
Equipamiento disponible
 PCI 00 Acción Preparatoria Computación Avanzada en Aplicaciones Biomédicas CaaB (High Performance Computing applied to Life Sciences) Equipamiento disponible Participantes Universidad de Málaga, España
PCI 00 Acción Preparatoria Computación Avanzada en Aplicaciones Biomédicas CaaB (High Performance Computing applied to Life Sciences) Equipamiento disponible Participantes Universidad de Málaga, España
Tema: Historia de los Microprocesadores
 Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Historia de los Microprocesadores 1 Contenidos La década de los
Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Historia de los Microprocesadores 1 Contenidos La década de los
 Qué se entiende por diseño arquitectónico? Comprende el establecimiento de un marco de trabajo estructural básico para un sistema. Alude a la estructura general del software y el modo en que la estructura
Qué se entiende por diseño arquitectónico? Comprende el establecimiento de un marco de trabajo estructural básico para un sistema. Alude a la estructura general del software y el modo en que la estructura
Guía de uso del Cloud Datacenter de acens
 guíasdeuso Guía de uso del Cloud Datacenter de Calle San Rafael, 14 28108 Alcobendas (Madrid) 902 90 10 20 www..com Introducción Un Data Center o centro de datos físico es un espacio utilizado para alojar
guíasdeuso Guía de uso del Cloud Datacenter de Calle San Rafael, 14 28108 Alcobendas (Madrid) 902 90 10 20 www..com Introducción Un Data Center o centro de datos físico es un espacio utilizado para alojar
Los mayores cambios se dieron en las décadas de los setenta, atribuidos principalmente a dos causas:
 SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
UNIVERSIDAD CARLOS III DE MADRID DEPARTAMENTO DE INFORMÁTICA INGENIERÍA EN INFORMÁTICA. ARQUITECTURA DE COMPUTADORES II 19 de junio de 2007
 UNIVERSIDAD CARLOS III DE MADRID DEPARTAMENTO DE INFORMÁTICA INGENIERÍA EN INFORMÁTICA. ARQUITECTURA DE COMPUTADORES II 19 de junio de 2007 Para la realización del presente examen se dispondrá de 2 1/2
UNIVERSIDAD CARLOS III DE MADRID DEPARTAMENTO DE INFORMÁTICA INGENIERÍA EN INFORMÁTICA. ARQUITECTURA DE COMPUTADORES II 19 de junio de 2007 Para la realización del presente examen se dispondrá de 2 1/2
Técnicas SuperEscalares en la Paralelización de Bibliotecas de Computación Matricial sobre Procesadores Multinúcleo y GPUs
 Técnicas SuperEscalares en la Paralelización de Bibliotecas de Computación Matricial sobre Procesadores Multinúcleo y GPUs Enrique S. Quintana-Ortí quintana@icc.uji.es High Performance Computing & Architectures
Técnicas SuperEscalares en la Paralelización de Bibliotecas de Computación Matricial sobre Procesadores Multinúcleo y GPUs Enrique S. Quintana-Ortí quintana@icc.uji.es High Performance Computing & Architectures
Sensor de Temperatura utilizando el Starter Kit Javelin Stamp. Realizado por: Bertha Palomeque A. Rodrigo Barzola J.
 Sensor de Temperatura utilizando el Starter Kit Javelin Stamp Realizado por: Bertha Palomeque A. Rodrigo Barzola J. INTRODUCCION DIFERENCIAS EJEMPLOS JAVA Orientado a Objetos Multiplataforma Programar
Sensor de Temperatura utilizando el Starter Kit Javelin Stamp Realizado por: Bertha Palomeque A. Rodrigo Barzola J. INTRODUCCION DIFERENCIAS EJEMPLOS JAVA Orientado a Objetos Multiplataforma Programar
Talleres CLCAR. CUDA para principiantes. Título. Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.
 a CUDA para principiantes Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.com Tener un primer encuentro práctico con la programación en CUDA para personas
a CUDA para principiantes Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.com Tener un primer encuentro práctico con la programación en CUDA para personas
PCI 2010 Acción Preparatoria. Computación Avanzada en Aplicaciones Biomédicas. (High Performance Computing applied to Life Sciences)
") PCI 2010 Acción Preparatoria Computación Avanzada en Aplicaciones Biomédicas CaaB (High Performance Computing applied to Life Sciences) Descripción general Participantes Universidad de Málaga, España CIEMAT,
PCI 2010 Acción Preparatoria Computación Avanzada en Aplicaciones Biomédicas CaaB (High Performance Computing applied to Life Sciences) Descripción general Participantes Universidad de Málaga, España CIEMAT,
Colección de Tesis Digitales Universidad de las Américas Puebla. Morales Salcedo, Raúl
 1 Colección de Tesis Digitales Universidad de las Américas Puebla Morales Salcedo, Raúl En este último capitulo se hace un recuento de los logros alcanzados durante la elaboración de este proyecto de tesis,
1 Colección de Tesis Digitales Universidad de las Américas Puebla Morales Salcedo, Raúl En este último capitulo se hace un recuento de los logros alcanzados durante la elaboración de este proyecto de tesis,
CAPÍTULO 7 7. CONCLUSIONES
 CAPÍTULO 7 7. CONCLUSIONES 7.1. INTRODUCCIÓN 7.2. CONCLUSIONES PARTICULARES 7.3. CONCLUSIONES GENERALES 7.4. APORTACIONES DEL TRABAJO DE TESIS 7.5. PROPUESTA DE TRABAJOS FUTUROS 197 CAPÍTULO 7 7. Conclusiones
CAPÍTULO 7 7. CONCLUSIONES 7.1. INTRODUCCIÓN 7.2. CONCLUSIONES PARTICULARES 7.3. CONCLUSIONES GENERALES 7.4. APORTACIONES DEL TRABAJO DE TESIS 7.5. PROPUESTA DE TRABAJOS FUTUROS 197 CAPÍTULO 7 7. Conclusiones
Artículo Técnico: Análisis de las configuraciones de los sistemas híbridos fotovoltaicos.
 GRUPO DE SISTEMAS ELECTRÓNICOS DE POTENCIA (GSEP) LABORATORIO DE SISTEMAS FOTOVOLTAICOS (UC3M PV-Lab) Generaciones Fotovoltaicas de La Mancha División Fotovoltaica Artículo Técnico: Análisis de las configuraciones
GRUPO DE SISTEMAS ELECTRÓNICOS DE POTENCIA (GSEP) LABORATORIO DE SISTEMAS FOTOVOLTAICOS (UC3M PV-Lab) Generaciones Fotovoltaicas de La Mancha División Fotovoltaica Artículo Técnico: Análisis de las configuraciones
En caso de que el cliente nunca haya obtenido una concesión de licencia de un servidor DHCP:
 Servidor DHCP El protocolo de configuración dinámica de host (DHCP, Dynamic Host Configuration Protocol) es un estándar TCP/IP diseñado para simplificar la administración de la configuración IP de los
Servidor DHCP El protocolo de configuración dinámica de host (DHCP, Dynamic Host Configuration Protocol) es un estándar TCP/IP diseñado para simplificar la administración de la configuración IP de los
Tecnologías en la Educación Matemática. Expresiones. Datos. Expresiones Aritméticas. Expresiones Aritméticas 19/08/2014
 Tecnologías en la Educación Matemática jac@cs.uns.edu.ar Dpto. de Ciencias e Ingeniería de la Computación UNIVERSIDAD NACIONAL DEL SUR 1 Datos Los algoritmos combinan datos con acciones. Los datos de entrada
Tecnologías en la Educación Matemática jac@cs.uns.edu.ar Dpto. de Ciencias e Ingeniería de la Computación UNIVERSIDAD NACIONAL DEL SUR 1 Datos Los algoritmos combinan datos con acciones. Los datos de entrada
RBAC4WFSYS: Modelo de Acceso para Sistemas Workflow basado en RBAC
 RBAC4WFSYS: Modelo de Acceso para Sistemas Workflow basado en RBAC Proyecto Integrador de Tecnologías Computacionales Autor: Roberto García :: A00888485 Director: Jorge A. Torres Jiménez Contenido Introducción
RBAC4WFSYS: Modelo de Acceso para Sistemas Workflow basado en RBAC Proyecto Integrador de Tecnologías Computacionales Autor: Roberto García :: A00888485 Director: Jorge A. Torres Jiménez Contenido Introducción
Administración del conocimiento y aprendizaje organizacional.
 Capítulo 2 Administración del conocimiento y aprendizaje organizacional. 2.1 La Importancia Del Aprendizaje En Las Organizaciones El aprendizaje ha sido una de las grandes necesidades básicas del ser humano,
Capítulo 2 Administración del conocimiento y aprendizaje organizacional. 2.1 La Importancia Del Aprendizaje En Las Organizaciones El aprendizaje ha sido una de las grandes necesidades básicas del ser humano,
colegio de bachilleres de Chiapas plantel 56 catedrático: Jorge Roberto Nery Gonzales materia: hojas de calculo
 colegio de bachilleres de Chiapas plantel 56 catedrático: Jorge Roberto Nery Gonzales materia: hojas de calculo nombre del alumno: María Gladis Domínguez Domínguez grado : 5-to semestre grupo: c trabajo:
colegio de bachilleres de Chiapas plantel 56 catedrático: Jorge Roberto Nery Gonzales materia: hojas de calculo nombre del alumno: María Gladis Domínguez Domínguez grado : 5-to semestre grupo: c trabajo:
Introducción al Capacity planning para servicios
 Gestión y Planificación de Redes y Servicios Introducción al Capacity planning para servicios Area de Ingeniería Telemática http://www.tlm.unavarra.es Grado en Ingeniería en Tecnologías de Telecomunicación,
Gestión y Planificación de Redes y Servicios Introducción al Capacity planning para servicios Area de Ingeniería Telemática http://www.tlm.unavarra.es Grado en Ingeniería en Tecnologías de Telecomunicación,
Tema 1 Introducción. Arquitectura básica y Sistemas Operativos. Fundamentos de Informática
 Tema 1 Introducción. Arquitectura básica y Sistemas Operativos Fundamentos de Informática Índice Descripción de un ordenador Concepto básico de Sistema Operativo Codificación de la información 2 1 Descripción
Tema 1 Introducción. Arquitectura básica y Sistemas Operativos Fundamentos de Informática Índice Descripción de un ordenador Concepto básico de Sistema Operativo Codificación de la información 2 1 Descripción
www.gtbi.net soluciones en Fotogrametría Digital El software de análisis más potente basado en objetos de datos geoespaciales. Fotogrametría Digital
 soluciones en Fotogrametría Digital El software de análisis más potente basado en objetos de datos geoespaciales. Fotogrametría Digital www.gtbi.net LA MANERA DE ENTENDER EL MUNDO ESTÁ CAMBIANDO El usuario
soluciones en Fotogrametría Digital El software de análisis más potente basado en objetos de datos geoespaciales. Fotogrametría Digital www.gtbi.net LA MANERA DE ENTENDER EL MUNDO ESTÁ CAMBIANDO El usuario
El procesador. (mrebollo@dsic.upv.es) Sistemas Informáticos y Computación. Facultad de Administración y Dirección de Empresas
 Sistemas Informáticos y Computación. Facultad de Administración y Dirección de Empresas") El procesador Apellidos, Nombre Departamento Centro Rebollo Pedruelo, Miguel (mrebollo@dsic.upv.es) Sistemas Informáticos y Computación Facultad de Administración y Dirección de Empresas 1. Resumen El
El procesador Apellidos, Nombre Departamento Centro Rebollo Pedruelo, Miguel (mrebollo@dsic.upv.es) Sistemas Informáticos y Computación Facultad de Administración y Dirección de Empresas 1. Resumen El
Clases y Objetos. Informática II Ingeniería Electrónica
 Clases y Objetos Informática II Ingeniería Electrónica Los Tipos de Datos Hasta ahora, en un programa podemos usar para representar variables a: Tipos fundamentales : enteros (int), caracteres (char),
Clases y Objetos Informática II Ingeniería Electrónica Los Tipos de Datos Hasta ahora, en un programa podemos usar para representar variables a: Tipos fundamentales : enteros (int), caracteres (char),
 1 ÍNDICE... 3 Instalación... 4 Proceso de instalación en red... 6 Solicitud de Código de Activación... 11 Activación de Licencia... 14 2 3 REQUERIMIENTOS TÉCNICOS E INSTALACIÓN Requerimientos Técnicos
1 ÍNDICE... 3 Instalación... 4 Proceso de instalación en red... 6 Solicitud de Código de Activación... 11 Activación de Licencia... 14 2 3 REQUERIMIENTOS TÉCNICOS E INSTALACIÓN Requerimientos Técnicos
Introducción a las redes de computadores
 Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Luis Eduardo Peralta Molina Sistemas Operativos Instructor: José Doñe 2010-2940. Como crear un Servidor DHCP en ClearOS
 Servidores DHCP Como crear un Servidor DHCP en ClearOS Dynamic Host Configuration Protocol (DHCP) Protocolo de Configuracion Dinamica de Host, es un protocolo de Red que asigna automaticamente informacion
Servidores DHCP Como crear un Servidor DHCP en ClearOS Dynamic Host Configuration Protocol (DHCP) Protocolo de Configuracion Dinamica de Host, es un protocolo de Red que asigna automaticamente informacion
BPMN Business Process Modeling Notation
 BPMN (BPMN) es una notación gráfica que describe la lógica de los pasos de un proceso de Negocio. Esta notación ha sido especialmente diseñada para coordinar la secuencia de los procesos y los mensajes
BPMN (BPMN) es una notación gráfica que describe la lógica de los pasos de un proceso de Negocio. Esta notación ha sido especialmente diseñada para coordinar la secuencia de los procesos y los mensajes