Aprendizaje Supervisado Árboles de Decisión
|
|
|
- Virginia Tebar Villalba
- hace 7 años
- Vistas:
Transcripción
1 Aprendizaje Supervisado Árboles de Decisión

2 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado 100K No 3 No Soltero 70K No 4 Sí Casado 120K No 5 No Divorcia do 95K Fraude Sí 6 No Casado 60K No Tabla de Aprendizaje Id Reembolso Estado Civil Ingresos Anuales 7 No Soltero 80K No 8 Si Casado 100K No 9 No Soltero 70K No Tabla de Testing Fraude Evaluar Generar el Modelo Aplicar el Modelo Algoritmo de Aprendizaje Modelo Nuevos Individuos
3 Clasificación: Definición Dada una colección de registros (conjunto de entrenamiento) cada registro contiene un conjunto de variables (atributos) denominado x, con un variable (atributo) adicional que es la clase denominada y. El objetivo de la clasificación es encontrar un modelo (una función) para predecir la clase a la que pertenecería cada registro, esta asignación una clase se debe hacer con la mayor precisión posible. Un conjunto de prueba (tabla de testing) se utiliza para determinar la precisión del modelo. Por lo general, el conjunto de datos dado se divide en dos conjuntos al azar de el de entrenamiento y el de prueba.
4 Definición de Clasificación Dada una base de datos D = {t 1, t 2,, t n } de tuplas o registros (individuos) y un conjunto de clases C = {C 1, C 2,, C m }, el problema de la clasificación es encontrar una función f: D C tal que cada t i es asignada una clase C j. f: D C podría ser una Red Neuronal, un Árbol de Decisión, un modelo basado en Análisis Discriminante, o una Red Beyesiana.
5 v3 v5 v8 v1 v2 v4 v6
6 Ejemplo: Créditos en un Banco Tabla de Aprendizaje Variable Discriminante Con la Tabla de Aprendizaje se entrena (aprende) el modelo matemático de predicción, es decir, a partir de esta tabla se calcula la función f de la definición anterior.

7 Ejemplo: Créditos en un Banco Tabla de Testing Variable Discriminante Con la Tabla de Testing se valida el modelo matemático de predicción, es decir, se verifica que los resultados en individuos que no participaron en la construcción del modelo es bueno o aceptable. Algunas veces, sobre todo cuando hay pocos datos, se utiliza la Tabla de Aprendizaje también como de Tabla Testing.

8 Ejemplo: Créditos en un Banco Nuevos Individuos Variable Discriminante Con la Tabla de Nuevos Individuos se predice si estos serán o no buenos pagadores.
9 10 Un ejemplo de un árbol de decisión Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No Fraude Variables de División 2 No Casado 100K No 3 No Soltero 70K No Sí Reembolso No 4 Sí Casado 120K No 5 No Divorcia do 95K Sí 6 No Casado 60K No 7 Sí Divorcia do 220K No 8 No Soltero 85K Sí 9 No Casado 75K No NO Es-Civil Soltero, Divorciado Ingresos < 80K > 80K NO SÍ Casado NO 10 No Soltero 90K Sí Tabla de Aprendizaje Modelo: Árbol de Decisión
10 Aplicando el modelo de árbol para predecir la clase para una nueva observación 10 Inicia desde la raíz del árbol Datos de Prueba Reebolso Estado Civil Ingresos Fraude Sí Reembolso No No Casado 80K? NO Soltero, Divorciado Es-Civil Casado Ingresos < 80K > 80K NO NO SÍ
11 Aplicando el modelo de árbol para predecir la clase para una nueva observación 10 Datos de Prueba Reebolso Estado Civil Ingresos Fraude Sí Reembolso No No Casado 80K? NO Soltero, Divorciado Es-Civil Casado Ingresos < 80K > 80K NO NO SÍ
12 Aplicando el modelo de árbol para predecir la clase para una nueva observación 10 Datos de Prueba Reebolso Estado Civil Ingresos Fraude Sí Reembolso No No Casado 80K? NO Soltero, Divorciado Es-Civil Casado Ingresos < 80K > 80K NO NO SÍ
13 Aplicando el modelo de árbol para predecir la clase para una nueva observación 10 Datos de Prueba Reebolso Estado Civil Ingresos Fraude Sí Reembolso No No Casado 80K? NO Soltero, Divorciado Es-Civil Casado Ingresos < 80K > 80K NO NO SÍ
14 Aplicando el modelo de árbol para predecir la clase para una nueva observación 10 Datos de Prueba Reebolso Estado Civil Ingresos Fraude No Casado 80K? Sí Reembolso No NO Soltero, Divorciado Es-Civil Casado Ingresos < 80K > 80K NO NO SÍ
15 Aplicando el modelo de árbol para predecir la clase para una nueva observación 10 Datos de Prueba FRAUDE (S/N) Reebolso Estado Civil Ingresos Fraude Si Reembolso No No Casado 80K? NO Soltero, Divorciado Est.Civil Casado Asigna No a la variable de Clase Fraude Ingresos <= 80K > 80K NO NO YES
16 Cómo se generan los árboles de decisión? Muchos algoritmos usan una versión con un enfoque "top-down" o "dividir y conquista" conocido como Algoritmo de Hunt. Sea D t el conjunto de registros de entrenamiento en un nodo t dado. Sea y t = {y 1, y 2,, y c } el conjunto de etiquetas de las clases.
17 Algoritmo de Hunt: Si todos los registros D t pertenecen a la misma clase y t, entonces t es un nodo hoja que se etiqueta como y t Si D t contiene registros que pertenecen a más de una clase, se escoge una variable (atributo) para dividir los datos en subconjuntos más pequeños. Recursivamente se aplica el procedimiento a cada subconjunto.
18 Un ejemplo del algoritmo de Hunt 10 Sí Reembolso No Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No Fraude Sí No Fraude Reembolso Soltero, Divorciado Fraude No Fraude No Estado Civil Casado No Fraude Fraude Sí No Fraude No Fraude Reembolso Soltero, Divorciado Ingresos Anuales No Estado Civil < 80K >= 80K Fraude Casado No Fraude 2 No Casado 100K No 3 No Soltero 70K No 4 Sí Casado 120K No 5 No Divorciado 95K Sí 6 No Casado 60K No 7 Sí Divorciado 220K No 8 No Soltero 85K Sí 9 No Casado 75K No 10 No Soltero 90K Sí Cómo se escoge el orden de las variables?
19 Cómo aplicar el algoritmo de Hunt? Por lo general, se lleva a cabo de manera que la separación que se elige en cada etapa sea óptima de acuerdo con algún criterio. Sin embargo, puede no ser óptima al final del algoritmo (es decir no se encuentre un árbol óptimo como un todo). Aún así, este el enfoque computacional es eficiente por lo que es muy popular.
20 Cómo aplicar el algoritmo de Hunt? Utilizando el enfoque de optimización aún se tienen que decidir tres cosas: 1. Cómo dividiremos las variables? 2. Qué variables (atributos) utilizar y en que orden? Qué criterio utilizar para seleccionar la "mejor" división? 3. Cuándo dejar de dividir? Es decir, Cuándo termina el algoritmo?
21 Cómo aplicar el algoritmo de Hunt? Para la pregunta 1, se tendrán en cuenta sólo divisiones binarias tanto para predictores numéricos como para los categóricos, esto se explica más adelante (Método CART). Para la pregunta 2 se considerarán el Error de Clasificación, el Índice de Gini y la Entropía. La pregunta 3 tiene una respuesta difícil de dar porque implica la selección del modelo. Se debe tomar en cuenta qué tanto se quieren afinar las reglas generadas.
22 Pregunta #1: Solamente se usarán divisiones Binarias (Método CART): Nominales: Ordinales: Como en las nominales, pero sin violar el orden {Pequeño, Mediano} {Deportivo, Lujo} Tamaño Tipo carro {Grande} {Familiar} {Mediano, Grande} Numéricas: Frecuentemente se divide en el punto medio ó Tamaño Ingresos > 80K? {Pequeño} Sí No
23 Pregunta #2: Se usarán los siguientes criterios de IMPUREZA: el Error de Clasificación, el Índice de Gini y la Entropía, para esto se define la siguiente probabilidad: p(j t)= La probalidad de pertenecer a la clase j estando en el nodo t. Muchas veces simplemente se usa p j
24 Pregunta #2: Se usarán el Error de Clasificación, el Índice de Gini y la Entropía Error de clasificación: Error( t) 1 max[ p( j t)] j Índice de Gini: GINI ( t) 1 j [ p( j t)] 2 Entropía: Entropía t) p( j t)log p( j t) ( 2 j
25 Ejemplo de cálculo de índices: Padre Node N1 Node N2 Node N3
26 Ejemplo de cálculo de Gini GINI ( t) 1 j [ p( j t)] 2 C1 0 C2 6 P(C1) = 0/6 = 0 P(C2) = 6/6 = 1 Gini = 1 P(C1) 2 P(C2) 2 = = 0 C1 1 C2 5 P(C1) = 1/6 P(C2) = 5/6 Gini = 1 (1/6) 2 (5/6) 2 = C1 2 C2 4 P(C1) = 2/6 P(C2) = 4/6 Gini = 1 (2/6) 2 (4/6) 2 = 0.444
27 Ejemplo de cálculo de la Entropía C1 0 C2 6 P(C1) = 0/6 = 0 P(C2) = 6/6 = 1 Entropía = 0 log 0 1 log 1 = 0 0 = 0 C1 1 C2 5 P(C1) = 1/6 P(C2) = 5/6 Entropía = (1/6) log 2 (1/6) (5/6) log 2 (5/6) = 0.65 C1 2 C2 4 P(C1) = 2/6 P(C2) = 4/6 Entropía = (2/6) log 2 (2/6) (4/6) log 2 (4/6) = 0.92
28 Ejemplo de cálculo del Error de Clasificación C1 0 C2 6 Error Clasificación = 1-max[0/6,6/6]= 0 C1 1 C2 5 Error Clasificación = 1-max[1/6,5/6]= 0,167 C1 2 C2 4 Error Clasificación = 1-max[2/6,4/6]= 0,333
29 Comparación Gráfica
30 Gini Split Después de que el índice de Gini se calcula en cada nodo, el valor total del índice de Gini se calcula como el promedio ponderado del índice de Gini en cada nodo: GINI split k i 1 n i n GINI ( i)
31 Ejemplo de cálculo GINI Split padre =18 Cardinalidad=18 Padre Node N1 Node N2 Node N3
32 Ejemplo de cálculo de GINI split C1 0 C2 6 P(C1) = 0/6 = 0 P(C2) = 6/6 = 1 Gini = 1 P(C1) 2 P(C2) 2 = = 0 C1 1 C2 5 P(C1) = 1/6 P(C2) = 5/6 Gini = 1 (1/6) 2 (5/6) 2 = C1 2 C2 4 P(C1) = 2/6 P(C2) = 4/6 Gini = 1 (2/6) 2 (4/6) 2 = GINI split = (6/18)*0+(6/18)*0.278+(6/18)*0.444 = 0.24 En este caso todos los pesos son iguales porque todas las clases tienen 6 elementos
33 Entropía Split Después de que el índice de Entropía se calcula en cada nodo, el valor total del índice de Entropía se calcula como el promedio ponderado del índice de Entropía en cada nodo: Entropia split k i 1 n i n Entropia( i)
34 Error de Clasificación Split Después de que el Error de Clasificación (EC) se calcula en cada nodo, el valor total del índice del EC se calcula como el promedio ponderado del índice EC en cada nodo: EC split k i 1 n i n EC( i)
35 Información Ganada IG Split Cada vez que se va a hacer una nueva división en el árbol (split the tree) se debe comparar el grado de impureza del nodo padre respecto al grado de impureza de los nodos hijos. Esto se calcula con el índice de Información Ganada (IG), que es la resta de la impureza del nodo padre menos el promedio ponderado de las impurezas de los nodos hijos. La idea en IG Split sea máximo y esto se logra si el promedio ponderado de las impurezas de los nodos hijos es mínimo. IG split I( padre) k i 1 ni n I( i) Donde I es el índice de GINI, la Entropía o el Error de Clasificación.
36 Ejemplo: Información Ganada IG Split Padre C1 7 C2 3 Gini = 0.42 Gini(N1) = 1 (3/3) 2 (0/3) 2 = 0 GINI split = = 3/10 * 0 + 7/10 * 0.49 = IG split Sí I( padre) Nodo N1 A? N1 N2 C1 3 4 C2 0 3 Gini=0.361 k i 1 ni n I( i) No Nodo N2 Gini(N2) = 1 (4/7) 2 (3/7) 2 =
37 Cómo escoger la mejor división? Se debe escoger la variable B ya que maximiza la Información Ganada al minimizar GINI split
38 Cómo escoger la mejor división? Pero si se tiene solamente división En caso de tener división múltiple binaria se escoge esta división se escoge esta división ya que maximiza ya que maximiza a Información la Información Ganada al minimizar GINI Ganada al minimizar GINI split split

39 Cómo escoger la mejor división? La variable Annual Income se debe dividir en 97 ya que maximiza la Información Ganada al minimizar GINI split
40 10 Porqué se escoge Reembolso como variable inicial? Id Reembolso Estado Civil Ingresos Anuales Fraude 1 Sí Soltero 125K No Sí Reembolso No 2 No Casado 100K No 3 No Soltero 70K No 4 Sí Casado 120K No No(F) 3 Sí(F) 0 No(F) 4 Sí(F) 3 5 No Divorciado 95K Sí 6 No Casado 60K No 7 Sí Divorciado 220K No 8 No Soltero 85K Sí GINI(No) = 1-(4/7) 2 -(3/7) 2 = = No Casado 75K No 10 No Soltero 90K Sí GINI(Sí) = 1-(0/3) 2 -(3/3) 2 = = 0 GINI split = (3/10)*0+(7/10)* =
41 10 Porqué se escoge Reembolso como variable inicial? Id Reembolso Estado Civil Ingresos Anuales Fraude 1 Sí Soltero 125K No Soltero Divorciado No(F) 3 Sí(F) 3 Estado Civil Casado No(F) 4 Sí(F) 0 GINI(Casado) = 1-(0/4) 2 -(4/4) 2 = 0 2 No Casado 100K No 3 No Soltero 70K No 4 Sí Casado 120K No 5 No Divorciado 95K Sí 6 No Casado 60K No 7 Sí Divorciado 220K No 8 No Soltero 85K Sí 9 No Casado 75K No 10 No Soltero 90K Sí GINI(Soltero/Divorciado) = 1-(3/6) 2 -(3/6) 2 = = 0.5 GINI split = (6/10)*0.5+(4/10)* 0 = 0.3
42 10 Porqué se escoge Reembolso como variable inicial? Id Reembolso Estado Civil Ingresos Anuales Fraude 1 Sí Soltero 125K No Ingresos Anuales < 80K >=80K No(F) 3 Sí(F) 0 No(F) 4 Sí(F) 3 GINI(>=80K) = 1-(3/7) 2 -(4/7) 2 = No Casado 100K No 3 No Soltero 70K No 4 Sí Casado 120K No 5 No Divorciado 95K Sí 6 No Casado 60K No 7 Sí Divorciado 220K No 8 No Soltero 85K Sí 9 No Casado 75K No 10 No Soltero 90K Sí GINI(<80K) = 1-(0/3) 2 -(3/3) 2 = = 0 GINI split = (3/10)*0+(7/10)* 0.49 = 0.343
43 Pregunta #3 Cuándo dejar de dividir? Esta es una difícil ya que implica sutil selección de modelos. Una idea sería controlar el Error de Clasificación (o el Índice de Gini o la Entropía) en el conjunto de datos de prueba de manera que se detendrá cuando el índice selecciona comience a aumentar. La "Poda" (pruning) es la técnica más popular. Usada en el Método CART propuesto por Breiman, Friedman, Olshen, and Stone, 1984, (CART=Classification And Regression Trees)
44 Algoritmo CART Para cada nodo v del Árbol hacer los pasos 1 y 2 1. Para j= 1,2,,p calcular: (p=número de variables) Todas las divisiones binarias correspondientes a la variable discriminante Y La división binaria óptima d(j) correspondiente a la variable Y, es decir la división binaria maximiza el descenso de la impureza 2. Recursivamente calcular la mejor división binaria para d(1), d(2),,d(p) FIN
45 Árbol podado y reestructurado
46 Árboles de Decisión en Rattle > library(rattle) Rattle: A free graphical interface for data mining with R. Versión Copyright (c) Togaware Pty Ltd. Escriba 'rattle()' para agitar, sacudir y rotar sus datos. > rattle()

47 Ejemplo 1: IRIS.CSV Ejemplo con la tabla de datos IRIS IRIS Información de variables: 1.sepal largo en cm 2.sepal ancho en cm 3.petal largo en cm 4.petal ancho en cm 5.clase: Iris Setosa Iris Versicolor Iris Virginica
48 > library(scatterplot3d) > scatterplot3d(datos$p.ancho,datos$s.largo,datos$s.ancho)
) >")
49 > library(rgl) > D <- as.matrix(dist(datos[,1:4])) > heatmap(d)

50 Ejemplo 1: iris.csv
51 Árboles de Decisión en Ratlle
52
53
54 Reglas en Rattle Árbol como reglas: Rule number: 2 [tipo=setosa cover=33 (31%) prob=1.00] p.largo< 2.6 Rule number: 7 [tipo=virginica cover=35 (33%) prob=0.00] p.largo>=2.6 p.largo>=4.85 Rule number: 6 [tipo=versicolor cover=37 (35%) prob=0.00] p.largo>=2.6 p.largo< 4.85

55 Matriz de confusión en Rattle (Matriz de Error)
56 Ejemplo 2: Credit-Scoring MuestraAprendizajeCredito2500.csv MuestraTestCredito2500.csv
57 Descripción de Variables MontoCredito MontoCuota 1= Muy Bajo 1 =Muy Bajo 2= Bajo 2 =Bajo 3= Medio 3 =Medio 4= Alto 4 =Alto IngresoNeto GradoAcademico 1= Muy Bajo 1 =Bachiller 2= Bajo 2 =Licenciatura 3= Medio 3 =Maestría 4= Alto 4 =Doctorado CoeficienteCreditoAvaluo BuenPagador 1= Muy Bajo 1 =NO 2= Bajo 2 =Si 3= Medio 4= Alto
58 Árboles de Decisión en Rattle

59
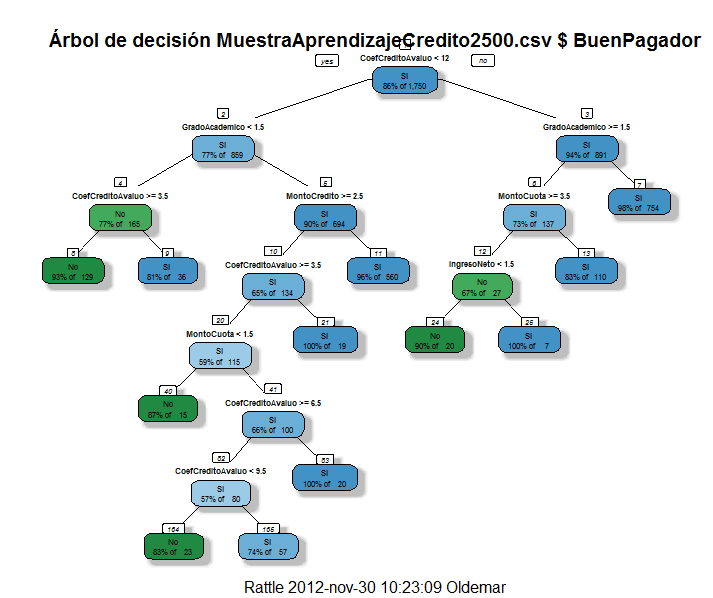
60
61 Reglas en Rattle Árbol como reglas: Rule number: 25 [BuenPagador=Si cover=7 (0%) prob=1.00] CoefCreditoAvaluo>=11.5 GradoAcademico>=1.5 MontoCuota>=3.5 IngresoNeto>=1.5 Rule number: 21 [BuenPagador=Si cover=19 (1%) prob=1.00] CoefCreditoAvaluo< 11.5 GradoAcademico>=1.5 MontoCredito>=2.5 CoefCreditoAvaluo< 3.5..

62 Matriz de confusión en Rattle (Matriz de Error)
63 Una curva ROC compara la tasa de falsos positivos con la de verdaderos positivos. El área bajo la curva ROC = Curva ROC
64 Árboles de Decisión en R
65 El paquete tree utiliza el algoritmo de Hunt Instalando y usando el paquete tree : install.packages('tree',dependencies=true) library(tree)
66 Árboles de Decisión en R
67 El paquete rpart utiliza el algoritmo CART + Pruning (poda) Instalando y usando el paquete rpart : install.packages('rpart',dependencies=true) library(rpart)

68 Gracias.
Aprendizaje Supervisado Máquinas Vectoriales de Soporte
 Aprendizaje Supervisado Máquinas Vectoriales de Soporte Tipos de Variables 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado
Aprendizaje Supervisado Máquinas Vectoriales de Soporte Tipos de Variables 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado
Aprendizaje Supervisado Clasificación Bayesiana (Método de Naïve Bayes)
") Aprendizaje Supervisado Clasificación Bayesiana (Método de Naïve Bayes) 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No Fraude Algoritmo
Aprendizaje Supervisado Clasificación Bayesiana (Método de Naïve Bayes) 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No Fraude Algoritmo
Aprendizaje Supervisado K - Vecinos más cercanos Knn-Method
 Aprendizaje Supervisado K - Vecinos más cercanos Knn-Method 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado 100K No 3 No
Aprendizaje Supervisado K - Vecinos más cercanos Knn-Method 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado 100K No 3 No
Aprendizaje Supervisado Análisis Discriminante (Lineal y Cuadrático)
") Aprendizaje Supervisado Análisis Discriminante (Lineal y Cuadrático) 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado 100K
Aprendizaje Supervisado Análisis Discriminante (Lineal y Cuadrático) 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado 100K
Análisis Exploratorio de Datos
 Análisis Exploratorio de Datos 10 Qué son los Datos? Una variable es una propiedad o característica de un Individuo Ejemplos: color de ojos de un persona, temperatura, estado civil Una colección de variables
Análisis Exploratorio de Datos 10 Qué son los Datos? Una variable es una propiedad o característica de un Individuo Ejemplos: color de ojos de un persona, temperatura, estado civil Una colección de variables
Clasificación Supervisada. Métodos jerárquicos. CART
 Clasificación Supervisada. Métodos jerárquicos. CART Ricardo Fraiman 2 de abril de 2010 Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y n ) E {1,..., m}. Típicamente E = R d.
Clasificación Supervisada. Métodos jerárquicos. CART Ricardo Fraiman 2 de abril de 2010 Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y n ) E {1,..., m}. Típicamente E = R d.
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos. - Sesión 11 -
 Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 11 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Resolución manual de clasificación bayesiana
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 11 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Resolución manual de clasificación bayesiana
Aux 6. Introducción a la Minería de Datos
 Aux 6. Introducción a la Minería de Datos Gastón L Huillier 1,2, Richard Weber 2 glhuilli@dcc.uchile.cl 1 Departamento de Ciencias de la Computación Universidad de Chile 2 Departamento de Ingeniería Industrial
Aux 6. Introducción a la Minería de Datos Gastón L Huillier 1,2, Richard Weber 2 glhuilli@dcc.uchile.cl 1 Departamento de Ciencias de la Computación Universidad de Chile 2 Departamento de Ingeniería Industrial
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Clustering: Auto-associative Multivariate Regression Tree (AAMRT)
") Introducción Tipos Validación AAMRT Clustering: Auto-associative Multivariate Regression Tree (AAMRT) Miguel Bernal C Quantil 12 de diciembre de 2013 Miguel Bernal C Quantil Matemáticas Aplicadas Contenido
Introducción Tipos Validación AAMRT Clustering: Auto-associative Multivariate Regression Tree (AAMRT) Miguel Bernal C Quantil 12 de diciembre de 2013 Miguel Bernal C Quantil Matemáticas Aplicadas Contenido
Perceptrón simple y perceptrón multicapa
 UNL - FICH - Departamento de Informática - Ingeniería Informática Inteligencia Computacional Guía de trabajos prácticos Perceptrón simple y perceptrón multicapa. Objetivos Aplicar diferentes arquitecturas
UNL - FICH - Departamento de Informática - Ingeniería Informática Inteligencia Computacional Guía de trabajos prácticos Perceptrón simple y perceptrón multicapa. Objetivos Aplicar diferentes arquitecturas
Tareas de la minería de datos: clasificación. CI-2352 Intr. a la minería de datos Prof. Braulio José Solano Rojas ECCI, UCR
 Tareas de la minería de datos: clasificación CI-2352 Intr. a la minería de datos Prof. Braulio José Solano Rojas ECCI, UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja
Tareas de la minería de datos: clasificación CI-2352 Intr. a la minería de datos Prof. Braulio José Solano Rojas ECCI, UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja
Árboles de clasificación/decisión mediante R
 Árboles de clasificación/decisión mediante R Paquete Hay dos paquetes de R que cubren este asunto: tree y rpart. Trabajaremos con el segundo porque 1. Está incluido en la distribución básica de R. 2. La
Árboles de clasificación/decisión mediante R Paquete Hay dos paquetes de R que cubren este asunto: tree y rpart. Trabajaremos con el segundo porque 1. Está incluido en la distribución básica de R. 2. La
Aprendizaje Automático
 id3 id3 como búsqueda Cuestiones Adicionales Regresión Lineal. Árboles y Reglas de Regresión Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje
id3 id3 como búsqueda Cuestiones Adicionales Regresión Lineal. Árboles y Reglas de Regresión Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje
Jesús García Herrero TÉCNICAS DE REGRESIÓN NO LINEAL
 Jesús García Herrero TÉCNICAS DE REGRESIÓN NO LINEAL En esta clase se presenta un método de inducción de modelos numéricos de regresión a partir de datos. En el tema de técnicas clásicas se presentó la
Jesús García Herrero TÉCNICAS DE REGRESIÓN NO LINEAL En esta clase se presenta un método de inducción de modelos numéricos de regresión a partir de datos. En el tema de técnicas clásicas se presentó la
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Tareas de la minería de datos: clasificación. PF-5028 Minería de datos Prof. Braulio José Solano Rojas UCR
 Tareas de la minería de datos: clasificación PF-5028 Minería de datos Prof. Braulio José Solano Rojas UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja o asocia datos
Tareas de la minería de datos: clasificación PF-5028 Minería de datos Prof. Braulio José Solano Rojas UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja o asocia datos
Introducción a SPSS Árboles de Clasificación. Jorge Del Río L. Consultor Estadístico
 Introducción a SPSS Árboles de Clasificación Jorge Del Río L. Consultor Estadístico Introducción Es un módulo que contiene diferentes procedimientos para resolver problemas de predicción y clasificación
Introducción a SPSS Árboles de Clasificación Jorge Del Río L. Consultor Estadístico Introducción Es un módulo que contiene diferentes procedimientos para resolver problemas de predicción y clasificación
Métodos de Clasificación sin Métrica. Reconocimiento de Patrones- 2013
 Métodos de Clasificación sin Métrica Reconocimiento de Patrones- 03 Métodos de Clasificación sin Métrica Datos nominales sin noción de similitud o distancia (sin orden). Escala nominal: conjunto de categorías
Métodos de Clasificación sin Métrica Reconocimiento de Patrones- 03 Métodos de Clasificación sin Métrica Datos nominales sin noción de similitud o distancia (sin orden). Escala nominal: conjunto de categorías
Técnicas Multivariadas Avanzadas
 Métodos basados en árboles Universidad Nacional Agraria La Molina 2014-2 Introducción Introducción Se describen métodos basados en árboles para regresión y clasicación. Estos métodos requieren estraticar
Métodos basados en árboles Universidad Nacional Agraria La Molina 2014-2 Introducción Introducción Se describen métodos basados en árboles para regresión y clasicación. Estos métodos requieren estraticar
ARBOLES DE DECISION. Miguel Cárdenas-Montes. 1 Introducción. Objetivos: Entender como funcionan los algoritmos basados en árboles de decisión.
 ARBOLES DE DECISION Miguel Cárdenas-Montes Los árboles de decisión son estructuras lógicas con amplia utilización en la toma de decisión, la predicción y la minería de datos. Objetivos: Entender como funcionan
ARBOLES DE DECISION Miguel Cárdenas-Montes Los árboles de decisión son estructuras lógicas con amplia utilización en la toma de decisión, la predicción y la minería de datos. Objetivos: Entender como funcionan
SISTEMAS INTELIGENTES
 SISTEMAS INTELIGENTES T9: Árboles de Decisión www.aic.uniovi.es/ssii Sistemas Inteligentes T9: Árboles de decisión Índice Árboles de decisión para clasificación Mecanismo de inducción: divide y vencerás
SISTEMAS INTELIGENTES T9: Árboles de Decisión www.aic.uniovi.es/ssii Sistemas Inteligentes T9: Árboles de decisión Índice Árboles de decisión para clasificación Mecanismo de inducción: divide y vencerás
Estadística Multivariada Computacional Introducción al Aprendizaje Automático (parte 1)
") Estadística Multivariada Computacional Introducción al Aprendizaje Automático (parte 1) Mathias Bourel IMERL - Facultad de Ingeniería, Universidad de la República, Uruguay 24 de octubre de 2016 M.Bourel
Estadística Multivariada Computacional Introducción al Aprendizaje Automático (parte 1) Mathias Bourel IMERL - Facultad de Ingeniería, Universidad de la República, Uruguay 24 de octubre de 2016 M.Bourel
VIII Jornadas de Usuarios de R
 VIII Jornadas de Usuarios de R Análisis del Abandono en el Sector Bancario Predicción del abandono de clientes Albacete, 17 de Noviembre de 2016 I. INDICE : Modelo Abandonos I. COMPRENSIÓN DEL NEGOCIO
VIII Jornadas de Usuarios de R Análisis del Abandono en el Sector Bancario Predicción del abandono de clientes Albacete, 17 de Noviembre de 2016 I. INDICE : Modelo Abandonos I. COMPRENSIÓN DEL NEGOCIO
ÁRBOLES DE CLASIFICACIÓN Y REGRESIÓN
 ÁRBOLES DE CLASIFICACIÓN Y REGRESIÓN Los árboles de clasificación y regresión (CART=Classification and Regression Trees) son una alternativa al análisis tradicional de clasificación/discriminación o a
ÁRBOLES DE CLASIFICACIÓN Y REGRESIÓN Los árboles de clasificación y regresión (CART=Classification and Regression Trees) son una alternativa al análisis tradicional de clasificación/discriminación o a
Estadística con R. Clasificadores
 Estadística con R Clasificadores Análisis discriminante lineal (estadístico) Árbol de decisión (aprendizaje automático) Máquina soporte vector (aprendizaje automático) Análisis discriminante lineal (AD)
Estadística con R Clasificadores Análisis discriminante lineal (estadístico) Árbol de decisión (aprendizaje automático) Máquina soporte vector (aprendizaje automático) Análisis discriminante lineal (AD)
Arboles de Decisión (II) Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile
 Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile") Arboles de Decisión (II) Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile Arboles de Decisión Algoritmo de Hunt (I) Nodo interior Nodo por expandir Nodo hoja Algoritmo de Hunt
Arboles de Decisión (II) Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile Arboles de Decisión Algoritmo de Hunt (I) Nodo interior Nodo por expandir Nodo hoja Algoritmo de Hunt
Aprendizaje Automático
 Aprendizaje Automático Andrea Mesa 21 de mayo de 2010 Aprendizaje automático Otras denominaciones: machine learning, statistical learning, data mining, inteligencia artificial. Las técnicas de Aprendizaje
Aprendizaje Automático Andrea Mesa 21 de mayo de 2010 Aprendizaje automático Otras denominaciones: machine learning, statistical learning, data mining, inteligencia artificial. Las técnicas de Aprendizaje
Aprendizaje inductivo
 Inteligencia Artificial Aprendizaje inductivo Ing. Sup. en Informática, 4º Curso académico: 2011/2012 Profesores: Ramón Hermoso y Matteo Vasirani Aprendizaje Resumen: 3. Aprendizaje automático 3.1 Introducción
Inteligencia Artificial Aprendizaje inductivo Ing. Sup. en Informática, 4º Curso académico: 2011/2012 Profesores: Ramón Hermoso y Matteo Vasirani Aprendizaje Resumen: 3. Aprendizaje automático 3.1 Introducción
Inteligencia en Redes de Comunicaciones - 06 Aprendizaje
 El objetivo de este tema es realizar una introducción a los conceptos, fundamentos y técnicas básicas de aprendizaje computacional. En primer lugar se formalizará el concepto de aprendizaje y se describirán
El objetivo de este tema es realizar una introducción a los conceptos, fundamentos y técnicas básicas de aprendizaje computacional. En primer lugar se formalizará el concepto de aprendizaje y se describirán
Práctica 5: Clasificación con número variable de ejemplos.
 5º INGENIERÍA DE TELECOMUNICACIÓN INTELIGENCIA ARTIFICIAL Y RECONOCIMIENTO DE PATRONES Práctica 5: Clasificación con número variable de ejemplos. Objetivos: Utilización de conjuntos de entrenamiento y
5º INGENIERÍA DE TELECOMUNICACIÓN INTELIGENCIA ARTIFICIAL Y RECONOCIMIENTO DE PATRONES Práctica 5: Clasificación con número variable de ejemplos. Objetivos: Utilización de conjuntos de entrenamiento y
Ampliación de Algoritmos y Estructura de Datos Curso 02/03. Ejercicios
 272. En un problema determinado, una solución está dada por una tupla de n elementos (x, x 2,..., x n ). Para cada elemento existen en total m posibles valores. Comparar el número de nodos generados para
272. En un problema determinado, una solución está dada por una tupla de n elementos (x, x 2,..., x n ). Para cada elemento existen en total m posibles valores. Comparar el número de nodos generados para
José Noel Caraballo Irmannette Torres Lugo Universidad de Puerto Rico en Cayey
 José Noel Caraballo Irmannette Torres Lugo Universidad de Puerto Rico en Cayey Importancia de la investigación institucional y las decisiones sustentadas por datos. Criterios de admisión a la UPR como
José Noel Caraballo Irmannette Torres Lugo Universidad de Puerto Rico en Cayey Importancia de la investigación institucional y las decisiones sustentadas por datos. Criterios de admisión a la UPR como
Sesión 014b. Interpretando un Árbol de Decisión 1480-Técnicas Estadísticas en Investigación de Mercados Grado en Estadística empresarial Curso
 Sesión 014b. Interpretando un Árbol de Decisión 1480-Técnicas Estadísticas en Investigación de Mercados Grado en Estadística empresarial Curso 2012-13 Segundo semestre Profesor: Xavier Barber i Vallés
Sesión 014b. Interpretando un Árbol de Decisión 1480-Técnicas Estadísticas en Investigación de Mercados Grado en Estadística empresarial Curso 2012-13 Segundo semestre Profesor: Xavier Barber i Vallés
MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión.
 MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión. 1 Objetivos del tema Conocer en qué consiste un árbol de decisión. Aprender los problemas que pueden
MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión. 1 Objetivos del tema Conocer en qué consiste un árbol de decisión. Aprender los problemas que pueden
I. CARACTERISTICAS DEL ALGORITMO ID3
 I. CARACTERISTICAS DEL ALGORITMO ID3 El investigador J. Ross Quinlan desarrolló el algoritmo conocido como ID3 (Induction Decision Trees) en el año de 1983. Pertenece a la familia TDIDT (Top-Down Induction
I. CARACTERISTICAS DEL ALGORITMO ID3 El investigador J. Ross Quinlan desarrolló el algoritmo conocido como ID3 (Induction Decision Trees) en el año de 1983. Pertenece a la familia TDIDT (Top-Down Induction
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Random Forests. Teoría y ejemplos. Romain Gouron. Conferencia 9, GLAM, Doble titulo Ecole Centrale de Nantes (Francia)
") Teoría y ejemplos 1 1 Departamiento de Ingenería Matemática Doble titulo Ecole Centrale de Nantes (Francia) Conferencia 9, GLAM, 2016 Outline 1 Árboles de decisión Construcción 2 3 Rotation forest Gradient
Teoría y ejemplos 1 1 Departamiento de Ingenería Matemática Doble titulo Ecole Centrale de Nantes (Francia) Conferencia 9, GLAM, 2016 Outline 1 Árboles de decisión Construcción 2 3 Rotation forest Gradient
2. Algoritmos genéticos y redes neuronales 3. Inducción de árboles clasificadores. Inducción de árboles de clasificación. Aprendizaje UPM UPM
 1. Preliminares Aprendizaje 2. Algoritmos genéticos y redes neuronales 3. Inducción de árboles clasificadores 4. Inducción de reglas 5. Minería de datos c 2010 DIT-ETSIT- Aprendizaje: árboles transp. 1
1. Preliminares Aprendizaje 2. Algoritmos genéticos y redes neuronales 3. Inducción de árboles clasificadores 4. Inducción de reglas 5. Minería de datos c 2010 DIT-ETSIT- Aprendizaje: árboles transp. 1
Algoritmos y Estructuras de Datos Curso 04/05. Ejercicios
 0. En un problema determinado, una solución está dada por una tupla de n elementos (x, x,..., x n ). Para cada elemento existen en total m posibles valores. Comparar el número de nodos generados para resolver
0. En un problema determinado, una solución está dada por una tupla de n elementos (x, x,..., x n ). Para cada elemento existen en total m posibles valores. Comparar el número de nodos generados para resolver
Proyecto 6. Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial.
 Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial. Funcionamiento: Se realiza un test en cada nodo interno del árbol, a medida que
Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial. Funcionamiento: Se realiza un test en cada nodo interno del árbol, a medida que
Complementación y ampliación de la currícula de la Maestría 2017 Maestría en Generación y Análisis de Información Estadística
 ampliación de la currícula Maestría en Generación y Análisis de Información Estadística Programa abierto de ampliación de la currícula Maestría en Generación y Análisis de Información Estadística La Maestría
ampliación de la currícula Maestría en Generación y Análisis de Información Estadística Programa abierto de ampliación de la currícula Maestría en Generación y Análisis de Información Estadística La Maestría
Minería de Datos. Árboles de Decisión. Fac. Ciencias Ing. Informática Otoño de Dept. Matesco, Universidad de Cantabria
 Minería de Datos Árboles de Decisión Cristina Tîrnăucă Dept. Matesco, Universidad de Cantabria Fac. Ciencias Ing. Informática Otoño de 2012 Twenty questions Intuición sobre los árboles de decisión Juego
Minería de Datos Árboles de Decisión Cristina Tîrnăucă Dept. Matesco, Universidad de Cantabria Fac. Ciencias Ing. Informática Otoño de 2012 Twenty questions Intuición sobre los árboles de decisión Juego
Jesús García Herrero TÉCNICAS DE INDUCCIÓN-II
 Jesús García Herrero TÉCNICAS DE INDUCCIÓN-II En esta clase se continúa con el desarrollo de métodos de inducción de modelos lógicos a partir de datos. Se parte de las limitaciones del método ID3 presentado
Jesús García Herrero TÉCNICAS DE INDUCCIÓN-II En esta clase se continúa con el desarrollo de métodos de inducción de modelos lógicos a partir de datos. Se parte de las limitaciones del método ID3 presentado
Inteligencia Artificial: Su uso para la investigación
 Inteligencia Artificial: Su uso para la investigación Dra. Helena Montserrat Gómez Adorno Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas helena.adorno@iimas.unam.mx 1 Introducción
Inteligencia Artificial: Su uso para la investigación Dra. Helena Montserrat Gómez Adorno Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas helena.adorno@iimas.unam.mx 1 Introducción
Guía de Ejercicios Aprendizaje de Máquinas Inteligencia Articial (CC52A)
") Guía de Ejercicios Aprendizaje de Máquinas Inteligencia Articial (CC52A) 6 de noviembre de 2007 1. Arboles de Decision 1. Investigue las ventajas y desventajas de los árboles de decisión versus los siguientes
Guía de Ejercicios Aprendizaje de Máquinas Inteligencia Articial (CC52A) 6 de noviembre de 2007 1. Arboles de Decision 1. Investigue las ventajas y desventajas de los árboles de decisión versus los siguientes
Aprendizaje Automático. Objetivos. Funciona? Notas
 Introducción Las técnicas que hemos visto hasta ahora nos permiten crear sistemas que resuelven tareas que necesitan inteligencia La limitación de estos sistemas reside en que sólo resuelven los problemas
Introducción Las técnicas que hemos visto hasta ahora nos permiten crear sistemas que resuelven tareas que necesitan inteligencia La limitación de estos sistemas reside en que sólo resuelven los problemas
Técnicas de Minería de Datos
 Técnicas de Minería de Datos Act. Humberto Ramos S. 1 Qué es Minería de datos? El desarrollo de dispositivos tecnológicos para acumular datos a bajo costo. Acumulación o registro de gran cantidad de datos.
Técnicas de Minería de Datos Act. Humberto Ramos S. 1 Qué es Minería de datos? El desarrollo de dispositivos tecnológicos para acumular datos a bajo costo. Acumulación o registro de gran cantidad de datos.
Introducción a los sistemas Multiclasificadores. Carlos J. Alonso González Departamento de Informática Universidad de Valladolid
 Introducción a los sistemas Multiclasificadores Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Combinación de modelos 2. Descomposición bias-varianza 3. Bagging
Introducción a los sistemas Multiclasificadores Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Combinación de modelos 2. Descomposición bias-varianza 3. Bagging
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Clasificadores Débiles - AdaBoost
 Capítulo 3 Clasificadores Débiles - AdaBoost El término boosting hace referencia a un tipo de algoritmos cuya finalidad es encontrar una hipótesis fuerte a partir de utilizar hipótesis simples y débiles.
Capítulo 3 Clasificadores Débiles - AdaBoost El término boosting hace referencia a un tipo de algoritmos cuya finalidad es encontrar una hipótesis fuerte a partir de utilizar hipótesis simples y débiles.
El Juego como Problema de Búsqueda
 El Juego como Problema de Búsqueda En este algoritmo identificamos dos jugadores: max y min. El objetivo es encontrar la mejor movida para max. Supondremos que max mueve inicialmente y que luego se turnan
El Juego como Problema de Búsqueda En este algoritmo identificamos dos jugadores: max y min. El objetivo es encontrar la mejor movida para max. Supondremos que max mueve inicialmente y que luego se turnan
Tópicos Selectos en Aprendizaje Maquinal. Algoritmos para Reconocimiento de Patrones
 Tópicos Selectos en Aprendizaje Maquinal Guía de Trabajos Prácticos N 1 (2da. parte) Algoritmos para Reconocimiento de Patrones 20 de Octubre de 2010 1. Objetivos Introducir conceptos básicos de aprendizaje
Tópicos Selectos en Aprendizaje Maquinal Guía de Trabajos Prácticos N 1 (2da. parte) Algoritmos para Reconocimiento de Patrones 20 de Octubre de 2010 1. Objetivos Introducir conceptos básicos de aprendizaje
10 EXÁMENES
 10 EXÁMENES 2014-2018 Convocatoria Extraordinaria de Septiembre 1 de Septiembre de 2014 1. (1 pto.) a) Aunque por abuso del lenguaje hemos hablado de minería de datos y de KDD como sinónimos, indica las
10 EXÁMENES 2014-2018 Convocatoria Extraordinaria de Septiembre 1 de Septiembre de 2014 1. (1 pto.) a) Aunque por abuso del lenguaje hemos hablado de minería de datos y de KDD como sinónimos, indica las
Bases de Datos Multimedia
 Bases de Datos Multimedia Capítulo 3 Algoritmos de búsqueda por similitud Este material se basa en el curso de Base de Datos Multimedia del DCC de la Universidad de Chile (Prof. Benjamín Bustos). 3.1 Conceptos
Bases de Datos Multimedia Capítulo 3 Algoritmos de búsqueda por similitud Este material se basa en el curso de Base de Datos Multimedia del DCC de la Universidad de Chile (Prof. Benjamín Bustos). 3.1 Conceptos
Minería de Datos. Árboles de Decisión. Fac. Ciencias Ing. Informática Otoño de Dept. Matesco, Universidad de Cantabria
 Minería de Datos Árboles de Decisión Cristina Tîrnăucă Dept. Matesco, Universidad de Cantabria Fac. Ciencias Ing. Informática Otoño de 2012 Twenty questions Intuición sobre los árboles de decisión Juego
Minería de Datos Árboles de Decisión Cristina Tîrnăucă Dept. Matesco, Universidad de Cantabria Fac. Ciencias Ing. Informática Otoño de 2012 Twenty questions Intuición sobre los árboles de decisión Juego
TRABAJO FIN DE ASIGNATURA
 INTELIGENCIA EN REDES DE COMUNICACIONES TRABAJO FIN DE ASIGNATURA Luis Javier Duque Cuadrado 1 Breve descripción de los algoritmos elegidos 1.1 Clasificación a) Árboles de decisión de un nivel (decision
INTELIGENCIA EN REDES DE COMUNICACIONES TRABAJO FIN DE ASIGNATURA Luis Javier Duque Cuadrado 1 Breve descripción de los algoritmos elegidos 1.1 Clasificación a) Árboles de decisión de un nivel (decision
CART s. Walter Sosa-Escudero. Universisad de San Andres y CONICET
 Universisad de San Andres y CONICET Motivacion Modelo flexible e interpretable para la relacion entre Y y X. Arboles: partir el espacio de atributos en rectangulos, y ajustar un modelo simple para Y dentro
Universisad de San Andres y CONICET Motivacion Modelo flexible e interpretable para la relacion entre Y y X. Arboles: partir el espacio de atributos en rectangulos, y ajustar un modelo simple para Y dentro
Introducción Clustering jerárquico Clustering particional Clustering probabilista Conclusiones. Clustering. Clasificación no supervisada
 Clustering Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Clustering jerárquico 3 Clustering particional 4 Clustering probabilista 5 Conclusiones Introducción Objetivos
Clustering Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Clustering jerárquico 3 Clustering particional 4 Clustering probabilista 5 Conclusiones Introducción Objetivos
PARTE II: ALGORÍTMICA
 Programa de teoría Parte I. Estructuras de Datos.. Abstracciones y especificaciones.. Conjuntos y diccionarios.. Representación de conjuntos mediante árboles. 4. Grafos. Parte II. Algorítmica.. Análisis
Programa de teoría Parte I. Estructuras de Datos.. Abstracciones y especificaciones.. Conjuntos y diccionarios.. Representación de conjuntos mediante árboles. 4. Grafos. Parte II. Algorítmica.. Análisis
Programa de teoría. Algoritmos y Estructuras de Datos II. 3. Algoritmos voraces. 1. Análisis de algoritmos 2. Divide y vencerás
 Programa de teoría Algoritmos y Estructuras de Datos II 1. Análisis de algoritmos 2. Divide y vencerás 3. Algoritmos voraces 4. Programación dinámica 5. Backtracking 6. Ramificación y poda A.E.D. II 1
Programa de teoría Algoritmos y Estructuras de Datos II 1. Análisis de algoritmos 2. Divide y vencerás 3. Algoritmos voraces 4. Programación dinámica 5. Backtracking 6. Ramificación y poda A.E.D. II 1
Tema 7: Aprendizaje de árboles de decisión
 Inteligencia Artificial 2 Curso 2002 03 Tema 7: Aprendizaje de árboles de decisión José A. Alonso Jiménez Miguel A. Gutiérrez Naranjo Francisco J. Martín Mateos José L. Ruiz Reina Dpto. de Ciencias de
Inteligencia Artificial 2 Curso 2002 03 Tema 7: Aprendizaje de árboles de decisión José A. Alonso Jiménez Miguel A. Gutiérrez Naranjo Francisco J. Martín Mateos José L. Ruiz Reina Dpto. de Ciencias de
Análisis de Datos. Combinación de clasificadores. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Combinación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción Diversos algoritmos de clasificación están limitados a resolver problemas binarios, es decir, con dos
Análisis de Datos Combinación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción Diversos algoritmos de clasificación están limitados a resolver problemas binarios, es decir, con dos
Métodos de Inteligencia Artificial
 Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden: Clasificador Bayesiano Clasificación Clasificador
Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden: Clasificador Bayesiano Clasificación Clasificador
Análisis de Datos. Validación de clasificadores. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Validación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción La mayoría de los clasificadores que se han visto requieren de uno o más parámetros definidos libremente,
Análisis de Datos Validación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción La mayoría de los clasificadores que se han visto requieren de uno o más parámetros definidos libremente,
3. Árboles de decisión
 3.1 Introducción Método para aproximación de funciones objetivo que tengan valores discretos (clasificación) Uno de los métodos mas extensamente usados para inferencia inductiva Capaz de aprender hipótesis
3.1 Introducción Método para aproximación de funciones objetivo que tengan valores discretos (clasificación) Uno de los métodos mas extensamente usados para inferencia inductiva Capaz de aprender hipótesis
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur MODELOS: ÁRBOLES DE DECISIÓN Y REGLAS Datos de entrada 91 71 75 81 Nublado 90 72 Nublado 70 75 80 75 70
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur MODELOS: ÁRBOLES DE DECISIÓN Y REGLAS Datos de entrada 91 71 75 81 Nublado 90 72 Nublado 70 75 80 75 70
Tópicos Selectos en Aprendizaje Maquinal. Clasificación y Regresión con Datos Reales
 Tópicos Selectos en Aprendizaje Maquinal Guía de Trabajos Prácticos N 2 Clasificación y Regresión con Datos Reales 18 de septiembre de 2014 1. Objetivos Introducir conceptos básicos de aprendizaje automático.
Tópicos Selectos en Aprendizaje Maquinal Guía de Trabajos Prácticos N 2 Clasificación y Regresión con Datos Reales 18 de septiembre de 2014 1. Objetivos Introducir conceptos básicos de aprendizaje automático.
Árboles de decisión en aprendizaje automático y minería de datos
 Árboles de decisión en aprendizaje automático y minería de datos Tratamiento Inteligente de la Información y Aplicaciones Juan A. Botía Departamento de Ingeniería de la Información y las Comunicaciones
Árboles de decisión en aprendizaje automático y minería de datos Tratamiento Inteligente de la Información y Aplicaciones Juan A. Botía Departamento de Ingeniería de la Información y las Comunicaciones
ALGORITMO ID3. Objetivo
 ALGORITMO ID3 Desarrollado por J. Ross Quinlan en 1983. ID3 significa Induction Decision Trees. Pertenece a la familia TDIDT (Top- Down Induction of Decision Trees). Objetivo Construir un árbol de decisión
ALGORITMO ID3 Desarrollado por J. Ross Quinlan en 1983. ID3 significa Induction Decision Trees. Pertenece a la familia TDIDT (Top- Down Induction of Decision Trees). Objetivo Construir un árbol de decisión
Capítulo 8. Árboles. Continuar
 Capítulo 8. Árboles Continuar Introducción Uno de los problemas principales para el tratamiento de los grafos es que no guardan una estructura establecida y que no respetan reglas, ya que la relación entre
Capítulo 8. Árboles Continuar Introducción Uno de los problemas principales para el tratamiento de los grafos es que no guardan una estructura establecida y que no respetan reglas, ya que la relación entre
PARTE II: ALGORÍTMICA
 PARTE II: ALGORÍTMICA 5.. Método general 5.2. Análisis de tiempos de ejecución 5.3. Ejemplos de aplicación 5.3.. Problema de la mochila 0/ 5.3.2. Problema de la asignación 5.3.3. Resolución de juegos A.E.D.
PARTE II: ALGORÍTMICA 5.. Método general 5.2. Análisis de tiempos de ejecución 5.3. Ejemplos de aplicación 5.3.. Problema de la mochila 0/ 5.3.2. Problema de la asignación 5.3.3. Resolución de juegos A.E.D.
INTRODUCTION TO MACHINE LEARNING ISABELLE GUYON
 INTRODUCTION TO MACHINE LEARNING ISABELLE GUYON 2008-02-31 Notas tomadas por: María Eugenia Rojas Qué es Machine Learning? El proceso de aprendizaje de maquina consiste en tener una gran base de datos
INTRODUCTION TO MACHINE LEARNING ISABELLE GUYON 2008-02-31 Notas tomadas por: María Eugenia Rojas Qué es Machine Learning? El proceso de aprendizaje de maquina consiste en tener una gran base de datos
Minería de datos (Algoritmos evolutivos)
") Minería de datos (Algoritmos evolutivos) M. en C. Sergio Luis Pérez Pérez UAM CUAJIMALPA, MÉXICO, D. F. Trimestre 14-I. Sergio Luis Pérez (UAM CUAJIMALPA) Curso de minería de datos 1 / 23 Extracción de
Minería de datos (Algoritmos evolutivos) M. en C. Sergio Luis Pérez Pérez UAM CUAJIMALPA, MÉXICO, D. F. Trimestre 14-I. Sergio Luis Pérez (UAM CUAJIMALPA) Curso de minería de datos 1 / 23 Extracción de
Análisis y Complejidad de Algoritmos. Arboles Binarios. Arturo Díaz Pérez
 Análisis y Complejidad de Algoritmos Arboles Binarios Arturo Díaz Pérez Arboles Definiciones Recorridos Arboles Binarios Profundidad y Número de Nodos Arboles-1 Arbol Un árbol es una colección de elementos,
Análisis y Complejidad de Algoritmos Arboles Binarios Arturo Díaz Pérez Arboles Definiciones Recorridos Arboles Binarios Profundidad y Número de Nodos Arboles-1 Arbol Un árbol es una colección de elementos,
Tema 2: Introducción a scikit-learn
 Tema 2: Introducción a scikit-learn José Luis Ruiz Reina Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla Razonamiento asistido por computador, 2017-18 Ejemplo:
Tema 2: Introducción a scikit-learn José Luis Ruiz Reina Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla Razonamiento asistido por computador, 2017-18 Ejemplo:
CI5438. Inteligencia Artificial II Clase 4: Aprendizaje en Árboles. Cap 18.3: RN
 CI5438. Inteligencia Artificial II Clase 4: Aprendizaje en Árboles de Decisión Cap 18.3: RN Universidad Simón Boĺıvar 5 de octubre de 2009 Árboles de Decisión Un árbol de decisión es un árbol de búsqueda
CI5438. Inteligencia Artificial II Clase 4: Aprendizaje en Árboles de Decisión Cap 18.3: RN Universidad Simón Boĺıvar 5 de octubre de 2009 Árboles de Decisión Un árbol de decisión es un árbol de búsqueda
ÁRBOLES CRISTIAN ALFREDO MUÑOZ ÁLVAREZ JUAN DAVID LONDOÑO CASTRO JUAN PABLO CHACÓN PEÑA EDUARDO GONZALES
 ÁRBOLES CRISTIAN ALFREDO MUÑOZ ÁLVAREZ JUAN DAVID LONDOÑO CASTRO JUAN PABLO CHACÓN PEÑA EDUARDO GONZALES ÁRBOL Un árbol es un grafo no dirigido, conexo, sin ciclos (acíclico), y que no contiene aristas
ÁRBOLES CRISTIAN ALFREDO MUÑOZ ÁLVAREZ JUAN DAVID LONDOÑO CASTRO JUAN PABLO CHACÓN PEÑA EDUARDO GONZALES ÁRBOL Un árbol es un grafo no dirigido, conexo, sin ciclos (acíclico), y que no contiene aristas
Segmentación de una cartera de clientes usando aprendizaje de máquina
 Inicio Segmentación de una cartera de clientes usando aprendizaje de máquina Universidad San Ignacio de Loyola I encuentro interdisciplinario de investigación desarrollo y tecnología USIL 2014 Inicio Inicio
Inicio Segmentación de una cartera de clientes usando aprendizaje de máquina Universidad San Ignacio de Loyola I encuentro interdisciplinario de investigación desarrollo y tecnología USIL 2014 Inicio Inicio
Elementos de máquinas de vectores de soporte
 Elementos de máquinas de vectores de soporte Clasificación binaria y funciones kernel Julio Waissman Vilanova Departamento de Matemáticas Universidad de Sonora Seminario de Control y Sistemas Estocásticos
Elementos de máquinas de vectores de soporte Clasificación binaria y funciones kernel Julio Waissman Vilanova Departamento de Matemáticas Universidad de Sonora Seminario de Control y Sistemas Estocásticos
Carteras minoristas. árbol de decisión. Ejemplo: Construcción de un scoring de concesión basado en un DIRECCIÓN GENERAL DE SUPERVISIÓN
 Carteras minoristas Ejemplo: Construcción de un scoring de concesión basado en un árbol de decisión Grupo de Tesorería y Modelos de Gestión de Riesgos Sergio Gavilá II Seminario sobre Basilea II Validación
Carteras minoristas Ejemplo: Construcción de un scoring de concesión basado en un árbol de decisión Grupo de Tesorería y Modelos de Gestión de Riesgos Sergio Gavilá II Seminario sobre Basilea II Validación
Aprendizaje inductivo no basado en el error Métodos competitivos supervisados.
 Aprendizaje inductivo no basado en el error Métodos competitivos supervisados. Aprendizaje basado en instancias Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido
Aprendizaje inductivo no basado en el error Métodos competitivos supervisados. Aprendizaje basado en instancias Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido
Scoring No Clientes (Modelización con información Big Data)
") Trabajo Fin de Máster Scoring No Clientes (Modelización con información Big Data) Iria Cañete Quian Máster en Técnicas Estadísticas Curso 2017-2018 ii Propuesta de Trabajo Fin de Máster iii iv Título en
Trabajo Fin de Máster Scoring No Clientes (Modelización con información Big Data) Iria Cañete Quian Máster en Técnicas Estadísticas Curso 2017-2018 ii Propuesta de Trabajo Fin de Máster iii iv Título en
Analizando patrones de datos
 Analizando patrones de datos SQL Server DM, Excel DM, Azure ML y R Ana María Bisbé York @ambynet http://amby.net/ Temario Introducción a Minería de datos MS Office Excel Herramientas de tabla y Minería
Analizando patrones de datos SQL Server DM, Excel DM, Azure ML y R Ana María Bisbé York @ambynet http://amby.net/ Temario Introducción a Minería de datos MS Office Excel Herramientas de tabla y Minería
Inducción de Árboles de Decisión ID3, C4.5
 Inducción de Árboles de Decisión ID3, C4.5 Contenido 1. Representación mediante árboles de decisión. 2. Algoritmo básico: divide y vencerás. 3. Heurística para la selección de atributos. 4. Espacio de
Inducción de Árboles de Decisión ID3, C4.5 Contenido 1. Representación mediante árboles de decisión. 2. Algoritmo básico: divide y vencerás. 3. Heurística para la selección de atributos. 4. Espacio de
Lingüística computacional
 Lingüística computacional Definición y alcance Escuela Nacional de Antropología e Historia (ENAH) Agosto diciembre de 2015 Lingüística Ciencias de la computación Lingüística computacional Estudio del lenguaje
Lingüística computacional Definición y alcance Escuela Nacional de Antropología e Historia (ENAH) Agosto diciembre de 2015 Lingüística Ciencias de la computación Lingüística computacional Estudio del lenguaje
Conjuntos de Clasificadores (Ensemble Learning)
") Aprendizaje Automático Segundo Cuatrimestre de 2016 Conjuntos de Clasificadores (Ensemble Learning) Gracias a Ramiro Gálvez por la ayuda y los materiales para esta clase. Bibliografía: S. Fortmann-Roe,
Aprendizaje Automático Segundo Cuatrimestre de 2016 Conjuntos de Clasificadores (Ensemble Learning) Gracias a Ramiro Gálvez por la ayuda y los materiales para esta clase. Bibliografía: S. Fortmann-Roe,
Examen Parcial. Attr1: A, B Attr2: A, B, C Attr3 1, 2, 3 Attr4; a, b Attr5: 1, 2, 3, 4
 Aprenentatge 0-03 Q Examen Parcial Nombre: (Examen ) Instrucciones. (0 puntos) Este examen dura horas. Responded todas las preguntas en estas hojas. Para las preguntas test poned un circulo alrededor de
Aprenentatge 0-03 Q Examen Parcial Nombre: (Examen ) Instrucciones. (0 puntos) Este examen dura horas. Responded todas las preguntas en estas hojas. Para las preguntas test poned un circulo alrededor de
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur EVALUACIÓN Evaluación: entrenamiento y test Una vez obtenido el conocimiento es necesario validarlo para
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur EVALUACIÓN Evaluación: entrenamiento y test Una vez obtenido el conocimiento es necesario validarlo para
IIC3633 Sistemas Recomendadores Functional Matrix Factorizations for Cold-Start Recommendation. Juan Navarro
 IIC3633 Sistemas Recomendadores Functional Matrix Factorizations for Cold-Start Recommendation Juan Navarro Referencia Zhou, K., Yang, S., and Zha, H. Functional matrix factorizations for cold-start recommendation.
IIC3633 Sistemas Recomendadores Functional Matrix Factorizations for Cold-Start Recommendation Juan Navarro Referencia Zhou, K., Yang, S., and Zha, H. Functional matrix factorizations for cold-start recommendation.
1. Método general. 2. Análisis de tiempos de ejecución. 3. Ejemplos de aplicación Problema de las 8 reinas Problema de la mochila 0/1.
 Backtracking. Método general. 2. Análisis de tiempos de ejecución. 3. Ejemplos de aplicación. 3.. Problema de las 8 reinas. 3.2. Problema de la mochila 0/. Método general El backtracking (método de retroceso
Backtracking. Método general. 2. Análisis de tiempos de ejecución. 3. Ejemplos de aplicación. 3.. Problema de las 8 reinas. 3.2. Problema de la mochila 0/. Método general El backtracking (método de retroceso
EPB 603 Sistemas del Conocimiento
 EPB 603 Sistemas del Conocimiento Dr. Oldemar Rodríguez R. Maestría en Administración de la Tecnología de la Información Escuela de Informática EIA411 EPB 603 - Minería Sistemas de del Datos Conocimiento
EPB 603 Sistemas del Conocimiento Dr. Oldemar Rodríguez R. Maestría en Administración de la Tecnología de la Información Escuela de Informática EIA411 EPB 603 - Minería Sistemas de del Datos Conocimiento
Análisis de Datos. Introducción al aprendizaje supervisado. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Desde la antigüedad, el problema de buscar patrones en datos es fundamental en diversas
Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Desde la antigüedad, el problema de buscar patrones en datos es fundamental en diversas
Métodos Predictivos en Minería de Datos
 Métodos Predictivos en Minería de Datos Tutor: El curso será impartido por Dr. Oldemar Rodríguez graduado de la Universidad de París IX y con un postdoctorado de la Universidad de Stanford. Duración: Cuatro
Métodos Predictivos en Minería de Datos Tutor: El curso será impartido por Dr. Oldemar Rodríguez graduado de la Universidad de París IX y con un postdoctorado de la Universidad de Stanford. Duración: Cuatro
D conjunto de N patrones etiquetados, cada uno de los cuales está caracterizado por n variables predictoras X 1,..., X n y la variable clase C.
 Tema 10. Árboles de Clasificación Pedro Larrañaga, Iñaki Inza, Abdelmalik Moujahid Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad del País Vasco Euskal Herriko Unibertsitatea
Tema 10. Árboles de Clasificación Pedro Larrañaga, Iñaki Inza, Abdelmalik Moujahid Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad del País Vasco Euskal Herriko Unibertsitatea
Apellidos:... Nombre:...
 Ejercicio 1 (1.5 puntos): Cuestiones Contestar a las siguientes preguntas de manera clara y concisa, usando el espacio en blanco que se deja a continuación: 1. Qué es un unificador de dos átomos? Describir
Ejercicio 1 (1.5 puntos): Cuestiones Contestar a las siguientes preguntas de manera clara y concisa, usando el espacio en blanco que se deja a continuación: 1. Qué es un unificador de dos átomos? Describir