Arquitecturas GPU v. 2015
|
|
|
- Gregorio Botella Carmona
- hace 6 años
- Vistas:
Transcripción

1 v units
2 GPU (Unidad de procesamiento gráfico) Retorno al concepto de COPROCESADOR: * Uno o varios procesadores con su propio repertorio de instrucciones (o el mismo) y memoria propia (aunque no siempre) conectado como un dispositivo de hardware adicionales en el sistema. * Se accede como cualquier otro dispositivo de I/O (comandos o DMA) a través de los buses del sistema. Ej. PCI-Express, AGP. * Para el software es otro núcleo al cual se le envían datos y rutinas para procesar. Marcas clásicas, en dispositivos independientes: - NVIDIA GeForce (juegos), Quadro (profesionales) - AMD ATI. Ahora vienen incoporados en la CPU: APU - AMD Phenom-II y Fusion - Intel Ivy-bridge
 GPU")
3 APU (accelerated processing unit) CPU multinúcleo + GPU + Bus de interconexión + Controlador de memoria Ivy Bridge processor, based on 22nm technology, packs a 4-core CPU and a 16-EU (or 16 shader cores) GPU HD4000

4 Organización sistema con GPU m
 o GPU de propósito general.")

5 GP-GPU * Entre los años 1999 y 2000, investigadores del sector informático y de otras disciplinas empezaron a utilizar las GPU para acelerar diversas aplicaciones de cálculo. * Este tipo de aplicación recibe el nombre de General Purpose GPU (GP-GPU) o GPU de propósito general. Sin embargo inicialmente no existían interfaces de programación especialmente dedicadas a este tipo de aplicación, dificultando el desarrollo * 2007 CUDA (Compute Unified Device Architecture) SDK, incluye un compilador con extensiones para C. Aún implica reescritura y reestructuración del programa y el código no es ejecutable en x86. * 2009 OpenCL (Open Computing Language) Plataforma un poco más genérica que CUDA. Para programa algoritmos paralelos en CPU, GPU, DSP, FPGA. Impulsado por Apple, Intel, Qualcomm, AMD, Nvidia, Altera, Samsung, Vivante, Imagination Technologies and ARM. * 2013 OpenACC (Open ACCelerators) Extensiones para código C, C++ y Fortran que permiten al programador especificarle al compilador como ejecutar el programa en paralelo. Cray, CAPS, Nvidia, PGI.
6 GP-GPU * 2010 Primeras GPU exclusivamente para cálculo: NVIDIA Tesla ( es GPU?) * 2012 Intel sale a competir en el mercado del cómputo científico. Xeon Phi ( es GPU?)
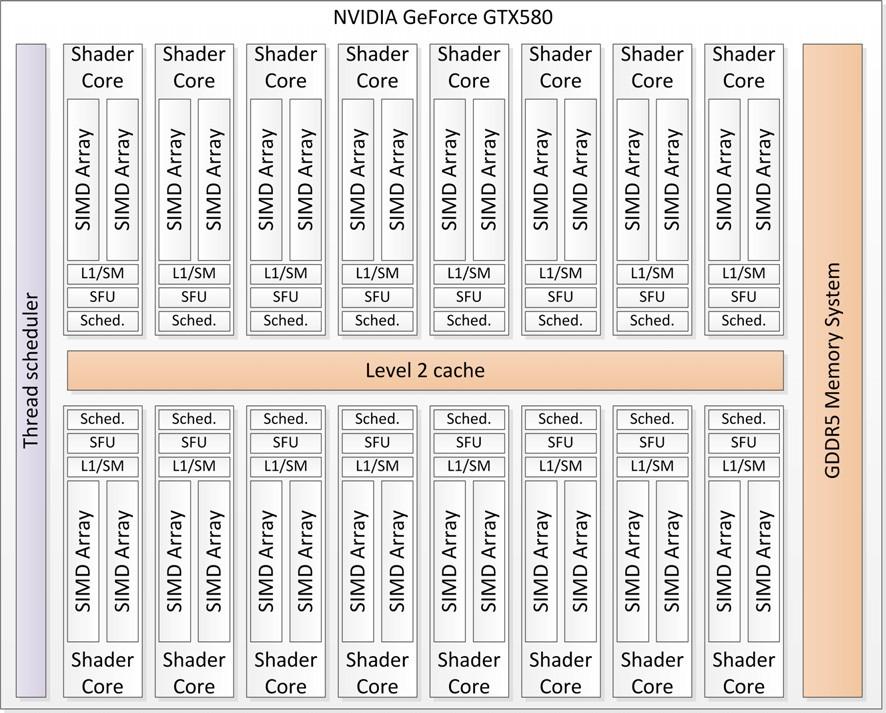
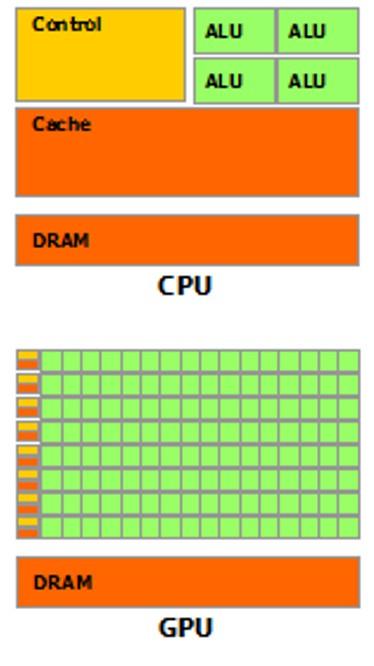
7 GP-GPU

8 NVIDIA CUDA * La resolución del problema se realiza mediante threads paralelos diminutos expresados en un kernel. * El programador agrupa los threads en bloques y los encola para para su ejecución en la GPU. * Ya en la GPU, el thread scheduler envía los bloques a los Streaming Multiprocessors que estén disponibles. * Cada SM ejecuta simultáneamente múltiples bloques haciendo temporal multithreading.
9 NVIDIA CUDA - SIMT * El hardware subdivide los bloques en grupos de 32 threads, llamados warps. * Todos los threads de un mismo warp se ejecutan en lock-step: todos los que están activos simultáneamente realizan la misma instrucción. * La metodología es similar a SIMD, ya que existe un único decodificador de instrucción para los 32 threads del warp, pero NO ES SIMD... * Cada miembro del thread tiene su propio contador de programa. En las bifurcaciones, los miembros del warp pueden diverger. La característica vectorial es invisible al programador, que puede no tenerla en cuenta, el hardware se encarga de ocultarla. * Pero si no la tiene en cuenta SE PAGA FUERTEMENTE EN PERFORMANCE. * NVIDIA llama a esto SIMT (Single Instruction Multiple Thread).

10 NVIDIA CUDA Temporal Multithreading * Cada unidad de cálculo ejecuta las instrucciones en orden y sin predicción de saltos. * Las latencias de las instrucciones pueden ser de decenas de ciclos de reloj, incluso centenas si hay accessos a memoria global. * Para ocultar la latencia cada SM intercala la ejecución de diferentes warps en las unidades de procesamiento, siempre buscando warps cuyas dependencias estén satisfechas. * Es responsabilidad del usuario que en todo momento hayan suficientes warps listos para ser ejecutados, o de lo contrario el SM tendrá que esperar y se pierde throughput.
11 NVIDIA CUDA - Performance * Generar suficiente trabajo para esconder la latencia de las instrucciones. * Evitar las bifurcaciones dentro de los warps. * Limitar el uso de variables DOUBLE a donde sea estrictamente necesario. * Respetar las limitaciones de la jerarquía de memoria: accesos alineados a memoria global, evitar las colisiones en memoria compartida, minimizar la cantidad de registros utilizados para no necesitar memoria local. * Dimensionar adecuadamente las unidades de trabajo!!! 440 puede parecer un número como cualquier otro para la cantidad de threads por bloque, pero ni es múltiplo de la cantidad de threads por warp (32), ni divide la cantidad de threads que aceptan típicamente las SM (256, 512, 768, etc.) por lo que las subutilizará. * Tener en cuenta las características de la GPU que se utilizará: lo óptimo en una GeForce puede ser nefasto en una Tesla (diferentes capacidades de SMs, arquitecturas de memoria diferentes, diferentes cantidades de unidades de procesamiento).
12 NVIDIA CUDA Ejemplo de kernel Ejemplo de kernel CUDA. El siguiente kernel realiza todo el trabajo en GPU necesario para hacer la operación A = α * X * XT + A Donde α es un escalar, X es un vector de largo n, y A es una matriz triangular superior de n2 elementos. En este programa n2 threads ejecutan sendas copias del código del kernel para realizar la operación matricial completa.

13 AMD ATI Similares en su organización interna a NVIDIA Se programan en OpenCL.

14 Xeon Phi No arrastran la herencia de GPU. En su lugar arrastran la herencia x86. Diseñados para cálculo científico. * 60 cores simples basados en P5 (Pentium!). * Cada core es superescalar, con Hyper-Threading de cuatro vías. * Set de instrucciones x86, con extensiones x64 y SIMD de 512 bits de ancho. * Caches coherentes de todos los cores. * OpenMP, OpenCL. Más cercano a la programación de multicores que a la de GPUs.
")
15 Intel Xeon Phi Knight's Landing Processor (72 cores) Die Map
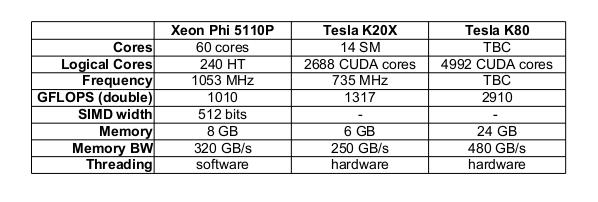
16 GP-GPU - Prestaciones
17 - fin -
Arquitecturas GPU v. 2013
 v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU. Clase 0 Lanzamiento del Curso. Motivación
 Computación de Propósito General en Unidades de Procesamiento Gráfico () Pablo Ezzatti, Martín Pedemonte Clase 0 Lanzamiento del Curso Contenido Evolución histórica en Fing Infraestructura disponible en
Computación de Propósito General en Unidades de Procesamiento Gráfico () Pablo Ezzatti, Martín Pedemonte Clase 0 Lanzamiento del Curso Contenido Evolución histórica en Fing Infraestructura disponible en
Arquitectura de aceleradores. Carlos Bederián IFEG CONICET GPGPU Computing Group FaMAF UNC bc@famaf.unc.edu.ar
 Arquitectura de aceleradores Carlos Bederián IFEG CONICET GPGPU Computing Group FaMAF UNC bc@famaf.unc.edu.ar Contenidos Cómo llegamos hasta acá Qué hay ahora Qué hace Cómo lo uso Hacia dónde parece que
Arquitectura de aceleradores Carlos Bederián IFEG CONICET GPGPU Computing Group FaMAF UNC bc@famaf.unc.edu.ar Contenidos Cómo llegamos hasta acá Qué hay ahora Qué hace Cómo lo uso Hacia dónde parece que
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
Seminario II: Introducción a la Computación GPU
 Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
Seminario II: Introducción a la Computación GPU CONTENIDO Introducción Evolución CPUs-Evolución GPUs Evolución sistemas HPC Tecnologías GPGPU Problemática: Programación paralela en clústers heterogéneos
Computación heterogénea y su programación. 1. Introducción a la computación heterogénea. Indice de contenidos [38 diapositivas]
![Computación heterogénea y su programación. 1. Introducción a la computación heterogénea. Indice de contenidos [38 diapositivas]](/thumbs/25/5865829.jpg "Computación heterogénea y su programación. 1. Introducción a la computación heterogénea. Indice de contenidos [38 diapositivas]") Computación heterogénea y su programación Manuel Ujaldón Nvidia CUDA Fellow Departmento de Arquitectura de Computadores Universidad de Málaga (España) Indice de contenidos [38 diapositivas] 1. Introducción
Computación heterogénea y su programación Manuel Ujaldón Nvidia CUDA Fellow Departmento de Arquitectura de Computadores Universidad de Málaga (España) Indice de contenidos [38 diapositivas] 1. Introducción
Arquitecturas vectoriales, SIMD y extensiones multimedia
 Arquitecturas vectoriales, SIMD y extensiones multimedia William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo. Andrew S. Tanenbaum, Organización
Arquitecturas vectoriales, SIMD y extensiones multimedia William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo. Andrew S. Tanenbaum, Organización
Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)
![Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)](/thumbs/36/17576386.jpg "Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)") Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial
 Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial Intel ha lanzado su procesador Xeon Phi en la Conferencia Internacional de Supercomputación de Alemania. El procesador
Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial Intel ha lanzado su procesador Xeon Phi en la Conferencia Internacional de Supercomputación de Alemania. El procesador
Múltiples GPU (y otras chauchas)
") Múltiples GPU (y otras chauchas) Clase 16, 21/11/2013 http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Carlos Bederián bc@famaf.unc.edu.ar IFEG-CONICET, FaMAF-UNC Motivación No desperdiciar
Múltiples GPU (y otras chauchas) Clase 16, 21/11/2013 http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Carlos Bederián bc@famaf.unc.edu.ar IFEG-CONICET, FaMAF-UNC Motivación No desperdiciar
Primeros pasos con CUDA. Clase 1
 Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Tile64 Many-Core. vs. Intel Xeon Multi-Core
 Tile64 Many-Core vs. Intel Xeon Multi-Core Comparación del Rendimiento en Bioinformática Myriam Kurtz Francisco J. Esteban Pilar Hernández Juan Antonio Caballero Antonio Guevara Gabriel Dorado Sergio Gálvez
Tile64 Many-Core vs. Intel Xeon Multi-Core Comparación del Rendimiento en Bioinformática Myriam Kurtz Francisco J. Esteban Pilar Hernández Juan Antonio Caballero Antonio Guevara Gabriel Dorado Sergio Gálvez
PREGUNTAS INFORMÁTICA MONITOR UPB EXAMEN 1
 PREGUNTAS INFORMÁTICA MONITOR UPB EXAMEN 1 1. Cuál de los siguientes componentes no forma parte del esquema general de un ordenador? A Memoria Principal B Disco Duro C Unidad de Control D Unidad Aritmético
PREGUNTAS INFORMÁTICA MONITOR UPB EXAMEN 1 1. Cuál de los siguientes componentes no forma parte del esquema general de un ordenador? A Memoria Principal B Disco Duro C Unidad de Control D Unidad Aritmético
Programación de GPUs con CUDA
 Programación de GPUs con CUDA Alvaro Cuno 23/01/2010 1 Agenda GPUs Cuda Cuda + OpenGL 2 GPUs (Graphics Processing Units) 3 Supercomputadores Mapa de los 100 supercomputadores Sudamérica: posiciones 306
Programación de GPUs con CUDA Alvaro Cuno 23/01/2010 1 Agenda GPUs Cuda Cuda + OpenGL 2 GPUs (Graphics Processing Units) 3 Supercomputadores Mapa de los 100 supercomputadores Sudamérica: posiciones 306
Instituto Tecnológico de Morelia
 Instituto Tecnológico de Morelia Arquitectura de Computadoras Unidad 1a Programa 1 Modelo de arquitecturas de cómputo. 1.1 Modelos de arquitecturas de cómputo. 1.1.1 Clásicas. 1.1.2 Segmentadas. 1.1.3
Instituto Tecnológico de Morelia Arquitectura de Computadoras Unidad 1a Programa 1 Modelo de arquitecturas de cómputo. 1.1 Modelos de arquitecturas de cómputo. 1.1.1 Clásicas. 1.1.2 Segmentadas. 1.1.3
ELEMENTOS HARDWARE DEL ORDENADOR. Tarjeta gráfica
 ELEMENTOS HARDWARE DEL ORDENADOR Tarjeta gráfica Qué es? Tarjeta Gráfica 1. Interpreta los datos que le llegan del procesador, ordenándolos y calculando el valor de cada píxel, lo almacena en la memoria
ELEMENTOS HARDWARE DEL ORDENADOR Tarjeta gráfica Qué es? Tarjeta Gráfica 1. Interpreta los datos que le llegan del procesador, ordenándolos y calculando el valor de cada píxel, lo almacena en la memoria
INFORMATICA III. Capítulo I: Plataformas
 INFORMATICA III Capítulo I: Plataformas Plataformas Hardware Modelos de sistemas Sistemas operativos Herramientas de desarrollo Informática III Pág. 2 Plataformas Hardware Modelos de sistemas Sistemas
INFORMATICA III Capítulo I: Plataformas Plataformas Hardware Modelos de sistemas Sistemas operativos Herramientas de desarrollo Informática III Pág. 2 Plataformas Hardware Modelos de sistemas Sistemas
Familia de procesadores Intel x86
 Familia de procesadores Intel x86 Mario Medina C. mariomedina@udec.cl Intel 8086 y 8088 8086: 1978, 29K transistores 8 Registros de 16 bits Bus de datos de 16 bits Bus de dirección de 20 bits Multiplexado
Familia de procesadores Intel x86 Mario Medina C. mariomedina@udec.cl Intel 8086 y 8088 8086: 1978, 29K transistores 8 Registros de 16 bits Bus de datos de 16 bits Bus de dirección de 20 bits Multiplexado
Técnicas SuperEscalares en la Paralelización de Bibliotecas de Computación Matricial sobre Procesadores Multinúcleo y GPUs
 Técnicas SuperEscalares en la Paralelización de Bibliotecas de Computación Matricial sobre Procesadores Multinúcleo y GPUs Enrique S. Quintana-Ortí quintana@icc.uji.es High Performance Computing & Architectures
Técnicas SuperEscalares en la Paralelización de Bibliotecas de Computación Matricial sobre Procesadores Multinúcleo y GPUs Enrique S. Quintana-Ortí quintana@icc.uji.es High Performance Computing & Architectures
INEL 4206 Microprocesadores Texto: Barry B Brey, The Intel Microprocessors: 8va. Ed., Prentice Hall, 2009
 Introducción al Curso Microprocesadores INEL 4206 Microprocesadores Texto: Barry B Brey, The Intel Microprocessors: Architecture, Programming and Interfacing. 8va. Ed., Prentice Hall, 2009 Prof. José Navarro
Introducción al Curso Microprocesadores INEL 4206 Microprocesadores Texto: Barry B Brey, The Intel Microprocessors: Architecture, Programming and Interfacing. 8va. Ed., Prentice Hall, 2009 Prof. José Navarro
FLAG/C. Una API para computación matricial sobre GPUs. M. Jesús Zafont Alberto Martín Francisco Igual Enrique S. Quintana-Ortí
 FLAG/C Una API para computación matricial sobre GPUs M. Jesús Zafont Alberto Martín Francisco Igual Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universitat Jaume I de Castellón
FLAG/C Una API para computación matricial sobre GPUs M. Jesús Zafont Alberto Martín Francisco Igual Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universitat Jaume I de Castellón
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Organización del Computador I. Introducción e Historia
 Organización del Computador I Introducción e Historia Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz de
Organización del Computador I Introducción e Historia Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz de
FUNCIONAMIENTO DEL ORDENADOR
 FUNCIONAMIENTO DEL ORDENADOR COMPUTACIÓN E INFORMÁTICA Datos de entrada Dispositivos de Entrada ORDENADOR PROGRAMA Datos de salida Dispositivos de Salida LOS ORDENADORES FUNCIONAN CON PROGRAMAS Los ordenadores
FUNCIONAMIENTO DEL ORDENADOR COMPUTACIÓN E INFORMÁTICA Datos de entrada Dispositivos de Entrada ORDENADOR PROGRAMA Datos de salida Dispositivos de Salida LOS ORDENADORES FUNCIONAN CON PROGRAMAS Los ordenadores
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS
 INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano sorts@dtic.ua.es Vicente Morell Giménez vmorell@dccia.ua.es Universidad de Alicante Departamento de tecnología informática y computación
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano sorts@dtic.ua.es Vicente Morell Giménez vmorell@dccia.ua.es Universidad de Alicante Departamento de tecnología informática y computación
cuevogenet Paralelización en CUDA de la Dinámica Evolutiva de Redes Génicas Dirigido por: Fernando Díaz del Río José Luis Guisado Lizar
 cuevogenet Paralelización en CUDA de la Dinámica Evolutiva de Redes Génicas Realizado por: Raúl García Calvo Dirigido por: Fernando Díaz del Río José Luis Guisado Lizar Objetivos Implementar un algoritmo
cuevogenet Paralelización en CUDA de la Dinámica Evolutiva de Redes Génicas Realizado por: Raúl García Calvo Dirigido por: Fernando Díaz del Río José Luis Guisado Lizar Objetivos Implementar un algoritmo
Introducción a la arquitectura de computadores
 Introducción a la arquitectura de computadores Departamento de Arquitectura de Computadores Arquitectura de computadores Se refiere a los atributos visibles por el programador que trabaja en lenguaje máquina
Introducción a la arquitectura de computadores Departamento de Arquitectura de Computadores Arquitectura de computadores Se refiere a los atributos visibles por el programador que trabaja en lenguaje máquina
Intel XeonPhi Workshop
 Intel XeonPhi Workshop Elena Núñez-González Unidad Informática Científica - CIEMAT Madrid, 11 de Febrero de 2015 Evento Lugar, Fecha Índice Introducción MIC Intel Xeon Phi Arquitectura Intel Xeon Phi Entorno
Intel XeonPhi Workshop Elena Núñez-González Unidad Informática Científica - CIEMAT Madrid, 11 de Febrero de 2015 Evento Lugar, Fecha Índice Introducción MIC Intel Xeon Phi Arquitectura Intel Xeon Phi Entorno
Introducción a los Sistemas Operativos
 Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
FUNDAMENTOS DE COMPUTACION INVESTIGACION PROCESADORES DIANA CARRIÓN DEL VALLE DOCENTE: JOHANNA NAVARRO ESPINOSA TRIMESTRE II
 FUNDAMENTOS DE COMPUTACION INVESTIGACION PROCESADORES DIANA CARRIÓN DEL VALLE DOCENTE: JOHANNA NAVARRO ESPINOSA TRIMESTRE II 2013 Características principales de la arquitectura del procesador AMD Phenom
FUNDAMENTOS DE COMPUTACION INVESTIGACION PROCESADORES DIANA CARRIÓN DEL VALLE DOCENTE: JOHANNA NAVARRO ESPINOSA TRIMESTRE II 2013 Características principales de la arquitectura del procesador AMD Phenom
Multiplicación de Matrices en Sistemas cc-numa Multicore. Autor: Jesús Cámara Moreno Director: Domingo Giménez Cánovas
 Multiplicación de Matrices en Sistemas cc-numa Multicore Autor: Jesús Cámara Moreno Director: Domingo Giménez Cánovas Índice de Contenido 1. Introducción 2. Línea de Investigación 3. Sistemas Empleados
Multiplicación de Matrices en Sistemas cc-numa Multicore Autor: Jesús Cámara Moreno Director: Domingo Giménez Cánovas Índice de Contenido 1. Introducción 2. Línea de Investigación 3. Sistemas Empleados
Nociones básicas de computación paralela
 Nociones básicas de computación paralela Javier Cuenca 1, Domingo Giménez 2 1 Departamento de Ingeniería y Tecnología de Computadores Universidad de Murcia 2 Departamento de Informática y Sistemas Universidad
Nociones básicas de computación paralela Javier Cuenca 1, Domingo Giménez 2 1 Departamento de Ingeniería y Tecnología de Computadores Universidad de Murcia 2 Departamento de Informática y Sistemas Universidad
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators
 Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Maribel Castillo, Francisco D. Igual, Rafael Mayo, Gregorio Quintana-Ortí, Enrique S. Quintana-Ortí, Robert van de Geijn Grupo
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Maribel Castillo, Francisco D. Igual, Rafael Mayo, Gregorio Quintana-Ortí, Enrique S. Quintana-Ortí, Robert van de Geijn Grupo
UNA NUEVA GENERACIÓN: HÍBRIDOS CPU/GPU. Microprocesadores para Comunicaciones. Paloma Monzón Rodríguez 42217126M
 UNA NUEVA GENERACIÓN: HÍBRIDOS CPU/GPU Microprocesadores para Comunicaciones 2010 Paloma Monzón Rodríguez 42217126M Índice 1. Introducción... 3 2. Unidad Central de Procesamiento (CPU)... 4 Arquitectura
UNA NUEVA GENERACIÓN: HÍBRIDOS CPU/GPU Microprocesadores para Comunicaciones 2010 Paloma Monzón Rodríguez 42217126M Índice 1. Introducción... 3 2. Unidad Central de Procesamiento (CPU)... 4 Arquitectura
Unidad I: Organización del Computador. Ing. Marglorie Colina
 Unidad I: Organización del Computador Ing. Marglorie Colina Arquitectura del Computador Atributos de un sistema que son visibles a un programador (Conjunto de Instrucciones, Cantidad de bits para representar
Unidad I: Organización del Computador Ing. Marglorie Colina Arquitectura del Computador Atributos de un sistema que son visibles a un programador (Conjunto de Instrucciones, Cantidad de bits para representar
Las optimizaciones pueden realizarse de diferentes formas. Las optimizaciones se realizan en base al alcance ofrecido por el compilador.
 Unidad III: Optimización Las optimizaciones pueden realizarse de diferentes formas. Las optimizaciones se realizan en base al alcance ofrecido por el compilador. La optimización va a depender del lenguaje
Unidad III: Optimización Las optimizaciones pueden realizarse de diferentes formas. Las optimizaciones se realizan en base al alcance ofrecido por el compilador. La optimización va a depender del lenguaje
DESARROLLO DE APLICACIONES EN CUDA
 DESARROLLO DE APLICACIONES EN CUDA Curso 2014 / 15 Procesadores Gráficos y Aplicaciones en Tiempo Real Alberto Sánchez GMRV 2005-2015 1/30 Contenidos Introducción Debugging Profiling Streams Diseño de
DESARROLLO DE APLICACIONES EN CUDA Curso 2014 / 15 Procesadores Gráficos y Aplicaciones en Tiempo Real Alberto Sánchez GMRV 2005-2015 1/30 Contenidos Introducción Debugging Profiling Streams Diseño de
HPC y GPUs. GPGPU y software libre. Emilio J. Padrón González DE UNIVERSIDADE DA CORUNA GAC.UDC.ES
 HPC y GPUs GPGPU y software libre Emilio J. Padrón González DE UNIVERSIDADE DA CORUNA GAC.UDC.ES Workshop HPC y Software Libre Ourense, Octubre 2011 Contenidos 1 Introducción Evolución CPUs Evolución GPUs
HPC y GPUs GPGPU y software libre Emilio J. Padrón González DE UNIVERSIDADE DA CORUNA GAC.UDC.ES Workshop HPC y Software Libre Ourense, Octubre 2011 Contenidos 1 Introducción Evolución CPUs Evolución GPUs
Computación Híbrida, Heterogénea y Jerárquica
 Computación Híbrida, Heterogénea y Jerárquica http://www.ditec.um.es/ javiercm/curso psba/ Curso de Programación en el Supercomputador Ben-Arabí, febrero-marzo 2012 Organización aproximada de la sesión,
Computación Híbrida, Heterogénea y Jerárquica http://www.ditec.um.es/ javiercm/curso psba/ Curso de Programación en el Supercomputador Ben-Arabí, febrero-marzo 2012 Organización aproximada de la sesión,
Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria
 que procesa datos siguiendo unas instrucciones almacenadas en su memoria") 1.2. Jerarquía de niveles de un computador Qué es un computador? Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria Es un sistema tan complejo
1.2. Jerarquía de niveles de un computador Qué es un computador? Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria Es un sistema tan complejo
Arquitectura de GPUs
 Arquitectura de GPUs Carlos Bederián, Nicolás Wolovick FaMAF, Universidad Nacional de Córdoba, Argentina 1 de Agosto de 2012 ECAR12@DC.UBA Revisión 3739, 2012-08-02 Introducción Organización GPU: cálculo
Arquitectura de GPUs Carlos Bederián, Nicolás Wolovick FaMAF, Universidad Nacional de Córdoba, Argentina 1 de Agosto de 2012 ECAR12@DC.UBA Revisión 3739, 2012-08-02 Introducción Organización GPU: cálculo
INFORMATICA III. Capítulo I: Plataformas
 INFORMATICA III Capítulo I: Plataformas Plataformas Hardware Modelos de sistemas Sistemas operativos Herramientas de desarrollo Informática III Pág. 2 Plataformas Hardware Modelos de sistemas Sistemas
INFORMATICA III Capítulo I: Plataformas Plataformas Hardware Modelos de sistemas Sistemas operativos Herramientas de desarrollo Informática III Pág. 2 Plataformas Hardware Modelos de sistemas Sistemas
Arquitectura de Computadoras. Anexo Clase 8 Buses del Sistema
 Arquitectura de Computadoras Anexo Clase 8 Buses del Sistema Estructuras de interconexión Todas las unidades han de estar interconectadas. Existen distintos tipos de interconexiones para los distintos
Arquitectura de Computadoras Anexo Clase 8 Buses del Sistema Estructuras de interconexión Todas las unidades han de estar interconectadas. Existen distintos tipos de interconexiones para los distintos
PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS
 Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Threads, SMP y Microkernels. Proceso
 Threads, SMP y Microkernels Proceso Propiedad de los recursos a un proceso se le asigna un espacio de dirección virtual para guardar su imagen Calendarización/ejecución sigue una ruta de ejecución la cual
Threads, SMP y Microkernels Proceso Propiedad de los recursos a un proceso se le asigna un espacio de dirección virtual para guardar su imagen Calendarización/ejecución sigue una ruta de ejecución la cual
CLUSTER FING: ARQUITECTURA Y APLICACIONES
 CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
Qué es un programa informático?
 Qué es un programa informático? Un programa informático es una serie de comandos ejecutados por el equipo. Sin embargo, el equipo sólo es capaz de procesar elementos binarios, es decir, una serie de 0s
Qué es un programa informático? Un programa informático es una serie de comandos ejecutados por el equipo. Sin embargo, el equipo sólo es capaz de procesar elementos binarios, es decir, una serie de 0s
Tema 1: Arquitectura de ordenadores, hardware y software
 Fundamentos de Informática Tema 1: Arquitectura de ordenadores, hardware y software 2010-11 Índice 1. Informática 2. Modelo de von Neumann 3. Sistemas operativos 2 1. Informática INFORMación automática
Fundamentos de Informática Tema 1: Arquitectura de ordenadores, hardware y software 2010-11 Índice 1. Informática 2. Modelo de von Neumann 3. Sistemas operativos 2 1. Informática INFORMación automática
SOPORTE FÍSICO O HARDWARE (I)
") SOPORTE FÍSICO O HARDWARE (I) 4.1. DISTINCIÓN ENTRE SOPORTE TÉCNICO Y SOPORTE LÓGICO 4.2. ESQUEMA DE LA ORGANIZACIÓN FÍSICA DEL ORDENADOR 4.3. LA PLACA BASE 4.4. EL MICROPROCESADOR 4.5. LA 4.6. LOS BUSES
SOPORTE FÍSICO O HARDWARE (I) 4.1. DISTINCIÓN ENTRE SOPORTE TÉCNICO Y SOPORTE LÓGICO 4.2. ESQUEMA DE LA ORGANIZACIÓN FÍSICA DEL ORDENADOR 4.3. LA PLACA BASE 4.4. EL MICROPROCESADOR 4.5. LA 4.6. LOS BUSES
Arquitectura de Computadores II
 Facultad de Ingeniería Universidad de la República Instituto de Computación Temas Repaso de conceptos Microcontroladores CISC vs RISC CISC Complex Instruct Set Computers RISC Reduced Instruct Set Computers
Facultad de Ingeniería Universidad de la República Instituto de Computación Temas Repaso de conceptos Microcontroladores CISC vs RISC CISC Complex Instruct Set Computers RISC Reduced Instruct Set Computers
Velocidades Típicas de transferencia en Dispositivos I/O
 Entradas Salidas Velocidades Típicas de transferencia en Dispositivos I/O Entradas/Salidas: Problemas Amplia variedad de periféricos Entrega de diferentes cantidades de datos Diferentes velocidades Variedad
Entradas Salidas Velocidades Típicas de transferencia en Dispositivos I/O Entradas/Salidas: Problemas Amplia variedad de periféricos Entrega de diferentes cantidades de datos Diferentes velocidades Variedad
Montaje y Reparación de Sistemas Microinformáticos
 Montaje y Reparación de Sistemas s Es uno de los componentes más imprescindible del equipo informático. Al igual que el resto de tarjetas de expansión, la tarjeta gráfica se conecta al bus PCIe. Algunas
Montaje y Reparación de Sistemas s Es uno de los componentes más imprescindible del equipo informático. Al igual que el resto de tarjetas de expansión, la tarjeta gráfica se conecta al bus PCIe. Algunas
Tema 2.1. Hardware. Arquitectura básica
 Tema 2.1 Hardware. Arquitectura básica 1 Partes Fundamentales Partes Fundamentales: Unidad Central de Proceso Procesador Microprocesador CPU-UCP Memoria Principal: Memoria Central Placa Base Chipset Buses
Tema 2.1 Hardware. Arquitectura básica 1 Partes Fundamentales Partes Fundamentales: Unidad Central de Proceso Procesador Microprocesador CPU-UCP Memoria Principal: Memoria Central Placa Base Chipset Buses
Estudio de la Wii U: CPU y GPU. Michael Harry O'Gay García Microprocesadores para comunicaciones ULPGC
 Estudio de la Wii U: CPU y GPU Michael Harry O'Gay García Microprocesadores para comunicaciones ULPGC Índice Índice...2 Introducción...2 Diseño del Hardware...3 El CPU: Espresso...4 El GPU: Latte...4 Comparación
Estudio de la Wii U: CPU y GPU Michael Harry O'Gay García Microprocesadores para comunicaciones ULPGC Índice Índice...2 Introducción...2 Diseño del Hardware...3 El CPU: Espresso...4 El GPU: Latte...4 Comparación
Lectura # 2. Lectura de apoyo al curso
 Evolución de las PC A continuación veremos cómo fueron cambiando las computadoras personales de acuerdo a las nuevas tecnologías que fueron apareciendo, estudiando las distintas generaciones hasta hoy.
Evolución de las PC A continuación veremos cómo fueron cambiando las computadoras personales de acuerdo a las nuevas tecnologías que fueron apareciendo, estudiando las distintas generaciones hasta hoy.
Sistemas Multiprocesador de Memoria Compartida Comerciales
 Sistemas Multiprocesador de Memoria Compartida Comerciales Florentino Eduardo Gargollo Acebrás, Pablo Lorenzo Fernández, Alejandro Alonso Pajares y Andrés Fernández Bermejo Escuela Politécnia de Ingeniería
Sistemas Multiprocesador de Memoria Compartida Comerciales Florentino Eduardo Gargollo Acebrás, Pablo Lorenzo Fernández, Alejandro Alonso Pajares y Andrés Fernández Bermejo Escuela Politécnia de Ingeniería
Arquitecturas y Computación de Alto Rendimiento SISTEMAS PARA COMPUTACIÓN DE ALTO RENDIMIENTO. Índice
 Arquitecturas y Computación de Alto Rendimiento SISTEMAS PARA COMPUTACIÓN DE ALTO RENDIMIENTO 1 Índice 1. Necesidades de cómputo. Exascale. Arquitecturas de altas prestaciones. Top 500. Green 500 2. Memoria
Arquitecturas y Computación de Alto Rendimiento SISTEMAS PARA COMPUTACIÓN DE ALTO RENDIMIENTO 1 Índice 1. Necesidades de cómputo. Exascale. Arquitecturas de altas prestaciones. Top 500. Green 500 2. Memoria
UNIVERSIDAD DE OVIEDO MÁSTER EN TECNOLOGÍAS DE LA INFORMACIÓN Y COMUNICACIONES EN REDES MÓVILES - TICRM TESIS DE MÁSTER
 UNIVERSIDAD DE OVIEDO MÁSTER EN TECNOLOGÍAS DE LA INFORMACIÓN Y COMUNICACIONES EN REDES MÓVILES - TICRM TESIS DE MÁSTER DISEÑO, IMPLEMENTACIÓN Y VALIDACIÓN DE UNA ESTACIÓN DE TRABAJO PARA LA RESOLUCIÓN
UNIVERSIDAD DE OVIEDO MÁSTER EN TECNOLOGÍAS DE LA INFORMACIÓN Y COMUNICACIONES EN REDES MÓVILES - TICRM TESIS DE MÁSTER DISEÑO, IMPLEMENTACIÓN Y VALIDACIÓN DE UNA ESTACIÓN DE TRABAJO PARA LA RESOLUCIÓN
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS
 GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
Introducción a la computación paralela
 Introducción a la computación paralela Mario Medina C. mariomedina@udec.cl Porqué computación paralela? Avances tecnológicos (HW) Avances en conocimientos (SW) Tópicos a comentar Ley de Moore Ley de Kryder
Introducción a la computación paralela Mario Medina C. mariomedina@udec.cl Porqué computación paralela? Avances tecnológicos (HW) Avances en conocimientos (SW) Tópicos a comentar Ley de Moore Ley de Kryder
Tema 12. El Hardware de la Realidad Virtual
 El Hardware de la Realidad Virtual Evolución en tecnología gráfica 1 La RV llega vinculada a las capacidades gráficas de los microordenadores. 2 Evolución en tecnología gráfica 2 Los pequeños ordenadores
El Hardware de la Realidad Virtual Evolución en tecnología gráfica 1 La RV llega vinculada a las capacidades gráficas de los microordenadores. 2 Evolución en tecnología gráfica 2 Los pequeños ordenadores
Sistemas Operativos. Tema 1. Arquitectura Básica de los Computadores
 Sistemas Operativos. Tema 1 Arquitectura Básica de los Computadores http://www.ditec.um.es/so Departamento de Ingeniería y Tecnología de Computadores Universidad de Murcia Sistemas Operativos. Tema 1 Arquitectura
Sistemas Operativos. Tema 1 Arquitectura Básica de los Computadores http://www.ditec.um.es/so Departamento de Ingeniería y Tecnología de Computadores Universidad de Murcia Sistemas Operativos. Tema 1 Arquitectura
Introducción. Por último se presentarán las conclusiones y recomendaciones pertinentes.
 Introducción En el presente documento se explicarán las consideraciones realizadas para implementar la convolución bidimensional en la arquitectura CUDA. En general se discutirá la metodología seguida
Introducción En el presente documento se explicarán las consideraciones realizadas para implementar la convolución bidimensional en la arquitectura CUDA. En general se discutirá la metodología seguida
Tema: Microprocesadores
 Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Microprocesadores Arq. de Computadora I Ing. Carlos Ortega H. 1
Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Microprocesadores Arq. de Computadora I Ing. Carlos Ortega H. 1
TRABAJOS DE MICROPROCESADORES PARA COMUNICACIONES
 TRABAJOS DE MICROPROCESADORES PARA COMUNICACIONES Unas 16 horas de trabajo (máximo), 10+ slides (+ portada, índice, referencias y links), 8+ paginas Word, presentación de 20 minutos en clase. En las referencias
TRABAJOS DE MICROPROCESADORES PARA COMUNICACIONES Unas 16 horas de trabajo (máximo), 10+ slides (+ portada, índice, referencias y links), 8+ paginas Word, presentación de 20 minutos en clase. En las referencias
DEFINICIÓN RAZONES PARA HACER UN MANTENIMIENTO AL PC
 DEFINICIÓN El mantenimiento del computador es aquel que debemos realizar al computador cada cierto tiempo, bien sea para corregir fallas existentes o para prevenirlas. El periodo de mantenimiento depende
DEFINICIÓN El mantenimiento del computador es aquel que debemos realizar al computador cada cierto tiempo, bien sea para corregir fallas existentes o para prevenirlas. El periodo de mantenimiento depende
ÍNDICE INTRODUCCIÓN AL PROCESAMIENTO PARALELO ARQUITECTURA E INGENIERÍA DE COMPUTADORES TEMA1
 GRUPO DE ARQUITECTURA DE COMPUTADORES INTRODUCCIÓN AL PROCESAMIENTO PARALELO ARQUITECTURA E INGENIERÍA DE COMPUTADORES TEMA1 ÍNDICE!! Procesamiento paralelo!! Condiciones de paralelismo "! Concepto de
GRUPO DE ARQUITECTURA DE COMPUTADORES INTRODUCCIÓN AL PROCESAMIENTO PARALELO ARQUITECTURA E INGENIERÍA DE COMPUTADORES TEMA1 ÍNDICE!! Procesamiento paralelo!! Condiciones de paralelismo "! Concepto de
1. Introducción a la Arquitectura de Computadoras
 1. Introducción a la Arquitectura de Computadoras M. Farias-Elinos Contenido Definiciones Estructura de una computadora Evolución de las computadoras Generaciones de computadoras Evolución de la família
1. Introducción a la Arquitectura de Computadoras M. Farias-Elinos Contenido Definiciones Estructura de una computadora Evolución de las computadoras Generaciones de computadoras Evolución de la família
Recopilación presentada por 1
 Aula Aula de de Informática Informática del del Centro Centro de de Participación Participación Activa Activa para para Personas Personas Mayores Mayores de de El El Ejido Ejido (Almería). (Almería). Consejería
Aula Aula de de Informática Informática del del Centro Centro de de Participación Participación Activa Activa para para Personas Personas Mayores Mayores de de El El Ejido Ejido (Almería). (Almería). Consejería
MEMORIA EJERCICIO 1 EJERCICIO 2
 MEMORIA EJERCICIO 1 Determinar el mapa de memoria de un procesador con 16 señales de bus de direcciones, una señal de asentimiento de bus de direcciones AS, una señal de lectura R, otra de escritura W
MEMORIA EJERCICIO 1 Determinar el mapa de memoria de un procesador con 16 señales de bus de direcciones, una señal de asentimiento de bus de direcciones AS, una señal de lectura R, otra de escritura W
Estructura de un Ordenador
 Estructura de un Ordenador 1. Unidad Central de Proceso (CPU) 2. Memoria Principal 3. El Bus: La comunicación entre las distintas unidades 4. La unión de todos los elementos: la placa Base Estructura de
Estructura de un Ordenador 1. Unidad Central de Proceso (CPU) 2. Memoria Principal 3. El Bus: La comunicación entre las distintas unidades 4. La unión de todos los elementos: la placa Base Estructura de
Introducción a la Computación. Capítulo 10 Repertorio de instrucciones: Características y Funciones
 Introducción a la Computación Capítulo 10 Repertorio de instrucciones: Características y Funciones Que es un set de instrucciones? La colección completa de instrucciones que interpreta una CPU Código máquina
Introducción a la Computación Capítulo 10 Repertorio de instrucciones: Características y Funciones Que es un set de instrucciones? La colección completa de instrucciones que interpreta una CPU Código máquina
Universidad Católica Nuestra Señora de la Asunción Facultad de Ciencias y Tecnología Departamento de Ingeniería Electrónica e Informática
 Universidad Católica Nuestra Señora de la Asunción Facultad de Ciencias y Tecnología Departamento de Ingeniería Electrónica e Informática Teoría y Aplicación de la Informática 2 Tarjetas Gráficas de ultima
Universidad Católica Nuestra Señora de la Asunción Facultad de Ciencias y Tecnología Departamento de Ingeniería Electrónica e Informática Teoría y Aplicación de la Informática 2 Tarjetas Gráficas de ultima
Aceleradores gráficos. Su impacto en el bus del sistema.
 Aceleradores gráficos. Su impacto en el bus del sistema. Conceptos básicos Controladora de video tradicional en modo gráfico Buffer de video en placas ISA se ubica en el rango de posiciones de memoria
Aceleradores gráficos. Su impacto en el bus del sistema. Conceptos básicos Controladora de video tradicional en modo gráfico Buffer de video en placas ISA se ubica en el rango de posiciones de memoria
EVOLUCION PROCESADORES AMD (ADVANCED MICRO DEVICES)
") EVOLUCION PROCESADORES AMD (ADVANCED MICRO DEVICES) AMD AM286 Es la copia del intel 80286, creado con permiso de intel. Por petición de IBM como segunda fuente, tienen arquitectura interna de 16 bits,
EVOLUCION PROCESADORES AMD (ADVANCED MICRO DEVICES) AMD AM286 Es la copia del intel 80286, creado con permiso de intel. Por petición de IBM como segunda fuente, tienen arquitectura interna de 16 bits,
OBJETIVO 1.-.CONOCER EL COMPUTADOR Y SUS PARTES EXTERNAS E INTERNAS.
 OBJETIVO 1.-.CONOCER EL COMPUTADOR Y SUS PARTES EXTERNAS E INTERNAS. 1. Define clasificación del dispositivo (Dispositivos:Entrada, salida, e/s, almacenamiento) 2. Características de cada tipo de dispositivos.
OBJETIVO 1.-.CONOCER EL COMPUTADOR Y SUS PARTES EXTERNAS E INTERNAS. 1. Define clasificación del dispositivo (Dispositivos:Entrada, salida, e/s, almacenamiento) 2. Características de cada tipo de dispositivos.
Modelado de los computadores paralelos
 Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Sist s em e a m s s O per e ativos o. s Unidad V Entrada Sali l d i a.
 Sistemas Operativos. Unidad V Entrada Salida. Programación de Entrada y Salida Introducción. Comunicación de los procesos con el mundo externo : Mecanismo de E/S de información. Aspectos que diferencian
Sistemas Operativos. Unidad V Entrada Salida. Programación de Entrada y Salida Introducción. Comunicación de los procesos con el mundo externo : Mecanismo de E/S de información. Aspectos que diferencian
Hardware Gráfico. Tarjeta gráfica. Resolución. Standards de resolución. Profundidad de color (Colour depth)
") Tarjeta gráfica Hardware Gráfico Hardware responsable de crear la imagen que se muestra en el monitor Con el incremento de las necesidades multimedia y 3D, su importancia ha crecido hasta el nivel de que
Tarjeta gráfica Hardware Gráfico Hardware responsable de crear la imagen que se muestra en el monitor Con el incremento de las necesidades multimedia y 3D, su importancia ha crecido hasta el nivel de que
Tecnología de software para sistemas de tiempo real
 1 dit UPM Tecnología de software para sistemas de tiempo real Juan Antonio de la Puente DIT/UPM Motivación Las herramientas y la tecnología de software que se usan para construir otros tipos de sistemas
1 dit UPM Tecnología de software para sistemas de tiempo real Juan Antonio de la Puente DIT/UPM Motivación Las herramientas y la tecnología de software que se usan para construir otros tipos de sistemas
Arquitecturas basadas en computación gráfica (GPU)
") Arquitecturas basadas en computación gráfica (GPU) Francesc Guim Ivan Rodero PID_00184818 CC-BY-NC-ND PID_00184818 Arquitecturas basadas en computación gráfica (GPU) Los textos e imágenes publicados en
Arquitecturas basadas en computación gráfica (GPU) Francesc Guim Ivan Rodero PID_00184818 CC-BY-NC-ND PID_00184818 Arquitecturas basadas en computación gráfica (GPU) Los textos e imágenes publicados en
Clasificación n de los Sistemas Operativos. Clasificación de los SO Estructuras de los SO Modos de procesamiento
 Clasificación n de los Sistemas Operativos Contenidos Clasificación de los SO Estructuras de los SO Modos de procesamiento Se pueden clasificar en Sistemas monolíticos Sistemas por capas Sistemas cliente/servidor
Clasificación n de los Sistemas Operativos Contenidos Clasificación de los SO Estructuras de los SO Modos de procesamiento Se pueden clasificar en Sistemas monolíticos Sistemas por capas Sistemas cliente/servidor
Tarjetas gráficas para acelerar el cómputo complejo
 LA TECNOLOGÍA Y EL CÓMPUTO AVANZADO Tarjetas gráficas para acelerar el cómputo complejo Tarjetas gráficas para acelerar el cómputo complejo Jorge Echevarría * La búsqueda de mayor rendimiento A lo largo
LA TECNOLOGÍA Y EL CÓMPUTO AVANZADO Tarjetas gráficas para acelerar el cómputo complejo Tarjetas gráficas para acelerar el cómputo complejo Jorge Echevarría * La búsqueda de mayor rendimiento A lo largo
6. PROCESADORES SUPERESCALARES Y VLIW
 6. PROCESADORES SUPERESCALARES Y VLIW 1 PROCESADORES SUPERESCALARES Y VLIW 1. Introducción 2. El modelo VLIW 3. El cauce superescalar 4. Superescalar con algoritmo de Tomasulo 2 PROCESADORES SUPERESCALARES
6. PROCESADORES SUPERESCALARES Y VLIW 1 PROCESADORES SUPERESCALARES Y VLIW 1. Introducción 2. El modelo VLIW 3. El cauce superescalar 4. Superescalar con algoritmo de Tomasulo 2 PROCESADORES SUPERESCALARES
Arquitecturas de Computadoras II. Febrero 2013
 Arquitecturas de Computadoras II Febrero 2013 1 Sabes... 1. Cuál es la Arquitectura Von Neumann? 2. Qué es Programación? 3. Qué es un algoritmo? 4. Qué es un programa? 5. Qué es un sistema? 6. Materias
Arquitecturas de Computadoras II Febrero 2013 1 Sabes... 1. Cuál es la Arquitectura Von Neumann? 2. Qué es Programación? 3. Qué es un algoritmo? 4. Qué es un programa? 5. Qué es un sistema? 6. Materias
EL CLUSTER FING: COMPUTACIÓN DE ALTO DESEMPEÑO EN FACULTAD DE INGENIERÍA
 EL CLUSTER FING: COMPUTACIÓN DE ALTO DESEMPEÑO EN FACULTAD DE INGENIERÍA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY EL CLUSTER
EL CLUSTER FING: COMPUTACIÓN DE ALTO DESEMPEÑO EN FACULTAD DE INGENIERÍA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY EL CLUSTER
Parte I:Teoría. Tema 3:Introducción a los Sistemas operativos. Instalación
 Tema 3:Introducción a los Sistemas operativos. Instalación Parte I:Teoría Introducción a los SO Componentes Llamadas al sistema Estructura del Kernel Drivers Esta obra está bajo una licencia Reconocimiento-No
Tema 3:Introducción a los Sistemas operativos. Instalación Parte I:Teoría Introducción a los SO Componentes Llamadas al sistema Estructura del Kernel Drivers Esta obra está bajo una licencia Reconocimiento-No
Tema 2: Lenguaje máquina. La interfaz entre el hardware y el software
 Tema 2: Lenguaje máquina La interfaz entre el hardware y el software 1 Índice Introducción. Formatos de Instrucción. Modos de Direccionamiento. Ortogonalidad y Regularidad. Frecuencia de Utilización de
Tema 2: Lenguaje máquina La interfaz entre el hardware y el software 1 Índice Introducción. Formatos de Instrucción. Modos de Direccionamiento. Ortogonalidad y Regularidad. Frecuencia de Utilización de
SISTEMAS OPERATIVOS Arquitectura de computadores
 SISTEMAS OPERATIVOS Arquitectura de computadores Erwin Meza Vega emezav@unicauca.edu.co Esta presentación tiene por objetivo mostrar los conceptos generales de la arquitectura de los computadores, necesarios
SISTEMAS OPERATIVOS Arquitectura de computadores Erwin Meza Vega emezav@unicauca.edu.co Esta presentación tiene por objetivo mostrar los conceptos generales de la arquitectura de los computadores, necesarios
168(W) x 72.87(H) x 25(D) mm Size. Abrazadera de perfil bajo (opción)
 x 72.87(H) x 25(D) mm Size. Abrazadera de perfil bajo (opción)") Especificación Output GPU Dimension Software Accessory 1 x Dual-Link DVI 1 x HDMI 1 x D-Sub(VGA) 650 MHz Reloj de núcleo 80 x Procesadores de flujo 40 nm Chip 1024 MB Tamaño 1334 MHz Efectiva 168(W) x
Especificación Output GPU Dimension Software Accessory 1 x Dual-Link DVI 1 x HDMI 1 x D-Sub(VGA) 650 MHz Reloj de núcleo 80 x Procesadores de flujo 40 nm Chip 1024 MB Tamaño 1334 MHz Efectiva 168(W) x
UNIVERSIDAD CARLOS III DE MADRID PARALELIZACIÓN PARA EL ALGORITMO DE LOS FILTROS DE KALMAN. Trabajo Fin de Grado. Septiembre de 2012
 USO DE TÉCNICAS DE PARALELIZACIÓN PARA EL ALGORITMO DE LOS FILTROS DE KALMAN Trabajo Fin de Grado Septiembre de 2012 Autor: Javier Rodríguez Arroyo Tutor: Luis Miguel Sánchez García Co-tutor: Javier Fernández
USO DE TÉCNICAS DE PARALELIZACIÓN PARA EL ALGORITMO DE LOS FILTROS DE KALMAN Trabajo Fin de Grado Septiembre de 2012 Autor: Javier Rodríguez Arroyo Tutor: Luis Miguel Sánchez García Co-tutor: Javier Fernández
IMPLEMENTACIÓN DE CÓDIGO CFD PARALELO PARA FLUJO COMPRESIBLE
 IMPLEMENTACIÓN DE CÓDIGO CFD PARALELO PARA FLUJO COMPRESIBLE RESUMEN S. C. Chan Chang, G. Weht, M. Montes Departamento Mecánica Aeronáutica, Facultad de Ingeniería, Instituto Universitario Aeronáutico
IMPLEMENTACIÓN DE CÓDIGO CFD PARALELO PARA FLUJO COMPRESIBLE RESUMEN S. C. Chan Chang, G. Weht, M. Montes Departamento Mecánica Aeronáutica, Facultad de Ingeniería, Instituto Universitario Aeronáutico
MICROPROCESADORES, EVOLUCIÓN HISTÓRICA Y CARACTERÍSTICAS TÉCNICAS BÁSICAS
 MICROPROCESADORES, EVOLUCIÓN HISTÓRICA Y CARACTERÍSTICAS TÉCNICAS BÁSICAS Se muestra a continuación la evolución histórica de los microprocesadores fabricados por INTEL (fundada en 1968 por Robert Noyce,
MICROPROCESADORES, EVOLUCIÓN HISTÓRICA Y CARACTERÍSTICAS TÉCNICAS BÁSICAS Se muestra a continuación la evolución histórica de los microprocesadores fabricados por INTEL (fundada en 1968 por Robert Noyce,
CAR. Responsable : María del Carmen Heras Sánchez. Asesores Técnicos : Daniel Mendoza Camacho Yessica Vidal Quintanar.
 CAR Responsable : María del Carmen Heras Sánchez Asesores Técnicos : Daniel Mendoza Camacho Yessica Vidal Quintanar http://acarus2.uson.mx Infraestructura de Hardware Software Conexiones remotas http://acarus2.uson.mx
CAR Responsable : María del Carmen Heras Sánchez Asesores Técnicos : Daniel Mendoza Camacho Yessica Vidal Quintanar http://acarus2.uson.mx Infraestructura de Hardware Software Conexiones remotas http://acarus2.uson.mx
ARQUITECTURA BÁSICA DEL ORDENADOR: Hardware y Software. IES Miguel de Cervantes de Sevilla
 ARQUITECTURA BÁSICA DEL ORDENADOR: Hardware y Software. IES Miguel de Cervantes de Sevilla Índice de contenido 1.- Qué es un ordenador?...3 2.-Hardware básico de un ordenador:...3 3.-Software...4 3.1.-Software
ARQUITECTURA BÁSICA DEL ORDENADOR: Hardware y Software. IES Miguel de Cervantes de Sevilla Índice de contenido 1.- Qué es un ordenador?...3 2.-Hardware básico de un ordenador:...3 3.-Software...4 3.1.-Software
Arquitectura de Computadores
 Arquitectura de Computadores 1. Introducción 2. La CPU 3. Lenguaje Máquina 4. La Memoria 5. Sistemas de Entrada/Salida 6. CPU Segmentada (Pipeline) 7. Memoria Caché 8. Arquitecturas RISC Arquitectura de
Arquitectura de Computadores 1. Introducción 2. La CPU 3. Lenguaje Máquina 4. La Memoria 5. Sistemas de Entrada/Salida 6. CPU Segmentada (Pipeline) 7. Memoria Caché 8. Arquitecturas RISC Arquitectura de
Tema V Generación de Código
 Tema V Generación de Código Una vez que se ha realizado la partición HW/SW y conocemos las operaciones que se van a implementar por hardware y software, debemos abordar el proceso de estas implementaciones.
Tema V Generación de Código Una vez que se ha realizado la partición HW/SW y conocemos las operaciones que se van a implementar por hardware y software, debemos abordar el proceso de estas implementaciones.
Chipsets página 1 CONJUNTO DE CHIPS PARA SOCKET 7
 Chipsets página 1 El conjunto de chips, o chipset, es un elemento formado por un determinado número de circuitos integrados en el que se han incluido la mayoría de los componentes que dotan a un ordenador
Chipsets página 1 El conjunto de chips, o chipset, es un elemento formado por un determinado número de circuitos integrados en el que se han incluido la mayoría de los componentes que dotan a un ordenador
TEMA II: ALMACENAMIENTO DE LA INFORMACIÓN
 CUESTIONES A TRATAR: Existe un tipo único tipo de memoria en un determinado computador? Todas las memorias de un computador tienen la misma función?. Qué es la memoria interna de un computador? Por qué
CUESTIONES A TRATAR: Existe un tipo único tipo de memoria en un determinado computador? Todas las memorias de un computador tienen la misma función?. Qué es la memoria interna de un computador? Por qué
SISTEMAS DE MULTIPROCESAMIENTO
 SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función
SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función