Métodos de ensambles
|
|
|
- María Soledad Ojeda Paz
- hace 6 años
- Vistas:
Transcripción
1 Métodos de ensambles
2 Outline Ensambles en general Bagging Random Forest Boosting
3 Introducción Ensamble: conjunto grande de modelos que se usan juntos como un meta modelo Idea base conocida: usar conocimiento de distintas fuentes al tomar decisiones
4 Ejemplos conocidos El comité de expertos: muchos elementos todos con alto conocimiento todos sobre el mismo tema votan Gabinete de asesores: Ensambles planos: -Fusión -Bagging -Boosting -Random Forest Ensambles divisivos: expertos en diferentes áreas. -Mixture of experts alto conocimiento -Stacking hay una cabeza que decide quién sabe del tema
5 Componentes base Dos componentes base: Un método para seleccionar o construir los miembros Ejemplo: misma o distinta área Un método para combinar las decisiones Votación, promedio, función de disparo
6 Dividir el problema en una serie de subproblemas con mínima sobreposición Estrategia de divide & conquer Útiles para atacar problemas grandes Se necesita una función que decida que clasificador tiene que actuar Ensambles divisivos
7 Ensambles planos Muchos expertos, todos buenos Necesito que sean lo mejor posible individualmente De lo contrario, usualmente no sirven Pero necesito que opinen distinto en algunos casos Si todos opinan siempre igual me quedo con uno solo!

8 Caso de éxito
9 Formalización Un camino posible es la via estadística Se habla del dilema Sesgo-varianza O Bias-variance Ejemplo

10 Ejemplo: Datos

11 Ejemplo: Sesgo

12 Ejemplo: Varianza
13 Que funciones utilizar? Funciones rígidas: Buena estimación de los parámetros óptimos poca flexibilidad Funciones flexibles: Buen ajuste mala estimación de los parámetros óptimos Error de sesgo Error de varianza Sesgo y Varianza
14 El dilema Los predictores sin sesgo tienen alta varianza (y al revés) Hay dos formas de resolver el dilema: Disminuir la varianza de los predictores sin sesgo Construir muchos predictores y promediarlos: Bagging y Random Forest Reducir el sesgo de los predictores estables Construir una secuencia tal que la combinación tenga menos sesgo: Boosting
15 Divisivos
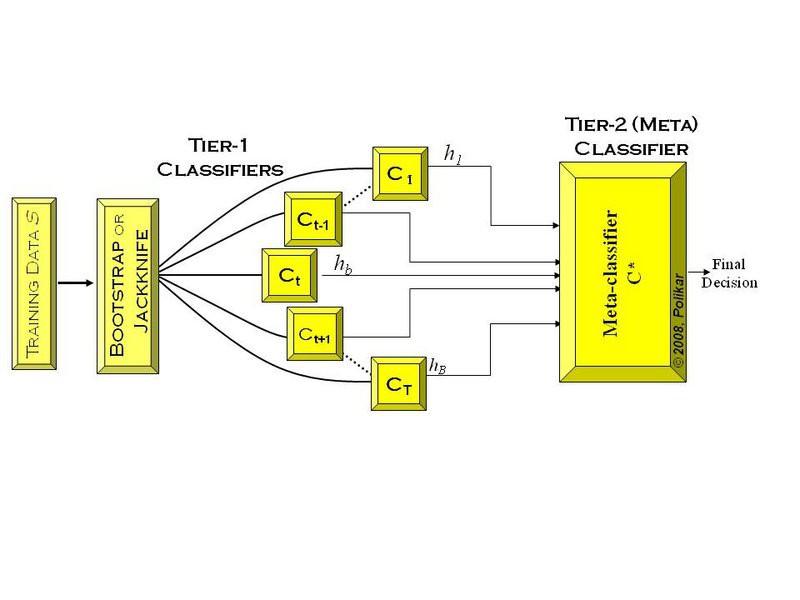
16 Stacking

17 Mixture of experts
18 Bagging
19 Disminuir la varianza Si tenemos realmente predictores sin sesgo, la media de estos en cada punto tiene que ser el valor real de la función a predecir. En ese caso, los errores que cometen los distintos predictores se cancelan. Eso es equivalente a pedir que los errores de los predictores estén decorrelacionados, que sean lo más diversos entre sí.
20 Disminuir... (2) Idea: Construir un conjunto de predictores Sin sesgo (lo más precisos posible) Decorrelacionados (lo más diversos posible) Promediarlos para conseguir un predictor con poco sesgo y poca varianza
21 Bootstrap aggregating (Leo Breiman, 96) Usar predictores buenos pero inestables Bagging Árboles y ANN sobre todo Conseguir diversidad perturbando los datos Como los predictores son inestables, pequeños cambios en los datos dan cambios importantes en los modelos
22 La idea de Bagging es usar bootstraps Un bootstrap es una muestra al azar de la misma longitud, con repetición >sample(1:10,rep=t) > Datos perturbados El bootstrap no introduce bias en ninguna estadística (propiedad importante) Cada predictor se entrena sobre un bootstrap del conjunto de entrenamiento
23 Regla de combinación Para regresión/ranking: promedio simple de las predicciones de cada modelo Para clasificación: Cada modelo vota por una clase. La que tiene más votos es elegida. Cada modelo estima la probabilidad de clase. Se promedian. La de mayor probabilidad se elige. Modelo 1 Modelo 2 Modelo 3 Votos Probs. Clase A Clase B
24 Regla de combinación Para clustering: Creamos una matriz que cuenta cuantas veces cada par de puntos termina en el mismo cluster, y clusterizamos esa matriz de similitud.
25 Entrada: Conjunto de datos D={(xi, yi), i=1,m}, donde xi X e yi Y={1,..., k} Algoritmo de aprendizaje WeakLearn Inicializar: wi(1) = 1/m Repetir i=1,m t = 1, 2,..., T: tomar una muestra Dt a partir de D muestreando con probabilidad wi(t). utilizar WeakLearn en Dt para obtener un clasificador ft : X Y Salida: Hipótesis final: Algoritmo: Bagging (clasificación)
26 Cuántos predictores? El único parámetro a fijar es el total de predictores T Los errores de Train y test convergen suavemente. Se usa un número grande de predictores directamente (100, 500)

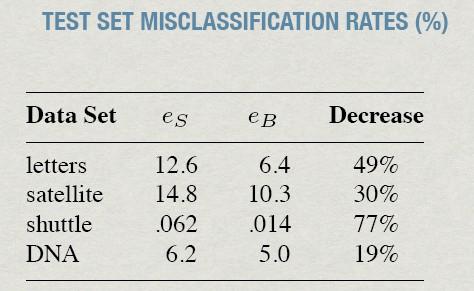
27 De: Bagging Predictors, Leo Breiman, Machine Learning, 24: , 1996 Comparación de resultados

28 De: Bagging Predictors, Leo Breiman, Machine Learning, 24: , 1996 es es modelo individual, eb es Bagging Comparación de resultados

29 De: Bagging Predictors, Leo Breiman, Machine Learning, 24: , 1996 Comparación de resultados
30 De: Bagging Predictors, Leo Breiman, Machine Learning, 24: , 1996 es es modelo individual, eb es Bagging Comparación de resultados

31 De: Bagging Predictors, Leo Breiman, Machine Learning, 24: , 1996 es es modelo individual, eb es Bagging Resultados: clasificador estable
32 Otras formas de generar diversidad: Sub-sampling de los datos Hasta el 50% (Half & Half Bagging) Agregar ruido Variar los modelos en vez de los datos Cambiar la forma de ajustar los modelos Cambiar la condición inicial (ANN) Variantes
33 De: Popular ensemble methods, D.Opitz y R. Maclin, Journal of Artificial Intelligence research, 11:169198, 1999 Stan es modelo individual, Bag es Bagging, Simp es ensemble variando solo la condición inicial Resultados: ANN
34 Variantes Otras formas de combinar: Usar probabilidades en vez de votos Usar pesos estadísticos en la combinación Votos pesados : los mejores clasificadores tienen más fuerza en la decisión Funciona igual o mejor que el uniforme
35 Resumen: Bagging Método simple y efectivo para crear ensembles Reduce la varianza al promediar predictores diversos Usa bootstraps y predictores inestables Se suele usar con árboles y redes Con redes BP es mejor usar sólo la diversidad natural del entrenamiento
36 Random Forest Generando más diversidad
37 Problema con bagging + trees Usar bootstraps genera diversidad, pero los árboles siguen estando muy correlacionados Las mismas variables tienden a ocupar los primeros cortes siempre. Ejemplo: Dos árboles generados con rpart a partir de bootstraps del dataset Pima.tr. La misma variable está en la raíz
38 Solución propuesta Agregar un poco de azar al crecimiento En cada nodo, seleccionar un grupo chico de variables al azar y evaluar sólo esas variables. No agrega sesgo: A la larga todas las variables entran en juego Agrega varianza: pero eso se soluciona fácil promediando modelos Es efectivo para decorrelacionar los árboles
39 Random Forest: Algoritmo
40 Observaciones Construye los árboles hasta separar todo. No hay podado. No hay criterio de parada. El valor de m (mtry en R) es importante. El default es sqrt(p) que suele ser bueno. Si uso m=p recupero bagging El número de árboles no es importante, mientras sean muchos. 500, 1000, 2000.
41 Resultados
42 Resultados
43 Resultados Orden típico
44 Sub-productos de RF Out-of-bag estimation Medida de importancia de las variables Gráfica de proximidad
45 Out-of-bag estimation Cuando se toma un bootstrap hay puntos que quedan fuera (se los llama OOB) Son muchos, un tercio del total en media Para cada predictor hay un conjunto OOB que no usó durante el entrenamiento Se pueden usar para estimar errores de predicción sin sesgo

46 Out-of-bag estimation Puntos Predictores Bootstraps
47 Out-of-bag estimation Para cada punto del train set formo un subensamble que tiene sólo los clasificadores que no entrenaron con ese punto. Hago predicciones sobre todo el conjunto de train y promedio. Se llaman predicciones OOB, errores OOB Son una buena estima del error de test Tienen un sesgo seguro, estiman de más, porque están calculadas con un ensamble más chico
48 Ejemplo: OOB
49 Importancia de las variables Dos criterios: Gini: Media de la reducción del Gini cuando se usó cada variable, promediada en el RF Randomization: Aumento del error OOB cuando cada variable se randomiza por separado Los dos se estiman fácilmente Suelen ser equivalentes (con excepciones)
50 Gráficas de proximidad Modo interno de proyectar datos en bajas dimensiones (como PCA o MDS) Calcula una matriz de distancias entre los datos basada en cuantas veces los puntos terminan en un mismo nodo de un árbol Puntos cercanos deberían terminar juntos más seguido Hace un MDS de esas distancias
51 Ejemplo
52 Resumen: RF Mejora de bagging sólo para árboles Mejores predicciones que Bagging. Muy usado. Casi automático. Resultados comparables a los mejores métodos actuales. Subproductos útiles, sobre todo la estima OOB y la importancia de variables.
53 Boosting
54 El dilema sesgo-varianza Los predictores sin sesgo tienen alta varianza (y al revés) Hay dos formas de resolver el dilema: Disminuir la varianza de los predictores sin sesgo Construir muchos predictores y promediarlos: Bagging y Random Forest Reducir el sesgo de los predictores estables Construir una secuencia tal que la combinación tenga menos sesgo: Boosting
55 Introducción a boosting Es relativamente fácil construir un clasificador con un error apenas menor al 50% en cualquier problema de dos clases balanceado. (weaklerner, rules-of-thumb) Es mucho más difícil conseguir uno que dé un error arbitrariamente chico en cualquier problema (stronglerner) Problema central en teoría del aprendizaje: se puede crear un stronglerner combinando weaklerners?
56 Idea central Construir una secuencia de clasificadores débiles, donde cada uno aprenda un poco de lo que le falta a la secuencia previa Como los clasificadores débiles pueden mejorar un poco en cualquier problema, la secuencia converge a error cero
57 Cómo se implementa? Es un método de ensemble, hay que definir 2 cosas: Como se construye cada clasificador, con que datos Como se combinan los clasificadores
58 Conjuntos de entrenamiento Se trabaja con boostraps, como en bagging. Pero la muestra no se toma con pesos estadísticos uniformes. Se busca poner énfasis en aprender los puntos que fueron mal clasificados previamente por el ensamble Para eso, se le aumenta el peso estadístico a los errores, y se le baja a los aciertos
59 Combinación Se hace una suma de votos (como Bagging) Los pesos en la suma no son uniformes Se da más peso a los clasificadores que son mejores

60 Algoritmo Adaboost (1)
61 Algoritmo Adaboost (2)

62 Weak lerner: partición paralela a un eje Ejemplo
")
63 Ejemplo (2)
")
64 Ejemplo (3)
")
65 Ejemplo (y 4)
66 Error de entrenamiento Se puede probar que el error sobre los datos de ajuste converge a cero Si el weaklearn de verdad puede siempre hacer algo mejor que el azar
67 Se espera sobreajuste El error de train tiende a cero El clasificador se vuelve más complejo a cada paso Error de test

68 Pero en realidad no sobreajusta Peor, el error en test sigue bajando con el error de train en 0. Se necesita una explicación! Error de test real
69 Margen El error de test solo mide la clase La respuesta de adaboost es mas compleja, es la suma pesada de votos por una clase y la otra Hay que tener en cuanta la fuerza de la respuesta, la calidad Margen: (fracción pesada de votos correctos) (fracción incorrecta)
70 Margen y error Teorema 1: Mayor margen es equivalente a una menor cota superior en el error de test Teorema 2: Boosting incrementa en cada iteración el margen de los datos Conclusión: El error de test baja porque boosting aumenta el margen

71 Siempre sobre el conjunto de entrenamiento Distribución del margen
72 Otras derivaciones Costo exponencial Adaboost minimiza a cada paso una función de costo exponencial El costo exponencial es una cota superior del error de clasificación
73 Teoría de juegos Boosting es un juego entre el booster y el weeklearn. La estrategia óptima da el algoritmo Adaboost Y varias más. Otras derivaciones (2)
74 Originalmente solo clasificación binaria Fue extendido eficientemente para: Regresión Clasif. Multiclase Ranking Extensiones
75 Boosting sobre árboles De: Popular ensemble methods, D.Opitz y R. Maclin, Journal of Artificial Intelligence research, 11:169198, 1999 Stan es modelo individual, Bag es Bagging, Simp es ensemble variando solo la condición inicial, Ada es adaboost Resultados
76 Boosting sobre ANN De: Popular ensemble methods, D.Opitz y R. Maclin, Journal of Artificial Intelligence research, 11:169198, 1999 Stan es modelo individual, Bag es Bagging, Simp es ensemble variando solo la condición inicial, Ada es adaboost Resultados
77 Resumen - Pros Eficiente, simple y fácil de programar Sólo un parámetro ajustable (T, fácil) Flexible, funciona con casi cualquier learner Efectivo, tiene garantías de funcionamiento (siempre que el weaklearn cumpla) Extensión a muchos problemas en ML
78 La performance depende no sólo de los datos, también del Weaklearn Falla si: Resumen - Constras Weak son demasiado fuertes (overfitting) Weak demasiado débiles Tiene problemas con el ruido, en particular con el ruido uniforme
Aprendizaje: Boosting y Adaboost
 Técnicas de Inteligencia Artificial Aprendizaje: Boosting y Adaboost Boosting 1 Indice Combinando clasificadores débiles Clasificadores débiles La necesidad de combinar clasificadores Bagging El algoritmo
Técnicas de Inteligencia Artificial Aprendizaje: Boosting y Adaboost Boosting 1 Indice Combinando clasificadores débiles Clasificadores débiles La necesidad de combinar clasificadores Bagging El algoritmo
Tema 15: Combinación de clasificadores
 Tema 15: Combinación de clasificadores p. 1/21 Tema 15: Combinación de clasificadores Abdelmalik Moujahid, Iñaki Inza, Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial
Tema 15: Combinación de clasificadores p. 1/21 Tema 15: Combinación de clasificadores Abdelmalik Moujahid, Iñaki Inza, Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial
Aprendizaje Automático
 Aprendizaje Automático Andrea Mesa 21 de mayo de 2010 Aprendizaje automático Otras denominaciones: machine learning, statistical learning, data mining, inteligencia artificial. Las técnicas de Aprendizaje
Aprendizaje Automático Andrea Mesa 21 de mayo de 2010 Aprendizaje automático Otras denominaciones: machine learning, statistical learning, data mining, inteligencia artificial. Las técnicas de Aprendizaje
Random Forests. Felipe Parra
 Applied Mathematics Random Forests Abril 2014 Felipe Parra Por que Arboles para Clasificación PERFIL DE RIESGO: definir con qué nivel de aversión al riesgo se toman decisiones Interpretación intuitiva
Applied Mathematics Random Forests Abril 2014 Felipe Parra Por que Arboles para Clasificación PERFIL DE RIESGO: definir con qué nivel de aversión al riesgo se toman decisiones Interpretación intuitiva
Inteligencia Artificial. Aprendizaje neuronal. Ing. Sup. en Informática, 4º. Curso académico: 2011/2012 Profesores: Ramón Hermoso y Matteo Vasirani
 Inteligencia Artificial Aprendizaje neuronal Ing. Sup. en Informática, 4º Curso académico: 20/202 Profesores: Ramón Hermoso y Matteo Vasirani Aprendizaje Resumen: 3. Aprendizaje automático 3. Introducción
Inteligencia Artificial Aprendizaje neuronal Ing. Sup. en Informática, 4º Curso académico: 20/202 Profesores: Ramón Hermoso y Matteo Vasirani Aprendizaje Resumen: 3. Aprendizaje automático 3. Introducción
Minería de Datos. Árboles de Decisión. Fac. Ciencias Ing. Informática Otoño de Dept. Matesco, Universidad de Cantabria
 Minería de Datos Árboles de Decisión Cristina Tîrnăucă Dept. Matesco, Universidad de Cantabria Fac. Ciencias Ing. Informática Otoño de 2012 Twenty questions Intuición sobre los árboles de decisión Juego
Minería de Datos Árboles de Decisión Cristina Tîrnăucă Dept. Matesco, Universidad de Cantabria Fac. Ciencias Ing. Informática Otoño de 2012 Twenty questions Intuición sobre los árboles de decisión Juego
Aprendizaje basado en ejemplos.
 Aprendizaje basado en ejemplos. In whitch we describe agents that can improve their behavior through diligent study of their own experiences. Porqué queremos que un agente aprenda? Si es posible un mejor
Aprendizaje basado en ejemplos. In whitch we describe agents that can improve their behavior through diligent study of their own experiences. Porqué queremos que un agente aprenda? Si es posible un mejor
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC)
") GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC) Curso Académico: 2015-2016 Programa: Centro: Universidad: Máster Universitario en Ingeniería Informática Escuela Politécnica Superior
GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC) Curso Académico: 2015-2016 Programa: Centro: Universidad: Máster Universitario en Ingeniería Informática Escuela Politécnica Superior
Validación Cruzada (cross-validation) y Remuestreo (bootstrapping)
 y Remuestreo (bootstrapping)") Validación Cruzada (cross-validation) y Remuestreo (bootstrapping) Padres de cross-validation y el bootstrapping Bradley Efron y Rob Tibshirani Bradley Efron Rob Tibshirani Enfoque: tabla de aprendizaje
Validación Cruzada (cross-validation) y Remuestreo (bootstrapping) Padres de cross-validation y el bootstrapping Bradley Efron y Rob Tibshirani Bradley Efron Rob Tibshirani Enfoque: tabla de aprendizaje
CRITERIOS DE SELECCIÓN DE MODELOS
 Inteligencia artificial y reconocimiento de patrones CRITERIOS DE SELECCIÓN DE MODELOS 1 Criterios para elegir un modelo Dos decisiones fundamentales: El tipo de modelo (árboles de decisión, redes neuronales,
Inteligencia artificial y reconocimiento de patrones CRITERIOS DE SELECCIÓN DE MODELOS 1 Criterios para elegir un modelo Dos decisiones fundamentales: El tipo de modelo (árboles de decisión, redes neuronales,
Métodos Estadísticos Multivariados
 Métodos Estadísticos Multivariados Victor Muñiz ITESM Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre 2011 1 / 20 Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre
Métodos Estadísticos Multivariados Victor Muñiz ITESM Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre 2011 1 / 20 Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre
Técnicas de Clasificación Supervisada DRA. LETICIA FLORES PULIDO
 Técnicas de Clasificación Supervisada DRA. LETICIA FLORES PULIDO 2 Objetivo El objetivo principal de las técnicas de clasificación supervisada es obtener un modelo clasificatorio válido para permitir tratar
Técnicas de Clasificación Supervisada DRA. LETICIA FLORES PULIDO 2 Objetivo El objetivo principal de las técnicas de clasificación supervisada es obtener un modelo clasificatorio válido para permitir tratar
Tema 2. Descripción Conjunta de Varias Variables
 Tema 2. Descripción Conjunta de Varias Variables Cuestiones de Verdadero/Falso 1. La covarianza mide la relación lineal entre dos variables, pero depende de las unidades de medida utilizadas. 2. El análisis
Tema 2. Descripción Conjunta de Varias Variables Cuestiones de Verdadero/Falso 1. La covarianza mide la relación lineal entre dos variables, pero depende de las unidades de medida utilizadas. 2. El análisis
Métodos de agregación de modelos y aplicaciones
 Métodos de agregación de modelos y aplicaciones Model aggregation methods and applications Mathias Bourel 1 Recibido: Mayo 2012 Aprobado: Agosto 2012 Resumen.- Los métodos de agregación de modelos en aprendizaje
Métodos de agregación de modelos y aplicaciones Model aggregation methods and applications Mathias Bourel 1 Recibido: Mayo 2012 Aprobado: Agosto 2012 Resumen.- Los métodos de agregación de modelos en aprendizaje
Proyecto 6. Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial.
 Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial. Funcionamiento: Se realiza un test en cada nodo interno del árbol, a medida que
Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial. Funcionamiento: Se realiza un test en cada nodo interno del árbol, a medida que
El pequeño círculo de la NO-O aporta un NO funcional a la salida, de modo que invierte los estados de la misma.
 Diapositiva 1 Diapositiva 2 Este problema se ha incluido en el trabajo para casa, por lo que no se resolverá por completo aquí. Nótese que: (1) la salida será o + o V cc, (2) hay realimentación positiva,
Diapositiva 1 Diapositiva 2 Este problema se ha incluido en el trabajo para casa, por lo que no se resolverá por completo aquí. Nótese que: (1) la salida será o + o V cc, (2) hay realimentación positiva,
Aplicación de Vectores Estadísticos de Características y Ensambles para el Reconocimiento Automático del Llanto de Bebés
 Aplicación de Vectores Estadísticos de Características y Ensambles para el Reconocimiento Automático del Llanto de Bebés Amaro Camargo Erika, Reyes García Carlos A. Instituto Nacional de Astrofísica, Óptica
Aplicación de Vectores Estadísticos de Características y Ensambles para el Reconocimiento Automático del Llanto de Bebés Amaro Camargo Erika, Reyes García Carlos A. Instituto Nacional de Astrofísica, Óptica
INDICE. Prólogo a la Segunda Edición
 INDICE Prólogo a la Segunda Edición XV Prefacio XVI Capitulo 1. Análisis de datos de Negocios 1 1.1. Definición de estadística de negocios 1 1.2. Estadística descriptiva r inferencia estadística 1 1.3.
INDICE Prólogo a la Segunda Edición XV Prefacio XVI Capitulo 1. Análisis de datos de Negocios 1 1.1. Definición de estadística de negocios 1 1.2. Estadística descriptiva r inferencia estadística 1 1.3.
Ajustes de datos: transformación de datos. Capítulo 9 de McCune y Grace 2002
 Ajustes de datos: transformación de datos. Capítulo 9 de McCune y Grace 2002 Razones estadísticas para transformar datos Mejorar las suposiciones de algunas técnicas estadísticas: normalidad, linealidad,
Ajustes de datos: transformación de datos. Capítulo 9 de McCune y Grace 2002 Razones estadísticas para transformar datos Mejorar las suposiciones de algunas técnicas estadísticas: normalidad, linealidad,
Teoría de la decisión
 1.- Un problema estadístico típico es reflejar la relación entre dos variables, a partir de una serie de Observaciones: Por ejemplo: * peso adulto altura / peso adulto k*altura * relación de la circunferencia
1.- Un problema estadístico típico es reflejar la relación entre dos variables, a partir de una serie de Observaciones: Por ejemplo: * peso adulto altura / peso adulto k*altura * relación de la circunferencia
Funcionamiento, interfaz y formato de los datos en GARP
 Grupo de investigación Ecología de Zonas Áridas CENTRO ANDALUZ PARA LA EVALUACIÓN Y SEGUIMIENTO DEL CAMBIO GLOBAL Funcionamiento, interfaz y formato de los datos en GARP Elisa Liras Dpto. Biología Vegetal
Grupo de investigación Ecología de Zonas Áridas CENTRO ANDALUZ PARA LA EVALUACIÓN Y SEGUIMIENTO DEL CAMBIO GLOBAL Funcionamiento, interfaz y formato de los datos en GARP Elisa Liras Dpto. Biología Vegetal
Otros aspectos. Procesado de la entrada Procesado de la salida. Carlos J. Alonso González Departamento de Informática Universidad de Valladolid
 Otros aspectos Procesado de la entrada Procesado de la salida Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Procesado de la entrada 1. Motivación y tareas
Otros aspectos Procesado de la entrada Procesado de la salida Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Procesado de la entrada 1. Motivación y tareas
PENSAMIENTO CRÍTICO Qué es? capacidad de recopilar y evaluar la información lógico, equilibrado y reflexivo
 PENSAMIENTO CRÍTICO Qué es? El pensamiento crítico es la capacidad de recopilar y evaluar la información de un modo lógico, equilibrado y reflexivo, para ser capaces de llegar a conclusiones que están
PENSAMIENTO CRÍTICO Qué es? El pensamiento crítico es la capacidad de recopilar y evaluar la información de un modo lógico, equilibrado y reflexivo, para ser capaces de llegar a conclusiones que están
ADMINISTRACION DE OPERACIONES
 Sesión4: Métodos cuantitativos ADMINISTRACION DE OPERACIONES Objetivo específico 1: El alumno conocerá y aplicara adecuadamente los métodos de pronóstico de la demanda para planear la actividad futura
Sesión4: Métodos cuantitativos ADMINISTRACION DE OPERACIONES Objetivo específico 1: El alumno conocerá y aplicara adecuadamente los métodos de pronóstico de la demanda para planear la actividad futura
Tema 9: Contraste de hipótesis.
 Estadística 84 Tema 9: Contraste de hipótesis. 9.1 Introducción. El objetivo de este tema es proporcionar métodos que permiten decidir si una hipótesis estadística debe o no ser rechazada, en base a los
Estadística 84 Tema 9: Contraste de hipótesis. 9.1 Introducción. El objetivo de este tema es proporcionar métodos que permiten decidir si una hipótesis estadística debe o no ser rechazada, en base a los
BÚSQUEDA INTELIGENTE BASADA EN METAHEURÍSTICAS
 Departamento de Inteligencia Artificial Grupo de Análisis de Decisiones y Estadística BÚSQUEDA INTELIGENTE BASADA EN METAHEURÍSTICAS PRÁCTICAS 1 Existen varias características que pueden causar dificultades
Departamento de Inteligencia Artificial Grupo de Análisis de Decisiones y Estadística BÚSQUEDA INTELIGENTE BASADA EN METAHEURÍSTICAS PRÁCTICAS 1 Existen varias características que pueden causar dificultades
Estadística para la toma de decisiones
 Estadística para la toma de decisiones ESTADÍSTICA PARA LA TOMA DE DECISIONES. 1 Sesión No. 7 Nombre: Distribuciones de probabilidad para variables continúas. Objetivo Al término de la sesión el estudiante
Estadística para la toma de decisiones ESTADÍSTICA PARA LA TOMA DE DECISIONES. 1 Sesión No. 7 Nombre: Distribuciones de probabilidad para variables continúas. Objetivo Al término de la sesión el estudiante
FACULTAD DE INGENIERÍA
 FACULTAD DE INGENIERÍA II JORNADAS DE DATA MINING CONFERENCIA 7.- " CASO SNOOP CONSULTING-ORACLE Fernando Das Neves Gerente de I+D de Snoop Consulting-Oracle Data Mining Technologies IAE - Pilar, 7 y 8
FACULTAD DE INGENIERÍA II JORNADAS DE DATA MINING CONFERENCIA 7.- " CASO SNOOP CONSULTING-ORACLE Fernando Das Neves Gerente de I+D de Snoop Consulting-Oracle Data Mining Technologies IAE - Pilar, 7 y 8
Unidad 5 Control Estadístico de la Calidad. Administración de Operaciones III
 Unidad 5 Control Estadístico de la Calidad Administración de Operaciones III 1 Contenido 1. Antecedentes del control estadístico de la calidad 2. Definición 3. Importancia y aplicación 4. Control estadístico
Unidad 5 Control Estadístico de la Calidad Administración de Operaciones III 1 Contenido 1. Antecedentes del control estadístico de la calidad 2. Definición 3. Importancia y aplicación 4. Control estadístico
Tema 13: Distribuciones de probabilidad. Estadística
 Tema 13: Distribuciones de probabilidad. Estadística 1. Variable aleatoria Una variable aleatoria es una función que asocia a cada elemento del espacio muestral, de un experimento aleatorio, un número
Tema 13: Distribuciones de probabilidad. Estadística 1. Variable aleatoria Una variable aleatoria es una función que asocia a cada elemento del espacio muestral, de un experimento aleatorio, un número
Métodos para escribir algoritmos: Diagramas de Flujo y pseudocódigo
 TEMA 2: CONCEPTOS BÁSICOS DE ALGORÍTMICA 1. Definición de Algoritmo 1.1. Propiedades de los Algoritmos 2. Qué es un Programa? 2.1. Cómo se construye un Programa 3. Definición y uso de herramientas para
TEMA 2: CONCEPTOS BÁSICOS DE ALGORÍTMICA 1. Definición de Algoritmo 1.1. Propiedades de los Algoritmos 2. Qué es un Programa? 2.1. Cómo se construye un Programa 3. Definición y uso de herramientas para
Método de cuadrados mínimos
 REGRESIÓN LINEAL Gran parte del pronóstico estadístico del tiempo está basado en el procedimiento conocido como regresión lineal. Regresión lineal simple (RLS) Describe la relación lineal entre dos variables,
REGRESIÓN LINEAL Gran parte del pronóstico estadístico del tiempo está basado en el procedimiento conocido como regresión lineal. Regresión lineal simple (RLS) Describe la relación lineal entre dos variables,
Ejemplo: El problema de la mochila. Algoritmos golosos. Algoritmos y Estructuras de Datos III. Segundo cuatrimestre 2013
 Técnicas de diseño de algoritmos Algoritmos y Estructuras de Datos III Segundo cuatrimestre 2013 Técnicas de diseño de algoritmos Algoritmos golosos Backtracking (búsqueda con retroceso) Divide and conquer
Técnicas de diseño de algoritmos Algoritmos y Estructuras de Datos III Segundo cuatrimestre 2013 Técnicas de diseño de algoritmos Algoritmos golosos Backtracking (búsqueda con retroceso) Divide and conquer
Distribuciones muestrales. Distribución muestral de Medias
 Distribuciones muestrales. Distribución muestral de Medias TEORIA DEL MUESTREO Uno de los propósitos de la estadística inferencial es estimar las características poblacionales desconocidas, examinando
Distribuciones muestrales. Distribución muestral de Medias TEORIA DEL MUESTREO Uno de los propósitos de la estadística inferencial es estimar las características poblacionales desconocidas, examinando
Análisis Probit. StatFolio de Ejemplo: probit.sgp
 STATGRAPHICS Rev. 4/25/27 Análisis Probit Resumen El procedimiento Análisis Probit está diseñado para ajustar un modelo de regresión en el cual la variable dependiente Y caracteriza un evento con sólo
STATGRAPHICS Rev. 4/25/27 Análisis Probit Resumen El procedimiento Análisis Probit está diseñado para ajustar un modelo de regresión en el cual la variable dependiente Y caracteriza un evento con sólo
Cómo se usa Data Mining hoy?
 Cómo se usa Data Mining hoy? 1 Conocer a los clientes Detectar segmentos Calcular perfiles Cross-selling Detectar buenos clientes Evitar el churning, attrition Detección de morosidad Mejora de respuesta
Cómo se usa Data Mining hoy? 1 Conocer a los clientes Detectar segmentos Calcular perfiles Cross-selling Detectar buenos clientes Evitar el churning, attrition Detección de morosidad Mejora de respuesta
MÓDULO 1: GESTIÓN DE CARTERAS
 MÓDULO 1: GESTIÓN DE CARTERAS TEST DE EVALUACIÓN 1 Una vez realizado el test de evaluación, cumplimenta la plantilla y envíala, por favor, antes del plazo fijado. En todas las preguntas sólo hay una respuesta
MÓDULO 1: GESTIÓN DE CARTERAS TEST DE EVALUACIÓN 1 Una vez realizado el test de evaluación, cumplimenta la plantilla y envíala, por favor, antes del plazo fijado. En todas las preguntas sólo hay una respuesta
Otra característica poblacional de interés es la varianza de la población, 2, y su raíz cuadrada, la desviación estándar de la población,. La varianza
 CARACTERÍSTICAS DE LA POBLACIÓN. Una pregunta práctica en gran parte de la investigación de mercado tiene que ver con el tamaño de la muestra. La encuesta, en principio, no puede ser aplicada sin conocer
CARACTERÍSTICAS DE LA POBLACIÓN. Una pregunta práctica en gran parte de la investigación de mercado tiene que ver con el tamaño de la muestra. La encuesta, en principio, no puede ser aplicada sin conocer
Regresión lineal SIMPLE MÚLTIPLE N A Z IRA C A L L E J A
 Regresión lineal REGRESIÓN LINEAL SIMPLE REGRESIÓN LINEAL MÚLTIPLE N A Z IRA C A L L E J A Qué es la regresión? El análisis de regresión: Se utiliza para examinar el efecto de diferentes variables (VIs
Regresión lineal REGRESIÓN LINEAL SIMPLE REGRESIÓN LINEAL MÚLTIPLE N A Z IRA C A L L E J A Qué es la regresión? El análisis de regresión: Se utiliza para examinar el efecto de diferentes variables (VIs
INSTITUTO POLITÉCNICO NACIONAL SECRETARIA ACADEMICA DIRECCIÓN DE ESTUDIOS PROFESIONALES EN INGENIERÍA Y CIENCIAS FÍSICO MATEMÁTICAS
 ESCUELA: UPIICSA CARRERA: INGENIERÍA EN TRANSPORTE ESPECIALIDAD: COORDINACIÓN: ACADEMIAS DE MATEMÁTICAS DEPARTAMENTO: CIENCIAS BÁSICAS PROGRAMA DE ESTUDIO ASIGNATURA: ESTADÍSTICA APLICADA CLAVE: TMPE SEMESTRE:
ESCUELA: UPIICSA CARRERA: INGENIERÍA EN TRANSPORTE ESPECIALIDAD: COORDINACIÓN: ACADEMIAS DE MATEMÁTICAS DEPARTAMENTO: CIENCIAS BÁSICAS PROGRAMA DE ESTUDIO ASIGNATURA: ESTADÍSTICA APLICADA CLAVE: TMPE SEMESTRE:
Tema 7: Estadística y probabilidad
 Tema 7: Estadística y probabilidad En este tema revisaremos: 1. Representación de datos e interpretación de gráficas. 2. Estadística descriptiva. 3. Probabilidad elemental. Representaciones de datos Cuatro
Tema 7: Estadística y probabilidad En este tema revisaremos: 1. Representación de datos e interpretación de gráficas. 2. Estadística descriptiva. 3. Probabilidad elemental. Representaciones de datos Cuatro
Puntuación Z ESTADÍSTICA APLICADA A LA EDUCACIÓN I. L.A. y M.C.E. Emma Linda Diez Knoth
 1 Puntuación Z ESTADÍSTICA APLICADA A LA EDUCACIÓN I Qué es la Puntuación Z? 2 Los puntajes Z son transformaciones que se pueden hacer a los valores o puntuaciones de una distribución normal, con el propósito
1 Puntuación Z ESTADÍSTICA APLICADA A LA EDUCACIÓN I Qué es la Puntuación Z? 2 Los puntajes Z son transformaciones que se pueden hacer a los valores o puntuaciones de una distribución normal, con el propósito
DISTRIBUCIÓN N BINOMIAL
 DISTRIBUCIÓN N BINOMIAL COMBINACIONES En muchos problemas de probabilidad es necesario conocer el número de maneras en que r objetos pueden seleccionarse de un conjunto de n objetos. A esto se le denomina
DISTRIBUCIÓN N BINOMIAL COMBINACIONES En muchos problemas de probabilidad es necesario conocer el número de maneras en que r objetos pueden seleccionarse de un conjunto de n objetos. A esto se le denomina
Aux 6. Introducción a la Minería de Datos
 Aux 6. Introducción a la Minería de Datos Gastón L Huillier 1,2, Richard Weber 2 glhuilli@dcc.uchile.cl 1 Departamento de Ciencias de la Computación Universidad de Chile 2 Departamento de Ingeniería Industrial
Aux 6. Introducción a la Minería de Datos Gastón L Huillier 1,2, Richard Weber 2 glhuilli@dcc.uchile.cl 1 Departamento de Ciencias de la Computación Universidad de Chile 2 Departamento de Ingeniería Industrial
El método simplex 1. 1 Forma estándar y cambios en el modelo. 2 Definiciones. 3 Puntos extremos y soluciones factibles básicas. 4 El método simplex.
 El método simplex Forma estándar y cambios en el modelo. Definiciones. Puntos extremos y soluciones factibles básicas. 4 El método simplex. Definiciones y notación. Teoremas. Solución factible básica inicial.
El método simplex Forma estándar y cambios en el modelo. Definiciones. Puntos extremos y soluciones factibles básicas. 4 El método simplex. Definiciones y notación. Teoremas. Solución factible básica inicial.
Medidas descriptivas I. Medidas de tendencia central A. La moda
 Medidas descriptivas I. Medidas de tendencia central A. La moda Preparado por: Roberto O. Rivera Rodríguez Coaching de matemática Escuela Eduardo Neuman Gandía 1 Introducción En muchas ocasiones el conjunto
Medidas descriptivas I. Medidas de tendencia central A. La moda Preparado por: Roberto O. Rivera Rodríguez Coaching de matemática Escuela Eduardo Neuman Gandía 1 Introducción En muchas ocasiones el conjunto
Estadística Descriptiva. SESIÓN 11 Medidas de dispersión
 Estadística Descriptiva SESIÓN 11 Medidas de dispersión Contextualización de la sesión 11 En la sesión anterior se explicaron los temas relacionados con la dispersión, una de las medidas de dispersión,
Estadística Descriptiva SESIÓN 11 Medidas de dispersión Contextualización de la sesión 11 En la sesión anterior se explicaron los temas relacionados con la dispersión, una de las medidas de dispersión,
Fracciones y fractales
 C APÍTULO 0 Fracciones y fractales Resumen del contenido El tema del Capítulo 0 es la investigación de patrones en el diseño fractal. No se intimide si no ha visto fractales anteriormente. El propósito
C APÍTULO 0 Fracciones y fractales Resumen del contenido El tema del Capítulo 0 es la investigación de patrones en el diseño fractal. No se intimide si no ha visto fractales anteriormente. El propósito
Localización. CI-2657 Robótica M.Sc. Kryscia Ramírez Benavides
 M.Sc. Kryscia Ramírez Benavides Problemas de Navegación de los Robots Dónde estoy?. Dónde he estado? Mapa de decisiones. A dónde voy? Planificación de misiones. Cuál es la mejor manera de llegar? Planificación
M.Sc. Kryscia Ramírez Benavides Problemas de Navegación de los Robots Dónde estoy?. Dónde he estado? Mapa de decisiones. A dónde voy? Planificación de misiones. Cuál es la mejor manera de llegar? Planificación
Modelos de probabilidad. Modelos de probabilidad. Modelos de probabilidad. Proceso de Bernoulli. Objetivos del tema:
 Modelos de probabilidad Modelos de probabilidad Distribución de Bernoulli Distribución Binomial Distribución de Poisson Distribución Exponencial Objetivos del tema: Al final del tema el alumno será capaz
Modelos de probabilidad Modelos de probabilidad Distribución de Bernoulli Distribución Binomial Distribución de Poisson Distribución Exponencial Objetivos del tema: Al final del tema el alumno será capaz
Teoría de juegos Andrés Ramos Universidad Pontificia Comillas
 Teoría de juegos Andrés Ramos Universidad Pontificia Comillas http://www.iit.upcomillas.es/aramos/ Andres.Ramos@upcomillas.es TEORÍA DE JUEGOS 1 Teoría de juegos 1. Matriz de pagos 2. Clasificación 3.
Teoría de juegos Andrés Ramos Universidad Pontificia Comillas http://www.iit.upcomillas.es/aramos/ Andres.Ramos@upcomillas.es TEORÍA DE JUEGOS 1 Teoría de juegos 1. Matriz de pagos 2. Clasificación 3.
Estadística Descriptiva
 M. en C. Juan Carlos Gutiérrez Matus Instituto Politécnico Nacional 2004 IPN UPIICSA c 2004 Juan C. Gutiérrez Matus Desde la segunda mitad del siglo anterior, el milagro industrial sucedido en Japón, hizo
M. en C. Juan Carlos Gutiérrez Matus Instituto Politécnico Nacional 2004 IPN UPIICSA c 2004 Juan C. Gutiérrez Matus Desde la segunda mitad del siglo anterior, el milagro industrial sucedido en Japón, hizo
Estadís5ca. María Dolores Frías Domínguez Jesús Fernández Fernández Carmen María Sordo. Tema 2. Modelos de regresión
 Estadís5ca Tema 2. Modelos de regresión María Dolores Frías Domínguez Jesús Fernández Fernández Carmen María Sordo Departamento de Matemá.ca Aplicada y Ciencias de la Computación Este tema se publica bajo
Estadís5ca Tema 2. Modelos de regresión María Dolores Frías Domínguez Jesús Fernández Fernández Carmen María Sordo Departamento de Matemá.ca Aplicada y Ciencias de la Computación Este tema se publica bajo
UNIVERSIDAD DEL VALLE DE MÉXICO PROGRAMA DE ESTUDIO DE LICENCIATURA PRAXIS MES XXI
 UNIVERSIDAD DEL VALLE DE MÉXICO PROGRAMA DE ESTUDIO DE LICENCIATURA PRAXIS MES XXI NOMBRE DE LA ASIGNATURA: PROBABILIDAD Y ESTADÍSTICA PARA CIENCIAS ECONÓMICO ADMINISTRATIVAS FECHA DE ELABORACIÓN: ENERO
UNIVERSIDAD DEL VALLE DE MÉXICO PROGRAMA DE ESTUDIO DE LICENCIATURA PRAXIS MES XXI NOMBRE DE LA ASIGNATURA: PROBABILIDAD Y ESTADÍSTICA PARA CIENCIAS ECONÓMICO ADMINISTRATIVAS FECHA DE ELABORACIÓN: ENERO
INTERVALOS DE CONFIANZA. La estadística en cómic (L. Gonick y W. Smith)
") INTERVALOS DE CONFIANZA La estadística en cómic (L. Gonick y W. Smith) EJEMPLO: Será elegido el senador Astuto? 2 tamaño muestral Estimador de p variable aleatoria poblacional? proporción de personas que
INTERVALOS DE CONFIANZA La estadística en cómic (L. Gonick y W. Smith) EJEMPLO: Será elegido el senador Astuto? 2 tamaño muestral Estimador de p variable aleatoria poblacional? proporción de personas que
Matemáticas 2.º Bachillerato. Intervalos de confianza. Contraste de hipótesis
 Matemáticas 2.º Bachillerato Intervalos de confianza. Contraste de hipótesis Depto. Matemáticas IES Elaios Tema: Estadística Inferencial 1. MUESTREO ALEATORIO Presentación elaborada por el profesor José
Matemáticas 2.º Bachillerato Intervalos de confianza. Contraste de hipótesis Depto. Matemáticas IES Elaios Tema: Estadística Inferencial 1. MUESTREO ALEATORIO Presentación elaborada por el profesor José
VARIANTES EN EL DISEÑO DE LOS ENSAYOS CLÍNICOS CON ASIGNACIÓN ALEATORIA. Sandra Flores Moreno. AETSA 21 de Diciembre de 2006
 VARIANTES EN EL DISEÑO DE LOS ENSAYOS CLÍNICOS CON ASIGNACIÓN ALEATORIA Sandra Flores Moreno. AETSA 21 de Diciembre de 2006 VARIANTES EN EL DISEÑO DE ENSAYOS CLÍNICOS CON ASIGNACIÓN ALEATORIA *INTRODUCCIÓN
VARIANTES EN EL DISEÑO DE LOS ENSAYOS CLÍNICOS CON ASIGNACIÓN ALEATORIA Sandra Flores Moreno. AETSA 21 de Diciembre de 2006 VARIANTES EN EL DISEÑO DE ENSAYOS CLÍNICOS CON ASIGNACIÓN ALEATORIA *INTRODUCCIÓN
GRAFICOS DE CONTROL DATOS TIPO VARIABLES
 GRAFICOS DE CONTROL DATOS TIPO VARIABLES OBJETIVO DEL LABORATORIO El objetivo del presente laboratorio es que el estudiante conozca y que sea capaz de seleccionar y utilizar gráficos de control, para realizar
GRAFICOS DE CONTROL DATOS TIPO VARIABLES OBJETIVO DEL LABORATORIO El objetivo del presente laboratorio es que el estudiante conozca y que sea capaz de seleccionar y utilizar gráficos de control, para realizar
Masters: Experto en Direccion y Gestion de Proyectos. Project Management
 Masters: Experto en Direccion y Gestion de Proyectos. Project Management Objetivos Describir la naturaleza de un proyecto y los ciclos de vida del mismo. Presentar las fases del proceso de planificación
Masters: Experto en Direccion y Gestion de Proyectos. Project Management Objetivos Describir la naturaleza de un proyecto y los ciclos de vida del mismo. Presentar las fases del proceso de planificación
CONTRASTE SOBRE UN COEFICIENTE DE LA REGRESIÓN
 Modelo: Y =! 1 +! 2 X + u Hipótesis nula: Hipótesis alternativa H 1 :!!! 2 2 Ejemplo de modelo: p =! 1 +! 2 w + u Hipótesis nula: Hipótesis alternativa: H :!! 1 2 1. Como ilustración, consideremos un modelo
Modelo: Y =! 1 +! 2 X + u Hipótesis nula: Hipótesis alternativa H 1 :!!! 2 2 Ejemplo de modelo: p =! 1 +! 2 w + u Hipótesis nula: Hipótesis alternativa: H :!! 1 2 1. Como ilustración, consideremos un modelo
Agro 6998 Conferencia 2. Introducción a los modelos estadísticos mixtos
 Agro 6998 Conferencia Introducción a los modelos estadísticos mixtos Los modelos estadísticos permiten modelar la respuesta de un estudio experimental u observacional en función de factores (tratamientos,
Agro 6998 Conferencia Introducción a los modelos estadísticos mixtos Los modelos estadísticos permiten modelar la respuesta de un estudio experimental u observacional en función de factores (tratamientos,
NOCIONES DE ESTADÍSTICA CURSO PRÁCTICO DE CLIMATOLOGÍA 2011
 NOCIONES DE ESTADÍSTICA CURSO PRÁCTICO DE CLIMATOLOGÍA 2011 CÓMO CARACTERIZAR UNA SERIE DE DATOS? POSICIÓN- dividen un conjunto ordenado de datos en grupos con la misma cantidad de individuos CENTRALIZACIÓN-
NOCIONES DE ESTADÍSTICA CURSO PRÁCTICO DE CLIMATOLOGÍA 2011 CÓMO CARACTERIZAR UNA SERIE DE DATOS? POSICIÓN- dividen un conjunto ordenado de datos en grupos con la misma cantidad de individuos CENTRALIZACIÓN-
Carrera: Integrantes de la Academia de Ingeniería Industrial: M.C. Ramón García González. Integrantes de la
 1.- DATOS DE LA ASIGNATURA Nombre de la asignatura: Carrera: Ingeniería de calidad Licenciatura en Ingeniería Industrial Clave de la asignatura: Horas teoría horas práctica - créditos 4-0 - 8 2.- HISTORIA
1.- DATOS DE LA ASIGNATURA Nombre de la asignatura: Carrera: Ingeniería de calidad Licenciatura en Ingeniería Industrial Clave de la asignatura: Horas teoría horas práctica - créditos 4-0 - 8 2.- HISTORIA
4.1 Análisis bivariado de asociaciones
 4.1 Análisis bivariado de asociaciones Los gerentes posiblemente estén interesados en el grado de asociación entre dos variables Las técnicas estadísticas adecuadas para realizar este tipo de análisis
4.1 Análisis bivariado de asociaciones Los gerentes posiblemente estén interesados en el grado de asociación entre dos variables Las técnicas estadísticas adecuadas para realizar este tipo de análisis
Bloque 1. Contenidos comunes. (Total: 3 sesiones)
") 4º E.S.O. OPCIÓN A 1.1.1 Contenidos 1.1.1.1 Bloque 1. Contenidos comunes. (Total: 3 sesiones) Planificación y utilización de procesos de razonamiento y estrategias de resolución de problemas, tales como
4º E.S.O. OPCIÓN A 1.1.1 Contenidos 1.1.1.1 Bloque 1. Contenidos comunes. (Total: 3 sesiones) Planificación y utilización de procesos de razonamiento y estrategias de resolución de problemas, tales como
Complejidad computacional (Análisis de Algoritmos)
") Definición. Complejidad computacional (Análisis de Algoritmos) Es la rama de las ciencias de la computación que estudia, de manera teórica, la optimización de los recursos requeridos durante la ejecución
Definición. Complejidad computacional (Análisis de Algoritmos) Es la rama de las ciencias de la computación que estudia, de manera teórica, la optimización de los recursos requeridos durante la ejecución
ANALISIS DE CLUSTER CON SPSS: INMACULADA BARRERA
 ANALISIS DE CLUSTER CON SPSS: INMACULADA BARRERA ANALISIS DE CLUSTER EN SPSS Opción: Analizar Clasificar ANALISIS DE CLUSTER EN SPSS Tres posibles OPCIONES 1.- Cluster en dos etapas 2.- K-means 3.- Jerárquicos
ANALISIS DE CLUSTER CON SPSS: INMACULADA BARRERA ANALISIS DE CLUSTER EN SPSS Opción: Analizar Clasificar ANALISIS DE CLUSTER EN SPSS Tres posibles OPCIONES 1.- Cluster en dos etapas 2.- K-means 3.- Jerárquicos
Análisis y Diseño de Algoritmos
 Análisis y Diseño de Algoritmos Ordenamiento en Tiempo Lineal DR. JESÚS A. GONZÁLEZ BERNAL CIENCIAS COMPUTACIONALES INAOE Ordenamiento por Comparación (Comparison Sorts) Tiempo de ejecución HeapSort y
Análisis y Diseño de Algoritmos Ordenamiento en Tiempo Lineal DR. JESÚS A. GONZÁLEZ BERNAL CIENCIAS COMPUTACIONALES INAOE Ordenamiento por Comparación (Comparison Sorts) Tiempo de ejecución HeapSort y
Análisis de datos Categóricos
 Introducción a los Modelos Lineales Generalizados Universidad Nacional Agraria La Molina 2016-1 Introducción Modelos Lineales Generalizados Introducción Componentes Estimación En los capítulos anteriores
Introducción a los Modelos Lineales Generalizados Universidad Nacional Agraria La Molina 2016-1 Introducción Modelos Lineales Generalizados Introducción Componentes Estimación En los capítulos anteriores
Tema 5 Algunas distribuciones importantes
 Algunas distribuciones importantes 1 Modelo Bernoulli Distribución Bernoulli Se llama experimento de Bernoulli a un experimento con las siguientes características: 1. Se realiza un experimento con dos
Algunas distribuciones importantes 1 Modelo Bernoulli Distribución Bernoulli Se llama experimento de Bernoulli a un experimento con las siguientes características: 1. Se realiza un experimento con dos
 FACULTAD DE INGENIERÍA UNAM PROBABILIDAD Y ESTADÍSTICA Irene Patricia Valdez y Alfaro irenev@servidor.unam.m T E M A S DEL CURSO. Análisis Estadístico de datos muestrales.. Fundamentos de la Teoría de
FACULTAD DE INGENIERÍA UNAM PROBABILIDAD Y ESTADÍSTICA Irene Patricia Valdez y Alfaro irenev@servidor.unam.m T E M A S DEL CURSO. Análisis Estadístico de datos muestrales.. Fundamentos de la Teoría de
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos. - Sesión 9 -
 Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 9 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Qué es un modelo de Data Mining Qué es
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 9 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Qué es un modelo de Data Mining Qué es
UN PROBLEMA DE OPTIMIZACIÓN CON CABRI: LA REGRESIÓN LINEAL.
 UN PROBLEMA DE OPTIMIZACIÓN CON CABRI: LA REGRESIÓN LINEAL. Benjamín R. Sarmiento Lugo. Universidad Pedagógica Nacional bsarmiento@pedagogica.edu.co Esta conferencia está basada en uno de los temas desarrollados
UN PROBLEMA DE OPTIMIZACIÓN CON CABRI: LA REGRESIÓN LINEAL. Benjamín R. Sarmiento Lugo. Universidad Pedagógica Nacional bsarmiento@pedagogica.edu.co Esta conferencia está basada en uno de los temas desarrollados
INDICE 1. Introducción 2. Recopilación de Datos Caso de estudia A 3. Descripción y Resumen de Datos 4. Presentación de Datos
 INDICE Prefacio VII 1. Introducción 1 1.1. Qué es la estadística moderna? 1 1.2. El crecimiento y desarrollo de la estadística moderna 1 1.3. Estudios enumerativos en comparación con estudios analíticos
INDICE Prefacio VII 1. Introducción 1 1.1. Qué es la estadística moderna? 1 1.2. El crecimiento y desarrollo de la estadística moderna 1 1.3. Estudios enumerativos en comparación con estudios analíticos
Medidas de dispersión
 Medidas de dispersión Las medidas de dispersión nos informan sobre cuánto se alejan del centro los valores de la distribución. Las medidas de dispersión son: Rango o recorrido El rango es la diferencia
Medidas de dispersión Las medidas de dispersión nos informan sobre cuánto se alejan del centro los valores de la distribución. Las medidas de dispersión son: Rango o recorrido El rango es la diferencia
1. La Distribución Normal
 1. La Distribución Normal Los espacios muestrales continuos y las variables aleatorias continuas se presentan siempre que se manejan cantidades que se miden en una escala continua; por ejemplo, cuando
1. La Distribución Normal Los espacios muestrales continuos y las variables aleatorias continuas se presentan siempre que se manejan cantidades que se miden en una escala continua; por ejemplo, cuando
ESTADÍSTICA. Población Individuo Muestra Muestreo Valor Dato Variable Cualitativa ordinal nominal. continua
 ESTADÍSTICA Población Individuo Muestra Muestreo Valor Dato Variable Cualitativa ordinal nominal Cuantitativa discreta continua DISTRIBUCIÓN DE FRECUENCIAS Frecuencia absoluta: fi Frecuencia relativa:
ESTADÍSTICA Población Individuo Muestra Muestreo Valor Dato Variable Cualitativa ordinal nominal Cuantitativa discreta continua DISTRIBUCIÓN DE FRECUENCIAS Frecuencia absoluta: fi Frecuencia relativa:
Unidad IV: Distribuciones muestrales
 Unidad IV: Distribuciones muestrales 4.1 Función de probabilidad En teoría de la probabilidad, una función de probabilidad (también denominada función de masa de probabilidad) es una función que asocia
Unidad IV: Distribuciones muestrales 4.1 Función de probabilidad En teoría de la probabilidad, una función de probabilidad (también denominada función de masa de probabilidad) es una función que asocia
LOS SISTEMAS ADAPTATIVOS
 0010100100100101010110010001 0101010001010100101000101 0010100011110010110010001 11111111111010100010101001010010100010101010101 0010100011110101010101011100101001001010101100100010010100011110101010001
0010100100100101010110010001 0101010001010100101000101 0010100011110010110010001 11111111111010100010101001010010100010101010101 0010100011110101010101011100101001001010101100100010010100011110101010001
Consideración del Margen de Desvanecimiento con ICS Telecom en Planeación de Redes de Microceldas (NLOS)
") Consideración del Margen de Desvanecimiento con ICS Telecom en Planeación de Redes de Microceldas (NLOS) Agosto 2008 SEAN YUN Traducido por ANDREA MARÍN Modelando RF con Precisión 0 0 ICS Telecom ofrece
Consideración del Margen de Desvanecimiento con ICS Telecom en Planeación de Redes de Microceldas (NLOS) Agosto 2008 SEAN YUN Traducido por ANDREA MARÍN Modelando RF con Precisión 0 0 ICS Telecom ofrece
SISTEMAS INTELIGENTES
 SISTEMAS INTELIGENTES T8: Aprendizaje basado en instancias www.aic.uniovi.es/ssii Índice Aprendizaje basado en instancias Métricas NN Vecino más próximo: Regiones de Voronoi El parámetro K Problemas de
SISTEMAS INTELIGENTES T8: Aprendizaje basado en instancias www.aic.uniovi.es/ssii Índice Aprendizaje basado en instancias Métricas NN Vecino más próximo: Regiones de Voronoi El parámetro K Problemas de
4. NÚMEROS PSEUDOALEATORIOS.
 4. NÚMEROS PSEUDOALEATORIOS. En los experimentos de simulación es necesario generar valores para las variables aleatorias representadas estas por medio de distribuciones de probabilidad. Para poder generar
4. NÚMEROS PSEUDOALEATORIOS. En los experimentos de simulación es necesario generar valores para las variables aleatorias representadas estas por medio de distribuciones de probabilidad. Para poder generar
Departamento de Medicina Preventiva y Salud Publica e Historia de la Ciencia. Universidad Complutense de Madrid. SPSS para windows.
 TEMA 13 REGRESIÓN LOGÍSTICA Es un tipo de análisis de regresión en el que la variable dependiente no es continua, sino dicotómica, mientras que las variables independientes pueden ser cuantitativas o cualitativas.
TEMA 13 REGRESIÓN LOGÍSTICA Es un tipo de análisis de regresión en el que la variable dependiente no es continua, sino dicotómica, mientras que las variables independientes pueden ser cuantitativas o cualitativas.
2 Introducción a la inferencia estadística Introducción Teoría de conteo Variaciones con repetición...
 Contenidos 1 Introducción al paquete estadístico S-PLUS 19 1.1 Introducción a S-PLUS............................ 21 1.1.1 Cómo entrar, salir y consultar la ayuda en S-PLUS........ 21 1.2 Conjuntos de datos..............................
Contenidos 1 Introducción al paquete estadístico S-PLUS 19 1.1 Introducción a S-PLUS............................ 21 1.1.1 Cómo entrar, salir y consultar la ayuda en S-PLUS........ 21 1.2 Conjuntos de datos..............................
ESTADÍSTICA CON EXCEL
 ESTADÍSTICA CON EXCEL 1. INTRODUCCIÓN La estadística es la rama de las matemáticas que se dedica al análisis e interpretación de series de datos, generando unos resultados que se utilizan básicamente en
ESTADÍSTICA CON EXCEL 1. INTRODUCCIÓN La estadística es la rama de las matemáticas que se dedica al análisis e interpretación de series de datos, generando unos resultados que se utilizan básicamente en
1. INTRODUCCIÓN AL CONCEPTO DE LA INVESTIGACIÓN DE MERCADOS 1.1. DEFINICIÓN DE INVESTIGACIÓN DE MERCADOS 1.2. EL MÉTODO CIENTÍFICO 2.
 1. INTRODUCCIÓN AL CONCEPTO DE LA INVESTIGACIÓN DE MERCADOS 1.1. DEFINICIÓN DE INVESTIGACIÓN DE MERCADOS 1.2. EL MÉTODO CIENTÍFICO 2. GENERALIDADES SOBRE LAS TÉCNICAS DE INVESTIGACIÓN SOCIAL Y DE MERCADOS
1. INTRODUCCIÓN AL CONCEPTO DE LA INVESTIGACIÓN DE MERCADOS 1.1. DEFINICIÓN DE INVESTIGACIÓN DE MERCADOS 1.2. EL MÉTODO CIENTÍFICO 2. GENERALIDADES SOBRE LAS TÉCNICAS DE INVESTIGACIÓN SOCIAL Y DE MERCADOS
PROBABILIDAD Y ESTADISTICA (T Y P)
") PROBABILIDAD Y ESTADISTICA (T Y P) FICHA CURRICULAR DATOS GENERALES Departamento: Irrigación. Nombre del programa: Ingeniero en Irrigación Area: Matemáticas, Estadística y Cómputo Asignatura: Probabilidad
PROBABILIDAD Y ESTADISTICA (T Y P) FICHA CURRICULAR DATOS GENERALES Departamento: Irrigación. Nombre del programa: Ingeniero en Irrigación Area: Matemáticas, Estadística y Cómputo Asignatura: Probabilidad
FINANZAS. introducción a los derivados crediticios y, por último, un caso de cobertura de un porfolio de préstamos utilizando Credit Default Swaps.
 Colaboración: Gabriel Gambetta, CIIA 2007, Controller Financiero SAP Global Delivery. Profesor Especialización Administración Financiera (UBA) Profesor de Microeconomía (UBA) Este trabajo pretende encontrar
Colaboración: Gabriel Gambetta, CIIA 2007, Controller Financiero SAP Global Delivery. Profesor Especialización Administración Financiera (UBA) Profesor de Microeconomía (UBA) Este trabajo pretende encontrar
Taller de Explotación de Resultados de I+D. AUDITORÍA TECNOLÓGICA
 Taller de Explotación de Resultados de I+D. AUDITORÍA TECNOLÓGICA Zamudio, 17 de junio de 2009 SANTANDER Bantec Group. SAN SEBASTIAN PAMPLONA Índice» Objetivo de la Sesión» Qué entendemos por Auditoría
Taller de Explotación de Resultados de I+D. AUDITORÍA TECNOLÓGICA Zamudio, 17 de junio de 2009 SANTANDER Bantec Group. SAN SEBASTIAN PAMPLONA Índice» Objetivo de la Sesión» Qué entendemos por Auditoría
Deep Learning y Big Data
 y Eduardo Morales, Enrique Sucar INAOE (INAOE) 1 / 40 Contenido 1 2 (INAOE) 2 / 40 El poder tener una computadora que modele el mundo lo suficientemente bien como para exhibir inteligencia ha sido el foco
y Eduardo Morales, Enrique Sucar INAOE (INAOE) 1 / 40 Contenido 1 2 (INAOE) 2 / 40 El poder tener una computadora que modele el mundo lo suficientemente bien como para exhibir inteligencia ha sido el foco
Métodos de Clasificación sin Métrica. Reconocimiento de Patrones- 2013
 Métodos de Clasificación sin Métrica Reconocimiento de Patrones- 03 Métodos de Clasificación sin Métrica Datos nominales sin noción de similitud o distancia (sin orden). Escala nominal: conjunto de categorías
Métodos de Clasificación sin Métrica Reconocimiento de Patrones- 03 Métodos de Clasificación sin Métrica Datos nominales sin noción de similitud o distancia (sin orden). Escala nominal: conjunto de categorías
Tema 5. Muestreo y distribuciones muestrales
 1 Tema 5. Muestreo y distribuciones muestrales En este tema: Muestreo y muestras aleatorias simples. Distribución de la media muestral: Esperanza y varianza. Distribución exacta en el caso normal. Distribución
1 Tema 5. Muestreo y distribuciones muestrales En este tema: Muestreo y muestras aleatorias simples. Distribución de la media muestral: Esperanza y varianza. Distribución exacta en el caso normal. Distribución
1. VALORES FALTANTES 2. MECANISMOS DE PÉRDIDA
 1. VALORES FALTANTES Los valores faltantes son observaciones que en un se tenía la intención de hacerlas, pero por distintas razones no se obtuvieron. Puede ser que no se encuentre a un encuestado, entonces
1. VALORES FALTANTES Los valores faltantes son observaciones que en un se tenía la intención de hacerlas, pero por distintas razones no se obtuvieron. Puede ser que no se encuentre a un encuestado, entonces
Carrera: Ingeniería Civil CIM 0531
 1.- DATOS DE LA ASIGNATURA Nombre de la asignatura: Carrera: Clave de la asignatura: Horas teoría-horas práctica-créditos: Probabilidad y Estadística Ingeniería Civil CIM 0531 3 2 8 2.- HISTORIA DEL PROGRAMA
1.- DATOS DE LA ASIGNATURA Nombre de la asignatura: Carrera: Clave de la asignatura: Horas teoría-horas práctica-créditos: Probabilidad y Estadística Ingeniería Civil CIM 0531 3 2 8 2.- HISTORIA DEL PROGRAMA
matemáticas como herramientas para solución de problemas en ingeniería. PS Probabilidad y Estadística Clave de la materia: Cuatrimestre: 4
 PS0401 - Probabilidad y Estadística DES: Ingeniería Programa(s) Educativo(s): Ingeniería de Software Tipo de materia: Obligatoria Clave de la materia: PS0401 Cuatrimestre: 4 UNIVERSIDAD AUTÓNOMA DE Área
PS0401 - Probabilidad y Estadística DES: Ingeniería Programa(s) Educativo(s): Ingeniería de Software Tipo de materia: Obligatoria Clave de la materia: PS0401 Cuatrimestre: 4 UNIVERSIDAD AUTÓNOMA DE Área
Capítulo 8. Análisis Discriminante
 Capítulo 8 Análisis Discriminante Técnica de clasificación donde el objetivo es obtener una función capaz de clasificar a un nuevo individuo a partir del conocimiento de los valores de ciertas variables
Capítulo 8 Análisis Discriminante Técnica de clasificación donde el objetivo es obtener una función capaz de clasificar a un nuevo individuo a partir del conocimiento de los valores de ciertas variables
ESTADÍSTICA SEMANA 3
 ESTADÍSTICA SEMANA 3 ÍNDICE MEDIDAS DESCRIPTIVAS... 3 APRENDIZAJES ESPERADOS... 3 DEFINICIÓN MEDIDA DESCRIPTIVA... 3 MEDIDAS DE POSICIÓN... 3 MEDIDAS DE TENDENCIA CENTRAL... 4 MEDIA ARITMÉTICA O PROMEDIO...
ESTADÍSTICA SEMANA 3 ÍNDICE MEDIDAS DESCRIPTIVAS... 3 APRENDIZAJES ESPERADOS... 3 DEFINICIÓN MEDIDA DESCRIPTIVA... 3 MEDIDAS DE POSICIÓN... 3 MEDIDAS DE TENDENCIA CENTRAL... 4 MEDIA ARITMÉTICA O PROMEDIO...
Estimación con PROBE II
 Personal Software Process SM Estimación con PROBE II This material is approved for public release. Distribution is limited by the Software Engineering Institute to attendees. Sponsored by the U.S. Department
Personal Software Process SM Estimación con PROBE II This material is approved for public release. Distribution is limited by the Software Engineering Institute to attendees. Sponsored by the U.S. Department
I.PROGRAMA DE ESTUDIOS. Unidad 1. Conceptos básicos de la teoría de las estructuras
 I.PROGRAMA DE ESTUDIOS Unidad 1 Conceptos básicos de la teoría de las estructuras 1.1.Equilibrio 1.2.Relación fuerza desplazamiento 1.3.Compatibilidad 1.4.Principio de superposición 1.5.Enfoque de solución
I.PROGRAMA DE ESTUDIOS Unidad 1 Conceptos básicos de la teoría de las estructuras 1.1.Equilibrio 1.2.Relación fuerza desplazamiento 1.3.Compatibilidad 1.4.Principio de superposición 1.5.Enfoque de solución