SISTEMAS INTELIGENTES
|
|
|
- Raúl Camacho Ruiz
- hace 5 años
- Vistas:
Transcripción
1 SISTEMAS INTELIGENTES T12: Aprendizaje no Supervisado {jdiez, aic.uniovi.es
2 Índice Aprendizaje no Supervisado Clustering Tipos de clustering Algoritmos Dendogramas 1-NN K-means E-M Mapas auto-organizados (SOM) Por estimación de distancias Visualización Reducción de dimensionalidad Extracción de características
3 Aprendizaje No Supervisado (I) Podemos agrupar los ejemplos en base a sus características? Atributo 2 Atributo 1
4 Aprendizaje Inductivo No Supervisado (II) Datos de Entrenamiento Sistema de Aprendizaje Procesos Inductivos Agrupamiento Análisis Dependencias Visualización Conocimiento
5 Aprendizaje Inductivo No Supervisado (III) No hay clase Atributos Atr-1 Atr-n Clase ejemplo 1 clase ej-1 ejemplo m clase ej-m Tratamos de encontrar algún tipo de regularidad en los datos de entrada
6 Técnicas de aprendizaje no supervisado Clustering: agrupan objetos en regiones donde la similitud mutua es elevada Visualización: permiten observar el espacio de instancias en un espacio de menor dimensión Reducción de la dimensionalidad: los datos de entrada son agrupados en subespacios de una dimensión más baja que la inicial Extracción de características: construyen nuevos atributos (pocos) a partir de los atributos originales (muchos)
7 Clustering Objetivo: descubrir estructura en los datos de entrada Busca agrupamientos entre los ejemplos de forma que cada grupo sea homogéneo y distintos de los demás Cuántos grupos? Métodos para descubrir estas estructuras Representar la estructura: formar los grupos Describir la estructura: indicar las fronteras que separan los clusters Definir la estructura: asignar nombres útiles a los clusters Definición formal de cluster: agregación de puntos en el espacio de entrada donde la distancia entre cada par de objetos es menor que la distancia de cualquiera de ellos a otro objeto que no pertenece al cluster
8 Métodos de Clustering Jerárquicos: los datos se agrupan de manera arborescente Pueden ser top-down o bottom-up Ej: Dendogramas, Por estimación de distancias No jerárquicos: generar particiones a un solo nivel Ej: k-means Paramétricos: asumen que las densidades condicionales de los grupos tienen cierta forma paramétrica conocida (p.e. Gaussiana), y se reduce a estimar los parámetros Ej: Algoritmo EM No paramétricos: no asumen nada sobre el modo en el que se agrupan los objetos Ej: 1NN, Por estimación de distancias
9 Dendograma (I) Un método sencillo consiste en ir agrupando pares de individuos según su similitud. Se va aumentando el límite de distancia para hacer grupos. Esto nos da diferentes agrupaciones a distintos niveles, de una manera jerárquica
10 Dendograma (II)
11 1-NN (Nearest Neighbour) Dado una serie de ejemplos en un espacio, se conecta cada ejemplo con su ejemplo más cercano La conectividad entre ejemplos genera los grupos Puede generar muchos grupos pequeños Existen variantes: k-nn o como el spanning tree que para de agrupar cuando llega a un número de grupos G1 G4 G3 G2
12 k means (I) Se utiliza para encontrar los k puntos más densos en el conjunto de datos Algoritmo k-means es Se seleccionan aleatoriamente k centros Repetir Asignar cada ejemplo al conjunto con el centro más cercano Calcular los puntos medios de los k conjuntos Mientras los conjuntos no varíen Devolver los k centros Fin Algoritmo Determinar k no es fácil Si k se elige muy pequeño, se agruparían grupos distintos Si k se elige muy grande, hay centros que se quedan huérfanos Incluso con k exacto, puede haber algún centro que quede huérfano El valor de k se suele determinar heurísticamente Depende de los centros iniciales Se puede ejecutar con distintas semillas
13 k means (II)
14 k means (III)
15 k means (IV)
16 Algoritmo EM (I) Expectation Maximization, Maximum Likelihood Estimate (Dempster et al. 1977) Es la base de muchos algoritmos: Autoclass, HMM, Se utiliza cuando tenemos variables ocultas o latentes Se adapta al clustering: <x, grupo?> Idea intuitiva, consta de dos pasos: Paso de Estimación: dada la hipótesis actual h, estimamos las variables ocultas Paso de Maximización: una vez estimadas las variables ocultas, generamos una nueva hipótesis h Se repiten los pasos EM hasta que no cambia la hipótesis
17 Algoritmo EM (II) Partimos de un conjunto { <x 1 >,, <x n > } Generamos ejemplos en base a dos distribuciones normales Pretendemos asignar cada ejemplo a uno de los dos grupos Si conocemos la desviación de las dos distribuciones normales (igual), el problema pasa por descubrir la media de cada una de ellas Queremos saber a que grupo pertenece cada ejemplo <x i, grupo1 o grupo2 } La hipótesis que buscamos son h=<µ 1,µ 2 > y tratamos de hacerlo a través de dos variables ocultas <x, z 1,z 2 > z i será la probabilidad de que pertenezca al grupo i
18 Algoritmo EM (III) Algoritmo: Inicialización: generamos aleatoriamente h=<µ 1,µ 2 > Paso E: Estimamos los valores z 1,z 2 para todos los ejemplos usando h Paso M: En base a las estimaciones Maximizamos la hipótesis h, medias) Paso E: Paso M: generando una nueva hipótesis h =<µ 1,µ 2 > (mover las E[ z ij ] = m i= 1 p( x 2 n= 1 = p( x x i = E[ zij] x µ j = m E[ z ] i= 1 ij µ = µ i x i j ) µ = µ n ) = e 2 1 2σ n= 1 e 2 ( x i 1 2σ µ 2 j ( x i ) 2 µ n ) 2
")
19 Algoritmo EM (IV)
20 Mapas auto-organizados (I) Self-Organizing Maps (SOM) o redes de Kohonen, o de memoria asociativa, LVQ (linear-vector quantization) [Kohonen]
21 Mapas auto-organizados (II) Se dispone de un mapa o retícula finita formada por nodos con un vector de la misma dimensión que los ejemplos de entrada Durante el entrenamiento, para cada ejemplo se calcula el nodo más próximo (nodo vencedor) Ese nodo, y sus vecinos, se adaptan para aproximarse al vector de entrada. Este proceso mantiene la topología El mapa final, a través de sus nodos, agrupa los ejemplos en clusters. Cada nodo agrupa un cierto número de ejemplos El mapa final se puede etiquetar, asignando a cada nodo la clase mayoritaria de los ejemplos que representa Gracias a que mantiene la topología, el mapa muestra la distancia entre los distintos grupos Permite visualizar los datos de entrada en un plano de dos dimensiones

22 Mapas auto-organizados (III)
23 Por estimación de distancias (I) Parte de una matriz de similitud (o de distancias) entre cada uno de los objetos ej 1 ej i ej m ej 1 ej j ej m S ij Se considera que dos objetos están próximos si son similares y diferentes de los mismos objetos Mediante un proceso iterativo, se transforma la matriz hasta que finalmente converge a una matriz binaria: El valor 0 indican que esos dos objetos pertenecen a un mismo cluster El valor distinto de 0, que pertenecen a distintos grupos Si se repite el proceso con cada submatriz resultante, tenemos un cluster jerárquico
 = ij s ( t + 1) = ij k k s ( t ) p ij max{ s ( t ) 1 2 ik p ( t + 1)log ik jk : k } ( t + 1)log 2 1 2 1 ik ( p ( t + 1) + p ( t + 1) ) ik ( t + 1) + jk ( p ( t + 1) + p ( t + 1) ) jk p ( t + 1) p")
24 Por estimación de distancias (II) En cada iteración se transforma la matriz en dos pasos Normalización: usando una norma L X Se vuelven a calcular las similitudes: divergencia Jensen-Shannon p ( t + 1) = ij s ( t + 1) = ij k k s ( t ) p ij max{ s ( t ) 1 2 ik p ( t + 1)log ik jk : k } ( t + 1)log ik ( p ( t + 1) + p ( t + 1) ) ik ( t + 1) + jk ( p ( t + 1) + p ( t + 1) ) jk p ( t + 1) p jk ik

25 Visualización: SOM (I)
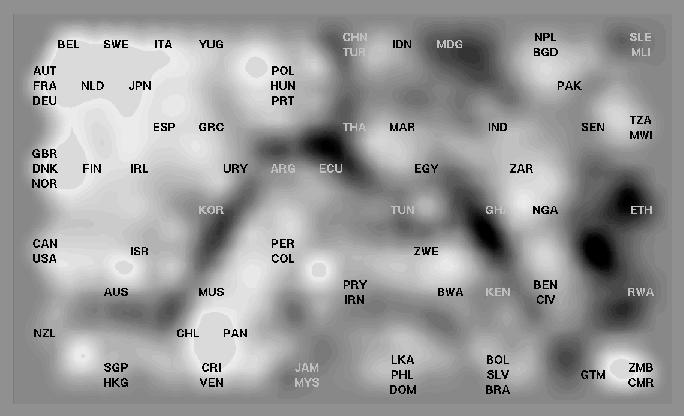
26 Visualización: SOM (II)
27 Análisis Estadísticos Se pueden utilizar como paso previo para determinar el método más apropiado para un aprendizaje supervisado Se utilizan como preprocesos para la limpieza y preparación de datos para el uso de métodos supervisados Ejemplos: Estudio de la distribución de los datos Estimación de Densidad Detección datos anómalos Análisis de dispersión (p.ej. las funciones de separabilidad pueden considerarse como técnicas muy simples no supervisadas)
28 Reducción de dimensionalidad Por qué es interesante? Hay atributos que resultan nocivos para el aprendizaje: Irrelevancia: el atributo no ofrece capacidad de discriminación en el aprendizaje Separación de la información: una información interesante puede estar recogida en varios atributos Se trata de aumentar la densidad de la información reduciendo el espacio de entrada PCA Análisis de componentes principales Combinan variables redundantes en una única variable (componente o factor) FA Análisis de factores Clase de algoritmos que incluyen PCA
29 Análisis de Componentes Principales Objetivo: Encontrar un espacio de dimensión menor que preserve la mayor cantidad de información que contiene el espacio original J qué dirección contiene más información? K
30 Correlaciones y Asociaciones Permiten establecer relevancia/irrelevancia de factores y si aquélla es positiva o negativa respecto a otro factor o variable a estudiar Coeficiente de correlación y matrices de correlación n Cov( x, y) 1 Cor( x, y) = Cov( x, y) = ( x i µ x)( yi µ y ) σ σ n i= 1 x y Asociaciones (cuando los atributos son discretos) Ejemplo: tabaquismo y alcoholismo están asociados. Dependencias funcionales: asociación unidireccional Ejemplo: el nivel de riesgo de enfermedades cardiovasculares depende del tabaquismo y alcoholismo (entre otras cosas)
31 Asociaciones y dependencias Se buscan asociaciones de la siguiente forma: (x 1 = a) (x 4 = b) De los n casos del conjunto de entrada que las dos comparaciones sean verdaderas o falsas será cierto en rc casos: Tc = certeza de la regla = rc/n Si consideramos valores nulos, tenemos también un número de casos en los que se aplica satisfactoriamente (diferente de Tc) y denominado Ts Se buscan dependencias de la siguiente forma (IF Ante THEN Cons): if (x 1 = a, x 3 =c, x 5 =d) then (x 4 =b, x 2 =a) De los n casos de entrada, el antecendente se puede hacer cierto en ra casos y de estos en rc casos se hace también el consecuente Tenemos dos parámetros Tc (confidence/accuracy) y Ts (support): Tc= certeza de la regla =rc/ra, fuerza o confianza P(Cons Ante) Ts = mínimo nº de casos o porcentaje en los que se aplica satisfactoriamente (rc o rc /n respectivamente). Llamado también prevalencia: P(Cons Ante)
32 Reglas de asociación y dependencia DNI Renta Familiar Ciudad Profesión Edad Hijos Obeso Casado Barcelona Ejecutivo 45 3 S S Melilla Abogado 25 0 S N León Ejecutivo 35 2 S S Valencia Camarero 30 0 S S Benidorm Animador 30 0 N N Asociaciones: Casado e (Hijos > 0) están asociados (80%, 4 casos). Obeso y casado están asociados (80%, 4 casos) Dependencias: (Hijos > 0) Casado (100%, 2 casos). Casado Obeso (100%, 3 casos) Condiciones que se suelen imponer: Tc > 95% Ts > 20 (absoluto) o 50% (relativo) No es un problema inductivo, es un problema completamente determinado, sin criterios de evaluación y relativamente simple
33 Clustering conceptual Una partición de los datos es buena sii cada clase tiene una buena interpretación conceptual Cada grupo queda caracterizado por un concepto Tiene en cuenta las relaciones semánticas entre los atributos Intenta introducir la mayor información sobre el contexto COBWEB Genera un árbol (clasificación) Cada nodo hace referencia a un concepto y contiene la descripción probabilística de los atributos (y de la clase si la hubiera) Recorre el árbol en sentido descendente buscando el mejor lugar en el que colocar cada ejemplo Usa una medida, la utilidad de la categoría, para decidir cual es el mejor punto para añadir No es sencillo explicarlo en una transparencia
34 Extracción de características Idea intuitiva: Pretenden descubrir variables dependientes (y=f(x)) a partir de variables independientes (x) No necesitan conocer las variables dependientes
Minería de Datos Web. Cursada 2018
 Minería de Datos Web Cursada 2018 Proceso de Minería de Texto Clustering de Documentos Clasificación de Documentos Es un método supervisado para dividir documentos en base a categorías predefinidas Los
Minería de Datos Web Cursada 2018 Proceso de Minería de Texto Clustering de Documentos Clasificación de Documentos Es un método supervisado para dividir documentos en base a categorías predefinidas Los
TÉCNICAS DE AGRUPAMIENTO
 TÉCNICAS DE AGRUPAMIENTO José D. Martín Guerrero, Emilio Soria, Antonio J. Serrano PROCESADO Y ANÁLISIS DE DATOS AMBIENTALES Curso 2009-2010 Page 1 of 11 1. Algoritmo de las C-Medias. Algoritmos de agrupamiento
TÉCNICAS DE AGRUPAMIENTO José D. Martín Guerrero, Emilio Soria, Antonio J. Serrano PROCESADO Y ANÁLISIS DE DATOS AMBIENTALES Curso 2009-2010 Page 1 of 11 1. Algoritmo de las C-Medias. Algoritmos de agrupamiento
Prof. Dra. Silvia Schiaffino ISISTAN
 Clustering ISISTAN sschia@ea.unicen.edu.ar Clustering: Concepto Cluster: un número de cosas o personas similares o cercanas, agrupadas Clustering: es el proceso de particionar un conjunto de objetos (datos)
Clustering ISISTAN sschia@ea.unicen.edu.ar Clustering: Concepto Cluster: un número de cosas o personas similares o cercanas, agrupadas Clustering: es el proceso de particionar un conjunto de objetos (datos)
Introducción Clustering jerárquico Clustering particional Clustering probabilista Conclusiones. Clustering. Clasificación no supervisada
 Clustering Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Clustering jerárquico 3 Clustering particional 4 Clustering probabilista 5 Conclusiones Introducción Objetivos
Clustering Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Clustering jerárquico 3 Clustering particional 4 Clustering probabilista 5 Conclusiones Introducción Objetivos
Sistemas de Percepción Visión por Computador
 Nota: Algunas de las imágenes que aparecen en esta presentación provienen del libro: Visión por Computador: fundamentos y métodos. Arturo de la Escalera Hueso. Prentice Hall. Sistemas de Percepción Visión
Nota: Algunas de las imágenes que aparecen en esta presentación provienen del libro: Visión por Computador: fundamentos y métodos. Arturo de la Escalera Hueso. Prentice Hall. Sistemas de Percepción Visión
Detección y segmentación de objetos
 24 de abril de 2013 ¾Qué es segmentación? Segmentación Objetivo El objetivo de la segmentación de una imagen es el agrupamiento de ciertos píxeles de la imagen en regiones correspondientes a objetos contenidos
24 de abril de 2013 ¾Qué es segmentación? Segmentación Objetivo El objetivo de la segmentación de una imagen es el agrupamiento de ciertos píxeles de la imagen en regiones correspondientes a objetos contenidos
Tema 5: SEGMENTACIÓN (II) I N G E N I E R Í A I N F O R M Á T I C A
 I N G E N I E R Í A I N F O R M Á T I C A") Tema 5: SEGMENTACIÓN (II) 1 I N G E N I E R Í A I N F O R M Á T I C A Tema 5: Segmentación Los algoritmos de segmentación se basan en propiedades básicas de los valores del nivel de gris: 2 - Discontinuidad:
Tema 5: SEGMENTACIÓN (II) 1 I N G E N I E R Í A I N F O R M Á T I C A Tema 5: Segmentación Los algoritmos de segmentación se basan en propiedades básicas de los valores del nivel de gris: 2 - Discontinuidad:
Técnicas de Clustering
 Técnicas de Clustering Programa Introducción Métodos Divisivos Métodos Jerárquicos Algunos otros métodos Cuantos clusters? estabilidad Introducción Definiciones previas: Cluster: Agrupamiento de objetos.
Técnicas de Clustering Programa Introducción Métodos Divisivos Métodos Jerárquicos Algunos otros métodos Cuantos clusters? estabilidad Introducción Definiciones previas: Cluster: Agrupamiento de objetos.
Object Recognition as Machine Translation: Learning a Lexicon for a Fixed Image Vocabulary
 Object Recognition as Machine Translation: Learning a Lexicon for a Fixed Image Vocabulary P. Duygulu, K. Barnard, J.F.G. de Freitas, and D.A. Forsyth Dr. Enrique Sucar 1 Victor Hugo Arroyo Dominguez 1
Object Recognition as Machine Translation: Learning a Lexicon for a Fixed Image Vocabulary P. Duygulu, K. Barnard, J.F.G. de Freitas, and D.A. Forsyth Dr. Enrique Sucar 1 Victor Hugo Arroyo Dominguez 1
Clustering: Auto-associative Multivariate Regression Tree (AAMRT)
") Introducción Tipos Validación AAMRT Clustering: Auto-associative Multivariate Regression Tree (AAMRT) Miguel Bernal C Quantil 12 de diciembre de 2013 Miguel Bernal C Quantil Matemáticas Aplicadas Contenido
Introducción Tipos Validación AAMRT Clustering: Auto-associative Multivariate Regression Tree (AAMRT) Miguel Bernal C Quantil 12 de diciembre de 2013 Miguel Bernal C Quantil Matemáticas Aplicadas Contenido
Métodos no supervisados: Agrupamiento
 Métodos no supervisados: Agrupamiento Agrupamiento clustering- Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Introducción. Basados en particiones 3. Métodos
Métodos no supervisados: Agrupamiento Agrupamiento clustering- Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Introducción. Basados en particiones 3. Métodos
Clasificación Clasific NO SUPERV SUPER ISAD IS A AD AGRUPAMIENTO
 Clasificación NO SUPERVISADA AGRUPAMIENTO Clasificación No Supervisada Se trata de construir clasificadores sin información a priori, o sea, a partir de conjuntos de patrones no etiquetados Objetivo: Descubrir
Clasificación NO SUPERVISADA AGRUPAMIENTO Clasificación No Supervisada Se trata de construir clasificadores sin información a priori, o sea, a partir de conjuntos de patrones no etiquetados Objetivo: Descubrir
Tema 5: SEGMENTACIÓN (II) I N G E N I E R Í A I N F O R M Á T I C A
 I N G E N I E R Í A I N F O R M Á T I C A") Tema 5: SEGMENTACIÓN (II) 1 I N G E N I E R Í A I N F O R M Á T I C A Tema 5: Segmentación Los algoritmos de segmentación se basan en propiedades básicas de los valores del nivel de gris: 2 - Discontinuidad:
Tema 5: SEGMENTACIÓN (II) 1 I N G E N I E R Í A I N F O R M Á T I C A Tema 5: Segmentación Los algoritmos de segmentación se basan en propiedades básicas de los valores del nivel de gris: 2 - Discontinuidad:
Modelos Ocultos de Markov Continuos
 Modelos Ocultos de Markov Continuos José Antonio Camarena Ibarrola Modelos Ocultos de Markov Continuos p.1/15 Idea fundamental Los Modelos Ocultos de Markov Discretos trabajan con secuencias de observaciones
Modelos Ocultos de Markov Continuos José Antonio Camarena Ibarrola Modelos Ocultos de Markov Continuos p.1/15 Idea fundamental Los Modelos Ocultos de Markov Discretos trabajan con secuencias de observaciones
1. Análisis de Conglomerados
 1. Análisis de Conglomerados El objetivo de este análisis es formar grupos de observaciones, de manera que todas las unidades en un grupo sean similares entre ellas pero que sean diferentes a aquellas
1. Análisis de Conglomerados El objetivo de este análisis es formar grupos de observaciones, de manera que todas las unidades en un grupo sean similares entre ellas pero que sean diferentes a aquellas
RECONOCIMIENTO DE PAUTAS. ANÁLISIS DE CONGLOMERADOS (Cluster Analysis)
") RECONOCIMIENTO DE PAUTAS ANÁLISIS DE CONGLOMERADOS (Cluster Analysis) Análisis de conglomerados los análisis exploratorios de datos (como PCA) determinan relaciones generales entre datos en ocasiones no
RECONOCIMIENTO DE PAUTAS ANÁLISIS DE CONGLOMERADOS (Cluster Analysis) Análisis de conglomerados los análisis exploratorios de datos (como PCA) determinan relaciones generales entre datos en ocasiones no
Índice general. Prefacio...5
 Índice general Prefacio...5 Capítulo 1 Introducción...13 1.1 Introducción...13 1.2 Los datos...19 1.3 Etapas en los procesos de big data...20 1.4 Minería de datos...21 1.5 Estructura de un proyecto de
Índice general Prefacio...5 Capítulo 1 Introducción...13 1.1 Introducción...13 1.2 Los datos...19 1.3 Etapas en los procesos de big data...20 1.4 Minería de datos...21 1.5 Estructura de un proyecto de
TEMA 1: INTRODUCCIÓN N AL PROCESADO Y ANÁLISIS DE DATOS
 Procesado y Análisis de Datos Ambientales. Curso 2009-2010. José D. Martín, Emilio Soria, Antonio J. Serrano TEMA 1: INTRODUCCIÓN N AL PROCESADO Y ANÁLISIS DE DATOS ÍNDICE Introducción. Selección de variables.
Procesado y Análisis de Datos Ambientales. Curso 2009-2010. José D. Martín, Emilio Soria, Antonio J. Serrano TEMA 1: INTRODUCCIÓN N AL PROCESADO Y ANÁLISIS DE DATOS ÍNDICE Introducción. Selección de variables.
Clasificación Supervisada
 Clasificación Supervisada Ricardo Fraiman 26 de abril de 2010 Resumen Reglas de Clasificación Resumen Reglas de Clasificación Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y
Clasificación Supervisada Ricardo Fraiman 26 de abril de 2010 Resumen Reglas de Clasificación Resumen Reglas de Clasificación Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y
Aprendizaje No Supervisado
 Aprendizaje Automático Segundo Cuatrimestre de 2015 Aprendizaje No Supervisado Supervisado vs. No Supervisado Aprendizaje Supervisado Clasificación y regresión. Requiere instancias etiquetadas para entrenamiento.
Aprendizaje Automático Segundo Cuatrimestre de 2015 Aprendizaje No Supervisado Supervisado vs. No Supervisado Aprendizaje Supervisado Clasificación y regresión. Requiere instancias etiquetadas para entrenamiento.
Examen de Teoría de (Introducción al) Reconocimiento de Formas
 Reconocimiento de Formas") Examen de Teoría de (Introducción al) Reconocimiento de Formas Facultad de Informática, Departamento de Sistemas Informáticos y Computación Universidad Politécnica de Valencia, Enero de 007 Apellidos:
Examen de Teoría de (Introducción al) Reconocimiento de Formas Facultad de Informática, Departamento de Sistemas Informáticos y Computación Universidad Politécnica de Valencia, Enero de 007 Apellidos:
CLUSTERING. Eduardo Morales y Jesús González
 CLUSTERING Eduardo Morales y Jesús González Clustering (Agrupamiento) 2 Proceso de agrupar datos en clases o clusters de tal forma que los objetos de un cluster: Tengan alta similaridad entre ellos Baja
CLUSTERING Eduardo Morales y Jesús González Clustering (Agrupamiento) 2 Proceso de agrupar datos en clases o clusters de tal forma que los objetos de un cluster: Tengan alta similaridad entre ellos Baja
Clasificación. Agrupación de las partes de una imagen de forma homogénea
 Clasificación Agrupación de las partes de una imagen de forma homogénea Clasificación o clustering Intenta clasificar los píxeles directamente en clases, en función de ciertas características de cada píxel.
Clasificación Agrupación de las partes de una imagen de forma homogénea Clasificación o clustering Intenta clasificar los píxeles directamente en clases, en función de ciertas características de cada píxel.
INTELIGENCIA DE NEGOCIO
 INTELIGENCIA DE NEGOCIO 2016-2017 n n n n n n n n Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Minería de Datos. Ciencia de Datos Tema 3. Modelos de Predicción: Clasificación, regresión y
INTELIGENCIA DE NEGOCIO 2016-2017 n n n n n n n n Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Minería de Datos. Ciencia de Datos Tema 3. Modelos de Predicción: Clasificación, regresión y
Reconocimiento de Formas
 Reconocimiento de Formas Técnicas no Supervisadas: clustering José Martínez Sotoca Objetivo: Estudio de la estructura de un conjunto de datos, división en agrupaciones. Características: Homogeneidad o
Reconocimiento de Formas Técnicas no Supervisadas: clustering José Martínez Sotoca Objetivo: Estudio de la estructura de un conjunto de datos, división en agrupaciones. Características: Homogeneidad o
TÉCNICAS INTELIGENTES EN BIOINFORMÁTICA CLUSTERING
 TÉCNICAS INTELIGENTES EN BIOINFORMÁTICA CLUSTERING Mario de J. Pérez Jiménez Grupo de investigación en Computación Natural Dpto. Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla
TÉCNICAS INTELIGENTES EN BIOINFORMÁTICA CLUSTERING Mario de J. Pérez Jiménez Grupo de investigación en Computación Natural Dpto. Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla
Análisis Estadístico de Datos Climáticos. Análisis de agrupamiento (o clusters)
") Análisis Estadístico de Datos Climáticos Análisis de agrupamiento (o clusters) A. Díaz - M. Bidegain M. Barreiro Facultad de Ciencias Facultad de Ingeniería 2011 Objetivo Idear una clasificación o esquema
Análisis Estadístico de Datos Climáticos Análisis de agrupamiento (o clusters) A. Díaz - M. Bidegain M. Barreiro Facultad de Ciencias Facultad de Ingeniería 2011 Objetivo Idear una clasificación o esquema
CLASIFICACIÓN PROBLEMA SOLUCIÓN
 Capítulo 7 Análisis Cluster CLASIFICACIÓN Asignar objetos en su lugar correspondiente dentro de un conjunto de categorías establecidas o no. PROBLEMA Dado un conjunto de m objetos (animales, plantas, minerales...),
Capítulo 7 Análisis Cluster CLASIFICACIÓN Asignar objetos en su lugar correspondiente dentro de un conjunto de categorías establecidas o no. PROBLEMA Dado un conjunto de m objetos (animales, plantas, minerales...),
TÉCNICAS INTELIGENTES EN BIOINFORMÁTICA CLUSTERING
 TÉCNICAS INTELIGENTES EN BIOINFORMÁTICA CLUSTERING Mario de J. Pérez Jiménez Grupo de investigación en Computación Natural Dpto. Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla
TÉCNICAS INTELIGENTES EN BIOINFORMÁTICA CLUSTERING Mario de J. Pérez Jiménez Grupo de investigación en Computación Natural Dpto. Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla
Examen Parcial. Attr1: A, B Attr2: A, B, C Attr3 1, 2, 3 Attr4; a, b Attr5: 1, 2, 3, 4
 Aprenentatge 0-03 Q Examen Parcial Nombre: (Examen ) Instrucciones. (0 puntos) Este examen dura horas. Responded todas las preguntas en estas hojas. Para las preguntas test poned un circulo alrededor de
Aprenentatge 0-03 Q Examen Parcial Nombre: (Examen ) Instrucciones. (0 puntos) Este examen dura horas. Responded todas las preguntas en estas hojas. Para las preguntas test poned un circulo alrededor de
Métodos de modelado y clasificación de patrones. clasificación de patrones
 FUNDAMENTOS DEL RECONOCIMIENTO AUTOMÁTICO DE LA VOZ Métodos de modelado y clasificación de patrones Agustín Álvarez Marquina Introducción. Modelado y clasificación de patrones Objetivos: Agrupar el conjunto
FUNDAMENTOS DEL RECONOCIMIENTO AUTOMÁTICO DE LA VOZ Métodos de modelado y clasificación de patrones Agustín Álvarez Marquina Introducción. Modelado y clasificación de patrones Objetivos: Agrupar el conjunto
Clasificación estadística de patrones
 Clasificación estadística de patrones Clasificador gaussiano César Martínez cmartinez _at_ fich.unl.edu.ar Tópicos Selectos en Aprendizaje Maquinal Doctorado en Ingeniería, FICH-UNL 19 de setiembre de
Clasificación estadística de patrones Clasificador gaussiano César Martínez cmartinez _at_ fich.unl.edu.ar Tópicos Selectos en Aprendizaje Maquinal Doctorado en Ingeniería, FICH-UNL 19 de setiembre de
Análisis de Datos. Introducción al aprendizaje supervisado. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Reconocimiento de patrones (RP): clasificar objetos en un número de categorías o clases.
Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Reconocimiento de patrones (RP): clasificar objetos en un número de categorías o clases.
ANÁLISIS DE CONGLOMERADOS (CLUSTER ANALYSIS)
") ANÁLISIS DE CONGLOMERADOS (CLUSTER ANALYSIS) AGRUPAMIENTOS Cuál agrupamiento es mejor? MÉTODOS DE AGRUPACIÓN Métodos jerárquicos: Los objetos se agrupan (dividen) i por partes hasta clasificar todos los
ANÁLISIS DE CONGLOMERADOS (CLUSTER ANALYSIS) AGRUPAMIENTOS Cuál agrupamiento es mejor? MÉTODOS DE AGRUPACIÓN Métodos jerárquicos: Los objetos se agrupan (dividen) i por partes hasta clasificar todos los
Reconocimiento de Patrones
 Reconocimiento de Patrones Técnicas de validación (Clasificación Supervisada) Jesús Ariel Carrasco Ochoa Instituto Nacional de Astrofísica, Óptica y Electrónica Clasificación Supervisada Para qué evaluar
Reconocimiento de Patrones Técnicas de validación (Clasificación Supervisada) Jesús Ariel Carrasco Ochoa Instituto Nacional de Astrofísica, Óptica y Electrónica Clasificación Supervisada Para qué evaluar
Análisis de Datos. Introducción al aprendizaje supervisado. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Desde la antigüedad, el problema de buscar patrones en datos es fundamental en diversas
Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Desde la antigüedad, el problema de buscar patrones en datos es fundamental en diversas
Redes de Neuronas de Base Radial
 Redes de Neuronas de Base Radial 1 Introducción Redes multicapa con conexiones hacia delante Única capa oculta Las neuronas ocultas poseen carácter local Cada neurona oculta se activa en una región distinta
Redes de Neuronas de Base Radial 1 Introducción Redes multicapa con conexiones hacia delante Única capa oculta Las neuronas ocultas poseen carácter local Cada neurona oculta se activa en una región distinta
Carteras minoristas. árbol de decisión. Ejemplo: Construcción de un scoring de concesión basado en un DIRECCIÓN GENERAL DE SUPERVISIÓN
 Carteras minoristas Ejemplo: Construcción de un scoring de concesión basado en un árbol de decisión Grupo de Tesorería y Modelos de Gestión de Riesgos Sergio Gavilá II Seminario sobre Basilea II Validación
Carteras minoristas Ejemplo: Construcción de un scoring de concesión basado en un árbol de decisión Grupo de Tesorería y Modelos de Gestión de Riesgos Sergio Gavilá II Seminario sobre Basilea II Validación
Módulo Minería de Datos Diplomado Por Elizabeth León Guzmán, Ph.D. Profesora Ingeniería de Sistemas Grupo de Investigación MIDAS
 Módulo Minería de Datos Diplomado Por Elizabeth León Guzmán, Ph.D. Profesora Ingeniería de Sistemas Grupo de Investigación MIDAS Agrupamiento Dividir los datos en grupos (clusters), de tal forma que los
Módulo Minería de Datos Diplomado Por Elizabeth León Guzmán, Ph.D. Profesora Ingeniería de Sistemas Grupo de Investigación MIDAS Agrupamiento Dividir los datos en grupos (clusters), de tal forma que los
Clasicación Automática de Documentos
 Clasicación Automática de Documentos Carlos G. Figuerola, José Luis Alonso Berrocal, Angel F. Zazo Universidad de Salamanca Grupo REINA http://reina.usal.es Carlos G. Figuerola (Grupo REINA) Clasicación
Clasicación Automática de Documentos Carlos G. Figuerola, José Luis Alonso Berrocal, Angel F. Zazo Universidad de Salamanca Grupo REINA http://reina.usal.es Carlos G. Figuerola (Grupo REINA) Clasicación
REDES AUTOORGANIZATIVAS
 Tema 5: Redes Autoorganizativas Sistemas Conexionistas 1 REDES AUTOORGANIZATIVAS 1. Introducción a la Autoorganización. 2. Regla de Hebb. 3. Aprendizaje Competitivo. 3.1. Carácterísticas. 3.2. Ventajas
Tema 5: Redes Autoorganizativas Sistemas Conexionistas 1 REDES AUTOORGANIZATIVAS 1. Introducción a la Autoorganización. 2. Regla de Hebb. 3. Aprendizaje Competitivo. 3.1. Carácterísticas. 3.2. Ventajas
Clustering INAOE. Outline. Introducción. Medidas de similaridad. Algoritmos. k-means COBWEB. Clustering. basado en probabilidades.
 INAOE (INAOE) 1 / 52 1 2 3 4 5 6 7 8 9 10 (INAOE) 2 / 52 es el proceso de agrupar datos en clases o clusters de tal forma que los objetos de un cluster tengan una alta entre ellos, y baja (sean muy diferentes)
INAOE (INAOE) 1 / 52 1 2 3 4 5 6 7 8 9 10 (INAOE) 2 / 52 es el proceso de agrupar datos en clases o clusters de tal forma que los objetos de un cluster tengan una alta entre ellos, y baja (sean muy diferentes)
Clustering: Algoritmos
 Clustering: Algoritmos Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Algoritmo: K-medias 3 Algoritmo: BFR 4 Algoritmo: CURE Introducción Acotar el problema Complejidad
Clustering: Algoritmos Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Algoritmo: K-medias 3 Algoritmo: BFR 4 Algoritmo: CURE Introducción Acotar el problema Complejidad
Influencia de la moda en dinámica social con interacción global
 Defensa de Tesis de Maestría Influencia de la moda en dinámica social con interacción global Lic. Marino Gavidia Tutor: Dr. Mario Cosenza http://www.cff.ula.ve/caoticos/ Centro de Física Fundamental Área
Defensa de Tesis de Maestría Influencia de la moda en dinámica social con interacción global Lic. Marino Gavidia Tutor: Dr. Mario Cosenza http://www.cff.ula.ve/caoticos/ Centro de Física Fundamental Área
VQ. Algorítmica de reconocimiento de voz VQ.1. Reconocimiento de patrones
 VQ. Algorítmica de reconocimiento de voz VQ.1. Reconocimiento de patrones Por reconocimiento de patrones se entiende la realización de una comparación entre una muestra representativa de la señal de voz,
VQ. Algorítmica de reconocimiento de voz VQ.1. Reconocimiento de patrones Por reconocimiento de patrones se entiende la realización de una comparación entre una muestra representativa de la señal de voz,
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Introducción a Aprendizaje no Supervisado
 Introducción a Aprendizaje no Supervisado Felipe Suárez, Álvaro Riascos 25 de abril de 2017 2 / 33 Contenido 1. Motivación 2. k-medias Algoritmos Implementación 3. Definición 4. Motivación 5. Aproximación
Introducción a Aprendizaje no Supervisado Felipe Suárez, Álvaro Riascos 25 de abril de 2017 2 / 33 Contenido 1. Motivación 2. k-medias Algoritmos Implementación 3. Definición 4. Motivación 5. Aproximación
REDES NEURONALES NO SUPERVISADAS
 Redes no supervisadas REDES NEURONALES NO SUPERVISADAS Redes no supervisadas El cerebro tiene la capacidad de auto-organizarse a partir de los estímulos recibidos y esto lo logra de manera no supervisada.
Redes no supervisadas REDES NEURONALES NO SUPERVISADAS Redes no supervisadas El cerebro tiene la capacidad de auto-organizarse a partir de los estímulos recibidos y esto lo logra de manera no supervisada.
Correlaciones en la red
 Correlaciones en la red Homofilia Layout de red social en consonancia con dos variables de contexto: raza y edad Race, School Integration, and Friendship Segregation in America, James Moody 2001 como se
Correlaciones en la red Homofilia Layout de red social en consonancia con dos variables de contexto: raza y edad Race, School Integration, and Friendship Segregation in America, James Moody 2001 como se
Simulación I. Investigación Operativa, Grado en Estadística y Empresa, 2011/12
 Simulación I Prof. José Niño Mora Investigación Operativa, Grado en Estadística y Empresa, 2011/12 Esquema Modelos de simulación y el método de Montecarlo Ejemplo: estimación de un área Ejemplo: estimación
Simulación I Prof. José Niño Mora Investigación Operativa, Grado en Estadística y Empresa, 2011/12 Esquema Modelos de simulación y el método de Montecarlo Ejemplo: estimación de un área Ejemplo: estimación
Comunidades. Buscando grupos naturales de nodos
 Comunidades Buscando grupos naturales de nodos cliques, -componentes (Newman 7.8.1, 7.8.2) similaridad (N7.12) Geometria: means topologia: equivalencia estructural vs equivalencia regular Clustering jerarquico
Comunidades Buscando grupos naturales de nodos cliques, -componentes (Newman 7.8.1, 7.8.2) similaridad (N7.12) Geometria: means topologia: equivalencia estructural vs equivalencia regular Clustering jerarquico
Aprendizaje Automático
 Regresión Lineal: Descenso de Gradiente Árboles de Regresión: M5 Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje (PLG) Departamento de Informática
Regresión Lineal: Descenso de Gradiente Árboles de Regresión: M5 Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje (PLG) Departamento de Informática
Métodos de Inteligencia Artificial
 Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden: Clasificador Bayesiano Clasificación Clasificador
Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden: Clasificador Bayesiano Clasificación Clasificador
Técnicas de Preprocesado
 Técnicas de Preprocesado Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Por qué preprocesar p los datos? Técnicas de filtro Depuración
Técnicas de Preprocesado Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Por qué preprocesar p los datos? Técnicas de filtro Depuración
Econometría II Grado en finanzas y contabilidad
 Econometría II Grado en finanzas y contabilidad Variables aleatorias y procesos estocásticos. La FAC y el correlograma Profesora: Dolores García Martos E-mail:mdgmarto@est-econ.uc3m.es Este documento es
Econometría II Grado en finanzas y contabilidad Variables aleatorias y procesos estocásticos. La FAC y el correlograma Profesora: Dolores García Martos E-mail:mdgmarto@est-econ.uc3m.es Este documento es
Comparación de dos métodos de aprendizaje sobre el mismo problema
 Comparación de dos métodos de aprendizaje sobre el mismo problema Carlos Alonso González Grupo de Sistemas Inteligentes Departamento de Informática Universidad de Valladolid Contenido 1. Motivación 2.
Comparación de dos métodos de aprendizaje sobre el mismo problema Carlos Alonso González Grupo de Sistemas Inteligentes Departamento de Informática Universidad de Valladolid Contenido 1. Motivación 2.
Apellidos:... Nombre:...
 Ejercicio 1 (1.5 puntos): Cuestiones Contestar a las siguientes preguntas de manera clara y concisa, usando el espacio en blanco que se deja a continuación: 1. Qué es un unificador de dos átomos? Describir
Ejercicio 1 (1.5 puntos): Cuestiones Contestar a las siguientes preguntas de manera clara y concisa, usando el espacio en blanco que se deja a continuación: 1. Qué es un unificador de dos átomos? Describir
CLUSTERING. Bases de Datos Masivas
 1 CLUSTERING Bases de Datos Masivas 2 Temas Qué es clustering? K-Means Clustering Hierarchical Clustering QUÉ ES CLUSTERING? 3 Aprendizaje Supervisado vs. No Supervisado 4 Aprendizaje Supervisado: tanto
1 CLUSTERING Bases de Datos Masivas 2 Temas Qué es clustering? K-Means Clustering Hierarchical Clustering QUÉ ES CLUSTERING? 3 Aprendizaje Supervisado vs. No Supervisado 4 Aprendizaje Supervisado: tanto
Predicción de potencia en el parque eólico de Villonaco, Loja, Ecuador. Alberto Reyes y Tania Guerrero INER Ecuador
 Predicción de potencia en el parque eólico de Villonaco, Loja, Ecuador Alberto Reyes y Tania Guerrero INER Ecuador INTRODUCCIÓN El comportamiento del viento presenta alto grado de aleatoriedad, incertidumbre
Predicción de potencia en el parque eólico de Villonaco, Loja, Ecuador Alberto Reyes y Tania Guerrero INER Ecuador INTRODUCCIÓN El comportamiento del viento presenta alto grado de aleatoriedad, incertidumbre
ESTADISTICA. Tradicionalmente la aplicación del término estadística se ha utilizado en tres ámbitos:
 ESTADISTICA Tradicionalmente la aplicación del término estadística se ha utilizado en tres ámbitos: a) Estadística como enumeración de datos. b) Estadística como descripción, es decir, a través de un análisis
ESTADISTICA Tradicionalmente la aplicación del término estadística se ha utilizado en tres ámbitos: a) Estadística como enumeración de datos. b) Estadística como descripción, es decir, a través de un análisis
EVALUACIÓN EN APRENDIZAJE. Eduardo Morales y Jesús González
 EVALUACIÓN EN APRENDIZAJE Eduardo Morales y Jesús González Significancia Estadística 2 En estadística, se dice que un resultado es estadísticamente significante, cuando no es posible que se presente por
EVALUACIÓN EN APRENDIZAJE Eduardo Morales y Jesús González Significancia Estadística 2 En estadística, se dice que un resultado es estadísticamente significante, cuando no es posible que se presente por
Análisis multivariante II
 Análisis multivariante II Tema 1: Introducción Pedro Galeano Departamento de Estadística Universidad Carlos III de Madrid pedro.galeano@uc3m.es Curso 2016/2017 Grado en Estadística y Empresa Pedro Galeano
Análisis multivariante II Tema 1: Introducción Pedro Galeano Departamento de Estadística Universidad Carlos III de Madrid pedro.galeano@uc3m.es Curso 2016/2017 Grado en Estadística y Empresa Pedro Galeano
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur TIPOS DE TAREAS, MODELOS Y ALGORITMOS ? Datos Entrenamiento Algoritmo Modelo Galaxia espiral TAREAS / MODELOS
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur TIPOS DE TAREAS, MODELOS Y ALGORITMOS ? Datos Entrenamiento Algoritmo Modelo Galaxia espiral TAREAS / MODELOS
Visión de Alto Nivel. Dr. Luis Enrique Sucar INAOE. ccc.inaoep.mx/~esucar Sesión 5 Representación y Reconocimiento
 Visión de Alto Nivel Dr. Luis Enrique Sucar INAOE esucar@inaoep.mx ccc.inaoep.mx/~esucar Sesión 5 Representación y Reconocimiento 1 Visión de Alto Nivel orillas Representación del mundo textura color Descripción
Visión de Alto Nivel Dr. Luis Enrique Sucar INAOE esucar@inaoep.mx ccc.inaoep.mx/~esucar Sesión 5 Representación y Reconocimiento 1 Visión de Alto Nivel orillas Representación del mundo textura color Descripción
Aprendizaje no supervisado
 OPENCOURSEWARE REDES DE NEURONAS ARTIFICIALES Inés M. Galván José M. Valls Tema 4 1 Introducción Aprendizaje competitvo Otros algoritmos de agrupación 2 1 Introducción Características principales de las
OPENCOURSEWARE REDES DE NEURONAS ARTIFICIALES Inés M. Galván José M. Valls Tema 4 1 Introducción Aprendizaje competitvo Otros algoritmos de agrupación 2 1 Introducción Características principales de las
OPENCOURSEWARE REDES DE NEURONAS ARTIFICIALES Inés M. Galván José M. Valls. Preguntas y Ejercicios para Evaluación: Tema 4
 OPENCOURSEWARE REDES DE NEURONAS ARTIFICIALES Inés M. Galván José M. Valls Preguntas y Eercicios para Evaluación: Tema 4 1. Indique características del aprendizae no supervisado que no aparezcan en el
OPENCOURSEWARE REDES DE NEURONAS ARTIFICIALES Inés M. Galván José M. Valls Preguntas y Eercicios para Evaluación: Tema 4 1. Indique características del aprendizae no supervisado que no aparezcan en el
Sistemas Inteligentes. Tema B2T4: Aprendizaje no supervisado: algoritmo k-medias.
 Sistemas Inteligentes Escuela Técnica Superior de Informática Universitat Politècnica de València Tema B2T4: Aprendizaje no supervisado: algoritmo k-medias. Índice 1 Introducción 1 2 Agrupamientos particionales
Sistemas Inteligentes Escuela Técnica Superior de Informática Universitat Politècnica de València Tema B2T4: Aprendizaje no supervisado: algoritmo k-medias. Índice 1 Introducción 1 2 Agrupamientos particionales
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur KNN: VECINO(S) MAS CERCANO(S) K NEAREST NEIGHBORS (KNN) Altura Niño Adulto Mayor Se guardan todos los ejemplos
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur KNN: VECINO(S) MAS CERCANO(S) K NEAREST NEIGHBORS (KNN) Altura Niño Adulto Mayor Se guardan todos los ejemplos
ÍNDICE. Introducción... Capítulo 1. Técnicas de minería de datos y herramientas... 1
 ÍNDICE Introducción... XI Capítulo 1. Técnicas de minería de datos y herramientas... 1 Clasificación de las técnicas de minería de datos y herramientas más comunes... 1 Modelado originado por la teoría
ÍNDICE Introducción... XI Capítulo 1. Técnicas de minería de datos y herramientas... 1 Clasificación de las técnicas de minería de datos y herramientas más comunes... 1 Modelado originado por la teoría
Análisis de Datos. Combinación de clasificadores. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Combinación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción Diversos algoritmos de clasificación están limitados a resolver problemas binarios, es decir, con dos
Análisis de Datos Combinación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción Diversos algoritmos de clasificación están limitados a resolver problemas binarios, es decir, con dos
Las Redes Neuronales Artificiales y su importancia como herramienta en la toma de decisiones. Villanueva Espinoza, María del Rosario CAPÍTULO V
 CAPÍTULO V V. ALGORITMOS NEURONALES Los modelos neuronales utilizan varios algoritmos de estimación, aprendizaje o entrenamiento para encontrar los valores de los parámetros del modelo, que en la jerga
CAPÍTULO V V. ALGORITMOS NEURONALES Los modelos neuronales utilizan varios algoritmos de estimación, aprendizaje o entrenamiento para encontrar los valores de los parámetros del modelo, que en la jerga
OBJETIVO INTRODUCCIÓN
 Fecha: 1 de julio 2015 Tema: Red Kohonen OBJETIVO El objetivo de este tipo de red es conocer su historia, arquitectura, el aprendizaje, algoritmo, limitaciones y de cómo funciona. INTRODUCCIÓN Desde un
Fecha: 1 de julio 2015 Tema: Red Kohonen OBJETIVO El objetivo de este tipo de red es conocer su historia, arquitectura, el aprendizaje, algoritmo, limitaciones y de cómo funciona. INTRODUCCIÓN Desde un
Lingüística computacional
 Lingüística computacional Definición y alcance Escuela Nacional de Antropología e Historia (ENAH) Agosto diciembre de 2015 Lingüística Ciencias de la computación Lingüística computacional Estudio del lenguaje
Lingüística computacional Definición y alcance Escuela Nacional de Antropología e Historia (ENAH) Agosto diciembre de 2015 Lingüística Ciencias de la computación Lingüística computacional Estudio del lenguaje
Estadística y sus aplicaciones en Ciencias Sociales 5. Estimación. Facultad de Ciencias Sociales, UdelaR
 Estadística y sus aplicaciones en Ciencias Sociales 5. Estimación Facultad de Ciencias Sociales, UdelaR Índice 1. Repaso: estimadores y estimaciones. Propiedades de los estimadores. 2. Estimación puntual.
Estadística y sus aplicaciones en Ciencias Sociales 5. Estimación Facultad de Ciencias Sociales, UdelaR Índice 1. Repaso: estimadores y estimaciones. Propiedades de los estimadores. 2. Estimación puntual.
Análisis de Estructuras Espaciales Persistentes. Desempleo Departamental en Argentina.
 Análisis de Estructuras Espaciales Persistentes. Desempleo Departamental en Argentina. Marcos Herrera 1 1 CONICET IELDE - Universidad Nacional de Salta (Argentina) Seminario de Investigación Nº 27 8 de
Análisis de Estructuras Espaciales Persistentes. Desempleo Departamental en Argentina. Marcos Herrera 1 1 CONICET IELDE - Universidad Nacional de Salta (Argentina) Seminario de Investigación Nº 27 8 de
MÉTODOS AVANZADOS EN APRENDIZAJE ARTIFICIAL: TEORÍA Y APLICACIONES A PROBLEMAS DE PREDICCIÓN
 MÉTODOS AVANZADOS EN APRENDIZAJE ARTIFICIAL: TEORÍA Y APLICACIONES A PROBLEMAS DE PREDICCIÓN Manuel Sánchez-Montañés Luis Lago Ana González Escuela Politécnica Superior Universidad Autónoma de Madrid Teoría
MÉTODOS AVANZADOS EN APRENDIZAJE ARTIFICIAL: TEORÍA Y APLICACIONES A PROBLEMAS DE PREDICCIÓN Manuel Sánchez-Montañés Luis Lago Ana González Escuela Politécnica Superior Universidad Autónoma de Madrid Teoría
I. CARACTERISTICAS DEL ALGORITMO ID3
 I. CARACTERISTICAS DEL ALGORITMO ID3 El investigador J. Ross Quinlan desarrolló el algoritmo conocido como ID3 (Induction Decision Trees) en el año de 1983. Pertenece a la familia TDIDT (Top-Down Induction
I. CARACTERISTICAS DEL ALGORITMO ID3 El investigador J. Ross Quinlan desarrolló el algoritmo conocido como ID3 (Induction Decision Trees) en el año de 1983. Pertenece a la familia TDIDT (Top-Down Induction
Análisis multivariante II
 Análisis multivariante II Tema 2: Análisis de conglomerados Pedro Galeano Departamento de Estadística Universidad Carlos III de Madrid pedro.galeano@uc3m.es Curso 2016/2017 Grado en Estadística y Empresa
Análisis multivariante II Tema 2: Análisis de conglomerados Pedro Galeano Departamento de Estadística Universidad Carlos III de Madrid pedro.galeano@uc3m.es Curso 2016/2017 Grado en Estadística y Empresa
Análisis de Datos. Clasificación Bayesiana para distribuciones normales. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Clasificación Bayesiana para distribuciones normales Profesor: Dr. Wilfrido Gómez Flores 1 Funciones discriminantes Una forma útil de representar clasificadores de patrones es a través
Análisis de Datos Clasificación Bayesiana para distribuciones normales Profesor: Dr. Wilfrido Gómez Flores 1 Funciones discriminantes Una forma útil de representar clasificadores de patrones es a través
Análisis Global y Local. UCR ECCI CI-2414 Recuperación de Información Prof. Kryscia Daviana Ramírez Benavides
 UCR ECCI CI-2414 Recuperación de Información Prof. Kryscia Daiana Ramírez Benaides Análisis Global Realiza la expansión basado en la construcción de tesauros utilizando la colección completa de documentos
UCR ECCI CI-2414 Recuperación de Información Prof. Kryscia Daiana Ramírez Benaides Análisis Global Realiza la expansión basado en la construcción de tesauros utilizando la colección completa de documentos
GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC)
") GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC) Curso Académico: 2015-2016 Programa: Centro: Universidad: Máster Universitario en Ingeniería Informática Escuela Politécnica Superior
GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC) Curso Académico: 2015-2016 Programa: Centro: Universidad: Máster Universitario en Ingeniería Informática Escuela Politécnica Superior
Técnicas Multivariadas Avanzadas
 Métodos basados en árboles Universidad Nacional Agraria La Molina 2014-2 Introducción Introducción Se describen métodos basados en árboles para regresión y clasicación. Estos métodos requieren estraticar
Métodos basados en árboles Universidad Nacional Agraria La Molina 2014-2 Introducción Introducción Se describen métodos basados en árboles para regresión y clasicación. Estos métodos requieren estraticar
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Tema 7. Reconocimiento del locutor
 Tema 7. Reconocimiento del locutor 7.1.- Introducción 7.2.- Clasificación 7.3.- Fases del reconocimiento 7.4.- Técnicas de reconocimiento 7.5.- Evaluación 7.1.- Introducción Reconocimiento de voz: Identificar
Tema 7. Reconocimiento del locutor 7.1.- Introducción 7.2.- Clasificación 7.3.- Fases del reconocimiento 7.4.- Técnicas de reconocimiento 7.5.- Evaluación 7.1.- Introducción Reconocimiento de voz: Identificar
Figura 1: Propiedades de textura: (a) Suavidad, (b) Rugosidad y (c) Regularidad
 Suavidad, (b) Rugosidad y (c) Regularidad") 3 TEXTURA 3.1 CONCEPTO DE LA TEXTURA La textura es una característica importante utilizada en segmentación, identificación de objetos o regiones de interés en una imagen y obtención de forma. El uso de
3 TEXTURA 3.1 CONCEPTO DE LA TEXTURA La textura es una característica importante utilizada en segmentación, identificación de objetos o regiones de interés en una imagen y obtención de forma. El uso de
Introducción. Existen dos aproximaciones para resolver el problema de clasificación: Aproximación Generativa (vista en el Tema 3) Basada en:
 Basada en:") Introducción Eisten dos aproimaciones para resolver el problema de clasificación: Aproimación Generativa (vista en el Tema 3) Basada en: Modelar p(,w)=p( w)p(w) p( w) es la distribución condicional de
Introducción Eisten dos aproimaciones para resolver el problema de clasificación: Aproimación Generativa (vista en el Tema 3) Basada en: Modelar p(,w)=p( w)p(w) p( w) es la distribución condicional de
Introducción a la Prospección de Datos Masivos ( Data Mining )
") Introducción a la Prospección de Datos Masivos ( Data Mining ) José Hernández Orallo jorallo@dsic.upv.es Transparencias y otra documentación en: http://www.dsic.upv.es/~jorallo/master/ Máster de Ingeniería
Introducción a la Prospección de Datos Masivos ( Data Mining ) José Hernández Orallo jorallo@dsic.upv.es Transparencias y otra documentación en: http://www.dsic.upv.es/~jorallo/master/ Máster de Ingeniería
Aprendizaje de intervalos para Redes Bayesianas de Nodos Temporales
 Aprendizaje de intervalos para Redes Bayesianas de Nodos Temporales Pablo F. Hernández Leal Instituto Nacional de Astrofísica, Óptica y Electrónica Coordinación de Ciencias Computacionales Resumen En este
Aprendizaje de intervalos para Redes Bayesianas de Nodos Temporales Pablo F. Hernández Leal Instituto Nacional de Astrofísica, Óptica y Electrónica Coordinación de Ciencias Computacionales Resumen En este
Estadística Inferencial. Sesión 2. Distribuciones muestrales
 Estadística Inferencial. Sesión 2. Distribuciones muestrales Contextualización. Toda cantidad que se obtiene de una muestra con el propósito de estimar un parámetro poblacional se llama estadístico muestral
Estadística Inferencial. Sesión 2. Distribuciones muestrales Contextualización. Toda cantidad que se obtiene de una muestra con el propósito de estimar un parámetro poblacional se llama estadístico muestral
Inteligencia Computacional II Mapas auto-organizados
 Inteligencia Computacional II Mapas auto-organizados Dra. Ma. del Pilar Gómez Gil Ciencias Computacionales, INAOE pgomez@inaoep.mx Versión: 17-Junio-2015 (c) P. Gómez Gil. INAOE 2015 1 Auto-Organización
Inteligencia Computacional II Mapas auto-organizados Dra. Ma. del Pilar Gómez Gil Ciencias Computacionales, INAOE pgomez@inaoep.mx Versión: 17-Junio-2015 (c) P. Gómez Gil. INAOE 2015 1 Auto-Organización
Tema 9: Estadística descriptiva
 Tema 9: Estadística descriptiva Matemáticas específicas para maestros Grado en Educación Primaria Matemáticas específicas para maestros Tema 9: Estadística descriptiva Grado en Educación Primaria 1 / 47
Tema 9: Estadística descriptiva Matemáticas específicas para maestros Grado en Educación Primaria Matemáticas específicas para maestros Tema 9: Estadística descriptiva Grado en Educación Primaria 1 / 47
Análisis de Datos. Validación de clasificadores. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Validación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción La mayoría de los clasificadores que se han visto requieren de uno o más parámetros definidos libremente,
Análisis de Datos Validación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción La mayoría de los clasificadores que se han visto requieren de uno o más parámetros definidos libremente,
EL PRINCIPIO DE MÁXIMA VEROSIMILITUD (LIKELIHOOD)
") EL PRINCIPIO DE MÁXIMA VEROSIMILITUD (LIKELIHOOD) Fortino Vela Peón fvela@correo.xoc.uam.mx FVela-0 Objetivo Introducir las ideas básicas del principio de máxima verosimilitud. Problema Considere el experimento
EL PRINCIPIO DE MÁXIMA VEROSIMILITUD (LIKELIHOOD) Fortino Vela Peón fvela@correo.xoc.uam.mx FVela-0 Objetivo Introducir las ideas básicas del principio de máxima verosimilitud. Problema Considere el experimento
Algoritmos genéticos
 Algoritmos genéticos Introducción 2 Esquema básico 3 El problema de la mochila 7 Asignación de recursos 0 El problema del viajante 3 Variantes del esquema básico 5 Por qué funciona? 9 Observaciones finales
Algoritmos genéticos Introducción 2 Esquema básico 3 El problema de la mochila 7 Asignación de recursos 0 El problema del viajante 3 Variantes del esquema básico 5 Por qué funciona? 9 Observaciones finales
ANEXO 1. CONCEPTOS BÁSICOS. Este anexo contiene información que complementa el entendimiento de la tesis presentada.
 ANEXO 1. CONCEPTOS BÁSICOS Este anexo contiene información que complementa el entendimiento de la tesis presentada. Aquí se exponen técnicas de cálculo que son utilizados en los procedimientos de los modelos
ANEXO 1. CONCEPTOS BÁSICOS Este anexo contiene información que complementa el entendimiento de la tesis presentada. Aquí se exponen técnicas de cálculo que son utilizados en los procedimientos de los modelos
ESTIMACIÓN Estas transparencias contienen material adaptado del curso de PATTERN RECOGNITION AND MACHINE LEARNING de Heikki Huttunen y del libro Duda.
 ESTIMACIÓN Estas transparencias contienen material adaptado del curso de PATTERN RECOGNITION AND MACHINE LEARNING de Heikki Huttunen y del libro Duda. APRENDIZAJE AUTOMÁTICO, ESTIMACIÓN Y DETECCIÓN Introducción
ESTIMACIÓN Estas transparencias contienen material adaptado del curso de PATTERN RECOGNITION AND MACHINE LEARNING de Heikki Huttunen y del libro Duda. APRENDIZAJE AUTOMÁTICO, ESTIMACIÓN Y DETECCIÓN Introducción