ARQUITECTURA DEL COMPUTADOR
|
|
|
- Montserrat Salinas López
- hace 5 años
- Vistas:
Transcripción

1 1-11 Marzo de 2017 FACET -UNT ARQUITECTURA DEL COMPUTADOR Graciela Molina 1

2 MODELO VON NEUMANN RAM J. Von Neumann frente a la computadora IAS, I/O CU ALU CPU 2
3 MODELO VON NEUMANN Cómo trabaja? 1. FETCH: lee próxima instrucción RAM F I/O CU ALU CPU ? 3
4 MODELO VON NEUMANN Cómo trabaja? 2. DECODE: decodifica la instrucción RAM I/O D CU ALU CPU add r1, 0xF21E! 4
5 MODELO VON NEUMANN Cómo trabaja? 3. LOAD: lo que pide la instrucción RAM L I/O CU ALU CPU r2 0xF21E 5
6 MODELO VON NEUMANN Cómo trabaja? 4. EXECUTE: la operación RAM I/O CU ALU E CPU r1 r1 + r2 6
7 MODELO VON NEUMANN Cómo trabaja? 5. STORE: guarda el resultado en memoria RAM S I/O CU ALU CPU RAM r1 7
8 Puede hacerse más eficiente el trabajo? 8
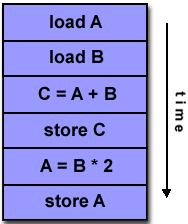
9 PROCESAMIENTO SECUENCIAL INST 1 INST F D L E S F D L E S 9

10 PIPELINING INST 1 INST F D F 10
11 PIPELINING INST 1 INST 2 INST F D L F D F 11
12 PIPELINING INST 1 INST 2 INST 3 INST F D L E F D L F D F 12
13 PIPELINING INST 1 INST 2 INST 3 INST 4 INST F D L E S F D L E F D L F D F 13
14 PIPELINING INST 1 INST 2 INST 3 INST 4 INST F D L E S F D L E F D L F D F 14
15 PIPELINING INST 1 INST 2 INST 3 INST 4 INST F D L E S F D L E S F D L E S F D L E S F D L E 9 10 S 15
16 z=a*b+c*d En realidad: z1=a*b z2=c*d z=z1+z2 PIPELINING C1. cargar a en R0 C2. cargar b en R1 C3. R2=R0*R1 cargar c en R3 C4.cargar d en R4 C5.R5=R3*R4 Inst. prox. operación C6. R6=R2+R5 Inst. prox. operación C7. almacenar R6 en z Inst. prox. operación 16
17 z=a*b+c*d En realidad: z1=a*b z2=c*d z=z1+z2 Dependencia PIPELINING C1. cargar a en R0 C2. cargar b en R1 C3. R2=R0*R1 cargar c en R3 C4.cargar d en R4 C5.R5=R3*R4 Inst. prox. operación C6. R6=R2+R5 Inst. prox. operación C7. almacenar R6 en z Inst. prox. operación 17
18 z=a*b+c*d PIPELINING En realidad: z1=a*b z2=c*d z=z1+z2 Cuanto ganamos? 1 paso de 8! + 3 más si la próxima operación es independiente C1. cargar a en R0 C2. cargar b en R1 C3. R2=R0*R1 cargar c en R3 C4.cargar d en R4 C5.R5=R3*R4 Inst. prox. operación C6. R6=R2+R5 Inst. prox. operación C7. almacenar R6 en z Inst. prox. operación 18
19 Cómo mejorar aún más? 19
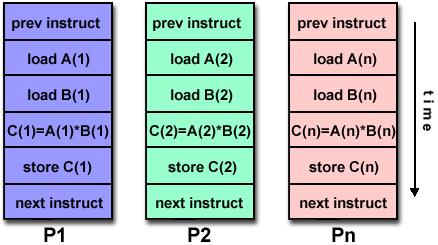
20 SUPERSCALING INST 1 F D L E S INST 2 F D L E S + de una instrucción, inst. independientes 20
21 SUPERSCALING Ojo! Sigue siendo escalar Paralelismo instrucción a nivel de Muchas instrucciones se ejecutan simultáneamente, generalmente combinado con pipelining. 21
22 PIPELINING + SUPERSCALING INST 1 F D L E S INST 2 F D L E S INST 3 F D L E S INST 4 F D L E S
23 PIPELINING z=a*b+c*d z1=a*b z2=c*d z=z1+z2 + SUPERSCALING C1. cargar a en R0 cargar b en R1 C2.R2=R0*R1 cargar c en R3 cargar d en R4 C3. R5=R3*R4 Próxima operación C4. R6=R2+R5 Próxima operación C5.almacenar R6 en z 23
24 PIPELINING z=a*b+c*d z1=a*b z2=c*d z=z1+z2 Pipelining + SUPERSCALING C1. cargar a en R0 cargar b en R1 C2.R2=R0*R1 cargar c en R3 cargar d en R4 C3. R5=R3*R4 Próxima operación C4. R6=R2+R5 Próxima operación C5.almacenar R6 en z 24
25 PIPELINING z=a*b+c*d z1=a*b z2=c*d z=z1+z2 superscaling + SUPERSCALING C1. cargar a en R0 cargar b en R1 C2.R2=R0*R1 cargar c en R3 cargar d en R4 C3. R5=R3*R4 Próxima operación C4. R6=R2+R5 Próxima operación C5.almacenar R6 en z 25
26 PIPELINING z=a*b+c*d z1=a*b z2=c*d z=z1+z2 Cuanto ganamos? 3 pasos de 8! + 3 si la próxima operación es independiente + SUPERSCALING C1. cargar a en R0 cargar b en R1 C2.R2=R0*R1 cargar c en R3 cargar d en R4 C3. R5=R3*R4 Próxima operación C4. R6=R2+R5 Próxima operación C5.almacenar R6 en z 26
27 Hasta aquí todas las operaciones son escalares! 27
28 OPERACIONES ESCALARES A1 + B1 = C1 A2 + B2 = C2 A3 + B3 = C3 A4 + B4 = C4 28
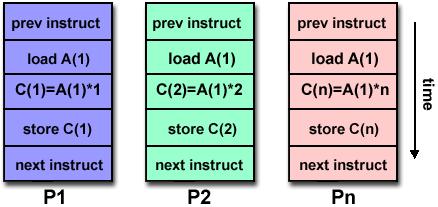
29 OPERACIONES VECTORIALES A1 B1 C1 A2 B2 C2 + = A3 B3 C3 A4 B4 C4 registros vectoriales! 29
30 CPU VECTORIAL Capaz de ejecutar operaciones matemáticas sobre múltiples datos de forma simultánea. (registros vectoriales) En general es adicional al pipelining superescalar. Instrucciones vectoriales especiales (SSE,AVX,etc) 30
31 Escalar vs Vectorial For (i=0;i<length;i++){ z[i]=a[i]+b[i]; } 31
32 Super escalar + pipeline For (i=0;i<length;i++){ z[i]=a[i]*b[i]+c[i]*d[i]; } 1. a[0] en R0 b[0] en R1 2. R2=R0*R1 c[0] en R3 D[0] en R4 3. R5=R3*R4 a[1] en R0 b[1] en R1 4. R6=R2+R5 c[1] en R3 d[1] en R4 5. R6 en z[0] R2=R0*R1 R5=R3*R4 a[2] en R0 b[2] en R1 Repetir pasos 4 5 según índice 32
33 Vectorial For (i=0;i<length;i++){ z[i]=a[i]*b[i]+c[i]*d[i]; } Los registros vectoriales pueden almacenar y operar en paralelo For (i=0;i<length;i+=2){ z[i]=a[i]*b[i]+c[i]*d[i]; en simultaneo z[i+1]=a[i+1]*b[i+1]+c[i+1]*d[i+1]; } 33
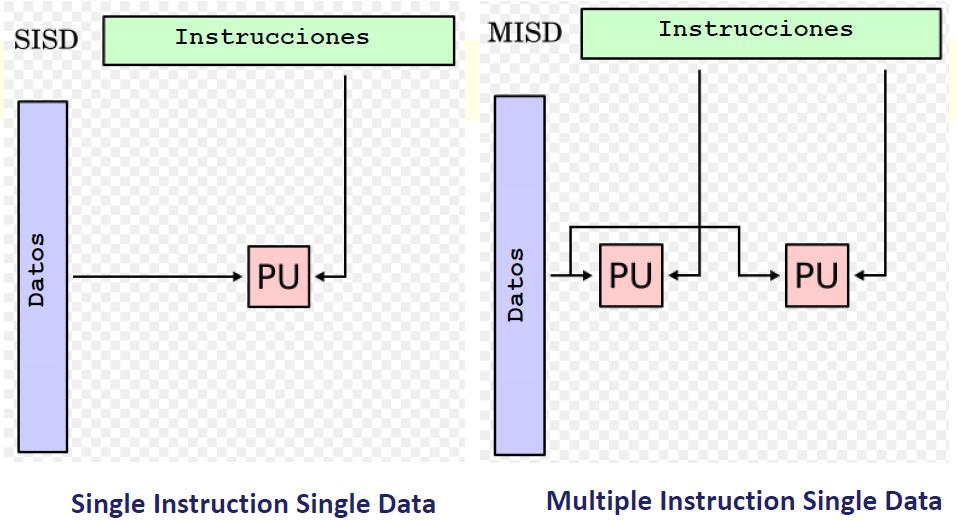

34 CLASIFICACIÓN DE ARQUITECTURAS 34
35 CLASIFICACIÓN DE ARQUITECTURAS Modelo tradicional Von Neumann Paralelismo de datos, Computación vectorial Pipelines Modelo general, (pueden ser procesadores de propósito gral o clusters de computadores) 35
36 CLASIFICACIÓN DE ARQUITECTURAS SISD SIMD MISD MIMD 36
37 PERFORMANCE Cómo medir? Unidad de medida FLOP/s Peak Performance (teórico): Estimación del desempeño de la CPU cuando trabaja a máxima velocidad 37
38 PERFORMANCE Cómo medir? Unidad de medida FLOP/s Benchmark Performance: Se utilizan herramientas específicas para medir el pico de performance real. Un ejemplo es Linpack, que es un paquete que resuelve un sistema de matrices densas (con valores aleatorios) de doble precisión (64 bits) y mide el rendimiento del sistema. 38
39 PERFORMANCE Cómo medir? Linpack 39
40 PERFORMANCE Cómo medir? Unidad de medida FLOP/s Real Performance: medición realizada con el programa que quiero correr. 40
41 JERARQUIA DE MEMORIA REGISTROS + Rápida MEMORIA CACHE + Barata MEMORIA PRINCIPAL DISCO DURO 41
42 JERARQUIA DE MEMORIA REGISTROS Registros: Cableados en el Procesador MEMORIA CACHE MEMORIA PRINCIPAL DISCO DURO 42
43 JERARQUIA DE MEMORIA REGISTROS Cache: Memoria rápida, cercana al procesador y cara MEMORIA CACHE MEMORIA PRINCIPAL DISCO DURO 43
44 JERARQUIA DE MEMORIA REGISTROS MEMORIA CACHE MEMORIA PRINCIPAL Memoria ppl: RAM, lenta y barata DISCO DURO 44
45 JERARQUIA DE MEMORIA REGISTROS MEMORIA CACHE MEMORIA PRINCIPAL Disco duro: lentísimo y baratísimo DISCO DURO 45


46 MEMORIA CACHE > costo > velocidad < capacidad Los datos se transfieren a cache en bloques de un determinado tamaño cache lines 46
47 MEMORIA CACHE Diseñada de acuerdo al principio de localidad espacial y temporal Por ejemplo, recorrer un vector con un loop Por ejemplo, un llamado a una función dentro de un loop 47
48 MEMORIA CACHE Diseñada de acuerdo al principio de localidad espacial y temporal Cada vez que se realiza una operación LOAD/STRORE puede ocurrir: cache miss o cache hit 48

49 MEMORIA CACHE 49
50 De manera más legible 0.3 ns 1s Level 1 cache access 0.9 ns 3s Level 2 cache access 2.8 ns 9s Level 3 cache access 12.9 ns 43 s Main memory access 120 ns 6 min μs 2-6 days 1-10 ms 1-12 months Internet: SF to NYC 40 ms 4 years Internet: SF to UK 81 ms 8 years Internet: SF to Australia 183 ms 19 years OS virtualization reboot 4s 423 years SCSI command time-out 30 s 3000 years Hardware virtualization reboot 40 s 4000 years Physical system reboot 5m 32 millenia 1 CPU cycle Solid-state disk I/O Rotational disk I/O 50
51 Todo esto para un único procesador! Actualmente más de un procesador 51

52 MULTIPROCESADORES Ley de Moore???? 52

53 COMO ES EN REALIDAD Básicamente von Neumann 53

54 COMO ES EN REALIDAD Básicamente von Neumann 54
55 ARQUITECTURA DE UN CLUSTER NonUniform Memory Access Symmetric MultProcessors CPU CPU CPU BUS INTERCONECT MAIN MEMORY CPU CPU CPU CPU CPU MAIN MAIN MAIN MAIN MEMORY MEMORY MEMORY MEMORY BUS INTERCONECT 55
56 ARQUITECTURA DE UN CLUSTER CPU CPU CPU CPU BUS MEM MEMORIA COMPARTIDA Ventajas + fácil al programador. Compartir datos +rápido y directo. CPU MEM CPU MEM CPU MEM CPU MEM BUS MEMORIA DISTRIBUIDA Ventajas Escalabilidad de memoria con el num de procesadores. Cada procesador puede acceder rápidamente a su propia memoria local sin interferencias y sin overhead. Relación costo beneficio: se puede usar hardware off the shelf con una performance muy razonable. 56
57 ARQUITECTURA DE UN CLUSTER CPU CPU CPU CPU BUS MEM MEMORIA COMPARTIDA Desventajas Escabalibilidad pobre: + procesadores, > trafico memoria procesador. Programador implementar la sincronización Costo: + difícil y caro diseñar y producir maquinas con memoria compartida a medida que se aumenta la cantidad de procesadores. CPU MEM CPU MEM CPU MEM CPU MEM BUS MEMORIA DISTRIBUIDA Desventajas El programador es responsabile de detalles la comunicación de datos entre procesos. en Complicado adaptar código existente basado en memoria compartida. El tiempo de acceso a los datos no es uniformes (y varia mucho!) 57
58 ARQUITECTURA DE UN CLUSTER... Symmetric MultProcessors NonUniform Memory Access 58
59 COMO IMPACTA EN EL DISEÑO DEL SOFTWARE? * Paralelismo Masivo * Complejidad Creciente * Menos eficiencia para software viejo * Poca previsibilidad HAY QUE PENSAR EN EL HW AL MOMENTO DE CODIFICAR! 59


60 Y ESO NO ES TODO... Aceleradores unidad de procesamiento de gráficos 60

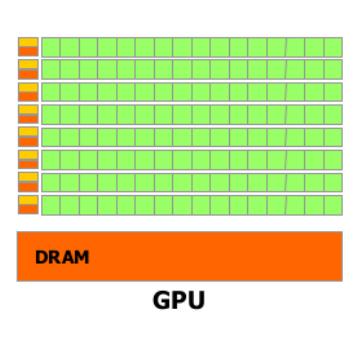
61 GPU : IDEA GENERAL Esquemáticamente la diferencia es: 61
62 GPU : IDEA GENERAL <ctrl <cache >ALUs Paralelismo masivo Para alimentar tantas ALUs Paralelismo de datos Suficiente como para ocultar la latencia 62

63 GPU : IDEA GENERAL 63
64 POR QUE ACELERA * Diseño muy escalable * Mucho ancho de banda * Muchos procesadores de baja frecuencia * Ideal para el procesado de data masiva 64
65 NO SIEMPRE ACELERA... * Hay que pasarle la información a la placa * Difícil sincronizar los procesadores * Ejecución en serie MUY lenta * Modelo de memoria demasiado complejo 65
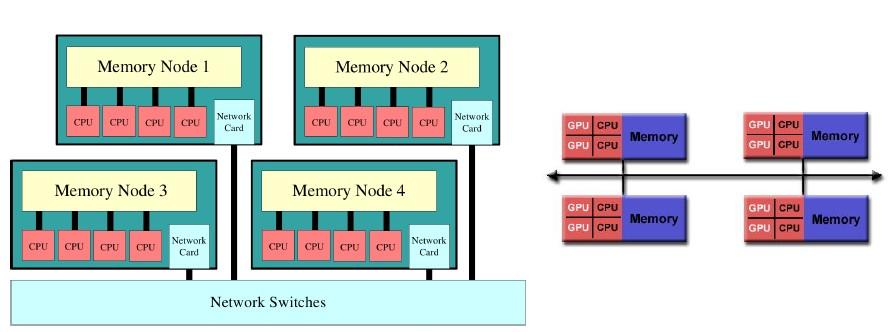
66 ARQUITECTURAS HIBRIDAS 66
67 1-11 Marzo de 2017 FACET -UNT ARQUITECTURA DEL COMPUTADOR Graciela Molina 67
Taxonomía de las arquitecturas
 Taxonomía de las arquitecturas 1 INTRODUCCIÓN 2 2 CLASIFICACIÓN DE FLYNN 3 2.1 SISD (SINGLE INSTRUCTION STREAM, SINGLE DATA STREAM) 3 2.2 SIMD (SINGLE INSTRUCTION STREAM, MULTIPLE DATA STREAM) 4 2.2.1
Taxonomía de las arquitecturas 1 INTRODUCCIÓN 2 2 CLASIFICACIÓN DE FLYNN 3 2.1 SISD (SINGLE INSTRUCTION STREAM, SINGLE DATA STREAM) 3 2.2 SIMD (SINGLE INSTRUCTION STREAM, MULTIPLE DATA STREAM) 4 2.2.1
Con estas consideraciones, Flynn clasifica los sistemas en cuatro categorías:
 Taxonomía de las arquitecturas 1 Introducción Introducción En este trabajo se explican en detalle las dos clasificaciones de computadores más conocidas en la actualidad. La primera clasificación, es la
Taxonomía de las arquitecturas 1 Introducción Introducción En este trabajo se explican en detalle las dos clasificaciones de computadores más conocidas en la actualidad. La primera clasificación, es la
MULTIPROCESADORES TIPOS DE PARALELISMO
 Todos los derechos de propiedad intelectual de esta obra pertenecen en exclusiva a la Universidad Europea de Madrid, S.L.U. Queda terminantemente prohibida la reproducción, puesta a disposición del público
Todos los derechos de propiedad intelectual de esta obra pertenecen en exclusiva a la Universidad Europea de Madrid, S.L.U. Queda terminantemente prohibida la reproducción, puesta a disposición del público
Paralelismo _Arquitectura de Computadoras IS603
 Paralelismo _Arquitectura de Computadoras IS603 INTRODUCCION El objetivo de esta investigación, es conceptualizar las diferentes tipos de paralelismo referente al área de Arquitectura de Computadoras,
Paralelismo _Arquitectura de Computadoras IS603 INTRODUCCION El objetivo de esta investigación, es conceptualizar las diferentes tipos de paralelismo referente al área de Arquitectura de Computadoras,
Arquitectura de Computadoras. Clase 9 Procesamiento paralelo
 Arquitectura de Computadoras Clase 9 Procesamiento paralelo Introducción al procesamiento paralelo Sea cual sea el nivel de prestaciones, la demanda de máquinas de mayor rendimiento seguirá existiendo.
Arquitectura de Computadoras Clase 9 Procesamiento paralelo Introducción al procesamiento paralelo Sea cual sea el nivel de prestaciones, la demanda de máquinas de mayor rendimiento seguirá existiendo.
Introducción a los sistemas de Multiprocesamiento Prof. Gilberto Díaz
 Universisdad de Los Andes Facultad de Ingeniería Escuela de Sistemas Introducción a los sistemas de Multiprocesamiento Prof. Gilberto Díaz gilberto@ula.ve Departamento de Computación, Escuela de Sistemas,
Universisdad de Los Andes Facultad de Ingeniería Escuela de Sistemas Introducción a los sistemas de Multiprocesamiento Prof. Gilberto Díaz gilberto@ula.ve Departamento de Computación, Escuela de Sistemas,
Modelos de computadores paralelos
 Modelos de computadores paralelos Domingo Giménez Departamento de Informática y Sistemas Universidad de Murcia, Spain dis.um.es/~domingo Universidad de Murcia 1 Contenido Programación paralela Modelos
Modelos de computadores paralelos Domingo Giménez Departamento de Informática y Sistemas Universidad de Murcia, Spain dis.um.es/~domingo Universidad de Murcia 1 Contenido Programación paralela Modelos
Clasificación de Flynn de los computadores
 Clasificación de Flynn de los computadores Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD Multiple instruction,
Clasificación de Flynn de los computadores Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD Multiple instruction,
Tema 7. Mejora del rendimiento: introducción a la segmentación y a las arquitecturas paralelas
 Tema 7. Mejora del rendimiento: introducción a la segmentación y a las arquitecturas paralelas Arquitectura de Computadores Curso 2009-2010 Transparencia: 2 / 21 Índice Introducción Taxonomía de Flynn
Tema 7. Mejora del rendimiento: introducción a la segmentación y a las arquitecturas paralelas Arquitectura de Computadores Curso 2009-2010 Transparencia: 2 / 21 Índice Introducción Taxonomía de Flynn
Arquitectura de Computadoras para Ingeniería
 Arquitectura de Computadoras para Ingeniería (Cód. 7526) 1 Cuatrimestre 2016 Dra. DCIC - UNS 1 Multiprocesadores 2 Clasificación de Flynn Clasificación de 1966 En función del flujo de instrucciones y datos
Arquitectura de Computadoras para Ingeniería (Cód. 7526) 1 Cuatrimestre 2016 Dra. DCIC - UNS 1 Multiprocesadores 2 Clasificación de Flynn Clasificación de 1966 En función del flujo de instrucciones y datos
Computación de Altas Prestaciones Sistemas computacionales
 Computación de Altas Prestaciones Sistemas computacionales Domingo Giménez Departamento de Informática y Sistemas Universidad de Murcia, Spain dis.um.es/~domingo Universidad de Murcia 1 Motivación Problemas
Computación de Altas Prestaciones Sistemas computacionales Domingo Giménez Departamento de Informática y Sistemas Universidad de Murcia, Spain dis.um.es/~domingo Universidad de Murcia 1 Motivación Problemas
Paralelismo en el procesador
 2017 Paralelismo en el procesador ARQUITECTURA DE COMPUTADORAS ING. ELMER PADILLA AUTOR: GERARDO ROBERTO MÉNDEZ LARIOS - 20111013326 Ciudad universitaria, Tegucigalpa M.D.C., 04 de mayo del 2017. Contenido
2017 Paralelismo en el procesador ARQUITECTURA DE COMPUTADORAS ING. ELMER PADILLA AUTOR: GERARDO ROBERTO MÉNDEZ LARIOS - 20111013326 Ciudad universitaria, Tegucigalpa M.D.C., 04 de mayo del 2017. Contenido
Procesamiento Paralelo
 Procesamiento Paralelo Arquitecturas de Computadoras Paralelas Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar
Procesamiento Paralelo Arquitecturas de Computadoras Paralelas Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar
ARQUITECTURA DE VON NEUMANN Y HARVARD
 ARQUITECTURA DE VON NEUMANN Y HARVARD ARQUITECTURA VON NEUMANN En esta arquitectura se observa que las computadoras utilizan el mismo dispositivo de almacenamiento para datos e instrucciones conectados
ARQUITECTURA DE VON NEUMANN Y HARVARD ARQUITECTURA VON NEUMANN En esta arquitectura se observa que las computadoras utilizan el mismo dispositivo de almacenamiento para datos e instrucciones conectados
Modelado de los computadores paralelos
 Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Organización del Computador I. Introducción e Historia
 Organización del Computador I Introducción e Historia Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz de
Organización del Computador I Introducción e Historia Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz de
Multiprocesamiento en Lenguaje C Conceptos básicos de la computación paralela
 Multiprocesamiento en Lenguaje C Conceptos básicos de la computación paralela Pertinencia de la enseñanza del cómputo paralelo en el currículo de las ingenierías Conceptos básicos de la computación paralela
Multiprocesamiento en Lenguaje C Conceptos básicos de la computación paralela Pertinencia de la enseñanza del cómputo paralelo en el currículo de las ingenierías Conceptos básicos de la computación paralela
Computación de Alta Performance Curso 2009 ARQUITECTURAS PARALELAS ARQUITECTURAS PARALELAS
 Computación de Alta Performance Curso 2009 CONTENIDO Arquitecturas secuenciales y paralelas. Clasificación de Flynn. Modelo SIMD. GPUs. Modelo SISD. Modelo SIMD. Arquitectura MIMD MIMD con memoria compartida.
Computación de Alta Performance Curso 2009 CONTENIDO Arquitecturas secuenciales y paralelas. Clasificación de Flynn. Modelo SIMD. GPUs. Modelo SISD. Modelo SIMD. Arquitectura MIMD MIMD con memoria compartida.
Procesamiento Paralelo
 Procesamiento Paralelo Arquitecturas de Computadoras Paralelas Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar
Procesamiento Paralelo Arquitecturas de Computadoras Paralelas Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar
GRADO EN INGENIERÍA DE COMPUTADORES
 GRADO EN INGENIERÍA DE COMPUTADORES Tema 1 Departamento Introducción al de paralelismo Automática Prof. Dr. José Antonio de Frutos Redondo Curso 2015-2016 Tema 1: Introducción Necesidad del procesamiento
GRADO EN INGENIERÍA DE COMPUTADORES Tema 1 Departamento Introducción al de paralelismo Automática Prof. Dr. José Antonio de Frutos Redondo Curso 2015-2016 Tema 1: Introducción Necesidad del procesamiento
Modelado de los computadores paralelos
 Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Clasificación de las Arquitecturas
 Clasificación de las Arquitecturas MIA José Rafael Rojano Cáceres Arquitectura de Computadoras I Por la taxonomía de Flynn 1 Flynn Flujo de datos Simple Múltiple Flujo de datos Simple Múltiple SISD MISD
Clasificación de las Arquitecturas MIA José Rafael Rojano Cáceres Arquitectura de Computadoras I Por la taxonomía de Flynn 1 Flynn Flujo de datos Simple Múltiple Flujo de datos Simple Múltiple SISD MISD
Contenidos. Arquitectura de ordenadores (fundamentos teóricos) Elementos de un ordenador. Periféricos
 Elementos de un ordenador. Periféricos") Arquitectura de ordenadores (fundamentos teóricos) Representación de la información Estructura de un microprocesador Memorias Sistemas de E/S Elementos de un ordenador Microprocesador Placa base Chipset
Arquitectura de ordenadores (fundamentos teóricos) Representación de la información Estructura de un microprocesador Memorias Sistemas de E/S Elementos de un ordenador Microprocesador Placa base Chipset
TEMA 10 INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS DISTRIBUIDOS. Introducción Hardware Software Aspectos de diseño
 TEMA 10 INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS DISTRIBUIDOS Introducción Hardware Software Aspectos de diseño 1 Introducción Aparecen en los 80 Desarrollo de Microprocesadores LAN Sistemas Distribuidos:
TEMA 10 INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS DISTRIBUIDOS Introducción Hardware Software Aspectos de diseño 1 Introducción Aparecen en los 80 Desarrollo de Microprocesadores LAN Sistemas Distribuidos:
TEMA 9. SISTEMAS OPERATIVOS DISTRIBUIDOS
 TEMA 9. SISTEMAS OPERATIVOS DISTRIBUIDOS Introducción Hardware Software Aspectos de diseño 1 Introducción Aparecen en los 80 Desarrollo de Microprocesadores LAN Sistemas Distribuidos: Gran nº de procesadores
TEMA 9. SISTEMAS OPERATIVOS DISTRIBUIDOS Introducción Hardware Software Aspectos de diseño 1 Introducción Aparecen en los 80 Desarrollo de Microprocesadores LAN Sistemas Distribuidos: Gran nº de procesadores
Trabajo de investigación Paralelismo en el procesador
 Universidad Nacional Autónoma de Honduras Facultad de Ingeniería Departamento de Ingeniería en Sistemas Trabajo de investigación Paralelismo en el procesador Saúl Armando Laínez Girón 20101006758 IS603
Universidad Nacional Autónoma de Honduras Facultad de Ingeniería Departamento de Ingeniería en Sistemas Trabajo de investigación Paralelismo en el procesador Saúl Armando Laínez Girón 20101006758 IS603
Tema 2. Arquitectura de CPU avanzadas 15/03/2011
 Tema 2. Arquitectura de CPU avanzadas. Juegos CISC y RISC. Proceso paralelo. Procesadores escalares y vectoriales. Segmentación. Caches multinivel. Índice Introducción... 1 Procesadores CISC y RISC...
Tema 2. Arquitectura de CPU avanzadas. Juegos CISC y RISC. Proceso paralelo. Procesadores escalares y vectoriales. Segmentación. Caches multinivel. Índice Introducción... 1 Procesadores CISC y RISC...
Arquitectura de Computadores II Clase #4
 Clase #4 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Contenido Unidad de control Control cableado Control microprogramado MIC-1 La Unidad de Control La instrucción
Clase #4 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Contenido Unidad de control Control cableado Control microprogramado MIC-1 La Unidad de Control La instrucción
Arquitectura de Computadores II Clase #4
 Clase #4 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Contenido Unidad de control Control cableado Control microprogramado MIC-1 1 La Unidad de Control La instrucción
Clase #4 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Contenido Unidad de control Control cableado Control microprogramado MIC-1 1 La Unidad de Control La instrucción
TEMA 2: Organización de computadores
 TEMA 2: Organización de computadores Procesadores Memorias Dispositivos de E/S 1 Computador Procesador, memoria, dispositivos de E/S CPU Unidad de control Unidad aritmética y lógica Registros Dispositivos
TEMA 2: Organización de computadores Procesadores Memorias Dispositivos de E/S 1 Computador Procesador, memoria, dispositivos de E/S CPU Unidad de control Unidad aritmética y lógica Registros Dispositivos
TEMA 1: EJECUCIÓN PARALELA: FUNDAMENTOS(I)
") Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas ARQUITECTURA DE COMPUTADORES II AUTORES: David Expósito Singh Florin Isaila Daniel Higuero Alonso-Mardones Javier García Blas Borja Bergua
Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas ARQUITECTURA DE COMPUTADORES II AUTORES: David Expósito Singh Florin Isaila Daniel Higuero Alonso-Mardones Javier García Blas Borja Bergua
TEMA II: ALMACENAMIENTO DE LA INFORMACIÓN
 CUESTIONES A TRATAR: Existe un tipo único tipo de memoria en un determinado computador? Todas las memorias de un computador tienen la misma función?. Qué es la memoria interna de un computador? Por qué
CUESTIONES A TRATAR: Existe un tipo único tipo de memoria en un determinado computador? Todas las memorias de un computador tienen la misma función?. Qué es la memoria interna de un computador? Por qué
Prerrequisito (s): DOMINIOS COGNITIVOS (Objetos de aprendizaje, temas y subtemas) UNIDAD I: INTRODUCCIÓN
: DOMINIOS COGNITIVOS (Objetos de aprendizaje, temas y subtemas) UNIDAD I: INTRODUCCIÓN") UNIVERSIDAD AUTÓNOMA DE CHIHUAHUA Clave: 08MSU0017H FACULTAD DE INGENIERÍA Clave: 08USU4053W ARQUITECTURA DE COMPUTADORAS DES: Ingeniería Ingeniería en Programa(s) Educativo(s): Ciencias de la Computación
UNIVERSIDAD AUTÓNOMA DE CHIHUAHUA Clave: 08MSU0017H FACULTAD DE INGENIERÍA Clave: 08USU4053W ARQUITECTURA DE COMPUTADORAS DES: Ingeniería Ingeniería en Programa(s) Educativo(s): Ciencias de la Computación
INFORMÁTICA APLICADA UNIDAD DIDÁCTICA 1. Tema 1 Sistemas informáticos
 INFORMÁTICA APLICADA UNIDAD DIDÁCTICA 1 Tema 1 Sistemas informáticos Introducción Desde la antigüedad el hombre ha diseñado máquinas y mecanismos que le permitan realizar su trabajo más fácil y cómodamente,
INFORMÁTICA APLICADA UNIDAD DIDÁCTICA 1 Tema 1 Sistemas informáticos Introducción Desde la antigüedad el hombre ha diseñado máquinas y mecanismos que le permitan realizar su trabajo más fácil y cómodamente,
Definición de prestaciones
 Definición de prestaciones En términos de velocidad. Diferentes puntos de vista: Tiempo de ejecución. Productividad (throughput) Medidas utilizadas En función de la duración del ciclo de reloj y del número
Definición de prestaciones En términos de velocidad. Diferentes puntos de vista: Tiempo de ejecución. Productividad (throughput) Medidas utilizadas En función de la duración del ciclo de reloj y del número
Aspectos avanzados de arquitectura de computadoras Superescalares I. Facultad de Ingeniería - Universidad de la República Curso 2017
 Aspectos avanzados de arquitectura de computadoras Superescalares I Facultad de Ingeniería - Universidad de la República Curso 2017 Instruction Level Parallelism Propiedad de un programa. Indica qué tanto
Aspectos avanzados de arquitectura de computadoras Superescalares I Facultad de Ingeniería - Universidad de la República Curso 2017 Instruction Level Parallelism Propiedad de un programa. Indica qué tanto
Aspectos avanzados de arquitectura de computadoras Multiprocesadores (I) Facultad de Ingeniería - Universidad de la República Curso 2017
 Facultad de Ingeniería - Universidad de la República Curso 2017") Aspectos avanzados de arquitectura de computadoras Multiprocesadores (I) Facultad de Ingeniería - Universidad de la República Curso 2017 Motivación Explotación de ILP estancada desde 2005 (aproximadamente)
Aspectos avanzados de arquitectura de computadoras Multiprocesadores (I) Facultad de Ingeniería - Universidad de la República Curso 2017 Motivación Explotación de ILP estancada desde 2005 (aproximadamente)
Objetivos. Objetivos. Arquitectura de Computadores. R.Mitnik
 Objetivos Objetivos Arquitecturas von Neumann Otras Unidad Central de Procesamiento (CPU) Responsabilidades Requisitos Partes de una CPU ALU Control & Decode Registros Electrónica y buses 2 Índice Capítulo
Objetivos Objetivos Arquitecturas von Neumann Otras Unidad Central de Procesamiento (CPU) Responsabilidades Requisitos Partes de una CPU ALU Control & Decode Registros Electrónica y buses 2 Índice Capítulo
Lusitania. Pensando en Paralelo. César Gómez Martín
 Lusitania Pensando en Paralelo César Gómez Martín cesar.gomez@cenits.es www.cenits.es Esquema Introducción a la programación paralela Por qué paralelizar? Tipos de computadoras paralelas Paradigmas de
Lusitania Pensando en Paralelo César Gómez Martín cesar.gomez@cenits.es www.cenits.es Esquema Introducción a la programación paralela Por qué paralelizar? Tipos de computadoras paralelas Paradigmas de
FUNCIONAMIENTO DEL ORDENADOR
 FUNCIONAMIENTO DEL ORDENADOR COMPUTACIÓN E INFORMÁTICA Datos de entrada Dispositivos de Entrada ORDENADOR PROGRAMA Datos de salida Dispositivos de Salida LOS ORDENADORES FUNCIONAN CON PROGRAMAS Los ordenadores
FUNCIONAMIENTO DEL ORDENADOR COMPUTACIÓN E INFORMÁTICA Datos de entrada Dispositivos de Entrada ORDENADOR PROGRAMA Datos de salida Dispositivos de Salida LOS ORDENADORES FUNCIONAN CON PROGRAMAS Los ordenadores
TEMA 4 PROCESAMIENTO PARALELO
 TEMA 4 PROCESAMIENTO PARALELO Tipos de plataformas de computación paralela Organización lógica Organización física Sistemas de memoria compartida Sistemas de memoria distribuida Tipos de plataformas de
TEMA 4 PROCESAMIENTO PARALELO Tipos de plataformas de computación paralela Organización lógica Organización física Sistemas de memoria compartida Sistemas de memoria distribuida Tipos de plataformas de
Pipeline de instrucciones
 Pipeline de instrucciones Manejo de Interrupciones Tipos: - Síncronas - Asíncronas Asíncronas: No están asociadas a ninguna instrucción. Se atienden normalmente al final de la instrucción en ejecución.
Pipeline de instrucciones Manejo de Interrupciones Tipos: - Síncronas - Asíncronas Asíncronas: No están asociadas a ninguna instrucción. Se atienden normalmente al final de la instrucción en ejecución.
Modelado de los computadores paralelos
 Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Taller de Programación Paralela
 Taller de Programación Paralela Departamento de Ingeniería Informática Universidad de Santiago de Chile March 17, 2008 Qué es paralelismo? Una estrategia compuesta de elementos de hardware y software para
Taller de Programación Paralela Departamento de Ingeniería Informática Universidad de Santiago de Chile March 17, 2008 Qué es paralelismo? Una estrategia compuesta de elementos de hardware y software para
Aspectos avanzados de arquitectura de computadoras Pipeline. Facultad de Ingeniería - Universidad de la República Curso 2017
 Aspectos avanzados de arquitectura de computadoras Pipeline Facultad de Ingeniería - Universidad de la República Curso 2017 Objetivo Mejorar el rendimiento Incrementar frecuencia de reloj? Ancho de los
Aspectos avanzados de arquitectura de computadoras Pipeline Facultad de Ingeniería - Universidad de la República Curso 2017 Objetivo Mejorar el rendimiento Incrementar frecuencia de reloj? Ancho de los
Computación de Altas Prestaciones Sistemas computacionales
 Computación de Altas restaciones Sistemas computacionales Javier Cuenca, Domingo Giménez Departamento de Informática y Sistemas Universidad de Murcia, Spain dis.um.es/~domingo Universidad de Murcia 1 Francisco
Computación de Altas restaciones Sistemas computacionales Javier Cuenca, Domingo Giménez Departamento de Informática y Sistemas Universidad de Murcia, Spain dis.um.es/~domingo Universidad de Murcia 1 Francisco
Ejecución serial: las tareas/instrucciones de un programa son ejecutadas de manera secuencial, una a la vez.
 Paralelismo Conceptos generales Ejecución serial: las tareas/instrucciones de un programa son ejecutadas de manera secuencial, una a la vez. Ejecución paralela: varias tareas/instrucciones de un programa
Paralelismo Conceptos generales Ejecución serial: las tareas/instrucciones de un programa son ejecutadas de manera secuencial, una a la vez. Ejecución paralela: varias tareas/instrucciones de un programa
Arquitectura de Computadoras. Clase 4 Segmentación de Instrucciones
 Arquitectura de Computadoras Clase 4 Segmentación de Instrucciones Segmentación de cauce: Conceptos básicos La segmentación de cauce (pipelining) es una forma particularmente efectiva de organizar el hardware
Arquitectura de Computadoras Clase 4 Segmentación de Instrucciones Segmentación de cauce: Conceptos básicos La segmentación de cauce (pipelining) es una forma particularmente efectiva de organizar el hardware
Programación Gráfica de Altas Prestaciones
 rogramación Gráfica de Altas restaciones lataformas de altas prestaciones para Infomática Gráfica. Máster de Desarrollo de Software Depto. de Lenguajes y Sistemas Informáticos lsi.ugr.es/~jmantas/ga 1.
rogramación Gráfica de Altas restaciones lataformas de altas prestaciones para Infomática Gráfica. Máster de Desarrollo de Software Depto. de Lenguajes y Sistemas Informáticos lsi.ugr.es/~jmantas/ga 1.
Arquitectura y Tecnología de Computadores (09/10) Organización. Jerarquía de Memoria
 Organización. Jerarquía de Memoria") Arquitectura (09/10) Area Arquitectura Organización. Jerarquía Memoria Motivación: Cómo clasificamos las técnicas basadas en organización l hardware? Cuáles son las principales técnicas relativas al sistema
Arquitectura (09/10) Area Arquitectura Organización. Jerarquía Memoria Motivación: Cómo clasificamos las técnicas basadas en organización l hardware? Cuáles son las principales técnicas relativas al sistema
Memoria y caché. Organización del Computador I, verano de 2016
 Organización del Computador I, verano de 2016 (2) El problema que nos ocupa hoy Tiempos de acceso en ciclos: Registro: 0-1 ciclos. Memoria: 50-200 ciclos. Disco: decenas de millones de ciclos. Dicho de
Organización del Computador I, verano de 2016 (2) El problema que nos ocupa hoy Tiempos de acceso en ciclos: Registro: 0-1 ciclos. Memoria: 50-200 ciclos. Disco: decenas de millones de ciclos. Dicho de
07 y 08 Sistemas distribuidos y paralelos y tarea 02
 07 y 08 Sistemas distribuidos y paralelos y tarea 02 Prof. Edgardo Adrián Franco Martínez http://computacion.cs.cinvestav.mx/~efranco efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco)
07 y 08 Sistemas distribuidos y paralelos y tarea 02 Prof. Edgardo Adrián Franco Martínez http://computacion.cs.cinvestav.mx/~efranco efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco)
ARQUITECTURA DE LOS SISTEMAS BASADOS EN MICROPROCESADOR
 ARQUITECTURA DE LOS SISTEMAS BASADOS EN MICROPROCESADOR Historia Bloques funcionales Dimensionamiento Estructura CPU Concepto de programa Interrupciones Buses Entrada / Salida Ejemplo de arquitectura:
ARQUITECTURA DE LOS SISTEMAS BASADOS EN MICROPROCESADOR Historia Bloques funcionales Dimensionamiento Estructura CPU Concepto de programa Interrupciones Buses Entrada / Salida Ejemplo de arquitectura:
Organización del Sistema de Memoria. 1. Tipos de memoria 2. Jerarquía de memoria 3. El principio de localidad 4. Organización de la memoria
 Organización del Sistema de Memoria 1. Tipos de memoria 2. Jerarquía de memoria 3. El principio de localidad 4. Organización de la memoria 1. Tipos de memoria La memoria se puede clasificar de acuerdo
Organización del Sistema de Memoria 1. Tipos de memoria 2. Jerarquía de memoria 3. El principio de localidad 4. Organización de la memoria 1. Tipos de memoria La memoria se puede clasificar de acuerdo
Programación Concurrente y Paralela. Unidad 1 Introducción
 Programación Concurrente y Paralela Unidad 1 Introducción Contenido 1.1 Concepto de Concurrencia 1.2 Exclusión Mutua y Sincronización 1.3 Corrección en Sistemas Concurrentes 1.4 Consideraciones sobre el
Programación Concurrente y Paralela Unidad 1 Introducción Contenido 1.1 Concepto de Concurrencia 1.2 Exclusión Mutua y Sincronización 1.3 Corrección en Sistemas Concurrentes 1.4 Consideraciones sobre el
Granularidad y latencia
 Niveles de paralelismo y latencias de comunicación Niveles de paralelismo. Granularidad o tamaño de grano. Latencia de comunicación. Particionado de los programas. Empaquetado de granos. Planificación
Niveles de paralelismo y latencias de comunicación Niveles de paralelismo. Granularidad o tamaño de grano. Latencia de comunicación. Particionado de los programas. Empaquetado de granos. Planificación
Arquitectura de Computadores II Clase #5
 Arquitectura de Computadores II Clase #5 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Algunas ideas para mejorar el rendimiento Obvio: incrementar la frecuencia
Arquitectura de Computadores II Clase #5 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Algunas ideas para mejorar el rendimiento Obvio: incrementar la frecuencia
Arquitectura de Computadores II Clase #7
 Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2009 Veremos Memoria virtual Resumen de ideas para mejorar performance 1 Recordemos:
Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2009 Veremos Memoria virtual Resumen de ideas para mejorar performance 1 Recordemos:
Introducción a los Sistemas Multiprocesadores
 Introducción a los Sistemas Multiprocesadores Multiprocesadores estilo Von Neumann Modelos de Organización Modelos de Programación Clasificación de los Multiprocesadores Por qué Sistemas Multiprocesadores?
Introducción a los Sistemas Multiprocesadores Multiprocesadores estilo Von Neumann Modelos de Organización Modelos de Programación Clasificación de los Multiprocesadores Por qué Sistemas Multiprocesadores?
Bases de Datos Paralelas. Carlos A. Olarte BDII
 Carlos A. Olarte (carlosolarte@puj.edu.co) BDII Contenido 1 Introducción 2 Paralelismo de I/O 3 Paralelismo entre Consultas 4 OPS Introducción Por qué tener bases de datos paralelas? Tipos de arquitecturas:
Carlos A. Olarte (carlosolarte@puj.edu.co) BDII Contenido 1 Introducción 2 Paralelismo de I/O 3 Paralelismo entre Consultas 4 OPS Introducción Por qué tener bases de datos paralelas? Tipos de arquitecturas:
Tema: Microprocesadores
 Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Microprocesadores Arq. de Computadora I Ing. Carlos Ortega H. 1
Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Microprocesadores Arq. de Computadora I Ing. Carlos Ortega H. 1
Memorias FORMAS DE ESCRITURA
 MEMORIAS Memorias FORMAS DE ESCRITURA BIG-ENDIAN: El bit más significativo en la dirección mas baja LITTLE-ENDIAN: El bit más significativo en la dirección mas alta Little-endian: INTEL Big-Endian: MOTOROLA,
MEMORIAS Memorias FORMAS DE ESCRITURA BIG-ENDIAN: El bit más significativo en la dirección mas baja LITTLE-ENDIAN: El bit más significativo en la dirección mas alta Little-endian: INTEL Big-Endian: MOTOROLA,
Arquitectura de Computadores II Clase #6
 Arquitectura de Computadores II Clase #6 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Recapitulando: donde estamos? Componentes clásicos de un computador Procesador
Arquitectura de Computadores II Clase #6 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Recapitulando: donde estamos? Componentes clásicos de un computador Procesador
6. PROCESADORES SUPERESCALARES Y VLIW
 6. PROCESADORES SUPERESCALARES Y VLIW 1 PROCESADORES SUPERESCALARES Y VLIW 1. Introducción 2. El modelo VLIW 3. El cauce superescalar 4. Superescalar con algoritmo de Tomasulo 2 PROCESADORES SUPERESCALARES
6. PROCESADORES SUPERESCALARES Y VLIW 1 PROCESADORES SUPERESCALARES Y VLIW 1. Introducción 2. El modelo VLIW 3. El cauce superescalar 4. Superescalar con algoritmo de Tomasulo 2 PROCESADORES SUPERESCALARES
15 de Octubre Crowne Plaza Ciudad de México. Simposio Técnico de Medición y Automatización. ni.com/mexico
 15 de Octubre Crowne Plaza Ciudad de México Simposio Técnico de Medición y Automatización ni.com/mexico Arquitecturas de Programación para Sistemas Multinúcleo Financiero Embebido Médico Científico Industrial
15 de Octubre Crowne Plaza Ciudad de México Simposio Técnico de Medición y Automatización ni.com/mexico Arquitecturas de Programación para Sistemas Multinúcleo Financiero Embebido Médico Científico Industrial
1.1. Modelos de arquitecturas de cómputo: clásicas, segmentadas, de multiprocesamiento.
 1.1. Modelos de arquitecturas de cómputo: clásicas, segmentadas, de multiprocesamiento. Arquitecturas Clásicas. Estas arquitecturas se desarrollaron en las primeras computadoras electromecánicas y de tubos
1.1. Modelos de arquitecturas de cómputo: clásicas, segmentadas, de multiprocesamiento. Arquitecturas Clásicas. Estas arquitecturas se desarrollaron en las primeras computadoras electromecánicas y de tubos
Arquitectura del Computador. Programación 1 er semestre 2013
 Arquitectura del Computador Programación 1 er semestre 2013 Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz
Arquitectura del Computador Programación 1 er semestre 2013 Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz
MÓDULO 1.4 ARQUITECTURA DE SOFTWARE CON UML
 INGENIERÍA DE SOFTWARE II MÓDULO 1.4 ARQUITECTURA DE SOFTWARE CON UML Gabriel Tamura gtamura@icesi.edu.co Cali, 2008 Arquitectura de Software con UML PROGRAMA 1. Motivación 2. La Taxonomía de Flynn 3.
INGENIERÍA DE SOFTWARE II MÓDULO 1.4 ARQUITECTURA DE SOFTWARE CON UML Gabriel Tamura gtamura@icesi.edu.co Cali, 2008 Arquitectura de Software con UML PROGRAMA 1. Motivación 2. La Taxonomía de Flynn 3.
Arquitectura de Computadoras
 Arquitectura de Computadoras Clase 7 Memoria Sistema de Memoria Los programadores desean acceder a cantidades ilimitadas de memoria rápida!! Solución práctica: Jerarquía de memoria organizada en niveles
Arquitectura de Computadoras Clase 7 Memoria Sistema de Memoria Los programadores desean acceder a cantidades ilimitadas de memoria rápida!! Solución práctica: Jerarquía de memoria organizada en niveles
2.- Con qué palabras inglesas se define la parte física del ordenador y cómo se llama la parte de programas, la que no se ve.
 CUESTIONARIO TEMA 2 UNIDADES FUNCIONALES. 1.- Definición de ordenador. Máquina electrónica capaz de almacenar información y tratarla automáticamente mediante operaciones matemáticas y lógicas controladas
CUESTIONARIO TEMA 2 UNIDADES FUNCIONALES. 1.- Definición de ordenador. Máquina electrónica capaz de almacenar información y tratarla automáticamente mediante operaciones matemáticas y lógicas controladas
Sistemas de Computadoras
 Sistemas de Computadoras Índice Concepto de Computadora Estructura de la Computadora Funcionamiento de la Computadora Historia de las Computadoras Montando una Computadora Computadora Un sistema de cómputo
Sistemas de Computadoras Índice Concepto de Computadora Estructura de la Computadora Funcionamiento de la Computadora Historia de las Computadoras Montando una Computadora Computadora Un sistema de cómputo
Tema 1: PROCESADORES SEGMENTADOS
 Tema 1: PROCESADORES SEGMENTADOS Tema 1: PROCESADORES SEGMENTADOS 1.1. Procesadores RISC frente a procesadores CISC. 1.2. Clasificación de las arquitecturas paralelas. 1.3. Evaluación y mejora del rendimiento
Tema 1: PROCESADORES SEGMENTADOS Tema 1: PROCESADORES SEGMENTADOS 1.1. Procesadores RISC frente a procesadores CISC. 1.2. Clasificación de las arquitecturas paralelas. 1.3. Evaluación y mejora del rendimiento
Pipeline de instrucciones
 Pipeline de instrucciones Manejo de Interrupciones Tipos: - Síncronas - Asíncronas Asíncronas: No están asociadas a ninguna instrucción. Se atienden normalmente al final de la instrucción en ejecución.
Pipeline de instrucciones Manejo de Interrupciones Tipos: - Síncronas - Asíncronas Asíncronas: No están asociadas a ninguna instrucción. Se atienden normalmente al final de la instrucción en ejecución.
COMPONENTES DEL PC LEONARDO OLIVARES VILLA MATEO CARDONA ARENAS
 COMPONENTES DEL PC LEONARDO OLIVARES VILLA MATEO CARDONA ARENAS Tipos de procesadores. Dedicados: Para desarrollar una tarea muy especifica. Ejecutando un único algoritmo de forma óptima. de propósito
COMPONENTES DEL PC LEONARDO OLIVARES VILLA MATEO CARDONA ARENAS Tipos de procesadores. Dedicados: Para desarrollar una tarea muy especifica. Ejecutando un único algoritmo de forma óptima. de propósito
UNIDAD 2. Unidad de Microprocesador (MPU) Microprocesadores Otoño 2011
 Microprocesadores Otoño 2011") 1 UNIDAD 2 Unidad de Microprocesador (MPU) Microprocesadores Otoño 2011 Contenido 2 Unidad de Microprocesador Generalizada Memoria Dispositivos de Entrada y Salida Sistemas basados en Microprocesadores
1 UNIDAD 2 Unidad de Microprocesador (MPU) Microprocesadores Otoño 2011 Contenido 2 Unidad de Microprocesador Generalizada Memoria Dispositivos de Entrada y Salida Sistemas basados en Microprocesadores
PROCESAMIENTO DISTRIBUIDO
 Pág. 1 INTRODUCCIÓN PROCESAMIENTO DISTRIBUIDO Arquitectura de comunicaciones: Software básico de una red de computadoras Brinda soporte para aplicaciones distribuidas Permite diferentes Sistemas Operativos
Pág. 1 INTRODUCCIÓN PROCESAMIENTO DISTRIBUIDO Arquitectura de comunicaciones: Software básico de una red de computadoras Brinda soporte para aplicaciones distribuidas Permite diferentes Sistemas Operativos
Jerarquía de memoria - Motivación
 Jerarquía de memoria - Motivación Idealmente uno podría desear una capacidad de memoria infinitamente grande, tal que cualquier. palabra podría estar inmediatamente disponible Estamos forzados a reconocer
Jerarquía de memoria - Motivación Idealmente uno podría desear una capacidad de memoria infinitamente grande, tal que cualquier. palabra podría estar inmediatamente disponible Estamos forzados a reconocer
1. Partes del ordenador. Nuevas Tecnologías y Sociedad de la Información
 1 1. Conceptos básicos 2 Qué hacen los ordenadores? Un ordenador trabaja únicamente con información. Cuatro funciones básicas: Recibe información (entrada). Procesa la información recibida. Almacena la
1 1. Conceptos básicos 2 Qué hacen los ordenadores? Un ordenador trabaja únicamente con información. Cuatro funciones básicas: Recibe información (entrada). Procesa la información recibida. Almacena la
Organización del Computador. Máquina de von Neumann Jerarquía de Niveles
 Organización del Computador Máquina de von Neumann Jerarquía de Niveles El modelo de Von Neumann Antes: programar era conectar cables (ENIAC) Hacer programas era mas una cuestión de ingeniería electrónica
Organización del Computador Máquina de von Neumann Jerarquía de Niveles El modelo de Von Neumann Antes: programar era conectar cables (ENIAC) Hacer programas era mas una cuestión de ingeniería electrónica
Estructura del Computador
 Estructura del Computador 1 definiciones preliminares Estructura: es la forma en que los componentes están interrelacionados Función: la operación de cada componente individual como parte de la estructura.
Estructura del Computador 1 definiciones preliminares Estructura: es la forma en que los componentes están interrelacionados Función: la operación de cada componente individual como parte de la estructura.
Departamento Ingeniería en Sistemas de Información
 ASIGNATURA: ARQUITECTURA DE MODALIDAD: COMPUTADORAS DEPARTAMENTO: ING. EN SIST. DE INFORMACION HORAS SEM.: Anual 4 horas AREA: COMPUTACIÓN HORAS/AÑO: 128 horas BLOQUE TECNOLOGÍAS BÁSICAS HORAS RELOJ 96
ASIGNATURA: ARQUITECTURA DE MODALIDAD: COMPUTADORAS DEPARTAMENTO: ING. EN SIST. DE INFORMACION HORAS SEM.: Anual 4 horas AREA: COMPUTACIÓN HORAS/AÑO: 128 horas BLOQUE TECNOLOGÍAS BÁSICAS HORAS RELOJ 96
Reducción de la penalización por fallo Técnica: Dar prioridad a los fallos de lectura sobre la escritura (I)
") Reducción de la penalización por fallo Técnica: Dar prioridad a los fallos de lectura sobre la escritura (I) Dar prioridad a los fallos de lectura sobre la escritura: En la caches WT el buffer de post-escritura
Reducción de la penalización por fallo Técnica: Dar prioridad a los fallos de lectura sobre la escritura (I) Dar prioridad a los fallos de lectura sobre la escritura: En la caches WT el buffer de post-escritura
Estructura general de una Computadora Arquitectura Estructura Von Neumann
 BUSES Estructura general de una Computadora Arquitectura Estructura Von Neumann Unidad Básica en estructura computador. Cargar programas, ingreso datos, resultados, etc. Estructura de buses BUSES Es un
BUSES Estructura general de una Computadora Arquitectura Estructura Von Neumann Unidad Básica en estructura computador. Cargar programas, ingreso datos, resultados, etc. Estructura de buses BUSES Es un
Conceptos básicos de procesamiento paralelo (1)
") Conceptos básicos de procesamiento paralelo (1) Paralelismo: En un sistema computador hay paralelismo cuando, al menos, durante algunos instantes de tiempo ocurren varios eventos similares Ejecución concurrente
Conceptos básicos de procesamiento paralelo (1) Paralelismo: En un sistema computador hay paralelismo cuando, al menos, durante algunos instantes de tiempo ocurren varios eventos similares Ejecución concurrente
UNIVERSIDAD DE GUADALAJARA
 UNIVERSIDAD DE GUADALAJARA CENTRO UNIVERSITARIO DE LOS ALTOS DIVISIÓN DE ESTUDIOS EN FORMACIONES SOCIALES LICENCIATURA: INGENIERÍA EN COMPUTACIÓN UNIDAD DE APRENDIZAJE POR OBJETIVOS ARQUITECTURA DE COMPUTADORAS
UNIVERSIDAD DE GUADALAJARA CENTRO UNIVERSITARIO DE LOS ALTOS DIVISIÓN DE ESTUDIOS EN FORMACIONES SOCIALES LICENCIATURA: INGENIERÍA EN COMPUTACIÓN UNIDAD DE APRENDIZAJE POR OBJETIVOS ARQUITECTURA DE COMPUTADORAS
Máquinas de alto rendimiento
 Todos los derechos de propiedad intelectual de esta obra pertenecen en exclusiva a la Universidad Europea de Madrid, S.L.U. Queda terminantemente prohibida la reproducción, puesta a disposición del público
Todos los derechos de propiedad intelectual de esta obra pertenecen en exclusiva a la Universidad Europea de Madrid, S.L.U. Queda terminantemente prohibida la reproducción, puesta a disposición del público
Modelos de Programación Paralela Prof. Gilberto Díaz
 Universisdad de Los Andes Facultad de Ingeniería Escuela de Sistemas Modelos de Programación Paralela Prof. Gilberto Díaz gilberto@ula.ve Departamento de Computación, Escuela de Sistemas, Facultad de Ingeniería
Universisdad de Los Andes Facultad de Ingeniería Escuela de Sistemas Modelos de Programación Paralela Prof. Gilberto Díaz gilberto@ula.ve Departamento de Computación, Escuela de Sistemas, Facultad de Ingeniería
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
Tema 0. Introducción a los computadores
 Tema 0 Introducción a los computadores 1 Definición de computador Introducción Máquina capaz de realizar de forma automática y en una secuencia programada cierto número de operaciones sobre unos datos
Tema 0 Introducción a los computadores 1 Definición de computador Introducción Máquina capaz de realizar de forma automática y en una secuencia programada cierto número de operaciones sobre unos datos
Unidad 1: Conceptos generales de Sistemas Operativos.
 Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los stmas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejec. de instrucciones e interrupciones y estructura
Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los stmas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejec. de instrucciones e interrupciones y estructura
Gestión de memoria Profesores y tutorías
 Teoría: Gestión de memoria Profesores y tutorías Raouf Senhadji Navarro Despacho: F062 Horario de tutorías: Lunes y miércoles de 12:00h a 13:30h y martes y jueves de 16:00h a 17:30h Prácticas y problemas:
Teoría: Gestión de memoria Profesores y tutorías Raouf Senhadji Navarro Despacho: F062 Horario de tutorías: Lunes y miércoles de 12:00h a 13:30h y martes y jueves de 16:00h a 17:30h Prácticas y problemas:
Créditos prácticos: Gil Montoya María Dolores TEMA 1º: Análisis del Rendimiento de un computador.(5 horas)
") Año académico: 2006-2007 Centro: Escuela Politécnica Superior Departamento: Arquitect. de Computadores y Electrónica Área: Arquitectura y Tecnología de Computadores Estudios: Ingeniero Técnico en Informática
Año académico: 2006-2007 Centro: Escuela Politécnica Superior Departamento: Arquitect. de Computadores y Electrónica Área: Arquitectura y Tecnología de Computadores Estudios: Ingeniero Técnico en Informática
Rendimiento John Hennessy David Patterson,
 Rendimiento John Hennessy David Patterson, Arquitectura de Computadores Un enfoque cuantitativo 1a Edición, Capítulos 1 y 2 (3a y 4a Edición, Capítulo 1) Rendimiento Introducción Cómo comparar la performance
Rendimiento John Hennessy David Patterson, Arquitectura de Computadores Un enfoque cuantitativo 1a Edición, Capítulos 1 y 2 (3a y 4a Edición, Capítulo 1) Rendimiento Introducción Cómo comparar la performance
Arquitectura de Computadores II Clase #7
 Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Memoria virtual 1 Recordemos: Jerarquía de Memoria Registros Instr.
Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Memoria virtual 1 Recordemos: Jerarquía de Memoria Registros Instr.
Arquitectura de Computadores II Clase #7
 Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Memoria virtual Recordemos: Jerarquía de Memoria Nivel Superior Registros
Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Memoria virtual Recordemos: Jerarquía de Memoria Nivel Superior Registros
Organizacion del Computador
 Universidad Nacional de Ingeniería Facultad de Ciencias Introducción a la Ciencia de la Computación Organizacion del Computador Prof: J. Solano 2011-I Objetivos Despues de estudiar este cap. el estudiante
Universidad Nacional de Ingeniería Facultad de Ciencias Introducción a la Ciencia de la Computación Organizacion del Computador Prof: J. Solano 2011-I Objetivos Despues de estudiar este cap. el estudiante
Arquitectura de Computadores
 Arquitectura de Computadores Departament d Informàtica de Sistemes i Computadors E.P.S.Alcoi 1 Bloque Temático II: Arquitectura de Computadores Tema 3: Introducción a la arquitectura de un computador Tema
Arquitectura de Computadores Departament d Informàtica de Sistemes i Computadors E.P.S.Alcoi 1 Bloque Temático II: Arquitectura de Computadores Tema 3: Introducción a la arquitectura de un computador Tema
Introducción a memorias cache
 Introducción a memorias cache Lección 6 Ing. Cristina Murillo Miranda Arquitectura de Sistemas Embebidos Programa de Maestría en Electrónica Énfasis en Sistemas Embebidos Escuela de Ingeniería en Electrónica
Introducción a memorias cache Lección 6 Ing. Cristina Murillo Miranda Arquitectura de Sistemas Embebidos Programa de Maestría en Electrónica Énfasis en Sistemas Embebidos Escuela de Ingeniería en Electrónica
Memoria. Rendimiento del caché
 Memoria Rendimiento del caché Medidas El tiempo de CPU se divide en: Ciclos de reloj usados en ejecutar el programa. Ciclos de reloj usados en detenciones (stalls) del sistema de memoria. La ecuación:
Memoria Rendimiento del caché Medidas El tiempo de CPU se divide en: Ciclos de reloj usados en ejecutar el programa. Ciclos de reloj usados en detenciones (stalls) del sistema de memoria. La ecuación:
INSTITUTO TECNOLÓGICO
 INSTITUTO TECNOLÓGICO DE NUEVO LAREDO Con la Ciencia por la Humanidad Introducción a la Ingeniería en Sistemas Computacionales y al Diseño de Algoritmos Curso propedéutico Instructor: Bruno López Takeyas
INSTITUTO TECNOLÓGICO DE NUEVO LAREDO Con la Ciencia por la Humanidad Introducción a la Ingeniería en Sistemas Computacionales y al Diseño de Algoritmos Curso propedéutico Instructor: Bruno López Takeyas