Gilberto Morales. Jonathan Nuñez Trejo
|
|
|
- María Elena Soriano Quintero
- hace 8 años
- Vistas:
Transcripción
1

2 A MIS PADRES Por ser ustedes el pilar en el cual me apoyo. Por estar cerca de mí compartiendo las experiencias más importantes de mi carrera. Porque gracias a su apoyo, he realizado una de mis mejores metas. Ustedes, que sin esperar nada, lo dieron todo. Porque nunca estuve solo. Porque siempre conté con su confianza. Por todo esto, quiero que sientan que el objetivo logrado, también es suyo y que la fuerza que me ayudó a conseguirlo, fue su amor. Con cariño y admiración. Quiero agradecer a mis padres el haberme apoyado para que pudiera seguir estudiando. Quiero agradecer a mi Madre, Francisca Santiago Nicolás, por estar siempre cercas de mi, por animarme en aquellos momentos de soledad, por estar siempre presente en mi vida, y por decirme con sus actos que se pueden lograr sueños y por inculcarme valores que hoy en día me hacen un hombre de bien. Quiero agradecer a mi Padre, Gilberto Morales Santiago, por confiar en mí, por nunca retirarme su apoyo para seguir estudiando, y por ser ejemplo en mi trayectoria profesional, y por infundir en mi valores como honestidad y tenacidad, enseñándome que con sacrificio y lucha se puede llegar hasta donde uno se lo proponga. También quiero agradecer a mis hermanos por confiar en mí y por demostrarme su cariño, lo que es fundamental para levantarse en momentos de debilidad. Gilberto Morales. A MI PAPÁ Gracias papá: por tu ejemplo silencioso, por enseñarme que en la vida lo único que cuenta es seguir adelante y seguir con valentía. Por enseñarme que el trabajo dignifica al hombre. Por todo tu cariño, comprensión y sobre todo tu alegría. Por ser un gran amigo y apoyarme siempre, sin importar cuan absurdo fuera y sobre todo por ser mi papá. Te quiero mucho papá. Ing. José H. Núñez A MI MAMÁ Gracias mamá: por respetar mis sentimientos, por permitirme valerme por mi misma. Por hacerme fuerte como tú, para poder enfrentar a la vida. Gracias por la luz de tu sabiduría, por estas alas que creaste, con tus consejos y ejemplo, que me han de llevar muy alto. Te quiero mucho mamá. Lilia Trejo Flores A MI HERMANA Por haberme apoyado en todo momento, por tus consejos, tus valores, por la motivación constante que me ha permitido ser una persona de bien, Porque sabes escuchar y brindar ayuda cuando es necesario pero más que nada gracias, por tu amor. Lic. Gpe. LIzbeth Núñez Trejo MARLEN En la vida se nos dan pocas oportunidades para salir adelante y contar con alguien que me induzca y me enseñe, que no debo darme por vencido para lograr nuevas metas e ideales. Dios me ha dado la suerte de tenerte. Compartir mis fracasos, triunfos, tristezas y alegrías. Infinitamente te agradezco todo el apoyo que me brindas para subir este escalón, que será el inicio de mi profesión. Con todo mi amor gracias. Marlene Cruz V. Jonathan Nuñez Trejo

3 El terminar una Carrera Universitaria no es un logro un individual, es también un logro que corresponde a mis padres que gracias a su dedicación, tiempo y esfuerzo me dieron todo el apoyo que necesité para hacer esto posible. Es por esto que les dedico esta Tesina y les doy gracias por todo. Agradezco a mi novia que me dio si apoyo durante mi carrera. Agradezco a mis compañeros de seminario con los que realice este trabajo que gracias a su esfuerzo se pudo lograr esta Tesina. Benjamín Porras. A mis hermanos, gracias por su apoyo incondicional en los momentos difíciles y por las enseñanzas que me dieron y que me continúan dando. Gracias Mama por hacer de mi lo que soy, Papa donde quiera que estés. ahora sí.. esto ya quedo. Miri gracias por soportarme y motivarme día con día para llevar a buen fin éste proyecto, que también es tuyo. Irlanda gracias por llegar a mi vida, gracias por ser mi motivación y sobre todo gracias por entender el tiempo que a veces no te pude dedicar. Pedro Patiño. A ti Señor, por darme las fuerzas necesarias para alcanzar esta meta. A mi Madre por enseñarme la esperanza de un futuro mejor. A mis Hermanos por darme la sabiduría y alegría que me ayudaron a superar los momentos más difíciles. Y, a ti Anel por prestarme el dinero para cursar este seminario. Oscar Fernando Presbitero ii

4 Índice INTRODUCCIÓN... 1 OBJETIVO... 1 PLANTEAMIENTO DEL PROBLEMA... 2 JUSTIFICACIÓN... 2 ALCANCE... 2 CAPÍTULO 1. INTRODUCCIÓN A LAS REDES DE DATOS INTRODUCCIÓN A LAS REDES LOCALES REDES LAN, MAN Y WAN SISTEMA DISTRIBUIDO Y RED LOCAL REDES DE COMUNICACIONES MÉTODO DE ACCESO AL MEDIO CÓMO FUNCIONA UNA RED TOPOLOGÍA DE UNA RED Topología Física Topología lógica INTERCONEXIÓN DE REDES HUBS (CONCENTRADORES) REPETIDORES BRIDGES (PUENTES) ROUTER GATEWAYS MODELO ISO/OSI ELEMENTOS DE UNA RED CAPÍTULO 2. DIRECCIONAMIENTO DIRECCIONAMIENTO IPV DIRECCIONES IP CLASE, A, B, C, D Y E DIRECCIONES PÚBLICAS DIRECCIONES PRIVADAS CAPÍTULO 3. PROTOCOLOS DE RUTEO DEFINICIÓN DE PROTOCOLO DE RUTEO OBJETIVO DE UN PROTOCOLO DE RUTEO COMO TRABAJAN LOS PROTOCOLOS DE RUTEO DESCRIPCIÓN DEL ENRUTAMIENTO ENRUTAMIENTO COMPARADO CON LA CONMUTACIÓN DETERMINACIÓN DE LA RUTA TABLAS DE ENRUTAMIENTO MÉTRICAS DE RUTEO IGP Y EGP Sistemas autónomos Identificación de las clases de protocolos de enrutamiento Características del protocolo de enrutamiento por vector-distancia Características del protocolo de enrutamiento de estado del enlace i

5 3.10 OSPF Descripción general de OSPF Terminología de OSPF BGP Terminología BGP Operación de BGP Formato de la cabecera del mensaje SELECCIÓN DE RUTAS IBGP EBGP EBGP MULTIHOP COMMUNITIES DE BGP ATRIBUTOS DE BGP PATH CAPÍTULO 4. RED PRIVADA VIRTUAL (VPN) VENTAJAS DE UNA VPN (RED PRIVADA VIRTUAL) TIPOS DE VPN TÚNEL ANCHO DE BANDA VPN IMPLEMENTACIONES CAPÍTULO 5. INTRODUCCIÓN A MPLS QUE ES MPLS? MPLS VPN DE CAPA MPLS VPN DE CAPA INGENIERÍA DE TRAFICO MPLS (MPLS TE) BENEFICIOS DE MPLS PARA PROVEEDORES DE SERVICIO RUTEO IP TRADICIONAL MODOS DE OPERACIÓN DE MPLS FORMATO DE ETIQUETAS MPLS TIPOS DE ETIQUETAS ENVÍO MPLS ARQUITECTURA MPLS UNICAST MENSAJES LDP HELLO ESPACIO DE ETIQUETAS NEGOCIACIÓN DE LA SESIÓN LDP COMPATIBILIDAD ENTRE TDP Y LDP ESTABLECIMIENTO DE LSP (LABEL-SWITCHED PATHS) ASIGNACIÓN, DISTRIBUCIÓN Y RETENCIÓN DE ETIQUETAS Construcción de la tabla de ruteo IP Asignación de etiquetas LA PUBLICACIÓN DE LAS TABLAS DE RUTEO VPN El backbone de la Tecnología MPLS VPN Conceptos de la Familia de Direcciones sobre los Protocolos de Enrutamiento Como configurar los Protocolos de Enrutamiento de un PE-CE TABLA DE ENVIÓ Y ENRUTAMIENTO VIRTUAL (VRF) CREAR NUEVAS VRF INTERACCIÓN ENTRE BGP Y VRF ii
... 49 5.5 BENEFICIOS DE MPLS PARA PROVEEDORES DE SERVICIO... 51 5.6 RUTEO IP TRADICIONAL.")
6 CAPÍTULO 6. DISEÑO DE LA CONFIGURACIÓN DE UNA RED MPLS PARA OFRECER SERVICIOS DE VPN PARA BASSHER NETWORKS ESTADO ACTUAL DISEÑO IMPLEMENTACIÓN RESULTADOS CONCLUSIONES ANEXOS ANEXO ANEXO ANEXO ANEXO ANEXO ANEXO ANEXO ANEXO ANEXO ANEXO ÍNDICE DE FIGURAS ÍNDICE DE TABLAS GLOSARIO BIBLIOGRAFÍA iii

7 Introducción MPLS(Multiprotocol Label Switching) IP(Internet Protocol) se habilita en una red para proporcionar servicios adicionales como redes privadas virtuales VPN, encapsulando paquetes de Capa 3 del modelo OSI o tramas de capa 2 usando etiquetas MPLS. Adicionalmente, MPLS habilita ingeniería de tráfico y otros servicios que no están disponibles en redes de IP tradicionales. La transición de una red IP a MPLS requiere una arquitectura lista de MPLS, todos los dispositivos en la ruta de envío requieren funcionalidades MPLS. Este es el requerimiento para ambos routers, el de Backbone (P) y del frontera PE (Provider Edge). Si MPLS soportara características y arquitecturas como MPLS VPN s o ingeniería de trafico MPLS (MPLS TE), ésta deberá implementarse como parte fundamental del diseño de la red, lo cual significa que debemos estar seguros que todos los dispositivos involucrados soporten funcionalidades avanzadas de MPLS. Los equipos del cliente (CE) generalmente no necesitan soportar MPLS y no necesitan tener habilitado MPLS en sus interfaces. La conmutación MPLS es desarrollada en la red del proveedor, sin embargo algunas funcionalidades avanzadas como Carrier-Suport-Carrier (CSC) requieren que los equipos del cliente (CE) también soporten MPLS. Objetivo Diseñar e implementar una arquitectura de red privada virtual cliente-proveedor sobre una infraestructura MPLS. 1
 y del frontera PE (Provider Edge).")
8 Planteamiento del problema Con la tecnología Frame Relay actual la integración de los nuevos clientes requiere de una gran inversión de recursos debido a que se requiere la creación de un circuito virtual permanente teniendo un costo elevado por mantenimiento y larga distancia entre equipos finales. Además de que el ruteo IP tradicional no permite la duplicidad de direccionamiento privado. Justificación Se recomienda implementar VPN sobre MPLS ya que proporciona mayor seguridad de datos, además de que permite aplicación de políticas de calidad QoS sobre los servicios del cliente, y es gracias a esto que se pueden aplicar prioridades a cierto tipo de tráfico como lo es video, voz, datos o a darle prioridad a alguna aplicación importante del cliente. Alcance El alcance involucra únicamente la implementación de RPV en capa 3 partiendo de la base teórica de direccionamiento, definición de VRF, ruteo dinámico y etiquetado dentro de MPLS. 2

9 Capítulo 1. Introducción a las redes de datos 1.1 Introducción a Las Redes Locales. Lo primero que se puede preguntar un usuario cuando se plantea la posibilidad de instalación o utilización de una red local, es saber cómo va a mejorar su trabajo en el ordenador al utilizar dicho entorno. La respuesta va a ser diferente según el tipo de trabajo que desempeñe. En resumen, una red local proporciona la facilidad de compartir recursos entre sus usuarios. Esto es: Supone compartir ficheros. Supone compartir impresoras. Se pueden utilizar aplicaciones específicas de red. Se pueden aprovechar las prestaciones cliente/servidor. Se puede acceder a sistemas de comunicación global. Compartir Ficheros: La posibilidad de compartir ficheros es la prestación principal de las redes locales. La aplicación básica consiste en utilizar ficheros de otros usuarios, sin necesidad de utilizar el disquete. La ventaja fundamental es la de poder disponer de directorios en la red a los que tengan acceso un grupo de usuarios, y en los que se puede guardar la información que compartan dichos grupos. Aplicaciones de Red: Existe un gran número de aplicaciones que aprovechan las redes locales para que el trabajo sea más provechoso. El tipo de aplicaciones más importante son los programas de correo electrónico. Un programa de correo electrónico permite el intercambio de mensajes entre los usuarios. Los mensajes pueden consistir en texto, sonido, imágenes, etc. y llevar asociados cualquier tipo de ficheros binarios. En cierto modo el correo electrónico llega a sustituir a ciertas reuniones y además permite el análisis más detallado del material que el resto de usuarios nos remitan. Aplicaciones Cliente/Servidor: Es un concepto muy importante en las redes locales para aplicaciones que manejan grandes volúmenes de información. Son programas que dividen su trabajo en dos partes, una parte cliente que se realiza en el ordenador del usuario y otra parte servidor que se realiza en un servidor con dos fines: Aliviar la carga de trabajo del ordenador cliente. Reducir el tráfico de la red. 1.2 Redes LAN, MAN y WAN Un criterio para clasificar redes de ordenadores es el que se basa en su extensión geográfica, es en este sentido en el que hablamos de redes LAN, MAN y WAN, 3

10 aunque esta documentación se centra en las redes de área local (LAN), nos dará una mejor perspectiva el conocer los otros dos tipos: MAN y WAN. Redes de Área Local (LAN). Son redes de propiedad privada, de hasta unos cuantos kilómetros de extensión. Por ejemplo una oficina o un centro educativo. Se usan para conectar computadoras personales o estaciones de trabajo, con objeto de compartir recursos e intercambiar información. Están restringidas en tamaño, lo cual significa que el tiempo de transmisión, en el peor de los casos, se conoce, lo que permite cierto tipo de diseños (deterministas) que de otro modo podrían resultar ineficientes. Además, simplifica la administración de la red. Suelen emplear tecnología de difusión mediante un cable sencillo al que están conectadas todas las máquinas. Operan a velocidades entre 10 y 100 Mbps. Tienen bajo retardo y experimentan pocos errores. Redes de Área Metropolitana (MAN) Son una versión mayor de la LAN y utilizan una tecnología muy similar. Actualmente esta clasificación ha caído en desuso, normalmente sólo distinguiremos entre redes LAN y WAN. Redes de Área Amplia (WAN). Son redes que se extienden sobre un área geográfica extensa. Contiene una colección de máquinas dedicadas a ejecutar los programas de usuarios (hosts). Estos están conectados por la red que lleva los mensajes de un host a otro. Estas LAN de host acceden a la subred de la WAN por un router. Suelen ser por tanto redes punto a punto. La subred tiene varios elementos: Líneas de comunicación: Mueven bits de una máquina a otra. Elementos de conmutación: Máquinas especializadas que conectan dos o más líneas de transmisión. Se suelen llamar encaminadores o routers. Cada host está después conectado a una LAN en la cual está el encaminador que se encarga de enviar la información por la subred. Una WAN contiene numerosos cables conectados a un par de encaminadores. Si dos encaminadores que no comparten cable desean comunicarse, han de hacerlo a través de encaminadores intermedios. El paquete se recibe completo en cada uno de los intermedios y se almacena allí hasta que la línea de salida requerida esté libre. Se pueden establecer WAN en sistemas de satélite o de radio en tierra en los que cada encaminador tiene una antena con la cual poder enviar y recibir la información. Por su naturaleza, las redes de satélite serán de difusión. 1.3 Sistema Distribuido Y Red Local No se debe confundir una red local con un sistema distribuido. Aunque parezca que son conceptos similares difieren en algunas cosas. Un sistema distribuido es multiusuario y multitarea. Todos los programas que se ejecuten en un sistema distribuido lo van a hacer sobre la CPU del servidor en lo 4
 que de otro modo podrían")
11 que en términos informáticos se denomina "tiempo compartido". Un sistema distribuido comparte la CPU. Sin embargo, en una intranet, lo que en realidad se denomina servidor, lo es, pero de ficheros o de bases de datos. Cada usuario tendrá un ordenador autónomo con su propia CPU dónde se ejecutarán las aplicaciones que correspondan. Además, con la aparición de la arquitectura cliente/servidor, la CPU del servidor puede ejecutar algún programa que el usuario solicite. Una red local puede tener distintas configuraciones que se verán más adelante, pero básicamente se pueden hablar de dos tipos: Red con un servidor: existe un servidor central que es el "motor" de la red. El servidor puede ser activo o pasivo dependiendo del uso que se le dé. Peer to peer: Una red de igual a igual. Todos los puestos de la red pueden hacer la función de servidor y de cliente. En una intranet, interesa tener un servidor web, que será la parte más importante de la red. 1.4 Redes de Comunicaciones. Dependiendo de su arquitectura y de los procedimientos empleados para transferir la información las redes de comunicación se clasifican en: Redes conmutadas Redes de difusión Redes Conmutadas: Consisten en un conjunto de nodos interconectados entre sí, a través de medios de transmisión (cables), formando la mayoría de las veces una topología mallada, donde la información se transfiere encaminándola del nodo de origen al nodo destino mediante conmutación entre nodos intermedios. Una transmisión de este tipo tiene 3 fases: Establecimiento de la conexión. Transferencia de la información. Liberación de la conexión. Se entiende por conmutación en un nodo, a la conexión física o lógica, de un camino de entrada al nodo con un camino de salida del nodo, con el fin de transferir la información que llegue por el primer camino al segundo. Un ejemplo de redes conmutadas son las redes de área extensa. Las redes conmutadas se dividen en: Conmutación de paquetes. Conmutación de circuitos. Conmutación de Paquetes: Se trata del procedimiento mediante el cual, cuando un nodo quiere enviar información a otro, la divide en paquetes. Cada paquete es 5

12 enviado por el medio con información de cabecera. En cada nodo intermedio por el que pasa el paquete se detiene el tiempo necesario para procesarlo. Otras características importantes de su funcionamiento son: En cada nodo intermedio se apunta una relación de la forma: "todo paquete con origen en el nodo A y destino en el nodo B tiene que salir por la salida 5 de mi nodo". Los paquetes se numeran para poder saber si se ha perdido alguno en el camino. Todos los paquetes de una misma transmisión viajan por el mismo camino. Pueden utilizar parte del camino establecido más de una comunicación de forma simultánea. Conmutación de Circuitos: Es el procedimiento por el que dos nodos se conectan, permitiendo la utilización de forma exclusiva del circuito físico durante la transmisión. En cada nodo intermedio de la red se cierra un circuito físico entre un cable de entrada y una salida de la red. La red telefónica es un ejemplo de conmutación de circuitos. Redes de Difusión: En este tipo de redes no existen nodos intermedios de conmutación; todos los nodos comparten un medio de transmisión común, por el que la información transmitida por un nodo es conocida por todos los demás. Ejemplo de redes de difusión son: Comunicación por radio. Comunicación por satélite. Comunicación en una red local. Redes Orientadas a Conexión: En estas redes existe el concepto de multiplexión de canales y puertos conocido como circuito o canal virtual, debido a que el usuario aparenta disponer de un recurso dedicado, cuando en realidad lo comparte con otros pues lo que ocurre es que atienden a ráfagas de tráfico de distintos usuarios. Redes no Orientadas a Conexión: Llamadas Datagramas, pasan directamente del estado libre al modo de transferencia de datos. Estas redes no ofrecen confirmaciones, control de flujo ni recuperación de errores aplicables a toda la red, aunque estas funciones si existen para cada enlace particular. Un ejemplo de este tipo de red es INTERNET. 1.5 Método de acceso al medio En las redes de difusión es necesario definir una estrategia para saber cuando una máquina puede empezar a transmitir para evitar que dos o más estaciones comiencen a transmitir a la vez (colisiones). CSMA. Se basa en que cada estación monitoriza o "escucha" el medio para determinar si éste se encuentra disponible para que la estación puede enviar su 6

13 mensaje, o por el contrario, hay algún otro nodo utilizándolo, en cuyo caso espera a que quede libre. Token El método del testigo (token) asegura que todos los nodos van a poder emplear el medio para transmitir en algún momento. Ese momento será cuando el nodo en cuestión reciba un paquete de datos especial denominado testigo. Aquel nodo que se encuentre en posesión del testigo podrá transmitir y recibir información, y una vez haya terminado, volverá a dejar libre el testigo y lo enviará a la próxima estación. 1.6 Cómo funciona Una Red Se puede pensar por un momento en el servicio de correos. Cuando alguien desea mandar una carta a otra persona, la escribe, la mete en un sobre con el formato impuesto por correos, le pone un sello y la introduce en un buzón; la carta es recogida por el cartero, clasificada por el personal de correos, según su destino y enviada a través de medios de transporte hacia la ciudad destino; una vez allí otro cartero irá a llevarla a la dirección indicada en el sobre; si la dirección no existe, al cabo del tiempo la carta devolverá al origen por los mismos cauces que llegó al supuesto destino. Más o menos, esta es la forma en que funciona una red : la carta escrita es la información que se quiere transmitir; el sobre y sello es el paquete con el formato impuesto por el protocolo que se utiliza en la transmisión; la dirección del destinatario es la dirección del nodo destino y la dirección del remitente, será la dirección del nodo origen, los medios de transporte que llevan la carta cerca del destino es el medio de transmisión (cable coaxial, fibra óptica ); las normas del servicio de correos, carteros y demás personal son los protocolos de comunicaciones establecidos. Si se supone que se está utilizando el modelo OSI de la ISO. Este modelo tiene 7 niveles, es como decir que la carta escrita pasa por 7 filtros diferentes (trabajadores con diferentes cargos) desde que la ponemos en el buzón hasta que llega al destino. Cada nivel de esta torre se encarga de realizar funciones diferentes en la información a transmitir. Cada nivel por el que pasa la información a transmitir que se ha insertado en un paquete, añade información de control, que el mismo nivel en el nodo destino irá eliminando. Además se encarga de cosas muy distintas: desde el control de errores, hasta la reorganización de la información transmitida cuando esta se ha fragmentado en tramas. Si la información va dirigida a una red diferente (otra ciudad en el caso de la carta), la trama debe llegar a un dispositivo de interconexión de redes (router, gateway, bridges), que decidirá, dependiendo de su capacidad, el camino que debe seguir la trama. Por eso es imprescindible que el paquete lleve la dirección destino y que esta contenga, además de la dirección que identifica al nodo, la dirección que identifica la red a la que pertenece el nodo. 7

14 1.7 Topología de una Red La topología de una red define únicamente la distribución del cable que interconecta los diferentes ordenadores, es decir, es el mapa de distribución del cable que forma la intranet. Define cómo se organiza el cable de las estaciones de trabajo. A la hora de instalar una red, es importante seleccionar la topología más adecuada a las necesidades existentes. Hay una serie de factores a tener en cuenta a la hora de decidirse por una topología de red concreta y son: La distribución de los equipos a interconectar. El tipo de aplicaciones que se van a ejecutar. La inversión que se quiere hacer. El coste que se quiere dedicar al mantenimiento y actualización de la red local. El tráfico que va a soportar la red local. La capacidad de expansión. Se debe diseñar una intranet teniendo en cuenta la escalabilidad. No se debe confundir el término topología con el de arquitectura. La arquitectura de una red engloba: La topología. El método de acceso al cable. Protocolos de comunicaciones. Actualmente la topología está directamente relacionada con el método de acceso al cable, puesto que éste depende casi directamente de la tarjeta de red y ésta depende de la topología elegida Topología Física. Es lo que hasta ahora se ha venido definiendo; la forma en la que el cableado se realiza en una red. Existen tres topologías físicas puras: Topología en anillo. Topología en bus. Topología en estrella. Existen mezclas de topologías físicas, dando lugar a redes que están compuestas por más de una topología física Topología en Bus. Consta de un único cable que se extiende de un ordenador al siguiente de un modo serie. Los extremos del cable se terminan con una resistencia denominada 8

15 terminador, que además de indicar que no existen más ordenadores en el extremo, permiten cerrar el bus. Sus principales ventajas son: Fácil de instalar y mantener. No existen elementos centrales del que dependa toda la red, cuyo fallo dejaría inoperativas a todas las estaciones. Sus principales inconvenientes son: Si se rompe el cable en algún punto, la red queda inoperativa por completo. Cuando se decide instalar una red de este tipo en un edificio con varias plantas, lo que se hace es instalar una red por planta y después unirlas todas a través de un bus troncal Topología en Anillo Sus principales características son: Figura 1.1 Topología de bus. El cable forma un bucle cerrado formando un anillo. Todos los ordenadores que forman parte de la red se conectan a ese anillo. Habitualmente las redes en anillo utilizan como método de acceso al medio el modelo "paso de testigo". Los principales inconvenientes serían: Si se rompe el cable que forma el anillo se paraliza toda la red. Es difícil de instalar. Requiere mantenimiento. Figura 1.2 Topología de Anillo. 9

16 Topología en Estrella Sus principales características son: Todas las estaciones de trabajo están conectadas a un punto central (concentrador), formando una estrella física. Habitualmente sobre este tipo de topología se utiliza como método de acceso al medio poolling, siendo el nodo central el que se encarga de implementarlo. Cada vez que se quiere establecer comunicación entre dos ordenadores, la información transferida de uno hacia el otro debe pasar por el punto central. existen algunas redes con esta topología que utilizan como punto central una estación de trabajo que gobierna la red. La velocidad suele ser alta para comunicaciones entre el nodo central y los nodos extremos, pero es baja cuando se establece entre nodos extremos. Este tipo de topología se utiliza cuando el trasiego de información se va a realizar preferentemente entre el nodo central y el resto de los nodos, y no cuando la comunicación se hace entre nodos extremos. Si se rompe un cable sólo se pierde la conexión del nodo que interconectaba. es fácil de detectar y de localizar un problema en la red Topología lógica. Figura 1.3 Topología de Estrella Es la forma de conseguir el funcionamiento de una topología física cableando la red de una forma más eficiente. Existen topologías lógicas definidas: Topología anillo-estrella: implementa un anillo a través de una estrella física. Topología bus-estrella: implementa una topología en bus a través de una estrella física. 10

17 Topología Anillo-Estrella Uno de los inconvenientes de la topología en anillo era que si el cable se rompía toda la red quedaba inoperativa; con la topología mixta anillo-estrella, éste y otros problemas quedan resueltos. Las principales características son: Cuando se instala una configuración en anillo, el anillo se establece de forma lógica únicamente, ya que de forma física se utiliza una configuración en estrella. Se utiliza un concentrador, o incluso un servidor de red (uno de los nodos de la red, aunque esto es el menor número de ocasiones) como dispositivo central, de esta forma, si se rompe algún cable sólo queda inoperativo el nodo que conectaba, y los demás pueden seguir funcionando. El concentrador utilizado cuando se está utilizando esta topología se denomina MAU (Unidad de Acceso Multiestación), que consiste en un dispositivo que proporciona el punto de conexión para múltiples nodos. Contiene un anillo interno que se extiende a un anillo externo. A simple vista, la red parece una estrella, aunque internamente funciona como un anillo. Cuando la MAU detecta que un nodo se ha desconectado (por haberse roto el cable, por ejemplo), puentea su entrada y su salida para así cerrar el anillo Topología Bus-Estrella Figura 1.4 Topología anillo-estrella Este tipo de topología es en realidad una estrella que funciona como si fuese en bus. Como punto central tiene un concentrador pasivo (hub) que implementa internamente el bus, y al que están conectados todos los ordenadores. La única diferencia que existe entre esta topología mixta y la topología en estrella con hub pasivo es el método de acceso al medio utilizado. 11

18 1.8 Interconexión de Redes Hace algunos años era impredecible la evolución que las comunicaciones, en el mundo de la informática, iban a tener: no podía prever que fuese necesaria la interconexión ya no sólo de varios ordenadores sino de cientos de ellos. No basta con tener los ordenadores en una sala conectados, es necesario conectarlos a su vez con los ordenadores del resto de las salas de una empresa, y con el resto de las sucursales de una empresa situadas en distintos puntos geográficos. La interconexión de redes permite, si se puede decir así, ampliar el tamaño de una intranet. Sin embargo el término interconexión se utiliza para unir redes independientes, no para ampliar el tamaño de una. El número de ordenadores que componen una intranet es limitado, depende de la topología elegida, (recuérdese que en la topología se define el cable a utilizar) aunque si lo único que se quisiera fuera sobrepasar el número de ordenadores conectados, podría pensarse en simplemente segmentar la intranet. Sin embargo existen otros factores a tener en cuenta. Cuando se elige la topología que va a tener una intranet se tienen en cuenta factores, como son la densidad de tráfico que ésta debe soportar de manera habitual, el tipo de aplicaciones que van a instalarse sobre ella, la forma de trabajo que debe gestionar, etc.; esto debe hacer pensar en que, uno de los motivos por el que se crean diferentes topologías es por tanto el uso que se le va a dar a la intranet. De aquí se puede deducir que en una misma empresa puede hacerse necesaria no la instalación de una única intranet, aunque sea segmentada, sino la implantación de redes independientes, con topologías diferentes e incluso arquitecturas diferentes y que estén interconectadas. Habitualmente la selección del tipo y los elementos físicos de una intranet, se ajusta a las necesidades que se tiene; por este motivo pueden encontrarse dentro de un mismo edificio, varias intranets con diferentes topologías, y con el tiempo pueden surgir la necesidad de interconectarlas. Se puede ver que por diferentes razones se hace necesaria tanto la segmentación como la interconexión de intranets, y que ambos conceptos a pesar de llevar a un punto en común, parte de necesidades distintas. Segmento. Un segmento es un bus lineal al que están conectadas varias estaciones y que termina en los extremos. Las características son: Cuando se tiene una red grande se divide en trozos, llamados segmentos a cada uno de ellos. Para interconectar varios segmentos se utilizan bridges o routers El rendimiento de una red aumenta al dividirla en segmentos A cada segmento junto a las estaciones a él conectadas se las llama subred 12

19 El dispositivo que se utiliza para segmentar una red debe ser inteligente ya que debe ser capaz de decidir hacia qué segmento debe enviar la información llegado a él: si hacia el mismo segmento desde el que la recibió o hacia otro segmento diferente HUBS (CONCENTRADORES) Dispositivo que interconecta host dentro de una red. Es el dispositivo de interconexión más simple que existe. Sus principales características son: Se trata de un armario de conexiones donde se centralizan todas las conexiones de una red, es decir un dispositivo con muchos puertos de entrada y salida. No tiene ninguna función aparte de centralizar conexiones. Se suelen utilizar para implementar topologías en estrella física, pero funcionando como un anillo o como un bus lógico. Hubs activos: permiten conectar nodos a distancias de hasta 609 metros, suelen tener entre 8 y 12 puertos y realizan funciones de amplificación y repetición de la señal. Los más complejos además realizan estadísticas. Hubs pasivos: son simples armarios de conexiones. Permiten conectar nodos a distancias de hasta 30 metros. Generalmente suelen tener entre 8 y 12 puertos REPETIDORES Sus principales características son: Conectan a nivel físico dos intranets, o dos segmentos de intranet. Hay que tener en cuenta que cuando la distancia entre dos host es grande, la señal que viaja por la línea se atenúa y hay que regenerarla. Permiten resolver problemas de limitación de distancias en un segmento de intranet. Se trata de un dispositivo que únicamente repite la señal transmitida evitando su atenuación; de esta forma se puede ampliar la longitud del cable que soporta la red. Al trabajar al nivel más bajo de la pila de protocolos obliga a que: o o Los dos segmentos que interconecta tenga el mismo acceso al medio y trabajen con los mismos protocolos. Los dos segmentos tengan la misma dirección de red. 13

20 1.8.3 BRIDGES (PUENTES) Sus principales características son: Son dispositivos que ayudan a resolver el problema de limitación de distancias, junto con el problema de limitación del número de nodos de una red. Trabajan al nivel de enlace del modelo OSI, por lo que pueden interconectar redes que cumplan las normas del modelo 802 (3, 4 y 5). Si los protocolos por encima de estos niveles son diferentes en ambas redes, el puente no es consciente, y por tanto no puede resolver los problemas que puedan presentársele. Se utilizan para: o o o o o Ampliar la extensión de la red, o el número de nodos que la constituyen. Reducir la carga en una red con mucho tráfico, uniendo segmentos diferentes de una misma red. Unir redes con la misma topología y método de acceso al medio, o diferentes. Cuando un puente une redes exactamente iguales, su función se reduce exclusivamente a direccionar el paquete hacia la subred destino. Cuando un puente une redes diferentes, debe realizar funciones de traducción entre las tramas de una topología a otra. Cada segmento de red, o red interconectada con un puente, tiene una dirección de red diferente. Los puentes no entienden de direcciones IP, ya que trabajan en otro nivel. Los puentes realizan las siguientes funciones: o o Reenvió de tramas: constituye una forma de filtrado. Un puente solo reenvía a un segmento a aquellos paquetes cuya dirección de red lo requiera, no traspasando el puente los paquetes que vayan dirigidos a nodos locales a un segmento. Por tanto, cuando un paquete llega a un puente, éste examina la dirección física destino contenido en él, determinando así si el paquete debe atravesar el puente o no. Técnicas de aprendizaje: los puentes construyen tablas de dirección que describen las rutas, bien sea mediante el examen del flujo de los paquetes (puenteado transparente) o bien con la obtención de la información de los "paquetes exploradores" (encaminamiento fuente) que han aprendido durante sus viajes la topología de la red. Los primeros puentes requerían que los gestores de la red introdujeran a mano las tablas de dirección. 14

21 Los puentes trabajan con direcciones físicas ROUTER Sus principales características son: Es como un puente incorporando características avanzadas. Trabajan a nivel de red del modelo OSI, por tanto trabajan con direcciones IP. Un router es dependiente del protocolo. Permite conectar redes de área local y de área extensa. Habitualmente se utilizan para conectar una red de área local a una red de área extensa. Son capaces de elegir la ruta más eficiente que debe seguir un paquete en el momento de recibirlo. La forma que tienen de funcionar es la siguiente. o o o Cuando llega un paquete al router, éste examina la dirección destino y lo envía hacia allí a través de una ruta predeterminada. Si la dirección destino pertenece a una de las redes que el router interconecta, entonces envía el paquete directamente a ella; en otro caso enviará el paquete a otro router más próximo a la dirección destino. Para saber el camino por el que el router debe enviar un paquete recibido, examina sus propias tablas de encaminamiento. Existen routers multiprotocolo que son capaces de interconectar redes que funcionan con distintos protocolos; para ello incorporan un software que pasa un paquete de un protocolo a otro, aunque no son soportados todos los protocolos. Cada segmento de red conectado a través de un router tiene una dirección de red diferente GATEWAYS Sus características principales son: Se trata de un ordenador u otro dispositivo que interconecta redes radicalmente distintas. Trabaja al nivel de aplicación del modelo OSI. Cuando se habla de pasarelas a nivel de redes de área local, en realidad se está hablando de routers. 15
22 Son capaces de traducir información de una aplicación a otra, como por ejemplo las pasarelas de correo electrónico. 1.9 Modelo ISO/OSI OSI: Open System Interconnections: fue creado a partir del año 1978, con el fin de conseguir la definición de un conjunto de normas que permitieran interconectar diferentes equipos, posibilitando de esta forma la comunicación entre ellos. El modelo OSI fue aprobado en Un sistema abierto debe cumplir las normas que facilitan la interconexión tanto a nivel hardware como software con otros sistemas (arquitecturas distintas). Este modelo define los servicios y los protocolos que posibilita la comunicación, dividiéndolos en 7 niveles diferentes, en el que cada nivel se encarga de problemas de distinta naturaleza interrelacionándose con los niveles contiguos, de forma que cada nivel se abstrae de los problemas que los niveles inferiores solucionan para dar solución a un nuevo problema, del que se abstraerán a su vez los niveles superiores. NIVELES FUNCIÓN Aplicación Semántica de los datos Presentación Representación de los datos Sesión Diálogo ordenado Transporte Extremo a extremo Red Encaminamiento Enlace Punto a punto Físico Eléctrico/Mecánico Tabla 1.1 Tabla del modelo de referencia OSI. Se puede decir que la filosofía de este modelo se basa en la idea de dividir un problema grande (la comunicación en sí), en varios problemas pequeños, 16
23 independizando cada problema del resto. Es un método parecido a las cadenas de montaje de las fábricas.; los niveles implementan a un grupo de operarios de una cadena, y cada nivel, al igual que en la cadena de montaje, supone que los niveles anteriores han solucionado unos problemas de los que él se abstraerá para dar solución a unos nuevos problemas, de los que se abstraerán los niveles superiores Elementos De Una Red Los principales elementos que necesitamos para instalar una red son: Tarjetas de interfaz de red. Cable. Protocolos de comunicaciones. Sistema operativo de red. Aplicaciones capaces de funcionar en red. Capítulo 2. Direccionamiento Para que dos sistemas se comuniquen, se deben poder identificar y localizar entre sí. La combinación de letras (dirección de red) y el número (dirección del host) crean una dirección única para cada dispositivo conectado a la red. Cada computadora conectada a una red TCP/IP debe recibir un identificador exclusivo o una dirección IP. Esta dirección, que opera en la Capa 3, permite que una computadora localice a otra computadora en la red. Todas las computadoras también cuentan con una dirección física exclusiva, conocida como dirección MAC. Estas son asignadas por el fabricante de la tarjeta de interfaz de la red. Las direcciones MAC operan en la Capa 2 del modelo OSI. Una dirección IP es una secuencia de unos y ceros de 32 bits. La dirección aparece escrita en forma de cuatro números decimales separados por puntos. Por ejemplo, la dirección IP de una computadora es Esta forma de escribir una dirección se conoce como formato decimal punteado Direccionamiento IPv4 Un Router envía los paquetes desde la red origen a la red destino utilizando el protocolo IP. Los paquetes deben incluir un identificador tanto para la red origen como para la red destino. Utilizando la dirección IP de una red destino, un Router puede enviar un paquete a la red correcta. Cuando un paquete llega a un Router conectado a la red destino, éste utiliza la dirección IP para localizar el computador en particular conectado a la red. 17
24 Cada dirección IP consta de dos partes. Una parte identifica la red donde se conecta el sistema y la segunda identifica el sistema en particular de esa red. Cada octeto varía de 0 a 255. Cada uno de los octetos se divide en 256 subgrupos y éstos, a su vez, se dividen en otros 256 subgrupos con 256 direcciones cada uno. Al referirse a una dirección de grupo inmediatamente arriba de un grupo en la jerarquía, se puede hacer referencia a todos los grupos que se ramifican a partir de dicha dirección como si fueran una sola unidad. Este tipo de dirección recibe el nombre de dirección jerárquica porque contiene diferentes niveles. Una dirección IP combina estos dos identificadores en un solo número. Este número debe ser un número exclusivo, porque las direcciones repetidas harían imposible el enrutamiento. La primera parte identifica la dirección de la red del sistema. La segunda parte, la parte del host, identifica qué máquina en particular de la red Direcciones IP Clase, A, B, C, D y E Para adaptarse a redes de distintos tamaños y para ayudar a clasificarlas, las direcciones IP se dividen en grupos llamados clases. Esto se conoce como direccionamiento classful. Cada dirección IP completa de 32 bits se divide en la parte de la red y parte del host. Un bit o una secuencia de bits al inicio de cada dirección determinan su clase. Son cinco las clases de direcciones IP como muestra la Tabla 2.1. Tabla 2.1 Clases de direcciones IP. La dirección Clase A se diseñó para admitir redes de tamaño extremadamente grande, de más de 16 millones de direcciones de host disponibles. Las direcciones IP Clase A utilizan sólo el primer octeto para indicar la dirección de la red. Los tres octetos restantes son para las direcciones host. La red se reserva para las pruebas de loopback. Los Routers o las máquinas locales pueden utilizar esta dirección para enviar paquetes nuevamente hacia ellos mismos. Por lo tanto, no se puede asignar este número a una red. La dirección Clase B se diseñó para cumplir las necesidades de redes de tamaño moderado a grande. Una dirección IP Clase B utiliza los primeros dos de los cuatro octetos para indicar la dirección de la red. Los dos octetos restantes especifican las direcciones del host. El espacio de direccionamiento Clase C es el que se utiliza más frecuentemente en las clases de direcciones originales. 18
25 Este espacio de direccionamiento tiene el propósito de admitir redes pequeñas con un máximo de 254 hosts. La dirección Clase D se creó para permitir multicast en una dirección IP. Una dirección multicast es una dirección exclusiva de red que dirige los paquetes con esa dirección destino hacia grupos predefinidos de direcciones IP. Por lo tanto, una sola estación puede transmitir de forma simultánea una sola corriente de datos a múltiples receptores. Se ha definido una dirección Clase E. Sin embargo, la Fuerza de tareas de ingeniería de Internet (IETF) ha reservado estas direcciones para su propia investigación. Por lo tanto, no se han emitido direcciones Clase E para ser utilizadas en Internet. Los primeros cuatro bits de una dirección Clase E siempre son 1s. Por lo tanto, el rango del primer octeto para las direcciones Clase E es a , o 240 a Direcciones Públicas. Las direcciones públicas son parte de Internet y por lo tanto validas en ella, este tipo de direcciones son administradas por la IANA (Internet Assigned Numbers Authorty) y los proveedores de servicios de Internet tienen que adquirir grupos de direcciones IP para asignar a sus clientes Direcciones Privadas. Las direcciones son para uso de en redes corporativas o particulares y no forman parte del esquema de direccionamiento de Internet. Técnicamente es posible utilizar cualquier plan de direccionamiento IP en una red privada, pero la IANA en la RFC 1918 ha reservado los tres siguientes grupos de direcciones, las cuales se muestran en la Tabla 2.2: Tabla 2.2 Clases de direcciones Privadas. 19
26 Capítulo 2. Protocolos de ruteo 2.1 Definición de protocolo de ruteo Un protocolo es un conjunto de reglas que determina cómo se comunican las computadoras entre sí a través de las redes. Las computadoras se comunican intercambiando mensajes de datos. Para aceptar y actuar sobre estos mensajes, las computadoras deben contar con definiciones de cómo interpretar el mensaje. Un protocolo describe lo siguiente: El formato al cual el mensaje se debe conformar La manera en que las computadoras intercambian un mensaje dentro del contexto de una actividad en particular 2.2 Objetivo de un protocolo de ruteo Un protocolo de ruteo es el mecanismo usado para actualizar los dispositivos de capa 3 (routers). Cuando todos ellos tienen el mismo conocimiento exacto de la red, pueden enrutar los paquetes de datos a través de la mejor ruta para llegar a su destino. 2.3 Como trabajan los protocolos de ruteo Los routers participantes anuncian las redes que ellos conocen de sus vecinos por medio de actualizaciones de ruteo. Las rutas aprendidas de las actualizaciones de ruteo, son colocadas en la tabla de ruteo. 2.4 Descripción del enrutamiento La función de enrutamiento es una función de la Capa 3 del modelo OSI. El enrutamiento es un esquema de organización jerárquico que permite que se agrupen direcciones individuales. Estas direcciones individuales son tratadas como unidades únicas hasta que se necesita la dirección destino para la entrega final de los datos. El enrutamiento es el proceso de hallar la ruta más eficiente desde un dispositivo a otro. El dispositivo primario que realiza el proceso de enrutamiento es el Router, para mejor entendimiento ver Figura
27 Figura 2.1 Descripción del enrutamiento Las siguientes son las dos funciones principales de un Router: Los Routers deben mantener tablas de enrutamiento y asegurarse de que otros Routers conozcan las modificaciones a la topología de la red. Cuando los paquetes llegan a una interfaz, el Router debe utilizar la tabla de enrutamiento para establecer el destino. El Router envía los paquetes a la interfaz apropiada, agrega la información de entramado necesaria para esa interfaz, y luego transmite la trama. Un Router es un dispositivo de la capa de red que usa una o más métricas de enrutamiento para determinar cuál es la ruta óptima a través de la cual se debe enviar el tráfico de red. Las métricas de enrutamiento son valores que se utilizan para determinar las ventajas de una ruta sobre otra. 2.5 Enrutamiento comparado con la conmutación La diferencia es que la conmutación tiene lugar en la Capa 2, o sea, la capa de enlace de los datos, en el modelo OSI y el enrutamiento en la Capa 3, esto se ilustra en la Figura 3.2. Esta diferencia significa que el enrutamiento y la conmutación usan información diferente en el proceso de desplazar los datos desde el origen al destino. 21
28 Figura 2.2 Enrutamiento comparado con la conmutación Figura 2.3 Tablas ARP La figura 3.3 muestra las tablas ARP de las direcciones MAC de Capa 2 y las tablas de enrutamiento de las direcciones IP de Capa 3. Cada interfaz de computador y de Router mantiene una tabla ARP para comunicaciones de Capa 2. La tabla ARP funciona sólo para el dominio de broadcast al cual está conectada. El Router también mantiene una tabla de enrutamiento que le permite enrutar los datos fuera del dominio de broadcast. Los switches Capa 2 construyen su tabla usando direcciones MAC. Cuando un host va a mandar información a una dirección IP que no es local, entonces manda la trama al router más cercano., también conocida como su Gateway por defecto. El host utiliza las direcciones MAC del Router como la dirección MAC destino. 22
29 Un switch interconecta segmentos que pertenecen a la misma red o subred lógicas. Para los host que no son locales, el switch reenvía la trama a un router en base a la dirección MAC destino. El router examina la dirección destino de Capa 3 para llevar a cabo la decisión de la mejor ruta. El host X sabe la dirección IP del router puesto que en la configuración del host se incluye la dirección del Gateway por defecto. 2.6 Determinación de la ruta La determinación de la ruta ocurre a nivel de la capa de red. La determinación de la ruta permite que un Router compare la dirección destino con las rutas disponibles en la tabla de enrutamiento, y seleccione la mejor ruta. Los Routers conocen las rutas disponibles por medio del enrutamiento estático o dinámico. El Router utiliza la determinación de la ruta para decidir por cuál puerto debe enviar un paquete en su trayecto al destino, ver Figura 3.4. Figura 2.4 Funcionamiento del Router. Se utiliza el siguiente proceso durante la determinación de la ruta para cada paquete que se enruta: El router compara la dirección IP del paquete recibido contra las tablas que tiene. Se obtiene la dirección destino del paquete. Se aplica la máscara de la primera entrada en la tabla de enrutamiento a la dirección destino. Se compara el destino enmascarado y la entrada de la tabla de enrutamiento. Si hay concordancia, el paquete se envía al puerto que está asociado con la entrada de la tabla. 23

30 Si no hay concordancia, se compara con la siguiente entrada de la tabla. Si el paquete no concuerda con ninguno de las entradas de la tabla, el Router verifica si se envió una ruta por defecto. Si se envió una ruta por defecto, el paquete se envía al puerto asociado. Una ruta por defecto es aquella que está configurada por el administrador de la red como la ruta que debe usarse si no existe concordancia con las entradas de la tabla de enrutamiento. El paquete se elimina si no hay una ruta por defecto. Por lo general se envía un mensaje al dispositivo emisor que indica que no se alcanzó el destino. 2.7 Tablas de enrutamiento Los Routers utilizan protocolos de enrutamiento para crear y guardar tablas de enrutamiento que contienen información sobre las rutas, como lo nuestra la Figura 3.4. Esto ayuda al proceso de determinación de la ruta. Figura 2.5 Tabla de enrutamiento. Los Routers mantienen información importante en sus tablas de enrutamiento, que incluye lo siguiente: Tipo de protocolo: El tipo de protocolo de enrutamiento que creó la entrada en la tabla de enrutamiento. Asociaciones entre destino/siguiente salto: Estas asociaciones le dicen al Router que un destino en particular está directamente conectado al Router, o que puede ser alcanzado utilizando un Router denominado "salto siguiente" en el trayecto hacia el destino final. 24
31 Métrica de enrutamiento: Los distintos protocolos de enrutamiento utilizan métricas de enrutamiento distintas. Las métricas de enrutamiento se utilizan para determinar la conveniencia de una ruta. Interfaces de salida: La interfaz por la que se envían los datos para llegar a su destino final. Los Routers se comunican entre sí para mantener sus tablas de enrutamiento por medio de la transmisión de mensajes de actualización del enrutamiento. Algunos protocolos de enrutamiento transmiten estos mensajes de forma periódica, mientras que otros lo hacen cuando hay cambios en la topología de la red. Algunos protocolos transmiten toda la tabla de enrutamiento en cada mensaje de actualización, y otros transmiten sólo las rutas que se han modificado. Un Router crea y guarda su tabla de enrutamiento, analizando las actualizaciones de enrutamiento de los Routers vecinos. 2.8 Métricas de ruteo. Las métricas pueden tomar como base una sola característica de la ruta, o pueden calcularse tomando en cuenta distintas características. Las siguientes son las métricas más utilizadas en los protocolos de enrutamiento: Ancho de banda: La capacidad de datos de un enlace. En general, se prefiere un enlace Ethernet de 10 Mbps a una línea arrendada de 64 kbps. Retardo: La cantidad de tiempo requerido para transportar un paquete a lo largo de cada enlace desde el origen hacia el destino Carga: La cantidad de actividad en un recurso de red. Confiabilidad: Generalmente se refiere al índice de error de cada enlace de red. Número de saltos: El número de Routers que un paquete debe atravesar antes de llegar a su destino. La distancia que deben atravesar los datos entre un Router y otro equivale a un salto. Una ruta cuyo número de saltos es cuatro indica que los datos que se transportan a través de esa ruta deben pasar por cuatro Routers antes de llegar a su destino final en la red. Si existen varias rutas hacia un mismo destino, se elige la ruta con el menor número de saltos. Tictacs: El retardo en el enlace de datos medido en tictacs de reloj PC de IBM. Un tictac dura aproximadamente 1/18 de segundo. Costo: Un valor arbitrario asignado por un administrador de red que se basa por lo general en el ancho de banda, el gasto monetario u otra medida. 2.9 IGP y EGP Un sistema autónomo es una red o conjunto de redes bajo un control común de administración. Un sistema autónomo está compuesto por Routers que presentan una visión coherente del enrutamiento al mundo exterior. 25
32 Los Protocolos de enrutamiento de Gateway interior (IGP) y los Protocolos de enrutamiento de Gateway exterior (EGP) son dos tipos de protocolos de enrutamiento. Los IGP enrutan datos dentro de un sistema autónomo. Protocolo de información de enrutamiento (RIP) y (RIPv2). Protocolo de enrutamiento de Gateway interior (IGRP) Protocolo de enrutamiento de Gateway interior mejorado (EIGRP) Primero la ruta libre más corta (OSPF) Protocolo de sistema intermedio-sistema intermedio (IS-IS). Los EGP enrutan datos entre sistemas autónomos. Un ejemplo de EGP es el protocolo de Gateway fronterizo (BGP) Sistemas autónomos Figura 2.6 Protocolos IGP y EGP Un sistema autónomo (AS) es un conjunto de redes bajo una administración común, las cuales comparten una estrategia de enrutamiento común. Para el mundo exterior, el AS es una entidad única. El AS puede ser administrado por uno o más operadores, a la vez que presenta un esquema unificado de enrutamiento hacia el mundo exterior. Este sistema se muestra en la figura 3.7. Los números de identificación de cada AS son asignados por el Registro estadounidense de números de la Internet (ARIN), los proveedores de servicios o el administrador de la red. Este sistema autónomo es un número de 16 bits. 26


33 Figura 2.7 Sistemas autónomos Cuando todos los routers de una red se encuentran operando con la misma información, se dice que la red ha hecho convergencia. Una rápida convergencia es deseable, ya que reduce el período de tiempo durante el cual los routers toman decisiones de enrutamiento erróneas. Los sistemas autónomos (AS) permiten la división de la red global en subredes de menor tamaño, más manejables. Cada AS cuenta con su propio conjunto de reglas y políticas, y con un único número AS que lo distingue de los demás sistemas autónomos del mundo. Figura 2.8 Comunicación entre sistemas autónomos Identificación de las clases de protocolos de enrutamiento La mayoría de los algoritmos de enrutamiento pertenecen a una de estas dos categorías: Vector-distancia Estado del enlace Híbrido El método de enrutamiento por vector-distancia determina la dirección (vector) y la distancia hacia cualquier enlace en la red. El método de estado del enlace, también denominado "primero la ruta más corta", recrea la topología exacta de toda la red. 27
34 2.9.3 Características del protocolo de enrutamiento por vectordistancia Los protocolos de enrutamiento por vector-distancia envían copias periódicas de las tablas de enrutamiento de un router a otro. Estas actualizaciones periódicas entre routers informan de los cambios de topología. Los algoritmos de enrutamiento basados en el vector-distancia también se conocen como algoritmos Bellman-Ford. Esto se muestra en la figura 3.9. Cada router recibe una tabla de enrutamiento de los routers conectados directamente a él. Figura 2.9 Vector distancia Sin embargo, los algoritmos de vector-distancia no permiten que un router conozca la topología exacta de una red, ya que cada router solo ve a sus routers vecinos. Cada router que utiliza el enrutamiento por vector-distancia comienza por identificar sus propios vecinos. 28

35 Figura 2.10 Identificación entre routers. La interfaz que conduce a las redes conectadas directamente tiene una distancia de 0. A medida que el proceso de descubrimiento de la red avanza, los routers descubren la mejor ruta hacia las redes de destino, de acuerdo a la información de vector-distancia que reciben de cada vecino. Las actualizaciones de las tablas de enrutamiento se producen al haber cambios en la topología. Al igual que en el proceso de descubrimiento de la red, las actualizaciones de cambios de topología avanzan paso a paso, de un router a otro. Los algoritmos de vector-distancia hacen que cada router envíe su tabla de enrutamiento completa a cada uno de sus vecinos adyacentes. Las tablas de enrutamiento incluyen información acerca del costo total de la ruta (definido por su métrica) y la dirección lógica del primer router en la ruta hacia cada una de las redes indicadas en la tabla. Esto se muestra en la Figura Figura 2.11 Métrica de enrutamiento. 29
36 2.9.4 Características del protocolo de enrutamiento de estado del enlace El segundo algoritmo básico que se utiliza para enrutamiento es el algoritmo de estado del enlace. Los algoritmos de estado del enlace también se conocen como algoritmos Dijkstra o SPF ("primero la ruta más corta"). Los protocolos de enrutamiento de estado del enlace mantienen una base de datos compleja, con la información de la topología de la red. El algoritmo de vector-distancia provee información indeterminada sobre las redes lejanas y no tiene información acerca de los routers distantes. El algoritmo de enrutamiento de estado del enlace mantiene información completa sobre routers lejanos y su interconexión. El enrutamiento de estado del enlace utiliza: - Publicaciones de estado del enlace (LSA): una publicación del estado del enlace (LSA) es un paquete pequeño de información sobre el enrutamiento, el cual es enviado de router a router. - Base de datos topológica: una base de datos topológica es un cúmulo de información que se ha reunido mediante las LSA. - Algoritmo SPF: el algoritmo "primero la ruta más corta" (SPF) realiza cálculos en la base de datos, y el resultado es el árbol SPF. - Tablas de enrutamiento: una lista de las rutas e interfaces conocidas. El proceso de descubrimiento de la red inicia con el intercambio de LSAs de las redes conectadas directamente al router, de las cuales tiene información directa. Cada router, en paralelo con los demás, genera una base de datos topológica que contiene toda la información recibida por intercambio de LSAs. Esto se muestra en la Figura
37 Figura 2.12 Protocolo de enrutamiento de estado de enlace. El algoritmo SPF determina la conectividad de la red. El router construye esta topología lógica en forma de árbol, con él mismo como raíz, y cuyas ramas son todas las rutas posibles hacia cada subred de la red. Luego ordena dichas rutas, y coloca las ruta más cortas primero (SPF). El router elabora una lista de las mejores rutas a las redes de destino, y de las interfaces que permiten llegar a ellas. Esta información se incluye en la tabla de enrutamiento. También mantiene otras bases de datos, de los elementos de la topología y de los detalles del estado de la red, lo cual se ilustra en la Figura Figura 2.13 Algoritmo SPF. 31
38 El router que primero conoce de un cambio en la topología envía la información al resto de los routers, para que puedan usarla para hacer sus actualizaciones y publicaciones, como se muestra la Figura Figura 2.14 Actualización de la tabla con SPF Esto implica el envío de información de enrutamiento, la cual es común a todos los routers de la red. Para lograr la convergencia, cada router monitorea sus routers vecinos, sus nombres, el estado de la interconexión y el costo del enlace con cada uno de ellos OSPF Descripción general de OSPF OSPF es un protocolo de enrutamiento del estado de enlace basado en estándares abiertos. Se describe en diversos estándares de la Fuerza de Tareas de Ingeniería de Internet (IETF).Como se ve en la Figura En comparación con RIP v1 y v2, OSPF es el IGP preferido porque es escalable. Una desventaja de usar OSPF es que solo soporta el conjunto de protocolos TCP/IP. OSPF se puede usar y configurar en una sola área en las redes pequeñas. 32


39 Figura 2.15 Backbone OSPF También se puede utilizar en las redes grandes. Tal como se muestra en la Figura 3.16, las redes OSPF grandes utilizan un diseño jerárquico. Varias áreas se conectan a un área de distribución o a un área 0 que también se denomina backbone. El enfoque del diseño permite el control extenso de las actualizaciones de enrutamiento. La definición de área reduce el gasto de procesamiento, acelera la convergencia, limita la inestabilidad de la red a un área y mejora el rendimiento Terminología de OSPF Figura 2.16 Redes OSPF. Los routers de estado de enlace identifican a los routers vecinos y luego se comunican con los vecinos identificados. El protocolo OSPF tiene su propia terminología. Esto se muestra en la Figura
40 Figura 2.17 Publicaciones de estado de enlace OSPF OSPF reúne la información de los routers vecinos acerca del estado de enlace de cada router OSPF. Con esta información se inunda a todos los vecinos. Un router OSPF publica sus propios estados de enlace y traslada los estados de enlace recibidos. Los routers procesan la información acerca de los estados de enlace y crean una base de datos del estado de enlace. Cada router del área OSPF tendrá la misma base de datos del estado de enlace. Por lo tanto, cada router tiene la misma información sobre el estado del enlace y los vecinos de cada uno de los demás routers. Cada router luego aplica el algoritmo SPF, desarrollado por un especialista holandés en informática en 1959 llamado Dijkstra. A su propia copia de la base de datos. Este cálculo determina la mejor ruta hacia un destino. El algoritmo SPF va sumando el costo, un valor que corresponde generalmente al ancho de banda. La ruta de menor costo se agrega a la tabla de enrutamiento, que se conoce también como la base de datos de envío. Cada router mantiene una lista de vecinos adyacentes, que se conoce como base de datos de adyacencia. La base de datos de adyacencia es una lista de todos los routers vecinos con los que un router ha establecido comunicación bidireccional. Esto es exclusivo de cada router. Para reducir la cantidad de intercambios de la información de enrutamiento entre los distintos vecinos de una misma red, los routers de OSPF seleccionan un router designado (DR) y un router designado de respaldo (BDR) que sirven como puntos de enfoque para el intercambio de información de enrutamiento. OSPF ofrece soluciones a los siguientes problemas: Velocidad de convergencia Admite la Máscara de subred de longitud variable (VLSM) Tamaño de la red Selección de ruta. Agrupación de miembros 34
41 2.11 BGP BGP (Border Gateway Protocol) es conocido como el protocolo de ruteo para Internet. Es usado para compartir información de ruteo entre los diferentes Sistemas Autónomos (AS). BGP v4 puede hacer sumarización de rutas y CIDR. BGP utiliza TCP como protocolo confiable para la transmisión. Usa el puerto 179 para establecer las conexiones. BGP no se preocupa del ruteo INTRA-AS Terminología BGP AS: Conjunto de dispositivos bajo el mismo control administrativo, que es usado por un IGP para ruteo INTRA-AS y un EGP para ruteo INTER-AS. BGP Speaker: Cualquier equipo de ruteo que esta arrancando un BGP routing procedo. PEERS: Se forman cuando dos BGP Speakers hacen una conexión TCP entre ellos. ebgp: External Border Gateway Protocol, es el protocolo de ruteo usado para intercambiar información de ruteo entre BGP peer en diferentes AS ibgp: Internal Border Gateway Protocol, es el protocolo de ruteo usado para intercambiar información de ruteo entre BGP peers en el mismo AS. INTER-AS routing: Es el routing que ocurre entre diferentes AS. INTRA-AS AS routing: Es el routing que ocurre dentro del mismo AS Operación de BGP Todos los BGP Speakers dentro del mismo AS usan ibgp para comunicarse entre ellos. Multiples BGP speaking dentro del mismo AS deben ser peer entre ellos. ibgp debe ser un full mesh, no significa que todos los dispositivos deban ser conectados con cada uno, aunque todos deben ser alcanzables a través de capa 3. ebgp requiere conectividad capa 3 entre ellos. Después de formar peers, se usa la información para crear mapas libres de loop del AS involucrado (BGP Tree). Una vez formado los peers, y se ha creado el árbol BGP, ellos inician el intercambio de información de ruteo. 35
42 El BGP speaking, primero intercambia su tabla BGP en su totalidad y luego son actualizaciones incrementales de su tabla de ruteo BGP y Keepalive messages para mantener la conexión Formato de la cabecera del mensaje El mensaje básico del formato de la cabecera está dividido en: Un campo Marker de 16 Byte Un campo Length de 2 Byte Un campo Type de 1 Byte Marker: Es usado para detectar una pérdida de sincronismo entre un conjunto de peers y también autentifica mensajes entrantes. Length: Indica el largo del mensaje entero incluyendo el campo Marker. El valor es entre 19 y 4096 octetos. Type: Indica el tipo de código de los mensajes. Hay 4 valores: OPEN UPDATE NOTIFICATION KEEPALIVE Mensaje Open. Es el primer mensaje enviado después que una sesión TCP se ha formado. Cuando el mensaje Open es aceptado, un mensaje Keepalive confirma el mensaje Open. Luego incrementales mensajes Updates, mensajes de Notificación y Keepalive serán intercambiados entre los BGP peers. El mensaje Open es de tamaño fijo en el BGP Header Version: Es un campo de 1 Byte que indica que version de BGP se está corriendo BGPv3 o BGPv4. My AS: Este es un campo de 2 Bytes que indica el Sistema Autonomo del router BGP. Hold time: Es el máximo periodo de tiempo en segundos que pasa entre la recepción exitosa de un mensaje keepalive o un mensaje de actualización BGP identifier: Es un campo de 4 Bytes que identifica el ID del router. En las implementaciones de cisco, el ID es calculado con la IP mas alta entre las loopbacks asignadas a los routers dentro de la negociación BGP. Optional parameters: Este es un campo de tamaño variable usado para indicar parámetros opcionales usados durante la fase de negociación BGP. Optional parameter length: Este es un campo de 1 Byte usado para indicar el tamaño del campo de los parámetros opcionales. 36
43 Mensaje Update. Después que se ha formado peers, ellos intercambian incrementales mensajes Update. Contienen la información de ruteo para BGP y es usado para construir un ambiente libre de loop. El mensaje Update contiene al menos una ruta feasible y multiples rutas unfeasible para retirar. Mensaje Keepalive Son usados para asegurar conectividad entre peers, es de tamaño fijo. Un keepalive mensaje es enviado para restaurar el Hola Timer. El intervalo es de un tercio del valor del hola timer. Esto es porque el hola timer debe ser al menos 3 segundos si este no es cero. Un keepalive no será enviado si un mensaje update fue enviado. Si el hola timer es seteado a cero, un keepalive nunca será enviado. Mensaje de Notificación. Cada vez que un error ocurre durante una sesión BGP, el BGP speaker genera un mensaje de notificación. Tan pronto como el BGP speaker genera la notificación la sesión es terminada. Negociación de Vecindad. Antes que BGP puedan comunicarse deben ser vecinos o peers. El primer paso es formar una sesión TCP 179 con cada otro. Después el BGP speaker envía un mensaje Open, para luego enviar incrementales mensajes Update, notificación y keepalive. El proceso de la formación de vecinos es conocido como Finite State Machine Finite State Machine Hay seis posibles estados: Idle: Es el primer estado, el BGP speaker espera por un BGP Start event, para luego iniciar el connect retry timer, se inicia el TCP connector al BGP speaker que quiere como peer y escucha cualquier conexión iniciado por el otro BGP speaker. El BGP speaker entonces cambiará su estado a connection. Si hay errores la sesión TCP finaliza y el estado vuelve a estado Idle. Connection: BGP está esperando por la conexión TCP sea formado. Una vez que la conexión es completada, se limpia el connect retry timer, y se envía un mensaje Open al remoto BGP speaker y pasa al estado Open Sent. Si la conexión TCP no es formada, se restaura el connect retry timer, continua escuchando un intento de conexión del remoto BGP speaker y su estado pasa a Activo. Si el connect retry timer expira, se resetea el timer, se inicia una sesión TCP, se sigue escuchando por intentos de conexión del remoto y permanece en el estado conexión. Si hay un error se cierra la conexión TCP y se pasa al estado Idle. Active: El BGPspeaker está intentando iniciar una sesión TCP. Una vez que la conexión es completada, se limpia el conté retry timer, inicialización completa, y se envía un Open al remoto BGP speaker y pasa al estado Open Sent. 37
44 Open Sent: El BGP speaker está esperando recibir un Open desde el remoto BGP speaker. Al recibir el Open todos los campos serán chequeados. Si un error es detectado enviará un mensaje de notificación al remoto y terminará el TCP y pasa al estado Idle. Si ningún error se ha encontrado en el Open el BGP speaker enviará un keepalive y negocian los valores del keepalive timer y hold timer. Un valor de 0 significa que el keepalive timer y el hold timer nunca serán reseteados. Después de la negociación se determinará si la conexión será ibgp o ebgp, porque esto afectará el proceso de UPdate. Una vez que que el tipo de BGP es determinado, pasa al estado Open Confirm. Durante este estado es posible recibir un TCP disconnect, si esto ocurre el estado pasa a Activo. Si hay un error pasa al estado Idle. Open Confirm: El BGP speaker esperará recibir un keepalive desde el remoto. Una vez recibido, se resetea el hello timer y pasa al estado establecido. En este punto la relación de peer ha sido formada. Si una notificación es recibido en vez de un keepalive pasa al estado Idle. En caso que el hola timer expira antes que el keepalive es recibido, el BGP speaker enviará una notificación al remoto y terminará la sesión TCP y su estado a Idle. Establecido: Todas las negociaciones están completadas. Los BGP peers intercambiarán Update, Keepalive. Cada vez que se recibe un Update o Keepalive éste reseteará su hold timer. Si el hold timer expira antes que un Update o Keepalive es recibido, el BGP speaker enviará una notificación a su peer, terminará la sesión TCP y pasará al estado Idle. Una vez alcanzado el estado Establecido se inicia el intercambio de información de ruteo Selección de Rutas Cuando se aprende una ruta, esta necesita pasar a través del Routing Information Base (RIB). Un RIB está dividido en: Adj-RIBs-In Loc-RIB Adj-RIBs-Out Figura 2.18 División de un RIB. 1. El BGP speaker recibe las rutas BGP 2. Las rutas son colocadas en el Adj-RIBs-In 3. Las rutas son enviadas al Inbound Policy Engine 4. el IPE filtra y manipula rutas basadas en la política seteada por el administrador. Las rutas que son filtradas son sacadas 5. Las demás rutas BGP son enviadas al Loc-RIB 38
45 6. Se almacena las rutas en el Loc-RIB. El router usa estas rutas para hacer decisiones de ruteo BGP 7. Las rutas son direccionadas al Outboind Policy Engine. 8. El OPE filtra y manipula rutas basado en las políticas seteada por el administrador. Las rutas que son filtradas son sacadas. 9. Las rutas son enviadas al Adj-RIBs-Out 10. Las rutas recibidas son almacenadas en el Adj-RIBs-Out 11. Todas las rutas son advertidas a los peers ibgp ibgp define el peering entre dos vecinos BGP dentro del mismo AS. Se puede utilizar ibgp en los AS de tránsito. Los AS de tránsito reenvían el tráfico desde un AS hacia otro. Si no se utilizara ibgp, las rutas aprendidas por ebgp serían redistribuidas dentro del IGP y redistribuidas de nuevo en el proceso de BGP de otro router ebgp. ibgp proporciona la mejor forma de controlar las rutas para el AS de transito. Con ibgp la información de las rutas externas (atributos) son reenviados. ibgp es preferido sobre otras redistribuciones ya que los IGPs no entienden de AS paths y otros atributos de BGP. Es importante configurar una red totalmente mallada de vecinos ibgp dentro del AS para evitar bucles de routing. El router ibgp no redistribuye la información en otros peers ibgp. ibgp: Distancia administrativa de ebgp ebgp describe el peering BGP entre vecinos de diferentes AS, los vecinos ebgp deben de tener una subred en común. ibgp: Distancia administrativa de ebgp Multihop Los peers ebgp pueden ser configurados sin estar directamente conectados, saltando varias redes, mediante ebgp Multihop. ebgp Multihop también se utiliza para establecer el peering con las direcciones de loopback. Esta es una característica propietaria de Cisco IOS. El routing interno del AS (IGP) deberá de estar perfectamente configurado para que el ebgp Multihop pueda funcionar. Multihop no es posible configurarlo en ibgp Communities de BGP El atributo communities es un atributo global opcional y transitivo y es un número En el rango Las communities más comunes son: 39
46 internet: Anuncia esta ruta a Internet, todos los routers pertenecen a esta community no-export: No anuncia esta ruta a otros peers ebgp no-advertise: No anuncia esta ruta a ningún peer local-as: Envía esta ruta a otros peers en otros subsistemas autónomos dentro de la misma confederación local 2.17 Atributos de BGP Path Los atributos de BGP se dividen siguiendo el siguiente esquema: Well-Known: Se reconocen en todas las implementaciones de BGP. Mandatory: Tienen que ser incluidos en todas la actualizaciones. Next-Hop: Dirección IP que alcanza el destino. Origin: i(igp), e(egp),?(incompleto). AS-Path: Número de ASs para alcanzar el destino y lista de los mismos. Discretionary: No tienen que ser incluidos en todas las actualizaciones Local-Preference: Indica el path para salir del AS Atomic Aggregator: Informa a los peers BGP que existe una ruta menos específica a un destino Optional: No necesitan ser soportados por el proceso BGP. Transitive: Los routers los anunciarán, aunque ellos no los soporten. MED: Le dice al peer ebgp el path preferido para entrar en el AS Community: Agrupa redes para asignación de políticas Agregator: Incluye la IP y el AS del router que origina la ruta agregada Non Transitive: Los routers no los anunciarán. Atributo Next-Hop. Este atributo nos indica la dirección IP del siguiente salto ebgp que vamos a utilizar para alcanzar el destino. Para definir el siguiente salto como el vecino en si utilizaremos el comando next-hop-self. Atributo Local Preferente. El atributo local preference indica cual es el camino para salir del AS local, este atributo no se pasará a vecinos ebgp. Por defecto en routers Cisco es 100 y se prefiere la local preference más grande. Atributo Origin. El atributo Origin define el origen de la información del path: IGP: Indicado con una i, presente si la ruta se ha aprendido con el comando network EGP: Indicado con una e, presente si la ruta ha sido aprendida desde otro AS 40
47 Incomplete: Indicado con un?, aprendido de una redistribución de la ruta Atributo AS Path Length. El AS Path Length lista los ASs que se atraviesan para llegar los destinos Atributo MED. El atributo MED, también conocido como métrica, indica a los peers de ebgp el path preferido para entrar en el AS desde fuera. Por defecto el valor del MED es 0 y cuanto más bajo sea el valor es más preferible. Cisco además ha añadido dos funcionalidades nuevas al MED que permiten realizar comparaciones: bgp deterministic-med compara valores de MED en las rutas anunciadas por diferentes peers del mismo AS bgp always-compare-med compara el atributo MED de diferentes ASs para seleccionar el path más adecuado. Atributo Community. Este atributo no participa en el proceso de selección de path, pero sirve para agrupar políticas o decisiones que aplican a estas rutas Atributo Weight. Weight es específico de Cisco y no se propaga a otros routers. Los valores del weight están en el rango , y las rutas a un destino con un weight mayor son preferidas sobre las otras. El weight puede ser utilizado en vez de la local preference para influenciar en la selección del path a los peers externos de BGP. La diferencia principal es que el weight no se envía entre peers y la local preference se envía entre peers ibgp Proceso de Decisión de BGP. Por defecto BGP selecciona un único path a un destino, a no ser que se configure maximum paths, y el proceso es el siguiente: 1. Si el next hop al path está caído se descarta el path 2. Si el path es interno, la sincronización está habilitada, y el path no está en IGP se descarta el path 3. Se selecciona el path con mayor weight 4. Si el weight es igual se selecciona la menor local preference 5. Si la local preference es igual se selecciona el path que haya sido originado en el router local 6. Si el path no ha sido originado por el router local se selecciona la que tenga el AS-Path más corto 7. Si todos tienen el AS-Path de la misma longitud se selecciona en primer lugar los paths originados en el AS local 8. Si los Origin Code son iguales se selecciona la que tenga el MED más pequeño 9. Si el MED es igual se prefiere el path ebgp antes que el ibgp 10. Si los MED son iguales se prefiere el que tenga el vecino IGP más cercano 41
48 Capítulo 3. Red privada virtual (VPN) Una VPN es una red privada que se construye dentro de una infraestructura de red pública, como la Internet global. La VPN es un servicio que ofrece conectividad segura y confiable en una infraestructura de red pública compartida, como la Internet. Las VPN conservan las mismas políticas de seguridad y administración que una red privada. Son la forma más económica de establecer una conexión punto-a-punto entre usuarios remotos y la red de un cliente de la empresa. 3.1 Ventajas de una VPN (Red Privada Virtual) Una de sus ventajas más importantes es su integridad, confidencialidad y seguridad de datos. Las VPN s reducen costos y son sencillas de usar. Su instalación es sencilla en cualquier PC. Su control de acceso esta basado en políticas de la organización. Los algoritmos de compresión que utiliza una VPN optimizan el tráfico del usuario. Las VPN s evitan el alto costo de las actualizaciones y mantenimiento de PC's remotas. Las VPN s ahorran en costos de comunicaciones y en costes operacionales. Los trabajadores, mediante el uso de las VPN s, pueden acceder a los servicios de la compañía sin necesidad de llamadas. Una organización puede ofrecer servicios a sus socios mediante VPN s, ya que éstas permiten acceso controlado y brindan un canal seguro para compartir la información de las organizaciones. 42
49 Figura 3.1 Donde utilizar VPN 3.2 TIPOS DE VPN A continuación se describen los tres principales tipos de VPN: VPN de acceso: Las VPN de acceso brindan acceso remoto a un trabajador móvil y una oficina pequeña/oficina hogareña (SOHO), a la sede de la red interna o externa, mediante una infraestructura compartida. Las VPN de acceso usan tecnologías analógicas, de acceso telefónico, RDSI, línea de suscripción digital (DSL), IP móvil y de cable para brindar conexiones seguras a usuarios móviles, empleados a distancia y sucursales. Redes internas VPN: Las redes internas VPN conectan a las oficinas regionales y remotas a la sede de la red interna mediante una infraestructura compartida, utilizando conexiones dedicadas. Las redes internas VPN difieren de las redes externas VPN, ya que sólo permiten el acceso a empleados de la empresa. Este esquema se utiliza para conectar oficinas remotas con la sede central de organización. El servidor VPN, que posee un vínculo permanente a Internet, acepta las conexiones vía Internet provenientes de los sitios y establece el túnel VPN. Los servidores de las sucursales se conectan a Internet utilizando los servicios de su proveedor local de Internet, típicamente mediante conexiones de banda ancha. Esto permite eliminar los costosos vínculos punto a punto tradicionales, sobre todo en las comunicaciones internacionales. Redes externas VPN: Las redes externas VPN conectan a socios comerciales a la sede de la red mediante una infraestructura compartida, utilizando conexiones dedicadas. Las redes externas VPN difieren de las redes internas VPN, ya que permiten el acceso a usuarios que no pertenecen a la empresa. Esto se ilustra en la figura
50 Figura 3.2 Implementación de una red VPN La principal motivación del uso y difusión de esta tecnología es la reducción de los costos de comunicaciones directos, tanto en líneas dial-up como en vínculos WAN dedicados. Los costos se reducen drásticamente en estos casos: En el caso de accesos remotos, llamadas locales a los ISP (Internet Service Provider) en vez de llamadas de larga distancia a los servidores de acceso remoto de la organización. O también mediante servicios de banda ancha. En el caso de conexiones punto a punto, utilizando servicios de banda ancha para acceder a Internet, y desde Internet llegar al servidor VPN de la organización. Todo esto a un costo sensiblemente inferior al de los vínculos WAN dedicados. 3.3 Túnel Los paquetes de datos de una VPN viajan por medio de un túnel definido en la red pública. El túnel es la conexión definida entre dos puntos en modo similar a como lo hacen los circuitos en una topología WAN basada en paquetes. A diferencia de los protocolos orientados a paquetes, capaces de enviar los datos a través de una variedad de rutas antes de alcanzar el destino final, un túnel representa un circuito virtual dedicado entre dos puntos. Para crear el túnel es preciso que un protocolo especial encapsule cada paquete origen en uno nuevo que incluya los campos de control necesarios para crear, gestionar y deshacer el túnel. Adicionalmente las VPNs emplean el túnel con propósitos de seguridad. Los paquetes utilizan inicialmente funciones de cifrado, autenticación o integridad de datos, y después se encapsulan en paquetes IP (Internet Protocol). Posteriormente los paquetes son descrifrados en su destino. Entre los principales protocolos utilizados para el proceso de tunneling se pueden mencionar: 44
51 PPTP (Point-to-Point Tunneling Protocol). PPTP es un protocolo de red que permite la realización de transferencias desde clientes remotos a servidores localizados en redes privadas. Para ello emplea tanto líneas telefónicas conmutadas como Internet. PPTP es una extensión de PPP que soporta control de flujos y túnel multiprotocolo sobre IP. L2F (Layer 2 Forwarding). El protocolo L2F tiene como objetivo proporcionar un mecanismo de tunneling para el transporte de tramas a nivel de enlace: HDLC, PPP, SLIP, etc. El proceso de tunneling involucra tres protocolos diferentes: el protocolo pasajero representa el protocolo de nivel superior que debe encapsularse; el protocolo encapsulador indica el protocolo que será empleado para la creación, mantenimiento y destrucción del túnel de comunicación (el protocolo encapsulador es L2F); y el protocolo portador será el encargado de realizar el transporte de todo el conjunto. L2TP (Layer 2 Tunneling Protocol). Encapsula características PPTP y L2F como un todo, resolviendo los problemas de interoperatividad entre ambos protocolos. Permite el túnel del nivel de enlace de PPP, de forma que los paquetes IP, IPX y AppleTalk enviados de forma privada, puedan ser transportados por Internet. Para seguridad de los datos se apoya en IPSec. IPSec(IP Secure). Protocolo de seguridad que opera sobre la capa de red que proporciona un canal seguro para los datos. Ofrece integridad, autenticación, control de acceso y confidencialidad para el envío de paquetes IP por Internet. 3.4 Ancho de banda VPN Podemos encontrar otra motivación en el deseo de mejorar el ancho de banda utilizado en conexiones dial-up. Las conexiones VPN de banda ancha mejoran notablemente la capacidad del vínculo. 3.5 Implementaciones Todas las opciones disponibles en la actualidad caen en tres categorías básicas: soluciones de hardware, soluciones basadas en cortafuegos y aplicaciones VPN por software. El protocolo estándar de hecho es el IPSEC, pero también tenemos PPTP, L2F, L2TP, SSL/TLS, SSH, etc. Cada uno con sus ventajas y desventajas en cuanto a seguridad, facilidad, mantenimiento y tipos de clientes soportados. Actualmente hay una línea de productos en crecimiento relacionada con el protocolo SSL/TLS, que intenta hacer más amigable la configuración y operación de estas soluciones. Las soluciones de hardware casi siempre ofrecen mayor rendimiento y facilidad de configuración, aunque no tienen la flexibilidad de las versiones por software. Dentro de esta familia tenemos a los productos de Nortel, Cisco, Linksys, Netscreen, Symantec, Nokia, US Robotics, D-link etc. 45
52 En el caso basado en Firewall, se obtiene un nivel de seguridad alto por la protección que brinda el Firewall, pero se pierde en rendimiento. Muchas veces se ofrece hardware adicional para procesar la carga VPN. Por ejemplo: Checkpoint NG, Cisco Pix. Las aplicaciones VPN por software son las más configurables y son ideales cuando surgen problemas de interoperatividad en los modelos anteriores. Obviamente el rendimiento es menor y la configuración más delicada, porque se suma el sistema operativo y la seguridad del equipo en general. Aquí tenemos por ejemplo a las soluciones nativas de Windows, Linux y los Unix en general. Por ejemplo productos de código abierto (Open Source) como OpenSSH, OpenVPN y FreeS/Wan. Capítulo 4. Introducción a MPLS MPLS IP se habilita en una red para proporcionar servicios adicionales como redes privadas virtuales VPN, encapsulando paquetes de Capa 3 del modelo OSI o tramas de capa 2 usando etiquetas MPLS. Adicionalmente, MPLS habilita ingeniería de tráfico y otros servicios que no están disponibles en redes de IP tradicionales. La transición de una red IP a MPLS requiere una arquitectura lista de MPLS, todos los dispositivos en la ruta de envío requieren funcionalidades MPLS. Este es el requerimiento para ambos routers, el de Backbone (P) y del frontera PE (Provider Edge). Si MPLS soportara características y arquitecturas como MPLS VPN s o ingeniería de trafico MPLS (MPLS TE), ésta deberá implementarse como parte fundamental del diseño de la red, lo cual significa que debemos estar seguros que todos los dispositivos involucrados soporten funcionalidades avanzadas de MPLS. Los equipos del cliente (CE) generalmente no necesitan soportar MPLS y no necesitan tener habilitado MPLS en sus interfaces. La conmutación MPLS es desarrollada en la red del proveedor, sin embargo algunas funcionalidades avanzadas como Carrier-Suport-Carrier (CSC) requieren que los equipos del cliente (CE) también soporten MPLS. Esto se ilustra en la Figura
53 Figura 4.1 Conexiones MPLS 4.1 Que es MPLS? MPLS es un mecanismo de envío, en donde el proceso de envío de paquetes se basa en etiquetas. Las etiquetas pueden corresponder a la IP de destino u otro parámetro como el marcado de QoS o la dirección de origen. MPLS está diseñado también para soportar el envío de otro protocolo de ruteo. Con MPLS habilitado en la red, los equipos asignan etiquetas a rutas definidas llamadas Label Switched Path (LSP) entre puntos finales. Gracias a esto, el proceso de ruteo es llevado acabo solo en los equipos frontera (PE) de la red. En una red ATM con MPLS habilitado, los Switches ATM tienen noción de IP y pueden correr protocolos de ruteo. Las etiquetas MPLS son establecidas dinámicamente basadas en información de capa 3. Cuando MPLS es habilitado, los Switches ATM intercambian etiquetas en formato ATM para redes de capa 3 y más allá, crean una topología Full-Mesh entre equipos finales (LSP) basados en información de capa 3. Ahora con los Switches ATM habilitados con MPLS se pueden realizar procesos óptimos de ruteo a lo largo de la red. La funcionalidad de MPLS configurada en los equipos, puede ser dividida en dos partes; el nivel de control y el nivel de datos. El nivel de control intercambia información de ruteo de capa 3 así como etiquetas. Algunos protocolos de ruteo como OSPF, EIGRP, IS-IS y BGP pueden ser usados en el nivel de control. El protocolo de capa 3 es usado para propagar información de ruteo. En este caso OSPF es usado para distribuir información de accesibilidad de capa 3 recibiendo y enviando actualizaciones de ruteo. El mecanismo de intercambio de etiquetas Label Distribution Protocol (LDP) simplemente propaga etiquetas que son usadas por destinos de capa 3. En éste ejemplo el LDP propaga la base de información de etiquetas, Label Information Base (LIB), en especifico recibe la etiqueta 17 que es usada para paquetes con dirección de destino 10.x.x.x. 47
54 El nivel de datos es un simple algoritmo de envío basado en etiquetas que es independiente del protocolo de ruteo y del mecanismo de intercambio de etiquetas. La base de información de envío de etiquetas (LFIB) es usada para enviar paquetes basados en etiquetas. Este es propagado por el protocolo de intercambio de etiquetas usado en el nivel de control. La etiqueta generada por el LDP es guardada en la base de información de etiquetas (LIB). Puesto que la etiqueta es de un equipo adyacente, ésta es propagada en la base de información de envío de etiquetas ( LFIB). Una etiqueta local es generada y enviada a los equipos vecinos. 4.2 MPLS VPN de capa 2 La Tecnología MPLS VPN de Capa 2 es usada para proporcionar VPN s encapsulado la trama completa VPN -no los paquetes de capa 3-, con el uso de etiquetas MPLS. Estas son usadas para enviar las tramas a través del backbone MPLS. Las VPN s MPLS de capa 2 son implementadas en escenarios punto a punto y soportan una propagación transparente de protocolos de capa 2 de OSI, como pueden ser Frame-Relay, ATM, PPP, HDLC, y Ethernet. Conexiones multipunto de capa 2 pueden ser establecidas para crear VLAN s a través del backbone MPLS. 4.3 MPLS VPN de capa 3 La tecnología MPLS VPN de capa 3 provee la funcionalidad de VPN multipunto con el direccionamiento directo entre dispositivos del cliente y equipos del proveedor. La privacidad es implementada usando tablas de ruteo para cada VPN que evita que diferentes VPN puedan comunicarse entre si. MPLS VPN de capa 3 provee un óptimo envío dentro del Backbone MPLS. Las VPN tradicionales requieren una conectividad Full-Mesh para proporcionar el mismo servicio. MPLS VPN de capa 3 proporciona soporte para Ipv4, los equipos del cliente (CE) pueden usar algún protocolo de ruteo o usar ruteo estático para intercambiar información con el equipo del proveedor (PE). Multiprotocol BGP es usando dentro del Backbone MPLS para transportar información de ruteo de las VPN s de los clientes a lo largo de la red. Como se puede ver en la Figura
55 Figura 4.2 MPLS VPN de capa Ingeniería de trafico MPLS (MPLS TE) La ingeniería de trafico MPLS (MPLS TE) es usada para optimizar los recursos dentro de la red, alineando el flujo de trafico entre los equipos usando enlaces redundantes y rutas desiguales. MPLS TE puede ser usada también con otros mecanismos de calidades de servicio (QoS) para garantizar ancho de banda entre equipos finales y retardos garantizados para cada tipo de tráfico dentro de la VPN. Adicionalmente MPLS TE provee mecanismos de rápida recuperación (FastreRoute) en caso de caídas de enlaces o problemas en la ruta. En la Figura 5.3 se puede apreciar lo dicho anteriormente. Figura 4.3 Ingeniería de trafico MPLS (MPLS TE) MPLS TE puede ser benéfico para todas las tecnologías y/o aplicaciones que requieran un ancho de banda, delay, jitter garantizado, mapeando eficazmente los recursos existentes. MPLS TE no amplia el ancho de banda y no reduce los problemas relacionados con la insuficiencia de recursos en la red pero ayuda a eficientar el mapeo de todos estos recursos especialmente con las rutas redundantes. Con la introducción de diferenciación de servicios (DiffServ), y concientes del ancho de banda garantizado que soporta MPLS TE, específicos DSCP o IP Precedence pueden ser mapeados en túneles específicos de MPLS TE, estos 49
56 túneles pueden ser opcionalmente usados con ancho de banda estrictamente garantizado a través del Backbone MPLS. MPLS TE y QoS son mecanismos que pueden ser usados en conjunto dentro de la red MPLS garantizando ancho de banda, delay y jitter para aplicaciones altamente demandantes. Múltiples servicios pueden ser implementados individualmente o en combinación. MPLS permite a una sola red ser usada para proveer servicios de acceso a Internet, MPLS VPN s de capa 2, MPLS VPN de capa 3; MPLS también mejora todos estos servicios ofreciendo QoS y optimizando la utilización de recursos dentro de la red. Figura 4.4 Beneficios MPLS Comparada con la topología VPN tradicional como ATM o Frame-Relay, MPLS VPN de capa 3 proporciona una mayor escalabilidad en términos de operación (envío de paquetes a través de la ruta más optima) y administración (agregando y removiendo enlaces del cliente). Agregar un nuevo Site a la red MPLS VPN de capa 3 solo requiere cambios en la configuración en un solo equipo del proveedor (PE), el protocolo de ruteo debe tener cuidado en la construcción de un nuevo LSP. Agregar un nuevo Site en la topología tradicional VPN requiere cambios en todos los Switches ATM/FR involucrados así como en los equipos del cliente. Esto se ilustra en la Figura
57 Figura 4.5 MPLS VPN de capa 3 contra VPN Tradicional. 4.5 Beneficios de MPLS para proveedores de servicio MPLS es una tecnología que inicialmente encontró aplicación en redes de proveedores de servicio. Esto permitió a ISP s ofrecer nuevos tipos de servicios como MPLS VPN de capa 3 así como servicios tradicionales como ATM o Frame- Relay usando MPLS VPN de capa 2. Las MPLS VPN de capa 3 permiten una fácil implementación en topologías complejas como la sobre-posición de VPN, Extranets, VPN s con servicios centralizados, administración de VPN s y algunos otros. Estas topologías de VPN son mas difíciles de implementar usando tecnología tradicional de capa 2 como ATM o FR. Los servicios de MPLS VPN pueden ser integrados con otros servicios como acceso a Internet, acceso a Internet a través de Firewall, acceso remoto basado en IPSec, acceso por dial-up y administración centralizada para servicios IP como por ejemplo DNS, DHCP y Web-Hosting para las VPN s. Los siguientes son ejemplos de cómo una MPLS puede ser usada dentro de una red corporativa; - Optima utilización del ancho de banda de los enlaces a través de MPLS TE. - Una mejora en los tiempos de convergencia en caso de falla en los enlaces usando MPLS TE y MPLS Fast-reRoute. - MPLS VPN de capa 2 puede ser usado para extender la red actual usando enlaces existentes de capa 2 como ATM o FR. - MPLS VPN de capa 3 ayuda a segmentar una red plana en segmentos mas pequeños mejorando la administración, ofreciendo una mayor seguridad aislando estos segmentos en VPN s separadas. - MPLS VPN de capa 3 permite reducir la complejidad de la topología WAN eliminado las conexiones punto a punto y permitiendo la comunicación de cualquiera a cualquiera dentro del Backbone. 51
58 - Esto permite a las redes corporativas ofrecer servicios a todos sus departamentos como Extranets y compartir recursos, convirtiéndose así en un proveedor de servicios. Adicionalmente sí una red corporativa está usado servicios MPLS a través de un ISP, se puede considerar administrar sus propios equipos o dejar que el ISP lo haga. Los siguientes son algunas de las ventajas de usar servicios basados en MPLS sobre VPN s tradicionales de capa 2; - MPLS VPN de capa 3 ofrece una conexión IP de cualquiera a cualquiera sin costo adicional, no hay costo por PVC ni por largas distancias. - MPLS VPN de capa 2 y 3 pueden ser escaladas utilizando mecanismos avanzados de QoS. - MPLS VPN de capa 2 ofrece servicios similares para redes ATM o FR y algunos otros servicios de capa 2, Ethernet, PPP, etc. - MPLS VPN de capa 3 soporta la integración compleja de topologías de VPN, Internet, Extranet, centralización de servicios, acceso a Internet, administración e integración de VPN basada en IPSec. - MPLS VPN de capa 3 reduce el costo de operación de una red corporativa pudiendo delegar la administración al proveedor de servicios, administrando tanto los equipos (CE), como el direccionamiento y servicios (ejemplo DNS), etc. La administración de servicios puede reducir el costo de operación para redes en empresas pequeñas y medianas, la implementación de VPN en los Sites del cliente provee conexiones Ethernet así como algunos otros servicios IP relacionados; - asignación de direccionamiento por medio de DHCP. - DNS - Ruteo. - QoS. - Seguridad. - Acceso a Internet. La administración propia es usada principalmente en empresas donde las políticas internas obligan la administración de la red por parte del departamento de redes interno, principalmente por razones de seguridad, por lo que requieren la administración de los equipos (CE), así mismo la posibilidad de conectar a múltiples proveedores de servicio por lo que el ruteo se vuelve complejo. 52
59 4.6 Ruteo IP tradicional El proceso de ruteo es efectuado en cada unos de los equipos involucrados, así, cada equipo en la red realiza decisiones independientes para el envío de paquetes, MPLS ayuda a reducir el numero de procesos de ruteo y la posibilidad de cambiar los criterios para el envío. Con IP sobre una red ATM, es posible que las topologías de capa 2 y 3 no concuerden, porque los dispositivos de capa 2 contienen información estática de como están interconectados con dispositivos de capa 3. Esto lleva procesos ineficientes de ruteo y a una sobre-utilización de ancho de banda. Los protocolos de ruteo, excepto EIGRP, no soportan el balanceo de tráfico sobre enlace asimétricos, -rutas desiguales-, resultando en la sobre-utilización del enlace primario mientras que el secundario permanece sin uso. El ruteo IP tradicional no proporciona un mecanismo escalable que permita la utilización del ancho de banda del enlace de respaldo. Las políticas basadas en ruteo (Policy-Based Routing) pueden ser usadas para el envío de paquetes basado en otros parámetros, pero no es posible en redes con alto volumen de tráfico. 4.7 Modos de operación de MPLS MPLS está diseñado para usar virtualmente cualquier medio y encapsulamiento de capa 2, la mayoría de los encapsulamientos están basados en tramas. Con MPLS basado en tramas un encabezado de 32 bits es insertado entre los encabezados de capa 2 y 3. MPLS sobre ATM es un caso especial porque puede usar un modo de tramas o la etiqueta puede ser insertada dentro del encabezado ATM de cada celda. En MPLS en modo de trama, cuando el equipo frontera (PE) recibe un paquete IP normal, se realiza el proceso de ruteo. La tabla de ruteo muestra que la etiqueta puede ser adjuntada al paquete, la etiqueta pues, es insertada entre el encabezado de la trama de capa 2 y el encabezado de capa 3, el paquete etiquetado es enviado. Ver figura 5.6. Figura 4.6 Etiqueta MPLS. En MPLS en modo de celda, el encabezado ATM identificador de Ruta Virtual VPI y el identificador de Canal Virtual (VPI/VCI), son usados para mantener las etiquetas y realizar decisiones de envío. El encabezado original MPLS de 32 bits es conservado en la trama pero no es usado en el proceso de conmutación de etiquetas. Esto se ilustra en la figura
.")
60 Figura 4.7 Encabezado ATM. 4.8 Formato de etiquetas MPLS. MPLS utiliza un encabezado de 32 bits que contiene la etiqueta, un campo experimental, el indicador de botton-of-stack y un campo TTL (time to live). El encabezado de 32 bits de MPLS inicia con una etiqueta de 20 bits que tiene un significado local, el cual puede cambiar con cada salto. El campo experimental de 3 bits actualmente es utilizado para definir la clase de servicio, de forma similar al IP Precedence para el paquete IP. Por default, los equipos Cisco copian automáticamente el valor del IP Precedence a éste campo durante la colocación de la etiqueta adjunta al paquete IP- y la copia de nueva cuenta del campo experimental al IP Precedence durante el retiro de la misma. Sin embargo éste comportamiento puede ser cambiado con adición de políticas de QoS. MPLS permite que varias etiquetas puedan ser insertadas. El bit indicador de botton-of-stack es usado para identificar sí la etiqueta es la última antes del encabezado IP. El bit en la última etiqueta del paquete es puesto en 1. Un campo TTL de 8 bits es usado para prevenir que un paquete esté viajando en la red indefinidamente. El campo TTL es decrementado en cada salto. Ver figura 5.8. Figura 4.8 Formato de etiqueta MPLS. 54
61 4.9 Tipos de etiquetas. Existen dos tipos de etiquetas utilizadas por los equipos; Label Switched Routers (LSR); Etiquetas LSR fronterizas que son posicionadas en los límites del dominio MPLS. Las funciones principales son etiquetar los paquetes y enviarlos dentro del dominio MPLS o remover etiquetas y enviar los paquetes fuera del dominio MPLS. El modo de celda MPLS utiliza LSR ATM. El equipo ATM fronterizo, segmenta los paquetes en celdas y asigna la etiqueta en el campo VPI/VCI del encabezado ATM o reensambla las celdas ATM formado paquetes. Etiquetas LSR existen dentro del Backbone MPLS. Las funciones principales son enviar paquetes etiquetados cambiando la etiqueta. Ambos equipos LSR frontera y de Backbone, son capaces de conmutar los dos tipos de etiquetas además de funciones de ruteo IP. El equipo de Backbone tiene todas sus interfaces habilitadas con MPLS mientras que el frontera tiene algunas interfaces que no se habilitan. Esto se muestra en la figura Figura Envío MPLS. Figura 4.9 Dominio MPLS El envío MPLS se basa en el intercambio de etiquetas. Un equipo habilitado con MPLS puede cambiar, insertar o remover etiquetas. En la frontera del dominio MPLS, la inserción de la etiqueta se realiza cuando el equipo frontera LSR efectúa el proceso creación de la tabla de ruteo y asigna o inserta la etiqueta 23 al paquete. El paquete es enviado hacia los LSR en el Backbone. Los equipos LSR en el centro del dominio aceptan el paquete con la etiqueta de 23 y la cambian basándose en el contenido de la tabla de envío de etiquetas (LFIB). El paquete es enviado con una nueva etiqueta de 25. Los equipos frontera de salida, quitan ésta etiqueta y realizan el proceso de ruteo enviando el paquete hacia fuera del Backbone MPLS. Esto se ilustra en la Figura
62 Figura 4.10 Intercambio de etiquetas MPLS 4.11 Arquitectura MPLS Unicast Antes del proceso de ruteo y entrega de paquetes, la ruta a través de la red conocida como LSP (Label Switched Path) deberá ser creada por medio del intercambio de información de ruteo y etiquetas entre equipos adyacentes. La siguiente figura 5.11a muestra los bloques de información creados por los equipos habilitados con MPLS. El nivel de control contiene el protocolo de ruteo que intercambia información de ruteo y mantiene las tablas actualizadas. Esto combina CEF (Cisco Express Forwarding), la tabla de ruteo IP o la Base de Información de Envío (Forwarding Information Base) FIB en el nivel de datos para crear la FEC. El protocolo de distribución de etiquetas LDP en el nivel de control, intercambia etiquetas y las guarda en la Base de Información de Etiquetas (LIB). La información en la LIB es usada después para propagar información por el nivel de datos y ofrecer funcionalidades de MPLS. En el nivel de control las etiquetas son asignadas por el equipo del siguiente salto y agregadas en la FIB. Las etiquetas generadas localmente son agregadas a la Base de Información de Envío de Etiquetas (LFIB) como etiquetas de entrada. Las etiquetas asignadas por el router del siguiente salto son agregadas como etiquetas de salida. Sí el equipo recibe un paquete IP donde la tabla FIB indica que la dirección de destino del paquete tiene una etiqueta asignada, el paquete será enviado como un paquete IP etiquetado. Cuando el paquete ha llegado al último equipo de la red MPLS, la etiqueta es removida y éste es enviado como un paquete IP tradicional. Esto se 56
63 Figura 4.11 Arquitectura MPLS Unicast La figura 5.12 muestra un escenario donde el paquete IP es enviado exitosamente usando la tabla FIB. Por otro lado los paquetes etiquetados no son enviados debido a la perdida de información en la tabla LFIB. Una función normal de MPLS previene que esto pase, ya que ningún equipo adyacente usara una etiqueta a menos que éste equipo lo haya anunciado previamente. El ejemplo ilustra que la conmutación de etiquetas solo tratará de usar la tabla LFIB sí el paquete de entrada está etiquetado, incluso sí la dirección de destino es alcanzable usando la tabla FIB. Figura 4.12 Tabla FIB La siguiente Figura 5.13 muestra a un router donde OSPF es usado para intercambiar información de ruteo y LDP es usado para intercambiar etiquetas. Un paquete IP de entrada es enviado usando la tabla FIB, donde la etiqueta del siguiente salto indica que el paquete de salida deberá ser marcado con una etiqueta de 3. Un paquete de entrada etiquetado es enviado usando la tabla LFIB, donde la etiqueta 5 (significado local) es cambiada por la etiqueta 3 del siguiente salto. 57


64 4.12 Mensajes LDP Hello Figura 4.13 Intercambio de información a través de OSPF Cuando MPLS es habilitado en un equipo, TDP y LDP automáticamente trataran de encontrar vecinos utilizando mensajes Multicast y estableciendo sesiones TCP con los vecinos encontrados. Los mensajes Hello utilizan paquetes UDP con la dirección Multicast hacia todos los equipos alcanzables a través de la interfaz. El puerto UDP y TCP 646 es usado por LDP, el puerto 711 es usado por TDP. El mensaje Hello puede contener la dirección de transporte Type-Lengh-Value (TLV), que solicita al vecino a abrir una sesión TCP para la dirección de transporte, en lugar de la dirección de origen que es encontrada en el encabezado IP. El indicador LDP de 6 bytes es usado para identificar a un vecino y el espacio para la etiqueta. Sesiones múltiples pueden establecerse entre dos equipos (LSR) sí ellos utilizan múltiples espacios de etiquetas. Esto se ilustra en la figura Figura 4.14 Mensajes LDP Hello 58
65 4.13 Espacio de etiquetas La Figura 5.15 ilustra como tres de cuatro routers habilitados con MPLS tratan de encontrar vecinos enviando mensajes periódicos Hello vía UDP. Los mensajes Hello solicitan al peer abrir una sesión TCP para la dirección de transporte Transport Address TLV. A menos que otra cosa sea especificada, el router ID LDP es anunciado como dirección de transporte en el mensaje LDP Discovery Hello. Los equipos con la dirección IP más alta inician la sesión TCP. Después de que la sesión TCP se ha establecido, se intercambian etiquetas y se continúa enviando los mensajes LDP Hello para poder descubrir nuevos peers o fallas potenciales. Figura 4.15 Mensajes periódicos Hello vía UDP Negociación de la sesión LDP Una vez que los mensajes Hello han sido intercambiados se crea la sesión LDP entre los dos equipos LSR, la sesión puede usar TCP para ofrecer una conexión fiable. Una vez que la sesión TCP se ha establecido, se intercambian mensajes de inicialización, los equipos LSR comienzan a enviar mensajes keepalive y una vez que el primer mensaje keepalive ha sido enviado, los equipos LSR pueden comenzar a intercambiar etiquetas para redes que se encuentren en su tabla de ruteo principal. Ver la figura
66 Figura 4.16 Intercambio de mensajes Keepalive Compatibilidad entre TDP y LDP Funcionalmente hablando TDP y LDP son equivalentes pero no compatibles. LDP soporta varias características como etiqueta explicita nula y vector de ruta (Path Vector TLV), que no son soportadas en TDP. Equipos con TDP y LDP no se pueden comunicar entre sí porque no usan un protocolo de distribución de etiquetas común. También no es aconsejable usar LDP y TDP en el mismo enlace, sin embargo durante la fase de migración, un dominio MPLS puede usar LDP en algunos enlaces y TDP en otros pero no LDP y TDP en uno solo. Un equipo LSR puede usar TDP y LDP en la misma interfaz para permitir el intercambio de etiquetas con equipos de otras marcas. Esto se muestra en la Figura Figura 4.17 Compatibilidad entre TDP y LDP 4.16 Establecimiento de LSP (Label-Switched Paths). Hay cuatro pasos generales en el establecimiento de las rutas de conmutación de etiquetas LSP. LDP y TDP son habilitados dentro de la red MPLS para intercambiar etiquetas asignadas a redes IP destino. LDP y TDP facilitan éste intercambio estableciendo sesiones TCP entre los equipos LSR adyacentes. Antes de que el LSP pueda ser creado, cada equipo LSR dentro del dominio MPLS deberá establecer canales de comunicación con sus equipos LSR vecinos. 60
67 El equipo LSR inicia éste proceso intercambiando mensajes Hello, una vez que el mensaje Hello ha sido intercambiado, la sesión TCP puede ser establecida entre cualquier equipo que tenga habilitado MPLS. La etiqueta MPLS puede entonces ser generada localmente por cualquier equipo LSR en el dominio y guardada en la LIB del equipo o en la tabla LFIB. Una vez que el equipo LSR genera la etiqueta local, éste la comparte con los equipos directamente conectados a él, quienes a su vez, colocan la etiqueta en su tabla LIB. Sí ésta etiqueta es del equipo del siguiente salto, también podrá ser colocada en las tablas FIB y LFIB del equipo. Esto se ilustra en la siguiente figura Figura 4.18 Establecimiento de LSP 4.17 Asignación, distribución y retención de etiquetas Construcción de la tabla de ruteo IP. La asignación y distribución de etiquetas en el modo MPLS por paquete, sigue los siguientes pasos: - Los protocolos de ruteo construyen la tabla de ruteo IP. - Cada equipo LSR (Label Switched Router) asigna una etiqueta local a cada red destino independiente encontrada en la tabla de ruteo. - Cada LSR anuncia sus etiquetas asignadas localmente a todos los equipos LSR usando LDP o TDP. - Cada equipo LSR construye su propia base de información de etiquetas Label Information Base (LIB), la base de información de envío de etiquetas Label Forwarding information Base (LFIB) y la base de información de envío Forwarding Information Base (FIB), basadas en la etiquetas recibidas. Los protocolos de ruteo IP son utilizados para crear la tabla de ruteo en todos los equipos LSR. Estas tablas son creadas usando información IP sin información de las etiquetas. Todos los equipos en la red aprenden la red X vía IGP usando OSPF, IS-IS, o EIGRP. 61
68 La tabla FIB en el router A en la figura 5.19 muestra que la red X es mapeada a la dirección IP del siguiente salto hacia el router B, al mismo tiempo la etiqueta para alcanzar la red X no está disponible para el router B, lo que significa que todos los paquetes con destino a la red X serán enviados como paquetes IP no etiquetados Asignación de etiquetas Figura 4.19 Tabla FIB Cada equipo LSR asigna una etiqueta local a cada red destino encontrada en la tabla de ruteo IP, las etiquetas locales son asignadas asyncronamente. El router B genera una etiqueta con significado local y único de 25, la cual es asignada a la red IP destino X, el router B asigna ésta etiqueta independiente a los otros equipos en la red. Cuando la etiqueta es asignada a un prefijo IP, ésta es guardada en las tablas LIB y LFIB del router. La tabla LIB es utilizada para mantener un mapeo entre el prefijo IP, en éste caso la red X, la etiqueta local 25, y las etiquetas actualmente no disponibles asignadas para alcanzar éste prefijo por los vecinos LDP y TDP. La tabla LFIB es modificada para contener la etiqueta local mapeada, removiendo la etiqueta, lo que significa que la etiqueta es removida de los paquetes de datos para ser enviados hacia la red X como paquetes no etiquetados. La acción de remover la etiqueta es usada hasta que la etiqueta de salida hacia la red X es recibida por el equipo del siguiente salto usando LDP o TDP. 62
69 Figura 4.20 Asignación de etiquetas 4.18 La publicación de las Tablas de Ruteo VPN El backbone de la Tecnología MPLS VPN Para operar en todos los niveles, los equipos frontera PE (provider-edge, por sus siglas en inglés) deben mantener un numero de tablas de ruteo (ver figura 1 en anexo). Los equipos PE soportan diversas peticiones de ruteo usando un número de tablas de ruteo IP. La tabla de ruteo global IP, la tabla de ruteo IP que está siempre presente en los ruteadores basados en el IOS, aún cuando no esta corriendo la conmutación de etiquetas MPLS VPN, contiene todo el corazón de las rutas que son insertadas por el Protocolo de Gateway Interior (IGP), y las rutas de Internet que son insertadas desde la tabla IPv4 BGP global. Las tablas VRF (Virtual Routing Routing) contienen conjuntos de rutas de sitios con los mismos requerimientos de ruteo. Las VRF s son llenadas con la información intercambiada de la Intra-VPN IGP con el CE (Costumer-Edge) y con las rutas VPNv4 recibidas a través de las sesiones MP-BGP desde los otros ruteadores PE (provider-edge) Conceptos de la Familia de Direcciones sobre los Protocolos de Enrutamiento Los protocolos de enrutamiento entre equipos frontera (PE) y equipos del cliente (CE), necesitan ser configurados como VRF s individuales, es decir, como sitios en la misma VPN. Las diferentes VRF s no pueden compartir el mismo protocolo de enrutamiento PE-CE, por lo que los protocolos de enrutamiento por VRF pueden ser configurados en dos maneras: como familias de direcciones 63
70 individuales pertenecientes al mismo proceso de enrutamiento o como procesos separados para cada VRF. El contexto de enrutamiento de las VRF es seleccionado con el comando address-family ipv4 vrf name en los procesos de enrutamiento RIP, BGP y EIGRP. Todos los parámetros del protocolo de enrutamiento de las VRF tales como el número de redes, interfaces pasivas, vecinos, y los filtros son configurados en ésta familia de de direcciones Como configurar los Protocolos de Enrutamiento de un PE-CE Para configurar enrutamiento estático dentro del protocolo de enrutamiento PE- CE, se puede seguir los siguientes pasos: Paso 1 - Configurar rutas estáticas por VRF. ip route vrf - Redistribuir las rutas estáticas VPN en MP-BGP Paso 2 router bgp as-number address-family ipv4 vrf-name redistribute static - Configurar una ruta estática predeterminada hacia el ruteador PE. ip route Solo RIPv2 es soportado como protocolo de enrutamiento PE-CE Tabla de Envió y Enrutamiento Virtual (VRF) Una VRF (Virtual Routing and Forwarding) es el enrutamiento y envió para un conjunto de dispositivos con requerimientos de conectividad idéntica. Las VRF abarcan una tabla de ruteo IP, idéntica en su función a la tabla de enrutamiento IP en IOS, las tablas de envió de Cisco (CEF, Cisco Express Forwarding) y especificaciones de protocolo de enrutamiento corren desde las VRF s. El IOS tradicional de Cisco puede soportar diferentes protocolos de ruteo, en algunos casos separar completamente una copia del mismo protocolo de ruteo (por ejemplo, varios procesos OSPF ó EIGRP). Para algunos protocolos de ruteo como RIP ó BGP, el IOS soporta solo una copia del protocolo habilitado en el equipo. 64
71 Estos protocolos no pueden ser usados directamente entre equipos PE y CE en VPN, como cada VPN necesita uno diferente, la copia incomunicada del protocolo de ruteo previene filtración indeseada de rutas entre VPNs. Además las VPNs pueden usar el traslape de direcciones IP, por ejemplo cada VPN podría usar subredes de red , que podrían llevar a confusiones de ruteo, sí todas las VPNs comparten la misma copia del protocolo de ruteo. Esto se muestra en la figura Figura 4.21 Envió y Enrutamiento Virtual (VRF) Como inicializar las tablas de enrutamiento VPN Para inicializar la tabla de ruteo VPN, se deben seguir los siguientes pasos: Crear una VRF. Ip vrf vrf-name Asignar la ruta mas distinguida al VRF. rd route-distinguisher Especificar los objetivos a exportar e importar route-target {import export both }route-target-ext-community Asignar interfaces a VRF Ip vrf forwarding vrf-name 4.20 Crear nuevas VRF Para configurar una tabla de ruteo VRF debe usar el comando ip vrf en el modo de configuración global. Para remover la tabla de ruteo debe usar no antes del comando. A continuación se muestran los pasos a seguir: Router(config)#ip vrf vrf-name Router(config-vrf)#rd route-distingisher 65
72 Router(config-vrf)#route-target{import export both}route-target-ext-community Router(config-if)#ip vrf forwarding vrf-name En algunos casos de red VPN, el router PE soporta dos clientes de VPN. En el siguiente ejemplo el cliente A tiene cinco áreas y esta usando BGP y RIP con el proveedor de servicios. El cliente B tienes dos áreas y usa solo RIP. Ambos clientes usan la red Para ilustrar el uso de los comandos de configuración MPLS-VPN, configuraremos el equipo PE en una muestra de red con dos clientes VPN. Primero las VRFs son configuradas para el cliente A y B usando el comando ip vrf. Después, el route distiguiser y el route-target son asignados a las VRFs. Como estos clientes solo requieren simple conectividad VPN, el mismo route distiguiser será utilizado para un mismo cliente en cada equipo PE sobre el backbone MPLS- VPN. Para simplificar la configuración el route-target es configurado del mismo modo que el route distiguiser. Finalmente las interfaces del lado del proveedor son asignadas a la nueva VRF. Figura 4.22 Creación VRF 4.21 Interacción entre BGP y VRF El proceso de BGP sobre MPLS en un equipo con capacidad para VPN realiza 3 tareas diferentes. - BGP puede ser usado como el protocolo entre equipos proveedor y equipos cliente para intercambiar las rutas VPN entre los equipos frontera y cliente. - Las rutas VPNv4 son propagadas a través del backbone MPLS-VPN usando el protocolo BGP entre los equipos del proveedor. - Independientemente de la arquitectura de MPLS VPN, el equipo proveedor también puede usar BGP Externo (EBGP) para recibir y propagar en escenarios donde el equipo proveedor e también usado para proveer conectividad de internet a los clientes. 66
73 Los tres mecanismos de intercambio son ocupados en un proceso con BGP, y como solo se puede configurar un proceso BGP por equipo, se usan las familias de direcciones para configurar todos los 3 diferentes mecanismos de intercambio. Las rutas recibidas de instancias de protocolos con VRF o de procesos de ruteo con VRF dedicadas son agregadas en las tablas de ruteo IP contenidas sin la VRF. La tabla de envío por VRF, es entonces construida de tablas de ruteo de cada VRF y es usada para transmitir todos los paquetes recibidos a través de las interfaces asociadas con la VRF. Al igual que los equipos con RIP, los equipos del cliente configurados con BGP anuncian sus redes a través de sesiones de EBGP al equipo frontera. Los vecinos BGP de los clientes son asociados con VRF s individuales en el equipo frontera, esto permite varias instancias de procesos de rotueo BGP para poner actualizaciones en la tabla de ruteo para cada VRF correspondiente. Debería de haber una sobre escritura entre una actualización RIP y una actualización EBGP, los mecanismos de selección de ruta estándar y la distancia administrativa son usados en la tabla de ruteo IP por la VRF, la ruta BGP toma la precedencia sobre la ruta RIP. MP BGP es usado en el backbone MPLS VPN para transferir las rutas VPN, los prefijos con un diferenciador de ruta como el 96-bit VPNv4 entre los equipos frontera. El proceso backbone de BPG parece exactamente igual a un proceso de instalación IBGP estándar desde la perspectiva de las VRF. Las rutas RIP por VRF por lo tanto tiene que ser redistribuidas en la instancia de la VRF del proceso BGP para permitirles ser propagadas a través del backbone PM-BGP hacia otros equipos frontera. Las rutas RIP que son distribuidas a la instancia de la VRF en el proceso de BGP así como las rutas BGP recibidas desde equipos configurados con BGP son copiadas dentro de la tabla MP-BGP para ser propagadas posteriormente hacia otros equipos frontera. A esto se le llama Exportar. Como el otro equipo frontera inició generando rutas VPNv4, en nuestro equipo frontera el proceso MP-BGP recibirá estas rutas. Los equipos son filtrados en base a una ruta a seguir y los atributos son adjuntados a ellos e insertados dentro de la propia tabla de ruteo de VRF basado en la ruta de importación configurada para VRF s individuales. Los diferenciadores de ruta que fueron preparados por equipo frontera de origen, son removidos antes de que la ruta sea insertada en la tabla de ruteo de la VRF. Este proceso de inserción es llamado oficialmente importación. Las rutas VPNv4 MP-IBGP recibidas de otro equipo frontera y las seleccionadas por el importador de rutas de la VRF son propagadas de manera automática como rutas IPv4 hacia todos los vecinos de los equipos cliente configurados con BGP de cada equipo frontera. Las mismas rutas, aunque sean agregadas a la tabla de ruteo por VRF, no son propagadas automáticamente en los equipos cliente configurados con RIP. Para propagar estas rutas a los clientes configurados con RIP, la redistribución debe ser 67
74 configurada manualmente entre las instancias de las VRF de BGP y las instancias de las VRF de RIP. Cuando las rutas IBGP de las tablas de ruteo IP de VRF son exitosamente distribuidas a las instancias de VRF del proceso RIP, RIP anuncia estas nuevas rutas a los equipos cliente configurados con RIP, de tal manera que la conectividad es transparente de punto a punto entre los equipos cliente. Los equipos frontera reciben paquetes IPV4 de los equipos cliente y los separa en la instancia de la VRF apropiada. Las rutas cliente de la tabla de VRF son exportadas como rutas de la VPNv4 a MP-BGP y son propagadas a otros equipos frontera. Las sesiones MP-BGP entre los equipos frontera son por lo tanto, sesiones BGP interno (IBGP) y son sujetas a las reglas de Split horizon de IBGP. Por lo tanto se requiere un acoplamiento completo entre las sesiones MP-IBGP de los equipos frontera o se pueden usar redundancias para reducir los requerimientos de acoplamiento IBGP. La arquitectura MPLS/VPN soporta también sesiones de MP- EBGP (Multiprotocol BGP). Los equipos frontera reciben los paquetes MP-BGP e importan las rutas VPNv4 a las VRF s basadas en las rutas etiquetadas agregadas a las rutas VPNv4 entrantes, e importaran las rutas etiquetadas configuradas en las VRF. Las rutas VPNv4 instaladas en las VRF son convertidas a IPv4 y luego propagadas a los equipos cliente. Las direcciones de actualización VPNv4 propagadas en el MP-BGP están compuestas de un diferenciador de ruta de 64-bit s y una dirección IPv4 de 32- bits s del cliente. Las direcciones VPNv4 son una versión expandida de 96-bits de las direcciones IPv4 usadas para la propagación de información de ruteo. El Diferenciador de Ruta (RD) es la parte extendida la cual habilita a los equipos frontera para diferenciar entre los posibles traslapes de rutas de actualización de las diferentes VPNs. El formato de prefijo de VPNv4 permite un solo protocolo de ruteo (ej. MP- BGP) para transportar la información de ruteo a múltiples VPNs. El formato del diferenciador de ruta es similar al formato de la comunidad atributos extendidos de BGP. VPN MPLS usa un apilado de etiquetas, la primera etiqueta es usada para alcanzar la salida del router frontera y la segunda etiqueta (etiqueta VPN) es asignada por la salida de equipo frontera para su operación MPLS VPN apropiada. Las etiquetas de VPN tienen que ser propagadas entre los equipos frontera para habilitar el envío de paquetes. MP-BGP fue escogido como el mecanismo de propagación. Todas las actualizaciones MP-BGP llevan una etiqueta asignada por la salida del equipo frontera junto con el prefijo de 96-bit VPNv4. Los equipos frontera asignan una etiqueta a cada ruta VPN recibida por el equipo del cliente y para cada resumen de rutas dentro del equipo frontera. Esta etiqueta es usada como una segunda etiqueta en el apilado de etiquetas de MPLS por el ingreso a los equipos frontera cuando VPN empaqueta las etiquetas. Las etiquetas 68
75 de VPN son asignadas localmente por el equipo frontera que pueden ser revisadas mediante el comando tag-switching fowarding vrf. Las etiquetas de VPN asignadas por la salida de los equipos frontera son comunicadas a todos los equipos frontera junto con los prefijos VPNv4 en las actualizaciones MP-BGP. Estas etiquetas VPN pueden ser revisadas en el comando show ip bgp vpnv4 all tags en el equipo frontera de ingreso. Los equipos que tienen una etiqueta de entrada pero no etiqueta de salida, son las rutas recibidas desde el equipo cliente. Las etiquetas de entrada fueron asignadas por el equipo frontera local. Las rutas con una etiqueta de salida pero no etiqueta de entrada son las rutas recibidas por el equipo frontera. Las etiquetas de salida son asignadas por el otro equipo remoto frontera. El equipo frontera de ingreso tiene 2 etiquetas asociadas con etiqueta VPN remota para el siguiente salto de BGP (que es el equipo frontera de egreso) asignada por el siguiente salto al equipo vía Protocolo de distribución de etiqueta (LDP), el cual es tomado de la etiqueta de información base (LIB) así como de la etiqueta de VPN asignada por el equipo frontera remoto (egreso) y propagada por las actualizaciones de MP-BGP. Ambas etiquetas son combinadas en el apilado de etiquetas e instaladas en las tablas de envío de la VRF. El apilado de etiquetas en la tabla de envío de la VRF puede ser revisada con el comando show ip cef vrf detail. La primera etiqueta en el apilado de etiquetas es la etiqueta TDP/LDP hacia la salida del equipo frontera y la segunda etiqueta es la etiqueta VPN anunciada por el equipo frontera de salida. Capítulo 5. Diseño de la configuración de una red MPLS para ofrecer servicios de VPN para Bassher Networks. 5.1 Estado actual La empresa Bassher Networks es una compañía dedicada a proveer de servicios digitales a los clientes, interconectando las diferentes instancias de los clientes por medio de Circuitos Virtuales Privados a través de Frame Relay. En este caso, para proporcional la conectividad de dos de sus clientes desde la Ciudad de México hasta Monterrey Nuevo León se tiene equipos en Guadalajara que sirvan de repetidores en la creación de los PVC. Para la creación del PVC del cliente Azul se asigna un DLCI igual a 120 entre el equipo CPE y el equipo frontera ubicado en la Ciudad de México, este a su vez, se acuerdo a la disponibilidad de los circuitos disponibles puede optar por realizar la conexión por medio de sus DLCI igual a 140 o 150, uno a la vez, para alcanzar al equipo de la nube ubicado en Guadalajara. Una vez en esta ciudad se podría alcanzar directamente el equipo frontera en Monterrey por medio de los DLCIs 160 o 170 dependiendo del caso o en caso de encontrarse saturado un enlace directo, 69
76 se tendría que saltar a su equipo homónimo en la misma ciudad para después alcanzar el equipo frontera deseado. Una vez en el equipo frontera en Monterrey se tiene un DLCI igual a 180 hacia el equipo CPE ubicado ya en el edificio corporativo del cliente. En forma similar se puede describir la conexión del equipo Verde a través de la nube del proveedor. Se cuenta con un DLCI de 130 en el equipo del cliente ubicado en la oficina en la Ciudad de México y el equipo frontera también ubicado en la Ciudad de México, desde este equipo en adelante se utiliza la misma infraestructura utilizada para dar servicios al cliente Azul, es decir se cuenta con dos DLCIs hacia dos equipos en la ciudad de Guadalajara y de ahí se cuenta con otros dos DLCI hasta el equipo frontera en la Ciudad de Monterrey, teniendo en cuenta que se tiene un enlace entre los equipos de Guadalajara para dar redundancia al los circuitos en caso de ocurrir algún problema de corte de comunicación en la nube. Del equipo frontera ubicado en Monterrey se tiene un DLCI hacia el equipo CPE del cliente ubicado en su edificio Corporativo. De esta manera por cada sitio nuevo de cada cliente o por cada cliente nuevo es necesario la creación de un único PVC desde un equipo hasta el otro equipo del cliente siendo difícil su administración en cuanto a cambios de los clientes se refiere. Además de que para el cliente es necesario pagar por cada segmento del PVC, pagando así la larga distancia del enlace. Y por otra parte no tiene manera de proporcionar alguna preferencia a algún tipo de tráfico generado por lo que en ocasiones los servicios de voz del cliente se escuchan entrecortados. Para mayor regencia consulte el Anexo Diseño Diseño e implementación de las configuraciones de los clientes hacia el proveedor de servicios utilizando BGP como protocolo de ruteo para el anuncio de redes hacia la VPN. Diseño e implementación de QoS en los enlaces de acceso permitiendo diferenciar el tráfico de aplicaciones criticas para los clientes. Diseño e implementación de la infraestructura de Backbone del proveedor de servicios utilizando OSPF como protocolo de ruteo entre los equipos Backbone, dentro del área 4. MPLS como protocolo de distribución de etiquetas en el core y MPBGPv4 para el intercambio de información de ruteo entre equipos frontera ibgp. En la se muestra el esquema propuesto y los alcances en cuanto a las configuraciones definidas, las cuales involucraran cambios tanto en el PE como en CPE. 5.3 Implementación Implementación de la configuración de enlaces de RPV. Se contempla la elaboración de un laboratorio de pruebas utilizando el emulador Dynamips con 70
77 versiones de IOS 7200 de Cisco, implementado la topología de backbone del ISP así como el acceso de los clientes a la RPV. El escenario contempla la operación de 4 equipos 7200 dentro del Core del proveedor, dos clientes con un sitio remoto y un corporativo para cada uno, empleando igualmente equipos Se decidió por la utilización de OSPF como protocolo de ruteo para interconectar los 4 equipos de la red del proveedor (Backbone), ya que como protocolo de estado de enlace, cada equipo configurado con OSPF puede proporcionar una visión completa de la topología de la red y gracias a que las actualizaciones son desencadenadas solamente por cambios en la red, los tiempos de convergencia son relativamente mas rápidos comparados con cualquier protocolo de vector de distancia. Uno de los desafíos de trabajar con redes de proveedores de servicio (ISP) es que son redes complejas y de gran alcance, OSPF proporciona una escalabilidad que permite una expansión considerable sin la necesidad de realizar cambios que impacten a toda la red, con el manejo de áreas, OSPF confina los cambios asociados a una sola área. En nuestra implementación se utilizo una sola área (área 4), lo que nos permitió aislar el proceso de ruteo y las actualizaciones a solo 4 equipos, no limitando un futuro crecimiento sin impacto en la topología actual. Para mayor referencia véase el Anexo 2. Para la configuración de cada equipo del proveedor, se acceso al modo de configuración global y posteriormente se definió el ruteo OSPF con el comando router ospf 10, para nuestra implementación estaremos manejando el process ID 10 para todos los equipos de la nube y el segmento de red por lo que se configurará dentro del proceso de OSPF con el comando network área 4 esto nos permite confinar todo el proceso de ruteo de OSPF a una sola área. Una vez configurado OSPF dentro de los equipos, se procede a configurar las interfaces que estarán interactuando en éste proceso, se entra al modo de configuración de interfaz y se configuran las IP de cada interfaz, para las configuraciones de las interfaces loopback de los equipos con el comando interface loopback 0, se utilizara la IP para el equipo VPN_MEX, la para el VPN_GDL1, la para el VPN_MTY y la para el VPN_GDL2, todas con mascara de 32 bits, con el comando ip address x.x.x.x , esto nos ayudara a determinar, por un lado el DR (Designated Router) para OSPF y por el otro, las direcciones sobre las cuales se configuraran las vecindades para ibgp. En la parte de configuración de las interfaces se utilizará una mascara de 30 bits en conexiones punto a punto dentro del backbone debido a que solo permite dos direcciones por enlace, ahorrándose así direcciones disponibles, los comandos interface serial 0/X y ip address x.x.x.x y.y.y.y, nos ayudaran en este proceso. Para una mayor referencia del direccionamiento ver el Anexo 4. Debido a que se considero involucrar enlaces con tecnología ATM, fue necesario pensar en un protocolo que permitiera la convivencia entre ésta tecnología y 71
78 enlaces dedicados de FR y en algunos casos enlaces punto a punto con PPP. MPLS fue configurado ya que permite tomar dediciones de ruteo basados en etiquetas ruteando tanto tramas de capa 2 como paquetes de capa 3. Para nuestro desarrollo y debido a las limitantes del propio emulador, no se configuro ATM sobre ninguna interfaz. Tomando como referencia todas las interfaces que se interconectan con equipos dentro de la nube se configuró el tag-switching ip en cada equipo involucrado, esto nos permite habilitar la generación y asignación de etiquetas dentro de nuestro dominio MPLS. Para mayor referencia respecto a la configuración de los equipos ver el Anexo 4. Una problemática común en redes de clientes, es que la mayoría de ellos manejan un direccionamiento privado, esto quiere decir que, podemos encontrar miles de compañías manejando el mismo segmento de red. Partiendo de ésta problemática, se configuraron dos clientes manejando el mismo direccionamiento y al mismo tiempo se implementó una solución que permitiera recibir el mismo segmento de red en IPv4 de estos dos clientes y poderlos transportar a través de la nube hacia su respectivo destino por medio de VPNv4. Para este efecto se configuraron la sesiones de ibgp entre los equipos frontera (PE) VPN_MEX y VPN_MTY. De lado de MEX se configuró el BGP con router bgp 10 se deshabilita la sincronización con no syncronization y se define la vecindad con el equipo VPN_MTY apuntando a la loopback con el comando neighbor remote-as 10, en este comando el AS 10 indica que se trata de una sesión interna de BGP (ibgp), con el comando neighbor update-source loopback 0, indicamos de que interfaz se tomaran las actualizaciones para el proceso de ruteo de BGP, finalmente deshabilitamos la sumarización de rutas en BGP con el comando no auto-summary. Como se estarán manejando VRF, se declara el address family para esta sesión de ibgp y ambos equipos puedan intercambiar prefijos a través de la nube, el comando address-family vpnv4 permitirá habilitar el protocolo en el equipo, el comando neighbor activate definirá la dirección IP del vecino ibgp y finalmente habilitaremos el intercambio de comunidades estándar y extendidas entre estas vecindades con el comando neighbor send-community both. Para mayor referencia revisar el Anexo 5. Hasta este punto, hemos configurado todas las interfaces que conectan cada equipo del proveedor entre si, se habilito OSPF con el área 4 para garantizar el anuncio de la red (Backbone) y se habilito el tag-switching ip en las interfaces para habilitar MPLS y generar las etiquetas dentro de la nube, ahora, estaremos en disponibilidad para configurar los enlaces de los clientes y posteriormente recibir sus anuncios. Como parte inicial de la configuración de deben definir las VRF s destinadas a cada cliente así como el route-distinguisher que será el identificador único para cada una de ellas. El comando ip vrf AZUL definirá el nombre para la VRF de acuerdo a cliente, en nuestro caso manejaremos dos, los cuales se llamaran verde y azul. Se configurara el route-distinguisher con el comando rd 10:37 en donde el 10 definirá nuestro AS y el 37 será el identificador para este cliente (AZUL) en especifico, definiremos el rd 10:47 para el cliente VERDE. Una vez que tengamos 72
79 definidas las VRF s en cada equipo frontera que reciba alguno de estos clientes, configuraremos los route-targets para indicar en que equipos importaremos y exportaremos las propiedades de las comunidades extendidas de BGP. Los comandos route-target import 10:37 y route-target export 10:37, nos ayudaran para este propósito, de igual forma se configuraran en todos los equipos frontera que reciban servicios para estos clientes, en nuestro caso VPN_MEX y VPN_MTY. El anexo 3 muestra a detalle esta configuración Una vez definidas las VRF s, configuraremos las interfaces de acceso de estos clientes para posteriormente configurar los equipos del cliente. Como ya se ha mencionado los equipos frontera (PE) son los que reciben los anuncios de los clientes, se procede a configurarlos para este efecto. En el esquema estamos manejando enlaces E1 para cada circuito, entramos al modo de configuración global del equipo y posteriormente al modo de configuración de interfaz, se configura el ancho de banda físico para el enlace con el comando bandwitdh 1984, se le asocia con la VRF para este cliente en especifico con el comando ip vrf forwarding AZUL, esto le indica al equipo que estaremos recibiendo anuncios del cliente AZUL a través de esta interfaz. Se le aplica el direccionamiento a esta serial de acuerdo con la igualmente con una mascara de 30 bits con la ayuda del comando ip address x.x.x.x , definimos el tipo de encapsulamiento en este caso ppp, encapsulation ppp, y le indicamos al equipo que estaremos reservando el 100% del ancho de banda para aplicar las políticas de calidad en el enlace, como bien sabemos, por default el IOS toma como referencia el 75% del ancho de banda físico definido para aplicar QoS. Utilizamos el comando max-reserved-bandwidth 100 para este efecto. Finalmente aplicaremos una política de calidad para el enlace para la diferenciación de tráfico, service-policy output BW_1984_P3_512_P2_1024. El anexo 6 muestra en detalle la configuración para cada uno de los cliente así como el mapa de QoS el cual es igualmente aplicado en las seriales que reciben trafico de los cliente. Una vez que se han configurado las interfaces de acceso de los clientes, se configura el ebgp para recibir el anuncio de redes y enviarlo a través de la nube. Se configuran los address-family para cada cliente con el comando addressfamily ipv4 vrf AZUL indicando que se estarán recibiendo paquetes IPv4 de la vrf AZUL, en nuestro caso vamos a redistribuir las rutas estáticas así como las redes conectadas en nuestras seriales con los comandos redistribute connected y redistribute static, definiremos las vecindades hacia el cliente con el comando neighbor x.x.x.x remote-as que es el AS del cliente, activamos la vecindad con el comando neighbor x.x.x.x activate y posteriormente habilitamos sobre el equipo la posibilidad de recibir anuncios de equipos que pertenezcan al mismo AS con el comando neighbor as-override, de igual forma como lo hicimos en la configuración de ibgp, deshabilitamos la sincronización con no syncronization y la sumarización de rutas con no auto-summary. Para mayor referencia revisar el Anexo 7 73
80 Una vez que se han configurado las interfaces de lado del equipo frontera, ya podemos configurar la interfaz del equipo del cliente para levantar los enlaces físicos y posteriormente el ruteo. En el CPE configuraremos la interfaz física de igual forma que de lado del PE, entramos al modo de configuración global, posteriormente entramos al modo de configuración de interfaz y definimos el ancho de banda físico que tenemos contratado con el comando bandwitdh 1984, el direccionamiento lo asignaremos de acuerdo a la igualmente considerando una mascara de 30 bits , como de lado del PE tenemos un encapsulamiento PPP, tendremos que configurarlo de igual forma en el CPE con el comando encapsulation ppp, pensando en el mapa de QoS destinaremos todo el ancho de banda para este propósito con el comando max-reserved-bandwidth 100, como hemos visto para estas configuraciones debemos de hacer coincidir los valores con los aplicados en el PE. Finalmente aplicamos la política de calidad que manejaremos en el equipo remoto con el comando service-policy output BW_1984_P3_512_P2_1024, ya que como sabemos los equipos CPE son los responsables del etiquetado y marcado de los paquetes que dentro de su red se generen. Para efectos este proyecto quitaran los mensajes de actividad sobre las Fastethernet para garantizar que siempre estén activas -ya que no tenemos ningún cable conectado a ellas-, esto lo conseguimos con el comando no keepalive, y asignamos la dirección IP con el comando network x.x.x.x Una vez que se tienen habilitadas las interfaces procedemos a la configuración de la parte del ruteo, inicialmente para garantizar que la sesión de TCP se active entre las vecindades de BGP configuramos la ruta estática por defecto con el comando ip route x.x.x.x, siendo x la dirección IP de la interfaz del equipo frontera a la que llega el servicio, una vez que se garantiza que se llega por ping al equipo frontera, se configura la parte del BGP en el CEP. Se entra al modo de configuración global y se configura el BGP con el comando router bgp 65194, donde es el AS local de este cliente, se deshabilita la sincronización de BGP con no syncronization. Se define la IP de vecino ebgp con el comando neighbor x.x.x.x remote-as 10, donde x es la IP de la interfaz del equipo frontera al que llega este servicio y 10 el AS del proveedor. Se ingresa el comando network x.x.x.x el cual adhiere la red local en el proceso de anunciamiento de BGP hacia la nube. Para una mayor referencia checar el Anexo 8. Una de las exigencias primordiales sobre las tecnologías de VPN son la de poder ofrecer calidades de servicio en los enlaces que permitan darle un manejo adecuado a los diferentes tipos de trafico que se generan. Para este fin, los equipos del cliente (CPE) son configurados para realizar tres funciones básicas para la diferenciación de tráfico; la clasificación, el marcado y la aplicación de una política para un encolamiento específico. En nuestro caso práctico, no fue posible emular la señalización de un Call-Manager por lo que la clasificación se omitió. Se 74
81 configuraron tres mapas de calidades para la P3 (voz), P2 (datos críticos) y P0 (default) tanto en los CPE que son los equipos que se encargan del etiquetado y el marking como en los PE que se encargan de darle una prioridad al trafico a través de la nube. Para configurar la parte de QoS, se entra al modo de configuración global y se crea un class-map llamado precedence2 con el comando class-map match-all Precedence2 y después indicamos que se haga coincidencia con la precedencia de datos críticos que es P2, con el comando match ip precedence 2, de igual forma se crea un class-map para los paquetes de voz con los comandos, classmap match-all Precedence3 y match ip precedence 3, ya que tenemos creados estos mapas, se creara una política en la cual definiremos los anchos de banda destinados para cada encolamiento, policy-map BW_1984_P3_512_P2_1024, misma que aplicaremos sobre cada interface en la que queramos diferenciar el trafico. Asociamos la clase anteriormente definida dentro del policy-map con class Precedence3 y le damos una prioridad de 512 con class Precedence3 cuando tenemos la definición de la política, posteriormente le indicamos las acciones a seguir en cuanto comience a recibir los paquetes etiquetados, en este caso queremos que los paquetes de voz tengan un ancho de banda de 512 y se le asigne una etiqueta de P3, se tomaran como trafico 3 y los excesos de tiraran, ya que no interesa la retransmisión de paquetes de voz, esto lo logramos con el comando police conform-action set-prec-transmit 3 exceed-action drop. Para los paquetes de datos críticos asociamos el class-map dentro del policy y le definimos el ancho de banda así como las acciones a tomar en cuanto empiece a recibir paquetes de datos. Definimos el ancho de banda destinado para datos críticos con el comando bandwidth 1024 y le definimos dentro del policy las acciones con police conform-action set-prec-transmit 2 exceed-action set-prec-transmit 1 en donde indicamos que los paquetes serán tomados con P2 y las ráfagas en exceso serán enviadas a la precedencia P1, en este caso no importan las retransmisiones ya que son datos. Por default, el IOS define un encolamiento por defecto en el que se envía todo el trafico que no caiga dentro del los encolamientos anteriores. Como estamos tratando con paquetes que se originan en el CPE, será este equipo el encargado de clasificar, marcar y aplicar una política al trafico, por lo que la política servicepolicy output BW_1984_P3_512_P2_1024 será aplicada en la interfaz que conecta al CPE con el proveedor y de lado del equipo frontera se aplicara la misma política para que los paquetes sean tratados con una prioridad cuando viajen por la nube. Para mayor referencia sobre la aplicación de las políticas de calidad ver el Anexo Resultados Como parte del protocolo de pruebas para validar servicios se realizaron pruebas de conectividad de LAN a LAN con ping resultando exitosas, se revisaron las tablas de BGP y de ruteo en los equipos del cliente para garantizar que se estuvieran anunciando todas las redes. Se hicieron pruebas de trace extendido para determinar la ruta que toman los paquetes y se generaron eventos de fallas 75
82 dentro del backbone para comprobar la redundancia y garantizar la disponibilidad de los servicios. Para una mayor referencia ver el Anexo 10. CORPORATIVO_AZUL#ping Protocol [ip]: Target IP address: Repeat count [5]: 100 Datagram size [100]: Timeout in seconds [2]: Extended commands [n]: y Source address or interface: Type of service [0]: Set DF bit in IP header? [no]: Validate reply data? [no]: Data pattern [0xABCD]: Loose, Strict, Record, Timestamp, Verbose[none]: Sweep range of sizes [n]: Type escape sequence to abort. Sending 100, 100-byte ICMP Echos to , timeout is 2 seconds: Packet sent with a source address of !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Success rate is 100 percent (100/100), round-trip min/avg/max = 28/28/41 ms CORPORATIVO_AZUL# CORPORATIVO_AZUL #show ip bgp sum BGP router identifier , local AS number Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd h 4 CORPORATIVO_AZUL # VPN_MTY#show ip bgp vpnv4 vrf AZUL neighbors BGP neighbor is , vrf AZUL, remote AS 65194, external link BGP version 4, remote router ID BGP state = Established, up for 17h VPN_MTY#show ip bgp vpnv4 vrf AZUL neighbors routes BGP table version is , local router ID is Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale Origin codes: i - IGP, e - EGP,? - incomplete Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 10:37 (default for vrf AZUL) *> / i *> / i 76
83 Total number of prefixes 2 VPN_MTY# Debido a que no fue posible emular la señalización del call-manager se hicieron pruebas entre el sitio remoto y su corporativo con un ping extendido etiquetando los paquetes con la calidad de servicio de voz (96) y posteriormente la de datos críticos (64) validando el correcto funcionamiento del mapa de calidad tanto en equipos CPE como en PE involucrados. CORPORATIVO_AZUL #sh policy-map interface serial 1/0 Serial1/0 Service-policy output: service-policy output BW_1984_P3_512_P2_1024 queue stats for all priority classes: queue limit 248 (packets) (queue depth/total drops/no-buffer drops) 0/0/0 (pkts queued/bytes queued) 149/9588 Class-map: Precedence3 (match-all) (100) 100 packets, 9588 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: ip precedence 3 (6934) Priority 50 (%) (512 kbps) burst (bytes) police: cir bps, bc bytes conformed 149 packets, 9588 bytes; actions: transmit exceeded 0 packets, 0 bytes; actions: drop conformed 0 bps, exceed 0 bps Class-map: Precedence2 (match-all) (6937/3) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: ip precedence 2 (0) Queueing queue limit 96 (packets) (queue depth/total drops/no-buffer drops) 0/0/0 (pkts queued/bytes queued) 0/0 bandwidth 40.00% (%) (0 kbps) police: cir bps, bc bytes conformed 0 packets, 0 bytes; actions: transmit 77
84 exceeded 0 packets, 0 bytes; actions: set-prec-transmit 1 conformed 0 bps, exceed 0 bps Queue-limit 96 Class-map: class-default (match-any) (0) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: any (6943) 0 packets, 0 bytes 0 minute rate 0 bps Queueing Fair-queue: per-flow queue limit Conclusiones Gracias a su gran facilidad en la configuración, las VPN sobre MPLS aparecen como una opción muy viable para empresas que requieran comunicación con sus sitios remotos ofreciendo una calidad en sus servicios y una alta disponibilidad operativa. Con el establecimiento de etiquetas de capa 2, MPLS ofrece una opción para la integración de tecnologías como ATM e IP que por si solas, no son compatibles entre si. La fácil configuración en los equipos del proveedor hacen que sean una opción con una baja significativa en los costos asociados con la administración dentro de la nube, ya que para agregar a un cliente nuevo solo es necesario modificar la configuración de los equipos frontera que reciben a estos clientes, a diferencia de los enlaces FR en donde cada PVC se tenia que configurar en cada equipo de la ruta para llegar a su destino, además de que FR no permite aplicar calidades en el servicio. 78


85 Anexos Anexo 1 Anexo 1 Estado actual de la red del proveedor. CPE Anexo 2 P CPE CPE PE P MPLS BACKBONE OSPF área PE CPE Anexo 2 Alcances de la configuración de OSPF. 79
Introducción a las Redes
 Introducción a las Redes Tabla de Contenidos 1. Introducción a las Redes... 2 1.1 Clasificación de las redes y topología... 3 1.1.1 Según su distribución...3 1.1.2 Según su tamaño...6 1. Introducción a
Introducción a las Redes Tabla de Contenidos 1. Introducción a las Redes... 2 1.1 Clasificación de las redes y topología... 3 1.1.1 Según su distribución...3 1.1.2 Según su tamaño...6 1. Introducción a
INTRODUCCION. Ing. Camilo Zapata czapata@udea.edu.co Universidad de Antioquia
 INTRODUCCION. Ing. Camilo Zapata czapata@udea.edu.co Universidad de Antioquia Qué es una Red? Es un grupo de computadores conectados mediante cables o algún otro medio. Para que? compartir recursos. software
INTRODUCCION. Ing. Camilo Zapata czapata@udea.edu.co Universidad de Antioquia Qué es una Red? Es un grupo de computadores conectados mediante cables o algún otro medio. Para que? compartir recursos. software
Arquitectura de Redes y Comunicaciones
 DIRECCIONAMIENTO IP Una dirección IP es un número que identifica de manera lógica y jerárquica a una interfaz de un dispositivo (habitualmente una computadora) dentro de una red que utilice el protocolo
DIRECCIONAMIENTO IP Una dirección IP es un número que identifica de manera lógica y jerárquica a una interfaz de un dispositivo (habitualmente una computadora) dentro de una red que utilice el protocolo
EL MODELO DE ESTRATIFICACIÓN POR CAPAS DE TCP/IP DE INTERNET
 1 EL MODELO DE ESTRATIFICACIÓN POR CAPAS DE TCP/IP DE INTERNET La familia de protocolos TCP/IP fue diseñada para permitir la interconexión entre distintas redes. El mejor ejemplo es Internet: se trata
1 EL MODELO DE ESTRATIFICACIÓN POR CAPAS DE TCP/IP DE INTERNET La familia de protocolos TCP/IP fue diseñada para permitir la interconexión entre distintas redes. El mejor ejemplo es Internet: se trata
(decimal) 128.10.2.30 (hexadecimal) 80.0A.02.1E (binario) 10000000.00001010.00000010.00011110
 128.10.2.30 (hexadecimal) 80.0A.02.1E (binario) 10000000.00001010.00000010.00011110") REDES Internet no es un nuevo tipo de red física, sino un conjunto de tecnologías que permiten interconectar redes muy distintas entre sí. Internet no es dependiente de la máquina ni del sistema operativo
REDES Internet no es un nuevo tipo de red física, sino un conjunto de tecnologías que permiten interconectar redes muy distintas entre sí. Internet no es dependiente de la máquina ni del sistema operativo
1.- FUNCION DE UNA RED INFORMATICA
 1.- FUNCION DE UNA RED INFORMATICA Una red de computadoras, también llamada red de ordenadores, red de comunicaciones de datos o red informática, es un conjunto de equipos informáticos y software conectados
1.- FUNCION DE UNA RED INFORMATICA Una red de computadoras, también llamada red de ordenadores, red de comunicaciones de datos o red informática, es un conjunto de equipos informáticos y software conectados
AREA DE TECNOLOGIA E INFORMATICA. Introducción a las Redes de computadores
 AREA DE TECNOLOGIA E INFORMATICA Introducción a las Redes de computadores 1 Concepto Una Red es un conjunto de ordenadores interconectados entre si mediante cable o por otros medios inalámbricos. 2 Utilidad
AREA DE TECNOLOGIA E INFORMATICA Introducción a las Redes de computadores 1 Concepto Una Red es un conjunto de ordenadores interconectados entre si mediante cable o por otros medios inalámbricos. 2 Utilidad
Redes I Clase # 3. Licda. Consuelo E. Sandoval
 Redes I Clase # 3 Licda. Consuelo E. Sandoval 1. PROCESAMIENTO CENTRALIZADO El proceso centralizado es utilizado en los Mainframes, Minicomputadoras y en las Micro multiusuario. Los enlaces a estas máquinas
Redes I Clase # 3 Licda. Consuelo E. Sandoval 1. PROCESAMIENTO CENTRALIZADO El proceso centralizado es utilizado en los Mainframes, Minicomputadoras y en las Micro multiusuario. Los enlaces a estas máquinas
ESCUELA NORMAL PROF. CARLOS A CARRILLO
 ESCUELA NORMAL PROF. CARLOS A CARRILLO QUE ES UNA RED L A S T I C S E N L A E D U C A C I O N P R E E S C O L A R P R O F. C R U Z J O R G E A R A M B U R O A L U M N A : D U L C E C O R A Z Ó N O C H
ESCUELA NORMAL PROF. CARLOS A CARRILLO QUE ES UNA RED L A S T I C S E N L A E D U C A C I O N P R E E S C O L A R P R O F. C R U Z J O R G E A R A M B U R O A L U M N A : D U L C E C O R A Z Ó N O C H
Redes de Comunicaciones. José Manuel Vázquez Naya
 Redes de Comunicaciones José Manuel Vázquez Naya Contenido Introducción a las redes Conceptos básicos Ventajas de las redes Clasificación según su ubicación (LAN, MAN, WAN) Componentes básicos de una red
Redes de Comunicaciones José Manuel Vázquez Naya Contenido Introducción a las redes Conceptos básicos Ventajas de las redes Clasificación según su ubicación (LAN, MAN, WAN) Componentes básicos de una red
TELECOMUNICACIONES Y REDES
 TELECOMUNICACIONES Y REDES Redes Computacionales I Prof. Cristian Ahumada V. Unidad V: Capa de Red OSI 1. Introducción. 2. Protocolos de cada Red 3. Protocolo IPv4 4. División de Redes 5. Enrutamiento
TELECOMUNICACIONES Y REDES Redes Computacionales I Prof. Cristian Ahumada V. Unidad V: Capa de Red OSI 1. Introducción. 2. Protocolos de cada Red 3. Protocolo IPv4 4. División de Redes 5. Enrutamiento
Dispositivos de Red Hub Switch
 Dispositivos de Red Tarjeta de red Para lograr el enlace entre las computadoras y los medios de transmisión (cables de red o medios físicos para redes alámbricas e infrarrojos o radiofrecuencias para redes
Dispositivos de Red Tarjeta de red Para lograr el enlace entre las computadoras y los medios de transmisión (cables de red o medios físicos para redes alámbricas e infrarrojos o radiofrecuencias para redes
FUNDAMENTOS DE REDES Y CONECTIVIDAD REDES INFORMATICAS
 FUNDAMENTOS DE REDES Y CONECTIVIDAD REDES INFORMATICAS 1 REDES INFORMÁTICAS Se puede definir una red informática como un sistema de comunicación que conecta ordenadores y otros equipos informáticos entre
FUNDAMENTOS DE REDES Y CONECTIVIDAD REDES INFORMATICAS 1 REDES INFORMÁTICAS Se puede definir una red informática como un sistema de comunicación que conecta ordenadores y otros equipos informáticos entre
LAS TIC. Cintyha Lizbeth Gómez Salazar. Lic. Cruz Jorge Fernández Aramburo. 0 1 / 0 8 / 2 0 1 3
 LAS TIC. Cintyha Lizbeth Gómez Salazar. Lic. Cruz Jorge Fernández Aramburo. PREESCOLAR. 0 1 / 0 8 / 2 0 1 3 INTRODUCCIÓN. Actualmente curso la Lic. En preescolar en la escuela normal Carlos A. Carrillo
LAS TIC. Cintyha Lizbeth Gómez Salazar. Lic. Cruz Jorge Fernández Aramburo. PREESCOLAR. 0 1 / 0 8 / 2 0 1 3 INTRODUCCIÓN. Actualmente curso la Lic. En preescolar en la escuela normal Carlos A. Carrillo
1 NIC/MAU(Tarjeta de red) "Network Interface Card"
 Network Interface Card") INTRODUCCION En esta unidad trataremos el tema de los dispositivos que se utilizan en el momento de crear una red. En algunas ocasiones se utilizan otros dispositivos para proporcionar flexibilidad o capacidad
INTRODUCCION En esta unidad trataremos el tema de los dispositivos que se utilizan en el momento de crear una red. En algunas ocasiones se utilizan otros dispositivos para proporcionar flexibilidad o capacidad
CAPAS DEL MODELO OSI (dispositivos de interconexión)
") SWITCHES CAPAS DEL MODELO OSI (dispositivos de interconexión) 7. Nivel de aplicación En esta capa se ubican los gateways y el software(estación de trabajo) 6. Nivel de presentación En esta capa se ubican
SWITCHES CAPAS DEL MODELO OSI (dispositivos de interconexión) 7. Nivel de aplicación En esta capa se ubican los gateways y el software(estación de trabajo) 6. Nivel de presentación En esta capa se ubican
TEMA: Las Redes. NOMBRE Torres Castillo Ana Cristina. PROFESOR: Genaro Israel Casas Pruneda. MATERIA: Las TICS en la educación.
 TEMA: Las Redes NOMBRE Torres Castillo Ana Cristina. PROFESOR: Genaro Israel Casas Pruneda. MATERIA: Las TICS en la educación. QUÉ ES UNA RED? Una red informática es un conjunto de dispositivos interconectados
TEMA: Las Redes NOMBRE Torres Castillo Ana Cristina. PROFESOR: Genaro Israel Casas Pruneda. MATERIA: Las TICS en la educación. QUÉ ES UNA RED? Una red informática es un conjunto de dispositivos interconectados
1. Topología de BUS / Linear Bus. 2. Topología de Estrella / Star. 3. Topología de Estrella Cableada / Star Wired Ring. 4. Topología de Árbol / Tree
 TOPOLOGÍA DE REDES Las topologías más corrientes para organizar las computadoras de una red son las de punto a punto, de bus, en estrella y en anillo. La topología de punta a punta es la más sencilla,
TOPOLOGÍA DE REDES Las topologías más corrientes para organizar las computadoras de una red son las de punto a punto, de bus, en estrella y en anillo. La topología de punta a punta es la más sencilla,
Problemas sobre Dispositivos de Interconexión Sistemas Telemáticos I
 Problemas sobre Dispositivos de Interconexión Sistemas Telemáticos I Universidad Rey Juan Carlos Mayo de 2005 Problema 1 1. Dada la red de la figura, indica razonadamente las características que debe tener
Problemas sobre Dispositivos de Interconexión Sistemas Telemáticos I Universidad Rey Juan Carlos Mayo de 2005 Problema 1 1. Dada la red de la figura, indica razonadamente las características que debe tener
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS
 ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Jorge Alexander Silva Gómez. Documento: 1095826555 FICHA NÚMERO COLEGIO: Instituto Madre del Buen Concejo FECHA: Abril 23 del
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Jorge Alexander Silva Gómez. Documento: 1095826555 FICHA NÚMERO COLEGIO: Instituto Madre del Buen Concejo FECHA: Abril 23 del
REDES INFORMATICAS: Protocolo IP
 REDES INFORMATICAS: Protocolo IP 1. PRINCIPIOS BÁSICOS DE IP El protocolo IP se basa en tres principios básicos: Un direccionamiento de los ordenadores. Un tipo de dato: el datragrama IP. Un algoritmo
REDES INFORMATICAS: Protocolo IP 1. PRINCIPIOS BÁSICOS DE IP El protocolo IP se basa en tres principios básicos: Un direccionamiento de los ordenadores. Un tipo de dato: el datragrama IP. Un algoritmo
Redes Informáticas. Redes Informáticas Prof. Annabella Silvia Lía Llermanos
 Redes Informáticas Definición de Redes Informáticas Se puede definir una red informática como un sistema de comunicación que conecta ordenadores y otros equipos informáticos entre sí, con la finalidad
Redes Informáticas Definición de Redes Informáticas Se puede definir una red informática como un sistema de comunicación que conecta ordenadores y otros equipos informáticos entre sí, con la finalidad
Ayudantía Nro.3 Redes De Datos CIT2100-1. Profesor: Cristian Tala
 Ayudantía Nro.3 Redes De Datos CIT2100-1 Profesor: Cristian Tala Ayudante: Gabriel Del Canto Hoy día veremos: - Modelo TCP/IP - Modelo TCP/IP - Es un modelo de descripción de protocolos de red creado en
Ayudantía Nro.3 Redes De Datos CIT2100-1 Profesor: Cristian Tala Ayudante: Gabriel Del Canto Hoy día veremos: - Modelo TCP/IP - Modelo TCP/IP - Es un modelo de descripción de protocolos de red creado en
Concentradores de cableado
 Concentradores de cableado Un concentrador es un dispositivo que actúa como punto de conexión central entre los nodos que componen una red. Los equipos conectados al propio concentrador son miembros de
Concentradores de cableado Un concentrador es un dispositivo que actúa como punto de conexión central entre los nodos que componen una red. Los equipos conectados al propio concentrador son miembros de
Efectos de los dispositivos de Capa 2 sobre el flujo de datos 7.5.1 Segmentación de la LAN Ethernet
 7.5 Efectos de los dispositivos de Capa 2 sobre el flujo de datos 7.5.1 Segmentación de la LAN Ethernet 1 2 3 3 4 Hay dos motivos fundamentales para dividir una LAN en segmentos. El primer motivo es aislar
7.5 Efectos de los dispositivos de Capa 2 sobre el flujo de datos 7.5.1 Segmentación de la LAN Ethernet 1 2 3 3 4 Hay dos motivos fundamentales para dividir una LAN en segmentos. El primer motivo es aislar
REDES INFORMÁTICAS REDES LOCALES. Tecnología de la Información y la Comunicación
 REDES INFORMÁTICAS REDES LOCALES INDICE 1. Las redes informáticas 1.1 Clasificación de redes. Red igualitaria. Red cliente-servidor 2. Las redes de área local 2.1 Estructura de una LAN 2.2 Protocolos de
REDES INFORMÁTICAS REDES LOCALES INDICE 1. Las redes informáticas 1.1 Clasificación de redes. Red igualitaria. Red cliente-servidor 2. Las redes de área local 2.1 Estructura de una LAN 2.2 Protocolos de
Capas del Modelo ISO/OSI
 Modelo ISO/OSI Fue desarrollado en 1984 por la Organización Internacional de Estándares (ISO), una federación global de organizaciones que representa aproximadamente a 130 países. El núcleo de este estándar
Modelo ISO/OSI Fue desarrollado en 1984 por la Organización Internacional de Estándares (ISO), una federación global de organizaciones que representa aproximadamente a 130 países. El núcleo de este estándar
CAPITULO 1. Redes de Area Local LAN
 CAPITULO 1 Redes de Area Local LAN Objetivos Dispositivos de LAN Básicos Evolución de los dispositivos de Red Aspectos básicos del flujo de datos a través de las LAN s Desarrollo de una LAN Qué son las
CAPITULO 1 Redes de Area Local LAN Objetivos Dispositivos de LAN Básicos Evolución de los dispositivos de Red Aspectos básicos del flujo de datos a través de las LAN s Desarrollo de una LAN Qué son las
Conceptos de redes. LAN (Local Area Network) WAN (Wide Area Network)
 WAN (Wide Area Network)") Conceptos de redes. Una red de ordenadores permite conectar a los mismos con la finalidad de compartir recursos e información. Hablando en términos de networking, lo importante es que todos los dispositivos
Conceptos de redes. Una red de ordenadores permite conectar a los mismos con la finalidad de compartir recursos e información. Hablando en términos de networking, lo importante es que todos los dispositivos
TELECOMUNICACIONES Y REDES
 TELECOMUNICACIONES Y REDES Redes Computacionales I Prof. Cristian Ahumada V. Unidad II: Comunicación en la red Contenido 1. Introducción: conceptos generales 2. Estructura de Comunicación Genérica 3. Historia
TELECOMUNICACIONES Y REDES Redes Computacionales I Prof. Cristian Ahumada V. Unidad II: Comunicación en la red Contenido 1. Introducción: conceptos generales 2. Estructura de Comunicación Genérica 3. Historia
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS
 ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Karen Andrea Marín Mendoza Documento: 98110301014 FICHA NÚMERO COLEGIO Instituto Madre Del Buen Consejo FECHA: 23 de abril 2014
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Karen Andrea Marín Mendoza Documento: 98110301014 FICHA NÚMERO COLEGIO Instituto Madre Del Buen Consejo FECHA: 23 de abril 2014
REDES DE COMPUTADORAS REDES DE COMPUTADORAS CARACTERISTICAS DE LAS REDES 02/01/2012 ING. BOLIVAR ALCOCER
 REDES DE COMPUTADORAS ING. BOLIVAR ALCOCER REDES DE COMPUTADORAS DEFINICION. Una red de computadoras es una interconexión de computadoras para compartir información, recursos(discos, impresoras, escáner,
REDES DE COMPUTADORAS ING. BOLIVAR ALCOCER REDES DE COMPUTADORAS DEFINICION. Una red de computadoras es una interconexión de computadoras para compartir información, recursos(discos, impresoras, escáner,
Redes (4º Ing. Informática Univ. Cantabria)
") Problema 1 Sea la red de la figura: Indica en cada uno de los siguientes casos si se trata de una entrega directa o indirecta y cuál es la dirección MAC que aparecerá en las tramas generadas por el nodo
Problema 1 Sea la red de la figura: Indica en cada uno de los siguientes casos si se trata de una entrega directa o indirecta y cuál es la dirección MAC que aparecerá en las tramas generadas por el nodo
Diseño de Redes de Área Local
 REDES DE AREA LOCAL Diseño de Redes de Área Local REDES DE AREA LOCAL Pág. 1/40 OBJETIVOS DEL DISEÑO DE LAN El primer paso es establecer y documentar los objetivos de diseño. Estos objetivos son específicos
REDES DE AREA LOCAL Diseño de Redes de Área Local REDES DE AREA LOCAL Pág. 1/40 OBJETIVOS DEL DISEÑO DE LAN El primer paso es establecer y documentar los objetivos de diseño. Estos objetivos son específicos
PROTOCOLOS DE ENRUTAMIENTO
 PROTOCOLOS DE ENRUTAMIENTO Los protocolos de enrutamiento son el conjunto de reglas utilizadas por un router cuando se comunica con otros router con el fin de compartir información de enrutamiento. Dicha
PROTOCOLOS DE ENRUTAMIENTO Los protocolos de enrutamiento son el conjunto de reglas utilizadas por un router cuando se comunica con otros router con el fin de compartir información de enrutamiento. Dicha
Telecomunicaciones: redes e Internet
 http://www.dsic.upv.es/asignaturas/fade/oade Telecomunicaciones: redes e Internet Ofimática para ADE. Curso 2003-2004 Fac. de Admón. y Dirección de Empresas Univ. Politécnica de Valencia Objetivos Comprender
http://www.dsic.upv.es/asignaturas/fade/oade Telecomunicaciones: redes e Internet Ofimática para ADE. Curso 2003-2004 Fac. de Admón. y Dirección de Empresas Univ. Politécnica de Valencia Objetivos Comprender
DE REDES Y SERVIDORES
 ADMINISTRACIÓN DE REDES Y SERVIDORES Introducción ESCUELA DE INGENIERÍA DE SISTEMAS Y COMPUTACION JOHN GÓMEZ CARVAJAL johncar@univalle.edu.co http://eisc.univalle.edu.co/~johncar/ars/ Qué es una Red? Es
ADMINISTRACIÓN DE REDES Y SERVIDORES Introducción ESCUELA DE INGENIERÍA DE SISTEMAS Y COMPUTACION JOHN GÓMEZ CARVAJAL johncar@univalle.edu.co http://eisc.univalle.edu.co/~johncar/ars/ Qué es una Red? Es
Institución Educativa Inem Felipe Pérez de Pereira 2012 Estrategia taller. AREA: Sistemas de información Taller 1 2 3 4 Previsto 1 2 3 4 5 6 7 8 9 10
 Grado 10º Tiempo (semanas) GUÍA DE FUNDAMENTACIÓN Institución Educativa AREA: Sistemas de información Taller 1 2 3 4 Previsto 1 2 3 4 5 6 7 8 9 10 Fecha Real 1 2 3 4 5 6 7 8 9 10 Área/proyecto: es y Mantenimiento
Grado 10º Tiempo (semanas) GUÍA DE FUNDAMENTACIÓN Institución Educativa AREA: Sistemas de información Taller 1 2 3 4 Previsto 1 2 3 4 5 6 7 8 9 10 Fecha Real 1 2 3 4 5 6 7 8 9 10 Área/proyecto: es y Mantenimiento
COMUNICACIÓN Y REDES DE COMPUTADORES II. Clase 02. Aspetos basicos de Networking Parte 1 de 2
 COMUNICACIÓN Y REDES DE COMPUTADORES II Clase 02 Aspetos basicos de Networking Parte 1 de 2 1 Contenido de la Clase 1. Terminología de Networking 1. Redes de Datos 2. Historia de las redes informáticas
COMUNICACIÓN Y REDES DE COMPUTADORES II Clase 02 Aspetos basicos de Networking Parte 1 de 2 1 Contenido de la Clase 1. Terminología de Networking 1. Redes de Datos 2. Historia de las redes informáticas
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS
 ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: _Edward augusto florez carrillo Documento: 96070218361 FICHA NÚMERO COLEGIO Madre del buen consejo FECHA: _23/04/2014_ 1) Marca
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: _Edward augusto florez carrillo Documento: 96070218361 FICHA NÚMERO COLEGIO Madre del buen consejo FECHA: _23/04/2014_ 1) Marca
MODELO OSI Y DISPOSITIVOS DE RED POR CAPA
 El propósito de un repetidor es regenerar y retemporizar las señales de red a nivel de los bits para permitir que los bits viajen a mayor distancia a través de los medios. Tenga en cuenta la Norma de cuatro
El propósito de un repetidor es regenerar y retemporizar las señales de red a nivel de los bits para permitir que los bits viajen a mayor distancia a través de los medios. Tenga en cuenta la Norma de cuatro
UNIDAD FORMATIVA 1: Instalación y Configuración de los Nodos de Area Local
 UNIDAD FORMATIVA 1: Instalación y Configuración de los Nodos de Area Local OBJETIVOS: - Explicar las topologías de una red local en función de las tecnologías y arquitecturas existentes. - Clasificar los
UNIDAD FORMATIVA 1: Instalación y Configuración de los Nodos de Area Local OBJETIVOS: - Explicar las topologías de una red local en función de las tecnologías y arquitecturas existentes. - Clasificar los
EL MODELO DE ESTRATIFICACIÓN POR CAPAS DE TCP/IP DE INTERNET
 1 EL MODELO DE ESTRATIFICACIÓN POR CAPAS DE TCP/IP DE INTERNET Cada capa de la pila añade a los datos a enviar a la capa inferior, información de control para que el envío sea correcto. Esta información
1 EL MODELO DE ESTRATIFICACIÓN POR CAPAS DE TCP/IP DE INTERNET Cada capa de la pila añade a los datos a enviar a la capa inferior, información de control para que el envío sea correcto. Esta información
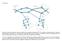 Introducción Internet no tiene una estructura real, pero existen varios backbone principales. Estos se construyen a partir de líneas y routers de alta velocidad. Conectados a los backbone hay redes regionales
Introducción Internet no tiene una estructura real, pero existen varios backbone principales. Estos se construyen a partir de líneas y routers de alta velocidad. Conectados a los backbone hay redes regionales
Universidad de Antioquia Juan D. Mendoza V.
 Universidad de Antioquia Juan D. Mendoza V. El router es una computadora diseñada para fines especiales que desempeña un rol clave en el funcionamiento de cualquier red de datos. la determinación del mejor
Universidad de Antioquia Juan D. Mendoza V. El router es una computadora diseñada para fines especiales que desempeña un rol clave en el funcionamiento de cualquier red de datos. la determinación del mejor
1 of 6. Visualizador del examen - ENetwork Chapter 5 - CCNA Exploration: Network Fundamentals (Versión 4.0)
") 1 of 6 Visualizador del examen - ENetwork Chapter 5 - CCNA Exploration: Network Fundamentals (Versión 4.0) 1 Qué información se agrega durante la encapsulación en la Capa 3 de OSI? MAC (Control de acceso
1 of 6 Visualizador del examen - ENetwork Chapter 5 - CCNA Exploration: Network Fundamentals (Versión 4.0) 1 Qué información se agrega durante la encapsulación en la Capa 3 de OSI? MAC (Control de acceso
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS
 ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: MAYRA CABALLERO Documento: 97071008138 FICHA NÚMERO COLEGIO: Instituto madre del buen consejo FECHA: 23 DE ABRIL 1) Marca la
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: MAYRA CABALLERO Documento: 97071008138 FICHA NÚMERO COLEGIO: Instituto madre del buen consejo FECHA: 23 DE ABRIL 1) Marca la
DIRECCIONAMIENTO IPv4
 DIRECCIONAMIENTO IPv4 Para el funcionamiento de una red, todos sus dispositivos requieren una dirección IP única: La dirección MAC. Las direcciones IP están construidas de dos partes: el identificador
DIRECCIONAMIENTO IPv4 Para el funcionamiento de una red, todos sus dispositivos requieren una dirección IP única: La dirección MAC. Las direcciones IP están construidas de dos partes: el identificador
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS
 ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Angie Karolinne Pinilla Castro Documento: 97032416270 FICHA NÚMERO : 2 COLEGIO : Instituto Madre del Buen Consejo FECHA: 23/04/2014
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Angie Karolinne Pinilla Castro Documento: 97032416270 FICHA NÚMERO : 2 COLEGIO : Instituto Madre del Buen Consejo FECHA: 23/04/2014
INSTALACIÓN, OPERACIÓN Y PROGRAMACIÓN DE EQUIPOS Y SISTEMAS TELEFÓNICOS
 09-06-2015 1 Descripción y funcionamiento de una central PABX 09-06-2015 2 Un PBX o PABX (siglas en inglés de Private Branch Exchange y Private Automatic Branch Exchange para PABX), la cual es la red telefónica
09-06-2015 1 Descripción y funcionamiento de una central PABX 09-06-2015 2 Un PBX o PABX (siglas en inglés de Private Branch Exchange y Private Automatic Branch Exchange para PABX), la cual es la red telefónica
Capítulo 5. Cliente-Servidor.
 Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Aspectos Básicos de Networking
 Aspectos Básicos de Networking ASPECTOS BÁSICOS DE NETWORKING 1 Sesión No. 4 Nombre: Capa de transporte del modelo OSI Objetivo: Al término de la sesión el participante aplicará las principales características
Aspectos Básicos de Networking ASPECTOS BÁSICOS DE NETWORKING 1 Sesión No. 4 Nombre: Capa de transporte del modelo OSI Objetivo: Al término de la sesión el participante aplicará las principales características
Unidad I: La capa de Red
 ARP El protocolo de resolución de direcciones es responsable de convertir las dirección de protocolo de alto nivel (direcciones IP) a direcciones de red físicas. Primero, consideremos algunas cuestiones
ARP El protocolo de resolución de direcciones es responsable de convertir las dirección de protocolo de alto nivel (direcciones IP) a direcciones de red físicas. Primero, consideremos algunas cuestiones
Introducción a la Administración de una Red bajo IP
 Introducción a la Administración de una Red bajo IP Introducción IP es un protocolo de la capa de red, que sirve para encaminar los paquetes de un origen a un destino Este protocolo es el que mantiene
Introducción a la Administración de una Red bajo IP Introducción IP es un protocolo de la capa de red, que sirve para encaminar los paquetes de un origen a un destino Este protocolo es el que mantiene
INSTITUCIÓN EDUCATIVA JOSÉ EUSEBIO CARO ÁREA DE TECNOLOGÍA E INFORMÁTICA 2016 DOCENTE HARDWARE DE RED
 INSTITUCIÓN EDUCATIVA JOSÉ EUSEBIO CARO ÁREA DE TECNOLOGÍA E INFORMÁTICA 2016 DOCENTE JESÚS EDUARDO MADROÑERO RUALES CORREO jesus.madronero@hotmail.com TEMA REDES DE COMPUTADORES III GRADO NOVENO FECHA
INSTITUCIÓN EDUCATIVA JOSÉ EUSEBIO CARO ÁREA DE TECNOLOGÍA E INFORMÁTICA 2016 DOCENTE JESÚS EDUARDO MADROÑERO RUALES CORREO jesus.madronero@hotmail.com TEMA REDES DE COMPUTADORES III GRADO NOVENO FECHA
DIRECCIONAMIENTO DE RED. Direcciones IPv4
 DIRECCIONAMIENTO DE RED Direcciones IPv4 Introducción La dirección de capa de red que permiten la comunicación de datos entre los hosts en la misma red o en diversas redes. El protocolo de internet versión
DIRECCIONAMIENTO DE RED Direcciones IPv4 Introducción La dirección de capa de red que permiten la comunicación de datos entre los hosts en la misma red o en diversas redes. El protocolo de internet versión
Qué son los protocolos de enrutamiento Dinámico?
 Sistemas Operativos SISTEMAS OPERATIVOS 1 Sesión No. 4 Nombre: Protocolos de enrutamiento dinámico Contextualización Qué son los protocolos de enrutamiento Dinámico? Los protocolos de enrutamiento dinámico
Sistemas Operativos SISTEMAS OPERATIVOS 1 Sesión No. 4 Nombre: Protocolos de enrutamiento dinámico Contextualización Qué son los protocolos de enrutamiento Dinámico? Los protocolos de enrutamiento dinámico
Capa de TRANSPORTE. Ing. José Martín Calixto Cely Original: Galo Valencia P.
 Capa de TRANSPORTE Ing. José Martín Calixto Cely Original: Galo Valencia P. Capa de Transporte La Capa 1 crea y transporta las corrientes de bits; La Capa 2 encapsula los paquetes de datos en tramas, y
Capa de TRANSPORTE Ing. José Martín Calixto Cely Original: Galo Valencia P. Capa de Transporte La Capa 1 crea y transporta las corrientes de bits; La Capa 2 encapsula los paquetes de datos en tramas, y
Fundación Universitaria San. Direccionamiento IP
 Fundación Universitaria San S Mateo - Interconectividad II Direccionamiento IP Qué son las direcciones IP? Una dirección IP es un número que identifica de manera lógica y jerárquica a una interfaz de un
Fundación Universitaria San S Mateo - Interconectividad II Direccionamiento IP Qué son las direcciones IP? Una dirección IP es un número que identifica de manera lógica y jerárquica a una interfaz de un
Hay dos tipos de conexiones posibles cuando se trata de redes. Punto a punto conexiones proporciona un enlace dedicado entre dos dispositivos.
 Informáticas I 4.5 Estructuras físicas de red Hemos dicho que una red es una de dos o más dispositivos conectan juntos y que se configura un camino para que la comunicación a ser alcanzado entre los dos.
Informáticas I 4.5 Estructuras físicas de red Hemos dicho que una red es una de dos o más dispositivos conectan juntos y que se configura un camino para que la comunicación a ser alcanzado entre los dos.
CLASIFICACION DE LAS REDES POR TOPOLOGIAS DE RED
 CLASIFICACION DE LAS REDES POR TOPOLOGIAS DE RED La topología de red es la representación geométrica de la relación entre todos los enlaces y los dispositivos que los enlazan entre sí (habitualmente denominados
CLASIFICACION DE LAS REDES POR TOPOLOGIAS DE RED La topología de red es la representación geométrica de la relación entre todos los enlaces y los dispositivos que los enlazan entre sí (habitualmente denominados
INTRODUCCIÓN. El protocolo TCP, funciona en el nivel de transporte del modelo de referencia OSI, proporcionando un transporte fiable de datos.
 INTRODUCCIÓN Aunque poca gente sabe lo que es TCP/IP todos lo emplean indirectamente y lo confunden con un solo protocolo cuando en realidad son varios, de entre los cuales destaca y es el mas importante
INTRODUCCIÓN Aunque poca gente sabe lo que es TCP/IP todos lo emplean indirectamente y lo confunden con un solo protocolo cuando en realidad son varios, de entre los cuales destaca y es el mas importante
FUNDAMENTOS DE REDES CONCEPTOS DE LA CAPA DE RED
 FUNDAMENTOS DE REDES CONCEPTOS DE LA CAPA DE RED Mario Alberto Cruz Gartner malcruzg@univalle.edu.co CONTENIDO Direcciones privadas Subredes Máscara de Subred Puerta de Enlace Notación Abreviada ICMP Dispositivos
FUNDAMENTOS DE REDES CONCEPTOS DE LA CAPA DE RED Mario Alberto Cruz Gartner malcruzg@univalle.edu.co CONTENIDO Direcciones privadas Subredes Máscara de Subred Puerta de Enlace Notación Abreviada ICMP Dispositivos
TELECOMUNICACIONES Y REDES
 TELECOMUNICACIONES Y REDES Redes Computacionales I Prof. Cristian Ahumada V. Unidad X: Planificación y Cableado de una Red Contenido 1. Introducción. 2. LAN: Realización de la conexión física 3. Interconexiones
TELECOMUNICACIONES Y REDES Redes Computacionales I Prof. Cristian Ahumada V. Unidad X: Planificación y Cableado de una Red Contenido 1. Introducción. 2. LAN: Realización de la conexión física 3. Interconexiones
Fundamentos de Redes LI. Unidad III Modelos de Comunicaciones 3.1 Modelo de referencia OSI.
 3.1 Modelo de referencia OSI. Durante las últimas dos décadas ha habido un enorme crecimiento en la cantidad y tamaño de las redes. Muchas de ellas sin embargo, se desarrollaron utilizando implementaciones
3.1 Modelo de referencia OSI. Durante las últimas dos décadas ha habido un enorme crecimiento en la cantidad y tamaño de las redes. Muchas de ellas sin embargo, se desarrollaron utilizando implementaciones
T5.- Redes de datos. TEMA 5 REDES DE DATOS. 1.1.- Elementos de la comunicación. 1.1.- Elementos de la comunicación.
 TECNOLOGÍAS DE LA INFORMACIÓN Y LA COMUNICACIÓN. TEMA 5 REDES DE DATOS. 1.1.- Elementos de la comunicación. 1.2.- Vías de comunicación. 1.3.- Componentes hardware de una red. 1.1.- Elementos de la comunicación.
TECNOLOGÍAS DE LA INFORMACIÓN Y LA COMUNICACIÓN. TEMA 5 REDES DE DATOS. 1.1.- Elementos de la comunicación. 1.2.- Vías de comunicación. 1.3.- Componentes hardware de una red. 1.1.- Elementos de la comunicación.
Direcciones IP IMPLANTACIÓN DE SISTEMAS OPERATIVOS 1º ASIR. En redes IPv4.
 Direcciones IP En redes IPv4. IMPLANTACIÓN DE SISTEMAS OPERATIVOS Cada ordenador en Internet dispone de una dirección IP única de 32 bits. Estos 32 bits,o 4 bytes, se representan normalmente como se muestra
Direcciones IP En redes IPv4. IMPLANTACIÓN DE SISTEMAS OPERATIVOS Cada ordenador en Internet dispone de una dirección IP única de 32 bits. Estos 32 bits,o 4 bytes, se representan normalmente como se muestra
UNLaM REDES Y SUBREDES DIRECCIONES IP Y CLASES DE REDES:
 DIRECCIONES IP Y CLASES DE REDES: La dirección IP de un dispositivo, es una dirección de 32 bits escritos en forma de cuatro octetos. Cada posición dentro del octeto representa una potencia de dos diferente.
DIRECCIONES IP Y CLASES DE REDES: La dirección IP de un dispositivo, es una dirección de 32 bits escritos en forma de cuatro octetos. Cada posición dentro del octeto representa una potencia de dos diferente.
Redes Informáticas Temas: Concepto de Red de computadoras, Propósito de la Red, Clasificación según su cobertura geográfica. Topologías.
 Redes Informáticas Temas: Concepto de Red de computadoras, Propósito de la Red, Clasificación según su cobertura geográfica. Topologías. Docente: Lic. Mariela R. Saez Qué es una Red Informática? Una red,
Redes Informáticas Temas: Concepto de Red de computadoras, Propósito de la Red, Clasificación según su cobertura geográfica. Topologías. Docente: Lic. Mariela R. Saez Qué es una Red Informática? Una red,
TOPOLOGÍAS DE RED. TOPOLOGÍA FÍSICA: Es la forma que adopta un plano esquemático del cableado o estructura física de la red.
 TOPOLOGÍAS DE RED QUE ES UNA TOPOLOGIA? Una red informática está compuesta por equipos que están conectados entre sí mediante líneas de comunicación (cables de red, etc.) y elementos de hardware (adaptadores
TOPOLOGÍAS DE RED QUE ES UNA TOPOLOGIA? Una red informática está compuesta por equipos que están conectados entre sí mediante líneas de comunicación (cables de red, etc.) y elementos de hardware (adaptadores
8 Conjunto de protocolos TCP/IP y direccionamiento IP
 8 Conjunto de protocolos TCP/IP y direccionamiento IP 8.1 Introducción a TCP/IP 8.1.1 Historia de TCP/IP El Departamento de Defensa de EE.UU. (DoD) creó el modelo de referencia TCP/IP porque necesitaba
8 Conjunto de protocolos TCP/IP y direccionamiento IP 8.1 Introducción a TCP/IP 8.1.1 Historia de TCP/IP El Departamento de Defensa de EE.UU. (DoD) creó el modelo de referencia TCP/IP porque necesitaba
Roles y Características
 dominio Roles y Características Una vez instalado Windows Server 2008 y configuradas algunas opciones básicas de Windows Server 2008 desde el Panel de Control o desde el Administrador del Servidor, las
dominio Roles y Características Una vez instalado Windows Server 2008 y configuradas algunas opciones básicas de Windows Server 2008 desde el Panel de Control o desde el Administrador del Servidor, las
Conmutación. Conmutación telefónica. Justificación y definición.
 telefónica Justificación y definición de circuitos de mensajes de paquetes Comparación de las técnicas de conmutación Justificación y definición. Si se atiende a las arquitecturas y técnicas utilizadas
telefónica Justificación y definición de circuitos de mensajes de paquetes Comparación de las técnicas de conmutación Justificación y definición. Si se atiende a las arquitecturas y técnicas utilizadas
CFGM. Servicios en red. Unidad 2. El servicio DHCP. 2º SMR Servicios en Red
 CFGM. Servicios en red Unidad 2. El servicio DHCP CONTENIDOS 1 1. Introducción 1.1. Qué es el servicio DHCP 2.1. Características generales del servicio DHCP 2.2. Funcionamiento del protocolo DHCP 2.3.
CFGM. Servicios en red Unidad 2. El servicio DHCP CONTENIDOS 1 1. Introducción 1.1. Qué es el servicio DHCP 2.1. Características generales del servicio DHCP 2.2. Funcionamiento del protocolo DHCP 2.3.
CSIR2121. Administración de Redes I
 CSIR2121 Administración de Redes I Objetivos: Al finalizar la clase el estudiante podrá: Mencionar el propósito del desarrollo del modelo TCP/IP. Explicar cada una de las capas del modelo TCP/IP. Comparar
CSIR2121 Administración de Redes I Objetivos: Al finalizar la clase el estudiante podrá: Mencionar el propósito del desarrollo del modelo TCP/IP. Explicar cada una de las capas del modelo TCP/IP. Comparar
Univ. de Concepción del Uruguay Facultad de Ciencias Agrarias Ingeniería Agrónoma
 INFORMÁTICA Univ. de Concepción del Uruguay Facultad de Ciencias Agrarias Ingeniería Agrónoma Informática Teoría Unidad 5 Prof. Ing Ezequiel Benavente Ciclo lectivo 2014 Diferencias entre un Modem y un
INFORMÁTICA Univ. de Concepción del Uruguay Facultad de Ciencias Agrarias Ingeniería Agrónoma Informática Teoría Unidad 5 Prof. Ing Ezequiel Benavente Ciclo lectivo 2014 Diferencias entre un Modem y un
EXAMEN RECUPERACIÓN SEGUNDA EVALUACION
 EXAMEN RECUPERACIÓN SEGUNDA EVALUACION (Presencial) C.F.G.S. DESARROLLO DE APLICACIONES INFORMÁTICAS MÓDULO: Sistemas Informáticos Multiusuario y en Red NOMBRE: I.E.S. Valliniello Avilés 28 Abril -2007
EXAMEN RECUPERACIÓN SEGUNDA EVALUACION (Presencial) C.F.G.S. DESARROLLO DE APLICACIONES INFORMÁTICAS MÓDULO: Sistemas Informáticos Multiusuario y en Red NOMBRE: I.E.S. Valliniello Avilés 28 Abril -2007
Capa de red de OSI. Semestre 1 Capítulo 5 Universidad Cesar Vallejo Edwin Mendoza emendozatorres@gmail.com
 Capa de red de OSI Semestre 1 Capítulo 5 Universidad Cesar Vallejo Edwin Mendoza emendozatorres@gmail.com Capa de red: Comunicación de host a host Procesos básicos en la capa de red. 1. Direccionamiento
Capa de red de OSI Semestre 1 Capítulo 5 Universidad Cesar Vallejo Edwin Mendoza emendozatorres@gmail.com Capa de red: Comunicación de host a host Procesos básicos en la capa de red. 1. Direccionamiento
Protocolo ARP. Address Resolution Protocol
 Protocolo ARP Address Resolution Protocol 1 Problema Ambiente: una LAN La máquina A (con una cierta IP) quiere enviar un paquete IP a la máquina B de su misma LAN (de la cual conoce su IP) Tiene que armar
Protocolo ARP Address Resolution Protocol 1 Problema Ambiente: una LAN La máquina A (con una cierta IP) quiere enviar un paquete IP a la máquina B de su misma LAN (de la cual conoce su IP) Tiene que armar
TEMA 2 Componentes y estructura de una red de telecomunicación.
 TEMA 2 Componentes y estructura de una red de telecomunicación. 1. Modelo para las telecomunicaciones Las redes de telecomunicación constituyen la infraestructura básica de transporte para el intercambio
TEMA 2 Componentes y estructura de una red de telecomunicación. 1. Modelo para las telecomunicaciones Las redes de telecomunicación constituyen la infraestructura básica de transporte para el intercambio
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS
 ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: kleider torres Arévalo Documento: T.I 10024659147 FICHA NÚMERO: 33 COLEGIO: Instituto Madre Del Buen Consejo FECHA: 23 abril
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: kleider torres Arévalo Documento: T.I 10024659147 FICHA NÚMERO: 33 COLEGIO: Instituto Madre Del Buen Consejo FECHA: 23 abril
Redes (elaboración de cables y teoría de redes)
") Redes (elaboración de cables y teoría de redes) Que son Redes? Las redes interconectan computadoras con distintos sistemas operativos, ya sea dentro de una empresa u organización (LANs) o por todo el mundo
Redes (elaboración de cables y teoría de redes) Que son Redes? Las redes interconectan computadoras con distintos sistemas operativos, ya sea dentro de una empresa u organización (LANs) o por todo el mundo
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS
 ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Alvaro Andres Angarita Sierra Documento: _TI: 97021024400 FICHA NÚMERO 2 COLEGIO Madre del Buen Consejo FECHA: _23-Abril-2014
ACTIVIDAD No. 2 REPASO DE REDES INFORMATICAS GRADO 11 Nombre(s) y Apellidos: Alvaro Andres Angarita Sierra Documento: _TI: 97021024400 FICHA NÚMERO 2 COLEGIO Madre del Buen Consejo FECHA: _23-Abril-2014
Rede de área local (LAN)
") Rede de área local (LAN) LAN son las siglas de Local Area Network, Red de área local. Una LAN es una red que conecta los ordenadores en un área relativamente pequeña y predeterminada (como una habitación,
Rede de área local (LAN) LAN son las siglas de Local Area Network, Red de área local. Una LAN es una red que conecta los ordenadores en un área relativamente pequeña y predeterminada (como una habitación,
Concepto y tipo de redes
 Concepto y tipo de redes Definición de red Una red es un proceso que permite la conexión de equipos para: Compartir recursos. Comunicación remota. Optimiza el uso del equipo. Toda red está formada por:
Concepto y tipo de redes Definición de red Una red es un proceso que permite la conexión de equipos para: Compartir recursos. Comunicación remota. Optimiza el uso del equipo. Toda red está formada por:
El Modelo de Referencia OSI
 El Modelo de Referencia OSI Tabla de Contenidos 2. El Modelo de Referencia OSI... 2 2.1 Nivel físico...4 2.2 Nivel de enlace... 4 2.3 Nivel de red... 5 2.4 Nivel de transporte...5 2.5 Nivel de sesión...
El Modelo de Referencia OSI Tabla de Contenidos 2. El Modelo de Referencia OSI... 2 2.1 Nivel físico...4 2.2 Nivel de enlace... 4 2.3 Nivel de red... 5 2.4 Nivel de transporte...5 2.5 Nivel de sesión...
INSTITUTO TECNOLÓGICO ESPAÑA
 TUTOR: ING. DIEGO VÁSCONEZ INSTITUTO TECNOLÓGICO ESPAÑA ESTUDIANTE: MARCO CORRALES ESPÍN ESPECIALIDAD: 6º INFORMÁTICA TRABAJO DE REDES DE DATOS PRÁCTICA DE LABORATORIO 13 ASPECTOS BÁSICOS DE DIRECCIONAMIENTO
TUTOR: ING. DIEGO VÁSCONEZ INSTITUTO TECNOLÓGICO ESPAÑA ESTUDIANTE: MARCO CORRALES ESPÍN ESPECIALIDAD: 6º INFORMÁTICA TRABAJO DE REDES DE DATOS PRÁCTICA DE LABORATORIO 13 ASPECTOS BÁSICOS DE DIRECCIONAMIENTO
Seminario Electrónico de Soluciones Tecnológicas sobre Acceso Remoto. 1 de 12
 Seminario Electrónico de Soluciones Tecnológicas sobre Acceso Remoto 1 de 12 Seminario Electrónico de Soluciones Tecnológicas sobre Acceso Remoto 3 Bienvenida. 4 Objetivos. 5 Aplicaciones para las empresas
Seminario Electrónico de Soluciones Tecnológicas sobre Acceso Remoto 1 de 12 Seminario Electrónico de Soluciones Tecnológicas sobre Acceso Remoto 3 Bienvenida. 4 Objetivos. 5 Aplicaciones para las empresas
Introducción a las LAN, WAN y al Internetworking. Contenido
 Introducción a las LAN, WAN y al Internetworking Daniel Morató Area de Ingeniería Telemática Departamento de Automática y Computación Universidad Pública de Navarra daniel.morato@unavarra.es http://www.tlm.unavarra.es/asignaturas/lpr
Introducción a las LAN, WAN y al Internetworking Daniel Morató Area de Ingeniería Telemática Departamento de Automática y Computación Universidad Pública de Navarra daniel.morato@unavarra.es http://www.tlm.unavarra.es/asignaturas/lpr
4.1 Qué es una red de ordenadores?
 Unidad 2. Redes En esta unidad aprenderás: Qué es y para qué sirve una red de ordenadores Qué tipo de redes existen Qué hardware es necesario para formar una red LAN Hasta hace algún tiempo tener un ordenador
Unidad 2. Redes En esta unidad aprenderás: Qué es y para qué sirve una red de ordenadores Qué tipo de redes existen Qué hardware es necesario para formar una red LAN Hasta hace algún tiempo tener un ordenador
TOPOLOGÍA. Bus lineal. Topología anillo. Topología doble anillo. Topología estrella. Jerarquía. Malla. Hibridas.
 TOPOLOGÍA Una topología es la estructura física de una interconexión a la red entre dos o más nodos de información. Para lograr la una buena clasificación de las topologías es necesario dividirlas en simples
TOPOLOGÍA Una topología es la estructura física de una interconexión a la red entre dos o más nodos de información. Para lograr la una buena clasificación de las topologías es necesario dividirlas en simples
GUIA No 3 PRIMER PERIODO DECIMO GRADO SELECCIÓN DE DISEÑOS
 GUIA No 3 PRIMER PERIODO DECIMO GRADO SELECCIÓN DE DISEÑOS COMPETENCIAS: 3.1 Evalúo y selecciono con argumentos, mis propuestas y decisiones en torno a un diseño INDICADOR DESEMPEÑO: Diseña mediante esquemas
GUIA No 3 PRIMER PERIODO DECIMO GRADO SELECCIÓN DE DISEÑOS COMPETENCIAS: 3.1 Evalúo y selecciono con argumentos, mis propuestas y decisiones en torno a un diseño INDICADOR DESEMPEÑO: Diseña mediante esquemas
CONCEPTOS BASICOS DE REDES
 BENEMERITA Y CENTENARIA ESCUELA NORMAL DEL ESTADO CONCEPTOS BASICOS DE REDES LAS TICS EN LA EDUCACION PREESCOLAR 1 B 2013 L U I S A M A R I A R I N C O N C A S T R O Conceptos Básicos de Redes Red de Computadoras
BENEMERITA Y CENTENARIA ESCUELA NORMAL DEL ESTADO CONCEPTOS BASICOS DE REDES LAS TICS EN LA EDUCACION PREESCOLAR 1 B 2013 L U I S A M A R I A R I N C O N C A S T R O Conceptos Básicos de Redes Red de Computadoras
Capítulo 11: Capa 3 - Protocolos
 Capítulo 11: Capa 3 - Protocolos Descripción general 11.1 Dispositivos de Capa 3 11.1.1 Routers 11.1.2 Direcciones de Capa 3 11.1.3 Números de red únicos 11.1.4 Interfaz/puerto del router 11.2 Comunicaciones
Capítulo 11: Capa 3 - Protocolos Descripción general 11.1 Dispositivos de Capa 3 11.1.1 Routers 11.1.2 Direcciones de Capa 3 11.1.3 Números de red únicos 11.1.4 Interfaz/puerto del router 11.2 Comunicaciones
Los mayores cambios se dieron en las décadas de los setenta, atribuidos principalmente a dos causas:
 SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
Es un conjunto de dispositivos interconectados entre si que comparten recursos y/o servicios como video, voz y datos a través de medios guiados, no
 Es un conjunto de dispositivos interconectados entre si que comparten recursos y/o servicios como video, voz y datos a través de medios guiados, no guiados o una combinación de ambos. El medio de transmisión
Es un conjunto de dispositivos interconectados entre si que comparten recursos y/o servicios como video, voz y datos a través de medios guiados, no guiados o una combinación de ambos. El medio de transmisión
1. Instala servicios de configuración dinámica, describiendo sus características y aplicaciones.
 Módulo Profesional: Servicios en Red. Código: 0227. Resultados de aprendizaje y criterios de evaluación. 1. Instala servicios de configuración dinámica, describiendo sus características y aplicaciones.
Módulo Profesional: Servicios en Red. Código: 0227. Resultados de aprendizaje y criterios de evaluación. 1. Instala servicios de configuración dinámica, describiendo sus características y aplicaciones.
Conjunto de computadores, equipos de comunicaciones y otros dispositivos que se pueden comunicar entre sí, a través de un medio en particular.
 Que es una red? Conjunto de computadores, equipos de comunicaciones y otros dispositivos que se pueden comunicar entre sí, a través de un medio en particular. Cuantos tipos de redes hay? Red de área personal,
Que es una red? Conjunto de computadores, equipos de comunicaciones y otros dispositivos que se pueden comunicar entre sí, a través de un medio en particular. Cuantos tipos de redes hay? Red de área personal,
Redes de Computadoras Capítulo 7: Equipos de comunicaciones
 Redes de Computadoras Capítulo 7: Equipos de comunicaciones Eduardo Interiano Contenido Equipos de comunicaciones LAN Segmentación de LAN Conmutación LAN Dominios de colisión Redes virtuales de área local
Redes de Computadoras Capítulo 7: Equipos de comunicaciones Eduardo Interiano Contenido Equipos de comunicaciones LAN Segmentación de LAN Conmutación LAN Dominios de colisión Redes virtuales de área local
210.25.2.0 => 11010010.00011001.00000010.00000000
 Subredes.- Cuando se trabaja con una red pequeña, con pocos host conectados, el administrador de red puede fácilmente configurar el rango de direcciones IP usado para conseguir un funcionamiento óptimo
Subredes.- Cuando se trabaja con una red pequeña, con pocos host conectados, el administrador de red puede fácilmente configurar el rango de direcciones IP usado para conseguir un funcionamiento óptimo