INTRODUCCION A LA COMPUTACION PARALELA. 2nd Workshop: New Frontiers of Bioinformatics in Latin America Gridding Biology. Dr.
|
|
|
- Aarón Fernando Toro Quintero
- hace 6 años
- Vistas:
Transcripción
1 INTRODUCCION A LA COMPUTACION PARALELA 2nd Workshop: New Frontiers of Bioinformatics in Latin America Gridding Biology Dr. Pablo Guillén Universidad de Los Andes de Noviembre de 2004
2 Qué es el Paralelismo? Una estrategia para ejecutar grandes tareas complejas, de forma más rápida. Una tarea grande puede ser ejecutada serialmente (un paso seguido de otro) o puede descomponerse en tareas más pequeñas para ser ejecutadas simultáneamente, es decir, en paralelo. El paralelismo es hecho: Descomponiendo las tareas en tareas más pequeñas Asignando las tareas más pequeñas a múltiples trabajadores para trabajar simultáneamente Coordinando los trabajadores
3 Programación en secuencial Tradicionalmente, los programas han sido escritos para computadores seriales: Una instrucción es ejecutada a un tiempo Usando un solo procesador La velocidad de procesamiento depende en la rapidez que la data puede ser movida a través del Hardware

4 La necesidad de máquinas rápidas Existen diferentes clases de problemas que requieren un procesamiento más rápido: Problemas de simulación y modelaje: Basados en aproximaciones sucesivas Más cálculo, más precisión Problemas dependientes de los cálculos y manipulación de grandes cantidades de datos: Procesamiento de señal e imágenes Rendering de imágenes Base de datos

5 La necesidad de máquinas rápidas Problemas de cómputo intensivo: Modelaje de clima Dinámica de fluidos Dinámica de población Genoma Humano Simulación de yacimientos petrolíferos (Sísmica)
6 COMPUTO EN PARALELO Múltiples procesadores (Los trabajadores) Red (Enlace entre los trabajadores) Ambiente para crear y administrar el procesamiento en paralelo Sistema operativo Paradigma de la programación en paralelo Pase de mensajes: MPI Paralelismo de datos: Implantado en Bibliotecas Fortran 90 / High Performance Fortran OpenMP Un algoritmo paralelo y un programa paralelo
7 Programación en paralelo La programación en paralelo involucra: Descomponer un algoritmo o data en partes Distribuir las partes como tareas, las cuales son trabajadas en múltiples procesadores simultáneamente Coordinar el trabajo y la comunicación de estos procesadores Consideraciones de la programación en paralelo: El tipo de arquitectura paralela que está siendo usada El tipo de comunicación que está siendo usada
8 Taxonomia de la Arquitectura Todos los computadores paralelos usan múltiples procesadores Existen diferentes métodos usados para clasificar los computadores No existe una taxonomia que se ajuste a los diseños La taxonomia de Flynn's usa la relación de instrucciones del programa a datos del programa. Las cuatro categorías son: SISD Single Instruction, Single Data Stream SIMD Single Instruction, Multiple Data Stream MISD - Multiple Instruction, Single Data Stream MIMD Multiple Instruction, Multiple Data Stream
9 Modelo SISD: Single Instruction, Single Data Stream No es un computador paralelo Computador de von Neumann serial convencional Una única instrucción es emitida cada ciclo de reloj Cada instrucción opera sobre un único elemento de data (escalar) Está limitado por el número de instrucciones que pueden ser emitidas en una unidad de tiempo dada La ejecución es frecuentemente medida en MIPS (million of instructions per second) o frecuencia del reloj MHz (Megahertz)
10 Modelo SIMD: Single Instruction, Multiple Data Stream Es una arquitectura de von Neumann con un mayor poder en las instrucciones Cada instrucción puede operar en más de un elemento de datos La ejecución es medida en MFLOPS (millions of floating point operations per second) Existencia de dos tipos: Vectorial SIMD Paralelo SIMD

11 Modelo SIMD: Single Instruction, Multiple Data Stream
12 Modelo MIMD: Multiple Instructions, Multiple Data El paralelismo es alcanzado conectando juntos múltiples procesadores Incluye todas las formas de configuraciones de multiprocesadores Cada procesador ejecuta su propio flujo de instrucciones independientemente de los otros procesadores sobre un único flujo de data
13 Modelo MIMD: Multiple Instructions, Multiple Data Ventajas Los procesadores pueden ejecutar múltiples flujos de trabajos simultáneamente Cada procesador puede ejecutar cualquier operación sin considerar lo que otros procesadores están haciendo Desventajas Es necesario un balanceo de carga y sincronización para coordinar los procesadores al final de las estructuras paralelas en las aplicaciones Puede ser difícil de programar
14 Modelo MIMD: Multiple Instructions, Multiple Data
15 Memoria de las Arquitecturas La manera en que los procesadores se comunican es dependiente de la arquitectura de la memoria, la cual, a su vez, afectaría como escribir un programa en paralelo Los tipos de memoria son: Memoria Compartida Memoria Distribuida
16 Memoria Compartida Múltiples procesadores operan independientemente pero comparten los mismos recursos de memoria Solo un procesador puede acceder a una posición de la memoria compartida a un tiempo La sincronización es obtenida controlando la escritura y lectura a la memoria compartida Ventajas Fácil uso La data compartida es rápida a través de las tareas (velocidad de acceso a memoria)
17 Memoria Compartida Desventajas La memoria está limitada por el ancho de banda. Un aumento de procesadores sin un aumento del ancho banda puede causar un cuello de botella El usuario es el responsable para especificar la sincronización Ejemplos: Cray Y-MP, Convex C-2, Cray C-90

18 SUNE Procesadores SUN Procesadores
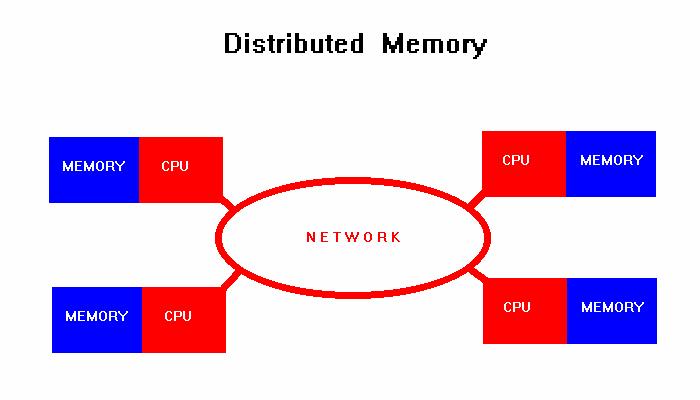
19 Memoria Distribuida Múltiples procesadores operan independientemente pero cada uno tiene su propia memoria La data es compartida a través de una red de comunicación usando pases de mensajes El usuario es el responsable de la sincronización usando pase de mensajes Ventajas La memoria es escalable al número de procesadores. Cada procesador puede rápidamente acceder a su propia memoria sin interferencia
20 Memoria Distribuida Desventajas El usuario es el responsable para enviar y recibir data a través de los procesadores Ejemplos: ncube Hypercube, Intel Hypercube, IBM SP1, SP2
21 Cluster 4 Procesadores
22 Memoria Procesador (arreglo) Memoria Distribuida MPP - Massively Parallel Processor Memoria Compartida SMP - Symmetric Multiprocessor Procesadores idénticos Acceso igual a la memoria Algunas veces llamado UMA Uniform Memory Access, o CC-UMA - Cache Coherent UMA Cache coherente significa que si un procesador actualiza una posición en la memoria compartida, todos los otros procesadores conocen acerca de la actualización
23 Memoria Procesador (arreglo) NUMA - Non-Uniform Memory Access Algunas veces llamado CC-NUMA - Cache Coherent NUMA A menudo hecho enlazando dos o más SMPs Un SMP puede directamente acceder la memoria de otro SMP No todos los procesadores tienen igual tiempo de acceso a toda la memoria El acceso de memoria a través del enlace es lento
24 Memoria Procesador (arreglo) Combinaciones Múltiples SMPs son conectados por una red Los Procesadores dentro de un SMP se comunican vía memoria Requieren pase de mensajes entre SMPs Un SMP no puede directamente acceder a la memoria de otro SMP Múltiples procesadores de memoria distribuida conectados a una gran memoria compartida La transferencia de memoria local a memoria compartida es transparente al usuario
25 COMUNICACIÓN DE LOS PROCESADORES Red de comunicación De una manera de coordinar las tareas de múltiples nodos trabajando en el mismo problema, alguna forma de comunicación inter-procesadores es requerida para: Transmitir la información y data entre los procesadores Sincronizar las actividades de los nodos Memoria distribuida
26 COMUNICACIÓN DE LOS PROCESADORES Conectividad entre los nodos Los nodos son conectados unos a otros por un switch nativo Los nodos son conectados a la red (y por tanto, uno a otro) vía la ethernet Tipos de comunicación ip - Internet Protocol (TCP/IP) se ejecuta sobre la ethernet o se ejecuta sobre el switch us-userspace se ejecuta sobre el switch
27 Paradigmas de la Programación en Paralelo Existen muchos métodos de programación en computadores paralelos. Dos de los más usados son pase de mensajes y paralelismo de datos. Pase de mensajes: el usuario hace llamadas a bibliotecas para explícitamente compartir información entre los procesadores. Paralelismo de datos: un particionamiento de la data determina el paralelismo. Memoria compartida: múltiples procesos comparten un espacio de memoria común.
28 Paradigmas de la Programación en Paralelo Operación remota a memoria: un conjunto de procesos en la cual un proceso puede acceder la memoria de otro proceso sin su participación Threads (hebras, hilos): un proceso teniendo múltiples (concurrentes) trayectorias de ejecución Modelo combinado: compuesto de dos o más de los presentados anteriormente.
29 Pase de mensajes El modelo de pases de mensajes se define como: Un conjunto de procesos usando solo memoria local Los procesos se comunican enviando y recibiendo mensajes La transferencia de data requiere operaciones cooperativas para ser ejecutada por cada proceso (una operación de envío debe tener una operación de recepción) La programación con pases de mensajes es hecha enlazando y haciendo llamadas a bibliotecas las cuales administran el intercambio de data entre los procesadores
30 Paralelismo de datos El modelo de paralelismo de datos se define como: Cada proceso trabaja sobre una parte diferente de la misma estructura de datos. Usa un enfoque Single Program Multiple Data (SPMD). La data es distribuida a través de los procesadores. Todo el pase de mensajes es transparente al programador La programación con un modelo de paralelismo de datos se satisface escribiendo un programa con directivas de paralelismo de datos y compilando el programa con un compilador de paralelismo de datos. El compilador convierte el programa en código estándar y llama una biblioteca de pase de mensajes para distribuir la data a todos los procesos
31 Implantación Pase de mensajes: Message Passing Interface (MPI) Una biblioteca portable y estándar de pase de mensajes Disponible para programas en Fortran y C Disponible para diferentes máquinas paralelas La comunicación entre tareas es por pase de mensajes Todo el paralelismo es explícito: el programador es el responsable del paralelismo del programa y la implantación de las directivas MPI El modelo de programación es SPMD (Single Program Multiple Data)
32 Implantación F90 / High Performance Fortran (HPF) Fortran 90 (F90) - (ISO / ANSI extensión estándar a Fortran 77) High Performance Fortran (HPF) - extensiones a F90 para soportar programación de paralelismo de datos Directivas de compilación permiten al programador la distribución y asignación de la data
33 Pasos para crear un Programa en Paralelo 1. Si existe un código serial, depure (debug) el código completamente 2. Use opciones de optimización 3. Identifique las partes del código que pueden ser ejecutadas concurrentemente: Requiere un buen conocimiento del código Explote cualquier paralelismo inherente que pueda existir Puede requerir reestructurar el programa y/o algoritmo Puede requerir un nuevo algoritmo. Use técnicas de Profiling, Optimización y de Ejecución
34 Pasos para crear un Programa en Paralelo 4. Particionar el programa: Paralelismo funcional Paralelismo de datos Una combinación de ambos 5. Desarrolle el código: El código puede estar influenciado/determinado por la arquitectura de la máquina Escoja un paradigma de programación Determine la comunicación 6. Compile, pruebe y Depure
35 Descomponer el Programa Existen tres métodos para descomponer un problema en tareas más pequeñas para ser ejecutadas en paralelo: Descomposición Funcional, Descomposición de Dominio, o una combinación de ambos Descomposición Funcional (Paralelismo Funcional) Descomponer el problema en diferentes tareas las cuales pueden ser distribuidas a múltiples procesadores para su ejecución de manera simultánea Es bueno cuando no existe una estructura estática o fija del número de cálculos a ser ejecutados
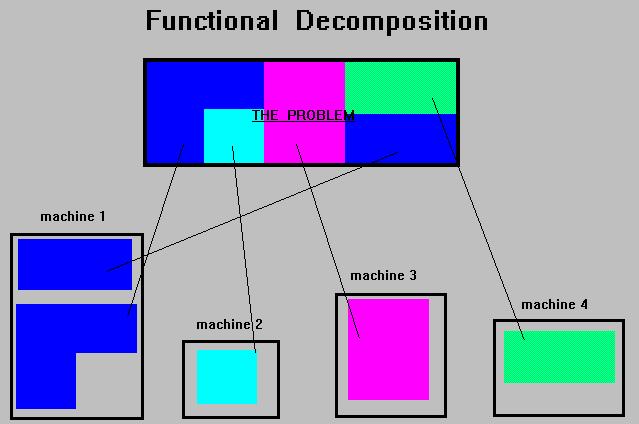
36
37 Descomposición de Dominio (Paralelismo de Datos) Descomponer los datos del problema y distribuir porciones de datos a múltiples procesadores para su ejecución de manera simultánea Es bueno de usar en problemas donde: La data es estática (factorizar y resolver grandes matrices o esquema de diferencia finitas) El dominio es fijo pero los cálculos dentro de diferentes regiones del dominio son dinámicos (modelos de fluidos)
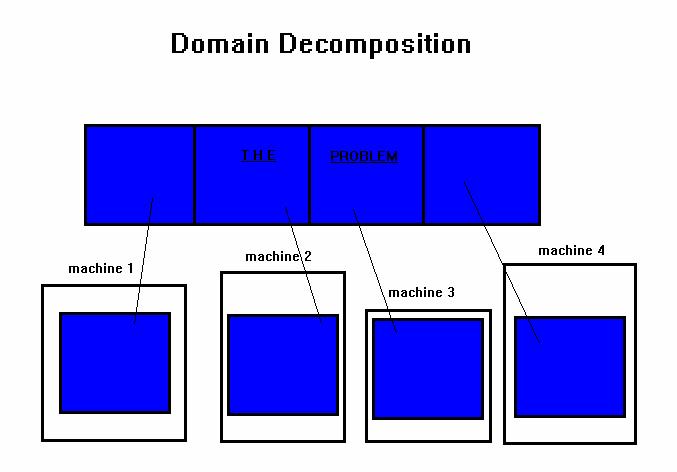
38
39 Comunicación Entender las comunicaciones entre los procesadores es esencial. La comunicación de pase de mensajes es programada explícitamente. El programador debe entender y codificar la comunicación Los compiladores de paralelismo de datos hacen toda la comunicación transparente. El programador no necesita entender las comunicaciones subyacentes La buena ejecución del código va a depender de la escritura del algoritmo con la mejor comunicación posible
40 Comunicación Los tipos de comunicaciones para pase de mensajes y paralelismo de datos son exactamente los mismos. Las comunicaciones en computadores de memoria distribuida: Punto a Punto De uno a todos De todos a todos Cómputo colectivo
41 Comunicación Punto a Punto El método más básico de comunicación entre dos procesadores es el mensaje punto a punto. El procesador origen envía el mensaje al procesador destino. El procesador destino recibe el mensaje. El mensaje comúnmente incluye la información, la longitud del mensaje, la dirección del destinatario y posiblemente una bandera. Típicamente las bibliotecas de pases de mensajes subdividen los envíos y recepciones básicos en dos tipos: Con bloqueo el proceso espera hasta que el mensaje sea transmitido Sin bloqueo el proceso continúa aún si el mensaje no ha sido transmitido
42
43 Comunicación Uno a todos Un proceso puede tener información la cual los otros procesos requieren. Un broadcast es un mensaje enviado a muchos otros procesos. Una comunicación uno a todos ocurre cuando un procesador envía la misma información a muchos otros procesos.
44

45 Comunicación Todos a todos Una comunicación de todos a todos cada proceso envía su única información a todos los otros procesos.
46 Ley de Amdahl's Diseño y consideraciones de ejecución Ley de Amdahl's postula que la aceleración del programa es definida por la fracción del código (P) la cual es paralelizada: 1 speedup = P
47 Diseño y consideraciones de ejecución Si nada del código puede ser paralelizado, P = 0 y la aceleración = 1 (aceleración nula). Si todo el código paralelizado, P = 1 y la aceleración es infinita (en teoría). Si 50% del código puede ser paralelizado, la aceleración máxima = 2, lo cual significa que el código se ejecutará el doble de rápido.
48 Diseño y consideraciones de ejecución Introduciendo el número de procesadores ejecutando la fracción paralela de trabajo, la relación puede ser modelada por: 1 speedup = P + S --- N donde P = fracción paralela, N = número de procesadores y S = fracción serial.
49 Diseño y consideraciones de ejecución Existen límites a la escalabilidad del paralelismo. Por ejemplo, con P =.50,.90 y.99 (50%, 90% and 99% del código es paralelizable): speedup N P =.50 P =.90 P =
50 Balanceo de carga El balanceo de carga se refiere a la distribución de las tareas, de una manera tal, que se asegura más eficientemente la ejecución en paralelo Si las tareas no están distribuidas de una manera balanceada, se podría estar esperando por la culminación de una tarea, mientras las otras ya han finalizado El performance puede ser incrementado si el trabajo puede ser uniformemente distribuido
51 Granularidad De una manera de coordinar entre diferentes procesadores trabajando en el mismo problema, alguna forma de comunicación entre ellos es requerido La razón entre cómputo y comunicación es conocida como la granularidad Paralelismo de grano fino (Fine-grain parallelism)
52 Paralelismo de grano fino (Fine-grain parallelism) Todas las tareas ejecutan un pequeño número de instrucciones entre ciclos de comunicación Es baja la razón cómputo a comunicación Facilita el balanceo de carga Implica alta comunicación y menos oportunidad para una mejora de performance Si la granularidad es fina, es posible que el tiempo requerido para la comunicación y sincronización entre las tareas sea mayor que el tiempo de cómputo
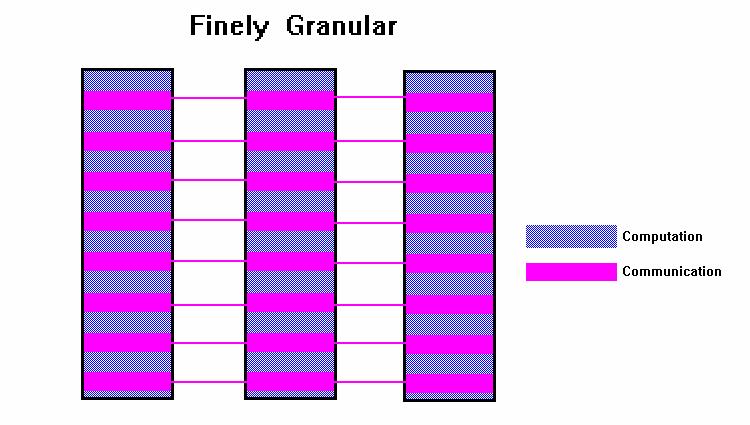
53
54 Paralelismo de grano grueso (Coarse-grain parallelism) Definido por grandes cómputos los cuales consisten de un gran número de instrucciones entre puntos de comunicación Es alta la razón cómputo a comunicación Implica más oportunidad para una mejora de performance Es más díficil para balancear la carga eficientemente La granularidad más eficiente es dependiente del algoritmo y el hardware en el cual éste se ejecutará
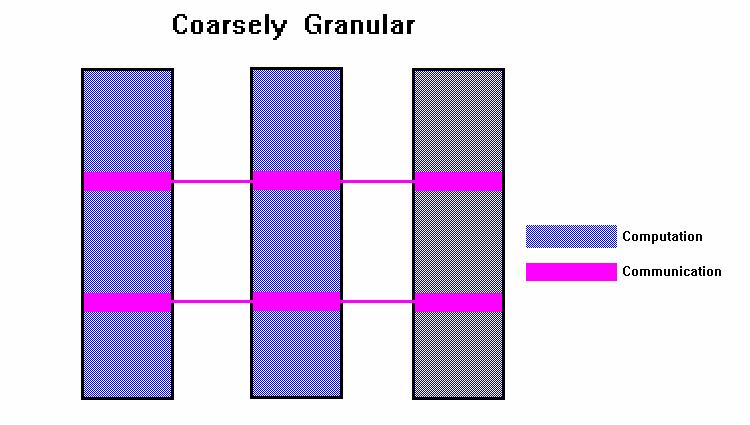
55
56 Dependencia de data Una dependencia de data existe cuando ocurre múltiple uso de una misma posición de memoria Una dependencia de data: frecuentemente inhibe la ejecución en paralelo Ejemplo 1: DO J = START, END A(J) = A(J-1) * 2 ENDDO Se debe haber calculado el valor de A(J-1) antes de calcular el valor de A(J)
57 Dependencia de data Si la tarea 2 tiene A(J) y la tarea 1 tiene A(J-1), el valor de A(J) es dependiente en: Memoria distribuida La tarea 2 obteniendo el valor de A(J-1) de la tarea 1 Memoria compartida La tarea 2 lee A(J-1) antes o después que la tarea 1 actualiza ésta
58 Cálculo de PI Paralelismo trivial Computacionalmente intensivo Comunicación mínima Operaciones de I/O mínimas El valor de PI puede ser calculado de muchas maneras, las cuales pueden ser facilmente paralelizables
59 Cálculo de PI Descripción del problema serial Consideremos el siguiente método de aproximar PI 1. Inscriba un círculo en un cuadrado 2. Genere puntos aleatorios en el cuadrado 3. Determine el número de puntos en el cuadrado que están también en el círculo 4. Sea r el número de puntos en el círculo dividido por el número de puntos en el cuadrado 5. PI ~ 4 r 6 Observar que mientras más puntos son generados, mejor será la aproximación
60 Cálculo de PI Pseudo-código serial para este procedimiento: npoints = circle_count = 0 do j = 1,npoints generate 2 random numbers between 0 and 1 xcoordinate = random1; ycoordinate = random2 if (xcoordinate, ycoordinate) inside circle then circle_count = circle_count + 1 end do PI = 4.0*circle_count/npoints
61
62 Cálculo de PI Solución Paralela: Pase de mensajes Estrategia de paralelización: descomponer el lazo en porciones los cuales pueden ser ejecutados por los procesadores Para aproximar PI: Cada procesador ejecuta su porción del lazo un número de veces Cada procesador puede hacer su trabajo sin requerir alguna información de los otros procesadores (no existe dependencia de data) Esta situación es conocida como paralelismo trivial Un proceso actúa como maestro y colecciona los resultados (modelo SPMD)
63 Cálculo de PI Solución Paralela: Pase de mensajes Pseudo-código: La letras Rojas incluye pase de mensajes npoints = circle_count = 0 p = number of processors num = npoints/p do j = 1, num generate 2 random numbers between 0 and 1 xcoordinate = random1 ; ycoordinate = random2 if (xcoordinate, ycoordinate) inside circle then circle_count = circle_count + 1 end do
64 if I am MASTER endif Cálculo de PI Solución Paralela: Pase de mensajes receive from WORKER their circle_counts compute PI (use MASTER and WORKER calculations) else if I am WORKER send to MASTER circle_count

65 GRACIAS!
Lusitania. Pensando en Paralelo. César Gómez Martín
 Lusitania Pensando en Paralelo César Gómez Martín cesar.gomez@cenits.es www.cenits.es Esquema Introducción a la programación paralela Por qué paralelizar? Tipos de computadoras paralelas Paradigmas de
Lusitania Pensando en Paralelo César Gómez Martín cesar.gomez@cenits.es www.cenits.es Esquema Introducción a la programación paralela Por qué paralelizar? Tipos de computadoras paralelas Paradigmas de
ARQUITECTURAS PARA PROCESAMIENTO PARALELO
 1 de 6 27/11/11 13:08 ARQUITECTURAS PARA PROCESAMIENTO PARALELO Facultad de Ingeniería de Sistemas Información para el Proyecto REYCYT RESUMEN Se presenta información general relativa a las diferentes
1 de 6 27/11/11 13:08 ARQUITECTURAS PARA PROCESAMIENTO PARALELO Facultad de Ingeniería de Sistemas Información para el Proyecto REYCYT RESUMEN Se presenta información general relativa a las diferentes
07 y 08 Sistemas distribuidos y paralelos y tarea 02
 07 y 08 Sistemas distribuidos y paralelos y tarea 02 Prof. Edgardo Adrián Franco Martínez http://computacion.cs.cinvestav.mx/~efranco efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco)
07 y 08 Sistemas distribuidos y paralelos y tarea 02 Prof. Edgardo Adrián Franco Martínez http://computacion.cs.cinvestav.mx/~efranco efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco)
SISTEMAS DE MULTIPROCESAMIENTO
 SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función
SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función
UNIDAD II Metodología de programación paralela. Lic. Jesús Germán Andrés PAUTSCH - FCEQyN - UNaM
 UNIDAD II Metodología de programación paralela UNIDAD II: Metodología de programación paralela Metodología de programación paralela Algunos conceptos que nos ayudarán a entender mejor el tema. Modelos
UNIDAD II Metodología de programación paralela UNIDAD II: Metodología de programación paralela Metodología de programación paralela Algunos conceptos que nos ayudarán a entender mejor el tema. Modelos
Threads, SMP y Microkernels. Proceso
 Threads, SMP y Microkernels Proceso Propiedad de los recursos a un proceso se le asigna un espacio de dirección virtual para guardar su imagen Calendarización/ejecución sigue una ruta de ejecución la cual
Threads, SMP y Microkernels Proceso Propiedad de los recursos a un proceso se le asigna un espacio de dirección virtual para guardar su imagen Calendarización/ejecución sigue una ruta de ejecución la cual
Paradigma de paso de mensajes
 Paradigma de paso de mensajes Curso 2011-2012 Índice Visión lógica del paradigma de paso de mensajes. Operaciones básicas en paso de mensajes. Operaciones bloqueantes. Operaciones no bloqueantes. MPI:
Paradigma de paso de mensajes Curso 2011-2012 Índice Visión lógica del paradigma de paso de mensajes. Operaciones básicas en paso de mensajes. Operaciones bloqueantes. Operaciones no bloqueantes. MPI:
MINUTA: Taller en UAEMEX, Toluca. Construcción de Tecnología HPC
 MINUTA: Taller en UAEMEX, Toluca Construcción de Tecnología HPC de MESA: Taller DE construcción de Tacnología HPC Sesión: # 1 a la 5 INFORMACIÓN GENERAL FECHA: 213 al 17 de julio 2015 Construcción de Tecnología
MINUTA: Taller en UAEMEX, Toluca Construcción de Tecnología HPC de MESA: Taller DE construcción de Tacnología HPC Sesión: # 1 a la 5 INFORMACIÓN GENERAL FECHA: 213 al 17 de julio 2015 Construcción de Tecnología
Plataformas paralelas
 Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
Qué es un programa informático?
 Qué es un programa informático? Un programa informático es una serie de comandos ejecutados por el equipo. Sin embargo, el equipo sólo es capaz de procesar elementos binarios, es decir, una serie de 0s
Qué es un programa informático? Un programa informático es una serie de comandos ejecutados por el equipo. Sin embargo, el equipo sólo es capaz de procesar elementos binarios, es decir, una serie de 0s
:Arquitecturas Paralela basada en clusters.
 Computación de altas prestaciones: Arquitecturas basadas en clusters Sesión n 1 :Arquitecturas Paralela basada en clusters. Jose Luis Bosque 1 Introducción Computación de altas prestaciones: resolver problemas
Computación de altas prestaciones: Arquitecturas basadas en clusters Sesión n 1 :Arquitecturas Paralela basada en clusters. Jose Luis Bosque 1 Introducción Computación de altas prestaciones: resolver problemas
Introducción a las Arquitecturas Paralelas. Arquitectura de Computadoras II Fac. Cs. Exactas UNCPBA Prof. Marcelo Tosini 2015
 Introducción a las Arquitecturas Paralelas Arquitectura de Computadoras II Fac. Cs. Exactas UNCPBA Prof. Marcelo Tosini 2015 Procesamiento Paralelo Uso de muchas unidades de proceso independientes para
Introducción a las Arquitecturas Paralelas Arquitectura de Computadoras II Fac. Cs. Exactas UNCPBA Prof. Marcelo Tosini 2015 Procesamiento Paralelo Uso de muchas unidades de proceso independientes para
Las optimizaciones pueden realizarse de diferentes formas. Las optimizaciones se realizan en base al alcance ofrecido por el compilador.
 Unidad III: Optimización Las optimizaciones pueden realizarse de diferentes formas. Las optimizaciones se realizan en base al alcance ofrecido por el compilador. La optimización va a depender del lenguaje
Unidad III: Optimización Las optimizaciones pueden realizarse de diferentes formas. Las optimizaciones se realizan en base al alcance ofrecido por el compilador. La optimización va a depender del lenguaje
Diseño arquitectónico 1ª edición (2002)
") Unidades temáticas de Ingeniería del Software Diseño arquitectónico 1ª edición (2002) Facultad de Informática objetivo Los sistemas grandes se descomponen en subsistemas que suministran un conjunto relacionado
Unidades temáticas de Ingeniería del Software Diseño arquitectónico 1ª edición (2002) Facultad de Informática objetivo Los sistemas grandes se descomponen en subsistemas que suministran un conjunto relacionado
Tema 2 Introducción a la Programación en C.
 Tema 2 Introducción a la Programación en C. Contenidos 1. Conceptos Básicos 1.1 Definiciones. 1.2 El Proceso de Desarrollo de Software. 2. Lenguajes de Programación. 2.1 Definición y Tipos de Lenguajes
Tema 2 Introducción a la Programación en C. Contenidos 1. Conceptos Básicos 1.1 Definiciones. 1.2 El Proceso de Desarrollo de Software. 2. Lenguajes de Programación. 2.1 Definición y Tipos de Lenguajes
Curso-Taller Programación Paralela con lenguaje C bajo Linux. MCC. Salazar Martínez Hilario
 Curso-Taller Programación Paralela con lenguaje C bajo Linux MCC. Salazar Martínez Hilario Mayo 2011 Programación Paralela La que se realiza usando procesos separados. Interactúan intercambiando información.
Curso-Taller Programación Paralela con lenguaje C bajo Linux MCC. Salazar Martínez Hilario Mayo 2011 Programación Paralela La que se realiza usando procesos separados. Interactúan intercambiando información.
La Máquina de Acceso Aleatorio (Random Access Machine)
") La Máquina de Acceso Aleatorio (Random Access Machine) Nuestro modelo de cómputo secuencial es la máquina de acceso aleatorio (RAM, Random Access Machine) mostrada en la Figura 2.1, y que consiste de:
La Máquina de Acceso Aleatorio (Random Access Machine) Nuestro modelo de cómputo secuencial es la máquina de acceso aleatorio (RAM, Random Access Machine) mostrada en la Figura 2.1, y que consiste de:
Unidad II Arquitectura de Computadoras
 Unidad II Arquitectura de Computadoras Arquitectura de Computadoras -LATIC Contenido Qué es una computadora? Tipos de computadoras Evolución de las computadoras El modelo de Von Neumann La unidad central
Unidad II Arquitectura de Computadoras Arquitectura de Computadoras -LATIC Contenido Qué es una computadora? Tipos de computadoras Evolución de las computadoras El modelo de Von Neumann La unidad central
EVOLUCIÓN DE LOS PROCESADORES
 EVOLUCIÓN DE LOS PROCESADORES Lecturas recomendadas: * Tanembaum, A. Organización de computadoras. Cap. 1 * Stallings, W. Organización y arquitectura de computadores. Cap. 2 Arquitectura de una computadora
EVOLUCIÓN DE LOS PROCESADORES Lecturas recomendadas: * Tanembaum, A. Organización de computadoras. Cap. 1 * Stallings, W. Organización y arquitectura de computadores. Cap. 2 Arquitectura de una computadora
Fecha de entrega: Miércoles 4 de Septiembre. Campus: Villahermosa. Carrera : Ingeniería en Sistemas Compuacionales. Nombre del maestro: Carlos Castro
 Nombre del estudiante: Giovanna Kristhel Mendoza Castillo Nombre del trabajo: Investigación sobre los Sistemas Operativos distribuidos Fecha de entrega: Miércoles 4 de Septiembre Campus: Villahermosa Carrera
Nombre del estudiante: Giovanna Kristhel Mendoza Castillo Nombre del trabajo: Investigación sobre los Sistemas Operativos distribuidos Fecha de entrega: Miércoles 4 de Septiembre Campus: Villahermosa Carrera
Modelado de los computadores paralelos
 Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la rogramación aralela, araninfo Cengage Learning, 2008 Figuras tomadas directamente
El Bueno, el Malo y el Feo
 El Bueno, el Malo y el Feo Mejorando la Eficiencia y Calidad del Software Paralelo Ricardo Medel Argentina Systems & Tools SSG-DPD Basado en un guión de Eric W. Moore - Senior Technical Consulting Engineer
El Bueno, el Malo y el Feo Mejorando la Eficiencia y Calidad del Software Paralelo Ricardo Medel Argentina Systems & Tools SSG-DPD Basado en un guión de Eric W. Moore - Senior Technical Consulting Engineer
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA
 CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
MICROCONTROLADORES PIC16F84 ING. RAÚL ROJAS REÁTEGUI
 MICROCONTROLADORES PIC16F84 ING. RAÚL ROJAS REÁTEGUI DEFINICIÓN Es un microcontrolador de Microchip Technology fabricado en tecnología CMOS, completamente estático es decir si el reloj se detiene los datos
MICROCONTROLADORES PIC16F84 ING. RAÚL ROJAS REÁTEGUI DEFINICIÓN Es un microcontrolador de Microchip Technology fabricado en tecnología CMOS, completamente estático es decir si el reloj se detiene los datos
FUNCIONAMIENTO DEL ORDENADOR
 FUNCIONAMIENTO DEL ORDENADOR COMPUTACIÓN E INFORMÁTICA Datos de entrada Dispositivos de Entrada ORDENADOR PROGRAMA Datos de salida Dispositivos de Salida LOS ORDENADORES FUNCIONAN CON PROGRAMAS Los ordenadores
FUNCIONAMIENTO DEL ORDENADOR COMPUTACIÓN E INFORMÁTICA Datos de entrada Dispositivos de Entrada ORDENADOR PROGRAMA Datos de salida Dispositivos de Salida LOS ORDENADORES FUNCIONAN CON PROGRAMAS Los ordenadores
Hilos y Procesamiento en paralelo
 2 Hilos y Procesamiento en paralelo En este capitulo se explican los conceptos fundamentales relacionados con el procesamiento en paralelo. Se explica que es un hilo y los diferentes tipos de hilos. También
2 Hilos y Procesamiento en paralelo En este capitulo se explican los conceptos fundamentales relacionados con el procesamiento en paralelo. Se explica que es un hilo y los diferentes tipos de hilos. También
MULTIPROCESADORES (MIMD)
") CAPITULO 6 MULTIPROCESADORES (MIMD) 6.1 - Generalidades de Multiprocesadores. Pueden clasificarse en esta categoría muchos sistemas multiprocesadores y sistemas multicomputadores. Un multiprocesador se
CAPITULO 6 MULTIPROCESADORES (MIMD) 6.1 - Generalidades de Multiprocesadores. Pueden clasificarse en esta categoría muchos sistemas multiprocesadores y sistemas multicomputadores. Un multiprocesador se
Sistemas Distribuidos. Bibliografía: Introducción a los Sistemas de Bases de Datos Date, C.J.
 Sistemas Distribuidos Bibliografía: Introducción a los Sistemas de Bases de Datos Date, C.J. Bases de datos distribuidas implica que una sola aplicación deberá ser capaz de trabajar en forma transparente
Sistemas Distribuidos Bibliografía: Introducción a los Sistemas de Bases de Datos Date, C.J. Bases de datos distribuidas implica que una sola aplicación deberá ser capaz de trabajar en forma transparente
Objetivos. Objetivos. Arquitectura de Computadores. R.Mitnik
 Objetivos Objetivos Arquitecturas von Neumann Otras Unidad Central de Procesamiento (CPU) Responsabilidades Requisitos Partes de una CPU ALU Control & Decode Registros Electrónica y buses 2 Índice Capítulo
Objetivos Objetivos Arquitecturas von Neumann Otras Unidad Central de Procesamiento (CPU) Responsabilidades Requisitos Partes de una CPU ALU Control & Decode Registros Electrónica y buses 2 Índice Capítulo
Herramientas para el estudio de prestaciones en clusters de computación científica, aplicación en el Laboratorio de Computación Paralela
 Introducción Herramientas Estudio Conclusiones Herramientas para el estudio de prestaciones en clusters de computación científica, aplicación en el Laboratorio de Computación Paralela Ingeniería en Informática
Introducción Herramientas Estudio Conclusiones Herramientas para el estudio de prestaciones en clusters de computación científica, aplicación en el Laboratorio de Computación Paralela Ingeniería en Informática
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
Conceptos generales de sistemas distribuidos
 Departament d Arquitectura de Computadors Conceptos generales de sistemas distribuidos Sistema distribuido Un sistema en el que los componentes hardware y/o software ubicados en computadores en red, se
Departament d Arquitectura de Computadors Conceptos generales de sistemas distribuidos Sistema distribuido Un sistema en el que los componentes hardware y/o software ubicados en computadores en red, se
Herramientas Informáticas I Software: Sistemas Operativos
 Herramientas Informáticas I Software: Sistemas Operativos Facultad de Ciencias Económicas y Jurídicas Universidad Nacional de La Pampa Sistemas Operativos. Es el software base que permite trabajar como
Herramientas Informáticas I Software: Sistemas Operativos Facultad de Ciencias Económicas y Jurídicas Universidad Nacional de La Pampa Sistemas Operativos. Es el software base que permite trabajar como
Area Académica: Sistemas Computacionales. Tema: Elementos de diseño de memoria caché
 Area Académica: Sistemas Computacionales Tema: Elementos de diseño de memoria caché Profesor: Raúl Hernández Palacios Periodo: 2011 Keywords: Memory, cache memory. Tema: Elementos de diseño de memoria
Area Académica: Sistemas Computacionales Tema: Elementos de diseño de memoria caché Profesor: Raúl Hernández Palacios Periodo: 2011 Keywords: Memory, cache memory. Tema: Elementos de diseño de memoria
TEMA 5: PARALELISMO A NIVEL DE HILOS, TAREAS Y PETICIONES (TLP, RLP) (primera parte).
 (primera parte).") TEMA 5: PARALELISMO A NIVEL DE HILOS, TAREAS Y PETICIONES (TLP, RLP) (primera parte). SISTEMAS PARALELOS Y DISTRIBUIDOS. 3º GIC www.atc.us.es Dpto. de Arquitectura y Tecnología de Computadores. Universidad
TEMA 5: PARALELISMO A NIVEL DE HILOS, TAREAS Y PETICIONES (TLP, RLP) (primera parte). SISTEMAS PARALELOS Y DISTRIBUIDOS. 3º GIC www.atc.us.es Dpto. de Arquitectura y Tecnología de Computadores. Universidad
Tema 2. Arquitectura de CPU avanzadas 15/03/2011
 Tema 2. Arquitectura de CPU avanzadas. Juegos CISC y RISC. Proceso paralelo. Procesadores escalares y vectoriales. Segmentación. Caches multinivel. Índice Introducción... 1 Procesadores CISC y RISC...
Tema 2. Arquitectura de CPU avanzadas. Juegos CISC y RISC. Proceso paralelo. Procesadores escalares y vectoriales. Segmentación. Caches multinivel. Índice Introducción... 1 Procesadores CISC y RISC...
Introducción HPC. Curso: Modelización y simulación matemática de sistemas. Esteban E. Mocskos (emocskos@dc.uba.ar) Escuela Complutense Latinoamericana
 Escuela Complutense Latinoamericana") Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción HPC Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales,
Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción HPC Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales,
Introducción a Computación
 Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
IMPLEMENTACIÓN DE COMPUTACIÓN DE ALTO RENDIMIENTO Y PROGRAMACIÓN PARALELA EN CÓDIGOS COMPUTACIONALES CARLOS ANDRÉS ACOSTA BERLINGHIERI
 IMPLEMENTACIÓN DE COMPUTACIÓN DE ALTO RENDIMIENTO Y PROGRAMACIÓN PARALELA EN CÓDIGOS COMPUTACIONALES CARLOS ANDRÉS ACOSTA BERLINGHIERI UNIVERSIDAD EAFIT ESCUELA DE INGENIERÍAS ÁREA DE DISEÑO MEDELLÍN 2009
IMPLEMENTACIÓN DE COMPUTACIÓN DE ALTO RENDIMIENTO Y PROGRAMACIÓN PARALELA EN CÓDIGOS COMPUTACIONALES CARLOS ANDRÉS ACOSTA BERLINGHIERI UNIVERSIDAD EAFIT ESCUELA DE INGENIERÍAS ÁREA DE DISEÑO MEDELLÍN 2009
TEMA 3. CONCEPTOS FUNDAMENTALES DEL NIVEL DEL SISTEMA OPERATIVO. Definición y objetivos de un S.O
 TEMA 3. CONCEPTOS FUNDAMENTALES DEL NIVEL DEL SISTEMA OPERATIVO Definición y objetivos de un S.O Definición y objetivos del sistema operativo Estructura, componentes y servicios de un S.O Llamadas al sistema
TEMA 3. CONCEPTOS FUNDAMENTALES DEL NIVEL DEL SISTEMA OPERATIVO Definición y objetivos de un S.O Definición y objetivos del sistema operativo Estructura, componentes y servicios de un S.O Llamadas al sistema
Multiplicación de Matrices en Sistemas cc-numa Multicore. Autor: Jesús Cámara Moreno Director: Domingo Giménez Cánovas
 Multiplicación de Matrices en Sistemas cc-numa Multicore Autor: Jesús Cámara Moreno Director: Domingo Giménez Cánovas Índice de Contenido 1. Introducción 2. Línea de Investigación 3. Sistemas Empleados
Multiplicación de Matrices en Sistemas cc-numa Multicore Autor: Jesús Cámara Moreno Director: Domingo Giménez Cánovas Índice de Contenido 1. Introducción 2. Línea de Investigación 3. Sistemas Empleados
Módulo: Modelos de programación para Big Data
 Program. paralela/distribuida Módulo: Modelos de programación para Big Data (título original: Entornos de programación paralela basados en modelos/paradigmas) Fernando Pérez Costoya Introducción Big Data
Program. paralela/distribuida Módulo: Modelos de programación para Big Data (título original: Entornos de programación paralela basados en modelos/paradigmas) Fernando Pérez Costoya Introducción Big Data
Nociones básicas de computación paralela
 Nociones básicas de computación paralela Javier Cuenca 1, Domingo Giménez 2 1 Departamento de Ingeniería y Tecnología de Computadores Universidad de Murcia 2 Departamento de Informática y Sistemas Universidad
Nociones básicas de computación paralela Javier Cuenca 1, Domingo Giménez 2 1 Departamento de Ingeniería y Tecnología de Computadores Universidad de Murcia 2 Departamento de Informática y Sistemas Universidad
Arquitecturas vectoriales, SIMD y extensiones multimedia
 Arquitecturas vectoriales, SIMD y extensiones multimedia William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo. Andrew S. Tanenbaum, Organización
Arquitecturas vectoriales, SIMD y extensiones multimedia William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo. Andrew S. Tanenbaum, Organización
Computación Paralela Móvil
 Algoritmos y Programación Paralela Facultad de Informática Universidad de Murcia Copyleft c 2008. Reproducción permitida bajo los términos de la licencia de documentación libre GNU. Contenido 1 Introducción
Algoritmos y Programación Paralela Facultad de Informática Universidad de Murcia Copyleft c 2008. Reproducción permitida bajo los términos de la licencia de documentación libre GNU. Contenido 1 Introducción
Introducción a la arquitectura de computadores
 Introducción a la arquitectura de computadores Departamento de Arquitectura de Computadores Arquitectura de computadores Se refiere a los atributos visibles por el programador que trabaja en lenguaje máquina
Introducción a la arquitectura de computadores Departamento de Arquitectura de Computadores Arquitectura de computadores Se refiere a los atributos visibles por el programador que trabaja en lenguaje máquina
Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria
 que procesa datos siguiendo unas instrucciones almacenadas en su memoria") 1.2. Jerarquía de niveles de un computador Qué es un computador? Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria Es un sistema tan complejo
1.2. Jerarquía de niveles de un computador Qué es un computador? Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria Es un sistema tan complejo
Sistemas distribuidos
 Sistemas distribuidos El primer elemento clave en un sistema distribuido es la red. Definición Cualquier conjunto de dos o más equipos informáticos interconectados entre sí con el objetivo de compartir
Sistemas distribuidos El primer elemento clave en un sistema distribuido es la red. Definición Cualquier conjunto de dos o más equipos informáticos interconectados entre sí con el objetivo de compartir
Procesador Concepto Tipos Velocidad de proceso Características funciones aritmético- lógicas y de control
 Tecnologías de Hardware Puntos a Desarrollar Procesador Concepto Tipos Velocidad de proceso Características funciones aritmético- lógicas y de control Memoria Principal Memoria RAM Concepto Características
Tecnologías de Hardware Puntos a Desarrollar Procesador Concepto Tipos Velocidad de proceso Características funciones aritmético- lógicas y de control Memoria Principal Memoria RAM Concepto Características
Cuando el lenguaje si importa
 Cuando el lenguaje si importa de software financiero J. Daniel Garcia Grupo ARCOS Universidad Carlos III de Madrid 11 de mayo de 2016 cbed J. Daniel Garcia ARCOS@UC3M (josedaniel.garcia@uc3m.es) Twitter
Cuando el lenguaje si importa de software financiero J. Daniel Garcia Grupo ARCOS Universidad Carlos III de Madrid 11 de mayo de 2016 cbed J. Daniel Garcia ARCOS@UC3M (josedaniel.garcia@uc3m.es) Twitter
Los valores obtenidos de speedup tienden a incrementarse hasta los ocho procesadores. al usar diez procesadores éste se mantiene igual o decrece. Esto
 En la Figura 6.9 se muestra el speedup obtenido en el tiempo de ejecución al ejecutar la aplicación con las distintas pol ticas de mapping, que pueden ser comparadas con el caso ideal. En el Apéndice D
En la Figura 6.9 se muestra el speedup obtenido en el tiempo de ejecución al ejecutar la aplicación con las distintas pol ticas de mapping, que pueden ser comparadas con el caso ideal. En el Apéndice D
Tecnológico Nacional de México INSTITUTO TECNOLÓGICO DE SALINA CRUZ
 Tecnológico Nacional de México INSTITUTO TECNOLÓGICO DE SALINA CRUZ UNIDAD 2: ENRUTAMIENTO ESTÁTICO Y DINÁMICO ACTIVIDAD: TRABAJO DE INVESTIGACIÓN 1 MATERIA: REDES DE COMPUTADORAS DOCENTE: SUSANA MÓNICA
Tecnológico Nacional de México INSTITUTO TECNOLÓGICO DE SALINA CRUZ UNIDAD 2: ENRUTAMIENTO ESTÁTICO Y DINÁMICO ACTIVIDAD: TRABAJO DE INVESTIGACIÓN 1 MATERIA: REDES DE COMPUTADORAS DOCENTE: SUSANA MÓNICA
ALGORITMOS PARALELOS Tema 1: Introducción a la Computación Paralela
 ALGORITOS ARALELOS Tema 1: Introducción a la Computación aralela Necesidad de la computación paralela Qué es la programación paralela? odelos de computadores Evaluación de los computadores paralelos Introducción
ALGORITOS ARALELOS Tema 1: Introducción a la Computación aralela Necesidad de la computación paralela Qué es la programación paralela? odelos de computadores Evaluación de los computadores paralelos Introducción
Arquitectura de Computadores II Clase #7
 Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Memoria virtual 1 Recordemos: Jerarquía de Memoria Registros Instr.
Arquitectura de Computadores II Clase #7 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Veremos Memoria virtual 1 Recordemos: Jerarquía de Memoria Registros Instr.
Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011
 Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Programación concurrente
 Programación concurrente Josep Jorba Esteve Remo Suppi Boldrito P07/M2106/02841 FUOC P07/M2106/02841 2 Programación concurrente FUOC P07/M2106/02841 Programación concurrente Índice Introducción... 5 Objetivos...
Programación concurrente Josep Jorba Esteve Remo Suppi Boldrito P07/M2106/02841 FUOC P07/M2106/02841 2 Programación concurrente FUOC P07/M2106/02841 Programación concurrente Índice Introducción... 5 Objetivos...
Una dirección IP es una secuencia de unos y ceros de 32 bits. La Figura muestra un número de 32 bits de muestra.
 DIRECCIONAMIENTO IP Un computador puede estar conectado a más de una red. En este caso, se le debe asignar al sistema más de una dirección. Cada dirección identificará la conexión del computador a una
DIRECCIONAMIENTO IP Un computador puede estar conectado a más de una red. En este caso, se le debe asignar al sistema más de una dirección. Cada dirección identificará la conexión del computador a una
Lic. Saidys Jiménez Quiroz. Área de Tecnología e Informática. Grado 6 - Cescoj
 Lic. Saidys Jiménez Quiroz Área de Tecnología e Informática Grado 6 - Cescoj 2011 NÚCLEO BÁSICO N 2: INTRODUCCIÓN A LA INFORMÁTICA. SESIÓN DE APRENDIZAJE N 2.3: CLASIFICACIÓN DE LOS COMPUTADORES. COMPETENCIA:
Lic. Saidys Jiménez Quiroz Área de Tecnología e Informática Grado 6 - Cescoj 2011 NÚCLEO BÁSICO N 2: INTRODUCCIÓN A LA INFORMÁTICA. SESIÓN DE APRENDIZAJE N 2.3: CLASIFICACIÓN DE LOS COMPUTADORES. COMPETENCIA:
Sist s em e a m s s O per e ativos o. s Unidad V Entrada Sali l d i a.
 Sistemas Operativos. Unidad V Entrada Salida. Programación de Entrada y Salida Introducción. Comunicación de los procesos con el mundo externo : Mecanismo de E/S de información. Aspectos que diferencian
Sistemas Operativos. Unidad V Entrada Salida. Programación de Entrada y Salida Introducción. Comunicación de los procesos con el mundo externo : Mecanismo de E/S de información. Aspectos que diferencian
INDICE Control de dispositivos específicos Diseño asistido por computadora Simulación Cálculos científicos
 INDICE Parte I. La computadora digital: organización, operaciones, periféricos, lenguajes y sistemas operativos 1 Capitulo 1. La computadora digital 1.1. Introducción 3 1.2. Aplicaciones de las computadoras
INDICE Parte I. La computadora digital: organización, operaciones, periféricos, lenguajes y sistemas operativos 1 Capitulo 1. La computadora digital 1.1. Introducción 3 1.2. Aplicaciones de las computadoras
Unidad I Marco teórico sobre redes de computadoras
 Unidad I Marco teórico sobre redes de computadoras Qué son las redes de computadoras? Una RED de computadoras es cualquier sistema de computación que enlaza dos o más computadoras. Conjunto de dispositivos
Unidad I Marco teórico sobre redes de computadoras Qué son las redes de computadoras? Una RED de computadoras es cualquier sistema de computación que enlaza dos o más computadoras. Conjunto de dispositivos
Concurrencia y paralelismo
 Introducción a los Sistemas Operativos Concurrencia y paralelismo 1. Ejecución de programas. Procesos. 2. Multiprogramación Bibliografía Silberschatz and Galvin Sistemas Operativos. Conceptos fundamentales.
Introducción a los Sistemas Operativos Concurrencia y paralelismo 1. Ejecución de programas. Procesos. 2. Multiprogramación Bibliografía Silberschatz and Galvin Sistemas Operativos. Conceptos fundamentales.
Sistema de archivos de Google. Mario Alonso Carmona Dinarte A71437
 Sistema de archivos de Google Mario Alonso Carmona Dinarte A71437 Agenda - Introducción - Definición GFS - Supuestos - Diseño & Caracteristícas - Ejemplo funcionamiento (paso a paso) - Caracteristicas
Sistema de archivos de Google Mario Alonso Carmona Dinarte A71437 Agenda - Introducción - Definición GFS - Supuestos - Diseño & Caracteristícas - Ejemplo funcionamiento (paso a paso) - Caracteristicas
una red de equipos no puede funcionar sin un sistema operativo de red
 Concepto El sistema operativo de red permite la interconexión de ordenadores para poder acceder a los servicios y recursos. Al igual que un equipo no puede trabajar sin un sistema operativo, una red de
Concepto El sistema operativo de red permite la interconexión de ordenadores para poder acceder a los servicios y recursos. Al igual que un equipo no puede trabajar sin un sistema operativo, una red de
Organización del Computador I. Introducción e Historia
 Organización del Computador I Introducción e Historia Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz de
Organización del Computador I Introducción e Historia Introducción Qué es una computadora? Stallings: Máquina digital electrónica programable para el tratamiento automático de la información, capaz de
SILABO DE SISTEMAS OPERATIVOS
 UNIVERSIDAD PRIVADA DEL NORTE Facultad de Ingeniería I. DATOS GENERALES SILABO DE SISTEMAS OPERATIVOS 1.1. Facultad : Ingeniería. 1.2. Carrera Profesional : Ingeniería de Sistemas. 1.3. Tipo de Curso :
UNIVERSIDAD PRIVADA DEL NORTE Facultad de Ingeniería I. DATOS GENERALES SILABO DE SISTEMAS OPERATIVOS 1.1. Facultad : Ingeniería. 1.2. Carrera Profesional : Ingeniería de Sistemas. 1.3. Tipo de Curso :
Aplicaciones Concurrentes
 PROGRAMACIÓN CONCURRENTE TEMA 6 Aplicaciones Concurrentes ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN PROGRAMACIÓN CONCURRENTE Aplicaciones Concurrentes
PROGRAMACIÓN CONCURRENTE TEMA 6 Aplicaciones Concurrentes ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN PROGRAMACIÓN CONCURRENTE Aplicaciones Concurrentes
El Modelo. Aplicación. Presentación. Sesión. Transporte. Red. Enlace. Físico
 El Modelo Es una arquitectura por niveles para el diseño de sistemas de red que permiten la comunicación entre todos los dispositivos de computadoras. Esta compuesto por siete niveles separados, pero relacionados,
El Modelo Es una arquitectura por niveles para el diseño de sistemas de red que permiten la comunicación entre todos los dispositivos de computadoras. Esta compuesto por siete niveles separados, pero relacionados,
Algoritmos. Medios de expresión de un algoritmo. Diagrama de flujo
 Algoritmos En general, no hay una definición formal de algoritmo. Muchos autores los señalan como listas de instrucciones para resolver un problema abstracto, es decir, que un número finito de pasos convierten
Algoritmos En general, no hay una definición formal de algoritmo. Muchos autores los señalan como listas de instrucciones para resolver un problema abstracto, es decir, que un número finito de pasos convierten
Jorge De Nova Segundo
 Jorge De Nova Segundo Una red peer-to-peer, red de pares, red entre iguales, red entre pares o red punto a punto (P2P, por sus siglas en inglés) es una red de computadoras en la que todos o algunos aspectos
Jorge De Nova Segundo Una red peer-to-peer, red de pares, red entre iguales, red entre pares o red punto a punto (P2P, por sus siglas en inglés) es una red de computadoras en la que todos o algunos aspectos
6. Entrada y Salida Explicación de la interfaz entre el computador y el mundo exterior.
 6. Entrada y Salida Explicación de la interfaz entre el computador y el mundo exterior. 6.1. El subsistema de E/S Qué es E/S en un sistema computador? Aspectos en el diseño del subsistema de E/S: localización
6. Entrada y Salida Explicación de la interfaz entre el computador y el mundo exterior. 6.1. El subsistema de E/S Qué es E/S en un sistema computador? Aspectos en el diseño del subsistema de E/S: localización
ÍNDICE INTRODUCCIÓN AL PROCESAMIENTO PARALELO ARQUITECTURA E INGENIERÍA DE COMPUTADORES TEMA1
 GRUPO DE ARQUITECTURA DE COMPUTADORES INTRODUCCIÓN AL PROCESAMIENTO PARALELO ARQUITECTURA E INGENIERÍA DE COMPUTADORES TEMA1 ÍNDICE!! Procesamiento paralelo!! Condiciones de paralelismo "! Concepto de
GRUPO DE ARQUITECTURA DE COMPUTADORES INTRODUCCIÓN AL PROCESAMIENTO PARALELO ARQUITECTURA E INGENIERÍA DE COMPUTADORES TEMA1 ÍNDICE!! Procesamiento paralelo!! Condiciones de paralelismo "! Concepto de
Usuario. Programas de Aplicación. Sistema Operativo. Hardware. Figura 1. Sistema de cómputo estructurado por capas.
 Generalidades acerca de los sistemas operativos Hoy en día muchas personas, usan las computadoras de una forma muy fácil, muchos incluso creen que la máquina tiene incorporada todas las potencialidades
Generalidades acerca de los sistemas operativos Hoy en día muchas personas, usan las computadoras de una forma muy fácil, muchos incluso creen que la máquina tiene incorporada todas las potencialidades
de Gran Canaria Centro de Tecnología Médica Programación Concurrente
 Universidad de Las Palmas de Gran Canaria Centro de Tecnología Médica http://www.ctm.ulpgc.es Tema 1: Introducción a la Escuela Técnica Superior de Ingenieros de Telecomunicación Conceptos Fundamentales
Universidad de Las Palmas de Gran Canaria Centro de Tecnología Médica http://www.ctm.ulpgc.es Tema 1: Introducción a la Escuela Técnica Superior de Ingenieros de Telecomunicación Conceptos Fundamentales
Estructuras de Control
 Algorítmica y Lenguajes de Programación Estructuras de Control Estructuras de Control. Introducción Hasta ahora algoritmos han consistido en simples secuencias de instrucciones Existen tareas más complejas
Algorítmica y Lenguajes de Programación Estructuras de Control Estructuras de Control. Introducción Hasta ahora algoritmos han consistido en simples secuencias de instrucciones Existen tareas más complejas
Comunicación de Datos I Profesora: Anaylen López Sección IC631 MODELO OSI
 Comunicación de Datos I Profesora: Anaylen López Sección IC631 MODELO OSI Arquitectura de Redes Definición Formal: Se define una arquitectura de red como un conjunto de niveles y protocolos que dan una
Comunicación de Datos I Profesora: Anaylen López Sección IC631 MODELO OSI Arquitectura de Redes Definición Formal: Se define una arquitectura de red como un conjunto de niveles y protocolos que dan una
Tema 2 Conceptos básicos de programación. Fundamentos de Informática
 Tema 2 Conceptos básicos de programación Fundamentos de Informática Índice Metodología de la programación Programación estructurada 2 Pasos a seguir para el desarrollo de un programa (fases): Análisis
Tema 2 Conceptos básicos de programación Fundamentos de Informática Índice Metodología de la programación Programación estructurada 2 Pasos a seguir para el desarrollo de un programa (fases): Análisis
Algoritmos en paralelo para una variante del problema bin packing
 Algoritmos en paralelo para una variante del problema bin packing Proyecto : 542-144-261 MSc. Geovanni Figueroa M. MSc. Ernesto Carrera R. Instituto Tecnológico de Costa Rica Vicerrectoría de Investigación
Algoritmos en paralelo para una variante del problema bin packing Proyecto : 542-144-261 MSc. Geovanni Figueroa M. MSc. Ernesto Carrera R. Instituto Tecnológico de Costa Rica Vicerrectoría de Investigación
Métodos para escribir algoritmos: Diagramas de Flujo y pseudocódigo
 TEMA 2: CONCEPTOS BÁSICOS DE ALGORÍTMICA 1. Definición de Algoritmo 1.1. Propiedades de los Algoritmos 2. Qué es un Programa? 2.1. Cómo se construye un Programa 3. Definición y uso de herramientas para
TEMA 2: CONCEPTOS BÁSICOS DE ALGORÍTMICA 1. Definición de Algoritmo 1.1. Propiedades de los Algoritmos 2. Qué es un Programa? 2.1. Cómo se construye un Programa 3. Definición y uso de herramientas para
Aspectos Básicos de Networking
 Aspectos Básicos de Networking ASPECTOS BÁSICOS DE NETWORKING 1 Sesión No. 4 Nombre: Capa de transporte del modelo OSI Contextualización Existen diferencias en los servicios de protocolos? Los protocolos
Aspectos Básicos de Networking ASPECTOS BÁSICOS DE NETWORKING 1 Sesión No. 4 Nombre: Capa de transporte del modelo OSI Contextualización Existen diferencias en los servicios de protocolos? Los protocolos
Elementos Diagramas de Clases Clase:
 Diagramas de Clases Un diagrama de clases o estructura estática muestra el conjunto de clases y objeto importantes que forman parte de un sistema, junto con las relaciones existentes entre clases y objetos.
Diagramas de Clases Un diagrama de clases o estructura estática muestra el conjunto de clases y objeto importantes que forman parte de un sistema, junto con las relaciones existentes entre clases y objetos.
Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC
 Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC INTRODUCCIÓN HPC: High Performance Computer System Qué es un supercomputador? Computador diseñado para ofrecer la mayor capacidad de
Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC INTRODUCCIÓN HPC: High Performance Computer System Qué es un supercomputador? Computador diseñado para ofrecer la mayor capacidad de
TEMA 9: DIAGRAMA DE OBJETOS, SECUENCIA Y DESPLIEGUE EN UML
 TEMA 9: DIAGRAMA DE OBJETOS, SECUENCIA Y DESPLIEGUE EN UML Diagramas en UML El bloque de construcción básico de UML es un Diagrama Introducción a UML 2 1 Diagrama de Objetos en UML Se utilizan para visualizar,
TEMA 9: DIAGRAMA DE OBJETOS, SECUENCIA Y DESPLIEGUE EN UML Diagramas en UML El bloque de construcción básico de UML es un Diagrama Introducción a UML 2 1 Diagrama de Objetos en UML Se utilizan para visualizar,
Manipulación de procesos
 Manipulación de procesos Las primeras computadoras solo podían manipular un programa a la vez. El programa tenía control absoluto sobre todo el sistema. Con el desarrollo vertiginoso del hardware ese panorama
Manipulación de procesos Las primeras computadoras solo podían manipular un programa a la vez. El programa tenía control absoluto sobre todo el sistema. Con el desarrollo vertiginoso del hardware ese panorama
Bus I 2 C. Introducción
 Bus I 2 C Introducción 1980: Philips desarrolla el Bus de 2 alambres I 2 C para la comunicación de circuitos integrados. Se han otorgado licencias a mas de 50 compañías, encontrándonos con más de 1000
Bus I 2 C Introducción 1980: Philips desarrolla el Bus de 2 alambres I 2 C para la comunicación de circuitos integrados. Se han otorgado licencias a mas de 50 compañías, encontrándonos con más de 1000
ESTRUCTURA BÁSICA DE UN ORDENADOR
 ESTRUCTURA BÁSICA DE UN ORDENADOR QUÉ ES UN ORDENADOR? Un ordenador es una máquina... QUÉ ES UN ORDENADOR? Un ordenador es una máquina... QUÉ ES UN ORDENADOR? Un ordenador es una máquina... Qué son los
ESTRUCTURA BÁSICA DE UN ORDENADOR QUÉ ES UN ORDENADOR? Un ordenador es una máquina... QUÉ ES UN ORDENADOR? Un ordenador es una máquina... QUÉ ES UN ORDENADOR? Un ordenador es una máquina... Qué son los
UNIVERSIDAD DE GUADALAJARA
 UNIVERSIDAD DE GUADALAJARA CENTRO UNIVERSITARIO DE LOS ALTOS DIVISIÓN DE ESTUDIOS EN FORMACIONES SOCIALES LICENCIATURA: INGENIERÍA EN COMPUTACIÓN UNIDAD DE APRENDIZAJE POR OBJETIVOS ORGANIZACIÓN DE COMPUTADORAS
UNIVERSIDAD DE GUADALAJARA CENTRO UNIVERSITARIO DE LOS ALTOS DIVISIÓN DE ESTUDIOS EN FORMACIONES SOCIALES LICENCIATURA: INGENIERÍA EN COMPUTACIÓN UNIDAD DE APRENDIZAJE POR OBJETIVOS ORGANIZACIÓN DE COMPUTADORAS
Tema: Microprocesadores
 Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Microprocesadores Arq. de Computadora I Ing. Carlos Ortega H. 1
Universidad Nacional de Ingeniería Arquitectura de Maquinas I Unidad I: Introducción a los Microprocesadores y Microcontroladores. Tema: Microprocesadores Arq. de Computadora I Ing. Carlos Ortega H. 1
Computadora y Sistema Operativo
 Computadora y Sistema Operativo Según la RAE (Real Academia de la lengua española), una computadora es una máquina electrónica, analógica o digital, dotada de una memoria de gran capacidad y de métodos
Computadora y Sistema Operativo Según la RAE (Real Academia de la lengua española), una computadora es una máquina electrónica, analógica o digital, dotada de una memoria de gran capacidad y de métodos
PROFInet. Índice. Tecnologías de Control
 PROFInet Tecnologías de Control Índice TEMA PROFInet Conceptos Básicos 1. Introducción 2. Fundamentos 3. Sistemas de Transmisión en Tiempo Real 4. Dispositivos Descentralizados de Campo 5. Control de Movimientos
PROFInet Tecnologías de Control Índice TEMA PROFInet Conceptos Básicos 1. Introducción 2. Fundamentos 3. Sistemas de Transmisión en Tiempo Real 4. Dispositivos Descentralizados de Campo 5. Control de Movimientos
Introducción a los Sistemas Operativos
 Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
Arquitectura de Computadoras para Ingeniería
 Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Arquitectura de Computadoras para Ingeniería Ejercicios Trabajo Práctico N 7 Jerarquía de Memoria Primer Cuatrimestre de
Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Arquitectura de Computadoras para Ingeniería Ejercicios Trabajo Práctico N 7 Jerarquía de Memoria Primer Cuatrimestre de
UNIDAD 1. COMPONENTES DEL COMPUTADOR
 UNIDAD 1. COMPONENTES DEL COMPUTADOR OBJETIVO Nº 1.1: DEFINICIÓN DE COMPUTADOR: Es un dispositivo electrónico compuesto básicamente de un procesador, una memoria y los dispositivos de entrada/salida (E/S).
UNIDAD 1. COMPONENTES DEL COMPUTADOR OBJETIVO Nº 1.1: DEFINICIÓN DE COMPUTADOR: Es un dispositivo electrónico compuesto básicamente de un procesador, una memoria y los dispositivos de entrada/salida (E/S).
Procesadores superescalares. Introducción
 Procesadores superescalares Introducción Introducción El término superescalar (superscalar) fue acuñado a fines de los 80s. Todas las CPUs modernas son superescalares. Es un desarrollo de la arquitectura
Procesadores superescalares Introducción Introducción El término superescalar (superscalar) fue acuñado a fines de los 80s. Todas las CPUs modernas son superescalares. Es un desarrollo de la arquitectura
Primeros pasos con CUDA. Clase 1
 Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Usando el Sistema Operativo
 Sistemas Operativos Pontificia Universidad Javeriana Enero de 2010 Los sistemas operativos Los sistemas operativos Perspectivas del Computador Concepto general El sistema operativo es parte del software
Sistemas Operativos Pontificia Universidad Javeriana Enero de 2010 Los sistemas operativos Los sistemas operativos Perspectivas del Computador Concepto general El sistema operativo es parte del software
Andres Felipe Rojas / Nancy Gelvez. UNESCO UNIR ICT & Education Latam Congress 2016
 Distributed processing using cosine similarity for mapping Big Data in Hadoop (Procesamiento distribuido usando similitud de coseno para mapear Big Data en Haddop) Andres Felipe Rojas / Nancy Gelvez UNESCO
Distributed processing using cosine similarity for mapping Big Data in Hadoop (Procesamiento distribuido usando similitud de coseno para mapear Big Data en Haddop) Andres Felipe Rojas / Nancy Gelvez UNESCO
Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial
 Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial Intel ha lanzado su procesador Xeon Phi en la Conferencia Internacional de Supercomputación de Alemania. El procesador
Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial Intel ha lanzado su procesador Xeon Phi en la Conferencia Internacional de Supercomputación de Alemania. El procesador