Alejandro Molina Zarca
|
|
|
- Ramona Hernández Rico
- hace 7 años
- Vistas:
Transcripción
1 Compute Unified Device Architecture (CUDA) Que es CUDA? Por qué CUDA? Dónde se usa CUDA? El Modelo CUDA Escalabilidad Modelo de programación Programación Heterogenea Memoria Compartida Alejandro Molina Zarca
2 Qué es CUDA? CUDA es una arquitectura de cálculo paralelo que hace referencia tanto a un compilador como a un conjunto de herramientas de desarrollo creadas por NVIDIA. Permite a los programadores usar una variación de C/C++ para codificar algoritmos en una GPU de NVIDIA. Mediante wrappers se puede utilizar Python, Fortran, Java, OpenGL y Direct3D.
3 Por qué CUDA? Hoy en día, el mercado demanda aplicaciones en tiempo real, alta definición y 3D que obtienen un alto rendimiento únicamente mediante el paralelismo. CUDA intenta explotar las ventajas de las GPU frente a las CPU de propósito general utilizando el paralelismo que ofrecen sus múltiples nucleos. En aplicaciones que utilicen numerosos hilos que relicen tareas independientes (que es lo que hacen las GPU al procesar gráficos de manera natural), una GPU podrá ofrecer un gran rendimiento.
4 Por qué CUDA?
5 Por qué CUDA?
6 Donde se usa CUDA? En prácticamente todas las aplicaciones de video actuales. AMBER, simulador de dinámica molecular. Numerix y CompatibL en el mercado financiero. En la actualidad existen más de 700 clusters de GPUs instalados en compañias Fortune 500 de todo el mundo, lo que incluye empresas como Schlumberger y Chevron en el sector energético o BNP Pariba en el sector bancario.

7 El Modelo CUDA CUDA intenta aprovechar el gran paralelismo, y el alto ancho de banda de la memoria en las GPU en aplicaciones con un gran coste aritmético frente a realizar numerosos accesos a memoria principal.
8 Escalabilidad El objetivo es que se desarrolle software con paralelismo escalable que aproveche el número de nucleos disponibles de forma transparente. Un programa multitarea se particiona automáticamente en bloques de hilos independientes, acorde al número de nucleos disponibles.

9 Escalabilidad Los mismos bloques, se dividen de forma óptima según el número de nucleos del sistema.
10 Modelo de programación CUDA extiende C, permitiendo al programador definir funciones denominadas kernel que son ejecutadas por N hilos diferentes en paralelo. Un kernel es ejecutado por uno o más bloques de hilos. Hay un límite de hilos por bloque que depende de los recursos del sistema. Actualmente es de Un hilo tiene un identificador único, accesible dentro del kernel mediante la variable threadidx.
11 Modelo de programación: - Kernel Mediante la sentencia global definimos el kernel Identificador de hilo Un bloque de N hilos Llamada al Kernel
12 Modelo de programacion Para mayor comodidad del programador, la variable threadidx es un vector de tres componentes gracias a la cual los hilos pueden ser identificados por su indice en una, dos y tres dimensiones. Los bloques de hilos también poseen una variable blockidx con el mismo propósito. La dimensión de un bloque es accesible mediante la variable blockdim.


13 Modelo de programación Las compoenentes x e y indican la posicion dentro del bloque en caso del thread, o del grid en caso del bloque.

14 Modelo de programación La cantidad de hilos por bloque y la cantidad de bloques pueden establecerse utilizando: Int dim3 Los hilos de un mismo bloque pueden coordinarse mediante la sentencia syncthreads().
15 Jerarquía de memoria Cada hilo posee una memoria local privada. Cada bloque de hilos tiene una memoria compartida visible a todos los hilos del bloque. Todos los hilos tienen acceso a la memoria global del sistema.

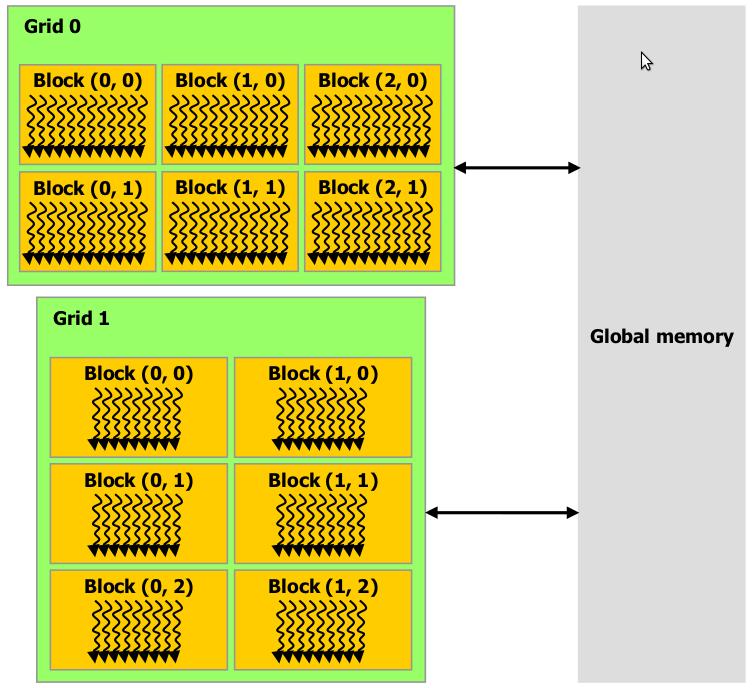
16 Jerarquía de memoria
17 Programación Heterogenea El modelo de programación de CUDA asume que los bloques que ejecutan los kernel se ejecutarán en la GPU mientras que el resto se ejecutará en la CPU. Tanto la GPU como la CPU mantienen su propio espacio de memoria DRAM, con lo que en tiempo de ejecución se deben gestionar las transferencias entre los dos espacios de memoria.
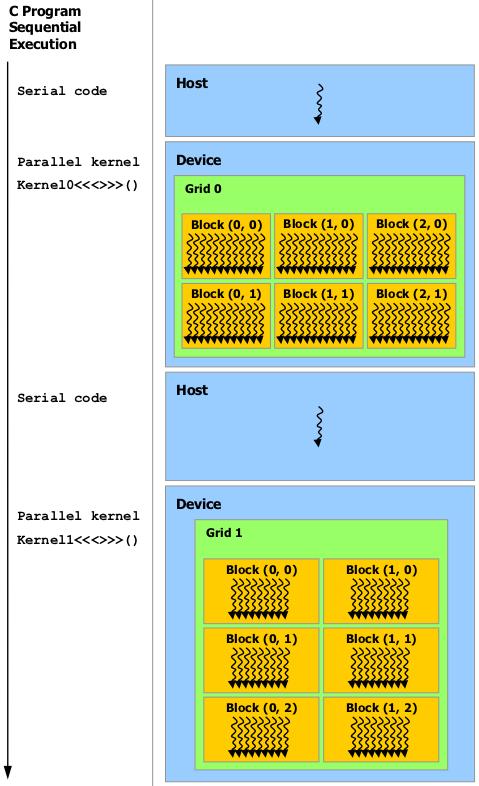
18 Programación Heterogenea
19 Memoria Compartida CUDA recomienda en la medida de lo posible, trabajar con memoria compartida, evitando así la sobrecarga sobre los accesos a memoria global. En el ejemplo de la multiplicación de matrices, sin memoria compartida, cada hilo leería una fila y columna de las matrices y calcularía el elemento de la matriz resultante. Partiendo la matriz en bloques, podemos mantener ocupado un bloque de hilos utilizando la memoria compartida.
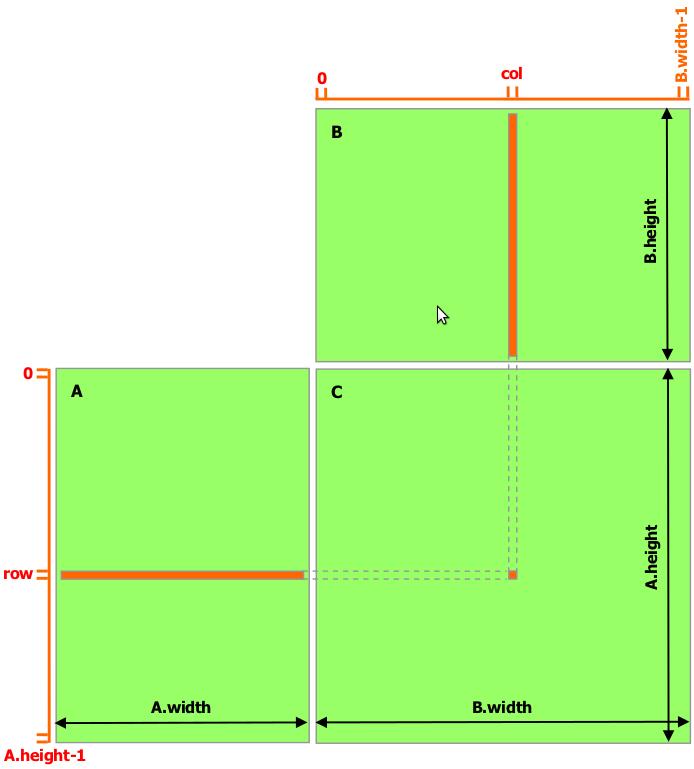
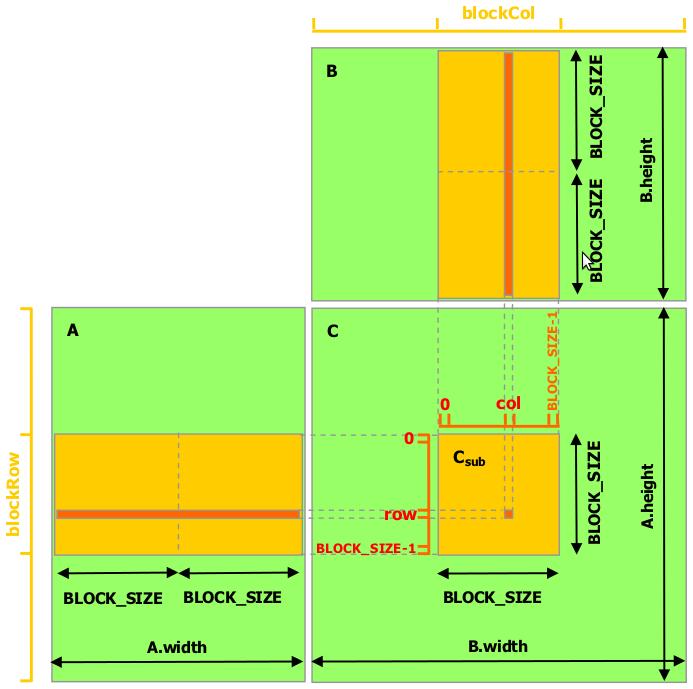
20 Memoria Compartida
21 Memoria Compartida La sentencia device permite construir una submatriz, asi como obtener y establecer elementos a partir de una matriz.
CUDA: MODELO DE PROGRAMACIÓN
 CUDA: MODELO DE PROGRAMACIÓN Autor: Andrés Rondán Tema: GPUGP: nvidia CUDA. Introducción En Noviembre de 2006, NVIDIA crea CUDA, una arquitectura de procesamiento paralelo de propósito general, con un
CUDA: MODELO DE PROGRAMACIÓN Autor: Andrés Rondán Tema: GPUGP: nvidia CUDA. Introducción En Noviembre de 2006, NVIDIA crea CUDA, una arquitectura de procesamiento paralelo de propósito general, con un
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Alvaro Cuno 23/01/2010 1 CUDA Arquitectura de computación paralela de propósito general La programación para la arquitectura CUDA puede hacerse usando lenguaje
CUDA (Compute Unified Device Architecture) Alvaro Cuno 23/01/2010 1 CUDA Arquitectura de computación paralela de propósito general La programación para la arquitectura CUDA puede hacerse usando lenguaje
Introducción a Cómputo Paralelo con CUDA C/C++
 UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO Facultad de Ingeniería Introducción a Cómputo Paralelo con CUDA C/C++ Laboratorio de Intel y Cómputo de alto desempeño Elaboran: Revisión: Ing. Laura Sandoval Montaño
UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO Facultad de Ingeniería Introducción a Cómputo Paralelo con CUDA C/C++ Laboratorio de Intel y Cómputo de alto desempeño Elaboran: Revisión: Ing. Laura Sandoval Montaño
Primeros pasos con CUDA. Clase 1
 Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Introducción a la Arquitectura y Plataforma de Programación de Cómputo Paralelo CUDA (36 hrs) Instructor M. en C. Cristhian Alejandro Ávila-Sánchez
 Instructor M. en C. Cristhian Alejandro Ávila-Sánchez") Introducción a la Arquitectura y Plataforma de Programación de Cómputo Paralelo CUDA (36 hrs) I Presentación: Instructor M. en C. Cristhian Alejandro Ávila-Sánchez CUDA (Compute Unified Device Architecture)
Introducción a la Arquitectura y Plataforma de Programación de Cómputo Paralelo CUDA (36 hrs) I Presentación: Instructor M. en C. Cristhian Alejandro Ávila-Sánchez CUDA (Compute Unified Device Architecture)
CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS
 CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS Leopoldo N. Gaxiola, Juan J. Tapia Centro de Investigación y Desarrollo de Tecnología Digital Instituto Politécnico Nacional Avenida
CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS Leopoldo N. Gaxiola, Juan J. Tapia Centro de Investigación y Desarrollo de Tecnología Digital Instituto Politécnico Nacional Avenida
INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA. Francisco Javier Hernández López
 INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA Francisco Javier Hernández López http://www.cimat.mx/~fcoj23 Guanajuato, Gto. Noviembre de 2012 Introducción a la Programación en CUDA 2 Qué es el Cómputo Paralelo
INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA Francisco Javier Hernández López http://www.cimat.mx/~fcoj23 Guanajuato, Gto. Noviembre de 2012 Introducción a la Programación en CUDA 2 Qué es el Cómputo Paralelo
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
V. OPTIMIZACIÓN PARA COMPUTACIÓN GPU EN CUDA
 V. OPTIMIZACIÓN PARA COMPUTACIÓN GPU EN CUDA La arquitectura de una GPU es básicamente distinta a la de una CPU. Las GPUs están estructuradas de manera paralela y disponen de un acceso a memoria interna
V. OPTIMIZACIÓN PARA COMPUTACIÓN GPU EN CUDA La arquitectura de una GPU es básicamente distinta a la de una CPU. Las GPUs están estructuradas de manera paralela y disponen de un acceso a memoria interna
Aplicaciones Concurrentes
 PROGRAMACIÓN CONCURRENTE TEMA 6 Aplicaciones Concurrentes ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN PROGRAMACIÓN CONCURRENTE Aplicaciones Concurrentes
PROGRAMACIÓN CONCURRENTE TEMA 6 Aplicaciones Concurrentes ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN PROGRAMACIÓN CONCURRENTE Aplicaciones Concurrentes
Introducción a la programación de códigos paralelos con CUDA y su ejecución en un GPU multi-hilos
 Introducción a la programación de códigos paralelos con CUDA y su ejecución en un GPU multi-hilos Gerardo A. Laguna-Sánchez *, Mauricio Olguín-Carbajal **, Ricardo Barrón-Fernández *** Recibido: 02 de
Introducción a la programación de códigos paralelos con CUDA y su ejecución en un GPU multi-hilos Gerardo A. Laguna-Sánchez *, Mauricio Olguín-Carbajal **, Ricardo Barrón-Fernández *** Recibido: 02 de
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS
 INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano [email protected] Vicente Morell Giménez [email protected] Universidad de Alicante Departamento de tecnología informática y computación
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano [email protected] Vicente Morell Giménez [email protected] Universidad de Alicante Departamento de tecnología informática y computación
CDI Arquitecturas que soportan la concurrencia. granularidad
 granularidad Se suele distinguir concurrencia de grano fino es decir, se aprovecha de la ejecución de operaciones concurrentes a nivel del procesador (hardware) a grano grueso es decir, se aprovecha de
granularidad Se suele distinguir concurrencia de grano fino es decir, se aprovecha de la ejecución de operaciones concurrentes a nivel del procesador (hardware) a grano grueso es decir, se aprovecha de
Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial
 Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial Intel ha lanzado su procesador Xeon Phi en la Conferencia Internacional de Supercomputación de Alemania. El procesador
Intel lanza su procesador Caballero Medieval habilitado para Inteligencia Artificial Intel ha lanzado su procesador Xeon Phi en la Conferencia Internacional de Supercomputación de Alemania. El procesador
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Computación en procesadores gráficos
 Programación con CUDA Ejercicio 8 José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos
Programación con CUDA Ejercicio 8 José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos
Paralelismo _Arquitectura de Computadoras IS603
 Paralelismo _Arquitectura de Computadoras IS603 INTRODUCCION El objetivo de esta investigación, es conceptualizar las diferentes tipos de paralelismo referente al área de Arquitectura de Computadoras,
Paralelismo _Arquitectura de Computadoras IS603 INTRODUCCION El objetivo de esta investigación, es conceptualizar las diferentes tipos de paralelismo referente al área de Arquitectura de Computadoras,
DESARROLLO DE APLICACIONES EN CUDA
 DESARROLLO DE APLICACIONES EN CUDA Curso 2014 / 15 Procesadores Gráficos y Aplicaciones en Tiempo Real Alberto Sánchez GMRV 2005-2015 1/30 Contenidos Introducción Debugging Profiling Streams Diseño de
DESARROLLO DE APLICACIONES EN CUDA Curso 2014 / 15 Procesadores Gráficos y Aplicaciones en Tiempo Real Alberto Sánchez GMRV 2005-2015 1/30 Contenidos Introducción Debugging Profiling Streams Diseño de
MAGMA. Matrix Algebra on GPU and Multicore Architecture. Ginés David Guerrero Hernández
 PLASMA GPU MAGMA Rendimiento Trabajo Futuro MAGMA Matrix Algebra on GPU and Multicore Architecture Ginés David Guerrero Hernández [email protected] Grupo de Arquitecturas y Computación Paralela
PLASMA GPU MAGMA Rendimiento Trabajo Futuro MAGMA Matrix Algebra on GPU and Multicore Architecture Ginés David Guerrero Hernández [email protected] Grupo de Arquitecturas y Computación Paralela
Hilos. Módulo 4. Departamento de Informática Facultad de Ingeniería Universidad Nacional de la Patagonia San Juan Bosco. Hilos
 Hilos Módulo 4 Departamento de Informática Facultad de Ingeniería Universidad Nacional de la Patagonia San Juan Bosco Hilos Revisión Modelos Multihilados Librerías de Hilos Aspectos sobre Hilos Ejemplos
Hilos Módulo 4 Departamento de Informática Facultad de Ingeniería Universidad Nacional de la Patagonia San Juan Bosco Hilos Revisión Modelos Multihilados Librerías de Hilos Aspectos sobre Hilos Ejemplos
GPU-Ejemplo CUDA. Carlos García Sánchez
 Carlos García Sánchez 1 2 Contenidos Motivación GPU vs. CPU GPU vs. Vectoriales CUDA Sintaxis Ejemplo 2 3 Motivación Computación altas prestaciones: www.top500.org 1º: Titan (300mil AMD-Opteron + 19mil
Carlos García Sánchez 1 2 Contenidos Motivación GPU vs. CPU GPU vs. Vectoriales CUDA Sintaxis Ejemplo 2 3 Motivación Computación altas prestaciones: www.top500.org 1º: Titan (300mil AMD-Opteron + 19mil
Caracterización de las aplicaciones paralelas en cuanto a la petición de recursos
 Caracterización de las aplicaciones paralelas en cuanto a la petición de recursos Marisa Gil ([email protected]) ENtornos Operativos para la Gestión de Recursos de Aplicaciones Paralelas CURSO 1.998-99
Caracterización de las aplicaciones paralelas en cuanto a la petición de recursos Marisa Gil ([email protected]) ENtornos Operativos para la Gestión de Recursos de Aplicaciones Paralelas CURSO 1.998-99
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Sistemas Operativos. Procesos
 Sistemas Operativos Procesos Agenda Proceso. Definición de proceso. Contador de programa. Memoria de los procesos. Estados de los procesos. Transiciones entre los estados. Bloque descriptor de proceso
Sistemas Operativos Procesos Agenda Proceso. Definición de proceso. Contador de programa. Memoria de los procesos. Estados de los procesos. Transiciones entre los estados. Bloque descriptor de proceso
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU. Clase 0 Lanzamiento del Curso. Motivación
 Computación de Propósito General en Unidades de Procesamiento Gráfico () Pablo Ezzatti, Martín Pedemonte Clase 0 Lanzamiento del Curso Contenido Evolución histórica en Fing Infraestructura disponible en
Computación de Propósito General en Unidades de Procesamiento Gráfico () Pablo Ezzatti, Martín Pedemonte Clase 0 Lanzamiento del Curso Contenido Evolución histórica en Fing Infraestructura disponible en
Prof. María Alejandra Quintero. Informática Año
 Prof. María Alejandra Quintero Informática Año 2014-2015 Es la acción de escribir programas de computación con el objetivo de resolver un determinado problema. Implica escribir instrucciones para indicarle
Prof. María Alejandra Quintero Informática Año 2014-2015 Es la acción de escribir programas de computación con el objetivo de resolver un determinado problema. Implica escribir instrucciones para indicarle
Programación Concurrente Recopilación de teoría referente a la materia
 UNIVERSIDAD AMERICANA Programación Concurrente Recopilación de teoría referente a la materia Ing. Luis Müller Esta es una recopilación de la teoría referente a la asignatura Programación Concurrente, a
UNIVERSIDAD AMERICANA Programación Concurrente Recopilación de teoría referente a la materia Ing. Luis Müller Esta es una recopilación de la teoría referente a la asignatura Programación Concurrente, a
Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria
 que procesa datos siguiendo unas instrucciones almacenadas en su memoria") 1.2. Jerarquía de niveles de un computador Qué es un computador? Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria Es un sistema tan complejo
1.2. Jerarquía de niveles de un computador Qué es un computador? Sistema electrónico digital (binario) que procesa datos siguiendo unas instrucciones almacenadas en su memoria Es un sistema tan complejo
Introducción a la Programación Paralela
 Proyecto Universidad-Secundaria Incorporación de contenidos de programación paralela en la rama de tecnologías informáticas Facultad Informática, Universidad de Murcia e Instituto de Enseñanza Secundaria
Proyecto Universidad-Secundaria Incorporación de contenidos de programación paralela en la rama de tecnologías informáticas Facultad Informática, Universidad de Murcia e Instituto de Enseñanza Secundaria
UNIDAD II. Software del Computador. Ing. Yesika Medina Ing. Yesika Medina
 UNIDAD II Software del Computador SOFTWARE Se denomina software a todos los componentes intangibles de una computadora, formados por el conjunto de programas y procedimientos necesarios para hacer posible
UNIDAD II Software del Computador SOFTWARE Se denomina software a todos los componentes intangibles de una computadora, formados por el conjunto de programas y procedimientos necesarios para hacer posible
Flaviu Vasile Buturca TRABAJO FINAL DE CARRERA. Dirigido por Carles Aliagas Castell. Grado de Ingeniería Informática
 Flaviu Vasile Buturca Programación Algoritmos paralela CUDAen CUDA TRABAJO FINAL DE CARRERA Dirigido por Carles Aliagas Castell Grado de Ingeniería Informática Tarragona 2016 UNIVERSIDAD ROVIRA I VIRGILI
Flaviu Vasile Buturca Programación Algoritmos paralela CUDAen CUDA TRABAJO FINAL DE CARRERA Dirigido por Carles Aliagas Castell Grado de Ingeniería Informática Tarragona 2016 UNIVERSIDAD ROVIRA I VIRGILI
FLAG/C. Una API para computación matricial sobre GPUs. M. Jesús Zafont Alberto Martín Francisco Igual Enrique S. Quintana-Ortí
 FLAG/C Una API para computación matricial sobre GPUs M. Jesús Zafont Alberto Martín Francisco Igual Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universitat Jaume I de Castellón
FLAG/C Una API para computación matricial sobre GPUs M. Jesús Zafont Alberto Martín Francisco Igual Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universitat Jaume I de Castellón
TAREA 1. INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS.
 1 TAREA 1. INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS. 1- Cuáles son las principales funciones de un sistema operativo? Los Sistemas Operativos tienen como objetivos o funciones principales lo siguiente; Comodidad;
1 TAREA 1. INTRODUCCIÓN A LOS SISTEMAS OPERATIVOS. 1- Cuáles son las principales funciones de un sistema operativo? Los Sistemas Operativos tienen como objetivos o funciones principales lo siguiente; Comodidad;
Departamento de Arquitectura de computadores y electrónica Universidad de Almería. Tesis Doctoral
 Departamento de Arquitectura de computadores y electrónica Universidad de Almería Tesis Doctoral Computación algebraica dispersa con procesadores grácos y su aplicación en tomografía electrónica Francisco
Departamento de Arquitectura de computadores y electrónica Universidad de Almería Tesis Doctoral Computación algebraica dispersa con procesadores grácos y su aplicación en tomografía electrónica Francisco
IMPLEMENTACIÓN Y EVALUACIÓN DE UN ALGORITMO ABC EN GPU
 PONTIFICIA UNIVERSIDAD CATÓLICA DE VALPARAÍSO FACULTAD DE INGENIERÍA ESCUELA DE INGENIERÍA INFORMÁTICA IMPLEMENTACIÓN Y EVALUACIÓN DE UN ALGORITMO ABC EN GPU MARIO ANDRÉS HERRERA LETELIER MARCELO ALEJANDRO
PONTIFICIA UNIVERSIDAD CATÓLICA DE VALPARAÍSO FACULTAD DE INGENIERÍA ESCUELA DE INGENIERÍA INFORMÁTICA IMPLEMENTACIÓN Y EVALUACIÓN DE UN ALGORITMO ABC EN GPU MARIO ANDRÉS HERRERA LETELIER MARCELO ALEJANDRO
ARQUITECTURA DEL COMPUTADOR
 1-11 Marzo de 2017 FACET -UNT ARQUITECTURA DEL COMPUTADOR Graciela Molina [email protected] [email protected] 1 MODELO VON NEUMANN RAM J. Von Neumann frente a la computadora IAS, 1952.
1-11 Marzo de 2017 FACET -UNT ARQUITECTURA DEL COMPUTADOR Graciela Molina [email protected] [email protected] 1 MODELO VON NEUMANN RAM J. Von Neumann frente a la computadora IAS, 1952.
MULTIPROGRAMACIÓN. Introducción a al Multitarea
 MULTIPROGRAMACIÓN Introducción a al Multitarea Introducción a la Multitarea Conceptos básicos Se refiere a la capacidad de un sistema operativo de ejecutar múltiples procesos, también llamados tareas,
MULTIPROGRAMACIÓN Introducción a al Multitarea Introducción a la Multitarea Conceptos básicos Se refiere a la capacidad de un sistema operativo de ejecutar múltiples procesos, también llamados tareas,
Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)
![Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)](/thumbs/36/17576386.jpg "Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)") Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
TEMA 4 PROCESAMIENTO PARALELO
 TEMA 4 PROCESAMIENTO PARALELO Tipos de plataformas de computación paralela Organización lógica Organización física Sistemas de memoria compartida Sistemas de memoria distribuida Tipos de plataformas de
TEMA 4 PROCESAMIENTO PARALELO Tipos de plataformas de computación paralela Organización lógica Organización física Sistemas de memoria compartida Sistemas de memoria distribuida Tipos de plataformas de
PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS
 Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Principios de Computadoras II
 Departamento de Ingeniería Electrónica y Computadoras Ing. Ricardo Coppo [email protected] Qué es un Objeto? Un objeto es una instancia de una clase Las clases actuán como modelos que permiten la creación
Departamento de Ingeniería Electrónica y Computadoras Ing. Ricardo Coppo [email protected] Qué es un Objeto? Un objeto es una instancia de una clase Las clases actuán como modelos que permiten la creación
Tema 7. Mejora del rendimiento: introducción a la segmentación y a las arquitecturas paralelas
 Tema 7. Mejora del rendimiento: introducción a la segmentación y a las arquitecturas paralelas Arquitectura de Computadores Curso 2009-2010 Transparencia: 2 / 21 Índice Introducción Taxonomía de Flynn
Tema 7. Mejora del rendimiento: introducción a la segmentación y a las arquitecturas paralelas Arquitectura de Computadores Curso 2009-2010 Transparencia: 2 / 21 Índice Introducción Taxonomía de Flynn
Arquitecturas de Altas Prestaciones y Supercomputación
 Arquitecturas de Altas Prestaciones y Supercomputación Presentación del itinerario Julio de 2014 Arquitecturas de Altas Prestaciones y Supercomputación Julio de 2014 1 / 15 Agenda Introducción 1 Introducción
Arquitecturas de Altas Prestaciones y Supercomputación Presentación del itinerario Julio de 2014 Arquitecturas de Altas Prestaciones y Supercomputación Julio de 2014 1 / 15 Agenda Introducción 1 Introducción
Introducción a los Sistemas Operativos
 Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria [email protected] 1 Índice General Conceptos sobre ordenadores Concepto
Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria [email protected] 1 Índice General Conceptos sobre ordenadores Concepto
Introducción al Computo Distribuido
 Introducción al Computo Distribuido Facultad de Cs. de la Computación Juan Carlos Conde Ramírez Distributed Computing Contenido 1 Introducción 2 Importancia del Hardware 3 Importancia del Software 1 /
Introducción al Computo Distribuido Facultad de Cs. de la Computación Juan Carlos Conde Ramírez Distributed Computing Contenido 1 Introducción 2 Importancia del Hardware 3 Importancia del Software 1 /
cuevogenet Paralelización en CUDA de la Dinámica Evolutiva de Redes Génicas Dirigido por: Fernando Díaz del Río José Luis Guisado Lizar
 cuevogenet Paralelización en CUDA de la Dinámica Evolutiva de Redes Génicas Realizado por: Raúl García Calvo Dirigido por: Fernando Díaz del Río José Luis Guisado Lizar Objetivos Implementar un algoritmo
cuevogenet Paralelización en CUDA de la Dinámica Evolutiva de Redes Génicas Realizado por: Raúl García Calvo Dirigido por: Fernando Díaz del Río José Luis Guisado Lizar Objetivos Implementar un algoritmo
Introducción a la Computación Paralela
 Metodología de la Programación Paralela Facultad Informática, Universidad de Murcia Introducción a la Computación Paralela Bibliografía básica Introducción Del curso, capítulos 1 a 6 De esta sesión, capítulos
Metodología de la Programación Paralela Facultad Informática, Universidad de Murcia Introducción a la Computación Paralela Bibliografía básica Introducción Del curso, capítulos 1 a 6 De esta sesión, capítulos
Arquitecturas Híbridas o Heterogéneas
 Arquitecturas Híbridas o Heterogéneas Paralelo entre NVIDIA CUDA y Parallel Studio XE para Intel Xeon Phi Laura Marcela Ramírez Patiño 2130064 Lenin Eduardo Guerrero Hernández 2092028 Universidad Industrial
Arquitecturas Híbridas o Heterogéneas Paralelo entre NVIDIA CUDA y Parallel Studio XE para Intel Xeon Phi Laura Marcela Ramírez Patiño 2130064 Lenin Eduardo Guerrero Hernández 2092028 Universidad Industrial
Procesos y Threads Procesos y Threads. Rendimiento Rendimiento (paralelismo) (paralelismo) Productividad Productividad
 (paralelismo) Productividad Productividad") Procesos y Threads Procesos y Threads Procesos Procesos Threads Threads Concurrencia Concurrencia Ventajas Ventajas Modelos Modelos Información Información adicional (PCB) adicional (PCB) Preparado Preparado
Procesos y Threads Procesos y Threads Procesos Procesos Threads Threads Concurrencia Concurrencia Ventajas Ventajas Modelos Modelos Información Información adicional (PCB) adicional (PCB) Preparado Preparado
Variables, expresiones y sentencias
 Introducción a la Programación Pontificia Universidad Javeriana Generado con LAT E X Febrero de 2010 Recorderis Recorderis Algoritmo Colección de instrucciones junto con un orden en el cual deben ser ejecutados.
Introducción a la Programación Pontificia Universidad Javeriana Generado con LAT E X Febrero de 2010 Recorderis Recorderis Algoritmo Colección de instrucciones junto con un orden en el cual deben ser ejecutados.
UNIVERSIDAD DE GUADALAJARA
 UNIVERSIDAD DE GUADALAJARA CENTRO UNIVERSITARIO DE LOS ALTOS DIVISIÓN DE ESTUDIOS EN FORMACIONES SOCIALES LICENCIATURA: INGENIERÍA EN COMPUTACIÓN UNIDAD DE APRENDIZAJE POR OBJETIVOS ARQUITECTURA DE COMPUTADORAS
UNIVERSIDAD DE GUADALAJARA CENTRO UNIVERSITARIO DE LOS ALTOS DIVISIÓN DE ESTUDIOS EN FORMACIONES SOCIALES LICENCIATURA: INGENIERÍA EN COMPUTACIÓN UNIDAD DE APRENDIZAJE POR OBJETIVOS ARQUITECTURA DE COMPUTADORAS
TEMA 2: PROGRAMACIÓN PARALELA (I)
") Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas ARQUITECTURA DE COMPUTADORES II AUTORES: David Expósito Singh Florin Isaila Daniel Higuero Alonso-Mardones Javier García Blas Borja Bergua
Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas ARQUITECTURA DE COMPUTADORES II AUTORES: David Expósito Singh Florin Isaila Daniel Higuero Alonso-Mardones Javier García Blas Borja Bergua
6.1 Base De Datos Centralizada
 6. Infraestructura El tipo de infraestructura o bien arquitectura, se debe de elegir pensando en el sistema a ejecutar, las necesidades que este tendrá, el tipo de usuario que lo utilizará, la seguridad
6. Infraestructura El tipo de infraestructura o bien arquitectura, se debe de elegir pensando en el sistema a ejecutar, las necesidades que este tendrá, el tipo de usuario que lo utilizará, la seguridad
RECONOCIMIENTO DE OBJETOS PARA APOYO A PERSONAS INVIDENTES BASADO EN DEEP LEARNING
 RECONOCIMIENTO DE OBJETOS PARA APOYO A PERSONAS INVIDENTES BASADO EN DEEP LEARNING Israel Rivera Zárate Instituto Politécnico Nacional-CIDETEC [email protected] Miguel Hernández Bolaños Instituto Politécnico
RECONOCIMIENTO DE OBJETOS PARA APOYO A PERSONAS INVIDENTES BASADO EN DEEP LEARNING Israel Rivera Zárate Instituto Politécnico Nacional-CIDETEC [email protected] Miguel Hernández Bolaños Instituto Politécnico
Concurrencia de Procesos
 Concurrencia de Procesos Dos o mas procesos, se dice que son concurrentes o paralelos, cuando se ejecutan al mismo tiempo. Esta concurrencia puede darse en un sistema con un solo procesador (pseudo paralelismo)
Concurrencia de Procesos Dos o mas procesos, se dice que son concurrentes o paralelos, cuando se ejecutan al mismo tiempo. Esta concurrencia puede darse en un sistema con un solo procesador (pseudo paralelismo)
CUDA 5.5 y Visual Studio Express 2012 para Escritorio. Primeros pasos.
 CUDA 5.5 y Visual Studio Express 2012 para Escritorio. Primeros pasos. La nueva versión de CUDA 5.5 es completamente compatible con la plataforma de desarrollo Visual Studio Express 2012 para escritorio
CUDA 5.5 y Visual Studio Express 2012 para Escritorio. Primeros pasos. La nueva versión de CUDA 5.5 es completamente compatible con la plataforma de desarrollo Visual Studio Express 2012 para escritorio
Java para no Programadores
 Java para no Programadores Programa de Estudio Java para no Programadores Aprende a programar con una de las tecnologías más utilizadas en el mercado de IT. Este curso está orientado a quienes no tienen
Java para no Programadores Programa de Estudio Java para no Programadores Aprende a programar con una de las tecnologías más utilizadas en el mercado de IT. Este curso está orientado a quienes no tienen
COLEGIO DE ESTUDIOS DE POSGRADO DE LA CIUDAD DE MÉXICO
 COLEGIO DE ESTUDIOS DE POSGRADO DE LA CIUDAD DE MÉXICO ELABORO: ALEJANDRA FUERTES FRANCISCO TEMA: LENGUAJES DE PROGRAMACIÓN INTRODUCCIÓN Un lenguaje de programación es un conjunto de instrucciones que
COLEGIO DE ESTUDIOS DE POSGRADO DE LA CIUDAD DE MÉXICO ELABORO: ALEJANDRA FUERTES FRANCISCO TEMA: LENGUAJES DE PROGRAMACIÓN INTRODUCCIÓN Un lenguaje de programación es un conjunto de instrucciones que
Tema III. Multihilo. Desarrollo de Aplicaciones para Internet Curso 12 13
 Tema III. Multihilo Desarrollo de Aplicaciones para Internet Curso 12 13 Índice 1.Introducción 2.Tipos de Concurrencia 3.Hilos en Java 4.Implementación de un SNB i. Sin Hilos ii. Con Hilos iii.con Pool
Tema III. Multihilo Desarrollo de Aplicaciones para Internet Curso 12 13 Índice 1.Introducción 2.Tipos de Concurrencia 3.Hilos en Java 4.Implementación de un SNB i. Sin Hilos ii. Con Hilos iii.con Pool
Introducción a Cómputo Paralelo con CUDA C/C++
 UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO Facultad de Ingeniería Introducción a Cómputo Paralelo con CUDA C/C++ Laboratorio de Intel para la Academia y Cómputo de alto desempeño Elaboran: Revisión: Ing.
UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO Facultad de Ingeniería Introducción a Cómputo Paralelo con CUDA C/C++ Laboratorio de Intel para la Academia y Cómputo de alto desempeño Elaboran: Revisión: Ing.
Contenidos: Definiciones:
 Contenidos: Definiciones. Esquema de un ordenador. Codificación de la información. Parámetros básicos de un ordenador. Programas e instrucciones. Proceso de ejecución de una instrucción. Tipos de instrucciones.
Contenidos: Definiciones. Esquema de un ordenador. Codificación de la información. Parámetros básicos de un ordenador. Programas e instrucciones. Proceso de ejecución de una instrucción. Tipos de instrucciones.
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU. Clase 1 Introducción
 Computación de Propósito General en Unidades de Procesamiento Gráfico () P. Ezzatti, M. Pedemontey E. Dufrechou Clase 1 Introducción Contenido Un poco de historia El pipeline gráfico Tarjetas programables
Computación de Propósito General en Unidades de Procesamiento Gráfico () P. Ezzatti, M. Pedemontey E. Dufrechou Clase 1 Introducción Contenido Un poco de historia El pipeline gráfico Tarjetas programables
Java para no Programadores
 Java para no Programadores Programa de Estudio Java para no Programadores Aprende a programar con una de las tecnologías más utilizadas en el mercado de IT y comienza tu camino como desarrollador Java.
Java para no Programadores Programa de Estudio Java para no Programadores Aprende a programar con una de las tecnologías más utilizadas en el mercado de IT y comienza tu camino como desarrollador Java.