Segmentación del Path de Datos
|
|
|
- Patricia Ávila Piñeiro
- hace 5 años
- Vistas:
Transcripción


1 Maestría en Electrónica Arquitectura de Computadoras Unidad 5 (Parte II) M. C. Felipe Santiago Espinosa Abril/2018

2 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup = 2*n/ = number of stages 2
3 MIPS Pipeline Five stages, one step per stage 1. IF: Instruction fetch from memory 2. ID: Instruction decode & register read 3. EX: Execute operation or calculate address 4. MEM: Access memory operand 5. WB: Write result back to register 3
4 Pipeline Performance Assume time for stages is 100ps for register read or write 200ps for other stages Compare pipelined datapath with single-cycle datapath Instr Instr fetch Register read ALU op Memory access Register write Total time lw 200ps 100 ps 200ps 200ps 100 ps 800ps sw 200ps 100 ps 200ps 200ps 700ps R-format 200ps 100 ps 200ps 100 ps 600ps beq 200ps 100 ps 200ps 500ps 4
 Pipelined (T c = 200ps) 5")
5 Pipeline Performance Single-cycle (T c = 800ps) Pipelined (T c = 200ps) 5
6 Pipeline Speedup If all stages are balanced i.e., all take the same time Time between instructions pipelined = Time between instructions nonpipelined Number of stages If not balanced, speedup is less Speedup due to increased throughput Latency (time for each instruction) does not decrease 6
7 Pipelining and ISA Design MIPS ISA designed for pipelining All instructions are 32-bits Easier to fetch and decode in one cycle c.f. x86: 1- to 17-byte instructions Few and regular instruction formats Can decode and read registers in one step Load/store addressing Can calculate address in 3 rd stage, access memory in 4 th stage Alignment of memory operands Memory access takes only one cycle 7
8 Hazards Situations that prevent starting the next instruction in the next cycle Structure hazards A required resource is busy Data hazard Need to wait for previous instruction to complete its data read/write Control hazard Deciding on control action depends on previous instruction 8
9 Structure Hazards Conflict for use of a resource In MIPS pipeline with a single memory Load/store requires data access Instruction fetch would have to stall for that cycle Would cause a pipeline bubble Hence, pipelined datapaths require separate instruction/data memories Or separate instruction/data caches 9

10 Data Hazards An instruction depends on completion of data access by a previous instruction add $s0, $t0, $t1 sub $t2, $s0, $t3 10


11 Forwarding (aka Bypassing) Use result when it is computed Don t wait for it to be stored in a register Requires extra connections in the datapath 11


12 Load-Use Data Hazard Can t always avoid stalls by forwarding If value not computed when needed Can t forward backward in time! 12
13 Code Scheduling to Avoid Stalls Reorder code to avoid use of load result in the next instruction C code for A = B + E; C = B + F; stall stall lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t2 sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 13 cycles lw $t1, 0($t0) lw $t2, 4($t0) lw $t4, 8($t0) add $t3, $t1, $t2 sw $t3, 12($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 11 cycles 13
14 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always fetch correct instruction Still working on ID stage of branch In MIPS pipeline Need to compare registers and compute target early in the pipeline Add hardware to do it in ID stage 14


15 Stall on Branch Wait until branch outcome determined before fetching next instruction 15
16 Branch Prediction Longer pipelines can t readily determine branch outcome early Stall penalty becomes unacceptable Predict outcome of branch Only stall if prediction is wrong In MIPS pipeline Can predict branches not taken Fetch instruction after branch, with no delay 16

17 MIPS with Predict Not Taken Prediction correct Prediction incorrect 17
18 More-Realistic Branch Prediction Static branch prediction Based on typical branch behavior Example: loop and if-statement branches Predict backward branches taken Predict forward branches not taken Dynamic branch prediction Hardware measures actual branch behavior e.g., record recent history of each branch Assume future behavior will continue the trend When wrong, stall while re-fetching, and update history 18
19 Pipeline Summary The BIG Picture Pipelining improves performance by increasing instruction throughput Executes multiple instructions in parallel Each instruction has the same latency Subject to hazards Structure, data, control Instruction set design affects complexity of pipeline implementation 19

20 MIPS Pipelined Datapath MEM Right-to-left flow leads to hazards WB 20


21 Pipeline registers Need registers between stages To hold information produced in previous cycle 21
22 Pipeline Operation Cycle-by-cycle flow of instructions through the pipelined datapath Single-clock-cycle pipeline diagram Shows pipeline usage in a single cycle Highlight resources used c.f. multi-clock-cycle diagram Graph of operation over time We ll look at single-clock-cycle diagrams for load & store 22

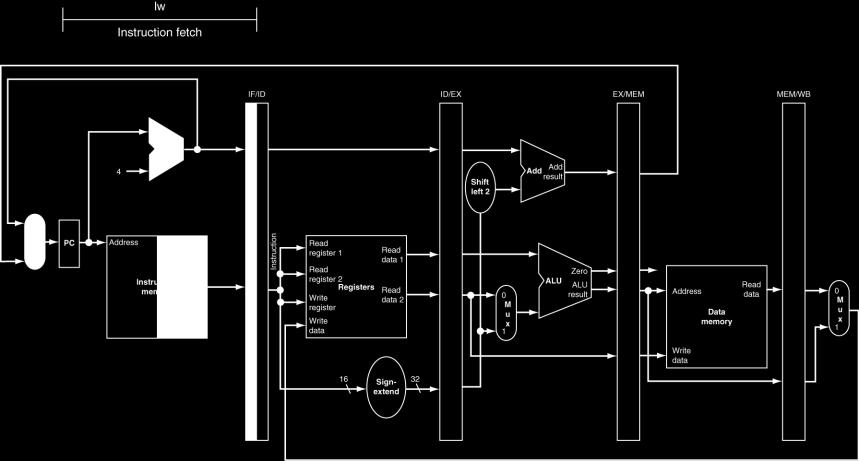
23 IF for Load, Store, 23

24 ID for Load, Store, 24
25 EX for Load 25
26 MEM for Load 26

27 WB for Load Wrong register number 27

28 Corrected Datapath for Load 28

29 EX for Store 29
30 MEM for Store 30

31 WB for Store 31

32 Multi-Cycle Pipeline Diagram Traditional form 32
33 Multi-Cycle Pipeline Diagram Form showing resource usage 33

34 Single-Cycle Pipeline Diagram State of pipeline in a given cycle 34

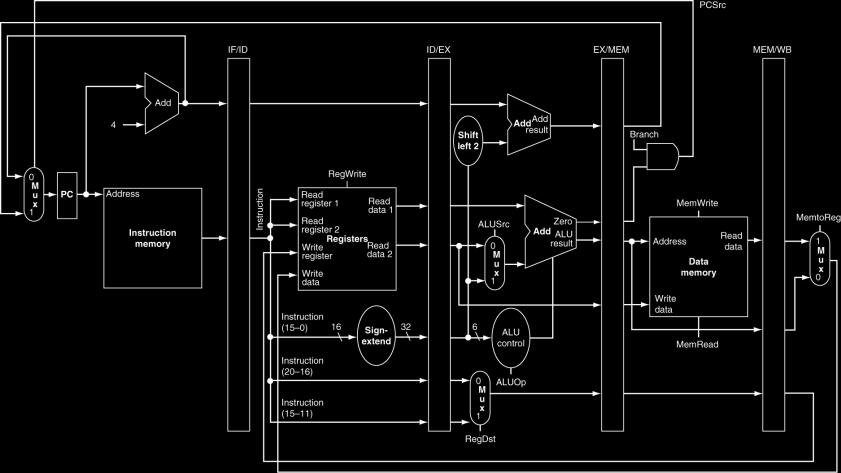
35 Pipelined Control (Simplified) 35


36 Pipelined Control Control signals derived from instruction As in single-cycle implementation 36

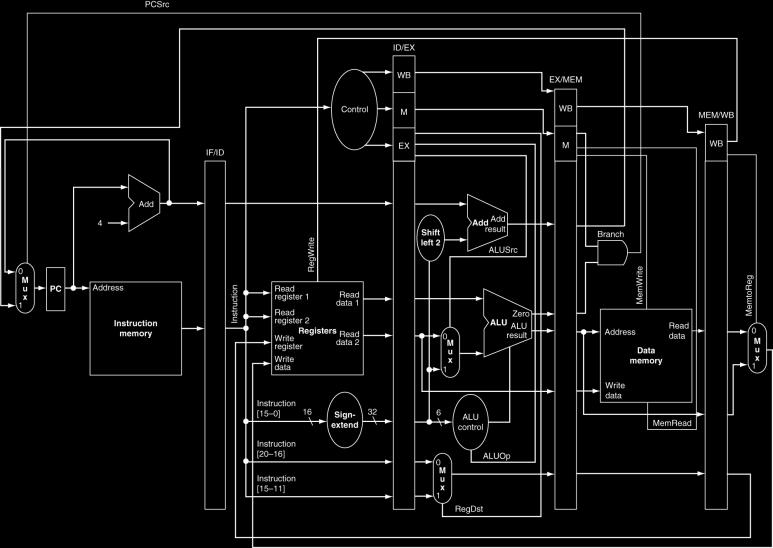
37 Pipelined Control 37
38 Ejemplo: Evaluar la ejecución de las instrucciones siguientes a través de un procesador segmentado: lw $10, 20 ($1) sub $11, $2, $3 and $12, $4, $5 or $13, $6, $7 add $14, $8, $9 Respuesta: Se requieren 5 ciclos de reloj para concluir con la instrucción lw Cuando lw termina su ejecución, las siguientes instrucciones se producen una por ciclo de reloj. En total se requiere de 9 ciclos para la ejecución de las cinco instrucciones. 38
39 Ciclo de reloj no. 1 39
40 Ciclo de reloj no. 2 40

41 Ciclo de reloj no. 3 41

42 Ciclo de reloj no. 4 42

43 Ciclo de reloj no. 5 43

44 Ciclo de reloj no. 6 44

45 Ciclo de reloj no. 7 45
46 Ciclo de reloj no. 8 46
47 Ciclo de reloj no. 9 47
48 Data Hazards in ALU Instructions Consider this sequence: sub $2, $1,$3 and $12,$2,$5 or $13,$6,$2 add $14,$2,$2 sw $15,100($2) We can resolve hazards with forwarding How do we detect when to forward? 48
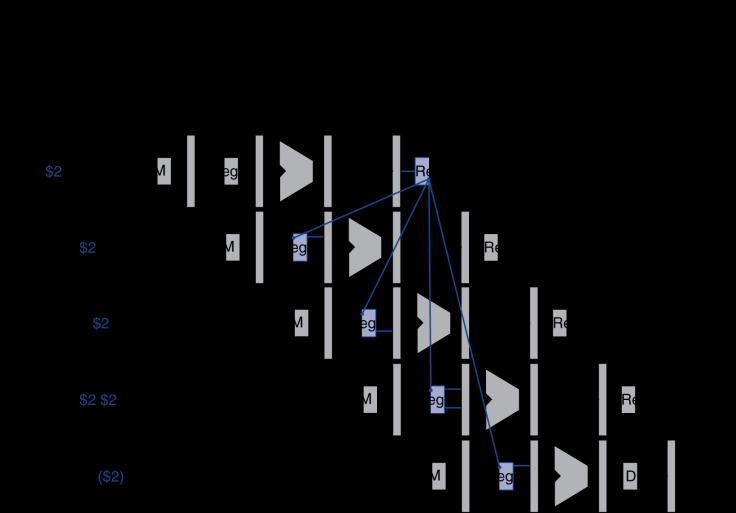
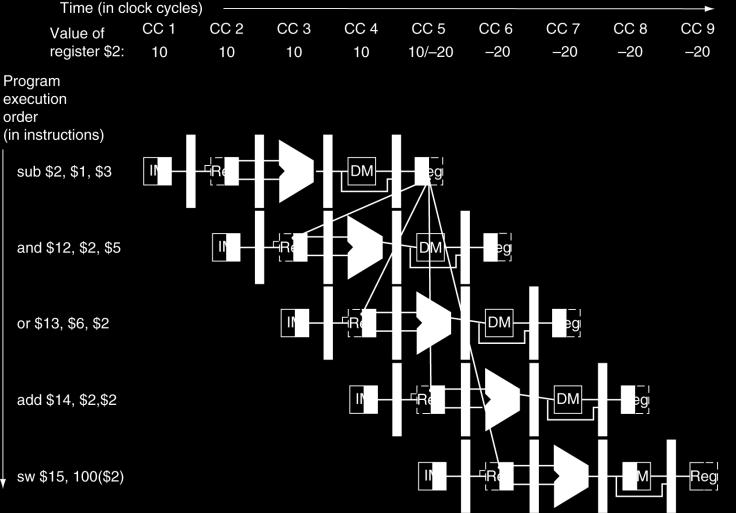
49 Dependencies & Forwarding 49
50 Detecting the Need to Forward ALU operand register numbers in EX stage are given by ID/EX.RegisterRs, ID/EX.RegisterRt Data hazards when 1a. EX/MEM.RegisterRd = ID/EX.RegisterRs 1b. EX/MEM.RegisterRd = ID/EX.RegisterRt 2a. MEM/WB.RegisterRd = ID/EX.RegisterRs 2b. MEM/WB.RegisterRd = ID/EX.RegisterRt Fwd from EX/MEM pipeline reg Fwd from MEM/WB pipeline reg 50
51 Detecting the Need to Forward But only if forwarding instruction will write to a register! EX/MEM.RegWrite, MEM/WB.RegWrite And only if Rd for that instruction is not $zero EX/MEM.RegisterRd 0, MEM/WB.RegisterRd 0 51
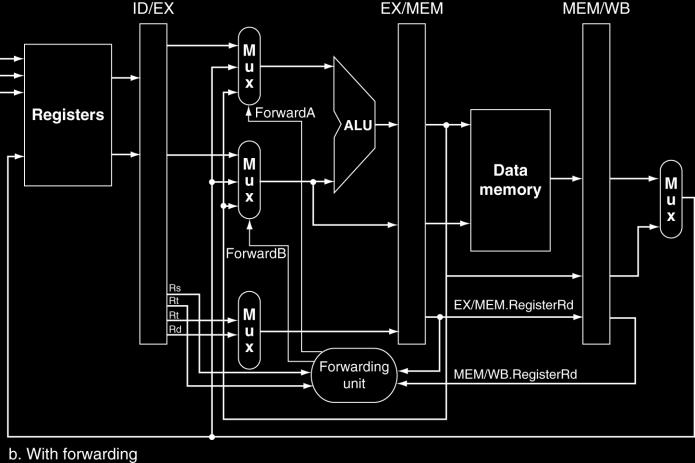
52 Forwarding Paths 52
53 Forwarding Conditions EX hazard if (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) ForwardA = 10 if (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) ForwardB = 10 MEM hazard if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01 if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01 53
54 Double Data Hazard Consider the sequence: add $1,$1,$2 add $1,$1,$3 add $1,$1,$4 Both hazards occur Want to use the most recent Revise MEM hazard condition Only fwd if EX hazard condition isn t true 54
55 Revised Forwarding Condition MEM hazard if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) and (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01 if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) and (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01 55

56 Datapath with Forwarding 56

57 Load-Use Data Hazard Need to stall for one cycle 57
58 Load-Use Hazard Detection Check when using instruction is decoded in ID stage ALU operand register numbers in ID stage are given by IF/ID.RegisterRs, IF/ID.RegisterRt Load-use hazard when ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)) If detected, stall and insert bubble 58
59 How to Stall the Pipeline Force control values in ID/EX register to 0 EX, MEM and WB do nop (no-operation) Prevent update of PC and IF/ID register Using instruction is decoded again Following instruction is fetched again 1-cycle stall allows MEM to read data for lw Can subsequently forward to EX stage 59
60 Stall/Bubble in the Pipeline Stall inserted here 60

61 Stall/Bubble in the Pipeline Or, more accurately 61


62 Datapath with Hazard Detection 62
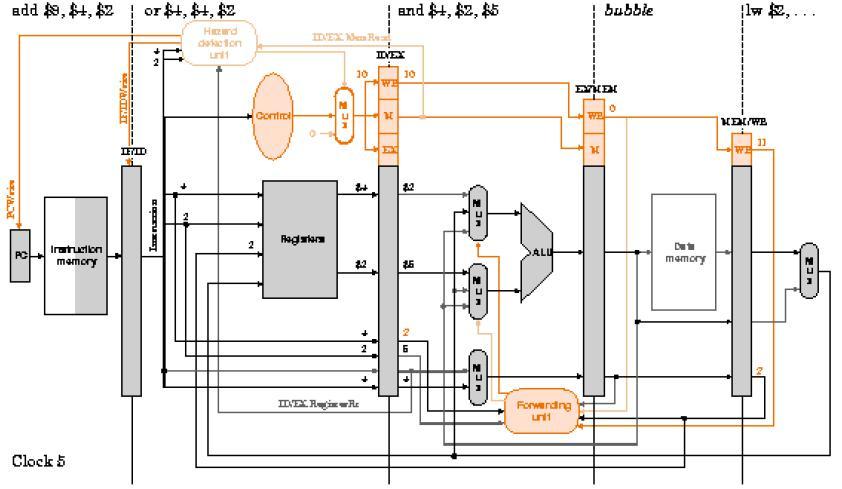
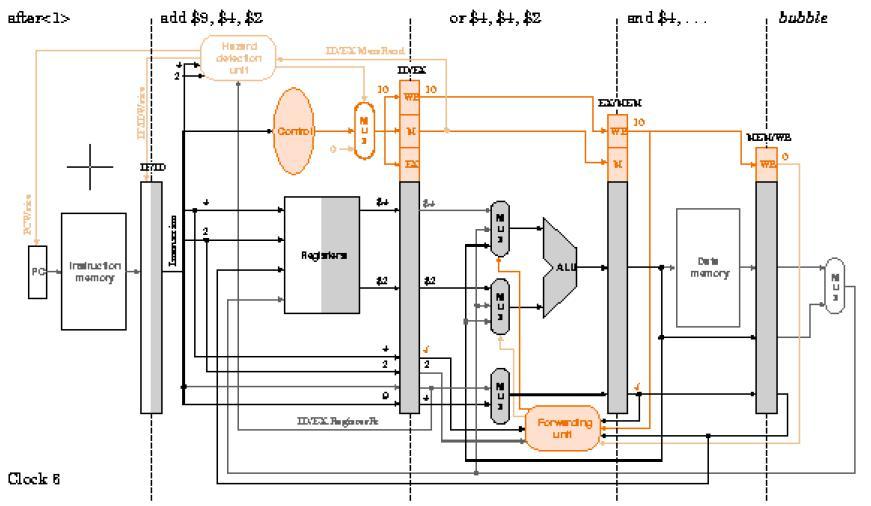
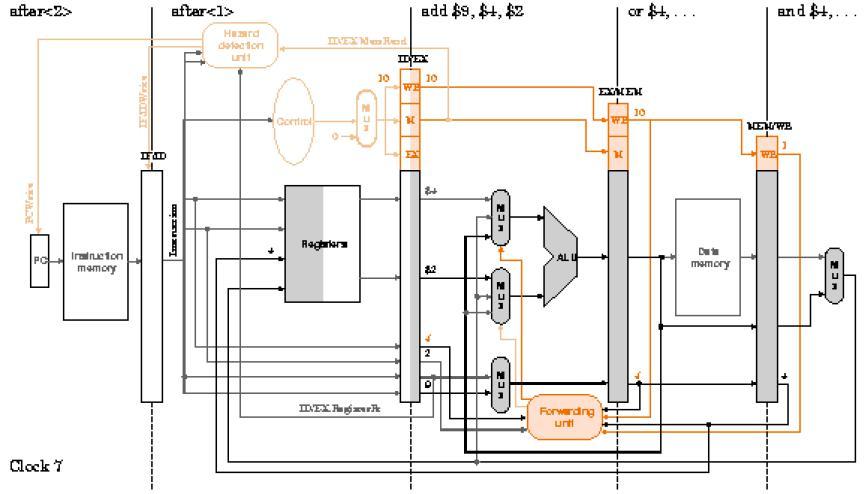
63 Ejemplo: Con la unidad de anticipación y la unidad de detección de riesgos incorporadas en el procesador segmentando, analice su comportamiento ciclo a ciclo durante la ejecución del código: lw $2, 20($1) and $4, $2, $5 or $4, $4, $2 add $9, $4, $2 Se revisarán los ciclos del 2 al 7 para observar cómo se inserta la burbuja y cómo avanza sin afectar la ejecución del programa. También se notará que no hay conflictos entre ambas unidades. Desarrolle la representación Multi-ciclos para observar el comportamiento global de la ejecución. 63
64 64
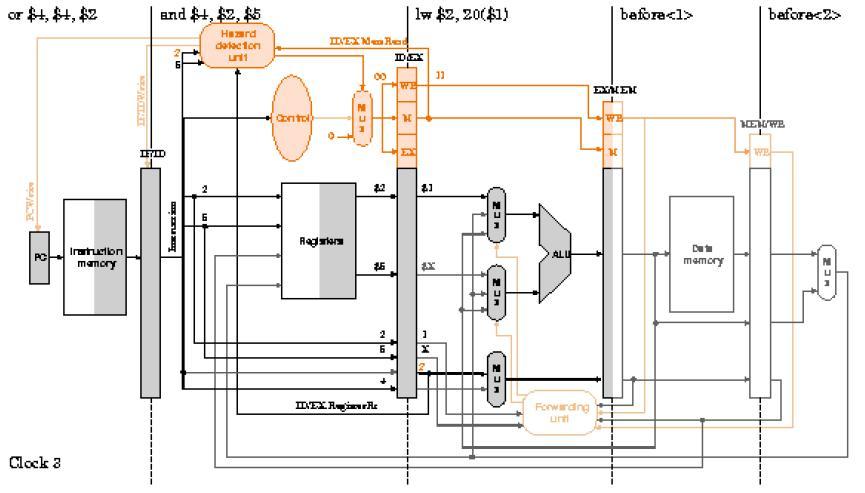
65 65
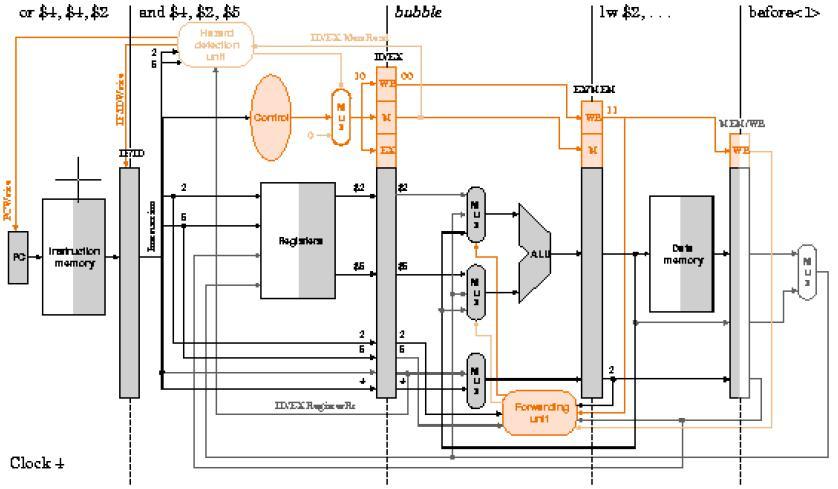
66 66
67 67
68 68
69 69
70 Stalls and Performance The BIG Picture Stalls reduce performance But are required to get correct results Compiler can arrange code to avoid hazards and stalls Requires knowledge of the pipeline structure 70
71 Branch Hazards If branch outcome determined in MEM Flush these instructions (Set control values to 0) PC 71
72 Incorporando Saltos Incondicionales Los saltos incondicionales (J) se pueden ejecutar tan pronto se identifica a la instrucción. Esto se hace en la etapa ID. Dos acciones deben realizarse: Anular la instrucción que está en la etapa IF limpiando el registro IF/ID. Remplazar el valor del PC por el destino del salto. 72

73 Implementación que resuelve a BEQ en la etapa MEM y a J en la etapa ID 73
74 Reducing Branch Delay Move hardware to determine outcome to ID stage Target address adder Register comparator Example: branch taken 36: sub $10, $4, $8 40: beq $1, $3, 7 44: and $12, $2, $5 48: or $13, $2, $6 52: add $14, $4, $2 56: slt $15, $6, $ : lw $4, 50($7) 74

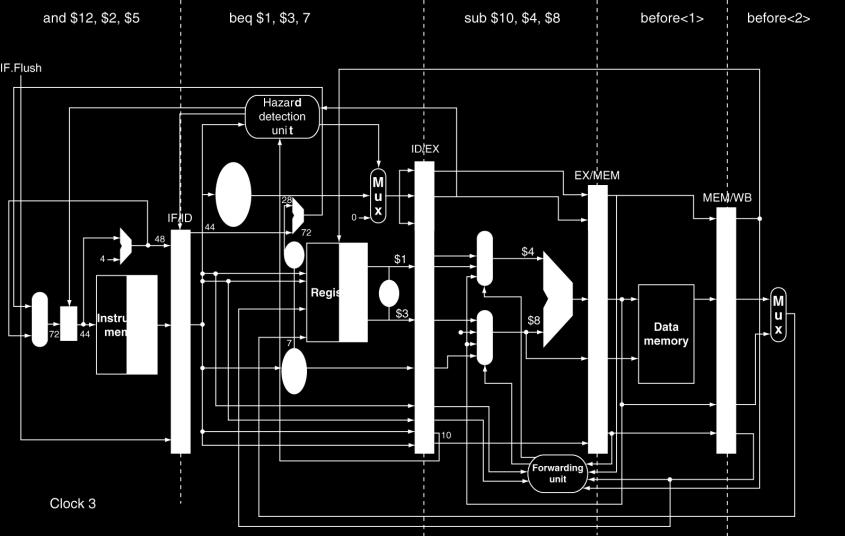
75 Example: Branch Taken 75

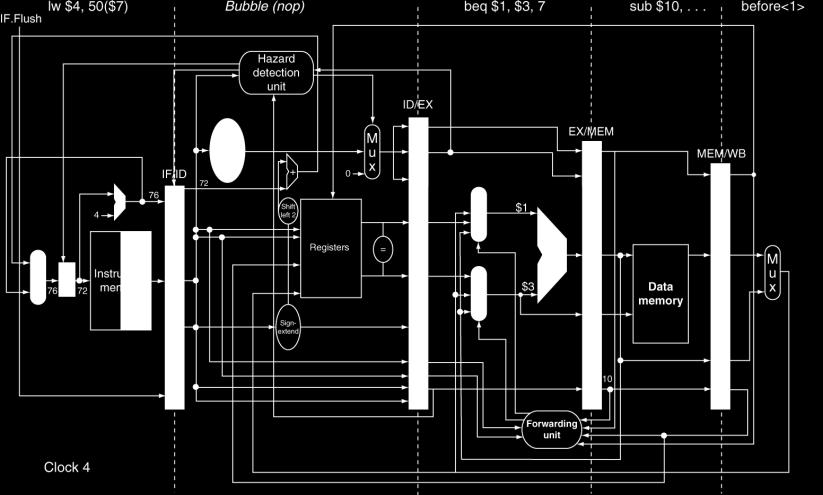
76 Example: Branch Taken 76
77 Data Hazards for Branches If a comparison register is a destination of 2 nd or 3 rd preceding ALU instruction add $1, $2, $3 IF ID EX MEM WB add $4, $5, $6 IF ID EX MEM WB IF ID EX MEM WB beq $1, $4, target IF ID EX MEM WB Can resolve using forwarding 77
78 Data Hazards for Branches If a comparison register is a destination of preceding ALU instruction or 2 nd preceding load instruction Need 1 stall cycle lw $1, addr IF ID EX MEM WB add $4, $5, $6 IF ID EX MEM WB beq stalled IF ID beq $1, $4, target ID EX MEM WB 78
79 Data Hazards for Branches If a comparison register is a destination of immediately preceding load instruction Need 2 stall cycles lw $1, addr IF ID EX MEM WB beq stalled IF ID beq stalled ID beq $1, $0, target ID EX MEM WB 79
80 Ejercicio: Comparación de Implementaciones Comparar el rendimiento de una implementación de un solo ciclo de reloj (PSC) con una implementación segmentada (PSEG). Considerando un programa de prueba con la siguiente distribución de instrucciones: Tipo Frecuencia Cargas 20 % Almacenamientos 15 % Brincos 20 % Saltos 5 % Aritmético Lógicas 40 % Tiempos de operación para las unidades funcionales: 2 ns - acceso a memoria, 2 ns - operación de la ALU, 1 ns acceso a registros. Para la implementación segmentada suponer que: la mitad de las instrucciones de carga están inmediatamente seguidas por una instrucción que usará el valor obtenido de la memoria, que una cuarta parte de los brincos condicionales si se realizan y sólo producen un retraso de 1 ciclo de reloj y que los saltos incondicionales también requieren de 1 ciclo de reloj adicional. 80
81 Ejercicios: 1. Por medio de una representación de múltiples ciclos de la segmentación, representar la ejecución de las siguientes instrucciones: Add $2, $5, $4 Add $4, $2, $5 Lw $5, 100($2) Add $3, $5, $4 Beq $8, $8, s1 And $1, $2, $3 Or $4, $5, $6 s1: Sub $7, $8, $9 Mostrar las líneas por medio de las cuales se resuelven las dependencias de datos y/o mostrar la inserción de burbujas si es que se requieren. Suponga que los brincos se resuelven en la etapa ID. 81
82 Ejercicios (Comprensión y ampliación de la implementación). Utilizando como base la figura de la diapositiva 73, analice como avanzan las instrucciones durante su ejecución: add $t5, $t1, $t0 beq $t2, $t3, et1 Suponga que están ubicadas en la dirección 4000diez, que los registros $t0 y $t1 tienen los valores 30 y 40 respectivamente, que $t2 y $t3 tienen el dato 33 y que la etiqueta está ubicada 10 instrucciones después de la que se está evaluando. Resalte las líneas que estarán activas durante la ejecución y escriba el valor de cada una de esas líneas. A la misma figura, agregue el hardware necesario (camino de datos y control) para que soporte la instrucción addi. De manera similar, agregue el hardware necesario para que el procesador soporte la instrucción jal. 82
Segmentación del Path de Datos
 Maestría en Electrónica Arquitectura de Computadoras Unidad 5 Segmentación del Path de Datos M. C. Felipe Santiago Espinosa Abril/2018 Introduction CPU performance factors Instruction count Determined
Maestría en Electrónica Arquitectura de Computadoras Unidad 5 Segmentación del Path de Datos M. C. Felipe Santiago Espinosa Abril/2018 Introduction CPU performance factors Instruction count Determined
Forwarding versus Stalling
 Forwarding versus Stalling Dependencias Considerar el siguiente código: 1.sub $2, $1, $3 2.and $12, $2, $5 3.or $13, $6, $2 4.add $14, $2, $2 5.sw $15, 100($2) Las instrucciones 2 a 5 dependen de $2. Universidad
Forwarding versus Stalling Dependencias Considerar el siguiente código: 1.sub $2, $1, $3 2.and $12, $2, $5 3.or $13, $6, $2 4.add $14, $2, $2 5.sw $15, 100($2) Las instrucciones 2 a 5 dependen de $2. Universidad
Forwarding versus Stalling
 Forwarding versus Stalling Dependencias Considerar el siguiente código: 1.sub $2, $1, $3 2.and $12, $2, $5 3.or $13, $6, $2 4.add $14, $2, $2 5.sw $15, 100($2) Las instrucciones 2 a 5 dependen de $2. Universidad
Forwarding versus Stalling Dependencias Considerar el siguiente código: 1.sub $2, $1, $3 2.and $12, $2, $5 3.or $13, $6, $2 4.add $14, $2, $2 5.sw $15, 100($2) Las instrucciones 2 a 5 dependen de $2. Universidad
Pipeline (Segmentación)
") Pipeline (Segmentación) Segmentación (Pipeline) Es una técnica de implementación por medio de la cual se puede traslapar la ejecución de instrucciones. En la actualidad la segmentación es una de las tecnologías
Pipeline (Segmentación) Segmentación (Pipeline) Es una técnica de implementación por medio de la cual se puede traslapar la ejecución de instrucciones. En la actualidad la segmentación es una de las tecnologías
Arquitectura de Computadores II Clase #5
 Arquitectura de Computadores II Clase #5 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Algunas ideas para mejorar el rendimiento Obvio: incrementar la frecuencia
Arquitectura de Computadores II Clase #5 Facultad de Ingeniería Universidad de la República Instituto de Computación Curso 2010 Algunas ideas para mejorar el rendimiento Obvio: incrementar la frecuencia
EE 361L Implementation Notes for Subproject 1
 EE 361L Implementation Notes for Subproject 1 You are to implement the pipelined MIPSL so that it can execute the instructions: add addi beq Assume the controller of the pipelined MIPSL works according
EE 361L Implementation Notes for Subproject 1 You are to implement the pipelined MIPSL so that it can execute the instructions: add addi beq Assume the controller of the pipelined MIPSL works according
Ejercicios para el 3er parcial
 Problema 1: Representar la ejecución de las siguientes instrucciones: Add $2, $5, $4 Add $4, $2, $5 Lw $5, 100($2) Add $3, $5, $4 Beq $8, $8, s1 And $1, $2, $3 OR $4, $5, $6 s1: Sub $7, $8, $9 Ejercicios
Problema 1: Representar la ejecución de las siguientes instrucciones: Add $2, $5, $4 Add $4, $2, $5 Lw $5, 100($2) Add $3, $5, $4 Beq $8, $8, s1 And $1, $2, $3 OR $4, $5, $6 s1: Sub $7, $8, $9 Ejercicios
Aspectos avanzados de arquitectura de computadoras Pipeline. Facultad de Ingeniería - Universidad de la República Curso 2017
 Aspectos avanzados de arquitectura de computadoras Pipeline Facultad de Ingeniería - Universidad de la República Curso 2017 Objetivo Mejorar el rendimiento Incrementar frecuencia de reloj? Ancho de los
Aspectos avanzados de arquitectura de computadoras Pipeline Facultad de Ingeniería - Universidad de la República Curso 2017 Objetivo Mejorar el rendimiento Incrementar frecuencia de reloj? Ancho de los
Pipelining. Introducción
 Pipelining Introducción Definición Técnica de implementación. Consiste en ejecutar traslapadas varias instrucciones al mismo tiempo. Universidad de Sonora Arquitectura de Computadoras 2 Ejemplo Pasos para
Pipelining Introducción Definición Técnica de implementación. Consiste en ejecutar traslapadas varias instrucciones al mismo tiempo. Universidad de Sonora Arquitectura de Computadoras 2 Ejemplo Pasos para
Segmentación: Mejora del rendimiento. IEC UTM Moisés E. Ramírez G. Segmentación
 Segmentación: Mejora del rendimiento IEC UTM Moisés E. Ramírez G. 1 Segmentación La segmentación (pipelining) es una técnica de implementación por la cual se solapa la ejecución de múltiples instrucciones.
Segmentación: Mejora del rendimiento IEC UTM Moisés E. Ramírez G. 1 Segmentación La segmentación (pipelining) es una técnica de implementación por la cual se solapa la ejecución de múltiples instrucciones.
Procesador Segmentado
 Organización del Computador I Verano Procesador Segmentado Basado en el capítulo 4 del libro de Patterson y Hennessy Verano 2014 Profesora Borensztejn Segmentación Descompone una determinada operación
Organización del Computador I Verano Procesador Segmentado Basado en el capítulo 4 del libro de Patterson y Hennessy Verano 2014 Profesora Borensztejn Segmentación Descompone una determinada operación
Tema 6. Introducción a la segmentación avanzada: Riesgos
 Tema 6. Introducción a la segmentación avanzada: Riesgos Organización de Computadores LUIS ENRIQUE MORENO LORENTE RAÚL PÉRULA MARTÍNEZ ALBERTO BRUNETE GONZALEZ DOMINGO MIGUEL GUINEA GARCIA ALEGRE CESAR
Tema 6. Introducción a la segmentación avanzada: Riesgos Organización de Computadores LUIS ENRIQUE MORENO LORENTE RAÚL PÉRULA MARTÍNEZ ALBERTO BRUNETE GONZALEZ DOMINGO MIGUEL GUINEA GARCIA ALEGRE CESAR
Fig Riesgos por dependencias de datos.
 5.4 Riesgos por dependencia de datos Hasta el momento se han considerado secuencias de código en las que no hay dependencias de datos, en esos casos la implementación mostrada en la figura 5.23 trabaja
5.4 Riesgos por dependencia de datos Hasta el momento se han considerado secuencias de código en las que no hay dependencias de datos, en esos casos la implementación mostrada en la figura 5.23 trabaja
Arquitectura Segmentada: Conceptos básicosb
 Arquitectura Segmentada: Conceptos básicosb Diseño de Sistemas Digitales EL-3310 I SEMESTRE 2008 4 ARQUITECTURA SEGMENTADA (PIPELINING) (4 SEMANAS) 4.1 Conceptos básicos de la arquitectura segmentada Paralelismo
Arquitectura Segmentada: Conceptos básicosb Diseño de Sistemas Digitales EL-3310 I SEMESTRE 2008 4 ARQUITECTURA SEGMENTADA (PIPELINING) (4 SEMANAS) 4.1 Conceptos básicos de la arquitectura segmentada Paralelismo
Introducción a paralelismo a nivel de instrucción
 Introducción a paralelismo a nivel de instrucción Arquitectura de Computadores J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Grupo
Introducción a paralelismo a nivel de instrucción Arquitectura de Computadores J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Grupo
MIPS: Modelo de programación. (I Parte)
") MIPS: Modelo de programación (I Parte) MIPS: Microprocessor without Interlocked Pipeline Stages Trabajaremos como MIPS Son similares a las desarrolladas en los años 80 Cerca de 100 millones de procesadores
MIPS: Modelo de programación (I Parte) MIPS: Microprocessor without Interlocked Pipeline Stages Trabajaremos como MIPS Son similares a las desarrolladas en los años 80 Cerca de 100 millones de procesadores
Tema 1: PROCESADORES SEGMENTADOS
 Tema 1: PROCESADORES SEGMENTADOS 1.1. Procesadores RISC frente a procesadores CISC. 1.2. Clasificación de las arquitecturas paralelas. 1.3. Evaluación y mejora del rendimiento de un computador. 1.4. Características
Tema 1: PROCESADORES SEGMENTADOS 1.1. Procesadores RISC frente a procesadores CISC. 1.2. Clasificación de las arquitecturas paralelas. 1.3. Evaluación y mejora del rendimiento de un computador. 1.4. Características
Lecture 8. Computer Decisions
 Lecture 8 Computer Decisions 1 ASIDE Instructions Involving Index Register X Instructions involving X always involve two bytes, or 16-bits. For example, LDX $1000, will load X with the byte located at
Lecture 8 Computer Decisions 1 ASIDE Instructions Involving Index Register X Instructions involving X always involve two bytes, or 16-bits. For example, LDX $1000, will load X with the byte located at
Pipeline o Segmentación Encausada
 Pipeline o Segmentación Encausada Material Elaborado por el Profesor Ricardo González A partir de Materiales de las Profesoras Angela Di Serio Patterson David, Hennessy John Organización y Diseño de Computadores
Pipeline o Segmentación Encausada Material Elaborado por el Profesor Ricardo González A partir de Materiales de las Profesoras Angela Di Serio Patterson David, Hennessy John Organización y Diseño de Computadores
Arquitectura de Computadores - 2001
 IV. Segmentación o Pipelining Alternativas de Implementación de Procesador 1. Procesador Uniciclo CPI = 1 Pero Período de Reloj Grande 2. Procesador Multiciclo CPI > 1 Pero Período de Reloj más Pequeño
IV. Segmentación o Pipelining Alternativas de Implementación de Procesador 1. Procesador Uniciclo CPI = 1 Pero Período de Reloj Grande 2. Procesador Multiciclo CPI > 1 Pero Período de Reloj más Pequeño
Tutorías con Grupos Reducidos (TGR) Sesión 2: Paralelismo a Nivel de Instrucción
 Sesión 2: Paralelismo a Nivel de Instrucción") Tutorías con Grupos Reducidos (TGR) Sesión 2: Paralelismo a Nivel de Instrucción ESTRUCTURA DE COMPUTADORES Grupo de Arquitectura de Computadores (GAC) Dyer Rolán García (GAC) Paralelismo a nivel de instrucción
Tutorías con Grupos Reducidos (TGR) Sesión 2: Paralelismo a Nivel de Instrucción ESTRUCTURA DE COMPUTADORES Grupo de Arquitectura de Computadores (GAC) Dyer Rolán García (GAC) Paralelismo a nivel de instrucción
Arquitectura de Computadoras Trabajo Práctico N 8 Pipeline de Instrucciones 1 Primer Cuatrimestre de 2016
 Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Ejercicios Arquitectura de Computadoras Trabajo Práctico N 8 Pipeline de Instrucciones 1 Primer Cuatrimestre de 2016 1. La
Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Ejercicios Arquitectura de Computadoras Trabajo Práctico N 8 Pipeline de Instrucciones 1 Primer Cuatrimestre de 2016 1. La
Segmentación del ciclo de instrucción
 Segmentación del ciclo de instrucción v.2012 William Stallings, Organización y Arquitectura de Computadores, Capítulo 11: Estructura y función de la CPU. John Hennessy David Patterson, Arquitectura de
Segmentación del ciclo de instrucción v.2012 William Stallings, Organización y Arquitectura de Computadores, Capítulo 11: Estructura y función de la CPU. John Hennessy David Patterson, Arquitectura de
Organización del Computador I Verano. Control Multiciclo. Basado en el capítulo 5 del libro de Patterson y Hennessy
 Organización del Computador I Verano Control Multiciclo Basado en el capítulo 5 del libro de Patterson y Hennessy Verano 2014 Profesora Borensztejn Resumen Step name Instruction fetch Instruction decode/register
Organización del Computador I Verano Control Multiciclo Basado en el capítulo 5 del libro de Patterson y Hennessy Verano 2014 Profesora Borensztejn Resumen Step name Instruction fetch Instruction decode/register
Fundamentos de los Computadores Grado en Ingeniería Informática (hasta final del diseño monociclo)
") 8. Diseño del Procesador Fundamentos de los Computadores Grado en Ingeniería Informática (hasta final del diseño monociclo) Objetivos Plantear y modificar una ruta de datos para un repertorio de instrucciones
8. Diseño del Procesador Fundamentos de los Computadores Grado en Ingeniería Informática (hasta final del diseño monociclo) Objetivos Plantear y modificar una ruta de datos para un repertorio de instrucciones
Arquitectura de Computadoras Trabajo Práctico N 7 Pipeline de Instrucciones Primer Cuatrimestre de 2010
 Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Ejercicios Arquitectura de Computadoras Trabajo Práctico N 7 Pipeline de Instrucciones Primer Cuatrimestre de 2010 1. La
Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Ejercicios Arquitectura de Computadoras Trabajo Práctico N 7 Pipeline de Instrucciones Primer Cuatrimestre de 2010 1. La
El procesador. Diseño del control
 El procesador Diseño del control Datapath MIPS simple Universidad de Sonora Arquitectura de Computadoras 2 MIPS simple El datapath anterior cubre instrucciones: Aritméticas-lógicas: add, sub, and, or y
El procesador Diseño del control Datapath MIPS simple Universidad de Sonora Arquitectura de Computadoras 2 MIPS simple El datapath anterior cubre instrucciones: Aritméticas-lógicas: add, sub, and, or y
Segmentación del ciclo de instrucción
 Segmentación del ciclo de instrucción William Stallings, Organización y Arquitectura de Computadores, Capítulo 11: Estructura y función de la CPU. John Hennessy David Patterson, Arquitectura de Computadores
Segmentación del ciclo de instrucción William Stallings, Organización y Arquitectura de Computadores, Capítulo 11: Estructura y función de la CPU. John Hennessy David Patterson, Arquitectura de Computadores
Estructura de Computadores 2 [08/09] Entrada/Salida en procesadores MIPS
![Estructura de Computadores 2 [08/09] Entrada/Salida en procesadores MIPS](/thumbs/61/45627813.jpg "Estructura de Computadores 2 [08/09] Entrada/Salida en procesadores MIPS") Estructura de Computadores 2 [08/09] Entrada/Salida en procesadores MIPS GAC: Grupo de Arquitectura de Computadores Dpt. Electrónica e Sistemas. Universidade da Coruña. Bibliografía Computer Organization
Estructura de Computadores 2 [08/09] Entrada/Salida en procesadores MIPS GAC: Grupo de Arquitectura de Computadores Dpt. Electrónica e Sistemas. Universidade da Coruña. Bibliografía Computer Organization
Organización del Computador I Verano. MIPS (2 de 2) Basado en el capítulo 2 del libro de Patterson y Hennessy
 Basado en el capítulo 2 del libro de Patterson y Hennessy") Organización del Computador I Verano MIPS (2 de 2) Basado en el capítulo 2 del libro de Patterson y Hennessy Verano 2014 Profesora Borensztejn Arquitectura MIPS (R2000) Registros Formato de Instrucción
Organización del Computador I Verano MIPS (2 de 2) Basado en el capítulo 2 del libro de Patterson y Hennessy Verano 2014 Profesora Borensztejn Arquitectura MIPS (R2000) Registros Formato de Instrucción
Tema 5. Segmentación: conceptos básicos
 Tema 5. Segmentación: conceptos básicos Organización de Computadores LUIS ENRIQUE MORENO LORENTE RAÚL PÉRULA MARTÍNEZ ALBERTO BRUNETE GONZALEZ DOMINGO MIGUEL GUINEA GARCIA ALEGRE CESAR AUGUSTO ARISMENDI
Tema 5. Segmentación: conceptos básicos Organización de Computadores LUIS ENRIQUE MORENO LORENTE RAÚL PÉRULA MARTÍNEZ ALBERTO BRUNETE GONZALEZ DOMINGO MIGUEL GUINEA GARCIA ALEGRE CESAR AUGUSTO ARISMENDI
TEMA 4. ARQUITECTURA IA-64
 TEMA 4. ARQUITECTURA IA-64 Stalling, W.Computer Organization and Architecture cap. 15 Intel IA-64 Architecture Software Developer s Manual Generalidades IA-64 Desarrollo conjunto Intel-HP Nueva arquitectura
TEMA 4. ARQUITECTURA IA-64 Stalling, W.Computer Organization and Architecture cap. 15 Intel IA-64 Architecture Software Developer s Manual Generalidades IA-64 Desarrollo conjunto Intel-HP Nueva arquitectura
El procesador. Datapath y control
 El procesador Datapath y control Introducción En esta parte del curso contiene: Las principales técnicas usadas en el diseño de un procesador. La construcción del datapath y del control. Estudiaremos la
El procesador Datapath y control Introducción En esta parte del curso contiene: Las principales técnicas usadas en el diseño de un procesador. La construcción del datapath y del control. Estudiaremos la
Arquitectura de Computadoras. Clase 4 Segmentación de Instrucciones
 Arquitectura de Computadoras Clase 4 Segmentación de Instrucciones Segmentación de cauce: Conceptos básicos La segmentación de cauce (pipelining) es una forma particularmente efectiva de organizar el hardware
Arquitectura de Computadoras Clase 4 Segmentación de Instrucciones Segmentación de cauce: Conceptos básicos La segmentación de cauce (pipelining) es una forma particularmente efectiva de organizar el hardware
Circuitos Digitales II y Laboratorio Fundamentos de Arquitectura de Computadores
 Departamento de Ingeniería Electrónica Facultad de Ingeniería Circuitos Digitales II y Laboratorio Fundamentos de Arquitectura de Computadores Unidad 5: IPS Pipeline Prof. Felipe Cabarcas cabarcas@udea.edu.co
Departamento de Ingeniería Electrónica Facultad de Ingeniería Circuitos Digitales II y Laboratorio Fundamentos de Arquitectura de Computadores Unidad 5: IPS Pipeline Prof. Felipe Cabarcas cabarcas@udea.edu.co
Tratamiento de Excepciones en MIPS
 Tratamiento de en MIPS Elías Todorovich Arquitectura I - Curso 2013 Riesgos de Control Las direcciones del PC no son secuenciales (PC = PC + 4) en los siguientes casos: Saltos condicionales (beq, bne)
Tratamiento de en MIPS Elías Todorovich Arquitectura I - Curso 2013 Riesgos de Control Las direcciones del PC no son secuenciales (PC = PC + 4) en los siguientes casos: Saltos condicionales (beq, bne)
Pregunta 1 Suponga que una muestra de 35 observaciones es obtenida de una población con media y varianza. Entonces la se calcula como.
 Universidad de Costa Rica Programa de Posgrado en Computación e Informática Doctorado en Computación e Informática Curso Estadística 18 de febrero 2013 Nombre: Segundo examen corto de Probabilidad Pregunta
Universidad de Costa Rica Programa de Posgrado en Computación e Informática Doctorado en Computación e Informática Curso Estadística 18 de febrero 2013 Nombre: Segundo examen corto de Probabilidad Pregunta
Flashcards Series 2 Las Necesidades de la Vida
 Flashcards Series 2 Las Necesidades de la Vida Flashcards are one of the quickest and easiest ways to test yourself on Spanish vocabulary, no matter where you are! Test yourself on just these flashcards
Flashcards Series 2 Las Necesidades de la Vida Flashcards are one of the quickest and easiest ways to test yourself on Spanish vocabulary, no matter where you are! Test yourself on just these flashcards
Organización del Computador I Verano. Aritmética (4 de 5) Basado en el capítulo 4 del libro de Patterson y Hennessy Multiplicaciones y Divisiones
 Basado en el capítulo 4 del libro de Patterson y Hennessy Multiplicaciones y Divisiones") Organización del Computador I Verano Aritmética (4 de 5) Basado en el capítulo 4 del libro de Patterson y Hennessy Multiplicaciones y Divisiones Verano 2014 Profesora Borensztejn MULTIPLICACIONES 1011
Organización del Computador I Verano Aritmética (4 de 5) Basado en el capítulo 4 del libro de Patterson y Hennessy Multiplicaciones y Divisiones Verano 2014 Profesora Borensztejn MULTIPLICACIONES 1011
Modos de Direccionamiento
 Modos de Direccionamiento Modos de direccionamiento del 8051 La CPU tiene la habilidad de accesar los datos de varias formas Se podría especificar el dato directamente en la instrucción Para datos en la
Modos de Direccionamiento Modos de direccionamiento del 8051 La CPU tiene la habilidad de accesar los datos de varias formas Se podría especificar el dato directamente en la instrucción Para datos en la
IE12_ CONSOLIDACIÓN Y DESARROLLO DE NUEVAS TÉCNICAS DE EVALUACIÓN INTENSIVAS ON-LINE YA IMPLEMENTADAS POR EL GIE E4
 IE12_13-03001 - CONSOLIDACIÓN Y DESARROLLO DE NUEVAS TÉCNICAS DE EVALUACIÓN Departamento de Estructuras de la Edificación Escuela Técnica Superior de Arquitectura de Madrid Universidad Politécnica de Madrid
IE12_13-03001 - CONSOLIDACIÓN Y DESARROLLO DE NUEVAS TÉCNICAS DE EVALUACIÓN Departamento de Estructuras de la Edificación Escuela Técnica Superior de Arquitectura de Madrid Universidad Politécnica de Madrid
Plataformas de soporte computacional: arquitecturas avanzadas,
 Plataformas de soporte computacional: arquitecturas avanzadas, sesión Diego R. Llanos, Belén Palop Departamento de Informática Universidad de Valladolid {diego,b.palop}@infor.uva.es Índice. Arquitectura
Plataformas de soporte computacional: arquitecturas avanzadas, sesión Diego R. Llanos, Belén Palop Departamento de Informática Universidad de Valladolid {diego,b.palop}@infor.uva.es Índice. Arquitectura
ARQUITECTURA DE COMPUTADORES CAPÍTULO 2. PROCESADORES SEGMENTADOS
 ARQUITECTURA DE COMPUTADORES P2.1. Se tiene un sencillo sistema RISC con control en un único ciclo (similar al descrito en la asignatura). Las instrucciones son de 32 bits y los bits se distribuyen como
ARQUITECTURA DE COMPUTADORES P2.1. Se tiene un sencillo sistema RISC con control en un único ciclo (similar al descrito en la asignatura). Las instrucciones son de 32 bits y los bits se distribuyen como
Flashcards Series 4 El Hotel
 Flashcards Series 4 El Hotel Flashcards are one of the quickest and easiest ways to test yourself on Spanish vocabulary, no matter where you are! Test yourself on just these flashcards at first. Then,
Flashcards Series 4 El Hotel Flashcards are one of the quickest and easiest ways to test yourself on Spanish vocabulary, no matter where you are! Test yourself on just these flashcards at first. Then,
La Unidad de Control y el Camino de Datos
 Prof. Rodrigo Araya E. raraya@inf.utfsm.cl Universidad Técnica Federico Santa María Departamento de Informática Valparaíso, 1 er Semestre 2006 1 2 3 Contenido Veremos el diseño completo de un subconjunto
Prof. Rodrigo Araya E. raraya@inf.utfsm.cl Universidad Técnica Federico Santa María Departamento de Informática Valparaíso, 1 er Semestre 2006 1 2 3 Contenido Veremos el diseño completo de un subconjunto
The Data Path. The Microarchitecture Level. Data Path Ops. Microarchitecture 1 8/20/2011
 The Microarchitecture Level lies between digital logic level and ISA level uses digital circuits to implement machine instructions instruction set can be: implemented directly in hardware (RISC) interpreted
The Microarchitecture Level lies between digital logic level and ISA level uses digital circuits to implement machine instructions instruction set can be: implemented directly in hardware (RISC) interpreted
3. SEGMENTACIÓN DEL CAUCE
 3. SEGMENTACIÓN DEL CAUCE 1 SEGMENTACIÓN DEL CAUCE 1. Conceptos básicos 2. Etapas del MIPS64 3. Riesgos 4. Operaciones muticiclo 2 SEGMENTACIÓN DEL CAUCE 1. Conceptos básicos 3 Conceptos básicos Ciclo
3. SEGMENTACIÓN DEL CAUCE 1 SEGMENTACIÓN DEL CAUCE 1. Conceptos básicos 2. Etapas del MIPS64 3. Riesgos 4. Operaciones muticiclo 2 SEGMENTACIÓN DEL CAUCE 1. Conceptos básicos 3 Conceptos básicos Ciclo
16/04/2012. Introducción. Construyendo el Datapath. Esquema de implementación Simple. Unidad de Control. Arquitectura de Computadoras Primavera 2012
 /4/22 Introducción rquitectura de Computadoras Primavera 22 Construyendo el path Esquema de implementación Simple Unidad de Control 2 Los elementos básicos de un sistema de computo son: Nos centraremos
/4/22 Introducción rquitectura de Computadoras Primavera 22 Construyendo el path Esquema de implementación Simple Unidad de Control 2 Los elementos básicos de un sistema de computo son: Nos centraremos
Ejercicios de Paralelismo a Nivel de Instrucción
 Ejercicios de Paralelismo a Nivel de Instrucción J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores Grupo
Ejercicios de Paralelismo a Nivel de Instrucción J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores Grupo
CONTROLADORA PARA PIXELS CONPIX
 The LedEdit Software Instructions 1, Install the software to PC and open English version: When we installed The LedEdit Software, on the desktop we can see following icon: Please Double-click it, then
The LedEdit Software Instructions 1, Install the software to PC and open English version: When we installed The LedEdit Software, on the desktop we can see following icon: Please Double-click it, then
Qué es Pipelining? Es una técnica de implementación en la que se superpone la ejecución de varias instrucciones.
 Qué es Pipelining? Es una técnica de implementación en la que se superpone la ejecución de varias instrucciones. Aprovecha el paralelismo entre instrucciones en una corriente secuencial de instrucciones.
Qué es Pipelining? Es una técnica de implementación en la que se superpone la ejecución de varias instrucciones. Aprovecha el paralelismo entre instrucciones en una corriente secuencial de instrucciones.
Might. Área Lectura y Escritura. In order to understand the use of the modal verb might we will check some examples:
 Might Área Lectura y Escritura Resultados de aprendizaje Conocer el uso del verbo modal might. Aplicar el verbo modal might en ejercicios de escritura. Contenidos 1. Verbo modal might. Debo saber - Verbos
Might Área Lectura y Escritura Resultados de aprendizaje Conocer el uso del verbo modal might. Aplicar el verbo modal might en ejercicios de escritura. Contenidos 1. Verbo modal might. Debo saber - Verbos
El procesador. Datapath para las instrucciones de brinco
 El procesador Datapath para las instrucciones de brinco Instrucciones de brinco Dos tipos de instrucciones de brincos: 1. Brinco condicional. beq $t0, $t1, Etiqueta ; if t0 == t1 goto Etiqueta 2. Brinco
El procesador Datapath para las instrucciones de brinco Instrucciones de brinco Dos tipos de instrucciones de brincos: 1. Brinco condicional. beq $t0, $t1, Etiqueta ; if t0 == t1 goto Etiqueta 2. Brinco
Superescalares. Scheduling estático
 Superescalares Scheduling estático Introducción La CPU ejecuta las instrucciones en orden. El compilador: Puede cambiar el orden de ejecución. Genera el paquete de emisión. Trata de prevenir o reducir
Superescalares Scheduling estático Introducción La CPU ejecuta las instrucciones en orden. El compilador: Puede cambiar el orden de ejecución. Genera el paquete de emisión. Trata de prevenir o reducir
Exercise List 3 - Microeconomics II Moral Hazard - Screening- Signaling
 Exercise List 3 - Microeconomics II Moral Hazard - Screening- Signaling Exercise The optimal contract when effort level is observed: The optimal contract to implement e = 0: w 0 = w 0 = w 5 = π = 8. The
Exercise List 3 - Microeconomics II Moral Hazard - Screening- Signaling Exercise The optimal contract when effort level is observed: The optimal contract to implement e = 0: w 0 = w 0 = w 5 = π = 8. The
Organización de la Computadora
 Sistemas Operativos Pontificia Universidad Javeriana Febrero de 2010 Arquitectura Introducción Arquitectura Arquitectura de Von Newumann El Sistema operativo provee abstracciones para que el hardware pueda
Sistemas Operativos Pontificia Universidad Javeriana Febrero de 2010 Arquitectura Introducción Arquitectura Arquitectura de Von Newumann El Sistema operativo provee abstracciones para que el hardware pueda
Arquitectura de Computadoras I Ingeniería de Sistemas Curso 2017
 Arquitectura de Computadoras I Ingeniería de Sistemas Curso 217 Práctica de Laboratorio: Microprocesador MIPS Segmentado El objetivo de esta práctica es implementar el microprocesador MIPS (visto en clase
Arquitectura de Computadoras I Ingeniería de Sistemas Curso 217 Práctica de Laboratorio: Microprocesador MIPS Segmentado El objetivo de esta práctica es implementar el microprocesador MIPS (visto en clase
Definición de prestaciones
 Definición de prestaciones En términos de velocidad. Diferentes puntos de vista: Tiempo de ejecución. Productividad (throughput) Medidas utilizadas En función de la duración del ciclo de reloj y del número
Definición de prestaciones En términos de velocidad. Diferentes puntos de vista: Tiempo de ejecución. Productividad (throughput) Medidas utilizadas En función de la duración del ciclo de reloj y del número
Flip-flops. Luis Entrena, Celia López, Mario García, Enrique San Millán. Universidad Carlos III de Madrid
 Flip-flops Luis Entrena, Celia López, Mario García, Enrique San Millán Universidad Carlos III de Madrid 1 igital circuits and microprocessors Inputs Output Functions Outputs State Functions State Microprocessor
Flip-flops Luis Entrena, Celia López, Mario García, Enrique San Millán Universidad Carlos III de Madrid 1 igital circuits and microprocessors Inputs Output Functions Outputs State Functions State Microprocessor
Prof. Aidsa Santiago. Cesar A Aceros Moreno
 BIENVENIDOS INGE3016 Prof. Aidsa Santiago. Cesar A Aceros Moreno REPASO TOP DOWN PROGRAM DEVELOPMENT Son 5 sencillos pasos: 1. Determinar la salida del programa. 2. Determinar las entradas del programa.
BIENVENIDOS INGE3016 Prof. Aidsa Santiago. Cesar A Aceros Moreno REPASO TOP DOWN PROGRAM DEVELOPMENT Son 5 sencillos pasos: 1. Determinar la salida del programa. 2. Determinar las entradas del programa.
SEGMENTACIÓN EN LA EJECUCIÓN DE INSTRUCCIONES
 Capítulo 3: MIPS SEGMENTACIÓN EN LA EJECUCIÓN DE INSTRUCCIONES Parte del material fue desarrollado en la Escuela Politécnica Superior de la Universidad Autónoma de Madrid. Arqui1-UNICEN Introducción Para
Capítulo 3: MIPS SEGMENTACIÓN EN LA EJECUCIÓN DE INSTRUCCIONES Parte del material fue desarrollado en la Escuela Politécnica Superior de la Universidad Autónoma de Madrid. Arqui1-UNICEN Introducción Para
Pipelining o Segmentación de Instrucciones
 Pipelining o Segmentación de Instrucciones La segmentación de instrucciones es similar al uso de una cadena de montaje en una fábrica de manufacturación. En las cadenas de montaje, el producto pasa a través
Pipelining o Segmentación de Instrucciones La segmentación de instrucciones es similar al uso de una cadena de montaje en una fábrica de manufacturación. En las cadenas de montaje, el producto pasa a través
ELO311 Estructuras de Computadores Digitales. Operaciones MIPS para Control de flujo
 ELO311 Estructuras de Computadores Digitales Operaciones MIPS para Control de flujo Tomás Arredondo Vidal Este material está basado en: material de apoyo del texto de David Patterson, John Hennessy, "Computer
ELO311 Estructuras de Computadores Digitales Operaciones MIPS para Control de flujo Tomás Arredondo Vidal Este material está basado en: material de apoyo del texto de David Patterson, John Hennessy, "Computer
Real Time Systems. Part 2: Cyclic schedulers. Real Time Systems. Francisco Martín Rico. URJC. 2011
 Real Time Systems Part 2: Cyclic schedulers Scheduling To organise the use resources to guarantee the temporal requirements A scheduling method is composed by: An scheduling algorithm that calculates the
Real Time Systems Part 2: Cyclic schedulers Scheduling To organise the use resources to guarantee the temporal requirements A scheduling method is composed by: An scheduling algorithm that calculates the
GRADO EN INGENIERÍA DE COMPUTADORES
 GRADO EN INGENIERÍA DE COMPUTADORES Computadores VLIW Departamento Computadores superescalares de Automática Prof. Dr. José Antonio de Frutos Redondo Curso 2013-2014 Computadores VLIW y superescalares
GRADO EN INGENIERÍA DE COMPUTADORES Computadores VLIW Departamento Computadores superescalares de Automática Prof. Dr. José Antonio de Frutos Redondo Curso 2013-2014 Computadores VLIW y superescalares
Diseño de la ruta de datos multiciclo. Procesador Multiciclo. Diseño de la ruta de datos multiciclo. Diseño de la ruta de datos multiciclo
 lw sw mem. instrución banco reg. mu LU mem. dato mu Camino crítico mem. instrución banco reg. mu LU mem. dato setup beq mem. instrución banco reg. mu LU mu setup R mem. instrución banco reg. mu LU mu setup
lw sw mem. instrución banco reg. mu LU mem. dato mu Camino crítico mem. instrución banco reg. mu LU mem. dato setup beq mem. instrución banco reg. mu LU mu setup R mem. instrución banco reg. mu LU mu setup
UNIDAD 5: Mejora del rendimiento con la segmentación.
 UNIDAD 5: Mejora del rendimiento con la segmentación. 5.1 Un resumen de segmentación La segmentación (pipelining) es una técnica de implementación por la cual se solapa la ejecución de múltiples instrucciones.
UNIDAD 5: Mejora del rendimiento con la segmentación. 5.1 Un resumen de segmentación La segmentación (pipelining) es una técnica de implementación por la cual se solapa la ejecución de múltiples instrucciones.
Ada County Existing/Resale
 Ada County Existing/Resale tember 2018 ket Statistics Report provided by Boise Regional REALTORS Key Metrics 2017 2018 % Chg YTD 2017 YTD 2018 % Chg Closed Sales 811 616-24.0% 6,301 6,136-2.6% Median Sales
Ada County Existing/Resale tember 2018 ket Statistics Report provided by Boise Regional REALTORS Key Metrics 2017 2018 % Chg YTD 2017 YTD 2018 % Chg Closed Sales 811 616-24.0% 6,301 6,136-2.6% Median Sales
Ada County Existing/Resale
 Ada County Existing/Resale October 2018 ket Statistics Report provided by Boise Regional REALTORS Data from the Intermountain MLS as of ember 11, 2018 Key Metrics Oct 2017 Oct 2018 % Chg YTD 2017 YTD 2018
Ada County Existing/Resale October 2018 ket Statistics Report provided by Boise Regional REALTORS Data from the Intermountain MLS as of ember 11, 2018 Key Metrics Oct 2017 Oct 2018 % Chg YTD 2017 YTD 2018
MANUAL DE FARMACIA CLINICA Y ATENCION FARMACEUTICA. EL PRECIO ES EN DOLARES BY JOAQUIN HERRERA CARRANZA
 MANUAL DE FARMACIA CLINICA Y ATENCION FARMACEUTICA. EL PRECIO ES EN DOLARES BY JOAQUIN HERRERA CARRANZA DOWNLOAD EBOOK : MANUAL DE FARMACIA CLINICA Y ATENCION HERRERA CARRANZA PDF Click link bellow and
MANUAL DE FARMACIA CLINICA Y ATENCION FARMACEUTICA. EL PRECIO ES EN DOLARES BY JOAQUIN HERRERA CARRANZA DOWNLOAD EBOOK : MANUAL DE FARMACIA CLINICA Y ATENCION HERRERA CARRANZA PDF Click link bellow and
Segmentación de cauce
 Segmentación de cauce 11ª Semana Bibliografía: [HAM03] Cap.8 Organización de Computadores. Hamacher, Vranesic, Zaki. McGraw-Hill 2003 Signatura ESIIT/C.1 HAM org [STA8] Sec.12.4 Organización y Arquitectura
Segmentación de cauce 11ª Semana Bibliografía: [HAM03] Cap.8 Organización de Computadores. Hamacher, Vranesic, Zaki. McGraw-Hill 2003 Signatura ESIIT/C.1 HAM org [STA8] Sec.12.4 Organización y Arquitectura
Decodificador de funciones v.2
 Decodificador de funciones v.. Introducción Este decodificador de funciones posee cuatro salidas para activar luces, fumígeno, etc. Dirección de locomotoras corta y larga hasta 9999 Control de las salidas
Decodificador de funciones v.. Introducción Este decodificador de funciones posee cuatro salidas para activar luces, fumígeno, etc. Dirección de locomotoras corta y larga hasta 9999 Control de las salidas
Arquitectura de Computadores
 Arquitectura de Computadores 1. Introducción 2. La CPU 3. Lenguaje Máquina 4. La Memoria 5. Sistemas de Entrada/Salida 6. Segmentación (Pipeline) MIPS 64 7. Memoria Caché 8. Arquitecturas RISC Arquitectura
Arquitectura de Computadores 1. Introducción 2. La CPU 3. Lenguaje Máquina 4. La Memoria 5. Sistemas de Entrada/Salida 6. Segmentación (Pipeline) MIPS 64 7. Memoria Caché 8. Arquitecturas RISC Arquitectura
ARQUITECTURA DE COMPUTADORES CAPÍTULO 2. PROCESADORES SEGMENTADOS
 ARQUIECURA DE COMPUADORES P2.1. Se tiene un sencillo sistema RISC con control en un único ciclo (similar al descrito en la asignatura). Las instrucciones son de 32 bits y los bits se distribuyen como en
ARQUIECURA DE COMPUADORES P2.1. Se tiene un sencillo sistema RISC con control en un único ciclo (similar al descrito en la asignatura). Las instrucciones son de 32 bits y los bits se distribuyen como en
EC - Bibliografía EC -
 . Introducción 2. IPS 3. Segmentación 4. Riesgos estructurales 5. Riesgos de datos 6. Riesgos de control 7. Riesgos de control con riesgos LDE 8. Resumen Bibliografía Hennessy Patterson Apendice A, 4ª
. Introducción 2. IPS 3. Segmentación 4. Riesgos estructurales 5. Riesgos de datos 6. Riesgos de control 7. Riesgos de control con riesgos LDE 8. Resumen Bibliografía Hennessy Patterson Apendice A, 4ª
Repaso de funciones exponenciales y logarítmicas. Review of exponential and logarithmic functions
 Repaso de funciones exponenciales y logarítmicas Review of exponential and logarithmic functions Las funciones lineales, cuadráticas, polinómicas y racionales se conocen como funciones algebraicas. Las
Repaso de funciones exponenciales y logarítmicas Review of exponential and logarithmic functions Las funciones lineales, cuadráticas, polinómicas y racionales se conocen como funciones algebraicas. Las
Sección de procesamiento: El camino de datos
 Sección de procesamiento: El camino de datos Montse Bóo Cepeda Este trabajo está publicado bajo licencia Creative Commons Attribution- NonCommercial-ShareAlike 2.5 Spain. Estructura del curso 1. Evolución
Sección de procesamiento: El camino de datos Montse Bóo Cepeda Este trabajo está publicado bajo licencia Creative Commons Attribution- NonCommercial-ShareAlike 2.5 Spain. Estructura del curso 1. Evolución
PIPELINING: Antes de adentrarnos en el tema, veremos una analogía de un pipeline:
 PIPELINING: Antes de adentrarnos en el tema, veremos una analogía de un pipeline: Observemos que la técnica de Pipelining no mejora el tiempo de cada tarea, sino el tiempo de toda la carga de trabajo.
PIPELINING: Antes de adentrarnos en el tema, veremos una analogía de un pipeline: Observemos que la técnica de Pipelining no mejora el tiempo de cada tarea, sino el tiempo de toda la carga de trabajo.
Arquitectura t de Computadores
 Arquitectura t de Computadores Tema 3 Segmentación (Pipelining) i 1 Índice 1. Segmentación 2. Riesgos (Hazards) 3. Forwarding 4. Implementación del pipelining 5. Tratamiento de las interrupciones 6. Complicaciones
Arquitectura t de Computadores Tema 3 Segmentación (Pipelining) i 1 Índice 1. Segmentación 2. Riesgos (Hazards) 3. Forwarding 4. Implementación del pipelining 5. Tratamiento de las interrupciones 6. Complicaciones
ELO311 Estructuras de Computadores Digitales. Pipeline (Segmentación)
") ELO311 Estructuras de Computadores Digitales Pipeline (Segmentación) Tomás Arredondo Vidal Este material está basado en: material de apoyo del texto de David Patterson, John Hennessy, "Computer Organization
ELO311 Estructuras de Computadores Digitales Pipeline (Segmentación) Tomás Arredondo Vidal Este material está basado en: material de apoyo del texto de David Patterson, John Hennessy, "Computer Organization
Modelo de von Neumann
 Conceptos básicos Modelo de von Neumann También conocida como arquitectura de Princeton. Propuesta por John von Neumann en 1945. Partes de una computadora digital: Unidad de procesamiento (CPU unidad central
Conceptos básicos Modelo de von Neumann También conocida como arquitectura de Princeton. Propuesta por John von Neumann en 1945. Partes de una computadora digital: Unidad de procesamiento (CPU unidad central
Los números. 0 cero 1 uno / un 2 dos 3 tres 4 cuatro. 6 seis 7 siete 8 ocho 9 nueve 10 diez 5 cinco
 53 31 16 0 cero 1 uno / un 2 dos 3 tres 4 cuatro 6 seis 7 siete 8 ocho 9 nueve 10 diez 5 cinco 11 - once 12 - doce 13 - trece 14 - catorce 17 - diecisiete 18 - dieciocho 19 - diecinueve 20 - veinte 15
53 31 16 0 cero 1 uno / un 2 dos 3 tres 4 cuatro 6 seis 7 siete 8 ocho 9 nueve 10 diez 5 cinco 11 - once 12 - doce 13 - trece 14 - catorce 17 - diecisiete 18 - dieciocho 19 - diecinueve 20 - veinte 15
Primer Semestre Laboratorio de Electrónica Universidad de San Carlos de Guatemala. Electrónica 5. Aux. Marie Chantelle Cruz.
 Laboratorio de Electrónica Universidad de San Carlos de Guatemala Primer Semestre 2017 Overview 1 Cortex La más usada para dispositivos móviles Encoding por 32 bits, excepto Thumb y Thumb-2 15x32bits registros
Laboratorio de Electrónica Universidad de San Carlos de Guatemala Primer Semestre 2017 Overview 1 Cortex La más usada para dispositivos móviles Encoding por 32 bits, excepto Thumb y Thumb-2 15x32bits registros
Level 1 Spanish, 2012
 90908 909080 1SUPERVISOR S Level 1 Spanish, 2012 90908 Demonstrate understanding of a variety of spoken Spanish texts on areas of most immediate relevance 9.30 am Tuesday 4 December 2012 Credits: Five
90908 909080 1SUPERVISOR S Level 1 Spanish, 2012 90908 Demonstrate understanding of a variety of spoken Spanish texts on areas of most immediate relevance 9.30 am Tuesday 4 December 2012 Credits: Five
Level 1 Spanish, 2016
 90911 909110 1SUPERVISOR S Level 1 Spanish, 2016 90911 Demonstrate understanding of a variety of Spanish texts on areas of most immediate relevance 2.00 p.m. Thursday 24 November 2016 Credits: Five Achievement
90911 909110 1SUPERVISOR S Level 1 Spanish, 2016 90911 Demonstrate understanding of a variety of Spanish texts on areas of most immediate relevance 2.00 p.m. Thursday 24 November 2016 Credits: Five Achievement
Do Now! Question 1: Pregunta 1
 Do Now! Question 1: What do you predict Scratch Cat will do according to this block of code? Write your response in your journal. Pregunta 1 : Qué predices el gato hará de acuerdo con este bloque de código?
Do Now! Question 1: What do you predict Scratch Cat will do according to this block of code? Write your response in your journal. Pregunta 1 : Qué predices el gato hará de acuerdo con este bloque de código?
Los nombres originales de los territorios, sitios y accidentes geograficos de Colombia (Spanish Edition)
") Los nombres originales de los territorios, sitios y accidentes geograficos de Colombia (Spanish Edition) Click here if your download doesn"t start automatically Los nombres originales de los territorios,
Los nombres originales de los territorios, sitios y accidentes geograficos de Colombia (Spanish Edition) Click here if your download doesn"t start automatically Los nombres originales de los territorios,
Segmentación del ciclo de instrucción v.2016
 Segmentación del ciclo de instrucción v.2016 John Hennessy & David Patterson, Arquitectura de Computadores Un enfoque cuantitativo, 4ª edición Apéndice A (Capítulos 5 y 6 de la 1ª edición) Segmentación
Segmentación del ciclo de instrucción v.2016 John Hennessy & David Patterson, Arquitectura de Computadores Un enfoque cuantitativo, 4ª edición Apéndice A (Capítulos 5 y 6 de la 1ª edición) Segmentación
Learning Spanish Like Crazy. Spoken Spanish Lección Uno. Listen to the following conversation. Male: Hola Hablas inglés? Female: Quién?
 Learning Spanish Like Crazy Spoken Spanish Lección Uno. Listen to the following conversation. Male: Hola Hablas inglés? Female: Quién? Male: Tú. Hablas tú inglés? Female: Sí, hablo un poquito de inglés.
Learning Spanish Like Crazy Spoken Spanish Lección Uno. Listen to the following conversation. Male: Hola Hablas inglés? Female: Quién? Male: Tú. Hablas tú inglés? Female: Sí, hablo un poquito de inglés.
Organización de Computadoras. Algunas temas tomados en 2ª evaluación integradora
 Organización de Computadoras Algunas temas tomados en 2ª evaluación integradora Temas de Arquitecturas 1- Describa mediante ejemplos los modos de direccionamiento que conozca. 2- Describa los distintos
Organización de Computadoras Algunas temas tomados en 2ª evaluación integradora Temas de Arquitecturas 1- Describa mediante ejemplos los modos de direccionamiento que conozca. 2- Describa los distintos
Convenciones. Introducción. Unidades principales en la implementación. El procesador: camino de datos y control. Tipos de elementos:
 Unidades principales en la implementación Data El procesador: camino de datos y control IEC UTM Moisés E. Ramírez G. 1 Register # PC Address Instruction Instruction Registers Register # ALU memory Register
Unidades principales en la implementación Data El procesador: camino de datos y control IEC UTM Moisés E. Ramírez G. 1 Register # PC Address Instruction Instruction Registers Register # ALU memory Register
Fundamentos de los Computadores Grado en Ingeniería Informática (desde diseño multiciclo en adelante)
") 8. Diseño del Procesador Fundamentos de los Computadores Grado en Ingeniería Informática (desde diseño multiciclo en adelante) Estructura del tema etodología de sincronización Diseño de un procesador IPS
8. Diseño del Procesador Fundamentos de los Computadores Grado en Ingeniería Informática (desde diseño multiciclo en adelante) Estructura del tema etodología de sincronización Diseño de un procesador IPS
TX MULTI MANUAL TX MULTI. Mando copiador multifrecuencia 1. PASOS PARA COPIAR UN MANDO CÓDIGO FIJO Y ROLLING ESTÁNDAR:
 MANUAL TX MULTI Mando copiador multifrecuencia 1. PASOS PARA COPIAR UN MANDO CÓDIGO FIJO Y ROLLING ESTÁNDAR: 1. Situar el mando original que desea copiar junto al TX Multi, en torno a 2-4 centímetros de
MANUAL TX MULTI Mando copiador multifrecuencia 1. PASOS PARA COPIAR UN MANDO CÓDIGO FIJO Y ROLLING ESTÁNDAR: 1. Situar el mando original que desea copiar junto al TX Multi, en torno a 2-4 centímetros de
Arquitectura t de Computadores Clase 10: Diseño del microprocesador monociclo pt.2
 Arquitectura t de Computadores Clase 10: Diseño del microprocesador monociclo pt.2 Departamento de Ingeniería de Sistemas Universidad id d de Antioquia i 2011 2 Unidad de control principal Mediante el
Arquitectura t de Computadores Clase 10: Diseño del microprocesador monociclo pt.2 Departamento de Ingeniería de Sistemas Universidad id d de Antioquia i 2011 2 Unidad de control principal Mediante el
Level 1 Spanish, 2013
 90911 909110 1SUPERVISOR S Level 1 Spanish, 2013 90911 Demonstrate understanding of a variety of Spanish texts on areas of most immediate relevance 9.30 am Tuesday 3 December 2013 Credits: Five Achievement
90911 909110 1SUPERVISOR S Level 1 Spanish, 2013 90911 Demonstrate understanding of a variety of Spanish texts on areas of most immediate relevance 9.30 am Tuesday 3 December 2013 Credits: Five Achievement
IJVM Instructions. Computer Architecture The instruction opcode is 8 bit wide. Offsets are 16 bits wide (stored in two consecutive bytes)
") (1) IJVM Instructions The instruction opcode is 8 bit wide Offsets are 16 bits wide (stored in two consecutive bytes) For IINC varnum and const are each 8 bits wide (cannot use WIDE) Variable references
(1) IJVM Instructions The instruction opcode is 8 bit wide Offsets are 16 bits wide (stored in two consecutive bytes) For IINC varnum and const are each 8 bits wide (cannot use WIDE) Variable references
Soluciones a ejercicios de Paralelismo a Nivel de instrucción
 Soluciones a ejercicios de Paralelismo a Nivel de instrucción J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores
Soluciones a ejercicios de Paralelismo a Nivel de instrucción J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores
Arquitectura de Computadores Problemas (hoja 2). Curso
. Curso") Arquitectura de Computadores Problemas (hoja 2). Curso 2012-13 1. Sea la siguiente secuencia de código de instrucciones en punto flotante para un computador similar al DLX que aplica gestión dinámica de
Arquitectura de Computadores Problemas (hoja 2). Curso 2012-13 1. Sea la siguiente secuencia de código de instrucciones en punto flotante para un computador similar al DLX que aplica gestión dinámica de
Programación lineal Optimización de procesos químicos DIQUIMA-ETSII
 Programación lineal PROGRAMACIÓN LINEAL PROGRAMACIÓN LINEAL se formula siguiendo el planteamiento general: Función objetivo Restricciones de igualdad Restricciones de desigualdad Límite variables PROGRAMACIÓN
Programación lineal PROGRAMACIÓN LINEAL PROGRAMACIÓN LINEAL se formula siguiendo el planteamiento general: Función objetivo Restricciones de igualdad Restricciones de desigualdad Límite variables PROGRAMACIÓN