Ricardo Aler Mur CLASIFICADORES KNN-I
|
|
|
- Julia Velázquez Moreno
- hace 7 años
- Vistas:
Transcripción
1 Ricardo Aler Mur CLASIFICADORES KNN-I En esta clase se habla del aprendizaje de modelos de clasificación y regresión basados en instancias o ejemplares. En concreto: Se define la clasificación y regresión basada en los vecinos más cercanos (KNN = k-nearest neighbours) Se explican algunas de las ventajas (no es necesario construir un modelo explícito) e inconvenientes de KNN, entre ellas, la lentitud en la clasificación cuando hay muchos datos, la dependencia de la función de distancia, la influencia nociva de atributos irrelevantes, la maldición de la dimensionalidad y la gran influencia del ruido en los datos. A continuación se muestra como se pueden solventar algunas de esas deficiencias: o Cómo seleccionar el parámetro K para combatir el ruido en los datos o Cómo seleccionar las instancias o datos más representativos para evitar la lentitud en la clasificación. Se explican las técnicas de edición (para eliminar datos engañosos/ruido) y las de condensación (para eliminar datos supérfluos), así como técnicas híbridas
2 o Por último, se explican los algoritmos RT1 / RT2 y RT3 que realizan edición y condensación de manera avanzada Se termina la clase introduciendo otra clase de algoritmos los basados en prototipos - que clasifican basándose en la idea de vecindad, pero que eliminan el problema de la lentitud en la clasificación al utilizar como modelo un conjunto de prototipos en lugar del conjunto de datos completo. En concreto, se explica un algoritmo de posicionamiento de prototipos denominado Learning Vector Quantization o LVQ.
3 Fases del análisis de datos Recopilación de los datos (tabla datos x atributos) Preproceso: De los datos De los atributos: Selección de atributos: Ranking Subset selection: CFS y WRAPPER Transformación / Generación de atributos: No supervisada: PCA, random projections, autoencoders Supervisada: mediante redes de neuronas Generación del modelo: Clasificación: árboles de decisión Regresión: Modelos lineales Árboles de modelos Evaluación: validación cruzada, matriz de confusión Despliegue y uso del modelo
4 KNN: VECINO(S) MAS CERCANO(S)
5 K NEAREST NEIGHBORS (KNN) Altura Niño Adulto Mayor Se guardan todos los ejemplos Peso 3
6 K NEAREST NEIGHBORS (KNN) Altura K=1 Niño Adulto Mayor Se guardan todos los ejemplos Peso 4

7 K=3 K NEAREST NEIGHBORS (KNN)
8 CARACTERISTICAS KNN KNN: Clasifica nuevas instancias como la clase mayoritaria de entre los k vecinos mas cercanos de entre los datos de entrenamiento KNN es un algoritmo perezoso (lazy) Durante el entrenamiento, sólo guarda las instancias, no construye ningún modelo (a diferencia de, por ejemplo, los árboles de decisión) La clasificación se hace cuando llega la instancia de test Es no paramétrico (no hace suposiciones sobre la distribución que siguen los datos, a diferencia de por ejemplo, un modelo lineal) El mejor modelo de los datos son los propios datos
9 CARACTERISTICAS KNN KNN es local: asume que la clase de un dato depende sólo de los k vecinos mas cercanos (no se construye un modelo global) No necesita adaptación para mas de dos clases (a diferencia de clasificadores lineales) Si se quiere hace regresión, calcular la media de los k vecinos Es sencillo
10 Problemas / limitaciones KNN Muy sensible a los atributos irrelevantes y la maldición de la dimensionalidad Muy sensible al ruido Lento, si hay muchos datos de entrenamiento (O(n*d) en almacenamiento y en tiempo) Depende de que la función de distancia sea la adecuada Normalmente es la Euclidea: En 2D: d(x i,x j ) 2 = (x i1 -x j1 ) 2 + (x i2 -x j2 ) 2 d(x i,x j ) = ((x i1 -x j1 ) 2 + (x i2 -x j2 ) 2 ) En dd: d(x i,x j ) 2 = (x i1 -x j1 ) 2 + (x i2 -x j2 ) (x id -x jd ) 2
11 Atributos irrelevantes 0 atributos irrelevantes Con el atributo relevante, se clasifica bien Atributo irrelevante Atributo irrelevante 1 atributo irrelevante Con el atributo irrelevante, se clasifica mal (las distancias cambian) Vecino mas cercano k=1 Atributo relevante
12 La maldición de la dimensionalidad Le afecta mucho, dado que KNN no crea un modelo global sino que utiliza los datos para representar las fronteras de separación Recordemos que el número de datos necesario para representar la superficie de una esfera en d dimensiones crece exponencialmente con d: O(r d )
13 Normalización Si los atributos son nominales, usar distancia de Hamming: Si el atributo e es nominal, en lugar del componente (x ie -x je ) 2 se usa δ(x ie, x je ): 0 si x ie =x je y 1 en caso contrario Es necesario normalizar los atributos para que atributos con mucho rango no tengan mas peso que los demás. Normalizaciones: Estandarización: x 1j = (x 1j -μ j )/σ j Normalización: x 1j = (x 1j -min j )/(max j -min i ) Es como usar una distancia ponderada: d(x i,x j ) = m 1 *(x i1 -x j1 ) 2 + m 2 *(x i2 -x j2 ) 2 + m 3 *(x i3 -x j3 ) m d *(x id -x jd ) 2

14 TESELACIÓN DE VORONOI K=1
15 PORQUÉ USAR K VECINOS? Con k=1, las instancias que son ruido (o solape entre clases) tienen mucha influencia Con k>1, se consideran mas vecinos y el ruido pierde influencia (es como hacer una promediado) Si k es muy alto, se pierde la idea de localidad En que se convierte KNN si k=número de datos? Para evitar que los vecinos lejanos tengan mucha influencia, se puede hacer que cada vecino vote de manera inversamente proporcional a la distancia 1/d Si hay dos clases, usar k impar para deshacer empates Se puede elegir k mediante validación cruzada

16 PORQUÉ USAR K VECINOS?
17 METODOLOGÍA ANÁLISIS DE DATOS Recopilación de los datos (tabla datos x atributos) Preproceso: De los datos: Normalización De los atributos: Selección de atributos: Ranking Subset selection: CFS y WRAPPER Transformación / Generación de atributos: No supervisada: PCA, random projections, autoencoders Supervisada: mediante redes de neuronas GENERACIÓN DE MODELOS / AJUSTE DE PARÁMETROS / SELECCIÓN DE MODELO Clasificación: árboles de decisión, reglas, KNN Regresión: modelos lineales, árboles de modelos, KNN Evaluación: validación cruzada, matriz de confusión Despliegue y uso del modelo
18 SELECCIÓN DE K A la elección de un modelo para un problema concreto se le denomina selección del modelo (model selection) Se puede seleccionar la familia o tipo del modelo: Separador lineal Árboles de decisión KNN Si se ha seleccionado una familia de modelos, hay que dar valor a ciertos parámetros Árboles de decisión: confidence factor KNN: K
19 SELECCIÓN DE K Se le puede dar valor a k mediante validación cruzada de los datos de entrenamiento (si es demasiado costoso en tiempo, se puede utilizar un solo conjunto de validación) No confundir con la validación cruzada que se hace para evaluar el modelo
20 Problemas / limitaciones KNN Lento, porque tiene que guardar todos los datos de entrenamiento Solución: eliminación de instancias supérfluas Muy sensible al ruido Solución: eliminación de instancias con ruido Depende de que la función de distancia sea la adecuada Solución (parcial): aprendizaje de la función distancia Muy sensible a los atributos irrelevantes y la maldición de la dimensionalidad: Solución: selección de atributos
21 SELECCIÓN DE INSTANCIAS Hay instancias supérfluas: no son necesarias para clasificar. Si las borramos, se decrementará el tiempo de clasificación Hay instancias que son ruido (o solape entre clases): confunden al clasificador. Si las borramos, mejorará el porcentaje de aciertos esperado Ruido Eliminación de supérfluas

22 SELECCIÓN DE INSTANCIAS Engañosas Supérfluas
23 DOS TIPOS DE TÉCNICAS Editing: eliminar instancias engañosas (ruido) Típicamente se eliminarán sólo unas pocas Condensación: eliminar instancias supérfluas: Se pueden llegar a eliminar muchas, las del interior, manteniendo las de la frontera
24 Wilson editing Wilson editing: elimina instancia x i si es clasificada incorrectamente por sus k vecinos: Excepciones en el interior de una clase Algunos puntos en la frontera (suaviza las fronteras) Repeated Wilson editing: repite Wilson editing hasta que no se pueda aplicar mas

25 Wilson editing: ejemplo 2

26 Wilson editing: ejemplo 3 Overlapping classes Original data Wilson editing with k=7
27 Wilson editing No quita demasiados datos (es decir, no hay gran mejora en eficiencia) Funciona bien si no hay demasiado ruido. Si hay mucho ruido, las instancias con ruido clasificarán bien a otras instancias con ruido
28 Condensed Nearest Neighbor (CNN) Intenta reducir el número de instancias, eliminando las supérfluas Va recorriendo las instancias, y si esa instancia ya está bien clasificada con las que ya hay guardadas, no la guarda. Sólo guarda aquellas que no se clasifican bien con las ya existentes (y por tanto, es crítica, es necesaria)

29 CNN 1. Inicializa store con x 1 2. Elige un x i fuera de store mal clasificado según store. Muévelo a store 3. Repite 2 hasta que no se muevan mas instancias a store 4. Para clasificar con KNN, usar store en lugar de los datos originales

30 CNN CNN depende mucho del orden en el que se toman las instancias

31 CNN
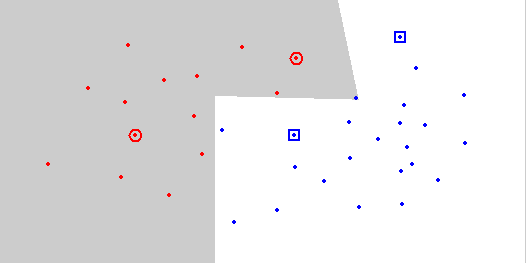
32 CNN
33 CNN
34 CNN
35 CNN CNN depende mucho del orden en el que se toman las instancias
36 Características de CNN +: positivo, -: negativo +: elimina todas aquellas instancias no críticas para la clasificación (reduce mucho la necesidad de almacenamiento) -: pero tiende a conservar aquellas instancias con ruido (puesto que son mal clasificadas por las instancias en Store) -: CNN depende mucho del orden en el que se toman las instancias
37 Reduced Nearest Neighbor rule (RNN) Es como CNN, pero comienza con todos los datos y va quitando aquellos que, al quitarlos, no hagan que alguna otra instancia pase a estar mal clasificada. Guarda las instancias críticas / necesarias para una clasificación correcta A diferencia de CNN, permite eliminar instancias ruido (puesto que no contribuyen a clasificar correctamente otras instancias, todo lo contrario)
38 No hay garantía de que CNN o RNN encuentren el conjunto consistente mínimo Datos originales Datos condensados Conjunto consistente mínimo
39 Edición y condensación La edición elimina el ruido y suaviza las fronteras, pero mantiene la mayor parte de los datos (mejora la capacidad de generalización pero no mejora la eficiencia) La condensación elimina gran cantidad de datos superfluos, pero mantiene los datos con ruido, puesto que CNN y RSS mantienen aquellos datos clasificados mal por los demás datos (y el ruido tiene siempre esta propiedad)
40 Híbridos: 1-Editar 2-Condensar Primero editar, luego condensar Original Edición Condensación
41 Algoritmos avanzados Editar / Condensar: RT3: D. Randall Wilson, Tony R. Martinez: Instance Pruning Techniques. ICML 1997: Iterative case filtering (ICF) Henry Brighton, Chris Mellish: Advances in Instance Selection for Instance-Based Learning Algorithms. Data Min. Knowl. Discov. 6(2): (2002)
42 RT1 / RT2 / RT3 Son algoritmos híbridos (condensación + edición) Objetivos de RT1 / RT2 / RT3 para mejorar a CNN: Que no dependa del orden (como le ocurría a CNN) Que elimine instancias con ruido Que elimine instancia supérfluas /SumedhaAhuja-EdithLaw/hybrid.html
43 RT1 / RT2 / RT3 RT1 está inspirado en RNN (que quitaba una instancia si con eso no hacía que otras instancias pasaran a estar mal clasificadas) Para cada instancia P, RT1 calcula sus asociados, Un asociado es una instancia que tiene a P como uno de sus k-vecinos. Es decir una instancia asociada a P es una instancia cuya clasificación puede verse afectada si quitamos P RT1 quita una instancia P si el número de asociados clasificados correctamente sin P es mayor o igual que los clasificados correctamente con P

44 RT1 k=3 La instancia tiene 6 asociados
45 Algoritmo de RT1
46 RT1 RT1 quita instancias con ruido, puesto que si se las quita eso no perjudica a la clasificación de los asociados, todo lo contrario RT1 quita instancias supérfluas en el centro de los clusters, porque en esos lugares todas las instancias son de la misma clase, por lo que quitar vecinos no es perjudicial RT1 tiende a guardar instancias no-ruido en la frontera, porque si la quitamos, otras instancias pueden pasar a estar mal clasificadas
47 RT2 / RT3 RT2 intenta quitar las instancias de los centros de los clusters primero Para ello, ordena las instancias por distancia a su vecino mas cercano que pertenezca a una clase distinta La idea es considerar antes aquellas instancias lejos de la frontera, pero para ello, hay que eliminar aquellas instancias con ruido en el interior de los clusters. Así, RT3 hace una primera pasada para quitar las instancias ruidosas (Wilson editing rule) RT3 por tanto tiende a conservar las instancias cerca de la frontera
48 RT2 / RT3
49 Algoritmo de RT2

50 RESULTADOS
51 CLASIFICACIÓN BASADA EN PROTOTIPOS
 y en tiempo (se computan muchas menos distancias cuando llega el dato de test)")
52 PROTOTIPOS Altura Altura Peso Mejora la eficiencia en espacio (sólo se guardan unos pocos prototipos) y en tiempo (se computan muchas menos distancias cuando llega el dato de test) Peso
53 Learning vector quantization (LVQ) Cada prototipo tiene una etiqueta Se clasifica según la clase del prototipo más cercano (o según sus regiones de Voronoi)
54 LVQ 1 LVQ I entrenamiento: Inicialización aleatoria repetir: presentar instancia de entrenamiento determinar prototipo más cercano Acercarlo o alejarlo de la instancia según la clase (y según la dirección de la línea que los une)
55 LVQ 2.1 LVQ 2.1 entrenamiento: Inicialización aleatoria repetir: presentar instancia de entrenamiento Determinar: prototipo más cercano correcto prototipo más cercano incorrecto Acercarlo o alejarlo si está dentro de una ventana
56 REGLA DE ACTUALIZACIÓN DE LVQ 2.1 Ventana: que no ocurra que un prototipo está muy cerca y otro muy lejos. Se puede forzar haciendo que el mas cercano esté suficientemente lejos (d cerca > s * d lejos ) ; s<1
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur KNN: VECINO(S) MAS CERCANO(S) K NEAREST NEIGHBORS (KNN) Altura Niño Adulto Mayor Se guardan todos los ejemplos
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur KNN: VECINO(S) MAS CERCANO(S) K NEAREST NEIGHBORS (KNN) Altura Niño Adulto Mayor Se guardan todos los ejemplos
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur SELECCIÓN DE INSTANCIAS Hay instancias supérfluas: no son necesarias para clasificar. Si las borramos, se
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur SELECCIÓN DE INSTANCIAS Hay instancias supérfluas: no son necesarias para clasificar. Si las borramos, se
Jesús García Herrero CLASIFICADORES KNN II: APRENDIZAJE DE PROTOTIPOS
 Jesús García Herrero CLASIFICADORES KNN II: APRENDIZAJE DE PROTOTIPOS En esta clase se completa el tema anterior de aprendizaje basados en instancias, enfatizando el aprendizaje de ejemplares. En particular,
Jesús García Herrero CLASIFICADORES KNN II: APRENDIZAJE DE PROTOTIPOS En esta clase se completa el tema anterior de aprendizaje basados en instancias, enfatizando el aprendizaje de ejemplares. En particular,
Aprendizaje inductivo no basado en el error Métodos competitivos supervisados.
 Aprendizaje inductivo no basado en el error Métodos competitivos supervisados. Aprendizaje basado en instancias Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido
Aprendizaje inductivo no basado en el error Métodos competitivos supervisados. Aprendizaje basado en instancias Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur Aprendizaje de distancias Kilian Q. Weinberger, Lawrence K. Saul: Distance Metric Learning for Large Margin
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur Aprendizaje de distancias Kilian Q. Weinberger, Lawrence K. Saul: Distance Metric Learning for Large Margin
Tareas de la minería de datos: clasificación. PF-5028 Minería de datos Prof. Braulio José Solano Rojas UCR
 Tareas de la minería de datos: clasificación PF-5028 Minería de datos Prof. Braulio José Solano Rojas UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja o asocia datos
Tareas de la minería de datos: clasificación PF-5028 Minería de datos Prof. Braulio José Solano Rojas UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja o asocia datos
Predicción basada en vecinos
 Predicción basada en vecinos Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Introducción Esquema de predicción directa Predicción basada
Predicción basada en vecinos Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Introducción Esquema de predicción directa Predicción basada
SISTEMAS INTELIGENTES
 SISTEMAS INTELIGENTES T8: Aprendizaje basado en instancias www.aic.uniovi.es/ssii Índice Aprendizaje basado en instancias Métricas NN Vecino más próximo: Regiones de Voronoi El parámetro K Problemas de
SISTEMAS INTELIGENTES T8: Aprendizaje basado en instancias www.aic.uniovi.es/ssii Índice Aprendizaje basado en instancias Métricas NN Vecino más próximo: Regiones de Voronoi El parámetro K Problemas de
Tareas de la minería de datos: clasificación. CI-2352 Intr. a la minería de datos Prof. Braulio José Solano Rojas ECCI, UCR
 Tareas de la minería de datos: clasificación CI-2352 Intr. a la minería de datos Prof. Braulio José Solano Rojas ECCI, UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja
Tareas de la minería de datos: clasificación CI-2352 Intr. a la minería de datos Prof. Braulio José Solano Rojas ECCI, UCR Tareas de la minería de datos: clasificación Clasificación (discriminación) Empareja
Examen Parcial. Attr1: A, B Attr2: A, B, C Attr3 1, 2, 3 Attr4; a, b Attr5: 1, 2, 3, 4
 Aprenentatge 0-03 Q Examen Parcial Nombre: (Examen ) Instrucciones. (0 puntos) Este examen dura horas. Responded todas las preguntas en estas hojas. Para las preguntas test poned un circulo alrededor de
Aprenentatge 0-03 Q Examen Parcial Nombre: (Examen ) Instrucciones. (0 puntos) Este examen dura horas. Responded todas las preguntas en estas hojas. Para las preguntas test poned un circulo alrededor de
Selección de atributos
 Selección de atributos Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Introducción Clasificación de las técnicas Esquema General Evaluadores
Selección de atributos Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Introducción Clasificación de las técnicas Esquema General Evaluadores
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur MODELOS: ÁRBOLES DE DECISIÓN Y REGLAS Datos de entrada 91 71 75 81 Nublado 90 72 Nublado 70 75 80 75 70
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur MODELOS: ÁRBOLES DE DECISIÓN Y REGLAS Datos de entrada 91 71 75 81 Nublado 90 72 Nublado 70 75 80 75 70
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur EVALUACIÓN Evaluación: entrenamiento y test Una vez obtenido el conocimiento es necesario validarlo para
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur EVALUACIÓN Evaluación: entrenamiento y test Una vez obtenido el conocimiento es necesario validarlo para
Aprendizaje Automático
 id3 id3 como búsqueda Cuestiones Adicionales Regresión Lineal. Árboles y Reglas de Regresión Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje
id3 id3 como búsqueda Cuestiones Adicionales Regresión Lineal. Árboles y Reglas de Regresión Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje
Métodos basados en instancias. K-vecinos, variantes
 Métodos basados en instancias K-vecinos, variantes Contenido 1. Caracterización 2. K-vecinos más próximos 3. Mejoras al algoritmo básico 4. Bibliografía 2 1. Caracterización Forma más sencilla de aprendizaje:
Métodos basados en instancias K-vecinos, variantes Contenido 1. Caracterización 2. K-vecinos más próximos 3. Mejoras al algoritmo básico 4. Bibliografía 2 1. Caracterización Forma más sencilla de aprendizaje:
Ricardo Aler Mur SELECCIÓN Y GENERACIÓN DE ATRIBUTOS-I
 Ricardo Aler Mur SELECCIÓN Y GENERACIÓN DE ATRIBUTOS-I En esta clase se habla de una parte importante del preprocesado de datos: la selección y generación de atributos. La selección de atributos consiste
Ricardo Aler Mur SELECCIÓN Y GENERACIÓN DE ATRIBUTOS-I En esta clase se habla de una parte importante del preprocesado de datos: la selección y generación de atributos. La selección de atributos consiste
ANÁLISIS DE DATOS. Ricardo Aler Mur
 ANÁLISIS DE DATOS Ricardo Aler Mur EXAMEN DE ANÁLISIS DE DATOS GRADO EN INFORMÁTICA ENERO 2014 10 puntos, 1 hora y media de duración. Responder cada pregunta con respuestas breves (unas pocas líneas).
ANÁLISIS DE DATOS Ricardo Aler Mur EXAMEN DE ANÁLISIS DE DATOS GRADO EN INFORMÁTICA ENERO 2014 10 puntos, 1 hora y media de duración. Responder cada pregunta con respuestas breves (unas pocas líneas).
Introducción a los sistemas Multiclasificadores. Carlos J. Alonso González Departamento de Informática Universidad de Valladolid
 Introducción a los sistemas Multiclasificadores Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Combinación de modelos 2. Descomposición bias-varianza 3. Bagging
Introducción a los sistemas Multiclasificadores Carlos J. Alonso González Departamento de Informática Universidad de Valladolid Contenido 1. Combinación de modelos 2. Descomposición bias-varianza 3. Bagging
CRITERIOS DE SELECCIÓN DE MODELOS
 Inteligencia artificial y reconocimiento de patrones CRITERIOS DE SELECCIÓN DE MODELOS 1 Criterios para elegir un modelo Dos decisiones fundamentales: El tipo de modelo (árboles de decisión, redes neuronales,
Inteligencia artificial y reconocimiento de patrones CRITERIOS DE SELECCIÓN DE MODELOS 1 Criterios para elegir un modelo Dos decisiones fundamentales: El tipo de modelo (árboles de decisión, redes neuronales,
Aprendizaje Basado en Instancias
 Aprendizaje Instancias Eduardo Morales, Hugo Jair Escalante Coordinación de Ciencias Computacionales Instituto Nacional de Astrofísica, Óptica y Electrónica Agosto, 2015 (INAOE) Agosto, 2015 1 / 80 1 2
Aprendizaje Instancias Eduardo Morales, Hugo Jair Escalante Coordinación de Ciencias Computacionales Instituto Nacional de Astrofísica, Óptica y Electrónica Agosto, 2015 (INAOE) Agosto, 2015 1 / 80 1 2
Módulo Minería de Datos Diplomado. Por Elizabeth León Guzmán, Ph.D. Profesora Ingeniería de Sistemas Grupo de Investigación MIDAS
 Módulo Minería de Datos Diplomado Por Elizabeth León Guzmán, Ph.D. Profesora Ingeniería de Sistemas Grupo de Investigación MIDAS Error de clasificación Algoritmo de aprendizaje h Entrenamiento DATOS Evaluación
Módulo Minería de Datos Diplomado Por Elizabeth León Guzmán, Ph.D. Profesora Ingeniería de Sistemas Grupo de Investigación MIDAS Error de clasificación Algoritmo de aprendizaje h Entrenamiento DATOS Evaluación
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Sistemas de Percepción Visión por Computador
 Nota: Algunas de las imágenes que aparecen en esta presentación provienen del libro: Visión por Computador: fundamentos y métodos. Arturo de la Escalera Hueso. Prentice Hall. Sistemas de Percepción Visión
Nota: Algunas de las imágenes que aparecen en esta presentación provienen del libro: Visión por Computador: fundamentos y métodos. Arturo de la Escalera Hueso. Prentice Hall. Sistemas de Percepción Visión
Introducción Clustering jerárquico Clustering particional Clustering probabilista Conclusiones. Clustering. Clasificación no supervisada
 Clustering Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Clustering jerárquico 3 Clustering particional 4 Clustering probabilista 5 Conclusiones Introducción Objetivos
Clustering Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Clustering jerárquico 3 Clustering particional 4 Clustering probabilista 5 Conclusiones Introducción Objetivos
Clasificación Supervisada
 Clasificación Supervisada Ricardo Fraiman 26 de abril de 2010 Resumen Reglas de Clasificación Resumen Reglas de Clasificación Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y
Clasificación Supervisada Ricardo Fraiman 26 de abril de 2010 Resumen Reglas de Clasificación Resumen Reglas de Clasificación Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y
Selección de Atributos. Dr. Jesús Ariel Carrasco Ochoa Oficina 8311
 Selección de Atributos Dr. Jesús Ariel Carrasco Ochoa ariel@inaoep.mx Oficina 8311 Contenido Introducción Estrategias de selección Técnicas filter Técnicas wrapper Técnicas híbridas Selección de atributos
Selección de Atributos Dr. Jesús Ariel Carrasco Ochoa ariel@inaoep.mx Oficina 8311 Contenido Introducción Estrategias de selección Técnicas filter Técnicas wrapper Técnicas híbridas Selección de atributos
TÉCNICAS DE AGRUPAMIENTO
 TÉCNICAS DE AGRUPAMIENTO José D. Martín Guerrero, Emilio Soria, Antonio J. Serrano PROCESADO Y ANÁLISIS DE DATOS AMBIENTALES Curso 2009-2010 Page 1 of 11 1. Algoritmo de las C-Medias. Algoritmos de agrupamiento
TÉCNICAS DE AGRUPAMIENTO José D. Martín Guerrero, Emilio Soria, Antonio J. Serrano PROCESADO Y ANÁLISIS DE DATOS AMBIENTALES Curso 2009-2010 Page 1 of 11 1. Algoritmo de las C-Medias. Algoritmos de agrupamiento
para la Selección Simultánea de Instancias y Atributos
 Algoritmosde Estimaciónde Distribuciones para la Selección Simultánea de Instancias y Atributos MAEB 2012 Albacete 8 10 Febrero Pablo Bermejo, José A. Gámez, Ana M. Martínez y José M. Puerta Universidad
Algoritmosde Estimaciónde Distribuciones para la Selección Simultánea de Instancias y Atributos MAEB 2012 Albacete 8 10 Febrero Pablo Bermejo, José A. Gámez, Ana M. Martínez y José M. Puerta Universidad
Índice general. Prefacio...5
 Índice general Prefacio...5 Capítulo 1 Introducción...13 1.1 Introducción...13 1.2 Los datos...19 1.3 Etapas en los procesos de big data...20 1.4 Minería de datos...21 1.5 Estructura de un proyecto de
Índice general Prefacio...5 Capítulo 1 Introducción...13 1.1 Introducción...13 1.2 Los datos...19 1.3 Etapas en los procesos de big data...20 1.4 Minería de datos...21 1.5 Estructura de un proyecto de
ANÁLISIS DE DATOS. Jesús García Herrero
 ANÁLISIS DE DATOS Jesús García Herrero ANALISIS DE DATOS EJERCICIOS Una empresa de seguros de automóviles quiere utilizar los datos sobre sus clientes para obtener reglas útiles que permita clasificar
ANÁLISIS DE DATOS Jesús García Herrero ANALISIS DE DATOS EJERCICIOS Una empresa de seguros de automóviles quiere utilizar los datos sobre sus clientes para obtener reglas útiles que permita clasificar
Tema 2 Primeros Modelos Computacionales
 Universidad Carlos III de Madrid OpenCourseWare Redes de Neuronas Artificiales Inés M. Galván - José Mª Valls Tema 2 Primeros Modelos Computacionales 1 Primeros Modelos Computacionales Perceptron simple
Universidad Carlos III de Madrid OpenCourseWare Redes de Neuronas Artificiales Inés M. Galván - José Mª Valls Tema 2 Primeros Modelos Computacionales 1 Primeros Modelos Computacionales Perceptron simple
1. Análisis de Conglomerados
 1. Análisis de Conglomerados El objetivo de este análisis es formar grupos de observaciones, de manera que todas las unidades en un grupo sean similares entre ellas pero que sean diferentes a aquellas
1. Análisis de Conglomerados El objetivo de este análisis es formar grupos de observaciones, de manera que todas las unidades en un grupo sean similares entre ellas pero que sean diferentes a aquellas
Clasificación de estados cerebralesusando neuroimágenes funcionales
 Clasificación de estados cerebralesusando neuroimágenes funcionales Clase 2: Reconocimiento de patrones en datos de neuroimagenes Enzo Tagliazucchi (tagliazucchi.enzo@googlemail.com) Primera clase: introducción
Clasificación de estados cerebralesusando neuroimágenes funcionales Clase 2: Reconocimiento de patrones en datos de neuroimagenes Enzo Tagliazucchi (tagliazucchi.enzo@googlemail.com) Primera clase: introducción
MÉTODOS AVANZADOS EN APRENDIZAJE ARTIFICIAL: TEORÍA Y APLICACIONES A PROBLEMAS DE PREDICCIÓN
 MÉTODOS AVANZADOS EN APRENDIZAJE ARTIFICIAL: TEORÍA Y APLICACIONES A PROBLEMAS DE PREDICCIÓN Manuel Sánchez-Montañés Luis Lago Ana González Escuela Politécnica Superior Universidad Autónoma de Madrid Teoría
MÉTODOS AVANZADOS EN APRENDIZAJE ARTIFICIAL: TEORÍA Y APLICACIONES A PROBLEMAS DE PREDICCIÓN Manuel Sánchez-Montañés Luis Lago Ana González Escuela Politécnica Superior Universidad Autónoma de Madrid Teoría
Aprendizaje basado en ejemplos.
 Aprendizaje basado en ejemplos. In whitch we describe agents that can improve their behavior through diligent study of their own experiences. Porqué queremos que un agente aprenda? Si es posible un mejor
Aprendizaje basado en ejemplos. In whitch we describe agents that can improve their behavior through diligent study of their own experiences. Porqué queremos que un agente aprenda? Si es posible un mejor
Técnicas de Clasificación Supervisada DRA. LETICIA FLORES PULIDO
 Técnicas de Clasificación Supervisada DRA. LETICIA FLORES PULIDO 2 Objetivo El objetivo principal de las técnicas de clasificación supervisada es obtener un modelo clasificatorio válido para permitir tratar
Técnicas de Clasificación Supervisada DRA. LETICIA FLORES PULIDO 2 Objetivo El objetivo principal de las técnicas de clasificación supervisada es obtener un modelo clasificatorio válido para permitir tratar
Clasificación Clasific NO SUPERV SUPER ISAD IS A AD AGRUPAMIENTO
 Clasificación NO SUPERVISADA AGRUPAMIENTO Clasificación No Supervisada Se trata de construir clasificadores sin información a priori, o sea, a partir de conjuntos de patrones no etiquetados Objetivo: Descubrir
Clasificación NO SUPERVISADA AGRUPAMIENTO Clasificación No Supervisada Se trata de construir clasificadores sin información a priori, o sea, a partir de conjuntos de patrones no etiquetados Objetivo: Descubrir
Inducción de Árboles de Decisión ID3, C4.5
 Inducción de Árboles de Decisión ID3, C4.5 Contenido 1. Representación mediante árboles de decisión. 2. Algoritmo básico: divide y vencerás. 3. Heurística para la selección de atributos. 4. Espacio de
Inducción de Árboles de Decisión ID3, C4.5 Contenido 1. Representación mediante árboles de decisión. 2. Algoritmo básico: divide y vencerás. 3. Heurística para la selección de atributos. 4. Espacio de
Clasificación mediante conjuntos
 Clasificación mediante conjuntos Gonzalo Martínez Muñoz Director: Dr. Alberto Suárez González Departamento de Ingeniería Informática Escuela Politécnica Superior Universidad Autónoma de Madrid diciembre
Clasificación mediante conjuntos Gonzalo Martínez Muñoz Director: Dr. Alberto Suárez González Departamento de Ingeniería Informática Escuela Politécnica Superior Universidad Autónoma de Madrid diciembre
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
AUTÓMATAS CELULARES MULTIESTADO APLICADOS A LA CLASIFICACIÓN CONTEXTUAL ITERATIVA DE IMÁGENES DE SATÉLITE
 1 AUTÓMATAS CELULARES MULTIESTADO APLICADOS A LA CLASIFICACIÓN CONTEXTUAL ITERATIVA DE IMÁGENES DE SATÉLITE - PROYECTO SOLERES - 24 de febrero de 2011 2 INDICE DEL SEMINARIO Autómatas celulares multiestado
1 AUTÓMATAS CELULARES MULTIESTADO APLICADOS A LA CLASIFICACIÓN CONTEXTUAL ITERATIVA DE IMÁGENES DE SATÉLITE - PROYECTO SOLERES - 24 de febrero de 2011 2 INDICE DEL SEMINARIO Autómatas celulares multiestado
Métodos de Inteligencia Artificial
 Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden: Clasificador Bayesiano Clasificación Clasificador
Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden: Clasificador Bayesiano Clasificación Clasificador
SELECCIÓN DE ATRIBUTOS EN R
 SELECCIÓN DE ATRIBUTOS EN R Fases del análisis de datos Recopilación de los datos (tabla datos x atributos) Preproceso: De los datos De los atributos: Selección de atributos: Ranking Subset selection;cfs
SELECCIÓN DE ATRIBUTOS EN R Fases del análisis de datos Recopilación de los datos (tabla datos x atributos) Preproceso: De los datos De los atributos: Selección de atributos: Ranking Subset selection;cfs
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos. - Sesión 11 -
 Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 11 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Resolución manual de clasificación bayesiana
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 11 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Resolución manual de clasificación bayesiana
Clasificación Supervisada. Métodos jerárquicos. CART
 Clasificación Supervisada. Métodos jerárquicos. CART Ricardo Fraiman 2 de abril de 2010 Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y n ) E {1,..., m}. Típicamente E = R d.
Clasificación Supervisada. Métodos jerárquicos. CART Ricardo Fraiman 2 de abril de 2010 Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y n ) E {1,..., m}. Típicamente E = R d.
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
El Perceptrón Multicapa
 El Perceptrón Multicapa N entradas M neuronas de salida L: neuronas en la capa oculta E = 1 p M ( zi ( k) yi ( k) ) k = 1 i= 1 Implementación de la función XOR Regiones de clasificación en función del
El Perceptrón Multicapa N entradas M neuronas de salida L: neuronas en la capa oculta E = 1 p M ( zi ( k) yi ( k) ) k = 1 i= 1 Implementación de la función XOR Regiones de clasificación en función del
Posibles trabajos HIA
 Posibles trabajos HIA Posibles trabajos Comparar otras herramientas de Minería de Datos con Weka Estudiar la influencia del ruido en bagging y boosting Estudiar la influencia del parámetro de poda en J48
Posibles trabajos HIA Posibles trabajos Comparar otras herramientas de Minería de Datos con Weka Estudiar la influencia del ruido en bagging y boosting Estudiar la influencia del parámetro de poda en J48
Tema 5. Clasificadores K-NN
 Tema 5 Clasificadores K-NN Abdelmalik Moujahid, Iñaki Inza y Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad del País Vasco Euskal Herriko Unibertsitatea
Tema 5 Clasificadores K-NN Abdelmalik Moujahid, Iñaki Inza y Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad del País Vasco Euskal Herriko Unibertsitatea
GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC)
") GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC) Curso Académico: 2015-2016 Programa: Centro: Universidad: Máster Universitario en Ingeniería Informática Escuela Politécnica Superior
GUÍA DOCENTE: Sistemas Basados en Conocimiento y Minería de Datos (SBC) Curso Académico: 2015-2016 Programa: Centro: Universidad: Máster Universitario en Ingeniería Informática Escuela Politécnica Superior
Aprendizaje no supervisado
 Aprendizaje no supervisado Algoritmo de K medias Julio Waissman Vilanova Licenciatura en Ciencias de la Computación Universidad de Sonora Curso Inteligencia Artificial Plan del curso Aprendizaje no supervisado
Aprendizaje no supervisado Algoritmo de K medias Julio Waissman Vilanova Licenciatura en Ciencias de la Computación Universidad de Sonora Curso Inteligencia Artificial Plan del curso Aprendizaje no supervisado
Análisis de Datos. Clasificación Bayesiana para distribuciones normales. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Clasificación Bayesiana para distribuciones normales Profesor: Dr. Wilfrido Gómez Flores 1 Funciones discriminantes Una forma útil de representar clasificadores de patrones es a través
Análisis de Datos Clasificación Bayesiana para distribuciones normales Profesor: Dr. Wilfrido Gómez Flores 1 Funciones discriminantes Una forma útil de representar clasificadores de patrones es a través
Aprendizaje no supervisado
 OPENCOURSEWARE REDES DE NEURONAS ARTIFICIALES Inés M. Galván José M. Valls Tema 4 1 Introducción Aprendizaje competitvo Otros algoritmos de agrupación 2 1 Introducción Características principales de las
OPENCOURSEWARE REDES DE NEURONAS ARTIFICIALES Inés M. Galván José M. Valls Tema 4 1 Introducción Aprendizaje competitvo Otros algoritmos de agrupación 2 1 Introducción Características principales de las
Clasificación estadística de patrones
 Clasificación estadística de patrones Clasificador gaussiano César Martínez cmartinez _at_ fich.unl.edu.ar Tópicos Selectos en Aprendizaje Maquinal Doctorado en Ingeniería, FICH-UNL 19 de setiembre de
Clasificación estadística de patrones Clasificador gaussiano César Martínez cmartinez _at_ fich.unl.edu.ar Tópicos Selectos en Aprendizaje Maquinal Doctorado en Ingeniería, FICH-UNL 19 de setiembre de
Tema 2: Introducción a scikit-learn
 Tema 2: Introducción a scikit-learn José Luis Ruiz Reina Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla Razonamiento asistido por computador, 2017-18 Ejemplo:
Tema 2: Introducción a scikit-learn José Luis Ruiz Reina Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla Razonamiento asistido por computador, 2017-18 Ejemplo:
El sistema fue desarrollado bajo el sistema operativo Windows XP de Microsoft, utilizando
 33 3 Diseño del Sistema de Reconocimiento de Letras. 3.. Introducción. El sistema fue desarrollado bajo el sistema operativo Windows XP de Microsoft, utilizando el entorno de desarrollo C++Builder Profesional
33 3 Diseño del Sistema de Reconocimiento de Letras. 3.. Introducción. El sistema fue desarrollado bajo el sistema operativo Windows XP de Microsoft, utilizando el entorno de desarrollo C++Builder Profesional
Análisis de Datos. Introducción al aprendizaje supervisado. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Desde la antigüedad, el problema de buscar patrones en datos es fundamental en diversas
Análisis de Datos Introducción al aprendizaje supervisado Profesor: Dr. Wilfrido Gómez Flores 1 Conceptos básicos Desde la antigüedad, el problema de buscar patrones en datos es fundamental en diversas
Redes de Neuronas de Base Radial
 Redes de Neuronas de Base Radial 1 Introducción Redes multicapa con conexiones hacia delante Única capa oculta Las neuronas ocultas poseen carácter local Cada neurona oculta se activa en una región distinta
Redes de Neuronas de Base Radial 1 Introducción Redes multicapa con conexiones hacia delante Única capa oculta Las neuronas ocultas poseen carácter local Cada neurona oculta se activa en una región distinta
Support Vector Machines
 Support Vector Machines Métodos Avanzados en Aprendizaje Artificial Luis F. Lago Fernández Manuel Sánchez-Montañés Ana González Universidad Autónoma de Madrid 6 de abril de 2010 L. Lago - M. Sánchez -
Support Vector Machines Métodos Avanzados en Aprendizaje Artificial Luis F. Lago Fernández Manuel Sánchez-Montañés Ana González Universidad Autónoma de Madrid 6 de abril de 2010 L. Lago - M. Sánchez -
Reconocimiento de Patrones
 Reconocimiento de Patrones Técnicas de validación (Clasificación Supervisada) Jesús Ariel Carrasco Ochoa Instituto Nacional de Astrofísica, Óptica y Electrónica Clasificación Supervisada Para qué evaluar
Reconocimiento de Patrones Técnicas de validación (Clasificación Supervisada) Jesús Ariel Carrasco Ochoa Instituto Nacional de Astrofísica, Óptica y Electrónica Clasificación Supervisada Para qué evaluar
Tema 15: Combinación de clasificadores
 Tema 15: Combinación de clasificadores p. 1/21 Tema 15: Combinación de clasificadores Abdelmalik Moujahid, Iñaki Inza, Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial
Tema 15: Combinación de clasificadores p. 1/21 Tema 15: Combinación de clasificadores Abdelmalik Moujahid, Iñaki Inza, Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial
Elementos de máquinas de vectores de soporte
 Elementos de máquinas de vectores de soporte Clasificación binaria y funciones kernel Julio Waissman Vilanova Departamento de Matemáticas Universidad de Sonora Seminario de Control y Sistemas Estocásticos
Elementos de máquinas de vectores de soporte Clasificación binaria y funciones kernel Julio Waissman Vilanova Departamento de Matemáticas Universidad de Sonora Seminario de Control y Sistemas Estocásticos
RECONOCIMIENTO DE PAUTAS
 RECONOCIMIENTO DE PAUTAS ANÁLISIS DISCRIMINANTE (Discriminant analysis) Reconocimiento de pautas supervisado si se cuenta con objetos cuya pertenencia a un grupo es conocida métodos: análisis de discriminantes
RECONOCIMIENTO DE PAUTAS ANÁLISIS DISCRIMINANTE (Discriminant analysis) Reconocimiento de pautas supervisado si se cuenta con objetos cuya pertenencia a un grupo es conocida métodos: análisis de discriminantes
Técnicas Supervisadas Aproximación no paramétrica
 Técnicas Supervisadas Aproximación no paramétrica 2016 Notas basadas en el curso Reconocimiento de Formas de F.Cortijo, Univ. de Granada Pattern Classification de Duda, Hart y Storck The Elements of Statistical
Técnicas Supervisadas Aproximación no paramétrica 2016 Notas basadas en el curso Reconocimiento de Formas de F.Cortijo, Univ. de Granada Pattern Classification de Duda, Hart y Storck The Elements of Statistical
Métodos de Inteligencia Artificial
 Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden Introducción Tipos de aprendizaje Aprendizaje cómo
Métodos de Inteligencia Artificial L. Enrique Sucar (INAOE) esucar@inaoep.mx ccc.inaoep.mx/esucar Tecnologías de Información UPAEP Agentes que Aprenden Introducción Tipos de aprendizaje Aprendizaje cómo
Reconocimiento de Formas
 Reconocimiento de Formas Técnicas No Paramétricas José Martínez Sotoca Índice Introducción. Ventanas de Parzen. Clasificación por Distancia Mínima (CDM). Regla del vecino mas próximo (1-NN / NN). Regla
Reconocimiento de Formas Técnicas No Paramétricas José Martínez Sotoca Índice Introducción. Ventanas de Parzen. Clasificación por Distancia Mínima (CDM). Regla del vecino mas próximo (1-NN / NN). Regla
Clasificación de documentos
 Minería de Datos Web P r o f. D r. M a r c e l o G. A r m e n t a n o I S I S TA N, F a c. d e C s. E x a c t a s, U N I C E N m a r c e l o. a r m e n t a n o @ i s i s t a n. u n i c e n. e d u. a r
Minería de Datos Web P r o f. D r. M a r c e l o G. A r m e n t a n o I S I S TA N, F a c. d e C s. E x a c t a s, U N I C E N m a r c e l o. a r m e n t a n o @ i s i s t a n. u n i c e n. e d u. a r
Introducción. Existen dos aproximaciones para resolver el problema de clasificación: Aproximación Generativa (vista en el Tema 3) Basada en:
 Basada en:") Introducción Eisten dos aproimaciones para resolver el problema de clasificación: Aproimación Generativa (vista en el Tema 3) Basada en: Modelar p(,w)=p( w)p(w) p( w) es la distribución condicional de
Introducción Eisten dos aproimaciones para resolver el problema de clasificación: Aproimación Generativa (vista en el Tema 3) Basada en: Modelar p(,w)=p( w)p(w) p( w) es la distribución condicional de
Clustering: Algoritmos
 Clustering: Algoritmos Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Algoritmo: K-medias 3 Algoritmo: BFR 4 Algoritmo: CURE Introducción Acotar el problema Complejidad
Clustering: Algoritmos Clasificación no supervisada Javier G. Sogo 10 de marzo de 2015 1 Introducción 2 Algoritmo: K-medias 3 Algoritmo: BFR 4 Algoritmo: CURE Introducción Acotar el problema Complejidad
ARBOLES DE DECISION. Miguel Cárdenas-Montes. 1 Introducción. Objetivos: Entender como funcionan los algoritmos basados en árboles de decisión.
 ARBOLES DE DECISION Miguel Cárdenas-Montes Los árboles de decisión son estructuras lógicas con amplia utilización en la toma de decisión, la predicción y la minería de datos. Objetivos: Entender como funcionan
ARBOLES DE DECISION Miguel Cárdenas-Montes Los árboles de decisión son estructuras lógicas con amplia utilización en la toma de decisión, la predicción y la minería de datos. Objetivos: Entender como funcionan
TEMA 1: INTRODUCCIÓN N AL PROCESADO Y ANÁLISIS DE DATOS
 Procesado y Análisis de Datos Ambientales. Curso 2009-2010. José D. Martín, Emilio Soria, Antonio J. Serrano TEMA 1: INTRODUCCIÓN N AL PROCESADO Y ANÁLISIS DE DATOS ÍNDICE Introducción. Selección de variables.
Procesado y Análisis de Datos Ambientales. Curso 2009-2010. José D. Martín, Emilio Soria, Antonio J. Serrano TEMA 1: INTRODUCCIÓN N AL PROCESADO Y ANÁLISIS DE DATOS ÍNDICE Introducción. Selección de variables.
Análisis de Datos. Combinación de clasificadores. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Combinación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción Diversos algoritmos de clasificación están limitados a resolver problemas binarios, es decir, con dos
Análisis de Datos Combinación de clasificadores Profesor: Dr. Wilfrido Gómez Flores 1 Introducción Diversos algoritmos de clasificación están limitados a resolver problemas binarios, es decir, con dos
CLASIFICACIÓN DE IMÁGENES DE SATÉLITE MEDIANTE AUTÓMATAS CELULARES
 1 CLASIFICACIÓN DE IMÁGENES DE SATÉLITE MEDIANTE AUTÓMATAS CELULARES Antonio Moisés Espínola Pérez - PROYECTO SOLERES - 15 de febrero de 2010 2 INDICE DEL SEMINARIO CLASIFICACION DE IMÁGENES DE SATÉLITE
1 CLASIFICACIÓN DE IMÁGENES DE SATÉLITE MEDIANTE AUTÓMATAS CELULARES Antonio Moisés Espínola Pérez - PROYECTO SOLERES - 15 de febrero de 2010 2 INDICE DEL SEMINARIO CLASIFICACION DE IMÁGENES DE SATÉLITE
Técnicas de Preprocesado
 Técnicas de Preprocesado Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Por qué preprocesar p los datos? Técnicas de filtro Depuración
Técnicas de Preprocesado Series Temporales Máster en Computación Universitat Politècnica de Catalunya Dra. Alicia Troncoso Lora 1 Contenido Por qué preprocesar p los datos? Técnicas de filtro Depuración
MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión.
 MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión. 1 Objetivos del tema Conocer en qué consiste un árbol de decisión. Aprender los problemas que pueden
MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión. 1 Objetivos del tema Conocer en qué consiste un árbol de decisión. Aprender los problemas que pueden
Métodos de Remuestreo en Aprendizaje Automático
 Métodos de Remuestreo en Aprendizaje Automático en datos, en hipótesis, y algunos otros trucos: Cross-validation, Bootstrap, Bagging, Boosting, Random Subspaces Lo que sabemos hasta ahora: Hemos visto
Métodos de Remuestreo en Aprendizaje Automático en datos, en hipótesis, y algunos otros trucos: Cross-validation, Bootstrap, Bagging, Boosting, Random Subspaces Lo que sabemos hasta ahora: Hemos visto
Qué es big dimension? Verónica Bolón Canedo 2/30
 Qué es big dimension? Verónica Bolón Canedo 2/30 Big dimension En esta nueva era de Big Data, los métodos de aprendizaje máquina deben adaptarse para poder tratar con este volumen de datos sin precedentes.
Qué es big dimension? Verónica Bolón Canedo 2/30 Big dimension En esta nueva era de Big Data, los métodos de aprendizaje máquina deben adaptarse para poder tratar con este volumen de datos sin precedentes.
Aprendizaje No Supervisado
 Aprendizaje Automático Segundo Cuatrimestre de 2015 Aprendizaje No Supervisado Supervisado vs. No Supervisado Aprendizaje Supervisado Clasificación y regresión. Requiere instancias etiquetadas para entrenamiento.
Aprendizaje Automático Segundo Cuatrimestre de 2015 Aprendizaje No Supervisado Supervisado vs. No Supervisado Aprendizaje Supervisado Clasificación y regresión. Requiere instancias etiquetadas para entrenamiento.
Inteligencia Artificial: Su uso para la investigación
 Inteligencia Artificial: Su uso para la investigación Dra. Helena Montserrat Gómez Adorno Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas helena.adorno@iimas.unam.mx 1 Introducción
Inteligencia Artificial: Su uso para la investigación Dra. Helena Montserrat Gómez Adorno Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas helena.adorno@iimas.unam.mx 1 Introducción
APRENDIZAJE BASADO EN INSTANCIAS. Eduardo Morales y Jesús González
 APRENDIZAJE BASADO EN INSTANCIAS Eduardo Morales y Jesús González Aprendizaje basado en Instancias 2 Diferente al tipo de aprendizaje que hemos visto Se almacenan los ejemplos de entrenamiento Para clasificar
APRENDIZAJE BASADO EN INSTANCIAS Eduardo Morales y Jesús González Aprendizaje basado en Instancias 2 Diferente al tipo de aprendizaje que hemos visto Se almacenan los ejemplos de entrenamiento Para clasificar
SISTEMAS INTELIGENTES
 SISTEMAS INTELIGENTES T12: Aprendizaje no Supervisado {jdiez, juanjo} @ aic.uniovi.es Índice Aprendizaje no Supervisado Clustering Tipos de clustering Algoritmos Dendogramas 1-NN K-means E-M Mapas auto-organizados
SISTEMAS INTELIGENTES T12: Aprendizaje no Supervisado {jdiez, juanjo} @ aic.uniovi.es Índice Aprendizaje no Supervisado Clustering Tipos de clustering Algoritmos Dendogramas 1-NN K-means E-M Mapas auto-organizados
Aprendizaje Automático
 Regresión Lineal: Descenso de Gradiente Árboles de Regresión: M5 Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje (PLG) Departamento de Informática
Regresión Lineal: Descenso de Gradiente Árboles de Regresión: M5 Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje (PLG) Departamento de Informática
Aprendizaje no supervisado: Mapas Auto-organizados SOM - Inspiración y objetivos - Aprendizaje - Ejemplo y aplicaciones
 índice Aprendizaje no supervisado: Mapas Auto-organizados SOM - Inspiración y objetivos - Aprendizaje - Ejemplo y aplicaciones 1 RNA No supervisadas: Mapas Auto-Organizados (SOM) Puntos cercanos en el
índice Aprendizaje no supervisado: Mapas Auto-organizados SOM - Inspiración y objetivos - Aprendizaje - Ejemplo y aplicaciones 1 RNA No supervisadas: Mapas Auto-Organizados (SOM) Puntos cercanos en el
Reconocimiento automático de rostros
 Reconocimiento automático de rostros Ponente: Dr. Wilfrido Gómez Flores Investigador CINVESTAV wgomez@tamps.cinvestav.mx Ciudad Victoria,, 7 de junio de 2017 1 Introducción 2 Reconocimiento de rostros
Reconocimiento automático de rostros Ponente: Dr. Wilfrido Gómez Flores Investigador CINVESTAV wgomez@tamps.cinvestav.mx Ciudad Victoria,, 7 de junio de 2017 1 Introducción 2 Reconocimiento de rostros
Reconocimiento de Formas
 Reconocimiento de Formas Técnicas no Supervisadas: clustering José Martínez Sotoca Objetivo: Estudio de la estructura de un conjunto de datos, división en agrupaciones. Características: Homogeneidad o
Reconocimiento de Formas Técnicas no Supervisadas: clustering José Martínez Sotoca Objetivo: Estudio de la estructura de un conjunto de datos, división en agrupaciones. Características: Homogeneidad o
Conjuntos de Clasificadores (Ensemble Learning)
") Aprendizaje Automático Segundo Cuatrimestre de 2016 Conjuntos de Clasificadores (Ensemble Learning) Gracias a Ramiro Gálvez por la ayuda y los materiales para esta clase. Bibliografía: S. Fortmann-Roe,
Aprendizaje Automático Segundo Cuatrimestre de 2016 Conjuntos de Clasificadores (Ensemble Learning) Gracias a Ramiro Gálvez por la ayuda y los materiales para esta clase. Bibliografía: S. Fortmann-Roe,
Estadística con R. Clasificadores
 Estadística con R Clasificadores Análisis discriminante lineal (estadístico) Árbol de decisión (aprendizaje automático) Máquina soporte vector (aprendizaje automático) Análisis discriminante lineal (AD)
Estadística con R Clasificadores Análisis discriminante lineal (estadístico) Árbol de decisión (aprendizaje automático) Máquina soporte vector (aprendizaje automático) Análisis discriminante lineal (AD)
RECONOCIMIENTO DE PATRONES DRA. LETICIA FLORES PULIDO
 RECONOCIMIENTO DE PATRONES DRA. LETICIA FLORES PULIDO 2 CONTENIDO TEMA1: INTRODUCCIÓN TEMA2: APRENDIZAJE MÁQUINA TEMA3: RECONOCIMIENTO DE PATRONES TEMA4: PROGRAMACIÓN EVOLUTIVA 3 TEMA 3 : RECONOCIMIENTO
RECONOCIMIENTO DE PATRONES DRA. LETICIA FLORES PULIDO 2 CONTENIDO TEMA1: INTRODUCCIÓN TEMA2: APRENDIZAJE MÁQUINA TEMA3: RECONOCIMIENTO DE PATRONES TEMA4: PROGRAMACIÓN EVOLUTIVA 3 TEMA 3 : RECONOCIMIENTO
Tópicos Selectos en Aprendizaje Maquinal. Algoritmos para Reconocimiento de Patrones
 Tópicos Selectos en Aprendizaje Maquinal Guía de Trabajos Prácticos N 1 Algoritmos para Reconocimiento de Patrones 18 de septiembre de 2014 1. Objetivos Introducir conceptos básicos de aprendizaje automático.
Tópicos Selectos en Aprendizaje Maquinal Guía de Trabajos Prácticos N 1 Algoritmos para Reconocimiento de Patrones 18 de septiembre de 2014 1. Objetivos Introducir conceptos básicos de aprendizaje automático.
Interfaz hombre máquina basado en el análisis de los gestos faciales mediante visión artificial
 UNIVERSIDAD DE ALCALÁ Escuela Politécnica Superior INGENIERÍA DE TELECOMUNICACIÓN Interfaz hombre máquina basado en el análisis de los gestos faciales mediante visión artificial Proyecto Fin de Carrera
UNIVERSIDAD DE ALCALÁ Escuela Politécnica Superior INGENIERÍA DE TELECOMUNICACIÓN Interfaz hombre máquina basado en el análisis de los gestos faciales mediante visión artificial Proyecto Fin de Carrera
Aprendizaje: Boosting y Adaboost
 Técnicas de Inteligencia Artificial Aprendizaje: Boosting y Adaboost Boosting 1 Indice Combinando clasificadores débiles Clasificadores débiles La necesidad de combinar clasificadores Bagging El algoritmo
Técnicas de Inteligencia Artificial Aprendizaje: Boosting y Adaboost Boosting 1 Indice Combinando clasificadores débiles Clasificadores débiles La necesidad de combinar clasificadores Bagging El algoritmo
Uso de Weka desde un script
 Uso de Weka desde un script Script para hacer una curva de aprendizaje Cómo usar Weka desde la línea de comandos para, por ejemplo, hacer una curva de aprendizaje Probar con: 20% de los datos, validación
Uso de Weka desde un script Script para hacer una curva de aprendizaje Cómo usar Weka desde la línea de comandos para, por ejemplo, hacer una curva de aprendizaje Probar con: 20% de los datos, validación
Clasificadores Débiles - AdaBoost
 Capítulo 3 Clasificadores Débiles - AdaBoost El término boosting hace referencia a un tipo de algoritmos cuya finalidad es encontrar una hipótesis fuerte a partir de utilizar hipótesis simples y débiles.
Capítulo 3 Clasificadores Débiles - AdaBoost El término boosting hace referencia a un tipo de algoritmos cuya finalidad es encontrar una hipótesis fuerte a partir de utilizar hipótesis simples y débiles.
ALGUNOS COMENTARIOS SOBRE GENERALIZACION EN BACKPROPAGATION
 ALGUNOS COMENTARIOS SOBRE GENERALIZACION EN BACKPROPAGATION En una RN entrenada, si las salidas calculadas por la red con nuevos ejemplos están próimas a los valores deseados, hay generalización (Haykin,
ALGUNOS COMENTARIOS SOBRE GENERALIZACION EN BACKPROPAGATION En una RN entrenada, si las salidas calculadas por la red con nuevos ejemplos están próimas a los valores deseados, hay generalización (Haykin,
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Aprendizaje Automático. Segundo Cuatrimestre de Clasificadores: Naive Bayes, Vecinos Más Cercanos, SVM
 Aprendizaje Automático Segundo Cuatrimestre de 2016 Clasificadores: Naive Bayes, Vecinos Más Cercanos, SVM Naive Bayes Naive Bayes Dada una nueva instancia con valores de atributos a 1, a 2,..., a n, su
Aprendizaje Automático Segundo Cuatrimestre de 2016 Clasificadores: Naive Bayes, Vecinos Más Cercanos, SVM Naive Bayes Naive Bayes Dada una nueva instancia con valores de atributos a 1, a 2,..., a n, su
Análisis de Datos. Estimación de distribuciones desconocidas: métodos no paramétricos. Profesor: Dr. Wilfrido Gómez Flores
 Análisis de Datos Estimación de distribuciones desconocidas: métodos no paramétricos Profesor: Dr. Wilfrido Gómez Flores 1 Introducción La estimación de densidad con modelos paramétricos asumen que las
Análisis de Datos Estimación de distribuciones desconocidas: métodos no paramétricos Profesor: Dr. Wilfrido Gómez Flores 1 Introducción La estimación de densidad con modelos paramétricos asumen que las
Capitulo 1: Introducción al reconocimiento de patrones (Secciones )
") Capitulo 1: Introducción al reconocimiento de patrones (Secciones 1.1-1.6) M A C H I N E P E R C E P T I O N U N E J E M P L O S I S T E M A S D E R E C O N O C I M I E N T O D E P A T R O N E S C I C
Capitulo 1: Introducción al reconocimiento de patrones (Secciones 1.1-1.6) M A C H I N E P E R C E P T I O N U N E J E M P L O S I S T E M A S D E R E C O N O C I M I E N T O D E P A T R O N E S C I C