Árboles de Decisión. Tomás Arredondo Vidal 26/3/08
|
|
|
- María Jesús Coronel Vera
- hace 8 años
- Vistas:
Transcripción
1 Árboles de Decisión Tomás Arredondo Vidal 26/3/08

2 Árboles de Decisión Contenidos Árboles de Decisión Sobreajuste Recorte (Pruning)
")
3 Investigación Relacionada a los Árboles de Decisión William of Occam inventa el criterio de Occam s razor Hunt usa el método (CLS) para modelar aprendizaje humano de conceptos s. Quinlan desarrolla ID3 con la heurística de ganancia de información para desarrollar sistemas expertos desde ejemplos 1970s Breiman, Friedman y otros desarrollan CART (Classification and Regression Trees) similar a ID3 1970s Una variedad de mejorar se introducen para acomodar ruido, características continuas, características incompletas, mejoras en métodos de división 1980s Quinlan s actualiza sistemas de decision (C4.5) Weka se incluye una versión en Java de C4.5 llamado J48.
 similar a ID3 1970s Una variedad de mejorar se introducen para acomodar ruido, características continuas, características")
4 Árboles de Decisión Clasificadores basados en árboles para instancias (datos) representados como vectores de características (features). Nodos prueban características, hay una rama para cada valor de la característica, las hojas especifican la categoría. color red blue green shape neg pos circle square triangle pos neg neg color red green blue shape B C circle square triangle A B C Pueden representar cualquier conjunción (AND) y disyunción (OR) Pueden representar cualquier función de clasificación de vectores de características discretas. Pueden ser rescritas como reglas, i.e. disjunctive normal form (DNF). red circle pos red circle A blue B; red square B green C; red triangle C
 y disyunción (OR) Pueden representar cualquier función de clasificación de vectores de características discretas. Pueden ser rescritas como reglas, i.e. disjunctive normal form (DNF).")
5 Propiedades de Árboles de Decisión Características (features) continuas (reales) pueden ser clasificadas al permitir nodos que dividan una característica real en dos rangos basados en umbrales (e.g. largo < 3 and largo 3) Árboles de clasificación tienen valores discretos en las ramas, árboles de regresión permiten outputs reales en las hojas Algoritmos para encontrar árboles consistentes son eficientes para procesar muchos datos de entrenamiento para tareas de datamining Pueden manejar ruido en datos de entrenamiento Ejemplos: Diagnostico medico Análisis de riesgo en crédito Clasificador de objetos para manipulador de robot (Tan 1993)
 Árboles de clasificación tienen valores discretos en las ramas, árboles de regresión permiten outputs reales en las hojas Algoritmos para")
6 Árbol de Decisión para PlayTennis Outlook Sunny Overcast Rain Humidity Wind High Normal Strong Weak No No

7 Árbol de Decisión para PlayTennis Outlook Sunny Overcast Rain Humidity Each internal node tests an attribute High No Normal Each branch corresponds to an attribute value node Each leaf node assigns a classification

8 Árbol de Decisión para Conjunción Outlook=Sunny Wind=Weak Outlook Sunny Overcast Rain Wind No No Strong No Weak

9 Árbol de Decisión para Disyunción Outlook=Sunny Wind=Weak Outlook Sunny Overcast Rain Wind Wind Strong Weak Strong Weak No No

10 Árbol de Decisión para XOR Outlook=Sunny XOR Wind=Weak Outlook Sunny Overcast Rain Wind Wind Wind Strong Weak Strong Weak Strong Weak No No No

11 Árbol de Decisión Árboles de decisión representan disyunciones de conjunciones Outlook Sunny Overcast Rain Humidity Wind High Normal Strong Weak No No (Outlook=Sunny Humidity=Normal) (Outlook=Overcast) (Outlook=Rain Wind=Weak)
 (Outlook=Overcast)")
12 Método Top-Down de Construcción Construir un árbol Top-Down usando dividir para conquistar. <big, red, circle>: + <small, red, circle>: + <small, red, triangle>: + <small, red, square>: <big, blue, circle>: <small, green, triangle>: - red blue <big, red, circle>: + <small, red, circle>: + <small, red, square>: <small, red, triangle>: + color green

13 Método Top-Down de Construcción Construir un árbol Top-Down usando dividir para conquistar. <big, red, circle>: + <small, red, circle>: + <small, red, triangle>: + <small, red, square>: <big, blue, circle>: <small, green, triangle>: - <big, red, circle>: + <small, red, circle>: + <small, red, square>: <small, red, triangle>: + <big, red, circle>: + <small, red, circle>: + color red blue green shape neg neg circle square triangle pos neg pos <small, green, triangle>: + <big, blue, circle>: <small, red, triangle>: + <small, red, square>:

14 Pseudocódigo para Construcción de Árbol DTree(examples, features) returns a tree If all examples are in one category, return a leaf node with that category label. Else if the set of features is empty, return a leaf node with the category label that is the most common in examples. Else pick a feature F and create a node R for it For each possible value v i of F: Let examples i be the subset of examples that have value v i for F Add an out-going edge E to node R labeled with the value v i. If examples i is empty then attach a leaf node to edge E labeled with the category that is the most common in examples. else call DTree(examples i, features {F}) and attach the resulting tree as the subtree under edge E. Return the subtree rooted at R.

15 Seleccionar una Buena Característica para Dividir Objetivo es tener un árbol que sea lo mas simple posible (de acuerdo a Occam s Razor) Encontrar un árbol mínimo de decisión (nodos, hojas o profundidad) es un problema de optimización NP-hard. El método top-down que divide para conquistar hace una búsqueda codiciosa (greedy) para obtener un árbol simple pero no garantiza que sea el mas simple. Se quiere seleccionar una característica que genera subconjuntos de ejemplos que son similares en una clase para que estén cerca de ser nodos hojas. Hay una variedad de heurísticas para elegir un buen test o condición, un método popular esta basado en el incremento de la información (information gain) que se origino con el sistema ID3 (Quinlan 1979).

16 Occam s Razor Occam s razor: Se debe preferir la hipótesis más corta que tenga coincidencia (o describa) con los datos Porque preferir hipótesis cortas? Argumentos a favor: Hay menos hipótesis cortas que largas Es poco probable que una hipótesis corta que describa los datos sea una coincidencia Una hipótesis larga que describa los datos puede ser una coincidencia (sobreajuste o overfitting) Argumentos en contra: Hay muchas maneras de definir hipótesis cortas y una definición depende de la representación interna del que aprende (i.e. una representación interna corta para uno puede ser larga para otro) Porque el tamaño de la hipótesis es importante?
 Porque el tamaño de la hipótesis es importante?")
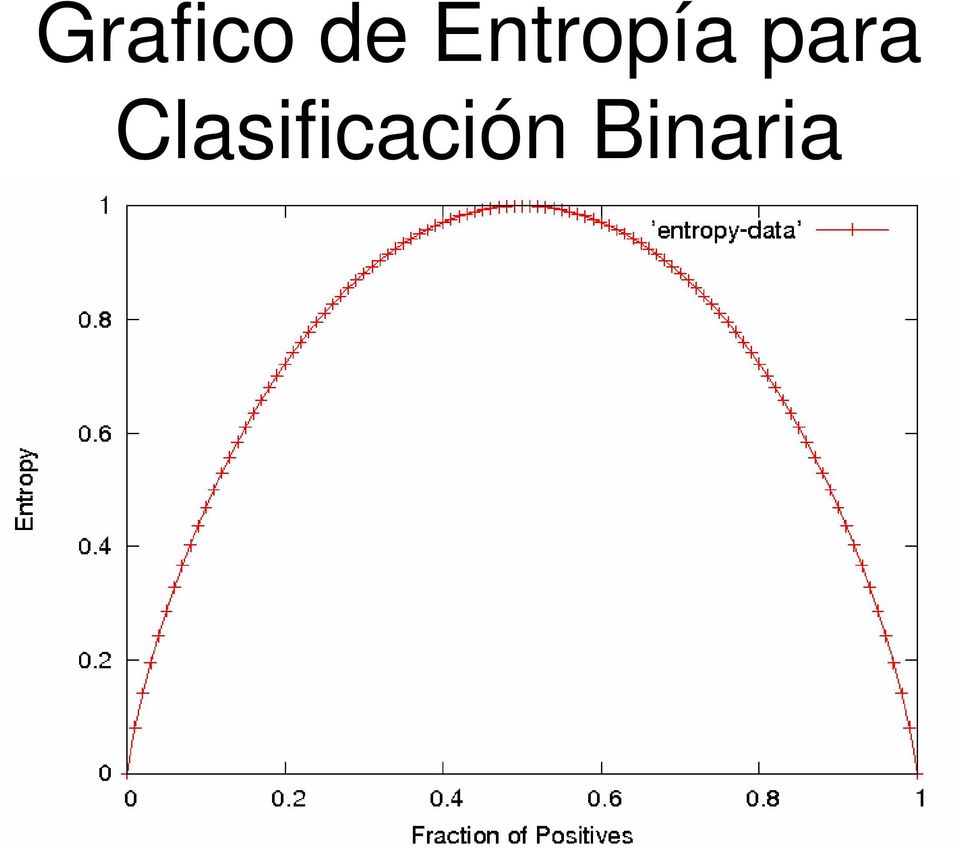
17 Entropía Entropía (incertidumbre, desorden, impureza) de un conjunto de ejemplos S, relativo a una clasificación binaria es: Entropy S ) = p log ( p ) p log ( ) ( p0 en el cual p 1 es la fracción de ejemplos positivos en S y p 0 es la fracción de negativos. Si todos los ejemplos están en una categoría, entropía es zero (definimos 0 log(0)=0) Si los ejemplos están igualmente mezclados (p 1 =p 0 =0.5), entropía es una máxima de 1. Entropía se puede ver como el máximo numero de bits requeridos en promedio para codificar la clase de un ejemplo en S. Para problemas de múltiples clases (multi-class) con c categorías, la entropía generaliza a: Entropy( S) = c i= 1 p i log ( p i 2 )

18 Grafico de Entropía para Clasificación Binaria
19 Incremento de la Información El incremento de información Gain(S, F) ocurre por reduccion en la entropia esperada al ordenar S basado en atributo F Sv Gain( S, F) = Entropy( S) Entropy( Sv ) S v Values ( F ) en el cual S v es el subconjunto de S que tiene el valor v para característica F. Entropía de cada subconjunto resultante se pondera por su tamaño relativo. Ejemplo: <big, red, circle>: + <small, red, circle>: + <small, red, square>: <big, blue, circle>: 2+, 2 : E=1 size 2+, 2 : E=1 color 2+, 2 : E=1 shape big small 1+,1 1+,1 E=1 E=1 Gain=1 ( ) = 0 red blue 2+,1 0+,1 E=0.918 E=0 Gain=1 ( ) = circle square 2+,1 0+,1 E=0.918 E=0 Gain=1 ( ) = 0.311

20 Ejemplo: Incremento de la Información Gain(S,A)=Entropy(S) - v values(a) S v / S Entropy(S v ) Entropy([29+,35-]) = -29/64 log 2 29/64 35/64 log 2 35/64 = 0.99 [29+,35-] A 1 =? A 2 =? [29+,35-] True False True False [21+, 5-] [8+, 30-] [18+, 33-] [11+, 2-]
![2 29/64 35/64 log 2 35/64 = 0.99 [29+,35-] A 1 =? A 2 =?](/docs-images/43/2484266/images/page_20.jpg "[29+,35-] True False True False [21+, 5-] [8+, 30-] [18+, 33-]")
21 Ejemplo: Incremento de la Cual atributo es mejor? Información [29+,35-] A 1 =? A 2 =? [29+,35-] True False True False [21+, 5-] [8+, 30-] [18+, 33-] [11+, 2-]
22 Ejemplo: Incremento de la Información Entropy([21+,5-]) = 0.71 Entropy([8+,30-]) = 0.74 Gain(S,A 1 )=Entropy(S) -26/64*Entropy([21+,5-]) -38/64*Entropy([8+,30-]) =0.27 Entropy([18+,33-]) = 0.94 Entropy([11+,2-]) = 0.62 Gain(S,A 2 )=Entropy(S) -51/64*Entropy([18+,33-]) -13/64*Entropy([11+,2-]) =0.12 [29+,35-] A 1 =? A 2 =? [29+,35-] True False True False [21+, 5-] [8+, 30-] [18+, 33-] [11+, 2-]
23 Ejemplo: Datos de Entrenamiento No Strong High Mild Rain D14 Weak Normal Hot Overcast D13 Strong High Mild Overcast D12 Strong Normal Mild Sunny D11 Strong Normal Mild Rain D10 Weak Normal Cold Sunny D9 No Weak High Mild Sunny D8 Weak Normal Cool Overcast D7 No Strong Normal Cool Rain D6 Weak Normal Cool Rain D5 Weak High Mild Rain D4 Weak High Hot Overcast D3 No Strong High Hot Sunny D2 No Weak High Hot Sunny D1 Play Tennis Wind Humidity Temp. Outlook Day
24 Ejemplo: Elejir Próximo Atributo S=[9+,5-] E=0.940 Humidity S=[9+,5-] E=0.940 Wind High Normal Weak Strong [3+, 4-] [6+, 1-] E=0.985 E=0.592 Gain(S, Humidity) = (7/14)*0.985 (7/14)*0.592 = [6+, 2-] [3+, 3-] E=0.811 E=1.0 Gain(S, Wind) =0.940-(8/14)*0.811 (6/14)*1.0 = 0.048
25 Ejemplo: Elejir Próximo Atributo S=[9+,5-] E=0.940 Outlook Sunny Over cast Rain [2+, 3-] [4+, 0] [3+, 2-] E=0.971 E=0.0 E=0.971 Gain(S, Outlook) = (5/14)* (4/14)*0.0 (5/14)* = 0.247
26 Ejemplo: Algoritmo ID3 [D1,D2,,D14] [9+,5-] Outlook Sunny Overcast Rain S sunny =[D1,D2,D8,D9,D11] [2+,3-] [D3,D7,D12,D13] [4+,0-]?? [D4,D5,D6,D10,D14] [3+,2-] Gain(S sunny, Humidity)=0.970-(3/5)0.0 2/5(0.0) = Gain(S sunny, Temp.)=0.970-(2/5)0.0 2/5(1.0)-(1/5)0.0 = Gain(S sunny, Wind)=0.970= -(2/5)1.0 3/5(0.918) = 0.019
27 Ejemplo: Algoritmo ID3 Outlook Sunny Overcast Rain Humidity [D3,D7,D12,D13] Wind High Normal Strong Weak No No [D1,D2] [D8,D9,D11] [D6,D14] [D4,D5,D10]
28 Búsqueda en Espacio de Hipótesis (H) de ID3 A A A2 A A A4
29 Búsqueda en Espacio de Hipótesis (H) de ID3 Búsqueda en espacio de hipótesis es completa! La función objetiva seguramente esta ahí Output es una hipótesis No hay vuelta atrás (backtracking) en los atributos seleccionados (búsqueda codiciosa) Mínima local (divisiones suboptimas) Selecciones de búsqueda estadística Robusto a ruidos en datos Preferencia de inducción (search bias) Prefiere árboles cortos que largos Pone atributos con alta ganancia de información cerca de la raíz
30 Búsqueda en Espacio de Hipótesis de ID3 Desarrolla aprendizaje en grupos (batch learning) que procesa todas las instancia de entrenamiento juntos en vez de aprendizaje incremental (incremental learning) que actualiza una hipótesis después de cada ejemplo. Garantizado de encontrar un árbol consistente con cualquier conjunto de entrenamiento libre de conflictos (i.e. vectores idénticos de características siempre asignados la misma clase), pero no necesariamente el árbol mas simple. Encuentra una hipótesis discreta.
31 Bias en Inducción de Árbol de Decisión Ganancia de información da una preferencia (bias) para árboles con profundidad mínima. El bias es una preferencia por algunas hipótesis (un bias de búsqueda) y no una restricción de hipótesis en el espacio H.
32 Ejemplo: Weka data> java weka.classifiers.trees.j48 -t contact-lenses.arff J48 pruned tree tear-prod-rate = reduced: none (12.0) tear-prod-rate = normal astigmatism = no: soft (6.0/1.0) astigmatism = yes spectacle-prescrip = myope: hard (3.0) spectacle-prescrip = hypermetrope: none (3.0/1.0) Number of Leaves : 4 Size of the tree : 7 Time taken to build model: 0.03 seconds Time taken to test model on training data: 0 seconds === Error on training data === Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % Total Number of Instances 24 === Confusion Matrix === a b c <-- classified as a = soft b = hard c = none === Stratified cross-validation === Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic 0.71 Mean absolute error 0.15 Root mean squared error Relative absolute error % Root relative squared error % Total Number of Instances 24 === Confusion Matrix === a b c <-- classified as a = soft b = hard c = none
33 Complejidad Computacional Peor caso construye un árbol completo en el cual cada camino en el árbol prueba cada característica. Asuma n ejemplos y m características. F 1 F m Máximo de n ejemplos esparcidos en todos los nodos de los m niveles En cada nivel, i, en el árbol, se debe examinar las m-i características que quedan para cada instancia en ese nivel para calcular las ganancias de información. m i= 1 i n = O( nm En la practica un árbol es raramente completo (numero de hojas es n) y la complejidad es lineal en m y n. 2 )
34 Árboles de Decisión Contenidos Árboles de Decisión Sobreajuste Recorte (Pruning)
35 Sobreajuste (Overfitting) Crear un árbol que clasifique todos los datos de entrenamiento perfectamente puede no llevarnos a un árbol con la mejor generalización a datos desconocidos. Puede haber error en los datos de entrenamiento que el árbol esta erróneamente ajustando. El algoritmo puede tomar malas decisiones cerca de las ramas basado en pocos datos que no reflejan tendencias confiables. Una hipótesis, h, se dice que sobreajusta (overfits) los datos de entrenamiento si es que existe otra hipótesis, h, la cual tiene más error que h en datos de entrenamiento pero menos error en datos independientes de prueba. on training data accuracy on test data hypothesis complexity
36 Ejemplo: Sobreajuste Probando la Ley de Ohm: V = IR (I = (1/R)V) Experimentalmente se miden 10 puntos Ajustar una curva a los datos resultantes current (I) voltage (V) Perfectamente se ajustan a los datos de entrenamiento con un polinomio de 9no grado (se pueden ajustar n puntos exactamente con un polinomio de grado n-1)
37 Ejemplo: Sobreajuste Probando la Ley de Ohm: V = IR (I = (1/R)V) current (I) voltage (V) Se mejora la generalización con una función lineal que se ajusta a los datos de entrenamiento con menor exactitud.
38 Sobreajuste de Ruido en Árboles de Decisión Ruido de características o categoría pueden causar sobreajuste: Agregar instancia (dato) ruidosa: <medium, blue, circle>: pos (pero realmente neg) color red green blue shape neg neg circle square triangle pos neg pos
39 Sobreajuste de Ruido en Árboles de Decisión Ruido de características o categoría pueden causar sobreajuste: Agregar instancia (dato) ruidosa: <medium, blue, circle>: pos (pero realmente neg) color red green blue shape neg circle square triangle small med pos neg pos neg <big, blue, circle>: <medium, blue, circle>: + Ruido también puede causar que diferentes instancias del mismo vector de característica tenga diferentes clases. Es imposible ajustar estos datos y se debe etiquetar la hoja con la clase de la mayoría. pos <big, red, circle>: neg (but really pos) Ejemplos conflictivos pueden surgir si es que las características son incompletas e inadecuadas. big neg
40 Árboles de Decisión Contenidos Árboles de Decisión Sobreajuste Recorte (Pruning)
41 Métodos de Prevención de Sobreajuste (Recorte o Pruning) Dos ideas básicas para árboles de decisión Prepruning: Parar de crecer el árbol en algún punto durante construcción top-down cuando no hay suficientes datos para toma de decisiones confiables. Postpruning: Crecer el árbol completo, entonces eliminar subarboles que no tengan suficiente evidencia. Etiquetar hoja que resulta de un recorte con la clase de la mayoría de los datos que quedan o con la distribución de probabilidades de la clase. Métodos para elegir subarboles a ser recortados: Validacion-cruzada: Reservar algunos datos de entrenamiento (validation set, tuning set) para evaluar utilidad de subarboles. Test estadístico: Usar un test estadístico en los datos de entrenamiento para determinar si alguna regularidad observada se puede eliminar por ser simplemente aleatoria. Minimum description length (MDL): Determinar si la complejidad adicional de la hipótesis es menos compleja que explícitamente recordar excepciones resultantes del recorte.
42 Reduced Error Pruning Un método basado en post-pruning y validación cruzada Partition training data in grow and validation sets. Build a complete tree from the grow data. Until accuracy on validation set decreases do: For each non-leaf node, n, in the tree do: Temporarily prune the subtree below n and replace it with a leaf labeled with the current majority class at that node. Measure and record the accuracy of the pruned tree on the validation set. Permanently prune the node that results in the greatest increase in accuracy on the validation set.
43 Problemas con Reduced Error Pruning El problema con este método es que potencialmente desperdicia datos de entrenamiento en el conjunto de validacion. Severidad de este problema depende de adonde estamos en la curva de aprendizaje: test accuracy number of training examples
44 Validación cruzada sin Perder Datos de Entrenamiento Se modifica el algoritmo de crecimiento para crecer al ancho primero y se para de crecer después de llegar a cierta complejidad especifica de un árbol. Requiere varias pruebas de diferentes recortes usando divisiones aleatorias de conjuntos de crecimiento y validación Se determina la complejidad del árbol y se calcula un promedio de complejidad C Se comienza crecer el árbol de todos los datos de entrenamiento pero se detiene cuando la complejidad llega a C.
45 Otras ideas en Árboles de Decisión Mejores criterios de división Ganancia de información prefiere características con muchos valores. Características continuas Predicción de funciones de valores reales (árboles de regresión) Características con costos Costos de misclasificación Aprendizaje incremental ID4 ID5 Grandes bases de datos que no caben en memoria Aplicaciones híbridas (i.e. robótica, reconocimiento patrones, )
46 Árboles de Decisión Referencias: [1] Mitchel, T., Machine Learning, McGraw Hill, 1997 [2] Karray, F., De Silva, C., Soft Computing and Intelligent Systems Design, Addison Wesley, 2004 [3] Mooney, R., Machine Learning Slides, University of Texas [4] Hoffman, F., Machine Learning Slides, Stockholm University
Práctica 1: Entorno WEKA de aprendizaje automático y data mining.
 PROGRAMA DE DOCTORADO TECNOLOGÍAS INDUSTRIALES APLICACIONES DE LA INTELIGENCIA ARTIFICIAL EN ROBÓTICA Práctica 1: Entorno WEKA de aprendizaje automático y data mining. Objetivos: Utilización de funciones
PROGRAMA DE DOCTORADO TECNOLOGÍAS INDUSTRIALES APLICACIONES DE LA INTELIGENCIA ARTIFICIAL EN ROBÓTICA Práctica 1: Entorno WEKA de aprendizaje automático y data mining. Objetivos: Utilización de funciones
Cómo se usa Data Mining hoy?
 Cómo se usa Data Mining hoy? 1 Conocer a los clientes Detectar segmentos Calcular perfiles Cross-selling Detectar buenos clientes Evitar el churning, attrition Detección de morosidad Mejora de respuesta
Cómo se usa Data Mining hoy? 1 Conocer a los clientes Detectar segmentos Calcular perfiles Cross-selling Detectar buenos clientes Evitar el churning, attrition Detección de morosidad Mejora de respuesta
PREPROCESADO DE DATOS PARA MINERIA DE DATOS
 Ó 10.1007/978-3-319-02738-8-2. PREPROCESADO DE DATOS PARA MINERIA DE DATOS Miguel Cárdenas-Montes Frecuentemente las actividades de minería de datos suelen prestar poca atención a las actividades de procesado
Ó 10.1007/978-3-319-02738-8-2. PREPROCESADO DE DATOS PARA MINERIA DE DATOS Miguel Cárdenas-Montes Frecuentemente las actividades de minería de datos suelen prestar poca atención a las actividades de procesado
Aprendizaje automático mediante árboles de decisión
 Aprendizaje automático mediante árboles de decisión Aprendizaje por inducción Los árboles de decisión son uno de los métodos de aprendizaje inductivo más usado. Hipótesis de aprendizaje inductivo: cualquier
Aprendizaje automático mediante árboles de decisión Aprendizaje por inducción Los árboles de decisión son uno de los métodos de aprendizaje inductivo más usado. Hipótesis de aprendizaje inductivo: cualquier
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Programación Genética
 Programación Genética Programación Genética consiste en la evolución automática de programas usando ideas basadas en la selección natural (Darwin). No sólo se ha utilizado para generar programas, sino
Programación Genética Programación Genética consiste en la evolución automática de programas usando ideas basadas en la selección natural (Darwin). No sólo se ha utilizado para generar programas, sino
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Capítulo 12: Indexación y asociación
 Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Introducción a selección de. Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012
 Introducción a selección de atributos usando WEKA Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012 Contenido 1 Introducción a WEKA El origen Interfaces
Introducción a selección de atributos usando WEKA Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012 Contenido 1 Introducción a WEKA El origen Interfaces
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Validation. Validación Psicométrica. Validation. Central Test. Central Test. Centraltest CENTRAL. L art de l évaluation. El arte de la evaluación
 Validation Validación Psicométrica L art de l évaluation Validation Central Test Central Test Centraltest L art de l évaluation CENTRAL test.com El arte de la evaluación www.centraltest.com Propiedades
Validation Validación Psicométrica L art de l évaluation Validation Central Test Central Test Centraltest L art de l évaluation CENTRAL test.com El arte de la evaluación www.centraltest.com Propiedades
Minería de Datos. Preprocesamiento: Reducción de Datos - Discretización
 Minería de Datos Preprocesamiento: Reducción de Datos - Discretización Dr. Edgar Acuña Departamento de Ciencias Matemáticas Universidad de Puerto Rico-Mayaguez E-mail: edgar.acuna@upr.edu, eacunaf@gmail.com
Minería de Datos Preprocesamiento: Reducción de Datos - Discretización Dr. Edgar Acuña Departamento de Ciencias Matemáticas Universidad de Puerto Rico-Mayaguez E-mail: edgar.acuna@upr.edu, eacunaf@gmail.com
3. Árboles de decisión
 3.1 Introducción Método para aproximación de funciones objetivo que tengan valores discretos (clasificación) Uno de los métodos mas extensamente usados para inferencia inductiva Capaz de aprender hipótesis
3.1 Introducción Método para aproximación de funciones objetivo que tengan valores discretos (clasificación) Uno de los métodos mas extensamente usados para inferencia inductiva Capaz de aprender hipótesis
Ingeniería del Software I Clase de Testing Funcional 2do. Cuatrimestre de 2007
 Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
Aprendizaje Basado en Similaridades (SBL) Árboles de Decisión (TDIDT) (INAOE) 1 / 65. Algoritmo ID3 Cómo le hace
 Árboles de Decisión (TDIDT) (INAOE) 1 / 65. Algoritmo ID3 Cómo le hace") INAOE (INAOE) 1 / 65 Contenido 1 2 (INAOE) 2 / 65 SBL Atributos Peludo? Edad? Tamaño? Clase si viejo grande león no joven grande no león si joven mediano león si viejo pequeño no león si joven pequeño
INAOE (INAOE) 1 / 65 Contenido 1 2 (INAOE) 2 / 65 SBL Atributos Peludo? Edad? Tamaño? Clase si viejo grande león no joven grande no león si joven mediano león si viejo pequeño no león si joven pequeño
Evaluando las Hipótesis Inductivas. Tomás Arredondo Vidal 8/9/2011
 Evaluando las Hipótesis Inductivas Tomás Arredondo Vidal 8/9/2011 Evaluando las Hipótesis Inductivas Contenidos Estimando la Precisión Comparando Hipótesis Comparando Algoritmos de Clasificación Evaluando
Evaluando las Hipótesis Inductivas Tomás Arredondo Vidal 8/9/2011 Evaluando las Hipótesis Inductivas Contenidos Estimando la Precisión Comparando Hipótesis Comparando Algoritmos de Clasificación Evaluando
CAPITULO 4 JUSTIFICACION DEL ESTUDIO. En este capítulo se presenta la justificación del estudio, supuestos y limitaciones de
 CAPITULO 4 JUSTIFICACION DEL ESTUDIO En este capítulo se presenta la justificación del estudio, supuestos y limitaciones de estudios previos y los alcances que justifican el presente estudio. 4.1. Justificación.
CAPITULO 4 JUSTIFICACION DEL ESTUDIO En este capítulo se presenta la justificación del estudio, supuestos y limitaciones de estudios previos y los alcances que justifican el presente estudio. 4.1. Justificación.
ESTIMACIÓN. puntual y por intervalo
 ESTIMACIÓN puntual y por intervalo ( ) Podemos conocer el comportamiento del ser humano? Podemos usar la información contenida en la muestra para tratar de adivinar algún aspecto de la población bajo estudio
ESTIMACIÓN puntual y por intervalo ( ) Podemos conocer el comportamiento del ser humano? Podemos usar la información contenida en la muestra para tratar de adivinar algún aspecto de la población bajo estudio
5.4. Manual de usuario
 5.4. Manual de usuario En esta sección se procederá a explicar cada una de las posibles acciones que puede realizar un usuario, de forma que pueda utilizar todas las funcionalidades del simulador, sin
5.4. Manual de usuario En esta sección se procederá a explicar cada una de las posibles acciones que puede realizar un usuario, de forma que pueda utilizar todas las funcionalidades del simulador, sin
ANÁLISIS DE DATOS NO NUMERICOS
 ANÁLISIS DE DATOS NO NUMERICOS ESCALAS DE MEDIDA CATEGORICAS Jorge Galbiati Riesco Los datos categóricos son datos que provienen de resultados de experimentos en que sus resultados se miden en escalas
ANÁLISIS DE DATOS NO NUMERICOS ESCALAS DE MEDIDA CATEGORICAS Jorge Galbiati Riesco Los datos categóricos son datos que provienen de resultados de experimentos en que sus resultados se miden en escalas
Análisis de Datos. Práctica de métodos predicción de en WEKA
 SOLUCION 1. Características de los datos y filtros Una vez cargados los datos, aparece un cuadro resumen, Current relation, con el nombre de la relación que se indica en el fichero (en la línea @relation
SOLUCION 1. Características de los datos y filtros Una vez cargados los datos, aparece un cuadro resumen, Current relation, con el nombre de la relación que se indica en el fichero (en la línea @relation
Introducción. Requisitos modelo C4.5. Introducción. Introducción. Requisitos modelo C4.5. Introducción. Capítulo 4: Inducción de árboles de decisión
 Capítulo 4: Inducción de árboles de decisión Introducción al Diseño de Experimentos para el Reconocimiento de Patrones Capítulo 4: Inducción de árboles de decisión Curso de doctorado impartido por Dr.
Capítulo 4: Inducción de árboles de decisión Introducción al Diseño de Experimentos para el Reconocimiento de Patrones Capítulo 4: Inducción de árboles de decisión Curso de doctorado impartido por Dr.
Práctica 11 SVM. Máquinas de Vectores Soporte
 Práctica 11 SVM Máquinas de Vectores Soporte Dedicaremos esta práctica a estudiar el funcionamiento de las, tan de moda, máquinas de vectores soporte (SVM). 1 Las máquinas de vectores soporte Las SVM han
Práctica 11 SVM Máquinas de Vectores Soporte Dedicaremos esta práctica a estudiar el funcionamiento de las, tan de moda, máquinas de vectores soporte (SVM). 1 Las máquinas de vectores soporte Las SVM han
Evaluación de modelos para la predicción de la Bolsa
 Evaluación de modelos para la predicción de la Bolsa Humberto Hernandez Ansorena Departamento de Ingeniería Telemática Universidad Carlos III de Madrid Madrid, España 10003975@alumnos.uc3m.es Rico Hario
Evaluación de modelos para la predicción de la Bolsa Humberto Hernandez Ansorena Departamento de Ingeniería Telemática Universidad Carlos III de Madrid Madrid, España 10003975@alumnos.uc3m.es Rico Hario
Árboles. Cursos Propedéuticos 2015. Dr. René Cumplido M. en C. Luis Rodríguez Flores
 Árboles Cursos Propedéuticos 2015 Dr. René Cumplido M. en C. Luis Rodríguez Flores Contenido de la sección Introducción Árbol genérico Definición y representación Árboles binarios Definición, implementación,
Árboles Cursos Propedéuticos 2015 Dr. René Cumplido M. en C. Luis Rodríguez Flores Contenido de la sección Introducción Árbol genérico Definición y representación Árboles binarios Definición, implementación,
GRÁFICAS DE CONTROL DE LA CALIDAD EMPLEANDO EXCEL Y WINSTATS
 GRÁFICAS DE CONTROL DE LA CALIDAD EMPLEANDO EXCEL Y WINSTATS 1) INTRODUCCIÓN Tanto la administración de calidad como la administración Seis Sigma utilizan una gran colección de herramientas estadísticas.
GRÁFICAS DE CONTROL DE LA CALIDAD EMPLEANDO EXCEL Y WINSTATS 1) INTRODUCCIÓN Tanto la administración de calidad como la administración Seis Sigma utilizan una gran colección de herramientas estadísticas.
1 1 0 1 x 1 0 1 1 1 1 0 1 + 1 1 0 1 0 0 0 0 1 1 0 1 1 0 0 0 1 1 1 1
 5.1.3 Multiplicación de números enteros. El algoritmo de la multiplicación tal y como se realizaría manualmente con operandos positivos de cuatro bits es el siguiente: 1 1 0 1 x 1 0 1 1 1 1 0 1 + 1 1 0
5.1.3 Multiplicación de números enteros. El algoritmo de la multiplicación tal y como se realizaría manualmente con operandos positivos de cuatro bits es el siguiente: 1 1 0 1 x 1 0 1 1 1 1 0 1 + 1 1 0
CAPÍTULO 4: ALGORITMOS DE APRENDIZAJE
 Capítulo 4 Algoritmos de Aprendizaje 26 CAPÍTULO 4: ALGORITMOS DE APRENDIZAJE En este capítulo se proporcionan las descripciones matemáticas de los principales algoritmos de aprendizaje para redes neuronales:
Capítulo 4 Algoritmos de Aprendizaje 26 CAPÍTULO 4: ALGORITMOS DE APRENDIZAJE En este capítulo se proporcionan las descripciones matemáticas de los principales algoritmos de aprendizaje para redes neuronales:
Capítulo V Operaciones Booleanas
 85 Capítulo V Operaciones Booleanas 5.1 Introducción Es muy posible que en muchos casos sea necesario comparar dos objetos y determinar cuál es su parte común. Esto implica intersectar los dos objetos
85 Capítulo V Operaciones Booleanas 5.1 Introducción Es muy posible que en muchos casos sea necesario comparar dos objetos y determinar cuál es su parte común. Esto implica intersectar los dos objetos
Aprendizaje Automático y Data Mining. Bloque IV DATA MINING
 Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
Generalización como búsqueda. El problema de aprendizaje por generalización puede verse como un problema de búsqueda:
 Generalización como búsqueda El problema de aprendizaje por generalización puede verse como un problema de búsqueda: El lenguaje de generalización corresponde a un espacio de hipótesis (espacio de búsqueda)
Generalización como búsqueda El problema de aprendizaje por generalización puede verse como un problema de búsqueda: El lenguaje de generalización corresponde a un espacio de hipótesis (espacio de búsqueda)
Administración de Empresas. 11 Métodos dinámicos de evaluación de inversiones 11.1
 Administración de Empresas. 11 Métodos dinámicos de evaluación de inversiones 11.1 TEMA 11: MÉTODOS DINÁMICOS DE SELECCIÓN DE INVERSIONES ESQUEMA DEL TEMA: 11.1. Valor actualizado neto. 11.2. Tasa interna
Administración de Empresas. 11 Métodos dinámicos de evaluación de inversiones 11.1 TEMA 11: MÉTODOS DINÁMICOS DE SELECCIÓN DE INVERSIONES ESQUEMA DEL TEMA: 11.1. Valor actualizado neto. 11.2. Tasa interna
Minería de Datos Web. 1 er Cuatrimestre 2015. Página Web. Prof. Dra. Daniela Godoy. http://www.exa.unicen.edu.ar/catedras/ageinweb/
 Minería de Datos Web 1 er Cuatrimestre 2015 Página Web http://www.exa.unicen.edu.ar/catedras/ageinweb/ Prof. Dra. Daniela Godoy ISISTAN Research Institute UNICEN University Tandil, Bs. As., Argentina http://www.exa.unicen.edu.ar/~dgodoy
Minería de Datos Web 1 er Cuatrimestre 2015 Página Web http://www.exa.unicen.edu.ar/catedras/ageinweb/ Prof. Dra. Daniela Godoy ISISTAN Research Institute UNICEN University Tandil, Bs. As., Argentina http://www.exa.unicen.edu.ar/~dgodoy
1.1. Introducción y conceptos básicos
 Tema 1 Variables estadísticas Contenido 1.1. Introducción y conceptos básicos.................. 1 1.2. Tipos de variables estadísticas................... 2 1.3. Distribuciones de frecuencias....................
Tema 1 Variables estadísticas Contenido 1.1. Introducción y conceptos básicos.................. 1 1.2. Tipos de variables estadísticas................... 2 1.3. Distribuciones de frecuencias....................
Clase 32: Árbol balanceado AVL
 Clase 32: Árbol balanceado AVL http://computacion.cs.cinvestav.mx/~efranco @efranco_escom efranco.docencia@gmail.com (Prof. Edgardo A. Franco) 1 Contenido Problema de los árboles binarios de búsqueda Variantes
Clase 32: Árbol balanceado AVL http://computacion.cs.cinvestav.mx/~efranco @efranco_escom efranco.docencia@gmail.com (Prof. Edgardo A. Franco) 1 Contenido Problema de los árboles binarios de búsqueda Variantes
Capítulo 1 Documentos HTML5
 Capítulo 1 Documentos HTML5 1.1 Componentes básicos HTML5 provee básicamente tres características: estructura, estilo y funcionalidad. Nunca fue declarado oficialmente pero, incluso cuando algunas APIs
Capítulo 1 Documentos HTML5 1.1 Componentes básicos HTML5 provee básicamente tres características: estructura, estilo y funcionalidad. Nunca fue declarado oficialmente pero, incluso cuando algunas APIs
Ampliación de Estructuras de Datos
 Ampliación de Estructuras de Datos Amalia Duch Barcelona, marzo de 2007 Índice 1. Diccionarios implementados con árboles binarios de búsqueda 1 2. TAD Cola de Prioridad 4 3. Heapsort 8 1. Diccionarios
Ampliación de Estructuras de Datos Amalia Duch Barcelona, marzo de 2007 Índice 1. Diccionarios implementados con árboles binarios de búsqueda 1 2. TAD Cola de Prioridad 4 3. Heapsort 8 1. Diccionarios
Introducción a la Programación 11 O. Humberto Cervantes Maceda
 Introducción a la Programación 11 O Humberto Cervantes Maceda Recordando En la sesión anterior vimos que la información almacenada en la memoria, y por lo tanto aquella que procesa la unidad central de
Introducción a la Programación 11 O Humberto Cervantes Maceda Recordando En la sesión anterior vimos que la información almacenada en la memoria, y por lo tanto aquella que procesa la unidad central de
Ingeniería en Informática
 Departamento de Informática Universidad Carlos III de Madrid Ingeniería en Informática Aprendizaje Automático Junio 2007 Normas generales del examen El tiempo para realizar el examen es de 3 horas No se
Departamento de Informática Universidad Carlos III de Madrid Ingeniería en Informática Aprendizaje Automático Junio 2007 Normas generales del examen El tiempo para realizar el examen es de 3 horas No se
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología
 Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
La NIC 32 acompaña a la NIC 39, instrumentos financieros: reconocimiento y medición.
 Como clausura del Quinto Curso de la Normas Internacionales de Información Financiera a través de fundación CEDDET y el IIMV, se realizó del 30 de octubre al 1 de noviembre de 2012, en Montevideo Uruguay,
Como clausura del Quinto Curso de la Normas Internacionales de Información Financiera a través de fundación CEDDET y el IIMV, se realizó del 30 de octubre al 1 de noviembre de 2012, en Montevideo Uruguay,
Manejo de versiones 392
 Manejo de versiones 392 El desarrollo de software es un trabajo en equipo y cierto grado de confusión es inevitable. No puedo reproducir el error en esta versión! Qué pasó con el arreglo de la semana pasada?
Manejo de versiones 392 El desarrollo de software es un trabajo en equipo y cierto grado de confusión es inevitable. No puedo reproducir el error en esta versión! Qué pasó con el arreglo de la semana pasada?
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos. - Sesión 9 -
 Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 9 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Qué es un modelo de Data Mining Qué es
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 9 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Qué es un modelo de Data Mining Qué es
Determinación de primas de acuerdo al Apetito de riesgo de la Compañía por medio de simulaciones
 Determinación de primas de acuerdo al Apetito de riesgo de la Compañía por medio de simulaciones Introducción Las Compañías aseguradoras determinan sus precios basadas en modelos y en información histórica
Determinación de primas de acuerdo al Apetito de riesgo de la Compañía por medio de simulaciones Introducción Las Compañías aseguradoras determinan sus precios basadas en modelos y en información histórica
Inducción de árboles de decisión. Qué son los árboles de decisión? Tipos de problemas abordables. Ejemplo de árbol de decisión 2
 1 Datamining y Aprendizaje Automatizado 05 Arboles de Decisión Prof. Carlos Iván Chesñevar Departamento de Cs. e Ing. de la Computación Universidad Nacional del Sur Email: cic@cs.uns.edu.ar / Http:\\cs.uns.edu.ar\~cic
1 Datamining y Aprendizaje Automatizado 05 Arboles de Decisión Prof. Carlos Iván Chesñevar Departamento de Cs. e Ing. de la Computación Universidad Nacional del Sur Email: cic@cs.uns.edu.ar / Http:\\cs.uns.edu.ar\~cic
7. Conclusiones. 7.1 Resultados
 7. Conclusiones Una de las preguntas iniciales de este proyecto fue : Cuál es la importancia de resolver problemas NP-Completos?. Puede concluirse que el PAV como problema NP- Completo permite comprobar
7. Conclusiones Una de las preguntas iniciales de este proyecto fue : Cuál es la importancia de resolver problemas NP-Completos?. Puede concluirse que el PAV como problema NP- Completo permite comprobar
DISEÑOS DE INVESTIGACIÓN
 DISEÑOS DE INVESTIGACIÓN María a Eugenia Mackey Estadística stica Centro Rosarino de Estudios Perinatales El diseño de un estudio es la estrategia o plan utilizado para responder una pregunta, y es la
DISEÑOS DE INVESTIGACIÓN María a Eugenia Mackey Estadística stica Centro Rosarino de Estudios Perinatales El diseño de un estudio es la estrategia o plan utilizado para responder una pregunta, y es la
IDENTIFICACIÓN DE SISTEMAS ASPECTOS PRÁCTICOS EN IDENTIFICACIÓN
 IDENTIFICACIÓN DE SISTEMAS ASPECTOS PRÁCTICOS EN IDENTIFICACIÓN Ing. Fredy Ruiz Ph.D. ruizf@javeriana.edu.co Maestría en Ingeniería Electrónica Pontificia Universidad Javeriana 2013 CONSIDERACIONES PRÁCTICAS
IDENTIFICACIÓN DE SISTEMAS ASPECTOS PRÁCTICOS EN IDENTIFICACIÓN Ing. Fredy Ruiz Ph.D. ruizf@javeriana.edu.co Maestría en Ingeniería Electrónica Pontificia Universidad Javeriana 2013 CONSIDERACIONES PRÁCTICAS
Tutorial: Uso básico de RapidMiner Parte II: Predicción de variables categóricas
 Tutorial: Uso básico de RapidMiner Parte II: Predicción de variables categóricas En esta segunda parte del tutorial, se presentará un ejemplo que enseñe cómo predecir una variable categórica. Es altamente
Tutorial: Uso básico de RapidMiner Parte II: Predicción de variables categóricas En esta segunda parte del tutorial, se presentará un ejemplo que enseñe cómo predecir una variable categórica. Es altamente
Base de datos II Facultad de Ingeniería. Escuela de computación.
 Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Guía de Preparación de Muestras para PLASTICOS para el Software de Formulación de Datacolor
 Guía de Preparación de Muestras para PLASTICOS para el Software de Formulación de Datacolor 1. Generalidades 2. Qué se necesita para comenzar? 3. Qué hacer para sistemas opacos y translúcidos? 4. Qué hacer
Guía de Preparación de Muestras para PLASTICOS para el Software de Formulación de Datacolor 1. Generalidades 2. Qué se necesita para comenzar? 3. Qué hacer para sistemas opacos y translúcidos? 4. Qué hacer
PUEDE MEDIRSE EL PODER DE VENTAS DE LOS ANUNCIOS BASADOS EN UN MENSAJE DE VENTA EMOCIONAL?
 El Uso Efectivo de las Emociones en Publicidad The ARS Group Debido a que las emociones pueden ser una poderosa fuerza de impulso en el comportamiento humano, los mercadólogos han incorporado, desde hace
El Uso Efectivo de las Emociones en Publicidad The ARS Group Debido a que las emociones pueden ser una poderosa fuerza de impulso en el comportamiento humano, los mercadólogos han incorporado, desde hace
Técnicas de valor presente para calcular el valor en uso
 Normas Internacionales de Información Financiera NIC - NIIF Guía NIC - NIIF NIC 36 Fundación NIC-NIIF Técnicas de valor presente para calcular el valor en uso Este documento proporciona una guía para utilizar
Normas Internacionales de Información Financiera NIC - NIIF Guía NIC - NIIF NIC 36 Fundación NIC-NIIF Técnicas de valor presente para calcular el valor en uso Este documento proporciona una guía para utilizar
Qué son los árboles de decisión? Inducción de árboles de decisión. Tipos de problemas abordables. Ejemplo: árbol de decisión 1
 Inducción de árboles de decisión Qué son los árboles de decisión? Cómo pueden inducirse automáticamente? inducción topdown de árboles de decisión cómo evitar el overfitting cómo convertir árboles en reglas
Inducción de árboles de decisión Qué son los árboles de decisión? Cómo pueden inducirse automáticamente? inducción topdown de árboles de decisión cómo evitar el overfitting cómo convertir árboles en reglas
Versión final 8 de junio de 2009
 GRUPO DE EXPERTOS «PLATAFORMA PARA LA CONSERVACIÓN DE DATOS ELECTRÓNICOS PARA CON FINES DE INVESTIGACIÓN, DETECCIÓN Y ENJUICIAMIENTO DE DELITOS GRAVES» ESTABLECIDO POR LA DECISIÓN 2008/324/CE DE LA COMISIÓN
GRUPO DE EXPERTOS «PLATAFORMA PARA LA CONSERVACIÓN DE DATOS ELECTRÓNICOS PARA CON FINES DE INVESTIGACIÓN, DETECCIÓN Y ENJUICIAMIENTO DE DELITOS GRAVES» ESTABLECIDO POR LA DECISIÓN 2008/324/CE DE LA COMISIÓN
ANÁLISIS DINÁMICO DEL RIESGO DE UN PROYECTO
 ANÁLISIS DINÁMICO DEL RIESGO DE UN PROYECTO Por: Pablo Lledó Master of Science en Evaluación de Proyectos (University of York) Project Management Professional (PMP) Profesor de Project Management y Evaluación
ANÁLISIS DINÁMICO DEL RIESGO DE UN PROYECTO Por: Pablo Lledó Master of Science en Evaluación de Proyectos (University of York) Project Management Professional (PMP) Profesor de Project Management y Evaluación
Árboles binarios de búsqueda ( BST )
") Árboles binarios de búsqueda ( BST ) mat-151 Alonso Ramírez Manzanares Computación y Algoritmos 24.04.2015 Arbol Binario de Búsqueda Un árbol binario de búsqueda (Binary Search Tree [BST]) es un árbol
Árboles binarios de búsqueda ( BST ) mat-151 Alonso Ramírez Manzanares Computación y Algoritmos 24.04.2015 Arbol Binario de Búsqueda Un árbol binario de búsqueda (Binary Search Tree [BST]) es un árbol
Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones.
 Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones. 2.1 Revisión sistema reconocimiento caracteres [9]: Un sistema de reconocimiento típicamente esta conformado por
Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones. 2.1 Revisión sistema reconocimiento caracteres [9]: Un sistema de reconocimiento típicamente esta conformado por
Capítulo 6. ÁRBOLES.
 67 Capítulo 6. ÁRBOLES. 6.1 Árboles binarios. Un árbol binario es un conjunto finito de elementos, el cual está vacío o dividido en tres subconjuntos separados: El primer subconjunto contiene un elemento
67 Capítulo 6. ÁRBOLES. 6.1 Árboles binarios. Un árbol binario es un conjunto finito de elementos, el cual está vacío o dividido en tres subconjuntos separados: El primer subconjunto contiene un elemento
MÁQUINA DE VECTORES DE SOPORTE
 MÁQUINA DE VECTORES DE SOPORTE La teoría de las (SVM por su nombre en inglés Support Vector Machine) fue desarrollada por Vapnik basado en la idea de minimización del riesgo estructural (SRM). Algunas
MÁQUINA DE VECTORES DE SOPORTE La teoría de las (SVM por su nombre en inglés Support Vector Machine) fue desarrollada por Vapnik basado en la idea de minimización del riesgo estructural (SRM). Algunas
TEMA 2: Representación de la Información en las computadoras
 TEMA 2: Representación de la Información en las computadoras Introducción Una computadora es una máquina que procesa información y ejecuta programas. Para que la computadora ejecute un programa, es necesario
TEMA 2: Representación de la Información en las computadoras Introducción Una computadora es una máquina que procesa información y ejecuta programas. Para que la computadora ejecute un programa, es necesario
CORRELACIÓN Y PREDICIÓN
 CORRELACIÓN Y PREDICIÓN 1. Introducción 2. Curvas de regresión 3. Concepto de correlación 4. Regresión lineal 5. Regresión múltiple INTRODUCCIÓN: Muy a menudo se encuentra en la práctica que existe una
CORRELACIÓN Y PREDICIÓN 1. Introducción 2. Curvas de regresión 3. Concepto de correlación 4. Regresión lineal 5. Regresión múltiple INTRODUCCIÓN: Muy a menudo se encuentra en la práctica que existe una
Covarianza y coeficiente de correlación
 Covarianza y coeficiente de correlación Cuando analizábamos las variables unidimensionales considerábamos, entre otras medidas importantes, la media y la varianza. Ahora hemos visto que estas medidas también
Covarianza y coeficiente de correlación Cuando analizábamos las variables unidimensionales considerábamos, entre otras medidas importantes, la media y la varianza. Ahora hemos visto que estas medidas también
ELO211: Sistemas Digitales. Tomás Arredondo Vidal 1er Semestre 2009
 ELO211: Sistemas Digitales Tomás Arredondo Vidal 1er Semestre 2009 Este material está basado en: textos y material de apoyo: Contemporary Logic Design 1 st / 2 nd edition. Gaetano Borriello and Randy Katz.
ELO211: Sistemas Digitales Tomás Arredondo Vidal 1er Semestre 2009 Este material está basado en: textos y material de apoyo: Contemporary Logic Design 1 st / 2 nd edition. Gaetano Borriello and Randy Katz.
Diagrama de Flujo (Flow Chart)
") Sociedad Latinoamericana para la Calidad Diagrama de Flujo (Flow Chart) Definir Medir Analizar Mejorar Controlar Creatividad Reunión de Datos Análisis de Datos Toma de Decisión Planeación Trabajo en Equipo
Sociedad Latinoamericana para la Calidad Diagrama de Flujo (Flow Chart) Definir Medir Analizar Mejorar Controlar Creatividad Reunión de Datos Análisis de Datos Toma de Decisión Planeación Trabajo en Equipo
3. Selección y Extracción de características. Selección: Extracción: -PCA -NMF
 3. Selección y Extracción de características Selección: - óptimos y subóptimos Extracción: -PCA - LDA - ICA -NMF 1 Selección de Características Objetivo: Seleccionar un conjunto de p variables a partir
3. Selección y Extracción de características Selección: - óptimos y subóptimos Extracción: -PCA - LDA - ICA -NMF 1 Selección de Características Objetivo: Seleccionar un conjunto de p variables a partir
EJEMPLO. Práctica de clustering
 Práctica de clustering Preparación de los ficheros binarios Para operar los ficheros binarios se ha utilizado una aplicación en Delphi que permite montar los ficheros ".arff" que usa Weka. La aplicación
Práctica de clustering Preparación de los ficheros binarios Para operar los ficheros binarios se ha utilizado una aplicación en Delphi que permite montar los ficheros ".arff" que usa Weka. La aplicación
Universidad Diego Portales Facultad de Economía y Empresa. 1. Reputación. Apuntes de Teoría de Juegos Profesor: Carlos R. Pitta
 En estas notas revisaremos los conceptos de reputación desde la perspectiva de información incompleta. Para ello usaremos el juego del ciempiés. Además, introduciremos los conceptos de juegos de señales,
En estas notas revisaremos los conceptos de reputación desde la perspectiva de información incompleta. Para ello usaremos el juego del ciempiés. Además, introduciremos los conceptos de juegos de señales,
Lección 1-Introducción a los Polinomios y Suma y Resta de Polinomios. Dra. Noemí L. Ruiz Limardo 2009
 Lección 1-Introducción a los Polinomios y Suma y Resta de Polinomios Dra. Noemí L. Ruiz Limardo 2009 Objetivos de la Lección Al finalizar esta lección los estudiantes: Identificarán, de una lista de expresiones
Lección 1-Introducción a los Polinomios y Suma y Resta de Polinomios Dra. Noemí L. Ruiz Limardo 2009 Objetivos de la Lección Al finalizar esta lección los estudiantes: Identificarán, de una lista de expresiones
Random Forests. Felipe Parra
 Applied Mathematics Random Forests Abril 2014 Felipe Parra Por que Arboles para Clasificación PERFIL DE RIESGO: definir con qué nivel de aversión al riesgo se toman decisiones Interpretación intuitiva
Applied Mathematics Random Forests Abril 2014 Felipe Parra Por que Arboles para Clasificación PERFIL DE RIESGO: definir con qué nivel de aversión al riesgo se toman decisiones Interpretación intuitiva
Árboles de decisión en aprendizaje automático y minería de datos
 Árboles de decisión en aprendizaje automático y minería de datos Tratamiento Inteligente de la Información y Aplicaciones Juan A. Botía Departamento de Ingeniería de la Información y las Comunicaciones
Árboles de decisión en aprendizaje automático y minería de datos Tratamiento Inteligente de la Información y Aplicaciones Juan A. Botía Departamento de Ingeniería de la Información y las Comunicaciones
342 SOBRE FORMAS TERNARIAS DE SEGUNDO GRADO.
 342 SOBRE FORMAS TERNARIAS DE SEGUNDO GRADO. ALGUNAS APLICACIONES A LA TEORIA DE LAS FORMAS BINARIAS. Encontrar una forma cuya duplicación produce una forma dada del género principal. Puesto que los elementos
342 SOBRE FORMAS TERNARIAS DE SEGUNDO GRADO. ALGUNAS APLICACIONES A LA TEORIA DE LAS FORMAS BINARIAS. Encontrar una forma cuya duplicación produce una forma dada del género principal. Puesto que los elementos
Modelado y simulación de proyecto
 Modelado y simulación de proyecto El objetivo de este caso es practicarse en las técnicas de Análisis Cuantitativo de Riesgos y de Modelado, para lo cual se utilizará el software @RISK for Project, el
Modelado y simulación de proyecto El objetivo de este caso es practicarse en las técnicas de Análisis Cuantitativo de Riesgos y de Modelado, para lo cual se utilizará el software @RISK for Project, el
DEFINICION. Ing. M.Sc. Fulbia Torres Asignatura: Estructuras de Datos Barquisimeto 2006
 ARBOLES ESTRUCTURAS DE DATOS 2006 DEFINICION Un árbol (tree) es un conjunto finito de nodos. Es una estructura jerárquica aplicable sobre una colección de elementos u objetos llamados nodos; uno de los
ARBOLES ESTRUCTURAS DE DATOS 2006 DEFINICION Un árbol (tree) es un conjunto finito de nodos. Es una estructura jerárquica aplicable sobre una colección de elementos u objetos llamados nodos; uno de los
ESTADÍSTICA APLICADA A LA INVESTIGACIÓN EN SALUD Medidas de Tendencia Central y Dispersión
 Descargado desde www.medwave.cl el 13 Junio 2011 por iriabeth villanueva Medwave. Año XI, No. 3, Marzo 2011. ESTADÍSTICA APLICADA A LA INVESTIGACIÓN EN SALUD Medidas de Tendencia Central y Dispersión Autor:
Descargado desde www.medwave.cl el 13 Junio 2011 por iriabeth villanueva Medwave. Año XI, No. 3, Marzo 2011. ESTADÍSTICA APLICADA A LA INVESTIGACIÓN EN SALUD Medidas de Tendencia Central y Dispersión Autor:
Resumen del trabajo sobre DNSSEC
 Resumen del trabajo sobre Contenido 1. -...2 1.1. - Definición...2 1.2. - Seguridad basada en cifrado...2 1.3. - Cadenas de confianza...3 1.4. - Confianzas...4 1.5. - Islas de confianza...4 2. - Conclusiones...5
Resumen del trabajo sobre Contenido 1. -...2 1.1. - Definición...2 1.2. - Seguridad basada en cifrado...2 1.3. - Cadenas de confianza...3 1.4. - Confianzas...4 1.5. - Islas de confianza...4 2. - Conclusiones...5
Decidir cuándo autenticar en dispositivos móviles a partir de modelos de machine learning 1
 Decidir cuándo autenticar en dispositivos móviles a partir de modelos de machine learning 1 En los dispositivos móviles como tablets o teléfonos celulares se tiene la opción de implementar o no un sistemas
Decidir cuándo autenticar en dispositivos móviles a partir de modelos de machine learning 1 En los dispositivos móviles como tablets o teléfonos celulares se tiene la opción de implementar o no un sistemas
Datos estadísticos. 1.3. PRESENTACIÓN DE DATOS INDIVIDUALES Y DATOS AGRUPADOS EN TABLAS Y GRÁFICOS
 .. PRESENTACIÓN DE DATOS INDIVIDUALES Y DATOS AGRUPADOS EN TABLAS Y GRÁFICOS Ser: Describir el método de construcción del diagrama de tallo, tabla de frecuencias, histograma y polígono. Hacer: Construir
.. PRESENTACIÓN DE DATOS INDIVIDUALES Y DATOS AGRUPADOS EN TABLAS Y GRÁFICOS Ser: Describir el método de construcción del diagrama de tallo, tabla de frecuencias, histograma y polígono. Hacer: Construir
Ejercicios. 1. Definir en Maxima las siguientes funciones y evaluarlas en los puntos que se indican:
 Ejercicios. 1. Definir en Maxima las siguientes funciones y evaluarlas en los puntos que se indican: 2. Graficar las funciones anteriores, definiendo adecuadamente los rangos de x e y, para visualizar
Ejercicios. 1. Definir en Maxima las siguientes funciones y evaluarlas en los puntos que se indican: 2. Graficar las funciones anteriores, definiendo adecuadamente los rangos de x e y, para visualizar
DE VIDA PARA EL DESARROLLO DE SISTEMAS
 MÉTODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS 1. METODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS CICLO DE VIDA CLÁSICO DEL DESARROLLO DE SISTEMAS. El desarrollo de Sistemas, un proceso
MÉTODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS 1. METODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS CICLO DE VIDA CLÁSICO DEL DESARROLLO DE SISTEMAS. El desarrollo de Sistemas, un proceso
Tema 10- Representación Jerárquica: Tema 10- Representación Jerárquica: Árboles Binarios
 Tema 10- Representación Jerárquica: Árboles Binarios Tema 10- Representación Jerárquica: Árboles Binarios Germán Moltó Escuela Técnica Superior de Ingeniería Informática Universidad Politécnica de Valencia
Tema 10- Representación Jerárquica: Árboles Binarios Tema 10- Representación Jerárquica: Árboles Binarios Germán Moltó Escuela Técnica Superior de Ingeniería Informática Universidad Politécnica de Valencia
Pronósticos. Pronósticos y gráficos Diapositiva 1
 Pronósticos Pronósticos Información de base Media móvil Pronóstico lineal - Tendencia Pronóstico no lineal - Crecimiento Suavización exponencial Regresiones mediante líneas de tendencia en gráficos Gráficos:
Pronósticos Pronósticos Información de base Media móvil Pronóstico lineal - Tendencia Pronóstico no lineal - Crecimiento Suavización exponencial Regresiones mediante líneas de tendencia en gráficos Gráficos:
IAP 1003 - ENTORNOS INFORMATIZADOS CON SISTEMAS DE BASES DE DATOS
 IAP 1003 - ENTORNOS INFORMATIZADOS CON SISTEMAS DE BASES DE DATOS Introducción 1. El propósito de esta Declaración es prestar apoyo al auditor a la implantación de la NIA 400, "Evaluación del Riesgo y
IAP 1003 - ENTORNOS INFORMATIZADOS CON SISTEMAS DE BASES DE DATOS Introducción 1. El propósito de esta Declaración es prestar apoyo al auditor a la implantación de la NIA 400, "Evaluación del Riesgo y
Programacion Genetica
 Programacion Genetica PG a Vuelo de Pajaro Desarrollado: EEUU en los 90s Pioneros: J. Koza pero Generalmente aplicado a: prediccion, clasificacion Propiedades generales: compite con NN y similares necesita
Programacion Genetica PG a Vuelo de Pajaro Desarrollado: EEUU en los 90s Pioneros: J. Koza pero Generalmente aplicado a: prediccion, clasificacion Propiedades generales: compite con NN y similares necesita
Procesamiento Digital de Imágenes. Compresión de imágenes
 FICH, UNL - Departamento de Informática - Ingeniería Informática Procesamiento Digital de Imágenes Guía de Trabajos Prácticos 8 Compresión de imágenes 2010 1. Objetivos Analizar las características y el
FICH, UNL - Departamento de Informática - Ingeniería Informática Procesamiento Digital de Imágenes Guía de Trabajos Prácticos 8 Compresión de imágenes 2010 1. Objetivos Analizar las características y el
Tema 2. Espacios Vectoriales. 2.1. Introducción
 Tema 2 Espacios Vectoriales 2.1. Introducción Estamos habituados en diferentes cursos a trabajar con el concepto de vector. Concretamente sabemos que un vector es un segmento orientado caracterizado por
Tema 2 Espacios Vectoriales 2.1. Introducción Estamos habituados en diferentes cursos a trabajar con el concepto de vector. Concretamente sabemos que un vector es un segmento orientado caracterizado por
Activos Intangibles Costos de Sitios Web
 SIC-32 Documentos publicados para acompañar a la Interpretación SIC-32 Activos Intangibles Costos de Sitios Web Esta versión incluye las modificaciones resultantes de las NIIF emitidas hasta el 31 de diciembre
SIC-32 Documentos publicados para acompañar a la Interpretación SIC-32 Activos Intangibles Costos de Sitios Web Esta versión incluye las modificaciones resultantes de las NIIF emitidas hasta el 31 de diciembre
Ejemplos básicos de webmathematica para profesores
 Ejemplos básicos de webmathematica para profesores Cualquier cálculo hecho dentro Mathematica puede ser realizado usando webmathematica con dos limitaciones significativas. Primero, al usar webmathematica,
Ejemplos básicos de webmathematica para profesores Cualquier cálculo hecho dentro Mathematica puede ser realizado usando webmathematica con dos limitaciones significativas. Primero, al usar webmathematica,
Support Vector Machines
 Support Vector Machines Separadores lineales Clasificacion binaria puede ser vista como la tarea de separar clases en el espacio de caracteristicas w T x + b > 0 w T x + b = 0 w T x + b < 0 f(x) = sign(w
Support Vector Machines Separadores lineales Clasificacion binaria puede ser vista como la tarea de separar clases en el espacio de caracteristicas w T x + b > 0 w T x + b = 0 w T x + b < 0 f(x) = sign(w
Comprendiendo las estrategias de mantenimiento
 2002 Emerson Process Management. Todos los derechos reservados. Vea este y otros cursos en línea en www.plantwebuniversity.com. Mantenimiento 101 Comprendiendo las estrategias de mantenimiento Generalidades
2002 Emerson Process Management. Todos los derechos reservados. Vea este y otros cursos en línea en www.plantwebuniversity.com. Mantenimiento 101 Comprendiendo las estrategias de mantenimiento Generalidades
Control de prestaciones de un proyecto
 Temario de la clase Gestión de Proyectos con problemas Control de prestaciones Clasificación de avaance de proyectos Formas de gestionar el término del proyecto Recomendaciones generales Qué hacer cuando
Temario de la clase Gestión de Proyectos con problemas Control de prestaciones Clasificación de avaance de proyectos Formas de gestionar el término del proyecto Recomendaciones generales Qué hacer cuando
Con el fin de obtener los datos, se procede con las siguientes instrucciones:
 Capitulo 3. La predicción de beneficios del mercado bursátil Este segundo caso de estudio va más allá en el uso de técnicas de minería de datos. El dominio específico utilizado para ilustrar estos problemas
Capitulo 3. La predicción de beneficios del mercado bursátil Este segundo caso de estudio va más allá en el uso de técnicas de minería de datos. El dominio específico utilizado para ilustrar estos problemas
Curso Práctico de Bioestadística Con Herramientas De Excel
 Curso Práctico de Bioestadística Con Herramientas De Excel Fabrizio Marcillo Morla MBA barcillo@gmail.com (593-9) 4194239 Fabrizio Marcillo Morla Guayaquil, 1966. BSc. Acuicultura. (ESPOL 1991). Magister
Curso Práctico de Bioestadística Con Herramientas De Excel Fabrizio Marcillo Morla MBA barcillo@gmail.com (593-9) 4194239 Fabrizio Marcillo Morla Guayaquil, 1966. BSc. Acuicultura. (ESPOL 1991). Magister
GUÍA DE USUARIO DEL CORREO
 REPÚBLICA BOLIVARIANA DE VENEZUELA MINISTERIO DEL PODER POPULAR PARA LA EDUCACIÓN DIRECCIÓN GENERAL DE LA OFICINA DE ADMINISTRACIÓN Y SERVICIOS DIVISIÓN DE SOPORTE TÉCNICO Y FORMACIÓN AL USUARIO GUÍA DE
REPÚBLICA BOLIVARIANA DE VENEZUELA MINISTERIO DEL PODER POPULAR PARA LA EDUCACIÓN DIRECCIÓN GENERAL DE LA OFICINA DE ADMINISTRACIÓN Y SERVICIOS DIVISIÓN DE SOPORTE TÉCNICO Y FORMACIÓN AL USUARIO GUÍA DE
Algoritmos de minería de datos incluidos en SQL Server 2008 1. Algoritmo de árboles de decisión de Microsoft [MIC2009a] Cómo funciona el algoritmo
![Algoritmos de minería de datos incluidos en SQL Server 2008 1. Algoritmo de árboles de decisión de Microsoft [MIC2009a] Cómo funciona el algoritmo](/thumbs/24/2246556.jpg "Algoritmos de minería de datos incluidos en SQL Server 2008 1. Algoritmo de árboles de decisión de Microsoft [MIC2009a] Cómo funciona el algoritmo") 1 Algoritmos de minería de datos incluidos en SQL Server 2008 Los algoritmos que aquí se presentan son: Árboles de decisión de Microsoft, Bayes naive de Microsoft, Clústeres de Microsoft, Serie temporal
1 Algoritmos de minería de datos incluidos en SQL Server 2008 Los algoritmos que aquí se presentan son: Árboles de decisión de Microsoft, Bayes naive de Microsoft, Clústeres de Microsoft, Serie temporal
Árbol binario. Elaborado por Ricardo Cárdenas cruz Jeremías Martínez Guadarrama Que es un árbol Introducción
 Árbol binario Elaborado por Ricardo Cárdenas cruz Jeremías Martínez Guadarrama Que es un árbol Introducción Un Árbol Binario es un conjunto finito de Elementos, de nombre Nodos de forma que: El Árbol Binario
Árbol binario Elaborado por Ricardo Cárdenas cruz Jeremías Martínez Guadarrama Que es un árbol Introducción Un Árbol Binario es un conjunto finito de Elementos, de nombre Nodos de forma que: El Árbol Binario
Estas visiones de la información, denominadas vistas, se pueden identificar de varias formas.
 El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
8.1. Introducción... 1. 8.2. Dependencia/independencia estadística... 2. 8.3. Representación gráfica: diagrama de dispersión... 3. 8.4. Regresión...
 Tema 8 Análisis de dos variables: dependencia estadística y regresión Contenido 8.1. Introducción............................. 1 8.2. Dependencia/independencia estadística.............. 2 8.3. Representación
Tema 8 Análisis de dos variables: dependencia estadística y regresión Contenido 8.1. Introducción............................. 1 8.2. Dependencia/independencia estadística.............. 2 8.3. Representación