Arboles de Decisión (II) Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile
|
|
|
- Juan Carlos Escobar Velázquez
- hace 7 años
- Vistas:
Transcripción
1 Arboles de Decisión (II) Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile
2 Arboles de Decisión
3 Algoritmo de Hunt (I) Nodo interior Nodo por expandir Nodo hoja
4 Algoritmo de Hunt (II) Nodos interiores Nodo por expandir Nodo hoja

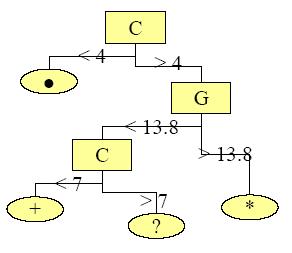
5 Algoritmo de Hunt (III)
6 Algoritmo de Hunt Main(Conjunto de Datos T) Expandir(T) Expandir(Conjunto de Datos S) If (todos los datos están en la misma clase) then return Encontrar el mejor split r Usar r para particonar S en S1 y S2 Expandir(S1) Expandir(S2)
7 Cuál es el mejor split? Buscamos splits que generen nodos hijos con la menor impureza posible (mayor pureza posible) Existen distintos métodos para eval splits. Criterios de Selección: Indice Gini Entropía (Ganancia de información) Test Chi-cuadrado Proporción de Ganancia de Información
8 Selección de splits usando índice Gini Recordar que cada nodo del árbol define un subconjunto de los datos de entrenamientos Dado un nodo t del árbol, Gini t el grado de pureza de t con respecto a las clases Gini t Mayor implica menor pureza Gini t mide = 1 Probabilidad de sacar dos registros de la misma clase
9 Indice Gini Gini t : probabilidad de NO sacar dos t registros de la misma clase del nodo Gini t =1 c C p t, c 2 C p t,c donde es el conjunto de clases y es la prob. de ocurrencia de la clase c en el nodo t
10 Indice Gini: ejemplo
11 Indice Gini Gini p t,c
12 Selección de Splits: GiniSplit Criterio de selección: selecciónar el split con menor gini ponderado (GiniSplit) Dado un split S={s1,,sn} de t GiniSplit t, s = s s S t Gini s
13 Ejemplo: weather.nominal Outlook Temp. Humidity Windy Play Sunny Hot High FALSE No Sunny Hot High TRUE No Overcast Hot High FALSE Yes Rainy Mild High FALSE Yes Rainy Cool Normal FALSE Yes Rainy Cool Normal TRUE No Overcast Cool Normal TRUE Yes Sunny Mild High FALSE No Sunny Cool Normal FALSE Yes Rainy Mild Normal FALSE Yes Sunny Mild Normal TRUE Yes Overcast Mild High TRUE Yes Overcast Hot Normal FALSE Yes Rainy Mild High TRUE No
14 Weather.nominal: splits En este caso todos los atributos son nominales En este ejemplo usaremos splits simples
15 Posibles splits
16 weather.nominal: atributos vs. clases Outlook Temperature Humidity Windy Play Yes No Yes No Yes No Yes No Yes No Sunny 2 3 Hot 2 2 High 3 4 FALSE Overcast 4 0 Mild 4 2 Normal 6 1 TRUE 3 3 Rainy 3 2 Cool 3 1

17 Posibles splits
= 0 Gini(rainy)= 0.48 GiniSplit = (5/14) 0.48 + 0 0.48 + (5/14) 0.")
18 Ejemplo Split simple sobre variable Outlook Gini(sunny) = = 0.48 Gini(overcast)= 0 Gini(rainy)= 0.48 GiniSplit = (5/14) (5/14) 0.48 = 0.35
19 Ejercicio: selección de splits usando Gini para weather.nominal 1. Dar el número de splits que necesitamos evaluar en la primera iteración del algoritmo de Hunt, para (a) splits complejos y (b) splits simples. 2. Seleccionar el mejor split usando el criterio del índice Gini Calcular el GiniSplit de cada split Determinar el mejor split
20 Cuál es el mejor split? Buscamos splits que generen nodos hijos con la menor impureza posible (mayor pureza posible) Existen distintos métodos para eval splits. Criterios de Selección: Indice Gini Entropía (Ganancia de información) Test Chi-cuadrado Proporción de Ganancia de Información
21 Teoría de Información Supongamos que transmitimos en un canal (o codificamos) símbolos en {x1,x2,,xn}. A primera vista, necesitamos log n bits por mensaje. Si el emisor y el receptr conocen la distribución de prb. P(X=xi)=pi, podríamos elabrar un código que requiera menos bits por mensaje.
22 Códigos de Huffman Símb. Prob. A.125 B.125 C.25 D A B.5 C D M cod. long. prob A ,125 0,375 B ,125 0,375 C ,250 0,500 D 1 1 0,500 0,500 average message length 1,750 Si usamos este código para enviar mensajes (A,B,C, o D) con la distribución de prob. dada, en promedio cada mensaje require 1.75 bits.
23 Entropía Entropía: mínimo teórico de bits promedio necesarios para trasmitir un conjunto de mensajes sobre {x1,x2,,xn} con distribución de prob. P(X=xi)=pi Entropy(P) = -(p 1 *log(p 1 ) + p 2 *log(p 2 ) p n *log(p n )) Información asociada a la distribución de probabilidades P. Ejemplos: Si P es (0.5, 0.5), Entropy(P) = 1 Si P es (0.67, 0.33), Entropy(P) = 0.92 Si P is (1, 0), Entropy(P)=0 Mientras más uniforme es P, mayor es su entropía
24 Entropía Entropía Min Gini
25 Selección de splits usando Entropía Entropy t = p t,c log 2 p t,c c C La entropía mide la impureza de los datos S Mide la información (num de bits) promedio necesaria para codificar las clases de los datos en el nodo t Casos extremos Todos los datos pertenecen a la misma clase (Nota: 0 log 0 = 0) Todas las clases son igualmente frecuentes C 1C2 C 1 C C 3 C 3 2 Entropía alta Entropía baja
26 Selección de Splits: Ganancia de Información Criterio para elegir un split: selecciónar el split con la mayor ganancia de información (Gain) Equivalente a seleccionar el split con la menor entropía ponderada Dado un split S={s1,,sn} de t Gain t,s =Entropy t s S s t Entropy s
27 Ejemplo: consideremos el split de Outlook Outlook Sunny Overcast Rainy Yes Yes No No No Yes Yes Yes Yes Yes Yes Yes No No
28 Ejemplo: Split simple de Outlook 2 Entropy S = p i log 2 p i i= log log =0.92 Entropy S sunny = 2 5 log log =0.97 Entropy S overcast = 4 4 log log =0.00 Entropy S rainy = 3 5 log log =0.97
29 Ejemplo: Cálculo de la Ganancia de información Gain S,outlook =Entropy S = =0.23 Gain S,temp =0.03 Gain S,humidity =0.15 Gain S,windy =0.05 v Values a S v S Entropy S v
30 Ejercicio: Expansión de nodo Sunny (probamos el split Temperature ) Outlook Sunny Temperature Overcast Rainy No No Yes No Yes
31 Cálculo de la Entropía para los nodos del split Temperature Entropy S =0.97 Entropy S hot = 0 2 log log =0 Entropy S mild = 1 2 log log 1 22 =1 Entropy S cool = 1 1 log log =0
32 Cálculo de la Ganancia para Temperature Gain S,temp =Entropy S v Values a S v S Entropy S v =0.57 Gain S, humidity =0.97 Gain S, windy =0.02 La ganancia de humidity es mayor Por lo que seleccionamos este split
33 Ejemplo: Arbol resultante Outlook Sunny Rainy High Humidity Normal Overcast Yes True Windy False No Yes No Yes
34 Entropía vs. Indice Gini Breiman, L., (1996).Technical note: Some properties of splitting criteria, Machine Learning 24, Conclusiones de estudio empírico: Gini: Tiende a seleccionar splits que aislan una clase mayoritaria en un nodo y el resto en otros nodos. Tiende a crear splits desbalanceados. Entropía: Favorece splits balanceados en número de datos.
35 Entropía vs. Indice Gini Indice Gini tiende a aislar clases numerosas de otras clases class A 40 class B 30 class C 20 class D 10 Entropía tiende a encontrar grupos de clases que suman más del 50% de los datos class A 40 class B 30 class C 20 class D 10 yes if age < 40 no yes if age < 65 no class A 40 class B 30 class C 20 class D 10 class A 40 class D 10 class B 30 class C 20 GiniSplit = 0,264 EntPond=0,259 GiniSplit=0,4 EntPond=0,254
36 Selección de split usando test Chi-cuadrado El test de chi-cuadrado se usa para testear la hipótesis nula de que dos variables son independientes. Es decir la ocurrencia de un valor de una variable no induce la ocurrencia del valor de otra variable. Usando el test de Chi-cuadrado mediremos la dependencia entre la variable del split y la variable de la clase.
37 Noción de dependencia de dos variable Consideramos que los datos son instancias de un vector aleatorio (X 1 ; : : : ; X n ; C) (x 1 ; : : : ; x n ; c) Es decir, cada instancia de este vector tiene asociada una probabilidad: Pr(X 1 = x 1 ; : : : ; X n = x n ; C = c)
38 Ejercicio: probabilidades para weather.nominal El vector de variables es (Outlook,Temp,Humidity,Windy,Play) Asumiendo que los datos corresponden a las probabilidades reales (esto no es siempre así por qué?) La variable de la clase es Play. Estime de los datos las siguientes probabilidades: P(Play=yes) P(Play=no) P(Play = yes, Outlook= sunny), P(play=no, Outlook=overcast) P(Outlook,Temp,Humidity) para todas las combinaciones. P(Play=yes Windy=false)
39 weather.nominal Outlook Temp. Humidity Windy Play Sunny Hot High FALSE No Sunny Hot High TRUE No Overcast Hot High FALSE Yes Rainy Mild High FALSE Yes Rainy Cool Normal FALSE Yes Rainy Cool Normal TRUE No Overcast Cool Normal TRUE Yes Sunny Mild High FALSE No Sunny Cool Normal FALSE Yes Rainy Mild Normal FALSE Yes Sunny Mild Normal TRUE Yes Overcast Mild High TRUE Yes Overcast Hot Normal FALSE Yes Rainy Mild High TRUE No
40 Dependencia Para dos variables Y; Z la probabilidad condicional se define como: Pr(Y = yjz = z) = Pr(Y = y; Z = z) Pr(Z = z) Y; Z son independientes si para todo par de valores y; z se tiene Pr(Y = yjz = z) = Pr(Y = y) Pr(Z = z)
41 Dependencia weather.nominal Son Outlook y Play independientes? Para responder esto podríamos Estimar la probabilidad Verificar si se cumple la condición de independencia Ejercicio: verificar esto.
42 Test de Chi-cuadrado En el caso general, los datos de entrenamiento sólo son una muestra de los datos en que usaremos el modelo (datos objetivo). El test de Chi-cuadrado es un método estadístico para decidir si hay dependencia en los datos objetivo en base a lo que observamos en los datos de entrenamiento.
43 Test de Chi-cuadrado Ejemplo: venta de té y café en un supermercado. Tenemos dos variables Café (C) y Té (T) Valores son compró o no-compró
44 Tabla de contingencia observada
45 Tabla de Contingencia Observada vs. Esperada Cada celda r=(r1,,rn), contiene el número de veces O(r) que ocurren juntos en los datos los valores r1,,rn Para una celda r=(r1,,rn), definimos el valor esperado de la celda si las variables son dependientes E(r): donde E(ri)=O(ri) es el número de ocurrencias de ri en la tabla
46 Tabla de Contingencia Observada vs. Esperada
47 Estimador Chi-cuadrado
48 Estimador Chi-cuadrado (cont.)
49 Uso de Chi-cuadrado para seleccionar splits Consideremo un split binario sobre una variable A. Las variables para la tabla de contingencia son C (variable de la clase) y A Cada nodo hijo representa un valor distinto para A Se calcula tabla de contingencia y estimador chi-cuadrado Se elige el split con el mejor estimador chicuadrado
50 Ejemplo Supongamos que el atributo A es Café (C), y la variable de la clase es Té (T) El split quedaría no Café si
51 Ejemplo: consideremos el split simple de Outlook Outlook Sunny Overcast Rainy Yes Yes No No No Yes Yes Yes Yes Yes Yes Yes No No
52 Tabla de Contingencia Observada vs. Esperada Observada Yes No Total Sunny Overcast Rainy Total Esperada Yes No Total Sunny Overcast Rainy Total
53 Tabla de Contingencia Esperada Yes No Total Sunny Overcast Rainy Total
54 Estimador Chi-Cuadrado Yes No Total Sunny Overcast Rainy Total 3.55 Grados de libertad =2, valor crítico a 95% de conf. = 5.99 Luego no rechazamos suposición de independencia Nota: el test de chi-cuadrado sólo se puede usar si no más del 10% de las celdas tienen menos de 5 de frecuencia observada..
55 Ejercicio: selección de splits usando chi-cuadrado en weather.nominal 1. Calcule el estimador chi-cuadrado para los splits simples de Windy y Humidity 2. Diga en base al test chi-cuadrado si estos splits son independientes de la variable de la clase.
56 Problemas de entropía e Indice Gini Favorecen splits con muchos nodos hijos. Favorece atributos con muchos valores. A Clas A Si No No Si si
57 Problemas de Entropía, Gini y Chi-cuadrado Favorecen splits con muchos nodos hijos. Favorece atributos con muchos valores. Solución 1.: usar splits binarios Solución 2: usar GainRatio
58 Efecto de la elección del criterio de selección de splits A pesar de lo reportado por Breiman, un estudio de Mingers (1989) cocluye: Los árboles obtenidos con distintas criterios de selección de splits no difieren significativamente en su poder predictivo El criterio sí afecta el tamaño del árbol obtenido La elección aleatoria de atributos produce árboles de alrededor del doble de tamaño que si utilizamos una medida de impureza Entre las medidas vistas, Gain ratio produce árboles pequeños y Chi-cuadrado produce árboles grandes
59 Referencias (no son obligatorias para el curso)
Arboles de Decisión (II) Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile
 Carlos Hurtado L. Depto de Ciencias de la Computación, Universidad de Chile") Arboles de Decisión (II) Carlos Hurtado L Depto de Ciencias de la Computación, Universidad de Chile Cuál es el mejor split? Buscamos splits que generen nodos hijos con la menor impureza posible (mayor
Arboles de Decisión (II) Carlos Hurtado L Depto de Ciencias de la Computación, Universidad de Chile Cuál es el mejor split? Buscamos splits que generen nodos hijos con la menor impureza posible (mayor
Redes Bayesianas (1) Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile
 Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile") Redes Bayesianas (1) Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile Referencia Bayesian networks without tears: making Bayesian networks more accessible to the probabilistically
Redes Bayesianas (1) Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile Referencia Bayesian networks without tears: making Bayesian networks more accessible to the probabilistically
Guía de Ejercicios Aprendizaje de Máquinas Inteligencia Articial (CC52A)
") Guía de Ejercicios Aprendizaje de Máquinas Inteligencia Articial (CC52A) 6 de noviembre de 2007 1. Arboles de Decision 1. Investigue las ventajas y desventajas de los árboles de decisión versus los siguientes
Guía de Ejercicios Aprendizaje de Máquinas Inteligencia Articial (CC52A) 6 de noviembre de 2007 1. Arboles de Decision 1. Investigue las ventajas y desventajas de los árboles de decisión versus los siguientes
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Entrada: Objetos caracterizables mediante propiedades. Salida: En árboles de decisión: una decisión (sí o no). En árboles de clasificación:
Aux 6. Introducción a la Minería de Datos
 Aux 6. Introducción a la Minería de Datos Gastón L Huillier 1,2, Richard Weber 2 glhuilli@dcc.uchile.cl 1 Departamento de Ciencias de la Computación Universidad de Chile 2 Departamento de Ingeniería Industrial
Aux 6. Introducción a la Minería de Datos Gastón L Huillier 1,2, Richard Weber 2 glhuilli@dcc.uchile.cl 1 Departamento de Ciencias de la Computación Universidad de Chile 2 Departamento de Ingeniería Industrial
Árboles de decisión en aprendizaje automático y minería de datos
 Árboles de decisión en aprendizaje automático y minería de datos Tratamiento Inteligente de la Información y Aplicaciones Juan A. Botía Departamento de Ingeniería de la Información y las Comunicaciones
Árboles de decisión en aprendizaje automático y minería de datos Tratamiento Inteligente de la Información y Aplicaciones Juan A. Botía Departamento de Ingeniería de la Información y las Comunicaciones
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Jesús García Herrero TÉCNICAS DE INDUCCIÓN-II
 Jesús García Herrero TÉCNICAS DE INDUCCIÓN-II En esta clase se continúa con el desarrollo de métodos de inducción de modelos lógicos a partir de datos. Se parte de las limitaciones del método ID3 presentado
Jesús García Herrero TÉCNICAS DE INDUCCIÓN-II En esta clase se continúa con el desarrollo de métodos de inducción de modelos lógicos a partir de datos. Se parte de las limitaciones del método ID3 presentado
Aprendizaje Automático Segundo Cuatrimestre de Árboles de Decisión
 Aprendizaje Automático Segundo Cuatrimestre de 2015 Árboles de Decisión Aproximación de Funciones Ejemplo: Un amigo juega al tenis los sábados. Juega o no, dependiendo del estado del tiempo. Cielo: {Sol,
Aprendizaje Automático Segundo Cuatrimestre de 2015 Árboles de Decisión Aproximación de Funciones Ejemplo: Un amigo juega al tenis los sábados. Juega o no, dependiendo del estado del tiempo. Cielo: {Sol,
Inteligencia Artificial Técnicas de clasificación
 Inteligencia Artificial Técnicas de clasificación ISISTAN - CONICET Clasificación: Agenda Concepto Clasificación Predicción Evaluación Árboles de Decisión Construcción Uso Poda Clasificador Bayesiano Ejemplos
Inteligencia Artificial Técnicas de clasificación ISISTAN - CONICET Clasificación: Agenda Concepto Clasificación Predicción Evaluación Árboles de Decisión Construcción Uso Poda Clasificador Bayesiano Ejemplos
Proyecto 6. Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial.
 Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial. Funcionamiento: Se realiza un test en cada nodo interno del árbol, a medida que
Árboles de decisión: Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial. Funcionamiento: Se realiza un test en cada nodo interno del árbol, a medida que
Clasificación. Clasificadores Bayesianos
 Clasificación Clasificadores Bayesianos Clasificadores Bayesianos Modela relaciones probabilisticas entre el conjunto de atributos y el atributo clase Probabilidad condicional: probabilidad de que una
Clasificación Clasificadores Bayesianos Clasificadores Bayesianos Modela relaciones probabilisticas entre el conjunto de atributos y el atributo clase Probabilidad condicional: probabilidad de que una
3. Árboles de decisión
 3.1 Introducción Método para aproximación de funciones objetivo que tengan valores discretos (clasificación) Uno de los métodos mas extensamente usados para inferencia inductiva Capaz de aprender hipótesis
3.1 Introducción Método para aproximación de funciones objetivo que tengan valores discretos (clasificación) Uno de los métodos mas extensamente usados para inferencia inductiva Capaz de aprender hipótesis
Técnicas de clasificación. Prof. Dra. Silvia Schiaffino ISISTAN - CONICET. Inteligencia Artificial
 Inteligencia Artificial Técnicas de clasificación ISISTAN - CONICET Clasificación: Agenda Concepto Clasificación Predicción Evaluación Árboles de Decisión Construcción Uso Poda Clasificador Bayesiano Ejemplos
Inteligencia Artificial Técnicas de clasificación ISISTAN - CONICET Clasificación: Agenda Concepto Clasificación Predicción Evaluación Árboles de Decisión Construcción Uso Poda Clasificador Bayesiano Ejemplos
Aprendizaje Automático
 Regresión Lineal: Descenso de Gradiente Árboles de Regresión: M5 Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje (PLG) Departamento de Informática
Regresión Lineal: Descenso de Gradiente Árboles de Regresión: M5 Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje (PLG) Departamento de Informática
Redes Bayesianas (3) Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile
 Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile") Redes Bayesianas (3) Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile Referencia Tutorial NIPS (Neural Information Processing Systems Conference) 2001: Learning Bayesian Networks
Redes Bayesianas (3) Carlos Hurtado L. Depto. de Ciencias de la Computación, Universidad de Chile Referencia Tutorial NIPS (Neural Information Processing Systems Conference) 2001: Learning Bayesian Networks
SISTEMAS INTELIGENTES
 SISTEMAS INTELIGENTES T9: Árboles de Decisión www.aic.uniovi.es/ssii Sistemas Inteligentes T9: Árboles de decisión Índice Árboles de decisión para clasificación Mecanismo de inducción: divide y vencerás
SISTEMAS INTELIGENTES T9: Árboles de Decisión www.aic.uniovi.es/ssii Sistemas Inteligentes T9: Árboles de decisión Índice Árboles de decisión para clasificación Mecanismo de inducción: divide y vencerás
Evaluación de Modelos (II) Carlos Hurtado L. Departamento de Ciencias de la Computación, U de Chile
 Carlos Hurtado L. Departamento de Ciencias de la Computación, U de Chile") Evaluación de Modelos (II) Carlos Hurtado L. Departamento de Ciencias de la Computación, U de Chile Comparación de Modelos Podemos estimar el error de cada modelo y rankear. Una alternativa más sólida
Evaluación de Modelos (II) Carlos Hurtado L. Departamento de Ciencias de la Computación, U de Chile Comparación de Modelos Podemos estimar el error de cada modelo y rankear. Una alternativa más sólida
Nicolás Rivera. 20 de Marzo de 2012
 Gramáticas Libre de Contexto Aleatorias. Nicolás Rivera 20 de Marzo de 2012 Pontificia Universidad Católica de Chile Tabla de Contenidos 1 Introducción Gramáticas Libres de Contexto Sistema de Producción
Gramáticas Libre de Contexto Aleatorias. Nicolás Rivera 20 de Marzo de 2012 Pontificia Universidad Católica de Chile Tabla de Contenidos 1 Introducción Gramáticas Libres de Contexto Sistema de Producción
MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión.
 MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión. 1 Objetivos del tema Conocer en qué consiste un árbol de decisión. Aprender los problemas que pueden
MASTER DE INGENIERÍA BIOMÉDICA. Métodos de ayuda al diagnóstico clínico. Tema 6: Árboles de decisión. 1 Objetivos del tema Conocer en qué consiste un árbol de decisión. Aprender los problemas que pueden
Aprendizaje Automatizado. Árboles de Clasificación
 Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Aprendizaje Automatizado Árboles de Clasificación Árboles de Clasificación Estudiaremos un algoritmo para la creación del árbol. Selección de atributos comenzando en el nodo raíz. Proceso recursivo. Árboles
Unidad 5: Entropía y Fuente del Teorema de Codificación de Shannon
 Unidad 5: Entropía y Fuente del Teorema de Codificación de Shannon En ésta unidad empezamos a ver la teoría de la información, al cual nos permitirá aprender mas sobre las propiedades fundamentales de
Unidad 5: Entropía y Fuente del Teorema de Codificación de Shannon En ésta unidad empezamos a ver la teoría de la información, al cual nos permitirá aprender mas sobre las propiedades fundamentales de
Aplicaciones de apoyo al diagnóstico médico. Identificación de objetos amigos y enemigos. Identificación de zonas afectadas por un desastre natural.
 Capítulo 5 Evaluación En muchas ocasiones requerimos hacer una evaluación muy precisa de nuestros algoritmos de aprendizaje computacional porque los vamos a utilizar en algún tipo de aplicación que así
Capítulo 5 Evaluación En muchas ocasiones requerimos hacer una evaluación muy precisa de nuestros algoritmos de aprendizaje computacional porque los vamos a utilizar en algún tipo de aplicación que así
Práctica 2: Utilización de WEKA desde la línea de comandos.
 PROGRAMA DE DOCTORADO TECNOLOGÍAS INDUSTRIALES APLICACIONES DE LA INTELIGENCIA ARTIFICIAL EN ROBÓTICA Práctica 2: Utilización de WEKA desde la línea de comandos. Objetivos: Utilización de WEKA desde la
PROGRAMA DE DOCTORADO TECNOLOGÍAS INDUSTRIALES APLICACIONES DE LA INTELIGENCIA ARTIFICIAL EN ROBÓTICA Práctica 2: Utilización de WEKA desde la línea de comandos. Objetivos: Utilización de WEKA desde la
Práctica 5. Códigos Huffman y Run-Length
 EC2422. Comunicaciones I Enero - Marzo 2009 Práctica 5. Códigos Huffman y Run-Length 1. Objetivos 1.1. Simular, usando MATLAB, un codificador y decodificador Huffman a fin de estudiar sus características
EC2422. Comunicaciones I Enero - Marzo 2009 Práctica 5. Códigos Huffman y Run-Length 1. Objetivos 1.1. Simular, usando MATLAB, un codificador y decodificador Huffman a fin de estudiar sus características
CI5438. Inteligencia Artificial II Clase 4: Aprendizaje en Árboles. Cap 18.3: RN
 CI5438. Inteligencia Artificial II Clase 4: Aprendizaje en Árboles de Decisión Cap 18.3: RN Universidad Simón Boĺıvar 5 de octubre de 2009 Árboles de Decisión Un árbol de decisión es un árbol de búsqueda
CI5438. Inteligencia Artificial II Clase 4: Aprendizaje en Árboles de Decisión Cap 18.3: RN Universidad Simón Boĺıvar 5 de octubre de 2009 Árboles de Decisión Un árbol de decisión es un árbol de búsqueda
Carteras minoristas. árbol de decisión. Ejemplo: Construcción de un scoring de concesión basado en un DIRECCIÓN GENERAL DE SUPERVISIÓN
 Carteras minoristas Ejemplo: Construcción de un scoring de concesión basado en un árbol de decisión Grupo de Tesorería y Modelos de Gestión de Riesgos Sergio Gavilá II Seminario sobre Basilea II Validación
Carteras minoristas Ejemplo: Construcción de un scoring de concesión basado en un árbol de decisión Grupo de Tesorería y Modelos de Gestión de Riesgos Sergio Gavilá II Seminario sobre Basilea II Validación
Clasificación Supervisada. Métodos jerárquicos. CART
 Clasificación Supervisada. Métodos jerárquicos. CART Ricardo Fraiman 2 de abril de 2010 Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y n ) E {1,..., m}. Típicamente E = R d.
Clasificación Supervisada. Métodos jerárquicos. CART Ricardo Fraiman 2 de abril de 2010 Descripción del problema Muestra de entrenamiento (X 1, Y 1 ),..., (X n, Y n ) E {1,..., m}. Típicamente E = R d.
Aprendizaje Automático
 id3 id3 como búsqueda Cuestiones Adicionales Regresión Lineal. Árboles y Reglas de Regresión Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje
id3 id3 como búsqueda Cuestiones Adicionales Regresión Lineal. Árboles y Reglas de Regresión Ingeniería Informática Fernando Fernández Rebollo y Daniel Borrajo Millán Grupo de Planificación y Aprendizaje
Aprendizaje Supervisado Árboles de Decisión
 Aprendizaje Supervisado Árboles de Decisión 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado 100K No 3 No Soltero 70K No
Aprendizaje Supervisado Árboles de Decisión 10 10 Modelo general de los métodos de Clasificación Id Reembolso Estado Civil Ingresos Anuales 1 Sí Soltero 125K No 2 No Casado 100K No 3 No Soltero 70K No
INFERENCIA ESTADÍSTICA. Metodología de Investigación. Tesifón Parrón
 Metodología de Investigación Tesifón Parrón Contraste de hipótesis Inferencia Estadística Medidas de asociación Error de Tipo I y Error de Tipo II α β CONTRASTE DE HIPÓTESIS Tipos de Test Chi Cuadrado
Metodología de Investigación Tesifón Parrón Contraste de hipótesis Inferencia Estadística Medidas de asociación Error de Tipo I y Error de Tipo II α β CONTRASTE DE HIPÓTESIS Tipos de Test Chi Cuadrado
Tema 7: Aprendizaje de árboles de decisión
 Inteligencia Artificial 2 Curso 2002 03 Tema 7: Aprendizaje de árboles de decisión José A. Alonso Jiménez Miguel A. Gutiérrez Naranjo Francisco J. Martín Mateos José L. Ruiz Reina Dpto. de Ciencias de
Inteligencia Artificial 2 Curso 2002 03 Tema 7: Aprendizaje de árboles de decisión José A. Alonso Jiménez Miguel A. Gutiérrez Naranjo Francisco J. Martín Mateos José L. Ruiz Reina Dpto. de Ciencias de
Variables aleatorias
 Variables aleatorias Un poco más general: si ahora S n está dada por la suma de variables independientes de la forma: S n =c 1 X 1 +... +c n X n, entonces la función generatriz viene dada por: Variables
Variables aleatorias Un poco más general: si ahora S n está dada por la suma de variables independientes de la forma: S n =c 1 X 1 +... +c n X n, entonces la función generatriz viene dada por: Variables
EVALUACIÓN EN APRENDIZAJE. Eduardo Morales y Jesús González
 EVALUACIÓN EN APRENDIZAJE Eduardo Morales y Jesús González Significancia Estadística 2 En estadística, se dice que un resultado es estadísticamente significante, cuando no es posible que se presente por
EVALUACIÓN EN APRENDIZAJE Eduardo Morales y Jesús González Significancia Estadística 2 En estadística, se dice que un resultado es estadísticamente significante, cuando no es posible que se presente por
2 de mar de 2004 Codificación de imágenes y v ideo
 Teoría de la Información 2 de mar de 2004 Codificación de imágenes y v ideo 2 de mar de 2004 Codificación de imágenes y video 2 El clima en el Río de la Plata...... N L N N L S N... N L L T L L L... N
Teoría de la Información 2 de mar de 2004 Codificación de imágenes y v ideo 2 de mar de 2004 Codificación de imágenes y video 2 El clima en el Río de la Plata...... N L N N L S N... N L L T L L L... N
2. Algoritmos genéticos y redes neuronales 3. Inducción de árboles clasificadores. Inducción de árboles de clasificación. Aprendizaje UPM UPM
 1. Preliminares Aprendizaje 2. Algoritmos genéticos y redes neuronales 3. Inducción de árboles clasificadores 4. Inducción de reglas 5. Minería de datos c 2010 DIT-ETSIT- Aprendizaje: árboles transp. 1
1. Preliminares Aprendizaje 2. Algoritmos genéticos y redes neuronales 3. Inducción de árboles clasificadores 4. Inducción de reglas 5. Minería de datos c 2010 DIT-ETSIT- Aprendizaje: árboles transp. 1
Estadística. Generalmente se considera que las variables son obtenidas independientemente de la misma población. De esta forma: con
 Hasta ahora hemos supuesto que conocemos o podemos calcular la función/densidad de probabilidad (distribución) de las variables aleatorias. En general, esto no es así. Más bien se tiene una muestra experimental
Hasta ahora hemos supuesto que conocemos o podemos calcular la función/densidad de probabilidad (distribución) de las variables aleatorias. En general, esto no es así. Más bien se tiene una muestra experimental
Tema 8: Árboles de decisión
 Introducción a la Ingeniería del Conocimiento Curso 2004 2005 Tema 8: Árboles de decisión Miguel A. Gutiérrez Naranjo Dpto. de Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla
Introducción a la Ingeniería del Conocimiento Curso 2004 2005 Tema 8: Árboles de decisión Miguel A. Gutiérrez Naranjo Dpto. de Ciencias de la Computación e Inteligencia Artificial Universidad de Sevilla
Introducción Método de Fisher Método de Bonferroni y FDR. Test Multiples. Graciela Boente 1. 1 Universidad de Buenos Aires and CONICET, Argentina
 1 Test Multiples Graciela Boente 1 1 Universidad de Buenos Aires and CONICET, Argentina 2 Ejemplo En muchos ejemplos, se realizan múltiples tests y se desea combinar los resultados de estos tests independientes
1 Test Multiples Graciela Boente 1 1 Universidad de Buenos Aires and CONICET, Argentina 2 Ejemplo En muchos ejemplos, se realizan múltiples tests y se desea combinar los resultados de estos tests independientes
Práctica 9. Árboles de decisión
 Práctica 9 Árboles de decisión En esta práctica vamos a ver un sistema de aprendizaje basado en árboles de decisión capaz de generar un conjunto de reglas. Este sistema es el más utilizado y conocido.
Práctica 9 Árboles de decisión En esta práctica vamos a ver un sistema de aprendizaje basado en árboles de decisión capaz de generar un conjunto de reglas. Este sistema es el más utilizado y conocido.
Modelos estadísticos y la entropía del lenguaje. Dr. Luis Alberto Pineda Cortés
 Modelos estadísticos y la entropía del lenguaje Dr. Luis Alberto Pineda Cortés Contenido Teoría de la probabilidad Modelos estadísticos Reconocimiento de voz Entropía (de un lenguaje) Cadenas de Markov
Modelos estadísticos y la entropía del lenguaje Dr. Luis Alberto Pineda Cortés Contenido Teoría de la probabilidad Modelos estadísticos Reconocimiento de voz Entropía (de un lenguaje) Cadenas de Markov
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA. Ricardo Aler Mur
 Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur MODELOS: ÁRBOLES DE DECISIÓN Y REGLAS Datos de entrada 91 71 75 81 Nublado 90 72 Nublado 70 75 80 75 70
Aprendizaje Automático para el Análisis de Datos GRADO EN ESTADÍSTICA Y EMPRESA Ricardo Aler Mur MODELOS: ÁRBOLES DE DECISIÓN Y REGLAS Datos de entrada 91 71 75 81 Nublado 90 72 Nublado 70 75 80 75 70
Dr. Abner A. Fonseca Livias
 UNIVERSIDAD NACIONAL HERMILIO VALDIZAN FACULTAD DE ENFERMERÍA Dr. Abner A. Fonseca Livias 3/21/2015 6:17 AM Dr. Abner Fonseca Livias 1 UNIVERSIDAD NACIONAL HERMILIO VALDIZAN ESCUELA DE POST GRADO Dr. Abner
UNIVERSIDAD NACIONAL HERMILIO VALDIZAN FACULTAD DE ENFERMERÍA Dr. Abner A. Fonseca Livias 3/21/2015 6:17 AM Dr. Abner Fonseca Livias 1 UNIVERSIDAD NACIONAL HERMILIO VALDIZAN ESCUELA DE POST GRADO Dr. Abner
Tarea 5: Estrategia voraz y Divide y
 Tarea 5: Estrategia voraz y Divide y Vencerás Estructura de Datos y Teoría de Algoritmos Entrega: 5 de noviembre de 2008 1. De acuerdo con lo demostrado en clase, un código de Huffman es de longitud promedio
Tarea 5: Estrategia voraz y Divide y Vencerás Estructura de Datos y Teoría de Algoritmos Entrega: 5 de noviembre de 2008 1. De acuerdo con lo demostrado en clase, un código de Huffman es de longitud promedio
DISTRIBUCIONES BIDIMENSIONALES
 La estadística unidimensional estudia los elementos de un conjunto de datos considerando sólo una variable o característica. Si ahora incorporamos, otra variable, y se observa simultáneamente el comportamiento
La estadística unidimensional estudia los elementos de un conjunto de datos considerando sólo una variable o característica. Si ahora incorporamos, otra variable, y se observa simultáneamente el comportamiento
Introducción a la Teoría de la Información
 Introducción a la Teoría de la Información Codificación de fuentes Facultad de Ingeniería, UdelaR (Facultad de Ingeniería, UdelaR) Teoría de la Información 1 / 43 Agenda 1 Codificación de fuente Definiciones
Introducción a la Teoría de la Información Codificación de fuentes Facultad de Ingeniería, UdelaR (Facultad de Ingeniería, UdelaR) Teoría de la Información 1 / 43 Agenda 1 Codificación de fuente Definiciones
ÁRBOLES DE CLASIFICACIÓN Y REGRESIÓN
 ÁRBOLES DE CLASIFICACIÓN Y REGRESIÓN Los árboles de clasificación y regresión (CART=Classification and Regression Trees) son una alternativa al análisis tradicional de clasificación/discriminación o a
ÁRBOLES DE CLASIFICACIÓN Y REGRESIÓN Los árboles de clasificación y regresión (CART=Classification and Regression Trees) son una alternativa al análisis tradicional de clasificación/discriminación o a
ANÁLISIS DE REGRESIÓN
 ANÁLISIS DE REGRESIÓN INTRODUCCIÓN Francis Galtón DEFINICIÓN Análisis de Regresión Es una técnica estadística que se usa para investigar y modelar la relación entre variables. Respuesta Independiente Y
ANÁLISIS DE REGRESIÓN INTRODUCCIÓN Francis Galtón DEFINICIÓN Análisis de Regresión Es una técnica estadística que se usa para investigar y modelar la relación entre variables. Respuesta Independiente Y
ARBOLES DE DECISION. Miguel Cárdenas-Montes. 1 Introducción. Objetivos: Entender como funcionan los algoritmos basados en árboles de decisión.
 ARBOLES DE DECISION Miguel Cárdenas-Montes Los árboles de decisión son estructuras lógicas con amplia utilización en la toma de decisión, la predicción y la minería de datos. Objetivos: Entender como funcionan
ARBOLES DE DECISION Miguel Cárdenas-Montes Los árboles de decisión son estructuras lógicas con amplia utilización en la toma de decisión, la predicción y la minería de datos. Objetivos: Entender como funcionan
Algoritmos glotones 2 (código de Huffman) mat-151
 mat-151") Algoritmos glotones 2 (código de Huffman) mat-151 Alonso Ramírez Manzanares Computación y Algoritmos 05.06.2009 Son técnicas muy efectivas para comprimir datos. Alcanzan una compresión de entre 20% y 90%
Algoritmos glotones 2 (código de Huffman) mat-151 Alonso Ramírez Manzanares Computación y Algoritmos 05.06.2009 Son técnicas muy efectivas para comprimir datos. Alcanzan una compresión de entre 20% y 90%
Estadística. Para el caso de dos variables aleatorias X e Y, se puede mostrar que. Pero y son desconocidos. Entonces. covarianza muestral
 Para el caso de dos variables aleatorias X e Y, se puede mostrar que Pero y son desconocidos. Entonces donde covarianza muestral Estimación de intervalos de confianza Cuál es el intervalo (de confianza)
Para el caso de dos variables aleatorias X e Y, se puede mostrar que Pero y son desconocidos. Entonces donde covarianza muestral Estimación de intervalos de confianza Cuál es el intervalo (de confianza)
Aprendizaje de árboles de decisión. Aprendizaje de árboles de decisión
 Aprendizaje de árboles de decisión José M. Sempere Departamento de Sistemas Informáticos y Computación Universidad Politécnica de Valencia Aprendizaje de árboles de decisión 1. Introducción. Definición
Aprendizaje de árboles de decisión José M. Sempere Departamento de Sistemas Informáticos y Computación Universidad Politécnica de Valencia Aprendizaje de árboles de decisión 1. Introducción. Definición
Random Subspace Method. Índice. 1. Random Subspace Method. 1. Introducción. 2. Objetivo. 3. Implementación. 4. Evaluación. 5.
 The Random Subspace Method for Constructing Decision Forests (IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 20, NO. 8, AUGUST 1998) Iñigo Barandiaran 1 Índice 1. Random Subspace
The Random Subspace Method for Constructing Decision Forests (IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 20, NO. 8, AUGUST 1998) Iñigo Barandiaran 1 Índice 1. Random Subspace
al Aprendizaje Automático Breve Introducción con WEKA Procesamiento del Lenguaje Natural Índice José María Gómez Hidalgo Evaluación y visualización
 Breve Introducción al Aprendizaje Automático con WEKA Procesamiento del Lenguaje Natural José María Gómez Hidalgo http://www.esp.uem.es/~jmgomez/ Índice Referencias Motivación Conceptos básicos El proceso
Breve Introducción al Aprendizaje Automático con WEKA Procesamiento del Lenguaje Natural José María Gómez Hidalgo http://www.esp.uem.es/~jmgomez/ Índice Referencias Motivación Conceptos básicos El proceso
Algoritmos en teoría de números
 Algoritmos en teoría de números IIC2283 IIC2283 Algoritmos en teoría de números 1 / 92 Para recordar: aritmética modular Dados dos números a, b Z, si b > 0 entonces existen α, β Z tales que 0 β < b y a
Algoritmos en teoría de números IIC2283 IIC2283 Algoritmos en teoría de números 1 / 92 Para recordar: aritmética modular Dados dos números a, b Z, si b > 0 entonces existen α, β Z tales que 0 β < b y a
Qué son los árboles de decisión? Inducción de árboles de decisión. Tipos de problemas abordables. Ejemplo: árbol de decisión 1
 Inducción de árboles de decisión Qué son los árboles de decisión? Cómo pueden inducirse automáticamente? inducción topdown de árboles de decisión cómo evitar el overfitting cómo convertir árboles en reglas
Inducción de árboles de decisión Qué son los árboles de decisión? Cómo pueden inducirse automáticamente? inducción topdown de árboles de decisión cómo evitar el overfitting cómo convertir árboles en reglas
Algoritmos y Complejidad
 Algoritmos y Complejidad Algoritmos greedy Pablo R. Fillottrani Depto. Ciencias e Ingeniería de la Computación Universidad Nacional del Sur Primer Cuatrimestre 2017 Algoritmos greedy Generalidades Problema
Algoritmos y Complejidad Algoritmos greedy Pablo R. Fillottrani Depto. Ciencias e Ingeniería de la Computación Universidad Nacional del Sur Primer Cuatrimestre 2017 Algoritmos greedy Generalidades Problema
ESTADÍSTICA BIVARIADA
 ESTADÍSTICA BIVARIADA Estadística y Tecnología de la Información y Comunicación ENRIQUE ÍÑIGUEZ CASTRO 1º de Enfermería, grupo 4. Subgrupo 16. Índice 1. Introducción.... 2 2. Objetivos.... 2 3. Metodología...
ESTADÍSTICA BIVARIADA Estadística y Tecnología de la Información y Comunicación ENRIQUE ÍÑIGUEZ CASTRO 1º de Enfermería, grupo 4. Subgrupo 16. Índice 1. Introducción.... 2 2. Objetivos.... 2 3. Metodología...
A. PRUEBAS DE BONDAD DE AJUSTE: B.TABLAS DE CONTINGENCIA. Chi cuadrado Metodo G de Fisher Kolmogorov-Smirnov Lilliefords
 A. PRUEBAS DE BONDAD DE AJUSTE: Chi cuadrado Metodo G de Fisher Kolmogorov-Smirnov Lilliefords B.TABLAS DE CONTINGENCIA Marta Alperin Prosora Adjunta de Estadística alperin@fcnym.unlp.edu.ar http://www.fcnym.unlp.edu.ar/catedras/estadistica
A. PRUEBAS DE BONDAD DE AJUSTE: Chi cuadrado Metodo G de Fisher Kolmogorov-Smirnov Lilliefords B.TABLAS DE CONTINGENCIA Marta Alperin Prosora Adjunta de Estadística alperin@fcnym.unlp.edu.ar http://www.fcnym.unlp.edu.ar/catedras/estadistica
Inducción de árboles de decisión. Qué son los árboles de decisión? Tipos de problemas abordables. Ejemplo de árbol de decisión 2
 1 Datamining y Aprendizaje Automatizado 05 Arboles de Decisión Prof. Carlos Iván Chesñevar Departamento de Cs. e Ing. de la Computación Universidad Nacional del Sur Email: cic@cs.uns.edu.ar / Http:\\cs.uns.edu.ar\~cic
1 Datamining y Aprendizaje Automatizado 05 Arboles de Decisión Prof. Carlos Iván Chesñevar Departamento de Cs. e Ing. de la Computación Universidad Nacional del Sur Email: cic@cs.uns.edu.ar / Http:\\cs.uns.edu.ar\~cic
Estimación de Parámetros.
 Estimación de Parámetros. Un estimador es un valor que puede calcularse a partir de los datos muestrales y que proporciona información sobre el valor del parámetro. Por ejemplo la media muestral es un
Estimación de Parámetros. Un estimador es un valor que puede calcularse a partir de los datos muestrales y que proporciona información sobre el valor del parámetro. Por ejemplo la media muestral es un
La distribucion de preferencias de colores es la misma tanto para personas de distinto nivel socioeconómico.
 ANEXO - PRUEBAS DE ASOCIACION A.1 Pruebas de asociacion Este tipo de pruebas testea la hipotesis nula que 2 factores (o atributos) no se encuentran asociados, respecto de la hipotesis alternativa que si
ANEXO - PRUEBAS DE ASOCIACION A.1 Pruebas de asociacion Este tipo de pruebas testea la hipotesis nula que 2 factores (o atributos) no se encuentran asociados, respecto de la hipotesis alternativa que si
D conjunto de N patrones etiquetados, cada uno de los cuales está caracterizado por n variables predictoras X 1,..., X n y la variable clase C.
 Tema 10. Árboles de Clasificación Pedro Larrañaga, Iñaki Inza, Abdelmalik Moujahid Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad del País Vasco Euskal Herriko Unibertsitatea
Tema 10. Árboles de Clasificación Pedro Larrañaga, Iñaki Inza, Abdelmalik Moujahid Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad del País Vasco Euskal Herriko Unibertsitatea
Breve Introducción. Perspectiva. Acercamientos Bayesianos. Algunas Características salientes de los Métodos Bayesianos
 Fundamentos de Aprendizaje Bayesiano Introducción: métodos probabilísticos (bayesianos) Hipótesis MAP y ML Aprendiz Naïve Bayesiano Ej: aprendizaje a partir de textos Mitchell Cap. 6 Breve Introducción
Fundamentos de Aprendizaje Bayesiano Introducción: métodos probabilísticos (bayesianos) Hipótesis MAP y ML Aprendiz Naïve Bayesiano Ej: aprendizaje a partir de textos Mitchell Cap. 6 Breve Introducción
Pruebas estadís,cas para evaluar relaciones
 Pruebas estadís,cas para evaluar relaciones Asociación entre dos variables categóricas Hipótesis: frecuencias de ocurrencias en las categorías de una variable son independientes de los frecuencias en la
Pruebas estadís,cas para evaluar relaciones Asociación entre dos variables categóricas Hipótesis: frecuencias de ocurrencias en las categorías de una variable son independientes de los frecuencias en la
7. Inferencia Estadística. Métodos Estadísticos para la Mejora de la Calidad 1
 7. Inferencia Estadística Métodos Estadísticos para la Mejora de la Calidad 1 Tema 7: Inferencia Estadística 1. Intervalos de confianza para μ con muestras grandes 2. Introducción al contraste de hipótesis
7. Inferencia Estadística Métodos Estadísticos para la Mejora de la Calidad 1 Tema 7: Inferencia Estadística 1. Intervalos de confianza para μ con muestras grandes 2. Introducción al contraste de hipótesis
Tests de hipótesis. Técnicas de validación estadística Bondad de ajuste. Pruebas de bondad de ajuste. Procedimiento en una prueba de hipótesis
 Tests de hipótesis Técnicas de validación estadística Bondad de ajuste Patricia Kisbye FaMAF 27 de mayo, 2008 Test - Prueba - Contraste. Se utilizan para contrastar el valor de un parámetro. Ejemplo: la
Tests de hipótesis Técnicas de validación estadística Bondad de ajuste Patricia Kisbye FaMAF 27 de mayo, 2008 Test - Prueba - Contraste. Se utilizan para contrastar el valor de un parámetro. Ejemplo: la
Validación de hipótesis de un proceso de Poisson no homogéneo
 Validación de hipótesis de un proceso de Poisson no homogéneo Georgina Flesia FaMAF 9 de junio, 2011 Proceso de Poisson no homogéneo H 0 ) Las llegadas diarias a un sistema ocurren de acuerdo a un Proceso
Validación de hipótesis de un proceso de Poisson no homogéneo Georgina Flesia FaMAF 9 de junio, 2011 Proceso de Poisson no homogéneo H 0 ) Las llegadas diarias a un sistema ocurren de acuerdo a un Proceso
Estimación del Probit Ordinal y del Logit Multinomial
 Estimación del Probit Ordinal y del Logit Multinomial Microeconomía Cuantitativa R. Mora Departmento de Economía Universidad Carlos III de Madrid Esquema Introducción 1 Introducción 2 3 Introducción El
Estimación del Probit Ordinal y del Logit Multinomial Microeconomía Cuantitativa R. Mora Departmento de Economía Universidad Carlos III de Madrid Esquema Introducción 1 Introducción 2 3 Introducción El
Aprendizaje Automático. Objetivos. Funciona? Notas
 Introducción Las técnicas que hemos visto hasta ahora nos permiten crear sistemas que resuelven tareas que necesitan inteligencia La limitación de estos sistemas reside en que sólo resuelven los problemas
Introducción Las técnicas que hemos visto hasta ahora nos permiten crear sistemas que resuelven tareas que necesitan inteligencia La limitación de estos sistemas reside en que sólo resuelven los problemas
Comparación de dos métodos de aprendizaje sobre el mismo problema
 Comparación de dos métodos de aprendizaje sobre el mismo problema Carlos Alonso González Grupo de Sistemas Inteligentes Departamento de Informática Universidad de Valladolid Contenido 1. Motivación 2.
Comparación de dos métodos de aprendizaje sobre el mismo problema Carlos Alonso González Grupo de Sistemas Inteligentes Departamento de Informática Universidad de Valladolid Contenido 1. Motivación 2.
Compresión. UCR ECCI CI-2414 Recuperación de Información Prof. M.Sc. Kryscia Daviana Ramírez Benavides
 UCR ECCI CI-2414 Recuperación de Información Prof. M.Sc. Kryscia Daviana Ramírez Benavides Introducción Grandes cantidades de información textual en la Internet. Se desea representar esta información con
UCR ECCI CI-2414 Recuperación de Información Prof. M.Sc. Kryscia Daviana Ramírez Benavides Introducción Grandes cantidades de información textual en la Internet. Se desea representar esta información con
I. CARACTERISTICAS DEL ALGORITMO ID3
 I. CARACTERISTICAS DEL ALGORITMO ID3 El investigador J. Ross Quinlan desarrolló el algoritmo conocido como ID3 (Induction Decision Trees) en el año de 1983. Pertenece a la familia TDIDT (Top-Down Induction
I. CARACTERISTICAS DEL ALGORITMO ID3 El investigador J. Ross Quinlan desarrolló el algoritmo conocido como ID3 (Induction Decision Trees) en el año de 1983. Pertenece a la familia TDIDT (Top-Down Induction
Principios de Bioestadística
 Principios de Bioestadística Dra. Juliana Giménez www.cii.org.ar Nos permite Llegar a conclusiones correctas acerca de procedimientos para el diagnostico Valorar protocolos de estudio e informes Se pretende
Principios de Bioestadística Dra. Juliana Giménez www.cii.org.ar Nos permite Llegar a conclusiones correctas acerca de procedimientos para el diagnostico Valorar protocolos de estudio e informes Se pretende
INTELIGENCIA DE NEGOCIO
 INTELIGENCIA DE NEGOCIO 2015-2016 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos Tema 4. Modelos de Predicción: Clasificación, regresión
INTELIGENCIA DE NEGOCIO 2015-2016 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos Tema 4. Modelos de Predicción: Clasificación, regresión
Modelos elección discreta y variable dependiente limitada
 Modelos elección discreta y variable dependiente limitada Profesor: Graciela Sanroman Facultad de Ciencias Económicas y Administración Año 2010 Modelos multinomiales Los modelos multinomiales son aquellos
Modelos elección discreta y variable dependiente limitada Profesor: Graciela Sanroman Facultad de Ciencias Económicas y Administración Año 2010 Modelos multinomiales Los modelos multinomiales son aquellos
Tema: Métodos de Ordenamiento. Parte 3.
 Programación IV. Guía 4 1 Facultad: Ingeniería Escuela: Computación Asignatura: Programación IV Tema: Métodos de Ordenamiento. Parte 3. Objetivos Específicos Identificar la estructura de algunos algoritmos
Programación IV. Guía 4 1 Facultad: Ingeniería Escuela: Computación Asignatura: Programación IV Tema: Métodos de Ordenamiento. Parte 3. Objetivos Específicos Identificar la estructura de algunos algoritmos
Árboles de Decisión. Tomás Arredondo Vidal 26/3/08
 Árboles de Decisión Tomás Arredondo Vidal 26/3/08 Árboles de Decisión Contenidos Árboles de Decisión Sobreajuste Recorte (Pruning) Investigación Relacionada a los Árboles de Decisión William of Occam inventa
Árboles de Decisión Tomás Arredondo Vidal 26/3/08 Árboles de Decisión Contenidos Árboles de Decisión Sobreajuste Recorte (Pruning) Investigación Relacionada a los Árboles de Decisión William of Occam inventa
Técnicas Cuantitativas para el Management y los Negocios I
 Técnicas Cuantitativas para el Management y los Negocios I Licenciado en Administración Módulo II: ESTADÍSTICA INFERENCIAL Contenidos Módulo II Unidad 4. Probabilidad Conceptos básicos de probabilidad:
Técnicas Cuantitativas para el Management y los Negocios I Licenciado en Administración Módulo II: ESTADÍSTICA INFERENCIAL Contenidos Módulo II Unidad 4. Probabilidad Conceptos básicos de probabilidad:
10.3. Sec. Prueba de hipótesis para la media poblacional. Copyright 2013, 2010 and 2007 Pearson Education, Inc.
 Sec. 10.3 Prueba de hipótesis para la media poblacional (μ) Para probar una hipótesis con respecto a la media poblacional, cuando la desviación estándar poblaciónal es desconocida, usamos una distribución-t
Sec. 10.3 Prueba de hipótesis para la media poblacional (μ) Para probar una hipótesis con respecto a la media poblacional, cuando la desviación estándar poblaciónal es desconocida, usamos una distribución-t
CC40A Complejidad de Kolmogorov
 CC40A Complejidad de Kolmogorov Ricardo Baeza Yates, Rodrigo Paredes Dept. de Ciencias de la Computación, Universidad de Chile. 1. Definiciones Básicas La Complejidad de Kolmogorov (CK) de un string s
CC40A Complejidad de Kolmogorov Ricardo Baeza Yates, Rodrigo Paredes Dept. de Ciencias de la Computación, Universidad de Chile. 1. Definiciones Básicas La Complejidad de Kolmogorov (CK) de un string s
Aprendizaje Automatizado
 Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Aprendizaje Automatizado Aprendizaje Automatizado Programas que mejoran su comportamiento con la experiencia. Dos formas de adquirir experiencia: A partir de ejemplos suministrados por un usuario (un conjunto
Inferencia Estadística
 ESTADISTICA INFERENCIA ESTADÍSTICA. TITULO: AUTOR: Una corta introducción teórica de inferencia estadística Test o Pruebas de hipótesis CHI-CUADRADO. Ejercicios resueltos y propuestos JUAN VICENTE GONZÁLEZ
ESTADISTICA INFERENCIA ESTADÍSTICA. TITULO: AUTOR: Una corta introducción teórica de inferencia estadística Test o Pruebas de hipótesis CHI-CUADRADO. Ejercicios resueltos y propuestos JUAN VICENTE GONZÁLEZ
~ ALGORITMO C4.5 ~ INGENIERÍA EN SISTEMAS COMPUTACIONALES INTELIGENCIA ARTIFICIAL ING. BRUNO LÓPEZ TAKEYAS
 INGENIERÍA EN SISTEMAS COMPUTACIONALES INTELIGENCIA ARTIFICIAL ~ ALGORITMO C4.5 ~ ING. BRUNO LÓPEZ TAKEYAS ALUMNOS: José Antonio Espino López Javier Eduardo Tijerina Flores Manuel Cedano Mendoza Eleazar
INGENIERÍA EN SISTEMAS COMPUTACIONALES INTELIGENCIA ARTIFICIAL ~ ALGORITMO C4.5 ~ ING. BRUNO LÓPEZ TAKEYAS ALUMNOS: José Antonio Espino López Javier Eduardo Tijerina Flores Manuel Cedano Mendoza Eleazar
Introducción al Análisis del Coste de Algoritmos
 1/11 Introducción al Análisis del Coste de Algoritmos Josefina Sierra Santibáñez 7 de noviembre de 2017 2/11 Eficiencia de un Algoritmo Analizar un algoritmo significa, en el contexto de este curso, predecir
1/11 Introducción al Análisis del Coste de Algoritmos Josefina Sierra Santibáñez 7 de noviembre de 2017 2/11 Eficiencia de un Algoritmo Analizar un algoritmo significa, en el contexto de este curso, predecir
Técnicas Multivariadas Avanzadas
 Métodos basados en árboles Universidad Nacional Agraria La Molina 2014-2 Introducción Introducción Se describen métodos basados en árboles para regresión y clasicación. Estos métodos requieren estraticar
Métodos basados en árboles Universidad Nacional Agraria La Molina 2014-2 Introducción Introducción Se describen métodos basados en árboles para regresión y clasicación. Estos métodos requieren estraticar
Unidad II. Análisis de Datos
 Unidad II. Análisis de Datos 2. 2. D I S T R I B U C I Ó N D E F R E C U E N C I A S 2. 3. P R U E B A D E H I P Ó T E S I S 2. 4. T A B U L A C I Ó N C R U Z A D A Distribución de frecuencias Cuántos
Unidad II. Análisis de Datos 2. 2. D I S T R I B U C I Ó N D E F R E C U E N C I A S 2. 3. P R U E B A D E H I P Ó T E S I S 2. 4. T A B U L A C I Ó N C R U Z A D A Distribución de frecuencias Cuántos
DISTRIBUCION DE FRECUENCIAS BIDIMENSIONALES RELACION DE DOS CARACTERES Relación entre variables cualitativas
 08/11/01 DISTRIBUCION DE FRECUENCIAS BIDIMENSIONALES RELACION DE DOS CARACTERES Relación entre variables cualitativas CARACTERES INDEPENDIENTES Respuesta a un tratamiento No Sí Total (marginales por filas)
08/11/01 DISTRIBUCION DE FRECUENCIAS BIDIMENSIONALES RELACION DE DOS CARACTERES Relación entre variables cualitativas CARACTERES INDEPENDIENTES Respuesta a un tratamiento No Sí Total (marginales por filas)
Tablas de contingencia y contrastes χ 2
 Tablas de contingencia y contrastes χ 2 Independencia Grado de Biología sanitaria M. Marvá e-mail: marcos.marva@uah.es Unidad docente de Matemáticas, Universidad de Alcalá 7 de diciembre de 2017 Contraste
Tablas de contingencia y contrastes χ 2 Independencia Grado de Biología sanitaria M. Marvá e-mail: marcos.marva@uah.es Unidad docente de Matemáticas, Universidad de Alcalá 7 de diciembre de 2017 Contraste
Podemos definir un contraste de hipótesis como un procedimiento que se basa en lo observado en las muestras y en la teoría de la probabilidad para
 VII. Pruebas de Hipótesis VII. Concepto de contraste de hipótesis Podemos definir un contraste de hipótesis como un procedimiento que se basa en lo observado en las muestras y en la teoría de la probabilidad
VII. Pruebas de Hipótesis VII. Concepto de contraste de hipótesis Podemos definir un contraste de hipótesis como un procedimiento que se basa en lo observado en las muestras y en la teoría de la probabilidad
Tema: Métodos de Ordenamiento. Parte 3.
 Programación IV. Guía No. 5 1 Facultad: Ingeniería Escuela: Computación Asignatura: Programación IV Tema: Métodos de Ordenamiento. Parte 3. Objetivos Específicos Identificar la estructura de algunos algoritmos
Programación IV. Guía No. 5 1 Facultad: Ingeniería Escuela: Computación Asignatura: Programación IV Tema: Métodos de Ordenamiento. Parte 3. Objetivos Específicos Identificar la estructura de algunos algoritmos
TABLAS DE CONTINGENCIA
 Tablas de contingencia 1 TABLAS DE CONTINGENCIA En SPSS, el procedimiento de Tablas de Contingencia crea tablas de clasificación doble y múltiple y, además, proporciona una serie de pruebas y medidas de
Tablas de contingencia 1 TABLAS DE CONTINGENCIA En SPSS, el procedimiento de Tablas de Contingencia crea tablas de clasificación doble y múltiple y, además, proporciona una serie de pruebas y medidas de
Tema 8: Árboles de Clasificación
 Tema 8: Árboles de Clasificación p. 1/11 Tema 8: Árboles de Clasificación Abdelmalik Moujahid, Iñaki Inza, Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Tema 8: Árboles de Clasificación p. 1/11 Tema 8: Árboles de Clasificación Abdelmalik Moujahid, Iñaki Inza, Pedro Larrañaga Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Tema 5. Muestreo y distribuciones muestrales
 1 Tema 5. Muestreo y distribuciones muestrales En este tema: Muestreo y muestras aleatorias simples. Distribución de la media muestral: Esperanza y varianza. Distribución exacta en el caso normal. Distribución
1 Tema 5. Muestreo y distribuciones muestrales En este tema: Muestreo y muestras aleatorias simples. Distribución de la media muestral: Esperanza y varianza. Distribución exacta en el caso normal. Distribución