Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU. Clase 5 Programación Avanzada y Optimización
|
|
|
- Jaime Maestre Rojo
- hace 7 años
- Vistas:
Transcripción
1 Computación de Propósito General en Unidades de Procesamiento Gráfico () P. Ezzatti, M. Pedemontey E. Dufrechou Clase 5 Programación Avanzada y Optimización Contenido Memoria compartida Conflicto de bancos Reduce Transferencias a memoria Código PTX Errores en tiempo de ejecución Algunas recomendaciones de performance 1
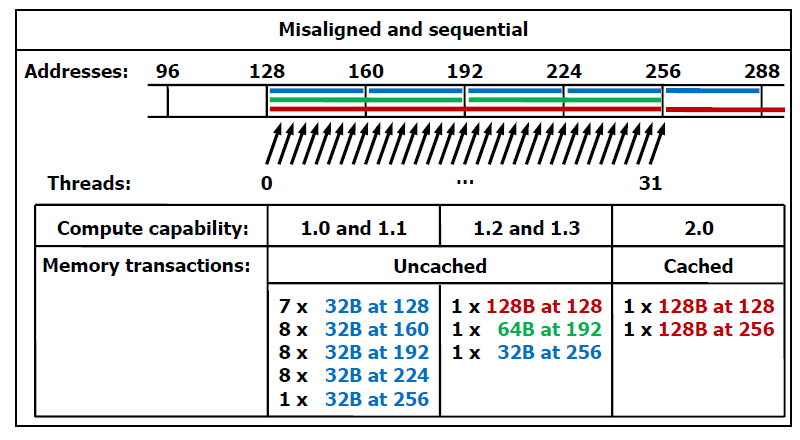
2 El acceso a memoria global es por segmentos. Incluso cuando solamente se quiere leer una palabra. Si no se usan todos los datos de un segmento, se está desperdiciando ancho de banda. Los segmentos están alineados a múltiplos de 32, 64 o 128 bytes. El acceso no alineado es más costoso que el acceso alineado. Coalesced access: Según Merriam-Webster to unite into a whole (unir en un todo). Podríamos traducirlo como acceso unido o fusionado. Cada solicitud de acceso a memoria global de un warp: se parte en dos solicitudes una para cada half-warp ambas solicitudes son atendidas (issued) independientemente. Los accesos a memoria de hilos de un half-warpse fusionan en una o más transacciones según características que dependen de las compute capability de la tarjeta. 2
3 Compute capabilities 1.0 y 1.1: Para lograr acceso fusionado en el half-warp se debe cumplir: o Los hilos deben acceder a la memoria en secuencia (i-ésimohilo accede a la i-ésima palabra). o Si el tamaño de palabra al que se accede es de 4 bytes, las 16 palabras deben estar en el mismo segmento de 64 bytes. o Si el tamaño de palabra al que se accede es de 8 bytes, las 16 palabras deben estar en el mismo segmento de 128 bytes. o Si el tamaño de palabra al que se accede es de 16 bytes, las 16 palabras deben estar en dos segmento contiguos de 128 bytes. Compute capabilities 1.0 y 1.1: Cuando se cumplen las condiciones: o Si el tamaño de palabra al que se accede es de 4 bytes, se hace una única transacción de 64 bytes. o Si el tamaño de palabra al que se accede es de 8 bytes, se hace una única transacción de 128 bytes. o Si el tamaño de palabra al que se accede es de 16 bytes, se hacen dos transacciones de 128 bytes. Si no se cumplen las condiciones, se realizan 16 transacciones separadas de 32 bytes cada una. Compute capabilities 1.2 y 1.3: Los hilos del half-warp pueden acceder a las palabras en cualquier orden, incluyendo la misma palabra, y solamente se realizará una transacción para cada segmento. El procedimiento de acceso del half-warp es el siguiente: o Se busca el segmento correspondiente al hilo con el id más chico. o El tamaño del segmento depende del tamaño de la palabra al que se quiere acceder: 32 bytes (palabras de 1 byte), 64 bytes (palabras de 2 bytes) y 128 bytes (palabras de 4, 8 y 16 bytes). o Se buscan los otros hilos que deban acceder a direcciones del mismo segmento. o Se intenta reducir el tamaño de la transacción y se realiza. o Se repite el proceso hasta que se atienda a todos los hilos del half-warp. 3
4 Compute capabilities 1.2 y 1.3: La reducción del tamaño de la transacción: o Si el tamaño es 128 bytes y solamente se usa la mitad superior o inferior, se reduce el tamaño a 64 bytes. o Si el tamaño es 64 bytes y solamente se usa la mitad superior o inferior, se reduce el tamaño a 32 bytes. Compute capabilities 2.x: Las transacciones a memoria global son cacheadas. Hay un caché L1 para cada multiprocesador y un caché L2 compartido por todos los multiprocesadores. La misma memoria física se usa como memoria compartida y caché L1 (se puede configurar 48 KB y 16 KB o 16 KB y 48 KB). El tamaño del caché L2 es 768 KB. Los accesos a memoria caché en L1 y L2 usan transacciones de 128 bytes. Los accesos a memoria caché solamente en L2 usan transacciones de 32 bytes. Compute capabilities 2.x: Si el tamaño de la palabra es de 8 bytes, se realizan dos solicitudes de 128 bytes, una para cada half-warp. Si el tamaño de la palabra es de 16 bytes, se realizan cuatro solicitudes de 128 bytes, una para cada quarter-warp. Cada solicitud se particiona en cache-lines. Si se produce un miss, se accede a la memoria global. Los hilos pueden acceder a las palabras en cualquier orden, incluso a las mismas palabras. 4
5 5
6 Ejemplo 1: global void CopiaOffset(float *output, float *input, int offset) { int idx = blockidx.x * blockdim.x + threadidx.x + offset; output[idx] = input[idx]; Lanzando veces 320 bloques de 128 hilos en una 9800 GTX+ (Comp. Cap1.1, 512 MB, 128 CUDA cores) Ejemplo 2 (gentileza de Robert Strzodka): Arrayof Structs(AoS) struct NormalStruct { Type1 comp1; Type2 comp2; Type3 comp3; ; typedef NormalStruct AoSContainer[SIZE]; Structof Arrays(SoA) struct SoAContainer{ Type1 comp1[size]; Type2 comp2[size]; Type3 comp3[size]; ; SoAContainer container; AoSContainer container; Ejemplo 2 (gentileza de Robert Strzodka): Arrayof Structs(AoS): container[1].comp3; container[2].comp3; container[3].comp3; container[4].comp3; Struct of Arrays(SoA): container.comp3[1]; container.comp3[2]; container.comp3[3]; container.comp3[4]; 6
7 Memoria Compartida Memoria Compartida Es cientos de veces más rápida que la memoria global. Puede usarse como una especie de caché para reducir los accesos a memoria global. Permite que los hilos de un mismo bloque puedan cooperar. Se puede usar para evitar accesos no coalesceda la memoria global: Los datos se guardan en forma intermedia en la memoria compartida. Se reordena el acceso a los datos para que cuando se copien de memoria compartida a memoria global el acceso sea coalesced. Memoria Compartida La memoria compartida se divide en módulos del mismo tamaño llamados bancos. Palabras de 32 bits contiguas están en bancos contiguos. Los bancos pueden ser accedidos simultáneamente. Si las lecturas o escrituras caen todas en bancos distintos, pueden ser atendidas simultáneamente. Cada banco puede atender una solicitud por ciclo. En general, si dos solicitudes caen en el mismo banco de memoria, se produce un conflicto (bankconflict) y el acceso al banco es serializado. Solamente se produce a nivel de half-warp. 7
. El acceso es más lento cuando: Varios hilos del half-warp acceden al mismo banco.")
8 Memoria Compartida Memoria Compartida Memoria Compartida No hay conflicto y el acceso es rápido cuando: Todos los hilos del half-warp acceden a diferentes bancos. Todos los hilos del half-warp leen la misma dirección (broadcast). El acceso es más lento cuando: Varios hilos del half-warp acceden al mismo banco. Se produce un conflicto y se debe serializar el acceso. Se requieren tantos ciclos como el máximo número de accesos al mismo banco. 8
9 Reduce Reduce Reducción en paralelo de la suma. Los datos se copian inicialmente de la memoria global a la memoria compartida. Solamente se realiza la primera etapa de la reducción. La suma de subtotales podría ser en: - GPU: haciendo más etapas de reducción. - CPU: transfiriendo a CPU los resultados intermedios y haciendo una iteración en CPU. Reduce Para declarar la memoria compartida se puede usar una constante: #define CANT_HILOS 128 global void reduction(float * output, float * input) { shared float intermedio[cant_hilos]; ; reduction <<<N_BLOCK,CANT_HILOS>>> (output,input); Para declarar la memoria compartida se puede hacer en forma dinámica con extern: global void reduction(float * output, float * input) { extern shared float intermedio[]; ; reduction <<<N_BLOCK,CANT_HILOS, CANT_HILOS*sizeof(float)>>> (output,input); 9
10 Reduce Primer enfoque Reduce Primer enfoque global void reduction(float * output, float * input){ extern shared float intermedio[]; int step = 1; int idx = blockidx.x * blockdim.x + threadidx.x; intermedio[threadidx.x] = input[idx]; while (step < blockdim.x) { if (threadidx.x%(2*step)==0) intermedio[threadidx.x] = intermedio[threadidx.x] + intermedio[threadidx.x + step]; syncthreads(); step = step * 2; syncthreads(); if (threadidx.x==0) output[blockidx.x] = intermedio[0]; Reduce Bloques 5000 Hilos 128 Primer enfoque Ejecutado en loop5000 x 128 veces en una 9800 GTX+ (Comp. Cap1.1, 512 MB, 128 CUDA cores), el tiempo de ejecución es aproximadamente 505 s. La implementación tiene varios problemas. El más importante es la divergencia de warps. 10
11 Reduce Segundo enfoque Reduce Segundo enfoque global void reduction(float * output, float * input){ extern shared float intermedio[]; int step = 1; int idx = blockidx.x * blockdim.x + threadidx.x; intermedio[threadidx.x] = input[idx]; while (step < blockdim.x) { if (threadidx.x < blockdim.x/step) intermedio[threadidx.x] = intermedio[threadidx.x] + intermedio[threadidx.x + step]; syncthreads(); step = step * 2; syncthreads(); if (threadidx.x==0) output[blockidx.x] = intermedio[0]; Reduce Segundo enfoque Bloques 5000 Hilos 128 Ejecutado en loop5000 x 128 veces en una 9800 GTX+ (Comp. Cap1.1, 512 MB, 128 CUDA cores), el tiempo de ejecución es aproximadamente 182 s. (mejora 2.77) Hay conflictos de bancos en el acceso a memoria compartida. 11
12 Reduce Tercer enfoque Reduce Tercer enfoque global void reduction(float * output, float * input){ extern shared float intermedio[]; int idx = blockidx.x * blockdim.x + threadidx.x; intermedio[threadidx.x] = input[idx]; int i = blockdim.x/2; while (i!= 0) { if (threadidx.x < i) intermedio[threadidx.x] = intermedio[threadidx.x] + intermedio[threadidx.x + i]; syncthreads(); i = i / 2; syncthreads(); if (threadidx.x==0) output[blockidx.x] = intermedio[0]; Reduce Tercer enfoque Bloques 5000 Hilos 128 Ejecutado en loop5000 x 128 veces en una 9800 GTX+ (Comp. Cap1.1, 512 MB, 128 CUDA cores), el tiempo de ejecución es aproximadamente 153 s. (mejora 3.30). Y si movemos el primer syncthreads()para adentro del if, así solamente sincronizamos los hilos que suman?? -Ojo!!! Son todos los hilos!!! 12
13 Transferencias a Memoria Transferencias a memoria Memoria no paginable Optimización de transferencias - Agrupar transferencias - Evitar transferencia de poca memoria cudahostalloc() - Mayor ancho de banda - Posibilidad de mapear memoria del host en el device. - Es un recurso limitado - Evita copia de paginable a no paginable. Transferencias a memoria Transferencias asincrónicas Utilizan streams(no entraremos en detalles) cudastreamcreate( &stream [ i ] ); cudamallochost( (void )& hostptr, NUM STREAMS size) ; cudamemcpyasync ( inputdevptr + i size, hostptr + i size, size, cudamemcpyhosttodevice, stream [ i ] ); Permiten solapar cálculos con transferencias. Ojo! Ahora las transferencias no sincronizan! 13
14 Código PTX Código PTX Recordemos la compilación El código PTX puede obtenerse Puede dar pistas de posibles optimizaciones del código C/C++ CUDA Application NVCC PTX Code PTX to Target Compiler CPU Code G80 GPU Target code Código PTX El código PTX se puede obtener compilando con la flag ptx: nvcc ptx algo.cu Se genera el archivo algo.ptx El código PTX permite hilar muy fino en aspectos del código CUDA que impactan en la performance. 14
15 Código PTX global void CopiaRara(float * output, float * input){ int idx = blockidx.x * blockdim.x + threadidx.x; output[idx] = input[idx] * 2.27; Inspeccionemos el código resultante (ver archivo1.ptx). ld.global.f32 %f1, [%rd4+0]; // id:17 cvt.f64.f32 %fd1, %f1; // mov.f64 %fd2, 0d400228f5c28f5c29; // 2.27 mul.f64 %fd3, %fd1, %fd2; // cvt.rn.f32.f64 %f2, %fd3; // Código PTX global void CopiaRara(float * output, float * input){ int idx = blockidx.x * blockdim.x + threadidx.x; output[idx] = input[idx] * 2.27f; Inspeccionemos el código resultante (ver archivo2.ptx). El mismo fragmento de programa se transformó en: ld.global.f32 %f1, [%rd4+0]; // id:17 mov.f32 %f2, 0f401147ae; // 2.27 mul.f32 %f3, %f1, %f2; Errores en tiempo de ejecución 15
16 Errores en tiempo de ejecución CUDA no avisa cuando se produce un error. Veamos un ejemplo: int main(int argc, char *argv[]){ float * input = NULL; int size = 1000 * sizeof(float); float * inputcpu = NULL; inputcpu = (float*) malloc (size); for (int j=0;j<1000);j++) { inputcpu[j]=j+1.1f; cudamemcpy(input,inputcpu,size, cudamemcpyhosttodevice); return 0; input no tiene memoria reservada y no da error!!!! Errores en tiempo de ejecución CUDA SDK provee macros en cutil.h para revisar errores. Cada llamada a la biblioteca CUDA se puede envolver con CUDA_SAFE_CALL() Luego de la ejecución de cada kernelpodemos revisar los errores con CUT_CHECK_ERROR() Errores en tiempo de ejecución A ver #include "cutil.h" int main(int argc, char *argv[]){ float * input = NULL; int size = 1000 * sizeof(float); float * inputcpu = NULL; inputcpu = (float*) malloc (size); for (int j=0;j<1000);j++) { inputcpu[j]=j+1.1f; cudamemcpy(input,inputcpu,size, cudamemcpyhosttodevice); CUDA_SAFE_CALL(cudaFree(input)); return 0; Sigue sin fallar!!!! y entonces???? 16
17 Errores en tiempo de ejecución Los errores de CUDA son asíncronos. El fallo se produce en cudamemcopy. La llamada a cudafree se realiza pero sin ejecutarse. Sugerencias: Envolver todas las llamadas la biblioteca CUDA con CUDA_SAFE_CALL() Después de un kernel cudathreadsychronize()para forzar que termine su ejecución Revisar los errores del kernel con CUT_CHECK_ERROR() Errores en tiempo de ejecución Ahora si!!! #include "cutil.h" int main(int argc, char *argv[]){ float * input = NULL; int size = 1000 * sizeof(float); float * inputcpu = NULL; inputcpu = (float*) malloc (size); for (int j=0;j<1000);j++) { inputcpu[j]=j+1.1f; CUDA_SAFE_CALL(cudaMemcpy(input,inputCPU,size, cudamemcpyhosttodevice)); CUDA_SAFE_CALL(cudaFree(input)); return 0; Cudaerror in file'error.cu' in line 32 : invaliddevicepointer. Algunas recomendaciones adicionales sobre performance 17
18 Algunas recomendaciones adicionales sobre performance Evitar la divergencia de hilos dentro de un warp. El número de bloques debe ser mayor al número de multiprocesadores: - De forma de mantener a todos los multiprocesadores ocupados. - Para permitir ocultar latencias cuando un bloque está trancado con un syncthreads()debe ser mayor al doble del número de multiprocesadores. El número de hilos por bloque debe ser un múltiplo de 32 (tamaño de warp). 18
Primeros pasos con CUDA. Clase 1
 Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Primeros pasos con CUDA Clase 1 Ejemplo: suma de vectores Comencemos con un ejemplo sencillo: suma de vectores. Sean A, B y C vectores de dimensión N, la suma se define como: C = A + B donde C i = A i
Memorias, opciones del compilador y otras yerbas. Clase 3
 Memorias, opciones del compilador y otras yerbas Clase 3 Memorias en CUDA Grid CUDA ofrece distintas memorias con distintas características. Block (0, 0) Shared Memory Block (1, 0) Shared Memory registros
Memorias, opciones del compilador y otras yerbas Clase 3 Memorias en CUDA Grid CUDA ofrece distintas memorias con distintas características. Block (0, 0) Shared Memory Block (1, 0) Shared Memory registros
SUMA de Vectores: Hands-on
 SUMA de Vectores: Hands-on Clase X http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Algunas preguntas practicas (1) Que pasa si los vectores a sumar son muy grandes? (2) Como saber en que
SUMA de Vectores: Hands-on Clase X http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Algunas preguntas practicas (1) Que pasa si los vectores a sumar son muy grandes? (2) Como saber en que
DESARROLLO DE APLICACIONES EN CUDA
 DESARROLLO DE APLICACIONES EN CUDA Curso 2014 / 15 Procesadores Gráficos y Aplicaciones en Tiempo Real Alberto Sánchez GMRV 2005-2015 1/30 Contenidos Introducción Debugging Profiling Streams Diseño de
DESARROLLO DE APLICACIONES EN CUDA Curso 2014 / 15 Procesadores Gráficos y Aplicaciones en Tiempo Real Alberto Sánchez GMRV 2005-2015 1/30 Contenidos Introducción Debugging Profiling Streams Diseño de
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
GPU-Ejemplo CUDA. Carlos García Sánchez
 Carlos García Sánchez 1 2 Contenidos Motivación GPU vs. CPU GPU vs. Vectoriales CUDA Sintaxis Ejemplo 2 3 Motivación Computación altas prestaciones: www.top500.org 1º: Titan (300mil AMD-Opteron + 19mil
Carlos García Sánchez 1 2 Contenidos Motivación GPU vs. CPU GPU vs. Vectoriales CUDA Sintaxis Ejemplo 2 3 Motivación Computación altas prestaciones: www.top500.org 1º: Titan (300mil AMD-Opteron + 19mil
CAPACIDAD COMPUTACIONAL: Tabla 1: Resumen de algunas características de GPUs CUDA.
 IV. CAPACIDAD COMPUTACIONAL: Debido al uso de la tecnología CUDA en computación numérica, se han definido una serie de capacidades que ofrecen más información acerca del rendimiento de los dispositivos
IV. CAPACIDAD COMPUTACIONAL: Debido al uso de la tecnología CUDA en computación numérica, se han definido una serie de capacidades que ofrecen más información acerca del rendimiento de los dispositivos
INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA. Francisco Javier Hernández López
 INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA Francisco Javier Hernández López http://www.cimat.mx/~fcoj23 Guanajuato, Gto. Noviembre de 2012 Introducción a la Programación en CUDA 2 Qué es el Cómputo Paralelo
INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA Francisco Javier Hernández López http://www.cimat.mx/~fcoj23 Guanajuato, Gto. Noviembre de 2012 Introducción a la Programación en CUDA 2 Qué es el Cómputo Paralelo
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Computación en procesadores gráficos
 Programación con CUDA Ejercicio 8 José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos
Programación con CUDA Ejercicio 8 José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos
Sistemas Complejos en Máquinas Paralelas
 Sistemas Complejos en Máquinas Paralelas Clase 1: OpenMP Francisco García Eijó Departamento de Computación - FCEyN UBA 15 de Mayo del 2012 Memoria compartida Las mas conocidas son las máquinas tipo Symmetric
Sistemas Complejos en Máquinas Paralelas Clase 1: OpenMP Francisco García Eijó Departamento de Computación - FCEyN UBA 15 de Mayo del 2012 Memoria compartida Las mas conocidas son las máquinas tipo Symmetric
Librería Thrust. Clase 4. http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases
 Librería Thrust Clase 4 http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Hasta aquí... CUDA C/C++ Control de bajo nivel del mapeo al hardware Desarrollo de algoritmos de alta performance.
Librería Thrust Clase 4 http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Hasta aquí... CUDA C/C++ Control de bajo nivel del mapeo al hardware Desarrollo de algoritmos de alta performance.
Arquitecturas y programación de procesadores gráficos. Nicolás Guil Mata Dpto. de Arquitectura de Computadores Universidad de Málaga
 Arquitecturas y programación de procesadores gráficos Dpto. de Arquitectura de Computadores Universidad de Málaga Indice Arquitectura de las GPUs Arquitectura unificada Nvidia: GT200 Diagrama de bloques
Arquitecturas y programación de procesadores gráficos Dpto. de Arquitectura de Computadores Universidad de Málaga Indice Arquitectura de las GPUs Arquitectura unificada Nvidia: GT200 Diagrama de bloques
Trabajo Práctico Número 6
 Página 1 de 6 Trabajo Práctico Número 6 Arquitectura de Computadoras 24/05/2014 Instrucciones Los problemas de ejercitación propuestos en el presente trabajo práctico pueden ser resueltos en forma individual
Página 1 de 6 Trabajo Práctico Número 6 Arquitectura de Computadoras 24/05/2014 Instrucciones Los problemas de ejercitación propuestos en el presente trabajo práctico pueden ser resueltos en forma individual
Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas]
![Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas]](/thumbs/68/58196775.jpg "Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas]") Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas] RIO 2014 Río Cuarto (Argentina), 20 de Febrero, 2014 1. 2. 3. 4. 5. 6. Balanceo dinámico de la carga. [2] Mejorando el paralelismo
Ejemplos de optimización para Kepler Contenidos de la charla [18 diapositivas] RIO 2014 Río Cuarto (Argentina), 20 de Febrero, 2014 1. 2. 3. 4. 5. 6. Balanceo dinámico de la carga. [2] Mejorando el paralelismo
Computación en procesadores gráficos
 Programación con CUDA José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos Modelo de programación
Programación con CUDA José Antonio Martínez García Francisco M. Vázquez López Manuel Ujaldón Martínez Portada Ester Martín Garzón Universidad de Almería Arquitectura de las GPUs Contenidos Modelo de programación
CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS
 CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS Leopoldo N. Gaxiola, Juan J. Tapia Centro de Investigación y Desarrollo de Tecnología Digital Instituto Politécnico Nacional Avenida
CÓMPUTO DE ALTO RENDIMIENTO EN MEMORIA COMPARTIDA Y PROCESADORES GRÁFICOS Leopoldo N. Gaxiola, Juan J. Tapia Centro de Investigación y Desarrollo de Tecnología Digital Instituto Politécnico Nacional Avenida
Estructuras de Datos Declaraciones Tipos de Datos
 Departamento de Informática Universidad Técnica Federico Santa María Estructuras de Datos Declaraciones Tipos de Datos Temas: 2-3-4 IWI-131, paralelo 01 Profesor: Teddy Alfaro O. Lenguaje de Programación
Departamento de Informática Universidad Técnica Federico Santa María Estructuras de Datos Declaraciones Tipos de Datos Temas: 2-3-4 IWI-131, paralelo 01 Profesor: Teddy Alfaro O. Lenguaje de Programación
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS
 INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano sorts@dtic.ua.es Vicente Morell Giménez vmorell@dccia.ua.es Universidad de Alicante Departamento de tecnología informática y computación
INTRODUCCIÓN A LA COMPUTACIÓN PARALELA CON GPUS Sergio Orts Escolano sorts@dtic.ua.es Vicente Morell Giménez vmorell@dccia.ua.es Universidad de Alicante Departamento de tecnología informática y computación
Organización lógica Identificación de bloque
 Cómo se encuentra un bloque si está en el nivel superior? La dirección se descompone en varios campos: Etiqueta (tag): se utiliza para comparar la dirección requerida por la CPU con aquellos bloques que
Cómo se encuentra un bloque si está en el nivel superior? La dirección se descompone en varios campos: Etiqueta (tag): se utiliza para comparar la dirección requerida por la CPU con aquellos bloques que
CUDA Overview and Programming model
 Departamento de Ciencias de la computación Universidad de Chile Modelado en 3D y sus Aplicaciones en Realidad Virtual CC68W CUDA Overview and Programming model Student: Juan Silva Professor: Dr. Wolfram
Departamento de Ciencias de la computación Universidad de Chile Modelado en 3D y sus Aplicaciones en Realidad Virtual CC68W CUDA Overview and Programming model Student: Juan Silva Professor: Dr. Wolfram
Algoritmo, Estructuras y Programación II Ing. Marglorie Colina
 Unidad III Punteros Algoritmo, Estructuras y Programación II Ing. Marglorie Colina Ejemplo: Paso de Punteros a una Función Arreglos (Arrays) Unidimensionales Los Arreglos son una colección de variables
Unidad III Punteros Algoritmo, Estructuras y Programación II Ing. Marglorie Colina Ejemplo: Paso de Punteros a una Función Arreglos (Arrays) Unidimensionales Los Arreglos son una colección de variables
PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS
 Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Grupo de Ing. Electrónica aplicada a Espacios INteligentes y TRAnsporte Área Audio-Visual PROGRAMACIÓN AVANZADA DE GPUs PARA APLICACIONES CIENTÍFICAS Torrevieja (Alicante) Del 19 al 22 de Julio Álvaro
Segunda Parte: TECNOLOGÍA CUDA
 Segunda Parte: (compute unified device architecture) 12 I. CUDA CUDA es una arquitectura de cálculo paralelo de NVIDIA que aprovecha la potencia de la GPU (unidad de procesamiento gráfico) para proporcionar
Segunda Parte: (compute unified device architecture) 12 I. CUDA CUDA es una arquitectura de cálculo paralelo de NVIDIA que aprovecha la potencia de la GPU (unidad de procesamiento gráfico) para proporcionar
Prácticas de Sistemas operativos
 Prácticas de Sistemas operativos David Arroyo Guardeño Escuela Politécnica Superior de la Universidad Autónoma de Madrid Sexta semana: memoria compartida Segunda práctica 1 Memoria compartida: ejercicio
Prácticas de Sistemas operativos David Arroyo Guardeño Escuela Politécnica Superior de la Universidad Autónoma de Madrid Sexta semana: memoria compartida Segunda práctica 1 Memoria compartida: ejercicio
Punteros. Definición Un puntero es un dato que contiene una dirección de memoria.
 Punteros Definición Un puntero es un dato que contiene una dirección de memoria. NOTA: Existe una dirección especial que se representa por medio de la constante NULL (definida en ) y se emplea
Punteros Definición Un puntero es un dato que contiene una dirección de memoria. NOTA: Existe una dirección especial que se representa por medio de la constante NULL (definida en ) y se emplea
Administración de Memoria
 Sistemas Operativos Departamento de Computación Facultad de Ciencias Exactas y Naturales Universidad de Buenos Aires 22 de septiembre de 2016 Administración de memoria Administrador de Memoria (Memory
Sistemas Operativos Departamento de Computación Facultad de Ciencias Exactas y Naturales Universidad de Buenos Aires 22 de septiembre de 2016 Administración de memoria Administrador de Memoria (Memory
PROGRAMACION ESTRUCTURADA: Tema 1. El lenguaje de programación C
 PROGRAMACION ESTRUCTURADA: Tema 1. El lenguaje de programación C Presenta: David Martínez Torres Universidad Tecnológica de la Mixteca Instituto de Computación Oficina No. 37 dtorres@mixteco.utm.mx Contenido
PROGRAMACION ESTRUCTURADA: Tema 1. El lenguaje de programación C Presenta: David Martínez Torres Universidad Tecnológica de la Mixteca Instituto de Computación Oficina No. 37 dtorres@mixteco.utm.mx Contenido
05 Funciones en lenguaje C. Diego Andrés Alvarez Marín Profesor Asociado Universidad Nacional de Colombia Sede Manizales
 05 Funciones en lenguaje C Diego Andrés Alvarez Marín Profesor Asociado Universidad Nacional de Colombia Sede Manizales 1 Temario Programación funcional Declaración (prototipos) y definición de funciones
05 Funciones en lenguaje C Diego Andrés Alvarez Marín Profesor Asociado Universidad Nacional de Colombia Sede Manizales 1 Temario Programación funcional Declaración (prototipos) y definición de funciones
Segundo control de teoría
 JUSTIFICA TODAS LAS RESPUESTAS. UNA RESPUESTA SIN JUSTIFICAR SE CONSIDERA INVALIDA EJERCICIO 1: Preguntas cortas (2 puntos) 1) Qué es el superbloque de un sistema de ficheros? qué tipo de información podemos
JUSTIFICA TODAS LAS RESPUESTAS. UNA RESPUESTA SIN JUSTIFICAR SE CONSIDERA INVALIDA EJERCICIO 1: Preguntas cortas (2 puntos) 1) Qué es el superbloque de un sistema de ficheros? qué tipo de información podemos
Bloque IV. Prácticas de programación en CUDA. David Miraut Marcos García Ricardo Suárez
 Bloque IV Prácticas de programación en CUDA David Miraut Marcos García Ricardo Suárez Control de flujo Situaciones no tratadas Claves con tamaños diferentes. Cada Wrap debería acceder a claves del mismo
Bloque IV Prácticas de programación en CUDA David Miraut Marcos García Ricardo Suárez Control de flujo Situaciones no tratadas Claves con tamaños diferentes. Cada Wrap debería acceder a claves del mismo
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Arquitecturas GPU v. 2015
 v. 2015 http://en.wikipedia.org/wiki/graphics_processing_unit http://en.wikipedia.org/wiki/stream_processing http://en.wikipedia.org/wiki/general-purpose_computing_on_graphics_processing_ units http://www.nvidia.com/object/what-is-gpu-computing.html
v. 2015 http://en.wikipedia.org/wiki/graphics_processing_unit http://en.wikipedia.org/wiki/stream_processing http://en.wikipedia.org/wiki/general-purpose_computing_on_graphics_processing_ units http://www.nvidia.com/object/what-is-gpu-computing.html
Arquitectura de Computadores Problemas (hoja 4). Curso
. Curso") Arquitectura de Computadores Problemas (hoja 4). Curso 2006-07 1. Sea un computador superescalar similar a la versión Tomasulo del DLX capaz de lanzar a ejecución dos instrucciones independientes por ciclo
Arquitectura de Computadores Problemas (hoja 4). Curso 2006-07 1. Sea un computador superescalar similar a la versión Tomasulo del DLX capaz de lanzar a ejecución dos instrucciones independientes por ciclo
Facultad de Ingeniería Industrial y de Sistemas v2.0 MA781U GESTION DE MEMORIA
 GESTION DE MEMORIA Preparado por: Angel Chata Tintaya (angelchata@hotmail.com) Resumen La memoria es el lugar donde residen procesos y datos de los programas del usuario y del sistema operativo; se debe
GESTION DE MEMORIA Preparado por: Angel Chata Tintaya (angelchata@hotmail.com) Resumen La memoria es el lugar donde residen procesos y datos de los programas del usuario y del sistema operativo; se debe
Arquitectura de Computadoras
 Arquitectura de Computadoras Clase 7 Memoria Sistema de Memoria Los programadores desean acceder a cantidades ilimitadas de memoria rápida!! Solución práctica: Jerarquía de memoria organizada en niveles
Arquitectura de Computadoras Clase 7 Memoria Sistema de Memoria Los programadores desean acceder a cantidades ilimitadas de memoria rápida!! Solución práctica: Jerarquía de memoria organizada en niveles
Administración de Memoria
 Sistemas Operativos Departamento de Computación Facultad de Ciencias Exactas y Naturales Universidad de Buenos Aires 30 de abril de 2015 MMU Unidad de Gestión de Memoria (MMU): Componente del sistema operativo
Sistemas Operativos Departamento de Computación Facultad de Ciencias Exactas y Naturales Universidad de Buenos Aires 30 de abril de 2015 MMU Unidad de Gestión de Memoria (MMU): Componente del sistema operativo
QUÉ ES LA MEMORIA CACHÉ?
 QUÉ ES LA MEMORIA CACHÉ? Es una memoria de acceso rápido que se encuentra entre la CPU y la MEMORIA PRINCIPAL El ser pequeña y rápida es muy útil para acceder a datos o instrucciones recientemente accedidas
QUÉ ES LA MEMORIA CACHÉ? Es una memoria de acceso rápido que se encuentra entre la CPU y la MEMORIA PRINCIPAL El ser pequeña y rápida es muy útil para acceder a datos o instrucciones recientemente accedidas
Ejercicios de jerarquía de memoria
 Ejercicios de jerarquía de memoria J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores Grupo ARCOS Departamento
Ejercicios de jerarquía de memoria J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores Grupo ARCOS Departamento
UNIVERSIDAD DE BURGOS Área de Tecnología Electrónica INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA
 UNIVERSIDAD DE BURGOS Área de Tecnología Electrónica INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA César Represa Pérez José María Cámara Nebreda Pedro Luis Sánchez Ortega Introducción a la programación en CUDA
UNIVERSIDAD DE BURGOS Área de Tecnología Electrónica INTRODUCCIÓN A LA PROGRAMACIÓN EN CUDA César Represa Pérez José María Cámara Nebreda Pedro Luis Sánchez Ortega Introducción a la programación en CUDA
Sistemas Operativos II Junio 2006 Nombre:
 Sistemas Operativos II Junio 2006 Nombre: ITIS Castellano Ejercicio 1 [1 punto] 1. Por qué es más eficiente el cambio de contexto entre threads (hilos) que entre procesos? 2. Describe brevemente la diferencia
Sistemas Operativos II Junio 2006 Nombre: ITIS Castellano Ejercicio 1 [1 punto] 1. Por qué es más eficiente el cambio de contexto entre threads (hilos) que entre procesos? 2. Describe brevemente la diferencia
Inside Kepler. I. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes ( )
![Inside Kepler. I. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes ( )](/thumbs/70/62983111.jpg "Inside Kepler. I. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes ( )") Índice de contenidos [25 diapositivas] Inside Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3 diapositivas] 2. Los cores
Índice de contenidos [25 diapositivas] Inside Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3 diapositivas] 2. Los cores
Sistemas de Computación Memoria. 2º Semestre, 2008 José Miguel Rubio L.
 Sistemas de Computación Memoria 2º Semestre, 2008 José Miguel Rubio L. jose.rubio.l@ucv.cl http://www.inf.ucv.cl/~jrubio Técnicas de Administración de Memoria 2 Al administrar la memoria física, ocurren
Sistemas de Computación Memoria 2º Semestre, 2008 José Miguel Rubio L. jose.rubio.l@ucv.cl http://www.inf.ucv.cl/~jrubio Técnicas de Administración de Memoria 2 Al administrar la memoria física, ocurren
Palabras reservadas de C++ y C. Una palabra reservada no puede declararse como un identificador, esto haría un conflicto entre conectores y funciones.
 Palabras reservadas de C++ y C Una palabra reservada no puede declararse como un identificador, esto haría un conflicto entre conectores y funciones. A continuación se muestra el link del listado de palabras
Palabras reservadas de C++ y C Una palabra reservada no puede declararse como un identificador, esto haría un conflicto entre conectores y funciones. A continuación se muestra el link del listado de palabras
Administración de memoria
 DC - FCEyN - UBA Sistemas Operativos, 1c-2012 Saber qué partes de la memoria están en uso y cuáles no Saber qué partes de la memoria están en uso y cuáles no Asignar memoria a los procesos cuando la necesitan
DC - FCEyN - UBA Sistemas Operativos, 1c-2012 Saber qué partes de la memoria están en uso y cuáles no Saber qué partes de la memoria están en uso y cuáles no Asignar memoria a los procesos cuando la necesitan
Prof. Dr. Paul Bustamante
 Prácticas de C++ Practica Nº 10 Informática II Fundamentos de Programación Prof. Dr. Paul Bustamante INDICE 1.1 EJERCICIO 1: MI PRIMER FICHERO EN BINARIO... 1 1.2 EJERCICIO 2: LEYENDO MI PRIMER FICHERO
Prácticas de C++ Practica Nº 10 Informática II Fundamentos de Programación Prof. Dr. Paul Bustamante INDICE 1.1 EJERCICIO 1: MI PRIMER FICHERO EN BINARIO... 1 1.2 EJERCICIO 2: LEYENDO MI PRIMER FICHERO
Memoria. Organización de memorias estáticas.
 Memoria 1 Memoria Organización de memorias estáticas. 2 Memoria En memoria físicas con bus de datos sea bidireccional. 3 Memoria Decodificación en dos niveles. 4 Necesidad de cantidades ilimitadas de memoria
Memoria 1 Memoria Organización de memorias estáticas. 2 Memoria En memoria físicas con bus de datos sea bidireccional. 3 Memoria Decodificación en dos niveles. 4 Necesidad de cantidades ilimitadas de memoria
ENTRADA-SALIDA. 2. Dispositivos de Carácter: Envía o recibe un flujo de caracteres No es direccionable, no tiene operación de búsqueda
 Tipos de Dispositivos ENTRADA-SALIDA 1. Dispositivos de Bloque: Almacena información en bloques de tamaño fijo (512b hasta 32Kb) Se puede leer o escribir un bloque en forma independiente 2. Dispositivos
Tipos de Dispositivos ENTRADA-SALIDA 1. Dispositivos de Bloque: Almacena información en bloques de tamaño fijo (512b hasta 32Kb) Se puede leer o escribir un bloque en forma independiente 2. Dispositivos
Soluciones a ejercicios de jerarquía de memoria
 Soluciones a ejercicios de jerarquía de memoria J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores Grupo
Soluciones a ejercicios de jerarquía de memoria J. Daniel García Sánchez (coordinador) David Expósito Singh Javier García Blas Óscar Pérez Alonso J. Manuel Pérez Lobato Arquitectura de Computadores Grupo
Introducción a GPGPU y CUDA Doctorado en Tecnologías de la Información y las Telecomunicaciones
 Introducción a GPGPU y CUDA Doctorado en Tecnologías de la Información y las Telecomunicaciones ETSI Telecomunicación Universidad de Valladolid Mario Martínez-Zarzuela Febrero de 2015 Introducción CONTENIDO
Introducción a GPGPU y CUDA Doctorado en Tecnologías de la Información y las Telecomunicaciones ETSI Telecomunicación Universidad de Valladolid Mario Martínez-Zarzuela Febrero de 2015 Introducción CONTENIDO
Programación I Funciones
 1 Funciones Iván Cantador 2 Funciones: definición, sintaxis, ejemplos (I) Una funciónes un bloque de sentencias identificado con un nombre que se ejecutan de manera secuencial ofreciendo una funcionalidad
1 Funciones Iván Cantador 2 Funciones: definición, sintaxis, ejemplos (I) Una funciónes un bloque de sentencias identificado con un nombre que se ejecutan de manera secuencial ofreciendo una funcionalidad
El operador contenido ( ) permite acceder al contenido de
 permite acceder al contenido de") 3. Memoria Dinámica y Punteros Objetivos: Distinguir los conceptos de memoria estática y memoria dinámica Comprender el concepto de puntero como herramienta de programación Conocer cómo se definen y cómo
3. Memoria Dinámica y Punteros Objetivos: Distinguir los conceptos de memoria estática y memoria dinámica Comprender el concepto de puntero como herramienta de programación Conocer cómo se definen y cómo
Programación Estructurada
 Programación Estructurada PROGRAMACIÓN ESTRUCTURADA 1 Sesión No. 2 Nombre: El lenguaje de programación C Contextualización Una constante en todos los lenguajes de programación (viejos y nuevos) es la implementación
Programación Estructurada PROGRAMACIÓN ESTRUCTURADA 1 Sesión No. 2 Nombre: El lenguaje de programación C Contextualización Una constante en todos los lenguajes de programación (viejos y nuevos) es la implementación
Archivos & Cadenas CURSO DE PROGRAMACIÓN EN C. Centro de Investigación y de Estudios Avanzados del IPN. CINVESTAV - Tamaulipas.
 Archivos & Cadenas CURSO DE PROGRAMACIÓN EN C Centro de Investigación y de Estudios Avanzados del IPN. CINVESTAV - Tamaulipas. Febrero 2016 [Curso de programación en C] - Archivos & Cadenas 1/17 Archivos
Archivos & Cadenas CURSO DE PROGRAMACIÓN EN C Centro de Investigación y de Estudios Avanzados del IPN. CINVESTAV - Tamaulipas. Febrero 2016 [Curso de programación en C] - Archivos & Cadenas 1/17 Archivos
Descubriendo Kepler. 1. Presentación de la arquitectura. Agradecimientos. Indice de contenidos [46 diapositivas]
![Descubriendo Kepler. 1. Presentación de la arquitectura. Agradecimientos. Indice de contenidos [46 diapositivas]](/thumbs/28/12635433.jpg "Descubriendo Kepler. 1. Presentación de la arquitectura. Agradecimientos. Indice de contenidos [46 diapositivas]") Agradecimientos Descubriendo Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga A los ingenieros de Nvidia, por compartir ideas, material, diagramas, presentaciones,...
Agradecimientos Descubriendo Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga A los ingenieros de Nvidia, por compartir ideas, material, diagramas, presentaciones,...
Elementos de un programa en C
 Elementos de un programa en C Un programa en C consta de uno o más archivos. Un archivo es traducido en diferentes fases. La primera fase es el preprocesado, que realiza la inclusión de archivos y la sustitución
Elementos de un programa en C Un programa en C consta de uno o más archivos. Un archivo es traducido en diferentes fases. La primera fase es el preprocesado, que realiza la inclusión de archivos y la sustitución
ESTRUCTURA DE DATOS. Memoria estática Memoria dinámica Tipo puntero Declaración de punteros Gestión de memoria dinámica Resumen ejemplo
 ESTRUCTURA DE DATOS Memoria estática Memoria dinámica Tipo puntero Declaración de punteros Gestión de memoria dinámica Resumen ejemplo DATOS ESTÁTICOS Su tamaño y forma es constante durante la ejecución
ESTRUCTURA DE DATOS Memoria estática Memoria dinámica Tipo puntero Declaración de punteros Gestión de memoria dinámica Resumen ejemplo DATOS ESTÁTICOS Su tamaño y forma es constante durante la ejecución
Introducción a los Sistemas Operativos
 Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
Introducción a los Sistemas Operativos Pedro Corcuera Dpto. Matemática Aplicada y Ciencias de la Computación Universidad de Cantabria corcuerp@unican.es 1 Índice General Conceptos sobre ordenadores Concepto
Tema 6: Memoria dinámica
 : Programación 2 Curso 2013-2014 Índice 1 2 3 El tamaño es fijo y se conoce al implementar el programa Declaración de variables int i=0; char c; float vf[3]={1.0, 2.0, 3.0}; i c vf[0] vf[1] vf[2] 0 1.0
: Programación 2 Curso 2013-2014 Índice 1 2 3 El tamaño es fijo y se conoce al implementar el programa Declaración de variables int i=0; char c; float vf[3]={1.0, 2.0, 3.0}; i c vf[0] vf[1] vf[2] 0 1.0
Es una API (Aplication Program Interface) que se usa para paralelismo basado en hilos múltiples en entornos de memoria compartida
 que se usa para paralelismo basado en hilos múltiples en entornos de memoria compartida") Algo de OPENMP Memoria Compartida Threads O hilos, se definen como flujos de instrucciones independientes, que se ejecutan separadamente del programa principal. Con estos hilos se aprovecha mucho una máquina
Algo de OPENMP Memoria Compartida Threads O hilos, se definen como flujos de instrucciones independientes, que se ejecutan separadamente del programa principal. Con estos hilos se aprovecha mucho una máquina
Threads. Hilos - Lightweight process - Procesos ligeros
 Threads Hilos - Lightweight process - Procesos ligeros 1 Temario Concepto y Beneficios Estructuras de implementación: Servidor- Trabajador, Equipo, Pipeline Reconocimiento: En el espacio del usuario /
Threads Hilos - Lightweight process - Procesos ligeros 1 Temario Concepto y Beneficios Estructuras de implementación: Servidor- Trabajador, Equipo, Pipeline Reconocimiento: En el espacio del usuario /
Examen Final de Teoría. Grupo de teoría:
 Preguntas Cortas (2 puntos) 1. Respecto a la optimización de gestión de memoria CoW, explica brevemente: a. Qué soporte hardware utiliza el sistema para poder implementarla? b. Qué permisos aplica el sistema
Preguntas Cortas (2 puntos) 1. Respecto a la optimización de gestión de memoria CoW, explica brevemente: a. Qué soporte hardware utiliza el sistema para poder implementarla? b. Qué permisos aplica el sistema
Tema 05: Elementos de un programa en C
 Tema 05: Elementos de un programa en C M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com edfrancom@ipn.mx @edfrancom edgardoadrianfrancom Estructuras de datos (Prof. Edgardo A. Franco) 1
Tema 05: Elementos de un programa en C M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com edfrancom@ipn.mx @edfrancom edgardoadrianfrancom Estructuras de datos (Prof. Edgardo A. Franco) 1
6. Entrada y Salida Explicación de la interfaz entre el computador y el mundo exterior.
 6. Entrada y Salida Explicación de la interfaz entre el computador y el mundo exterior. 6.1. El subsistema de E/S Qué es E/S en un sistema computador? Aspectos en el diseño del subsistema de E/S: localización
6. Entrada y Salida Explicación de la interfaz entre el computador y el mundo exterior. 6.1. El subsistema de E/S Qué es E/S en un sistema computador? Aspectos en el diseño del subsistema de E/S: localización
Francisco Javier Hernández López
 Francisco Javier Hernández López fcoj23@cimat.mx http://www.cimat.mx/~fcoj23 Ejecución de más de un cómputo (cálculo) al mismo tiempo o en paralelo, utilizando más de un procesador. Arquitecturas que hay
Francisco Javier Hernández López fcoj23@cimat.mx http://www.cimat.mx/~fcoj23 Ejecución de más de un cómputo (cálculo) al mismo tiempo o en paralelo, utilizando más de un procesador. Arquitecturas que hay
Memoria Dinámica en C++
 Memoria Dinámica en C++ Algoritmos y Estructuras de Datos II DC-FCEyN-UBA 26 de Agosto de 2015 AED2 (DC-FCEyN-UBA) Memoria Dinámica en C++ 26 de Agosto de 2015 1 / 46 Repaso: Qué es una variable? Matemática:
Memoria Dinámica en C++ Algoritmos y Estructuras de Datos II DC-FCEyN-UBA 26 de Agosto de 2015 AED2 (DC-FCEyN-UBA) Memoria Dinámica en C++ 26 de Agosto de 2015 1 / 46 Repaso: Qué es una variable? Matemática:
Sistema de memoria. Introducción
 Sistema de memoria Introducción Memorias de acceso aleatorio: Apropiadas para la memorización a largo plazo de programas. Grandes y lentas. Organización: n: líneas de direcciones. m: tamaño de palabra.
Sistema de memoria Introducción Memorias de acceso aleatorio: Apropiadas para la memorización a largo plazo de programas. Grandes y lentas. Organización: n: líneas de direcciones. m: tamaño de palabra.
Jerarquía de memoria - Motivación
 Jerarquía de memoria - Motivación Idealmente uno podría desear una capacidad de memoria infinitamente grande, tal que cualquier. palabra podría estar inmediatamente disponible Estamos forzados a reconocer
Jerarquía de memoria - Motivación Idealmente uno podría desear una capacidad de memoria infinitamente grande, tal que cualquier. palabra podría estar inmediatamente disponible Estamos forzados a reconocer
Estructura de los sistemas de cómputo
 Estructura de los sistemas de cómputo Introducción Elementos básicos de un computador Registro del procesador Ejecución de las instrucciones Interrupciones Hardware de protección Introducción Qué es un
Estructura de los sistemas de cómputo Introducción Elementos básicos de un computador Registro del procesador Ejecución de las instrucciones Interrupciones Hardware de protección Introducción Qué es un
Velocidades Típicas de transferencia en Dispositivos I/O
 Entradas Salidas Velocidades Típicas de transferencia en Dispositivos I/O Entradas/Salidas: Problemas Amplia variedad de periféricos Entrega de diferentes cantidades de datos Diferentes velocidades Variedad
Entradas Salidas Velocidades Típicas de transferencia en Dispositivos I/O Entradas/Salidas: Problemas Amplia variedad de periféricos Entrega de diferentes cantidades de datos Diferentes velocidades Variedad
Sistemas Operativos. Curso 2016 Administración de memoria II
 Sistemas Operativos Curso 2016 Administración de memoria II Agenda Memoria Virtual. Paginación. Segmentación. Segmentación con paginación. Sistemas Operativos Curso 2016 Administración de memoria II 2/35
Sistemas Operativos Curso 2016 Administración de memoria II Agenda Memoria Virtual. Paginación. Segmentación. Segmentación con paginación. Sistemas Operativos Curso 2016 Administración de memoria II 2/35
Subsistemas de memoria. Departamento de Arquitectura de Computadores
 Subsistemas de memoria Departamento de Arquitectura de Computadores Índice Introducción. Conceptos básicos Características de los sistemas de memoria Jerarquías de memoria Memoria Principal Características
Subsistemas de memoria Departamento de Arquitectura de Computadores Índice Introducción. Conceptos básicos Características de los sistemas de memoria Jerarquías de memoria Memoria Principal Características
Arquitectura de Computadoras para Ingeniería
 Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Arquitectura de Computadoras para Ingeniería Ejercicios Trabajo Práctico N 7 Jerarquía de Memoria Primer Cuatrimestre de
Departamento de Cs. e Ingeniería de la Computación Universidad Nacional del Sur Arquitectura de Computadoras para Ingeniería Ejercicios Trabajo Práctico N 7 Jerarquía de Memoria Primer Cuatrimestre de
Sistemas de Computación I/O. 2º Semestre, 2008 José Miguel Rubio L. jose.rubio.l@ucv.cl http://www.inf.ucv.cl/~jrubio
 Sistemas de Computación I/O 2º Semestre, 2008 José Miguel Rubio L. jose.rubio.l@ucv.cl http://www.inf.ucv.cl/~jrubio Funciones: Enviar comandos a los dispositivos Detectar interrupciones. El usuario no
Sistemas de Computación I/O 2º Semestre, 2008 José Miguel Rubio L. jose.rubio.l@ucv.cl http://www.inf.ucv.cl/~jrubio Funciones: Enviar comandos a los dispositivos Detectar interrupciones. El usuario no
Tipos de datos y Operadores Básicos
 Módulo I: Conceptos Básicos Tema 1. Qué es un ordenador? Tema 2. Cómo se representan los datos en un ordenador? Tema 3. Qué es un lenguaje de programación? Tema 4. Cómo se hace un programa informático?
Módulo I: Conceptos Básicos Tema 1. Qué es un ordenador? Tema 2. Cómo se representan los datos en un ordenador? Tema 3. Qué es un lenguaje de programación? Tema 4. Cómo se hace un programa informático?
CPU MEMORIAS CACHE. Memorias caché. Memoria caché = memoria de tamaño pequeño y acceso rápido situada entre la CPU y la memoria principal.
 MEMORIAS CACHE Memoria caché = memoria de tamaño pequeño y acceso rápido situada entre la CPU y la memoria principal. Tiempo ciclo memoria > tiempo de ciclo del procesador la CPU debe esperar a la memoria
MEMORIAS CACHE Memoria caché = memoria de tamaño pequeño y acceso rápido situada entre la CPU y la memoria principal. Tiempo ciclo memoria > tiempo de ciclo del procesador la CPU debe esperar a la memoria
Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]
![Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]](/thumbs/27/10261315.jpg "Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]") Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
Punteros. Programación en C 1
 Punteros Programación en C 1 Índice Variables y direcciones de memoria. Punteros definición, declaración e inicialización. Punteros declaración, asignación y dereferencia. Puntero nulo, tipo void. Aritmética
Punteros Programación en C 1 Índice Variables y direcciones de memoria. Punteros definición, declaración e inicialización. Punteros declaración, asignación y dereferencia. Puntero nulo, tipo void. Aritmética
Paralelización de algoritmos para el procesado de imágenes de teledetección
 UNIVERSIDAD DE ALCALÁ Escuela Politécnica Superior INGENIERÍA DE TELECOMUNICACIÓN Trabajo Fin de Carrera Paralelización de algoritmos para el procesado de imágenes de teledetección Alberto Monescillo Álvarez
UNIVERSIDAD DE ALCALÁ Escuela Politécnica Superior INGENIERÍA DE TELECOMUNICACIÓN Trabajo Fin de Carrera Paralelización de algoritmos para el procesado de imágenes de teledetección Alberto Monescillo Álvarez
Computación matricial dispersa con GPUs y su aplicación en Tomografía Electrónica
 con GPUs y su aplicación en Tomografía Electrónica F. Vázquez, J. A. Martínez, E. M. Garzón, J. J. Fernández Portada Universidad de Almería Contenidos Computación matricial dispersa Introducción a SpMV
con GPUs y su aplicación en Tomografía Electrónica F. Vázquez, J. A. Martínez, E. M. Garzón, J. J. Fernández Portada Universidad de Almería Contenidos Computación matricial dispersa Introducción a SpMV
Tema 18: Memoria dinámica y su uso en C
 Tema 18: Memoria dinámica y su uso en C M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com edfrancom@ipn.mx @edfrancom edgardoadrianfrancom Estructuras de datos (Prof. Edgardo A. Franco) 1
Tema 18: Memoria dinámica y su uso en C M. en C. Edgardo Adrián Franco Martínez http://www.eafranco.com edfrancom@ipn.mx @edfrancom edgardoadrianfrancom Estructuras de datos (Prof. Edgardo A. Franco) 1
Introducción a la Computación. Capítulo 10 Repertorio de instrucciones: Características y Funciones
 Introducción a la Computación Capítulo 10 Repertorio de instrucciones: Características y Funciones Que es un set de instrucciones? La colección completa de instrucciones que interpreta una CPU Código máquina
Introducción a la Computación Capítulo 10 Repertorio de instrucciones: Características y Funciones Que es un set de instrucciones? La colección completa de instrucciones que interpreta una CPU Código máquina
Organización de Computadoras
 Organización de Computadoras SEMANA 10 UNIVERSIDAD NACIONAL DE QUILMES Qué vimos? Mascaras Repeticiones controladas Arreglos Modo indirecto Q5 Hoy! Memorias: Características Memorias ROM Jerarquía de memorias
Organización de Computadoras SEMANA 10 UNIVERSIDAD NACIONAL DE QUILMES Qué vimos? Mascaras Repeticiones controladas Arreglos Modo indirecto Q5 Hoy! Memorias: Características Memorias ROM Jerarquía de memorias
GESTION DE LA MEMORIA
 GESTION DE LA MEMORIA SISTEMAS OPERATIVOS Generalidades La memoria es una amplia tabla de datos, cada uno de los cuales con su propia dirección Tanto el tamaño de la tabla (memoria), como el de los datos
GESTION DE LA MEMORIA SISTEMAS OPERATIVOS Generalidades La memoria es una amplia tabla de datos, cada uno de los cuales con su propia dirección Tanto el tamaño de la tabla (memoria), como el de los datos
Aspectos avanzados de arquitectura de computadoras Jerarquía de Memoria II. Facultad de Ingeniería - Universidad de la República Curso 2017
 Aspectos avanzados de arquitectura de computadoras Jerarquía de Memoria II Facultad de Ingeniería - Universidad de la República Curso 2017 Técnicas Básicas (1/5) Mayor Tamaño de Caché Mejora obvia: Aumentar
Aspectos avanzados de arquitectura de computadoras Jerarquía de Memoria II Facultad de Ingeniería - Universidad de la República Curso 2017 Técnicas Básicas (1/5) Mayor Tamaño de Caché Mejora obvia: Aumentar
Cómputo paralelo con openmp y C
 Cómputo paralelo con openmp y C Sergio Ivvan Valdez Peña Guanajuato, México. 13 de Marzo de 2012 Sergio Ivvan Valdez Peña Cómputo Guanajuato, paralelo conméxico. openmp y () C 13 de Marzo de 2012 1 / 27
Cómputo paralelo con openmp y C Sergio Ivvan Valdez Peña Guanajuato, México. 13 de Marzo de 2012 Sergio Ivvan Valdez Peña Cómputo Guanajuato, paralelo conméxico. openmp y () C 13 de Marzo de 2012 1 / 27
Computación de Propósito General en Unidades de Procesamiento Gráfico. Clase 7-ALN y GPUs GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () P. Ezzatti, M. Pedemontey E. Dufrechou Clase 7 ALN en GPUs 1 Contenido Conceptos básicos de ALN Problemas Tipo de datos y matrices
Computación de Propósito General en Unidades de Procesamiento Gráfico () P. Ezzatti, M. Pedemontey E. Dufrechou Clase 7 ALN en GPUs 1 Contenido Conceptos básicos de ALN Problemas Tipo de datos y matrices
48 ContactoS 84, (2012)
") 48 ContactoS 84, 47 55 (2012) Recibido: 31 de enero de 2012. Aceptado: 03 de mayo de 2012. Resumen En los últimos años la tecnología de las unidades de procesamiento de gráficos (GPU-Graphics Processsing
48 ContactoS 84, 47 55 (2012) Recibido: 31 de enero de 2012. Aceptado: 03 de mayo de 2012. Resumen En los últimos años la tecnología de las unidades de procesamiento de gráficos (GPU-Graphics Processsing
Bases de Datos Paralelas. Carlos A. Olarte BDII
 Carlos A. Olarte (carlosolarte@puj.edu.co) BDII Contenido 1 Introducción 2 Paralelismo de I/O 3 Paralelismo entre Consultas 4 OPS Introducción Por qué tener bases de datos paralelas? Tipos de arquitecturas:
Carlos A. Olarte (carlosolarte@puj.edu.co) BDII Contenido 1 Introducción 2 Paralelismo de I/O 3 Paralelismo entre Consultas 4 OPS Introducción Por qué tener bases de datos paralelas? Tipos de arquitecturas:
Sistemas Operativos Práctica 3
 Sistemas Operativos Práctica 3 Ing. Andrés Bustamante afbustamanteg@unal.edu.co Ingeniería de Sistemas Facultad de Ingeniería Universidad de la Amazonia 2009 1. Objetivo El objetivo de la práctica es que
Sistemas Operativos Práctica 3 Ing. Andrés Bustamante afbustamanteg@unal.edu.co Ingeniería de Sistemas Facultad de Ingeniería Universidad de la Amazonia 2009 1. Objetivo El objetivo de la práctica es que
Sistema Cache. Técnicas Digitales III Ing. Gustavo Nudelman Universidad Tecnológica Nacional - Facultad Regional Buenos Aires
 Sistema Cache Técnicas Digitales III Ing. Gustavo Nudelman 2012 RAM dinámica Almacena un bit como una capacidad espuria en un transistor La necesidad de conservar la carga y la lectura destructiva obliga
Sistema Cache Técnicas Digitales III Ing. Gustavo Nudelman 2012 RAM dinámica Almacena un bit como una capacidad espuria en un transistor La necesidad de conservar la carga y la lectura destructiva obliga
FACULTAD DE INFORMATICA SISTEMAS OPERATIVOS 3º de Informática.
 FACULTAD DE INFORMATICA SISTEMAS OPERATIVOS 3º de Informática. PROBLEMAS SOBRE SISTEMAS DE FICHEROS 1. Calcular el número de accesos a disco necesarios para leer 20 bloques lógicos consecutivos (no necesariamente
FACULTAD DE INFORMATICA SISTEMAS OPERATIVOS 3º de Informática. PROBLEMAS SOBRE SISTEMAS DE FICHEROS 1. Calcular el número de accesos a disco necesarios para leer 20 bloques lógicos consecutivos (no necesariamente
1 Primitivas básicas de OpenMP
 1 Primitivas básicas de OpenMP Consultar la página oficial de la plataforma OpenMP http://www.openmp.org/drupal/ Pragmas Es una directiva para el compilador que permite la definición de nuevas directivas
1 Primitivas básicas de OpenMP Consultar la página oficial de la plataforma OpenMP http://www.openmp.org/drupal/ Pragmas Es una directiva para el compilador que permite la definición de nuevas directivas
2. Variables dinámicas
 2. Variables dinámicas 1. Introducción 2. Gestión de memoria dinámica 3. Punteros y variables dinámicas en lenguaje algorítmico 4. Gestión de memoria dinámica y punteros en C Bibliografía Biondi y Clavel.
2. Variables dinámicas 1. Introducción 2. Gestión de memoria dinámica 3. Punteros y variables dinámicas en lenguaje algorítmico 4. Gestión de memoria dinámica y punteros en C Bibliografía Biondi y Clavel.
Taller de Sistemas Operativos. Administración de memoria (kernel) 2012
 2012") Taller de Sistemas Operativos Administración de memoria (kernel) 2012 Agenda Introducción Páginas Obtener y liberar memoria Zonas de memoria Slab allocator Buddy system Zone allocator Pools de memoria
Taller de Sistemas Operativos Administración de memoria (kernel) 2012 Agenda Introducción Páginas Obtener y liberar memoria Zonas de memoria Slab allocator Buddy system Zone allocator Pools de memoria
Introducción a la Computación (Matemática)
") Introducción a la Computación (Matemática) Primer Cuatrimestre de 2016 Brevísima Introducción a la Organización de Computadoras 1 Mapa de la materia Programas simples en C++. Especificación de problemas.
Introducción a la Computación (Matemática) Primer Cuatrimestre de 2016 Brevísima Introducción a la Organización de Computadoras 1 Mapa de la materia Programas simples en C++. Especificación de problemas.
GPGPU Avanzado. Sistemas Complejos en Máquinas Paralelas. Esteban E. Mocskos (emocskos@dc.uba.ar) 5/6/2012
 5/6/2012") Sistemas Complejos en Máquinas Paralelas GPGPU Avanzado Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales, UBA CONICET 5/6/2012 E. Mocskos (UBA CONICET) GPGPU Avanzado 5/6/2012
Sistemas Complejos en Máquinas Paralelas GPGPU Avanzado Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales, UBA CONICET 5/6/2012 E. Mocskos (UBA CONICET) GPGPU Avanzado 5/6/2012
TEMA 12: MEJORA DE LAS PRESTACIONES DE LA MEMORIA
 TEMA 12: MEJORA DE LAS PRESTACIONES DE LA MEMORIA PRINCIPAL. 1. Introducción. 2. Aumentar el ancho de la memoria. 3. Memoria entrelazada. 4. Bancos de memoria independientes. 5. Tecnología de las memorias.
TEMA 12: MEJORA DE LAS PRESTACIONES DE LA MEMORIA PRINCIPAL. 1. Introducción. 2. Aumentar el ancho de la memoria. 3. Memoria entrelazada. 4. Bancos de memoria independientes. 5. Tecnología de las memorias.
Arquitectura de Computadoras para Ingeniería
 Arquitectura de Computadoras para Ingeniería (Cód. 7526) 1 Cuatrimestre 2016 Dra. Dana K. Urribarri DCIC - UNS Dana K. Urribarri AC 2016 1 Jerarquía de Memoria Dana K. Urribarri AC 2016 2 Indexado físico
Arquitectura de Computadoras para Ingeniería (Cód. 7526) 1 Cuatrimestre 2016 Dra. Dana K. Urribarri DCIC - UNS Dana K. Urribarri AC 2016 1 Jerarquía de Memoria Dana K. Urribarri AC 2016 2 Indexado físico
Tema III: Componentes de un Sistema Operativo
 Tema III: Componentes de un Sistema Operativo Concepto de proceso Jerarquía de memoria: Concepto de memoria cache Memoria virtual Partición Sistema de ficheros Sistema de entrada/salida: Driver y controladora
Tema III: Componentes de un Sistema Operativo Concepto de proceso Jerarquía de memoria: Concepto de memoria cache Memoria virtual Partición Sistema de ficheros Sistema de entrada/salida: Driver y controladora