Computación matricial dispersa con GPUs y su aplicación en Tomografía Electrónica
|
|
|
- Jorge Jiménez Prado
- hace 8 años
- Vistas:
Transcripción

1 con GPUs y su aplicación en Tomografía Electrónica F. Vázquez, J. A. Martínez, E. M. Garzón, J. J. Fernández Portada Universidad de Almería

2 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 2

3 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 3

4 SpMV: Producto matriz dispersa vector Operación ampliamente utilizada Procesamiento de imágenes, simulación, ingeniería de control, etc.. Aumentar el rendimiento de SpMV equivale a aumentar el rendimiento de estas aplicaciones Matriz dispersa > 90% del total son ceros Representación en formato denso excede capacidad de memoria x > 150 GB La mayoría de las operaciones son cero 4

5 Matriz dispersa. Ventajas: No se realizan operaciones sobre elementos nulos ya que no se representan El espacio de memoria se reduce considerablemente Inconvenientes: Pérdida de la estructura densa: Número de columnas Necesario usar otras estructuras de datos que permitan la identificación de cada entrada de la matriz Formatos de representación 5

6 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 6

7 El rendimiento de SpMV viene determinado por: Formato de representación utilizado Patrón de la matriz 7

8 Formatos de representación N. Bell, M. Garland CRS, CRS-vector, COO, ELL, HYB M. M. Baskaran, R. Bordawekar SpMV4GPU J. W. Choi, A. Singth, R. W. Vuduc Georgia, USA BELLPACK A. Monakov, A. Lokhmotov, A. Avestiyan Moscow, Russia Sliced ELLPACK 8


9 CRS A: Elementos no nulos de la matriz J: Índices de columna start: Inicio y fin de cada fila 9

10 SpMV CRS: 1 thread por fila int x = blockidx.x * blockdim.x + threadidx.x; if(x<n){ int i, k, p; float svalue=0.0; } i=start[x]; k=start[x+1]; SpMV GPU: u = Av for (p=i;p<k;p++){ svalue+=a[p] * v[ J[p] ]; } u[x]=svalue; 10

11 CRS Acceso a memoria no coalescente Desbalanceo de carga si el número de no nulos por fila es muy distinto entre threads de un mismo bloque Indirección en el acceso a v int x = blockidx.x * blockdim.x + threadidx.x; if(x<n){ int i, k, p; float svalue=0.0; i=start[x]; k=start[x+1]; for (p=i;p<k;p++){ svalue+=a[p] * v[ J[p] ]; } u[x]=svalue; } 11
{ svalue+=a[p] * v[ J[p] ]; }")

12 SpMV CRS-vector: 32 threads por fila 12


13 SpMV CRS-vector: Etapa de reducción-suma 13

14 CRS-vector Acceso a memoria coalescente parcial Coalescencia parcial: No tiene en cuenta la alineación de segmentos: 3º half-warp: thread_id: Segmentos: 0..15, , , thread_id 32 toca 3º segmento posición 37 thread_id 43 toca 4º segmento posición 48 Aumenta el paralelismo al aumentar el número de threads por fila Desbalanceo a nivel de fila si el número de no nulos no es múltiplo de 32. 1ª fila tiene 37 no nulos, threads parados en la 2ª iteración 14


15 SpMV4GPU: 16 threads por fila + segmentos alineados 15

16 SpMV4GPU Acceso a memoria coalescente total Disminuye el grado de desbalanceo con respecto a CRSvector al destinar la mitad de threads a cada fila P.ej: Fila con 60 no nulos y siguiente con 5 no nulos SpMV4GPU:» 1ª fila: 4 iteraciones, 4 threads parados en la última iteración» 2ª fila: 1 iteración, 11 threads parados CRS-vector:» 1ª fila: 2 iteraciones, 4 threads parados en la última iteración» 2ª fila: 1 iteración, 27 threads parados 16


17 COO: 1 thread por elemento no nulo A: Elementos no nulos de la matriz I, J: Índices de fila y columna 17

18 COO Límite físico en el número máximo de threads que pueden ejecutarse Capacidad de cómputo 1.x: threads (65535 bloques x 512 threads/bloque) Capacidad de cómputo 2.x: threads (65535 bloques x 1024 threads/bloque) Acceso a memoria coalescente Desestructuración de la matriz. Requiere un acceso adicional a I para obtener el índice de fila Función atómica de suma. El resultado de una fila ha de ser actualizado por varios threads simultáneamente 18


19 ELL Computación matricial dispersa A: Valores de la matriz. Dimensión N x max J: Índices de columna. Dimensión N x max max: Máximo de elementos no nulos entre todas las filas Estructura regular 19

{ value = A[N * p + x]; col = J[N * p + x]; if (value <> 0) svalue+=value * v[ col ]; }")
20 SpMV ELL SpMV GPU: u = Av int x = blockidx.x * blockdim.x + threadidx.x; if(x<n){ int p, col; float value, svalue=0.0; } for (p=0;p<max;p++){ value = A[N * p + x]; col = J[N * p + x]; if (value <> 0) svalue+=value * v[ col ]; } u[x]=svalue; 20
![0; } for (p=0;p<max;p++){ value = A[N * p + x]; col = J[N *](/docs-images/45/9890748/images/page_20.jpg "p + x]; if (value <> 0) svalue+=value * v[ col ]; }")
21 ELL Acceso a memoria coalescente parcial Computación innecesaria. max es un valor global entre todas las filas de la matriz. Todos los threads han de llegar a max y realizar la comprobación value <> 0 Pérdida de rendimiento en situaciones en las que max y el número de elementos no nulos de la fila sean muy distintos Divergencia. La sentencia if incluye una divergencia que produce una serialización en los threads que cumplen la condición 21
22 HYB Trata de eliminar los problemas de ELL Distribuye la matriz en dos estructuras: ELL y COO para eliminar las discordancias entre el número de no nulos de cada fila y max Las filas con 2/3 de max ELL Resto COO Una misma fila está representada con dos formatos Se necesitan varios kernels para realizar SpMV Imposible realizar precálculos durante la realización de SpMV 22

23 BELLPACK Tres parámetros Sub-bloque denso: r x c División en sub-matrices de R filas No es un formato general Válido para matrices con Sub-bloques r x c densos 23

24 BELLPACK Cada sub-matriz de R filas con sub-bloques r x c se representa en ELL Sólo se almacena el índice de columna del primer elemento del sub-bloque 24
25 BELLPACK Válido para matrices que presentan una estructuras de subbloques densos No es un formato de representación general Necesario tunning de parámetros: Tamaño del sub-bloque: r x c Tamaño de las sub-matrices: R Tamaño del bloque de threads para la ejecución: BS Dada la reordenación previa de filas, es necesario una reordenación posterior del vector resultado Acceso a memoria coalescente total 25
26 Sliced ELLPACK División en grupos de S filas Si S = 1 CRS Si S = N ELL Reordenación inicial de filas Bloque de BS threads por S filas T=BS/S: Nº de threads por fila Si T > 1 Reducción-suma 26
27 Sliced ELLPACK Parámetro max de ELL variable cada S filas No sufre la sobrecarga de ELL en filas con un número de no nulos muy distinto Uso variable del número de threads por fila Permite la adaptación a distintos tipos de matrices 1 thread en filas muy dispersas Varios threads en matrices con menos filas, pero menos dispersas Acceso a memoria coalescente total Necesario tunning de T y S Reordenación del vector resultado 27
28 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 28
29 ELLR-T: Basado en el formato ELL R: Nueva estructura de datos que indica el número de elementos no nulos por fila: rl T: Número de threads que calculan una fila T puede ser: 1, 2, 4, 8, 16 ó 32 Con T = 1, ELLR-1 equivale a ELLR y es la versión inicial Ventajas: Elimina la sobrecarga de ELL mediante el vector rl Estructura regular de la matriz ajustada a max No requiere reordenación de filas Sencillez, permite realizar precálculos Ajuste de BS y T mediante modelo analítico de ejecución Coalescencia total, mejor rendimiento 29
30 ELLR A: Valores de la matriz J: Índices de columna rl: Longitud de cada fila 30

31 ELLR 31

32 Operaciones ELL vs ELLR Accesos a memoria 307 vs 169 ELLR: Tiempos de espera reducidos a max local del warp 32
33 ELLR-T T threads calculan una fila Aumenta número de threads totales de ejecución Aumenta número de bloques totales de ejecución Aumenta longitud de la cola de bloques por multiprocesador Implica: Aumentar paralelismo Ocupación: Ocultación de latencias en el acceso a memoria Aumenta el número de warps/bloques/threads activos Capacidad de cómputo 1.x: Capacidad de cómputo 2.x:
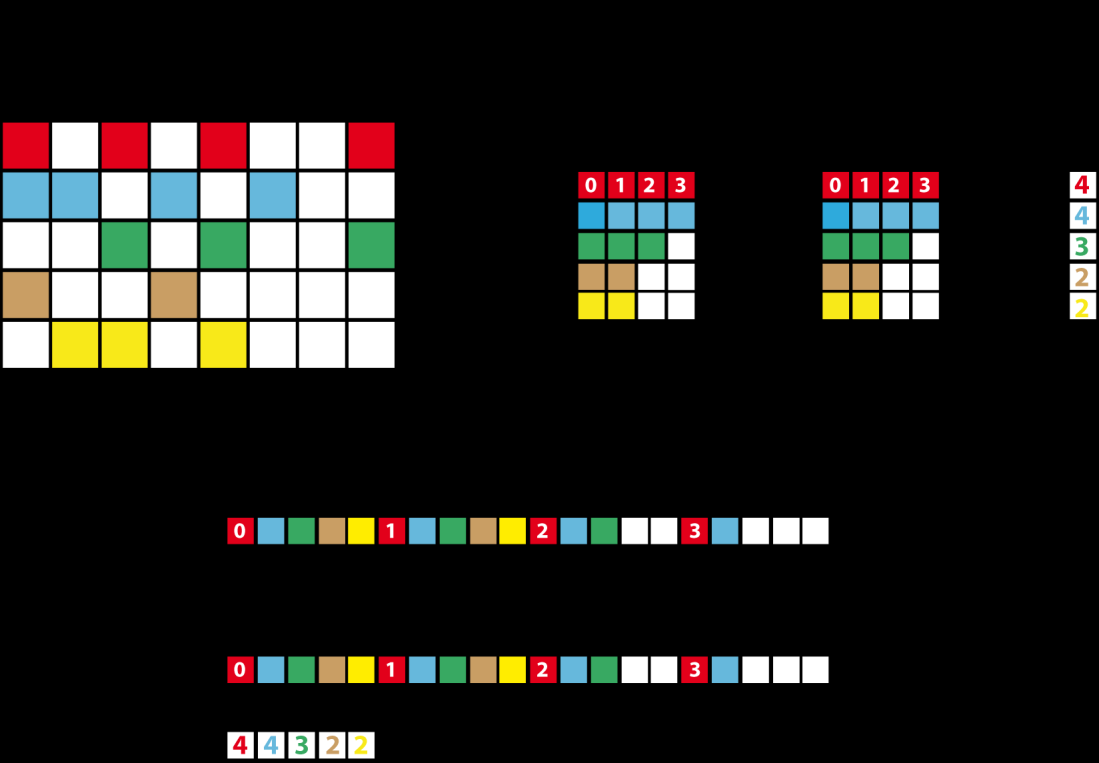
34 ELLR-T 34

35 ELLR-T 35

36 ELLR-T 36

37 37

38 38

39 39
40 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 40

41 Conjunto de matrices 41

42 42

43 43
44 Matriz (GFLOPS) BELLPACK C1060 Sliced ELLPACK GTX 280 ELLR-T GTX 285 mac_econ -- 10,14 8,25 qcd5_ ,67 29,29 mc2depi -- 20,03 23,60 rma ,60 24,38 cop20k_a -- 13,01 16,74 dense ,67 30,26 cant 27 24,74 30,01 pdb1hys 21 25,56 29,62 consph 27 28,40 29,64 shipsec ,53 29,92 pwtk 23 28,52 31,48 44
45 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 45
46 Modelo analítico de ejecución ELLR-T Objetivo: Determinar a tiempo real T y BS Ejecución: 1. Lectura del histograma de la matriz rl 2. Aplicación del modelo y obtención de T y BS 3. Lectura de la matriz y representación en ELLR-T 4. Llamada al kernel SpMV de ELLR-T con tamaño de bloque BS 46

47 Bases de diseño Asignación de bloques a los multiprocesadores de la GPU SpMV está limitado por los accesos a memoria Contar número de accesos a memoria de cada SM Rendimiento de SpMV ligado al multiprocesador más lento 47
48 Características No modela el acceso al vector v en caché de texturas Evalúa los tamaños de bloque que generan una ocupación del 100% Capacidad de cómputo 1.x: BS=128, 256, 512 Capacidad de cómputo 2.x: BS=256, 512, 768 Resultados 91% acierto cuando se utiliza caché de texturas para v 97% acierto cuando no se utiliza caché de texturas para v 48

49 49
50 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 50
51 Tomografía Electrónica Métodos de reconstrucción WBP y SIRT Adquisición de imágenes mediante geometría de eje único de giro La imagen de proyección contiene la información de las rebanadas perpendiculares al eje de giro para un determinado ángulo En la práctica toda la información de una misma rebanada se agrupa en una estructura llamada sinograma La apilación de las reconstrucciones 2D de los sinogramas dan lugar al volúmen 3D 51
52 Tomografía Electrónica WBP: Weighted BackProjection Retroproyección de las imágenes de proyección para cada ángulo de giro 52
53 Tomografía Electrónica WBP: Weighted BackProjection Weighted: Filtro paso alto con el objeto de eliminar el ruido implícito en el proceso de retroproyección Complejidad del orden O(N 3 x M). N: Núm. Voxels, M: Núm. Imágenes de proyección La reconstrucción está fuertemente afectada por la limitación de los ángulos de giro y la función de transferencia del microscopio, lo que se traduce en un emborronamiento de la imagen Válido para la obtención de una vista preliminar del espécimen 53
54 Tomografía Electrónica SIRT: Simultaneous Iterative Reconstruction Technique Cada iteración: a) Proyección b) Cálculo de error c) Retroproyección 54
55 Tomografía Electrónica SIRT: Simultaneous Iterative Reconstruction Technique Más robusto en presencia de ruido y limitación ángulos de giro Altos requerimientos computacionales Reconstrucciones de mayor calidad que WBP a) WBP b) SIRT 55
56 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 56
57 WBP Matricial for s in Nslices g s = B p s Tomografía Electrónica Rebanada 4 x 4 nbins = 4, ntilts = 1 57

58 Tomografía Electrónica WBP Matricial: Patrón general 58
59 Tomografía Electrónica WBP Matricial: Niveles de simetría General Sym1: Elementos adyacentes Sym2: Nivel de filas Sym3: Angular A: A 1, A 2, A 3, A 12, A 13, A 23, A 123 B: B 1, B 2, B 3, B 12, B 13, B 23, B 123 Cada nivel de simetría reduce la matriz en un 50% 59
60 Tomografía Electrónica WBP Matricial: ELLR General 60

61 Tomografía Electrónica WBP Geforce GTX

62 Tomografía Electrónica WBP Geforce GTX
63 Contenidos Computación matricial dispersa Introducción a SpMV Formatos de representación de matrices dispersas Formatos ELLR y ELLR-T Evaluación comparativa Modelo analítico de ejecución ELLR-T Tomografía Electrónica Métodos de reconstrucción WBP, SIRT WBP Matricial SIRT Matricial 63
64 Tomografía Electrónica SIRT Matricial Proyección: q k = A g k Cálculo de error: e k = (p q k ) / w Retroproyección: g k+1 = g k + B e k A = B T 64
65 SIRT Matricial Tomografía Electrónica A: General B: Sym2 65

66 Tomografía Electrónica SIRT 66
67 Tomografía Electrónica SIRT 67

68 Tomografía Electrónica WBP: 25 min vs 10 seg SIRT: 38 horas vs 19 min 68

69 Contraportada 69
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Una variable de clase escalar tiene un nivel de indirección igual a 1. Por ejemplo, las variables i, b y x definidas como se muestra a continuación.
 Descripción de la semántica de ALFA En esta descripción sólo se mencionarán los aspectos en los que el lenguaje de programación ALFA pueda diferir de otros lenguajes de programación de alto nivel. Se sobreentienden
Descripción de la semántica de ALFA En esta descripción sólo se mencionarán los aspectos en los que el lenguaje de programación ALFA pueda diferir de otros lenguajes de programación de alto nivel. Se sobreentienden
Procesamiento Digital de Imágenes. Compresión de imágenes
 FICH, UNL - Departamento de Informática - Ingeniería Informática Procesamiento Digital de Imágenes Guía de Trabajos Prácticos 8 Compresión de imágenes 2010 1. Objetivos Analizar las características y el
FICH, UNL - Departamento de Informática - Ingeniería Informática Procesamiento Digital de Imágenes Guía de Trabajos Prácticos 8 Compresión de imágenes 2010 1. Objetivos Analizar las características y el
DIRECTRICES Y ORIENTACIONES GENERALES PARA LAS PRUEBAS DE ACCESO A LA UNIVERSIDAD
 Curso Asignatura 2014/2015 MATEMÁTICAS II 1º Comentarios acerca del programa del segundo curso del Bachillerato, en relación con la Prueba de Acceso a la Universidad La siguiente relación de objetivos,
Curso Asignatura 2014/2015 MATEMÁTICAS II 1º Comentarios acerca del programa del segundo curso del Bachillerato, en relación con la Prueba de Acceso a la Universidad La siguiente relación de objetivos,
1. Manejo de memoria estática 2. Manejo de memoria dinámica
 1. Manejo de memoria estática 2. Manejo de memoria dinámica *La administración de memoria de una computadora es una tarea fundamental debido a que la cantidad de memoria es limitada. *El sistema operativo
1. Manejo de memoria estática 2. Manejo de memoria dinámica *La administración de memoria de una computadora es una tarea fundamental debido a que la cantidad de memoria es limitada. *El sistema operativo
!!!!!!!! !!!!! Práctica!4.! Programación!básica!en!C.! ! Grado!en!Ingeniería!!en!Electrónica!y!Automática!Industrial! ! Curso!2015H2016!
 INFORMÁTICA Práctica4. ProgramaciónbásicaenC. GradoenIngenieríaenElectrónicayAutomáticaIndustrial Curso2015H2016 v2.1(18.09.2015) A continuación figuran una serie de ejercicios propuestos, agrupados por
INFORMÁTICA Práctica4. ProgramaciónbásicaenC. GradoenIngenieríaenElectrónicayAutomáticaIndustrial Curso2015H2016 v2.1(18.09.2015) A continuación figuran una serie de ejercicios propuestos, agrupados por
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS
 GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
INFORMÁTICA. Práctica 5. Programación en C. Grado en Ingeniería en Electrónica y Automática Industrial. Curso 2013-2014. v1.0 (05.03.
 INFORMÁTICA Práctica 5. Programación en C. Grado en Ingeniería en Electrónica y Automática Industrial Curso 2013-2014 v1.0 (05.03.14) A continuación figuran una serie de ejercicios propuestos, agrupados
INFORMÁTICA Práctica 5. Programación en C. Grado en Ingeniería en Electrónica y Automática Industrial Curso 2013-2014 v1.0 (05.03.14) A continuación figuran una serie de ejercicios propuestos, agrupados
Fundamentos de Matemática Aplicada. (Prácticas)
") Fundamentos de Matemática Aplicada (Prácticas) Damián Ginestar Peiró UNIVERSIDAD POLITÉCNICA DE VALENCIA 1 Índice general 1. Matrices dispersas 3 1.0.1. Esquemas de almacenamiento.............. 3 1.0.2.
Fundamentos de Matemática Aplicada (Prácticas) Damián Ginestar Peiró UNIVERSIDAD POLITÉCNICA DE VALENCIA 1 Índice general 1. Matrices dispersas 3 1.0.1. Esquemas de almacenamiento.............. 3 1.0.2.
1. Generalidades. M. en C. Mario Farias-Elinos
 1. Generalidades M. en C. Mario Farias-Elinos 1 Contenido Introducción Arquitectura de computadoras Arquitectura de un sistema operativo Introducción 2 Introducción Qué es un sistema operativo? Intermediario
1. Generalidades M. en C. Mario Farias-Elinos 1 Contenido Introducción Arquitectura de computadoras Arquitectura de un sistema operativo Introducción 2 Introducción Qué es un sistema operativo? Intermediario
Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]
![Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]](/thumbs/27/10261315.jpg "Ejemplos de optimización para Kepler. 1. Balanceo dinámico de la carga. Contenidos de la charla [18 diapositivas]") Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
Ejemplos de optimización para Kepler Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga Contenidos de la charla [18 diapositivas] 1. Balanceo dinámico de la carga.
PROGRAMACION VECTORIAL RAFAEL VALDÉS VALDAZO UO196581 ÁNGEL MARÍA VILABOA PÉREZ UO197092 BLOQUE PARALELAS 4º INFORMÁTICA UNIVERSIDAD DE OVIEDO
 PROGRAMACION VECTORIAL RAFAEL VALDÉS VALDAZO UO196581 ÁNGEL MARÍA VILABOA PÉREZ UO197092 BLOQUE PARALELAS 4º INFORMÁTICA UNIVERSIDAD DE OVIEDO INTRODUCCIÓN Ligada al concepto de vector Decodifica instrucciones
PROGRAMACION VECTORIAL RAFAEL VALDÉS VALDAZO UO196581 ÁNGEL MARÍA VILABOA PÉREZ UO197092 BLOQUE PARALELAS 4º INFORMÁTICA UNIVERSIDAD DE OVIEDO INTRODUCCIÓN Ligada al concepto de vector Decodifica instrucciones
Departamento de Arquitectura de computadores y electrónica Universidad de Almería. Tesis Doctoral
 Departamento de Arquitectura de computadores y electrónica Universidad de Almería Tesis Doctoral Computación algebraica dispersa con procesadores grácos y su aplicación en tomografía electrónica Francisco
Departamento de Arquitectura de computadores y electrónica Universidad de Almería Tesis Doctoral Computación algebraica dispersa con procesadores grácos y su aplicación en tomografía electrónica Francisco
Procesos. Planificación del Procesador.
 Procesos. Planificación del Procesador. Sistemas Operativos. Tema 2. Concepto de Proceso. Una definición sencilla: Programa en ejecución. Entidad pasiva Programa RECURSOS CPU Memoria Ficheros Dispositivos
Procesos. Planificación del Procesador. Sistemas Operativos. Tema 2. Concepto de Proceso. Una definición sencilla: Programa en ejecución. Entidad pasiva Programa RECURSOS CPU Memoria Ficheros Dispositivos
Hardware y Estructuras de Control. Memoria Virtual. Ejecución de un Programa. Ejecución de un Programa
 Memoria Virtual Capítulo 8 Hardware y Estructuras de Control Las referencias de memoria se traducen a direcciones físicas dinámicamente en tiempo de ejecución Un proceso puede ser intercambiado hacia dentro
Memoria Virtual Capítulo 8 Hardware y Estructuras de Control Las referencias de memoria se traducen a direcciones físicas dinámicamente en tiempo de ejecución Un proceso puede ser intercambiado hacia dentro
SEGURIDAD Y PROTECCION DE FICHEROS
 SEGURIDAD Y PROTECCION DE FICHEROS INTEGRIDAD DEL SISTEMA DE ARCHIVOS ATAQUES AL SISTEMA PRINCIPIOS DE DISEÑO DE SISTEMAS SEGUROS IDENTIFICACIÓN DE USUARIOS MECANISMOS DE PROTECCIÓN Y CONTROL INTEGRIDAD
SEGURIDAD Y PROTECCION DE FICHEROS INTEGRIDAD DEL SISTEMA DE ARCHIVOS ATAQUES AL SISTEMA PRINCIPIOS DE DISEÑO DE SISTEMAS SEGUROS IDENTIFICACIÓN DE USUARIOS MECANISMOS DE PROTECCIÓN Y CONTROL INTEGRIDAD
GRAFOS. Prof. Ing. M.Sc. Fulbia Torres
 ESTRUCTURAS DE DATOS 2006 Prof. DEFINICIÓN Un grafo consta de un conjunto de nodos(o vértices) y un conjunto de arcos (o aristas). Cada arco de un grafo se especifica mediante un par de nodos. Denotemos
ESTRUCTURAS DE DATOS 2006 Prof. DEFINICIÓN Un grafo consta de un conjunto de nodos(o vértices) y un conjunto de arcos (o aristas). Cada arco de un grafo se especifica mediante un par de nodos. Denotemos
Calendarización anual Programa de matemáticas 2º básico
 Calendarización anual Programa de matemáticas 2º básico Esta calendarización está pensada para un horario de 10 horas pedagógicas semanales. 1. Se basa en el trabajo de profesoras que han trabajado con
Calendarización anual Programa de matemáticas 2º básico Esta calendarización está pensada para un horario de 10 horas pedagógicas semanales. 1. Se basa en el trabajo de profesoras que han trabajado con
Capítulo 12: Indexación y asociación
 Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
21.1.2. TEOREMA DE DETERMINACIÓN DE APLICACIONES LINEALES
 Aplicaciones lineales. Matriz de una aplicación lineal 2 2. APLICACIONES LINEALES. MATRIZ DE UNA APLICACIÓN LINEAL El efecto que produce el cambio de coordenadas sobre una imagen situada en el plano sugiere
Aplicaciones lineales. Matriz de una aplicación lineal 2 2. APLICACIONES LINEALES. MATRIZ DE UNA APLICACIÓN LINEAL El efecto que produce el cambio de coordenadas sobre una imagen situada en el plano sugiere
Introducción a Matlab.
 Introducción a Matlab. Ejercicios básicos de manipulación de imágenes. Departamento de Ingeniería electrónica, Telecomunicación y Automática. Área de Ingeniería de Sistemas y Automática OBJETIVOS: Iniciación
Introducción a Matlab. Ejercicios básicos de manipulación de imágenes. Departamento de Ingeniería electrónica, Telecomunicación y Automática. Área de Ingeniería de Sistemas y Automática OBJETIVOS: Iniciación
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti M. Pedemonte Práctico Programación con CUDA Práctica 0: Ejecución del ejemplo visto en teórico (suma de
Práctica 1ª: Introducción a Matlab. 1er curso de Ingeniería Industrial: Ingeniería de Control
 1er curso de Ingeniería Industrial: Ingeniería de Control Práctica 1ª: Introducción a Matlab Departamento de Ingeniería electrónica, Telecomunicación y Automática. Área de Ingeniería de Sistemas y Automática
1er curso de Ingeniería Industrial: Ingeniería de Control Práctica 1ª: Introducción a Matlab Departamento de Ingeniería electrónica, Telecomunicación y Automática. Área de Ingeniería de Sistemas y Automática
Introducción. Por último se presentarán las conclusiones y recomendaciones pertinentes.
 Introducción En el presente documento se explicarán las consideraciones realizadas para implementar la convolución bidimensional en la arquitectura CUDA. En general se discutirá la metodología seguida
Introducción En el presente documento se explicarán las consideraciones realizadas para implementar la convolución bidimensional en la arquitectura CUDA. En general se discutirá la metodología seguida
Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322
 Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322 Nicole García Gómez 2830047-6 Diego Riquelme Adriasola 2621044-5 RESUMEN.- La minería de datos corresponde a la extracción
Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322 Nicole García Gómez 2830047-6 Diego Riquelme Adriasola 2621044-5 RESUMEN.- La minería de datos corresponde a la extracción
No se requiere que los discos sean del mismo tamaño ya que el objetivo es solamente adjuntar discos.
 RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
Manual de rol gestor de GAV para moodle 2.5
 Manual de rol gestor de GAV para moodle 2.5 Consultas LDAP-GAUR... 2 Buscar en LDAP datos de un usuario... 2 Docentes... 3 Buscar en GAUR datos de un docente... 3 Buscar en GAUR la docencia de un docente
Manual de rol gestor de GAV para moodle 2.5 Consultas LDAP-GAUR... 2 Buscar en LDAP datos de un usuario... 2 Docentes... 3 Buscar en GAUR datos de un docente... 3 Buscar en GAUR la docencia de un docente
DIAGRAMA DE GANTT. Este gráfico consiste simplemente en un sistema de coordenadas en que se indica:
 INTRODUCCION DIAGRAMA DE GANTT Diagrama de Gantt: Los cronogramas de barras o gráficos de Gantt fueron concebidos por el ingeniero norteamericano Henry L. Gantt, uno de los precursores de la ingeniería
INTRODUCCION DIAGRAMA DE GANTT Diagrama de Gantt: Los cronogramas de barras o gráficos de Gantt fueron concebidos por el ingeniero norteamericano Henry L. Gantt, uno de los precursores de la ingeniería
Plataformas de soporte computacional: arquitecturas avanzadas,
 Plataformas de soporte computacional: arquitecturas avanzadas, sesión 2 Diego. Llanos, Belén Palop Departamento de Informática Universidad de Valladolid {diego,b.palop}@infor.uva.es Índice 1. Segmentación
Plataformas de soporte computacional: arquitecturas avanzadas, sesión 2 Diego. Llanos, Belén Palop Departamento de Informática Universidad de Valladolid {diego,b.palop}@infor.uva.es Índice 1. Segmentación
Heterogénea y Jerárquica
 Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
GRUPOS PUNTUALES. 4.- Si un plano de simetría contiene un eje de orden n, existen n planos que contienen el eje. formando entre ellos ángulos de
 GRUPOS PUNTUALES Existen algunas relaciones entre elementos de simetría que pueden ser útiles a la hora de deducir cuales son los conjuntos de estos que forman grupo. 1.- Todos los elementos de simetría
GRUPOS PUNTUALES Existen algunas relaciones entre elementos de simetría que pueden ser útiles a la hora de deducir cuales son los conjuntos de estos que forman grupo. 1.- Todos los elementos de simetría
MC ENRIQUE MARTINEZ PEÑA. Maestría en Ingeniería. Introducción al PDI Representación de la imagen Operaciones básicas con imágenes
 Maestría en Ingeniería Procesamiento Digital de Imágenes Contenido Introducción al PDI Representación de la imagen Operaciones básicas con imágenes 2 1 Inteligencia artificial La inteligencia artificial
Maestría en Ingeniería Procesamiento Digital de Imágenes Contenido Introducción al PDI Representación de la imagen Operaciones básicas con imágenes 2 1 Inteligencia artificial La inteligencia artificial
Aplicaciones Lineales
 Aplicaciones Lineales Concepto de aplicación lineal T : V W Definición: Si V y W son espacios vectoriales con los mismos escalares (por ejemplo, ambos espacios vectoriales reales o ambos espacios vectoriales
Aplicaciones Lineales Concepto de aplicación lineal T : V W Definición: Si V y W son espacios vectoriales con los mismos escalares (por ejemplo, ambos espacios vectoriales reales o ambos espacios vectoriales
Procedimientos para agrupar y resumir datos
 Procedimientos para agrupar y resumir datos Contenido Introducción Presentación de los primeros n valores Uso de funciones de agregado 4 Fundamentos de GROUP BY 8 Generación de valores de agregado dentro
Procedimientos para agrupar y resumir datos Contenido Introducción Presentación de los primeros n valores Uso de funciones de agregado 4 Fundamentos de GROUP BY 8 Generación de valores de agregado dentro
Segmentación de Imágenes en Procesadores Many-Core
 Universidad de Santiago de Compostela Segmentación de Imágenes en Procesadores Many-Core Lilien Beatriz Company Garay Fernández lilien.gf@gmail.com Indice 1. Introducción Single-chip Cloud Computer (SCC)
Universidad de Santiago de Compostela Segmentación de Imágenes en Procesadores Many-Core Lilien Beatriz Company Garay Fernández lilien.gf@gmail.com Indice 1. Introducción Single-chip Cloud Computer (SCC)
Universidad de Córdoba. Trabajo de Fin de Máster
 Universidad de Córdoba Máster en Sistemas Inteligentes Trabajo de Fin de Máster Minería de Reglas de Asociación en GPU Córdoba, Julio de 2013 Autor: Alberto Cano Rojas Director: Dr. Sebastián Ventura Soto
Universidad de Córdoba Máster en Sistemas Inteligentes Trabajo de Fin de Máster Minería de Reglas de Asociación en GPU Córdoba, Julio de 2013 Autor: Alberto Cano Rojas Director: Dr. Sebastián Ventura Soto
De acuerdo con sus características podemos considerar tres tipos de vectores:
 CÁLCULO VECTORIAL 1. ESCALARES Y VECTORES 1.1.-MAGNITUDES ESCALARES Y VECTORIALES Existen magnitudes físicas cuyas cantidades pueden ser expresadas mediante un número y una unidad. Otras, en cambio, requieren
CÁLCULO VECTORIAL 1. ESCALARES Y VECTORES 1.1.-MAGNITUDES ESCALARES Y VECTORIALES Existen magnitudes físicas cuyas cantidades pueden ser expresadas mediante un número y una unidad. Otras, en cambio, requieren
e-mailing Solution La forma más efectiva de llegar a sus clientes.
 e-mailing Solution La forma más efectiva de llegar a sus clientes. e-mailing Solution Es muy grato para nosotros presentarles e-mailing Solution, nuestra solución de e-mail Marketing para su empresa. E-Mailing
e-mailing Solution La forma más efectiva de llegar a sus clientes. e-mailing Solution Es muy grato para nosotros presentarles e-mailing Solution, nuestra solución de e-mail Marketing para su empresa. E-Mailing
PROBLEMAS MÉTRICOS. Página 183 REFLEXIONA Y RESUELVE. Diagonal de un ortoedro. Distancia entre dos puntos. Distancia de un punto a una recta
 PROBLEMAS MÉTRICOS Página 3 REFLEXIONA Y RESUELVE Diagonal de un ortoedro Halla la diagonal de los ortoedros cuyas dimensiones son las siguientes: I) a =, b =, c = II) a = 4, b =, c = 3 III) a =, b = 4,
PROBLEMAS MÉTRICOS Página 3 REFLEXIONA Y RESUELVE Diagonal de un ortoedro Halla la diagonal de los ortoedros cuyas dimensiones son las siguientes: I) a =, b =, c = II) a = 4, b =, c = 3 III) a =, b = 4,
ATIENDE Registro de la atención de un cliente
 ATIENDE Registro de la atención de un cliente El sistema de medición de calidad de atención ATIENDE genera un registro de la atención de un cliente en una oficina comercial. Permite grabar el audio de
ATIENDE Registro de la atención de un cliente El sistema de medición de calidad de atención ATIENDE genera un registro de la atención de un cliente en una oficina comercial. Permite grabar el audio de
CAPÍTULO 7 7. CONCLUSIONES
 CAPÍTULO 7 7. CONCLUSIONES 7.1. INTRODUCCIÓN 7.2. CONCLUSIONES PARTICULARES 7.3. CONCLUSIONES GENERALES 7.4. APORTACIONES DEL TRABAJO DE TESIS 7.5. PROPUESTA DE TRABAJOS FUTUROS 197 CAPÍTULO 7 7. Conclusiones
CAPÍTULO 7 7. CONCLUSIONES 7.1. INTRODUCCIÓN 7.2. CONCLUSIONES PARTICULARES 7.3. CONCLUSIONES GENERALES 7.4. APORTACIONES DEL TRABAJO DE TESIS 7.5. PROPUESTA DE TRABAJOS FUTUROS 197 CAPÍTULO 7 7. Conclusiones
Capítulo 5 Programación del algoritmo en LabVIEW
 Programación del algoritmo en LabVIEW En este capítulo se describen las funciones que se emplearon para implementar el control PID wavenet en LabVIEW. El algoritmo wavenet fue implementado en LabVIEW para
Programación del algoritmo en LabVIEW En este capítulo se describen las funciones que se emplearon para implementar el control PID wavenet en LabVIEW. El algoritmo wavenet fue implementado en LabVIEW para
Este documento enumera los diferentes tipos de Diagramas Matriciales y su proceso de construcción. www.fundibeq.org
 DIAGRAMA MATRICIAL 1.- INTRODUCCIÓN Este documento enumera los diferentes tipos de Diagramas Matriciales y su proceso de construcción. Muestra su potencial, como herramienta indispensable para la planificación
DIAGRAMA MATRICIAL 1.- INTRODUCCIÓN Este documento enumera los diferentes tipos de Diagramas Matriciales y su proceso de construcción. Muestra su potencial, como herramienta indispensable para la planificación
SERVIDOR WEB PARA ACCESO EN TIEMPO REAL A INFORMACIÓN METEOROLÓGICA DISTRIBUIDA
 SERVIDOR WEB PARA ACCESO EN TIEMPO REAL A INFORMACIÓN METEOROLÓGICA DISTRIBUIDA E. SÁEZ, M. ORTIZ, F. QUILES, C. MORENO, L. GÓMEZ Área de Arquitectura y Tecnología de Computadores. Departamento de Arquitectura
SERVIDOR WEB PARA ACCESO EN TIEMPO REAL A INFORMACIÓN METEOROLÓGICA DISTRIBUIDA E. SÁEZ, M. ORTIZ, F. QUILES, C. MORENO, L. GÓMEZ Área de Arquitectura y Tecnología de Computadores. Departamento de Arquitectura
Modelización y Balanceo de la Carga Computacional en la Simulación Paralela de la Dispersión Atmosférica de Contaminantes
 Modelización y Balanceo de la Carga Computacional en la Simulación Paralela de la Dispersión Atmosférica de Contaminantes Diego R. Martínez diegorm@dec.usc.es Dpto. Electrónica y Computación Universidad
Modelización y Balanceo de la Carga Computacional en la Simulación Paralela de la Dispersión Atmosférica de Contaminantes Diego R. Martínez diegorm@dec.usc.es Dpto. Electrónica y Computación Universidad
Documentación Técnica. Diseño de interfaces. Conciliación Contable. Cash Flow Manager
 Diseño de interfaces Conciliación Contable Cash Flow Manager INDICE DISEÑO DE INTERFACES SISTEMA DE CONCILIACIÓN 3 VISIÓN GLOBAL... 3 Entrada de movimientos bancarios 3 Entrada de movimientos contables
Diseño de interfaces Conciliación Contable Cash Flow Manager INDICE DISEÑO DE INTERFACES SISTEMA DE CONCILIACIÓN 3 VISIÓN GLOBAL... 3 Entrada de movimientos bancarios 3 Entrada de movimientos contables
Administración Logística de Materiales
 Administración Logística de Materiales Para un mejor conocimiento de la industria acerca de distribución física, manufactura y compras, se estableció el programa de administración logística de materiales.
Administración Logística de Materiales Para un mejor conocimiento de la industria acerca de distribución física, manufactura y compras, se estableció el programa de administración logística de materiales.
PRESUPUESTO BASE CERO ORGANISMO PÚBLICO DEL SISTEMA NACIONAL DE COORDINACIÓN FISCAL
 PRESUPUESTO BASE CERO ORGANISMO PÚBLICO DEL SISTEMA NACIONAL DE COORDINACIÓN FISCAL Cómo mejorar la forma de asignar o reasignar los Recursos Públicos? LAS ALTERNATIVAS DE MEJORA: PbR Y PbC El PbR es proceso
PRESUPUESTO BASE CERO ORGANISMO PÚBLICO DEL SISTEMA NACIONAL DE COORDINACIÓN FISCAL Cómo mejorar la forma de asignar o reasignar los Recursos Públicos? LAS ALTERNATIVAS DE MEJORA: PbR Y PbC El PbR es proceso
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570
 Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
Tutorial CUDA Univ. de Santiago. 6 y 7 de Agosto, 2013
 Tutorial CUDA Univ. de Santiago. 6 y 7 de Agosto, 2013 La suma por reducción Este código realiza la suma de un vector de N elementos mediante un operador binario de reducción, es decir, en log 2 (N) pasos.
Tutorial CUDA Univ. de Santiago. 6 y 7 de Agosto, 2013 La suma por reducción Este código realiza la suma de un vector de N elementos mediante un operador binario de reducción, es decir, en log 2 (N) pasos.
Diseño orientado al flujo de datos
 Diseño orientado al flujo de datos Recordemos que el diseño es una actividad que consta de una serie de pasos, en los que partiendo de la especificación del sistema (de los propios requerimientos), obtenemos
Diseño orientado al flujo de datos Recordemos que el diseño es una actividad que consta de una serie de pasos, en los que partiendo de la especificación del sistema (de los propios requerimientos), obtenemos
GESTION OPERATIVA. Niveles de gestión
 GESTION OPERATIVA La gestión deja de ser una tarea aislada para constituirse en una herramienta que sirve para ejecutar las acciones necesarias que permitan ordenar, disponer y organizar los recursos de
GESTION OPERATIVA La gestión deja de ser una tarea aislada para constituirse en una herramienta que sirve para ejecutar las acciones necesarias que permitan ordenar, disponer y organizar los recursos de
Instructivo de Microsoft Excel 2003
 Instructivo de Microsoft Excel 2003 El presente instructivo corresponde a una guía básica para el manejo del programa y la adquisición de conceptos en relación a este utilitario. Que es Microsoft Excel?
Instructivo de Microsoft Excel 2003 El presente instructivo corresponde a una guía básica para el manejo del programa y la adquisición de conceptos en relación a este utilitario. Que es Microsoft Excel?
Propuesta Matriz de Actividades para un Ciclo de Vida de Explotación de Datos
 Propuesta Matriz de Actividades para un Ciclo de Vida de Explotación de Datos Britos, P. 1,2 ; Fernández, E. 2,1 ; García Martínez, R 1,2 1 Centro de Ingeniería del Software e Ingeniería del Conocimiento.
Propuesta Matriz de Actividades para un Ciclo de Vida de Explotación de Datos Britos, P. 1,2 ; Fernández, E. 2,1 ; García Martínez, R 1,2 1 Centro de Ingeniería del Software e Ingeniería del Conocimiento.
Hoja de problemas Estructuras de Control
 Departamento de Estadística, I.O. y Computación Ingeniería Técnica Industrial - Electrónica Industrial Fundamentos de Informática Hoja de problemas Estructuras de Control 1. Cuál es el efecto de las siguientes
Departamento de Estadística, I.O. y Computación Ingeniería Técnica Industrial - Electrónica Industrial Fundamentos de Informática Hoja de problemas Estructuras de Control 1. Cuál es el efecto de las siguientes
15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores.
 UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
Infraestructura Tecnológica. Sesión 1: Infraestructura de servidores
 Infraestructura Tecnológica Sesión 1: Infraestructura de servidores Contextualización La infraestructura de cualquier servicio o mecanismo es importante, define el funcionamiento de los elementos en que
Infraestructura Tecnológica Sesión 1: Infraestructura de servidores Contextualización La infraestructura de cualquier servicio o mecanismo es importante, define el funcionamiento de los elementos en que
INFORME TÉCNICO PREVIO DE EVALUACIÓN DE SOFTWARE SOFTWARE MICROSOFT VISUAL STUDIO PREMIUM
 INFORME TÉCNICO PREVIO DE EVALUACIÓN DE SOFTWARE SOFTWARE MICROSOFT VISUAL STUDIO PREMIUM I-OS-35-2015 1. Nombre del Área : Oficina de Sistemas 2. Responsables de la Evaluación : Eduardo Vasquez Díaz Ronald
INFORME TÉCNICO PREVIO DE EVALUACIÓN DE SOFTWARE SOFTWARE MICROSOFT VISUAL STUDIO PREMIUM I-OS-35-2015 1. Nombre del Área : Oficina de Sistemas 2. Responsables de la Evaluación : Eduardo Vasquez Díaz Ronald
Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)
![Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)](/thumbs/36/17576386.jpg "Kepler. 1. Presentación de la arquitectura. Índice de contenidos [25 diapositivas] Kepler, Johannes (1571-1630)") Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
Índice de contenidos [25 diapositivas] Manuel Ujaldón Nvidia CUDA Fellow Dpto. Arquitectura de Computadores Universidad de Málaga 1. Presentación de la arquitectura [3] 2. Los cores y su organización [7]
USABILIDAD Y ACCESIBILIDAD EN WEB Guillermo M. Martínez de la Teja
 USABILIDAD Y ACCESIBILIDAD EN WEB Guillermo M. Martínez de la Teja "La usabilidad trata sobre el comportamiento humano; reconoce que el humano es emotivo, no está interesado en poner demasiado esfuerzo
USABILIDAD Y ACCESIBILIDAD EN WEB Guillermo M. Martínez de la Teja "La usabilidad trata sobre el comportamiento humano; reconoce que el humano es emotivo, no está interesado en poner demasiado esfuerzo
 Introducción En los años 60 s y 70 s cuando se comenzaron a utilizar recursos de tecnología de información, no existía la computación personal, sino que en grandes centros de cómputo se realizaban todas
Introducción En los años 60 s y 70 s cuando se comenzaron a utilizar recursos de tecnología de información, no existía la computación personal, sino que en grandes centros de cómputo se realizaban todas
5.1Definición transformación lineal de núcleo ó kernel, e imagen de una transformación lineal y sus propiedades
 5- ransformaciones Lineales 5Definición transformación lineal de núcleo ó kernel, e imagen de una transformación lineal sus propiedades Se denomina transformación lineal a toda función,, cuo dominio codominio
5- ransformaciones Lineales 5Definición transformación lineal de núcleo ó kernel, e imagen de una transformación lineal sus propiedades Se denomina transformación lineal a toda función,, cuo dominio codominio
Capítulo 4. Vectores y matrices. 4.1 Declaración de tablas. 4.2 Declaración estática de tablas
 Capítulo 4 Vectores y matrices En FORTRAN se puede utilizar un tipo especial de variable que sirve, en particular, para almacenar vectores y matrices. De esta forma, se utiliza un sólo nombre para referirse
Capítulo 4 Vectores y matrices En FORTRAN se puede utilizar un tipo especial de variable que sirve, en particular, para almacenar vectores y matrices. De esta forma, se utiliza un sólo nombre para referirse
SEWERIN. Pre Localización De Fugas de Agua
 SEWERIN Pre Localización De Fugas de Agua Ventajas del sistema La Pre localización de fugas de agua consiste en la escucha de la red en varios puntos. Para ello se utilizan loggers que graban sus sonidos
SEWERIN Pre Localización De Fugas de Agua Ventajas del sistema La Pre localización de fugas de agua consiste en la escucha de la red en varios puntos. Para ello se utilizan loggers que graban sus sonidos
LA MEDIDA Y SUS ERRORES
 LA MEDIDA Y SUS ERRORES Magnitud, unidad y medida. Magnitud es todo aquello que se puede medir y que se puede representar por un número. Para obtener el número que representa a la magnitud debemos escoger
LA MEDIDA Y SUS ERRORES Magnitud, unidad y medida. Magnitud es todo aquello que se puede medir y que se puede representar por un número. Para obtener el número que representa a la magnitud debemos escoger
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
SISTEMAS DE INFORMACIÓN I TEORÍA
 CONTENIDO: TIPOS DE SI: SISTEMAS DE AUTOMATIZACIÓN DE OFICINAS, GROUPWARE, SISTEMA DE WORKFLOW Material diseñado y elaborado por: Prof. Anna Cecilia Grimán SISTEMAS DE AUTOMATIZACIÓN DE OFICINAS Los Sistemas
CONTENIDO: TIPOS DE SI: SISTEMAS DE AUTOMATIZACIÓN DE OFICINAS, GROUPWARE, SISTEMA DE WORKFLOW Material diseñado y elaborado por: Prof. Anna Cecilia Grimán SISTEMAS DE AUTOMATIZACIÓN DE OFICINAS Los Sistemas
Nombre de la asignatura: Programación Estructurada. Créditos: 3-2 - 5. Aportación al perfil
 Nombre de la asignatura: Programación Estructurada Créditos: 3-2 - 5 Aportación al perfil Diseñar, analizar y construir equipos y/o sistemas electrónicos para la solución de problemas en el entorno profesional,
Nombre de la asignatura: Programación Estructurada Créditos: 3-2 - 5 Aportación al perfil Diseñar, analizar y construir equipos y/o sistemas electrónicos para la solución de problemas en el entorno profesional,
Vectores en el espacio
 Vectores en el espacio Un sistema de coordenadas tridimensional se construye trazando un eje Z, perpendicular en el origen de coordenadas a los ejes X e Y. Cada punto viene determinado por tres coordenadas
Vectores en el espacio Un sistema de coordenadas tridimensional se construye trazando un eje Z, perpendicular en el origen de coordenadas a los ejes X e Y. Cada punto viene determinado por tres coordenadas
Técnicas de Planeación y Control
 Técnicas de Planeación y Control 1 Sesión No. 6 Nombre: Plan maestro de producción Contextualización En algunas empresas el éxito que se tiene es el de lograr abastecer sus productos en cortos espacios
Técnicas de Planeación y Control 1 Sesión No. 6 Nombre: Plan maestro de producción Contextualización En algunas empresas el éxito que se tiene es el de lograr abastecer sus productos en cortos espacios
Geometría analítica. Impreso por Juan Carlos Vila Vilariño Centro I.E.S. PASTORIZA
 Conoce los vectores, sus componentes y las operaciones que se pueden realizar con ellos. Aprende cómo se representan las rectas y sus posiciones relativas. Impreso por Juan Carlos Vila Vilariño Centro
Conoce los vectores, sus componentes y las operaciones que se pueden realizar con ellos. Aprende cómo se representan las rectas y sus posiciones relativas. Impreso por Juan Carlos Vila Vilariño Centro
Taller 3 Obras son amores
 Taller 3 Obras son amores competencia traducir una idea en un plan de acción aprendizajes esperados Conocimientos Identificar los recursos mínimos y tiempos necesarios para concretar las actividades del
Taller 3 Obras son amores competencia traducir una idea en un plan de acción aprendizajes esperados Conocimientos Identificar los recursos mínimos y tiempos necesarios para concretar las actividades del
FaceFinder MÓDULO DE BÚSQUEDA DE PERSONAS DENTRO DE UNA BASE DE DATOS DE ROSTROS
 FaceFinder MÓDULO DE BÚSQUEDA DE PERSONAS DENTRO DE UNA BASE DE DATOS DE ROSTROS Introducción Los algoritmos utilizados para el procesamiento de imágenes son de complejidad computacional alta. Por esto
FaceFinder MÓDULO DE BÚSQUEDA DE PERSONAS DENTRO DE UNA BASE DE DATOS DE ROSTROS Introducción Los algoritmos utilizados para el procesamiento de imágenes son de complejidad computacional alta. Por esto
ESTRUCTURA DE DATOS: ARREGLOS
 ESTRUCTURA DE DATOS: ARREGLOS 1. Introduccion 2. Arreglos - Concepto - Caracteristicas 3. Arreglos Unidimensionales 4. Arreglos Bidimensionales 5. Ventajas del uso de arreglos 6. Ejemplo 1. Introducción
ESTRUCTURA DE DATOS: ARREGLOS 1. Introduccion 2. Arreglos - Concepto - Caracteristicas 3. Arreglos Unidimensionales 4. Arreglos Bidimensionales 5. Ventajas del uso de arreglos 6. Ejemplo 1. Introducción
Arquitectura de Computadores: Exámenes y Controles
 2º curso / 2º cuatr. Grado en Ing. Informática Doble Grado en Ing. Informática y Matemáticas Arquitectura de Computadores: Exámenes y Controles Examen de Prácticas AC 05/07/2013 resuelto Material elaborado
2º curso / 2º cuatr. Grado en Ing. Informática Doble Grado en Ing. Informática y Matemáticas Arquitectura de Computadores: Exámenes y Controles Examen de Prácticas AC 05/07/2013 resuelto Material elaborado
CENTRO DE POSTGRADO MARCO NORMATIVO PARA LA ORGANIZACIÓN DE LOS TRABAJOS DE FIN DE MÁSTER UNIVERSITARIO
 CENTRO DE POSTGRADO MARCO NORMATIVO PARA LA ORGANIZACIÓN DE LOS TRABAJOS DE FIN DE MÁSTER UNIVERSITARIO El Trabajo Fin de Máster (TFM) tiene como finalidad evaluar individualmente los conocimientos avanzados
CENTRO DE POSTGRADO MARCO NORMATIVO PARA LA ORGANIZACIÓN DE LOS TRABAJOS DE FIN DE MÁSTER UNIVERSITARIO El Trabajo Fin de Máster (TFM) tiene como finalidad evaluar individualmente los conocimientos avanzados
GUÍA PARA UN ESCANEO ÓPTIMO
 Condiciones para obtener un buen escaneo Los factores que intervienen en el proceso de escaneo son ambientales, propios de la configuración y calibración del escáner así como del objeto a escanear. El
Condiciones para obtener un buen escaneo Los factores que intervienen en el proceso de escaneo son ambientales, propios de la configuración y calibración del escáner así como del objeto a escanear. El
Procesadores de lenguaje Tema 5 Comprobación de tipos
 Procesadores de lenguaje Tema 5 Comprobación de tipos Departamento de Ciencias de la Computación Universidad de Alcalá Resumen Sistemas de tipos. Expresiones de tipo. Equivalencia de tipos. Sobrecarga,
Procesadores de lenguaje Tema 5 Comprobación de tipos Departamento de Ciencias de la Computación Universidad de Alcalá Resumen Sistemas de tipos. Expresiones de tipo. Equivalencia de tipos. Sobrecarga,
Computación de Propósito General en Unidades de Procesamiento Gráfico GPGPU
 Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
Computación de Propósito General en Unidades de Procesamiento Gráfico () E. Dufrechou, P. Ezzatti, M. Pedemontey J.P. Silva Clases 4 Programación Contenido Modelo de programación Introducción Programación
UNIVERSIDAD DR. JOSE MATIAS DELGADO
 NOMBRE DE LA ASIGNATURA: PROGRAMACIÓN DE COMPUTADORAS 2 a. Generalidades. Número de Orden: Prerrequisit o (s): 20 Código: PRC 2 PRC 1 Ciclo Académico: Área: IV Especializa da U.V.: 4 Duración del Ciclo
NOMBRE DE LA ASIGNATURA: PROGRAMACIÓN DE COMPUTADORAS 2 a. Generalidades. Número de Orden: Prerrequisit o (s): 20 Código: PRC 2 PRC 1 Ciclo Académico: Área: IV Especializa da U.V.: 4 Duración del Ciclo
Guía para la instalación de discos duro SATA y Configuración RAID
 Guía para la instalación de discos duro SATA y Configuración RAID 1. Guía para la instalación de discos duro SATA... 2 1.1 Instalación de discos duros serie ATA (SATA)... 2 2. Guía para Configuracións
Guía para la instalación de discos duro SATA y Configuración RAID 1. Guía para la instalación de discos duro SATA... 2 1.1 Instalación de discos duros serie ATA (SATA)... 2 2. Guía para Configuracións
NIC 36. Deterioro en el valor de los activos
 NIC 36 Deterioro en el valor de los activos NIC 36 Objetivo El objetivo de la NIC es asegurar que una empresa tenga valuados sus activos por un importe no mayor a su valor recuperable. Alcance Se aplica
NIC 36 Deterioro en el valor de los activos NIC 36 Objetivo El objetivo de la NIC es asegurar que una empresa tenga valuados sus activos por un importe no mayor a su valor recuperable. Alcance Se aplica
Dirección de Planificación Universitaria Dirección de Planificación Universitaria 0819-07289 Panamá, Rep. de Panamá 0819-07289 Panamá, Rep.
 Comparación de las tasas de aprobación, reprobación, abandono y costo estudiante de dos cohortes en carreras de Licenciatura en Ingeniería en la Universidad Tecnológica de Panamá Luzmelia Bernal Caballero
Comparación de las tasas de aprobación, reprobación, abandono y costo estudiante de dos cohortes en carreras de Licenciatura en Ingeniería en la Universidad Tecnológica de Panamá Luzmelia Bernal Caballero
IBM Maximo: soporte a la evolución en la función del Mantenimiento
 IBM Maximo: soporte a la evolución en la función del Mantenimiento Soporte a iniciativas RCM: El mantenimiento preventivo y la gestión de activos en acción Miguel Ángel Gallardo Vendedor especialista en
IBM Maximo: soporte a la evolución en la función del Mantenimiento Soporte a iniciativas RCM: El mantenimiento preventivo y la gestión de activos en acción Miguel Ángel Gallardo Vendedor especialista en
Estas visiones de la información, denominadas vistas, se pueden identificar de varias formas.
 El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
Fundamentos de la Visión Artificial. Prof. Dr. Francisco Gómez Rodríguez Prof. Manuel J. Domínguez Morales 1
 Fundamentos de la Visión Artificial Prof. Dr. Francisco Gómez Rodríguez Prof. Manuel J. Domínguez Morales 1 Índice 1. Introducción a lavisión Artificial 2. Adquisición y representación de imágenes 3. Filtrado
Fundamentos de la Visión Artificial Prof. Dr. Francisco Gómez Rodríguez Prof. Manuel J. Domínguez Morales 1 Índice 1. Introducción a lavisión Artificial 2. Adquisición y representación de imágenes 3. Filtrado
Informe de Seguimiento nº. 01/2012 del expediente nº. ABR_I_1139
 Denominación del Título Máster en Economía y Finanzas Universidad solicitante Universidad Internacional Menéndez Pelayo Rama de Conocimiento Ciencias Sociales y Jurídicas ANECA, conforme a lo establecido
Denominación del Título Máster en Economía y Finanzas Universidad solicitante Universidad Internacional Menéndez Pelayo Rama de Conocimiento Ciencias Sociales y Jurídicas ANECA, conforme a lo establecido
CAPÍTULO 2 COLUMNAS CORTAS BAJO CARGA AXIAL SIMPLE
 CAPÍTULO 2 COLUMNAS CORTAS BAJO CARGA AXIAL SIMPLE 2.1 Comportamiento, modos de falla y resistencia de elementos sujetos a compresión axial En este capítulo se presentan los procedimientos necesarios para
CAPÍTULO 2 COLUMNAS CORTAS BAJO CARGA AXIAL SIMPLE 2.1 Comportamiento, modos de falla y resistencia de elementos sujetos a compresión axial En este capítulo se presentan los procedimientos necesarios para
GEOMETRÍA PLANA TFM 2013 DIFICULTADES Y ERRORES MANIFESTADOS POR ESTUDIANTES DE 1º DE E.S.O. DURANTE EL APRENDIZAJE DE GEOMETRÍA PLANA
 GEOMETRÍA PLANA María Pérez Prados DIFICULTADES Y ERRORES MANIFESTADOS POR ESTUDIANTES DE 1º DE E.S.O. DURANTE EL APRENDIZAJE DE GEOMETRÍA PLANA TFM 2013 Ámbito MATEMÁTICAS MÁSTER UNIVERSITARIO EN FORMACIÓN
GEOMETRÍA PLANA María Pérez Prados DIFICULTADES Y ERRORES MANIFESTADOS POR ESTUDIANTES DE 1º DE E.S.O. DURANTE EL APRENDIZAJE DE GEOMETRÍA PLANA TFM 2013 Ámbito MATEMÁTICAS MÁSTER UNIVERSITARIO EN FORMACIÓN
Unidad 5 Utilización de Excel para la solución de problemas de programación lineal
 Unidad 5 Utilización de Excel para la solución de problemas de programación lineal La solución del modelo de programación lineal (pl) es una adaptación de los métodos matriciales ya que el modelo tiene
Unidad 5 Utilización de Excel para la solución de problemas de programación lineal La solución del modelo de programación lineal (pl) es una adaptación de los métodos matriciales ya que el modelo tiene
RESUMEN INFORMATIVO PROGRAMACIÓN DIDÁCTICA CURSO 2013/2014
 RESUMEN INFORMATIVO PROGRAMACIÓN DIDÁCTICA CURSO 2013/2014 FAMILIA PROFESIONAL: INFORMATICA Y COMUNICACIONES MATERIA: 28. DESARROLLO WEB EN ENTORNO SERVIDOR CURSO: 2º DE CFGS DESARROLLO DE APLICACIONES
RESUMEN INFORMATIVO PROGRAMACIÓN DIDÁCTICA CURSO 2013/2014 FAMILIA PROFESIONAL: INFORMATICA Y COMUNICACIONES MATERIA: 28. DESARROLLO WEB EN ENTORNO SERVIDOR CURSO: 2º DE CFGS DESARROLLO DE APLICACIONES
I.E.S.MEDITERRÁNEO CURSO 2015 2016 DPTO DE MATEMÁTICAS PROGRAMA DE RECUPERACIÓN DE LOS APRENDIZAJES NO ADQUIRIDOS EN MATEMÁTICAS DE 3º DE E.S.O.
 PROGRAMA DE RECUPERACIÓN DE LOS APRENDIZAJES NO ADQUIRIDOS EN MATEMÁTICAS DE 3º DE E.S.O. Este programa está destinado a los alumnos que han promocionado a cursos superiores sin haber superado esta materia.
PROGRAMA DE RECUPERACIÓN DE LOS APRENDIZAJES NO ADQUIRIDOS EN MATEMÁTICAS DE 3º DE E.S.O. Este programa está destinado a los alumnos que han promocionado a cursos superiores sin haber superado esta materia.
Nuevos requerimientos del SAT para contabilidad electrónica
 Nuevos requerimientos del SAT para contabilidad electrónica Antecedentes Ha sido publicada una resolución en el mes de Abril de 2014 donde se establecen los lineamientos a seguir para el registro e integración
Nuevos requerimientos del SAT para contabilidad electrónica Antecedentes Ha sido publicada una resolución en el mes de Abril de 2014 donde se establecen los lineamientos a seguir para el registro e integración
Sistemas Operativos Windows 2000
 Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Trabajo Práctico Final. Transformada Rápida de Fourier con Paralelismo
 Trabajo Práctico Final Transformada Rápida de Fourier con Paralelismo Sistemas Operativos II Facultad de Ciencias Exactas, Físicas y aturales UC Mauricio G. Jost 2009 Índice 1. Introducción 1 2. Marco
Trabajo Práctico Final Transformada Rápida de Fourier con Paralelismo Sistemas Operativos II Facultad de Ciencias Exactas, Físicas y aturales UC Mauricio G. Jost 2009 Índice 1. Introducción 1 2. Marco
La inteligencia de marketing que desarrolla el conocimiento
 La inteligencia de marketing que desarrolla el conocimiento SmartFocus facilita a los equipos de marketing y ventas la captación de consumidores con un enfoque muy relevante y centrado en el cliente. Ofrece
La inteligencia de marketing que desarrolla el conocimiento SmartFocus facilita a los equipos de marketing y ventas la captación de consumidores con un enfoque muy relevante y centrado en el cliente. Ofrece
Clasificación de Música por Genero Utilizando Redes Neuronales Artificiales. Elkin García, Germán Mancera, Jorge Pacheco
 Clasificación de Música por Genero Utilizando Redes Neuronales Artificiales Elkin García, Germán Mancera, Jorge Pacheco Presentación Los autores han desarrollado un método de clasificación de música a
Clasificación de Música por Genero Utilizando Redes Neuronales Artificiales Elkin García, Germán Mancera, Jorge Pacheco Presentación Los autores han desarrollado un método de clasificación de música a
IL DEL ACOPLAMIENTO ALEATORIO VS. IL DEL CABLE DE CONEXIÓN MAESTRO
 Componentes de Avanzada Libro Blanco Marzo 2012 IL DEL ACOPLAMIENTO ALEATORIO VS. IL DEL CABLE DE CONEXIÓN MAESTRO Ky Ly - Ingeniero en Jefe SENKO COMPONENTES DE AVANZADA,INC BRAZIL +55-21-2430-5971 SALES-BRAZIL@SENKO.COM
Componentes de Avanzada Libro Blanco Marzo 2012 IL DEL ACOPLAMIENTO ALEATORIO VS. IL DEL CABLE DE CONEXIÓN MAESTRO Ky Ly - Ingeniero en Jefe SENKO COMPONENTES DE AVANZADA,INC BRAZIL +55-21-2430-5971 SALES-BRAZIL@SENKO.COM
FACULTAD DE INGENIERÍA FORESTAL EXCELENCIA ACADÉMICA QUE CONTRIBUYE AL DESARROLLO DE LAS CIENCIAS FORESTALES
 IDENTIFICACIÓN DE LA ASIGNATURA Nombre: Matemáticas Fundamentales Código: 0701479 Área Específica: Ciencias Básicas Semestre de Carrera: Primero JUSTIFICACIÓN El estudio de las matemáticas es parte insustituible
IDENTIFICACIÓN DE LA ASIGNATURA Nombre: Matemáticas Fundamentales Código: 0701479 Área Específica: Ciencias Básicas Semestre de Carrera: Primero JUSTIFICACIÓN El estudio de las matemáticas es parte insustituible
EVOLUCIÓN DE LA TECNOLOGÍA LASER SCANNER. IMPLICACIONES EN SU USO EN CENTRALES NUCLEARES E INSTALACIONES RADIOCTIVAS
 EVOLUCIÓN DE LA TECNOLOGÍA LASER SCANNER. IMPLICACIONES EN SU USO EN CENTRALES NUCLEARES E INSTALACIONES RADIOCTIVAS FRANCISCO SARTI FERNÁNDEZ. CT3 INGENIERÍA JESUS BONET. Leica Geosystems Octubre 2012
EVOLUCIÓN DE LA TECNOLOGÍA LASER SCANNER. IMPLICACIONES EN SU USO EN CENTRALES NUCLEARES E INSTALACIONES RADIOCTIVAS FRANCISCO SARTI FERNÁNDEZ. CT3 INGENIERÍA JESUS BONET. Leica Geosystems Octubre 2012