Statisticians, like artists, have the bad habit of falling in love with their models. George Box
|
|
|
- Sebastián Iglesias Castellanos
- hace 6 años
- Vistas:
Transcripción
1 Statisticians, like artists, have the bad habit of falling in love with their models. George Box

2 /R/glms.htm *
3

4
5

6

7

8

9

10

11

12

13

14
15 Los ajustes de µ i se calculan mediante g 1 p ( j=1 β jx jj ), una vez estimados los parámetros del vector β, los cuales se estiman por máxima verosimilitud. Para valorar el ajuste en los modelos lineales generalizados podemos utilizar estadísticos basados en la deviance, que es una generalización del Error Cuadrático Medio. El ECM es una medida popular de medir el error, 1 N 1=1, N (y i µ i ) 2 que también se puede calcular con su versión utilizando los residuos de Pearson: r p = (y i µ i ) vvv(µ i )

16 El problema del Error Cuadrático Medio como medida de bondad de ajuste reside en que siempre decrece con la complejidad (número de parámetros, p) del modelo, a pesar de poder no existir ganancia significativa con un modelo más complejo. Los métodos de ajuste buscan minimizar discrepancias y se adaptan a los datos utilizados. De hecho, con suficientes parámetros el ECM es nulo, y el modelo carece de valor como herramienta predictiva o explicativa, simplemente reproduce los datos utilizados para el ajuste. Por ello para comparar entre modelos se suelen utilizar, para valorar la ganancia de introducir más complejidad en la modelización, los estadísticos AIC y BIC; o el estadístico Chi-cuadrado, que se define como la diferencia de deviances entre los modelos de comparación. Es típico comparar el modelo de interés con el llamado modelo nulo de o mínima parametrización.
17 Deviance: 2 log. vvvvvvvvvvvvv AIC: BIC: 2 log. vvvvvvvvvvvvv + 2 p SELECCIÓN DE MODELOS 2 log. vvvvvvvvvvvvv + p llll BIC tiende a penalizar más los modelos complejos y con N (>9) elevado suele favorecer modelos simples. Por qué las definiciones anteriores de Deviance, AIC y BIC? Pues porque con respuesta Gaussiana, y asumiendo desviación típica conocida, se verifica: N 2 log. vvvvvvvvvvvvv = (y i µ i ) 2 1=1

18 Tarea-5 Tarea-1
19 Tarea-1
20 Tarea-1
21 Tarea-1
22 Tarea-1 /dat a.pri ncet on.e du/r/ glms.htm
23 Tarea-1
24 Tarea-1 3
25 Tarea-1 Un conjunto de pequeñas mutuas aseguradoras del sector del automóvil tienen franquiciada con una reaseguradora las reclamaciones por responsabilidad civil que superan determinado importe. En la base de datos asociada, se recoge información sobre la zona de circulación preferente (Zona: Area1: Nada lluviosa; Area2: Algo lluviosa; Area3: Bastante lluviosa; Area4: Muy lluviosa), la franja de negocio (además de particulares) donde opera la mutua (Tipo: 1: Profesionales y Empresas; 2: Profesionales o Empresas; 3: Sólo particulares), el Volumen de las primas percibidas, el número de reclamaciones (Claims) que superaron el importe franquiciado en el último mes y el número de Polizas suscritas. dataset<- read.csv(file=" sep=";") names(dataset) table(dataset$claims) Vamos a estudiar el efecto de los distintos factores en el número de reclamaciones que el reasegurador recibe de cada mutua.
26 Tarea-1 La variable respuesta es el número de reclamaciones. Claims. Un posible predictor (quizás el más obvio) podría ser el Volumen de las primas pagadas; ya que es un indicador del tamaño del riesgo transferido a la reaseguradora. La figura muestra el valor de la variable respuesta frente al predictor, con el número de observaciones en cada punto como símbolos). Existe relación? # Figura Datos1 <- as.data.frame(table(dataset$claims,dataset$volumen)) Datos1 <- as.data.frame(apply((datos1[datos1$freq!=0, ]), 2, as.numeric)) with(datos1, plot(var2, Var1, type = "n", xlab="volumen primas", ylab="numero de reclamaciones")) points(datos1$var2, Datos1$Var1, pch=as.character(datos1$freq))
27 Tarea-1 Para disponer de una visión más nítida de la posible relación entre estas variables agrupamos la variable Volumen en categorías. ( 23.25, , , , , , , >30.25) cortes = c(-inf, 23.25, 24.25, 25.25, 26.25, 27.25, 28.25, 29.25, 30.25, Inf) Grupo <- cut(datos1$var2, cortes) media.claims <- tapply(datos1$var1, Grupo, mean) media.vol <- tapply(datos1$var2, Grupo, mean) plot(media.vol, media.claims, pch=19, xlab="volumen primas", ylab="numero de reclamaciones", ylim=c(0,6), xlim=c(22,32))
28 Tarea-1 La estimación del modelo por MV y link canónico aporta el siguiente resultado: Variable Coeficiente Error std. p-value (Intercept) e-09 *** Volumen < 2e-16 *** Modelo.log <- glm(claims ~ Volumen, data= dataset, family=poisson) summary(modelo.log) # Efecto multiplicativo La estimación del modelo por MV con link identidad aporta el resultado: Variable Coeficiente Error std. p-value (Intercept) <2e-16 *** Volumen <2e-16 *** Modelo.id <- glm(claims~volumen, data= dataset, family=poisson(link=identity),start=coef(modelo.log)) summary(modelo.id) # Efecto lineal Qué modelo sería preferible en este caso? AIC(Modelo.log) = AIC(Modelo.id) =
),bty=\"l\", type=\"p\", pch=16) ind<-order(dataset$volumen) lines(x= dataset$volumen[ind], y=modelo.")
29 Tarea-1 plot(x=media.vol, y=media.claims, xlab="volumen primas", ylab=expression(paste("numero medio de reclamaciones: ", {lambda})),bty="l", type="p", pch=16) ind<-order(dataset$volumen) lines(x= dataset$volumen[ind], y=modelo.log$fitted.values[ind]) lines(x= dataset$volumen[ind], y=modelo.id$fitted.values[ind]) arrows(x0=23.5,y0=2.9,x1=23.5,y1=predict(modelo.log,newdata=data.frame(volumen=23.5), type="response"), length=.2) text(x=23.5,y=3,"log Link") arrows(x0=29.75,y0=3.1,x1=29.75,y1=predict(modelo.id,newdata=data.frame(volumen=29.75), type="response"), length=.2) text(x=29.75,y=2.9,"identity Link")
30 Es la respuesta Poisson adecuada? Los datos presentan sobredispersión (en Poisson media y varianza coinciden): tapply(datos1$var1, Grupo, function(x) c(length(x), sum(x), mean=mean(x), variance=var(x))) Possible solución: respuesta Binomial Negativa. Especificación Tarea-1 Volumen Nº Mutuas Reclamaciones Media Varianza >
31 Como alternativa los datos podrían ser ajustados utilizando como variable respuesta un modelo Binomial Negativo en lugar de uno Poisson: library(mass); Modelo.bn <- glm.nb(claims ~ Volumen, data=dataset) Especificación Tarea-1 Variable Coeficiente Error std. p-value (Intercept) *** Volumen e-05 *** glm.nb(claims ~ Volumen, data=dataset, link=identity, start = coef(modelo.id), init.theta=1) Obteniéndose un mejor ajuste global, como muestra el AIC ( vs ).
32 T A R E A 1 Especificación Tarea-1 Considera la muestra de asegurados disponible en el fichero Omitiendo el hecho de los diferentes períodos de exposición al riesgo de cada póliza, modeliza la variable numerosi utilizando como modelo para la variable respuesta un modelo discreto de conteo de datos, en el que el valor esperado dependa al menos de algunos de los siguientes factores de riesgo: o Del conductor: Sexo (sexocondu), Edad (edad) y Zona de circulación (prov/ccaa); o Del vehículo: Potencia (potencia), Antigüedad del vehículo (antivehi). Discretiza las variables utilizando los puntos de corte y el número de categorías que estimes oportuno en cada caso. (i) Realiza una tabla con las predicciones de número de siniestros que predecirías para un conductor con cada uno de los perfiles que se obtienen combinando todas las categorías de las variables. (Es decir, opten la base de una tarifa). (ii) Interpreta el efecto de las variables en el número de siniestros. (iii) Si has testeado varios modelos con distintos modelos para la variable respuesta, razona cual piensas debería ser utilizado. Para ampliar lo visto en clase te sugiero consultes el documento: Regression Models for Count Data in R,
33 Tarea-2
 varíe cuando varían los valores de los predictores.")
34 Tarea-2 Al contrario que el modelo lineal de probabilidad, el modelo de regresión logística (probit) permite que el ratio de cambio sobre la probabilidad (el impacto) varíe cuando varían los valores de los predictores.
35 Tarea-2

36 Tarea-2
37 Tarea-2 Aceptación producto Frecuencia
38 Tarea-2
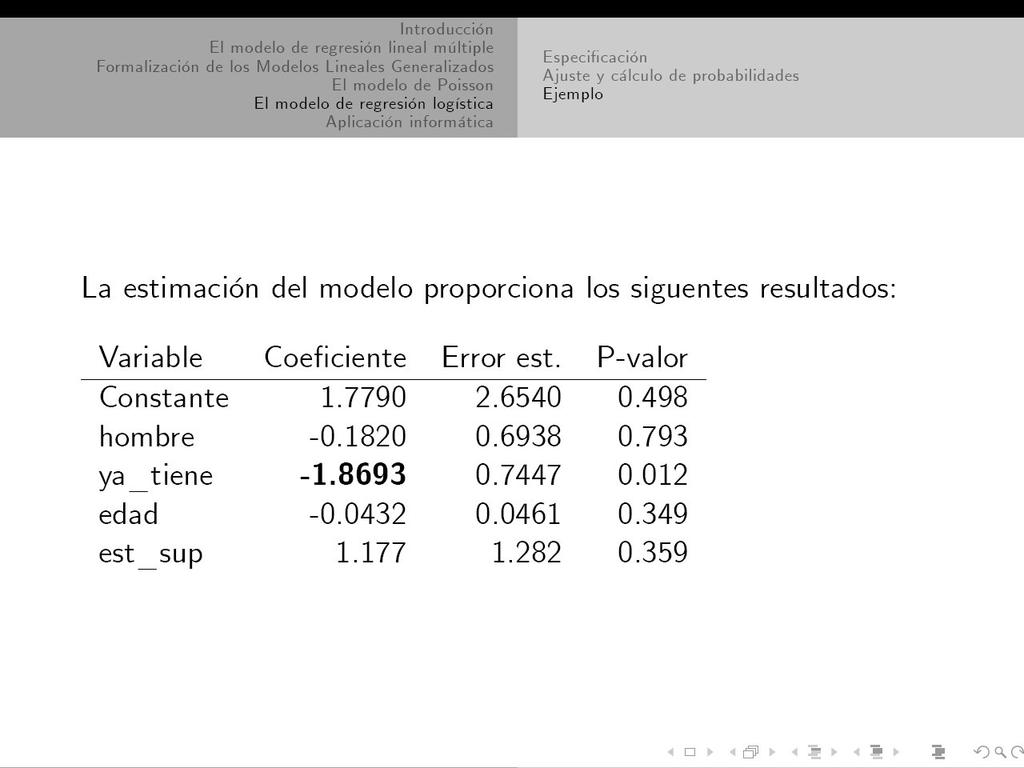
39 Tarea-2
40 Tarea-2
41 Tarea-2 Retomamos el ejemplo de las mutuas y vamos a estudiar, como variable respuesta, si una mutua realiza o no reclamaciones en un mes cualquiera (variable dicotómica) y a estudiar los factores que explican la probabilidad de hacerlo.
42 Tarea-2 dataset <- read.csv(file=" sep=";") dataset$siclaims <- as.numeric(dataset$claims>0) Datos1 <- as.data.frame(table(dataset$siclaims,dataset$volumen)) Datos1 <- as.data.frame(apply((datos1[datos1$freq!=0, ]), 2, as.numeric)) with(datos1, plot(var2, Var1, type = "n", xlab="volumen primas", ylab="proporción reclamaciones")) points(datos1$var2, Datos1$Var1, pch=as.character(datos1$freq)) cortes = c(-inf, 23.25, 24.25, 25.25, 26.25, 27.25, 28.25, 29.25, 30.25, Inf) Grupo <- cut(datos1$var2, cortes) media.claims <- tapply(datos1$var1, Grupo, mean) media.vol <- tapply(datos1$var2, Grupo, mean) points(media.vol, media.claims, pch=19, cex = 0.8, col="darkmagenta") fit.logit <- glm(siclaims ~Volumen, data=dataset, family=binomial) fit.probit <- glm(siclaims ~Volumen, data=dataset, family=binomial("probit")) fit.lm <- glm(siclaims ~Volumen, data=dataset) fit.lm2 <- glm(media.claims ~ media.vol, weights= as.vector(table(grupo))) ind<-order(dataset$volumen) points(dataset$volumen[ind], y=fit.logit$fitted.values[ind], type="l", col="red", lty=3, lwd=1.2) points(dataset$volumen[ind], y=fit.probit$fitted.values[ind], type="l", col="blue", lty=2, lwd=1.2) points(dataset$volumen[ind], y=fit.lm$fitted.values[ind], type="l", col="green", lty=1, lwd=2) abline(fit.lm2, col="yellow", lty=4, lwd=2) legend("bottomright", c("logit","probit","lineal", "Lineal.Av"), col=c("red","blue","green", "yellow"), lty=c(3,2,1,4), lwd=c(1.2,1.2,2,2), bty = "n")
43 Tarea-2 Hasta ahora se ha utilizado un único predictor. Obviamente los modelos anteriores pueden ser computados con múltiples predictores. Por ejemplo, incluyendo Zona (factor con 4 niveles) se obtiene: fit.logit2 <- glm(siclaims ~ Volumen + Zona, data=dataset, family=binomial) summary(fit.logit2) Variable Coeficiente Error std. p-value (Intercept) e-05 *** Volumen e-06 *** ZonaArea ZonaArea ZonaArea new.base1 <- data.frame(volumen = seq(20,34,0.1), Zona=rep("Area1",141)) new.base2 <- data.frame(volumen = seq(20,34,0.1), Zona=rep("Area2",141)) new.base3 <- data.frame(volumen = seq(20,34,0.1), Zona=rep("Area3",141)) new.base4 <- data.frame(volumen = seq(20,34,0.1), Zona=rep("Area4",141)) with(datos1, plot(var2, Var1, type = "n", xlab="volumen primas", ylab="proporción estimada")) lines(seq(20,34,0.1), predict(fit.logit2, new.base1, "response"), col="red") lines(seq(20,34,0.1), predict(fit.logit2, new.base2, "response"), col="blue") lines(seq(20,34,0.1), predict(fit.logit2, new.base3, "response"), col="brown") lines(seq(20,34,0.1), predict(fit.logit2, new.base4, "response"), col="yellow") legend("bottomright", c("area1","area2","area3", "Area4"), col=c("red","blue","brown","yellow"), lty=c(1,1,1,1), bty = "n")
44 Tarea-2 El efecto de los factores (variables dummies) es desplazar las curvas estimadas, al igual que en el modelo lineal se manifestaba en una modificación del intercepto.
45 Tarea-2 Qué variables incluir? Cómo seleccionar el modelo? Nos restringimos a modelos con efectos principales e interacciones. dataset$tipo <- as.factor(dataset$tipo) Modelos Diferencia de Modelo Predictores Deviance df AIC comparados Deviance 1 Z*T*V Z*T + Z*V + T*V (2)-(1) 3.2 (df=3) 3a Z*T + T*V (3a)-(2) 3.7 (df=3) 3b Z*V + T*V (3b)-(2) 7.9 (df=6) 3Z Z*T + Z*V (3c)-(2) 0.0 (df=2) 4a T + Z*V (4a)-(3c) 8.0 (df=6) 4b V + Z*T (4b)-(3c) 3.9 (df=3) 5 Z + T + V (5)-(4b) 9.0 (df=6) 6a Z + T (6a)-(5) 22.2 (df=1) 6b T + V (6b)-(5) 7.8 (df=3) 6Z Z + V (6c)-(5) 0.8 (df=2) 7a Z (7a)-(6c) 24.5 (df=1) 7b V (7b)-(6c) 7.0 (df=3) 8 Ninguno (8)-(7b) 31.3 (df=1) fit.logit5 <- glm(siclaims ~ Volumen + Zona + Tipo, data=dataset, family=binomial) fit.logit4b <- glm(siclaims ~ Volumen + Zona * Tipo, data=dataset, family=binomial) anova(fit.logit5, fit.logit4b); pchisq(9.0153,6)
46 T A R E A 2 Especificación Tarea-2 Considera la muestra de asegurados disponible en el fichero Teniendo en cuenta el hecho de los diferentes períodos de exposición al riesgo de cada póliza (weights), modeliza la variable dicotómica siniestro (=1, ha dado parte de algún siniestro; =0 no ha dado parte de ningún siniestro), utilizando para la variable respuesta un modelo dicotómico en el que la probabilidad de sufrir un siniestro dependa al menos de las siguientes factores: o Del conductor: Sexo (sexocondu), Edad (edad) y Zona de circulación (prov/ccaa); o Del vehículo: Potencia (potencia), Antigüedad del vehículo (antivehi). Realiza el ajuste utilizando el link canónico y el link probit. Discretiza las variables utilizando los puntos de corte y el número de categorías que estimes oportuno en cada caso. (i) Realiza una tabla con las predicciones de probabilidad de sufrir al menos un siniestro que correspondería a un conductor con cada uno de los perfiles que se obtienen combinando todas las categorías de las variables. (ii) Elabora la tabla para cada modelo y razona cual piensas debería ser utilizado.
47 Comandos en software conocido glm, vglm, gamlss, glmnet, pscl, OTRO SOFTWARE: STATA, SAS, S-PLUS,. OTROS ASPECTOS Y MODELOS :
Análisis de datos Categóricos
 Introducción a los Modelos Lineales Generalizados Universidad Nacional Agraria La Molina 2016-1 Introducción Modelos Lineales Generalizados Introducción Componentes Estimación En los capítulos anteriores
Introducción a los Modelos Lineales Generalizados Universidad Nacional Agraria La Molina 2016-1 Introducción Modelos Lineales Generalizados Introducción Componentes Estimación En los capítulos anteriores
Método de cuadrados mínimos
 REGRESIÓN LINEAL Gran parte del pronóstico estadístico del tiempo está basado en el procedimiento conocido como regresión lineal. Regresión lineal simple (RLS) Describe la relación lineal entre dos variables,
REGRESIÓN LINEAL Gran parte del pronóstico estadístico del tiempo está basado en el procedimiento conocido como regresión lineal. Regresión lineal simple (RLS) Describe la relación lineal entre dos variables,
Regresión lineal SIMPLE MÚLTIPLE N A Z IRA C A L L E J A
 Regresión lineal REGRESIÓN LINEAL SIMPLE REGRESIÓN LINEAL MÚLTIPLE N A Z IRA C A L L E J A Qué es la regresión? El análisis de regresión: Se utiliza para examinar el efecto de diferentes variables (VIs
Regresión lineal REGRESIÓN LINEAL SIMPLE REGRESIÓN LINEAL MÚLTIPLE N A Z IRA C A L L E J A Qué es la regresión? El análisis de regresión: Se utiliza para examinar el efecto de diferentes variables (VIs
Unidad IV: Distribuciones muestrales
 Unidad IV: Distribuciones muestrales 4.1 Función de probabilidad En teoría de la probabilidad, una función de probabilidad (también denominada función de masa de probabilidad) es una función que asocia
Unidad IV: Distribuciones muestrales 4.1 Función de probabilidad En teoría de la probabilidad, una función de probabilidad (también denominada función de masa de probabilidad) es una función que asocia
Desigualdad de ingresos en Costa Rica a la luz de las ENIGH 2004 y 2013
 SIMPOSIO Encuesta Nacional de Ingresos y Gastos de los Hogares Desigualdad de ingresos en Costa Rica a la luz de las ENIGH 2004 y 2013 Andrés Fernández Arauz Marzo 2015 Introducción INEC (2014): la desigualdad
SIMPOSIO Encuesta Nacional de Ingresos y Gastos de los Hogares Desigualdad de ingresos en Costa Rica a la luz de las ENIGH 2004 y 2013 Andrés Fernández Arauz Marzo 2015 Introducción INEC (2014): la desigualdad
> y <- c(19, 57, 29, 63, 29, 49, 27, 53, 23, 47, 33, 66, 47, 55, 23, 50, + 24, 37, 42, 68, 43, 52, 30, 42) > ly <- length( y )
 > ly <- length( y )") Preferencia por un nuevo Detergente: Para un estudio de mercado sobre las preferencias entre un nuevo detergente Xx y uno standard Mm se consideró una muestra de 1008 consumidores, a los que se preguntó
Preferencia por un nuevo Detergente: Para un estudio de mercado sobre las preferencias entre un nuevo detergente Xx y uno standard Mm se consideró una muestra de 1008 consumidores, a los que se preguntó
Por ejemplo, si se desea discriminar entre créditos que se devuelven o que presentan
 Regresión Logística Introducción El problema de clasificación en dos grupos puede abordarse introduciendo una variable ficticia binaria para representar la pertenencia de una observación a uno de los dos
Regresión Logística Introducción El problema de clasificación en dos grupos puede abordarse introduciendo una variable ficticia binaria para representar la pertenencia de una observación a uno de los dos
INTERPRETACIÓN DE LA REGRESIÓN. Interpretación de la regresión
 INTERPRETACIÓN DE LA REGRESIÓN Este gráfico muestra el salario por hora de 570 individuos. 1 Interpretación de la regresión. regresión Salario-Estudios Source SS df MS Number of obs = 570 ---------+------------------------------
INTERPRETACIÓN DE LA REGRESIÓN Este gráfico muestra el salario por hora de 570 individuos. 1 Interpretación de la regresión. regresión Salario-Estudios Source SS df MS Number of obs = 570 ---------+------------------------------
Agro 6998 Conferencia 2. Introducción a los modelos estadísticos mixtos
 Agro 6998 Conferencia Introducción a los modelos estadísticos mixtos Los modelos estadísticos permiten modelar la respuesta de un estudio experimental u observacional en función de factores (tratamientos,
Agro 6998 Conferencia Introducción a los modelos estadísticos mixtos Los modelos estadísticos permiten modelar la respuesta de un estudio experimental u observacional en función de factores (tratamientos,
PATRONES DE DISTRIBUCIÓN ESPACIAL
 PATRONES DE DISTRIBUCIÓN ESPACIAL Tipos de arreglos espaciales Al azar Regular o Uniforme Agrupada Hipótesis Ecológicas Disposición al Azar Todos los puntos en el espacio tienen la misma posibilidad de
PATRONES DE DISTRIBUCIÓN ESPACIAL Tipos de arreglos espaciales Al azar Regular o Uniforme Agrupada Hipótesis Ecológicas Disposición al Azar Todos los puntos en el espacio tienen la misma posibilidad de
Los modelos lineales (regresión, ANOVA, ANCOVA), se basan en los siguientes supuestos:
, se basan en los siguientes supuestos:") GLM-Introducción Los modelos lineales (regresión, ANOVA, ANCOVA), se basan en los siguientes supuestos: 1. Los errores se distribuyen normalmente. 2. La varianza es constante. 3. La variable dependiente
GLM-Introducción Los modelos lineales (regresión, ANOVA, ANCOVA), se basan en los siguientes supuestos: 1. Los errores se distribuyen normalmente. 2. La varianza es constante. 3. La variable dependiente
T4. Modelos con variables cualitativas
 T4. Modelos con variables cualitativas Ana J. López y Rigoberto Pérez Dpto Economía Aplicada. Universidad de Oviedo Curso 2010-2011 Ana J. López y Rigoberto Pérez (Dpto EconomíaT4. Aplicada. Modelos Universidad
T4. Modelos con variables cualitativas Ana J. López y Rigoberto Pérez Dpto Economía Aplicada. Universidad de Oviedo Curso 2010-2011 Ana J. López y Rigoberto Pérez (Dpto EconomíaT4. Aplicada. Modelos Universidad
Introducción a la regresión ordinal
 Introducción a la regresión ordinal Jose Barrera jbarrera@mat.uab.cat 20 de mayo 2009 Jose Barrera (UAB) Introducción a la regresión ordinal 20 de mayo 2009 1 / 11 Introducción a la regresión ordinal 1
Introducción a la regresión ordinal Jose Barrera jbarrera@mat.uab.cat 20 de mayo 2009 Jose Barrera (UAB) Introducción a la regresión ordinal 20 de mayo 2009 1 / 11 Introducción a la regresión ordinal 1
INTRODUCCIÓN AL ANÁLISIS DE DATOS ORIENTACIONES (TEMA Nº 7)
") TEMA Nº 7 DISTRIBUCIONES CONTINUAS DE PROBABILIDAD OBJETIVOS DE APRENDIZAJE: Conocer las características de la distribución normal como distribución de probabilidad de una variable y la aproximación de
TEMA Nº 7 DISTRIBUCIONES CONTINUAS DE PROBABILIDAD OBJETIVOS DE APRENDIZAJE: Conocer las características de la distribución normal como distribución de probabilidad de una variable y la aproximación de
INDICE. Prólogo a la Segunda Edición
 INDICE Prólogo a la Segunda Edición XV Prefacio XVI Capitulo 1. Análisis de datos de Negocios 1 1.1. Definición de estadística de negocios 1 1.2. Estadística descriptiva r inferencia estadística 1 1.3.
INDICE Prólogo a la Segunda Edición XV Prefacio XVI Capitulo 1. Análisis de datos de Negocios 1 1.1. Definición de estadística de negocios 1 1.2. Estadística descriptiva r inferencia estadística 1 1.3.
Documento de Trabajo. Debo inscribir más de 22 créditos?
 Documento de Trabajo Debo inscribir más de 22 créditos? Rodrigo Navia Carvallo 2004 El autor es Ph.D in Economics, Tulane University, EEUU. Máster of Arts in Economics, Tulane University, EEUU. Licenciado
Documento de Trabajo Debo inscribir más de 22 créditos? Rodrigo Navia Carvallo 2004 El autor es Ph.D in Economics, Tulane University, EEUU. Máster of Arts in Economics, Tulane University, EEUU. Licenciado
2 Introducción a la inferencia estadística Introducción Teoría de conteo Variaciones con repetición...
 Contenidos 1 Introducción al paquete estadístico S-PLUS 19 1.1 Introducción a S-PLUS............................ 21 1.1.1 Cómo entrar, salir y consultar la ayuda en S-PLUS........ 21 1.2 Conjuntos de datos..............................
Contenidos 1 Introducción al paquete estadístico S-PLUS 19 1.1 Introducción a S-PLUS............................ 21 1.1.1 Cómo entrar, salir y consultar la ayuda en S-PLUS........ 21 1.2 Conjuntos de datos..............................
Tercera práctica de REGRESIÓN.
 Tercera práctica de REGRESIÓN. DATOS: fichero practica regresión 3.sf3 1. Objetivo: El objetivo de esta práctica es aplicar el modelo de regresión con más de una variable explicativa. Es decir regresión
Tercera práctica de REGRESIÓN. DATOS: fichero practica regresión 3.sf3 1. Objetivo: El objetivo de esta práctica es aplicar el modelo de regresión con más de una variable explicativa. Es decir regresión
Medidas de dispersión
 Medidas de dispersión Las medidas de dispersión nos informan sobre cuánto se alejan del centro los valores de la distribución. Las medidas de dispersión son: Rango o recorrido El rango es la diferencia
Medidas de dispersión Las medidas de dispersión nos informan sobre cuánto se alejan del centro los valores de la distribución. Las medidas de dispersión son: Rango o recorrido El rango es la diferencia
1 Introducción. 2 Modelo. Hipótesis del modelo MODELO DE REGRESIÓN LOGÍSTICA
 MODELO DE REGRESIÓN LOGÍSTICA Introducción A grandes rasgos, el objetivo de la regresión logística se puede describir de la siguiente forma: Supongamos que los individuos de una población pueden clasificarse
MODELO DE REGRESIÓN LOGÍSTICA Introducción A grandes rasgos, el objetivo de la regresión logística se puede describir de la siguiente forma: Supongamos que los individuos de una población pueden clasificarse
Teoría de la decisión
 1.- Un problema estadístico típico es reflejar la relación entre dos variables, a partir de una serie de Observaciones: Por ejemplo: * peso adulto altura / peso adulto k*altura * relación de la circunferencia
1.- Un problema estadístico típico es reflejar la relación entre dos variables, a partir de una serie de Observaciones: Por ejemplo: * peso adulto altura / peso adulto k*altura * relación de la circunferencia
LAB 13 - Análisis de Covarianza - CLAVE
 LAB 13 - Análisis de Covarianza - CLAVE Se realizó un experimento para estudiar la eficacia de un promotor de crecimiento en terneros en lactación. Se usaron cuatro dosis de la droga (0, 2.5, 5 y 7.5 mg).
LAB 13 - Análisis de Covarianza - CLAVE Se realizó un experimento para estudiar la eficacia de un promotor de crecimiento en terneros en lactación. Se usaron cuatro dosis de la droga (0, 2.5, 5 y 7.5 mg).
478 Índice alfabético
 Índice alfabético Símbolos A, suceso contrario de A, 187 A B, diferencia de los sucesos A y B, 188 A/B, suceso A condicionado por el suceso B, 194 A B, intersección de los sucesos A y B, 188 A B, unión
Índice alfabético Símbolos A, suceso contrario de A, 187 A B, diferencia de los sucesos A y B, 188 A/B, suceso A condicionado por el suceso B, 194 A B, intersección de los sucesos A y B, 188 A B, unión
ESTADÍSTICA. Tema 4 Regresión lineal simple
 ESTADÍSTICA Grado en CC. de la Alimentación Tema 4 Regresión lineal simple Estadística (Alimentación). Profesora: Amparo Baíllo Tema 4: Regresión lineal simple 1 Estructura de este tema Planteamiento del
ESTADÍSTICA Grado en CC. de la Alimentación Tema 4 Regresión lineal simple Estadística (Alimentación). Profesora: Amparo Baíllo Tema 4: Regresión lineal simple 1 Estructura de este tema Planteamiento del
Análisis de regresión lineal simple
 Análisis de regresión lineal simple El propósito de un análisis de regresión es la predicción Su objetivo es desarrollar un modelo estadístico que se pueda usar para predecir los valores de una variable
Análisis de regresión lineal simple El propósito de un análisis de regresión es la predicción Su objetivo es desarrollar un modelo estadístico que se pueda usar para predecir los valores de una variable
Universidad de la República, Facultad de Ciencias Económicas y Administración.
 Universidad de la República, Facultad de Ciencias Económicas y Administración. ECONOMETRIA II- CURSO 2010 Practica 5 MODELOS DE VARIABLE DEPENDIENTE TRUNCADA CENSURADA, MODELOS DE SELECTIVIDAD, MODELOS
Universidad de la República, Facultad de Ciencias Económicas y Administración. ECONOMETRIA II- CURSO 2010 Practica 5 MODELOS DE VARIABLE DEPENDIENTE TRUNCADA CENSURADA, MODELOS DE SELECTIVIDAD, MODELOS
GRAFICOS DE CONTROL DATOS TIPO VARIABLES
 GRAFICOS DE CONTROL DATOS TIPO VARIABLES OBJETIVO DEL LABORATORIO El objetivo del presente laboratorio es que el estudiante conozca y que sea capaz de seleccionar y utilizar gráficos de control, para realizar
GRAFICOS DE CONTROL DATOS TIPO VARIABLES OBJETIVO DEL LABORATORIO El objetivo del presente laboratorio es que el estudiante conozca y que sea capaz de seleccionar y utilizar gráficos de control, para realizar
La eficiencia de los programas
 La eficiencia de los programas Jordi Linares Pellicer EPSA-DSIC Índice General 1 Introducción... 2 2 El coste temporal y espacial de los programas... 2 2.1 El coste temporal medido en función de tiempos
La eficiencia de los programas Jordi Linares Pellicer EPSA-DSIC Índice General 1 Introducción... 2 2 El coste temporal y espacial de los programas... 2 2.1 El coste temporal medido en función de tiempos
Métodos Estadísticos Multivariados
 Métodos Estadísticos Multivariados Victor Muñiz ITESM Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre 2011 1 / 20 Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre
Métodos Estadísticos Multivariados Victor Muñiz ITESM Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre 2011 1 / 20 Victor Muñiz (ITESM) Métodos Estadísticos Multivariados Agosto-Diciembre
ENUNCIADOS DE PROBLEMAS
 UNIVERSIDAD CARLOS III DE MADRID ECONOMETRÍA I 22 de Septiembre de 2007 ENUNCIADOS DE PROBLEMAS Muy importante: Tenga en cuenta que algunos resultados de las tablas han podido ser omitidos. PROBLEMA 1:
UNIVERSIDAD CARLOS III DE MADRID ECONOMETRÍA I 22 de Septiembre de 2007 ENUNCIADOS DE PROBLEMAS Muy importante: Tenga en cuenta que algunos resultados de las tablas han podido ser omitidos. PROBLEMA 1:
Indicaciones para el lector... xv Prólogo... xvii
 ÍNDICE Indicaciones para el lector... xv Prólogo... xvii 1. INTRODUCCIÓN Qué es la estadística?... 3 Por qué estudiar estadística?... 5 Empleo de modelos en estadística... 6 Perspectiva hacia el futuro...
ÍNDICE Indicaciones para el lector... xv Prólogo... xvii 1. INTRODUCCIÓN Qué es la estadística?... 3 Por qué estudiar estadística?... 5 Empleo de modelos en estadística... 6 Perspectiva hacia el futuro...
Análisis Probit. StatFolio de Ejemplo: probit.sgp
 STATGRAPHICS Rev. 4/25/27 Análisis Probit Resumen El procedimiento Análisis Probit está diseñado para ajustar un modelo de regresión en el cual la variable dependiente Y caracteriza un evento con sólo
STATGRAPHICS Rev. 4/25/27 Análisis Probit Resumen El procedimiento Análisis Probit está diseñado para ajustar un modelo de regresión en el cual la variable dependiente Y caracteriza un evento con sólo
Econometría de series de tiempo aplicada a macroeconomía y finanzas
 Econometría de series de tiempo aplicada a macroeconomía y finanzas Series de Tiempo no Estacionarias Carlos Capistrán Carmona ITAM Tendencias Una tendencia es un movimiento persistente de largo plazo
Econometría de series de tiempo aplicada a macroeconomía y finanzas Series de Tiempo no Estacionarias Carlos Capistrán Carmona ITAM Tendencias Una tendencia es un movimiento persistente de largo plazo
ESTADÍSTICA DESCRIPTIVA
 ESTADÍSTICA DESCRIPTIVA Medidas de tendencia central y de dispersión Giorgina Piani Zuleika Ferre 1. Tendencia Central Son un conjunto de medidas estadísticas que determinan un único valor que define el
ESTADÍSTICA DESCRIPTIVA Medidas de tendencia central y de dispersión Giorgina Piani Zuleika Ferre 1. Tendencia Central Son un conjunto de medidas estadísticas que determinan un único valor que define el
La distribución de Poisson es de tipo exponencial con parámetro dispersión 1.
 Reclaaciones y Edad (Pawitan). Una copañía aseguradora quiere conocer cóo depende el núero de reclaaciones de los clientes con cierta póliza, de su edad. El archivo reclaaciones.txt contiene los datos
Reclaaciones y Edad (Pawitan). Una copañía aseguradora quiere conocer cóo depende el núero de reclaaciones de los clientes con cierta póliza, de su edad. El archivo reclaaciones.txt contiene los datos
15. Regresión lineal. Te recomiendo visitar su página de apuntes y vídeos:
 15. Regresión lineal Este tema, prácticamente íntegro, está calacado de los excelentes apuntes y transparencias de Bioestadística del profesor F.J. Barón López de la Universidad de Málaga. Te recomiendo
15. Regresión lineal Este tema, prácticamente íntegro, está calacado de los excelentes apuntes y transparencias de Bioestadística del profesor F.J. Barón López de la Universidad de Málaga. Te recomiendo
Tema 4: Probabilidad y Teoría de Muestras
 Tema 4: Probabilidad y Teoría de Muestras Estadística. 4 o Curso. Licenciatura en Ciencias Ambientales Licenciatura en Ciencias Ambientales (4 o Curso) Tema 4: Probabilidad y Teoría de Muestras Curso 2008-2009
Tema 4: Probabilidad y Teoría de Muestras Estadística. 4 o Curso. Licenciatura en Ciencias Ambientales Licenciatura en Ciencias Ambientales (4 o Curso) Tema 4: Probabilidad y Teoría de Muestras Curso 2008-2009
SOLUCIÓN A LOS EJERCICIOS DEL SPSS Bivariante
 SOLUCIÓ A LOS EJERCICIOS DEL SPSS Bivariante. a). La media y la varianza de las variables estatura y peso en la escala de medida norteamericana. Peso Peso: Transformar -> Calcular: Libras.4536 Peso libras
SOLUCIÓ A LOS EJERCICIOS DEL SPSS Bivariante. a). La media y la varianza de las variables estatura y peso en la escala de medida norteamericana. Peso Peso: Transformar -> Calcular: Libras.4536 Peso libras
CM0244. Suficientable
 IDENTIFICACIÓN NOMBRE ESCUELA ESCUELA DE CIENCIAS NOMBRE DEPARTAMENTO Ciencias Matemáticas ÁREA DE CONOCIMIENTO MATEMATICAS, ESTADISTICA Y AFINES NOMBRE ASIGNATURA EN ESPAÑOL ESTADÍSTICA GENERAL NOMBRE
IDENTIFICACIÓN NOMBRE ESCUELA ESCUELA DE CIENCIAS NOMBRE DEPARTAMENTO Ciencias Matemáticas ÁREA DE CONOCIMIENTO MATEMATICAS, ESTADISTICA Y AFINES NOMBRE ASIGNATURA EN ESPAÑOL ESTADÍSTICA GENERAL NOMBRE
INDICE Capítulo I: Conceptos Básicos Capitulo II: Estadística Descriptiva del Proceso
 INDICE Capítulo I: Conceptos Básicos 1.- Introducción 3 2.- Definición de calidad 7 3.- Política de calidad 10 4.- Gestión de la calidad 12 5.- Sistema de calidad 12 6.- Calidad total 13 7.- Aseguramiento
INDICE Capítulo I: Conceptos Básicos 1.- Introducción 3 2.- Definición de calidad 7 3.- Política de calidad 10 4.- Gestión de la calidad 12 5.- Sistema de calidad 12 6.- Calidad total 13 7.- Aseguramiento
UN PROBLEMA DE OPTIMIZACIÓN CON CABRI: LA REGRESIÓN LINEAL.
 UN PROBLEMA DE OPTIMIZACIÓN CON CABRI: LA REGRESIÓN LINEAL. Benjamín R. Sarmiento Lugo. Universidad Pedagógica Nacional bsarmiento@pedagogica.edu.co Esta conferencia está basada en uno de los temas desarrollados
UN PROBLEMA DE OPTIMIZACIÓN CON CABRI: LA REGRESIÓN LINEAL. Benjamín R. Sarmiento Lugo. Universidad Pedagógica Nacional bsarmiento@pedagogica.edu.co Esta conferencia está basada en uno de los temas desarrollados
4.1 Análisis bivariado de asociaciones
 4.1 Análisis bivariado de asociaciones Los gerentes posiblemente estén interesados en el grado de asociación entre dos variables Las técnicas estadísticas adecuadas para realizar este tipo de análisis
4.1 Análisis bivariado de asociaciones Los gerentes posiblemente estén interesados en el grado de asociación entre dos variables Las técnicas estadísticas adecuadas para realizar este tipo de análisis
CORRELACIÓN Y REGRESIÓN. Juan José Hernández Ocaña
 CORRELACIÓN Y REGRESIÓN Juan José Hernández Ocaña CORRELACIÓN Muchas veces en Estadística necesitamos saber si existe una relación entre datos apareados y tratamos de buscar una posible relación entre
CORRELACIÓN Y REGRESIÓN Juan José Hernández Ocaña CORRELACIÓN Muchas veces en Estadística necesitamos saber si existe una relación entre datos apareados y tratamos de buscar una posible relación entre
UNA COMPARACIÓN DE LOS MODELOS POISSON Y BINOMIAL NEGATIVA CON STATA: UN EJERCICIO DIDÁCTICO
 3er Encuentro de Usuarios de Stata en México UNA COMPARACIÓN DE LOS MODELOS POISSON Y BINOMIAL NEGATIVA CON STATA: UN EJERCICIO DIDÁCTICO Noé Becerra Rodríguez Fortino Vela Peón Mayo, 2011 Mo9vación Ac#vidad
3er Encuentro de Usuarios de Stata en México UNA COMPARACIÓN DE LOS MODELOS POISSON Y BINOMIAL NEGATIVA CON STATA: UN EJERCICIO DIDÁCTICO Noé Becerra Rodríguez Fortino Vela Peón Mayo, 2011 Mo9vación Ac#vidad
Regresión y Correlación
 Relación de problemas 4 Regresión y Correlación 1. El departamento comercial de una empresa se plantea si resultan rentables los gastos en publicidad de un producto. Los datos de los que dispone son: Beneficios
Relación de problemas 4 Regresión y Correlación 1. El departamento comercial de una empresa se plantea si resultan rentables los gastos en publicidad de un producto. Los datos de los que dispone son: Beneficios
ÍNDICE CAPÍTULO 1. INTRODUCCIÓN
 ÍNDICE CAPÍTULO 1. INTRODUCCIÓN 1.1. OBJETO DE LA ESTADÍSTICA... 17 1.2. POBLACIONES... 18 1.3. VARIABLES ALEATORIAS... 19 1.3.1. Concepto... 19 1.3.2. Variables discretas y variables continuas... 20 1.3.3.
ÍNDICE CAPÍTULO 1. INTRODUCCIÓN 1.1. OBJETO DE LA ESTADÍSTICA... 17 1.2. POBLACIONES... 18 1.3. VARIABLES ALEATORIAS... 19 1.3.1. Concepto... 19 1.3.2. Variables discretas y variables continuas... 20 1.3.3.
Curva de Lorenz e Indice de Gini Curva de Lorenz
 Curva de Lorenz e Indice de Gini Curva de Lorenz La curva de Lorenz es útil para demostrar la diferencia entre dos distribuciones: por ejemplo quantiles de población contra quantiles de ingresos. También
Curva de Lorenz e Indice de Gini Curva de Lorenz La curva de Lorenz es útil para demostrar la diferencia entre dos distribuciones: por ejemplo quantiles de población contra quantiles de ingresos. También
Capítulo 8. Análisis Discriminante
 Capítulo 8 Análisis Discriminante Técnica de clasificación donde el objetivo es obtener una función capaz de clasificar a un nuevo individuo a partir del conocimiento de los valores de ciertas variables
Capítulo 8 Análisis Discriminante Técnica de clasificación donde el objetivo es obtener una función capaz de clasificar a un nuevo individuo a partir del conocimiento de los valores de ciertas variables
Ejercicio 1(10 puntos)
") ESTADISTICA Y SUS APLICACIONES EN CIENCIAS SOCIALES. Segundo Parcial Montevideo, 4 de julio de 2015. Nombre: Horario del grupo: C.I.: Profesor: Ejercicio 1(10 puntos) La tasa de desperdicio en una empresa
ESTADISTICA Y SUS APLICACIONES EN CIENCIAS SOCIALES. Segundo Parcial Montevideo, 4 de julio de 2015. Nombre: Horario del grupo: C.I.: Profesor: Ejercicio 1(10 puntos) La tasa de desperdicio en una empresa
5. Regresión Lineal Múltiple
 1 5. Regresión Lineal Múltiple Introducción La regresión lineal simple es en base a una variable independiente y una dependiente; en el caso de la regresión línea múltiple, solamente es una variable dependiente
1 5. Regresión Lineal Múltiple Introducción La regresión lineal simple es en base a una variable independiente y una dependiente; en el caso de la regresión línea múltiple, solamente es una variable dependiente
GUÍA 5 : EFECTO DEL ESTRÉS EN EL PESO DE RECIÉN NACIDOS
 GUÍA 5 : EFECTO DEL ESTRÉS EN EL PESO DE RECIÉN NACIDOS Se realizó un estudio a partir de una muestra aleatoria de mujeres atendidas por el departamento de obstetricia y ginecología de cierta clínica particular.
GUÍA 5 : EFECTO DEL ESTRÉS EN EL PESO DE RECIÉN NACIDOS Se realizó un estudio a partir de una muestra aleatoria de mujeres atendidas por el departamento de obstetricia y ginecología de cierta clínica particular.
PROGRAMA ACADEMICO Ingeniería Industrial
 1. IDENTIFICACIÓN DIVISION ACADEMICA Ingenierías DEPARTAMENTO Ingeniería Industrial PROGRAMA ACADEMICO Ingeniería Industrial NOMBRE DEL CURSO Análisis de datos en Ingeniería COMPONENTE CURRICULAR Profesional
1. IDENTIFICACIÓN DIVISION ACADEMICA Ingenierías DEPARTAMENTO Ingeniería Industrial PROGRAMA ACADEMICO Ingeniería Industrial NOMBRE DEL CURSO Análisis de datos en Ingeniería COMPONENTE CURRICULAR Profesional
UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO FACULTAD DE ESTUDIOS SUPERIORES CUAUTITLÁN PLAN DE ESTUDIOS DE LA LICENCIATURA EN QUÍMICA INDUSTRIAL
 UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO FACULTAD DE ESTUDIOS SUPERIORES CUAUTITLÁN PLAN DE ESTUDIOS DE LA LICENCIATURA EN QUÍMICA INDUSTRIAL PROGRAMA DE LA ASIGNATURA DE: IDENTIFICACIÓN DE LA ASIGNATURA
UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO FACULTAD DE ESTUDIOS SUPERIORES CUAUTITLÁN PLAN DE ESTUDIOS DE LA LICENCIATURA EN QUÍMICA INDUSTRIAL PROGRAMA DE LA ASIGNATURA DE: IDENTIFICACIÓN DE LA ASIGNATURA
TEMA 3: Contrastes de Hipótesis en el MRL
 TEMA 3: Contrastes de Hipótesis en el MRL Econometría I M. Angeles Carnero Departamento de Fundamentos del Análisis Económico Curso 2011-12 Econometría I (UA) Tema 3: Contrastes de Hipótesis Curso 2011-12
TEMA 3: Contrastes de Hipótesis en el MRL Econometría I M. Angeles Carnero Departamento de Fundamentos del Análisis Económico Curso 2011-12 Econometría I (UA) Tema 3: Contrastes de Hipótesis Curso 2011-12
INFERENCIA ESTADÍSTICA. Metodología de Investigación. Tesifón Parrón
 Metodología de Investigación Tesifón Parrón Contraste de hipótesis Inferencia Estadística Medidas de asociación Error de Tipo I y Error de Tipo II α β CONTRASTE DE HIPÓTESIS Tipos de Test Chi Cuadrado
Metodología de Investigación Tesifón Parrón Contraste de hipótesis Inferencia Estadística Medidas de asociación Error de Tipo I y Error de Tipo II α β CONTRASTE DE HIPÓTESIS Tipos de Test Chi Cuadrado
Universidad de Sonora Departamento de Matemáticas Área Económico Administrativa
 Universidad de Sonora Departamento de Matemáticas Área Económico Administrativa Materia: Estadística I Maestro: Dr. Francisco Javier Tapia Moreno Semestre: 015- Hermosillo, Sonora, a 14 de septiembre de
Universidad de Sonora Departamento de Matemáticas Área Económico Administrativa Materia: Estadística I Maestro: Dr. Francisco Javier Tapia Moreno Semestre: 015- Hermosillo, Sonora, a 14 de septiembre de
ANEXO 1. CONCEPTOS BÁSICOS. Este anexo contiene información que complementa el entendimiento de la tesis presentada.
 ANEXO 1. CONCEPTOS BÁSICOS Este anexo contiene información que complementa el entendimiento de la tesis presentada. Aquí se exponen técnicas de cálculo que son utilizados en los procedimientos de los modelos
ANEXO 1. CONCEPTOS BÁSICOS Este anexo contiene información que complementa el entendimiento de la tesis presentada. Aquí se exponen técnicas de cálculo que son utilizados en los procedimientos de los modelos
Discretas. Continuas
 UNIDAD 0. DISTRIBUCIÓN TEÓRICA DE PROBABILIDAD Discretas Binomial Distribución Teórica de Probabilidad Poisson Normal Continuas Normal Estándar 0.1. Una distribución de probabilidad es un despliegue de
UNIDAD 0. DISTRIBUCIÓN TEÓRICA DE PROBABILIDAD Discretas Binomial Distribución Teórica de Probabilidad Poisson Normal Continuas Normal Estándar 0.1. Una distribución de probabilidad es un despliegue de
Doc. Juan Morales Romero
 Análisis de Correlación y Regresión Lineal ANALISIS DE CORRELACION Conjunto de técnicas estadísticas empleadas para medir la intensidad de la asociación entre dos variables DIAGRAMA DE DISPERSION Gráfica
Análisis de Correlación y Regresión Lineal ANALISIS DE CORRELACION Conjunto de técnicas estadísticas empleadas para medir la intensidad de la asociación entre dos variables DIAGRAMA DE DISPERSION Gráfica
Definición de probabilidad
 Tema 5: LA DISTRIBUCIÓN NORMAL 1. INTRODUCCIÓN A LA PROBABILIDAD: Definición de probabilidad Repaso de propiedades de conjuntos (Leyes de Morgan) Probabilidad condicionada Teorema de la probabilidad total
Tema 5: LA DISTRIBUCIÓN NORMAL 1. INTRODUCCIÓN A LA PROBABILIDAD: Definición de probabilidad Repaso de propiedades de conjuntos (Leyes de Morgan) Probabilidad condicionada Teorema de la probabilidad total
Esta expresión polinómica puede expresarse como una expresión matricial de la forma; a 11 a 12 a 1n x 1 x 2 q(x 1, x 2,, x n ) = (x 1, x 2,, x n )
 = (x 1, x 2,, x n )") Tema 3 Formas cuadráticas. 3.1. Definición y expresión matricial Definición 3.1.1. Una forma cuadrática sobre R es una aplicación q : R n R que a cada vector x = (x 1, x 2,, x n ) R n le hace corresponder
Tema 3 Formas cuadráticas. 3.1. Definición y expresión matricial Definición 3.1.1. Una forma cuadrática sobre R es una aplicación q : R n R que a cada vector x = (x 1, x 2,, x n ) R n le hace corresponder
INTERVALOS DE CONFIANZA. La estadística en cómic (L. Gonick y W. Smith)
") INTERVALOS DE CONFIANZA La estadística en cómic (L. Gonick y W. Smith) EJEMPLO: Será elegido el senador Astuto? 2 tamaño muestral Estimador de p variable aleatoria poblacional? proporción de personas que
INTERVALOS DE CONFIANZA La estadística en cómic (L. Gonick y W. Smith) EJEMPLO: Será elegido el senador Astuto? 2 tamaño muestral Estimador de p variable aleatoria poblacional? proporción de personas que
Robusticidad de los Diseños D-óptimos a la Elección. de los Valores Locales para el Modelo Logístico
 Robusticidad de los Diseños D-óptimos a la Elección de los Valores Locales para el Modelo Logístico David Felipe Sosa Palacio 1,a,Víctor Ignacio López Ríos 2,a a. Escuela de Estadística, Facultad de Ciencias,
Robusticidad de los Diseños D-óptimos a la Elección de los Valores Locales para el Modelo Logístico David Felipe Sosa Palacio 1,a,Víctor Ignacio López Ríos 2,a a. Escuela de Estadística, Facultad de Ciencias,
UNIVERSIDAD CENTROCCIDENTAL LISANDRO ALVARADO DECANATO DE INGENIERIA CIVIL ESTADISTICA. CARÁCTER: Obligatoria DENSIDAD HORARIA HT HP HS UCS THS/SEM
 UNIVERSIDAD CENTROCCIDENTAL LISANDRO ALVARADO DECANATO DE INGENIERIA CIVIL ESTADISTICA CARÁCTER: Obligatoria PROGRAMA: Ingeniería Civil DEPARTAMENTO: Ciencias Básicas CODIGO SEMESTRE DENSIDAD HORARIA HT
UNIVERSIDAD CENTROCCIDENTAL LISANDRO ALVARADO DECANATO DE INGENIERIA CIVIL ESTADISTICA CARÁCTER: Obligatoria PROGRAMA: Ingeniería Civil DEPARTAMENTO: Ciencias Básicas CODIGO SEMESTRE DENSIDAD HORARIA HT
Determinación del tamaño de muestra (para una sola muestra)
") STATGRAPHICS Rev. 4/5/007 Determinación del tamaño de muestra (para una sola muestra) Este procedimiento determina un tamaño de muestra adecuado para la estimación o la prueba de hipótesis con respecto
STATGRAPHICS Rev. 4/5/007 Determinación del tamaño de muestra (para una sola muestra) Este procedimiento determina un tamaño de muestra adecuado para la estimación o la prueba de hipótesis con respecto
ESTADÍSTICA. Población Individuo Muestra Muestreo Valor Dato Variable Cualitativa ordinal nominal. continua
 ESTADÍSTICA Población Individuo Muestra Muestreo Valor Dato Variable Cualitativa ordinal nominal Cuantitativa discreta continua DISTRIBUCIÓN DE FRECUENCIAS Frecuencia absoluta: fi Frecuencia relativa:
ESTADÍSTICA Población Individuo Muestra Muestreo Valor Dato Variable Cualitativa ordinal nominal Cuantitativa discreta continua DISTRIBUCIÓN DE FRECUENCIAS Frecuencia absoluta: fi Frecuencia relativa:
PRUEBAS DE ACCESO A LA UNIVERSIDAD L.O.G.S.E
 PRUEBAS DE ACCESO A LA UNIVERSIDAD L.O.G.S.E CURSO 00-.003 - CONVOCATORIA: MATEMÁTICAS APLICADAS A LAS CIENCIAS SOCIALES - Cada alumno debe elegir sólo una de las pruebas (A o B) y, dentro de ella, sólo
PRUEBAS DE ACCESO A LA UNIVERSIDAD L.O.G.S.E CURSO 00-.003 - CONVOCATORIA: MATEMÁTICAS APLICADAS A LAS CIENCIAS SOCIALES - Cada alumno debe elegir sólo una de las pruebas (A o B) y, dentro de ella, sólo
Ing. Eduardo Cruz Romero w w w. tics-tlapa. c o m
 Ing. Eduardo Cruz Romero eduar14_cr@hotmail.com w w w. tics-tlapa. c o m La estadística es tan vieja como la historia registrada. En la antigüedad los egipcios hacían censos de las personas y de los bienes
Ing. Eduardo Cruz Romero eduar14_cr@hotmail.com w w w. tics-tlapa. c o m La estadística es tan vieja como la historia registrada. En la antigüedad los egipcios hacían censos de las personas y de los bienes
Pronósticos Automáticos
 Pronósticos Automáticos Resumen El procedimiento de Pronósticos Automáticos esta diseñado para pronosticar valores futuros en datos de una serie de tiempo. Una serie de tiempo consiste en un conjunto de
Pronósticos Automáticos Resumen El procedimiento de Pronósticos Automáticos esta diseñado para pronosticar valores futuros en datos de una serie de tiempo. Una serie de tiempo consiste en un conjunto de
Medidas de tendencia central y dispersión
 Estadística Aplicada a la Investigación en Salud Medwave. Año XI, No. 3, Marzo 2011. Open Access, Creative Commons. Medidas de tendencia central y dispersión Autor: Fernando Quevedo Ricardi (1) Filiación:
Estadística Aplicada a la Investigación en Salud Medwave. Año XI, No. 3, Marzo 2011. Open Access, Creative Commons. Medidas de tendencia central y dispersión Autor: Fernando Quevedo Ricardi (1) Filiación:
Seguros No Vida. Contenidos:
 Seguros No Vida Contenidos: Introducción Características esenciales de los seguros no vida Diferencias con los seguros de vida Variables aleatorias y distribuciones de probabilidad Ajustes y Estimación
Seguros No Vida Contenidos: Introducción Características esenciales de los seguros no vida Diferencias con los seguros de vida Variables aleatorias y distribuciones de probabilidad Ajustes y Estimación
Bioestadística para Reumatólogos
 Bioestadística para Reumatólogos Xavier Barber Vallés Mabel Sánchez Barrioluengo Colaboradores - Umh Todos los datos que se muestran son ficticios Tablas 2x2: Riesgos Relativos y Odds ratio En cada sociedad
Bioestadística para Reumatólogos Xavier Barber Vallés Mabel Sánchez Barrioluengo Colaboradores - Umh Todos los datos que se muestran son ficticios Tablas 2x2: Riesgos Relativos y Odds ratio En cada sociedad
ACTIVIDAD 2: La distribución Normal
 Actividad 2: La distribución Normal ACTIVIDAD 2: La distribución Normal CASO 2-1: CLASE DE BIOLOGÍA El Dr. Saigí es profesor de Biología en una prestigiosa universidad. Está preparando una clase en la
Actividad 2: La distribución Normal ACTIVIDAD 2: La distribución Normal CASO 2-1: CLASE DE BIOLOGÍA El Dr. Saigí es profesor de Biología en una prestigiosa universidad. Está preparando una clase en la
Distribuciones de probabilidad
 Distribuciones de probabilidad Prof, Dr. Jose Jacobo Zubcoff Departamento de Ciencias del Mar y Biología Aplicada Inferencia estadística: Parte de la estadística que estudia grandes colectivos a partir
Distribuciones de probabilidad Prof, Dr. Jose Jacobo Zubcoff Departamento de Ciencias del Mar y Biología Aplicada Inferencia estadística: Parte de la estadística que estudia grandes colectivos a partir
Algunas Distribuciones Continuas de Probabilidad. UCR ECCI CI-1352 Probabilidad y Estadística Prof. M.Sc. Kryscia Daviana Ramírez Benavides
 Algunas Distribuciones Continuas de Probabilidad UCR ECCI CI-1352 Probabilidad y Estadística Prof. M.Sc. Kryscia Daviana Ramírez Benavides Introducción El comportamiento de una variable aleatoria queda
Algunas Distribuciones Continuas de Probabilidad UCR ECCI CI-1352 Probabilidad y Estadística Prof. M.Sc. Kryscia Daviana Ramírez Benavides Introducción El comportamiento de una variable aleatoria queda
Transformaciones de variables
 Transformaciones de variables Introducción La tipificación de variables resulta muy útil para eliminar su dependencia respecto a las unidades de medida empleadas. En realidad, una tipificación equivale
Transformaciones de variables Introducción La tipificación de variables resulta muy útil para eliminar su dependencia respecto a las unidades de medida empleadas. En realidad, una tipificación equivale
Modelos Lineales Generalizados (GLM)
") 1 1 Departmento de Estadística y Departamento de Administración ITAM Seminario ITAM-CONAC Métodos Estadísticos en Actuaría I Auditorio Raúl Baillères, ITAM 3 de Noviembre de 2011 1. Conceptos Preliminares
1 1 Departmento de Estadística y Departamento de Administración ITAM Seminario ITAM-CONAC Métodos Estadísticos en Actuaría I Auditorio Raúl Baillères, ITAM 3 de Noviembre de 2011 1. Conceptos Preliminares
Teorema Central del Límite (1)
") Teorema Central del Límite (1) Definición. Cualquier cantidad calculada a partir de las observaciones de una muestra se llama estadístico. La distribución de los valores que puede tomar un estadístico
Teorema Central del Límite (1) Definición. Cualquier cantidad calculada a partir de las observaciones de una muestra se llama estadístico. La distribución de los valores que puede tomar un estadístico
Análisis secuencial de los resultados de la Evaluación Censal de Estudiantes
 Análisis secuencial de los resultados de la Evaluación Censal de Estudiantes Encuentro de Economistas del BCRP, 2014 Esquema Motivación Rendimientos en la prueba censal de estudiantes. Trabajos Previos
Análisis secuencial de los resultados de la Evaluación Censal de Estudiantes Encuentro de Economistas del BCRP, 2014 Esquema Motivación Rendimientos en la prueba censal de estudiantes. Trabajos Previos
Variable Aleatoria Continua. Principales Distribuciones
 Variable Aleatoria Continua. Definición de v. a. continua Función de Densidad Función de Distribución Características de las v.a. continuas continuas Ejercicios Definición de v. a. continua Las variables
Variable Aleatoria Continua. Definición de v. a. continua Función de Densidad Función de Distribución Características de las v.a. continuas continuas Ejercicios Definición de v. a. continua Las variables
INSTITUTO NACIONAL DE ESTADÍSTICAS (INE) 29 de Abril de 2016
 29 de Abril de 2016") ANEXO ESTADÍSTICO 1 : COEFICIENTES DE VARIACIÓN Y ERROR ASOCIADO AL ESTIMADOR ENCUESTA NACIONAL DE EMPLEO (ENE) INSTITUTO NACIONAL DE ESTADÍSTICAS (INE) 9 de Abril de 016 1 Este anexo estadístico es una
ANEXO ESTADÍSTICO 1 : COEFICIENTES DE VARIACIÓN Y ERROR ASOCIADO AL ESTIMADOR ENCUESTA NACIONAL DE EMPLEO (ENE) INSTITUTO NACIONAL DE ESTADÍSTICAS (INE) 9 de Abril de 016 1 Este anexo estadístico es una
Regresión con variables independientes cualitativas
 Regresión con variables independientes cualitativas.- Introducción...2 2.- Regresión con variable cualitativa dicotómica...2 3.- Regresión con variable cualitativa de varias categorías...6 2.- Introducción.
Regresión con variables independientes cualitativas.- Introducción...2 2.- Regresión con variable cualitativa dicotómica...2 3.- Regresión con variable cualitativa de varias categorías...6 2.- Introducción.
Teléfono:
 Apartado postal 17-01-218 1. DATOS INFORMATIVOS: MATERIA O MÓDULO: ESTADISTICA II CÓDIGO: 15017 CARRERA: Economía NIVEL: Cuarto No. CRÉDITOS: SEMESTRE / AÑO ACADÉMICO: III semestre 2011-2012 PROFESOR:
Apartado postal 17-01-218 1. DATOS INFORMATIVOS: MATERIA O MÓDULO: ESTADISTICA II CÓDIGO: 15017 CARRERA: Economía NIVEL: Cuarto No. CRÉDITOS: SEMESTRE / AÑO ACADÉMICO: III semestre 2011-2012 PROFESOR:
Variables estadísticas bidimensionales: problemas resueltos
 Variables estadísticas bidimensionales: problemas resueltos BENITO J. GONZÁLEZ RODRÍGUEZ (bjglez@ull.es) DOMINGO HERNÁNDEZ ABREU (dhabreu@ull.es) MATEO M. JIMÉNEZ PAIZ (mjimenez@ull.es) M. ISABEL MARRERO
Variables estadísticas bidimensionales: problemas resueltos BENITO J. GONZÁLEZ RODRÍGUEZ (bjglez@ull.es) DOMINGO HERNÁNDEZ ABREU (dhabreu@ull.es) MATEO M. JIMÉNEZ PAIZ (mjimenez@ull.es) M. ISABEL MARRERO
Marco de referencia. a) Es útil saber si la estrategia de tratamiento sin un. biológico (menos costosa), tiene mejor o igual eficacia
 Es útil saber si la estrategia de tratamiento sin un. biológico (menos costosa), tiene mejor o igual eficacia") Marco de referencia a) Es útil saber si la estrategia de tratamiento sin un biológico (menos costosa), tiene mejor o igual eficacia que la estrategia con un biológico en AR temprana. b) No hay estudios
Marco de referencia a) Es útil saber si la estrategia de tratamiento sin un biológico (menos costosa), tiene mejor o igual eficacia que la estrategia con un biológico en AR temprana. b) No hay estudios
PREGUNTAS TIPO EXAMEN- ESTADÍSTICA DESCRIPTIVA 2
 PREGUNTAS TIPO EXAMEN- ESTADÍSTICA DESCRIPTIVA 2 Preg. 1. Para comparar la variabilidad relativa de la tensión arterial diastólica y el nivel de colesterol en sangre de una serie de individuos, utilizamos
PREGUNTAS TIPO EXAMEN- ESTADÍSTICA DESCRIPTIVA 2 Preg. 1. Para comparar la variabilidad relativa de la tensión arterial diastólica y el nivel de colesterol en sangre de una serie de individuos, utilizamos
Cómo se hace la Prueba t a mano?
 Cómo se hace la Prueba t a mano? Sujeto Grupo Grupo Grupo Grupo 33 089 74 5476 84 7056 75 565 3 94 8836 75 565 4 5 704 76 5776 5 4 6 76 5776 6 9 8 76 5776 7 4 78 6084 8 65 45 79 64 9 86 7396 80 6400 0
Cómo se hace la Prueba t a mano? Sujeto Grupo Grupo Grupo Grupo 33 089 74 5476 84 7056 75 565 3 94 8836 75 565 4 5 704 76 5776 5 4 6 76 5776 6 9 8 76 5776 7 4 78 6084 8 65 45 79 64 9 86 7396 80 6400 0
CONTRASTES DE HIPÓTESIS NO PARAMÉTRICOS
 CONTRASTES DE HIPÓTESIS NO PARAMÉTRICOS 1 POR QUÉ SE LLAMAN CONTRASTES NO PARAMÉTRICOS? A diferencia de lo que ocurría en la inferencia paramétrica, ahora, el desconocimiento de la población que vamos
CONTRASTES DE HIPÓTESIS NO PARAMÉTRICOS 1 POR QUÉ SE LLAMAN CONTRASTES NO PARAMÉTRICOS? A diferencia de lo que ocurría en la inferencia paramétrica, ahora, el desconocimiento de la población que vamos
CLASE 10: RESUMEN DEL CURSO
 CLASE 10: RESUMEN DEL CURSO 10.1.-INTRODUCCIÓN Qué debemos valorar al enfrentarnos con el análisis de unos datos estadísticos? 1º TIPO DE ESTUDIO: - Datos Independientes - Datos Apareados 2º TIPO DE VARIABLES:
CLASE 10: RESUMEN DEL CURSO 10.1.-INTRODUCCIÓN Qué debemos valorar al enfrentarnos con el análisis de unos datos estadísticos? 1º TIPO DE ESTUDIO: - Datos Independientes - Datos Apareados 2º TIPO DE VARIABLES:
3. ASOCIACIÓN ENTRE DOS VARIABLES CUALITATIVAS
 1. INTRODUCCIÓN Este tema se centra en el estudio conjunto de dos variables. Dos variables cualitativas - Tabla de datos - Tabla de contingencia - Diagrama de barras - Tabla de diferencias entre frecuencias
1. INTRODUCCIÓN Este tema se centra en el estudio conjunto de dos variables. Dos variables cualitativas - Tabla de datos - Tabla de contingencia - Diagrama de barras - Tabla de diferencias entre frecuencias
La medición de la desigualdad económica
 La medición de la desigualdad económica La medida de desigualdad económica mas comúnmente utilizada es la distribución del ingreso percibido por las personas durante un periodo determinado de tiempo generalmente
La medición de la desigualdad económica La medida de desigualdad económica mas comúnmente utilizada es la distribución del ingreso percibido por las personas durante un periodo determinado de tiempo generalmente
Percepción de los Precios por Parte de los Hogares: El caso de la Electricidad en el Perú
 Percepción de los Precios por Parte de los Hogares: El caso de la Electricidad en el Perú Luis Bendezú Medina Universidad de Chile Diciembre 2007 Contenido Introducción Modelo Teórico Implementación Empírica
Percepción de los Precios por Parte de los Hogares: El caso de la Electricidad en el Perú Luis Bendezú Medina Universidad de Chile Diciembre 2007 Contenido Introducción Modelo Teórico Implementación Empírica
Modelos de PERT/CPM: Probabilístico
 INSTITUTO POLITÉCNICO NACIONAL ESCUELA SUPERIOR DE CÓMPUTO Modelos de PERT/CPM: Probabilístico M. En C. Eduardo Bustos Farías 1 Existen proyectos con actividades que tienen tiempos inciertos, es decir,
INSTITUTO POLITÉCNICO NACIONAL ESCUELA SUPERIOR DE CÓMPUTO Modelos de PERT/CPM: Probabilístico M. En C. Eduardo Bustos Farías 1 Existen proyectos con actividades que tienen tiempos inciertos, es decir,
SESIÓN PRÁCTICA 7: REGRESION LINEAL SIMPLE PROBABILIDAD Y ESTADÍSTICA. PROF. Esther González Sánchez. Departamento de Informática y Sistemas
 SESIÓN PRÁCTICA 7: REGRESION LINEAL SIMPLE PROBABILIDAD Y ESTADÍSTICA PROF. Esther González Sánchez Departamento de Informática y Sistemas Facultad de Informática Universidad de Las Palmas de Gran Canaria
SESIÓN PRÁCTICA 7: REGRESION LINEAL SIMPLE PROBABILIDAD Y ESTADÍSTICA PROF. Esther González Sánchez Departamento de Informática y Sistemas Facultad de Informática Universidad de Las Palmas de Gran Canaria
Datos binomiales 1.70 1.75 1.80 1.85. beetles$dosis
 Datos binomiales Modelos de dosis-respuesta Carga de datos y calculo de proporciones: beetles
Datos binomiales Modelos de dosis-respuesta Carga de datos y calculo de proporciones: beetles
Estadística Industrial. Universidad Carlos III de Madrid Series temporales Práctica 5
 Estadística Industrial Universidad Carlos III de Madrid Series temporales Práctica 5 Objetivo: Análisis descriptivo, estudio de funciones de autocorrelación simple y parcial de series temporales estacionales.
Estadística Industrial Universidad Carlos III de Madrid Series temporales Práctica 5 Objetivo: Análisis descriptivo, estudio de funciones de autocorrelación simple y parcial de series temporales estacionales.
Estadística y sus aplicaciones en Ciencias Sociales 7. El modelo de regresión simple. Facultad de Ciencias Sociales - UdelaR
 Estadística y sus aplicaciones en Ciencias Sociales 7. El modelo de regresión simple Facultad de Ciencias Sociales - UdelaR Índice 7.1 Introducción 7.2 Análisis de regresión 7.3 El Modelo de Regresión
Estadística y sus aplicaciones en Ciencias Sociales 7. El modelo de regresión simple Facultad de Ciencias Sociales - UdelaR Índice 7.1 Introducción 7.2 Análisis de regresión 7.3 El Modelo de Regresión
ESCUELA COMERCIAL CÁMARA DE COMERCIO EXTENSIÓN DE ESTUDIOS PROFESIONALES MAESTRÍA EN ADMINISTRACIÓN
 CICLO, ÁREA O MÓDULO: TERCER CUATRIMESTRE OBJETIVO GENERAL DE LA ASIGNATURA: Al termino del curso el alumno efectuara el análisis ordenado y sistemático de la Información, a través del uso de las técnicas
CICLO, ÁREA O MÓDULO: TERCER CUATRIMESTRE OBJETIVO GENERAL DE LA ASIGNATURA: Al termino del curso el alumno efectuara el análisis ordenado y sistemático de la Información, a través del uso de las técnicas
INSTITUTO POLITÉCNICO NACIONAL SECRETARIA ACADEMICA DIRECCIÓN DE ESTUDIOS PROFESIONALES EN INGENIERÍA Y CIENCIAS FÍSICO MATEMÁTICAS
 ESCUELA: UPIICSA CARRERA: INGENIERÍA EN TRANSPORTE ESPECIALIDAD: COORDINACIÓN: ACADEMIAS DE MATEMÁTICAS DEPARTAMENTO: CIENCIAS BÁSICAS PROGRAMA DE ESTUDIO ASIGNATURA: ESTADÍSTICA APLICADA CLAVE: TMPE SEMESTRE:
ESCUELA: UPIICSA CARRERA: INGENIERÍA EN TRANSPORTE ESPECIALIDAD: COORDINACIÓN: ACADEMIAS DE MATEMÁTICAS DEPARTAMENTO: CIENCIAS BÁSICAS PROGRAMA DE ESTUDIO ASIGNATURA: ESTADÍSTICA APLICADA CLAVE: TMPE SEMESTRE:
USO HERRAMIENTAS EXCEL PARA LA PREDICCION
 USO HERRAMIENTAS EXCEL PARA LA PREDICCION Nassir Sapag Chain MÉTODO DE REGRESIÓN LINEAL SIMPLE El método de Regresión Lineal (o Mínimos cuadrados) busca determinar una recta, o más bien la ecuación de
USO HERRAMIENTAS EXCEL PARA LA PREDICCION Nassir Sapag Chain MÉTODO DE REGRESIÓN LINEAL SIMPLE El método de Regresión Lineal (o Mínimos cuadrados) busca determinar una recta, o más bien la ecuación de