Multiprocesadores IEC-UTM
|
|
|
- Laura María Soledad Murillo Alcaraz
- hace 8 años
- Vistas:
Transcripción
1 Multiprocesadores IEC-UTM

2 Introducción Arquitectura de un equipo paralelo

3 Paradigmas de paralelismo Paradigma SIMD Paradigma Vector/Array Paradigma Sistólico

4 Clasificación de Flynn Flujo único de instrucciones, flujo único de datos (SISD). Flujo único de instrucciones, flujo múltiple de datos (SIMD). Flujos múltiples de instrucciones, flujo único de datos (MISD). Flujos múltiples de instrucciones, flujos múltiples de datos (MIMD).
.")
5 SISD Las computadoras que entran en la clasificación SISD tienen un único procesador y ejecutan una sola instrucción a la vez. Figura A.4. Arquitectura SISD

6 SIMD En esta arquitectura se tienen p procesadores idénticos, los cuales poseen una memoria local. Trabajan bajo un solo flujo de instrucciones originado por una unidad central de control, por lo que se tienen p flujos de datos. Figura A.5. Arquitectura SIMD

7 Processor board of a CRAY YMP vector computer (operational ca ). The board was liquid cooled and is one vector processor with shared memory (access to one central memory)

8 MISD Realizan múltiples instrucciones para un solo conjunto de datos. Figura A.6. Arquitectura MISD

9 MIMD La arquitectura MIMD está conformada por p procesadores, p flujos de instrucciones y p flujos de datos. Cada procesador trabaja de modo asíncrono bajo el control de un flujo de instrucciones proveniente de su propia unidad de control Figura A.7. Arquitectura MIMD

10 Clasificación de Flynn

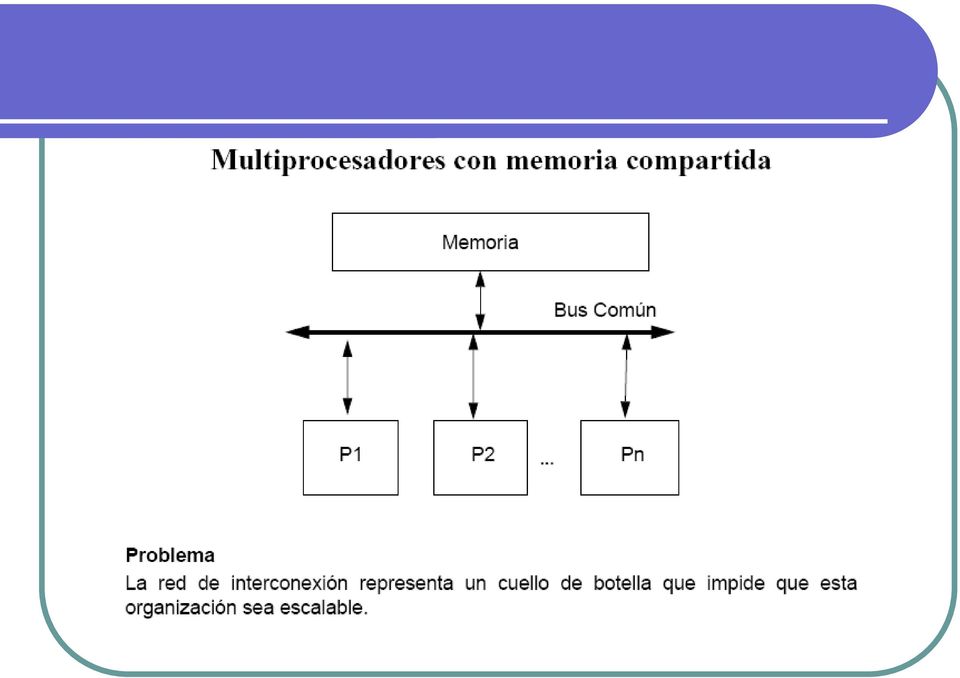
11 Cómo comparten datos los procesadores paralelos? Existen procesadores con un único espacio de direcciones, algunas veces llamados procesadores con memoria compartida, ofrecen al programador un único espacio de direcciones de memoria que todos los procesadores comparten. Los procesadores se comunican a través de variables compartidas en memoria, todos los procesadores tienen acceso a cualquier localidad de memoria a través de cargas y almacenamientos.

12 Shared Memory Systems cada nodo tiene acceso a una amplia memoria compartida que se añade a la memoria limitada privada, no compartida, propia de cada nodo. Los sistemas con memoria compartida, tienen multiples CPU s que comparten las mismas direcciones de memoria. Esto significa que que existe una única memoria que es accesada por todas las unidades de procesamiento. Los sistemas con memoria compartida pueden ser SIMD o MIMD, en dichos casos se pueden abreviar como SM-SIMD y SM-MIMD respectivamente. Para desarrollar programas usando este paradigma, se utiliza OpenMP disponible para C(++) y Fortran

13

14
15 Arquitectura de un sistema SMP

16 Tipos de procesadores con un único espacio de direcciones UMA (uniform memory access) En estos sistemas todos los procesadores toman el mismo tiempo de acceso a la memoria, también son conocidos como multiptocesadores simétricos (SMP, symmetric multiprocessors). Una computadora SMP se compone de microprocesadores independientes que se comunican con la memoria a través de un bus compartido. Dicho bus es un recurso de uso común. Por tanto, debe ser arbitrado para que solamente un microprocesador lo use en cada instante de tiempo. NUMA (nonuniform memory access) algunos accesos a memoria son más rápidos que otros dependiendo de cual procesador esté accesando y a cual palabra, son conocidos como multiprocesadores con acceso no uniforme a memoria Como podría esperarse, hay mas desafíos de programación para obtener un rendimiento más alto con un multiprocesador NUMA que con un multiprocesador UMA, pero las máquinas NUMA pueden escalar a grandes tamaños y por lo tanto son potencialmente de un rendimiento más alto.
 algunos accesos a memoria son más rápidos que otros dependiendo de cual procesador esté accesando y a cual palabra, son conocidos como multiprocesadores con acceso no")
17 Cómo se coordinan los procesadores paralelos? La sincronización es un mecanismo que permite bloquear a otros procesadores mientras sólo uno tiene privilegios de escritura sobre datos compartidos. El resto de los procesadores, en caso de requerir acceso a los datos deben esperar Las operaciones de lectura no tienen problemas de sincronización.

18
19

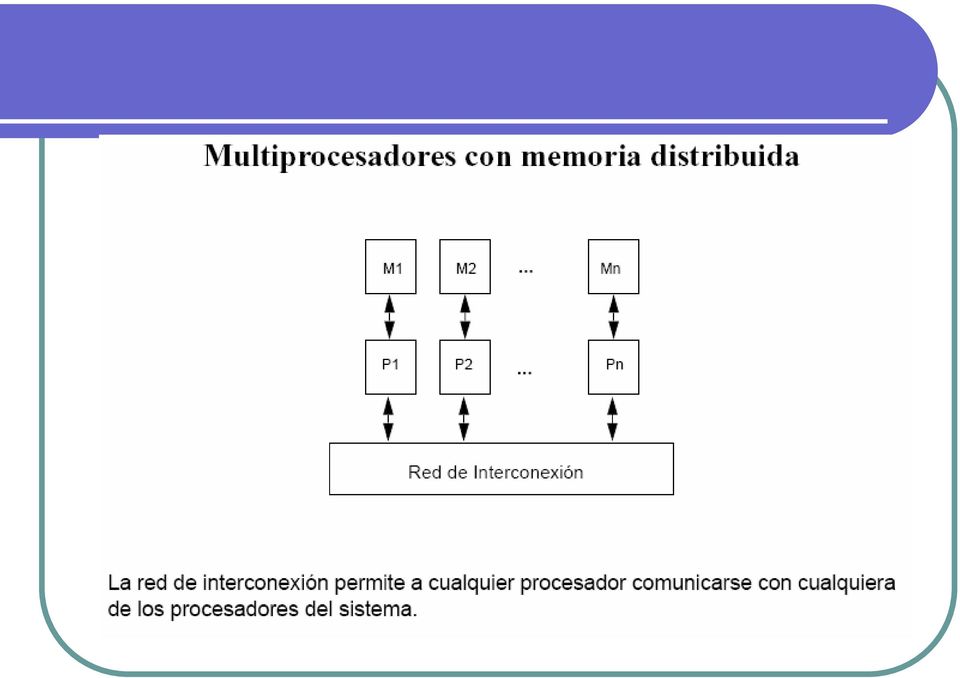
20 Distributed memory systems Cada CPU tiene su propia memoria, los CPU s están interconectados a través de una red de interconexión que permite intercambiar datos entre los diferentes nodos cuando se requiere. En este tipo de implementaciones, el desarrollador debe controlar donde está cada parte de la información, es decir debe controlar y administrar cada parte de los datos que son distribuidos en todos los nodos. Los sistemas distribuidos pueden ser SIMD o MIMD (DM- SIMD o DM-MIMD) Los sistemas de interconexión para MIMD, tienen una gran cantidad de topologías de interconexión. En general estas topologías son transparentes para el usuario de tal forma que permita la portabilidad de aplicaciones.

21 Paso de mensajes El modelo alternativo a la memoria compartida utiliza el paso de mensajes para comunicación entre procesadores. Los procesadores en diferentes computadoras de escritorio se comunican pasando mensajes sobre una red de interconexión. Los sistemas tienen rutinas para enviar y recibir mensajes, la coordinación es construida con los mensajes que se envían, dado que un procesador sabe cuando un mensaje es enviado y el procesador receptor sabe cuando un mensaje ha llegado. El procesador receptor puede entonces enviar un mensaje al emisor indicando que el mensaje ha llegado, si el emisor necesita confirmación.
22 MPI MPI es la primera biblioteca de paso de mensajes estándar que ofrece portabilidad, estandarización y una implementación eficiente de la ejecución paralela, está formada por una colección de rutinas que facilitan la comunicación entre procesadores en programas paralelos La estandarización asegura que las llamadas hechas en algún equipo se comportan de igual manera en otras máquinas, independientemente de la implementación usada. La portabilidad permite la implementación de programas en diferentes plataformas como Linux, Solaris, UNIX, Windows NT, entre otras. MPI ha sido fuertemente influenciado por las siguientes entidades: Centro de Investigaciones Watson de IBM, Intel's NX/2, Express, ncubes's Vértex p4 y PARMACS.
23 La estructura general de un programa MPI es la siguiente: Inicialización de la comunicación Comunicar para compartir datos entre procesos cada vez que sea necesario. Finalizar el ambiente paralelo. 1. Ejemplo: 2. #include <stdio.h> 3. #include <mpi.h> 4. main(int argc, char **argv){ 5. int soy, tam; 6. MPI_Init(&argc, &argv); 7. MPI_Comm_rank(MPI_COMM_WORLD, &soy); 8. MPI_Comm_size(MPI_COMM_WORLD, &tam); 9. printf(" Hola Mundo, soy %d de %d.\n, soy, tam); 10. MPI_Finalize(); 11. }
24 Ejemplo
25
26 Rutinas MPI_Send Basic blocking send operation. Routine returns only after the application buffer in the sending task is free for reuse. MPI_Send (&buf,count,datatype,dest,tag,comm) MPI_SEND (buf,count,datatype,dest,tag,comm,ierr) MPI_Recv Receive a message and block until the requested data is available in the application buffer in the receiving task. MPI_Recv (&buf,count,datatype,source,tag,comm,&status) MPI_RECV (buf,count,datatype,source,tag,comm,status,ierr)
27 Algunos problemas programando en MPI Buffering: In a perfect world, every send operation would be perfectly synchronized with its matching receive. This is rarely the case. Somehow or other, the MPI implementation must be able to deal with storing data when the two tasks are out of sync. Consider the following two cases: A send operation occurs 5 seconds before the receive is ready - where is the message while the receive is pending? Multiple sends arrive at the same receiving task which can only accept one send at a time - what happens to the messages that are "backing up"? The MPI implementation (not the MPI standard) decides what happens to data in these types of cases. Typically, a system buffer area is reserved to hold data in transit.
28 OpenMP OpenMP Is An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism The API is specified for C/C++ and Fortran. Supports Fortran (77, 90, and 95), C, and C++ Multiple platforms have been implemented including most Unix platforms and Windows NT OpenMP is based upon the existence of multiple threads in the shared memory programming paradigm. A shared memory process consists of multiple threads. OpenMP is an explicit (not automatic) programming model, offering the programmer full control over parallelization.
29 Fork - Join Model: OpenMP uses the fork-join model of parallel execution: All OpenMP programs begin as a single process: the master thread. The master thread executes sequentially until the first parallel region construct is encountered. FORK: the master thread then creates a team of parallel threads The statements in the program that are enclosed by the parallel region construct are then executed in parallel among the various team threads JOIN: When the team threads complete the statements in the parallel region construct, they synchronize and terminate, leaving only the master thread
30 C / C++ - General Code Structure in OpenMP
31 C / C++ - Parallel Region Example
32 Simple vector-add program Arrays A, B, C, and variable N will be shared by all threads. Variable I will be private to each thread; each thread will have its own unique copy. The iterations of the loop will be distributed dynamically in CHUNK sized pieces. Threads will not synchronize upon completing their individual pieces of work (NOWAIT).
33
34 Problemas y Retos Hardware Buscar organizaciones del sistema que permitan al software obtener una fracción significativa de la velocidad máxima del sistema. Aplicaciones y Algoritmos Identificar aplicaciones críticas que pueden beneficiarse del uso de los sistemas multiprocesadores. Encontrar algoritmos paralelos eficientes para resolver los núcleos computacionales más habituales. Herramientas Desarrollar herramientas (modelos de programación, compiladores, depuradores, monitorizadores de rendimiento, etc) que faciliten el uso del sistema.
35 Problemas en la programación paralela a. Las comunicaciones disminuyen la aceleración de los algoritmos paralelos - La ley de Amdahl b. El programador debe saber mucho acerca del hardware, un conocimiento amplio para escribir programas que sean rápidos y capaces de ejecutarse en un número variable de procesadores. c. Un programa adaptado a un multiprocesador no es transportable a otros multiprocesadores.
36 Cuello de botella de Von Neumann La velocidad de procesamiento del sistema está limitada entonces por la rapidez en que los datos e instrucciones pueden ser transportados desde la memoria hasta la unidad de procesamiento. Esta conexión entre la memoria y la unidad de procesamiento es conocida como el cuello de botella de Von Neumann. Este cuello de botella puede ser evitado empleando más de una unidad de procesamiento y muchas memorias, así varios flujos de datos pueden estar activos al mismo tiempo
37 La ley de Amdahl Un número pequeño de operaciones secuenciales puede limitar el factor de aceleración de un algoritmo paralelo, estas operaciones son necesarias para la sincronización de todos los procesadores. f = fracción de operaciones secuenciales p = # procesadores Sp = aceleración
38 Aplicación de la ley de Amdahl
39 Curvas de velocidad El propósito de estas curvas es comparar el tiempo del programa serial más rápido T1 contra el tiempo del programa paralelo equivalente T(N), donde N es el número de procesadores usados.
40 Curvas de rapidez
41 Curvas de rapidez El incremento del número de procesadores no siempre garantiza la disminución del tiempo en el que es realizada una determinada tarea. En el Instituto de Supercómputo de Minesota se hicieron pruebas al modelo de paralelización JavaSpMT (Java Speculative MultiThreading), que son librerías específicas para la programación de hilos. Una de las aplicaciones de prueba que se hicieron fue para resolver sistemas de ecuaciones lineales de nxn usando el método de eliminación gausiana. Las pruebas fueron hechas en un sistema multiprocesador IP25 SGI Challenge a 196 MHz con memoria compartida y 8 procesadores MIPS R Curvas de rapidez al utilizar 2, 4, y 8 procesadores para resolver un sistema de ecuaciones lineales de nxn, por el método de Gauss
42 Número de Imágenes procesadas Tiempo del programa secuencial, T(1) (min) Tiempo del programa en paralelo, T(2) (min) T(1)/T(2) Curva de incremento de velocidad T(1)/T(2) Número de imágenes procesadas
43 Comparación de los tiempos de procesamiento de los programas paralelo y el secuencial Tiem po (m in) 6 Programa secuencial Programa paralelo Número de imágenes procesadas
44 Granularidad Granularidad: se refiere al número de operaciones de cómputo realizadas en cada módulo del algoritmo paralelo. Granularidad gruesa.- ocurre cuando en el algoritmo hay un número elevado de operaciones de cómputo y como consecuencia tiene pocas operaciones de comunicación. Granularidad fina.- ocurre cuando el algoritmo tiene pocas operaciones de cómputo y un elevado número de comunicaciones.
45 Multiprocesadores conectados por un solo bus El alto rendimiento y el bajo costo de los microprocesadores inspiró renovados intereses en los multiprocesadores en los 60 s. Varios microprocesadores pueden colocarse adecuadamente en un bus común por diversas razones: Cada microprocesador es más pequeño que un procesador multi-chip, de manera que más procesadores pueden ser situados sobre un bus. La caché puede reducir el tráfico del bus. Se tienen los mecanismos para mantener la consistencia entre la caché y la memoria para multiprocesadores, así como caché y memoria se mantienen consistentes con I/O, por lo tanto se simplifica la programación.
46 El tráfico por procesador y el ancho de banda del bus determinan el número útil de procesadores en tales microprocesadores. Las caché s replican datos en sus memorias más rápidas tanto para reducir la latencia a los datos y reducir el tráfico de memoria sobre el bus.
47 Computadoras con multiprocesadores conectadas por un solo bus, disponibles en el mercado en 1997
48 Ejemplo: Programa paralelo (Un solo bus) Se quieren sumar 100, 000 números con una computadora cuyo multiprocesador es de un solo bus. Se asume que cuenta con 10 procesadores. Realizar un programa para esta tarea Respuesta: El primer paso consistiría en dividir el conjunto de números en subconjuntos del mismo tamaño. Dado que hay una memoria única para esta máquina, los subconjuntos tendrán diferentes direcciones de inicio que usará cada procesador. Pn es el número del procesador, entre 0 y 9. Todos los procesadores inician el programa ejecutando un lazo que suma sus subconjuntos de números: 1. Sum[ Pn ] = 0; 2. for ( i = 10000*Pn; i < 10000*(Pn + 1); i = i + 1 ) 3. Sum[ Pn ] = Sum[Pn] + A[i]; /* Suman sus áreas asignadas */
49 El siguiente paso consiste en sumar estas sumas parciales, se aplicará una estrategia del tipo divide y vencerás. La mitad de los procesadores sumará un par de las sumas parciales, después un cuarto sumará un par de cada una de las nuevas sumas parciales, y así hasta obtener una única suma final. Es conveniente que cada procesador tenga su propia versión de la variable de control de lazo i, de manera que se debe indicar que ésta es una variable privada (private).
50 En este ejemplo, los procesadores deben sincronizarse antes de que los procesadores consumidores intenten leer el resultado desde la ubicación de la memoria escrito por los 10 procesadores productores ; en otro caso, el consumidor puede leer los valores anteriores de los datos. El código es el siguiente (half es una variable privada): Half = 10; /* 10 procesadores en un multiprocesador de un bus Do { Synch(); /* Espera a que la suma parcial se complete */ If ( Half % 2!= 0 && Pn == 0 ) Sum[0] = Sum[0] + Sum[Half 1]; Half = Half / 2; /* Línea de división sobre los que suman If ( Pn < Half ) Sum[ Pn ] = Sum[ Pn ] + Sum[ Pn + Half ] } while ( Half!= 1); /* Termina con la suma final en Sum[0] */
51 Configuraciones de memoria compartida y distribuida
52 Suma de 16 números en paralelo
53 Configuraciones de redes de interconexión
54
55
56 Clusters Simplemente, cluster es un grupo de múltiples computadoras unidas mediante una red de alta velocidad, de tal forma que el conjunto es visto como un único ordenador, más potente que los comunes de escritorio. De un cluster se espera que presente combinaciones de los siguientes servicios: Alto rendimiento (High Performance) Alta disponibilidad (High Availability) Equilibrio de carga (Load Balancing) Escalabilidad (Scalability)
57 La construcción de los ordenadores del cluster es más fácil y económica debido a su flexibilidad: pueden tener todos la misma configuración de hardware y sistema operativo (cluster homogéneo), diferente rendimiento pero con arquitecturas y sistemas operativos similares (cluster semi-homogéneo), o tener diferente hardware y sistema operativo (cluster heterogéneo). Para que un cluster funcione como tal, no basta sólo con conectar entre sí los ordenadores, sino que es necesario proveer un sistema de manejo del cluster, el cual se encargue de interactuar con el usuario y los procesos que corren en él para optimizar el funcionamiento
58 Componentes de un cluster En general, un cluster necesita de varios componentes de software y hardware para poder funcionar. A saber: Nodos (los ordenadores o servidores) Conexiones de Red (Ethernet, Fast Ethernet, Gigabit Ethernet, Myrinet, Infiniband, SCI, ) Middleware (capa de abstracción entre el usuario y los sistemas operativos) genera la sensación al usuario de que utiliza un único ordenador muy potente (MOSIX, OpenMOSIX) Protocolos de Comunicación y servicios. Aplicaciones (pueden ser paralelas o no)
59 El middleware El middleware también debe poder migrar procesos entre servidores con distintas finalidades: balancear la carga: si un servidor está muy cargado de procesos y otro está ocioso, pueden transferirse procesos a este último para liberar de carga al primero y optimizar el funcionamiento; Mantenimiento de servidores: si hay procesos corriendo en un servidor que necesita mantenimiento o una actualización, es posible migrar los procesos a otro servidor y proceder a desconectar del cluster al primero priorización de trabajos: en caso de tener varios procesos corriendo en el cluster, pero uno de ellos de mayor importancia que los demás, puede migrarse este proceso a los servidores que posean más o mejores recursos para acelerar su procesamiento.
60 Grid Grid computing or grid clusters are a technology closely related to cluster computing. The key differences (by definitions which distinguish the two at all) between grids and traditional clusters are that grids connect collections of computers which do not fully trust each other, or which are geographically dispersed. Grids are thus more like a computing utility than like a single computer. In addition, grids typically support more heterogeneous collections than are commonly supported in clusters. Grid computing is optimized for workloads which consist of many independent jobs or packets of work, which do not have to share data between the jobs during the computation process. Grids serve to manage the allocation of jobs to computers which will perform the work independently of the rest of the grid cluster. Resources such as storage may be shared by all the nodes, but intermediate results of one job do not affect other jobs in progress on other nodes of the grid. An example of a very large grid is the Folding@home project. It is analyzing data that is used by researchers to find cures for diseases such as Alzheimer's and cancer. Another large project is the SETI@home project, which may be the largest distributed cluster in existence. It uses approximately three million home computers all over the world to analyze data from the Arecibo Observatory radiotelescope, searching for evidence of extraterrestrial intelligence.
61 Supercomputadoras Una supercomputadora es una computadora que es considerada en su momento de introducción, como lo máximo en capacidad de procesamiento y cálculo, con capacidades muy superiores a la de una computadora de uso común. Una supercomputadora es un tipo de computadora muy potente y rápida, diseñada para procesar enormes cantidades de información en poco tiempo y dedicada a una tarea específica. La primera vez que apareció el término fue en 1929 en el periodico New York World refiriéndose a una computadora construida en la Universidad de Columbia.
62 Historia En 1960, Seymour Cray trabajaba en la CDC (Control Data Corporation) fue quien introdujo la primera súpercomputadora, fue líder durante toda la década hasta que en 1970 Cray formó su propia compañía, Cray Research Durante 5 años ( ), Cray lideréo el mercado de supercomputadoras con sus nuevos diseños. Actualmente el mercado de las supercomputadoras está dominado por las empresas IBM y HP que han absorvido a muchas de las empresas que figuraron en la década de los 80 s, con la intensión de ganar experiencia.
63 Seymour Cray En 1957, junto con otros ingenieros fundó una nueva compañía denominada Control Data Corporation, en abreviatura CDC, para la cual construyó el CDC 1604, que fue uno de los primeros ordenadores comerciales que utilizaron transistores en lugar de tubos de vacío. En 1963, el CDC 6600, batió ampliamente en capacidad de cálculo y en coste al ordenador más potente de que disponía IBM en aquella época. En el año 1972 fundó Cray Research, con el compromiso de dedicarse a construir exclusivamente supercomputadores y además de uno en uno, por encargo. CRAY-1 (1976) en el Laboratorio Nacional Los Álamos, incorporaba el primer ejemplo práctico en funcionamiento de procesador vectorial, junto con el procesador escalar más rápido del momento, con una capacidad de 1 millón de palabras de 64 bits y un ciclo de 12,5 nanosegundos. Su coste se situaba en torno a los 10 millones de dólares.
64 El CRAY-2, entre 6 y 12 veces más rápido que su predecesor. Disponible en 1985, disponía de 256 millones de palabras y chips. Su interior se encontraba inundado con líquido refrigerante. En el año 1986, existían en todo el mundo unos 130 sistemas de este tipo, de los cuales más de 90 llevaban la marca Cray. A mediados de los 80 controlaba el 70% del mercado de la supercomputación. Sin embargo Seymour Cray se encontraba incómodo, pues la problemática empresarial le resultaba escasamente interesante y difícil de soportar. Cedió la presidencia, y dejó la responsabilidad del desarrollo tecnológico de la línea CRAY-2 a Steve Chen, que concibió y construyó los primeros multiprocesadores de la firma, conocidos como serie X- MP.
65 Primeros prototipos de investigación Eran equipos que variaban desde arquitecturas SIMD, SIMD/MIMD o completamente MIMD. Los principios usados para la construcción de estos equipos fueron útiles para las siguientes generaciones. Máquina Control Lugar y Fecha Illiac IV SIMD Universidad de Illinois, 1968 MPP SIMD Goodyear AeroSpace, 1980 HEP MIMD Finales de los 70 s PASM SIMD/MIMD Universidad Pardue, 1980 TRAC SIMD/MIMD U.T. Austin, 1977 NYU Ultra MIMD NYU, 1983 RP3 MIMD IBM, 1983 Cosmic Cube MIMD Caltech, 1980 Tabla 1. Primeras computadoras paralelas
66 Primera generación Estas computadoras fueron en principio proyectos de empresas comerciales. Máquina Control Lugar y Fecha NCUBE-1 MIMD NCUBE, 1988 GP1000 MIMD BBN, 1985 Balance MIMD Sequent, 1985 FX/8 Propio Alliant, 1985 ipsc/1 MIMD Intel, 1985 SUPRENUM MIMD GMD FIRST, 1985 MP-1 SIMD MasPar, 1985 CM-2 SIMD TMC, 1985 GF11 SIMD IBM, 1986 Tabla 2. Primera generación de computadoras paralelas
67 Segunda generación Gracias a la VLSI se pudieron construir computadoras cada vez más veloces y pequeñas. Máquina Control Lugar y Fecha AP1000 MIMD Fujitsu, 1991 Cedar MIMD Universidad de Illinois IPSC/2 ipsc/860 MIMD Intel, 1988/89 NCUBE-2 MIMD NCUBE, 1992 CM-5 MIMD TMC 1992 TC2000 MIMD BBN, 1989 Symmetry MIMD Sequent, 1990 FX/2800 MIMD Alliant, 1990 MP-2 SIMD MasPar, 1992 KSR1 MIMD Kendall Square 1989 Tabla 3. Segunda generación de computadoras paralelas
68 Tercera generación Existe una variedad mayor de equipos cada vez más complejos y son cada vez más comerciales. Los sistemas con memoria compartida prácticamente han desaparecido para optar por la memoria distribuida, dispuesta para cada unidad de procesamiento. Máquina Procesado r Fabricante MHz # elementos de procesamient o T3D Dec Alpha Cray Memoria (MB) VPP500 Propio GAs, Fujitsu Vector SP1 (SP2) RS/6000 IBM (64M 2GB) Paragon i860xp Intel XP/S Cenju-3 GC NEC/MIPS CR4400SC Motorola Pwr PC 601 NEC Parsytec CS-2 Sparc Meiko Limited Tabla 4. Tercera generación de computadoras paralelas
69 Las computadoras más rápidas del mundo ( Rank Site Computer # CPU s Year R max R peak 1 DOE/NNSA/LLNL United States BlueGene/L - eserver Blue Gene Solution IBM 131, , ,000 2 Oak Ridge National Laboratory United States Jaguar - Cray XT4/XT3 Cray Inc. 23, , ,350 3 NNSA/Sandia National Laboratories United States Red Storm - Sandia/ Cray Red Storm, Opteron 2.4 GHz dual core Cray Inc. 26, , ,411 4 IBM Thomas J. Watson Research Center United States BGW - eserver Blue Gene Solution IBM 40, , ,688 5 Stony Brook/BNL, New York Center for Computional Sciences United States New York Blue - eserver Blue Gene Solution IBM 36, , ,219 6 DOE/NNSA/LLNL United States ASC Purple - eserver pseries p GHz IBM 12, ,760 92,781 7 Rensselaer Polytechnic Institute, Computional Center for Nanotechnology Innovations United States eserver Blue Gene Solution IBM 32, ,032 91,750 8 NCSA United States Abe - PowerEdge 1955, 2.33 GHz, Infiniband Dell 9, ,680 89,587 9 Barcelona Supercomputing Center Spain MareNostrum - BladeCenter JS21 Cluster, PPC 970, 2.3 GHz, Myrinet IBM 10, ,630 94, Leibniz Rechenzentrum Germany HLRB-II - Altix GHz SGI 9, ,520 62,259.2
70 Tecnologías relevantes Hoy en día el diseño de Supercomputadoras se sustenta en 4 importantes tecnologías: La tecnología de registros vectoriales, creada por Seymour Cray, considerado el padre de la Supercomputación, quien inventó y patentó diversas tecnologías que condujeron a la creación de máquinas de computación ultra-rápidas. Esta tecnología permite la ejecución de innumerables operaciones aritméticas en paralelo. El sistema conocido como M.P.P. por las siglas de Massively Parallel Processors o Procesadores Masivamente Paralelos, que consiste en la utilización de cientos y a veces miles de microprocesadores estrechamente coordinados.
71 Tecnologías relevantes (cont) La tecnología de computación distribuida: los clusters de computadoras de uso general y relativo bajo costo, interconectados por redes locales de baja latencia y el gran ancho de banda. Cuasi-Supercómputo: Recientemente, con la popularización de la Internet, han surgido proyectos de computación distribuida en los que software especiales aprovechan el tiempo ocioso de miles de ordenadores personales para realizar grandes tareas por un bajo costo. A diferencia de las tres últimas categorías, el software que corre en estas plataformas debe ser capaz de dividir las tareas en bloques de cálculo independientes que no se ensamblaran ni comunicarán por varias horas. En esta categoría destacan BOINC y Folding@home, SETI@home.
72 Earth Simulator Desarrollado por las agencias japonesas NASDA, JAERI y JAMSTEC y en operación desde finales del año 2001, para aplicaciones de carácter científico siendo utilizado principalmente en simulaciones climáticas y de convección en el interior terrestre. Hasta finales del año 2003, ostentó el título de superordenador más rápido del mundo, con una capacitad computacional de más de 35 Teraflops CPUs especiales de 500 MHz fabricados por NEC Corporation 640 nodos, con 8 procesadores cada uno 8 GFLOPS por CPU (41 TFLOPS total) 2 GB (4 módulos de 512 MB FPLRAM) por CPU (10 TB total) memoria compartida en cada nodo Switch crossbar entre los nodos Ancho de banda de 16 GB/s entre los nodos Consumo de energía de 20 kva por nodo Sistema operativo Super-UX, basado en Unix
73 MareNostrum El superordenador más potente de Europa y el noveno en todo el mundo. Cuando fue puesto en marcha en 2005, el superordenador constaba de 2406 nodos de computación, cada uno de los cuales cuenta con procesadores duales IBM PowerPC 970FX de 64 bits a una velocidad de reloj de 2.2 GHz, 4812 CPUs en total. Actualmente cuenta con con 10,240 procesadores. Los nodos del ordenador se comunican entre sí a través de una red Myrinet de gran ancho de banda y baja latencia. El sistema cuenta con 20 terabytes de memoria central, 280 terabytes de disco. Utiliza el sistema operativo Suse Linux. Capacidad de cálculo de 62,63 teraflops (94,208 teraflops pico). Ocupa una instalación de 160 m² y pesa kg. El MareNostrum será utilizado en la investigación del genoma humano, la estructura de las proteínas y en el diseño de nuevos medicamentos. Myrinet es una red de interconexión de altas prestaciones. Desarrollado por Myricom. Una de sus principales características, además de su rendimiento, es que el procesamiento de las comunicaciones de red se hace a través de chips integrados en las tarjetas de red, descargando a la CPU de parte del procesamiento de las comunicaciones.
74 Kan Balam (super.unam.mx) El sistema HP Cluster Platform 4000, "KanBalam" es la supercomputadora paralela más poderosa de México y América Latina. Capacidad de procesamiento de Teraflops (7.113 billones de operaciones aritméticas por segundo). Cuenta con 1,368 procesadores (core AMD Opteron de 2.6 GHz) Memoria RAM total de 3,000 Gbytes y un sistema de almacenamiento masivo de 160 Terabytes.
75 Algunos términos importantes Superescalar: es el término utilizado para designar un tipo de arquitectura de procesador capaz de ejecutar más de una instrucción por ciclo de reloj. En la clasificación de Flynn, un procesador superescalar es un procesador de tipo MIMD (multiple instruction multiple data). Supersegmentado: Una solución para alcanzar mayores prestaciones, consiste en que muchas etapas de la segmentación requieren tareas que requieren menos de la mitad del ciclo de reloj, entonces se dobla la velocidad de reloj interna lo que permite que se realice una mayor cantidad de tareas en un ciclo de reloj externo. Procesamiento paralelo: un programa único que simultáneamente se ejecuta en múltiples procesadores. Paralelismo : es el proceso de realizar tareas concurrentemente Paradigma: es un modelo del mundo que se usa para formular una solución computacional a un problema
Introducción. Historia. Supercomputadoras, una visión general
 Introducción Una supercomputadora es una computadora que es considerada en su momento de introducción, como lo máximo en capacidad de procesamiento y cálculo, con capacidades muy superiores a la de una
Introducción Una supercomputadora es una computadora que es considerada en su momento de introducción, como lo máximo en capacidad de procesamiento y cálculo, con capacidades muy superiores a la de una
Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011
 Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
SISTEMAS DE MULTIPROCESAMIENTO
 SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función
SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función
:Arquitecturas Paralela basada en clusters.
 Computación de altas prestaciones: Arquitecturas basadas en clusters Sesión n 1 :Arquitecturas Paralela basada en clusters. Jose Luis Bosque 1 Introducción Computación de altas prestaciones: resolver problemas
Computación de altas prestaciones: Arquitecturas basadas en clusters Sesión n 1 :Arquitecturas Paralela basada en clusters. Jose Luis Bosque 1 Introducción Computación de altas prestaciones: resolver problemas
INTRODUCCIÓN. Que es un sistema operativo? - Es un programa. - Funciona como intermediario entre el usuario y los programas y el hardware
 INTRODUCCIÓN Que es un sistema operativo? - Es un programa. - Funciona como intermediario entre el usuario y los programas y el hardware INTRODUCCIÓN METAS: Brindar un entorno para que los usuarios puedan
INTRODUCCIÓN Que es un sistema operativo? - Es un programa. - Funciona como intermediario entre el usuario y los programas y el hardware INTRODUCCIÓN METAS: Brindar un entorno para que los usuarios puedan
15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores.
 UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC
 Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC INTRODUCCIÓN HPC: High Performance Computer System Qué es un supercomputador? Computador diseñado para ofrecer la mayor capacidad de
Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC INTRODUCCIÓN HPC: High Performance Computer System Qué es un supercomputador? Computador diseñado para ofrecer la mayor capacidad de
Sistemas Operativos Windows 2000
 Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
CLUSTER FING: ARQUITECTURA Y APLICACIONES
 CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Arquitectura: Clusters
 Universidad Simón Bolívar Arquitectura: Clusters Integrantes: - Aquilino Pinto - Alejandra Preciado Definición Conjuntos o conglomerados de computadoras construidos mediante la utilización de hardware
Universidad Simón Bolívar Arquitectura: Clusters Integrantes: - Aquilino Pinto - Alejandra Preciado Definición Conjuntos o conglomerados de computadoras construidos mediante la utilización de hardware
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
General Parallel File System
 General Parallel File System Introducción GPFS fue desarrollado por IBM, es un sistema que permite a los usuarios compartir el acceso a datos que están dispersos en múltiples nodos; permite interacción
General Parallel File System Introducción GPFS fue desarrollado por IBM, es un sistema que permite a los usuarios compartir el acceso a datos que están dispersos en múltiples nodos; permite interacción
LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN
 LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN Tabla de Contenidos LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN... 1 Tabla de Contenidos... 1 General... 2 Uso de los Lineamientos Estándares...
LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN Tabla de Contenidos LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN... 1 Tabla de Contenidos... 1 General... 2 Uso de los Lineamientos Estándares...
Capítulo 5. Cliente-Servidor.
 Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Introducción a las redes de computadores
 Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Global File System (GFS)...
...") Global File System (GFS)... Diferente a los sistemas de ficheros en red que hemos visto, ya que permite que todos los nodos tengan acceso concurrente a los bloques de almacenamiento compartido (a través
Global File System (GFS)... Diferente a los sistemas de ficheros en red que hemos visto, ya que permite que todos los nodos tengan acceso concurrente a los bloques de almacenamiento compartido (a través
Resolución de problemas en paralelo
 Resolución de problemas en paralelo Algoritmos Paralelos Tema 1. Introducción a la computación paralela (segunda parte) Vicente Cerverón Universitat de València Resolución de problemas en paralelo Descomposición
Resolución de problemas en paralelo Algoritmos Paralelos Tema 1. Introducción a la computación paralela (segunda parte) Vicente Cerverón Universitat de València Resolución de problemas en paralelo Descomposición
Generalidades Computacionales
 Capítulo 2 Generalidades Computacionales 2.1. Introducción a los Computadores Definición: Un computador es un dispositivo electrónico que puede transmitir, almacenar, recuperar y procesar información (datos).
Capítulo 2 Generalidades Computacionales 2.1. Introducción a los Computadores Definición: Un computador es un dispositivo electrónico que puede transmitir, almacenar, recuperar y procesar información (datos).
Figura 1.4. Elementos que integran a la Tecnología de Información.
 1.5. Organización, estructura y arquitectura de computadoras La Gráfica siguiente muestra la descomposición de la tecnología de información en los elementos que la conforman: Figura 1.4. Elementos que
1.5. Organización, estructura y arquitectura de computadoras La Gráfica siguiente muestra la descomposición de la tecnología de información en los elementos que la conforman: Figura 1.4. Elementos que
COMPUTADORES MULTINUCLEO. Stallings W. Computer Organization and Architecture 8ed
 COMPUTADORES MULTINUCLEO Stallings W. Computer Organization and Architecture 8ed Computador multinucleo Un computador multinúcleocombina dos o mas procesadores (llamados núcleos) en una única pieza de
COMPUTADORES MULTINUCLEO Stallings W. Computer Organization and Architecture 8ed Computador multinucleo Un computador multinúcleocombina dos o mas procesadores (llamados núcleos) en una única pieza de
UNIVERSIDAD TECNOLOGICA ECOTEC DIEGO BARRAGAN MATERIA: Sistemas Operativos 1 ENSAYO: Servidores BLADE
 UNIVERSIDAD TECNOLOGICA ECOTEC DIEGO BARRAGAN MATERIA: Sistemas Operativos 1 ENSAYO: Servidores BLADE AÑO: 2010 Qué es un servidor Blade? Blade Server es una arquitectura que ha conseguido integrar en
UNIVERSIDAD TECNOLOGICA ECOTEC DIEGO BARRAGAN MATERIA: Sistemas Operativos 1 ENSAYO: Servidores BLADE AÑO: 2010 Qué es un servidor Blade? Blade Server es una arquitectura que ha conseguido integrar en
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570
 Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
ARQUITECTURA DE DISTRIBUCIÓN DE DATOS
 4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
SISTEMAS DE INFORMACIÓN II TEORÍA
 CONTENIDO: EL PROCESO DE DISEÑO DE SISTEMAS DISTRIBUIDOS MANEJANDO LOS DATOS EN LOS SISTEMAS DISTRIBUIDOS DISEÑANDO SISTEMAS PARA REDES DE ÁREA LOCAL DISEÑANDO SISTEMAS PARA ARQUITECTURAS CLIENTE/SERVIDOR
CONTENIDO: EL PROCESO DE DISEÑO DE SISTEMAS DISTRIBUIDOS MANEJANDO LOS DATOS EN LOS SISTEMAS DISTRIBUIDOS DISEÑANDO SISTEMAS PARA REDES DE ÁREA LOCAL DISEÑANDO SISTEMAS PARA ARQUITECTURAS CLIENTE/SERVIDOR
Redes de Altas Prestaciones
 Redes de Altas Prestaciones TEMA 3 Redes SAN -Alta disponibilidad -Sistemas Redundantes -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Componentes de un SAN Términos más utilizados Topología
Redes de Altas Prestaciones TEMA 3 Redes SAN -Alta disponibilidad -Sistemas Redundantes -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Componentes de un SAN Términos más utilizados Topología
Plataformas paralelas
 Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
EXPEDIENTE: 2/2015 ADQUISICIÓN E INSTALACIÓN DE INFRAESTRUCTURA CIENTÍFICA Y TECNOLÓGICA PARA CÉNITS PLIEGO DE PRESCRIPCIONES TÉCNICAS
 EXPEDIENTE: 2/2015 ADQUISICIÓN E INSTALACIÓN DE INFRAESTRUCTURA CIENTÍFICA Y TECNOLÓGICA PARA CÉNITS PLIEGO DE PRESCRIPCIONES TÉCNICAS PLIEGO DE PRESCRIPCIONES TÉCNICAS. EXPTE 2/2015 Adquisición e instalación
EXPEDIENTE: 2/2015 ADQUISICIÓN E INSTALACIÓN DE INFRAESTRUCTURA CIENTÍFICA Y TECNOLÓGICA PARA CÉNITS PLIEGO DE PRESCRIPCIONES TÉCNICAS PLIEGO DE PRESCRIPCIONES TÉCNICAS. EXPTE 2/2015 Adquisición e instalación
Capítulo 1 Introducción a la Computación
 Capítulo 1 Introducción a la Computación 1 MEMORIA PRINCIPAL (RAM) DISPOSITIVOS DE ENTRADA (Teclado, Ratón, etc) C P U DISPOSITIVOS DE SALIDA (Monitor, Impresora, etc.) ALMACENAMIENTO (Memoria Secundaria:
Capítulo 1 Introducción a la Computación 1 MEMORIA PRINCIPAL (RAM) DISPOSITIVOS DE ENTRADA (Teclado, Ratón, etc) C P U DISPOSITIVOS DE SALIDA (Monitor, Impresora, etc.) ALMACENAMIENTO (Memoria Secundaria:
CAPÍTULO 1 Instrumentación Virtual
 CAPÍTULO 1 Instrumentación Virtual 1.1 Qué es Instrumentación Virtual? En las últimas décadas se han incrementado de manera considerable las aplicaciones que corren a través de redes debido al surgimiento
CAPÍTULO 1 Instrumentación Virtual 1.1 Qué es Instrumentación Virtual? En las últimas décadas se han incrementado de manera considerable las aplicaciones que corren a través de redes debido al surgimiento
No se requiere que los discos sean del mismo tamaño ya que el objetivo es solamente adjuntar discos.
 RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
Introducción a Computación
 Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
Los mayores cambios se dieron en las décadas de los setenta, atribuidos principalmente a dos causas:
 SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
Colección de Tesis Digitales Universidad de las Américas Puebla. Morales Salcedo, Raúl
 1 Colección de Tesis Digitales Universidad de las Américas Puebla Morales Salcedo, Raúl En este último capitulo se hace un recuento de los logros alcanzados durante la elaboración de este proyecto de tesis,
1 Colección de Tesis Digitales Universidad de las Américas Puebla Morales Salcedo, Raúl En este último capitulo se hace un recuento de los logros alcanzados durante la elaboración de este proyecto de tesis,
TEMA 4. Unidades Funcionales del Computador
 TEMA 4 Unidades Funcionales del Computador Álvarez, S., Bravo, S., Departamento de Informática y automática Universidad de Salamanca Introducción El elemento físico, electrónico o hardware de un sistema
TEMA 4 Unidades Funcionales del Computador Álvarez, S., Bravo, S., Departamento de Informática y automática Universidad de Salamanca Introducción El elemento físico, electrónico o hardware de un sistema
Pruebas y Resultados PRUEBAS Y RESULTADOS AGNI GERMÁN ANDRACA GUTIERREZ
 PRUEBAS Y RESULTADOS 57 58 Introducción. De la mano la modernización tecnológica que permitiera la agilización y simplificación de la administración de los recursos con los que actualmente se contaban
PRUEBAS Y RESULTADOS 57 58 Introducción. De la mano la modernización tecnológica que permitiera la agilización y simplificación de la administración de los recursos con los que actualmente se contaban
Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015
 Anexo A. Partida 3 Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015 CLUSTER LANCAD3 El bien a adquirir se describe a continuación y consiste en cúmulo de supercómputo
Anexo A. Partida 3 Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015 CLUSTER LANCAD3 El bien a adquirir se describe a continuación y consiste en cúmulo de supercómputo
computadoras que tienen este servicio instalado se pueden publicar páginas web tanto local como remotamente.
 Investigar Qué es un IIS? Internet Information Services o IIS es un servidor web y un conjunto de servicios para el sistema operativo Microsoft Windows. Originalmente era parte del Option Pack para Windows
Investigar Qué es un IIS? Internet Information Services o IIS es un servidor web y un conjunto de servicios para el sistema operativo Microsoft Windows. Originalmente era parte del Option Pack para Windows
HISTORIA Y EVOLUCIÓN DE LOS SISTEMAS OPERATIVOS
 HISTORIA Y EVOLUCIÓN DE LOS SISTEMAS OPERATIVOS Las primeras computadoras eran enormes máquinas que se ejecutaban desde una consola. El programador, quien además operaba el sistema de computación, debía
HISTORIA Y EVOLUCIÓN DE LOS SISTEMAS OPERATIVOS Las primeras computadoras eran enormes máquinas que se ejecutaban desde una consola. El programador, quien además operaba el sistema de computación, debía
Computacion de Alto Performance
 Computacion de Alto Performance Abraham Zamudio Abraham Zamudio Computacion de Alto Performance 1/47 Indice 1 Algunos Aspectos Teoricos 2 Paralelismo Computacional 3 Linux Cluster Hardware Software 4 MPICH
Computacion de Alto Performance Abraham Zamudio Abraham Zamudio Computacion de Alto Performance 1/47 Indice 1 Algunos Aspectos Teoricos 2 Paralelismo Computacional 3 Linux Cluster Hardware Software 4 MPICH
Laboratorio III de Sistemas de Telecomunicaciones Departamento de Telemática
 Proyecto: Interoperabilidad entre una Red de Telefonía IP y una red de Radio VHF Objetivos Lograr la interoperabilidad de clientes de VoIP con clientes de Radio VHF Implementar el servicio de Call Center
Proyecto: Interoperabilidad entre una Red de Telefonía IP y una red de Radio VHF Objetivos Lograr la interoperabilidad de clientes de VoIP con clientes de Radio VHF Implementar el servicio de Call Center
Procesador Pentium II 450 MHz Procesador Pentium II 400 MHz Procesador Pentium II 350 MHz Procesador Pentium II 333 MHz Procesador Pentium II 300 MHz
 PENTIUM El procesador Pentium es un miembro de la familia Intel de procesadores de propósito general de 32 bits. Al igual que los miembros de esta familia, el 386 y el 486, su rango de direcciones es de
PENTIUM El procesador Pentium es un miembro de la familia Intel de procesadores de propósito general de 32 bits. Al igual que los miembros de esta familia, el 386 y el 486, su rango de direcciones es de
Especificaciones de Hardware, Software y Comunicaciones
 Requisitos técnicos para participantes Especificaciones de Hardware, Software y Comunicaciones Versión Bolsa Nacional de Valores, S.A. Mayo 2014 1 Tabla de Contenido 1. Introducción... 3 2. Glosario...
Requisitos técnicos para participantes Especificaciones de Hardware, Software y Comunicaciones Versión Bolsa Nacional de Valores, S.A. Mayo 2014 1 Tabla de Contenido 1. Introducción... 3 2. Glosario...
Introducción HPC. Curso: Modelización y simulación matemática de sistemas. Esteban E. Mocskos (emocskos@dc.uba.ar) Escuela Complutense Latinoamericana
 Escuela Complutense Latinoamericana") Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción HPC Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales,
Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción HPC Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales,
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK. www.formacionhadoop.com
 CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
Arquitectura de el Hp Superdome INTEGRANTES: Islas Islas Roberto A. Ortiz Flores Enrique A. Rico Vázquez Alejandro. Sistemas Operativos Avanzados
 Arquitectura de el Hp Superdome INTEGRANTES: Islas Islas Roberto A. Ortiz Flores Enrique A. Rico Vázquez Alejandro Sistemas Operativos Avanzados HP SUPERDOME 9000 Características generales: El superdomo
Arquitectura de el Hp Superdome INTEGRANTES: Islas Islas Roberto A. Ortiz Flores Enrique A. Rico Vázquez Alejandro Sistemas Operativos Avanzados HP SUPERDOME 9000 Características generales: El superdomo
Intel Tera-Scale Computing Alumno: Roberto Rodriguez Alcala
 Intel Tera-Scale Computing Alumno: Roberto Rodriguez Alcala 1. Introducción Los procesadores con dos núcleos existen actualmente, y los procesadores de cuatro están insertándose en el mercado lentamente,
Intel Tera-Scale Computing Alumno: Roberto Rodriguez Alcala 1. Introducción Los procesadores con dos núcleos existen actualmente, y los procesadores de cuatro están insertándose en el mercado lentamente,
Guía de uso del Cloud Datacenter de acens
 guíasdeuso Guía de uso del Cloud Datacenter de Calle San Rafael, 14 28108 Alcobendas (Madrid) 902 90 10 20 www..com Introducción Un Data Center o centro de datos físico es un espacio utilizado para alojar
guíasdeuso Guía de uso del Cloud Datacenter de Calle San Rafael, 14 28108 Alcobendas (Madrid) 902 90 10 20 www..com Introducción Un Data Center o centro de datos físico es un espacio utilizado para alojar
ACTIVIDADES TEMA 1. EL LENGUAJE DE LOS ORDENADORES. 4º E.S.O- SOLUCIONES.
 1.- a) Explica qué es un bit de información. Qué es el lenguaje binario? Bit es la abreviatura de Binary digit. (Dígito binario). Un bit es un dígito del lenguaje binario que es el lenguaje universal usado
1.- a) Explica qué es un bit de información. Qué es el lenguaje binario? Bit es la abreviatura de Binary digit. (Dígito binario). Un bit es un dígito del lenguaje binario que es el lenguaje universal usado
Linux Week PUCP. Computación de Alto Rendimiento en Linux. rmiguel@senamhi.gob.pe
 Linux Week PUCP 2006 Computación de Alto Rendimiento en Linux Richard Miguel San Martín rmiguel@senamhi.gob.pe Agenda Computación Científica Computación Paralela High Performance Computing Grid Computing
Linux Week PUCP 2006 Computación de Alto Rendimiento en Linux Richard Miguel San Martín rmiguel@senamhi.gob.pe Agenda Computación Científica Computación Paralela High Performance Computing Grid Computing
Soluciones para entornos HPC
 Dr.. IT Manager / Project Leader @ CETA-Ciemat abelfrancisco.paz@ciemat.es V Jornadas de Supercomputación y Avances en Tecnología INDICE 1 2 3 4 HPC Qué? Cómo?..................... Computación (GPGPU,
Dr.. IT Manager / Project Leader @ CETA-Ciemat abelfrancisco.paz@ciemat.es V Jornadas de Supercomputación y Avances en Tecnología INDICE 1 2 3 4 HPC Qué? Cómo?..................... Computación (GPGPU,
Redes de Altas Prestaciones
 Redes de Altas Prestaciones TEMA 3 Tecnologías Soporte tolerante a fallos -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Topología en Alta Disponibilidad Tecnologías disponibles Tecnología
Redes de Altas Prestaciones TEMA 3 Tecnologías Soporte tolerante a fallos -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Topología en Alta Disponibilidad Tecnologías disponibles Tecnología
Introducción Componentes Básicos Concurrencia y Paralelismo Ejemplos Síntesis Lecturas Recomendadas. Arquitectura de Computadoras
 Arquitectura de Computadoras Contenidos 1 Introducción Computadora Arquitectura Partes de una arquitectura 2 Componentes Básicos CPU Jerarquía de Memoria 3 Concurrencia y Paralelismo Arquitecturas concurrentes
Arquitectura de Computadoras Contenidos 1 Introducción Computadora Arquitectura Partes de una arquitectura 2 Componentes Básicos CPU Jerarquía de Memoria 3 Concurrencia y Paralelismo Arquitecturas concurrentes
http://www.statum.biz http://www.statum.info http://www.statum.org
 ApiaMonitor Monitor de Infraestructura BPMS Por: Ing. Manuel Cabanelas Product Manager de Apia Manuel.Cabanelas@statum.biz http://www.statum.biz http://www.statum.info http://www.statum.org Abstract A
ApiaMonitor Monitor de Infraestructura BPMS Por: Ing. Manuel Cabanelas Product Manager de Apia Manuel.Cabanelas@statum.biz http://www.statum.biz http://www.statum.info http://www.statum.org Abstract A
INFORME Nº 052-2012-GTI INFORME TÉCNICO PREVIO DE EVALUACIÓN DE SOFTWARE
 INFORME Nº 052-2012-GTI INFORME TÉCNICO PREVIO DE EVALUACIÓN DE SOFTWARE 1. Nombre del Área El área encargada de la evaluación técnica para la actualización (en el modo de upgrade) del software IBM PowerVM
INFORME Nº 052-2012-GTI INFORME TÉCNICO PREVIO DE EVALUACIÓN DE SOFTWARE 1. Nombre del Área El área encargada de la evaluación técnica para la actualización (en el modo de upgrade) del software IBM PowerVM
Arquitecturas GPU v. 2013
 v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
picojava TM Características
 picojava TM Introducción El principal objetivo de Sun al introducir Java era poder intercambiar programas ejecutables Java entre computadoras de Internet y ejecutarlos sin modificación. Para poder transportar
picojava TM Introducción El principal objetivo de Sun al introducir Java era poder intercambiar programas ejecutables Java entre computadoras de Internet y ejecutarlos sin modificación. Para poder transportar
UNIVERSIDAD DE ORIENTE FACULTAD DE ICIENCIAS ECONOMICAS LAS REDES I. Licda. Consuelo Eleticia Sandoval
 UNIVERSIDAD DE ORIENTE FACULTAD DE ICIENCIAS ECONOMICAS LAS REDES I Licda. Consuelo Eleticia Sandoval OBJETIVO: ANALIZAR LAS VENTAJAS Y DESVENTAJAS DE LAS REDES DE COMPUTADORAS. Que es una red de computadoras?
UNIVERSIDAD DE ORIENTE FACULTAD DE ICIENCIAS ECONOMICAS LAS REDES I Licda. Consuelo Eleticia Sandoval OBJETIVO: ANALIZAR LAS VENTAJAS Y DESVENTAJAS DE LAS REDES DE COMPUTADORAS. Que es una red de computadoras?
Arquitectura de sistema de alta disponibilidad
 Mysql Introducción MySQL Cluster esta diseñado para tener una arquitectura distribuida de nodos sin punto único de fallo. MySQL Cluster consiste en 3 tipos de nodos: 1. Nodos de almacenamiento, son los
Mysql Introducción MySQL Cluster esta diseñado para tener una arquitectura distribuida de nodos sin punto único de fallo. MySQL Cluster consiste en 3 tipos de nodos: 1. Nodos de almacenamiento, son los
Soluciones innovadoras para optimizar su infraestructura TI. Virtualización con el sistema operativo i, PowerVM y Power Systems de IBM
 Soluciones innovadoras para optimizar su infraestructura TI Virtualización con el sistema operativo i, PowerVM y Power Systems de IBM Características principales Tenga éxito en su negocio simplemente con
Soluciones innovadoras para optimizar su infraestructura TI Virtualización con el sistema operativo i, PowerVM y Power Systems de IBM Características principales Tenga éxito en su negocio simplemente con
Programación en LabVIEW para Ambientes Multinúcleo
 Programación en LabVIEW para Ambientes Multinúcleo Agenda Introducción al Multithreading en LabVIEW Técnicas de Programación en Paralelo Consideraciones de Tiempo Real Recursos Evolución de la Instrumentación
Programación en LabVIEW para Ambientes Multinúcleo Agenda Introducción al Multithreading en LabVIEW Técnicas de Programación en Paralelo Consideraciones de Tiempo Real Recursos Evolución de la Instrumentación
Propuesta de Portal de la Red de Laboratorios Virtuales y Remotos de CEA
 Propuesta de Portal de la Red de Laboratorios Virtuales y Remotos de CEA Documento de trabajo elaborado para la Red Temática DocenWeb: Red Temática de Docencia en Control mediante Web (DPI2002-11505-E)
Propuesta de Portal de la Red de Laboratorios Virtuales y Remotos de CEA Documento de trabajo elaborado para la Red Temática DocenWeb: Red Temática de Docencia en Control mediante Web (DPI2002-11505-E)
CAPÍTULO 4 ANÁLISIS DE IMPLEMENTACIONES
 CAPÍTULO 4 ANÁLISIS DE IMPLEMENTACIONES En el anterior capítulo se realizaron implementaciones en una red de datos para los protocolos de autenticación Kerberos, Radius y LDAP bajo las plataformas Windows
CAPÍTULO 4 ANÁLISIS DE IMPLEMENTACIONES En el anterior capítulo se realizaron implementaciones en una red de datos para los protocolos de autenticación Kerberos, Radius y LDAP bajo las plataformas Windows
Presentación. 29/06/2005 Monografía de Adscripción 1
 Presentación Alumno: Uribe, Valeria Emilce Profesor Director: Mgter. David Luis La Red Martínez. Asignatura: Diseño y Administración de Datos. Corrientes 2005. 29/06/2005 Monografía de Adscripción 1 MONOGRAFIA
Presentación Alumno: Uribe, Valeria Emilce Profesor Director: Mgter. David Luis La Red Martínez. Asignatura: Diseño y Administración de Datos. Corrientes 2005. 29/06/2005 Monografía de Adscripción 1 MONOGRAFIA
Clusters de Alto Rendimiento
 Clusters de Alto Rendimiento Contenido: M. en A. Iliana Gómez Zúñiga iliana.gomez@redudg.udg.mx Expositor: L.S.I. Virgilio Cervantes Pérez virgilio@cencar.udg.mx Diseño: Lic. Genaro Ramirez genaro.ramirez@redudg.udg.mx
Clusters de Alto Rendimiento Contenido: M. en A. Iliana Gómez Zúñiga iliana.gomez@redudg.udg.mx Expositor: L.S.I. Virgilio Cervantes Pérez virgilio@cencar.udg.mx Diseño: Lic. Genaro Ramirez genaro.ramirez@redudg.udg.mx
Guía de instalación y configuración de IBM SPSS Modeler Social Network Analysis 16
 Guía de instalación y configuración de IBM SPSS Modeler Social Network Analysis 16 Contenido Capítulo 1. Introducción a IBM SPSS Modeler Social Network Analysis.... 1 Visión general de IBM SPSS Modeler
Guía de instalación y configuración de IBM SPSS Modeler Social Network Analysis 16 Contenido Capítulo 1. Introducción a IBM SPSS Modeler Social Network Analysis.... 1 Visión general de IBM SPSS Modeler
Motores de Búsqueda Web Tarea Tema 2
 Motores de Búsqueda Web Tarea Tema 2 71454586A Motores de Búsqueda Web Máster en Lenguajes y Sistemas Informáticos - Tecnologías del Lenguaje en la Web UNED 30/01/2011 Tarea Tema 2 Enunciado del ejercicio
Motores de Búsqueda Web Tarea Tema 2 71454586A Motores de Búsqueda Web Máster en Lenguajes y Sistemas Informáticos - Tecnologías del Lenguaje en la Web UNED 30/01/2011 Tarea Tema 2 Enunciado del ejercicio
Introducción. TEMA 3: Clusters de Computadores Personales
 Introducción TEMA 3: Clusters de Computadores Personales Laboratorio de Arquitecturas Avanzadas de Computadores 5º de Ingeniería Superior de Informática 2008/09 Alberto Sánchez alberto.sanchez@urjc.es
Introducción TEMA 3: Clusters de Computadores Personales Laboratorio de Arquitecturas Avanzadas de Computadores 5º de Ingeniería Superior de Informática 2008/09 Alberto Sánchez alberto.sanchez@urjc.es
Desarrollo de un cluster computacional para la compilación de. algoritmos en paralelo en el Observatorio Astronómico.
 Desarrollo de un cluster computacional para la compilación de algoritmos en paralelo en el Observatorio Astronómico. John Jairo Parra Pérez Resumen Este artículo muestra cómo funciona la supercomputación
Desarrollo de un cluster computacional para la compilación de algoritmos en paralelo en el Observatorio Astronómico. John Jairo Parra Pérez Resumen Este artículo muestra cómo funciona la supercomputación
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA
 CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
Instalación y mantenimiento de servicios de Internet. U.T.3.- Servicio DNS
 Instalación y mantenimiento de servicios de Internet U.T.3.- Servicio DNS 1 Qué es el servicio DNS? A los usuarios de Internet les resulta complicado trabajar con direcciones IP, sobre todo porque son
Instalación y mantenimiento de servicios de Internet U.T.3.- Servicio DNS 1 Qué es el servicio DNS? A los usuarios de Internet les resulta complicado trabajar con direcciones IP, sobre todo porque son
La Pirámide de Solución de TriActive TRICENTER
 Información sobre el Producto de TriActive: Página 1 Documento Informativo La Administración de Sistemas Hecha Simple La Pirámide de Solución de TriActive TRICENTER Información sobre las Soluciones de
Información sobre el Producto de TriActive: Página 1 Documento Informativo La Administración de Sistemas Hecha Simple La Pirámide de Solución de TriActive TRICENTER Información sobre las Soluciones de
Dispositivos de Red Hub Switch
 Dispositivos de Red Tarjeta de red Para lograr el enlace entre las computadoras y los medios de transmisión (cables de red o medios físicos para redes alámbricas e infrarrojos o radiofrecuencias para redes
Dispositivos de Red Tarjeta de red Para lograr el enlace entre las computadoras y los medios de transmisión (cables de red o medios físicos para redes alámbricas e infrarrojos o radiofrecuencias para redes
CLASIFICACIÓN DE LAS COMPUTADORAS. Ing. Erlinda Gutierrez Poma
 CLASIFICACIÓN DE LAS COMPUTADORAS Ing. Erlinda Gutierrez Poma Tipos de Computadoras Dentro de la evolución de las computadoras, han surgido diferentes equipos con diferentes tamaños y características según
CLASIFICACIÓN DE LAS COMPUTADORAS Ing. Erlinda Gutierrez Poma Tipos de Computadoras Dentro de la evolución de las computadoras, han surgido diferentes equipos con diferentes tamaños y características según
ATLANTE! i n f r a e s t r u c t u r a d e s u p e r C o m p u t a c i ó n G o b i e r n o d e C a n a r i a s!
 ATLANTE infraestructura G o b i e r n o! de d supercomputación e C a n a r i a s! v forma parte de la estrategia del Gobierno de Canarias de poner a disposición de investigadores y empresas canarios infraestructuras
ATLANTE infraestructura G o b i e r n o! de d supercomputación e C a n a r i a s! v forma parte de la estrategia del Gobierno de Canarias de poner a disposición de investigadores y empresas canarios infraestructuras
PRUEBAS DE SOFTWARE TECNICAS DE PRUEBA DE SOFTWARE
 PRUEBAS DE SOFTWARE La prueba del software es un elemento crítico para la garantía de la calidad del software. El objetivo de la etapa de pruebas es garantizar la calidad del producto desarrollado. Además,
PRUEBAS DE SOFTWARE La prueba del software es un elemento crítico para la garantía de la calidad del software. El objetivo de la etapa de pruebas es garantizar la calidad del producto desarrollado. Además,
INTRODUCCION. Ing. Camilo Zapata czapata@udea.edu.co Universidad de Antioquia
 INTRODUCCION. Ing. Camilo Zapata czapata@udea.edu.co Universidad de Antioquia Qué es una Red? Es un grupo de computadores conectados mediante cables o algún otro medio. Para que? compartir recursos. software
INTRODUCCION. Ing. Camilo Zapata czapata@udea.edu.co Universidad de Antioquia Qué es una Red? Es un grupo de computadores conectados mediante cables o algún otro medio. Para que? compartir recursos. software
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS
 GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
Heterogénea y Jerárquica
 Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
E-learning: E-learning:
 E-learning: E-learning: capacitar capacitar a a su su equipo equipo con con menos menos tiempo tiempo y y 1 E-learning: capacitar a su equipo con menos tiempo y Si bien, no todas las empresas cuentan con
E-learning: E-learning: capacitar capacitar a a su su equipo equipo con con menos menos tiempo tiempo y y 1 E-learning: capacitar a su equipo con menos tiempo y Si bien, no todas las empresas cuentan con
Autenticación Centralizada
 Autenticación Centralizada Ing. Carlos Rojas Castro Herramientas de Gestión de Redes Introducción En el mundo actual, pero en especial las organizaciones actuales, los usuarios deben dar pruebas de quiénes
Autenticación Centralizada Ing. Carlos Rojas Castro Herramientas de Gestión de Redes Introducción En el mundo actual, pero en especial las organizaciones actuales, los usuarios deben dar pruebas de quiénes
UNIVERSIDAD CARLOS III DE MADRID
 : Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas A R C O S I V E R S ID A D U N III I D R D A M D E I C A R L O S II UNIVERSIDAD CARLOS III DE MADRID Grupo de Arquitectura de Computadores,
: Grupo de Arquitectura de Computadores, Comunicaciones y Sistemas A R C O S I V E R S ID A D U N III I D R D A M D E I C A R L O S II UNIVERSIDAD CARLOS III DE MADRID Grupo de Arquitectura de Computadores,
Unidad 1: Conceptos generales de Sistemas Operativos.
 Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los sistemas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejecución de instrucciones e interrupciones
Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los sistemas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejecución de instrucciones e interrupciones
Clase 20: Arquitectura Von Neuman
 http://computacion.cs.cinvestav.mx/~efranco @efranco_escom efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco) 1 Contenido Arquitectura de una computadora Elementos básicos de una
http://computacion.cs.cinvestav.mx/~efranco @efranco_escom efranco.docencia@gmail.com Estructuras de datos (Prof. Edgardo A. Franco) 1 Contenido Arquitectura de una computadora Elementos básicos de una
1 GLOSARIO. Actor: Es un consumidor (usa) del servicio (persona, sistema o servicio).
 del servicio (persona, sistema o servicio).") 1 GLOSARIO A continuación se definen, en orden alfabético, los conceptos básicos que se han abordado a lo largo del desarrollo de la metodología para la gestión de requisitos bajo la Arquitectura Orientada
1 GLOSARIO A continuación se definen, en orden alfabético, los conceptos básicos que se han abordado a lo largo del desarrollo de la metodología para la gestión de requisitos bajo la Arquitectura Orientada
Redes de Computadores I
 Redes de Computadores I Proyecto Dropbox Guillermo Castro 201021015-4 Javier Garcés 201021002-2 4 de septiembre de 2013 3 PROTOCOLOS DB-LSP Y DB-LSP-DISC 1. Resumen La sincronización de archivos es hoy,
Redes de Computadores I Proyecto Dropbox Guillermo Castro 201021015-4 Javier Garcés 201021002-2 4 de septiembre de 2013 3 PROTOCOLOS DB-LSP Y DB-LSP-DISC 1. Resumen La sincronización de archivos es hoy,
Tema 4. Gestión de entrada/salida
 Tema 4. Gestión de entrada/salida 1. Principios de la gestión de E/S. 1.Problemática de los dispositivos de E/S. 2.Objetivos generales del software de E/S. 3.Principios hardware de E/S. 1. E/S controlada
Tema 4. Gestión de entrada/salida 1. Principios de la gestión de E/S. 1.Problemática de los dispositivos de E/S. 2.Objetivos generales del software de E/S. 3.Principios hardware de E/S. 1. E/S controlada
Algunas preguntas clave para el diseño de multiprocesadores son las siguientes:
 6. MULTIPROCESADORES 6.1 Introducción Algunos diseñadores de computadoras han mantenido la ilusión de crear una computadora poderosa simplemente conectando muchas computadoras pequeñas. Esta visión es
6. MULTIPROCESADORES 6.1 Introducción Algunos diseñadores de computadoras han mantenido la ilusión de crear una computadora poderosa simplemente conectando muchas computadoras pequeñas. Esta visión es
Apéndice A: Características de las Redes Locales
 Apéndice A: Características de las Redes Locales En este apéndice se muestran las principales características de hardware y software de las redes locales y de las computadoras que las componen y que se
Apéndice A: Características de las Redes Locales En este apéndice se muestran las principales características de hardware y software de las redes locales y de las computadoras que las componen y que se
Análisis de desempeño y modelo de escalabilidad para SGP
 Análisis de desempeño y modelo de escalabilidad para SGP Este documento es producto de la experiencia de Analítica en pruebas de stress sobre el software SGP. Estas pruebas se realizaron sobre un proceso
Análisis de desempeño y modelo de escalabilidad para SGP Este documento es producto de la experiencia de Analítica en pruebas de stress sobre el software SGP. Estas pruebas se realizaron sobre un proceso
Almacenamiento virtual de sitios web HOSTS VIRTUALES
 Almacenamiento virtual de sitios web HOSTS VIRTUALES El término Hosting Virtual se refiere a hacer funcionar más de un sitio web (tales como www.company1.com y www.company2.com) en una sola máquina. Los
Almacenamiento virtual de sitios web HOSTS VIRTUALES El término Hosting Virtual se refiere a hacer funcionar más de un sitio web (tales como www.company1.com y www.company2.com) en una sola máquina. Los
Capítulo 4: Requerimientos.
 Capítulo 4: Requerimientos. Una vez que se ha analizado con detalle los nuevos paradigmas en la educación, nos podemos dar cuenta que para poder apoyar cambios como estos y para poder desarrollar nuevos
Capítulo 4: Requerimientos. Una vez que se ha analizado con detalle los nuevos paradigmas en la educación, nos podemos dar cuenta que para poder apoyar cambios como estos y para poder desarrollar nuevos
Descripción de los Servicios Oracle contemplados en el Instrumento de Agregación de Demanda
 Descripción de los Servicios Oracle contemplados en el Instrumento de Agregación de Demanda A través del Instrumento de Agregación de Demanda para la Adquisición de Servicios Oracle, las Entidades Estatales
Descripción de los Servicios Oracle contemplados en el Instrumento de Agregación de Demanda A través del Instrumento de Agregación de Demanda para la Adquisición de Servicios Oracle, las Entidades Estatales
Análisis de aplicación: Virtual Machine Manager
 Análisis de aplicación: Virtual Machine Manager Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla
Análisis de aplicación: Virtual Machine Manager Este documento ha sido elaborado por el Centro de Apoyo Tecnológico a Emprendedores bilib, www.bilib.es Copyright 2011, Junta de Comunidades de Castilla
Conclusiones. Particionado Consciente de los Datos
 Capítulo 6 Conclusiones Una de las principales conclusiones que se extraen de esta tesis es que para que un algoritmo de ordenación sea el más rápido para cualquier conjunto de datos a ordenar, debe ser
Capítulo 6 Conclusiones Una de las principales conclusiones que se extraen de esta tesis es que para que un algoritmo de ordenación sea el más rápido para cualquier conjunto de datos a ordenar, debe ser
Procesos. Bibliografía. Threads y procesos. Definiciones
 Procesos Prof. Mariela Curiel Bibliografía A. Tanembaum & M. Van Steen. Sistemas Distribuidos. Principios y Paradigmas. 2da. Edición. Smith & Nair. The Architecture of Virtual Machines. IEEE Computer.
Procesos Prof. Mariela Curiel Bibliografía A. Tanembaum & M. Van Steen. Sistemas Distribuidos. Principios y Paradigmas. 2da. Edición. Smith & Nair. The Architecture of Virtual Machines. IEEE Computer.
Ventajas del almacenamiento de datos de nube
 Ventajas del almacenamiento de datos de nube Almacenar grandes volúmenes de información en una red de área local (LAN) es caro. Dispositivos de almacenamiento electrónico de datos de alta capacidad como
Ventajas del almacenamiento de datos de nube Almacenar grandes volúmenes de información en una red de área local (LAN) es caro. Dispositivos de almacenamiento electrónico de datos de alta capacidad como
Sistemas Operativos de Red
 Sistemas Operativos de Red Como ya se sabe las computadoras están compuestas físicamente por diversos componentes que les permiten interactuar mas fácilmente con sus operarios y hasta comunicarse con otras
Sistemas Operativos de Red Como ya se sabe las computadoras están compuestas físicamente por diversos componentes que les permiten interactuar mas fácilmente con sus operarios y hasta comunicarse con otras
Sistemas de Computadoras Índice
 Sistemas de Computadoras Índice Concepto de Computadora Estructura de la Computadora Funcionamiento de la Computadora Historia de las Computadoras Montando una Computadora Computadora Un sistema de cómputo
Sistemas de Computadoras Índice Concepto de Computadora Estructura de la Computadora Funcionamiento de la Computadora Historia de las Computadoras Montando una Computadora Computadora Un sistema de cómputo