Minería de Datos Web. 1 er Cuatrimestre Página Web. Prof. Dra. Daniela Godoy.
|
|
|
- Alfredo Márquez Núñez
- hace 8 años
- Vistas:
Transcripción
1 Minería de Datos Web 1 er Cuatrimestre 2015 Página Web Prof. Dra. Daniela Godoy ISISTAN Research Institute UNICEN University Tandil, Bs. As., Argentina dgodoy@exa.unicen.edu.ar
2 Clustering de Documentos Clasificación de Documentos Es un método supervisado para dividir documentos en base a categorías predefinidas Los ejemplos tienen que ser etiquetados (con clases asignadas) Clustering de Documentos Es un método no supervisado para dividir ejemplos en grupos cuando no existen categorías predefinidas El aprendizaje no supervisado es un método descriptivo para interpretar un conjunto de datos
3 Clustering de Documentos Es el proceso de buscar un agrupamiento natural en un conjunto de datos en base a su similitud Objetivo Dividir un conjunto de ejemplos (documentos) pertenecientes a clases desconocidas en subconjuntos disjuntos de clusters tal que: Los ejemplos que estén en un mismo cluster sean lo más similares posible entre sí Los ejemplos que estén en clusters diferentes sean lo más disímiles posible entre sí
4 Clustering de Documentos Espacio de características (términos) Los documentos se representan como vectores de frecuencia en un espacio de términos La similitud de dos documentos está dada por el coseno de ambos vectores
5 Clustering de Documentos Espacio de características (términos)
6 Clustering de Documentos Espacio de características (términos) Deportes Política Música
7 Clustering de Documentos El aprendizaje no supervisado es un método descriptivo para interpretar un conjunto de datos, algunas aplicaciones posibles: Clustering de los documentos recuperados para una consulta: se presentan los resultados de una búsqueda en forma más organizada y clara para el usuario (por ej. Vivísimo) Clustering de documentos en una colección: hipótesis de clustering, documentos similares tienden a ser relevantes a la misma consulta durante la recuperación de documentos, se agregan los documentos que pertenecen a un mismo cluster que los recuperados inicialmente para mejorar el recall Clustering para generación automática de taxonomías: para facilitar la exploración de documentos (por ej. Yahoo!)
8 Clustering de Documentos Hipótesis Documentos similares tienden a ser relevantes a la misma consulta Un buen método de clustering debería identificar clusters que sean tanto compactos como separados entre sí. Es decir, que tengan: Alta similitud intra-cluster Baja similitud inter-cluster
9 Scatter/Gather Técnica de navegación de resultados basada en clustering: Agrupa documentos en temas generales Muestra el contenido por términos típicos El usuario puede seleccionar clusters interesantes Se aplica nuevamente cluster para identificar clusters más específicos Con cada iteración los clusters son menores y más detallados Clustering y re-clustering es automático
10 Scatter/Gather
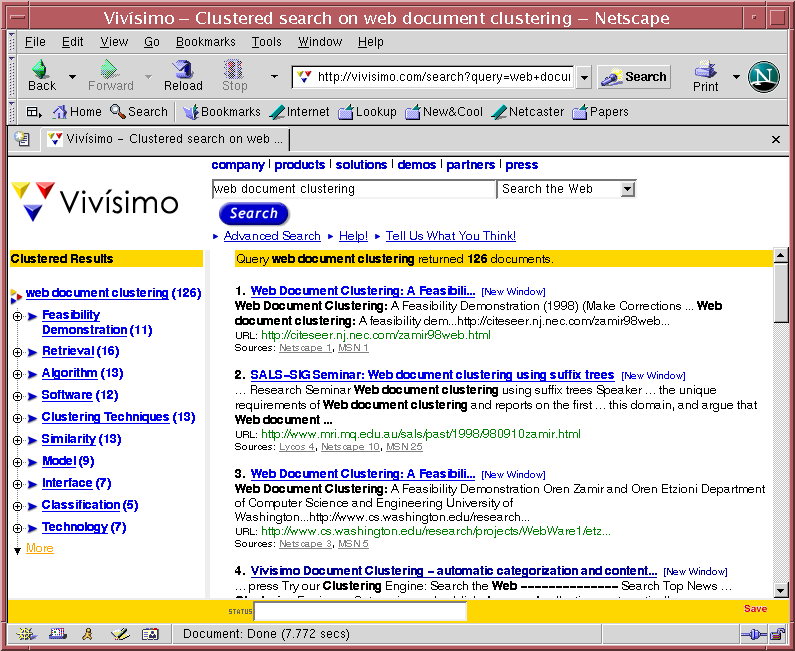
11 Vivísimo
12 Clustering de Documentos Algoritmos basados en particionamiento: Particionan el conjunto de datos D de n objetos en un conjunto de k clusters Dado un k, intentan encontrar una partición de k clusters que optimiza el criterio de particionamiento k-means: cada cluster es representado por su centro del cluster
13 Clustering basado en Particionamiento Objetivo Particionar un conjunto de documentos D, conteniendo n documentos, en k clusters Dado un valor de k, encontrar una partición en k clusters que optimice un criterio de particionamiento: k-means: cada cluster es representado por el centroide del cluster
14 K-Means Las instancias son vectores de valores reales Los clusters se basan en centroides o centros de gravedad, que son a media de las instancias en el cluster c: μ c = 1 c x c x Las instancias se reasignan a los clusters en base a su distancia a los centroides
15 K-Means k-means 1. Seleccionar aleatoriamente k ejemplos (semillas) para ser centroides de los clusters 2. Asignar cada ejemplo al centroide con el que tenga mayor similitud 3. Recalcular los centroides de acuerdo a los ejemplos asignados a cada cluster 4. Si no se satisface el criterio de terminación establecido volver a 2
16 K-Means Algoritmo: Sea sim la medida de distancia entre documentos Seleccionar k documentos aleatoriamente {s 1, s 2, s k } como semillas Hasta que se satisface un criterio de terminación Para cada documento x i : Asignar x i a el cluster c j talque sim(x i, s j ) sea la mínima (Actualizar las semillas de cada cluster) Para cada cluster c j s j = (c j )
17 K-Means k-means
18 K-Means Seleccionar k=2 semillas en forma aleatoria
19 K-Means Asignar cada ejemplo al centroide con el que tenga mayor similitud
20 K-Means Asignar cada ejemplo al centroide con el que tenga mayor similitud
21 K-Means Recalcular los centroides de acuerdo a los ejemplos asignados a cada cluster c c
22 K-Means Asignar cada ejemplo al centroide con el que tenga mayor similitud c c
23 K-Means Asignar cada ejemplo al centroide con el que tenga mayor similitud c c
24 K-Means Recalcular los centroides de acuerdo a los ejemplos asignados a cada cluster c c
25 K-Means Recalcular los centroides de acuerdo a los ejemplos asignados a cada cluster c c
26 K-Means Asignar cada ejemplo al centroide con el que tenga mayor similitud c c
27 K-Means Recalcular los centroides de acuerdo a los ejemplos asignados a cada cluster c c
28 K-Means Los ejemplos no cambian de cluster, se satisface el criterio de terminación c c
29 K-Means Ventajas: Entre los algoritmos de particionamiento es eficiente Implementación sencilla Desventajas: Necesito conocer k de antemano Sensible a outliers, puede caer en mínimos locales Sensitivo a la elección de las semillas iniciales algunas semillas pueden resultar en una taza de convergencia menor la selección de semillas se puede basar en heurísticas o resultados obtenidos por otros métodos Es aplicable cuando es posible calcular el centroide, como en el caso de los documentos, pero es de difícil aplicación en atributos categóricos
30 Clustering Jerárquico Los algoritmos jerárquicos construyen un árbol binario o dendograma a partir de un conjunto de ejemplos Un dendograma muestra como se combinan los clusters La raíz es un cluster que contiene todos los ejemplos y las hojas contienen cada una un ejemplo Cortando en diferentes niveles se consiguen diferentes clusters
31 Clustering Jerárquico Métodos de clustering: Aglomerativo (bottom-up) Métodos que comienzan con cada ejemplo en un cluster diferente y combinan iterativamente los clusters para formar clusters mayores Divisivo (top-down) Métodos que comienzan con todos los ejemplos en un mismo cluster y los separan sucesivamente en clusters de menor tamaño
32 Clustering Jerárquico Clustering Jerárquico Aglomerativo: Asume que existe una función de similitud que determina la similitud de dos instancias: Por ejemplo, similitud del coseno en caso de documentos Asume que existe una función de similitud que determina la similitud de dos clusters conteniendo múltiples instancias: Single link Complete link Group average
33 Clustering Jerárquico Single Link La similitud de los clusters es la de los dos ejemplos más similares entre ambos clusters
34 Clustering Jerárquico Single Link La similitud de los clusters es la de los dos ejemplos más similares entre ambos clusters Complete Link La similitud de los clusters es la de los dos ejemplos menos similares entre ambos clusters
35 Clustering Jerárquico Single Link La similitud de los clusters es la de los dos ejemplos más similares entre ambos clusters Complete Link La similitud de los clusters es la de los dos ejemplos menos similares entre ambos clusters Group Average Promedio de similitudes entre los ejemplos de ambos clusters
36 Clustering Jerárquico Clustering Aglomerativo Jerárquico: 1. Asignar cada ejemplo a un cluster diferente (n ejemplos, n clusters) 2. Encontrar el par de clusters más similares y combinarlos en un único cluster 3. Recalcular las similitud o distancias entre el nuevo cluster y los clusters restantes 4. Hasta que solo quede un cluster de tamaño n, volver a 2
37 Clustering Jerárquico Algoritmo: Comienza con todos los ejemplos en su propio cluster Hasta que quede un único cluster: Entre todos los cluster existentes determinar los dos clusters c i y c j que son más similares Reemplazar c i y c j por un único cluster c i c j
38 Clustering Jerárquico Asignar cada ejemplo a un cluster diferente d 1 d 2 d 3 d 4 d d d 3 10 d 1 d 2 d 3 d 4 d 4
39 Clustering Jerárquico Encontrar el par de clusters más similares y combinarlos en un único cluster d 1 d 2 d 3 d 4 d d d 3 10 d 1 d 2 d 3 d 4 d 4
40 Clustering Jerárquico Encontrar el par de clusters más similares y combinarlos en un único cluster d 1 d 2 d 3 d 4 d d d 3 10 d 1 d 4 d 2 d 3 d 4 c 1
41 Clustering Jerárquico Recalcular las similitud o distancias entre el nuevo cluster y los clusters restantes c 1 d 2 d 3 c d 2 15 d 3 d 1 d 4 d 2 d 3 c 1
42 Clustering Jerárquico Encontrar el par de clusters más similares y combinarlos en un único cluster c 1 d 2 d 3 c d 2 15 d 3 d 1 d 4 d 2 d 3 c 2
43 Clustering Jerárquico Recalcular las similitud o distancias entre el nuevo cluster y los clusters restantes c 2 d 3 c 2 20 d 2 d 3 d 1 d 4 d 2 d 3 c 2
44 Clustering Jerárquico Encontrar el par de clusters más similares y combinarlos en un único cluster c 2 d 3 c d 2 d 3 d 1 d 4 d 2 d 3
45 Clustering Jerárquico Únicamente queda un cluster de tamaño n c 3 c 3 d 1 d 4 d 2 d 3 c 3
46 Clustering Jerárquico Ventajas: No es necesario establecer un número de clusters Se puede explorar el dendograma en diferentes niveles, más rico para el análisis de los datos que el particionamiento Desventajas: No se recupera de decisiones incorrectas Computacionalmente costoso
Minería de Datos Web. Cursada 2018
 Minería de Datos Web Cursada 2018 Proceso de Minería de Texto Clustering de Documentos Clasificación de Documentos Es un método supervisado para dividir documentos en base a categorías predefinidas Los
Minería de Datos Web Cursada 2018 Proceso de Minería de Texto Clustering de Documentos Clasificación de Documentos Es un método supervisado para dividir documentos en base a categorías predefinidas Los
Similaridad y Clustering
 Similaridad y Clustering 1 web results motivación Problema 1: ambigüedad de consultas Problema 2: construcción manual de jerarquías de tópicos y taxonomías Problema 3: acelerar búsqueda por similaridad
Similaridad y Clustering 1 web results motivación Problema 1: ambigüedad de consultas Problema 2: construcción manual de jerarquías de tópicos y taxonomías Problema 3: acelerar búsqueda por similaridad
Método k-medias. [ U n a i n t r o d u c c i ó n ]
![Método k-medias. [ U n a i n t r o d u c c i ó n ]](/thumbs/26/8851985.jpg "Método k-medias. [ U n a i n t r o d u c c i ó n ]") Método k-medias [ U n a i n t r o d u c c i ó n ] Método K-Means (Nubes Dinámicas) 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6
Método k-medias [ U n a i n t r o d u c c i ó n ] Método K-Means (Nubes Dinámicas) 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6 7 8 9 0 0 3 4 5 6
Análisis Estadístico de Datos Climáticos
 Análisis Estadístico de Datos Climáticos Análisis de agrupamiento (o clusters) (Wilks, Cap. 14) Facultad de Ciencias Facultad de Ingeniería 2013 Objetivo Idear una clasificación o esquema de agrupación
Análisis Estadístico de Datos Climáticos Análisis de agrupamiento (o clusters) (Wilks, Cap. 14) Facultad de Ciencias Facultad de Ingeniería 2013 Objetivo Idear una clasificación o esquema de agrupación
CLASIFICACIÓN NO SUPERVISADA
 CLASIFICACIÓN NO SUPERVISADA CLASIFICACION IMPORTANCIA PROPÓSITO METODOLOGÍAS EXTRACTORES DE CARACTERÍSTICAS TIPOS DE CLASIFICACIÓN IMPORTANCIA CLASIFICAR HA SIDO, Y ES HOY DÍA, UN PROBLEMA FUNDAMENTAL
CLASIFICACIÓN NO SUPERVISADA CLASIFICACION IMPORTANCIA PROPÓSITO METODOLOGÍAS EXTRACTORES DE CARACTERÍSTICAS TIPOS DE CLASIFICACIÓN IMPORTANCIA CLASIFICAR HA SIDO, Y ES HOY DÍA, UN PROBLEMA FUNDAMENTAL
Base de datos II Facultad de Ingeniería. Escuela de computación.
 Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Facultad de Ciencias Económicas Universidad Nacional de Córdoba Carrera de Doctorado
 Facultad de Ciencias Económicas Universidad Nacional de Córdoba Carrera de Doctorado Materia: Estadística Aplicada a la Investigación Profesora: Dra. Hebe Goldenhersh Octubre del 2002 1 Determinación de
Facultad de Ciencias Económicas Universidad Nacional de Córdoba Carrera de Doctorado Materia: Estadística Aplicada a la Investigación Profesora: Dra. Hebe Goldenhersh Octubre del 2002 1 Determinación de
CLUSTERING MAPAS AUTOORGANIZATIVOS (KOHONEN) (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN)
 (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN)") CLASIFICACIÓN NO SUPERVISADA CLUSTERING Y MAPAS AUTOORGANIZATIVOS (KOHONEN) (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN) info@clustering.50webs.com Indice INTRODUCCIÓN 3 RESUMEN DEL CONTENIDO 3 APRENDIZAJE
CLASIFICACIÓN NO SUPERVISADA CLUSTERING Y MAPAS AUTOORGANIZATIVOS (KOHONEN) (RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN) info@clustering.50webs.com Indice INTRODUCCIÓN 3 RESUMEN DEL CONTENIDO 3 APRENDIZAJE
EL ANÁLISIS DE CONGLOMERADOS EN LOS ESTUDIOS DE MERCADO
 EL ANÁLISIS DE CONGLOMERADOS EN LOS ESTUDIOS DE MERCADO I. INTRODUCCIÓN Beatriz Meneses A. de Sesma * En los estudios de mercado intervienen muchas variables que son importantes para el cliente, sin embargo,
EL ANÁLISIS DE CONGLOMERADOS EN LOS ESTUDIOS DE MERCADO I. INTRODUCCIÓN Beatriz Meneses A. de Sesma * En los estudios de mercado intervienen muchas variables que son importantes para el cliente, sin embargo,
BASE DE DATOS UNIVERSIDAD DE LOS ANDES FACULTAD DE MEDICINA T.S.U. EN ESTADISTICA DE SALUD CATEDRA DE COMPUTACIÓN II. Comenzar presentación
 UNIVERSIDAD DE LOS ANDES FACULTAD DE MEDICINA T.S.U. EN ESTADISTICA DE SALUD CATEDRA DE COMPUTACIÓN II BASE DE DATOS Comenzar presentación Base de datos Una base de datos (BD) o banco de datos es un conjunto
UNIVERSIDAD DE LOS ANDES FACULTAD DE MEDICINA T.S.U. EN ESTADISTICA DE SALUD CATEDRA DE COMPUTACIÓN II BASE DE DATOS Comenzar presentación Base de datos Una base de datos (BD) o banco de datos es un conjunto
PREPROCESADO DE DATOS PARA MINERIA DE DATOS
 Ó 10.1007/978-3-319-02738-8-2. PREPROCESADO DE DATOS PARA MINERIA DE DATOS Miguel Cárdenas-Montes Frecuentemente las actividades de minería de datos suelen prestar poca atención a las actividades de procesado
Ó 10.1007/978-3-319-02738-8-2. PREPROCESADO DE DATOS PARA MINERIA DE DATOS Miguel Cárdenas-Montes Frecuentemente las actividades de minería de datos suelen prestar poca atención a las actividades de procesado
Capítulo 12: Indexación y asociación
 Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Sistemas de Recuperación de Información
 Sistemas de Recuperación de Información Los SRI permiten el almacenamiento óptimo de grandes volúmenes de información y la recuperación eficiente de la información ante las consultas de los usuarios. La
Sistemas de Recuperación de Información Los SRI permiten el almacenamiento óptimo de grandes volúmenes de información y la recuperación eficiente de la información ante las consultas de los usuarios. La
Procesamiento de Texto y Modelo Vectorial
 Felipe Bravo Márquez 6 de noviembre de 2013 Motivación Cómo recupera un buscador como Google o Yahoo! documentos relevantes a partir de una consulta enviada? Cómo puede procesar una empresa los reclamos
Felipe Bravo Márquez 6 de noviembre de 2013 Motivación Cómo recupera un buscador como Google o Yahoo! documentos relevantes a partir de una consulta enviada? Cómo puede procesar una empresa los reclamos
MINERIA DE DATOS Y Descubrimiento del Conocimiento
 MINERIA DE DATOS Y Descubrimiento del Conocimiento UNA APLICACIÓN EN DATOS AGROPECUARIOS INTA EEA Corrientes Maximiliano Silva La información Herramienta estratégica para el desarrollo de: Sociedad de
MINERIA DE DATOS Y Descubrimiento del Conocimiento UNA APLICACIÓN EN DATOS AGROPECUARIOS INTA EEA Corrientes Maximiliano Silva La información Herramienta estratégica para el desarrollo de: Sociedad de
Text Mining Introducción a Minería de Datos
 Text Mining Facultad de Matemática, Astronomía y Física UNC, Córdoba (Argentina) http://www.cs.famaf.unc.edu.ar/~laura SADIO 12 de Marzo de 2008 qué es la minería de datos? A technique using software tools
Text Mining Facultad de Matemática, Astronomía y Física UNC, Córdoba (Argentina) http://www.cs.famaf.unc.edu.ar/~laura SADIO 12 de Marzo de 2008 qué es la minería de datos? A technique using software tools
CURSO MINERÍA DE DATOS AVANZADO
 CURSO MINERÍA DE DATOS AVANZADO La minería de datos (en inglés, Data Mining) se define como la extracción de información implícita, previamente desconocida y potencialmente útil, a partir de datos. En
CURSO MINERÍA DE DATOS AVANZADO La minería de datos (en inglés, Data Mining) se define como la extracción de información implícita, previamente desconocida y potencialmente útil, a partir de datos. En
USO DE LA TECNOLOGIA COMO RECURSO PARA LA ENSEÑANZA. Sistema de búsqueda en Internet. Mtro. Julio Márquez Rodríguez
 USO DE LA TECNOLOGIA COMO RECURSO PARA LA ENSEÑANZA Sistema de búsqueda en Internet Mtro. Julio Márquez Rodríguez SISTEMA DE BUSQUEDA EN INTERNET Por el tipo de tecnología que utilizan, los sistemas de
USO DE LA TECNOLOGIA COMO RECURSO PARA LA ENSEÑANZA Sistema de búsqueda en Internet Mtro. Julio Márquez Rodríguez SISTEMA DE BUSQUEDA EN INTERNET Por el tipo de tecnología que utilizan, los sistemas de
Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones.
 Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones. 2.1 Revisión sistema reconocimiento caracteres [9]: Un sistema de reconocimiento típicamente esta conformado por
Capítulo 2. Técnicas de procesamiento digital de imágenes y reconocimiento de patrones. 2.1 Revisión sistema reconocimiento caracteres [9]: Un sistema de reconocimiento típicamente esta conformado por
NOTAS TECNICAS Nº 5. Clasificación del Sistema Educacional Chileno para efectos de comparabilidad internacional
 MINISTERIO DE EDUCACION DIVISON DE PLANIFICACION Y PRESUPUESTO NOTAS TECNICAS Nº 5 Clasificación del Sistema Educacional Chileno para efectos de comparabilidad internacional Departamento de Estudios y
MINISTERIO DE EDUCACION DIVISON DE PLANIFICACION Y PRESUPUESTO NOTAS TECNICAS Nº 5 Clasificación del Sistema Educacional Chileno para efectos de comparabilidad internacional Departamento de Estudios y
Fundamentos del diseño 3ª edición (2002)
") Unidades temáticas de Ingeniería del Software Fundamentos del diseño 3ª edición (2002) Facultad de Informática necesidad del diseño Las actividades de diseño afectan al éxito de la realización del software
Unidades temáticas de Ingeniería del Software Fundamentos del diseño 3ª edición (2002) Facultad de Informática necesidad del diseño Las actividades de diseño afectan al éxito de la realización del software
Introducción al Data Mining Clases 5. Cluster Analysis. Ricardo Fraiman Centro de Matemática, Udelar y Universidad de San Andrés, Argentina
 Introducción al Data Mining Clases 5 Cluster Analysis Ricardo Fraiman Centro de Matemática, Udelar y Universidad de San Andrés, Argentina Cluster Análisis 1 El término cluster analysis (usado por primera
Introducción al Data Mining Clases 5 Cluster Analysis Ricardo Fraiman Centro de Matemática, Udelar y Universidad de San Andrés, Argentina Cluster Análisis 1 El término cluster analysis (usado por primera
Estas visiones de la información, denominadas vistas, se pueden identificar de varias formas.
 El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos. - Sesión 9 -
 Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 9 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Qué es un modelo de Data Mining Qué es
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 9 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Actividad. Qué es un modelo de Data Mining Qué es
Encuesta Permanente de Hogares
 Minería de Datos Aplicada a la Encuesta Permanente de Hogares Disertante: Luis Alfonso Cutro Adscripto a la asignatura Diseño y Administración de Datos. Prof. Coordinador: Mgter. David Luís la Red Martínez
Minería de Datos Aplicada a la Encuesta Permanente de Hogares Disertante: Luis Alfonso Cutro Adscripto a la asignatura Diseño y Administración de Datos. Prof. Coordinador: Mgter. David Luís la Red Martínez
Redes de Kohonen y la Determinación Genética de las Clases
 Redes de Kohonen y la Determinación Genética de las Clases Angel Kuri Instituto Tecnológico Autónomo de México Octubre de 2001 Redes Neuronales de Kohonen Las Redes de Kohonen, también llamadas Mapas Auto-Organizados
Redes de Kohonen y la Determinación Genética de las Clases Angel Kuri Instituto Tecnológico Autónomo de México Octubre de 2001 Redes Neuronales de Kohonen Las Redes de Kohonen, también llamadas Mapas Auto-Organizados
Análisis de Sistemas. M.Sc. Lic. Aidee Vargas C. C. octubre 2007
 Análisis de Sistemas M.Sc. Lic. Aidee Vargas C. C. octubre 2007 Metodologías de Desarrollo de Software Las metodologías existentes se dividen en dos grandes grupos: Metodologías estructuradas Metodologías
Análisis de Sistemas M.Sc. Lic. Aidee Vargas C. C. octubre 2007 Metodologías de Desarrollo de Software Las metodologías existentes se dividen en dos grandes grupos: Metodologías estructuradas Metodologías
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos. - Sesión 12 -
 Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 12 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Fundamentos de clustering Ejemplo inicial Aplicaciones
Fundamentos y Aplicaciones Prácticas del Descubrimiento de Conocimiento en Bases de Datos - Sesión 12 - Juan Alfonso Lara Torralbo 1 Índice de contenidos Fundamentos de clustering Ejemplo inicial Aplicaciones
CONSIDERACIONES GENERALES DEL WEB MINING
 CONSIDERACIONES GENERALES DEL WEB MINING Sandra Milena Leal Elizabeth Castiblanco Calderón* RESUMEN: el presente artículo describe los conceptos básicos para la utilización del Webmining, dentro de los
CONSIDERACIONES GENERALES DEL WEB MINING Sandra Milena Leal Elizabeth Castiblanco Calderón* RESUMEN: el presente artículo describe los conceptos básicos para la utilización del Webmining, dentro de los
Unidad 1. Fundamentos en Gestión de Riesgos
 1.1 Gestión de Proyectos Unidad 1. Fundamentos en Gestión de Riesgos La gestión de proyectos es una disciplina con la cual se integran los procesos propios de la gerencia o administración de proyectos.
1.1 Gestión de Proyectos Unidad 1. Fundamentos en Gestión de Riesgos La gestión de proyectos es una disciplina con la cual se integran los procesos propios de la gerencia o administración de proyectos.
6.3.4. 4 Etapa : Caracterización de la partición P 4 de los n individuos de la tabla T(22, 3)
") 6.3.4. 4 Etapa : Caracterización de la partición P 4 de los n individuos de la tabla T(22, 3) - Resultados y conclusiones Las tres variables contribuyen significativamente a caracterizar las clases de
6.3.4. 4 Etapa : Caracterización de la partición P 4 de los n individuos de la tabla T(22, 3) - Resultados y conclusiones Las tres variables contribuyen significativamente a caracterizar las clases de
DISTRIBUCIÓN DE FRECUENCIAS
 UNIVERSIDAD DE COSTA RICA ESCUELA DE ESTADÍSTICA Prof. Olman Ramírez Moreira DISTRIBUCIÓN DE FRECUENCIAS FUENTE: Gómez, Elementos de Estadística Descriptiva Levin & Rubin. Estadística para Administradores
UNIVERSIDAD DE COSTA RICA ESCUELA DE ESTADÍSTICA Prof. Olman Ramírez Moreira DISTRIBUCIÓN DE FRECUENCIAS FUENTE: Gómez, Elementos de Estadística Descriptiva Levin & Rubin. Estadística para Administradores
ANALISIS MULTIVARIANTE
 ANALISIS MULTIVARIANTE Es un conjunto de técnicas que se utilizan cuando se trabaja sobre colecciones de datos en las cuáles hay muchas variables implicadas. Los principales problemas, en este contexto,
ANALISIS MULTIVARIANTE Es un conjunto de técnicas que se utilizan cuando se trabaja sobre colecciones de datos en las cuáles hay muchas variables implicadas. Los principales problemas, en este contexto,
Capítulo 1. Introducción
 Capítulo 1. Introducción El WWW es la mayor fuente de imágenes que día a día se va incrementando. Según una encuesta realizada por el Centro de Bibliotecas de Cómputo en Línea (OCLC) en Enero de 2005,
Capítulo 1. Introducción El WWW es la mayor fuente de imágenes que día a día se va incrementando. Según una encuesta realizada por el Centro de Bibliotecas de Cómputo en Línea (OCLC) en Enero de 2005,
Figura 4.1 Clasificación de los lenguajes de bases de datos
 1 Colección de Tesis Digitales Universidad de las Américas Puebla Romero Martínez, Modesto Este capítulo describen los distintos lenguajes para bases de datos, la forma en que se puede escribir un lenguaje
1 Colección de Tesis Digitales Universidad de las Américas Puebla Romero Martínez, Modesto Este capítulo describen los distintos lenguajes para bases de datos, la forma en que se puede escribir un lenguaje
Colegio Salesiano Don Bosco Academia Reparación Y Soporte Técnico V Bachillerato Autor: Luis Orozco. Subneteo
 Subneteo La función del Subneteo o Subnetting es dividir una red IP física en subredes lógicas (redes más pequeñas) para que cada una de estas trabajen a nivel envío y recepción de paquetes como una red
Subneteo La función del Subneteo o Subnetting es dividir una red IP física en subredes lógicas (redes más pequeñas) para que cada una de estas trabajen a nivel envío y recepción de paquetes como una red
Ingeniería del Software I Clase de Testing Funcional 2do. Cuatrimestre de 2007
 Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
Técnicas de análisis multivariante para agrupación
 TEMA 2: TÉCNICAS DE ANÁLISIS MULTIVARIANTE PARA AGRUPACIÓN Métodos cluster Técnicas de segmentación Clasificación no supervisada Ana Justel 1 Técnicas de análisis multivariante para agrupación Motivación
TEMA 2: TÉCNICAS DE ANÁLISIS MULTIVARIANTE PARA AGRUPACIÓN Métodos cluster Técnicas de segmentación Clasificación no supervisada Ana Justel 1 Técnicas de análisis multivariante para agrupación Motivación
4. MÉTODOS DE CLASIFICACIÓN
 4. MÉTODOS DE CLASIFICACIÓN Una forma de sintetizar la información contenida en una tabla multidimensional (por ejemplo una tabla léxica agregada), es mediante la conformación y caracterización de grupos.
4. MÉTODOS DE CLASIFICACIÓN Una forma de sintetizar la información contenida en una tabla multidimensional (por ejemplo una tabla léxica agregada), es mediante la conformación y caracterización de grupos.
WBS:Work Breakdown Structure. WBS - Work Breakdown Structure. WBS - Work Breakdown Structure. WBS:Work Breakdown Structure...
 WBS - Work Breakdown Structure WBS:Work Breakdown Structure WBS: es una descripción jerárquica del trabajo que se debe realizar para completar el proyecto. El trabajo se divide en actividades. Las actividades
WBS - Work Breakdown Structure WBS:Work Breakdown Structure WBS: es una descripción jerárquica del trabajo que se debe realizar para completar el proyecto. El trabajo se divide en actividades. Las actividades
Ampliación de Estructuras de Datos
 Ampliación de Estructuras de Datos Amalia Duch Barcelona, marzo de 2007 Índice 1. Diccionarios implementados con árboles binarios de búsqueda 1 2. TAD Cola de Prioridad 4 3. Heapsort 8 1. Diccionarios
Ampliación de Estructuras de Datos Amalia Duch Barcelona, marzo de 2007 Índice 1. Diccionarios implementados con árboles binarios de búsqueda 1 2. TAD Cola de Prioridad 4 3. Heapsort 8 1. Diccionarios
Introducción a selección de. Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012
 Introducción a selección de atributos usando WEKA Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012 Contenido 1 Introducción a WEKA El origen Interfaces
Introducción a selección de atributos usando WEKA Blanca A. Vargas Govea blanca.vargas@cenidet.edu.mx Reconocimiento de patrones cenidet Octubre 1, 2012 Contenido 1 Introducción a WEKA El origen Interfaces
MERCADOS FINANCIEROS: LOS FONDOS DE INVERSIÓN II
 MERCADOS FINANCIEROS: LOS FONDOS DE INVERSIÓN II 28 febrero de 2012 Javier Marchamalo Martínez Universidad Rey Juan Carlos SABER INTERPRETAR LOS RATIOS SIGNIFICATIVOS EN LA GESTIÓN POR BENCHMARK Ratio
MERCADOS FINANCIEROS: LOS FONDOS DE INVERSIÓN II 28 febrero de 2012 Javier Marchamalo Martínez Universidad Rey Juan Carlos SABER INTERPRETAR LOS RATIOS SIGNIFICATIVOS EN LA GESTIÓN POR BENCHMARK Ratio
Cuestionario: 1) Utilizas o haz utilizado la línea de colectivo 128? Sí, No? 2) Crees qué se encuentra en buen estado de servicio? Sí, No?
 Utilizas o haz utilizado la línea de colectivo 128? Sí, No? 2) Crees qué se encuentra en buen estado de servicio? Sí, No?") Cuestionario: 1) Utilizas o haz utilizado la línea de colectivo 128? Sí, No? 2) Crees qué se encuentra en buen estado de servicio? Sí, No? 3) El colectivo en su totalidad se encuentra en buen funcionamiento?
Cuestionario: 1) Utilizas o haz utilizado la línea de colectivo 128? Sí, No? 2) Crees qué se encuentra en buen estado de servicio? Sí, No? 3) El colectivo en su totalidad se encuentra en buen funcionamiento?
Recuperación de Información en Internet Tema 3: Principios de Recuperación de Información
 Recuperación de Información en Internet Tema 3: Principios de Recuperación de Información Mestrado Universitario Língua e usos profesionais Miguel A. Alonso Jesús Vilares Departamento de Computación Facultad
Recuperación de Información en Internet Tema 3: Principios de Recuperación de Información Mestrado Universitario Língua e usos profesionais Miguel A. Alonso Jesús Vilares Departamento de Computación Facultad
Métodos Iterativos para Resolver Sistemas Lineales
 Métodos Iterativos para Resolver Sistemas Lineales Departamento de Matemáticas, CCIR/ITESM 17 de julio de 2009 Índice 3.1. Introducción............................................... 1 3.2. Objetivos................................................
Métodos Iterativos para Resolver Sistemas Lineales Departamento de Matemáticas, CCIR/ITESM 17 de julio de 2009 Índice 3.1. Introducción............................................... 1 3.2. Objetivos................................................
Proyecto Help Desk en plataforma SOA Alcance del Sistema Versión 1.2. Historia de revisiones
 Proyecto Help Desk en plataforma SOA Alcance del Sistema Versión 1.2 Historia de revisiones Fecha Versión Descripción Autor 27/08/05 1.1 Definimos el Alcance del Sistema, en una primera instancia, priorizando
Proyecto Help Desk en plataforma SOA Alcance del Sistema Versión 1.2 Historia de revisiones Fecha Versión Descripción Autor 27/08/05 1.1 Definimos el Alcance del Sistema, en una primera instancia, priorizando
Aprendizaje Automático y Data Mining. Bloque IV DATA MINING
 Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final
![Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final](/thumbs/27/10370366.jpg "Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final") Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final INTRODUCCION En principio surgió la idea de un buscador que brinde los resultados en agrupaciones de
Catoira Fernando Fullana Pablo Rodriguez Federico [MINERIA DE LA WEB] Proyecto Final - Informe Final INTRODUCCION En principio surgió la idea de un buscador que brinde los resultados en agrupaciones de
Componentes de Integración entre Plataformas Información Detallada
 Componentes de Integración entre Plataformas Información Detallada Active Directory Integration Integración con el Directorio Activo Active Directory es el servicio de directorio para Windows 2000 Server.
Componentes de Integración entre Plataformas Información Detallada Active Directory Integration Integración con el Directorio Activo Active Directory es el servicio de directorio para Windows 2000 Server.
La inteligencia de marketing que desarrolla el conocimiento
 La inteligencia de marketing que desarrolla el conocimiento SmartFocus facilita a los equipos de marketing y ventas la captación de consumidores con un enfoque muy relevante y centrado en el cliente. Ofrece
La inteligencia de marketing que desarrolla el conocimiento SmartFocus facilita a los equipos de marketing y ventas la captación de consumidores con un enfoque muy relevante y centrado en el cliente. Ofrece
Ingeniería del Software I
 - 1 - Ingeniería del Software I Introducción al Modelo Conceptual 2do. Cuatrimestre 2005 INTRODUCCIÓN... 2 CLASES CONCEPTUALES... 3 ESTRATEGIAS PARA IDENTIFICAR CLASES CONCEPTUALES... 3 Utilizar lista
- 1 - Ingeniería del Software I Introducción al Modelo Conceptual 2do. Cuatrimestre 2005 INTRODUCCIÓN... 2 CLASES CONCEPTUALES... 3 ESTRATEGIAS PARA IDENTIFICAR CLASES CONCEPTUALES... 3 Utilizar lista
En nuestro capitulo final, daremos las conclusiones y las aplicaciones a futuro
 Capitulo 6 Conclusiones y Aplicaciones a Futuro. En nuestro capitulo final, daremos las conclusiones y las aplicaciones a futuro para nuestro sistema. Se darán las conclusiones para cada aspecto del sistema,
Capitulo 6 Conclusiones y Aplicaciones a Futuro. En nuestro capitulo final, daremos las conclusiones y las aplicaciones a futuro para nuestro sistema. Se darán las conclusiones para cada aspecto del sistema,
Registro (record): es la unidad básica de acceso y manipulación de la base de datos.
: es la unidad básica de acceso y manipulación de la base de datos.") UNIDAD II 1. Modelos de Bases de Datos. Modelo de Red. Representan las entidades en forma de nodos de un grafo y las asociaciones o interrelaciones entre estas, mediante los arcos que unen a dichos nodos.
UNIDAD II 1. Modelos de Bases de Datos. Modelo de Red. Representan las entidades en forma de nodos de un grafo y las asociaciones o interrelaciones entre estas, mediante los arcos que unen a dichos nodos.
MODELOS DE RECUPERACION
 RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN INGENIERÍA INFORMÁTICA RECUPERACIÓN Y ACCESO A LA INFORMACIÓN MODELOS DE RECUPERACION AUTOR: Rubén García Broncano NIA 100065530 grupo 81 1 INDICE 1- INTRODUCCIÓN
RECUPERACIÓN Y ORGANIZACIÓN DE LA INFORMACIÓN INGENIERÍA INFORMÁTICA RECUPERACIÓN Y ACCESO A LA INFORMACIÓN MODELOS DE RECUPERACION AUTOR: Rubén García Broncano NIA 100065530 grupo 81 1 INDICE 1- INTRODUCCIÓN
Sistemas de Sensación Segmentación, Reconocimiento y Clasificación de Objetos. CI-2657 Robótica M.Sc. Kryscia Ramírez Benavides
 Sistemas de Sensación Segmentación, Reconocimiento y Clasificación de Objetos CI-2657 Robótica M.Sc. Kryscia Ramírez Benavides Introducción La visión artificial, también conocida como visión por computador
Sistemas de Sensación Segmentación, Reconocimiento y Clasificación de Objetos CI-2657 Robótica M.Sc. Kryscia Ramírez Benavides Introducción La visión artificial, también conocida como visión por computador
Aspectos a considerar en la adopción por primera vez en la transición a las NIIF para PYMES
 Aspectos a considerar en la adopción por primera vez en la transición a las NIIF para PYMES Creo importante analizar los contenidos de la sección 35, ya que, son los que deben aplicarse técnicamente en
Aspectos a considerar en la adopción por primera vez en la transición a las NIIF para PYMES Creo importante analizar los contenidos de la sección 35, ya que, son los que deben aplicarse técnicamente en
SISTEMAS DE INFORMACIÓN I TEORÍA
 CONTENIDO: CICLO DE VIDA DE DESARROLLO DE SI FASES GENÉRICAS DEL CICLO DE VIDA DE DESARROLLO DE SI VISIÓN TRADICIONAL DEL CICLO DE VIDA DE DESARROLLO DE SI DE DESARROLLO DE SI: ANÁLISIS Material diseñado
CONTENIDO: CICLO DE VIDA DE DESARROLLO DE SI FASES GENÉRICAS DEL CICLO DE VIDA DE DESARROLLO DE SI VISIÓN TRADICIONAL DEL CICLO DE VIDA DE DESARROLLO DE SI DE DESARROLLO DE SI: ANÁLISIS Material diseñado
Autenticación Centralizada
 Autenticación Centralizada Ing. Carlos Rojas Castro Herramientas de Gestión de Redes Introducción En el mundo actual, pero en especial las organizaciones actuales, los usuarios deben dar pruebas de quiénes
Autenticación Centralizada Ing. Carlos Rojas Castro Herramientas de Gestión de Redes Introducción En el mundo actual, pero en especial las organizaciones actuales, los usuarios deben dar pruebas de quiénes
Plataforma e-ducativa Aragonesa. Manual de Administración. Bitácora
 Plataforma e-ducativa Aragonesa Manual de Administración Bitácora ÍNDICE Acceso a la administración de la Bitácora...3 Interfaz Gráfica...3 Publicaciones...4 Cómo Agregar una Publicación...4 Cómo Modificar
Plataforma e-ducativa Aragonesa Manual de Administración Bitácora ÍNDICE Acceso a la administración de la Bitácora...3 Interfaz Gráfica...3 Publicaciones...4 Cómo Agregar una Publicación...4 Cómo Modificar
El diseño de la base de datos de un Data Warehouse. Marta Millan millan@eisc.univalle.edu.co www.eisc.univalle.edu.co/materias
 El diseño de la base de datos de un Data Warehouse Marta Millan millan@eisc.univalle.edu.co www.eisc.univalle.edu.co/materias El modelo Multidimensional Principios básicos Marta Millan millan@eisc.univalle.edu.co
El diseño de la base de datos de un Data Warehouse Marta Millan millan@eisc.univalle.edu.co www.eisc.univalle.edu.co/materias El modelo Multidimensional Principios básicos Marta Millan millan@eisc.univalle.edu.co
Resumen de los cambios de la versión 2.0 a la 3.0 de las PA-DSS (normas de seguridad de datos para las aplicaciones de pago)
") Normas de seguridad de datos para las aplicaciones de pago de la PCI (industria de tarjetas de pago) Resumen de los cambios de la a la 3.0 de las PA-DSS (normas de seguridad de datos para las aplicaciones
Normas de seguridad de datos para las aplicaciones de pago de la PCI (industria de tarjetas de pago) Resumen de los cambios de la a la 3.0 de las PA-DSS (normas de seguridad de datos para las aplicaciones
ANALISIS DE CONGLOMERADOS
 ANALISIS DE CONGLOMERADOS Jorge Galbiati R Consiste en buscar grupos (conglomerados) en un conjunto de observaciones de forma tal que aquellas que pertenecen a un mismo grupo se parecen, mientras que aquellas
ANALISIS DE CONGLOMERADOS Jorge Galbiati R Consiste en buscar grupos (conglomerados) en un conjunto de observaciones de forma tal que aquellas que pertenecen a un mismo grupo se parecen, mientras que aquellas
Prof. Dra. Silvia Schiaffino ISISTAN
 Clustering ISISTAN sschia@ea.unicen.edu.ar Clustering: Concepto Cluster: un número de cosas o personas similares o cercanas, agrupadas Clustering: es el proceso de particionar un conjunto de objetos (datos)
Clustering ISISTAN sschia@ea.unicen.edu.ar Clustering: Concepto Cluster: un número de cosas o personas similares o cercanas, agrupadas Clustering: es el proceso de particionar un conjunto de objetos (datos)
TESIS DE MAGISTER EN INGENIERIA DE SOFTWARE CATEGORIZACION AUTOMATICA DE DOCUMENTOS CON MAPAS AUTO-ORGANIZADOS DE KOHONEN
 TESIS DE MAGISTER EN INGENIERIA DE SOFTWARE CATEGORIZACION AUTOMATICA DE DOCUMENTOS CON MAPAS AUTO-ORGANIZADOS DE KOHONEN Autor: Lic. Daniel Goldenberg Directores de Tesis: M. Ing. Hernán Merlino M. Ing.
TESIS DE MAGISTER EN INGENIERIA DE SOFTWARE CATEGORIZACION AUTOMATICA DE DOCUMENTOS CON MAPAS AUTO-ORGANIZADOS DE KOHONEN Autor: Lic. Daniel Goldenberg Directores de Tesis: M. Ing. Hernán Merlino M. Ing.
CATÁLOGO DE INFERENCIAS
 Las inferencias son los elementos claves en los modelos de conocimiento o Son los elementos constitutivos de los procesos de razonamiento No existe ningún estándar CommonKADS ofrece un catálogo que cubre
Las inferencias son los elementos claves en los modelos de conocimiento o Son los elementos constitutivos de los procesos de razonamiento No existe ningún estándar CommonKADS ofrece un catálogo que cubre
MANUAL DE USUARIO PANEL DE CONTROL Sistema para Administración del Portal Web. www.singleclick.com.co
 MANUAL DE USUARIO PANEL DE CONTROL Sistema para Administración del Portal Web www.singleclick.com.co Sistema para Administración del Portal Web Este documento es una guía de referencia en la cual se realiza
MANUAL DE USUARIO PANEL DE CONTROL Sistema para Administración del Portal Web www.singleclick.com.co Sistema para Administración del Portal Web Este documento es una guía de referencia en la cual se realiza
Tutorial de Subneteo Clase A, B, C - Ejercicios de Subnetting CCNA 1
 Tutorial de Subneteo Clase A, B, C - Ejercicios de Subnetting CCNA 1 La función del Subneteo o Subnetting es dividir una red IP física en subredes lógicas (redes más pequeñas) para que cada una de estas
Tutorial de Subneteo Clase A, B, C - Ejercicios de Subnetting CCNA 1 La función del Subneteo o Subnetting es dividir una red IP física en subredes lógicas (redes más pequeñas) para que cada una de estas
Indicaciones específicas para los análisis estadísticos.
 Tutorial básico de PSPP: Vídeo 1: Describe la interfaz del programa, explicando en qué consiste la vista de datos y la vista de variables. Vídeo 2: Muestra cómo crear una base de datos, comenzando por
Tutorial básico de PSPP: Vídeo 1: Describe la interfaz del programa, explicando en qué consiste la vista de datos y la vista de variables. Vídeo 2: Muestra cómo crear una base de datos, comenzando por
Planificación, Administración n de Bases de Datos. Bases de Datos. Ciclo de Vida de los Sistemas de Información. Crisis del Software.
 Planificación, n, Diseño o y Administración n de Crisis del Software Proyectos software de gran envergadura que se retrasaban, consumían todo el presupuesto disponible o generaban productos que eran poco
Planificación, n, Diseño o y Administración n de Crisis del Software Proyectos software de gran envergadura que se retrasaban, consumían todo el presupuesto disponible o generaban productos que eran poco
Inteligencia en Redes de Comunicaciones. Tema 7 Minería de Datos. Julio Villena Román, Raquel M. Crespo García, José Jesús García Rueda
 Inteligencia en Redes de Comunicaciones Tema 7 Minería de Datos Julio Villena Román, Raquel M. Crespo García, José Jesús García Rueda {jvillena, rcrespo, rueda}@it.uc3m.es Índice Definición y conceptos
Inteligencia en Redes de Comunicaciones Tema 7 Minería de Datos Julio Villena Román, Raquel M. Crespo García, José Jesús García Rueda {jvillena, rcrespo, rueda}@it.uc3m.es Índice Definición y conceptos
Es necesario conocer otras dos herramientas de búsqueda en Internet: los «metabuscadores» ó «motores de búsqueda» y los «portales».
 Búsqueda de información en la red Una de los usos más extendidos de Internet es la búsqueda de información útil para el/la usuario/a. Sin embargo, su localización no resulta siempre una tarea fácil debido
Búsqueda de información en la red Una de los usos más extendidos de Internet es la búsqueda de información útil para el/la usuario/a. Sin embargo, su localización no resulta siempre una tarea fácil debido
KNime. KoNstanz Information MinEr. KNime - Introducción. KNime - Introducción. Partes de la Herramienta. Editor Window. Repositorio de Nodos
 KNime - Introducción KNime Significa KoNstanz Information MinEr. Se pronuncia [naim]. Fue desarrollado en la Universidad de Konstanz (Alemania). Esta escrito en Java y su entorno grafico esta desarrollado
KNime - Introducción KNime Significa KoNstanz Information MinEr. Se pronuncia [naim]. Fue desarrollado en la Universidad de Konstanz (Alemania). Esta escrito en Java y su entorno grafico esta desarrollado
Clasificación de Música por Genero Utilizando Redes Neuronales Artificiales. Elkin García, Germán Mancera, Jorge Pacheco
 Clasificación de Música por Genero Utilizando Redes Neuronales Artificiales Elkin García, Germán Mancera, Jorge Pacheco Presentación Los autores han desarrollado un método de clasificación de música a
Clasificación de Música por Genero Utilizando Redes Neuronales Artificiales Elkin García, Germán Mancera, Jorge Pacheco Presentación Los autores han desarrollado un método de clasificación de música a
Presentación de Pyramid Data Warehouse
 Presentación de Pyramid Data Warehouse Pyramid Data Warehouse tiene hoy una larga historia, desde 1994 tiempo en el que su primera versión fue liberada, hasta la actual versión 8.00. El incontable tiempo
Presentación de Pyramid Data Warehouse Pyramid Data Warehouse tiene hoy una larga historia, desde 1994 tiempo en el que su primera versión fue liberada, hasta la actual versión 8.00. El incontable tiempo
En cualquier caso, tampoco es demasiado importante el significado de la "B", si es que lo tiene, lo interesante realmente es el algoritmo.
 Arboles-B Características Los árboles-b son árboles de búsqueda. La "B" probablemente se debe a que el algoritmo fue desarrollado por "Rudolf Bayer" y "Eduard M. McCreight", que trabajan para la empresa
Arboles-B Características Los árboles-b son árboles de búsqueda. La "B" probablemente se debe a que el algoritmo fue desarrollado por "Rudolf Bayer" y "Eduard M. McCreight", que trabajan para la empresa
Módulo de farmacia, stock y compras
 Módulo de farmacia, stock y compras Introducción... 2 Compras... 3 Remitos... 3 Facturas... 4 Proveedores... 5 Stock... 8 Configuración... 8 Componentes... 8 Familias de Ítems... 9 Ítems... 10 Productos...
Módulo de farmacia, stock y compras Introducción... 2 Compras... 3 Remitos... 3 Facturas... 4 Proveedores... 5 Stock... 8 Configuración... 8 Componentes... 8 Familias de Ítems... 9 Ítems... 10 Productos...
TEMA 4. Sistema Sexagesimal. Sistema Octal (base 8): sistema de numeración que utiliza los dígitos 0, 1, 2, 3, 4, 5,
: sistema de numeración que utiliza los dígitos 0, 1, 2, 3, 4, 5,") TEMA 4 Sistema Sexagesimal 4.0.- Sistemas de numeración Son métodos (conjunto de símbolos y reglas) ideados por el hombre para contar elementos de un conjunto o agrupación de cosas. Se clasifican en sistemas
TEMA 4 Sistema Sexagesimal 4.0.- Sistemas de numeración Son métodos (conjunto de símbolos y reglas) ideados por el hombre para contar elementos de un conjunto o agrupación de cosas. Se clasifican en sistemas
Diseño orientado al flujo de datos
 Diseño orientado al flujo de datos Recordemos que el diseño es una actividad que consta de una serie de pasos, en los que partiendo de la especificación del sistema (de los propios requerimientos), obtenemos
Diseño orientado al flujo de datos Recordemos que el diseño es una actividad que consta de una serie de pasos, en los que partiendo de la especificación del sistema (de los propios requerimientos), obtenemos
Darío Álvarez Néstor Lemo www.autonomo.edu.uy
 Data Mining para Optimización de Distribución de Combustibles Darío Álvarez Néstor Lemo Agenda Qué es DODC? Definición de Data Mining El ciclo virtuoso de Data Mining Metodología de Data Mining Tareas
Data Mining para Optimización de Distribución de Combustibles Darío Álvarez Néstor Lemo Agenda Qué es DODC? Definición de Data Mining El ciclo virtuoso de Data Mining Metodología de Data Mining Tareas
Redes de área local: Aplicaciones y servicios WINDOWS
 Redes de área local: Aplicaciones y servicios WINDOWS 4. Servidor DNS 1 Índice Definición de Servidor DNS... 3 Instalación del Servidor DNS... 5 Configuración del Servidor DNS... 8 2 Definición de Servidor
Redes de área local: Aplicaciones y servicios WINDOWS 4. Servidor DNS 1 Índice Definición de Servidor DNS... 3 Instalación del Servidor DNS... 5 Configuración del Servidor DNS... 8 2 Definición de Servidor
CREACIÓN DE MAPAS DE RECURSOS DIRIGIDOS A ESTRATEGIAS
 CREACIÓN DE MAPAS DE RECURSOS DIRIGIDOS A ESTRATEGIAS Actualización Septiembre 2012 Distrito Escolar Unificado de Los Angeles Agenda 2 Introducción Creación de Mapas de recursos Conclusión Objetivos y
CREACIÓN DE MAPAS DE RECURSOS DIRIGIDOS A ESTRATEGIAS Actualización Septiembre 2012 Distrito Escolar Unificado de Los Angeles Agenda 2 Introducción Creación de Mapas de recursos Conclusión Objetivos y
Tema: INSTALACIÓN Y PARTICIONAMIENTO DE DISCOS DUROS.
 1 Facultad: Ingeniería Escuela: Electrónica Asignatura: Arquitectura de computadoras Lugar de ejecución: Lab. de arquitectura de computadoras, edif. de electrónica. Tema: INSTALACIÓN Y PARTICIONAMIENTO
1 Facultad: Ingeniería Escuela: Electrónica Asignatura: Arquitectura de computadoras Lugar de ejecución: Lab. de arquitectura de computadoras, edif. de electrónica. Tema: INSTALACIÓN Y PARTICIONAMIENTO
CLASIFICACIÓN NO SUPERVISADA CLASIFICACIÓN NO SUPERVISADA N. QUEIPO, S. PINTOS COPYRIGHT 2005 FUNDAMENTOS DE DATA MINING Y SUS APLICACIONES
 DEFINICIÓN: AGRUPAR UN CONJUNTO DE n OBJETOS, DEFINIDOS POR p VARIABLES, EN c CLASES, DONDE EN CADA CLASE LOS ELEMENTOS POSEAN CARACTERÍSTICAS AFINES Y SEAN MÁS SIMILARES ENTRE SÍ QUE RESPECTO AELEMENTOS
DEFINICIÓN: AGRUPAR UN CONJUNTO DE n OBJETOS, DEFINIDOS POR p VARIABLES, EN c CLASES, DONDE EN CADA CLASE LOS ELEMENTOS POSEAN CARACTERÍSTICAS AFINES Y SEAN MÁS SIMILARES ENTRE SÍ QUE RESPECTO AELEMENTOS
2.4 Modelado conceptual
 2.4 Modelado conceptual 2.4. Búsqueda de conceptos Un modelo conceptual muestra clases conceptuales significativas en un dominio del problema; es el artefacto más importante que se crea durante el análisis
2.4 Modelado conceptual 2.4. Búsqueda de conceptos Un modelo conceptual muestra clases conceptuales significativas en un dominio del problema; es el artefacto más importante que se crea durante el análisis
APLICACIONES CON SOLVER OPCIONES DE SOLVER
 APLICACIONES CON SOLVER Una de las herramientas con que cuenta el Excel es el solver, que sirve para crear modelos al poderse, diseñar, construir y resolver problemas de optimización. Es una poderosa herramienta
APLICACIONES CON SOLVER Una de las herramientas con que cuenta el Excel es el solver, que sirve para crear modelos al poderse, diseñar, construir y resolver problemas de optimización. Es una poderosa herramienta
Algoritmos y Estructuras de Datos 2. Web Mining Esteban Meneses
 Algoritmos y Estructuras de Datos 2 Web Mining Esteban Meneses 2005 Motivación La Web contiene miles de millones de documentos con información sobre casi cualquier tópico. Es la Biblioteca de Alejandría
Algoritmos y Estructuras de Datos 2 Web Mining Esteban Meneses 2005 Motivación La Web contiene miles de millones de documentos con información sobre casi cualquier tópico. Es la Biblioteca de Alejandría
NOTAS SOBRE DIAGRAMAS DE FLUJOS DE DATOS
 NOTAS SOBRE DIAGRAMAS DE FLUJOS DE DATOS Diagrama de Flujo de Datos: Diagrama en forma de red que representa el flujo de datos y las transformaciones que se aplican sobre ellos al moverse desde la entrada
NOTAS SOBRE DIAGRAMAS DE FLUJOS DE DATOS Diagrama de Flujo de Datos: Diagrama en forma de red que representa el flujo de datos y las transformaciones que se aplican sobre ellos al moverse desde la entrada
http://www.statum.biz http://www.statum.info http://www.statum.org
 ApiaMonitor Monitor de Infraestructura BPMS Por: Ing. Manuel Cabanelas Product Manager de Apia Manuel.Cabanelas@statum.biz http://www.statum.biz http://www.statum.info http://www.statum.org Abstract A
ApiaMonitor Monitor de Infraestructura BPMS Por: Ing. Manuel Cabanelas Product Manager de Apia Manuel.Cabanelas@statum.biz http://www.statum.biz http://www.statum.info http://www.statum.org Abstract A
Máster en Ciencia y Tecnología Informática
 Departamento de Informática Universidad Carlos III de Madrid Máster en Ciencia y Tecnología Informática Programación Automática Examen Normas generales del examen El tiempo para realizar el examen es de
Departamento de Informática Universidad Carlos III de Madrid Máster en Ciencia y Tecnología Informática Programación Automática Examen Normas generales del examen El tiempo para realizar el examen es de
Prácticas ITIL para un mejor flujo de trabajo en el helpdesk
 Prácticas ITIL para un mejor flujo de trabajo en el helpdesk Se diferencia tres partes de gestión para mejorar la resolución de las incidencias de soporte técnico según el marco ITIL: 1. Gestión de Incidencias
Prácticas ITIL para un mejor flujo de trabajo en el helpdesk Se diferencia tres partes de gestión para mejorar la resolución de las incidencias de soporte técnico según el marco ITIL: 1. Gestión de Incidencias
Gestión de la Prevención de Riesgos Laborales. 1
 UNIDAD Gestión de la Prevención de Riesgos Laborales. 1 FICHA 1. LA GESTIÓN DE LA PREVENCIÓN DE RIESGOS LABORALES. FICHA 2. EL SISTEMA DE GESTIÓN DE LA PREVENCIÓN DE RIESGOS LABORALES. FICHA 3. MODALIDAD
UNIDAD Gestión de la Prevención de Riesgos Laborales. 1 FICHA 1. LA GESTIÓN DE LA PREVENCIÓN DE RIESGOS LABORALES. FICHA 2. EL SISTEMA DE GESTIÓN DE LA PREVENCIÓN DE RIESGOS LABORALES. FICHA 3. MODALIDAD
Jornadas de INCLUSION DIGITAL. a través de las TIC ORGANIZAN: CAPACITA: CLAEH
 Jornadas de INCLUSION DIGITAL a través de las TIC ORGANIZAN: CAPACITA: CLAEH BÚSQUEDAS EN INTERNET SABER BUSCAR La cantidad de información disponible en Internet es inmensa y crece día a día, lo que implica
Jornadas de INCLUSION DIGITAL a través de las TIC ORGANIZAN: CAPACITA: CLAEH BÚSQUEDAS EN INTERNET SABER BUSCAR La cantidad de información disponible en Internet es inmensa y crece día a día, lo que implica
CAPÍTULO VI PROCEDIMIENTO PARA PROGRAMAR LA PRODUCCIÓN. Las expectativas de ventas, como se acaba de reflejar, y
 CAPÍTULO VI PROCEDIMIENTO PARA PROGRAMAR LA PRODUCCIÓN El programa de producción se define en función de: 1 Las expectativas de ventas, como se acaba de reflejar, y Las características técnicas de la empresa.
CAPÍTULO VI PROCEDIMIENTO PARA PROGRAMAR LA PRODUCCIÓN El programa de producción se define en función de: 1 Las expectativas de ventas, como se acaba de reflejar, y Las características técnicas de la empresa.
Mesa de Ayuda Interna
 Mesa de Ayuda Interna Documento de Construcción Mesa de Ayuda Interna 1 Tabla de Contenido Proceso De Mesa De Ayuda Interna... 2 Diagrama Del Proceso... 3 Modelo De Datos... 4 Entidades Del Sistema...
Mesa de Ayuda Interna Documento de Construcción Mesa de Ayuda Interna 1 Tabla de Contenido Proceso De Mesa De Ayuda Interna... 2 Diagrama Del Proceso... 3 Modelo De Datos... 4 Entidades Del Sistema...
HADES: Hidrocarburos Análisis de Datos de Estaciones de Servicio
 Hidrocarburos: Análisis de Pablo Burgos Casado (Jefe de Área Desarrollo (SGTIC - MITYC)) María Teresa Simino Rueda Rubén Pérez Gómez Israel Santos Montero María Ángeles Rodelgo Sanchez 1. INTRODUCCIÓN
Hidrocarburos: Análisis de Pablo Burgos Casado (Jefe de Área Desarrollo (SGTIC - MITYC)) María Teresa Simino Rueda Rubén Pérez Gómez Israel Santos Montero María Ángeles Rodelgo Sanchez 1. INTRODUCCIÓN
MANUAL DE USUARIO BÁSICO TIENDA VIRTUAL Agregar o modificar categorías y productos a su tienda virtual
 MANUAL DE USUARIO BÁSICO TIENDA VIRTUAL Agregar o modificar categorías y productos a su tienda virtual INDICE 1. INICIE SU SESION DE ADMINISTRADOR 2. AGREGAR CATEGORÍAS 2.1 CREANDO, EDITANDO O ASIGNANDO
MANUAL DE USUARIO BÁSICO TIENDA VIRTUAL Agregar o modificar categorías y productos a su tienda virtual INDICE 1. INICIE SU SESION DE ADMINISTRADOR 2. AGREGAR CATEGORÍAS 2.1 CREANDO, EDITANDO O ASIGNANDO
Adelacu Ltda. www.adelacu.com Fono +562-218-4749. Graballo+ Agosto de 2007. Graballo+ - Descripción funcional - 1 -
 Graballo+ Agosto de 2007-1 - Índice Índice...2 Introducción...3 Características...4 DESCRIPCIÓN GENERAL...4 COMPONENTES Y CARACTERÍSTICAS DE LA SOLUCIÓN...5 Recepción de requerimientos...5 Atención de
Graballo+ Agosto de 2007-1 - Índice Índice...2 Introducción...3 Características...4 DESCRIPCIÓN GENERAL...4 COMPONENTES Y CARACTERÍSTICAS DE LA SOLUCIÓN...5 Recepción de requerimientos...5 Atención de
CAPITULO 4. Requerimientos, Análisis y Diseño. El presente capítulo explica los pasos que se realizaron antes de implementar
 CAPITULO 4 Requerimientos, Análisis y Diseño El presente capítulo explica los pasos que se realizaron antes de implementar el sistema. Para esto, primero se explicarán los requerimientos que fueron solicitados
CAPITULO 4 Requerimientos, Análisis y Diseño El presente capítulo explica los pasos que se realizaron antes de implementar el sistema. Para esto, primero se explicarán los requerimientos que fueron solicitados
Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322
 Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322 Nicole García Gómez 2830047-6 Diego Riquelme Adriasola 2621044-5 RESUMEN.- La minería de datos corresponde a la extracción
Mineria de datos y su aplicación en web mining data Redes de computadores I ELO 322 Nicole García Gómez 2830047-6 Diego Riquelme Adriasola 2621044-5 RESUMEN.- La minería de datos corresponde a la extracción