Taller Computación Altas Prestaciones. Pedro Antonio Varo Herrero
|
|
|
- Susana Aguilera Vera
- hace 8 años
- Vistas:
Transcripción


1 Taller Computación Altas Prestaciones Pedro Antonio Varo Herrero

2 Antes de nada!! Cosas a instalar: OpenMPI: Mpi4py: pip install mpi4py Cython: pip install cython

3 Que vamos a ver: 1. Que es esto del HPC 1. Algunos Supercomputadores 2. Arquitecturas y Tecnologías 3. MPI4Py 1. Como funciona 2. Sus métodos y diferencias con C 4. A Programar!!!

4 Supercomputador Marenostrum - Barcelona Peak Performance of 1,1 Petaflops TB of main memory Main Nodes 3,056 compute nodes 6,112 Processors 2x Intel SandyBridge-EP E5-2670/ M 8-core at 2.6 GH 3056 * 8cores*2Intel SB = 48,896 Cores 64 nodes with 8x16 GB DDR DIMMS (8GB/core) 64 nodes with 16x4 GB DDR DIMMS (4GB/core) 2880 nodes with 8x4 GB DDR DIMMS (2GB/core)
 64 nodes with")
5 NVIDIA GPU is a cluster with 128 Bull B505 blades each blade with the following configuration: 2 Intel E5649 (6-Core) processor at 2.53 GHz 2 M2090 NVIDIA GPU Cards Cada Nodo: 12 Núcleos Intel *2 Núcleos Cuda Total: 1536 Intel Cores GP-GPU BSC NVIDIA GPU Cluster MinoTauro - Barcelona 24 GB of Main memory Peak Performance: TFlops 250 GB SSD (Solid State Disk) as local storage 2 Infiniband QDR (40 Gbit each) to a nonblocking network RedHat Linux 14 links of 10 GbitEth to connect to BSC GPFS Storage
 as local storage 2 Infiniband QDR (40 Gbit each) to a nonblocking network RedHat Linux 14 links of 10 GbitEth")
6 The Cray XC30- Swiss National Supercomputing Centre (CSCS) Manufacturer: Cray Inc. Cores: 115,984 Linpack Performance (Rmax) 6,271 TFlop/s Theoretical Peak (Rpeak) 7, TFlop/s Nmax 4,128,768 Power: 2, kw Processor: Xeon E C 2.6GHz Rank: 6 June 2014


7 Arquitecturas según memoria Uniform Memory Access UMA Non-Uniform Memory Access NUMA Memory Memory Memory Memory Memory Memory Memory Memory Main Memory Memory Passing Message MPM



8 Paradigmas de Programación Paralela Por manejo de Threads. Por paso de mensajes. Hibrida: Threads + Paso de mensajes. Memory Red de interconexión



9 Multiprocessing MPI4Py PyCuda PyOpenCL Estándares de librerías de programación paralela

10 Multiprocessing MPI4Py PyCuda PyOpenCL Estándares de librerías de programación paralela

11 MPI Message Passing Interface Usado en arquitecturas de memoria distribuida. Da comunicación entre los distintos procesadores/nodos/maquinas del sistema. Se crean distintas procesos, cada uno con su propio espacio de memoria. Los datos entre procesos se comparten en el paso del mensaje. Código escalable. Estandar: MPI(C/C++,Fortran). Memory data Memory data(copy) Python -> MPI4Py CPU CPU Proyecto de Lisandro Dalcin, basado en MPI-1/2/3 Implementa la mayoría de funciones de MPI message Repo: Task 0 data Task 1 data message network message
 Python -> MPI4Py CPU CPU Proyecto de Lisandro Dalcin, basado en MPI-1/2/3 Implementa la mayoría de funciones de MPI")
12 MPI mpi4py Memory buffer data Core message Memory data(copy) Core buffer Task 0 data buffer message network Task 1 data buffer message Python -> MPI4Py Envia objetos Python o Arrays Repo: API: Des/Serialización de objetos, en ASCII o Binario: Pickle cpickle

13 MPI mpi4py Python -> MPI4Py Que nos hace falta instalar: Envia objetos Python o Arrays (Numpy) Una versión de MPI: OpenMPI o MPICH Repo: API: Python Modulo: mpi4py pip install mpi4py

14 MPI mpi4py Para empezar: Importar : from mpi4py import MPI Parámetros a obtener: comm = MPI.COMM_WORLD rank = MPI.COMM_WORLD.Get_rank() size = MPI.COMM_WORLD.Get_size() name = MPI.Get_processor_name() Para su ejecución: mpirun -np <P> python <code>.py
 Para su ejecución: mpirun -np <P> python")
15 MPI mpi4py Para empezar: Vamos a escribir un Hello World en paralelo y ejecutamos con diferentes números de procesos. Ejemplo: mpirun -np 4 python helloworld.py Output: Hello World!!, This is process 0 of 4, en nombre host Hello World!!, This is process 2 of 4, en nombre host Hello World!!, This is process 1 of 4, en nombre host Hello World!!, This is process 4 of 4, en nombre host

16 MPI mpi4py Para empezar: Hello World mpirun -np 4 python helloworld.py 1. from mpi4py import MPI rank = MPI.COMM_WORLD.Get_rank() 4. size = MPI.COMM_WORLD.Get_size() 5. name = MPI.Get_processor_name() print("hello, world! This is rank %d of %d running on %s" % (rank, size, name))

17 MPI - mpi4py Point-to-Point Comunications: Send( ) Rcv( ) Blocking: Esperan a que los datos se puedan enviar y modificar con seguridad. Send(),recv(),Send(), Recv(), SendRecv() Non-blocking: No esperan a que los datos se puedan enviar con seguridad y el proceso continua su tarea. Source data buffer message network Dest data buffer message Isend(), irecv(), Isend(), Irecv()

18 MPI - mpi4py MPI C vs MPI python mpi4py En C las funciones de comunicación suelen tener: 6 parámetros. Send/Recv(buf,size,datatype,dest,tag,comm) MPI_Recv(result, result sz, sz, result type, MPI MPI ANY ANY SOURCE,result, tag, tag, comm, comm, MPI MPI STATUS STATUS IGNORE); IGNORE); En Python, sólo 3 y nada de punteros. Send(data,dest, tag) / var=recv(source,tag) En data podemos enviar Cualquier objeto Python Si es un Array, indicando el tipo de dato del Array -> [Array,Type] MPI.COMM_WORLD.Send(data,dest=4,tag=0) Send([data,MPI.INT], dest=4,tag=0)
 / var=recv(source,tag) En data podemos enviar Cualquier objeto Python Si es un Array, indicando el tipo de dato del")
19 MPI - mpi4py Collective Communications:
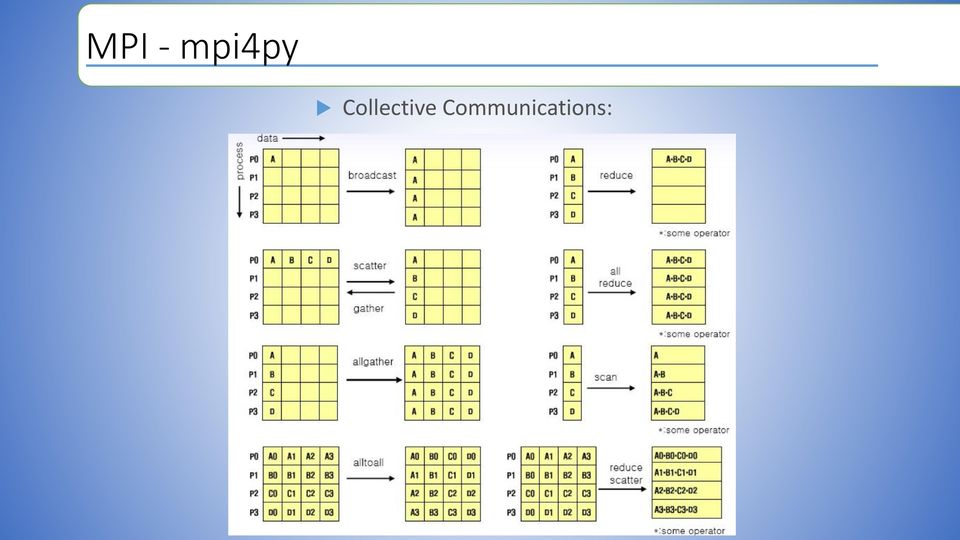
20 Collective Communications: MPI - mpi4py data=[0,1,2,3] Bcast(data, root=0) Data=Scatter(data,root=0) Data=Gather(data,root=0) Allgather(data_send, data_recv) Alltoall(data_send, data_recv)
 Allgather(data_send,")
21 Collective Communications: MPI - mpi4py data=[0,1,2,3] reduce(data, data_recv, op=sum root=0) allreduce(data, data_recv, op=sum) scan(data_send, data_recv, op=prod) reduce_scatter(data_send, data_recv, op=prod)
22 MPI - mpi4py Now, Think in Parallel!! Solve Problems, and Programming!!
23 MPI - mpi4py Probemos las funciones de MPI Ping-Pong Ring Calculo de PI en paralelo Multiplicación de Matrices Posible problema: TSP, Clasificaión con K-means, Comparación cadenas de ADN
24 MPI - mpi4py Ping-Pong 1. count = 0 2. for x in range(1000): 3. if rank == 0: comm.send(count, dest=1, tag=7) 5. count = comm.recv(source=1, tag=7) 6. else: 7. counter = comm.recv(source=0, tag=7) 8. counter += 1 9. comm.send(coun, dest=0, tag=7) if rank == 0: 12. print("total number of message exchanges: %d" % coun t)
25 MPI - mpi4py Ring 1.counter = 0 2.data = randint(0,100) 3.for x in range(size): 4. comm.send(data, dest=(rank+1)%size, tag=7) 5. data = comm.recv(source=(rank+size-1)%size, tag=7) 6. counter += data 7. 8.print("[%d] Total sum: %d" % (rank,counter))
26 MPI - mpi4py Algoritmo Genético en Islas Isla 1 Isla 5 Isla 2 Isla 4 Isla 3
27 MPI - mpi4py 3.0 Repetimos el proceso N generaciones Algoritmo Genético en Islas 3.8 Recibimos individuos de otra isla 3.1 Seleccionamos padres 3.2 Aplicamos el operador Crossover 3.7 Enviamos individuos a otra isla 3.3 Aplicamos el operador Mutación 3.6 Elegimos individuos para enviar 3.4 Aplicamos las reglas definidas 3.5 Evaluamos la población
28 MPI - mpi4py Pedro Antonio Varo Herrero Pedro Varo Pedro Antonio Varo Herrero Pedro Varo Herrero pevahe@gmail.com Now, Think in Parallel!! Solve Problems, and Programming!!
Programación Paralela y Distribuida
 Programación Paralela y Distribuida Cores, Threads and Nodes Pedro Antonio Varo Herrero pevahe@gmail.com Pedro Antonio Varo Herrero Estudiante 4º Curso - Universidad de Sevilla Grado Ing. Informática Tecnologías
Programación Paralela y Distribuida Cores, Threads and Nodes Pedro Antonio Varo Herrero pevahe@gmail.com Pedro Antonio Varo Herrero Estudiante 4º Curso - Universidad de Sevilla Grado Ing. Informática Tecnologías
High Performance Computing y Big Data en AWS. +info: (http://gac.udc.es) HPC y Big Data en AWS 16 Abril, 2012 1 / 14
 HPC y Big Data en AWS 16 Abril, 2012 1 / 14") High Performance Computing y Big Data en AWS +info: (http://gac.udc.es) HPC y Big Data en AWS 16 Abril, 212 1 / 14 High Performance Computing High Performance Computing (HPC) Afonta grandes problemas empresariales,
High Performance Computing y Big Data en AWS +info: (http://gac.udc.es) HPC y Big Data en AWS 16 Abril, 212 1 / 14 High Performance Computing High Performance Computing (HPC) Afonta grandes problemas empresariales,
Heterogénea y Jerárquica
 Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
Metodología de la Programación Paralela 2015-2016 Facultad Informática, Universidad de Murcia Computación Híbrida, Heterogénea y Jerárquica Contenidos 1 Sistemas 2 Paralelismo anidado 3 Programación híbrida
TIER 0 Centros europeos. TIER 1 Centros nacionales. TIER 2 Centros regionales y universidades
 www.bsc.es TIER 0 Centros europeos + Capacidad TIER 1 Centros nacionales TIER 2 Centros regionales y universidades + Equipos 2 1 BARCELONA SUPERCOMPUTING CENTER 4 2 5 6 3 7 8 4 9 10 5 11 12 6 Raw Data
www.bsc.es TIER 0 Centros europeos + Capacidad TIER 1 Centros nacionales TIER 2 Centros regionales y universidades + Equipos 2 1 BARCELONA SUPERCOMPUTING CENTER 4 2 5 6 3 7 8 4 9 10 5 11 12 6 Raw Data
Computacion de Alto Performance
 Computacion de Alto Performance Abraham Zamudio Abraham Zamudio Computacion de Alto Performance 1/47 Indice 1 Algunos Aspectos Teoricos 2 Paralelismo Computacional 3 Linux Cluster Hardware Software 4 MPICH
Computacion de Alto Performance Abraham Zamudio Abraham Zamudio Computacion de Alto Performance 1/47 Indice 1 Algunos Aspectos Teoricos 2 Paralelismo Computacional 3 Linux Cluster Hardware Software 4 MPICH
CAR. http://acarus.uson.mx/cursos2013/car.htm
 CAR http://acarus.uson.mx/cursos2013/car.htm Sistemas de CAR en la UNISON Responsable : María del Carmen Heras Sánchez Asesores Técnicos : Aracely Dzul Campos Daniel Mendoza Camacho Yessica Vidal Quintanar
CAR http://acarus.uson.mx/cursos2013/car.htm Sistemas de CAR en la UNISON Responsable : María del Carmen Heras Sánchez Asesores Técnicos : Aracely Dzul Campos Daniel Mendoza Camacho Yessica Vidal Quintanar
Múltiples GPU (y otras chauchas)
") Múltiples GPU (y otras chauchas) Clase 16, 21/11/2013 http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Carlos Bederián bc@famaf.unc.edu.ar IFEG-CONICET, FaMAF-UNC Motivación No desperdiciar
Múltiples GPU (y otras chauchas) Clase 16, 21/11/2013 http://fisica.cab.cnea.gov.ar/gpgpu/index.php/en/icnpg/clases Carlos Bederián bc@famaf.unc.edu.ar IFEG-CONICET, FaMAF-UNC Motivación No desperdiciar
Equipamiento disponible
 PCI 00 Acción Preparatoria Computación Avanzada en Aplicaciones Biomédicas CaaB (High Performance Computing applied to Life Sciences) Equipamiento disponible Participantes Universidad de Málaga, España
PCI 00 Acción Preparatoria Computación Avanzada en Aplicaciones Biomédicas CaaB (High Performance Computing applied to Life Sciences) Equipamiento disponible Participantes Universidad de Málaga, España
Mendieta. Carlos Bederián bc@famaf.unc.edu.ar IFEG-CONICET, FaMAF-UNC WHPC13
 Mendieta Carlos Bederián bc@famaf.unc.edu.ar IFEG-CONICET, FaMAF-UNC 1 Antes que nada ssh user@200.16.18.210 2 Especificaciones - Nodo Supermicro 1027GR-TRF 1U de altura Dual socket 2011 Fuentes de 1820W
Mendieta Carlos Bederián bc@famaf.unc.edu.ar IFEG-CONICET, FaMAF-UNC 1 Antes que nada ssh user@200.16.18.210 2 Especificaciones - Nodo Supermicro 1027GR-TRF 1U de altura Dual socket 2011 Fuentes de 1820W
UNIVERSIDAD CARLOS III DE MADRID DEPARTAMENTO DE INFORMÁTICA INGENIERÍA EN INFORMÁTICA. ARQUITECTURA DE COMPUTADORES II 19 de junio de 2007
 UNIVERSIDAD CARLOS III DE MADRID DEPARTAMENTO DE INFORMÁTICA INGENIERÍA EN INFORMÁTICA. ARQUITECTURA DE COMPUTADORES II 19 de junio de 2007 Para la realización del presente examen se dispondrá de 2 1/2
UNIVERSIDAD CARLOS III DE MADRID DEPARTAMENTO DE INFORMÁTICA INGENIERÍA EN INFORMÁTICA. ARQUITECTURA DE COMPUTADORES II 19 de junio de 2007 Para la realización del presente examen se dispondrá de 2 1/2
Soluciones para entornos HPC
 Dr.. IT Manager / Project Leader @ CETA-Ciemat abelfrancisco.paz@ciemat.es V Jornadas de Supercomputación y Avances en Tecnología INDICE 1 2 3 4 HPC Qué? Cómo?..................... Computación (GPGPU,
Dr.. IT Manager / Project Leader @ CETA-Ciemat abelfrancisco.paz@ciemat.es V Jornadas de Supercomputación y Avances en Tecnología INDICE 1 2 3 4 HPC Qué? Cómo?..................... Computación (GPGPU,
Arquitecturas GPU v. 2013
 v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
v. 2013 Stream Processing Similar al concepto de SIMD. Data stream procesado por kernel functions (pipelined) (no control) (local memory, no cache OJO). Data-centric model: adecuado para DSP o GPU (image,
Recursos y servicios HPC en el BIFI
 Recursos y servicios HPC en el BIFI Guillermo Losilla Anadón Responsable grupo HPC e infraestructuras de computación del BIFI guillermo@bifi.es Indice Grupo HPC@BIFI Servicio de cálculo y almacenamiento
Recursos y servicios HPC en el BIFI Guillermo Losilla Anadón Responsable grupo HPC e infraestructuras de computación del BIFI guillermo@bifi.es Indice Grupo HPC@BIFI Servicio de cálculo y almacenamiento
Cálculos en paralelo con FreeFem++
 Cálculos en paralelo con FreeFem++ J. Rafael Rodríguez Galván 4 al 8 de julio de 2011 J. Rafael Rodríguez Galván (UCA) Cálculos en paralelo con FreeFem++ 4 al 8 de julio de 2011 1 / 18 Outline 1 Cálculos
Cálculos en paralelo con FreeFem++ J. Rafael Rodríguez Galván 4 al 8 de julio de 2011 J. Rafael Rodríguez Galván (UCA) Cálculos en paralelo con FreeFem++ 4 al 8 de julio de 2011 1 / 18 Outline 1 Cálculos
Programación en Paralelo con MPI en Clusters Linux
 Programación en Paralelo con MPI en Clusters Linux Francisco Javier Rodríguez Arias 13 de marzo de 2006 Problema y Motivación En física se requiere hacer muchos cálculos. Para eso se hacen programas de
Programación en Paralelo con MPI en Clusters Linux Francisco Javier Rodríguez Arias 13 de marzo de 2006 Problema y Motivación En física se requiere hacer muchos cálculos. Para eso se hacen programas de
www.bsc.es Montserrat González Ferreiro RES management engineer
 www.bsc.es Montserrat González Ferreiro RES management engineer + Equipos + Capacidad 2 4 5 6 7 8 9 10 11 12 Raw Data 1-2TB por ejecución 2 ejecuciones/semana 10 máquinas Procesado de imagen Generación
www.bsc.es Montserrat González Ferreiro RES management engineer + Equipos + Capacidad 2 4 5 6 7 8 9 10 11 12 Raw Data 1-2TB por ejecución 2 ejecuciones/semana 10 máquinas Procesado de imagen Generación
CLUSTER FING: ARQUITECTURA Y APLICACIONES
 CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
CLUSTER FING: ARQUITECTURA Y APLICACIONES SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Clusters Cluster
Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC
 Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC INTRODUCCIÓN HPC: High Performance Computer System Qué es un supercomputador? Computador diseñado para ofrecer la mayor capacidad de
Javier Pérez Mato µp para Comunicaciones Curso 2008/09 ETSIT - ULPGC INTRODUCCIÓN HPC: High Performance Computer System Qué es un supercomputador? Computador diseñado para ofrecer la mayor capacidad de
BSC MARENOSTRUM. Javier Bartolomé Rodriguez Systems Group
 BSC MARENOSTRUM Javier Bartolomé Rodriguez Systems Group Proceso 2560 JS21, 2.3GHz 4 cores por placa 8 Gbytes 36 Gbytes disco SAS Redes Myrinet 2 Spine 1280 10 Clos256 2560 Tarjetas Myrinet Gigabit 10/100
BSC MARENOSTRUM Javier Bartolomé Rodriguez Systems Group Proceso 2560 JS21, 2.3GHz 4 cores por placa 8 Gbytes 36 Gbytes disco SAS Redes Myrinet 2 Spine 1280 10 Clos256 2560 Tarjetas Myrinet Gigabit 10/100
Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015
 Anexo A. Partida 2 Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015 CLUSTER LANCAD 2 El bien a adquirir se describe a continuación y consiste de un cúmulo de
Anexo A. Partida 2 Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015 CLUSTER LANCAD 2 El bien a adquirir se describe a continuación y consiste de un cúmulo de
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA
 CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
CLUSTER FING: PARALELISMO de MEMORIA DISTRIBUIDA SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción: arquitecturas
www.bsc.es RECURSOS SUPERCOMPUTACIÓN BSC- CNS RES PRACE
 www.bsc.es RECURSOS SUPERCOMPUTACIÓN CNS RES PRACE BSC- + Equipos + Capacidad TIER 0 Centros europeos TIER 1 Centros nacionales TIER 2 Centros regionales y universidades 2 BARCELONA SUPERCOMPUTING CENTER
www.bsc.es RECURSOS SUPERCOMPUTACIÓN CNS RES PRACE BSC- + Equipos + Capacidad TIER 0 Centros europeos TIER 1 Centros nacionales TIER 2 Centros regionales y universidades 2 BARCELONA SUPERCOMPUTING CENTER
EXPEDIENTE: 2/2015 ADQUISICIÓN E INSTALACIÓN DE INFRAESTRUCTURA CIENTÍFICA Y TECNOLÓGICA PARA CÉNITS PLIEGO DE PRESCRIPCIONES TÉCNICAS
 EXPEDIENTE: 2/2015 ADQUISICIÓN E INSTALACIÓN DE INFRAESTRUCTURA CIENTÍFICA Y TECNOLÓGICA PARA CÉNITS PLIEGO DE PRESCRIPCIONES TÉCNICAS PLIEGO DE PRESCRIPCIONES TÉCNICAS. EXPTE 2/2015 Adquisición e instalación
EXPEDIENTE: 2/2015 ADQUISICIÓN E INSTALACIÓN DE INFRAESTRUCTURA CIENTÍFICA Y TECNOLÓGICA PARA CÉNITS PLIEGO DE PRESCRIPCIONES TÉCNICAS PLIEGO DE PRESCRIPCIONES TÉCNICAS. EXPTE 2/2015 Adquisición e instalación
INFORME DE PASANTIA Clúster de Consolas de PlayStation 3
 Universidad de Carabobo Facultad experimental de ciencia y tecnología Departamento de Computación INFORME DE PASANTIA Clúster de Consolas de PlayStation 3 Tutor Académico: Dr. Germán Larrazábal Tutor Empresarial:
Universidad de Carabobo Facultad experimental de ciencia y tecnología Departamento de Computación INFORME DE PASANTIA Clúster de Consolas de PlayStation 3 Tutor Académico: Dr. Germán Larrazábal Tutor Empresarial:
MPI es un estándar de programación en paralelo mediante paso de mensajes que permite crear programas portables y eficientes.
 Programación paralela en MPI MPI es un estándar de programación en paralelo mediante paso de mensajes que permite crear programas portables y eficientes. Introducción a MPI MPI fue creado en 1993 como
Programación paralela en MPI MPI es un estándar de programación en paralelo mediante paso de mensajes que permite crear programas portables y eficientes. Introducción a MPI MPI fue creado en 1993 como
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS. CNCA Abril 2013
 FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
FUNDAMENTOS DE COMPUTACIÓN PARA CIENTÍFICOS CNCA Abril 2013 6. COMPUTACIÓN DE ALTO RENDIMIENTO Ricardo Román DEFINICIÓN High Performance Computing - Computación de Alto Rendimiento Técnicas, investigación
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570
 Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
Evaluación del rendimiento de procesadores Intel Nehalem. Modelos x7550, x5670 y x5570 Juan Carlos Fernández Rodríguez. Área de HPC. Centro Informático Científico de Andalucía (CICA) Junta de Andalucía
CENTRO DE SUPERCOMPUTACIÓN
 Uso del supercomputador Ben Arabí CENTRO DE SUPERCOMPUTACIÓN José Ginés Picón López Técnico de aplicaciones Murcia a 2 de Febrero de 2012 Uso del supercomputador Ben Arabí Descripción de la Arquitectura
Uso del supercomputador Ben Arabí CENTRO DE SUPERCOMPUTACIÓN José Ginés Picón López Técnico de aplicaciones Murcia a 2 de Febrero de 2012 Uso del supercomputador Ben Arabí Descripción de la Arquitectura
Ingeniero en Informática
 UNIVERSIDAD DE ALMERÍA Ingeniero en Informática CLÚSTER DE ALTO RENDIMIENTO EN UN CLOUD: EJEMPLO DE APLICACIÓN EN CRIPTOANÁLISIS DE FUNCIONES HASH Autor Directores ÍNDICE 1. Introducción 2. Elastic Cluster
UNIVERSIDAD DE ALMERÍA Ingeniero en Informática CLÚSTER DE ALTO RENDIMIENTO EN UN CLOUD: EJEMPLO DE APLICACIÓN EN CRIPTOANÁLISIS DE FUNCIONES HASH Autor Directores ÍNDICE 1. Introducción 2. Elastic Cluster
Requisitos Técnicos de Cluster Heterogéneo.
 Requisitos Técnicos de Cluster Heterogéneo. Expediente CONSU02010018OP de suministro de un sistema de computación heterogéneo con procesadores gráficos y de propósito general para investigación para el
Requisitos Técnicos de Cluster Heterogéneo. Expediente CONSU02010018OP de suministro de un sistema de computación heterogéneo con procesadores gráficos y de propósito general para investigación para el
PPTSU DESCRIPCIÓN Y CARACTERÍSTICAS TÉCNICAS:
 PLIEGO DE PRESCRIPCIONES TÉCNICAS PARA LA CONTRATACIÓN DEL SUMINSITRO E INSTALACIÓN DE UN SISTEMA DE COMPUTACIÓN Y ALMACENAMIENTO DE ALTAS PRESTACIONES Y DEL EQUIPAMIENTO AUXILIAR DE ALIMENTACIÓN, REFRIGERACIÓN
PLIEGO DE PRESCRIPCIONES TÉCNICAS PARA LA CONTRATACIÓN DEL SUMINSITRO E INSTALACIÓN DE UN SISTEMA DE COMPUTACIÓN Y ALMACENAMIENTO DE ALTAS PRESTACIONES Y DEL EQUIPAMIENTO AUXILIAR DE ALIMENTACIÓN, REFRIGERACIÓN
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
Lenguaje de Programación: Go
 Centro de Investigación y de Estudios Avanzados del I.P.N 9 de Noviembre de 2011 Go Es un lenguaje de programación de propósito general que es promovido por: Rob Pike, Robert Griesemer, Ken Thompson, Russ
Centro de Investigación y de Estudios Avanzados del I.P.N 9 de Noviembre de 2011 Go Es un lenguaje de programación de propósito general que es promovido por: Rob Pike, Robert Griesemer, Ken Thompson, Russ
TIER 0 TIER 1 TIER 2
 www.bsc.es + Equipos + Capacidad TIER 0 Centros europeos TIER 1 Centros nacionales TIER 2 Centros regionales y universidades 2 BARCELONA SUPERCOMPUTING CENTER 4 5 6 7 8 9 10 11 12 Raw Data 1-2TB por ejecución
www.bsc.es + Equipos + Capacidad TIER 0 Centros europeos TIER 1 Centros nacionales TIER 2 Centros regionales y universidades 2 BARCELONA SUPERCOMPUTING CENTER 4 5 6 7 8 9 10 11 12 Raw Data 1-2TB por ejecución
15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores.
 UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
Organización del Centro de Cálculo
 Organización del Centro de Cálculo Problemas Septiembre 2007 40 servidores sin identificar Ubicación de Servidores aleatoria Servidores cayéndose constantemente Ni un servidor en rack Red y cableado a
Organización del Centro de Cálculo Problemas Septiembre 2007 40 servidores sin identificar Ubicación de Servidores aleatoria Servidores cayéndose constantemente Ni un servidor en rack Red y cableado a
Las TIC y la Supercomputacion en la Universitat de Valencia
 V Jornadas Usuarios de la RES Universitat de Valencia 26 octubre 2011 Las TIC y la Supercomputacion en la Universitat de Valencia Servei d Informatica El Servei d Informatica en la UV: organizacion Gobierno
V Jornadas Usuarios de la RES Universitat de Valencia 26 octubre 2011 Las TIC y la Supercomputacion en la Universitat de Valencia Servei d Informatica El Servei d Informatica en la UV: organizacion Gobierno
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS
 GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
GPU IMPLEMENTATIONS OF SCHEDULING HEURISTICS FOR HETEROGENEOUS COMPUTING ENVIRONMENTS MAURO CANABÉ SERGIO NESMACHNOW Centro de Cálculo, Facultad de Ingeniería Universidad de la República, Uruguay GPU IMPLEMENTATIONS
Curso: Uso de infraestructuras Clúster y Grid para proyectos de e-ciencia. Lanzamiento y Monitoreo de Jobs en Condor. GRID COLOMBIA - RENATA [Ciudad]
![Curso: Uso de infraestructuras Clúster y Grid para proyectos de e-ciencia. Lanzamiento y Monitoreo de Jobs en Condor. GRID COLOMBIA - RENATA [Ciudad]](/thumbs/24/4016813.jpg "Curso: Uso de infraestructuras Clúster y Grid para proyectos de e-ciencia. Lanzamiento y Monitoreo de Jobs en Condor. GRID COLOMBIA - RENATA [Ciudad]") Curso: Uso de infraestructuras Clúster y Grid para proyectos de e-ciencia Lanzamiento y Monitoreo GRID COLOMBIA - RENATA [Ciudad] Lanzamiento y Monitoreo Matchmaking con ClassAds Comandos basicos Envio
Curso: Uso de infraestructuras Clúster y Grid para proyectos de e-ciencia Lanzamiento y Monitoreo GRID COLOMBIA - RENATA [Ciudad] Lanzamiento y Monitoreo Matchmaking con ClassAds Comandos basicos Envio
Procesamiento Paralelo
 Procesamiento Paralelo Introducción a MPI Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar http://www.frbb.utn.edu.ar/hpc/
Procesamiento Paralelo Introducción a MPI Javier Iparraguirre Universidad Tecnológica Nacional, Facultad Regional Bahía Blanca 11 de Abril 461, Bahía Blanca, Argentina jiparraguirre@frbb.utn.edu.ar http://www.frbb.utn.edu.ar/hpc/
Segmentación de Imágenes en Procesadores Many-Core
 Universidad de Santiago de Compostela Segmentación de Imágenes en Procesadores Many-Core Lilien Beatriz Company Garay Fernández lilien.gf@gmail.com Indice 1. Introducción Single-chip Cloud Computer (SCC)
Universidad de Santiago de Compostela Segmentación de Imágenes en Procesadores Many-Core Lilien Beatriz Company Garay Fernández lilien.gf@gmail.com Indice 1. Introducción Single-chip Cloud Computer (SCC)
Cómputo en paralelo con MPI
 Cómputo en paralelo con MPI Miguel Vargas-Félix miguelvargas@cimat.mx CIMAT, October 9, 2015 1/35 Clusters Beowulf Master node External network Slave nodes Network switch Características: Tecnología estandar
Cómputo en paralelo con MPI Miguel Vargas-Félix miguelvargas@cimat.mx CIMAT, October 9, 2015 1/35 Clusters Beowulf Master node External network Slave nodes Network switch Características: Tecnología estandar
Introducción HPC. Curso: Modelización y simulación matemática de sistemas. Esteban E. Mocskos (emocskos@dc.uba.ar) Escuela Complutense Latinoamericana
 Escuela Complutense Latinoamericana") Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción HPC Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales,
Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción HPC Esteban E. Mocskos (emocskos@dc.uba.ar) Facultad de Ciencias Exactas y Naturales,
EVALUACIÓN COMPARADA DEL RENDIMIENTO DEL PROCESADOR INTEL 5570 (NEHALEM)
") EVALUACIÓN COMPARADA DEL RENDIMIENTO DEL PROCESADOR INTEL 5570 (NEHALEM) Carlos Bernal, Ana Silva, Marceliano Marrón, Juan Antonio Ortega, Claudio J. Arjona Área de HPC Centro Informático Científico de
EVALUACIÓN COMPARADA DEL RENDIMIENTO DEL PROCESADOR INTEL 5570 (NEHALEM) Carlos Bernal, Ana Silva, Marceliano Marrón, Juan Antonio Ortega, Claudio J. Arjona Área de HPC Centro Informático Científico de
ATLANTE! i n f r a e s t r u c t u r a d e s u p e r C o m p u t a c i ó n G o b i e r n o d e C a n a r i a s!
 ATLANTE infraestructura G o b i e r n o! de d supercomputación e C a n a r i a s! v forma parte de la estrategia del Gobierno de Canarias de poner a disposición de investigadores y empresas canarios infraestructuras
ATLANTE infraestructura G o b i e r n o! de d supercomputación e C a n a r i a s! v forma parte de la estrategia del Gobierno de Canarias de poner a disposición de investigadores y empresas canarios infraestructuras
El Bueno, el Malo y el Feo
 El Bueno, el Malo y el Feo Mejorando la Eficiencia y Calidad del Software Paralelo Ricardo Medel Argentina Systems & Tools SSG-DPD Basado en un guión de Eric W. Moore - Senior Technical Consulting Engineer
El Bueno, el Malo y el Feo Mejorando la Eficiencia y Calidad del Software Paralelo Ricardo Medel Argentina Systems & Tools SSG-DPD Basado en un guión de Eric W. Moore - Senior Technical Consulting Engineer
Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015
 Anexo A. Partida 3 Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015 CLUSTER LANCAD3 El bien a adquirir se describe a continuación y consiste en cúmulo de supercómputo
Anexo A. Partida 3 Laboratorio Nacional de Cómputo de Alto Desempeño: Fortalecimiento de la Infraestructura 2015 CLUSTER LANCAD3 El bien a adquirir se describe a continuación y consiste en cúmulo de supercómputo
TUTORIAL: COMPUTACIÓN de ALTO DESEMPEÑO
 TUTORIAL : COMPUTACIÓN de ALTO DESEMPEÑO SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Computadores paralelos
TUTORIAL : COMPUTACIÓN de ALTO DESEMPEÑO SERGIO NESMACHNOW Centro de Cálculo, Instituto de Computación FACULTAD DE INGENIERÍA, UNIVERSIDAD DE LA REPÚBLICA, URUGUAY CONTENIDO Introducción Computadores paralelos
Servicios avanzados de supercomputación para la ciència y la ingeniería
 Servicios avanzados de supercomputación para la ciència y la ingeniería Servicios avanzados de supercomputación para la ciència y la ingeniería HPCNow! provee a sus clientes de la tecnología y soluciones
Servicios avanzados de supercomputación para la ciència y la ingeniería Servicios avanzados de supercomputación para la ciència y la ingeniería HPCNow! provee a sus clientes de la tecnología y soluciones
SEMINARIO PRÁCTICO Cómo elegir el sistema de cálculo científico ideal para mi investigación. Raúl Díaz rdiaz@sie.es
 ORGANIZA SEMINARIO PRÁCTICO Cómo elegir el sistema de cálculo científico ideal para mi investigación Raúl Díaz rdiaz@sie.es 1ª CUESTIÓN Necesito un sistema HPC? Si mi cálculo supera las 8 horas, un equipo
ORGANIZA SEMINARIO PRÁCTICO Cómo elegir el sistema de cálculo científico ideal para mi investigación Raúl Díaz rdiaz@sie.es 1ª CUESTIÓN Necesito un sistema HPC? Si mi cálculo supera las 8 horas, un equipo
II. DISEÑO DEL SISTEMA. Introducción Instalación por red Arranque por red
 II. DISEÑO DEL SISTEMA Introducción Instalación por red Arranque por red Qué es un cluster? Cluster de memoria Distribuida Nuestro Diseño Login SERVER PXE, NFS,TFTP, DHCP Internet DISKS NODOS DE COMPUTO
II. DISEÑO DEL SISTEMA Introducción Instalación por red Arranque por red Qué es un cluster? Cluster de memoria Distribuida Nuestro Diseño Login SERVER PXE, NFS,TFTP, DHCP Internet DISKS NODOS DE COMPUTO
Talleres CLCAR. CUDA para principiantes. Título. Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.
 a CUDA para principiantes Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.com Tener un primer encuentro práctico con la programación en CUDA para personas
a CUDA para principiantes Mónica Liliana Hernández Ariza, SC3UIS-CRC NVIDIA Research Center monicalilianahernandez8@gmail.com Tener un primer encuentro práctico con la programación en CUDA para personas
Paralelismo en Máquinas de Búsqueda
 Paralelismo en Máquinas de Búsqueda Mauricio Marin Yahoo! Research, Santiago Julio 2007 Yahoo! Confidential Clusters de Computadores Clusters de Computadores mensajes Yahoo! Confidential Yahoo! Confidential
Paralelismo en Máquinas de Búsqueda Mauricio Marin Yahoo! Research, Santiago Julio 2007 Yahoo! Confidential Clusters de Computadores Clusters de Computadores mensajes Yahoo! Confidential Yahoo! Confidential
Capacidad de procesamiento del compilador Python para el Sistema Operativo Windows y Linux Palabras Clave:
 Capacidad de procesamiento del compilador Python para el Sistema Operativo Windows y Linux Stiven Unsihuay, Paulo Pereira, Norma León unsihuay_carlos@hotmail.com, paulopereiraa10@gmail.com, nleonl@usmp.pe
Capacidad de procesamiento del compilador Python para el Sistema Operativo Windows y Linux Stiven Unsihuay, Paulo Pereira, Norma León unsihuay_carlos@hotmail.com, paulopereiraa10@gmail.com, nleonl@usmp.pe
Plataformas paralelas
 Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
Plataformas paralelas Curso 2011-2012 Elementos de un computador paralelo Hardware: Múltiples procesadores Múltiples memorias Redes de interconexión Software: Sistemas Operativos paralelos Programas orientados
La Red Española de Supercomputación RES
 La Red Española de Supercomputación RES 1 Qué es la RES? En marzo de 2007, el Ministerio de Educación y Ciencia (MEC) crea la Red Española de Supercomputación (RES), que consiste en una estructura distribuida
La Red Española de Supercomputación RES 1 Qué es la RES? En marzo de 2007, el Ministerio de Educación y Ciencia (MEC) crea la Red Española de Supercomputación (RES), que consiste en una estructura distribuida
Redes de Altas Prestaciones
 Redes de Altas Prestaciones TEMA 3 Tecnologías Soporte tolerante a fallos -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Topología en Alta Disponibilidad Tecnologías disponibles Tecnología
Redes de Altas Prestaciones TEMA 3 Tecnologías Soporte tolerante a fallos -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Topología en Alta Disponibilidad Tecnologías disponibles Tecnología
José Luis Montoya Restrepo
 José Luis Montoya Restrepo AGENDA Definición y Características. Metas de los sistemas distribuidos. Conceptos de Hardware y Software. Definición: Un sistema distribuido es: Una colección de computadores
José Luis Montoya Restrepo AGENDA Definición y Características. Metas de los sistemas distribuidos. Conceptos de Hardware y Software. Definición: Un sistema distribuido es: Una colección de computadores
Programación en Entornos Paralelos: MPI
 1-11 Marzo de 2017 FACET -UNT Programación en Entornos Paralelos: MPI Graciela Molina mgracielamolina@gmailcom TRADICIONALMENTE Procesamiento secuencial 2 TRADICIONALMENTE Procesamiento secuencial Si ya
1-11 Marzo de 2017 FACET -UNT Programación en Entornos Paralelos: MPI Graciela Molina mgracielamolina@gmailcom TRADICIONALMENTE Procesamiento secuencial 2 TRADICIONALMENTE Procesamiento secuencial Si ya
GANETEC SOLUTIONS HPC Farmacéuticas
 GANETEC SOLUTIONS HPC Farmacéuticas La integración de tecnologías HPC en el sector Farmacéutico y de la Bioinformática ha permitido grandes avances en diversos campos. NUESTRA VISIÓN Estas nuevas posibilidades
GANETEC SOLUTIONS HPC Farmacéuticas La integración de tecnologías HPC en el sector Farmacéutico y de la Bioinformática ha permitido grandes avances en diversos campos. NUESTRA VISIÓN Estas nuevas posibilidades
Resolución de problemas en paralelo
 Resolución de problemas en paralelo Algoritmos Paralelos Tema 1. Introducción a la computación paralela (segunda parte) Vicente Cerverón Universitat de València Resolución de problemas en paralelo Descomposición
Resolución de problemas en paralelo Algoritmos Paralelos Tema 1. Introducción a la computación paralela (segunda parte) Vicente Cerverón Universitat de València Resolución de problemas en paralelo Descomposición
Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011
 Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
SISTEMAS DE MULTIPROCESAMIENTO
 SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función
SISTEMAS DE MULTIPROCESAMIENTO Tema 1 Introducción 5º Curso de Automática y Electrónica Industrial. 1 Contenido Tema 1 Aplicaciones Incremento de las prestaciones Clasificación de los ordenadores en función
TEMA 5: PARALELISMO A NIVEL DE HILOS, TAREAS Y PETICIONES (TLP, RLP) (segunda parte)
 (segunda parte)") TEMA 5: PARALELISMO A NIVEL DE HILOS, TAREAS Y PETICIONES (TLP, RLP) (segunda parte) SISTEMAS PARALELOS Y DISTRIBUIDOS www.atc.us.es Dpto. de Arquitectura y Tecnología de Computadores. Universidad de Sevilla
TEMA 5: PARALELISMO A NIVEL DE HILOS, TAREAS Y PETICIONES (TLP, RLP) (segunda parte) SISTEMAS PARALELOS Y DISTRIBUIDOS www.atc.us.es Dpto. de Arquitectura y Tecnología de Computadores. Universidad de Sevilla
Facultad de Ingeniería ISSN: 0121-1129 revista.ingenieria@uptc.edu.co. Universidad Pedagógica y Tecnológica de Colombia. Colombia
 Facultad de Ingeniería ISSN: 0121-1129 revista.ingenieria@uptc.edu.co Universidad Pedagógica y Tecnológica de Colombia Colombia Amézquita-Mesa, Diego Germán; Amézquita-Becerra, Germán; Galindo-Parra, Omaira
Facultad de Ingeniería ISSN: 0121-1129 revista.ingenieria@uptc.edu.co Universidad Pedagógica y Tecnológica de Colombia Colombia Amézquita-Mesa, Diego Germán; Amézquita-Becerra, Germán; Galindo-Parra, Omaira
Oracle Database 12c: Flex ASM Por Wissem El Khlifi (Oracle ACE )
") Oracle Database 12c: Flex ASM Por Wissem El Khlifi (Oracle ACE ) 1. Introducción: La tecnología de almacenamiento ASM (Automatic Storage Management) llevo a cabo su aparición en la versión 10g de bases
Oracle Database 12c: Flex ASM Por Wissem El Khlifi (Oracle ACE ) 1. Introducción: La tecnología de almacenamiento ASM (Automatic Storage Management) llevo a cabo su aparición en la versión 10g de bases
Mejor tecnología para aplicación práctica NOMAD
 TECNOLOGÍA APLICACIÓN PRÁCTICA NOMAD: NOMADIC MODEL FOR THE DISPLAY ADAPTATION ORIENTED TO FINAL USERS NOMAD Mejor tecnología para aplicación práctica NOMAD Luis Carlos Niño Tavera Juan Carlos Nova El
TECNOLOGÍA APLICACIÓN PRÁCTICA NOMAD: NOMADIC MODEL FOR THE DISPLAY ADAPTATION ORIENTED TO FINAL USERS NOMAD Mejor tecnología para aplicación práctica NOMAD Luis Carlos Niño Tavera Juan Carlos Nova El
General Parallel File System
 General Parallel File System Introducción GPFS fue desarrollado por IBM, es un sistema que permite a los usuarios compartir el acceso a datos que están dispersos en múltiples nodos; permite interacción
General Parallel File System Introducción GPFS fue desarrollado por IBM, es un sistema que permite a los usuarios compartir el acceso a datos que están dispersos en múltiples nodos; permite interacción
Introducción a Computación
 Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
Curso: Modelización y simulación matemática de sistemas Metodología para su implementación computacional Introducción a Computación Esteban E. Mocskos (emocskos@dc.uba.ar) Facultades de Ciencias Exactas
Intel XeonPhi Workshop
 Intel XeonPhi Workshop Elena Núñez-González Unidad Informática Científica - CIEMAT Madrid, 11 de Febrero de 2015 Evento Lugar, Fecha Índice Introducción MIC Intel Xeon Phi Arquitectura Intel Xeon Phi Entorno
Intel XeonPhi Workshop Elena Núñez-González Unidad Informática Científica - CIEMAT Madrid, 11 de Febrero de 2015 Evento Lugar, Fecha Índice Introducción MIC Intel Xeon Phi Arquitectura Intel Xeon Phi Entorno
Beneficios del uso del HPC en la industria
 Beneficios del uso del HPC en la industria ~ Cinzia Zannoni - CINECA Índice CINECA Computing Center Aplicaciónes industriales del HPC Prototipado: de físico a digital Optimización de diseño Diseño de fármacos
Beneficios del uso del HPC en la industria ~ Cinzia Zannoni - CINECA Índice CINECA Computing Center Aplicaciónes industriales del HPC Prototipado: de físico a digital Optimización de diseño Diseño de fármacos
Adquisición de Datos usando Matlab
 21 Adquisición de Datos usando Matlab Bruno Vargas Tamani Facultad de Ingeniería Electrónica y Eléctrica, Universidad Nacional Mayor de San Marcos, Lima, Perú RESUMEN: La interconexión a nivel de computadoras
21 Adquisición de Datos usando Matlab Bruno Vargas Tamani Facultad de Ingeniería Electrónica y Eléctrica, Universidad Nacional Mayor de San Marcos, Lima, Perú RESUMEN: La interconexión a nivel de computadoras
Programación híbrida en arquitecturas cluster de multicore. Escalabilidad y comparación con memoria compartida y pasaje de mensajes.
 Programación híbrida en arquitecturas cluster de multicore. Escalabilidad y comparación con memoria compartida y pasaje de mensajes. Fabiana Leibovich, Armando De Giusti, Marcelo Naiouf, Laura De Giusti,
Programación híbrida en arquitecturas cluster de multicore. Escalabilidad y comparación con memoria compartida y pasaje de mensajes. Fabiana Leibovich, Armando De Giusti, Marcelo Naiouf, Laura De Giusti,
Computación Híbrida, Heterogénea y Jerárquica
 Computación Híbrida, Heterogénea y Jerárquica http://www.ditec.um.es/ javiercm/curso psba/ Curso de Programación en el Supercomputador Ben-Arabí, febrero-marzo 2012 Organización aproximada de la sesión,
Computación Híbrida, Heterogénea y Jerárquica http://www.ditec.um.es/ javiercm/curso psba/ Curso de Programación en el Supercomputador Ben-Arabí, febrero-marzo 2012 Organización aproximada de la sesión,
Cluster Beowulf/MPI en Debian
 1- Configuración de la red: Cluster Beowulf/MPI en Debian En este artículo utilizamos la topología estrella para la configuración del Cluster. La configuración lo haremos suponiendo que ya tenemos una
1- Configuración de la red: Cluster Beowulf/MPI en Debian En este artículo utilizamos la topología estrella para la configuración del Cluster. La configuración lo haremos suponiendo que ya tenemos una
Sistemas Multiprocesador de Memoria Compartida Comerciales
 Sistemas Multiprocesador de Memoria Compartida Comerciales Florentino Eduardo Gargollo Acebrás, Pablo Lorenzo Fernández, Alejandro Alonso Pajares y Andrés Fernández Bermejo Escuela Politécnia de Ingeniería
Sistemas Multiprocesador de Memoria Compartida Comerciales Florentino Eduardo Gargollo Acebrás, Pablo Lorenzo Fernández, Alejandro Alonso Pajares y Andrés Fernández Bermejo Escuela Politécnia de Ingeniería
Modelo de paso de mensajes
 Modelo de paso de mensajes Miguel Alfonso Castro García mcas@xanum.uam.mx Universidad Autónoma Metropolitana - Izt 17 de noviembre de 2016 Contenido 1 Comunicación punto a punto 2 3 Comunicación punto
Modelo de paso de mensajes Miguel Alfonso Castro García mcas@xanum.uam.mx Universidad Autónoma Metropolitana - Izt 17 de noviembre de 2016 Contenido 1 Comunicación punto a punto 2 3 Comunicación punto
Modelo de aplicaciones CUDA
 Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Modelo de aplicaciones CUDA Utilización de GPGPUs: las placas gráficas se utilizan en el contexto de una CPU: host (CPU) + uno o varios device o GPUs Procesadores masivamente paralelos equipados con muchas
Implementación de un Cluster de Computadoras con software libre para Computación Científica en Jicamarca
 Implementación de un Cluster de Computadoras con software libre para Computación Científica en Jicamarca A.Zamudio M. Milla Contenido de la Presentación 1 Radio Observatorio de Jicamarca 2 3 4 5 6 Índice
Implementación de un Cluster de Computadoras con software libre para Computación Científica en Jicamarca A.Zamudio M. Milla Contenido de la Presentación 1 Radio Observatorio de Jicamarca 2 3 4 5 6 Índice
CAR. Responsable : María del Carmen Heras Sánchez. Asesores Técnicos : Daniel Mendoza Camacho Yessica Vidal Quintanar.
 CAR Responsable : María del Carmen Heras Sánchez Asesores Técnicos : Daniel Mendoza Camacho Yessica Vidal Quintanar http://acarus2.uson.mx Infraestructura de Hardware Software Conexiones remotas http://acarus2.uson.mx
CAR Responsable : María del Carmen Heras Sánchez Asesores Técnicos : Daniel Mendoza Camacho Yessica Vidal Quintanar http://acarus2.uson.mx Infraestructura de Hardware Software Conexiones remotas http://acarus2.uson.mx
Brevísimo tutorial de MPI (Message Passing Interface) Miguel Vargas
 Miguel Vargas") Brevísimo tutorial de MPI (Message Passing Interface) Miguel Vargas 19/10/10 1/33 Contenido Contenido Clusters Beowulf MPI (Message Passing Interface) Comunicación entre procesos Un programa simple con
Brevísimo tutorial de MPI (Message Passing Interface) Miguel Vargas 19/10/10 1/33 Contenido Contenido Clusters Beowulf MPI (Message Passing Interface) Comunicación entre procesos Un programa simple con
Solución al Primer Reto
 En el reto que se planteaba en el primer articulo se pedía conseguir toda la información posible sobre la maquina virtual que se suministra y a través de dicha información descubrir vulnerabilidades e
En el reto que se planteaba en el primer articulo se pedía conseguir toda la información posible sobre la maquina virtual que se suministra y a través de dicha información descubrir vulnerabilidades e
Dibujo Técnico Industrial. Prof. Aquiles M. Garcia.
 Dibujo Técnico Industrial. Prof. Aquiles M. Garcia. Presentación. El presente programa de estudios por competencias, tiene la finalidad de interpretar todas las formas de dibujo en la Ingeniería industrial,
Dibujo Técnico Industrial. Prof. Aquiles M. Garcia. Presentación. El presente programa de estudios por competencias, tiene la finalidad de interpretar todas las formas de dibujo en la Ingeniería industrial,
Servidor. Comenzaremos por confirmar que el servicio NFS esta instalado y ejecutandose desde la terminal, escribiremos lo siguiente: #rpm -q nfs-utils
 NFS Red Hat Enterprise Linux 6 provee dos mecanismos para compartir archivos y carpetas con otros sistemas operativos por medio de la red. Una de las opciones es utilizar una tecnologia llamada samba.
NFS Red Hat Enterprise Linux 6 provee dos mecanismos para compartir archivos y carpetas con otros sistemas operativos por medio de la red. Una de las opciones es utilizar una tecnologia llamada samba.
TRES PREGUNTAS SOBRE El Supercomputador ALTAMIRA Abierto a la Innovación
 TRES PREGUNTAS SOBRE El Abierto a la Innovación P1: Qué es un supercomputador? SUPERCOMPUTADOR: Muy alta velocidad de cálculo Ranking mundial: Top500 #1 mundial (USA): 16 Peta flops Se construye conectando
TRES PREGUNTAS SOBRE El Abierto a la Innovación P1: Qué es un supercomputador? SUPERCOMPUTADOR: Muy alta velocidad de cálculo Ranking mundial: Top500 #1 mundial (USA): 16 Peta flops Se construye conectando
Redes de Altas Prestaciones
 Redes de Altas Prestaciones TEMA 3 Redes SAN -Alta disponibilidad -Sistemas Redundantes -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Componentes de un SAN Términos más utilizados Topología
Redes de Altas Prestaciones TEMA 3 Redes SAN -Alta disponibilidad -Sistemas Redundantes -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Componentes de un SAN Términos más utilizados Topología
INTRODUCCIÓN A LA PROGRAMACIÓN DE COMPUTADORES DE MEMORIA DISTRIBUIDA USANDO MPI SISTEMAS PARALELOS Y DISTRIBUIDOS
 INTRODUCCIÓN A LA PROGRAMACIÓN DE COMPUTADORES DE MEMORIA DISTRIBUIDA USANDO MPI 1 Y DISTRIBUIDOS GRADO EN INGENIERÍA INFORMÁTICA INGENIERÍA DE COMPUTADORES ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA
INTRODUCCIÓN A LA PROGRAMACIÓN DE COMPUTADORES DE MEMORIA DISTRIBUIDA USANDO MPI 1 Y DISTRIBUIDOS GRADO EN INGENIERÍA INFORMÁTICA INGENIERÍA DE COMPUTADORES ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA
Uso de modelos PGAS para computación de Alto Rendimiento en clusters Beowulf
 Uso de modelos PGAS para computación de Alto Rendimiento en clusters Beowulf D Elía, Dalcin, Sarraf, López, Battaglia, Rodríguez, Sonzogni Centro de Investigación de Métodos Computacionales (CIMEC) (new
Uso de modelos PGAS para computación de Alto Rendimiento en clusters Beowulf D Elía, Dalcin, Sarraf, López, Battaglia, Rodríguez, Sonzogni Centro de Investigación de Métodos Computacionales (CIMEC) (new
Tutorial: Python + Soap Web Service. Daniel Montenegro Cordero
 Tutorial: Python + Soap Web Service Daniel Montenegro Cordero Python - Lenguaje de programación interpretado. - Filosofia código legible. - Permite programación orientada a objetos, imperativa y funcional.
Tutorial: Python + Soap Web Service Daniel Montenegro Cordero Python - Lenguaje de programación interpretado. - Filosofia código legible. - Permite programación orientada a objetos, imperativa y funcional.
Programación estructurada
 3. Funciones Programación estructurada Cuando un programa crece: Es importante mantenerlo ordenado No repetir código Agrupar el código según su función Dar nombre a las operaciones comunes var cantidad
3. Funciones Programación estructurada Cuando un programa crece: Es importante mantenerlo ordenado No repetir código Agrupar el código según su función Dar nombre a las operaciones comunes var cantidad
Workflow, BPM y Java Resumen de la presentación de Tom Baeyens
 Workflow, BPM y Java Resumen de la presentación de Tom Baeyens Workflow, BPM y Java Página 1 de 11 1. Introducción Tom Baeyens es el fundador y arquitecto del proyecto de JBoss jbpm, la máquina de workflow
Workflow, BPM y Java Resumen de la presentación de Tom Baeyens Workflow, BPM y Java Página 1 de 11 1. Introducción Tom Baeyens es el fundador y arquitecto del proyecto de JBoss jbpm, la máquina de workflow
Gestor de Colas SGE. 1. Qué es? 2. Configuración actual en CICA 3. Comandos 4. Trabajos Paralelos 5. Entorno gráfico QMON
 Gestor de Colas SGE 1. Qué es? 2. Configuración actual en CICA 3. Comandos 4. Trabajos Paralelos 5. Entorno gráfico QMON 1. Qué es? SGE (Sun Grid Engine) es un gestor de colas, realizado por Sun Microsystems.
Gestor de Colas SGE 1. Qué es? 2. Configuración actual en CICA 3. Comandos 4. Trabajos Paralelos 5. Entorno gráfico QMON 1. Qué es? SGE (Sun Grid Engine) es un gestor de colas, realizado por Sun Microsystems.
Uso del supercomputador Ben Arabí
 Uso del supercomputador Ben Arabí CENTRO DE SUPERCOMPUTACIÓN José Ginés Picón López Técnico de aplicaciones Murcia a 11 de Marzo de 2011 Uso del supercomputador Ben Arabí Descripción de la Arquitectura
Uso del supercomputador Ben Arabí CENTRO DE SUPERCOMPUTACIÓN José Ginés Picón López Técnico de aplicaciones Murcia a 11 de Marzo de 2011 Uso del supercomputador Ben Arabí Descripción de la Arquitectura
Proyecto Grid Computing
 Proyecto Grid Computing Éric Lajeunesse Olivier Piché Definición de una GRID: DTDI Una infraestructura que permite el acceso y procesamiento concurrente de un programa entre varias entidades computacionales
Proyecto Grid Computing Éric Lajeunesse Olivier Piché Definición de una GRID: DTDI Una infraestructura que permite el acceso y procesamiento concurrente de un programa entre varias entidades computacionales
Herramienta para la construcción de un cluster y la distribución de carga entre los nodos
 Herramienta para la construcción de un cluster y la distribución de carga entre los nodos Rubén A. González García 1, Gabriel Gerónimo Castillo 2 1 Universidad Juárez Autónoma de Tabasco, Av. Universidad
Herramienta para la construcción de un cluster y la distribución de carga entre los nodos Rubén A. González García 1, Gabriel Gerónimo Castillo 2 1 Universidad Juárez Autónoma de Tabasco, Av. Universidad
Arquitectura de el Hp Superdome INTEGRANTES: Islas Islas Roberto A. Ortiz Flores Enrique A. Rico Vázquez Alejandro. Sistemas Operativos Avanzados
 Arquitectura de el Hp Superdome INTEGRANTES: Islas Islas Roberto A. Ortiz Flores Enrique A. Rico Vázquez Alejandro Sistemas Operativos Avanzados HP SUPERDOME 9000 Características generales: El superdomo
Arquitectura de el Hp Superdome INTEGRANTES: Islas Islas Roberto A. Ortiz Flores Enrique A. Rico Vázquez Alejandro Sistemas Operativos Avanzados HP SUPERDOME 9000 Características generales: El superdomo
El Supercomputador MareNostrum
 El Supercomputador MareNostrum Omar El-Asmar Moreno Indice 1. Introducción.. Pag 2 2. Centro Nacional de Supercomputación de Barcelona..Pags 2-4 3. El supercomputador MareNostrum Pags 4-12 3.1 MareNostrum
El Supercomputador MareNostrum Omar El-Asmar Moreno Indice 1. Introducción.. Pag 2 2. Centro Nacional de Supercomputación de Barcelona..Pags 2-4 3. El supercomputador MareNostrum Pags 4-12 3.1 MareNostrum
Conclusiones. Particionado Consciente de los Datos
 Capítulo 6 Conclusiones Una de las principales conclusiones que se extraen de esta tesis es que para que un algoritmo de ordenación sea el más rápido para cualquier conjunto de datos a ordenar, debe ser
Capítulo 6 Conclusiones Una de las principales conclusiones que se extraen de esta tesis es que para que un algoritmo de ordenación sea el más rápido para cualquier conjunto de datos a ordenar, debe ser
ACTIVIDADES TEMA 1. EL LENGUAJE DE LOS ORDENADORES. 4º E.S.O- SOLUCIONES.
 1.- a) Explica qué es un bit de información. Qué es el lenguaje binario? Bit es la abreviatura de Binary digit. (Dígito binario). Un bit es un dígito del lenguaje binario que es el lenguaje universal usado
1.- a) Explica qué es un bit de información. Qué es el lenguaje binario? Bit es la abreviatura de Binary digit. (Dígito binario). Un bit es un dígito del lenguaje binario que es el lenguaje universal usado
Hecho por Víctor Orozco (tuxtor@shekalug.org) Puerto paralelo
 Puerto paralelo") Hecho por Víctor Orozco (tuxtor@shekalug.org) Puerto paralelo Un puerto paralelo es una interfaz entre un ordenador y un periférico cuya principal característica es que los bits de datos viajan juntos
Hecho por Víctor Orozco (tuxtor@shekalug.org) Puerto paralelo Un puerto paralelo es una interfaz entre un ordenador y un periférico cuya principal característica es que los bits de datos viajan juntos