Clusters de Computadores Tolerantes a Fallos" Dolores I Rexachs (UAB)
|
|
|
- Julián Cáceres Casado
- hace 8 años
- Vistas:
Transcripción
1 SEMINARIO DE SUPERCOMPUTACION: Simplificación del uso de los computadores paralelos, acercando el computador paralelo al usuario Clusters de Computadores Tolerantes a Fallos" Dolores I Rexachs (UAB) 1

2 SEMINARIO DE SUPERCOMPUTACION: Simplificación del uso de los computadores paralelos, acercando el computador paralelo al usuario Clusters de Computadores Tolerantes a Fallos" Dolores I Rexachs (UAB) 2

3 Clusters de Computadores Tolerantes a Fallos Introducción. Conceptos básicos. Fallos y Errores Medidas de fiabilidad Técnicas de Redundancia Protocolos de rollback-recovery basados en Checkpoint y log de mensajes Replicación de Datos Arquitectura distribuida para tolerancia a fallos en grandes Clusters: Redundant Array of Distributed Independent Checkpoints (RADIC): Replicación de Datos para Tolerancia a Fallos en multiclusters: FTDR 3
: Replicación de Datos para")
4 Bibliografía Fault Tolerance in Distributed Systems. P. Jalote. Prentice Hall 1994 Elnozahy, E.N.; Alvisi, L.; Wang, Y. & Johnson, D.B. A Survey of Rollback-recovery Protocols in Messagepassing Systems. ACM Computing Surveys, ACM Press, 2002, 34, Introduction to Parallel Computing (2nd Edition). A. Grama, A. Gupta, G. Karypis, V. Kumar. Pearson Addison Wesley,

5 Cluster: Objetivos de funcionamiento Cluster de alto rendimiento (HP) Enlazar muchos ordenadores para conseguir que funcionen en equipo y obtengan la solución de un problema más rápida trabajando todos juntos en el mismo problema independientemente. Cluster de alta disponibilidad (HAC) Conseguir un sistema de ordenadores mas fiable, compartiendo trabajos y con un funcionamiento redundante, de tal manera que si un ordenador falla otro se encarga de realizar su trabajo. Alta disponibilidad de Procesamiento: Cluster; Nodo; Red de Interconexión Datos: Almacenamiento: RAID 5

6 Introducción Clusters cada vez mas grandes y complejos. Tiempos de cómputo ininterrumpido más largos Componentes trabajando cerca de los límites tecnológicos. Importante: Fiabilidad / Disponibilidad del sistema. La probabilidad de fallos es mucho mayor Es crítico mantenerlos funcionando Es necesario considerar técnicas de Tolerancia a Fallos

7 Cluster de alta disponibilidad (HAC) Intenta mantener en todo momento la prestación de servicio encubriendo los fallos que se pueden producir Requisitos de un HAC Fiabilidad Disponibilidad: Porcentaje del tiempo en el cual el sistema está disponible para el usuario Facilidad de mantenimiento: Facilidad de mantener el sistema en condiciones de operación (reparaciones, actualizaciones, etc) tanto a nivel hardware como software El sistema está disponible el máximo tiempo posible (availability) 7
 tanto a nivel hardware como software El sistema está disponible el máximo tiempo")
8 Grandes sistemas Charng-da Lu 8

9 Fiabilidad en grandes sistemas Charng-da Lu 9

10 Necesidad de los sistemas Tolerantes a Fallos Es un problema? Actualmente Aplicaciones Propósito general Históricamente Militares Telemáticas (comunicaciones) Sistemas Fiables Aplicaciones Industriales (Tiempo real) Espaciales y Aeronáuticas Aumenta el número de componentes aumenta probabilidad de fallo Funcionamiento 24 horas x 7 días Tareas críticas que no pueden interrumpir el servicio Computador / Aplicación Paralelo Aumentan el tiempo de ejecución 10

11 Fiabilidad Fiabilidad: (reliability) Medida del éxito con el que el sistema cumple con alguna de las especificaciones obligatorias de su comportamiento Importante: Tiempo durante el cual el sistema puede operar sin pararse (MTTF) Avería (failure) : Cuando el comportamiento de un sistema se desvía del especificado, se dice que se ha producido una avería. Las averías se manifiestan en el comportamiento externo del sistema, pero son el resultado de errores (errors) internos Las causas mecánicas o algorítmicas de los errores se llaman fallos (faults) Fiabilidad 11
 internos Las causas mecánicas")
12 Retos a la fiabilidad Charng-da Lu 12
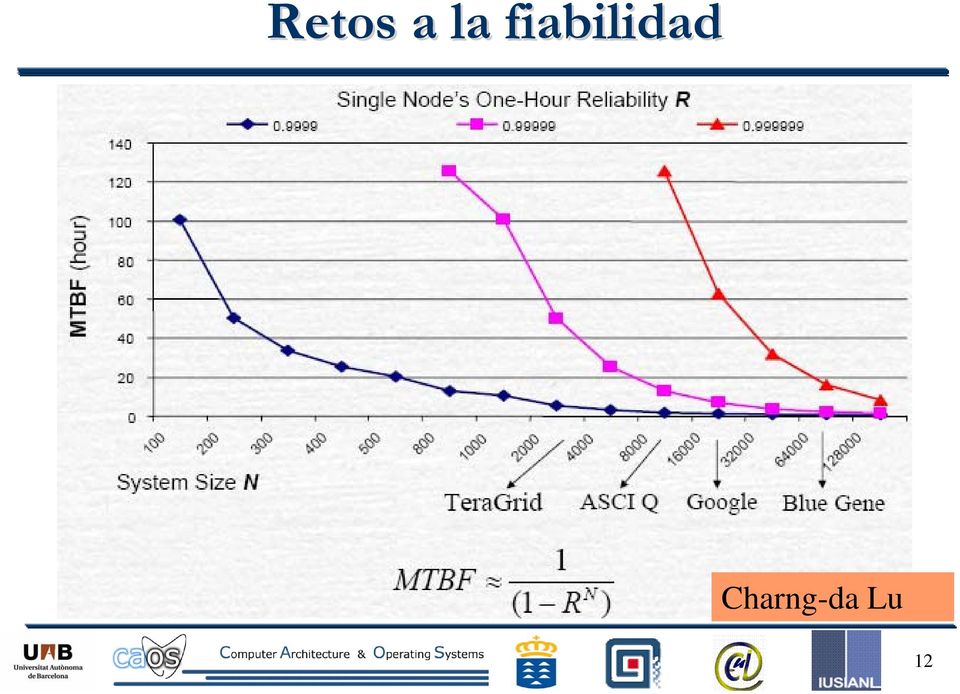
13 Tiempo sin servicio anual Tiempo sin servicio anual % de Uptime % de Dowtime Anual Normalizado (segundos) 98,0000% 2,0000% 7,30 días ,0 99,0000% 1,0000% 3,65 días ,0 99,8000% 0,2000% 17 horas, 30 minutos 63000,0 99,9000% 0,1000% 8 horas, 45 minutos 31500,0 99,9900% 0,0100% 52 minutos, 30 segundos 3150,0 99,9990% 0,0010% 5 minutos, 15 segundos 315,0 99,9999% 0,0001% 31,5 segundos 31,5 13

14 Ejemplos: VISA Visa Internacional tuvo 92 minutos sin servicio en los últimos 12 años (99.998%). Es probablemente la instalación comercial más segura del mundo 5 minutos sin servicio significan dejar de procesar 55 millones de dólares en pagos transacciones por segundo (100 trx por segundo) 14

15 Problemas que ocasionan los fallos Crash Omisión Tiempo Bizantino Crash: un componente se para o pierde su estado interno Omisión: Causa que un componente no responda a alguna entrada Tiempo: El componente responde demasiado pronto o demasiado tarde (fallo de rendimiento) Bizantino: Fallos arbitrarios 15
 Bizantino: Fallos")
16 Estrategias para obtener fiabilidad Especificación, diseño e implementación 16

17 Limitaciones de la prevención n de fallos Los componentes de hardware fallan, a pesar de las técnicas de prevención La prevención es insuficiente si: La frecuencia o la duración de las reparaciones es inaceptable no se puede detener el sistema para efectuar operaciones de mantenimiento Ejemplo: naves espaciales no tripuladas La alternativa es utilizar técnicas de tolerancia de fallos Informalmente: la capacidad de un sistema a comportarse de una forma bien definida a pesar de que ocurra un fallo 17

18 Diseño o de sistemas tolerantes a fallos Lo ideal es identificar todos los posibles fallos y evaluar las técnicas adecuadas de tolerancia a fallos Fallos que se pueden anticipar, (fallos de disco, sensores para monitorización) Predicción Fallos que no se pueden anticipar Recuperación Objetivo Maximizar la fiabilidad del sistema Minimizar la redundancia. Cuanto mayor es la redundancia mayor complejidad tiene es sistema siendo más propenso a errores Es necesario gestionar adecuadamente la redundancia 18

19 Sistema tolerante a fallos Un Sistema Tolerante a Fallos es aquel que posee la capacidad interna para preservar la ejecución correcta de las tareas a pesar de la ocurrencia de fallos Hardware o Software. 19

20 Fallo / Error / Avería F E A! La garantía de funcionamiento de un sistema disminuye debido a la existencia de: Fallo: defecto o imperfección física en el HW o SW del sistema Error estado interno incorrecto del sistema. Es consecuencia de un fallo Puede ocasionar una avería Avería: El servicio entregado por el sistema no es el especificado. Usuario: el sistema no funciona bien. Debe impedirse que los fallos de todos estos tipos causen averías 20

21 Objetivo El OBJETIVO de la la Tolerancia a Fallos: Evitar la la avería del sistema, incluso en presencia de fallos, es es decir, tratar de conseguir que el el sistema sigua funcionando En sistemas Tolerantes a Fallos, se enmascara la presencia de los fallos usando redundancia (en cualquier nivel). Basado en proteger el trabajo no el computador 21
22 Sistema tolerante a fallos = sistema redundante. La tolerancia de fallos se basa en la redundancia Se utilizan componentes adicionales para detectar los fallos y recuperar el comportamiento correcto. Esto aumenta La complejidad del sistema y puede introducir fallos adicionales El coste del sistema El overhead Puede haber redundancia en cualquier nivel: Redundancia en el hardware: utilización de componentes hardware extra Redundancia temporal: repetición de las operaciones y comparación de los resultados Redundancia en la información: codificación de los datos Redundancia en el software: realización de varias versiones de un mismo programa y del uso de técnicas de consistencia para comprobar que el sistema funciona correctamente. 22
23 Reto: Balancear 23
24 Grados de tolerancia de fallos Tolerancia completa (fail operational) El sistema sigue funcionando, al menos durante un tiempo, sin perder funcionalidad ni prestaciones Degradación aceptable (fail soft, graceful degradation) El sistema sigue funcionando con una pérdida parcial de funcionalidad o prestaciones hasta la reparación del fallo Parada segura (fail safe) El sistema se detiene en un estado que asegura la integridad del entorno hasta que se repare el fallo El grado de tolerancia de fallos necesario depende de la aplicación 24
25 Capas Aplicación (libre de fallos) Middleware (tolerancia a fallos) Cluster (fallos posibles) 25
26 Incorporar Tolerancia a Fallos en clusters Diseñar estrategias para que: Proporcione un sistema fiable con elementos no fiables No degrade prestaciones en ausencia de fallos Mínima sobrecarga (Overhead) Degrade lo mínimo en presencia de fallos: Tolere un número razonablemente alto de fallos Detecte y No deshabilite nodos sanos Bajo Coste: No requiera demasiado hardware extra No introduzca penalizaciones: aumento de la latencia, overhead Sea escalable Sea transparente, M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M Necesitamos Sistemas fiables que permiten la construcción de aplicaciones masivamente paralelas M M M M M M M 26
27 Fiabilidad tolerancia a fallos Requiere Seleccionar el tipo de fallos a proteger Protección: Redundancia Detección Diagnóstico Recuperación: En caso de fallos volver a uno de estos estados y reiniciar la ejecución Reconfiguración: si es necesario Por qué tiene una rueda de repuesto en el coche? Fiabilidad Por qué se van quitando? 27
28 Seleccionar el tipo de fallos a proteger El diseño de la tolerancia a fallos requiere Especificar la clase de fallos que pueden ser tolerados. Especificar los componentes o conceptos que proporcionan protección contra los fallos de todas las clases de fallos toleradas. Cuantos más fallos son tolerados, mejor logramos un sistema con alta disponibilidad (HA) Problema: Coste 28
29 Hardware es sólo s un enlace en la cadena de la disponibilidad (availability) Untested environment No Change Management Overloaded Weak Problem Detection Application Failure 40% Forgot Something Lack of Procedures Backup Errors / Security Operator Error 40% Other 20% but there is more to be considered - Gartner Group,
30 Tipos de fallos: Clasificación n dependiendo de la duración Fallos permanentes: Permanecen hasta que se reparan Ejemplo: roturas de hardware, errores de diseño de software Fallos transitorios: Desaparecen solos al cabo de un tiempo. Se deben a interferencias externas. La forma en que aparecen y la duración es aleatoria Ejemplo: interferencias en comunicaciones Fallos intermitentes: Fallos transitorios que ocurren de vez en cuando, se deben a cierta combinación específica del sistema Ejemplo: calentamiento de un componente de hardware Debe impedirse que los fallos de todos estos tipos causen averías 30
31 Alternativas para incorporar la protección n a Fallos Redundancia de componentes. Hardware extra Redundancia a nivel de información. Realizado desde la aplicación: aplicaciones que incorporan mecanismos de TF. Transparente al usuario (middleware): mecanismos transparentes al usuario, para proteger, detectar fallos, recuperar cuando ocurre un fallo Técnicas: Checkpoint y log de mensajes Replicación de datos 31
32 Mecanismos para Tolerancia a fallos Los nodos en los clusters fallan Cuál es la solución? Re-ejecución de procesos en el nodo fallado? Reparación No siempre es posible o aceptable Re-ejecución de procesos en otros nodos? Redundancia Replicación de datos: Requiere tenerlo en cuenta (SPMD, MW) Checkpointing y migración: Puede ocasionar problema de consistencia Checkpointing y log: Puede ocasionar un gran overhead Dificultades con algunos tipos de aplicaciones Consistencia: Efecto dominó, Aplicaciones que modifican el entorno 32
33 Software view of hardware failures Two classes of faults Fail-stop: a failed processor ceases all operation and does not further corrupt system state Byzantine: arbitrary failures Our focus: Nothing to do with adversaries Fail-Stop Faults 33
34 Posibles configuraciones de Tolerancia a Fallos en Clusters: Activo-Pasivo: Las aplicaciones se ejecutan sobre un conjunto de nodos (activos), mientras que los restantes actúan como backups redundantes de los servicios ofrecidos. Activo-Activo: Todos los nodos actúan como servidores activos de una o más aplicaciones y potencialmente como backups para las aplicaciones que se ejecutan en otros nodos. En cualquier caso, el fallo de un nodo, provoca la migración de las aplicaciones que ejecutaba, a otro nodo del sistema. Si la migración es automática se denomina failover, si es manual switchover. 34
35 Activo-Activo Activo: O 0 O O 2 2 O 3 3 P 1 P 2 P 4 Recursos constantes: degradación Nodo Nodo sobre sobre cargado cargado Posibilidad: Reparación 35
36 Activo-Pasivo Pasivo: P e Prestaciones constantes: Módulos de reserva 36
37 El reto de la recuperación Recovery Point Objective (RPO) How fresh does your data need to be? Recovery Time Objective (RTO) What is your downtime tolerance? Wks Days Hrs Mins Secs Secs Mins Hrs Days Wks Recovery Point Recovery Time File and Print Web Server ebusiness 37
38 Recuperación Rehacer el trabajo debe llevar menos tiempo que hacerlo No es invariable en el tiempo, dependiendo del momento varía Latencia Overhead Coste Se debe equilibrar redundancia y recuperación Time Disaster Recovery Time Objective Business Resumes Ciclo adecuado Ciclo demasiado largo 38
39 Problema: Fallos en clusters La probabilidad de fallos incrementa con el número de nodos (se reduce el MTBF) Aplicaciones con tiempos de ejecución largos (más sensibles al MTBF) Acabar correctamente la aplicación a pesar del fallo de algún nodo Requiere: Detección, Diagnóstico Prevención Recuperación Reconfiguración No siempre es posible o aceptable Re-ejecución de la aplicación Tolerancia a fallos Introduce: Overhead Coste,.. 39
40 Tolerancia a fallos: resumen Capacidad de continuar el procesamiento en presencia de fallos. Alta Disponibilidad: requiere duplicidad y redundancia El fallo debe ser transparente al usuario Lo ideal es identificar todos los posibles fallos y evaluar las técnicas adecuadas de tolerancia a fallos Predicción de fallos (Fault Forecasting): Fallos que se pueden anticipar, por ejemplo, fallos de disco Obtención a priori de la garantía de funcionamiento del sistema. Se realiza una evaluación del comportamiento del sistema ante la ocurrencia del fallo. Fallos que se pueden eliminar: (Fault Removal): Mantenimiento Reducir la presencia (número, seriedad) y el alcance de los fallos mediante: verificación, diagnosis y corrección Tolerancia a Fallos (Fault Tolerant): Fallos que se pueden recuperar Minimizar la redundancia. Mayor redundancia mayor complejidad tiene el sistema más propenso a errores Es necesario gestionar adecuadamente la redundancia Maximizar la fiabilidad del sistema 40
41 Introducción. Conceptos básicos. Organización Definición de fallo, error y avería Garantía de funcionamiento Medidas de fiabilidad Técnicas para aumentar la fiabilidad de un sistema: Técnicas de Redundancia: Checkpoint Modelos, terminología y aspectos generales del rollbackrecovery 41
42 Garantía a de funcionamiento (Dependability) Garantía de Funcionamiento (Confiabilidad) de un sistema informático es la propiedad que permite a sus usuarios depositar una confianza justificada en el servicio que les proporciona. 42
43 Garantía a de funcionamiento (Dependability) Dependiendo de la aplicación, la garantía de funcionamiento pondrá énfasis en un subconjunto de estas características: El sistema funciona sin interrupciones: Fiabilidad (Reliability) El sistema está disponible el máximo tiempo posible (Availability) El sistema no provoca averías catastróficas: Seguridad (Safety)(Proporciona los resultados correctamente) El sistema es fácilmente reparable o utilizable (Serviceability o maintainability) El sistema impide el acceso no autorizado: confidencialidad (confidentiality) El sistema impide la alteración inadecuada de la información: Integridad (integrity) R A S 43
44 Garantía a de funcionamiento: Medidas Confiabilidad (Medidas) Servicio disponible continuamente Disponibilidad de utilización Aptitud para reparaciones y cambios Fiabilidad (R) Disponibilidad (A) Utilizable (S) Fiabilidad -λt = R(t) = e MTBF =1 λ Tiempo Pr oductivo*100 UtilizaciónSistemaTotal(%) = TiempoTotal 44
45 Garantía a de funcionamiento Componentes Garantía de funcionamiento (confiabilidad) Impedimentos (Problemas/daños) Medios (herramientas) Atributos (medidas) Fallo Ejecución Especificación Validación Disponibilidad Fiabilidad Avería Predicción de fallos Tolerancia a fallos Eliminación de fallos Prevención de fallos Seguridad Error circunstancias que causan o son producto los el métodos, modo de y la las herramientas no medidas confiabilidad mediante y soluciones las cuales requeridas se puede estimar para la entregar calidad un de servicio un servicio confiable confiable Mantenimiento 45
46 Medidas de tolerancia a fallos Medida MTTF (mean time to failure) MTTR (mean time to repair) MTBF (mean time between failure) MTBI (mean time between interrupts) Significado Tiempo esperado hasta la ocurrencia de la avería Tiempo medio para reparar el sistema Tiempo medio entre los defectos del sistema Tiempo medio entre las interrupciones del sistema 46
47 Soporte para Disponibilidad Un diseño de alta disponibilidad y robusto requiere Fiabilidad: Durante cuanto tiempo puede operar un sistema sin pararse (MTTF) Disponibilidad: Porcentaje del tiempo que el sistema está disponible para el usuario (MTBF) o (MTBI: Tiempo medio entre interrupciones) Facilidad de Mantenimiento: Indica la facilidad de mantener el sistema en condiciones de operación (reparaciones, actualizaciones, ), tanto a nivel hardware como software (MTTR) MTBI = Tiempototal N º deint errupciones Reliability (Fiabilidad) Availability (Disponibilidad) Serviceability (Reparable) 47
48 Fiabilidad y seguridad Fiabilidad: probabilidad de proporcionar el servicio especificado Para una tasa de fallos de λ averías/hora la media de tiempo entre averías MTTF=1/ λ Si MTTF > 10 9 hablamos de sistemas ultrafiables Seguridad: Los sistemas críticos deben ser fiables. Ciertos proyectos requieren certificación oficial Según Hecht y Hecht (1986), los sistemas software complejos, por cada millón de líneas de código contienen una media de errores El 90% de esos errores pueden ser detectados con sistemas de comprobación. 200 errores de los restantes se detectan durante el primer año. Los 1800 restantes permanecen sin detectar Los requisitos de fiabilidad y seguridad en los STR son mayores que en el resto 48
49 Disponibilidad Disponibilidad = MTBF MTBF + MTTR MTBF = Mean Time Between Failure (Tiempo Medio Entre Fallos) MTTR = Maximun Time To Repair (Máximo Tiempo de Reparación) MTBF MTBF Nodo Sistema Tiempode Pr oducción = N º defallosdeln odo Tiempode Pr oducción = N º defallosdelsistema 49
50 Ciclo de operación-reparaci reparación n de un cluster Disponibilidad = MTTF MTTF + MTTR MTTF (Mean Time To Failure): Tiempo esperado hasta la ocurrencia de la avería MTTR (Mean Time To Repair): Tiempo medio para reparar el sistema 50
51 Aumentar la disponibilidad Opciones Incrementar MTTF incrementar la fiabilidad (difícil) Reducir MTTR Reducir el tiempo de reparación es más habitual en clusters. Se puede conseguir mediante: componentes hardware redundantes aislados programación crítica sujeta a votación (redundancia de ejecución con posterior votación de los resultados) 51
52 Overhead por tolerancia a fallos Overhead que se introduce en cada una de las fases de la tolerancia a fallos: Qué medimos? Protección: Overhead: redundancia, envío, almacenamiento Checkpoint Overhead: es el incremento en el tiempo de ejecución de la aplicación debido a la realización de checkpoint Latencia del Checkpoint: es el tiempo necesario para salvar el checkpoint (depende del tamaño del checkpoint) Detección del error Latencia del error Diagnóstico Latencia del error Recuperación del error: Overhead: Controlador + Reejecución Reconfiguración: consistencia global del sistema overhead controlador 52
53 Relación n temporal en el proceso de creación n de los fallos, errores y averías as Tiempo de inactividad (Fallo dormido): TI = te - tf Tiempo de latencia (Fallo latente): TL = td - te Cobertura es la probabilidad de detectar el fallo (Cobertura en la detección, en la localización, en el aislamiento, en la reconfiguración y en la recuperación) 53
54 Detección n de errores Los fallos no pueden ser observados de forma directa, sino que deben ser deducidos a través de la presencia de errores. Método o error a comprobar función a observar Temporizadores de guardia Heartbeat: Mecanismo de diagnosis de fallo: los nodos del cluster envían un flujo periódico de mensajes de control a los demás. Si el flujo se interrumpe, se diagnostica un fallo en algún nodo o en la red. Puede haber nodos de diagnosis que se dedican a controlar este flujo de mensajes de control. Cuando se detecta el fallo, el nodo que lo detecta debe notificar a los otros nodos que hay un componente con fallo. Seguidamente, el gestor de recursos debe reasignar los servicios de ese componente fallado. 54
55 Latencia Latencia del error: desde el instante en que se produce el fallo hasta que se manifiesta el error. Durante este tiempo de latencia, se dice que el fallo no es efectivo y que el error está latente. Latencia de detección del error Latencia de la producción de la avería. Semanas Días Horas Minutos Segundos Segundos Minutos Horas Días Semanas 55
56 Modelo de Recuperación Se trata de situar el sistema en un estado correcto desde el que pueda seguir funcionando Hay dos estrategias básicas de llevarla a cabo: Recuperación directa (hacia adelante) (FER): Se avanza desde un estado erróneo haciendo correcciones sobre partes del estado Recuperación inversa o Recuperación hacia atrás (BER): Se retrocede a un estado anterior correcto que se ha guardado previamente Los procesos en ejecución periódicamente guardan un estado consistente (checkpoint) en un almacenamiento estable. Tras el fallo, el sistema se reconfigura para aislar el componente erróneo, recupera el último estado consistente y reanuda las operaciones (esto se denomina rollback recovery) Quién: El humano: administrador o propietario del trabajo El sistema: distintas políticas para recuperar 56
57 Recuperación n hacia atrás 57
58 Recuperación n inversa Consiste en retroceder a un estado anterior correcto y ejecutar un segmento de programa alternativo (con otro algoritmo) El punto al que se retrocede se llama punto de recuperación (recovery point) La acción de guardar el estado se llama chekpointing No es necesario averiguar la causa ni la situación del fallo Sirve para fallos imprevistos No puede deshacer los errores que aparecen en el sistema controlado! Tiempo Punto de Recuperación Objetivo (RPO) Estado Consistente (Checkpoint) Crash 58
59 Modelo de Recuperación n transparente El sistema: Se pueden utilizar distintas políticas para recuperar Recuperar los procesos en otros recursos del sistema y continuar la ejecución: ejemplo: RADIC Recuperar los procesos en un nuevo conjunto de recursos, si es posible: Ejemplo RADIC-X Recuperar los procesos en el mismo recurso al que fue asignado, después de reparado: Ejemplo RADIC-X Poner los procesos en la cola y esperar a que se le asignen recursos para continuarlo: Ejemplo: FTDR 59
60 Checkpointing Checkpoint-Recovery: da a una aplicación o sistema la capacidad de salvar su estado, y tolerar fallos permitiendo que una ejecución que ha fallado, recuperar en un estado salvado en un punto anterior. Ideas claves Salvar estado de ejecución Proporcionar mecanismos de recuperación en presencia de fallos Permitir tolerancia de fallos previstos. Proporciona el mecanismo para la migración de proceso en los sistemas distribuidos por razones de la tolerancia de avería o balancear de la carga 60
61 Checkpoint Recovery La imagen básicab Una vez el fallo ha sido detectado y el proceso se ha recuperado, en su último checkpoint es necesario asegurar la consistencia del estado causada por la interdependencia entre tareas 61
62 Introducción. Conceptos básicos. Organización Definición de fallo, error y avería Garantía de funcionamiento Medidas de fiabilidad Técnicas para aumentar la fiabilidad de un sistema: Técnicas de Redundancia: Checkpoint Modelos, terminología y aspectos generales del rollbackrecovery 62
63 Checkpoint Checkpoint: Lugar en el programa, en que se interrumpe el procesamiento normal, para preservar la información del estado necesaria para permitir reasumir el procesamiento en un instante posterior Periódicamente se salva el estado del proceso Después del fallo, el proceso puede ser recomenzado desde un estado conocido almacenando Requiere que el proceso se suspenda durante el tiempo que se almacena su estado Consume recursos de E/S Checkpointing: es el proceso de salvar la información del estado 63
64 Checkpointing-Recovery Checkpoint: da a una aplicación o sistema la capacidad de salvar su estado y tolerar fallos capacitando una fase ejecutiva de tratamiento de fallo para recuperar a un estado salvado anterior al fallo. Rollback recovery: El proceso de reasumir un cómputo volviendo al estado salvado Cuestiones claves Salvar estado periódicamente Proporcionar mecanismos de recuperación en la presencia de fallos que garanticen la consistencia Proporcionar mecanismos para migración de procesos en sistemas distribuidos Puede requerir balanceo de carga 64
65 Aspectos de checkpointing Frecuencia de checkpointing: relacionado con el overhead. Depende de la probabilidad de fallo y la importancia de la computación. Nos interesa Overhead mínimo Recuperación rápida Tiempo de Computación perdida: poca Contenido del checkpointing: el estado del proceso debe salvarse en un almacenamiento estable 65
66 Algoritmos de checkpointing Algoritmos de checkpointing Sistemas uniprocesador Sistemas Multiprocesador Enfoques estáticos Enfoques Dinámicos Enfoques estáticos Enfoques Dinámicos Métodos basados en grafos Sistemas con Memoria Compartida Métodos basados En el compilador Enfoques basados en cache Sistemas con Memoria Compartida Distribuida Enfoques basados en memoria Sistemas de Paso de Mensajes 66
67 Clasificación: Checkpoint / Restart (Elnozahy 96) Checkpoint Coordinación Checkpoint distribuido Salvar el estado No coordinado Inducido por comunicación Coordinado Aplicación Sistema No bloqueante Bloqueante 67
68 Checkpoint Coordinado No Bloqueante (Chandy/Lamport). Todos los procesos coordinan sus checkpoints, de forma que el estado global del sistema es coherente (Chandy & Lamport Algorithm) El objetivo es hacer un checkpoint de la aplicación cuando no exista tránsito de mensajes entre dos nodos sincronización global flush de la red Gran overhead en ejecución libre de fallos En el caso de fallo, todos los procesos hacen roll back a sus checkpoints Alto coste para recuperación de fallo Eficiente cuando la frecuencia es baja No escalable restart detección/ global stop fallo Ckpt Sync Nodos 68
69 Checkpoint coordinado No bloqueante 69
70 Checkpointing Co-ordinado ordinado Bloqueante: Barreras P Q R Barrier Barrier Barrier Many programs are bulk-synchronous (BSP model of Valiant) At barrier, all processes can take checkpoints. assumption: no messages are in-flight across the barrier Parallel program reduces to sequential state saving problem But many new parallel programs do not have global barriers.. 70
71 Checkpoint Inducido por Comunicación No requiere sincronización global para proporcionar una coherencia global El nº de checkpoint forzado incrementa linealmente con el nº de nodos No escala Es impredecible la frecuencia de checkpoint Detección de un posible estado inconsistente obliga a checkpoint bloqueante de algunos procesos Gran overhead en ejecución libre de fallos Poco usado en la práctica 71
72 Checkpoint no coordinado No existe una sincronización global (escalable) Nodos: pueden hacer checkpoint en cualquier momento (independientemente de los otros) Necesita log no determinístico de eventos: Mensajes en transito restart detección fallo Ckpt Nodos 72
73 Checkpoint en Computadores Paralelos Problema: existen múltiples flujos de ejecución y no existe un reloj global Es difícil iniciar checkpoints en todos los flujos de ejecución en el mismo instante de tiempo para tener checkpoint concurrentes que permitan un rollback recovery consistente 73
74 Consistencia en Sistemas con Paso de Mensaje Estado consistente: Debe reflejar la recepción de mensajes Métodos de checkpointing en clusters Debemos tener en cuenta los mensajes y sus dependencias Después de un fallo deberían ejecutarse en el mismo orden previo al fallo Este mensaje no está en el estado del remitente 74
75 Definiciones Relación de Precedencia: ocurren antes (LAMPORT): a y b son 2 eventos del mismo proceso si a ocurre antes que b : a b si el evento a envía un mensaje y b es el evento que recibe dicho mensaje: a b Eventos concurrentes: 2 eventos a y son concurrentes : a b si a / b yb / a Checkpoint local: evento que guarda el estado de un proceso en un procesador en un instante dado Checkpoint global: conjunto de checkpoints locales, uno de cada procesador Checkpoint global consistente: Un estado global es consistente si todos los eventos incluidos forman un conjunto concurrente. Un Checkpoint global consistente es un conjunto de checkpoint locales, uno de cada procesador, tal que cada checkpoint local es concurrente a cada uno de los otros checkpoint locales Rollback recovery: es un proceso de reasumir/recuperar un computo de un checkpoint global consistente 75
76 Estados consistentes Dos procesos P y Q, cada uno tiene 2 checkpoint realizados El mensaje m es enviado por P a Q Conjuntos de checkpoint que representan estados consistentes del sistema: {P_1, Q_1}: Ningún checkpoint tiene información sobre m {P_2, Q_2}: P_2 indica que m fue enviado; Q_2 indica que fue recibido {P_2, Q_1}: P_2 indica que m fue enviado; Q_1 no tiene información sobre la recepción de m P Q P_1 Q_1 m Q_2 P_2 Tiempo 76
77 Estados inconsistentes: Mensajes huérfanos Mensajes huérfanos: {P_1, Q_2} es un estado inconsistente; P_1 no recuerda el envío de m, mientras Q_2 recuerda haberlo recibido Línea de recuperación: El conjunto de checkpoints que representan un estado del sistema consistente El rollback debe volver a un estado consistente, es decir buscar una línea de recuperación para hacer el restart a partir de ahí {P_1, Q_1}: Corte consistente {P_2, Q_1}: P no retransmite m ; Q no recuerda haber recibido m. El proceso de recuperación necesita añadir al checkpoint un log de mensajes separado recordando lo recibido por Q 77
SEMINARIO DE SUPERCOMPUTACION: Procesamiento Paralelo
 SEINARIO E SUPERCOPUTACION: Procesamiento Paralelo Cluster de Computadores: Tolerancia a Fallos 1 Organización * Introducción. * Tolerancia a fallos en cluster * Alternativas Usuarios expertos: Aplicaciones
SEINARIO E SUPERCOPUTACION: Procesamiento Paralelo Cluster de Computadores: Tolerancia a Fallos 1 Organización * Introducción. * Tolerancia a fallos en cluster * Alternativas Usuarios expertos: Aplicaciones
Computación de Alta Performance Curso 2009 TOLERANCIA A FALLOS COMPUTACIÓN DE ALTA PERFORMANCE 2009 TOLERANCIA A FALLOS
 Computación de Alta Performance Curso 2009 TOLERANCIA A FALLOS INTRODUCCIÓN Clusters cada vez más grandes y complejos. Tiempo de cómputo ininterrumpidos cada vez más largos. Componentes trabajando cerca
Computación de Alta Performance Curso 2009 TOLERANCIA A FALLOS INTRODUCCIÓN Clusters cada vez más grandes y complejos. Tiempo de cómputo ininterrumpidos cada vez más largos. Componentes trabajando cerca
COMPUTACIÓN DE ALTA PERFORMANCE
 COMPUTACIÓN DE ALTA PERFORMANCE 2011 1 TOLERANCIA A FALLOS COMPUTACIÓN DE ALTA PERFORMANCE Curso 2011 Sergio Nesmachnow (sergion@fing.edu.uy) Santiago Iturriaga (siturria@fing.edu.uy) Gerardo Ares (gares@fing.edu.uy)
COMPUTACIÓN DE ALTA PERFORMANCE 2011 1 TOLERANCIA A FALLOS COMPUTACIÓN DE ALTA PERFORMANCE Curso 2011 Sergio Nesmachnow (sergion@fing.edu.uy) Santiago Iturriaga (siturria@fing.edu.uy) Gerardo Ares (gares@fing.edu.uy)
Arquitectura de sistema de alta disponibilidad
 Mysql Introducción MySQL Cluster esta diseñado para tener una arquitectura distribuida de nodos sin punto único de fallo. MySQL Cluster consiste en 3 tipos de nodos: 1. Nodos de almacenamiento, son los
Mysql Introducción MySQL Cluster esta diseñado para tener una arquitectura distribuida de nodos sin punto único de fallo. MySQL Cluster consiste en 3 tipos de nodos: 1. Nodos de almacenamiento, son los
PRUEBAS DE SOFTWARE TECNICAS DE PRUEBA DE SOFTWARE
 PRUEBAS DE SOFTWARE La prueba del software es un elemento crítico para la garantía de la calidad del software. El objetivo de la etapa de pruebas es garantizar la calidad del producto desarrollado. Además,
PRUEBAS DE SOFTWARE La prueba del software es un elemento crítico para la garantía de la calidad del software. El objetivo de la etapa de pruebas es garantizar la calidad del producto desarrollado. Además,
Plataformas operativas de tecnologías de información. Afinación del rendimiento
 Plataformas operativas de tecnologías de información Afinación del rendimiento Afinación del Rendimiento Tolerancia a fallos. Fiabilidad. Recuperación. Alta disponibilidad. Interoperabilidad con otros
Plataformas operativas de tecnologías de información Afinación del rendimiento Afinación del Rendimiento Tolerancia a fallos. Fiabilidad. Recuperación. Alta disponibilidad. Interoperabilidad con otros
DISCOS RAID. Se considera que todos los discos físicos tienen la misma capacidad, y de no ser así, en el que sea mayor se desperdicia la diferencia.
 DISCOS RAID Raid: redundant array of independent disks, quiere decir conjunto redundante de discos independientes. Es un sistema de almacenamiento de datos que utiliza varias unidades físicas para guardar
DISCOS RAID Raid: redundant array of independent disks, quiere decir conjunto redundante de discos independientes. Es un sistema de almacenamiento de datos que utiliza varias unidades físicas para guardar
Apuntes Recuperación ante Fallas - Logging
 Lic. Fernando Asteasuain -Bases de Datos 2008 - Dpto. Computación -FCEyN-UBA 1 Apuntes Recuperación ante Fallas - Logging Nota: El siguiente apunte constituye sólo un apoyo para las clases prácticas del
Lic. Fernando Asteasuain -Bases de Datos 2008 - Dpto. Computación -FCEyN-UBA 1 Apuntes Recuperación ante Fallas - Logging Nota: El siguiente apunte constituye sólo un apoyo para las clases prácticas del
PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación. II MODELOS y HERRAMIENTAS UML. II.2 UML: Modelado de casos de uso
 PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación II MODELOS y HERRAMIENTAS UML 1 1 Modelado de casos de uso (I) Un caso de uso es una técnica de modelado usada para describir lo que debería hacer
PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación II MODELOS y HERRAMIENTAS UML 1 1 Modelado de casos de uso (I) Un caso de uso es una técnica de modelado usada para describir lo que debería hacer
1. Introducción a la Gestión de Redes
 1. Concepto de gestión de red. 2.1. Gestión Autónoma. 2.2. Gestión Homogénea. 2.3. Gestión Heterogénea. 2.4. Gestión Integrada. 3. Recursos utilizados en gestión de red. 4.1. Monitorización de red. 4.2.
1. Concepto de gestión de red. 2.1. Gestión Autónoma. 2.2. Gestión Homogénea. 2.3. Gestión Heterogénea. 2.4. Gestión Integrada. 3. Recursos utilizados en gestión de red. 4.1. Monitorización de red. 4.2.
 q
q Los mayores cambios se dieron en las décadas de los setenta, atribuidos principalmente a dos causas:
 SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
SISTEMAS DISTRIBUIDOS DE REDES 1. SISTEMAS DISTRIBUIDOS Introducción y generalidades La computación desde sus inicios ha sufrido muchos cambios, desde los grandes equipos que permitían realizar tareas
ADMINISTRACIÓN DE BASES DE DATOS DISTRIBUIDAS
 5 ADMINISTRACIÓN DE BASES DE DATOS DISTRIBUIDAS Contenido: 5.1 Conceptos Generales Administración de Bases de Datos Distribuidas 5.1.1 Administración la Estructura de la Base de Datos 5.1.2 Administración
5 ADMINISTRACIÓN DE BASES DE DATOS DISTRIBUIDAS Contenido: 5.1 Conceptos Generales Administración de Bases de Datos Distribuidas 5.1.1 Administración la Estructura de la Base de Datos 5.1.2 Administración
PLATAFORMA DE ENVÍO DE SMS CON MÁXIMA DISPONIBILIDAD
 PLATAFORMA DE ENVÍO DE SMS CON MÁXIMA DISPONIBILIDAD Redundante, multi-localización y sin puntos de fallo digital@soydigital.com Tel 902 153 644 Fax 922 683 135 www.soydigital.com Avda. Marítima, 25 Edf.
PLATAFORMA DE ENVÍO DE SMS CON MÁXIMA DISPONIBILIDAD Redundante, multi-localización y sin puntos de fallo digital@soydigital.com Tel 902 153 644 Fax 922 683 135 www.soydigital.com Avda. Marítima, 25 Edf.
Ingeniería de Software. Pruebas
 Ingeniería de Software Pruebas Niveles de prueba Pruebas unitarias Niveles Pruebas de integración Pruebas de sistema Pruebas de aceptación Alpha Beta Niveles de pruebas Pruebas unitarias Se enfocan en
Ingeniería de Software Pruebas Niveles de prueba Pruebas unitarias Niveles Pruebas de integración Pruebas de sistema Pruebas de aceptación Alpha Beta Niveles de pruebas Pruebas unitarias Se enfocan en
WINDOWS 2008 7: COPIAS DE SEGURIDAD
 1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
Gestión de Configuración del Software
 Gestión de Configuración del Software Facultad de Informática, ciencias de la Comunicación y Técnicas Especiales Herramientas y Procesos de Software Gestión de Configuración de SW Cuando se construye software
Gestión de Configuración del Software Facultad de Informática, ciencias de la Comunicación y Técnicas Especiales Herramientas y Procesos de Software Gestión de Configuración de SW Cuando se construye software
No se requiere que los discos sean del mismo tamaño ya que el objetivo es solamente adjuntar discos.
 RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
RAIDS MODO LINEAL Es un tipo de raid que muestra lógicamente un disco pero se compone de 2 o más discos. Solamente llena el disco 0 y cuando este está lleno sigue con el disco 1 y así sucesivamente. Este
ARQUITECTURA DE DISTRIBUCIÓN DE DATOS
 4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
4 ARQUITECTURA DE DISTRIBUCIÓN DE DATOS Contenido: Arquitectura de Distribución de Datos 4.1. Transparencia 4.1.1 Transparencia de Localización 4.1.2 Transparencia de Fragmentación 4.1.3 Transparencia
4. Programación Paralela
 4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
4. Programación Paralela La necesidad que surge para resolver problemas que requieren tiempo elevado de cómputo origina lo que hoy se conoce como computación paralela. Mediante el uso concurrente de varios
MODERNIZANDO PCN Y RECUPERACION DE DESASTRES UTILIZANDO VIRTUALIZACION Y LA NUBE
 MODERNIZANDO PCN Y RECUPERACION DE DESASTRES UTILIZANDO VIRTUALIZACION Y LA NUBE Este material y todos y cada uno de los contenidos en él incorporados constituyen una adaptación de las conferencias de
MODERNIZANDO PCN Y RECUPERACION DE DESASTRES UTILIZANDO VIRTUALIZACION Y LA NUBE Este material y todos y cada uno de los contenidos en él incorporados constituyen una adaptación de las conferencias de
Elementos requeridos para crearlos (ejemplo: el compilador)
") Generalidades A lo largo del ciclo de vida del proceso de software, los productos de software evolucionan. Desde la concepción del producto y la captura de requisitos inicial hasta la puesta en producción
Generalidades A lo largo del ciclo de vida del proceso de software, los productos de software evolucionan. Desde la concepción del producto y la captura de requisitos inicial hasta la puesta en producción
Novedades en Q-flow 3.02
 Novedades en Q-flow 3.02 Introducción Uno de los objetivos principales de Q-flow 3.02 es adecuarse a las necesidades de grandes organizaciones. Por eso Q-flow 3.02 tiene una versión Enterprise que incluye
Novedades en Q-flow 3.02 Introducción Uno de los objetivos principales de Q-flow 3.02 es adecuarse a las necesidades de grandes organizaciones. Por eso Q-flow 3.02 tiene una versión Enterprise que incluye
Resolución de problemas en paralelo
 Resolución de problemas en paralelo Algoritmos Paralelos Tema 1. Introducción a la computación paralela (segunda parte) Vicente Cerverón Universitat de València Resolución de problemas en paralelo Descomposición
Resolución de problemas en paralelo Algoritmos Paralelos Tema 1. Introducción a la computación paralela (segunda parte) Vicente Cerverón Universitat de València Resolución de problemas en paralelo Descomposición
LA LOGÍSTICA COMO FUENTE DE VENTAJAS COMPETITIVAS
 LA LOGÍSTICA COMO FUENTE DE VENTAJAS COMPETITIVAS Los clientes compran un servicio basandose en el valor que reciben en comparacion con el coste en el que incurren. Por, lo tanto, el objetivo a largo plazo
LA LOGÍSTICA COMO FUENTE DE VENTAJAS COMPETITIVAS Los clientes compran un servicio basandose en el valor que reciben en comparacion con el coste en el que incurren. Por, lo tanto, el objetivo a largo plazo
SISTEMAS DE INFORMACIÓN II TEORÍA
 CONTENIDO: EL PROCESO DE DISEÑO DE SISTEMAS DISTRIBUIDOS MANEJANDO LOS DATOS EN LOS SISTEMAS DISTRIBUIDOS DISEÑANDO SISTEMAS PARA REDES DE ÁREA LOCAL DISEÑANDO SISTEMAS PARA ARQUITECTURAS CLIENTE/SERVIDOR
CONTENIDO: EL PROCESO DE DISEÑO DE SISTEMAS DISTRIBUIDOS MANEJANDO LOS DATOS EN LOS SISTEMAS DISTRIBUIDOS DISEÑANDO SISTEMAS PARA REDES DE ÁREA LOCAL DISEÑANDO SISTEMAS PARA ARQUITECTURAS CLIENTE/SERVIDOR
Manual de Procedimiento. CREACION-ADMINISTRACION, RESPALDO DE DATOS Y CONTINUIDAD DEL NEGOCIO Procesos y Responsabilidades ECR Evaluadora Prefin S.A.
 CREACION-ADMINISTRACION, RESPALDO DE DATOS Y CONTINUIDAD DEL NEGOCIO Procesos y Responsabilidades ECR Evaluadora Prefin S.A. NUMERO REVISION: 01 Manual de Procedimiento CONTENIDO 1. Algunas Definiciones.
CREACION-ADMINISTRACION, RESPALDO DE DATOS Y CONTINUIDAD DEL NEGOCIO Procesos y Responsabilidades ECR Evaluadora Prefin S.A. NUMERO REVISION: 01 Manual de Procedimiento CONTENIDO 1. Algunas Definiciones.
ADMINISTRACIÓN CENTRALIZADA DELL POWERVAULT DL2000 CON TECNOLOGÍA SYMANTEC
 ADMINISTRACIÓN CENTRALIZADA DELL POWERVAULT DL2000 CON TECNOLOGÍA SYMANTEC RESUMEN EJECUTIVO Es un método ideal para que cualquier departamento de TI logre realizar respaldos y restauraciones más rápidas
ADMINISTRACIÓN CENTRALIZADA DELL POWERVAULT DL2000 CON TECNOLOGÍA SYMANTEC RESUMEN EJECUTIVO Es un método ideal para que cualquier departamento de TI logre realizar respaldos y restauraciones más rápidas
1. Aplica medidas de seguridad pasiva en sistemas informáticos describiendo características de entornos y relacionándolas con sus necesidades
 Módulo Profesional: Seguridad informática. Código: 0226. Resultados de aprendizaje y criterios de evaluación. 1. Aplica medidas de seguridad pasiva en sistemas informáticos describiendo características
Módulo Profesional: Seguridad informática. Código: 0226. Resultados de aprendizaje y criterios de evaluación. 1. Aplica medidas de seguridad pasiva en sistemas informáticos describiendo características
Procesos. Bibliografía. Threads y procesos. Definiciones
 Procesos Prof. Mariela Curiel Bibliografía A. Tanembaum & M. Van Steen. Sistemas Distribuidos. Principios y Paradigmas. 2da. Edición. Smith & Nair. The Architecture of Virtual Machines. IEEE Computer.
Procesos Prof. Mariela Curiel Bibliografía A. Tanembaum & M. Van Steen. Sistemas Distribuidos. Principios y Paradigmas. 2da. Edición. Smith & Nair. The Architecture of Virtual Machines. IEEE Computer.
SEMANA 12 SEGURIDAD EN UNA RED
 SEMANA 12 SEGURIDAD EN UNA RED SEGURIDAD EN UNA RED La seguridad, protección de los equipos conectados en red y de los datos que almacenan y comparten, es un hecho muy importante en la interconexión de
SEMANA 12 SEGURIDAD EN UNA RED SEGURIDAD EN UNA RED La seguridad, protección de los equipos conectados en red y de los datos que almacenan y comparten, es un hecho muy importante en la interconexión de
Capítulo IV. Manejo de Problemas
 Manejo de Problemas Manejo de problemas Tabla de contenido 1.- En qué consiste el manejo de problemas?...57 1.1.- Ventajas...58 1.2.- Barreras...59 2.- Actividades...59 2.1.- Control de problemas...60
Manejo de Problemas Manejo de problemas Tabla de contenido 1.- En qué consiste el manejo de problemas?...57 1.1.- Ventajas...58 1.2.- Barreras...59 2.- Actividades...59 2.1.- Control de problemas...60
Instalación y mantenimiento de servicios de Internet. U.T.3.- Servicio DNS
 Instalación y mantenimiento de servicios de Internet U.T.3.- Servicio DNS 1 Qué es el servicio DNS? A los usuarios de Internet les resulta complicado trabajar con direcciones IP, sobre todo porque son
Instalación y mantenimiento de servicios de Internet U.T.3.- Servicio DNS 1 Qué es el servicio DNS? A los usuarios de Internet les resulta complicado trabajar con direcciones IP, sobre todo porque son
I INTRODUCCIÓN. 1.1 Objetivos
 I INTRODUCCIÓN 1.1 Objetivos En el mundo de la informática, la auditoría no siempre es aplicada en todos las empresas, en algunos de los casos son aplicadas por ser impuestas por alguna entidad reguladora,
I INTRODUCCIÓN 1.1 Objetivos En el mundo de la informática, la auditoría no siempre es aplicada en todos las empresas, en algunos de los casos son aplicadas por ser impuestas por alguna entidad reguladora,
Acuerdo de Nivel de Servicio o Service Level Agreement (SLA) para servicios de Hospedaje Virtual
 para servicios de Hospedaje Virtual") Acuerdo de Nivel de Servicio o Service Level Agreement (SLA) para servicios de Hospedaje Virtual A continuación detallamos los niveles de servicio garantizados para los servicios de Hospedaje Virtual:
Acuerdo de Nivel de Servicio o Service Level Agreement (SLA) para servicios de Hospedaje Virtual A continuación detallamos los niveles de servicio garantizados para los servicios de Hospedaje Virtual:
Resumen del trabajo sobre DNSSEC
 Resumen del trabajo sobre Contenido 1. -...2 1.1. - Definición...2 1.2. - Seguridad basada en cifrado...2 1.3. - Cadenas de confianza...3 1.4. - Confianzas...4 1.5. - Islas de confianza...4 2. - Conclusiones...5
Resumen del trabajo sobre Contenido 1. -...2 1.1. - Definición...2 1.2. - Seguridad basada en cifrado...2 1.3. - Cadenas de confianza...3 1.4. - Confianzas...4 1.5. - Islas de confianza...4 2. - Conclusiones...5
LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER
 LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER GUÍA DE LABORATORIO Nº 1O Actividad de Proyecto No. 12: ESTABLECER PLANES DE RESGUARDO, RESTAURACION Y CONTINGENCIA. Estructura de contenidos.
LABORATORIO 10. ADMINISTRACIÓN DE COPIAS DE SEGURIDAD EN SQL SERVER GUÍA DE LABORATORIO Nº 1O Actividad de Proyecto No. 12: ESTABLECER PLANES DE RESGUARDO, RESTAURACION Y CONTINGENCIA. Estructura de contenidos.
Redes de Altas Prestaciones
 Redes de Altas Prestaciones TEMA 3 Redes SAN -Alta disponibilidad -Sistemas Redundantes -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Componentes de un SAN Términos más utilizados Topología
Redes de Altas Prestaciones TEMA 3 Redes SAN -Alta disponibilidad -Sistemas Redundantes -Curso 2010 Redes de Altas Prestaciones - Indice Conceptos Componentes de un SAN Términos más utilizados Topología
Introducción a las redes de computadores
 Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Introducción a las redes de computadores Contenido Descripción general 1 Beneficios de las redes 2 Papel de los equipos en una red 3 Tipos de redes 5 Sistemas operativos de red 7 Introducción a las redes
Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011
 Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Clusters Nicolás Zarco Arquitectura Avanzada 2 Cuatrimestre 2011 Introducción Aplicaciones que requieren: Grandes capacidades de cómputo: Física de partículas, aerodinámica, genómica, etc. Tradicionalmente
Utilidades de la base de datos
 Utilidades de la base de datos Desde esta opcion del menú de Access, podemos realizar las siguientes operaciones: Convertir Base de datos Compactar y reparar base de datos Administrador de tablas vinculadas
Utilidades de la base de datos Desde esta opcion del menú de Access, podemos realizar las siguientes operaciones: Convertir Base de datos Compactar y reparar base de datos Administrador de tablas vinculadas
MODULO: MERCADEO. Acuerdo de Nivel de Servicio (ANS) Service Level Agreement (SLA) MODELO DE MUESTRA SIN VALOR COMERCIAL
 Service Level Agreement (SLA) MODELO DE MUESTRA SIN VALOR COMERCIAL") MODULO: MERCADEO Acuerdo de Nivel de Servicio (ANS) Service Level Agreement (SLA) 1 Servicio de Soporte. El presente apartado constituye las condiciones de soporte y mantenimiento por parte de enncloud
MODULO: MERCADEO Acuerdo de Nivel de Servicio (ANS) Service Level Agreement (SLA) 1 Servicio de Soporte. El presente apartado constituye las condiciones de soporte y mantenimiento por parte de enncloud
Windows Server 2012: Infraestructura de Escritorio Virtual
 Windows Server 2012: Infraestructura de Escritorio Virtual Módulo 1: Application Virtualization Módulo del Manual Autores: James Hamilton-Adams, Content Master Publicado: 5 de Octubre 2012 La información
Windows Server 2012: Infraestructura de Escritorio Virtual Módulo 1: Application Virtualization Módulo del Manual Autores: James Hamilton-Adams, Content Master Publicado: 5 de Octubre 2012 La información
Ventajas del almacenamiento de correo electrónico
 Ventajas del almacenamiento de correo electrónico El correo electrónico no es solo uno de los medios de comunicación más importantes, sino también una de las fuentes de información más extensas y de mayor
Ventajas del almacenamiento de correo electrónico El correo electrónico no es solo uno de los medios de comunicación más importantes, sino también una de las fuentes de información más extensas y de mayor
Symantec Backup Exec System Recovery 7.0 Server Edition. Recuperación de sistemas en cuestión de minutos, en lugar de en horas o días
 PRINCIPALES VENTAJAS TANGIBLES Recuperación de sistemas Windows completos en cuestión de minutos, en lugar de en horas o días Symantec ha demostrado de manera pública y en reiteradas ocasiones que Backup
PRINCIPALES VENTAJAS TANGIBLES Recuperación de sistemas Windows completos en cuestión de minutos, en lugar de en horas o días Symantec ha demostrado de manera pública y en reiteradas ocasiones que Backup
Mantenimiento de Sistemas de Información
 de Sistemas de Información ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 1 ACTIVIDAD MSI 1: REGISTRO DE LA PETICIÓN...4 Tarea MSI 1.1: Registro de la Petición... 4 Tarea MSI 1.2: Asignación de la Petición... 5 ACTIVIDAD
de Sistemas de Información ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 1 ACTIVIDAD MSI 1: REGISTRO DE LA PETICIÓN...4 Tarea MSI 1.1: Registro de la Petición... 4 Tarea MSI 1.2: Asignación de la Petición... 5 ACTIVIDAD
INFORME Nº1 PROPUESTA METODOLÓGICA Y PLAN DE TRABAJO DESARROLLO DE UN SISTEMA INTEGRADO DE GESTIÓN PARA EL GOBIERNO REGIONAL DE ATACAMA
 INFORME Nº1 PROPUESTA METODOLÓGICA Y PLAN DESARROLLO DE UN SISTEMA INTEGRADO DE GESTIÓN PARA EL GOBIERNO REGIONAL DE ATACAMA con destino a GORE DE ATACAMA ELIMCO SISTEMAS Alfredo Barros Errázuriz 1954
INFORME Nº1 PROPUESTA METODOLÓGICA Y PLAN DESARROLLO DE UN SISTEMA INTEGRADO DE GESTIÓN PARA EL GOBIERNO REGIONAL DE ATACAMA con destino a GORE DE ATACAMA ELIMCO SISTEMAS Alfredo Barros Errázuriz 1954
Capítulo 12: Indexación y asociación
 Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Capítulo 12: Indexación y asociación Conceptos básicos Índices ordenados Archivos de índice de árbol B+ Archivos de índice de árbol B Asociación estática Asociación dinámica Comparación entre indexación
Expansión en línea de la Capacidad RAID & Migración del nivel RAID
 Expansión en línea de la Capacidad RAID & Migración del nivel RAID "No necesita dejar el servidor inactivo cuando expanda o migre sus volúmenes RAID" El desafío de los Negocios modernos El mayor desafío
Expansión en línea de la Capacidad RAID & Migración del nivel RAID "No necesita dejar el servidor inactivo cuando expanda o migre sus volúmenes RAID" El desafío de los Negocios modernos El mayor desafío
Análisis del Sistema de Información
 Análisis del Sistema de Información 1 1. Definición y objetivos análisis.(del gr. ἀνάλυσις). 1. m. Distinción y separación de las partesdeun todo hasta llegar a conocer sus principios o elementos. 2. m.
Análisis del Sistema de Información 1 1. Definición y objetivos análisis.(del gr. ἀνάλυσις). 1. m. Distinción y separación de las partesdeun todo hasta llegar a conocer sus principios o elementos. 2. m.
COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA
 COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA Autor: Carlos Javier Martín González. Licenciado en Física Teórica por la Universidad Autónoma de Madrid. Analista programador y funcional. Desarrollador
COPIAS DE SEGURIDAD AUTOMÁTICAS DE DIRECCIONES CALLEÇPAÑA Autor: Carlos Javier Martín González. Licenciado en Física Teórica por la Universidad Autónoma de Madrid. Analista programador y funcional. Desarrollador
UNIVERSIDAD AUTÓNOMA DEL CARIBE PROCEDIMIENTO DE ATENCIÓN DE INCIDENTES Y REQUERIMIENTOS PARA EQUIPOS DE CÓMUPUTO Y/O PERIFÉRICOS GESTIÓN INFORMÁTICA
 Página: 1/5 UNIVERSIDAD AUTÓNOMA DEL CARIBE INCIDENTES Y REQUERIMIENTOS PARA EQUIPOS DE CÓMUPUTO Y/O GESTIÓN INFORMÁTICA Página: 2/5 1. OBJETO Satisfacer los requerimientos que hagan los usuarios para
Página: 1/5 UNIVERSIDAD AUTÓNOMA DEL CARIBE INCIDENTES Y REQUERIMIENTOS PARA EQUIPOS DE CÓMUPUTO Y/O GESTIÓN INFORMÁTICA Página: 2/5 1. OBJETO Satisfacer los requerimientos que hagan los usuarios para
Alta disponibilidad de los servicios en la SGTIC del MEH
 Alta disponibilidad de los servicios en la SGTIC del MEH Emilio Raya López Marcos Llama Pérez Página 1 de 1 Página 2 de 2 Índice 1. INTRODUCCIÓN... 4 2. IMPLANTACIÓN DE CLUSTERS GEOGRÁFICOS CON MICROSOFT
Alta disponibilidad de los servicios en la SGTIC del MEH Emilio Raya López Marcos Llama Pérez Página 1 de 1 Página 2 de 2 Índice 1. INTRODUCCIÓN... 4 2. IMPLANTACIÓN DE CLUSTERS GEOGRÁFICOS CON MICROSOFT
Uso de la red telefónica
 Copyright y marca comercial 2004 palmone, Inc. Todos los derechos reservados. palmone, Treo, los logotipos de palmone y Treo, Palm, Palm OS, HotSync, Palm Powered, y VersaMail son algunas de las marcas
Copyright y marca comercial 2004 palmone, Inc. Todos los derechos reservados. palmone, Treo, los logotipos de palmone y Treo, Palm, Palm OS, HotSync, Palm Powered, y VersaMail son algunas de las marcas
Prácticas ITIL para un mejor flujo de trabajo en el helpdesk
 Prácticas ITIL para un mejor flujo de trabajo en el helpdesk Se diferencia tres partes de gestión para mejorar la resolución de las incidencias de soporte técnico según el marco ITIL: 1. Gestión de Incidencias
Prácticas ITIL para un mejor flujo de trabajo en el helpdesk Se diferencia tres partes de gestión para mejorar la resolución de las incidencias de soporte técnico según el marco ITIL: 1. Gestión de Incidencias
GENERALIDADES DE BASES DE DATOS
 GENERALIDADES DE BASES DE DATOS A fin de evitar que idénticos datos se encuentren repetidos en múltiples archivos, parece necesario que los comunes se almacenen en un archivo único y que este archivo sea
GENERALIDADES DE BASES DE DATOS A fin de evitar que idénticos datos se encuentren repetidos en múltiples archivos, parece necesario que los comunes se almacenen en un archivo único y que este archivo sea
Sistemas de Información Administrativo - Universidad Diego Portales. Cátedra : Sistemas de Información Administrativa S.I.A.
 Cátedra : Sistemas de Información Administrativa S.I.A. Escuela de Contadores Auditores Tema: Ingeniería del Software Estrategias de Pruebas Relator: Sr. Eduardo Leyton G Pruebas del Software (Basado en
Cátedra : Sistemas de Información Administrativa S.I.A. Escuela de Contadores Auditores Tema: Ingeniería del Software Estrategias de Pruebas Relator: Sr. Eduardo Leyton G Pruebas del Software (Basado en
 El 6% de los ordenadores sufren pérdidas de Están sus datos seguros? información a lo largo de un año. El 90% de los ordenadores no están siendo respaldados con copias de seguridad fiables. El 15% de los
El 6% de los ordenadores sufren pérdidas de Están sus datos seguros? información a lo largo de un año. El 90% de los ordenadores no están siendo respaldados con copias de seguridad fiables. El 15% de los
Plan de estudios ISTQB: Nivel Fundamentos
 Plan de estudios ISTQB: Nivel Fundamentos Temario 1. INTRODUCCIÓN 2. FUNDAMENTOS DE PRUEBAS 3. PRUEBAS A TRAVÉS DEL CICLO DE VIDA DEL 4. TÉCNICAS ESTÁTICAS 5. TÉCNICAS DE DISEÑO DE PRUEBAS 6. GESTIÓN DE
Plan de estudios ISTQB: Nivel Fundamentos Temario 1. INTRODUCCIÓN 2. FUNDAMENTOS DE PRUEBAS 3. PRUEBAS A TRAVÉS DEL CICLO DE VIDA DEL 4. TÉCNICAS ESTÁTICAS 5. TÉCNICAS DE DISEÑO DE PRUEBAS 6. GESTIÓN DE
Sistemas de memoria robustos o tolerantes a fallos. Noel Palos Pajares Rubén Suárez del Campo Jorge Martín Vázquez
 Sistemas de memoria robustos o tolerantes a fallos Noel Palos Pajares Rubén Suárez del Campo Jorge Martín Vázquez Índice Introducción Qué son los sistemas tolerantes a fallos o robustos. Tipos de fallos
Sistemas de memoria robustos o tolerantes a fallos Noel Palos Pajares Rubén Suárez del Campo Jorge Martín Vázquez Índice Introducción Qué son los sistemas tolerantes a fallos o robustos. Tipos de fallos
PROCEDIMIENTO DE EVALUACIÓN Y ACREDITACIÓN DE LAS COMPETENCIAS PROFESIONALES CUESTIONARIO DE AUTOEVALUACIÓN PARA LAS TRABAJADORAS Y TRABAJADORES
 MINISTERIO DE EDUCACIÓN, CULTURA Y DEPORTE SECRETARÍA DE ESTADO DE EDUCACIÓN, FORMACIÓN PROFESIONAL Y UNIVERSIDADES DIRECCIÓN GENERAL DE FORMACIÓN PROFESIONAL INSTITUTO NACIONAL DE LAS CUALIFICACIONES
MINISTERIO DE EDUCACIÓN, CULTURA Y DEPORTE SECRETARÍA DE ESTADO DE EDUCACIÓN, FORMACIÓN PROFESIONAL Y UNIVERSIDADES DIRECCIÓN GENERAL DE FORMACIÓN PROFESIONAL INSTITUTO NACIONAL DE LAS CUALIFICACIONES
QuickQualifier POR QUÉ SYMANTEC BACKUP EXEC SYSTEM RECOVERY?...2 ARGUMENTOS DE PESO...2 PERSONAS DE CONTACTO CLAVES...4 PREGUNTAS GENERALES...
 QuickQualifier Symantec Backup Exec System Recovery Restauración de sistemas Windows en cualquier momento, desde cualquier lugar y en prácticamente cualquier dispositivo POR QUÉ SYMANTEC BACKUP EXEC SYSTEM
QuickQualifier Symantec Backup Exec System Recovery Restauración de sistemas Windows en cualquier momento, desde cualquier lugar y en prácticamente cualquier dispositivo POR QUÉ SYMANTEC BACKUP EXEC SYSTEM
Seminario Electrónico de Soluciones Tecnológicas sobre Content Networking
 Seminario Electrónico de Soluciones Tecnológicas sobre Content Networking 1 de 13 Seminario Electrónico de Soluciones Tecnológicas sobre Content Networking 3 Bienvenida. 4 Objetivos. 5 Soluciones comerciales
Seminario Electrónico de Soluciones Tecnológicas sobre Content Networking 1 de 13 Seminario Electrónico de Soluciones Tecnológicas sobre Content Networking 3 Bienvenida. 4 Objetivos. 5 Soluciones comerciales
http://www.statum.biz http://www.statum.info http://www.statum.org
 ApiaMonitor Monitor de Infraestructura BPMS Por: Ing. Manuel Cabanelas Product Manager de Apia Manuel.Cabanelas@statum.biz http://www.statum.biz http://www.statum.info http://www.statum.org Abstract A
ApiaMonitor Monitor de Infraestructura BPMS Por: Ing. Manuel Cabanelas Product Manager de Apia Manuel.Cabanelas@statum.biz http://www.statum.biz http://www.statum.info http://www.statum.org Abstract A
Implantación y Aceptación del Sistema
 y Aceptación del Sistema 1 y Aceptación del Sistema ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 2 ACTIVIDAD IAS 1: ESTABLECIMIENTO DEL PLAN DE IMPLANTACIÓN...5 Tarea IAS 1.1: De finición del Plan de... 5 Tarea IAS
y Aceptación del Sistema 1 y Aceptación del Sistema ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 2 ACTIVIDAD IAS 1: ESTABLECIMIENTO DEL PLAN DE IMPLANTACIÓN...5 Tarea IAS 1.1: De finición del Plan de... 5 Tarea IAS
Soluciones VMware para la Continuidad del Negocio y la Recuperación ante Desastres
 Soluciones VMware para la Continuidad del Negocio y la Recuperación ante Desastres Diego Cicero VMware Sr. Systems Engineer Qué son la continuidad del negocio y la recuperación ante desastres (BCDR)? Continuidad
Soluciones VMware para la Continuidad del Negocio y la Recuperación ante Desastres Diego Cicero VMware Sr. Systems Engineer Qué son la continuidad del negocio y la recuperación ante desastres (BCDR)? Continuidad
CALIDAD DE SOFTWARE (CSO) Práctica 2: Calidad de Arquitecturas Software. Introducción a ATAM
 Práctica 2: Calidad de Arquitecturas Software. Introducción a ATAM") CALIDAD DE SOFTWARE (CSO) Práctica 2: Calidad de Arquitecturas Software Introducción a ATAM Índice Qué es ATAM? Cuáles son las salidas de ATAM? Las fases y pasos de ATAM Ejemplo de aplicación de ATAM Introducción
CALIDAD DE SOFTWARE (CSO) Práctica 2: Calidad de Arquitecturas Software Introducción a ATAM Índice Qué es ATAM? Cuáles son las salidas de ATAM? Las fases y pasos de ATAM Ejemplo de aplicación de ATAM Introducción
Contenido. Qué es el interbloqueo? Cómo prevenirlo? Cómo evitarlo? Cómo detectarlo? Interbloqueo. Cruce en un Puente. Qué es?
 Contenido Interbloqueo Qué es el? Cómo prevenirlo? Cómo evitarlo? Cómo detectarlo? Qué es? Bloqueo permanente de un conjunto de procesos que para terminar necesitan o bien los recursos del sistema, o bien
Contenido Interbloqueo Qué es el? Cómo prevenirlo? Cómo evitarlo? Cómo detectarlo? Qué es? Bloqueo permanente de un conjunto de procesos que para terminar necesitan o bien los recursos del sistema, o bien
Técnicas empleadas. además de los discos las controladoras.
 RAID Introducción En los últimos años, la mejora en la tecnología de semiconductores ha significado un gran incremento en la velocidad de los procesadores y las memorias principales que, a su vez, exigen
RAID Introducción En los últimos años, la mejora en la tecnología de semiconductores ha significado un gran incremento en la velocidad de los procesadores y las memorias principales que, a su vez, exigen
Capítulo III. Manejo de Incidentes
 Manejo de Incidentes Manejo de Incidentes Tabla de contenido 1.- En qué consiste el manejo de incidentes?...45 1.1.- Ventajas...47 1.2.- Barreras...47 2.- Requerimientos...48 3.- Clasificación de los incidentes...48
Manejo de Incidentes Manejo de Incidentes Tabla de contenido 1.- En qué consiste el manejo de incidentes?...45 1.1.- Ventajas...47 1.2.- Barreras...47 2.- Requerimientos...48 3.- Clasificación de los incidentes...48
Arquitectura de red distribuida: escalabilidad y equilibrio de cargas en un entorno de seguridad
 Arquitectura de red distribuida: escalabilidad y equilibrio de cargas en un entorno de seguridad por Warren Brown Las compañías multinacionales y los hospitales, universidades o entidades gubernamentales
Arquitectura de red distribuida: escalabilidad y equilibrio de cargas en un entorno de seguridad por Warren Brown Las compañías multinacionales y los hospitales, universidades o entidades gubernamentales
www.spensiones.cl/tea Transferencia Electrónica de Archivos (TEA) Normas Técnicas
 Normas Técnicas") Transferencia Electrónica de Archivos (TEA) Normas Técnicas Fecha de actualización: 15 de abril de 2015 1. Características de los enlaces de comunicaciones La comunicación con la Superintendencia de Pensiones
Transferencia Electrónica de Archivos (TEA) Normas Técnicas Fecha de actualización: 15 de abril de 2015 1. Características de los enlaces de comunicaciones La comunicación con la Superintendencia de Pensiones
Traslado de Data Center
 Traslado de Data Center Traslado de Data Center Análisis y metodología garantizan el éxito en el traslado de los Data Center Planificar, analizar y documentar son claves a la hora de realizar la migración
Traslado de Data Center Traslado de Data Center Análisis y metodología garantizan el éxito en el traslado de los Data Center Planificar, analizar y documentar son claves a la hora de realizar la migración
RODRIGO TAPIA SANTIS (rtapiasantis@gmail com) has a. non-transferable license to use this Student Guide
 has a. non-transferable license to use this Student Guide") Introducción Objetivos del Curso Al finalizar este curso, debería estar capacitado para: Instalar, crear y administrar Oracle Database 11g Versión 2 Configurar la base de datos para una aplicación Utilizar
Introducción Objetivos del Curso Al finalizar este curso, debería estar capacitado para: Instalar, crear y administrar Oracle Database 11g Versión 2 Configurar la base de datos para una aplicación Utilizar
Capítulo 5. Cliente-Servidor.
 Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Capítulo 5. Cliente-Servidor. 5.1 Introducción En este capítulo hablaremos acerca de la arquitectura Cliente-Servidor, ya que para nuestra aplicación utilizamos ésta arquitectura al convertir en un servidor
Herramientas Software Unycop Win. Cuándo hay que hacer uso de las Herramientas Software?
 Cuándo hay que hacer uso de las Herramientas Software? Estas herramientas son necesarias cuando se produce un deterioro en alguna Base de datos. Estos deterioros se hacen evidentes cuando, al entrar en
Cuándo hay que hacer uso de las Herramientas Software? Estas herramientas son necesarias cuando se produce un deterioro en alguna Base de datos. Estos deterioros se hacen evidentes cuando, al entrar en
Copyright 2011 - bizagi. Gestión de Cambios Documento de Construcción Bizagi Process Modeler
 Copyright 2011 - bizagi Gestión de Cambios Bizagi Process Modeler Tabla de Contenido Gestión de Cambios... 4 Descripción... 4 Principales factores en la Construcción del Proceso... 5 Modelo de Datos...
Copyright 2011 - bizagi Gestión de Cambios Bizagi Process Modeler Tabla de Contenido Gestión de Cambios... 4 Descripción... 4 Principales factores en la Construcción del Proceso... 5 Modelo de Datos...
UNIVERSIDAD TECNOLOGICA ECOTEC DIEGO BARRAGAN MATERIA: Sistemas Operativos 1 ENSAYO: Servidores BLADE
 UNIVERSIDAD TECNOLOGICA ECOTEC DIEGO BARRAGAN MATERIA: Sistemas Operativos 1 ENSAYO: Servidores BLADE AÑO: 2010 Qué es un servidor Blade? Blade Server es una arquitectura que ha conseguido integrar en
UNIVERSIDAD TECNOLOGICA ECOTEC DIEGO BARRAGAN MATERIA: Sistemas Operativos 1 ENSAYO: Servidores BLADE AÑO: 2010 Qué es un servidor Blade? Blade Server es una arquitectura que ha conseguido integrar en
SEPARAR Y ADJUNTAR UNA BASE DE DATOS. Separar una base de datos
 SEPARAR Y ADJUNTAR UNA BASE DE DATOS Separar una base de datos Al separar una base de datos la está eliminando de la instancia de SQL Server, pero la deja intacta en sus archivos de datos y en los archivos
SEPARAR Y ADJUNTAR UNA BASE DE DATOS Separar una base de datos Al separar una base de datos la está eliminando de la instancia de SQL Server, pero la deja intacta en sus archivos de datos y en los archivos
SAQQARA. Correlación avanzada y seguridad colaborativa_
 SAQQARA Correlación avanzada y seguridad colaborativa_ Tiene su seguridad 100% garantizada con su SIEM?_ Los SIEMs nos ayudan, pero su dependencia de los eventos y tecnologías, su reducida flexibilidad
SAQQARA Correlación avanzada y seguridad colaborativa_ Tiene su seguridad 100% garantizada con su SIEM?_ Los SIEMs nos ayudan, pero su dependencia de los eventos y tecnologías, su reducida flexibilidad
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología
 Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
General Parallel File System
 General Parallel File System Introducción GPFS fue desarrollado por IBM, es un sistema que permite a los usuarios compartir el acceso a datos que están dispersos en múltiples nodos; permite interacción
General Parallel File System Introducción GPFS fue desarrollado por IBM, es un sistema que permite a los usuarios compartir el acceso a datos que están dispersos en múltiples nodos; permite interacción
Ley Orgánica de Protección de Datos
 Hécate GDocS Gestión del documento de seguridad Ley Orgánica de Protección de Datos 2005 Adhec - 2005 EFENET 1. GDocS - Gestión del Documento de Seguridad GDocS es un programa de gestión que permite mantener
Hécate GDocS Gestión del documento de seguridad Ley Orgánica de Protección de Datos 2005 Adhec - 2005 EFENET 1. GDocS - Gestión del Documento de Seguridad GDocS es un programa de gestión que permite mantener
5. Gestión de la Configuración del Software (GCS)
") 5. Gestión de la Configuración del Software (GCS) 5.1. La Configuración del Software El resultado del proceso de ingeniería del software es una información que se puede dividir en tres amplias categorías:
5. Gestión de la Configuración del Software (GCS) 5.1. La Configuración del Software El resultado del proceso de ingeniería del software es una información que se puede dividir en tres amplias categorías:
Unidad 1: Conceptos generales de Sistemas Operativos.
 Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los sistemas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejecución de instrucciones e interrupciones
Unidad 1: Conceptos generales de Sistemas Operativos. Tema 2: Estructura de los sistemas de computación. 2.1 Funcionamiento de los sistemas de computación. 2.2 Ejecución de instrucciones e interrupciones
SISTEMAS Y MANUALES DE LA CALIDAD
 SISTEMAS Y MANUALES DE LA CALIDAD NORMATIVAS SOBRE SISTEMAS DE CALIDAD Introducción La experiencia de algunos sectores industriales que por las características particulares de sus productos tenían necesidad
SISTEMAS Y MANUALES DE LA CALIDAD NORMATIVAS SOBRE SISTEMAS DE CALIDAD Introducción La experiencia de algunos sectores industriales que por las características particulares de sus productos tenían necesidad
V i s i t a V i r t u a l e n e l H o s p i t a l
 V i s i t a V i r t u a l e n e l H o s p i t a l Manual de Restauración del PC Septiembre 2011 TABLA DE CONTENIDOS SOBRE EL SOFTWARE... 3 CONSIDERACIONES ANTES DE RESTAURAR... 4 PROCEDIMIENTO DE RECUPERACION...
V i s i t a V i r t u a l e n e l H o s p i t a l Manual de Restauración del PC Septiembre 2011 TABLA DE CONTENIDOS SOBRE EL SOFTWARE... 3 CONSIDERACIONES ANTES DE RESTAURAR... 4 PROCEDIMIENTO DE RECUPERACION...
Sistema de Gestión de la Seguridad de la Información, UNE-ISO/IEC 27001
 Sistema de Gestión de la Seguridad de la Información, UNE-ISO/IEC 27001 Aníbal Díaz Gines Auditor de SGSI Certificación de Sistemas Applus+ Sistema de Gestión de la Seguridad de la Información, UNE-ISO/IEC
Sistema de Gestión de la Seguridad de la Información, UNE-ISO/IEC 27001 Aníbal Díaz Gines Auditor de SGSI Certificación de Sistemas Applus+ Sistema de Gestión de la Seguridad de la Información, UNE-ISO/IEC
1. Instala sistemas operativos en red describiendo sus características e interpretando la documentación técnica.
 Módulo Profesional: Sistemas operativos en red. Código: 0224. Resultados de aprendizaje y criterios de evaluación. 1. Instala sistemas operativos en red describiendo sus características e interpretando
Módulo Profesional: Sistemas operativos en red. Código: 0224. Resultados de aprendizaje y criterios de evaluación. 1. Instala sistemas operativos en red describiendo sus características e interpretando
IAP 1005 - CONSIDERACIONES PARTICULARES SOBRE LA AUDITORÍA DE LAS EMPRESAS DE REDUCIDA DIMENSIÓN
 IAP 1005 - CONSIDERACIONES PARTICULARES SOBRE LA AUDITORÍA DE LAS EMPRESAS DE REDUCIDA DIMENSIÓN Introducción 1. Las Normas Internacionales de Auditoría (NIA) se aplican a la auditoría de la información
IAP 1005 - CONSIDERACIONES PARTICULARES SOBRE LA AUDITORÍA DE LAS EMPRESAS DE REDUCIDA DIMENSIÓN Introducción 1. Las Normas Internacionales de Auditoría (NIA) se aplican a la auditoría de la información
15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores.
 UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
UNIDAD TEMÁTICA 5: MULTIPROCESADORES. 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 TEMA 15: ARQUITECTURA DE LOS MULTIPROCESADORES.
Sistemas Operativos Windows 2000
 Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Servicio de Alta, Baja, Modificación y Consulta de usuarios Medusa
 Documentos de Proyecto Medusa Documentos de: Serie: Manuales Servicio de Alta, Baja, Modificación y Consulta del documento: Fecha 22 de febrero de 2007 Preparado por: José Ramón González Luis Aprobado
Documentos de Proyecto Medusa Documentos de: Serie: Manuales Servicio de Alta, Baja, Modificación y Consulta del documento: Fecha 22 de febrero de 2007 Preparado por: José Ramón González Luis Aprobado
Tema 3. Tecnologías y arquitecturas tolerantes a errores. Alta disponibilidad. Gestión de la redundancia, clustering.
 Tema 3. Tecnologías y arquitecturas tolerantes a errores. Alta disponibilidad. Gestión de la redundancia, clustering. Esquema Índice de contenido 1 Introducción... 2 2 Arquitecturas redundantes y su gestión...
Tema 3. Tecnologías y arquitecturas tolerantes a errores. Alta disponibilidad. Gestión de la redundancia, clustering. Esquema Índice de contenido 1 Introducción... 2 2 Arquitecturas redundantes y su gestión...
UNIVERSIDAD DE ORIENTE FACULTAD DE CIENCIAS ECONOMICAS
 UNIVERSIDAD DE ORIENTE FACULTAD DE CIENCIAS ECONOMICAS AUDITORIA DE SISTEMAS COMPUTACIONALES TIPOS DE AUDITORIA LIC. FRANCISCO D. LOVOS Tipos de Auditorías Auditoría de Base de Datos Auditoría de Desarrollo
UNIVERSIDAD DE ORIENTE FACULTAD DE CIENCIAS ECONOMICAS AUDITORIA DE SISTEMAS COMPUTACIONALES TIPOS DE AUDITORIA LIC. FRANCISCO D. LOVOS Tipos de Auditorías Auditoría de Base de Datos Auditoría de Desarrollo
Guía de Instalación para clientes de WebAdmin
 Panda Managed Office Protection Guía de Instalación para clientes de WebAdmin Tabla de contenidos 1. Introducción... 4 2. Instalación de Panda Managed Office Protection a partir de una instalación de Panda
Panda Managed Office Protection Guía de Instalación para clientes de WebAdmin Tabla de contenidos 1. Introducción... 4 2. Instalación de Panda Managed Office Protection a partir de una instalación de Panda
Universidad de Colima Facultad de Ingeniería Mecánica y Eléctrica. Base de Datos I. Maestra: Martha E. Evangelista Salazar
 Universidad de Colima Facultad de Ingeniería Mecánica y Eléctrica Base de Datos I Maestra: Martha E. Evangelista Salazar Introducción a los conceptos de Bases de Datos a).- Definiciones básicas sobre bases
Universidad de Colima Facultad de Ingeniería Mecánica y Eléctrica Base de Datos I Maestra: Martha E. Evangelista Salazar Introducción a los conceptos de Bases de Datos a).- Definiciones básicas sobre bases
PROCEDIMIENTO DE EVALUACIÓN Y ACREDITACIÓN DE LAS COMPETENCIAS PROFESIONALES CUESTIONARIO DE AUTOEVALUACIÓN PARA LAS TRABAJADORAS Y TRABAJADORES
 MINISTERIO DE EDUCACIÓN SECRETARÍA DE ESTADO DE EDUCACIÓN Y FORMACIÓN PROFESIONAL DIRECCIÓN GENERAL DE FORMACIÓN PROFESIONAL INSTITUTO NACIONAL DE LAS CUALIFICACIONES PROCEDIMIENTO DE EVALUACIÓN Y ACREDITACIÓN
MINISTERIO DE EDUCACIÓN SECRETARÍA DE ESTADO DE EDUCACIÓN Y FORMACIÓN PROFESIONAL DIRECCIÓN GENERAL DE FORMACIÓN PROFESIONAL INSTITUTO NACIONAL DE LAS CUALIFICACIONES PROCEDIMIENTO DE EVALUACIÓN Y ACREDITACIÓN
1.1.- Objetivos de los sistemas de bases de datos 1.2.- Administración de los datos y administración de bases de datos 1.3.- Niveles de Arquitectura
 1. Conceptos Generales 2. Modelo Entidad / Relación 3. Modelo Relacional 4. Integridad de datos relacional 5. Diseño de bases de datos relacionales 6. Lenguaje de consulta estructurado (SQL) 1.1.- Objetivos
1. Conceptos Generales 2. Modelo Entidad / Relación 3. Modelo Relacional 4. Integridad de datos relacional 5. Diseño de bases de datos relacionales 6. Lenguaje de consulta estructurado (SQL) 1.1.- Objetivos
Guía Rápida de Inicio
 Guía Rápida de Inicio 1. Acerca de esta Guía Esta guía le ayudará a instalar y dar los primeros pasos con BitDefender Security for SharePoint. Para disponer de instrucciones detalladas, por favor, diríjase
Guía Rápida de Inicio 1. Acerca de esta Guía Esta guía le ayudará a instalar y dar los primeros pasos con BitDefender Security for SharePoint. Para disponer de instrucciones detalladas, por favor, diríjase