Sistemas Inteligentes para la Gestión de la Empresa
|
|
|
- Alejandra Rey Peralta
- hace 8 años
- Vistas:
Transcripción
1 Sistemas Inteligentes para la Gestión de la Empresa Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Depuración y Calidad de Datos Tema 3. Análisis Predictivo para la Empresa Tema 4. Modelos avanzados de Analítica de Empresa Tema 5. Análisis de Transacciones y Mercados Tema 6. Big Data

2 Objetivos Conocer el problema de big data. Conocer las tecnologías asociadas para la resolución de problemas. Conocer el diseño de algoritmos en big data.

3 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Algunas Aplicaciones 5. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 6. Deep Learning 7. Diseño de Algoritmos para Big Data

4 Tema 6. Big Data Contenido Introducción a Big data Paradigma MapReduce Bibliografía A. Fernandez, S. Río, V. López, A. Bawakid, M.J. del Jesus, J.M. Benítez, F. Herrera, Big Data with Cloud Computing: An Insight on the Computing Environment, MapReduce and Programming Frameworks. WIREs Data Mining and Knowledge Discovery 4:5 (2014)
 380-409 http://issuu.")
5 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Algunas Aplicaciones 5. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 6. Deep Learning 7. Diseño de Algoritmos para Big Data

6 Big Data Ciencia Nuestro mundo gira en torno a los datos Bases de datos de astronomía, genómica, datos medio-ambientales, datos de transporte, Ciencias Sociales y Humanidades Libros escaneados, documentos históricos, datos sociales, Negocio y Comercio Ventas de corporaciones, transacciones de mercados, censos, tráfico de aerolíneas, Entretenimiento y Ocio Imágenes en internet, películas, ficheros MP3, Medicina Datos de pacientes, datos de escaner, radiografías Industria, Energía, Sensores, 6

7 Big Data Alex ' Sandy' Pentland, director del programa de emprendedores del 'Media Lab' del Massachusetts Institute of Technology (MIT) Considerado por 'Forbes' como uno de los siete científicos de datos más poderosos del mundo 7

8 Big Data 8

9 Qué es Big Data? No hay una definición estándar Big data es una colección de datos grande, complejos, muy difícil de procesar a través de herramientas de gestión y procesamiento de datos tradicionales Big Data son datos cuyo volumen, diversidad y complejidad requieren nueva arquitectura, técnicas, algoritmos y análisis para gestionar y extraer valor y conocimiento oculto en ellos... 9

10 Qué es Big Data? 10
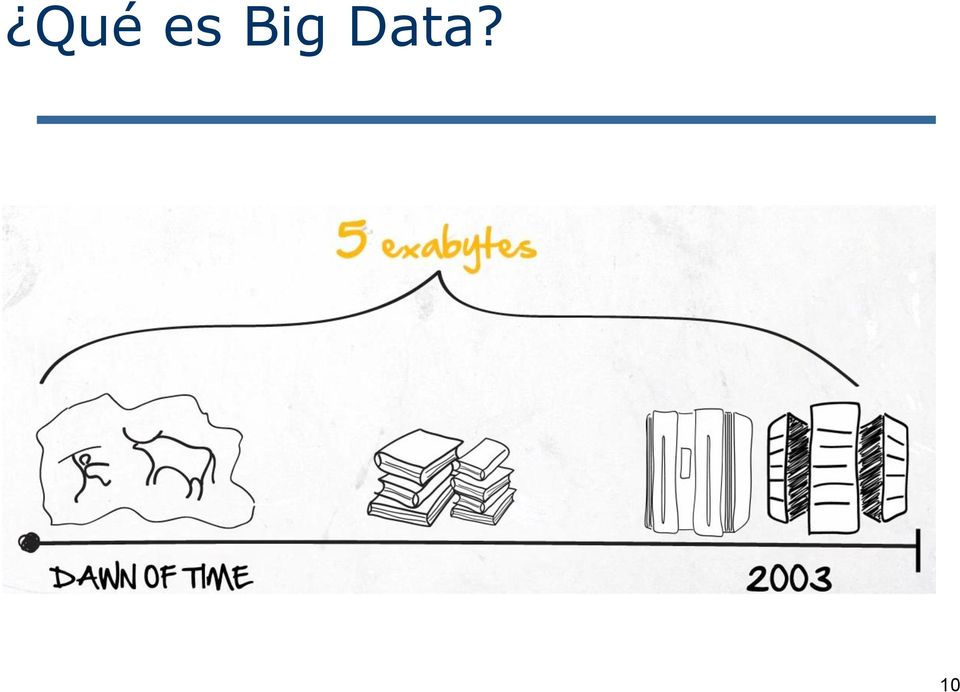
11 Qué es Big Data? 11
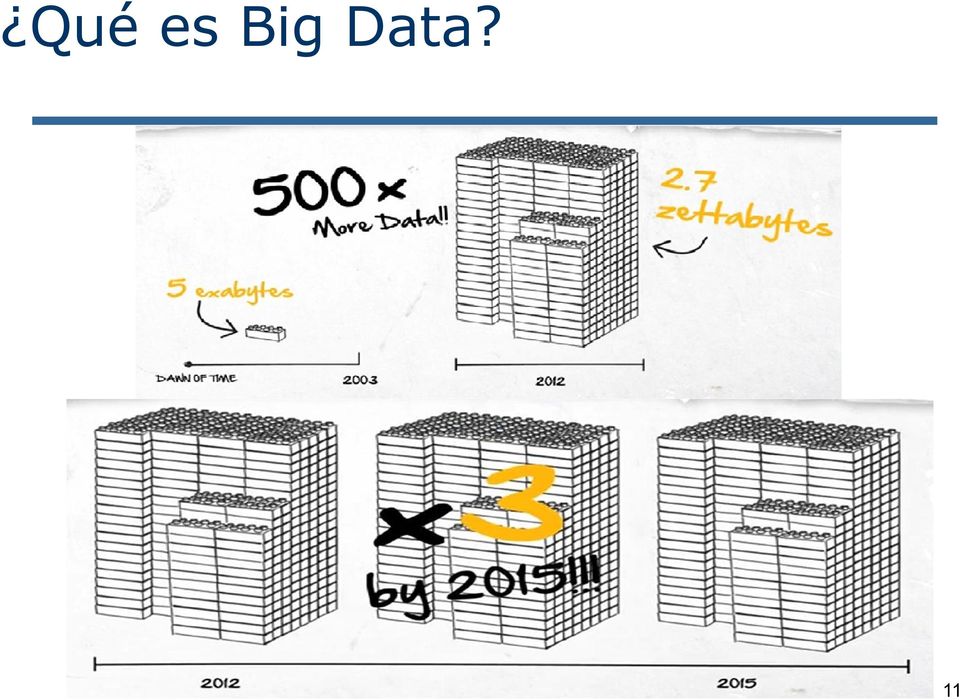

12 Qué es Big Data? Las 3 V s de Big Data Volumen Big Data Variedad Velocidad 12

13 Qué es Big Data? 3 V s de Big Data 13

14 Qué es Big Data? 3 V s de Big Data 1ª: Volumen 14

15 Qué es Big Data? 3 V s de Big Data 15

16 Qué es Big Data? 3 V s de Big Data Los DATOS se generan muy rápido y necesitan ser procesados rápidamente Online Data Analytics 2ª: Velocidad Decisiones tardías oportunidades perdidas Ejemplos: E-Promociones: Basadas en la posición actual e historial de compra envío de promociones en el momento de comercios cercanos a la posición Monitorización/vigilancia sanitaria: Monitorización sensorial de las actividades del cuerpo cualquier medida anormal requiere una reacción inmediata 16

17 Qué es Big Data? 3 V s de Big Data 17



18 Qué es Big Data? 3 V s de Big Data Varios formatos y estructuras: 3ª: Variedad Texto, numéricos, imágenes, audio, video, sequencias, series temporales Una sola aplicación puede generar muchos tipos de datos Extracción de conocimiento Todos estos tipos de datos necesitan ser analizados conjuntamente 18

19 Qué es Big Data? 4ª V Veracidad 4ªV Veracidad 19

20 Qué es Big Data? 5 V s --> Valor 5ªV = Valor 20


21 Qué es Big Data? Las 8 V s de Big Data Veracidad Valor Variedad Variabilidad Velocidad Validez Volumen Big Data Volatilidad 21
22 Qué es Big Data? Big data es cualquier característica sobre los datos que represente un reto para las funcionalidades de un sistema. 22
23 Qué es Big Data? Big data incluye datos estructurados con datos no estructurados, imágenes, vídeos 23
24 Qué es Big Data? Quién genera Big Data? Dispositivos móviles (seguimiento de objetos) Redes sociales y multimedia (todos generamos datos) Instrumentos científicos (colección de toda clase de datos) Redes de sensores (se miden toda clase de datos) El progreso y la innovación ya no se ven obstaculizados por la capacidad de recopilar datos, sino por la capacidad de gestionar, analizar, sintetizar, visualizar, y descubrir el conocimiento de los datos recopilados de manera oportuna y en una forma escalable 24
25 Big Data. Aplicaciones Astronomía Genómica Telefonía Transacciones de tarjetas de crédito Tráfico en Internet Procesamiento de información WEB 25
26 Big Data. Ejemplo Evolutionary Computation for Big Data and Big Learning Workshop Big Data Competition 2014: Self-deployment track Objective: Contact map prediction Details: 32 million instances 631 attributes (539 real & 92 nominal values) 2 classes 98% of negative examples About 56.7GB of disk space Evaluation: True positive rate True negative rate TPR TNR
27 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Algunas Aplicaciones 5. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 6. Deep Learning 7. Diseño de Algoritmos para Big Data
28 MapReduce Problema: Escalabilidad de grandes cantidades de datos Ejemplo: Exploración 100 TB en 1 50 MB/sec = 23 días Exploración en un clúster de 1000 nodos = 33 minutos Solución Divide-Y-Vencerás Una sola máquina no puede gestionar grandes volúmenes de datos de manera eficiente 28
29 MapReduce Escalabilidad de grandes cantidades de datos Exploración 100 TB en 1 50 MB/sec = 23 días Exploración en un clúster de 1000 nodos = 33 minutos Solución Divide-Y-Vencerás Qué ocurre cuando el tamaño de los datos aumenta y los requerimientos de tiempo se mantiene? Hace unos años: Había que aumentar los recursos de hardware (número de nodos). Esto tiene limitaciones de espacio, costes, Google 2004: Paradigma MapReduce 29
30 MapReduce Escalabilidad de grandes cantidades de datos Exploración 100 TB en 1 50 MB/sec = 23 días Exploración en un clúster de 1000 nodos = 33 minutos Solución Divide-Y-Vencerás MapReduce Modelo de programación de datos paralela Concepto simple, elegante, extensible para múltiples aplicaciones Creado por Google (2004) Procesa 20 PB de datos por día (2004) Popularizado por el proyecto de codigo abierto Hadoop Usado por Yahoo!, Facebook, Amazon, 30
31 MapReduce MapReduce es el entorno más popular para Big Data Basado en la estructura Valorllave. Dos operaciones: 1. Función Map : Procesa bloques de información 2. Función Reduce function: Fusiona los resultados previous de acuerdo a su llave. + Una etapa intermedia de agrupamiento por llave (Shuffling) input (k, v) (k, v) (k, v ) input input input map map map map k, list(v ) Shuffling: group values by keys reduce reduce reduce v (k, v ) k, list(v ) v (k, v) (k, v ) k, list(v ) v output output output map (k, v) list (k, v ) reduce (k, list(v )) v (k, v) (k, v ) J. Dean, S. Ghemawat, MapReduce: Simplified data processing on large clusters, Communications of the ACM 51 (1) (2008)
32 MapReduce Flujo de datos MapReduce map (k,v) list(k,v ) reduce (k,list(v )) v
33 MapReduce Una imagen completa del proceso MapReduce 33
34 MapReduce
35 MapReduce Características Paralelización automática: Dependiendo del tamaño de ENTRADA DE DATOS se crean mutiples tareas MAP Dependiendo del número de intermedio <clave, valor> particiones se crean tareas REDUCE Escalabilidad: Funciona sobre cualquier cluster de nodos/procesadores Puede trabajar desde 2 a 10,000 máquinas Transparencia programación Manejo de los fallos de la máquina Gestión de comunicación entre máquina 35
36 MapReduce Tiempo de ejecución: Características Partición de datos Programación de la tarea Manejo de los fallos de la máquina Gestión de comunicación entre máquina 36

37 MapReduce Número de BLOQUES? El número de bloques es independiente del número de nodos disponibles. Va a estar asociado al tamaño y características del problema. 37

38 Almacenamiento MapReduce de los BLOQUES. El número de bloques es independiente del número de nodos disponibles 38

39 MapReduce Flujo de datos en MapReduce, transparente para el programador Ficheros de entrada Ficheros Intermedios Ficheros salida 39
40 MapReduce Aspectos a analizar: Proceso map: Puede crear conjuntos de datos muy pequeños, lo cual puede ser un inconveniente para algunos problemas. Ejemplo: Problemas de Clasificación. Nos podríamos encontrar con el problema de falta de densidad de datos y de clases con muy pocos datos (clasificación no balanceada). 40
41 MapReduce Aspectos a analizar: Proceso reduce: Debe combinar las soluciones de todos los modelos/procesos intermedios Esta es la fase más creativa porque hay que conseguir crear un modelo global de calidad asociado al problema que se desea resolver a partir de los modelos intermedios. 41
42 MapReduce Resumiendo: Ventaja frente a los modelos distribuidos clásicos: El modelo de programación paralela de datos de MapReduce oculta la complejidad de la distribución y tolerancia a fallos Claves de su filosofía: Es escalable: se olvidan los problemas de hardware más barato: se ahorran costes en hardware, programación y administración MapReduce no es adecuado para todos los problemas, pero cuando funciona, puede ahorrar mucho tiempo Bibliografía: A. Fernandez, S. Río, V. López, A. Bawakid, M.J. del Jesus, J.M. Benítez, F. Herrera, Big Data with Cloud Computing: An Insight on the Computing Environment, MapReduce and Programming Frameworks. WIREs Data Mining and Knowledge Discovery 4:5 (2014)
43 MapReduce Limitaciones If all you have is a hammer, then everything looks like a nail. Los siguientes tipos de algoritmos son ejemplos en los que MapReduce no funciona bien: Iterative Graph Algorithms Gradient Descent Expectation Maximization 43
44 Hadoop 44

 Task tracker Job tracker Name node Data node Task tracker Data node http://hadoop.")
45 Hadoop Hadoop Distributed File System (HDFS) es un sistema de archivos distribuido, escalable y portátil escrito en Java para el framework Hadoop Map Reduce Layer HDFS Layer Creado por Doug Cutting (chairman of board of directors of the Apache Software Foundation, 2010) Task tracker Job tracker Name node Data node Task tracker Data node 45
46 Hadoop Primer hito de Hadoop: July Hadoop Wins Terabyte Sort Benchmark Uno de los grupos de Yahoo Hadoop ordenó 1 terabyte de datos en 209 segundos, superando el récord anterior de 297 segundos en la competición anual de ordenación de un terabyte (Daytona). Esta es la primera vez que un programa en Java de código abierto ganó la competición. hours-terabyte html 46
47 Hadoop Qué es Apache Hadoop? Apache Hadoop es un proyecto que desarrolla software de código abierto fiable, escalable, para computación distribuida Hadoop se puede ejecutar de tres formas distintas (configuraciones): 1. Modo Local / Standalone. Se ejecuta en una única JVM (Java Virtual Machine). Esto es útil para depuración 2. Modo Pseudo-distribuido (simulando así un clúster o sistema distribuido de pequeña escala) 3. Distribuido (Clúster) 47
: El sistema de ficheros que proporciona el acceso Hadoop YARN: Marco para el manejo de recursos de programación y grupo de trabajo.")
48 Hadoop El proyecto Apache Hadoop incluye los módulos: Hadoop Common: Las utilidades comunes que apoyan los otros módulos de Hadoop. Hadoop Distributes File System (HDFS): El sistema de ficheros que proporciona el acceso Hadoop YARN: Marco para el manejo de recursos de programación y grupo de trabajo. Hadoop MapReduce: Un sistema de basado en YARN o para el procesamiento en paralelo de grandes conjuntos de datos. Ecosistema Apache Hadoop incluye más de 150 proyectos: Avro: Un sistema de serialización de datos. Cassandra: Una base de datos escalable multi-master sin puntos individuales y fallo Chukwa: Un sistema de recogida de datos para la gestión de grandes sistemas distribuidos. Hbase: Una base de datos distribuida, escalable que soporta estructurado de almacenamiento de datos para tablas de gran tamaño. Hive: Un almacén de datos que proporciona el Resumen de datos para tablas de gran tamaño. Pig: Lenguaje para la ejecución de alto nivel de flujo de datos para computación paralela. Tez: Sustituye al modelo MapShuffleReduce por un flujo de ejecución con grafos acíclico dirigido (DAG) Giraph: Procesamiento iterativo de grafos Mahout: Aprendizaje automático escalable (biblioteca de minería de datos) Recientemente: Apache 48

 The features of each node are: Microprocessors: 2 x Intel Xeon E5-2620 (6 cores/12 threads, 2 GHz, 15 MB Cache) RAM 64 GB DDR3")
49 Hadoop Cómo accedo a una plataforma Hadoop? Plataformas Cloud con instalación de Hadoop Amazon Elastic Compute Cloud (Amazon EC2) Windows Azure // Instalación en un cluster Ejemplo ATLAS, infraestructura del grupo SCI 2 S Cluster ATLAS: 4 super servers from Super Micro Computer Inc. (4 nodes per server) The features of each node are: Microprocessors: 2 x Intel Xeon E (6 cores/12 threads, 2 GHz, 15 MB Cache) RAM 64 GB DDR3 ECC 1600MHz, Registered 1 HDD SATA 1TB, 3Gb/s; (system) 1 HDD SATA 2TB, 3Gb/s; (distributed file system) 49
50 Hadoop Cómo puedo instalar Hadoop? Distribución que ofrece Cloudera para Hadoop. udera/en/why-cloudera/hadoop-andbig-data.html Qué es Cloudera? Cloudera es la primera distribución Apache Hadoop comercial y no-comercial. 50
51 Mahout Software de Ciencia de Datos Generation 1ª Generación 2ª Generación Ejemplos KNIME, SAS, R, Weka, SPSS, KEEL Mahout, Pentaho, Cascading Scalabilidad Vertical Horizontal (over Hadoop) Algoritmos disponibles Algoritmos No disponibles Tolerancia a Fallos Huge collection of algorithms Practically nothing Single point of failure Small subset: sequential logistic regression, linear SVMs, Stochastic Gradient Descendent, k-means clustering, Random forest, etc. Vast no.: Kernel SVMs, Multivariate Logistic Regression, Conjugate Gradient Descendent, ALS, etc. Most tools are FT, as they are built on top of Hadoop

52 Mahout Biblioteca de código abierto en APACHE 52


53 Mahout Cuatro grandes áreas de aplicación Agrupamiento Clasificación Sistemas de Recomendaciones Asociación 53
54 Mahout Caso de estudio: Random Forest para KddCup99 54
55 Mahout Caso de estudio: Random Forest para KddCup99 Implementación RF Mahout Partial: Es un algoritmo que genera varios árboles de diferentes partes de los datos (maps). Dos fases: Fase de Construcción Fase de Clasificación 55
56 Mahout Caso de estudio: Random Forest para KddCup99 Class Instance Number normal DOS PRB R2L U2R 52 Tiempo en segundos para ejecución Cluster ATLAS: 16 nodos -Microprocessors: 2 x Intel E (6 cores/12 56
57 Mahout Caso de estudio: Random Forest para KddCup99 Class Instance Number normal DOS PRB R2L U2R 52 Tiempo en segundos para Big Data con Cluster ATLAS: 16 nodos -Microprocessors: 2 x Intel E (6 cores/12 57
58 Índice Qué es Big Data? MapReduce: Paradigma de Programación para Big Data (Google) Plataforma Hadoop (Open access) Librería Mahout para Big Data Limitaciones de MapReduce
59 Hadoop Mahout Qué algoritmos puedo encontrar para Hadoop? Analizamos 10 algoritmos muy conocidos Decision trees (C4.5, Cart)(MReC4.5) K-Means SVM Apriori knn Naïve Bayes EM (Expectation Maximization) PageRank Adaboost Limitaciones de MapReduce Palit, I., Reddy, C.K., Scalable and parallel boosting with mapreduce. IEEE TKDE 24 (10), pp (Amazon EC2 cloud, CGL-MapReduce: (modelos No disponibles 59
60 Limitaciones de MapReduce If all you have is a hammer, then everything looks like a nail. Los siguientes tipos de algoritmos son ejemplos en los que MapReduce no funciona bien: Iterative Graph Algorithms Gradient Descent Expectation Maximization 60
61 Limitaciones de MapReduce Algoritmos de grafos iterativos. Existen muchas limitaciones para estos algoritmos. Ejemplo: Cada iteración de PageRank se corresponde a un trabajo de MapReduce. Se han propuesto una serie de extensiones de MapReduce o modelos de programación alternativa para acelerar el cálculo iterativo: Pregel (Google) Implementación: 61

62 Limitaciones de MapReduce Enrique Alfonseca 62

63 Limitaciones de MapReduce Procesos con flujos acíclicos de procesamiento de datos
64 Limitaciones de MapReduce GIRAPH (APACHE Project) ( Procesamiento iterativo de grafos GPS - A Graph Processing System, (Stanford) para Amazon's EC2 Twister (Indiana University) Clusters propios PrIter (University of Massachusetts Amherst, Northeastern University-China) Cluster propios y Amazon EC2 cloud Distributed GraphLab (Carnegie Mellon Univ.) Amazon's EC2 Spark (UC Berkeley) (Apache Foundation) HaLoop (University of Washington) Amazon s EC2 GPU based platforms Mars Grex 64
 abstraction, allowing iterative algorithms. It s about 100 times faster than Hadoop. Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J.")
65 Limitaciones de MapReduce Spark (UC Berkeley) It started as a research project at UC Berkeley in the AMPLab, which focuses on big data analytics. It introduces the resilient distributed datasets (RDD) abstraction, allowing iterative algorithms. It s about 100 times faster than Hadoop. Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauley, M., Franklin, M., Shenker, S., and Stoica, I. Resilient Distributed Datasets: A fault-tolerant abstraction for in-memory cluster computing. NSDI Hadoop Spark ML Lib Spark Big Data in-memory 65
66 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Algunas Aplicaciones 5. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 6. Deep Learning 7. Diseño de Algoritmos para Big Data
67 Apache Spark Generation Examples 1st Generation SAS, R, Weka, SPSS, KEEL 2nd Generation Mahout, Pentaho, Cascading Scalability Vertical Horizontal (over Hadoop) Algorithms Available Algorithms Not Available Fault- Tolerance Huge collection of algorithms Practically nothing Single point of failure Small subset: sequential logistic regression, linear SVMs, Stochastic Gradient Decendent, k- means clustsering, Random forest, etc. Vast no.: Kernel SVMs, Multivariate Logistic Regression, Conjugate Gradient Descendent, ALS, etc. Most tools are FT, as they are built on top of Hadoop 3nd Generation Spark, Haloop, GraphLab, Pregel, Giraph, ML over Storm Horizontal (Beyond Hadoop) Much wider: CGD, ALS, collaborative filtering, kernel SVM, matrix factorization, Gibbs sampling, etc. Multivariate logistic regression in general form, k-means clustering, etc. Work in progress to expand the set of available algorithms FT: HaLoop, Spark Not FT: Pregel, GraphLab, Giraph

68 Apache Spark
69 Apache Spark Arquitectura de Hadoop V1
70 Apache Spark Evolución de Hadoop

71 Apache Spark Apache Hadoop YARN es el sistema operativo de datos de Hadoop 2, responsable de la gestión del acceso a los recursos críticos de Hadoop. YARN permite al usuario interactuar con todos los datos de múltiples maneras al mismo tiempo, haciendo de Hadoop una verdadera plataforma de datos multiuso y lo que le permite tomar su lugar en una arquitectura de datos moderna.

72 Apache Spark


73 Apache Spark Enfoque InMemory HDFS Hadoop + SPARK Fast and expressive cluster computing
74 Esquema de computación más flexible que MapReduce. Permite la flujos acíclicos de procesamiento de datos, algoritmos iterativos Apache Spark Ecosistema Apache Spark Big Data in-memory. Spark permite realizar trabajos paralelizados totalmente en memoria, lo cual reduce mucho los tiempos de procesamiento. Sobre todo si se trata de unos procesos iterativos. En el caso de que algunos datos no quepan en la memoria, Spark seguirá trabajando y usará el disco duro para volcar aquellos datos que no se necesitan en este momento (Hadoop commodity hardware ). Spark ofrece una API para Java, Python y Scala
75 Apache Spark October 10, 2014 Using Spark on 206 EC2 nodes, we completed the benchmark in 23 minutes. This means that Spark sorted the same data 3X faster using 10X fewer machines. All the sorting took place on disk (HDFS), without using Spark s inmemory cache.

76 Apache Spark November 5,
77 Apache Spark Spark Programming Model KEY Concept: RDD (Resilient Distributed Datasets) Write programs in terms of operations on distributed data sets Collection of objects spread across a cluster, stored in RAM or on Disk Built through parallel transformations on distributed datasets Automaticallly rebuilt on failure RDD operations: transformations and actions Transformations (e.g. map, filter, groupby) (Lazy operations to build RDSs from other RDSs) Actions (eg. Count, collect, save ) (Return a result or write it a storage) Zaharia Zaharia M, Chowdhury M, Das T, Dave A, Ma J, McCauley M, Franklin MJ, Shenker S, Stoica I. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. In: 9th USENIX Conference on Networked Systems Design and Implementation, San Jose, CA, 2012, 1 14.
78 Apache Spark Spark Operations Transformations (define a new RDD) map filter sample groupbykey reducebykey sortbykey flatmap union join cogroup cross mapvalues Actions (return a result to driver program) collect reduce count save lookupkey Zaharia Zaharia M, Chowdhury M, Das T, Dave A, Ma J, McCauley M, Franklin MJ, Shenker S, Stoica I.
79 Apache Spark Enfoque InMemory Ecosistema Apache Spark Futura versión de Mahout con Spark wered+by+spark Databricks, Groupon, ebay inc., Amazon, Hitachi, Nokia, Yahoo!,
80 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 5. Deep Learning 6. Algunas Aplicaciones 7. Diseño de Algoritmos para Big Data

81 Aprendizaje automática en Big Data. Bibliotecas Biblioteca de código abierto Currently Mahout supports mainly three use cases: Recommendation mining takes users' behavior and from that tries to find items users might like. Clustering takes e.g. text documents and groups them into groups of topically related documents. Classification learns from existing categorized documents what documents of a specific category look like and is able to assign unlabelled documents to the (hopefully) correct category. 81
82 Aprendizaje automática en Big Data. Bibliotecas Historia 82

83 Aprendizaje automática en Big Data. Bibliotecas Historia 83

84 Aprendizaje automática en Big Data. Bibliotecas Historia 84
85 Aprendizaje automática en Big Data. Bibliotecas 85
86 Aprendizaje automática en Big Data. Bibliotecas Algoritmos Es una buena librería para introducirse en el uso de MapReduce sobre Hadoop 86

87 Aprendizaje automática en Big Data. Bibliotecas
88 Aprendizaje automática en Big Data. Bibliotecas
89 Aprendizaje automática en Big Data. Bibliotecas
90 Aprendizaje automática en Big Data. Bibliotecas
91 Aprendizaje automática en Big Data. Bibliotecas
92 Aprendizaje automática en Big Data. Bibliotecas
93 Aprendizaje automática en Big Data. Bibliotecas
94 Aprendizaje automática en Big Data. Bibliotecas Performance
95 Aprendizaje automática en Big Data. Bibliotecas
96 Aprendizaje automática en Big Data. Bibliotecas R packages using MapReduce: RHadoop RHIPE Hadoop Streaming R packages using Spark: SparkR SparkFernTreeR
97 Aprendizaje automática en Big Data. Bibliotecas RHadoop It is a collection of five R packages for connecting between Hadoop and R environment. rmr: It is an interface to perform MapReduce inside the R environment. rhdfs: It is an R interface for providing the HDFS commands from the R console. rhbase: It is an R interface for operating Hadoop MapReduce HBase data source stored at the distributed network via a Thrift server. plymr: This R package enables the R user to perform common data manipulation operations (plyr). ravro: The ravro package provides tools to allow reading of Avro data files into R.

98 Aprendizaje automática en Big Data. Bibliotecas Hadoop Streaming It is one of utilities provided by Hadoop to perform MapReduce job with executable scripts, such as Mapper and Reducer. The Hadoop streaming supports the Perl, Python, PHP, R, and C++ programming languages.

99 Aprendizaje automática en Big Data. Bibliotecas Rhipe It is a package that attempts to integrate R and Hadoop by using the concept Divide and Recombine (D & R). The D & R model is alike MapReduce provided by Hadoop.

100 Aprendizaje automática en Big Data. Bibliotecas SparkR It is an R package that integrates R with Spark and enables native R commands in a distributed mode.
101 Aprendizaje automática en Big Data. Bibliotecas SparkR Features and Advantages As Apache Spark providing a schema based on Resilient Distributed Datasets, SparkR offers many processes not only map and reduce, for example, filter, groupby, broadcast, etc. Since R supports functional programming, it is efficient on coding and quite similar to Scala. It is fault tolerant, scalable storage, distributed file systems as Spark. We can directly use available R packages by executing includepackage. Since SparkR works on R, we gain many benefits regarding visualizations, statistics, and other primitive functions in R. It works on the interactive mode, which is easy to use for data analysis.
102 Aprendizaje automática en Big Data. Bibliotecas SparkR Functions Basically, they are the same as Spark, but with additional functions: lapply, lapplypartition, and includepackage. Input data (create RDD): Load datasets (textfile). Create objects (parallelize). Types of RDD operations: Transformations: lapply, filterrdd, lapplypartition, etc Actions: reduce, reducebykey, take, collect, etc. Output data: Save to a file(object) (saveastextfile, saveasobjectfile). Print (collect, collectpartition).

103 Aprendizaje automática en Big Data. Bibliotecas SparkR
104 Aprendizaje automática en Big Data. Bibliotecas SparkFernTreeR (Lala Riza) It is an R package implementing random forest and random ferns for big data on the Apache Spark framework (with SparkR). It can be used on standalone machine(without SparkR) and cluster. Random forest is used for classification, regression, density estimation/clustering, and manifold learning. Random fern method is used for classification.
105 Aprendizaje automática en Big Data. Bibliotecas SparkFernTreeR (Lala Riza) It allows to parallelize based on data, model (tree), and both. For example, if testing data are small (less than 30% of RAM), we can parallelize trees instead of the data. Functions included in the packages: Learning: dectree, randforest, SparkRF, SparkFerns. Prediction: predict (S3), predictsparkforest, predictsparkferns.
106 Aprendizaje automática en Big Data. Bibliotecas SparkFernTreeR (Lala Riza) An example using IRIS data set
 Adaptada para")

107 Aprendizaje automática en Big Data. Bibliotecas Sofia-ML: Suit Of Fast Incremental Algorithms for Machine Learning Desarrollada por David Sculley (Google) Adaptada para problemas de extracción de conocimiento muy grandes Capaz de diseñar SVM a partir de ejemplos en 0.1 Incluye: segundos en un procesador a 2.4 GHz SVM (diferentes kernels), Regresión logística Redes neuronales: Passive-Aggresive Perceptron ROMMA, K-means Existe también un paquete en R para Sofia ML
108 Aprendizaje automática en Big Data. Bibliotecas Sofia-ML: Suit Of Fast Incremental Algorithms for Machine Learning
109 Aprendizaje automática en Big Data. Bibliotecas Wowpal Wabbit (Fast Learning) Fast & Incremental Learning) John Langford (Yahoo! and Microsoft) (A package in Debian & R) List of available algorithms: Active learning algorithms. Matrix factorization. Neural networks. BFGS. Stochastic gradient descent. Conjugate gradient, etc. A. Agarwal, O. Chapelle, M. Dudík, J. Langford. A Reliable Effective Terascale Linear Learning System. JMLR 15 (2014)
110 Aprendizaje automática en Big Data. Bibliotecas Wowpal Wabbit (Fast Learning)

111 Aprendizaje automática en Big Data. Bibliotecas MapReduce sobre GPU
112 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data Nota: Deep Learning no es big data per se, introduce el uso de estructuras de aprendizaje que requieren de arquitecturas de procesamiento eficientes, distribuido (GPU, ) 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 5. Deep Learning 6. Algunas Aplicaciones 7. Diseño de Algoritmos para Big Data
113 Aprendizaje automática en Big Data. Bibliotecas Deep Learning: El aprendizaje profundo es un conjunto de algoritmos que intento de modelar abstracciones de alto nivel en los datos mediante el uso de arquitecturas compuestas de transformación no lineales múltiple. Bibliografía: L. Deng and D. Yu. Deep Learning methods and applications. Foundations and Trends in Signal Processing Vol. 7, Issues 3-4, 2014.
114 Aprendizaje automática en Big Data. Bibliotecas Algunas definiciones (Deng and Yu, 2014)
115 Aprendizaje automática en Big Data. Bibliotecas Algunas definiciones (Deng and Yu, 2014)
116 Aprendizaje automática en Big Data. Bibliotecas Algunas definiciones (Deng and Yu, 2014)
117 Aprendizaje automática en Big Data. Bibliotecas Algunas definiciones (Deng and Yu, 2014)
118 Aprendizaje automática en Big Data. Bibliotecas Human information processing mechanisms (e.g., vision and audition),however, suggest the need of deep architectures for extracting complex structure and building internal representation from rich sensory inputs. Historically, the concept of deep learning originated from artificial neural network research. (Hence, one may occasionally hear the discussion of new-generation neural networks. ) Feed-forward neural networks or MLPs with many hidden layers, which are often referred to as deep neural networks (DNNs), are good examples of the models with a deep architecture.
119 Aprendizaje automática en Big Data. Bibliotecas Machine learning: Shallow-structured arquitectures Gaussian mixture models (GMMs), linear or nonlinear dynamical systems, conditional, random fields (CRFs), maximum entropy (MaxEnt) models, Support vector machines (SVMs), logistic regression, kernel regression, multilayer perceptrons (MLPs) with a single hidden layer including extreme learning machines (ELMs). These architectures typically contain at most one or two layers of nonlinear feature transformations.

120 Aprendizaje automática en Big Data. Bibliotecas Traditional recognition approaches Features are not learning

121 Aprendizaje automática en Big Data. Bibliotecas Shallow vs. deep architectures
122 Aprendizaje automática en Big Data. Bibliotecas k j Backpropagation w jk v ij Minimize error of calculated output Adjust weights Gradient Descent Procedure Forward Phase Backpropagation of errors For each sample, multiple epochs i
123 Aprendizaje automática en Big Data. Bibliotecas Problems with Backpropagation Multiple hidden Layers Get stuck in local optima start weights from random positions Slow convergence to optimum large training set needed Only use labeled data most data is unlabeled
124 Aprendizaje automática en Big Data. Bibliotecas Hierarchical Learning Natural progression from low level to high level structure as seen in natural complexity Easier to monitor what is being learnt and to guide the machine to better subspaces Usually best when input space is locally structured spatial or temporal: images, language, etc. vs arbitrary input features
125 Aprendizaje automática en Big Data. Bibliotecas Deep Architecture (Train networks with many layers) Multiple hidden layers Motivation (why go deep?) Approximate complex decision boundary Fewer computational units for same functional mapping Hierarchical Learning Increasingly complex features work well in different domains Vision, Audio,
126 Aprendizaje automática en Big Data. Bibliotecas Deep Architecture (Train networks with many layers) Some Models: Deep networks for unsupervised or generative learning: deep belief network (DBN, a stack of restricted Boltzmann machines (RBMs). Deep networks for supervised learning: Deep Neural Networks (DNN), Convolutional neural network (CNN), in which each module consists of a convolutional layer and a pooling layer, CNNs have been found highly effective and been commonly used in computer vision and image recognition). Hybrid deep networks: DBN-DNN (when DBN is used to initialize the training of a DNN, the resulting network is sometimes called the DBN DNN)
127 Aprendizaje automática en Big Data. Bibliotecas Convolutional Neural Networks Each layer combines (merges, smoothes) patches from previous layers Typically tries to compress large data (images) into a smaller set of robust features, based on local variations Basic convolution can still create many features

128 Aprendizaje automática en Big Data. Bibliotecas Convolutional Neural Networks C layers are convolutions, S layers pool/sample
129 Aprendizaje automática en Big Data. Bibliotecas ImageNet Classification with Deep Convolutional Neural Networks Part of: Advances in Neural Information Processing Systems 25 (NIPS 2012) ImageNet is a dataset of over 15 million labeled high-resolution images belonging to roughly 22,000 categories. The images were collected from the web and labeled by human labelers using Amazon s Mechanical Turk crowdsourcing tool. Starting in 2010, as part of the Pascal Visual Object Challenge, an annual competition called the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) has been held. ILSVRC uses a subset of ImageNet with roughly 1000 images in each of 1000 categories. In all, there are roughly 1.2 million training images, 50,000 validation images, and 150,000 testing images.
130 Aprendizaje automática en Big Data. Bibliotecas Google Brain is a deep learning research project at Google Google cuenta, desde hace tres años con el departamento conocido como Google Brain (dirigido por Andrew Ng, Univ. Stanford, responsable de un curso de coursera de machine learning) dedicado a esta técnica entre otras. En 2013, Google adquirió la compañía DNNresearch Inc de uno de los padres del Deep Learning (Geoffrey Hinton). En enero de 2014 se hizo con el control de la startup Deepmind Technologies una pequeña empresa londinense en la trabajaban que algunos de los mayores expertos en deep learning.


131 Aprendizaje automática en Big Data. Bibliotecas Google Brain is a deep learning research project at Google
132 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle (A. Herrera-Poyatos) Andrés Herrera Poyatos Repositorio en GitHub con el código:

133 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle Desarrollar un reconocedor de dígitos es uno de los problemas clásicos de la ciencia de datos. Sirve de benchmark para probar los nuevos algoritmos. Ningún un humano acierta el 100%! Aplicación práctica: detección de matrículas, conversión de escritura a mano en texto

134 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle Kaggle mantiene una competición pública: Datos a analizar: MNIST DATA
135 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle Data Set: Training Set: Imágenes Test Set: Imágenes Imagen: 10 clases: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 28x28 píxeles Ejemplo: Puntuación para la clasificación general: índice de acierto sobre un 25% del Test Set.
136 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle 1. Primer paso 1. Probar los algoritmos más conocidos para usarlos como benchmark KNN con k = 10 Random Forest con 1000 árboles en Kaggle en Kaggle 2. Optimizar los parámetros de un algoritmo sencillo Cross Validation sobre KNN para encontrar el mejor valor de k. Solución: K= en Kaggle
137 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle 2. Visualización Media de todas las imágenes del training set por clases: Observación: Incluso las medias no están centradas (ver 6 y 7). Esto provoca problemas para clasificarlas correctamente. Solución: Preprocesamiento
138 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle 3. Preprocesamiento Idea: Eliminar las filas y columnas de píxeles en blanco. Problema: Las nuevas imágenes tienen diferentes dimensiones.
139 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle 3. Preprocesamiento Solución: Redimensionar las imágenes a 20x20 píxeles (tras el proceso anterior la imagen más grande tiene esa dimensión) Media de las imágenes del training set preprocesadas: Todas están centradas! KNN con k=1 sobre los datos preprocesados en Kaggle

140 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle Librería que contiene Deep Learning: H2O Récord del mundo en el problema MNIST sin preprocesamiento Soporte para R, Hadoop y Spark Funcionamiento: Crea una máquina virtual con Java en la que optimiza el paralelismo de los algoritmos.

141 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle
142 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle
143 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle 4. Deep Learning sobre MNIST DATA preprocesados Andrés Herrera Poyatos Repositorio en GitHub con el código:
144 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle 4. Deep Learning sobre MNIST DATA preprocesados hidden=c(1024,1024,2048) Andrés Herrera Poyatos Repositorio en GitHub con el código:
145 Aprendizaje automática en Big Data. Bibliotecas 4. Deep Learning sobre MNIST DATA preprocesados Tiempo de Ejecución: 2.5 horas de cómputo con un Procesador Intel i5 a 2.5 GHz. Resultados conseguidos: Deep Learning en Kaggle Preprocesamiento + Deep Learning en Kaggle El primer resultado era !
146 Aprendizaje automática en Big Data. Bibliotecas Caso estudio: Digit Recognizer Kaggle Librería de Deep Learning en Python nolearn - Web: Incluye: DBN y CNN.
147 Aprendizaje automática en Big Data. Bibliotecas Deep Learning Referencias: L. Deng and D. Yu. Deep Learning methods and applications. Foundations and Trends in Signal Processing Vol. 7, Issues 3-4, A fast learning algorithm for deep belief nets -- Hinton et al., 2006 Reducing the dimensionality of data with neural networks -- Hinton & Salakhutdinov Páginas web personales de los 2 investigadores de referencia: (G. Hinton) ml (Yosua Bengio)
148 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 5. Deep Learning 6. Algunas Aplicaciones 7. Diseño de Algoritmos para Big Data
149 Algunas aplicaciones Netflix (el origen de Kaggle)
150 Algunas aplicaciones Google Flu ( Detect pandemic risk in real time 2009, nuevo virus gripe A: cepa H1N1 Sanidad pública temía una pandemia similar a la de la gripe española de millones de afectados Decenas de millones de fallecidos No hay vacuna, hay que ralentizar la propagación Solución: Los centros de control y prevención de enfermedades (CDC) recopilan datos de los médicos Se consigue un panorama de la pandemia con un desfase, retraso de 2 semanas!
151 Algunas aplicaciones Google Flu Google puede predecir la propagación de la gripe ( ) analizando lo que la gente busca en internet J. Ginsberg, M.H. Mohebbi, R.S. Patel, L. Brammer, M.S. Smolinski, L. Brilliant. Detecting influenza epidemics using search engine query data. Nature 475 (2009) Google utilizó: Detect pandemic risk in real time + de 3.000M de búsquedas a diario 50 M de términos de búsqueda más utilizados Comparó esta lista con los datos de los CDC sobre propagación de gripe entre 2003 y 2008 Identificar a los afectados en base a sus búsquedas Buscaron correlaciones entre frecuencia de búsquedas de información y propagación de la gripe en tiempo y espacio
152 Algunas aplicaciones Google Flu Detect pandemic risk in real time Encontraron una combinación de 45 términos de búsqueda que al usarse con un modelo matemático presentaba una correlación fuerte entre su predicción y las cifras oficiales de la enfermedad Podían decir, como los CDC, a dónde se había propagado la gripe pero casi en tiempo real, no una o dos semanas después Con un método basado en Big Data Se ha extendido a 29 países En 2013 sobreestimó los niveles de gripe (x2 la estimación CDC) La sobreestimación puede deberse a la amplia cobertura mediática de la gripe que puede modificar comportamientos de búsqueda Los modelos se van actualizando anualmente
153 Algunas aplicaciones Google Flu Trends (2008) ( Detect pandemic risk in real time Wikipedia Usage Estimates Prevalence of Influenza-Like Illness in the United States in Near Real-Time David J. McIver, John S. Brownstein, Harvard Medical School, Boston Children s Hospital, Plos Computational Biology, Wikipedia traffic could be used to provide real time tracking of flu cases, according to the study published by John Brownstein. Wikipedia is better than Google at tracking flu trends? 154
154 Algunas aplicaciones Studies: Health, Social Media and Big Data You Are What You Tweet: Analyzing Twitter for Public Health Discovering Health Topics in Social Media Using Topic Models Michael J. Paul, Mark Dredze, Johns Hopkins University, Plos One, 2014 Analyzing user messages in social media can measure different population characteristics, including public health measures. A system filtering Twitter data can automatically infer health topics in 144 million Twitter messages from 2011 to ATAM discovered 13 coherent clusters of Twitter messages, some of which correlate with seasonal influenza (r = 0.689) and allergies (r = 0.810) temporal surveillance data, as well as exercise (r =.534) and obesity (r =2.631) related geographic survey data in the United States. 155


155 Algunas aplicaciones Big Data, Vol.2, 2,
156 Algunas aplicaciones Earthquakes and Social Media The United States Geological Survey Twitter searches increases in the volume of messages on earthquake and has been able to locate earthquakes with 90% accuracy.


157 Algunas aplicaciones
158 Algunas aplicaciones Objectives include: 1. Increasing the number of Big Data for Development (BD4D) innovation success cases 2. Lowering systemic barriers to big data for development adoption and scaling 3. Strengthening cooperation in the big data for development ecosystem 159


159 Algunas aplicaciones 160
160 Algunas aplicaciones potential-business-applications-ibms-watson-cloudecosystem By Dave Smith on November IBM is 12:22 preparing PM its Watson supercomputer technology to be utilized by thirdparty developers for the first time via a Watson cloud service called the 161
161 Algunas aplicaciones ECBDL 14 Big Data Competition Big Data Competition 2014: Self-deployment track Objective: Contact map prediction Details: 32 million instances 631 attributes (539 real & 92 nominal values) 2 classes 98% of negative examples About 56.7GB of disk space
162 Algunas aplicaciones ECBDL 14 Big Data Competition 2014 The challenge: Very large size of the training set Does not fit all together in memory. Even large for the test set (5.1GB, 2.9 million instances) Relatively high dimensional data. Low ratio (<2%) of true contacts. Imbalance rate: > 49 Unbalanced problem!
163 Algunas aplicaciones Our approach: ECBDL 14 Big Data Competition Balance the original training data Random Oversampling (As first idea, it was extended) 2. Detect relevant features. 1. Evolutionary Feature Weighting 3. Learning a model. Random Forest Classifiying test set.
164 Algunas aplicaciones ECBDL 14 Big Data Competition 2014 Results of the competition: Contact map prediction Team Name TPR TNR Acc TPR TNR Efdamis ICOS UNSW HyperEns PUC-Rio_ICA Test EmeraldLogic LidiaGroup EFDAMIS team ranked first in the ECBDL 14 big data competition
165 Algunas aplicaciones ECBDL 14 Big Data Competition
166 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 5. Deep Learning 6. Algunas Aplicaciones 7. Diseño de Algoritmos para Big Data
167 Índice Casos de estudio de aprendizaje no supervisado Casos de estudio de clasificación Casos de estudio de clasificación no balanceada Preprocesamiento de datos en Big Data

168 Aprendizaje no supervisado Mahout MLlib 169

169 Aprendizaje no supervisado Mahout: K-means clustering 170

170 Aprendizaje no supervisado Mahout: K-means clustering 171
171 Aprendizaje no supervisado Mahout: K-means clustering 172
172 Aprendizaje no supervisado Mahout: K-means clustering 173


173 Aprendizaje no supervisado 174
174 Aprendizaje no supervisado MLlib: K-means clustering 175
175 Aprendizaje no supervisado MLlib: FP-growth Mllib implements a parallel version of FP-growth called PFP, as described in Li et al., PFP: Parallel FP-growth for query recommendation. RecSys 08 Proceedings of the 2008 ACM conference on Recommender systems Pages PFP distributes the work of growing FP-trees based on the suffices of transactions, and hence more scalable than a single-machine implementation. 176
176 Índice Casos de estudio de aprendizaje no supervisado Casos de estudio de clasificación Casos de estudio de clasificación no balanceada Preprocesamiento de datos en Big Data
177 Clasificación Mahout MLlib 178
178 Clasificación: RF Caso de estudio: Random Forest para KddCup99 179
179 Clasificación: RF Caso de estudio: Random Forest para KddCup99 Implementación RF Mahout Partial: Es un algoritmo que genera varios árboles de diferentes partes de los datos (maps). Dos fases: Fase de Construcción 180

180 Clasificación: RF Caso de estudio: Random Forest para KddCup99 181
181 Clasificación: RF Caso de estudio: Random Forest para KddCup99 Implementación RF Mahout Partial: Es un algoritmo que genera varios árboles de diferentes partes de los datos (maps). Dos fases: Fase de Clasificación 182

182 Clasificación: RF Caso de estudio: Random Forest para KddCup99 Class Instance Number normal DOS PRB R2L U2R 52 Tiempo en segundos para ejecución secuencial Cluster ATLAS: 16 nodos -Microprocessors: 2 x Intel E (6 cores/12 183
 Cluster ATLAS: 16 nodos -Microprocessors: 2 x Intel E5-2620 (6")
183 Clasificación: RF Caso de estudio: Random Forest para KddCup99 Class Instance Number normal DOS PRB R2L U2R 52 Tiempo en segundos para Big Da con 20 Bloques (Maps) Cluster ATLAS: 16 nodos -Microprocessors: 2 x Intel E (6 cores/12 184
184 Clasificación: Generación Prototipos A Combined MapReduce-Windowing Two-Level Parallel Scheme for Evolutionary Prototype Generation I. Triguero, D. Peralta, J. Bacardit, S.García, F. Herrera. A Combined MapReduce-Windowing Two-Level Parallel Scheme for Evolutionary Prototype Generation. IEEE CEC Conference, I. Triguero
185 Clasificación: Generación Prototipos Prototype Generation: properties The NN classifier is one of the most used algorithms in machine learning. Prototype Generation (PG) processes learn new representative examples if needed. It results in more accurate results. Advantages: PG reduces the computational costs and high storage requirements of NN. Evolutionary PG algorithms highlighted as the best performing approaches. Main issues: Dealing with big data becomes impractical in terms of Runtime and Memory consumption. Especially for EPG. I. Triguero
186 Clasificación: Generación Prototipos Evolutionary Prototype Generation Evolutionary PG algorithms are typically based on adjustment of the positioning of the prototypes. Each individual encodes a single prototype or a complete generated set with real codification. The fitness function is computed as the classification performance in the training set using the Generated Set. Currently, best performing approaches use differential evolution. I. Triguero, S. García, F. Herrera, IPADE: Iterative Prototype Adjustment for Nearest Neighbor Classification. IEEE Transactions on Neural Networks 21 (12) (2010) More information about Prototype Reduction can be found in the SCI2S thematic website: I. Triguero
187 Clasificación: Generación Prototipos Parallelizing PG with MapReduce Map phase: Each map constitutes a subset of the original training data. It applies a Prototype Generation step. For evalution, it use Windowing: Incremental Learning with Alternating Strata (ILAS) As output, it returns a Generated Set of prototypes. Reduce phase: We established a single reducer. It consists of an iterative aggregation of all the resulting generated sets. As output, it returns the final Generated Set. I. Triguero
188 Clasificación: Generación Prototipos Parallelizing PG with MapReduce The key of a MapReduce data partitioning approach is usually on the reduce phase. Two alternative reducers: Join: Concatenates all the resulting generated sets. This process does not guarantee that the final generated set does not contain irrelevant or even harmful instances Fusion: This variant eliminates redundant prototypes by fusion of prototypes. Centroid-based PG methods: ICPL2 (Lam et al). W. Lam et al, Discovering useful concept prototypes for classification based on filtering and abstraction. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 14, no. 8, pp , 2002 I. Triguero
189 Clasificación: Generación Prototipos Windowing: Incremental Learning with Alternating Strata (ILAS) Training set is divided into strata, each iteration just uses one of the stratum. Training set 0 Ex/n 2 Ex/n 3 Ex/n Ex Iterations 0 Iter Main properties: Avoids a (potentially biased) static prototype selection This mechanism also introduces some generalization pressure J. Bacardit et al, Speeding-up pittsburgh learning classifier systems: Modeling time and accuracy In Parallel Problem Solving from Nature - PPSN VIII, ser. LNCS, vol. 3242, 2004, pp I. Triguero
190 Clasificación: Generación Prototipos The MRW-EPG scheme Windowing: Incremental Learning with Alternating Strata (ILAS) I. Triguero
191 Clasificación: Generación Prototipos Experimental Study PokerHand data set. 1 million of instances, 3x5 fcv. Performance measures: Accuracy, reduction rate, runtime, test classification time and speed up. PG technique tested: IPADECS. I. Triguero

192 Clasificación: Generación Prototipos Results PokerHand: Accuracy Test vs. Runtime results obtained by MRW-EPG I. Triguero

193 Clasificación: Generación Prototipos Results I. Triguero

194 Clasificación: Generación Prototipos Results: Speed-up I. Triguero
195 Clasificación: Generación Prototipos EPG for Big Data: Final Comments There is a good synergy between the windowing and MapReduce approaches. They complement themselves in the proposed twolevel scheme. Without windowing, evolutionary prototype generation could not be applied to data sets larger than approximately ten thousands instances The application of this model has resulted in a very big reduction of storage requirements and classification time for the NN rule. I. Triguero
196 Clasificación: Generación Prototipos EPG for Big Data: Final Comments Complete study: I. Triguero, D. Peralta, J. Bacardit, S. García, F. Herrera. MRPR: A MapReduce solution for prototype reduction in big data classification. Neurocomputing 150 (2015) ENN algorithm for Filtering

197 Fig. 6 Average runtime obtained by MRPR. (a) PokerHand Complete study: I. Triguero, D. Peralta, J. Bacardit, S. García, F. Herrera. MRPR: A MapReduce solution for Clasificación: Generación Prototipos EPG for Big Data: Final Comments
198 Clasificación: Boosting Referencia: I. Palit, C. Chandan, K. Reddy. Scalable and Parallel Boosting with MapReduce. IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 24, NO. 10, OCTOBER 2012,
199 Índice Casos de estudio de aprendizaje no supervisado Casos de estudio de clasificación Casos de estudio de clasificación no balanceada Preprocesamiento de datos en Big Data
200 Clasificación no balanceada S. del Río
201 Clasificación no balanceada S. del Río
202 Clasificación no balanceada S. del Río
203 Clasificación no balanceada S. del Río

204 Clasificación no balanceada S del Río, V López, JM Benítez, F Herrera On the use of MapReduce for S. del Río
205 Clasificación no balanceada S. del Río
206 Clasificación no balanceada S. del Río
207 Clasificación no balanceada S. del Río
208 Clasificación no balanceada S. del Río
209 Clasificación no balanceada S. del Río
210 Clasificación no balanceada S. del Río

211 Clasificación no balanceada Analysis of the sequential versions when the size of the data available is increased S. del Río
212 Clasificación no balanceada Analysis of the effectiveness in classification of the approaches (Potential problem: lack of density of the positive class for RUS/SMOTE) S. del Río
213 Clasificación no balanceada Average number of positive instances by mapper for kddcup DOS vs PRB (Potential problem: lack of density of the positive class) S. del Río
214 Clasificación no balanceada Coments It is needed to determine the threshold for the minority class with respect to the number of mappers in order to find the best configuration that provides a better performance and lesser response time. Considering the results of the SMOTE algorithm, is necessary to design new techniques that are able to generate synthetic data that represent the minority class instances in the best way. It is necessary to analyse some data intrinsic characteristics that interact with this issue aggravating the problem in order to increase the performance with imbalanced big data (e.g., presence of noisy, the small sample size problem or the dataset shift problem). S. del Río
215 Clasificación no balanceada: Caso de estudio Source of dataset: Protein Structure Prediction (PSP) aims to predict the 3D structure of a protein based on its primary sequence Primary Sequence 3D Structure J. Bacardit et al, Contact map prediction using a large-scale ensemble of rule sets and the fusion of multiple predicted structural features, Bioinformatics 28 (19) (2012)
216 Clasificación no balanceada: Caso de estudio Contact Map dataset A diverse set of 3262 proteins with known structure were selected 90% of this set was used for training 10% for test Instances were generated for pairs of AAs at least 6 positions apart in the chain (avoiding trivial contacts) The resulting training set contained 32 million pairs of AA and 631 attributes Less than 2% of those are actual contacts +60GB of disk space Test set of 2.89M instances Data files available at
217 Evolutionary Computation for Big Data and Big Learning Workshop ECBDL 14 Big Data Competition 2014: Self-deployment track Objective: Contact map prediction Details: 32 million instances 631 attributes (539 real & 92 nominal values) 2 classes 98% of negative examples About 56.7GB of disk space Evaluation: True positive rate True negative rate TPR TNR J. Bacardit et al, Contact map prediction using a large-scale ensemble of rule sets and the fusion of multiple predicted structural features, Bioinformatics 28 (19) (2012)
218 Evolutionary Computation for Big Data and Big Learning Workshop ECBDL 14 Big Data Competition 2014: Self-deployment track The challenge: Very large size of the training set Does not fit all together in memory. Even large for the test set (5.1GB, 2.9 million instances) Relatively high dimensional data. Low ratio (<2%) of true contacts. Imbalance rate: > 49 Imbalanced problem!
219 ECBDL 14 Big Data Competition Strategies to deal with imbalanced data sets: Data level vs algorithm level Over-Sampling Random Focused Retain influential examples Balance the training set Under-Sampling Random Focused Remove noisy instances in the decision boundaries Reduce the training set Cost Modifying (cost-sensitive) Algorithm-level approaches: A commont strategy to deal with the class imbalance is to choose an appropriate inductive bias. Boosting approaches: ensemble learning, AdaBoost, 220
220 ECBDL 14 Big Data Competition A MapReduce Approach 32 million instances, 98% of negative examples Low ratio of true contacts (<2%). Imbalance rate: > 49. Imbalanced problem! Previous study on extremely imbalanced big data: S. Río, V. López, J.M. Benítez, F. Herrera, On the use of MapReduce for Imbalanced Big Data using Random Forest. Information Sciences 285 (2014) Over-Sampling Random Focused Under-Sampling Random Focused Cost Modifying (cost-sensitive) Boosting/Bagging approaches (with preprocessing)
221 ECBDL 14 Big Data Competition Our approach: ECBDL 14 Big Data Competition Balance the original training data Random Oversampling (As first idea, it was extended) 2. Learning a model. Random Forest 3. Detect relevant features. 1. Evolutionary Feature Weighting Classifying test set.


222 ECBDL 14 Big Data Competition A MapReduce Approach for Random Oversampling Low ratio of true contacts (<2%). Imbalance rate: > 49. Imbalanced problem! Initial Map ROS-M-data 1 ROS-R-data 1 Reduce ROS-M-data 2 ROS-R-data 2 ROS-data Original dataset Final dataset ROS-M-data n ROS-R-data n Maps set S. Río, V. López, J.M. Benítez, F. Herrera, On the use of MapReduce for Imbalanced Big Data using Random Forest. Information Sciences, 2014.
223 ECBDL 14 Big Data Competition A MapReduce Approach for Random Oversampling

224 Predicted class ECBDL 14 Big Data Competition Building a model with Random Forest Bootstrap sample Building Random trees Majority Voting Select m variables at random for each node decision Compute best split using the m variables as CART Training dataset Fully grow the trees and do not prune them
225 ECBDL 14 Big Data Competition We initially focused on Oversampling rate: 100% RandomForest: Number of used features: 10 (log n +1); Number of trees: 100 Number of maps: {64, 190, 1024, 2048} TNR*TPR Nº mappers TPR_tst TNR_tst Test 64 0, , , How to increase the TPR rate? Very low TPR (relevant!) Idea: To increase the ROS percentaje
226 ECBDL 14 Big Data Competition How to increase the TPR rate? Idea: To increase the ROS percentaje Oversampling rate: {100, 105, 110, 115, 130} RandomForest: Number of used features:10; Number of trees: 100 Algorithms TPR TNR TNR*TPR Test ROS+RF (RS: 100%) ROS+RF (RS: 105%) ROS+RF (RS: 110%) ROS+RF (RS: 115%) ROS+RF (RS: 130%) The higher ROS percentage, the higher TPR and the lower TNR
227 ECBDL 14 Big Data Competition How to increase the performance? Third component: MapReduce Approach for Feature Weighting for getting a major performance over classes Map Side Each map read one block from dataset. Perform an Evolutionary Feature Weighting step. Output: a real vector that represents the degree of importance of each feature. Number of maps: (less than 1000 original data per map) Reduce Side Aggregate the feature s weights A feature is finally selected if it overcomes a given threshold. Output: a binary vector that represents the final selection I. Triguero, J. Derrac, S. García, F. Herrera, Integrating a Differential Evolution Feature Weighting scheme into Prototype Generation. Neurocomputing 97 (2012)
228 ECBDL 14 Big Data Competition
229 ECBDL 14 Big Data Competition Evolutionary Feature Weighting. It allows us to construct several subset of features (changing the threshold). 64 mappers Algorithms TNR*TPR TNR*TPR Training TPR TNR Test ROS+RF (130% - Feature Weighting 63) ROS+RF (115% - Feature Weighting 63) ROS+RF (100% - Feature Weighting 63)
230 ECBDL 14 Big Data Competition We decided to investigate: a) On the Random Forest: the influence of the Random Forest s parameters (internal features and number of trees) b) Higher number of features (90) and ROS with 140% 190 mappers Algorithms TNR*TPR TNR*TPR Training TPR TNR Test ROS+ RF (130%+ FW 63+6f+100t) ROS+ RF (130%+ FW 63+6f+200t) ROS+ RF (140%+ FW 63+15f+200t) ROS+ RF (140%+ FW 90+15f+200t) ROS+ RF (140%+ FW 90+25f+200t) Correct decisions with FW 90 and RF with 25f and 200 trees. Good trade off between TPR and TNR
231 ECBDL 14 Big Data Competition The less number of maps, the less TPR and the high TNR Algorithms 190 mappers TNR*TPR Training TPR TNR 64 mappers TNR*TPR Test ROS+ RF (140%+ FW 90+25f+200t) Algorithms TNR*TPR Training TPR TNR TNR*TPR Test ROS+ RF (130%+ FW 90+25f+200t) ROS+ RF (140%+ FW 90+25f+200t) mappers and we got 0.53 ROS (140 68) replications of the minority instances
232 ECBDL 14 Big Data Competition Current state: Our knowledge: Good configuration: FW 90 and RF with 25 f + 200t The higher ROS percentage, the higher TPR and the lower TNR The less number of maps, the less TPR and the high TNR and high accuracy. 4 days to finish the competion: 64 mappers Algorithms TNR*TPR Training TPR TNR TNR*TPR Test ROS+ RF (140%+ FW 90+25f+200t) Can we take decisions for improving the model?
233 ECBDL 14 Big Data Competition Last decision: We investigated to increase ROS until 180% with 64 mappers 64 mappers Algorithms TNR*TPR Training TPR TNR TNR*TPR Test ROS+ RF (130%+ FW 90+25f+200t) ROS+ RF (140%+ FW 90+25f+200t) ROS+ RF (150%+ FW 90+25f+200t) ROS+ RF (160%+ FW 90+25f+200t) 0, ROS+ RF (170%+ FW 90+25f+200t) ROS+ RF (180%+ FW 90+25f+200t) 0, To increase ROS and reduce the mappers number lead us to get a tradeoff with good results ROS replications of the minority instances
234 ECBDL 14 Big Data Competition ROS replications of the minority instances Experiments with 64 maps
235 ECBDL 14 Big Data Competition Evolutionary Computation for Big Data and Big Learning Workshop Results of the competition: Contact map prediction Team Name TPR TNR Acc TPR TNR Efdamis ICOS UNSW HyperEns PUC-Rio_ICA Test EmeraldLogic EFDAMIS team ranked first in the ECBDL 14 big data competition LidiaGroup
236 ECBDL 14 Big Data Competition Evolutionary Computation for Big Data and Big Learning Workshop Results of the competition: Contact map prediction Team Name TPR TNR Acc TPR TNR Efdamis ICOS UNSW Algorithms 64 mappers TNR*TPR Training TPR TNR TNR*TPR Test ROS+RF (130% - Feature Weighting 63) ROS+RF (115% - Feature Weighting 63) ROS+RF (100% - Feature Weighting 63) To increase ROS and to use Evolutionary feature weighting were two good decisions for getting the first position

237 ECBDL 14 Big Data Competition Our algorithm: ROSEFW-RF
238 ECBDL 14 Big Data Competition At the beginning ROS+RF (RS: 100%) TNR*TPR Nº mappers TPR_tst TNR_tst Test 64 0, , , At the end 64 mappers Algorithms TNR*TPR Training TPR TNR TNR*TPR Test ROS+ RF (160%+ FW 90+25f+200t) 0, ROS+ RF (170%+ FW 90+25f+200t) ROS+ RF (180%+ FW 90+25f+200t) 0,

239 ECBDL 14 Big Data Competition Timeline (364 predictions)

240 ECBDL 14 Big Data Competition Team Name Efdamis ICOS UNSW Learning strategy Oversampling+FS+Random Forest Oversampling+Ensemble of Rule sets Ensemble of Deep Learning classifiers Computational Infrastructure MapReduce Batch HPC Parallel HPC HyperEns SVM Parallel HPC PUC-Rio_ICA Linear GP GPUs EmeraldLogic ~Linear GP GPUs LidiaGroup 1-layer NN Spark??
241 ECBDL 14 Big Data Competition
242 Índice Casos de estudio de aprendizaje no supervisado Casos de estudio de clasificación Casos de estudio de clasificación no balanceada Preprocesamiento de datos en Big Data
243 Preprocesamiento de datos en Big Bata Hay muy pocos algoritmos de preprocesamiento de da Las posibilidades de algoritmos muy grandes: S. García, J. Luengo, F. Herrera Data Preprocessing in Data Mining Springer, Enero 2015
244 Preprocesamiento de datos en Big Bata ChiSqSelector ChiSqSelector stands for Chi-Squared feature selection. It operates on labeled data with categorical features. ChiSqSelector orders features based on a Chi-Squared test of independence from the class, and then filters (selects) the top features which are most closely related to the label. Model Fitting ChiSqSelector has the following parameters in the constructor: numtopfeatures number of top features that the selector will select (filter).
245 Preprocesamiento de datos en Big Bata 2 propuestas recientes: (Journal submission)
246 Preprocesamiento de datos en Big Bata 2 propuestas recientes: (BigDataSE2015 submission)
247 Sistemas Inteligentes para la Gestión de la Empresa TEMA 6. Big Data 1. Introducción a Big data 2. Paradigma MapReduce 3. Plataforma Apache Spark 4. Aprendizaje automático en Big Data. Bibliotecas y Algoritmos 5. Deep Learning 6. Algunas Aplicaciones 7. Diseño de Algoritmos para Big Data
248 Comentarios Finales Machine learning: Huge collection of algorithms Big data: A small subset of algorithms Para el diseño y/o adaptación de cualquier algoritmo es necesario diseñar de forma adecuada una fase de fusión de información por cuanto siempre será necesario utilizar funciones Map y Reduce cuando la base de datos sea muy grande. Igualmente los procedimientos iterativos requieren de un diseño adecuado para optimizar la eficiencia. Todavía se está en una fase muy temprana de diseño de algoritmos de aprendizaje automático para big data. El preprocesamiento de datos es esencial para mejorar el comportamiento de los algoritmos de aprendizaje. El diseño de estos algoritmos para big data está en una fase muy incipiente.


249 Comentarios Finales 250
Big Data. Francisco Herrera. Research Group on Soft Computing and Information Intelligent Systems (SCI 2 S) University of Granada, Spain
 University of Granada, Spain") Big Data Francisco Herrera Research Group on Soft Computing and Information Intelligent Systems (SCI 2 S) Dept. of Computer Science and A.I. University of Granada, Spain Email: herrera@decsai ugr es Email:
Big Data Francisco Herrera Research Group on Soft Computing and Information Intelligent Systems (SCI 2 S) Dept. of Computer Science and A.I. University of Granada, Spain Email: herrera@decsai ugr es Email:
Francisco Herrera. Dpto. Ciencias de la Computación e I.A. Universidad de Granada
 Francisco Herrera Dpto. Ciencias de la Computación e I.A. Universidad de Granada herrera@decsai.ugr.es Grupo de investigación SCI 2 S http://sci2s.ugr.es Big Data 2 Big Data Nuestro mundo gira en torno
Francisco Herrera Dpto. Ciencias de la Computación e I.A. Universidad de Granada herrera@decsai.ugr.es Grupo de investigación SCI 2 S http://sci2s.ugr.es Big Data 2 Big Data Nuestro mundo gira en torno
Big Data & Machine Learning. MSc. Ing. Máximo Gurméndez Universidad de Montevideo
 Big Data & Machine Learning MSc. Ing. Máximo Gurméndez Universidad de Montevideo Qué es Big Data? Qué es Machine Learning? Qué es Data Science? Ejemplo: Predecir origen de artículos QUÉ DIARIO LO ESCRIBIÓ?
Big Data & Machine Learning MSc. Ing. Máximo Gurméndez Universidad de Montevideo Qué es Big Data? Qué es Machine Learning? Qué es Data Science? Ejemplo: Predecir origen de artículos QUÉ DIARIO LO ESCRIBIÓ?
Francisco Herrera. Dpto. Ciencias de la Computación e I.A. Universidad de Granada
 Big Data Francisco Herrera Dpto. Ciencias de la Computación e I.A. Universidad de Granada herrera@decsai.ugr.es Grupo de investigación SCI 2 S http://sci2s.ugr.es Big Data Nuestro mundo gira en torno a
Big Data Francisco Herrera Dpto. Ciencias de la Computación e I.A. Universidad de Granada herrera@decsai.ugr.es Grupo de investigación SCI 2 S http://sci2s.ugr.es Big Data Nuestro mundo gira en torno a
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK. www.formacionhadoop.com
 CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
CURSO: APACHE SPARK CAPÍTULO 2: INTRODUCCIÓN A APACHE SPARK www.formacionhadoop.com Índice 1 Qué es Big Data? 2 Problemas con los sistemas tradicionales 3 Qué es Spark? 3.1 Procesamiento de datos distribuido
BIG DATA & SEGURIDAD UN MATRIMONIO DE FUTURO
 BIG DATA & SEGURIDAD UN MATRIMONIO DE FUTURO PRESENTACIÓN ANTONIO GONZÁLEZ CASTRO IT SECURITY DIRECTOR EN PRAGSIS TECHNOLOGIES agcastro@pragsis.com antoniogonzalezcastro.es @agonzaca linkedin.com/in/agonzaca
BIG DATA & SEGURIDAD UN MATRIMONIO DE FUTURO PRESENTACIÓN ANTONIO GONZÁLEZ CASTRO IT SECURITY DIRECTOR EN PRAGSIS TECHNOLOGIES agcastro@pragsis.com antoniogonzalezcastro.es @agonzaca linkedin.com/in/agonzaca
Big Data: retos a nivel de desarrollo. Ing. Jorge Camargo, MSc, PhD (c) jcamargo@bigdatasolubons.co
 jcamargo@bigdatasolubons.co") Big Data: retos a nivel de desarrollo Ing. Jorge Camargo, MSc, PhD (c) jcamargo@bigdatasolubons.co Cámara de Comercio de Bogotá Centro Empresarial Chapinero Agenda Introducción Bases de datos NoSQL Procesamiento
Big Data: retos a nivel de desarrollo Ing. Jorge Camargo, MSc, PhD (c) jcamargo@bigdatasolubons.co Cámara de Comercio de Bogotá Centro Empresarial Chapinero Agenda Introducción Bases de datos NoSQL Procesamiento
INTELIGENCIA DE NEGOCIO 2014-2015
 INTELIGENCIA DE NEGOCIO 2014-2015 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos Tema 4. Modelos de Predicción: Clasificación, regresión
INTELIGENCIA DE NEGOCIO 2014-2015 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos Tema 4. Modelos de Predicción: Clasificación, regresión
Hadoop. Cómo vender un cluster Hadoop?
 Hadoop Cómo vender un cluster Hadoop? ÍNDICE Problema Big Data Qué es Hadoop? Descripción HDSF Map Reduce Componentes de Hadoop Hardware Software 3 EL PROBLEMA BIG DATA ANTES Los datos los generaban las
Hadoop Cómo vender un cluster Hadoop? ÍNDICE Problema Big Data Qué es Hadoop? Descripción HDSF Map Reduce Componentes de Hadoop Hardware Software 3 EL PROBLEMA BIG DATA ANTES Los datos los generaban las
Yersinio Jiménez Campos Analista de datos Banco Nacional de Costa Rica
 Fundamentos Título de de Big la Data presentación utilizando MATLAB Yersinio Jiménez Campos Analista de datos Banco Nacional de Costa Rica 1 Agenda Qué es Big Data? Buenas prácticas en el manejo de memoria.
Fundamentos Título de de Big la Data presentación utilizando MATLAB Yersinio Jiménez Campos Analista de datos Banco Nacional de Costa Rica 1 Agenda Qué es Big Data? Buenas prácticas en el manejo de memoria.
The H Hour: Hadoop The awakening of the BigData. Antonio Soto SolidQ COO asoto@solidq.com @antoniosql
 The H Hour: Hadoop The awakening of the BigData Antonio Soto SolidQ COO asoto@solidq.com @antoniosql Tendencias de la Industria El nuevo rol del operador El operador de ayer Sigue el proceso basado en
The H Hour: Hadoop The awakening of the BigData Antonio Soto SolidQ COO asoto@solidq.com @antoniosql Tendencias de la Industria El nuevo rol del operador El operador de ayer Sigue el proceso basado en
ÍNDICE. Introducción... Capítulo 1. Conceptos de Big Data... 1
 ÍNDICE Introducción... XIII Capítulo 1. Conceptos de Big Data... 1 Definición, necesidad y características de Big Data... 1 Aplicaciones típicas de Big Data... 4 Patrones de detección del fraude... 4 Patrones
ÍNDICE Introducción... XIII Capítulo 1. Conceptos de Big Data... 1 Definición, necesidad y características de Big Data... 1 Aplicaciones típicas de Big Data... 4 Patrones de detección del fraude... 4 Patrones
FaceFinder MÓDULO DE BÚSQUEDA DE PERSONAS DENTRO DE UNA BASE DE DATOS DE ROSTROS
 FaceFinder MÓDULO DE BÚSQUEDA DE PERSONAS DENTRO DE UNA BASE DE DATOS DE ROSTROS Introducción Los algoritmos utilizados para el procesamiento de imágenes son de complejidad computacional alta. Por esto
FaceFinder MÓDULO DE BÚSQUEDA DE PERSONAS DENTRO DE UNA BASE DE DATOS DE ROSTROS Introducción Los algoritmos utilizados para el procesamiento de imágenes son de complejidad computacional alta. Por esto
Trabajo final de Ingeniería
 UNIVERSIDAD ABIERTA INTERAMERICANA Trabajo final de Ingeniería Weka Data Mining Jofré Nicolás 12/10/2011 WEKA (Data Mining) Concepto de Data Mining La minería de datos (Data Mining) consiste en la extracción
UNIVERSIDAD ABIERTA INTERAMERICANA Trabajo final de Ingeniería Weka Data Mining Jofré Nicolás 12/10/2011 WEKA (Data Mining) Concepto de Data Mining La minería de datos (Data Mining) consiste en la extracción
APACHE HADOOP. Daniel Portela Paz Javier Villarreal García Luis Barroso Vázquez Álvaro Guzmán López
 APACHE HADOOP Daniel Portela Paz Javier Villarreal García Luis Barroso Vázquez Álvaro Guzmán López Objetivos 1. Qué es Apache Hadoop? 2. Funcionalidad 2.1. Map/Reduce 2.2. HDFS 3. Casos prácticos 4. Hadoop
APACHE HADOOP Daniel Portela Paz Javier Villarreal García Luis Barroso Vázquez Álvaro Guzmán López Objetivos 1. Qué es Apache Hadoop? 2. Funcionalidad 2.1. Map/Reduce 2.2. HDFS 3. Casos prácticos 4. Hadoop
CURSO: DESARROLLADOR PARA APACHE HADOOP
 CURSO: DESARROLLADOR PARA APACHE HADOOP CAPÍTULO 1: INTRODUCCIÓN www.formacionhadoop.com Índice 1 Por qué realizar el curso de desarrollador para Apache Hadoop? 2 Requisitos previos del curso 3 Bloques
CURSO: DESARROLLADOR PARA APACHE HADOOP CAPÍTULO 1: INTRODUCCIÓN www.formacionhadoop.com Índice 1 Por qué realizar el curso de desarrollador para Apache Hadoop? 2 Requisitos previos del curso 3 Bloques
Objetos Distribuidos - Componentes. Middleware
 Objetos Distribuidos - Componentes Middleware Middleware Component Oriented Development Arquitecturas 3 Tier Middleware es el software que: conecta y comunica los componentes de una aplicacion distribuida
Objetos Distribuidos - Componentes Middleware Middleware Component Oriented Development Arquitecturas 3 Tier Middleware es el software que: conecta y comunica los componentes de una aplicacion distribuida
PINOT. La ingestión near real time desde Kafka complementado por la ingestión batch desde herramientas como Hadoop.
 PINOT Stratebi Paper (2015 info@stratebi.com www.stratebi.com) Pinot es la herramienta de análisis en tiempo real desarrollada por LinkedIn que la compañía ha liberado su código bajo licencia Apache 2.0,
PINOT Stratebi Paper (2015 info@stratebi.com www.stratebi.com) Pinot es la herramienta de análisis en tiempo real desarrollada por LinkedIn que la compañía ha liberado su código bajo licencia Apache 2.0,
Proyecto Fin de Carrera OpenNebula y Hadoop: Cloud Computing con herramientas Open Source
 Proyecto Fin de Carrera OpenNebula y Hadoop: Cloud Computing con herramientas Open Source Francisco Magaz Villaverde Consultor: Víctor Carceler Hontoria Junio 2012 Contenido Introducción Qué es Cloud Compu5ng?
Proyecto Fin de Carrera OpenNebula y Hadoop: Cloud Computing con herramientas Open Source Francisco Magaz Villaverde Consultor: Víctor Carceler Hontoria Junio 2012 Contenido Introducción Qué es Cloud Compu5ng?
Análisis de datos de accidentes de tráfico mediante soluciones BigData y Business Intelligence
 Análisis de datos de accidentes de tráfico mediante soluciones BigData y Business Intelligence Marc Alvarez Brotons Ingeniería Informática David Isern Alarcón 27/12/2014 1. Objetivos del proyecto 2. Enfoque
Análisis de datos de accidentes de tráfico mediante soluciones BigData y Business Intelligence Marc Alvarez Brotons Ingeniería Informática David Isern Alarcón 27/12/2014 1. Objetivos del proyecto 2. Enfoque
Soluciones Integrales en Inteligencia de Negocios
 Soluciones Integrales en Inteligencia de Negocios QUIENES SOMOS NUESTRA MISIÓN DATAWAREHOUSE MINERÍA DE DATOS MODELOS PREDICTIVOS REPORTERÍA Y DASHBOARD DESARROLLO DE APLICACIONES MODELOS DE SIMULACIÓN
Soluciones Integrales en Inteligencia de Negocios QUIENES SOMOS NUESTRA MISIÓN DATAWAREHOUSE MINERÍA DE DATOS MODELOS PREDICTIVOS REPORTERÍA Y DASHBOARD DESARROLLO DE APLICACIONES MODELOS DE SIMULACIÓN
Este proyecto tiene como finalidad la creación de una aplicación para la gestión y explotación de los teléfonos de los empleados de una gran compañía.
 SISTEMA DE GESTIÓN DE MÓVILES Autor: Holgado Oca, Luis Miguel. Director: Mañueco, MªLuisa. Entidad Colaboradora: Eli & Lilly Company. RESUMEN DEL PROYECTO Este proyecto tiene como finalidad la creación
SISTEMA DE GESTIÓN DE MÓVILES Autor: Holgado Oca, Luis Miguel. Director: Mañueco, MªLuisa. Entidad Colaboradora: Eli & Lilly Company. RESUMEN DEL PROYECTO Este proyecto tiene como finalidad la creación
Universidad de Guadalajara
 Universidad de Guadalajara Centro Universitario de Ciencias Económico-Administrativas Maestría en Tecnologías de Información Ante-proyecto de Tésis Selection of a lightweight virtualization framework to
Universidad de Guadalajara Centro Universitario de Ciencias Económico-Administrativas Maestría en Tecnologías de Información Ante-proyecto de Tésis Selection of a lightweight virtualization framework to
Conectores Pentaho Big Data Community VS Enterprise
 Conectores Pentaho Big Data Community VS Enterprise Agosto 2014 Stratebi Business Solutions www.stratebi.com info@stratebi.com Índice 1. Resumen... 3 2. Introducción... 4 3. Objetivo... 4 4. Pentaho Community
Conectores Pentaho Big Data Community VS Enterprise Agosto 2014 Stratebi Business Solutions www.stratebi.com info@stratebi.com Índice 1. Resumen... 3 2. Introducción... 4 3. Objetivo... 4 4. Pentaho Community
Agustiniano Ciudad Salitre School Computer Science Support Guide - 2015 Second grade First term
 Agustiniano Ciudad Salitre School Computer Science Support Guide - 2015 Second grade First term UNIDAD TEMATICA: INTERFAZ DE WINDOWS LOGRO: Reconoce la interfaz de Windows para ubicar y acceder a los programas,
Agustiniano Ciudad Salitre School Computer Science Support Guide - 2015 Second grade First term UNIDAD TEMATICA: INTERFAZ DE WINDOWS LOGRO: Reconoce la interfaz de Windows para ubicar y acceder a los programas,
CURSOS DE VERANO 2014
 CURSOS DE VERANO 2014 APROXIMACIÓN PRÁCTICA A LA CIENCIA DE DATOS Y BIG DATA: HERRAMIENTAS KNIME, R, HADOOP Y MAHOUT. Entorno de Procesamiento Hadoop Sara Del Río García 1 Qué es Hadoop? Es un proyecto
CURSOS DE VERANO 2014 APROXIMACIÓN PRÁCTICA A LA CIENCIA DE DATOS Y BIG DATA: HERRAMIENTAS KNIME, R, HADOOP Y MAHOUT. Entorno de Procesamiento Hadoop Sara Del Río García 1 Qué es Hadoop? Es un proyecto
MÁSTER: MÁSTER EXPERTO BIG DATA
 MÁSTER: MÁSTER EXPERTO BIG DATA Información detallada del máster www.formacionhadoop.com Este máster online está enfocado a los ingenieros que quieran aprender el despliegue y configuración de un cluster
MÁSTER: MÁSTER EXPERTO BIG DATA Información detallada del máster www.formacionhadoop.com Este máster online está enfocado a los ingenieros que quieran aprender el despliegue y configuración de un cluster
Big data A través de una implementación
 Big data A través de una implementación Lic. Diego Krauthamer Profesor Adjunto Interino del Área Base de Datos Universidad Abierta Interamericana Facultad de Tecnología Informática Buenos Aires. Argentina
Big data A través de una implementación Lic. Diego Krauthamer Profesor Adjunto Interino del Área Base de Datos Universidad Abierta Interamericana Facultad de Tecnología Informática Buenos Aires. Argentina
Cocinando con Big Data
 Cocinando con Big Data Javier Sánchez BDM Big Data jsanchez@flytech.es 91.300.51.09 21/11/2013 Javier Sánchez 1 Agenda Qué es Big Data? Receta Punto de Partida Para qué Big Data? Conclusiones 21/11/2013
Cocinando con Big Data Javier Sánchez BDM Big Data jsanchez@flytech.es 91.300.51.09 21/11/2013 Javier Sánchez 1 Agenda Qué es Big Data? Receta Punto de Partida Para qué Big Data? Conclusiones 21/11/2013
XII Encuentro Danysoft en Microsoft Abril 2015. Business Intelligence y Big Data XII Encuentro Danysoft en Microsoft Directos al código
 Business Intelligence y Big Data XII Encuentro Danysoft en Microsoft Directos al código Ana María Bisbé York Servicios Profesionales sp@danysoft.com 916 638683 www.danysoft.com Abril 2015 Sala 1 SQL Server
Business Intelligence y Big Data XII Encuentro Danysoft en Microsoft Directos al código Ana María Bisbé York Servicios Profesionales sp@danysoft.com 916 638683 www.danysoft.com Abril 2015 Sala 1 SQL Server
Diseño ergonómico o diseño centrado en el usuario?
 Diseño ergonómico o diseño centrado en el usuario? Mercado Colin, Lucila Maestra en Diseño Industrial Posgrado en Diseño Industrial, UNAM lucila_mercadocolin@yahoo.com.mx RESUMEN En los últimos años el
Diseño ergonómico o diseño centrado en el usuario? Mercado Colin, Lucila Maestra en Diseño Industrial Posgrado en Diseño Industrial, UNAM lucila_mercadocolin@yahoo.com.mx RESUMEN En los últimos años el
Tecnologías para el. datos en big data. Francisco Herrera
 Tecnologías para el procesamiento y analítica de datos en big data Francisco Herrera Dpto. Ciencias de la Computación e I.A. Universidad de Granada herrera@decsai.ugr.es Grupo de investigación SCI 2 S
Tecnologías para el procesamiento y analítica de datos en big data Francisco Herrera Dpto. Ciencias de la Computación e I.A. Universidad de Granada herrera@decsai.ugr.es Grupo de investigación SCI 2 S
ANÁLISIS Y DESARROLLO DE UNA PLATAFORMA BIG DATA
 ANÁLISIS Y DESARROLLO DE UNA PLATAFORMA BIG DATA Autor: de la Cierva Perreau de Pinninck, Leticia Director: Sonia García, Mario Tenés Entidad Colaboradora: VASS RESUMEN DEL PROYECTO Tras la realización
ANÁLISIS Y DESARROLLO DE UNA PLATAFORMA BIG DATA Autor: de la Cierva Perreau de Pinninck, Leticia Director: Sonia García, Mario Tenés Entidad Colaboradora: VASS RESUMEN DEL PROYECTO Tras la realización
Text Mining Introducción a Minería de Datos
 Text Mining Facultad de Matemática, Astronomía y Física UNC, Córdoba (Argentina) http://www.cs.famaf.unc.edu.ar/~laura SADIO 12 de Marzo de 2008 qué es la minería de datos? A technique using software tools
Text Mining Facultad de Matemática, Astronomía y Física UNC, Córdoba (Argentina) http://www.cs.famaf.unc.edu.ar/~laura SADIO 12 de Marzo de 2008 qué es la minería de datos? A technique using software tools
1. Ir a https://vmdepot.msopentech.com/list/index?sort=featured&search=kobli
 Procedimiento documentado para obtener cualquiera de las cuatro máquinas virtuales de Kobli en un clic (Especializadas, Colecciones privadas, Médicas y Rurales) desde VM Depot 1 y llevarla a la plataforma
Procedimiento documentado para obtener cualquiera de las cuatro máquinas virtuales de Kobli en un clic (Especializadas, Colecciones privadas, Médicas y Rurales) desde VM Depot 1 y llevarla a la plataforma
Software Libre para Aplicaciones de Big Data
 Software Libre para Aplicaciones de Big Data Club de Investigación Tecnológica San José, Costa Rica 2014.07.16 Theodore Hope! hope@aceptus.com Big Data: Qué es?! Conjuntos de datos de: " Alto volumen (TBs
Software Libre para Aplicaciones de Big Data Club de Investigación Tecnológica San José, Costa Rica 2014.07.16 Theodore Hope! hope@aceptus.com Big Data: Qué es?! Conjuntos de datos de: " Alto volumen (TBs
BIG DATA. Jorge Mercado. Software Quality Engineer
 BIG DATA Jorge Mercado Software Quality Engineer Agenda Big Data - Introducción Big Data - Estructura Big Data - Soluciones Conclusiones Q&A Big Data - Introducción Que es Big Data? Big data es el termino
BIG DATA Jorge Mercado Software Quality Engineer Agenda Big Data - Introducción Big Data - Estructura Big Data - Soluciones Conclusiones Q&A Big Data - Introducción Que es Big Data? Big data es el termino
Base de datos II Facultad de Ingeniería. Escuela de computación.
 Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Base de datos II Facultad de Ingeniería. Escuela de computación. Introducción Este manual ha sido elaborado para orientar al estudiante de Bases de datos II en el desarrollo de sus prácticas de laboratorios,
Qué significa Hadoop en el mundo del Big Data?
 Qué significa Hadoop en el mundo del Big Data? Un contenido para perfiles técnicos 2 ÍNDICE Qué significa Hadoop en el Universo Big Data?.... 3 El planteamiento: big data y data science.... 3 Los desafíos
Qué significa Hadoop en el mundo del Big Data? Un contenido para perfiles técnicos 2 ÍNDICE Qué significa Hadoop en el Universo Big Data?.... 3 El planteamiento: big data y data science.... 3 Los desafíos
Innovación empresarial disciplina DevOps
 Innovación empresarial disciplina DevOps Impulsar la entrega continua de software con DevOps Etienne Bertrand IBM DevOps Director 26 de Marzo de 2014 2014 IBM Corporation CEO Study 2012 conclusiones CEO
Innovación empresarial disciplina DevOps Impulsar la entrega continua de software con DevOps Etienne Bertrand IBM DevOps Director 26 de Marzo de 2014 2014 IBM Corporation CEO Study 2012 conclusiones CEO
Servicios avanzados de supercomputación para la ciència y la ingeniería
 Servicios avanzados de supercomputación para la ciència y la ingeniería Servicios avanzados de supercomputación para la ciència y la ingeniería HPCNow! provee a sus clientes de la tecnología y soluciones
Servicios avanzados de supercomputación para la ciència y la ingeniería Servicios avanzados de supercomputación para la ciència y la ingeniería HPCNow! provee a sus clientes de la tecnología y soluciones
CURSO/GUÍA PRÁCTICA GESTIÓN EMPRESARIAL DE LA INFORMACIÓN.
 SISTEMA EDUCATIVO inmoley.com DE FORMACIÓN CONTINUA PARA PROFESIONALES INMOBILIARIOS. CURSO/GUÍA PRÁCTICA GESTIÓN EMPRESARIAL DE LA INFORMACIÓN. Business Intelligence. Data Mining. PARTE PRIMERA Qué es
SISTEMA EDUCATIVO inmoley.com DE FORMACIÓN CONTINUA PARA PROFESIONALES INMOBILIARIOS. CURSO/GUÍA PRÁCTICA GESTIÓN EMPRESARIAL DE LA INFORMACIÓN. Business Intelligence. Data Mining. PARTE PRIMERA Qué es
CAPÍTULO 4 ANÁLISIS DE IMPLEMENTACIONES
 CAPÍTULO 4 ANÁLISIS DE IMPLEMENTACIONES En el anterior capítulo se realizaron implementaciones en una red de datos para los protocolos de autenticación Kerberos, Radius y LDAP bajo las plataformas Windows
CAPÍTULO 4 ANÁLISIS DE IMPLEMENTACIONES En el anterior capítulo se realizaron implementaciones en una red de datos para los protocolos de autenticación Kerberos, Radius y LDAP bajo las plataformas Windows
Marcos de Desarrollo. Diseño e implementación de aplicaciones Web con.net
 Marcos de Desarrollo Diseño e implementación de aplicaciones Web con.net Prácticas de laboratorio (.NET) Planificación de clases prácticas 1. Introducción al entorno de trabajo 2. Ejemplos C# 3. Ejemplos
Marcos de Desarrollo Diseño e implementación de aplicaciones Web con.net Prácticas de laboratorio (.NET) Planificación de clases prácticas 1. Introducción al entorno de trabajo 2. Ejemplos C# 3. Ejemplos
1. REQUISITOS DE SOFTWARE Y HARDWARE
 1. REQUISITOS DE SOFTWARE Y HARDWARE COMPONENTE MARCO REQUISITO De instalación de SQL Server instala los siguientes componentes de software requeridos por el producto:.net Framework 3.5 Service Pack 1
1. REQUISITOS DE SOFTWARE Y HARDWARE COMPONENTE MARCO REQUISITO De instalación de SQL Server instala los siguientes componentes de software requeridos por el producto:.net Framework 3.5 Service Pack 1
Sistemas Operativos Windows 2000
 Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Sistemas Operativos Contenido Descripción general 1 Funciones del sistema operativo 2 Características de 3 Versiones de 6 Sistemas Operativos i Notas para el instructor Este módulo proporciona a los estudiantes
Guía Rápida de Inicio
 Guía Rápida de Inicio 1. Acerca de esta Guía Esta guía le ayudará a instalar y dar los primeros pasos con BitDefender Security for SharePoint. Para disponer de instrucciones detalladas, por favor, diríjase
Guía Rápida de Inicio 1. Acerca de esta Guía Esta guía le ayudará a instalar y dar los primeros pasos con BitDefender Security for SharePoint. Para disponer de instrucciones detalladas, por favor, diríjase
RECOMENDACIÓN PERSONALIZADA Y BIG DATA
 1 RECOMENDACIÓN PERSONALIZADA Y BIG DATA Recomendaciones aplicadas a entornos de E-commerce Jornada Estadística y Big Data Societat Catalana d Estadística 3 Abril 2014 ÍNDICE 2 Caso práctico en recomendación
1 RECOMENDACIÓN PERSONALIZADA Y BIG DATA Recomendaciones aplicadas a entornos de E-commerce Jornada Estadística y Big Data Societat Catalana d Estadística 3 Abril 2014 ÍNDICE 2 Caso práctico en recomendación
30 oct. SAP Fraud Management. El Camino a la transparencia. La necesidad Gestionar en tiempo real. El medio Una plataforma in-memory
 SAP Fraud Management 30 oct 2014 El Camino a la transparencia SAP Fraud Management La necesidad Gestionar en tiempo real El medio Una plataforma in-memory La necesidad Gestionar en tiempo real 3 La necesidad:
SAP Fraud Management 30 oct 2014 El Camino a la transparencia SAP Fraud Management La necesidad Gestionar en tiempo real El medio Una plataforma in-memory La necesidad Gestionar en tiempo real 3 La necesidad:
Transición de su infraestructura de Windows Server 2003 a una solución moderna de Cisco y Microsoft
 Descripción general de la solución Transición de su infraestructura de Windows Server 2003 a una solución moderna de Cisco y Microsoft El soporte de Microsoft para todas las versiones de Windows Server
Descripción general de la solución Transición de su infraestructura de Windows Server 2003 a una solución moderna de Cisco y Microsoft El soporte de Microsoft para todas las versiones de Windows Server
PLATAFORMA SPARK: CATAPULTA MACHINE LEARNING
 PLATAFORMA SPARK: CATAPULTA MACHINE LEARNING Dr. Gabriel Guerrero www.saxsa.com.mx 29 de julio de 2015 Introducción La catapulta de Leonardo, una herramienta genial. Permite con poco esfuerzo enviar un
PLATAFORMA SPARK: CATAPULTA MACHINE LEARNING Dr. Gabriel Guerrero www.saxsa.com.mx 29 de julio de 2015 Introducción La catapulta de Leonardo, una herramienta genial. Permite con poco esfuerzo enviar un
Diplomado en Big Data
 160 horas Diplomado en Big Data BROCHURE, 2015 Contenido Quienes somos?... 3 Presentación del Programa... 4 Perfíl del Facilitador. 5 Objetivos.. 6 Información General.. 7 Plan de Estudio... 8-9 Plan de
160 horas Diplomado en Big Data BROCHURE, 2015 Contenido Quienes somos?... 3 Presentación del Programa... 4 Perfíl del Facilitador. 5 Objetivos.. 6 Información General.. 7 Plan de Estudio... 8-9 Plan de
Beneficios estratégicos para su organización. Beneficios. Características V.2.0907
 Herramienta de inventario que automatiza el registro de activos informáticos en detalle y reporta cualquier cambio de hardware o software mediante la generación de alarmas. Beneficios Información actualizada
Herramienta de inventario que automatiza el registro de activos informáticos en detalle y reporta cualquier cambio de hardware o software mediante la generación de alarmas. Beneficios Información actualizada
Como extender la capacidad Analítica conectando fuentes de datos Big Data en ArcGIS
 Como extender la capacidad Analítica conectando fuentes de datos Big Data en ArcGIS César Rodríguez Reinaldo Cartagena Agenda Fundamentos para Big Data La Analítica y Big Data generar conocimiento ArcGIS
Como extender la capacidad Analítica conectando fuentes de datos Big Data en ArcGIS César Rodríguez Reinaldo Cartagena Agenda Fundamentos para Big Data La Analítica y Big Data generar conocimiento ArcGIS
picojava TM Características
 picojava TM Introducción El principal objetivo de Sun al introducir Java era poder intercambiar programas ejecutables Java entre computadoras de Internet y ejecutarlos sin modificación. Para poder transportar
picojava TM Introducción El principal objetivo de Sun al introducir Java era poder intercambiar programas ejecutables Java entre computadoras de Internet y ejecutarlos sin modificación. Para poder transportar
La ayuda practica de hoy para los CIO s y responsables de servicio
 Ignacio Fernández Paul Director General España y Portugal Numara Software, Inc Febrero 2009 La ayuda practica de hoy para los CIO s y responsables de servicio Numara Software Con más de 50,000 clientes,
Ignacio Fernández Paul Director General España y Portugal Numara Software, Inc Febrero 2009 La ayuda practica de hoy para los CIO s y responsables de servicio Numara Software Con más de 50,000 clientes,
IBM PERFORMANCE EVENTS. Smarter Decisions. Better Results.
 Smarter Decisions. Better Results. 1 Aumente el valor de su BI con Análisis Predictivo José Ignacio Marín SPSS Sales Engineer 25/11/2010 2 Agenda Cómo está cambiando la toma de decisiones La potencia del
Smarter Decisions. Better Results. 1 Aumente el valor de su BI con Análisis Predictivo José Ignacio Marín SPSS Sales Engineer 25/11/2010 2 Agenda Cómo está cambiando la toma de decisiones La potencia del
Big Data en la nube. Use los datos. Obtenga información. La pregunta clave es: Qué puede hacer Doopex por mi negocio?
 Qué es Doopex? Big Data en la nube. Use los datos. Obtenga información. Seguramente, la pregunta clave no es Qué es Doopex?. La pregunta clave es: Qué puede hacer Doopex por mi negocio? El objetivo de
Qué es Doopex? Big Data en la nube. Use los datos. Obtenga información. Seguramente, la pregunta clave no es Qué es Doopex?. La pregunta clave es: Qué puede hacer Doopex por mi negocio? El objetivo de
Acerca de esté Catálogo
 Catálogo de Cursos 2015 Acerca de esté Catálogo En el presente documento podrá obtenerse la información necesaria sobre la oferta de cursos que Manar Technologies S.A.S. y su línea de educación Campus
Catálogo de Cursos 2015 Acerca de esté Catálogo En el presente documento podrá obtenerse la información necesaria sobre la oferta de cursos que Manar Technologies S.A.S. y su línea de educación Campus
La nueva arquitectura del paquete AMORE (A MORE Flexible Neural Network)
") La nueva arquitectura del paquete AMORE (A MORE Flexible Neural Network) III Jornadas de Usuarios de R Javier Alfonso Cendón, Manuel Castejón Limas, Joaquín Ordieres Mere, Camino Fernández Llamas Índice
La nueva arquitectura del paquete AMORE (A MORE Flexible Neural Network) III Jornadas de Usuarios de R Javier Alfonso Cendón, Manuel Castejón Limas, Joaquín Ordieres Mere, Camino Fernández Llamas Índice
Deep Learning y Big Data
 y Eduardo Morales, Enrique Sucar INAOE (INAOE) 1 / 40 Contenido 1 2 (INAOE) 2 / 40 El poder tener una computadora que modele el mundo lo suficientemente bien como para exhibir inteligencia ha sido el foco
y Eduardo Morales, Enrique Sucar INAOE (INAOE) 1 / 40 Contenido 1 2 (INAOE) 2 / 40 El poder tener una computadora que modele el mundo lo suficientemente bien como para exhibir inteligencia ha sido el foco
SOCIALIZANDO EL CAMPUS VIRTUAL ATENEA DE LA UPC. Cataluña
 SOCIALIZANDO EL CAMPUS VIRTUAL ATENEA DE LA UPC Isabel Gallego 1, Imma Torra 2, Sisco Villas 3, Joaquim Morte 4, Oriol Sánchez 5, Enric Ribot 6 1, 2, 3, 4, 5,6 Instituto de Ciencias de la Educación, Universidad
SOCIALIZANDO EL CAMPUS VIRTUAL ATENEA DE LA UPC Isabel Gallego 1, Imma Torra 2, Sisco Villas 3, Joaquim Morte 4, Oriol Sánchez 5, Enric Ribot 6 1, 2, 3, 4, 5,6 Instituto de Ciencias de la Educación, Universidad
NubaDat An Integral Cloud Big Data Platform. Ricardo Jimenez-Peris
 NubaDat An Integral Cloud Big Data Platform Ricardo Jimenez-Peris NubaDat Market Size 3 Market Analysis Conclusions Agenda Value Proposition Product Suite Competitive Advantages Market Gaps Big Data needs
NubaDat An Integral Cloud Big Data Platform Ricardo Jimenez-Peris NubaDat Market Size 3 Market Analysis Conclusions Agenda Value Proposition Product Suite Competitive Advantages Market Gaps Big Data needs
"Diseño, construcción e implementación de modelos matemáticos para el control automatizado de inventarios
 "Diseño, construcción e implementación de modelos matemáticos para el control automatizado de inventarios Miguel Alfonso Flores Sánchez 1, Fernando Sandoya Sanchez 2 Resumen En el presente artículo se
"Diseño, construcción e implementación de modelos matemáticos para el control automatizado de inventarios Miguel Alfonso Flores Sánchez 1, Fernando Sandoya Sanchez 2 Resumen En el presente artículo se
El Cliente y El Ingeniero de Software
 El Cliente y El Ingeniero de Software Juan Sebastián López Restrepo Abstract. The continuing evolution of technologies have made the software technology used more and more increasing, this trend has created
El Cliente y El Ingeniero de Software Juan Sebastián López Restrepo Abstract. The continuing evolution of technologies have made the software technology used more and more increasing, this trend has created
Guía Rápida de Puesta en Marcha de MailStore
 Guía Rápida de Puesta en Marcha de MailStore Primeros Pasos Paso 1: Requerimientos de sistema e instalación El servidor de MailStore se puede instalar en cualquier PC en la red. Si se esta utilizando un
Guía Rápida de Puesta en Marcha de MailStore Primeros Pasos Paso 1: Requerimientos de sistema e instalación El servidor de MailStore se puede instalar en cualquier PC en la red. Si se esta utilizando un
WINDOWS 2008 7: COPIAS DE SEGURIDAD
 1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
1.- INTRODUCCION: WINDOWS 2008 7: COPIAS DE SEGURIDAD Las copias de seguridad son un elemento fundamental para que el trabajo que realizamos se pueda proteger de aquellos problemas o desastres que pueden
CURSOS DE VERANO 2014
 CURSOS DE VERANO 2014 APROXIMACIÓN PRÁCTICA A LA CIENCIA DE DATOS Y BIG DATA: HERRAMIENTAS KNIME, R, HADOOP Y MAHOUT Introducción a Big Data Francisco Herrera Big Data Nuestro mundo gira en torno a los
CURSOS DE VERANO 2014 APROXIMACIÓN PRÁCTICA A LA CIENCIA DE DATOS Y BIG DATA: HERRAMIENTAS KNIME, R, HADOOP Y MAHOUT Introducción a Big Data Francisco Herrera Big Data Nuestro mundo gira en torno a los
CURSO PRESENCIAL: DESARROLLADOR BIG DATA
 CURSO PRESENCIAL: DESARROLLADOR BIG DATA Información detallada del curso www.formacionhadoop.com El curso se desarrolla durante 3 semanas de Lunes a Jueves. Se trata de un curso formato ejecutivo que permite
CURSO PRESENCIAL: DESARROLLADOR BIG DATA Información detallada del curso www.formacionhadoop.com El curso se desarrolla durante 3 semanas de Lunes a Jueves. Se trata de un curso formato ejecutivo que permite
Guía de licenciamiento de NAV en pago por uso
 Guía de licenciamiento de NAV en pago por uso Fecha de publicación: Mayo 2013 1 Uso de la guía Utilice esta guía para mejorar el uso del licenciamiento sobre Microsoft Dynamics NAV 2013 en modelo de pago
Guía de licenciamiento de NAV en pago por uso Fecha de publicación: Mayo 2013 1 Uso de la guía Utilice esta guía para mejorar el uso del licenciamiento sobre Microsoft Dynamics NAV 2013 en modelo de pago
Especificaciones de Hardware, Software y Comunicaciones
 Requisitos técnicos para participantes Especificaciones de Hardware, Software y Comunicaciones Versión Bolsa Nacional de Valores, S.A. Mayo 2014 1 Tabla de Contenido 1. Introducción... 3 2. Glosario...
Requisitos técnicos para participantes Especificaciones de Hardware, Software y Comunicaciones Versión Bolsa Nacional de Valores, S.A. Mayo 2014 1 Tabla de Contenido 1. Introducción... 3 2. Glosario...
REQUERIMIENTOS HARDWARE Y SOFTWARE QWEBDOCUMENTS VERSION 4
 Pág. 1 de 6 Ambiente centralizado SERVIDOR UNICO Servidor Hardware Procesador CORE Duo 4 GHz Memoria Ram 4 GB. 2 GB solo para la aplicación y los otros 2 GB para Base de datos, S.O y otro software necesario
Pág. 1 de 6 Ambiente centralizado SERVIDOR UNICO Servidor Hardware Procesador CORE Duo 4 GHz Memoria Ram 4 GB. 2 GB solo para la aplicación y los otros 2 GB para Base de datos, S.O y otro software necesario
III. INTRODUCCIÓN AL CLOUD COMPUTING
 III. INTRODUCCIÓN AL CLOUD COMPUTING Definición (I) Qué es el cloud computing? Nuevo paradigma de computación distribuida Provee un servicio de acceso a recursos computacionales: servidores, almacenamiento,
III. INTRODUCCIÓN AL CLOUD COMPUTING Definición (I) Qué es el cloud computing? Nuevo paradigma de computación distribuida Provee un servicio de acceso a recursos computacionales: servidores, almacenamiento,
Aprendizaje Automático y Data Mining. Bloque IV DATA MINING
 Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
Aprendizaje Automático y Data Mining Bloque IV DATA MINING 1 Índice Definición y aplicaciones. Grupos de técnicas: Visualización. Verificación. Descubrimiento. Eficiencia computacional. Búsqueda de patrones
BUSINESS INTELLIGENCE Y REDSHIFT
 Whitepaper BUSINESS INTELLIGENCE Y REDSHIFT BEE PART OF THE CHANGE hablemos@beeva.com www.beeva.com LAS SOLUCIONES QUE TU BI NECESITA Con Amazon Web Services (AWS) es posible disponer con solo unos clics
Whitepaper BUSINESS INTELLIGENCE Y REDSHIFT BEE PART OF THE CHANGE hablemos@beeva.com www.beeva.com LAS SOLUCIONES QUE TU BI NECESITA Con Amazon Web Services (AWS) es posible disponer con solo unos clics
CLOUD ENIAC BACKUP. Sus datos son importantes?
 CLOUD ENIAC BACKUP Sus datos son importantes? Proteja sus datos con Cloud Eniac Backup Descripción del Producto Cloud Eniac Backup es una solución perfecta de copias de seguridad en línea que automatiza
CLOUD ENIAC BACKUP Sus datos son importantes? Proteja sus datos con Cloud Eniac Backup Descripción del Producto Cloud Eniac Backup es una solución perfecta de copias de seguridad en línea que automatiza
Capítulo VI. Conclusiones. En este capítulo abordaremos la comparación de las características principales y
 Capítulo VI Conclusiones En este capítulo abordaremos la comparación de las características principales y de las ventajas cada tecnología Web nos ofrece para el desarrollo de ciertas aplicaciones. También
Capítulo VI Conclusiones En este capítulo abordaremos la comparación de las características principales y de las ventajas cada tecnología Web nos ofrece para el desarrollo de ciertas aplicaciones. También
Guía rápida del usuario. Disco duro virtual.
 Guía rápida del usuario. Disco duro virtual. Servicio de compartición de carpetas y archivos a través de Internet y sincronización con dispositivos móviles. Índice Introducción Definir espacio por defecto
Guía rápida del usuario. Disco duro virtual. Servicio de compartición de carpetas y archivos a través de Internet y sincronización con dispositivos móviles. Índice Introducción Definir espacio por defecto
Título del Proyecto: Sistema Web de gestión de facturas electrónicas.
 Resumen Título del Proyecto: Sistema Web de gestión de facturas electrónicas. Autor: Jose Luis Saenz Soria. Director: Manuel Rojas Guerrero. Resumen En la última década se han producido muchos avances
Resumen Título del Proyecto: Sistema Web de gestión de facturas electrónicas. Autor: Jose Luis Saenz Soria. Director: Manuel Rojas Guerrero. Resumen En la última década se han producido muchos avances
APLICATIVO WEB PARA LA ADMINISTRACIÓN DE LABORATORIOS Y SEGUIMIENTO DOCENTE EN UNISARC JUAN DAVID LÓPEZ MORALES
 APLICATIVO WEB PARA LA ADMINISTRACIÓN DE LABORATORIOS Y SEGUIMIENTO DOCENTE EN UNISARC JUAN DAVID LÓPEZ MORALES CORPORACIÓN UNIVERSITARIA SANTA ROSA DE CABAL CIENCIAS Y TECNOLOGÍAS DE INFORMACIÓN Y COMUNICACIÓN
APLICATIVO WEB PARA LA ADMINISTRACIÓN DE LABORATORIOS Y SEGUIMIENTO DOCENTE EN UNISARC JUAN DAVID LÓPEZ MORALES CORPORACIÓN UNIVERSITARIA SANTA ROSA DE CABAL CIENCIAS Y TECNOLOGÍAS DE INFORMACIÓN Y COMUNICACIÓN
Symantec Desktop and Laptop Option
 Symantec Desktop and Laptop Option Symantec Desktop and Laptop Option es una solución fácil de usar que ofrece copias de seguridad y recuperación de archivos automatizadas y confiables para equipos de
Symantec Desktop and Laptop Option Symantec Desktop and Laptop Option es una solución fácil de usar que ofrece copias de seguridad y recuperación de archivos automatizadas y confiables para equipos de
A continuación resolveremos parte de estas dudas, las no resueltas las trataremos adelante
 Modulo 2. Inicio con Java Muchas veces encontramos en nuestro entorno referencias sobre Java, bien sea como lenguaje de programación o como plataforma, pero, que es en realidad Java?, cual es su historia?,
Modulo 2. Inicio con Java Muchas veces encontramos en nuestro entorno referencias sobre Java, bien sea como lenguaje de programación o como plataforma, pero, que es en realidad Java?, cual es su historia?,
INTELIGENCIA DE NEGOCIO 2014-2015
 INTELIGENCIA DE NEGOCIO 2014-2015 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos. Ciencia de Datos Tema 4. Modelos de Predicción: Clasificación,
INTELIGENCIA DE NEGOCIO 2014-2015 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos. Ciencia de Datos Tema 4. Modelos de Predicción: Clasificación,
ESTUDIO, ANÁLISIS Y EVALUACIÓN DEL ENTORNO DE TRABAJO HADOOP. Entidad Colaboradora: ICAI Universidad Pontificia Comillas
 ESTUDIO, ANÁLISIS Y EVALUACIÓN DEL ENTORNO DE TRABAJO HADOOP. Autor: Director: Rubio Echevarria, Raquel Contreras Bárcena, David Entidad Colaboradora: ICAI Universidad Pontificia Comillas RESUMEN DEL PROYECTO
ESTUDIO, ANÁLISIS Y EVALUACIÓN DEL ENTORNO DE TRABAJO HADOOP. Autor: Director: Rubio Echevarria, Raquel Contreras Bárcena, David Entidad Colaboradora: ICAI Universidad Pontificia Comillas RESUMEN DEL PROYECTO
Big Data y BAM con WSO2
 Mayo 2014 Big Data y BAM con Leonardo Torres Centro Experto en SOA/BPM en atsistemas ofrece una completa suite de productos Open Source SOA y son contribuidores de muchos de los productos de Apache, como
Mayo 2014 Big Data y BAM con Leonardo Torres Centro Experto en SOA/BPM en atsistemas ofrece una completa suite de productos Open Source SOA y son contribuidores de muchos de los productos de Apache, como
Alessandro Chacón 05-38019. Ernesto Level 05-38402. Ricardo Santana 05-38928
 Alessandro Chacón 05-38019 Ernesto Level 05-38402 Ricardo Santana 05-38928 CONTENIDO Universo Digital Hadoop HDFS: Hadoop Distributed File System MapReduce UNIVERSO DIGITAL 161 EB 2006 Fuente: International
Alessandro Chacón 05-38019 Ernesto Level 05-38402 Ricardo Santana 05-38928 CONTENIDO Universo Digital Hadoop HDFS: Hadoop Distributed File System MapReduce UNIVERSO DIGITAL 161 EB 2006 Fuente: International
P á g i n a 1 / 15. M A N U A L I N S T A L A C I Ó N C o p y r i g h t 2 0 1 3 P r i v a t e P l a n e t L t d.
 Copyright 2013 Private Planet Ltd. Private Planet is a registered trademark of Private Planet Ltd. Some applications are not available in all areas. Application availability is subject to change. Other
Copyright 2013 Private Planet Ltd. Private Planet is a registered trademark of Private Planet Ltd. Some applications are not available in all areas. Application availability is subject to change. Other
COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX
 COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX En este manual se presenta el proceso de configuración de una Maquina Virtual en VirtualBox, que será utilizada para instalar un Servidor
COMO CONFIGURAR UNA MAQUINA VIRTUAL EN VIRTUALBOX PARA ELASTIX En este manual se presenta el proceso de configuración de una Maquina Virtual en VirtualBox, que será utilizada para instalar un Servidor
Instalación: Instalación de un agente en una máquina cliente y su registro en el sistema.
 HERRAMIENTA DE MONITORIZACIÓN DE SISTEMAS Autor: Sota Madorrán, Iñaki. Director: Igualada Moreno, Pablo. Entidad Colaboradora: Evotec Consulting, S.L. RESUMEN DEL PROYECTO El proyecto consiste en el diseño,
HERRAMIENTA DE MONITORIZACIÓN DE SISTEMAS Autor: Sota Madorrán, Iñaki. Director: Igualada Moreno, Pablo. Entidad Colaboradora: Evotec Consulting, S.L. RESUMEN DEL PROYECTO El proyecto consiste en el diseño,
Virginia Miguez Directora Administración Pública Intel Corporation Iberia virginia.miguez@intel.com
 Virginia Miguez Directora Administración Pública Intel Corporation Iberia virginia.miguez@intel.com 1 Eficiencia en el Centro de Datos = Servicios de TI entregados Recursos necesarios (energía, enfriamiento,
Virginia Miguez Directora Administración Pública Intel Corporation Iberia virginia.miguez@intel.com 1 Eficiencia en el Centro de Datos = Servicios de TI entregados Recursos necesarios (energía, enfriamiento,
Anexo 11. Manual de Administración
 PONTIFICIA UNIVERSIDAD JAVERIANA Anexo 11. Manual de Administración Para mantenimiento a los modelos y código fuente Alex Arias 28/05/2014 El presente documento muestra los requerimientos necesarios para
PONTIFICIA UNIVERSIDAD JAVERIANA Anexo 11. Manual de Administración Para mantenimiento a los modelos y código fuente Alex Arias 28/05/2014 El presente documento muestra los requerimientos necesarios para
INTRODUCCIÓN A LA PROGRAMACIÓN WEB UNIDAD. Estructura de contenidos: http://www.ucv.edu.pe/cis/ cisvirtual@ucv.edu.pe. 1.
 INTRODUCCIÓN A LA PROGRAMACIÓN WEB UNIDAD 1 Estructura de contenidos: 1. Programación Web 2. Sistema De Información 3. Sistema Web 4. Requisitos Para Sistemas Web Con Asp 5. Internet Information Server
INTRODUCCIÓN A LA PROGRAMACIÓN WEB UNIDAD 1 Estructura de contenidos: 1. Programación Web 2. Sistema De Información 3. Sistema Web 4. Requisitos Para Sistemas Web Con Asp 5. Internet Information Server
ADAPTACIÓN DE REAL TIME WORKSHOP AL SISTEMA OPERATIVO LINUX
 ADAPTACIÓN DE REAL TIME WORKSHOP AL SISTEMA OPERATIVO LINUX Autor: Tomás Murillo, Fernando. Director: Muñoz Frías, José Daniel. Coordinador: Contreras Bárcena, David Entidad Colaboradora: ICAI Universidad
ADAPTACIÓN DE REAL TIME WORKSHOP AL SISTEMA OPERATIVO LINUX Autor: Tomás Murillo, Fernando. Director: Muñoz Frías, José Daniel. Coordinador: Contreras Bárcena, David Entidad Colaboradora: ICAI Universidad
Esta solución de fácil uso está orientada a cualquier industria, ya sea una empresa del sector privado o del sector público.
 1 En la actualidad el 80% de la información de una empresa está relacionada a un lugar. La variable de ubicación está presente en todas las áreas críticas de un negocio. Sin embargo, las organizaciones
1 En la actualidad el 80% de la información de una empresa está relacionada a un lugar. La variable de ubicación está presente en todas las áreas críticas de un negocio. Sin embargo, las organizaciones
INTELIGENCIA DE NEGOCIO 2015-2016
 INTELIGENCIA DE NEGOCIO 2015-2016 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos. Ciencia de Datos Tema 4. Modelos de Predicción: Clasificación,
INTELIGENCIA DE NEGOCIO 2015-2016 Tema 1. Introducción a la Inteligencia de Negocio Tema 2. Retos en Inteligencia de Negocio Tema 3. Minería de Datos. Ciencia de Datos Tema 4. Modelos de Predicción: Clasificación,
Ventajas del almacenamiento de datos de nube
 Ventajas del almacenamiento de datos de nube Almacenar grandes volúmenes de información en una red de área local (LAN) es caro. Dispositivos de almacenamiento electrónico de datos de alta capacidad como
Ventajas del almacenamiento de datos de nube Almacenar grandes volúmenes de información en una red de área local (LAN) es caro. Dispositivos de almacenamiento electrónico de datos de alta capacidad como
emuseum PUBLIQUE SUS COLECCIONES EN LA WEB Por qué elegir emuseum? Se integra fácilmente con TMS Búsqueda eficaz Completamente personalizable
 emuseum emuseum PUBLIQUE SUS COLECCIONES EN LA WEB emuseum es un sistema de publicación web que se integra perfectamente con TMS para publicar información en la web y dispositivos móviles. Mediante emuseum
emuseum emuseum PUBLIQUE SUS COLECCIONES EN LA WEB emuseum es un sistema de publicación web que se integra perfectamente con TMS para publicar información en la web y dispositivos móviles. Mediante emuseum
La Nueva Economía de los Datos
 La Nueva Economía de los Datos Tomas Garcia Director Almacenamiento IBM España, Portugal, Grecia e Israel 2014 IBM Corporation Las redes sociales, los móviles, cloud y big data están cambiando como vivimos,
La Nueva Economía de los Datos Tomas Garcia Director Almacenamiento IBM España, Portugal, Grecia e Israel 2014 IBM Corporation Las redes sociales, los móviles, cloud y big data están cambiando como vivimos,
MINERÍA DE DATOS Y SUS TENDENCIAS ACTUALES
 MINERÍA DE DATOS Y SUS TENDENCIAS ACTUALES Dr. Rafael Bello Pérez Departamento de Ciencias de la Computación Universidad Central de Las Villas, Cuba Email: rbellop@uclv.edu.cu Tomando de conferencias de
MINERÍA DE DATOS Y SUS TENDENCIAS ACTUALES Dr. Rafael Bello Pérez Departamento de Ciencias de la Computación Universidad Central de Las Villas, Cuba Email: rbellop@uclv.edu.cu Tomando de conferencias de