Sistema Recomendador para la Determinación de Medidas de Protección Contra Incendios - Norma IRAM N 3528 Método de Purt
|
|
|
- Ana Isabel Casado Ponce
- hace 8 años
- Vistas:
Transcripción
1 Sistema Recomendador para la Determinación de Medidas de Protección Contra Incendios - Norma IRAM N 3528 Método de Purt Prof. Ing. Mario Raúl López 1 y Dra. Milagros Gutiérrez 2 1 UTN-FRP Departamento Ingeniería Electromecánica. Av.Almafuerte N 1033-(3100) Paraná, Entre Ríos, Argentina. mrlopez@frp.utn.edu.ar 2 UTN-FRSF CIDISI Centro de Investigación y Desarrollo de Ingeniería en Sistemas de Información. Lavaisse 610-(3000) Santa Fé, Argentina. mmgutier@frsf.utn.edu.ar Resumen. Aunque existen numerosos métodos de evaluación numérica del riesgo de incendios, en la República Argentina para decidir sobre la aplicación de sistemas fijos de extinción y/o de detección de incendios, se utiliza la Norma IRAM Nº 3528 denominada INSTA- LACIONES FIJAS CONTRA INCENDIOS Evaluación del Riesgo por el Método de Purt, para la aplicación de sistemas automáticos de detección y extinción. El método se aplica en forma manual y su aplicación depende completamente de una persona o grupo especializado y está sujeto a errores. A partir de la conceptualización del dominio y -eventualmente- el desarrollo de un sistema recomendador sería posible dar soporte automatizado al profesional en la toma de decisión sobre la implementación del sistema de detección y/o extinción a utilizar en la planta. Palabras claves: Sistema recomendador, Incendio, método de Purt, norma IRAM. 1. Introducción El método de Gustav Purt[2] efectúa una evaluación del riesgo de incendio de forma general, dado que afirma que el cálculo excesivo de coeficientes que intervienen en el incendio tenga cierta influencia sobre el riesgo real; y tiene en cuenta que el fuego se produce en el contenido y en los edificios[1]

, en base al riesgo potencial existente, qué medios de lucha contra incendios son necesarios implementar en la actividad (primera intervención y elementos de protección tales como detección y")
2 Su finalidad es deducir (Fig. 1), en base al riesgo potencial existente, qué medios de lucha contra incendios son necesarios implementar en la actividad (primera intervención y elementos de protección tales como detección y extinción automática). El método se basa en el análisis de la acción destructora del fuego que se desarrolla en dos ámbitos diferenciados: edificio o continente y su contenido. El riesgo del edificio estriba en la posibilidad de que se produzca un daño importante en el inmueble: destrucción total del edificio. Para ello utiliza dos factores esenciales: La intensidad y duración del incendio. Figura 1: Proceso de Recomendación por Experto Humano La resistencia de los elementos constructivos. El riesgo del edificio o continente (GR) se centra en la posibilidad de la destrucción del inmueble, para su cálculo se utiliza la expresión: siendo: GR = (Q m.c + Q i ).B.L W.R i Q m = Coeficiente de la carga de fuego del contenido (Tabla I, sec ). C = Coeficiente de Combustibilidad del contenido (Tabla III, sec ). Q i B L W = Coeficiente de carga de fuego del continente (Tabla V y VI, sec ). = Coeficiente correspondiente a la situación e importancia del sector (Tabla VII, sec ). = Coeficiente de tiempo necesario para iniciar la extinción (Tabla VIII, sec ). = Coeficiente de resistencia al fuego del continente (Tabla IX, sec ). R i = Coeficiente de reducción del riesgo (Tabla X, sec ). El riesgo del contenido (IR) está constituido por los daños personales y materiales ocasionados a personas y cosas que se encuentren en el interior del edificio. Para su cálculo se utiliza la expresión:


3 donde: IR = H.D.F H D = coeficiente de daño a personas (Tabla XI). = coeficiente de peligro para los bienes (Tabla XII). F = coeficiente de influencia del humo (Tabla XIII). La obtención de los valores de GR e IR, a partir de los factores señalados, los cuales se encuentran tabulados, permite una vez llevado al siguiente gráfico (Fig. 2), obtener de forma rápida las medidas de detección y extinción más adecuadas al riesgo evaluado, dependiendo de la zona del diagrama en la que se encuentren las rectas x = IR e y = GR. (1) El riesgo es poco significativo; en general, son superfluas las medidas especiales. (2) Una instalación automática de protección contra incendio no es estrictamente necesaria ni recomendable. (3) Instalación automática de extinción necesaria; instalación de protección no apropiada al riesgo. (4) Instalación de protección necesaria; instalación automática de extinción no apropiada al riesgo; (5) Doble protección por instalación de predetección y extinción automática recomendable. Instalación de extinción necesaria. (6) Doble protección por instalación de predetección y extinción automática recomendable. Instalación de predetección necesaria. (7) Doble protección por instalación de predetección y extinción automática necesaria. Finalmente podemos señalar que por Figura 2: Diagrama de medidas, método de Gustav Purt tratarse de una Norma IRAM es de aplicación en todo el ámbito de la República Argentina y en todo tipo de industrias con la única excepción que representa la industria de los hidrocarburos. Actualmente la aplicación de esta norma, es realizada en forma manual por un especialista en la disciplina de la Higiene y la Seguridad en el Trabajo (Ley N de Riesgos del Trabajo, Ley N de Seguridad e Higiene en el Trabajo y Decreto Reglamentario N 351/79, Capítulo 18, artículos 160 al 187) quien realiza la búsqueda de los datos tabulados en la norma y calcula los índices correspondientes para determinar las medidas de seguridad a implementar
 El riesgo es poco significativo; en general, son superfluas las medidas especiales. (2) Una instalación automática de protección contra incendio no es estrictamente necesaria ni recomendable.")
4 2. Fundamentación En la actualidad, el método de Purt se aplica en forma manual, es decir, su utilización depende completamente de una persona o grupo especializado en la materia. Como toda actividad desarrollada en forma manual, está sujeta a errores, ya sea por distracción, falta de capacidad para manejar gran cantidad de información, falta de expertos, dificultades para adquirir entrenamiento, etc. Además no es posible hacer experimentos para ver si las medidas de seguridad funcionan, ya que no se puede hacer un ensayo de tipo destructivo, por pequeño que sea, en una planta que está en plena producción, y que, generalmente, son muy pocas las empresas que nacen con todos los elementos de seguridad. Para limitar la búsqueda y obtener tan pronto como sea posible una solución correcta dentro del conjunto de posibles soluciones, contar con una herramienta computacional que asista en la elaboración de una solución semi-automática es altamente deseable. Esta herramienta deberá estar orientada a tecnologías de sistemas basados en conocimientos[4] y sistemas recomendadores. Entonces, a partir de la conceptualización del dominio, la creación de un modelo[5, 6] y -eventualmente- el desarrollo de un sistema recomendador[7] sería posible lograr un sistema que de soporte al profesional en la toma de decisión sobre la implementación de las medidas de seguridad aplicando el método de Purt. Un sistema recomendador es aquel que brinda información oportuna que el usuario necesita para tomar mejores decisiones en la tarea que está llevando a cabo [8]. Este tipo de sistemas para poder tomar decisiones sobre qué recomendación hacer toma información disponible como ser: información sobre el perfil del usuario, decisiones tomadas con anterioridad, similaridad de características del entorno sobre la que se está tomando la decisión, entre otras. También debe contar con un mecanismo que le permita filtrar la información que encuentra disponible para solo mostrar la que es de interés para el usuario. Existen diferentes tipos de filtros que pueden ser utilizados en un sistema recomendador tales como filtros colaborativos [8] y filtros basados en contenido [9]. En muchos casos estas propuestas son usadas en conjunto dando lugar a filtros híbridos. 3. Propuesta En este trabajo nos proponemos la conceptualización y eventualmente el desarrollo de una solución que de soporte a los profesionales del área de Higiene y Seguridad en el Trabajo en la toma de decisiones en el campo de la lucha contra incendios. Esta solución estará basada en la utilización de los principios detallados en el método de Purt y cumpliendo lo estipulado en la Norma IRAM Se requiere que dicha solución facilite la recomendación de los dispositivos necesarios tanto sea para la extinción como para la detección temprana de incendios en inmuebles y explotaciones fabriles -continente y contenido- de los tipos constructivos más comunes y que sea de utilidad para los técnicos y profesionales del área

![Las ventajas de usar un sistema recomendador en la determinación de las medidas de seguridad contra incendios a implementar en plantas son evidentes[16, 17, 18]: Permanencia, Duplicación, Rapidez,](/docs-images/18/814221/images/5-0.png "Bajo costo, Fiabilidad, y consolidación de varios conocimientos.")
5 Las ventajas de usar un sistema recomendador en la determinación de las medidas de seguridad contra incendios a implementar en plantas son evidentes[16, 17, 18]: Permanencia, Duplicación, Rapidez, Bajo costo, Fiabilidad, y consolidación de varios conocimientos. Para facilitar la experimentación, actualmente inhabilitada por las características manuales del método y los elevados costos que significarían realizar un ensayo en cualquier planta fabril, este sistema deberá contar con una interfaz adecuada y amigable para que el usuario se vea cómodo para utilizarla introduciendo los datos básicos, y con una base de conocimiento apropiada donde se encuentren almacenados tablas y datos específicos con los valores de los distintos materiales y ambientes susceptibles de incendios. En este punto creemos que se hace indispensable la utilización de una ontología ([16, 17, 18]), donde pueda sistematizarse el conocimiento necesario: perfiles de usuarios, preferencias, tendencias, datos de materiales y específicos que hagan a la aplicación del método de Purt, etc. Esta ontología estará hospedada en un sitio de la web de fácil acceso para los usuarios, los cuales, como podrá apreciarse en la figura 3, no serán necesariamente expertos en la materia, Figura 3: Sistema Recomendador aunque el sistema si podrá aprovechar las recomendaciones de otros expertos o resultados similares efectuados previamente. La Ontología de materiales y datos específicos deberá contener la información necesaria para que el sistema realice el razonamiento adecuado, en función o como resultado de la aplicación del método, así tendríamos un algoritmo como el siguiente: % TR (Riesgo Total) es el valor del área del diagrama determinado % por las coordenadas IR y GR (riesgo contenido y continente) Si TR = 1 entonces Recomendacion1 Si TR = 2 entonces Recomendacion2... % Si TR cae fuera del diagrama aumentar resistencia al fuego & y decrementar sector de incendio y tiempo de extinción Recalculo(Resistencia,SectorIncendio,TiempoExtincion) Recomendacion1: VerificarMateriales... Recomendación2:


6 VerificarMateriales Recalculo(R,S,T):... Además, para evitar colisiones y resultar coherentes con el trabajo previo del experto humano donde ya ha establecido, por ejemplo, la distribución de extintores e hidrantes, las verificaciones de materiales y las recomendaciones que realice el sistema deberán tener en cuenta una clasificación como la que se observa en la siguiente figura 4 extraído de [19]. Figura 4: Cuadro Resumen Tipos de Materiales Combustibles 4. Conclusiones y Trabajos Futuros La evaluación del riesgo de incendio resulta fundamental a la hora de adoptar las medidas de prevención y protección necesarias en cada caso, ya que éstas deberán estar acordes con el riesgo detectado [12]

7 Aunque existen numerosos métodos de evaluación numérica, este método (Purt) tiene en cuenta que el fuego se produce en el contenido y en los edificios. Razones valederas para ser adoptado por la normativa argentina [14] que coincide con lo expresado por algunos autores [13]: «Si la finalidad del método consiste en deducir de la evaluación del riesgo las medidas de protección contra incendios, entonces el más apropiado es el del Dr. Gustav Purt». Por el lado de los sistemas recomendadores podemos decir, coincidiendo con [15], que estos sistemas de recomendación son ya ampliamente utilizados y debido a la gran cantidad de información de todo tipo que nos rodea, su presencia y utilidad es de esperar que aumente en el futuro. Este conocimiento se podrá integrar en bases de datos, donde usuarios comunes encontrarán la información precisa y podrán realizar inferencias buscando información relacionada. Además, podrán intercambiar sus datos siguiendo estos esquemas comunes consensuados, e incluso podrán reutilizarlos. En este sentido, estamos trabajando en la conceptualización de un modelo para la diversidad de materiales que se pueden encontrar, tanto en el contenido como el continente, de las plantas fabriles. Referencias [1] José Ma. Cortés Díaz. Seguridad e Higiene del Trabajo. Técnicas de prevención de riesgos laborales (Capítulo 17). 3ra edición. Editorial Alfaomega. México [2] Gustav Purt. Sistema de evaluación del riesgo de incendio que puede servir de base para el proyecto de instalaciones automáticas de protección contra incendios. Texto revisado de la conferencia pronunciada durante el sexto Seminario Internacional de Detección Automática de Incendios del IENT, celebrado en Aquisgran en Octubre de [3] Gretener, M. Determination des mesures de protection decoulant de l evaluation du danger potenciel d incendie. Berne, Ass. des etablissements cantonaux d assurances contre l ncendie [4] Russell, S. and P. Norvig. Artificial Intelligence. A modern approach. Third edition. Prentice hall [5] Speel P., Schreiber, A., van Joolingen, W., van Heijst G. and Beijer, G.J. Conceptual Modelling for Knowledge-Based Systems. en: Encyclopedia of Computer Science and Technology, Marce Dekker Inc., New York. [6] Robinson, S. Conceptual Modelling: Who Needs It? SCS M&S Magazine 2010 / n2 (April). [7] M. Montaner, A Taxonomy of Recommender Agents on the Internet, Artificial Intelligence Review 19, 2003, pp

8 [8] Prem Melville and Vikas Sindhwani. Recommender Systems. Encyclopedia of Machine Learning, [9] Mooney, R. J and Roy, L. Content-based book recommendation using learning for text categorization. In Workshop Recom. Sys.: Algo. and Evaluation [10] Actividades industriales Protección contra incendios Monografía. (consultado 8/1/2013). [11] Métodos de evaluación del riesgo de incendio, herramientas decisivas en la aplicación de las medidas de prevención y protección contra incendios de personas, bienes y actividades. Artículo. (consultado 9/1/2013) [12] Cortés Díaz, José María. Seguridad e Higiene del Trabajo. Técnicas de prevención de riesgos laborales. 3ra. edición 2002 Alfaomega grupo editor. México D.F. [13] Villanueva Muñoz, J.L.: Evaluación del riesgo de incendio. Método Gustav Purt. Notas Técnicas de Prevención. NTP Instituto Nacional de Seguridad e Higiene en el Trabajo. Madrid (1984). [14] Norma IRAM N 3528 INSTALACIONES FIJAS CONTRA INCENDIOS. Evaluación del Riesgo por el Método de Purt, para la aplicación de sistemas automáticos de detección y extinción. (1981) Argentina. [15] Sergio M. G. Nieto. Filtrado Colaborativo y Sistemas de Recomendación. Inteligencia en Redes de Comunicaciones.Ingeniería de Telecomunicación. Universidad Calos III de Madrid. [16] Sebastián Lendinez Teixeira. APO: APLICACIÓN PARA LA POBLA- CION DE ONTOLOGÍAS. INGENIERÍA TÉCNICA EN INFORMÁTICA DE GESTIÓN. Universidad Carlos III de Madrid. España. [17] Gleison Santos, Karina Villela, Lílian Schnaider, Ana Regina Rocha, Guilherme Horta Travassos. Building ontology based tools for a software development environment. COPPE/Federal University of Rio de Janeiro - Brasil. [18] Karin Koogan Breitman, Julio Cesar Sampaio do Prado Leite. Lexicon Based Ontology Construction. PUC-Rio, Computer Science Department, LES. Rio de Janeiro, RJ, Brazil. [19] Laboratorio de Producción. Prevención y Control de Incendios. Facultad Ingenieria Industrial. Colombia. Edición
![com/industria-y-materiales/actividadesindustriales-proteccion-contra-incendios/ Actividades industriales Protección contra incendios Monografía. (consultado 8/1/2013). [11] http://www.estrucplan.com.ar/articulos/verarticulo.](/docs-images/40/814221/images/page_8.jpg "asp?idarticulo=767 Métodos de evaluación del riesgo de incendio, herramientas decisivas en la aplicación de las medidas de prevención y protección contra incendios de personas, bienes y actividades.")
9 Modelado del proceso de destilación molecular mediante redes neuronales Carolina A. Allevi, Cecilia L. Pagliero, Miriam A. Martinello Departamento de Tecnología Química-Facultad de Ingeniería (UNRC-CONICET) Ruta 8 km Río Cuarto Argentina. callevi@ing.unrc.edu.ar Resumen. En este trabajo se presenta el modelado del proceso de destilación molecular mediante una red neuronal artificial para la predicción de la concentración del componente más volátil en el residuo y la relación residuo/alimentación (R/F) de una muestra binaria patrón. Los datos se obtuvieron por resolución numérica del modelo fenomenológico del proceso. Las redes neuronales tienen la capacidad de aprender, reconocer patrones de una serie de entradas y salidas, sin hipótesis previas sobre su naturaleza. Las entradas a la red fueron el flujo de alimentación (Q) y la temperatura del evaporador (T E ). Se desarrolló un modelo neuronal artificial feed-forward backpropagation compuesto por dos neuronas en la entrada, seis neuronas en una capa oculta y dos neuronas en la capa de salida. Se utilizó para el entrenamiento el algoritmo Levenberg-Marquartd, con el cual se alcanzo una buena predicción de los datos de validación, con un mínimo error cuadrático medio. Palabras Clave: Destilación Molecular, Redes Neuronales Artificiales. 1 Introducción La destilación molecular es un proceso de separación y purificación que se caracteriza por el alto vacío, las temperaturas reducidas y los bajos tiempos de residencia lo cual la hacen útil para materiales termolábiles. Como resultado de este proceso se obtienen dos fracciones a partir de una mezcla de componentes de volatilidades diferentes: la fracción pesada (residuo) y la fracción liviana (destilado). Existen muchas aplicaciones de destilación molecular para diferentes materiales, tales como la concentración de monoglicéridos [1], el enriquecimiento de metilchavicol [2], el enriquecimiento de oxiterpenos del aceite de naranja [3] y la desacidificación de aceites [4]. El proceso de separación por destilación molecular tiene lugar en cuatro etapas: (i) el transporte de componentes desde la mezcla líquida hacia la superficie de la película, (ii) la evaporación de los componentes más volátiles en la superficie de la película, (iii) el transporte de las moléculas evaporadas a través del espacio de destilación y 1278
 de una muestra binaria patrón. Los datos se obtuvieron por resolución numérica del modelo fenomenológico del proceso.")
10 (iv) la condensación de las moléculas evaporadas. La representación completa del proceso se realiza analizando todas las etapas mediante balances de cantidad de movimiento, de masa y de energía, aunque en general la etapa limitante es la primera y es la única que se tiene en cuenta en el modelo. Se han publicado distintos trabajos sobre el modelado y simulación de una mezcla binaria en dos tipos de destiladores: de película descendente y centrífugo [5], del modelado y la simulación del proceso de destilación molecular de un residuo de petróleo, resuelto por el método implícito de diferencias finitas de Crank-Nicholson [6]. Las redes neuronales artificiales representan una tecnología que tiene sus raíces en muchas disciplinas: Neurociencias, Matemáticas, Estadística e Ingeniería. Se aplican para diversos propósitos, tales como modelado, reconocimiento de patrones, identificación de sistemas no lineales, control de procesos, clasificación y agrupamiento, optimización, predicción y procesamiento de señales. Las redes neuronales se presentan como una herramienta prometedora para el modelado de sistemas complejos. Se han aplicado en la simulación de una planta de tratamiento de aguas residuales industriales, para determinar las propiedades ambientales de la corriente de salida [7], en la predicción de la caída de presión para fluidos no newtonianos a través de accesorios de tuberías [8]. Específicamente en destilación molecular, se utilizaron las redes neuronales como modelos predictivos para la concentración y recuperación de tocoferoles del destilado de desodorización de aceite de colza [9]. 2 Materiales y métodos En este trabajo se realiza el modelado mediante redes neuronales para la destilación molecular de una muestra binaria: dibutilftalato (DBP) y dibutilsebacato (DBS). Los datos se obtuvieron mediante el modelado matemático fenomenológico de la película del evaporador. El modelo se aplicó al destilador molecular KDL4 (UIC-GmbH), instalado en la planta piloto del Departamento de Tecnología Química de la Facultad de Ingeniería. El equipo de destilación molecular consiste en dos cilindros concéntricos, uno interno y otro externo. La evaporación ocurre en la superficie interna del cilindro exterior y la condensación en la superficie externa del cilindro interior. Consta de un sistema de rodillos logra el barrido de la película líquida sobre la superficie de evaporación la cual es una de las condiciones claves para una destilación satisfactoria. El sistema de rodillos es el responsable de la dispersión de la película sobre la superficie del evaporador, además de un mezclado permanente. Posee equipos auxiliarles como sistema de bombas en serie y baños termostáticos para el evaporador, el condensador y la alimentación. Se realizó el modelo matemático en dos dimensiones de la película que se forma en la pared del evaporador del destilador molecular. Para ello se establecieron una serie de 1279

11 suposiciones: estado estacionario, propiedades fisicoquímicas de los componentes constantes, fluido newtoniano, flujo laminar, coordenadas cilíndricas, temperaturas de pared del evaporador y del condensador constantes, sin difusión axial, ni flujo radial. Las ecuaciones que describen el proceso de destilación molecular son las ecuaciones de conservación de masa, de energía, y de cantidad de movimiento; y la ecuación de Langmuir-Knudsen para la evaporación de los componentes en la superficie de la película. Los datos obtenidos mediante el modelo matemático se utilizan para la selección, creación y configuración de la arquitectura de la red neuronal, la cual se usará con fines predictivos. En la Tabla 1 se muestran los datos obtenidos por el modelo matemático. En la misma se puede observar que las variables operativas que se modificaron fueron la temperatura del evaporador (T E ) y el flujo de alimentación (Q), permaneciendo constante la temperatura de alimentación (T F ) que para todos los casos fue T F = 370 K. Las variables de salida fueron la concentración del componente más volátil en el residuo (%X DBP ) y la relación residuo/alimentación (R/F). Tabla 1. Set de datos generados a partir del modelo matemático, los cuales han sido divididos en dos subconjuntos: datos para entrenamiento y datos para validación de las redes neuronales. T F =370K. Set Datos n T E Q % X DBP R/F ,5 49,06 0, ,5 45,88 0, ,93 0, ,5 41,27 0, ,81 0,80 Entrenamiento ,87 0, ,26 0, ,9 0, ,5 31,05 0, ,68 0, ,5 8,32 0, ,5 48,04 0, ,5 34,00 0,61 Validación ,00 0, ,5 41,27 0, ,5 14,08 0, ,84 0,61 En la Fig. 1 se muestra la variación de la concentración de DBP (%X DBP ) y R/F en función de la temperatura del evaporador (T E ). El aumento de la temperatura de evaporación produce la disminución de las dos variables de salida debido al mayor aporte energético y por lo tanto a una mayor evaporación del componente más volátil y menor producción de residuo. En la Fig.2 puede verse la variación de la concentración de (%X DBP ) y de R/F, en función del flujo de alimentación. Un aumento del flujo de alimentación se traduce en menos tiempo del material en el equipo, por lo tanto se produce una menor evaporación con concentraciones y relación de residuo/alimentación mayores. 1280

12 % X DBP XDBP vs TE R/F vs TE 0,9 0,7 R/F 0,5 0,3 0 0, T E (K) Fig. 1. R/F y %X DBP vs T E con Q =2,5mL/min % X DBP XDBP vs Q R/F vs Q Q (ml/min) 0,8 0,6 0,4 0,2 0 R/F Fig. 2. R/F y %X DBP vs Q con T E = 380K Luego de analizar los resultados del modelado se procede a la determinación de la mejor red neuronal que sea capaz de aprender y predecir correctamente los datos. Para ello se deben analizar distintas arquitecturas de redes, comparar diferentes algoritmos de entrenamiento, funciones de transferencia, a efectos de encontrar la óptima para esta aplicación. Y luego realizar la validación del modelo de redes obtenido. En la selección de la red se recolectan los datos donde se utilizaron un total de 17 datos, 65% de los cuales se usaron para el entrenamiento, y el 35% restante para validar la red (Tabla 1). Se creo una red neuronal de propagación hacia adelante con retropropagacion de los errores (feed-forward backpropagation). En la red de propagacion hacia adelante 1281
 0,8 0,6 0,4 0,2 0 R/F Fig. 2.")

13 todas las neuronas de una capa estan conectadas con neuronas de otras capas. La red seleccionada consta de una capa de entrada, una capa oculta y una capa de salida. En la capa de entrada no se realizan cálculos, su función es distribuir y enviar las señales de entrada a la capa oculta. Cada capa contiene un número de neuronas. La cantidad de neuronas en las capas de entrada y de salida quedan determinadas por las variables de entrada y de salida del proceso. Para la capa oculta, el numero de neuronas se determina por el método de prueba y error. Las neuronas en la capa de entrada son dos, debido a las dos variables de entrada: T E y Q. Se determinó que el número de neuronas en la capa oculta es 6, y la capa de salida contiene dos neuronas, una por cada variable de salida: R/F y %X DBP (Fig. 3). En cada capa se selecciona una función de transferencia. En este trabajo se seleccionó para la predicción, en la capa oculta la función de transferencia tangente hiperbólica y en la capa de salida la función lineal. Las conexiones entre neuronas, entre capas están ponderadas, a cada conexión se le asocia un peso.luego se selecciona la arquitecura de red y se inicializan los pesos donde la red puede partir de pesos iguales a cero o de valores aleatorios antes de que empiece a aprender. Inmediatamente empieza la etapa de entrenamiento para lo cual se debe seleccionar algún algoritmo de aprendizaje, en este caso se utilizó el algoritmo de aprendizaje de Leveberg-Marquardt. El objetivo del entrenamiento es conseguir que para la destilación molecular, el conjunto de datos de entradas produzca un conjunto de salidas deseadas. El proceso de entrenamiento consiste en la aplicación de diferentes vectores de entrada para que se ajusten los pesos de las interconexiones. El aprendizaje se realizó mediante la propagación del error hacia atrás consiste en dos pasos a través de las diferentes capas de la red: un paso hacia adelante y un paso hacia atrás. En el paso hacia adelante, un vector de entrada se aplica a los nodos de la red, y su efecto se propaga a través de la red capa por capa. Finalmente, un conjunto de salidas es producido como respuesta de la red. Durante el paso hacia adelante son establecidos los pesos sinápticos de la red. Durante el paso hacia atrás, los pesos son ajustados de acuerdo con la regla de corrección del error. Durante el entrenamiento los pesos convergen gradualmente hacia los valores que hacen que para cada entrada produzca la salida deseada. Fig.3. Red Neuronal. La cual consta de una capa de entrada con dos neuronas, una capa oculta con 6 neuronas y una capa de salida con dos neuronas. 1282

14 3 Resultados Los pesos sinápticos de las conexiones para la arquitectura de red óptima obtenidos son los mostrados en las Tablas 2 y 3. Una vez que la red neuronal ha sido entrenada, la red es validada mediante un conjunto de datos diferentes a los utilizados en el entrenamiento (Tabla 4). Tabla 2.Pesos de las conexiones entre la capa de entrada y la capa oculta (CO). Los pesos entre las entradas 1 y 2 y las neuronas de la CO se denotan W 1,j, W 2,j. Bias en la capa de ocultas (CO) j Bias nodos CO (CO) W1,j W2j Tabla 3. Pesos de las conexiones entre la capa de entrada y la capa oculta (CO). Los pesos entre las entradas 1 y 2 y las neuronas de la CO se denotan W 1,j, W 2,j. Bias en la capa de salida (CS) j Bias nodos CS (CS) W1,j W2j W3j W4j W5j W6j Tabla 4. Resultados de la etapa de validación Set Datos T E Q Modelo Matemático Modelo Neuronal X DBP (%) R/F X DBP (%) RF 360 2,5 48,04 0,94 47,34 0, ,5 34,00 0,61 30,18 0,55 Validación ,00 0,70 36,82 0, ,5 41,27 0,76 41,26 0, ,5 14,08 0,30 14,35 0, ,84 0,61 35,49 0,63 En la Fig. 4 se puede observar la disminución del error cuadrático medio a medida que las iteraciones avanzan con el entrenamiento. El entrenamiento se detuvo porque alcanzo la performance, el mínimo error. En las Fig. 5 y 6 se muestran la salida de la red versus los datos del modelo matemático (salidas deseadas). El ajuste de los datos es bueno debido a que se ve una pequeña dispersión de la recta a 45 grados que sería el ajuste perfecto donde las salidas de la red son iguales a las salidas del modelo. También puede verse en la Tabla 4 la buena predicción del modelo comparando los valores del modelo matemático con el neuronal. 1283
 j Bias nodos CO (CO) W1,j W2j 1-2.7230 3.3021 1.5370 2-2.4953 1.4505-1.9692 3 0.2929-2.6833-1.8145 4 1.7605 2.3559-2.7085 5 1.0240 0.0158-3.6053 6-3.0888-2.1998-2.")
15 10 2 Best Training Performance is e-005 at epoch 12 Train Best Goal Mean Squared Error (mse) Epochs Fig. 4. Error cuadrático medio de la red neuronal, el cual disminuye durante el entrenamiento, es decir durante la actualización de los pesos de las conexiones entre neuronas. 1 0,8 0,6 R/F mod 0,4 y=x 0, ,2 0,4 0,6 0,8 1 R/F RN Fig. 5. R/F mod del modelo matemático vs R/F RN obtenido de las redes neuronales 1284

16 %X DBPmod 20 y=x %X DBPRN Fig. 6. X DBPmod del modelado matemático vs X DBPRN obtenido de la red neuronal Conclusiones El modelado neuronal brinda las herramientas para analizar la influencia las variables del proceso de destilación molecular sobre las variables de respuesta sin necesidad de recurrir a la experimentación, siendo esta última una ventaja ya que se minimizan costos. El modelo neuronal encontrado es un buen modelo predictivo con bajo error, capaz de predecir valores en el rango estudiado, que además posibilita analizar la optimización y el control del proceso. Referencias 1. Fregolente L. V., Fregolente P. B. L., Chicuta A. M., Batistella C. B., MacielFilho R. and Wolf-Maciel M. R. Trans IChemE, Part A, Chemical Engineering Research and Design, 2007, 85(A11): Martins P. F., Carmona C., Martinez E. L., Sbaite P, MacielFilho R., Wolf Maciel M.R. Short path evaporation for methyl chavicol enrichment from basil essential oil. Separation and PurificationTechnology 87 (2012) Martins P.F., Medeiros H.H.R., Sbaite P., Wolf Maciel M.R. Enrichment of oxyterpenes from orange oil by short path evaporation. Separation and Purification Technology 116 (2013) Martinello M., Hecker G., Pramparo M. (2007). Grape seed oil deacidification by molecular distillation: Analysis of operative variables influence using the response surface methodology J. Food Eng.,81, Batistella C.B. and W. MacielM.R.. Modeling, simulation and analysis de molecular destillators: Centrifugal and falling film. European Symposium on Computer 6. ZuñigaLiñan L.,NascimentoLimab N.M.,1, Manentic F., Wolf Maciela M.R.,MacielFilhob R.,MedinadL.C.Experimental campaign, modeling, and sensitivity analysis for the molecular distillation of petroleum residues K+ 7. Gontarski, C.A., Mori M., Rodrigues P.R., Prenem L.F. Simulation of an industrial wastewater treatment plant using artificial neural networks. Comput. Chem. Eng 24 (2000), Bar N, Bandyopadhyay T.K., Biswas M.N., Das S.K..Prediction of pressure drop using artificial neural network for non-newtonian liquid flow through piping components.j. Petro. Sci. Eng. 71 (2010), Shao P., Jiang S.T., Ying Y.J. Optimization of molecular distillation for recovery oftocopherol from rapeseed oil deodorizer distillate using response surface and artificial neural network models. Food Bioprod. Process 85 (2007),

17 Problemas y Soluciones en la Completitud de Modelos en Lenguaje Natural Graciela D.S. Hadad 1,2, Claudia S. Litvak 1, Jorge H. Doorn 1,2 1 DIIT, Universidad Nacional de La Matanza, Argentina 2 Escuela de Informática, Universidad Nacional del Oeste, Argentina {ghadad, clitvak}@ing.unlam.edu.ar, jdoorn@exa.unicen.edu.ar Abstract. Un proceso de requisitos habitualmente se debe valer de modelos en lenguaje natural para facilitar la comunicación y validación con los clientes. Dichos modelos deben ser lo más precisos y completos posibles, dado que a partir de ellos se elaboran otros modelos necesarios para un desarrollo de software robusto. A lo largo de casi dos décadas, diversos autores en la Ingeniería de Requisitos han utilizado un modelo léxico con diferentes propósitos. Se han realizado varios estudios para establecer el grado de completitud del modelo léxico construido, obteniéndose en todos los casos un número excesivo de omisiones. En el presente trabajo, se ha detectado que varias de estas omisiones no eran efectivamente tales, y sólo contribuían a distorsionar los resultados de completitud obtenidos. Este hallazgo permitirá mejorar el método de estimación de completitud y, principalmente, establecer mejoras en la construcción del modelo léxico. Keywords: Ingeniería de Requisitos, Modelado de Requisitos, Completitud de Modelos, Léxico Extendido del Lenguaje. 1 Introducción En muchos de los procesos de requisitos propuestos por diversos autores [1] [2] [3] [4] [5] [6] [7] [8] se incluye la creación de un glosario como una de las actividades iníciales del mismo. Estos glosarios contienen los términos relevantes utilizados por los clientes del futuro sistema de software. El objetivo de estos glosarios es, en primer lugar, facilitar la comprensión del vocabulario del contexto del cual ha surgido la necesidad de un nuevo sistema [9]. Subsidiariamente, estos glosarios se utilizan para reforzar la legibilidad por parte de los clientes de los documentos que se generen [2] [4] [5]. Adicionalmente, suelen ser utilizados por los propios ingenieros de requisitos, como una fuente sólida de conocimiento para iniciar el estudio de ese contexto que define y condiciona las características del futuro sistema de software. Que un glosario sea una fuente de conocimiento es un hecho muy conocido en el dominio de la lingüística [10] [11]. Como ejemplo de esto es apropiado utilizar una vez más el muy conocido hecho que en algunas lenguas orientales, como el mandarín, taiwanés y otros, existen muchas palabras para arroz; en particular, hay 50 palabras en mandarín [12]. Esto se debe a que estas culturas tienen mucho para decir acerca del arroz y necesitan una gran precisión en el lenguaje para poder hacerlo. Un fenómeno parecido 1286

18 ocurre cuando en un texto o en un discurso se necesitan introducir nuevos conceptos; necesariamente el autor o el orador deben recurrir a la definición de los términos significativos que le permitirán introducir esos conceptos en forma precisa [13]. Retornando al uso de glosarios en el proceso de requisitos, estos enfoques proveen un punto de vista divergente de los clásicos enfoques top-down o bottom-up. Empezar por una revisión de un glosario no implica estudiar los inacabables detalles que se abordan en un enfoque bottom-up, ni procurar comprender la esencia del objeto de estudio a través de una visión panorámica. Por el contrario, empezar por un glosario significa aprovechar las abstracciones conceptuales ya realizadas por los hablantes de donde se extrajo ese glosario. Esto es notablemente importante ya que la información obtenida por este medio es más sencilla de obtener y más valiosa. De alguna manera podría decirse que de un glosario se obtiene información más concentrada y, por lo tanto, más útil para el proceso de requisitos. Sin embargo, no todo son loas al trabajar de esta manera. Aparece claramente la duda de la calidad del material de origen, es decir, la calidad del glosario. Y es aquí donde surge el aspecto más importante e insidioso de esa duda acerca de la calidad: la completitud del glosario. Omisiones en el glosario son entonces potenciales omisiones en el resto de los artefactos generados en las actividades del proceso de requisitos y en los requisitos mismos. En el presente artículo se revisan los resultados obtenidos a lo largo de varios proyectos en los que se abordaron diferentes formas de estimar la completitud de glosarios [14] [15] [16] [17] y se presentan nuevas visiones que aclaran en forma notoria los resultados de dichos trabajos, llegándose a caracterizar varias de las causas esenciales que provocan las omisiones observadas. En la sección siguiente se introduce el tema de completitud en los modelos de requisitos, en la sección 3 se presenta el trabajo realizado y en la sección 4 las conclusiones. 2 Completitud del Modelo Léxico Los estudios sobre la completitud de glosarios fueron realizados en el marco de un proceso de requisitos cuya primera actividad consiste en construir un modelo denominado Léxico Extendido del Lenguaje (LEL), procediendo inmediatamente a estudiar el contexto de donde surge la necesidad del sistema, guiado por el LEL [18] [19]. Los componentes del modelo LEL son el nombre del término, la noción y el impacto. En la noción se registra el significado o denotación del término y en el impacto se registra la connotación del mismo. La evolución del modelo LEL y de sus usos, desde su presentación [9] hasta el presente, ofrece algunos aspectos muy valiosos. En [20] se propusieron unas heurísticas para la construcción del LEL, que no fueron objetadas ni modificadas pese a haberse encontrado numerosos usos para este modelo [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33]. Algunos de estos usos son aplicaciones directas, sin modificaciones del modelo aunque con diferentes propósitos, mientras que otros usos modifican ligeramente el modelo. Sábat Neto [21] definió un glosario usando el modelo LEL, que registra la terminología relativa a requisitos no funcionales. Breitman y Leite [22] han presentado un proceso de construcción de una ontología de aplicación web a partir de un LEL. Leonardi y Leite [23] [34] han definido una estrategia para identificar reglas del negocio, en base 1287

19 a patrones, relacionándolas con las entradas de un LEL creado previamente. Fiorini et al. [25] han mostrado un enfoque sistemático para la descripción, almacenamiento y reuso de procesos, donde mediante patrones de proceso, marcan frases especiales del LEL. Ravid et al. [26] construyeron prototipos de requisitos por medio de escenarios (que denominan escenarios de casos de uso ), creando simultáneamente un LEL. Mauco et al. [29] [30] han propuesto un conjunto de heurísticas para derivar especificaciones formales escritas en el lenguaje de especificación RAISE a partir de modelos del LEL y de escenarios. Hadad et al. [Hadad 08] han presentado una heurística para derivar casos de uso a partir del LEL, junto con una herramienta que permite su creación. Leonardi et al. [32] construyeron una herramienta semiautomática para derivar diagramas de clases del universo de discurso a partir del LEL. Antonelli [35] ha propuesto una estrategia para identificar características transversales utilizando el LEL. Concurrentemente con estos trabajos, los primeros estudios de completitud del LEL [14] [15] comenzaron a crear dudas acerca de la calidad del mismo y de las heurísticas de construcción, al comprobar que diferentes ingenieros de requisitos, todos siguiendo las mismas heurísticas, llegaban a obtener LELs muy diferentes [17]. La completitud es una de las propiedades consideradas imprescindibles, tal es así que el estándar IEEE [36] la considera como una de las propiedades fundamentales que debe cumplir cada requisito individualmente y el conjunto de requisitos de software como un todo. Estudiar la completitud en la ingeniería de requisitos implica verificar si se ha elicitado y modelado toda la información perteneciente al contexto donde el sistema de software se implantará. El objetivo en un proyecto de software es obtener sistemas de software idealmente completos que respondan a todas las necesidades de los clientes. La incompletidud en procesos de requisitos fue estudiada por Firesmith [37], quien investigó el significado de la completitud y estableció algunos parámetros para prevenir la obtención de especificaciones de requisitos incompletas. El enfoque de Firesmith y el de Litvak et al. [15] [16] difieren en el sentido que Firesmith propugna una visión conceptual de la completitud mientras que los otros trabajos aspiran a desarrollar estrategias que permitan estimar la completitud y eventualmente actuar sobre sus causas. En el primer trabajo realizado por Doorn y Ridao [14] [38], se aplicó el método de captura-recaptura [39], utilizando la adaptación denominada Detection Profile Method [40], para predecir el número de elementos faltantes en el LEL y en escenarios, donde concluyeron que al aumentar el número de elicitadores (ingenieros de requisitos) la cantidad de elementos estimados se acercaría significativamente a la cantidad realmente existente en el dominio del problema. Para realizar este trabajo, dispusieron de nueve muestras del LEL desarrolladas sobre el mismo caso de estudio (ver 2ª columna de Tabla 1). El estudio presentado por Litvak et al. [15] aplicó también Detection Profile Method [40] incorporando correcciones semánticas previas a la aplicación de dicho método. En el trabajo posterior [16], se presentaron una serie de correcciones semánticas más refinadas, donde se estudió la relevancia, pertenencia, sinonimia y homonimia del contenido textual del modelo y se compararon con los resultados de los trabajos precedentes, concluyendo que se logró una mejor estimación de la completitud de modelos en lenguaje natural. En dicho estudio, el análisis semántico se realizó en dos etapas: una primera etapa entre los elementos de 1288
![[26] construyeron prototipos de requisitos por medio de escenarios (que denominan escenarios de casos de uso ), creando simultáneamente un LEL. Mauco et al.](/docs-images/40/814221/images/page_19.jpg "[29] [30] han propuesto un conjunto de heurísticas para derivar especificaciones formales escritas en el lenguaje de especificación RAISE a partir de modelos del LEL y de escenarios. Hadad et al.")
20 una misma muestra del LEL (intra-análisis), estudiando pertenencia, relevancia y redundancia de cada término, y una segunda etapa comparando los elementos entre las muestras (inter-análisis), estudiando sinónimos y homónimos (ver 3ª columna de Tabla 1). A fin de profundizar las comparaciones semánticas del estudio realizado, se agregaron nuevos léxicos del mismo caso de estudio, con un proceso de construcción más cuidado. En dicho nuevo trabajo [17], se comprobó que diferentes grupos de ingenieros trabajando sobre un mismo problema encuentran en el mejor de los casos sólo el 50% de los elementos del modelo. Los resultados obtenidos llevaron a la necesidad de profundizar la investigación y, por consiguiente, al presente trabajo (ver 4ª columna de Tabla 1). 3 Mejoras en la Estimación de Completitud Los resultados sobre completitud presentados en [14] y los obtenidos posteriormente al incorporar correcciones semánticas [16] [17] son cuanto menos alarmantes. Habiéndose estimado un nivel de incompletitud del 50% o superior, entonces si estas cifras son correctas, el modelo utilizado es inaceptable. Reconsiderando todos los aspectos del problema, apareció como muy probable que las cifras obtenidas hayan sido sobreestimadas. Es así que se incorpora a este estudio la hipótesis que existen omisiones aparentes. Realmente esta suposición existió en forma algo confusa en [16]. En los estudios y trabajos posteriores, que sustentan el presente artículo, esta hipótesis fue central en todo momento. Es así que una de las principales tareas consistió en distinguir las omisiones aparentes de las omisiones reales, siendo: Omisiones aparentes: aquellas detectadas como omisiones por la forma en que se realizaron las capturas. Omisiones reales: aquellas que se refieren a la ausencia de una unidad de información en el documento bajo estudio. Obviamente, es necesario reducir o eliminar las omisiones aparentes para lograr que las estimaciones de completitud sean correctas y descubrir las causas de ambos tipos de omisiones para luego desarrollar LELs con un grado de completitud alto. Esta visión ideal, consistente en perfeccionar la herramienta empleada en el estudio del problema para luego aplicarla, no ha podido ser llevada a la práctica. Esto se debe a que el análisis de cada aspecto del problema ha llevado, en la mayoría de los casos, a descubrir simultáneamente el origen esencial del defecto y la forma de corregirlo. En otras palabras, las mejoras logradas en la construcción del LEL se han producido en forma incremental y no se han concentrado ni en las omisiones aparentes ni en las omisiones reales, sino que se refieren a ambas. 3.1 Mejora de las Comparaciones Los resultados obtenidos en trabajos anteriores [14] [15] [16] [17], si bien fueron promisorios, hicieron evidente la necesidad de reducir el tamaño de las unidades comparadas entre las muestras del LEL. Esto se debió principalmente a la presencia de sentencias largas que tenían dos o más enunciados empotrados en ellas. 1289

21 La nueva propuesta consistió en incorporar al análisis semántico un análisis gramatical de cada sentencia del modelo LEL. Entonces, se comparó semántica y gramaticalmente el contenido de las muestras disponibles. Para cada término de una muestra, se consideró su noción e impacto como un conjunto de sentencias. En detalle: Se organizó gramaticalmente todo el conjunto de sentencias en Sujeto, Verbo y Resto del Predicado, buscando quién era realmente el sujeto en cada caso. Aquí se consideraron las sentencias con Sujeto tácito. Si dicho Sujeto era el mismo término del LEL, éste fue agregado. Si dicho sujeto se podía sobreentender, fue agregado. En los casos de sentencias subordinadas (o sea, contenidas en otras sentencias), se las desdobló y consideró individualmente, aplicando la misma acción del paso anterior sobre cada sentencia resultante. Respecto de los verbos, se ignoraron las diferencias por conjugaciones y tiempos verbales. Se consideraron también los sinónimos existentes de dichos verbos. Se convirtieron las sentencias que estaban en voz pasiva en voz activa. 3.2 Presencia de Jerarquías en el LEL Una segunda mejora en las comparaciones se logró estudiando con cuidado las jerarquías presentes en el LEL. El primer aspecto a ser considerado en relación con las mismas, es que en el LEL se pueden observar tanto jerarquías completas como jerarquías incompletas (ver Figura 1). A veces esto ocurre por defectos en la construcción del LEL y otras veces porque corresponde que sea así dada la estructura lingüística propia del contexto bajo estudio. Fig. 1. Jerarquías entre Términos del LEL Puede ocurrir que uno de los términos especializados esté fuera del alcance del contexto bajo estudio y, por ende, no sea un término del LEL, por lo cual se tendrá 1290
22 una jerarquía incompleta (ver Figura 1.b). También puede ocurrir que el término genérico esté fuera del alcance del contexto entonces será una jerarquía incompleta sin padre (ver Figura 1.c). Si se extendiera el alcance del glosario, entonces todo genérico tendría a su vez un genérico de orden superior. Sin embargo, esto no prospera mucho en LELs reales, ya que la gran mayoría de las jerarquías tienen sólo dos niveles, siendo muy excepcionales los casos de jerarquías más profundas. Se presenta frecuentemente una situación errónea, donde el genérico es considerado sinónimo de un especializado (ver Figura 1.d). Se ha descubierto que la existencia de jerarquías entre términos del LEL es un fuerte inductor de errores sutiles en los que un impacto correcto se desplaza incorrectamente entre los especializados y los genéricos. 3.3 Algunos Tipos de Omisiones Algunos ejemplos de tipos de omisiones halladas durante el presente trabajo se muestran en la Tabla 1. La 4ª columna de la Tabla 1 muestra en forma evidente la mejora en la detección de las omisiones reales y la reducción de las omisiones aparentes, frente a los trabajos realizados previamente, que utilizaron comparaciones solo sintácticas [14] o comparaciones solo semánticas [15][16][17]. Tabla 1. Ejemplos de omisiones halladas durante este estudio. Primera Comparación comparación sintáctica [14] semántica[15][16][17] Unidad de Término con noción e Nombre del término Comparación impacto como un todo Migración del impacto de un término existente a otro existente Falta de un término con traslado de un impacto a otro Sentencias contenidas en sentencias Sinónimos no considerados Término genérico como sinónimo de especializado Omisión aparente de impacto, no detectada. Omisión aparente de impacto, no detectada. Omisión real de término detectada. Omisión aparente de noción o impacto, no detectada. Dos omisiones aparentes de términos. Omisión real de término, no detectada. Omisión aparente de impacto, no detectada. Omisión aparente de impacto, no detectada. Omisión real de término detectada. Omisión aparente de noción o impacto, no detectada. No hay omisión. Omisión real de término, no detectada. Comparación actual semántica y gramatical Sentencia desagregada de noción e impacto No hay omisión. Omisión real de término detectada. No hay omisión. No hay omisión. Omisión real de término detectada. 4 Conclusiones Es conocido que el problema de completitud es de difícil abordaje. Más aún, se ha podido comprobar que en modelos construidos en lenguaje natural no sólo están 1291
23 ocultas las omisiones sino que también es complicado darse cuenta que las mismas puedan existir. En el caso del Léxico Extendido del Lenguaje se ha detectado reiteradamente la presencia de omisiones, pero es necesario aún mejorar los mecanismos de búsqueda y las heurísticas de construcción del modelo para reducirlas. Si bien es hoy conocido que las cifras presentadas en el primer estudio de completitud del LEL están sobredimensionadas, la alarma encendida en su oportunidad continúa vigente, ya que ninguno de los trabajos más meticulosos realizados posteriormente han descartado la existencia de omisiones en cantidad y calidad preocupantes. Se ignora la importancia de las omisiones reales y de algunas de las omisiones aparentes (por ejemplo, migración de impactos entre términos) sobre los modelos siguientes y finalmente sobre los requisitos mismos y sus atributos. Naturalmente, el estudio de estos aspectos es parte del trabajo futuro a ser encarado. Se planifica en un futuro próximo revisar las heurísticas de construcción del LEL bajo la óptica de este artículo y mejorarlas. Referencias 1. Constantine, L.: Joint Essential Modelling, User Requirements Modelling for Usability. Intl Conference on Requirements Engineering (Tutorial Notes), Colorado Springs, Constantine & Lockwood (1998) 2. Rolland, C., Ben Achour, C.: Guiding the construction of textual use case specifications. Data & Knowledge Engineering 25 (1998) Oberg, R., Probasco, L, Ericsson, M.: Applying Requirements Management with Use Cases. Rational Software Corporation (1998) 4. Alspaugh, T.A., Antón, A.I., Barnes, T., Mott, B.W.: An Integrated Scenario Management Strategy. Intl Symposium On Requirements Engineering, Irlanda, IEEE Computer Society Press (1999) Regnell, B., Kimbler, K., Wesslén, A.: Improving the Use Case Driven Approach to Requirements Engineering. 2nd IEEE International Symposium on Requirements Engineering, Marzo Parte de Ph.D. Thesis: Requirements Engineering with Use Cases a Basis for Software Development, Reporte Técnico 132, Paper I, Department of Communication Systems, Lund University (1999) Whitenack, B.G. Jr.: RAPPeL: A Requirements Analysis Process Pattern Language for Object Oriented Development. Knowledge Systems Corp. (1994) 7. Jacobson, I., Booch, G., Rumbaugh, J., The Unified Software Development Process, Addison- Wesley, Reading, MA, 1º edición, Febrero Díaz, I., Pastor, O., Moreno, L., Matteo, A.: Una Aproximación Lingüística de Ingeniería de Requisitos para OO-Method, VII Workshop Iberoamericano de Ingeniería de Requisitos y Desarrollo de Ambientes de Software, Arequipa, Perú (2004) 9. Leite, J.C.S.P.: Application Languages: A Product of Requirements Analysis. Computer Science Department of PUC-Rio, Brasil (1989) 10. Smeaton, A.F.: Natural Language Processing and Information Retrieval. Information Processing and Management, Vol. 26, Nº 1 (1990) Briner, L.L.: Identifying Keywords in Text Data Processing, Directions and Challenges, 15th Annual Technical Symposium (1996) Free Chinese & Japanese Online Dictionary, Oriental Outpost, visitado 28/5/ Berry, D.M., Kamsties, E.: Ambiguity in Requirements Specification. En: Leite, J.C.SP., Doorn, J.H(eds): Perspectives on Software Requirements, Kluwer Academic Publishers, EEUU (2004) Doorn, J.H., Ridao, M.: Completitud de Glosarios: Un Estudio Experimental. VI Workshop on Requirements Engineering, Brasil (2003) Litvak C.S., Hadad, G.D.S., Doorn, J.H.: Un abordaje al problema de completitud en requisitos de software. XVIII Congreso Argentino de Ciencias de la Computación, Bahía Blanca (2012) Litvak C.S., Hadad, G.D.S., Doorn, J.H.: Correcciones semánticas en métodos de estimación de completitud de modelos en lenguaje natural. XVI Workshop on Requirements Engineering, 1292
24 Montevideo, Uruguay (2013) Litvak C.S., Hadad, G.D.S., Doorn, J.H.: Mejoras semánticas para estimar la Completitud de Modelos en Lenguaje Natural. Primer Congreso Nacional de Ingeniería Informática / Sistemas de Información, Córdoba (2013) 18. Leite, J.C.S.P., Hadad, G.D.S., Doorn, J.H., Kaplan, G.N.: A Scenario Construction Process. Requirements Engineering Journal, Springer-Verlag London Ltd., Vol.5, Nº1 (2000) Leite, J.C.S.P., Doorn, J.H., Kaplan, G.N., Hadad, G.D.S., Ridao, M.N.: Defining System Context using Scenarios. In: Leite, J.C.S.P., Doorn, J.H. (eds): Perspectives on Software Requirements, Kluwer Academic Publishers, EEUU, ISBN: (2004) Hadad, G.D.S., Kaplan, G.N., Oliveros, A., Leite, J.C.S.P.: Construcción de Escenarios a partir del Léxico Extendido del Lenguaje. 26 JAIIO Jornadas Argentinas de Informática, Simposio en Tecnología de Software, Buenos Aires (1997) Sábat Neto, J.M.: Integrando Requisitos Não Funcionais à Modelagem Orientada a Objetos. M.Sc. Dissertation, Computer Science Department of PUC-Rio, Brasil (2000) 22. Breitman, K.K., Leite, J.C.S.P.: Ontology as a requirements engineering product. 11th IEEE Intl Conference on Requirements Engineering, EEUU, IEEE Computer Society (2003) Leonardi, M.C.: Una Estrategia de Modelado Conceptual de Objetos basada en Modelos de Requisitos en Lenguaje Natural. M.Sc. Dissertation, Universidad Nacional de La Plata, Argentina (2001) 24. Pimenta, M.S., Faust, R.: Eliciting Interactive Systems Requirements in a Language-Centred User- Designer Collaboration: A Semiotic Approach. Special Issue on HCI and Requirements of ACM SIGCHI Bulletin, Vol.29, Nº1 (1997) Fiorini, S.T., Leite, J.C.S.P., Lucena, C.J.P.: Reusing Process Patterns. 2nd International Workshop on Learning Software Organizations, Oulu-Finlandia (2000) Ravid, A., Berry, D. M.: A Method for Extracting and StatingSoftware Requirements that a User Interface Prototype Contains, Requirements Engineering Journal, Springer-Verlag, Vol.5, Nº4 (2000) De Bortoli, L.Â, Alencar Price, A.M.: O Uso de Workflow para Apoiar a Elicitação de Requisitos. III Workshop de Engenharia de Requisitos, Río de Janeiro, Brasil (2000) Estrada, H., Martínez, A., Pastor, O., Ortiz, J., Ríos, O.A.: Generación Automática de un Esquema Conceptual OO a Partir de un Modelo Conceptual de Flujo de Trabajo. IV Workshop on Requirements Engineering, Buenos Aires ( 2001) Mauco, M.V., George, C.: Using Requirements Engineering to Derive a Formal Specification. Reporte Técnico Nº 223, UNU/IIST, P.O. Box 3058, Macau (2000) 30. Mauco, M.V., Riesco, D., George, C.: Heuristics to Structure a Formal Specification in RSL from a Client-oriented Technique. 1st Annual Intl Conference on Computer and Information Science, ISBN: , Florida, EEUU (2001) 31. Hadad, G.D.S., Migliaro, A., Grieco, N.: Derivar casos de uso de un glosario. XIV Congreso Argentino de la Ciencia de la Computación, ISBN: , La Rioja (2008) Leonardi M.C., Ridao M., Mauco M.V., Felice L., Montejano G., Riesco D., Debnath N.: An ATL Transformation from Natural Language Requirements Models to Business Models of a MDA Project. 11th International Conference on Telecommunications for Intelligent Transport Systems, Rusia (2011) 33. Antonelli, R.L., Rossi, G., Leite, J.C.S., Oliveros, A.: Buenas prácticas en la especificación del dominio de una aplicación. 16th Workshop on Requirements Engineering, Uruguay (2013) 34. Leite J.C.S.P, Leonardi, M.C.: Business rules as organizational Policies. IEEE Ninth International Workshop on Software Specification and Design, IEEE Computer Society Press (1998) Antonelli, R.L.: Identificación temprana de características transversales en el lenguaje de la aplicación capturado con el Léxico Extendido del Lenguaje. Tesis de Doctorado, Facultad de Ciencias Informáticas, Universidad Nacional de La Plata (2012) 36. IEEE : IEEE Systems and software engineering - Life cycle processes - Requirements engineering, IEEE, Nueva York (2011) 37. Firesmith, D.: Are Your Requirements Complete? Journal of Object Technology, Vol.4, Nº1 (2005) Ridao, M., Doorn, J.H.: Estimación de Completitud en Modelos de Requisitos Basados en Lenguaje Natural. IX Workshop on Requirements Engineering, Brasil (2006) Otis, D.L., Burnham, K.P., White, G.C., Anderson, D.R.: Statistical inference from Capture on Closed Animal Populations. Wildlife Monograph, 62 (1978) 40. Wohlin, C., Runeson, P.: Defect content estimations from Review Data. 20th Intl Conference on Software Engineering, Japón (1998)
25 Análisis de desempeño de algoritmos de detección automática. Caso de estudio: detección de la capa esporádica E Maria G. Molina 1,2, Enrico Zuccheretti 3, Bruno Zolesi 3, Cesidio Bianchi 3, Umberto Sciacca 3, James B. Ariokasami 3,Miguel A. Cabrera 1 1 Laboratorio de Telecomunicaciones, Facultad de Ciencias Exactas y Tecnlogia (FACET), Universidad Nacional de Tucuman (UNT), Av. Independencia 1800, Tucuman, Argentina, gmolina@herrera.unt.edu.ar 2 Departamento de Ciencias de la Computacion, FACET, UNT, Av. Independencia 1800, Tucuman, Argentina, gmolina@herrera.unt.edu.ar 3 Istituto Nazionale de Geofisica e Vulcanologia, Via di Vigna Murata, Roma, Italia. enrico.zuccheretti@ingv.it Resumen. Actualmente gran parte de las mediciones ionosféricas se realizan mediante el uso de un radar HF denominado sondador ionosférico. Este equipo transmite pulsos cortos de señales de radio hacia los estratos de la alta atmósfera terrestre conocida como la ionosfera donde son reflejados y posteriormente recepcionados. Medir el tiempo de retardo entre la transmisión de la señal y la recepción de la misma permite estimar la altura virtual a la cual se produjo la reflexión. En este trabajo se realiza el estudio comparativo de algoritmos de detección en particular para la capa esporádica E. Se usaron algoritmos de umbral fijo, CA-CFAR (cell averaging- constant false alarm rate) y OS-CFAR (order statistics-constant false alarm rate). Los resultados preliminares muestran un comportamiento más robusto en el caso de OS-CFAR respecto a los otros dos algoritmos. Este trabajo muestra resultados parciales sobre estudios científicos aplicados a la detección de capas ionosféricas y por lo tanto es conveniente en el futuro realizar un estudio mas exhaustivo. Palabras Clave: Algoritmos, Detección automática, Radar, Sondador ionosférico. 1 Introducción Actualmente gran parte de las mediciones de parámetros ionosféricos se realizan mediante el uso de un sondador ionosféricos o ionosonda, el que básicamente es un 1294
26 radar en banda de HF. Este sistema transmite cortos pulsos de portadoras moduladas mediante un sistema de antenas con lóbulo de radiación orientado verticalmente hacia los estratos de la atmósfera superior terrestre y mide el retardo de las señales reflejadas por los estratos ionosféricos. Si es posible estimar el tiempo entre la transmisión de la señal y la recepción de la misma, entonces es posible estimar la altura en la cual se produjo la reflexión. Este tipo de sondaje es el denominado sondaje vertical y una vez realizado, mediante algoritmos de detección es posible determinar el tiempo de retardo y con ello la altura virtual de los estratos ionosféricos. Si se realizan sondajes continuos utilizando frecuencias entre 1 y 20 MHz, es posible obtener una representación grafica de la altura virtual en función de la frecuencia que se denomina ionograma. En este trabajo se estudió del comportamiento de diferentes algoritmos de detección analizando el caso de la capa esporádica E. Para ello se utilizaron datos obtenidos mediante el sondador ionosférico AIS-INGV (Advanced Ionospheric Sounder Instituto Nazionale di Geofisica e Vulcanologia) en el observatorio ionosférico de Roma (41.8 N, 12.5 E) durante Marzo de Los sondajes fueron realizados a una frecuencia fija de 3 MHz en horario diurno donde típicamente se forma el estrato Es (capa esporádica E). La comparación se realizó utilizando los algoritmos usando umbral fijo, CA-CFAR (cell averaging- constant false alarm rate) y OS-CFAR (order statistics-constant false alarm rate). Los resultados preliminares muestran un comportamiento más robusto en el caso de OS-CFAR respecto a los otros dos algoritmos. Este trabajo es parte de un estudio mas amplio sobre detección de capas ionosféricas y por lo tanto es conveniente en el futuro realizar un estudio mas exhaustivo. 2 Estratos ionosféricos y las telecomunicaciones Se puede definir a la ionósfera como una parte de la atmósfera terrestre donde iones y electrones están presentes en cantidades suficiente como para afectar la propagación de ondas electromagnéticas. Es la región de espacio localizada aproximadamente entre los 50 y 1000 km por encima de la superficie de la tierra y es la porción más alta de la atmósfera. Absorbe grandes cantidades de la energía radiante del sol, mediante procesos de disociación e ionización de distintas especies moleculares y atómicas que constituye la atmosfera terrestre. En este proceso se generan iones y electrones libres y se produce la absorción de la radiación letal para la vida en la tierra. La ionósfera no es uniforme, existiendo gradientes verticales de temperatura y densidad, o sea, está estratificada. Las regiones de la ionósfera varían en altura y en densidad de ionización con la hora del día, fluctúan con un patrón cuasi cíclico todo el año y de acuerdo con el ciclo de manchas solares de once años [1]. No existe una separación total entre sus regiones, sino un cambio en la densidad numérica de cargas, lo que marca la diferencia entre ellas. Así se pueden clasificar las distintas regiones como sigue: la región D está comprendida entre los 60 y los 90 km de altura, el orden de magnitud de la densidad electrónica es de 10 2 a 10 4 cm -3, la región E, entre 105 y 160 km con densidad electrónica del orden de 10 5 cm -3 y la 1295
27 región F sobre los 180 km, con densidad del orden de 10 5 a 10 6 cm -3. Esta última región tiene un pico de densidad máxima a una altura del orden de los 300 km. En los sistemas de comunicación de radio, las ondas se pueden propagar de varias formas, dependiendo del tipo de sistema y del ambiente. Si bien las ondas electromagnéticas viajan en línea recta, esta trayectoria puede ser alterada por el medio en el que se trasladan. Estas desviaciones en la trayectoria de la señales de radio influyen directamente en las radiocomunicaciones [1]. Dependiendo de cuán ionizada esté la ionósfera, las comunicaciones se ven afectadas en mayor o menor medida. Muchos sistemas de comunicación utilizan la ionósfera como medio para transmitir ondas de radio a grandes distancias. Algunas frecuencias de radio son absorbidas y otras reflejadas, lo que hace que las señales fluctúen con rapidez y que sigan rutas de propagación inesperadas. Las comunicaciones aeroterrestres, barco-puerto, las estaciones de radio de onda corta y algunas frecuencias de radio aficionados se ven afectados frecuentemente. En los últimos años los estudios de la ionósfera han despertado un renovado interés debido a que este medio interrumpe o modifica la fase y amplitud de las señales de comunicación en la banda L, como la de los sistemas de posicionamiento global, GLONAS, GPS, GALILEO, etc. 3 Detección automática de ecos ionosféricos Una de las funciones principales que debe llevar a cabo un radar es la detección del denominado blanco. Esta función no se realiza en un único paso sino que en general se puede realizar como una serie de etapas que dependen de las características del blanco [2]. En el caso del sondador ionosférico el blanco es la ionosfera que en un periodo corto de tiempo puede suponerse como un blanco no fluctuante [1]. El proceso comienza con la codificación de una señal portadora s(t) utilizando un código binario complementario C[t]. Luego esta señal codificada Tx(t) es enviada a la ionosfera y posteriormente recepcionada Rx(t). En un paso sucesivo, donde se da inicio al proceso de detección, esta señal será muestreada en cuadratura (I[t], Q[t]) y luego correlacionada con el código local (código original al momento de la codificación de la portadora). Con el fin de mejorar la relación señal a ruido, este proceso se integra coherentemente para varios pulsos [3]. En la Fig. 1 se muestra un esquema simplificado en las etapas de detección del sondador ionosféricos AIS- INGV. Luego de ser correlacionada e integrada coherentemente a la señal se le aplica algún algoritmo de detección automática que permita decidir si una determinada muestra es un eco o solo es producto de ruido o interferencia. Para ello es necesario establecer un valor de umbral de modo que toda medición que exceda este umbral será declarada como blanco. Existen numerosos algoritmos para la detección automática de blancos, cada uno trata de sortear numerosos problemas de detección que dependen de las características estadísticas de las señales y de los blancos. En el caso del sondador ionosféricos se probó el desempeño de tres algoritmos. Primero se estableció un umbral fijo (TFix) que se calculo usando todas las muestras 1296
28 de la señal. Para el cálculo del umbral se utilizo como estadística el valor promedio de todas las amplitudes de la señal. En segundo término se utilizo una ventana móvil alrededor de cada muestra para calcular las estadísticas usando también el promedio. La diferencia es que la ventana de tamaño N menor al total de muestra varía según la muestra que se trate obteniendo así un valor variable de umbral. Este algoritmo es conocido en la literatura de radares como CA-CFAR (Cell Averaging- Constant False Alarm Rate)[2] [4]. Por ultimo se utilizó el denominado algoritmo OS-CFAR (Order Statistics-Constant False Alarm Rate) el cual utiliza también una ventana móvil de tamaño N. En este caso las estadísticas se calculan ordenando las amplitudes en dicha ventana y seleccionando el k-esimo valor como representativo del nivel de interferencia alrededor de la muestra de interés. Si se elije el valor k-esimo como N/2, entonces la estadística utilizada es similar a una media móvil [2] [4]. Portadora Generador Código Complementario s(t) T x (t) C [ t ] Ionósfera (t) R x Muestreo en Cuadratura I[ t], Q[ t] Correlación e Integración Coherente 1800 Obtención pico del eco y Estimación de la Altura Virtual Km Figura 1. Esquema de las etapas de detección de ecos del sondador ionosférico AIS-INGV. 4 Datos y resultados Desde el punto de vista de la detección, dentro de una señal reflejada por un estrato ionosférico, una de las tareas mas complejas es la de estimar la altura de la capa 1297
29 esporádica E. Esto sucede a bajas alturas y en general los ecos provenientes de esta capa suceden en horario diurno, por lo tanto se realizaron sondajes diurnos a una frecuencia fija de 3 MHz. A fin de probar los algoritmos propuestos se realizó una campaña de recolección de datos por un periodo de tres días realizando sondajes cada dos minutos. La obtención de datos sin procesar se realizó en el observatorio ionosférico de Roma utilizando el sondador AIS-INGV (Marzo de 2014). Una de las situaciones típicas observadas ocurre cuando una porción de energía de la onda electromagnética transmitida es reflejada en la capa Es mientras que otra porción penetra más allá en altura hasta ser reflejada por la capa F. Desde el punto de vista de la detección ocurre que la energía retornada por la primera capa es inferior al resto y compite con ecos de mayor amplitud. Si el algoritmo utilizado para estimar el umbral usa todas las muestras que componen la señal, que es el caso de TFix, sucede que todas las amplitudes se encuentran en competencia y la detección de ecos más débiles como la capa E se ven afectados. En la Fig.2 se muestra un ejemplo de este caso. Si bien en el ejemplo todos los algoritmos detectan la capa E, TFix detecta levemente el pico. Mientras que los algoritmos CA-CFAR y OS-CFAR tienen una performance mejor, siendo este ultimo el que mejor provee información sobre el blanco. OS-CFAR además de detectar el pico del eco, muestra información de lo que sucede en los alrededores de este incluyendo información como la cantidad de muestras que componen el blanco. 04/04/ :52 UT Señal CA-CFAR OS-CFAR TFix Amplitud Mhz Fig. 2. Comparación de desempeño de los tres algoritmos propuestos para la detección de la capa E cuando compite con ecos de mayor amplitud. El eco alrededor de los 150 km corresponde a la capa Es. km Otro caso interesante ocurre cuando la capa E se encuentra bien definida y la señal transmitida incide prácticamente de manera vertical. En este caso el eco reflectado tendrá mayor energía de tal manera que puede ser reflejado nuevamente en tierra y reenviado hacia la ionosfera. Esto produce la aparición de múltiples reflexiones en los ionogramas. En la Fig. 3 se puede observar un caso con múltiples reflexiones. Respecto a los algoritmos de detección estudiados, se puede observar que nuevamente el algoritmo TFix ve disminuida su capacidad de detección debido a su característica global. El cálculo de estadísticas locales en ventanas móviles de los otros dos 1298
30 algoritmos permite que el eco detectado no compita con la energía de otros ecos. Una vez mas el algoritmo OS-CFAR provee mayor información sobre el eco y sobre su forma. 11/04/ :22 UT COMPARACION ENTRE ALGORITMOS DE DETECCION Señal CA-CFAR OS-CFAR TFix 25 Amplitud Mhz Fig. 3. Comparación de desempeño de los tres algoritmos propuestos para la detección de la capa E en el caso de múltiples reflexiones. El eco alrededor de los 11 km corresponde a la capa Es. km 4 Conclusiones Se han presentado casos de estudio sobre detección de capas ionosféricas esporádicas utilizando algoritmos desarrollados a tal fin para ser utilizados en sistemas digitales de sondaje ionosférico. Una de las tareas mas complejas que debe realizar un algoritmo de detección automática es la de detectar ecos de baja energía comparada con otros ecos dentro de la misma señal. En este trabajo se analizaron numerosos casos y se ejemplificaron dos de ellos. En ambas situaciones se observaron los inconvenientes que posee el algoritmo de detección utilizando un único umbral fijo (TFix). Esto se debe a que para obtener este valor de umbral se recurre a calcular el valor promedio de todas las muestras incluyendo a aquellos ecos de gran amplitud. Esta condición global produce un valor de umbral más apto para ecos de gran amplitud y puede enmascarar ecos de menor energía como el caso de la esporádica capa E. La solución propuesta en este trabajo es obtener un valor de umbral variable que se calcule con valores promedios (CA-CFAR) de manera local alrededor del valor que se esta testeando. De esta manera, las muestras para calcular el promedio alrededor del eco en la mayoría de los casos no contendrán otro eco. Por esto, el valor del umbral en la posición del eco es menor que en sus alrededores permitiendo la detección del mismo. Esta condición de localidad permite que ecos de menor energía sean detectados. Si además se obtiene un umbral variable usando como estadística una media móvil alrededor de la muestra de interés, además se pueden eliminar problemas como el cálculo de un promedio sesgado. Al reordenar ascendentemente en amplitud 1299
31 las muestras en la ventana y elegir el valor medio (OS-CFAR), el cálculo de las estadística desestima los valores mas altos que pueden corresponder a ecos. De este modo se obtiene una mejor performance como se muestra en los ejemplos seleccionados. Este estudio fue realizado como parte de un estudio mas completo sobre detección de ecos ionosféricos sin embargo estos resultados parciales muestran la robustez del algoritmo OS-CFAR en las condiciones descriptas. Para completar estos resultados es preciso realizar un estudio más extenso de casos y de datos. Agradecimientos. Este trabajo ha sido subsidiado de manera parcial por el Instituto de Geofísica y Vulcanología-Italia a través de Proyecto Bec.ar y Proyecto PICT Referencias 1. Rishbeth, H., and O. K. Garriot. Introduction to Ionospheric Physics, Academic Press, England. (1969) 2. Richard, G.. Radar System Performance Modeling, 2nd. Edit., Ed. Artech House, Norwood, MA. (2005) 3. Ariokiasamy, James B., C. Bianchi, U. Sciacca, G. Tutone and E. Zuccheretti. The new AIS- INGV Digital Ionosonde. Desing Report, Sezione di Geomagnetismo, Aeronomia e Geofisica Ambientale, Istituto Nazionale di Geofisica e Vulcanologia (INGV), Roma, Italia (2003) 4. Skolnik, M. I.. Introduction to radar systems, Mc. Graw-Hill, Tokyo. (1980) 1300
32 Estudio sobre Eficiencia Energética en Esquemas de Apagado Selectivo para Redes de Telefonía Móvil Silvina A. Grupalli 1,2, Martín G. Ferreyra 1,3 y Miguel A. Cabrera 1 1 Laboratorio de Telecomunicaciones, Depto. de Eléctrica, Electrónica y Computación (DEEC), Facultad de Ciencias Exactas y Tecnología (FACET), UNT. 2 Laboratorio de Instrumentación Industrial, DEEC, FACET, UNT. 3 Laboratorio de Física Experimental, Depto. de Física, FACET, UNT. sgrupalli@herrera.unt.edu.ar, mferreyra@herrera.unt.edu.ar, mcabrera@herrera.unt.edu.ar Resumen. En este trabajo se estudia cómo mejorar la eficiencia energética de una red de telefonía celular implementando un esquema de apagado selectivo de estaciones base (BS) para entornos urbanos de alta densidad. Como escenario se plantea una topología de red lineal, donde las BS se despliegan regularmente y los usuarios se distribuyen de manera uniforme, utilizando tecnologías 3G/4G con bandas de frecuencias admisibles en 900 MHz, 1900 MHz y 2100 MHz. Se analizan las relaciones entre potencias consumidas, ancho de banda disponible y porcentaje de apagado de la red mediante simulaciones basadas en el modelo de propagación COST 231-Walfisch-Ikegami. Por último se propone un indicador de eficiencia energética SG y se analizan los resultados obtenidos a partir del mismo. Palabras Clave:3G/4G, Apagado Selectivo, COST 231-Walfisch-Ikegami, Eficiencia Energética, Estaciones Base, Microceldas Celulares. 1 Introducción En la comunidad de redes móviles de última generación, existe una tendencia por parte de los operadores a tratar de reducir el consumo de energía de la red y a la implementación de redes que persiguen una reducción de la huella de contaminación ambiental manteniendo la calidad de servicio en función de los requerimientos de cobertura, capacidad y necesidades de los usuarios. Con este objetivo, se han instalado en los últimos años una mayor cantidad de estaciones base o BS (del inglés Base Station) para aumentar la capacidad de la red, que hoy representan alrededor del 80 % del total del consumo de energía de la red celular [1]. En este sentido, un camino eficaz para el ahorro energético en las redes celulares, es reducir el consumo de energía de las BS. Siendo que la carga de tráfico en las redes celulares fluctúa considerablemente debido a la alternancia de día y de noche, la movilidad del usuario y la naturaleza a ráfagas de las aplicaciones de datos [2] es necesario realizar el despliegue de las BS para satisfacer los requisitos de los usuarios respecto a la carga de tráfico pico. Sin embargo, esto causa que la mayoría de las mismas sean subutilizadas gran parte del tiempo, ya que la duración de la carga de tráfico pico suele ser bastante corta. Aun 1301
33 cuando la carga de tráfico es baja o incluso nula, una BS todavía consume gran parte de la energía pico, lo que significa que el consumo de energía de la misma no es proporcional a la carga de tráfico y gran parte de la energía se desperdicia durante el período de tráfico bajo. En los últimos años se han realizado varios estudios que trabajan en la desconexión de BS, centrados principalmente en la fase de funcionamiento de la red [3] - [8]. Otras líneas abordan la optimización del consumo de energía mediante umbrales de tráfico para la desconexión de la BS y evalúan el ahorro energético utilizando de los modos de suspensión [9]. Estudios más recientes intentan reducir el consumo de energía suponiendo que el tráfico de datos se mantiene siempre en el valor de pico y proponen que las estaciones base se pueden apagar selectivamente cuando la carga de tráfico es baja [10]. Hasta ahora, los escenarios planteados para el estudio de apagados selectivos, se sitúan en zonas urbanas y suburbanas desplegando un conjunto de macro celdas con amplios rangos de cobertura. Sin embargo existen escenarios urbanos más reducidos, con radios de cobertura críticos donde también es posible plantear un esquema de optimización de los recursos energéticos sin alterar la calidad de los servicios al usuario final. En este trabajo se estudia el problema de cómo implementar BS mejorando la eficiencia energética de la red, a partir de un modelo de apagado selectivo que se ajuste a este tipo de entornos. Para ello se ha considerado una topología de red lineal de BS homogéneas desplegadas regularmente y con usuarios distribuidos de manera uniforme. Se propone un escenario situado en un entorno urbano de alta densidad, donde red celular se implementa sobre tecnologías 3G/4G con bandas de frecuencias admisibles en 900 MHz, 1900 MHz y 2100 MHz. 2 Modelo de Apagado Selectivo El planteo de este modelo considera una red celular lineal como se muestra en la Fig. 1, donde un conjunto de BS homogéneas se despliegan con regularidad a lo largo de una línea, siendo d 0 la distancia entre las mismas. Se asume que todas las BS tienen igual potencia de transmisión máxima P t max y ancho de banda AB. Fig. 1. Red celular lineal homogénea desplegada regularmente Para cada BS se definen dos estados: Modo activo: con consumo de energía P a (Potencia con BS Activa) y Modo de reposo: con el consumo de energía P s (Potencia con BS Pasiva). Se asume que cada dispositivo móvil tiende a asociarse con la BS más cercana. La región de cobertura de cada BS está definida como una celda y la red puede ser dividida en N celdas del mismo tamaño. El tráfico en la red se distribuye uniformemente en función de las BS activas. La red posee N+1 estados, donde cada uno de ellos puede representarse como m, siendo m = {0, 1,, N}. Cada estado corresponde a una cierta proporción de estaciones de base en modo activo y otras en modo de reposo. Para cada estado se define una distancia intercelda, que representa la 1302
34 distancia media entre dos celdas activas. Suponiendo una red suficientemente extensa (N ), la potencia se evalúa por unidad de longitud utilizando la siguiente ecuación:.. (1) Donde representa el porcentaje de BS activas y 0 la unidad de longitud por la que se evalúa la potencia. Fig. 2 Estados de la red en tres condiciones de pagado selectivo: a) m=0 ; b) m=1 ; c) m=2 Existen dos esquemas básicos para el modelo de apagado: Apagado en modo de suspensión (o Standby): En este modo la BS queda fuera de servicio mediante el apagado de los amplificadores de potencia, quedando aún activos los equipos auxiliares (refrigeración, procesadores, fuentes de alimentación, etc.). La P s alcanza valores de hasta un 40 % de la P a [11]. Este tipo de apagado selectivo es el más utilizado en las investigaciones abordadas hasta el momento. Apagado Selectivo del Sitio Completo (o Switch Off): Consiste en la desconexión completa del sitio quedando activos solo los elementos necesarios para su reencendido. En este modo, el valor de P s es prácticamente nulo. 3 Modelo COST 231 Walfisch-Ikegami El modelo híbrido de propagación COST 231 Walfisch-Ikegami, es utilizado para realizar predicciones y estudios de cobertura en redes de telefonía celular de corto alcance (microceldas) dentro de los márgenes de frecuencias 900 MHZ, 1800MHz y 2100MHz. El modelo contempla dos opciones para el cálculo de las pérdidas de propagación, LOS ( Line of Sight, línea de visión directa entre el transmisor y el receptor) y NLOS ( No Line of Sight, no existe línea de visión directa entre el transmisor y el receptor) y además define los siguientes parámetros: h b [m]: Altura de la estación base a nivel de tierra, h m [m]: Altura de la estación móvil a nivel de tierra, h r [m]: Altura media de los edificios, w [m]: Ancho de la calle donde se encuentra la estación móvil, b [m]: Promedio de la distancia entre centros de edificios, d [Km]: Distancia entre la estación base y móvil, [ ]: Ángulo del rayo con el eje de la calle, L O [db]: Pérdidas por el espacio libre, L rts [db]: Pérdida por difracción del techo a la calle y pérdida esparcida, L msd [db]: Pérdida de difracción multipantalla y f [MHz]: Frecuencia de la portadora. 1303
35 Fig 3. Parámetros del Modelo COST 231 Walfisch-Ikegami Las pérdidas se modelan a partir de las siguientes ecuaciones: 1) En condiciones de LOS: log 20log (2) 2) En condiciones de NLOS:, 0, 0 Pérdidas por el espacio libre: log 20 log (4) log 10 log 20 log (5) Donde la pérdida por la orientación de la calle se corrige empíricamente según: , , ,55 90 En la Tabla 1 se resume el rango de validez del modelo: Tabla 1. Rango de validez del modelo COST 231- Walfisch-Ikegami Frecuencia de la portadora f [800 : 2000] MHz Altura de la antena de BS h b [4:50] m Altura de la antena móvil h m [1:3] m Distancia del móvil a la BS d [0,02:5] Km Por las características y alcance descriptos en este modelo, la utilización del mismo resulta apropiado para el estudio predictivo de radios de cobertura en los escenarios previstos para este trabajo. (6) (3) 4 Descripción del Escenario Para este estudio se ha considerado una topología de red lineal donde las BS homogéneas se despliegan regularmente y los usuarios se distribuyen de manera uniforme. La misma se sitúa en una zona urbana de alta densidad donde las BS conforman una red de microceldas con radios de cobertura solapados en un porcentaje superior al 50% y con distancias interceldas de 100 m. El grado de solapamiento 1304
36 responde a condiciones de saturación de la BS, inherentes a redes urbanas altamente congestionadas, donde un dispositivo móvil se asocia a la estación que tiene disponibilidad de ancho de banda y no necesariamente a la que se encuentra a menor distancia. Debido a que la distancia intercelda es considerablemente baja, las potencias que maneja cada microcelda se encuentran entre 2 y 10 W. Este trabajo analiza tres condiciones posibles para las BS, operando a 2W, 5W y 10W respectivamente. La frecuencia de operación de la red se establece en 1900 MHz. En la Tabla 2 se resumen las características de recepción para el dispositivo móvil: Tabla 2. Características de recepción para el dispositivo móvil Ancho de Banda del Canal Ancho de Banda 20 MHz 10 MHz 5 MHz AB [Mb/s] Sensibilidad Rx [dbm] 4-99,0-99,0-97,5 3,5-99,8-99,9-98, ,5-100,8-99,2 2,5-101,3-101,6-100, ,0-102,5-102,0 1,5-102,5-103,8-103, ,0-105,0-105,0 0,5-103,8-106,2-108,0 0,25-104,2-107,0-109,1 0, ,4-107,3-110,0 5 Simulaciones Inicialmente se propone como parámetros del modelo COST 231 Walfisch-Ikegami los siguientes: f=1900 MHz; h b =30 m; h m =1,5 m ; h r =20m ; w=10 m ; b=20m. En la Fig. 4 se muestran las predicciones obtenidas por el mismo, en las condiciones descriptas y utilizando potencias de transmisión P t igual a 2W, 5W y 10W respectivamente. Potencia en el Movil [dbm] Predicciones de Cobertura de las BS Distancia desde el móvil a la BS [m] Pt=10W Pt=5W Pt=2W Fig. 4. Predicciones del modelo COST 231 Walfisch-Ikegami utilizando potencias de transmisión P t igual a 2W, 5W y 10W respectivamente. 1305
37 Posteriormente se plantea el esquema de apagado de las BS desde 0 a 90%, lo que se traduce en un incremento de la distancia intercelda promedio a medida que éstas van quedando fuera de servicio. Combinando los resultados del modelo con las especificaciones de los dispositivos móviles enunciadas en la Tabla 2, se obtiene las curvas de la Fig. 5. Las mismas representan el máximo ancho de banda que puede alcanzar un dispositivo móvil ubicado a la distancia más desfavorable respecto de la BS a la que se encuentra asociado. Los cálculos fueron realizados contemplando canales de 5 y 10 MHz para potencias de transmisión P t igual a 2W, 5W y 10W. Ancho de banda [Mb/s] AB vs % de apagado para un ancho de canal de 5 Mhz 0 % de apagado de la red 0 % de apagado de la red 0 0,5 1 Pt=10W 0 0,5 1 Pt=10W Pt=5W Pt=5W Pt=2W Pt=2W (a) (b) Fig. 5. Ancho de banda máximo que puede alcanzar una estación móvil en el punto más desfavorable de la red como función del porcentaje de apagado de la misma, para ancho de canal de 5MHz en (a) y de 10 MHz en (b). Para poder comparar las variables de interés, se normalizan la potencia y el ancho de banda resultando Pm max =1 y AB max =1. Considerando que el esquema de apagado selectivo busca incrementar los rango de cobertura de cada microcelda como consecuencia de la disminución del tráfico, en la Fig.6 se plantean los siguientes resultados para un canal de 5MHz. Ancho de banda [Mb/s] AB vs % de apagado para un ancho de canal de 10 Mhz Fig. 6. Comparación normalizada del ancho de banda, potencia consumida en modo de suspensión (StandBy) y potencia consumida en modo de apagado total del sitio (Switch off) como función del % de apagado de la red, para un ancho de canal = 5MHz y Pt=2W en (a), Pt=5W en (b) y Pt=10W en (c). 1306
38 6 Estimación de la Eficiencia Energética en Función del Ancho de Banda Máximo Disponible Con el objetivo de cuantificar la eficiencia energética de la red, en este trabajo se establece el coeficiente SG como indicador de la relación ancho de banda disponible (AB) en función de la potencia consumida por las estaciones base por unidad de distancia en un esquema de apagado selectivo (Pm): (7) En la Fig. 7 se representa SG en función del porcentaje de apagado de la red. El valor máximo de cada curva establece el porcentaje para el cual se alcanza una máxima eficiencia energética en las condiciones estudiadas. Este indicador permite planificar el despliegue de una red de microceldas para atender las demandas de pico y generar un esquema de apagado selectivo que brinde la máxima eficiencia energética manteniendo la calidad de servicio al usuario final. Coeficiente SG 2,0 1,5 1,0 0,5 Coeficiente SG vs % de Apagado de la Red para Pt=2W, Pt=5W y Pt=10W Pm para Pt= 2W (Stby) Pm para Pt= 5W (Stby) Pm para Pt= 10W (Stby) Pm para Pt= 2W (SwOff) Pm para Pt= 5W (SwOff) Pm para Pt= 10W (SwOff) 0,0 0 0,2 0,4 0,6 0,8 1 % de apagado de la red Fig. 7. Coeficiente SG para distintas potencias de transmisión Pt y potencia total Pm en las modalidades del esquema de apagado selectivo de suspensión (Standby) y apagado total del sitio (Switch off). 7 Conclusiones En este trabajo se estudia cómo implementar BS mejorando la eficiencia energética de la red, a partir del planteo de un modelo de apagado selectivo que se ajusta a entornos urbanos de alta densidad. El concepto de microceldas con alto grado de solapamiento, se proyecta como solución para atender las demandas de pico en el tráfico de la red. Sin embargo, implica que una gran cantidad de puntos de transmisión quedan subutilizados cuando el tráfico de datos disminuye. En estas situaciones cobra 1307
39 importancia la implementación de esquemas de apagado selectivo que permitan optimizar los recursos mejorando la eficiencia energética. A partir de la propuesta de un indicador de la relación ancho de banda en función de la potencia consumida por kilómetro, se puede encontrar los puntos de mayor eficiencia energética en distintos escenarios variando la potencia de transmisión de las BS, el ancho de banda del canal de transmisión y los modos de apagado selectivo ya sea en modo de suspensión (standby) o en modo de apagado total del sitio (switch off). Referencias 1. Louhi J.T.: Energy efficiency of modern cellular base stations. Proceedings of IEEE INTELEC 2007, Roma, Italia (2007). 2. Oh E., Krishnamachari B., Liu X., Niu Z.: Towards dynamic energy efficient operation of cellular network infrastructure. IEEE Communications Magazine (2011), Vol. 49, no. 6, Niu Z., Wu Y., Gong J., Yang Z.: Cell zooming for cost-efficient green cellular networks. IEEE Communications Magazine (2010), Vol. 48, no. 11, Zhou S., Gong J., Yang Z., Niu Z., Yang P.: Green mobile Access network with dynamic base station energy saving. ACM Mobicom Poster (2009), Marsan M., Chiaraviglio L., Ciullo D., Meo M.:Optimal energy savings in cellular access networks. Proceedings of IEEE GreenCom, pp. 1-6, June, Marsan M., Chiaraviglio L., Ciullo D., Meo M.: Energy-efficient managment of UMTS access networks. Proceedings of ITC (2009), Peng C., Lee S., Lu S., Luo H., Li H.: Traffic-driven power saving in operational 3G cellular networks. Proceedings of ACM Mobicom 11 (2011), Son K., Kim H., Yi Y., Krishnamachari B.: Base station operation and user association mechanisms for energy-delay tradeoffs in Green cellular networks. IEEE Journal on Selected Areas in Communications (2011), Vol. 29. no Rengarajan B., Rizzo G., Marsan M.: Bounds on QoS-constrained energy savings in cellular access networks with sleep modes. Proceedings of ITC (2011), Wu Y., Niu Z.: Energy Efficient Base Station Deployment in Green Cellular Networks with Traffic Variations. First IEEE International Conference on Communications in China: Wireless Communication Systems (WCS), China (2012). 11. Deruyck M., Tanghe E., Joseph W., Martens L.: Characterization and optimization of the power consumption in wireless Access networks by taking daily traffic variations into account. EURASIP Journal on Wireless Communications and Networking (2012), 2012:
40 Alimentador en Cuadratura Impreso para Antena de Dipolos Cruzados Fernando Miranda Bonomi, Juan Ise, José Cangemi, Miguel Cabrera Laboratorio de Telecomunicaciones (LTC) del Dpto. de Electricidad, Electrónica y Computación (DEEC) de la Facultad de Ciencias Exactas y Tecnología (FACET) de la Universidad Nacional de Tucumán (UNT) fmirandabonomi@facet.unt.edu.ar Resumen. Este trabajo presenta el diseño de un alimentador para antena de dipolos cruzados que combina las funciones de adaptación de impedancia y de modo desbalanceado a balanceado con la función de acoplador híbrido en cuadratura, separando las polarizaciones circulares izquierda y derecha en dos puertos desbalanceados de 50 Ω para el conexionado directo a un transceptor. Esta configuración es especialmente favorable de utilizar en sistemas de radar de antena única puesto que la onda reflejada tiene una polarización circular opuesta a la emitida y puede por tanto emplearse uno de los puertos para transmisión y otro para recepción. Este desarrollo-concepto será parte integrante de un sistema de antenas para un radar de dispersión incoherente, en 432MHz, para estudios de alta atmósfera terrestre. Palabras Clave: Polarización Circular, Radar, Balun, Acoplador Híbrido, Circuito Impreso. 1 Introducción El Laboratorio de Telecomunicaciones (LTC) del Dpto. de Electricidad Electrónica y Computación (DEEC) de la FACET-UNT, en su carácter de integrante de la Red Argentina para el Estudio de la Atmósfera Superior (RAPEAS), organizada y subsidiada por CONICET, en colaboración con la Facultad de Ingeniería de la Universidad Nacional de La Plata, participa en el desarrollo de un prototipo de radar de dispersión incoherente (RDI) para estudios de alta atmósfera terrestre, con frecuencia de operación en 432 MHz. Un RDI es un sistema que emite señales de radio de alta intensidad que al incidir sobre el plasma ionosférico actúan sobre las partículas cargadas que lo componen generando un fenómeno de dispersión incoherente por el cual una porción de la energía incidente retorna al radar [1], [2]. Dadas las características físicas del medio bajo estudio en estos sistemas se emplea polarización circular para maximizar la energía de retorno captada por el receptor [2], [3]. En este contexto la red RAPEAS abordó el diseño y evaluación de distintos tipos de antenas elementales para la conformación del campo de antenas del RDI. Uno de los modelos de antena diseñados a tal fin por el LTC es un sistema de dipolos cruzados montados en torreta. Esta antena cumplirá alternativamente las funciones de transmisión y recepción, debiendo operar con polarizaciones circulares opuestas dado que el estado de polarización circular se invierte en la reflexión [4]. Por ello es 1309
41 necesario que el sistema de alimentación permita operar con ambas polarizaciones circulares. Alimentación en Cuadratura y Polarización Circular. Considérese una antena de dipolos cruzados en espacio vacío y un sistema de coordenadas rectangulares derecho x, y, z, orientado de modo que los ejes x e y contengan a los dipolos. Tomando un punto de observación p ubicado sobre el eje z en el campo lejano de la antena (z > 10λ), las componentes de campo eléctrico debidas a ambos dipolos en el punto de observación pueden descomponerse como superposiciones de campos eléctricos giratorios correspondientes a las componente dextrógira y levógira del modo de polarización lineal. La Tabla 1 plantea esta descomposición para una excitación de igual amplitud y diferente fase en los dipolos, tomando como referencia de fase y amplitud al campo debido al dipolo x en el punto p [4]. Tabla 1: Descomposición del campo eléctrico en superposición de vectores giratorios. Representación fasorial. Contribución Componente Levógira Componente Dextrógira Dipolo orientación x Dipolo orientación y Campo resultante La polarización resultante será circular si contiene solo campo levógiro o dextrógiro. Será lineal si contiene ambos en igual amplitud y será elíptica en otro caso. De observar las expresiones para el campo resultante expuestas en Tabla 1 se desprenden las condiciones para obtener una polarización circular pura, las cuales se resumen en la Tabla 2. Puede observarse entonces que la polarización circular de la onda se logrará mediante la alimentación en cuadratura (diferencia de fase de π /2 radianes, es decir 90 ) de los dipolos. 1310
42 Tabla 2: Condición de excitación para polarización circular. Tipo de polarización Condición Campo resultante Polarización izquierda Polarización derecha Acorde a lo expuesto, el alimentador de la antena de dipolos cruzados debe alimentar los dipolos con señales en cuadratura, además de los requerimientos usuales de adaptación de impedancia y conversión de modo de transmisión balanceado en los terminales del dipolo a desbalanceado en el extremo del cable coaxial de conexión, esta última función se conoce como balun [5], [6]. Se optó por integrar las tres funciones en un único elemento, fabricado con tecnología de línea de transmisión impresa. 2 Diseño y modelado El diseño debe cumplir las funciones de cuadratura, adaptación de impedancias y balun. Se decidió además ubicar el alimentador dentro de la torreta de soporte de los dipolos de modo de generar una unidad sellada antena-alimentador robusta y adaptable a uso en exteriores, cuya interfaz con el resto del sistema consista en un par de conectores coaxiales estándar de 50 Ω correspondientes a los modos circulares izquierdo y derecho. 2.1 Acoplador Híbrido en Cuadratura. Se adoptó un diseño acoplado mediante líneas en derivación, dada la simplicidad del diseño para una división de potencia en partes iguales y la disposición de los puertos de salida opuestos a los de entrada. Si la impedancia característica en todos los puertos es 50 Ω el acoplador híbrido en cuadratura por líneas en derivación se compone según muestra el diagrama esquemático de la Figura 1 [5], [6]. Se empleó un sustrato de material FR4 con permitividad eléctrica relativa ε r de 4,5 resultando en las dimensiones mostradas en el esquema. El diseño fue modelado, construido y medido, obteniéndose los resultados dados en Tabla 3. Puede observarse un error de fase significativo en los resultados de ensayo del prototipo, lo que produciría en la antena un modo elíptico en lugar de circular. Se consideró que los resultados obtenidos son satisfactorios para esta etapa de diseño del prototipo y se procedió con la adaptación de las dimensiones del diseño, relegando los ajustes a una etapa posterior del desarrollo. 1311
43 Adecuación a Dimensiones de la Torreta. El cuerpo de la torreta está formado por tubo estructural de sección cuadrada de aluminio, con una luz de 70 mm de lado. El ancho del acoplador originalmente diseñado excede la luz de la torreta, haciendo imposible su inclusión en la misma. A fin de posibilitar la integración se modificó el diseño empleando líneas en meandro para las derivaciones. Las líneas en meandro tienen un recorrido sinuoso en lugar de ser rectas, esto reduce la longitud del recorrido para una dada distancia eléctrica, a costa de incrementar el espacio ocupado en sentido transversal. En la Figura 2 se muestra el resultado final obtenido, los resultados de simulación se presentan en Tabla 4. No se realizó un prototipo de este diseño dado que restaba resolver la adaptación de modo e impedancia. Z Z0 P=1 Z=50 Ohm W=A mm L=E mm 3 W=B mm L=D mm 3 W=A mm L=E mm P=2 Z=50 Ohm A=2.82 B=4.82 C=93 D=91 E=10 Z0 = 50 Ω W=A mm L=C mm Z0 Er=4.5 H=1.5 mm T=0.05 mm Z0 W=A mm L=C mm P=4 Z=50 Ohm 3 3 P=3 Z=50 Ohm Z Z0 W=A mm L=E mm W=B mm L=D mm W=A mm L=E mm Figura 1. Diagrama esquemático de híbrido en cuadratura acoplado mediante líneas en derivación. Tabla 3: Parámetros de híbrido en cuadratura, valores ideales, resultados de simulación y ensayos sobre prototipo. La disposición de puertos corresponde a la Figura 1. Parámetro Unidad Valor Resultado Resultado Ideal Simulación Ensayo S 11 ; S 22 ; S 33 ; S 44 db - -40,18-15,78 S 21 ; S 34 db -3-3,09-3,38 S 31 ; S 24 db -3-3,04-3,35 S 41 ; S 32 db - -42,26-34,40 Arg(S 21 ) - Arg(S 31 ) grado sexagesimal 90 89,97 100,32 S 21 / S 31 db 0 0,05-0,
44 Figura 2: Híbrido en cuadratura, líneas en derivación en meandro. Gris lado inferior, negro lado superior. Tabla 4: Características simulación híbrido en cuadratura con derivaciones en meandro. Parámetro Unidad Resultado Observaciones Simulación S 11 ; S 22 ; S 33 ; S 44 db -28,09 ROE = 1,08 S 21 ; S 34 db -2,98 S 31 ; S 24 db -3,05 S 41 ; S 32 db -27,74 Arg(S 21 ) - Arg(S 31 ) grado sexagesimal 89,93 S 21 / S 31 db 0, Adaptación de Modo (balun) e Impedancia. La adaptación de impedancias y pasaje de modo desbalanceado a balanceado se implementaron mediante variación continua de geometría de línea de transmisión impresa. Partiendo desde una línea microstrip de 50 Ω para terminar en una línea de placas paralelas de 70 Ω, la que corresponde a la impedancia de alimentación del dipolo resonante. Se empleó variación lineal de la geometría, según se muestra en Figura 2a. Se modeló el diseño, obteniéndose los resultados mostrados en Tabla 5, los que fueron considerados satisfactorios para esta aplicación. Tabla 5: Balun. Resultados de simulación. Parámetro Unidad Ideal Resultado Simulación Observaciones S 11 ; S 44 db - -16,24 ROE 1,36 S 22 ; S 33 db - -16,23 ROE 1,37 S 21 ; S 34 db 0-0,22 S 31 ; S 24 db - -39,
45 (a) (b) Figura 2: a) Balun por variación progresiva de la geometría. b) Alimentador combinando híbrido de cuadratura y balun. Gris lado inferior, negro lado superior Tabla 6: Resultados simulación versión final alimentador. Parámetro Unidad Ideal Resultado Simulación Observaciones S 11 ; S 44 db - -23,77 ROE = 1,14 S 22 ; S 33 db - -30,05 ROE = 1,06 S 21 ; S 34 db -3-3,08 S 31 ; S 24 db -3-3,05 grado Arg(S 21 ) - Arg(S 31 ) sexagesimal 90 89,82 S 21 / S 31 db 0-0, Diseño Final del Alimentador. La suma de las longitudes de balun e híbrido en cuadratura inicialmente diseñados casi duplican la longitud de la torreta, que desde la base hasta el eje de los dipolos es de un cuarto de longitud de onda en el vacío a la frecuencia central de 432 MHz, esto es 173,6 mm. Se consideraron varias opciones para compatibilizar las dimensiones con el espacio disponible, y se optó por incluir la función de balun como parte integrante del híbrido en cuadratura. Esta opción cuenta con ventajas en cuanto a simpleza, robustez mecánica y bajas pérdidas energéticas pues la longitud eléctrica total de línea de transmisión impresa empleada se reduce aproximadamente a la mitad. Los dos tramos centrales de línea de transmisión en el híbrido en cuadratura fueron reemplazados por sendos balunes. Las líneas en derivación fueron realizadas en microcinta (microstrip) en un extremo y placas paralelas en el otro, conservando el 1314
46 diseño en meandro. El diseño fue modelado y optimizado empleando simulación electromagnética. En la Figura 2b se muestra el diseño final. Los resultados de simulación son dados en la Tabla 6. 3 Ensayo Para el ensayo en laboratorio del alimentador se empleó un analizador vectorial de redes (VNA). La conexión al VNA de que se dispone es desbalanceada. Para posibilitar el ensayo del alimentador, que tiene puertos balanceados, se procedió a conectar un par de alimentadores espalda con espalda por sus puertos balanceados. De este modo quedan expuestos solamente los puertos desbalanceados que pueden conectarse directamente al VNA. La conexión de los alimentadores por el lado balanceado se realizó tanto con polaridades coincidentes como con polaridades opuestas. 3.1 Dos alimentadores enfrentados Se emplearon dos alimentadores. Se conectaron en forma directa los puertos 2 y 3 del primer alimentador con los puertos 3 y 2 del segundo alimentador. Los puertos accesibles se definieron así: puertos 1 y 4 corresponden a sus homónimos del primer alimentador; puertos 2 y 3 corresponden a puertos 4 y 1 del segundo alimentador. De observar los valores ideales en Tabla 6, considerando la configuración descripta y una única onda incidente en el puerto 1. El puerto 4 es aislado por el primer híbrido. En el puerto 2 confluyen dos ondas en contrafase mientras que en el puerto 3 confluyen dos ondas en fase. Por lo tanto idealmente la totalidad de la energía incidente en el puerto 1 será transferida al puerto 3 y los otros dos puertos permanecerán aislados. Este ensayo representa con buena fidelidad la situación de utilización del alimentador, donde S 21 representa el modo circular indeseado (mientras más bajo mejor). La columna polaridad directa de la Tabla 7 resume los resultados obtenidos en la medición. Tabla 7: Resultados del ensayo de dos alimentadores enfrentados. Parámetro Unidad Ideal Polaridad Polaridad Observaciones directa inversa S 11 db - -28,02-22,37 ROE = 1,08 / 1,16 Modo circular S 21 db - -20,09-19,82 indeseado Modo circular S 31 db 0-1,19-1,05 deseado S 41 db - -18,88-18, Dos alimentadores enfrentados, polaridad inversa Este ensayo es similar al anterior, aunque en este caso los puertos 2 y 3 del primer alimentador se conectan con sus homólogos en el segundo híbrido y lo hacen con 1315
47 polaridad inversa (lado positivo del primer híbrido con lado negativo del segundo y viceversa). En este caso los puertos 2 y 3 corresponden a los puertos 1 y 2 del segundo alimentador, el análisis es el mismo que para el caso anterior. Los resultados se listan en la columna polaridad inversa de Tabla 7. Puede observarse un buen acuerdo entre ambas polarizaciones, lo que permite deducir que el modo balanceado fue bien logrado. 4 Conclusiones Se ha esbozado en el presente trabajo el proceso de desarrollo de un alimentador en cuadratura para antena de dipolos cruzados, exponiéndose a grandes rasgos las etapas del diseño junto con los compromisos a los que se arribó en cada caso. El resultado final es un alimentador en cuadratura integrado a la torreta de montaje de la antena, permitiendo simplificar el armado y conexionado de la misma. Se han observado desviaciones significativas entre el modelado y la realidad, las cuales son atribuibles a diferencias entre las propiedades dieléctricas del sustrato y los parámetros correspondientes del modelo y en menor medida a las tolerancias del proceso de fabricación. Cabe destacar que, no obstante las discrepancias observadas, los resultados obtenidos con el primer prototipo de alimentador fueron considerados suficientes para su empleo en el prototipo inicial de arreglo de antenas. Actualmente se están implementando, en el LTC, métodos de caracterización del sustrato dieléctrico a fin de corregir en buena medida las discrepancias entre modelo y realidad física. Agradecimientos. Este trabajo es subvencionado por la red RAPEAS (CONICET)y por el proyecto PICT (FONCyT). Los autores agradecen la colaboración del Laboratorio de Dieléctricos del Dpto. de Física, FACET-UNT para la utilización del instrumento VNA. Bibliografía 1. Evans, J.V.: Theory and practice of ionosphere study by Thomson scatter radar. Proceedings of the IEEE, vol.57, no.4 (1969) doi: /PROC Gordon, W.E.: Incoherent Scattering of Radio Waves by Free Electrons with Applications to Space Exploration by Radar. Proceedings of the IRE, vol.46, no.11 (1958) doi: /JRPROC Millman, G. H., Moceyunas, A. J., Sanders, A. E., Wyrick, R. F.: The effect of Faraday rotation on incoherent backscatter observations. J. Geophys. Res., Vol 66, (1961) doi: /JZ066i005p Kraus, J.D., Carver, K.R.: Electromagnetics. Second Edition. McGraw-Hill (1981). 5. Miranda, J. M., Sebastián, J. L., Sierra, M., Margineda, J.: Ingeniería de Microondas, Prentice Hall (2002). 1316
48 Método no Destructivo para Medición de Sustratos Dieléctricos: caso de estudio aplicado a diseño en RF Lino Condori, José Cangemi, Fernando Miranda Bonomi y Miguel Cabrera Laboratorio de Telecomunicaciones (LTC) del Dpto. de Electricidad, Electrónica y Computación (DEEC) de la Facultad de Ciencias Exactas y Tecnología (FACET) de la Universidad Nacional de Tucumán (UNT) fmirandabonomi@facet.unt.edu.ar Resumen. Se presenta un caso de estudio sobre método de cálculo y medición de permitividad dieléctrica, midiendo la resonancia de placas paralelas sin destrucción de la muestra analizada. En el diseño de estructuras electromagnéticas aplicadas a uso en RF, tales como líneas de transmisión y componentes pasivos, el valor de la permitividad es un parámetro necesario para el diseño de los mismos. La manifestación macroscópica de los mecanismos físicos del material provoca que los valores de permitividad dieléctrica, índice de refracción y pérdidas sean dependientes de la frecuencia. En el caso particular del sustrato conocido como FR4, es necesario determinar para cada caso la permitividad en función de la frecuencia, debido a la gran variabilidad de este valor. Se considera adecuado el método de medición para determinar un valor de permitividad dieléctrica en el diseño de circuitos de radiofrecuencia con error aceptable. Palabras Clave: Permitividad Dieléctrica, Tangente de Pérdidas, Líneas de Transmisión, Estructuras Electromagnéticas, Circuitos de Radiofrecuencia. 1 Introducción Una gran variedad de estructuras electromagnéticas, tales como líneas de transmisión, filtros, acopladores, antenas, etc., son diseñadas sobre metalizaciones de cobre, de simple o doble faz, adheridas a sustratos dieléctricos [1]. La interacción del campo eléctrico oscilante con la materia induce movimiento en los iones produciendo polarización por distorsión o por orientación. La respuesta del conjunto de dipolos es diferente para cada frecuencia, esto se denomina dispersión dieléctrica. La manifestación macroscópica de estos mecanismos físicos hace que el material presente valores de permitividad dieléctrica, índice de refracción y pérdidas dependientes de la frecuencia [2], [3]. Existen varios métodos para la caracterización de estos materiales, los que se pueden clasificar como técnicas de: reflexión y transmisión en guías, líneas y medios libres, puente y en resonadores [4]. Utilizando la técnica de resonancia, este trabajo realiza un estudio sobre un método no destructivo para medición rápida de las propiedades de dieléctricos utilizados en el diseño de circuitos de radiofrecuencia. Se busca estimar las propiedades dieléctricas de los sustratos que se encuentran disponibles comercialmente, los que en su mayoría están compuestos por fibra de 1317

49 vidrio con resina epoxi, denominados FR4. El método propuesto permite, al ser no destructivo, el empleo de la muestra medida en la fabricación de circuitos de RF. El mismo consiste en medir la respuesta en frecuencia de la cavidad formada por las metalizaciones en ambas caras de una placa doble faz mediante un analizador vectorial de redes (VNA, por sus siglas en inglés) y obtener a través del marco teórico propuesto valores de permitividad dieléctrica y perdidas en el dieléctrico para las frecuencias correspondientes a los modos de oscilación de la cavidad. 2. Método adoptado El método adoptado se basa en el empleo de una probeta de sustrato bajo prueba con metalización en ambas caras como resonador de placas paralelas, el cual se acopla de una manera simple a un analizador vectorial de redes [5]. La metodología consiste en medir el parámetro de reflexión del resonador, determinando así la frecuencia en la que se producen las resonancias y el ancho de banda de las mismas para luego cotejarlas con un modelo analítico y extraer así los parámetros de interés. Las mediciones se efectuaron con un analizador vectorial de redes Agilent 8712ET, con conectores tipo N del Laboratorio de Nanomateriales y Propiedades Dieléctricas del Dpto. de Física-FACET-UNT. La configuración empleada es la mostrada en la Figura 1, con acoplamiento directo entre las placas y el conector. Figura 1. Acoplamiento directo entre las placas de cobre y el conector N del VNA. 2.1 Modelo analítico del resonador Se emplea en el análisis de resultados el modelo de resonador de placas paralelas [5], [7]. La frecuencia de resonancia de un resonador de placas paralelas está dada por: (1) Donde f mn frecuencia correspondiente al modo de parámetros (m,n), c velocidad de la luz en el vacío, (a, d) largo y ancho de la probeta y ε r permitividad relativa del dieléctrico. El factor de calidad descargado con límites eléctricos con pérdidas, para un resonador de placas paralelas con un dieléctrico sin pérdidas, está definido como: 1318

50 (2) Dónde k, η, R s, b, a, d son el número de onda, la impedancia intrínseca del dieléctrico, la resistividad superficial del conductor, y las dimensiones de la probeta, respectivamente, como se observa en la Figura 2. El valor del número de onda, la impedancia intrínseca y la resistividad superficial se calculan con las Ecs. 3, 4 y 5, como sigue: (3) (4) (5) Donde σ conductividad eléctrica de la metalización, µ 0 permeabilidad magnética del vacío, ε 0 permitividad eléctrica del vacío y ω frecuencia angular. Figura 2. Dimensiones del sustrato con placas de cobre en sus caras superior e inferior. El factor de calidad cargado Q L, está determinado por la frecuencia de resonancia f 0 y su ancho de banda AB, siguiendo la siguiente relación: (6) 1319
51 Se puede encontrar el factor de calidad descargado Q U, para un ancho de banda de 3 db utilizando el método descripto en [6]: Siendo la relación entre el factor de calidad descargado del resonador y el factor de calidad cargado para un ancho de banda tomado entre puntos de -x db [6]. (7) (8) Donde es el módulo en partes por unidad del coeficiente de reflexión para la frecuencia de resonancia. El signo definido en la Ec. 8, corresponde al acoplamiento entre el analizador de redes y la probeta ensayada, un signo menos para sobreacoplamiento y un signo más para un subacoplamiento. Este acoplamiento se determina en la medición observando la lectura del coeficiente de reflexión en un diagrama de Smith. Una respuesta sobreacoplada tendrá un desarrollo de un círculo que tiende a encerrar el origen del diagrama de Smith (r=1, x=0), y por el contrario una respuesta subacoplada tendrá un desarrollo más pequeño que no encierra el origen. Las pérdidas en el dieléctrico (tan δ) se calculan con la Ec. 9, y están definidas por el factor de calidad del resonador Q d considerando paredes perfectamente conductoras [7]: (9) El caso que se analiza, se consideran tanto las pérdidas en los conductores como en el dieléctrico, por lo que se modela su factor de calidad descargado como se indica en la Ec. 10 como sigue: (10) 1320
52 3 Mediciones 3.1 Validación del método. Para validar el método antes propuesto se han realizado mediciones con un sustrato de alta calidad con valores conocidos a fin de estimar el error que se comete en la medición. El sustrato utilizado es el Rogers RT/Duroid 6002 [8], con sus valores de permitividad y tangente de pérdidas especificados por el fabricante. Se ha determinado utilizar este sustrato, porque el mismo presenta valores de permitividad similares de los que se estiman obtener en las mediciones del sustrato FR4. Los valores y resultados de cálculo están plasmados en la Fig. 3. Los resultados se obtuvieron determinando los modos de resonancia que se espera encontrar, utilizando la Ec. 1 y un valor aproximado de permitividad dieléctrica del sustrato a utilizar. Para comprender la lista de modos que se espera encontrar en el sustrato bajo prueba, se toman sus medidas, 6 pulgadas de ancho por 6 pulgadas de largo, y la permitividad relativa del mismo, 6) se obtiene así una lista en el rango de frecuencias de los modos que se pueden encontrar los que se detallan en la Tabla 1. Tabla 1: Lista de modos que se pueden encontrar en un sustrato Rogers RT/Duroid 6002 de 6 por 6. Frecuencia m N 567,9 MHz ,1 MHz ,7 MHz 2 0 Con el orden de modos determinados es posible determinar a qué modo pertenece cada pico de la medición de las pérdidas de retorno, y utilizando la Ec. 1 determinar el valor de la constante dieléctrica relativa del sustrato. 1321
53 Figura 3. Resultados de la medición del sustrato Rogers RT/Duroid Utilizando las Ecs. 2 a 10 se determina el valor de la del material. Se puede observar que la medición de la constante de permitividad dieléctrica relativa se encuentra dentro del rango dado por el fabricante. En cuanto a la tangente de pérdidas, vemos una discrepancia considerable ya que el valor dado por el fabricante es. 1322
54 3.2 Resultados de la medición de un sustrato FR4. Se presentan los resultados obtenidos en la medición de un sustrato FR4, se presentan a continuación en la Fig.4 Figura 4. Resultados de la medición del sustrato FR4 Podemos observar en la medición la gran variación de la permitividad dieléctrica en función de la frecuencia. Estos resultados son útiles para el diseño de circuitos de RF, ya que se depende directamente de la permitividad dieléctrica en el diseño de cualquier estructura electromagnética. 1323
55 4 Discusión final El método se comprueba válido para la obtención de la permitividad dieléctrica del sustrato. El orden del error conseguido es aceptable para determinar un valor de permitividad dieléctrica en el diseño de circuitos de radiofrecuencia. En cuanto a la determinación de la constante de pérdidas, se ha observado en las mediciones de sustrato Rogers, semejantes al ensayado como referencia para validar el método, un error similar al obtenido. Esto requiere una revisión del método para determinar la tangente de pérdidas, por lo que se propone continuar el estudio del método de Howell [9], el cual mejora la medición del factor de calidad cerrando las paredes metálicas, transformando la muestra en una cavidad rectangular, evitando las perdidas por radiación que puedan existir con este método. El método antes discutido sigue siendo válido a la hora de realizar diseños de circuitos y estructuras electromagnéticas, ya que la principal variable en el diseño es la permitividad dieléctrica. Agradecimientos. Subsidiado parcialmente por los Proyectos: PICT 2011/1008 (ANPCyT); CIUNT (UNT) 26/E408, PIDDEF 02/12 (MINDEF). Referencias [1] John D. Kraus y D. A. Fleisch, Electromagnetismo con aplicaciones, (Quinta Edición), Ed. McGraw-Hill, [2] J. C. Anderson, Dielectrics, Chapman & Hall, [3] A. von Hippel, Dielectrics and Waves, MIT Press, [4] J. M. Miranda, Sebastián, J. L.; Sierra, M.; Margineda, J.; Ingeniería de Microondas, Ed. Prentice Hall, [5] L.S. Napoli, J.J. Hugues: A Simple Technique for the Accurate Determination of the Microwave Dielectric Constant for Microwave Integrated Circuit Substrates. IEEE Transactions on Microwave Theory and Techniques, [6] R. S. Kwok, J. Liang.: Characterization of High Q Resonators for Microwave-Filter Applications. IEEE Transactions on Microwave Theory and Techniques, [7] D.M. Pozar: Microwave Engineering 4ed., [8] Rogers RT/Duroid 6002: laminate-data-sheet.pdf, [9] J.Q. Howell: A Quick Accurate Method to Measure the Dielectric Constant of Microwave Integrated-Circuit Substrates, IEEE Transactions on Microwave Theory and Techniques,
56 Consideraciones Generales sobre Diseño de Antenas Parche Rectangular Gustavo Robledo, Fernando Miranda Bonomi, Gianfranco Borgetto, Jonathan Druck, Juan Ise, Miguel Cabrera Laboratorio de Telecomunicaciones (LTC) del Dpto. de Electricidad, Electrónica y Computación (DEEC) de la Facultad de Ciencias Exactas y Tecnología (FACET) de la Universidad Nacional de Tucumán (UNT) fmirandabonomi@facet.unt.edu.ar Resumen. Este trabajo aborda el diseño de antenas tipo parche (conocidas por su nombre en inglés patch) rectangulares para operar a una frecuencia de 700MHz. La forma rectangular permite explicitar de manera sencilla su funcionamiento con el modelo de línea de transmisión. Sus características fundamentales, ganancia, pérdidas, impedancia de entrada y ancho de banda, se obtuvieron mediante la evaluación de campo lejano. La evaluación de las simulaciones frente a los valores finales obtenidos con mediciones del prototipo permite determinar las desviaciones en las magnitudes medidas, encontrándose así que la permitividad, espesor del dieléctrico, punto de alimentación y área del plano de tierra intervienen modificando significativamente la ganancia, impedancia de entrada y pérdidas del prototipo. Un diseño adecuado requiere que las magnitudes que intervienen sean obtenidas con la mayor exactitud posible. Dieléctricos con espesor considerable y baja permitividad son necesarios para obtener buena eficiencia y ganancia de la antena. Palabras clave: Eficiencia de Radiación, Enlace, Ganancia Directiva, Línea de Transmisión, Patch. 1 Introducción Una antena parche o patch es una de las tantas que se pueden encontrar en el mercado y unas de las más populares hoy en día debido a sus propiedades físicas y electromagnéticas, fácil construcción, portabilidad, bajo perfil y peso, etc, [1] y [2]. Tienen aplicaciones muy variadas que van desde el ámbito, militar en complejos sistemas para radares a bordo de naves y misiles o civil en sistemas miniatura de comunicaciones a corta distancia para usos en medicina, WiFi, receptores GPS integrados y típicas aplicaciones en telefonía móvil, entre otras. Consta de un parche o elemento radiante, separado del plano de tierra por un sustrato dieléctrico y alimentado de alguna forma, hueco radiante o contacto físico, mediante una línea microstrip o un cable coaxial respectivamente [3], [4] y [5]. Su facilidad de construcción la hace idónea para la implementación de configuraciones complejas como por ejemplo antenas inteligentes con orientación electrónica de haz [6], [7], [8] y [9]. 1325
57 Entre sus características más sobresalientes se pueden mencionar, robustez, bajo perfil, versatilidad, conformabilidad, facilidad de fabricación y bajo costo. Así también se pueden mencionar algunas desventajas, ancho de banda estrecho y pobre manejo de potencia. Para el diseño se escogió una forma rectangular de antena debido a que es más sencillo conceptualizar su funcionamiento con el modelo de línea de transmisión, el que será usado en el diseño final del elemento. La antena parche rectangular, puede ser representada como un arreglo de dos antenas ranura de ancho W, altura h, y separadas por una línea de baja impedancia de longitud L [10]. 2 Diseño de una antena parche Las especificaciones empleadas son las de Tabla 1. El sustrato o soporte dieléctrico de la antena está caracterizado al menos por dos parámetros críticos que intervienen en el diseño de la misma, estos son la permitividad eléctrica ε y espesor h. La Figura 1a presenta las dimensiones relevantes de la antena. a b Figura 1. a) Dimensiones relevantes en el diseño de una antena parche tomando en cuenta el modelo de línea de transmisión, b) diferencia entre la medida real y la efectiva del parche Tabla 1: Especificaciones de la antena parche. Especificación Símbolo Valor Frecuencia de operación f MHz Impedancia de entrada Z 0 50 Ω Por lo general estas antenas se realizan sobre placas de circuito impreso doble faz (dieléctrico metalizado por ambas caras) por lo que el espesor del sustrato y la de la lámina de cobre son prácticamente estándares de fabricación de estos componentes, debiendo así adoptarse en el diseño. El valor del espesor h del dieléctrico tiene importancia dentro de los cálculos de las dimensiones del parche, al igual que la permitividad del mismo, pero es más interesante analizar sus efectos en el comportamiento de la antena. Un sustrato de mucho espesor, además de incrementar la resistencia mecánica del elemento, aumenta la eficiencia de radiación, y aumenta el ancho de banda de la antena, [2] y [3]. Sin embargo aumentará el peso, la perdida dieléctrica, perdidas por ondas superficiales y será más sensible a interferencias 1326
58 originadas por radiaciones externas. Por lo que existe una relación de compromiso en la elección del espesor del sustrato que dependerá de la aplicación en la cual se utilice la antena [3]. La permitividad del dieléctrico tiene efectos significativos en el desempeño de la antena, por ejemplo un valor bajo de permitividad aumentara el campo en la periferia del parche y esto mejora la eficiencia de radiación. Por lo tanto es preferible tener permitividades bajas a menos que se construya un parche demasiado pequeño. La disminución de la permitividad es equivalente al aumento en el espesor del sustrato [3]. En el diseño aquí considerado se utilizó una placa de epoxi cuyos parámetros básicos se dan en Tabla 2. Tabla 2: Parámetros de placa epoxi. Parámetro Símbolo Valor Observaciones Espesor h 1,5 mm Permitividad relativa ε r 4,5 valor nominal Cabe destacar que el parámetro permitividad relativa ε r fue extraído de la hoja de datos del fabricante y es función de la frecuencia. Teniendo en cuenta el modelo de línea de transmisión es necesario obtener los valores de W y L, los que se pueden modelar para el modo TM 10 como se ilustra en las ecuaciones 1 y 2 [10]. Se calcula W, de la siguiente manera: (1) Como consecuencia de los efectos de borde del parche, existen líneas de campo que cruzan el aire y el dieléctrico, por lo que el espacio que rodea a la antena no posee una permitividad constante. Para tener en cuenta este efecto se calcula una permitividad relativa efectiva [10], de la siguiente forma: (2) Esto afecta las dimensiones efectivas del parche, es decir, existe una diferencia de las medidas efectivas respecto de la reales del parche. Es posible determinar esta desviación de la siguiente manera: (3) La Figura 1b muestra la diferencia entre la medida real y la efectiva del parche. La longitud efectiva se determina utilizando la relación
59 (4) Finalmente, mediante la relación 5 es posible determinar la longitud real del parche. Las medidas finales del parche son las dadas en Tabla 3. Tabla 3: Medidas de parche rectangular. Dimensión Símbolo Valor Ancho W 12,7 cm Longitud L 10,10 cm Una vez determinadas las dimensiones del parche, es necesario ubicar el punto de alimentación del mismo para que la impedancia de entrada de la antena sea de 50 Ω. Respecto de la dimensión W el conector será ubicado en su punto medio para evitar excitar modos de propagación superiores. La variación del campo eléctrico dentro del parche a lo largo de la dimensión L tiene forma cosenoidal, por lo que se tendrá un máximo de impedancia en los bordes del mismo y un mínimo de impedancia (un cortocircuito) en el centro [10]. La relación que permite determinar el punto de alimentación x f, se puede escribir como: (5) (6) 3 Simulación de la antena diseñada Se realizaron una serie de simulaciones utilizando el software CST, el que resulta una herramienta muy útil para la verificación de los cálculos y el análisis del comportamiento de la antena diseñada. Los resultados de la primera simulación se pueden observar en la Figuras 2. Se puede observar en la Figura 2 que la frecuencia de resonancia es 718,8 MHz, 18,8 MHz sobre el valor original de diseño, (se refleja un 25% de la onda incidente), una pérdida de retorno de 12 db, y una impedancia de entrada. Para mejorar la adaptación, se reposiciona el punto de alimentación en, cuyo valor se obtuvo de realizar varios ensayos sobre el simulador ajustando de manera iterativa su valor. Ahora se obtiene una frecuencia de resonancia de 720 MHz, una pérdida de retorno de 37,2 db (correspondiente a un ROE de 1,03) y una impedancia de entrada. 1328
60 Figura 2. Resultados de simulación electromagnética. 4 Construcción y ensayo de las antenas Se construyeron dos antenas en base a los resultados obtenidos. Las mediciones de los prototipos fueron realizadas utilizando un analizador de redes AGILENT 8712ET, facilitado por el Laboratorio de Dieléctricos del Dpto. de Física de la FACET-UNT. La columna Valor Inicial de Tabla 4 resume los resultados obtenidos al ensayar la antena con el punto de inserción ubicado en 3,1 cm como lo indica la simulación. Los datos obtenidos muestran una discrepancia significativa entre el modelo y la realidad experimental. Se conoce que disminuyendo la distancia del punto de inserción al borde de la línea se incrementa el valor de impedancia, por lo que se decidió disminuir paulatinamente la distancia del punto de inserción hasta obtener una adaptación óptima. Los valores finales obtenidos se presentan en la columna Valor Final de Tabla 4. Tabla 4: Ensayo y ajuste del prototipo. Medida Valor Inicial Valor Final Posición del punto de alimentación 31 mm 6 mm Frecuencia de resonancia 716,2 MHz 719,8 Impedancia de entrada (17 + j10) Ω (51 + j0,68) Ω Pérdida de retorno 6,24 db 39,2 db Relación de onda estacionaria 2,23 1,032 5 Estimación de la ganancia de potencia A fin de determinar las características de radiación de la antena se configuró un enlace de radio disponiendo una antena como transmisora y la otra como receptora. Para esto es necesario disponerlas a una determinada altura y distancia, dependiendo 1329
61 de la frecuencia a la que opere el sistema. Para que los resultados sean válidos es necesario estar en condiciones de campo lejano, esto es a una distancia mínima de 10 longitudes de onda [2]. Las antenas se elevaron lo suficiente para evitar obstrucción por primera zona de Fresnel [2], cuyo cálculo arrojó 76 cm, lo que llevó a disponerlas a 1,5 m respecto de tierra. La frecuencia a la cual se realizó el ensayo es de 719 MHz. La Tabla 5 lista el instrumental empleado en el ensayo. Previo al ensayo se midió la atenuación de cables y conectores obteniéndose un valor de atenuación A c de 11 db. Los resultados del ensayo de enlace se presentan en Tabla 6. Se empleó para determinar la ganancia el modelo de transmisión de Friis, presentado a continuación: Donde Calculando la atenuación en espacio libre A e esta da un valor de 44,34 db. Bajo la hipótesis que ambas antenas ganan lo mismo, es posible agrupar variables en una sola incógnita y escribir: Por lo que cada antena tendrá una ganancia de potencia, por debajo de la esperada para este tipo de antenas según los resultados obtenidos con el simulador. Tabla 5: Instrumental empleado en el ensayo de antenas. Rol Descripción Fabricante Modelo Transmisor Generador de señales de RF ED Laboratory SG 1240 Receptor Analizador de espectro GW Instek GSP 827 (7) (8) (9) Tabla 6: Ensayo de enlace con dos antenas parche. Parámetro Símbolo Valor Distancia entre antenas D 5,5 m Altura de instalación de antenas H 1,5 m Potencia transmitida P TX 0 dbm Potencia recibida P RX -52 dbm El desplazamiento en frecuencia y la poca ganancia que presentan las antenas, se originan por no tener un plano de masa infinito, el cual es hipótesis en todos los métodos de análisis de una antena parche [3]. Un criterio para la elección del tamaño del plano de masa es que sus dimensiones sean comparables a la longitud de onda en el vacío a la frecuencia de operación. Otra razón por la cual se obtuvo una ganancia tan pequeña, la cual se suma al efecto del plano de masa finito, es la baja eficiencia de la antena. La eficiencia de este tipo 1330
62 de antenas no se modifica sensiblemente con la relación entre W y L, sino que está sujeta fuertemente a las constantes del sustrato elegido, como su espesor h y su permitividad ε r [3]. a b Figura 3. a) Patrón de radiación Simulado en CST, b) Patrón de radiación Medido 6 Medición de Patrón de Radiación en el Plano Azimutal Otro parámetro necesario de conocer de una antena es su patrón de radiación. El ensayo consiste en dejar una de las antenas fijas, en este caso la trasmisora, y mover la otra a modo de sonda, siguiendo un círculo y tomando las medidas del ángulo que se desplaza y de la potencia que se recibe. Las mediciones tomadas y los resultados del ensayo se presentan en Figura 3. Se puede observar que son de forma similar, aunque sus escalas son diferentes. Se aprecia un lóbulo posterior significativo, el cual sería el resultado de un plano de masa demasiado pequeño para las dimensiones del dispositivo. 7 Incidencia del espesor del dieléctrico en la Ganancia Para verificar la influencia del espesor del dieléctrico, se decidió diseñar, construir y ensayar otro par de antenas empleando el doble de espesor en el sustrato. Se observó una mejora significativa en la ganancia de potencia, con un nuevo valor de 3,5 dbi. 8 Conclusiones Se han discutido criterios de diseño de antenas parche utilizando el modelo de línea de transmisión. A partir de las ecuaciones de diseño de la Sección 2 se obtuvieron 1331
63 valores iniciales que fueron introducidos en el software de simulación como punto de partida, junto con estimados de las características dieléctricas del sustrato utilizado en el diseño. Mediante simulaciones se optimizaron los parámetros. Se realizaron prototipos basados en dichas simulaciones, y se procedió a realizar mediciones de laboratorio para evaluar su desempeño. Los ensayos iniciales mostraron fuertes discrepancias en cuanto a la impedancia de entrada, por lo que se procedió de manera experimental a modificar la posición del punto de alimentación hasta lograr una adaptación de impedancia y ROE aceptables. El valor de ganancia de potencia alcanzado se considera poco satisfactorio para este tipo de antena, estimándose que este resultado podría deberse a fuertes pérdidas en el dieléctrico y/o en el cobre, lo que resulta en una baja eficiencia de radiación. Se estima que parte de la discrepancia observada se debe a la falta de datos experimentales sobre las características del sustrato empleado, esto es su permitividad y factor de pérdidas a la frecuencia de operación. Se realizó un segundo diseño siguiendo los pasos de las secciones 2 y 3 pero utilizando un dieléctrico del doble de espesor, comprobándose un aumento de la ganancia en un 133%. Se comprueba de manera preliminar la fuerte dependencia de la ganancia de potencia del espesor del dieléctrico. Siguiendo esta línea se está trabajando en mejorar el diseño antes presentado mediante la aplicación de conceptos de metamatariales. Agradecimientos. Subsidiado parcialmente por los Proyectos: PICT 2011/1008 (ANPCyT); CIUNT (UNT) 26/E408, PIDDEF 02/12 (MINDEF). Referencias 1. Kraus, J. D.: Antennas. Second Edition, McGraw-Hill (1988). 2. Kraus, J. D., Fleisch, D. A.: Electromagnetismo con aplicaciones. Quinta Edición. McGraw-Hill (2006). 3. Ramesh, Prakash, Inder, Apisak: Microstrip Antenna Desing Handbook. Artech House (2001). 4. Clenet M.: Design of a UHF Circularly Polarized Patch Antenna as a feed for a 9.1 metre Parabolic Reflector. Defence R&D Canada, Technical Memorandum, DRDC, Ottawa (2004). 5. Breed, G.: The Fundamentals of Patch Antenna Design and Performance. High Frequency Electronics. Summit Technical Media, LLC (2009). 6. Jordan, E. C., Balmain, K. G.: Electromagnetic waves and radiating systems. Prentice Hall, INC. (1968). 7. Godara, L. C.: Smart Antennas. CRC Press (2004). 8. Balanis, C. A.: Antenna Theory. Wiley-Interscience (2005). 9. Gonca, C., Sevg, L.: Design, Simulation and Tests of a Low-cost Microstrip Patch Antenna Arrays for the Wireless Communication. Turk Journal Elec. Engin, vol.13, N 1, (2005). 10. James, J. R., Hall, P.S.: Handbook of Microstrip Antennas. Peregrinus Ltd. (1989). 1332
64 Una aplicación para el modelo de implantación de software Alicia Mon 1, Fernando López Gil 2 1 Departamento de Ingeniería e Investigaciones Tecnológicas. Departamento de Ingeniería, Universidad Nacional de La Matanza. Florencio Varela San Justo (CP 1754) - Tel: alicialmon@gmail.com 2 Instituto de Investigación y Transferencia en Tecnología (ITT), Universidad Nacional del Noroeste de la Provincia de Buenos Aires. Newbery 355, Junín (CP 6000), Buenos Aires, Argentina flopezgil@hotmail.com Resumen. En el presente artículo se presenta un modelo para el proceso de implantación de software, en el que se definen sus subprocesos, actividades, productos y roles. Además se presenta una aplicación web que se ha desarrollado para dar soporte al usuario que quiera llevar a cabo la implantación de software siguiendo este proceso. Este modelo es el resultado de un trabajo de investigación que ha evaluado la etapa de puesta en marcha de nuevos productos software como un subproceso al interior del proceso software, que requiere de la definición de conceptos, tareas y productos que deben ser especificados y definidos en forma previa a la ejecución del mismo. La aplicación presentada fue desarrollada con el objetivo de aportar al usuario del modelo un acceso fácil y rápido a cada uno de los componentes que se han definido. Palabras Clave: Implantación de Sistemas. Proceso Software. Modelo de implantación, 1 Introducción Para los proyectos de tecnologías de la información (TI) existen diversos modelos de proceso y de gestión que dividen y guían el ordenamiento con sistematización del desarrollo, así como la implantación y el mantenimiento, dividiendo los procesos en sub-procesos y definiendo un conjunto de actividades que deben llevarse a cabo en el desarrollo y la puesta en marcha de los sistemas de información. Los modelos y estándares existentes, ordenan de manera prescriptiva las actividades esenciales que deben llevarse a cabo para un correcto desarrollo de proyectos de construcción, adaptación y o mantenimiento de software. 1333
65 Sin embargo, de la revisión de estos modelos, se puede decir que en general no dan detalles de las actividades necesarias para la puesta en marcha de un producto de software. En el presente artículo, se exponen los resultados de un Modelo creado y propuesto para el tratamiento de las actividades de la puesta en marcha de los sistemas, a través de la estandarización de las prácticas involucradas, sin especificar el orden de ejecución en el tiempo. También se expone una aplicación desarrollada a los efectos de permitir el soporte del modelo propuesto. 2 Modelo de implantación Los modelos más utilizados por la industria del software y servicios informáticos, son los específicos para software como el Estándar IEEE 1074 Standard for Developing Software Life Cycle Processes [1], el ISO Standard for Information Technology - Software Life Cycle Processes [2], el modelo integrado de ingeniería de software e ingeniería de sistemas CMMI Capability Maturity Model Integration [3], así como la metodología ágiles SCRUM [4]. En cuanto a la estandarización de actividades de gestión de proyectos, la guía de PMBOK A Guide to the Project Management Body of Knowledge [5], define el conjunto de actividades desde una perspectiva más genérica, aplicable en diferentes tipos de proyectos. El ITIL Information Technology Infrastructure Library [6] trabaja sobre las actividades para la gestión de servicios tecnológicos, en tanto que el SWBOK [7] proporciona una guía al conocimiento presente en Ingeniería de Software. Sin embargo del análisis de estos modelos se puede ver que el proceso de implantación del software es tratado generalmente de modo tangencial y sin una clara definición de sus actividades. Por ese motivo, se ha definido en este trabajo un modelo de trabajo que se dedica específicamente al proceso de la implantación del software. El Modelo de Implantación que se presenta, se ha estructurado en un conjunto de 10 sub-procesos a los cuales se les ha asignado un código de identificación. Asimismo, se les han asignado dimensiones de procesos y grupos de procesos siguiendo los criterios utilizados por la norma ISO/IEC [8] para poder tener un criterio de clasificación generalmente aceptado. La definición del Modelo de Proceso de Implantación, incluye el conjunto de actividades, no ordenadas en el tiempo, pero vinculadas entre sí por las relaciones de entrada y salida, así como por los productos que cada subprocesos genera y los roles involucrados [9] [10]. Los subprocesos definidos para el modelo propuesto son los siguientes: Tabla 1. Subprocesos de la implantación de software. Cód Procesos Dimensión Proceso Grupos Procesos DIST Distribución del software ensamblado Procesos primarios Ingeniería INST Instalación de software Procesos primarios Ingeniería CONF Configuración de software Procesos primarios Ingeniería / Procesos del cliente 1334
66 Cód Procesos Dimensión Proceso Grupos Procesos ACEP Aceptación de software Procesos primarios Procesos del cliente CONV Conversión de sistema Procesos primarios Ingeniería CAPA Capacitación de usuarios Procesos RRHH e Infraestructura organizacionales OPER Operación de software Procesos primarios Procesos de operación ACTP Actualización de los Procesos de la Organización Procesos organizacionales Procesos de mejora de procesos CIER Cierre de proyecto Procesos Gestión organizacionales GEST Gestión de la implantación Procesos organizacionales Gestión En el gráfico 1, se exponen los diferentes subprocesos agrupados de acuerdo al perfil que tiene mayor influencia sobre ellos y al conjunto de relaciones que existen entre los subprocesos. Los perfiles que se encuentran básicamente involucrados son: Tecnológico, Funcional, Operativo, Gestión y Administración del Conocimiento. Las relaciones que se observan en los subprocesos, está dada en algunos casos por la precedencia necesaria que tienen entre ellos y en otros por el control que el subproceso de Gestión de la Implantación tiene sobre el resto de los subprocesos. 2.1 Subprocesos Ilustración 1 Relaciones de los subprocesos de la implantación A continuación se dará una breve descripción de los diferentes sub-procesos del modelo desarrollado. Distribución del software ensamblado (DIST) Es el proceso que se encarga del ensamblado de los componentes de acuerdo a la tecnología utilizada, su preparación para ser instalados en un nuevo entorno y su posterior distribución. En el caso de ser un producto software comprado, sólo se consideraría la distribución. 1335
67 Instalación de software (INST) Es el proceso que se ocupa de transferir el nuevo software al entorno productivo. Se encarga de adaptar las condiciones de dicho entorno, de modo que el nuevo producto software pueda ejecutarse correctamente. Configuración de software (CONF) La configuración del software es el proceso en el cual se definen los parámetros del sistema de modo que éste responda a los diferentes casos de acuerdo a lo esperado por el usuario. Se basará para determinar este comportamiento en la información provista por la especificación, los casos de prueba y los usuarios referentes. Aceptación de software (ACEP) La aceptación del software consiste en un análisis de la información de evaluación entregada, comparado con la información de aceptación del usuario prevista, de modo de garantizar que el software instalado funciona como se esperaba. Cuando los resultados del análisis satisfacen los requisitos de aceptación del usuario, el sistema de software instalado se acepta. Conversión de sistema (CONV) La conversión de sistema consistirá en la definición de la estrategia de puesta en marcha del nuevo sistema, ya sea reemplazando a un sistema anterior o automatizando procesos manuales preexistentes. Capacitación de usuarios (CAPA) El proceso de capacitación consistirá en proporcionar a todas las personas involucradas en el uso del nuevo sistema, los conocimientos necesarios para llevar a cabo las actividades que les corresponden. Familiarizándose con la aplicación y los procesos automatizados, a fin de disminuir los problemas de operación. Operación de software (OPER) El proceso de operación del software es el que se encarga del uso habitual del mismo. Éste debe considerarse dentro de la implantación, ya que en una primera etapa el proceso requiere un mayor soporte para evitar retrasos y problemas operativos. Actualización de los Procesos de la Organización (ACTP) La actualización de los procesos de la organización consiste en actualizar toda la documentación y definición de procesos, en lo referente o que son afectados por el sistema implantado. Cierre de proyecto (CIER) El proceso cerrar proyecto es el necesario para finalizar todas las actividades de los diferentes grupos de procesos a fin de cerrar formalmente el proyecto o una fase del mismo. Gestión de la implantación (GEST) El proceso de gestión es el responsable de administrar y coordinar las diferentes actividades que se deben llevar a cabo a lo largo de la implantación. 1336
68 2.2 Roles del proceso Para la ejecución del conjunto de actividades definidas al interior de cada subproceso del Modelo de Implantación propuesto, se han definido un conjunto de Roles responsables con asignación de funciones. La siguiente Tabla 2, expone los roles definidos por el Modelo y la descripción de las funciones con su correspondiente identificación: Tabla 1 - Roles del proceso de implantación Cód. Nombre del Rol Descripción CLI Cliente Es la persona -física o jurídica- que mediante un pago solicita el producto software, que discute las cláusulas del contrato y su modo de cierre. Habitualmente también define los requisitos. URE Usuario referente Es un usuario final que por sus conocimientos de la organización o del proceso que debe realizar se lo puede tomar como idóneo para definir los requisitos. UFI Usuario final Es la persona a la cual va destinado el producto y que habitualmente trabaja directamente con este. USO Usuario área de Es la persona del área de IT interno a la organización que se ocupa soporte de dar el soporte del software. Interactúa con el usuario final. AFU Analista funcional Es la persona que hace de nexo entre los usuarios y el grupo de desarrollo. Tiene conocimiento del negocio y del uso de la aplicación. LPR Líder de proyecto Es la persona responsable del planeamiento del proyecto, del control de su ejecución y de la gestión de los recursos económicos, materiales y humanos asignados al mismo. PRU Responsable de pruebas Es la persona responsable de la planificación y ejecución de las pruebas del sistema. Particularmente pruebas de sistema y aceptación. CAP Capacitador Es la persona responsable de transferir a los diferentes usuarios -y/o involucrados- el conocimiento para el uso del software. AFE Terceros afectados Todas las personas que son afectadas por el proyecto, con mayor o menor grado de involucramiento que no son usuarios directos del software. TEC Personal técnico Es personal que pertenece al grupo de desarrollo de la aplicación y que se ocupa de llevar a cabo diferentes procesos de tipo técnicos. PRO Responsable de Es la persona encargada de recopilar y documentar el procesos funcionamiento de los diferentes procesos de la organización. CCM Responsable de la Es la persona responsable de la administración y registro de los gestión de cambios cambios en los proyectos de la organización PRV Proveedor Es la persona -física o jurídica- que mediante un cobro entregará el producto software que se requiere para la instalación. COM Comprador Es la persona responsable de las adquisiciones dentro de la organización. 2.3 Productos de las actividades La ejecución del conjunto de subprocesos definidos para el Modelo de Implantación, generan como resultado uno o varios Productos como salida. En este sentido, el Modelo propuesto define un conjunto de Productos que deben ser elaborados por cada uno de los subprocesos y que a su vez constituyen el producto de entrada para otro subproceso. Por cuestiones de espacio se omite el listado de los productos y descripciones. Los mismos se pueden encontrar en la herramienta propuesta más adelante. 1337
69 3 Aplicación Para asistir al usuario del modelo presentado, se ha desarrollado una aplicación web que permite al mismo tener visibilidad del proceso de implantación. La aplicación se construyó con la premisa que ésta debe ser simple y permite al usuario observar de modo claro las relaciones que se dan en el modelo propuesto entre los procesos, sus actividades, los productos y los diferentes roles involucrados. El objetivo principal de la aplicación es servir de soporte en la utilización del proceso de implantación propuesto para aquellos usuarios que lo quieran aplicar, utilizando la misma como una guía de las actividades que se deben considerar. 3.1 Desarrollo de la aplicación Desde el punto de vista tecnológico, se consideró importante crear una aplicación fácilmente utilizable, que no requiera ningún tipo de instalación y que tuviera el mayor alcance posible. Para lograrlo, la aplicación se desarrolló con tecnología web de modo que ésta pueda ser utilizada por el usuario desde un navegador, sin requerir ningún tipo de instalación ni configuración particular. 3.2 Interfaz Se definió un formato de interfaz estándar para toda la aplicación a fin de simplificar el aprendizaje del usuario. La interfaz de la aplicación se encuentra estructurada de la siguiente manera: Un panel de navegación, que nos permite ver el árbol de procesos y actividades del modelo, los roles y los productos. Una ventana principal donde encontramos la información del punto del panel de navegación que se ha seleccionado. Un encabezado que muestra el título de la aplicación y de la universidad Un pie, que permite ocultar o mostrar el panel de navegación. 3.3 Pantalla de inicio En esta pantalla principal podemos ver una introducción al modelo propuesto para la implantación, las características del mismo, la lista de los subprocesos definidos y un gráfico con su relación con las diferentes áreas de perfil con que se relaciona. 1338


70 Ilustración 2 Pantalla de inicio (Interfaz aplicación) 3.4 Pantalla proceso Como ejemplo del formato de las pantallas de la aplicación presentaremos la pantalla de procesos que es la que permite trabajar a partir de cada uno de los procesos del modelo. Al seleccionar un proceso en el panel de navegación, se accederá en el panel principal a los datos correspondientes al proceso seleccionado, donde podremos encontrar la descripción y objetivos del mismo. También se verá un esquema donde se encuentran relacionadas las diferentes actividades y productos del proceso. Ilustración 3 Pantalla proceso (Interfaz aplicación) 1339
71 Además en esta ventana encontraremos tres solapas más que corresponden al detalle de las actividades, los productos y roles involucrados que se encuentran relacionados con el proceso. Se puede ver la aplicación en funcionamiento y con el modelo de proceso de implantación completo en: 4 Conclusiones y trabajos futuros La investigación aquí expuesta, se propone definir a la puesta en marcha de proyectos informáticos, como un proceso específico en el marco del proceso software, en tanto que debe ser tratado como parte inherente a la definición del proceso software, y debe ser definido específicamente a través de un conjunto de principios básicos que permitan comprenderlo y abordarlo como un área dentro de la Ingeniería de Software o la Ingeniería de Sistemas plausible de ser gestionado por el impacto que genera. Se pretende difundir el uso de la herramienta desarrollada de modo tal que permita realizar un trabajo de validación del mismo, en contextos reales de la industria del software. En base a esta información recopilada, se propone continuar desarrollando el modelo. La validación permitirá revisar las diferentes prácticas y técnicas que se utilizan para la implantación y sus limitaciones, para mejorar el modelo y madurar en la puesta en marcha de los proyectos. Referencias 1. IEEE. IEEE Std IEEE Standard 1074 for Developing Software Life Cycle Processes. IEEE, ISO/IEC International Standard: Information Technology. Software Life Cycle Processes. ISO/IEC. Standard /Amd CMMI. Capability Maturity Model Integration Version 1.3. Carnegie Mellon University. Software Engineering Institute, USA, K., Schwaber Agile Project Management with Scrum. Ed. Microsoft Press, USA, PMBOK Guide, I. P. A Guide to the Project Management Body of Knowledge Fifth Edition. Project Management Institute Inc. Pennsylvania, USA, ITIL V3 Foundation Handbook, Ashley Hanna, John Windebank, Simon Adams, John Sowerby, Stuart Rance, Alison Cartlidge, The Stationery Office, IEEE. (2004). SWEBOK. Knowledge Creation Diffusion Utilization. 8. ISO/IEC. ISO/IEC Information Technology Software process assessment. ISO, International Electrotechnical Commission, Mon, Alicia; Estayno, Marcelo; López Gil, Fernando; De María, Eduardo. (2011) Definición de un proceso de implantación de sistemas. Infonor 2011, Chile. 10. Mon, Alicia; López Gil, Fernando. (2014) Implantación de Software, un Modelo Básico. WICC
72 QuVi: Una herramienta estadística para la toma de decisiones orientadas a obtener sistemas Web de Calidad Nicolás Tortosa, Noelia Pinto, César J. Acuña, Liliana Cuenca Pletsch, Bruno Demartino Grupo de Investigación en Ingeniería y Calidad de Software (GICS). Facultad Regional Resistencia, Universidad Tecnológica Nacional. French 414, Resistencia, Chaco. Resumen. Lograr calidad del software Web se ha convertido, en los últimos años, en uno de los principales objetivos de las organizaciones para mantener su nivel de competitividad. Por esto, la Industria del Software persigue el desarrollo de herramientas que colaboren en el proceso de obtención de productos Web de calidad. En trabajos anteriores hemos presentado WQF un framework para la Evaluación de Calidad de Aplicaciones Web, compuesto por un Modelo de Calidad (WQM) y un plugin web para realizar los procesos de evaluación de calidad (QUCO2). En este artículo se presenta el diseño de QuVi, una aplicación para la emisión de informes estadísticos en base a la información proporcionada por WQF, con el objetivo de permitir a los directivos de las organizaciones tomar decisiones en pos de la mejora de calidad en aplicaciones Web. Finalmente se incluyen los trabajos futuros que se afrontarán para afinar la herramienta presentada. Palabras Clave: Calidad, Software Web, Evaluación de Calidad 1 Introducción En pleno desarrollo emergente, en el campo de la Ingeniería del Software, las aplicaciones Web han alcanzado un auge importante en todos los ámbitos; llegando a formar parte, incuso, del crecimiento de las organizaciones. Estos sistemas ya no se consideran sólo como herramientas de apoyo, sino que se han convertido en un imperativo para el desarrollo y supervivencia de cualquier organización. Sumado a esto, la literatura demuestra el aumento de la preocupación por la obtención de productos de calidad en el ámbito de las aplicaciones Web. Así, teniendo en cuenta la definición que propone Pressman [2], la calidad del software representa la concordancia con los requerimientos funcionales y de rendimiento explícitamente establecidos, con los estándares de desarrollo explícitamente documentados y con las características implícitas que se espera de todo software desarrollado profesionalmente ; es decir que, si bien, debe diferenciarse entre calidad de producto y calidad de proceso de desarrollo; la definición de las metas del producto definen las 1341
73 características del proceso de obtención del mismo. En este sentido se viene trabajndo en el Grupo de Investigación en Ingeniería y Calidad de Software (GICS) de la Facultad Regional Resistencia, en el desarrollo e implementación de un framework para la Evaluación de Calidad de Aplicaciones Web, WQF [1]; el cual actualmente se compone de un Modelo de Calidad (WQM) y de un plugin web para llevar a cabo los procesos de evaluación de calidad (QUCO2) por parte de usuarios finales. De esta forma, surge la necesidad de contar con una herramienta que permita procesar la información recopilada y almacenada hasta el momento, que permita ejecutar acciones tendientes a mejorar la calidad del producto web evaluado. Por todo lo antes expuesto, el presente artículo tiene por objetivo explicar mejoras incorporadas al framework WQF detallando el diseño de una herramienta que permita la emisión de informes estadísticos que sean de utilidad en la toma de decisiones para los directivos de cualquier organización. Su desarrollo se enmarca en la línea de investigación Métricas y Calidad de Software correspondiente al Grupo de Investigación en Ingeniería y Calidad de Software (GICS) de la Facultad Regional Resistencia. En la sección 2 se describen los componentes actuales del framework WQF y su relación entre ellos. En la sección 3 se presenta el diseño del modelo propuesto para la herramienta QuVi, que extenderá las funcionalidades de WQF, y permitirá generar informes a partir de la información recolectada por otra de las herramientas de WQF. Finalmente, en la última sección se incluyen conclusiones y trabajos futuros que podrán realizarse teniendo como base esta herramienta en desarrollo. WQF: Framework para la evaluación de calidad en aplicaciones WEB Con el objetivo de gestionar los elementos de calidad se desarrolló WQF (Web Quality Framework), para posibilitar la evaluación de calidad orientado a aplicaciones Web, compuesto por un modelo de calidad (WQM) y QUCO2, una herramienta que almacena información respecto a los resultados obtenidos en las evaluaciones. WQM: Modelo de Calidad para Aplicaciones Web Teniendo en cuenta trabajos anteriormente publicados [3][4], brevemente se presenta en esta sección el modelo de calidad desarrollado, WQM (Web Quality Model). El mismo, hasta el momento, incluye el estudio de 3 métricas, que a su vez engloban un conjunto de características que son objeto de evaluación: a) Usabilidad: Permite medir la facilidad con la que las personas puede utilizar el sitio web para llegar a alcanzar sus propios objetivos. b) Confiabilidad: A partir de esta métrica se evalúa el grado de seguridad del sitio web permitiendo siempre mantener la misma performance en el tiempo bajo las demandas por las cuales fue definido. 1342
74 c) Funcionalidad: Esta métrica posibilida corroborar que el Sitio Web cumpla con las funciones que fueron definidas, evaluando la relación entre los resultados que se obtienen y los resultados esperados. Los criterios de calidad que se evalúan por métrica, junto a las opciones de cada uno, se consignan en la Tabla 1. Tabla 1. Relación entre métricas, sus criterios de calidad y las opciones de éstos Métrica Criterios de calidad Escala Descripción Valor Facilidad de Aprendizaje Muy complicado Complicado - - Retención en el tiempo Fácil Muy fácil Consistencia Consistencia en todo el sitio Consistencia en la mayor parte del sitio Inconsistencia en todo el sitio Recuperabilidad Si Usabilidad No - El Sitio presenta diferentes opciones para una misma tarea El Sitio presenta una única alternativa para una tarea. Pero no presenta Flexibilidad inconvenientes para llegar hasta la misma Es difícil intercambiar información - dentro del Sitio No se puede intercambiar información en el Sitio Confiabilidad Funcionalida d Frecuencia y severidad de las fallas Exactitud de las salidas Capacidad de Recuperación ante fallas Confiabilidad Adecuación Cumplimiento Confiabilidad Seguridad Errores graves continuamente Errores leves continuamente Errores leves sólo en ciertas funciones No se observan errores Si No - Si No - Completamente seguro Muy seguro Seguro Se observan zonas inseguras Completamente inseguro
75 QUCO2: Una herramienta para la evaluación de calidad de aplicaciones web QUCO2, es el componente de WQF que permite gestionar los elementos incluidos en el modelo y almacenar información respecto a los resultados obtenidos luego de cada proceso de evaluación ejecutado. Esta herramienta se presenta como un plugin on-line que admite la evaluación simultánea de diversas aplicaciones web por parte de un número ilimitado de usuarios finales, y ofrece al final del proceso un valor promedio de calidad asociado al sistema Web evaluado. QuVi: Una herramienta para la presentación de informes La información sobre los resultados de las evaluaciones recolectadas a través de QUCO2, en base al modelo de calidad WQM, representa valor agregado para la toma de decisiones, pues no solo hace referencia al nivel de calidad de la aplicación evaluada sino que también puede significar otros conocimientos útiles para la mejora continua. Así y teniendo en cuenta lo expresado por Romero Villafranca y Zúnica Ramajo, hoy día se vive en una sociedad estadística, donde se razona y se toman decisiones en base a datos y análisis estadísticos [5]. Por esto, se propone la implementación de QuVi, una aplicación que permite simplificar la realización de análisis de la información mediante el uso de reportes estadísticos que facilitan la interpretación de los valores obtenidos. El desarrollo de esta herramienta se basa en la Estadística Descriptiva, disciplina que engloba métodos para la recolección, presentación y caracterización de un conjunto de datos con el fin de describir adecuadamente las características de los mismos [ ]. Aplicaciones Web Evaluadas con QUCO2 QuVi Obtención de reportes estadísticos Fig.. Relación entre QUCO2 y QuVi QuVi se incluye a la suite de herramientas de WQF relacionándose directamente con la información recopilada en QUCO2, como se muestra en la Figura 1; presenta una visión integral de la calidad percibida por el usuario respecto a las aplicaciones web evaluadas y, por otro lado, aporta información que puede ser manipulada por los directivos de las organizaciones que la utilicen en el proceso de toma de decisiones. La herramienta que se presenta combina y organiza los datos en reportes estadísticos 1344
76 que permiten la observación de interrelaciones y dependencias entre las variables que se estudien. Esta aplicación debe ser utilizada por los directivos o responsables del área de Calidad de las organizaciones, quiénes deben estar capacitados en el uso y comprensión del modelo WQM sin que esto implique ahondar en detalles técnicos asociados. En el siguiente apartado se describen detalladamente los informes que forman parte, inicialmente, de QuVi. Modelo Propuesto El desarrollo de QuVi se llevará a cabo en etapas, comenzando por una aproximación que permita la obtención y visualización de la información, avanzando gradualmente hasta lograr un sistema integral para la toma de decisiones. En este sentido, durante esta primera etapa se contempla el cálculo estadístico de diferentes parámetros y la generación de gráficos, teniendo en cuenta varios tipos de análisis y a partir de la información obtenida durante el proceso de evaluación junto a sus resultados. Así el módulo de Emisión de Informes se compone de los siguientes reportes: a) Evaluación de Calidad: De acuerdo a la aplicación web que se seleccione para su estudio, este reporte informa el valor promedio de calidad asociado al nivel de calidad obtenido, según lo expresado en el modelo WQM. En el mismo se indica que el valor de calidad máxima ocupa el rango entre 20 y 22, el valor de calidad media el rango entre 14 y 20, el valor de calidad regular entre 8 y 14 y el mínimo nivel con un valor por debajo de 7 [7]. Para una mejor lectura, no sólo se presenta el valor y el nivel, sino que gráficamente se asocia un color tal como se indica en la Tabla 2, lo que ofrece, al usuario final, mayor legibilidad al analizar este informe. Tabla 2. Relación entre rango de valor de evaluación, nivel de calidad y color. NIVEL RANGO COLOR Calidad Máxima Calidad Media Calidad Regular Calidad Baja - Para complementar a este informe, se ofrecen (dos) gráficos estadísticos: - Diagrama de Frecuencias: Representado por un gráfico de columnas en el cual las ordenadas representan la frecuencia con la cual determinada magnitud toma el valor o conjunto de valores que figura en abscisas [ ]. Por ejemplo en la Figura 2, se muestra el diseño del diagrama que se presentará en el informe, en el cual el eje Y incluye los valores en promedio obtenidos por cada métrica, las cuales se representan en el eje X. Esto permite identificar cómo influye cada métrica al Valor de Calidad, de manera que podrán tomarse decisiones tendientes a ajustar aquéllas variables que.afecten la calidad del producto evaluado. 1345
77 Valores Promedios Usabilidad Confiabilidad Funcionalidad Métricas Fig. 2. Diagrama de Frecuencias de la Evaluación de Calidad - Gráfico de Caja y Bigotes: Este diagrama permite analizar y resumir un conjunto de datos, facilitando el estudio de la simetría de datos y la detección de valores atípicos. En este gráfico se dividen los datos en cuatro áreas de igual frecuencia, una caja central dividida en dos áreas por una línea vertical y otras dos áreas representadas por dos segmentos horizontales, denominados bigotes, que parten del centro de cada lado vertical de la caja [ ]. La gráfica de caja y bigotes, ejemplificada en la Figura 3, ofrece una representación visual de los datos basada en el resumen de 5 valores: Valor Mínimo, Valor Máximo, Cuartil 1, Mediana y Cuartil Fig. Ejemplo de Diagrama de Caja y Bigotes El Diagrama de Caja y Bigotes, ofrece valor agregado ya que al estar trabajando con datos obtenidos de encuestas, los mismos pueden estar sesgados por la subjetividad o errores humanos, por lo que es necesario contar no solo con un valor promedio sino también disponer de la distribución de todos los valores obtenidos. De esta forma, el informe de Evaluación de Calidad ofrece al usuario final datos claros y organizados representados por valores numéricos que permite una visión más amplia del proceso de evaluación que se realizó previamente y facilita la identificación de cuestiones que a priori pueden parecer irrelevantes. A partir de la información presentada en el reporte de Evaluación de Calidad, el usuario puede acceder a otros informes en busca de mayor detalle para el análisis respecto a la aplicación web seleccionada. b) Detalle por métrica: En este informe se tiene en cuenta lo definido en el modelo WQM, así para cada métrica (Usabilidad, Confiablidad o Funcionalidad) se 1346
78 obtienen también Diagramas de Frecuencias y Diagrama de Caja y Bigotes, graficados en las figuras 4 y 5, basados en el valor promedio para la Métrica y una desagregación de la misma en Criterios. Métrica: Confiabilidad Frecuencia y Severidad de las fallas Exactitud de las salidas Capacidad de Recuperación ante fallas Confiablidad Fig.. Ejemplo de Diagrama de Frecuencia para la Mètrica Confiabilidad Fig.. Ejemplo de Diagrama de Caja y Bigotes para la Mètrica Confiabilidad 3) Detalle por criterio: Este informe será útil para los casos en que se necesitara mayor nivel de detalle al presentar la información, pues incluye el valor promedio del Criterio, junto con un diagrama de frecuencias en el que se grafica cuántas veces se ha seleccionado cada opción tal como indica el ejemplo en la figura 6. Criterio: Frecuencia y Severidad de fallas Errores graves continuamente Errores leves continuamente Errores leves sólo en ciertas funciones No se observan errores Fig.. Ejemplo de Diagrama de Frecuencias para el Criterio de Frecuencia y Severidad de las Fallas de la Mètrica Confiabilidad 1347
79 3 Conclusiones y Trabajos Futuros El análisis de información disponible, es una de las bases más importantes en los procesos de una organización que desea desarrollar software de calidad. Por tal razón, y teniendo en cuenta la complejidad para valorar los sistemas Web, el estudio de los resultados obtenidos del proceso de evaluación de estos productos permitirá mejorar el control de la calidad asociado a los mismos. En este sentido, el diseño de QuVi se centró fundamentalmente en la producción de informes estadísticos, debido a que en experiencias previas utilizando WQF se comprobó que no basta con informar un valor de calidad a las organizaciones, sino que resulta necesario ofrecer un instrumento que permita reducir la incertidumbre y agilizar el proceso de toma de decisiones adecuadas. Así, como factor diferenciador del framework WQF, la herramienta estadística QuVi, tiene como fin facilitar la definición de metas objetivas e independientes y ofrecer información contundente para la toma de decisiones. Como trabajos futuros se pretende continuar con la segunda etapa incluyendo implementación e integración de QuVi al framework WQF, validando la herramienta a través de la realización de un caso práctico de estudio, a partir del cual se pueda obtener resultados reales surgidos del proceso de evaluación y que sirvan como feedback para ejecutar mejoras a la aplicación, incluyendo nuevos informes o modificando los existentes. Referencias 1. Aproximación a la Evaluación de la Calidad de Aplicaciones Web. Noelia Pinto; Nicolás Tortosa; Liliana Cuenca Pletsch; César J. Acuña; Cristina Greiner; Marcelo Estayno. Revista Ciencia y Tecnología. Año XIII. N 13. Universidad de Palermo. 2. Ingeniería del Software, Un Enfoque Práctico. ta. Edición. Roger Pressman QUCO: Desarrollo de una herramienta para medir la calidad de Aplicaciones Web. Nicolás Tortosa; Noelia Pinto; Cèsar Acuña; Liliana Cuenca Pletsch; Marcelo Estayno. 1 Congreso Nacional de Ingeniería Informática / Sistemas de Información. CONAIISI QUCO : Development of a tool for measuring the quality of Web applications. Nicolás Tortosa; Noelia Pinto; César Acuña; Liliana Raquel Cuenca Pletsch; Marcelo Estayno. X Workshop Ingeniería de Software. CACIC Métodos Estadísticos en Ingeniería. Rafael Romero Villafranca; Luisa Rosa Zúnica Ramajo. Universidad Politécnica de Valencia. 6. Estadística básica en administración: conceptos y aplicaciones. ta. Edición. Mark L. Berenson, David M. Levine. 7. QUCO : Una herramienta para medir la calidad de aplicaciones Web. Noelia Pinto; Nicolás Tortosa; Liliana Cuenca Pletsch; César J. Acuña; Marcelo Estayno. WICC Los gráficos en la gestión. Anorld Hoffman. Editores Técnicos Asociados, Barcelona. 9. Minería de datos: técnicas y herramientas. César Pérez López; Daniel Santín González. Paraninfo, Madrid. 1348
80 1349
81 1350
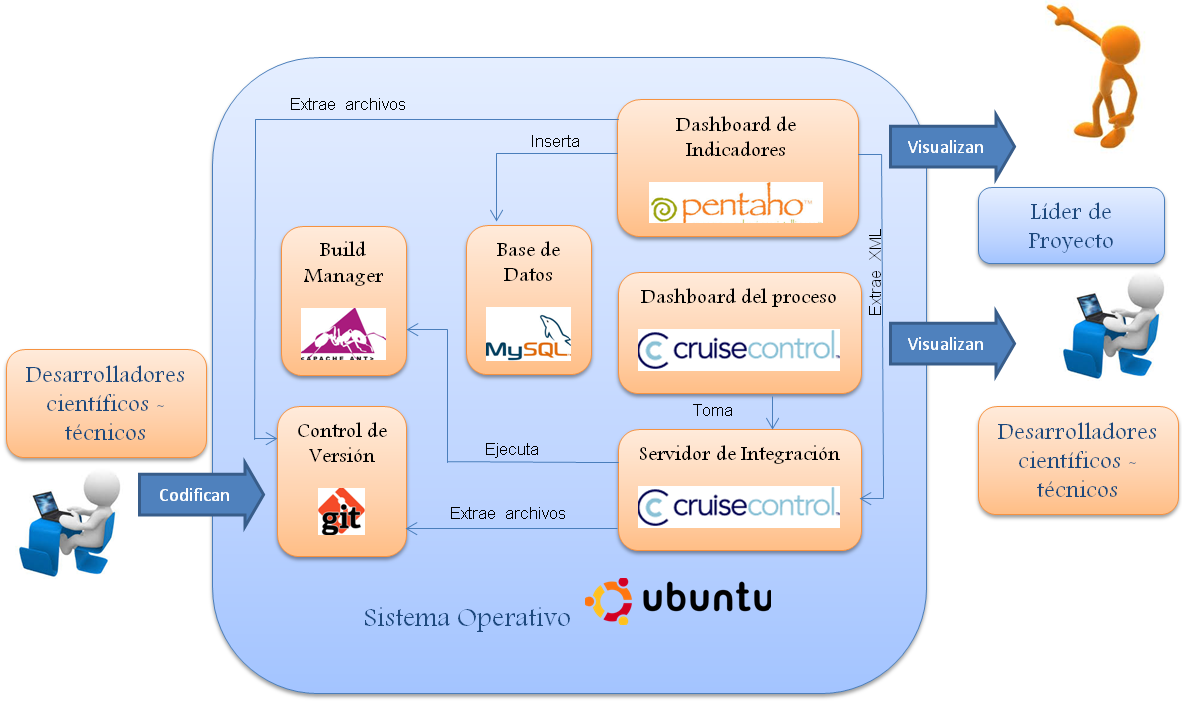
82 1351
83 1352
84 1353
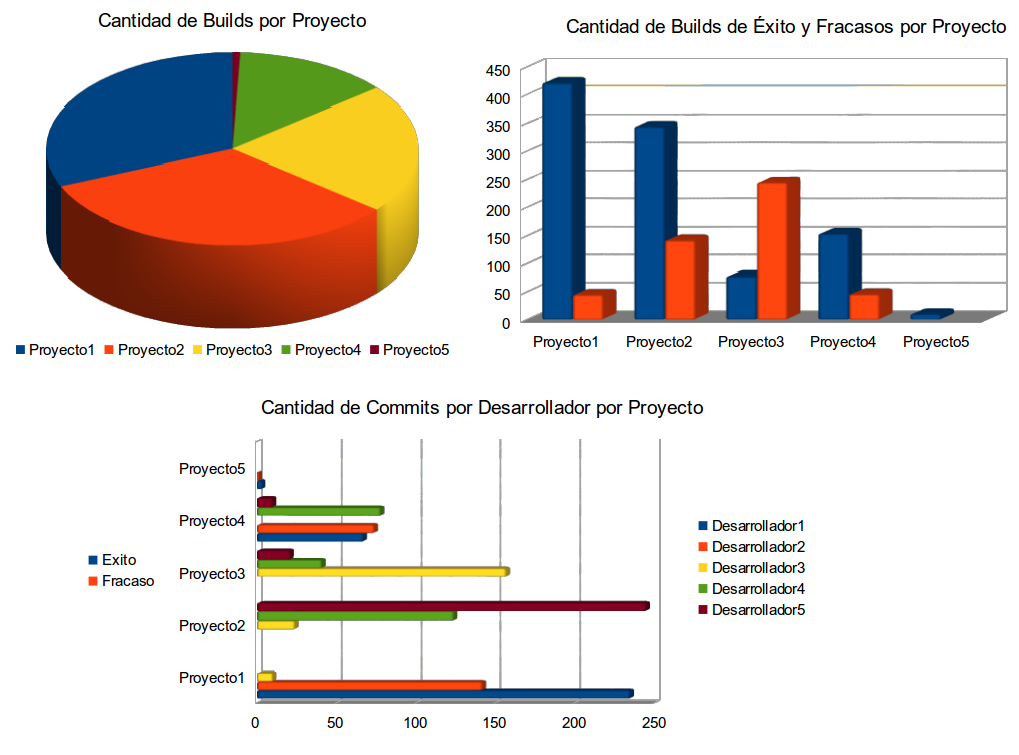
85 1354

86 1355
87 1356
88 Consideraciones generales sobre diseño de amplificadores de pequeña señal en UHF. Oscar Menocal, Zenón Saavedra, José Cangemi, Fernando Miranda Bonomi y Miguel Cabrera Laboratorio de Telecomunicaciones (LTC) del Dpto. de Electricidad, Electrónica y Computación (DEEC) de la Facultad de Ciencias Exactas y Tecnología (FACET) de la Universidad Nacional de Tucumán (UNT) zsaavedra@facet.unt.edu.ar Resumen. En este trabajo es tratado el diseño, simulación y construcción de un amplificador de microondas de pequeña señal para operar a la frecuencia de 990 MHz. Como criterio de diseño se utilizó polarización activa, máxima ganancia de transducción y redes adaptación con parámetros distribuidos. Para el diseño se parte de los parámetros de dispersión S, obtenidos en base a la frecuencia de operación y polarización adoptadas, del transistor. La implementación de las redes de adaptación se realizó empleando tramos de líneas en la entrada y en la salida. Una vez diseñado, simulado y optimizado, se procedió a su armado y medición de sus características. Se confirmara la importancia a la hora de trabajar con líneas de microstrip, conocer con un cierto grado de exactitud las características de los materiales con los que se trabaja. 1 Introducción. La amplificación de señales de RF y Microondas es uno de los procesos más importantes en sistemas de comunicación inalámbrica. Una de las aplicaciones importantes de un amplificador de microondas es en la salida de un transmisor, en donde una señal necesita amplificarse antes de ser transmitida. Las características que debe tener un amplificador dependen de su aplicación. Entre las de mayor interés están: ganancia, nivel de potencia de salida, ancho de banda, número de ruido, linealidad, eficiencia, topología, tipo de realimentación y la vía de alimentación. El amplificador de microondas amplifica la señal de entrada después de que la misma ha sido modulada en el transmisor. Los amplificadores de microondas combinan elementos activos con circuitos de línea de transmisión pasivos que proveen las funciones críticas a los sistemas e instrumentos de microondas. 2 Diseño del amplificador Las especificaciones del Amplificador objeto del diseño propuesto se listan en la Tabla
89 Tabla 1: Especificaciones del amplificador. Parámetro Frecuencia de trabajo 990 MHz Máxima Ganancia de Transducción Adaptación de impedancia con elementos distribuidos Polarización activa Para el diseño se eligió un transistor BJTBFR90, que es adecuado para esta aplicación, teniendo como características una alta ganancia de potencia, baja cifra de ruido y una frecuencia de operación de hasta2ghz. Elegido el transistor se fijó un punto de polarización de Vce = 10V e Ic = 14 ma, basándose en un compromiso entre ganancia y número de ruido. La Tabla 2 muestra los parámetros S obtenidos por interpolación de los valores dados por el fabricante en la hoja de datos del dispositivo. Tabla 2: Parámetros S (V CE =10 V, I C = 14 ma, f = 990 MHz): Parámetro Modulo Angulo 0, ,02º 3, ,859º 0,109 65,403º 0, ,208º Dónde: S 11 es el Coeficiente de reflexión puerto1, S 12 es el Coeficiente de transmisión de camino inverso, S 21 es el Coeficiente de transmisión de camino directo, S 22 es el Coeficiente de reflexión del puerto Estabilidad La estabilidad de un amplificador es una consideración muy importante en el diseño de un amplificador. En un dispositivo de dos puertos la inestabilidad es posible cuando sus puertos de entrada o salida presentan una resistencia negativa. O equivalentemente cuando el módulo del coeficiente de reflexión en entrada o salida supera la unidad, esto es Γ in > 1 y/o Γ out > 1. Un dispositivo de dos puertos se considera incondicionalmente estable para una frecuencia dada si las partes reales de las impedancias de entrada y salida Z in y Z out son positivas para todo el rango de valores de las impedancias de carga o de fuente. Si el dispositivo no es incondicionalmente estable algunos valores de las impedancias de carga o fuente pueden dar lugar a impedancias Z in y/o Z out con parte real negativa [1], [2], [4]. En términos de los coeficientes de reflexión, la condición de la estabilidad incondicional para una frecuencia dada se obtiene cuando se cumplen las siguientes condiciones: 1358
90 Dónde: Г G es el Coeficiente de reflexión del generador, Г C es el Coeficiente de reflexión de la carga, Г in es el Coeficiente de reflexión de entrada, Г out es el Coeficiente de reflexión de salida. La estabilidad incondicional de un amplificador se puede determinar a través de la condición de Rollet la condición de Edwards [1], [2], [4], como se enuncia a continuación: (1) (2) (3) Dónde:, K es el Coeficiente de Rollet, µ es el Coeficiente de Edwards. La Tabla 3 muestra las condiciones de estabilidad calculadas para este caso particular. Tabla 3: Condiciones de estabilidad. Símbolo Valor K 1,1510 0,3131 µ 1,2094 Al cumplirse las condiciones de Rollet y Edwards se concluye que el dispositivo es incondicionalmente estable [1], [2], [4]. 2.2 Redes de adaptación En la Figura 1 se encuentran detallados los elementos intervinientes para realizar una adaptación de impedancias. 1359
91 Figura 1: Diagrama de bloque de la red de adaptación para un dispositivo activo. La máxima ganancia Transducción se obtiene para = y = Los valores de los coeficientes de reflexión y se pueden escribir como sigue: (4) (5) Las soluciones para y que cumplan con las ecuaciones4 y 5. (6) Dónde: (7) (8) Los valores de la soluciones se encuentran listados en la Tabla 4. Tabla 4: Valores de los coeficientes de reflexión de la carga y del generador. Coeficiente Modulo Angulo 0, ,8º 0, ,4º 1360
92 2.2 Configuración de las redes adaptación La adaptación se realizó por medio de redes con parámetros distribuidos, utilizando tramos de línea de transmisión de impedancia Z 0 y líneas de longitud λ/4. La configuración de la red adoptada se muestra en la Figura 2 como sigue: a b Figura 2: a) Configuración de la red de adaptación a la entrada, b) red de adaptación a la salida de amplificador. Los parámetros de las líneas se encuentran listados en la Tabla 5. Tabla 5: Distancias obtenidas mediante el uso de la carta de Smith. Parámetro Símbolo Impedancia longitud Línea de transmisión 1 L 1 83,61 Ω 0,25 λ Línea de transmisión 2 L 2 50 Ω 0,20 λ Línea de transmisión 3 L 3 20,93 Ω 0,25 λ Línea de transmisión 4 L 4 50 Ω 0,25 λ Dónde λ es la longitud de onda a la frecuencia de operación. 2.3 Polarización Para polarizar el transistor BFR90 se escogió polarización activa [1], [3] para tener una mayor estabilidad en el punto de trabajo en función de las variaciones de temperatura. Teniendo en cuenta que el punto de polarización es V ce = 10 V e I c = 14 ma, se adoptó un valor de alimentación de 15 V, y se escogió como transistor de polarización al BC858B. Para aislar la fuente de polarización de la señal de RF se utilizó un resonador de cuarto de lambda terminado en un capacitor en derivación en conjunto con un choque en serie. 3 Simulación Para la misma es necesario conocerlas características del sustrato, las cuales fueron obtenidas mediante medición en el LTC, resultados que se presentan en la Tabla
93 Tabla 6: Parámetro del sustrato Parámetro Símbolo Valor Permitividad 4,3 Espesor de la metalización T 0,045 mm Altura del dieléctrico H 1,482 mm Tangente de pérdida tan δ 0,02 Para la adaptación con líneas microstrip se requiere las dimensiones físicas de las líneas (ancho y longitud), que se determinaron mediante el uso de fórmulas de diseño [1].Una vez implementadas las redes de adaptación se realizó el diseño final, cuyo esquema se muestra en Figura 3. En la Tabla 7 se encuentran los parámetros de las líneas de transmisión utilizadas. Figura 3: Circuito implementado con redes de adaptación de entrada y salida. Tabla 7: Descripción. Símbolo Z 0 Longitud Línea 1 50 Ω 0,20 λ Línea 2 83,61 Ω 0,25 λ Línea 3 20,93 Ω 0,25 λ Línea 4 50 Ω 0,20 λ Línea 5 y 6 50 Ω 0,25 λ 1362
94 Mediante simulación se obtubieron los parámetros Z in, Z out y S 21, listados en Tabla 8. Tabla 8: Valores obtenidos de las simulaciones. Parámetro Símbolo Valor Impedancia de entrada Z in (49,98 -j0,41)ω Impedancia de salida Z out (49,82+j0,05)Ω Ganancia G T 10,33 db Ancho de Banda B 500 MHz 4 Construcción del circuito A partir del diagrama esquemático se diseñó el layout, separando los tramos de líneas con el objetivo de evitar el acoplamiento por proximidad entre líneas. Una vez listo el layout se procedió al armado de la placa y verificación de la polarización. Los valores de polarización medidos sobre el prototipo se muestran en Tabla 9. Tabla 9: Valores obtenidos de polarización. Parámetro V CE I C Valor 10,5 V 13,5 ma 5 Medición del circuito Utilizando un Analizador de Redes modelo Agilent HP 8712ET, se hicieron las mediciones de Ganancia, Impedancia de entrada y de salida. Los resultados se presentan en Tabla 10. Tabla 10: Parámetros obtenidos de las mediciones Z in Z out Parámetro Ganancia Ancho de Banda Valor (72,69 j14,03) Ω (20,34 - j4,158) Ω 8,061 db 220 MHz 6 Conclusión Se ha presentado el diseño, simulación y construcción de un amplificador RF, con frecuencia de trabajo de 990 MHz, utilizando redes de adaptación con parámetros 1363
95 distribuidos y polarización activa. A partir de las ecuaciones de la sección 2 y realizando cálculos, se obtuvo valores iniciales que fueron simulados junto con las características del dieléctrico medidas en laboratorio, luego el diseño fue optimizando mediante simulaciones. Se procedió al armado y medición, obteniendo resultados que se ajustan a los especificados en el diseño de partida. Se observó un considerable corrimiento en frecuencia para la máxima ganancia, atribuible posiblemente a no conocer con exactitud las características del dieléctrico utilizado y a una diferencia entre los valores de la hoja de datos y los verdaderos del transistor. Al considerar en el diseño una permitividad relativa menor al valor verdadero, la velocidad de propagación dentro del resonador λ/4 fue menor a la esperada. Esta disminución se refleja en una mayor longitud eléctrica, correspondiente a una menor frecuencia de resonancia. De existir una diferencia entre los parámetros obtenidos de la hoja de datos del transistor y los reales, los parámetros de dispersión considerados serán erróneos, provocando esto un acarreamiento de error en los cálculos. De lo anterior se desprende la importancia de la caracterización del dieléctrico y los dispositivos utilizados, a fin de establecer parámetros de diseño propios de estos. Bibliografía 1. Gonzalez, G.:Microwave Transitor Amplifiers- Analysis and Design. Segunda Edicion. Prentice Hall (1997). 2. Pozar, D.M.: Microwave Engineering. John Wiley & Sons (2012). 3. Vendelin. G.: Desing of Amplifiers and Oscillators by the S- Parameter Method. Tercera edicion. 4. Bilbao, I.: Electrónica de Comunicaciones. FACET (2008) 1364
96 A DIFFERENTIAL EVOLUTIVE ALGORITHM TUNNED BY FUZZY CONTROLLERS Pablo Rovarini Díaz 1, Alvaro Fraga 2, Daniel Frías Silva 1 1 Universidad del Norte Santo Tomas de Aquino (Argentina) 2 Universidad Tecnológica Nacional (Argentina) pabloc2014@gmail.com gioalvaro@gmail.com Abstract. The purpose of this paper is to present an alternative differential evolution algorithm (DE) for solving unconstrained global optimization problems. The most important challenge in almost all optimization problems is CPU time. The performance and convergence speed of optimization algorithms have the most important effect on CPU time. In this work, the original differential evolution algorithm has been modified in order to increase the convergence speed of the optimization algorithm. In the new algorithm, we use Fuzzy Controllers theory, Liu and Lampinen idea, to achieve a reasonably simple structure that shows better results than the classical algorithm DE/rand/1/bin. Experimental results on a very popular benchmark problem are reported, and conclusions are derived. Keywords: Optimization - Differential Evolution Fuzzy Controllers Data Mining 1 Introduction Evolutionary computation (EC) uses an iterative process, involving growth and changes on an agent population. This population is then subjected to a method of selection trough a guided random search, using parallel processing methods to achieve efficient optimization. Differential Evolution algorithms (DE) as a class of EC have shown great power in solving continuous optimization problems, but it is still a challenging task to design an efficient strategy. In optimizing the performance of a system, the attempted objective aims to find a set of values of its parameters, with dimensionality, in order to lead to an improvement in its overall performance under given conditions. Usually, the parameters governing the performance of a systems are represented by parameter vectors, where is the number of vectors that make up the population (often does not change throughout the process, and the population is initialized, for, with a random distribution). The optimization task entails finding a parameter vector that minimizes a fitness function ( )( ), i.e.: 1365
97 ( ) ( ). (1) Where is a nonempty finite set, which serves as a search domain. In unrestricted problems. Since { ( )} { ( )}, our treatment is without loss of generality. The optimization task results difficult because of the existence of nonlinear objective functions with multiple local minima. A local minimum ( ) is defined as ( ), where denotes any p- norm measure. DE is a simple real parameters optimization algorithm, operating through cycles of steps shown in Figure 1. Compared to most other evolutionary algorithms (EA), differential evolutionary algorithms are much easier and simple to implement. The core of the algorithms takes only a few lines of code in any programming language, and this simplicity of code is important for professionals of other fields, as they are not usually experts in programming and always in the search of algorithms that could be easily implemented and adjusted to solve for specific problems in their domains. Its effectiveness and efficiency have been successfully demonstrated in many application fields such as pattern recognition, communication, socioeconomics, decision making and so on. DE outperforms many other optimization algorithms in terms of convergence speed and robustness over common benchmark problems and real world applications. It should be noted that although the Particle Swarm Algorithms (PSO) are also very easy to code. DE is by far superior to PSO and its variants when it is applied over a large set of real problems [1][2][3]. DE algorithms emerged as a very competitively EA more than a decade ago [4][5a][5b][6a] [6b]. The first article on DE appeared as a Technical Report presented by Storn and Price in 1995 [4]. After a year, its excellent performance in the optimization on large problems was demonstrated in the First International Contest on Evolutionary Optimization (ICEO) in May 1996, held in conjunction with the IEEE International Conference on Evolutionary Computation (CEC) in Nagoya (Japan). As a direct result of recent studies [1][7][2], despite its simplicity EDs exhibit better performance compared to a lot of other approaches when finding solutions over a wide variety of problems, including unimodal type, multi-mode, linearly separable, nonlinear and others spaces. One of the major problem users faces up when using a population based search technique such us DE is the setting/ tuning of parameters of control associated with it. Setting and tuning are crucial task in order to get the success of the algorithm. This difficulty can be minimized to some extent by using self-adaptive parameters. With a small number of control parameters ( in classical DE), many studies of its effects on the algorithmic performance are presented in this paper. Simple 1366
98 adaptation rules for and were developed in an attempt to improve performance algorithm without imposing any extra computational load [8][9][7]. DE presents a low complexity in the search space. Compared to some other successful real parameters optimizers, such as evolutionary algorithm using an adaptive strategy with covariance matrices (Covariance Matrix Adaptation Evolution Strategy: CMA- ES) [10] applied with great success by industrial environment for complex nonlinear problems and non-convex optimization of black box spaces up to 100 variables, make DE an interesting alternative This feature suggests extending the application of optimization problems in largescale search with large processing times Perhaps these features led to the popularity of DE between the research community worldwide. Over the past decade, the research in and with DE became huge and multifaceted, with amazing applications in the real world. 2 Basic DE Algorithm and Variations An algorithm that reflects the core structure of a simple DE is shown in Table 1 [11a]. Table 1. Basic DE algorithm Set maximal dimensionality D to consider Set the control parameters: // create initial population while do DE Binomial Recombination Algorithm for to ( ) end for end while set the population [ ] with [ ] // iterative loop while the termination criterion is not satisfied do for to // for each agent in the population step 1: mutation Generate a mutant vector [ ] corresponding to the target vector through a mutation scheme: ( ) step 2: crossover Generate a test vector [ ] corresponding to the target vector using binomial crossover ( [ ] ) step 3: selection Evaluate the test vector and the target vector using fitness function if ( ) ( ) then else end if 1367
99 end while end for This algorithm corresponds to the DE/rand/1/bin strategy originally proposed by Storn and Price. The strategy selection and control parameter with the best performance for a given problem is often unknown, although there are heuristic guides with the usual approach of trial-and- error. However, the strategy DE/rand/1/bin algorithm is very successful, and is undoubtedly the most used. In addition to this family, numerous derived strategies where developed to perturbed the vectors of a population. The motivation for developing such strategies comes from the fact that no single perturbation method was the best for all problems (No Free Lunch Theorem) [12]. Nowadays, numerous variants such as DE/best/1/bin or DE/current(local)-to-best/1/bin, can be found showing faster convergence by incorporating information about the best solution in the evolutionary search. Suggestions of Storn and Price on the control parameters are valid for many real problems, but they suffer the lack of the desirable generality. Because of the difficulty of establishing appropriate control variables, the investigation tried to change its course to automatically make adjustments [7]. For example, Brest and colleagues [8] proposed a self-adaptive version for DE with automatically adjusts of its control parameters and. Also Thangaraj and colleagues [13] introduced an efficient and simple algorithm, Differential Evolution Algorithm Parameters Based on Adaptive Control (ACDE) and Kumar and Pant [14,15] proposed a new Adaptive algorithm DE (ADE), later modified by embedding Adaptive Trigonometric mutation DE (ATDE), among others. The contribution made by Liu and Lampinen [16] is particularly important in the development of this paper. They applied Fuzzy Logic to DE (Differential Fuzzy Adaptive Evolution: FADE) with a strategy FADE/rand/1/bin. 3 Proposed Algorithm Our proposal consists of a method based on the application of Fuzzy Controllers (FC), a particular class of Fuzzy Systems (FS) [11b]. The FC shows significant advantages when it is necessary to choose an appropriate model for control processes of virtually any kind, showing extremely attractive characteristics it is easy to understand, smooth gradient, modular features, facilities for explaining operation, appropriate treatment of uncertainty inherently parallel, and robust. The FC module allows the replacement of the mathematical approach, avoiding the weakness (poor scalability in low management of non-monotonic functions). Figure 2 shows the general outline of the proposed method FCDE/rand/1/bin (Fuzzy Controller Differential Evolution: FCDE). It is interesting to work with the values given by using the mean square root concerning the change between successive generations over the whole population during the optimization process: ( ( ) ( ) ). (2) ( ( ) ( ) ). (3) 1368
100 ( Where ) is the component of i-th row and j-th column of the matrix, with ( for generating vectors of. ) represents the i-th component of the function vector value for the G-th generation;. Fig. 2. Optimization Methodology for FCDE/rand/1/bin The fuzzy controller uses a knowledge base composed by rules and term-sets that associate relevant system variables found in a database by an appropriate method of Data Mining. This Knowledge Base is constructed in an automated manner from a Data Base with relevant information using a knowledge extractor, in this case the Wang-Mendel algorithm modified [17]. Data variables are given in Table 2, with two output variables corresponding to y. Table 2. Data variables ( ) ( ( ) ( )) In Table 2, { }, the best individual in generation, ( ) the fitness value of the best individual in generation, the quadratic mean square of the difference between the best vector fitness and the fitness of the other vectors of the population. PC and FC variables are as defined earlier. This process creates a Knowledge Base with a set of production rules of the type: 1369
101 . (4) As usual the symbol should be interpreted according to the logical connector, with taken from the term-sets of variables, while and take values found from the term- sets of and. All the membership functions are trapezoidal, taking for input variables term- sets with three functions: Low (L), Medium (M) and High (H) within the range of validity of each variable. For output variables, we consider two term-sets each with five functions: Very Low (VL), Low (L), Medium (M), High (H) and Very High (VH) within the range of validity of each output variable. Through the process, it is required to face the problem of finding a suitable set of rules, and the option of select was a hybrid approach to meet the needs of most real problems. Before initializing the proposed system is necessary to establish ( ). values are taken following the suggested values by Storn and Price: from to, with a good initial choice of. The effective range of is usually taken as [ ], and the interval [ ] is suitable for when the function is separable, as it should be in the range [ ] when the parameters of the function are dependent. To build the KB a single run of the system is performed with fixed values of ( ) without any adaptation (using DE/rand/1/bin) performing an initialization step that ends with a population for, but adding calculations for. This KB accepts changes using any heuristics on the problem domain. In Liu and Lampinen, they construct the KB based on heuristics only, strongly simplifying its structure considering two fuzzy controllers, one for and one for with the same set of rules for both. Once this step is completed, and in order to shorten time, the algorithm uses the same initial population as before. are initialized take up the same strategy of Storn and Price and the whole system of Figure 2 runs until some termination criterion is satisfy [for example, based on a combination of the maximum number of allowed iterations or repeat values for five consecutive iterations (flat area) strategy was used]. 4 Benchmark Function Results Standard benchmark functions that can be used to compare optimization algorithms can be found elsewhere, and in particular, we test our model with five functions: Sphere [20] (De Jong F1), Rosenbrock [19] (De Jong F2), Quartic (De Jong F4), Schwefel Sine Function [22] and Rastrigin Function [21]. Because of its importance for our purposes, we show simulation results obtained for the Rastrigin function: ( ) ( ) (global minimum: ( ) ). It is a highly multimodal test function (the number of local minima in the Rastrigin function increases exponentially with ). This function is fairly difficult to optimize due to its large search space and its large number of local minima produced by the cosine modulation. For those reasons, it is frequently selected as reference for testing the performance of various optimization algorithms. The results are shown in Table 3. The results indicate that FCDE performs better than classic DE in terms of convergence speed, independently of the selected target 1370
 and Fitness (best).")
102 initialization value. This can be seen especially in the first 400 to 500 generations. This is attributed mostly to the more focused initialization strategy of FCDE. Performance comparisons of FCDE algorithm is performed with classical DE on the basis of standard performance measures CPU time, F,, G, Best Module, Fitness (Average) and Fitness (best). From the numerical results given in Table 3, we can see that FCDE algorithm gave better performance than classical DE in this test case. Table 3 RESULTS Functions ( ) ( ) The fuzzy controller was developed using Matlab Fuzzy Logic toolkit as we shown in Figure 4, 5 and 6. FCDE Fig. 4. Fuzzy-Logic Controller FCDE ( ) ( ) ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) Fig. 5. Sample Rules for FCDE 1371
. Table 4.")
103 Fig. 6. Variables Term-sets The true global minimum for the Rastrigin function is located at 0.0. However, FCDE gave the value near the true optimum and it is much better value in comparison to DE (Table 4). Table 4. Simulation results Time [ms] F G Best Module Fitness (Average) Fitness (best) DE FCDE DE FCDE DE FCDE Note: The values for FCDE are taken over the interval [ ] and Time = 372 ms 5 Conclusions This paper presents FCDE, a new model to minimize real functions with FCDE/rand/1/bin strategy, leading to FCDE better solution than DE. The extra run of DE/rand/1/bin algorithm allows as finding DB leading to an initial set of rules. This set can be changed depending on the extent of heuristics that are suitable and appropriate to the problem under study and it s a cheap price to pay for leaving the system adequately prepared to work on the same problem as many times as we need. We are currently involved in the implementation of FCDE/exp/1/bin and FCDE/trig/1/bin with trigonometric mutation extension [18]. 1372
104 References 1. Das S., Abraham A., U. K. Chakraborty U. K. and Konar A. (2009) Differential Evolution Using a Neighborhood Based Mutation Operator. IEEE Transactions on Evolutionary Computing, vol. 13, no. 3, pp Rahnamayan S., Tizhoosh H. R. and Salama M. (2008) Opposition based differential evolution. IEEE Transactions on Evolutionary Computing, vol. 12, no. 1, pp Vesterstrøm J. and Thomson R. A. (2004) - Comparative study of differential evolution, particle swarm optimization, and evolutionary algorithms on numerical benchmark problems. Proc. IEEE Congress Evolutionary Computing, pp Storn R. and Price K. V.(1995) - Differential evolution: A simple and efficient adaptive scheme for global optimization over continuous spaces. ICSI, USA, Tech. Rep. TR , 1995 [Online]: storn/litera.html 5a. Storn R. and Price K. V.(1996) - Minimizing the real functions of the ICEC 1996 contest by differential evolution. Proc. IEEE International Conference Evolutionary Computation, pp b. Storn R. (1996) - On the usage of differential evolution for function optimization. Proceedings North Am. Fuzzy Information Process. Soc., pp a. Price K. V. (1997) - Differential evolution vs. the functions of the 2nd ICEO. Proc. IEEE International Conference Evolutionary Computation, pp b. Price K. V. and Storn R.(1997) - Differential evolution: A simple evolution strategy for fast optimization. Dr. Dobb s Journal, vol. 22, no. 4, pp Zhang J. and Sanderson A. C.(2009) - JADE: Adaptive differential evolution with optional external archive. IEEE Transactions on Evolutionary Computing, vol. 13, no. 5, pp Brest J., Greiner S., Boskovic B., Mernik M. and Zumer V. (2006) Self-adapting control parameters in differential evolution: A comparative study on numerical benchmark problems. IEEE Transactions on Evolutionary Computing, vol. 10, no. 6, pp Qin A. K., Huang V. L. and Suganthan P. N. (2009) - Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Transactions on Evolutionary Computing, vol. 13, no. 2, pp Hansen N. and Kern S. (2004) Evaluating the CMA Evolution Strategy on Multimodal Test Functions. Proceedings Eighth International Conference on Parallel Problem Solving from Nature PPSN VIII, Springer, pp a. Rovarini Díaz, Figueroa M.M. (2014) Inteligencia Computacional: Fundamentos y Aplicaciones. Libro, Capítulo IV: Sistemas Difusos I. En proceso de edición final. 11b. Rovarini Díaz, Figueroa M.M. (2014) Inteligencia Computacional: Fundamentos y Aplicaciones. Libro, Capítulo V: Algoritmos Evolutivos. En proceso de edición final. 12. Chakraborty U. K. (Ed.) (2008) - Advances in Differential Evolution. Studies in Computational Intelligence. Berlin, Springer. 13. Thangaraj R. Pant M. & Abraham A. (2009) - A Simple Adaptive Differential Evolution Algorithm. NaBIC IEEE, pp Kumar P. and Pant M. (2010) - A Self-Adaptive Differential Evolution Algorithm for Global Optimization. Proceedings SEMCCO, pp
105 15. Kumar P. and Pant M. (2011) - A New Blend of DE and PSO Algorithms for Global Optimization Problems. Communications in Computer and Information Science, Vol 168, pp Liu J. and Lampinen J. (2005) - A fuzzy adaptive differential evolution algorithm. Journal Soft Computing A Fusion of Foundations Methodologies and Applications, vol. 9, no. 6, pp Wang Li-Xin (2003) - The WM Method Completed: A Flexible Fuzzy System Approach to Data Mining. IEEE Transactions on Fuzzy Systems, Vol. 11, No. 6, pp Hui-Yuan Fan, Lampinen J. (2003) - A trigonometric mutation operation to differential evolution. Journal of Global Optimization, Vol. 27, No 1, pp Rosenbrock H.H (1960) - An automatic method for finding the greatest or least value of a function. The Computer Journal, 3(3): De Jong, K. (1975). An Analysis of the Behaviour of a Class of Genetic Adaptive Systems. PhD thesis, University of Michigan. 21. Rastrigin L. (1974) - Extremal Control Systems. Nauka. In Russian. 22. Schwefel H.P. (1995) - Evolution and Optimum Seeking. John Wiley & Sons. Expanded version of [Schwefel, 1981]. 1374
106 Propuesta de un algoritmo evolutivo aplicado a la optimización de sistemas termodinámicos Luciano M. Hidalgo 1, Abigaíl R. N. Verazay 1, Virginia Battezzati 1, y Nilda Pérez Otero 1 1 Grupo de Investigación y Desarrollo en Informática Aplicada, Facultad de Ingeniería, Universidad Nacional de Jujuy, Ítalo Palanca S. S. de Jujuy, Argentina {lhidalgo.ing,abigailrn,virginiavir,nilperez}@gmail.com Resumen. Los cálculos de equilibrio de fase juegan un rol crucial en la simulación diseño y optimización de los procesos de separación. La dificultad de estos cálculos radica en que la forma de la función objetivo, altamente no lineal y no convexa, ocasiona que no exista una garantía para localizar el mínimo global. La necesidad de encontrar nuevas metaheurísticas que proporcionen un mejor desempeño en este tipo de problemas de optimización sigue aún vigente. En este trabajo se presenta el resultado de las modificaciones realizadas al algoritmo AEvol, un algoritmo genético con un operador sencillo, aplicado a la resolución de sistemas termodinámicos. La modificación consiste en la incorporación de un operador de cruza, el BLX-. Para la evaluación del nuevo algoritmo, se utilizaron los mismos casos de estudio reportados originalmente, obteniendo resultados satisfactorios. Palabras Clave: Computación evolutiva, Metaheurísticas, Modelado Termodinámico, Energía libre de Gibbs 1 Introducción Durante los últimos años, el uso de computadoras potentes y el desarrollo de la computación paralela permitieron el trabajo en modelos reales de mayor complejidad y envergadura [1]. Aunque se desarrollaron y aplicaron numerosos métodos estocásticos y determinísticos de optimización global a este tipo de problemas, todos presentan ciertas ventajas y desventajas. Incluso los métodos de optimización estocásticos, que han resultado más prometedores que los determinísticos, presentan limitaciones significativas para hallar el óptimo global forzando a negociar la velocidad y la confiabilidad de los resultados obtenidos. Entre los métodos estocásticos para resolver estos problemas se ha desarrollado un gran número de metaheurísticas, entre ellas los algoritmos evolutivos, inspirados en la selección natural y la evolución de las especies. Esta familia de técnicas, que opera sobre una población donde cada individuo representa una solución potencial al problema, es una de las más utilizadas debido a su eficiencia para proporcionar soluciones apropiadas/adecuadas con un bajo costo computacional. Sin embargo, está aún vigente la necesidad de encontrar nuevas metaheurísticas que 1375
107 proporcionen un mejor desempeño en problemas de optimización de Funciones Objetivo que tienden a concentrarse en mínimos locales, disminuyendo la probabilidad de hallar un mínimo global. [2] En un primer acercamiento a este problema, el Grupo de Investigación y Desarrollo en Informática Aplicada (GIDIA) de la Facultad de Ingeniería de la Universidad Nacional de Jujuy, como parte de su estudio sobre técnicas de inteligencia artificial aplicadas a la optimización en modelos de termodinámica propuso un algoritmo evolutivo con operador genético sencillo llamado AEvol [3], aplicado al cómputo de equilibrio de fases en sistemas termodinámicos de gran relevancia en procesos industriales, en general, y en procesos de separación, en particular [4]. La dificultad en el cálculo del equilibrio de fases radica en que la forma no convexa y altamente no lineal de la función objetivo inhibe la garantía de hallar un mínimo global mediante técnicas convencionales. La primera implementación de este algoritmo tuvo un comportamiento adecuado en los cálculos de mínimos de las funciones benchmarks seleccionadas y proporcionó resultados satisfactorios en los casos de estudio propuestos hasta el momento. Sin embargo, el interés en lograr una mejor relación entre la exploración y explotación del área de búsqueda motivó la realización de una nueva implementación de AEvol [5]. En el presente trabajo se expone una variante de la implementación de AEvol que incorpora el operador de cruza BLX- para la combinación de la información genética [6], con el objetivo de ampliar la búsqueda del espacio de soluciones y mejorar la tasa de éxitos disminuyendo la probabilidad de caer en mínimos locales y lograr independencia de los valores de inicialización del cómputo. El resto de este artículo se estructura como sigue: en la parte 2 se presenta los antecedentes del nuevo algoritmo y su nueva estructura, en la parte 3 se describen los casos de estudio en los que se aplica el algoritmo propuesto, en la parte 4 se presenta el diseño de los experimentos y un análisis de resultados y en la parte 5 se muestran las conclusiones. 2 Algoritmo propuesto 2.1 Algoritmos evolutivos Los algoritmos evolutivos son algoritmos que pertenecen a la rama de las metaheurísticas poblacionales que han sido aplicados exitosamente en la optimización de una gran variedad de problemas de optimización en dominios como planificación, diseño, identificación y simulación, control y clasificación, entre otros [5]. Estos algoritmos utilizan el proceso de aprendizaje colectivo de una población de individuos. Usualmente, cada individuo representa una posible solución dentro de espacio de soluciones de un problema dado. Los descendientes de los individuos se generan por medio de procesos aleatorios que modelan la mutación y la cruza. La mutación corresponde a una alteración o cambio de las características de un mismo individuo, mientras que la cruza intercambia información entre dos o más individuos existentes. Para asignar una medida de adaptación a los individuos se evalúa su comportamiento en el entorno. Tomando como base esta medida de adaptación el 1376
![proceso de selección favorece la reproducción de los mejores individuos [7]. La Fig.](/docs-images/18/814221/images/108-0.png "1 muestra la estructura general de un algoritmo evolutivo según se presenta en [5], en la etapa de reproducción se producen nuevas generaciones mediante diferentes operadores (cruza, mutación, entre")
108 proceso de selección favorece la reproducción de los mejores individuos [7]. La Fig. 1 muestra la estructura general de un algoritmo evolutivo según se presenta en [5], en la etapa de reproducción se producen nuevas generaciones mediante diferentes operadores (cruza, mutación, entre otros). Fig. 1. Estructura general de un algoritmo evolutivo. 2.2 AEvol Siguiendo la línea de la Estrategia Evolutiva [8], donde para la reproducción no se usan operadores de cruza, en AEvol sólo se aplica mutación para la generación de nuevas soluciones. Esto se hace mediante la generación de nuevas soluciones a partir de la definición de hipercuadrados en el espacio de búsqueda. En cada iteración se generan nuevas soluciones a partir de la mejor solución obtenida en la iteración. Para construir cada una de las soluciones se utilizan hipercuadrados concéntricos, con centro en las coordenadas de la mejor solución usando el método de partición geométrica, de acuerdo a la ecuación (1). La estructura de los hipercuadrados se muestra en la fig. 3. Donde es el semilado de cada uno de los hipercuadrados y, la cantidad de hipercuadrados. Una vez construidos los hipercuadrados se genera aleatoriamente un punto dentro de cada uno de ellos (zona 1, zona 2 y zona 3 en la Fig. 2). Se evalúa la función objetivo para cada uno de esos puntos y, finalmente, se agrega la mejor de las m soluciones a la lista de las soluciones de la iteración. El valor inicial del semilado, es un parámetro del algoritmo que se modifica en tiempo de ejecución en función de una variable que indica cuántas iteraciones han transcurrido sin obtener una mejor solución. La validación de AEvol se presentó en [3], en el mismo artículo se muestra la aplicación del algoritmo en la minimización de la función de Gibbs, función termodinámica relacionada al equilibrio de fases, en tres diferentes sistemas. Si bien el algoritmo se comportó de manera adecuada en los cálculos de mínimos de las funciones multimodales seleccionadas como benchmarks y los resultados obtenidos en los casos de estudio presentados se consideraron satisfactorios, se propuso la inclusión un operador de cruza, con el propósito de mejorar la tasa de éxitos. En el siguiente apartado se muestra la modificación de AEvol con el operador de cruza. (1) 1377
 [5]. Fig. 2.")
109 2.3 Incorporación del operador de cruza a AEvol En el diseño de una metaheurística se aconseja tener en cuenta dos criterios contradictorios, la diversificación (exploración del espacio de búsqueda) y la intensificación (explotación de las mejores soluciones halladas) [5]. Fig. 2. Tres hipercuadrados en 2 dimensiones, cada uno conteniendo un punto generado aleatoriamente tomando como base el punto. Al utilizar sólo un operador de mutación, en AEvol se priorizaba la diversificación sobre la intensificación. Con el objetivo de agregar intensificación al algoritmo se incorporó un operador de cruza. El operador seleccionado fue el BLX-alpha propuesto por [6]. A su vez se incorporaron tres criterios de selección de padres: ruleta, torneo y muestreo estocástico universal (stochastic universal sampling - SUS). La Fig. 3 muestra la estructura de AEvol con el operador de cruza. Fig. 3. Estructura de AEvol con el operador de cruza. Parámetros. A los parámetros de AEvol original: k, cantidad de soluciones iniciales; itertot, cantidad máxima de iteraciones, canthiper, cantidad de hipercudrados y sl, tamaño del semilado inicial; se agregan las variables canthijos y nocambia, que indica el número máximo de veces que se repetirá la mejor solución obtenida en el 1378
110 proceso de mutación antes de realizar el proceso de cruza. Cada una de las k soluciones tiene una variable llamada no_cambia que se inicializa en 1 y se incrementa cada vez que esa solución es rankeada como la mejor. En el caso que nocambia es igual a 0 (cero), el algoritmo sólo utiliza el operador de cruza. 3 Casos de Estudio Para el proceso de evaluación del algoritmo AEvol con el operador de cruza, se tomaron como casos de estudio, los sistemas utilizados para el estudio del algoritmo AEvol. Estos sistemas plantean un problema de equilibrio de fases cuya solución requiere la optimización de una función. Desde el punto de vista de la termodinámica, un sistema queda definido por su temperatura, presión y componentes. Dado que los valores de composición que corresponden a la condición de equilibrio a la temperatura y presión fijadas, son los que minimizan la Función de Gibbs, se evalúan como función objetivo (FO) mediante la ecuación (2). (2) Donde es la función de Gibbs, es el número de fases, nc es el número de componentes, n ij y µ ij son los números de moles y el potencial químico del componente i en la fase j, respectivamente. Considerando que: ( ) El problema de optimización se transforma en un problema de optimización no restringido y queda definido mediante la siguiente expresión [3]: El espacio de soluciones queda restringido al entorno (0,1) para las variables ; éstas se transforman luego en cantidad de componentes mediante las ecuaciones (3). Los valores de se calculan mediante el empleo de ecuaciones de estado (EoS); las EoS empleadas en este trabajo son la de Peng-Robinson (PR-EoS) [9] y la de Soave- Redlich-Kwong. (SRK-EoS) [10]. En la Tabla 1 se presentan los sistemas usados como casos de estudio para evaluar la performance del algoritmo propuesto. Todos los sistemas presentan dos fases a la temperatura y presión mostradas en la misma tabla. Tabla 1. Casos de Estudio (CE) propuestos. CE Componentes T(K) P(bar) F z j EoS 1 Metano + Sulfuro de Hidrógeno ; SRK 2 Dióxido de Carbono + Metano ; 0.80 PR 3 Metano + Dióxido de Carbono + Sulfuro de Hidrógeno ; ; PR (3) 1379
111 Para cada uno de los casos de estudio propuestos, se empleó el algoritmo evolutivo modificado con un operador de cruza con el propósito de minimizar la función de Gibbs. 4 Experimentación y Resultados 4.1 Experimentación La aplicación de AEvol modificado a los casos de estudio presentados en [3] tiene como objetivo estudiar las mejoras del algoritmo tras la incorporación del operador de cruza y evaluar el rendimiento de los tres métodos de selección implementados. Para cada uno de los casos de estudio se formularon nueve experimentos, en la tabla 2 se muestra la configuración de cada uno de ellos. Tabla 2. Experimentos realizados para cada caso de estudio. Experimento NoCambia Selección Iteraciones E(Id1,sel) 0 {Ruleta, Torneo, SUS} 500 E(Id2,sel) 5 {Ruleta, Torneo, SUS} 500 E(Id3,sel) 10 {Ruleta, Torneo, SUS} 500 E(Id4,sel) 0 {Ruleta, Torneo, SUS} 1000 E(Id5,sel) 5 {Ruleta, Torneo, SUS} 1000 E(Id6,sel) 10 {Ruleta, Torneo, SUS} 1000 E(Id7,sel) 0 {Ruleta, Torneo, SUS} 1500 E(Id8,sel) 5 {Ruleta, Torneo, SUS} 1500 E(Id9,sel) 10 {Ruleta, Torneo, SUS} 1500 Para cada experimento se calcularon los valores estadísticos mejor, peor, mediana y desviación estándar obtenidos al considerar los resultados de 30 ejecuciones independientes. A modo de ejemplo en la tabla 3 se presenta el resumen de resultados para los experimentos E(Id1,sel), E(Id2,sel) y E(Id3,sel) realizados para el CE 1. Los valores paramétricos del algoritmo considerados fueron: sl=(max-min)/10, k=10, canhiper=3, canthijos=5. Tabla 3. Resultados obtenidos para los experimentos E(Id1,sel), E(Id2,sel) y E(Id3,sel) del CE1. Experimento Peor Mejor Media Desv. Est. E(Id1,ruleta) -0, , , , E(Id1,torneo) -0, , , , E(Id1,SUS) -0, , , , E(Id2,ruleta) -0, , , , E(Id2,torneo) -0, , , , E(Id2,SUS) -0, , , , E(Id3,ruleta) -0, , , , E(Id3,torneo) -0, , , , E(Id3,SUS) -0, , , ,

112 4.2 Análisis de resultados Para el análisis de resultados se consideraron los valores de las medianas. Estos valores de compararon con la mediana obtenida al aplicar AEvol original a cada uno de los casos de estudio. La Fig. 4 presenta los resultados obtenidos para los experimentos E(Id1,sel), E(Id2,sel) y E(Id3,sel) del CE1, los resultados para los otros experimentos y casos de estudio son similares y no se muestran por cuestiones de espacio. Fig. 4. Comparación de los resultados obtenidos tras 500 iteraciones del algoritmo con cruza y la solución generada por el algoritmo original. Los experimentos permitieron determinar la mejor configuración de parámetros para cada uno de los casos de estudio, en la Tabla 4 se presentan estas configuraciones y en la Fig. 5 se muestra gráficamente la mejora obtenida al utilizar el algoritmo con el operador de cruza. Tabla 4. Mejores configuraciones del algoritmo para cada CE. CE NoCambia Selección Iteraciones 1 5 SUS Torneo Ruleta Conclusiones En este trabajo se presentó la modificación de AEvol, un algoritmo evolutivo con un operador de mutación sencillo. La modificación consistió en agregar un operador de cruza. Se utilizó el algoritmo en la resolución de problemas de equilibrio de fase (minimización de la función de Gibbs) para tres sistemas diferentes, que ya habían sido evaluados con la versión original del algoritmo. Los resultados obtenidos en los tres sistemas demuestran que se logró mejorar el desempeño del algoritmo al implementar el operador de cruza. Sin embargo, en vista de que para cada sistema se necesitó una configuración 1381

113 diferente de los parámetros del algoritmo, se considera interesante seguir investigando sobre estas características. (a) CE 1 (b) CE2 (c) CE3 Fig. 5. Comparación de los resultados del algoritmo original y el algoritmo con cruza para los 3 casos de uso. Referencias 1. Hernández, S., Leguizamón, G., Mezura-Montes, E. Hibridación de Evolución Diferencial utilizando Hill Climbing para resolver problemas de optimización con restricciones. XVIII Congreso Argentino de Ciencias de la Computación (CACIC 2012). ISBN Universidad Nacional del Sur. Bahía Blanca. (2012). 2. Bhargava, V., Fateen, S. E. K., Bonilla-Petriciolet, A. Cuckoo Search: A new nature-inspired optimization method for phase equilibrium calculations Fluid Phase Equilibria, Vol. 337 (2013). 3. Pérez Otero, N., Zacur J. L. (2012). Algoritmo evolutivo con un operador genético sencillo aplicado al cómputo de equilibrio de fases en sistemas termodinámicos. XVIII Congreso Argentino de Ciencias de la Computación. (CACIC 2012). ISBN Universidad Nacional del Sur. Bahía Blanca. (2012). 4. Zhang, H., Bonilla-Petriciolet, A., G. P. Rangaiah, A. A Review on Global Optimization Methods for Phase Equilibrium Modeling and Calculations. The Open Thermodynamics Journal. Vol. 5, (Suppl 1-M7) pp (2011) 5. Talbi, E. G. Metaheuristics: From design to implementation. ISBN Wiley Eds. (2009) 6. Eshelman L. J., Schaffer J. D. Real-Coded Genetic Algorithms and Interval-Schemata. Foundation of Genetic Algorithms 2, L.Darrell Whitley (Ed.) (Morgan Kaufmann Publishers, San Mateo), (1993). 7. Back, T., Fogel, D. B., Z. Michalewicz, (Eds.) Handbook of Evolutionary Computation (1st ed.). IOP Publ. Ltd., Bristol, UK, UK. Capítulo: B1.1 de Thomas Back. (1997). 8. Rechenberg, I. Cybernetic solution path of an experimental problem. Technical Report, Royal Aircraft Establishment Library Translation No. 1112, Farnborough, UK. (1965) 9. Peng, D.Y., Robinson, D.B. A new two constants equation of state. Industrial Engeenering Chemical Fundamental. Vol 15 pp (1976) 10. Soave, G. Equilibrium constants from a modified Redlich-Kwong equation of state Chemical Engenering Science Vol. 27 pp (1972) 1382
114 Aplicación de MDA para Procesos de Gobierno Electrónico Víctor Sánchez Rivero 1, José Farfán 1, Elizabeth Reinoso 1, Alejandro Vargas 1 y Marcelo Castro 1 1 Investigación + Desarrollo en Gobierno Electrónico / Facultad de Ingeniería / Universidad Nacional de Jujuy Ítalo Palanca N 10 / S. S. de Jujuy / Provincia de Jujuy {vdsanchezrivero, jhfarfan, edrreinoso, lavargas, mcastro}@fi.unju.edu.ar Resumen. El objetivo de este trabajo es analizar la conveniencia de aplicar una arquitctura dirigida por modelos (MDA) para implementar soluciones de Gobierno Electrónico (GE) en ámbitos gubenamentales. Es una obligación del Estado brindar los servicios demandados por el ciudadano, de una manera rápida, eficiente y que asegure la transparencia de los actos de gobierno. Por supuesto que estos objetivos resultan ideales la mayoría de las veces; ya que, en realidad, existen inconvenientes de gran peso que atentan contra el éxito de estas políticas de participación ciudadana. Diversos trabajos previos, basados en una metodología para formalizar el proceso de GE, posibilitaron el desarrollo de distintas herramientas para facilitar el proceso de implementación, y teniendo en cuenta los sistemas distribuidos; el software construido, en base a MDA, puede significar ventajas competitivas tales como productividad, portabilidad, mantenimiento y documentación, independencia de plataformas y especificidad del dominio; con lo cual es promisoria su aplicación. Palabras Clave: Gobierno Electrónico, Formalización, Interoperabilidad, MDA. 1 Introducción Un ciudadano tiene derechos y obligaciones para con el Estado, independientemente del ámbito en que se encuentre inserto, y al momento de realizar un trámite puede comenzar una verdadera odisea, lo cual le puede implicar una pérdida de tiempo y recursos por lo extremadamente burocrático que puede resultar el proceso involucrado para la concreción del mismo. La tecnología actual permite el acceso a innumerables mecanismos y sistemas para el manejo de la información, elemento esencial para la toma de decisiones en cualquier estrato gubernamental, ya sea público o privado. La web permite, a cualquier empresa, un posicionamiento global para promocionar y vender sus productos o servicios. En este sentido el Estado, ya sea nacional, provincial o municipal, estudió diversas alternativas de solución para ofrecer, al ciudadano común, servicios, información, eficiencia y transparencia en todos los procesos administrativos de su órbita de acción. Las tecnologías de la información y la comunicación (TIC) posibilitan el desarrollo de herramientas que faciliten, al ciudadano, el cumplimiento 1383
115 de sus obligaciones en tiempo y en forma; de una manera cómoda y sencilla empleando recursos disponibles mediante el uso de computadoras o similares. Se pueden mencionar, como ejemplo, el trabajo desarrollado por los gobiernos de Chile, Australia y Brasil. En nuestro país la aplicación de GE, en el ámbito gubernamental, es considerada una cuestión de estado, debido a que a través del Plan Nacional de Gobierno Electrónico se impulsa y fortalece la modernización del estado [1]. Sin embargo, el camino es largo y se complica aún más cuando la existencia o ausencia de decisiones políticas entorpecen la aplicación exitosa de procesos de GE. Dejando de lado el tinte político, la incorporación de soluciones de GE para dar respuesta a las demandas de servicios eficientes por parte del ciudadano, tiene como inconveniente la falta de un proceso formal estándar; que indique claramente los pasos necesarios para su implementación exitosa. Más adelante, en este documento, se detallará el resultado de una investigación para obtener la formalización de este proceso, a través de una metodología. El grupo de investigación IDGE (Investigación + Desarrollo en Gobierno Electrónico), de la Facultad de Ingeniería de la Universidad Nacional de Jujuy, viene trabajando desde el año 2007 en el tema y continuamente se analizan nuevas herramientas y metodologías que faciliten la implementación de este tipo de soluciones. Entre los objetivos alcanzados, se pueden mencionar a la herramienta metodologí@egov, que fue desarrollada en el marco del proyecto de investigación denominado Diseño y Desarrollo de una herramienta para automatizar el proceso de Gobierno Electrónico, y es un prototipo que continua en un proceso de refinamientos sucesivos, ya que una solución de GE es de aplicación compleja y requiere tener en cuenta una diversidad de aspectos involucrados [2]. Posteriormente, se estudió la aplicación de servicios digitales comunes reutilizables para GE, en especial SOA (Arquitectura Orientada a Servicios), con el objetivo de modelar una arquitectura orientada a servicios para GE [3]. Y en particular, se investigó la aplicación de Servicios Web, tales como SOAP (Simple Object Access Protocol) y REST (REpresentacional State Transfer) basados en sistemas distribuidos [4]. Los proyectos y trabajos mencionados con anterioridad, fueron el puntapié inicial para una nueva fuente de investigación: estudiar y establecer la posibilidad de aplicar arquitecturas basadas en MDA (Model Driven Architecture) para implementar soluciones de Gobierno Electrónico en algún organismo público. 2 Gobierno Electrónico: Caso de Estudio Entre las múltiples definiciones de Gobierno Electrónico (GE), una de la más adecuada, es la enunciada en la Carta Iberoamericana [5] que lo señala como el uso de las TIC, en los órganos de la Administración, para mejorar la información y los servicios ofrecidos a los ciudadanos, orientar la eficacia y eficiencia de la gestión pública e incrementar sustantivamente la transparencia del sector público y la participación de los ciudadanos ; de la cual se infiere las características esenciales 1384
116 que se persiguen, al implementar una solución de GE, ya sea en el ámbito de la Administración Pública Nacional, Provincial y/o Municipal de nuestro país. Demás está decir las ventajas que traen aparejada, para el ciudadano, el incorporar procesos de GE; sin embargo también involucran otros aspectos que pueden ser críticos y que deben ser consideradas cuidadosamente [6] tales como la brecha digital existente en la aplicación de las herramientas de las tecnologías de la información y la comunicación para todos los habitantes y la Planificación Estratégica de la Agenda Digital, que se desarrolla en Argentina. GE persigue una serie de principios que se deben cumplir [5] para que el mismo pueda ser considerado exitoso: Igualdad que no implique la existencia de restricciones o discriminaciones. Legalidad en lo concerniente a privacidad/protección de los datos personales. Conservación de las comunicaciones y documentos electrónicos. Transparencia y accesibilidad por parte de los ciudadanos. Proporcionalidad entre la seguridad que se requiere para la administración. Responsabilidad del gobierno por la realización de procesos por medios electrónicos. Adecuación de la tecnología empleada para cubrir las necesidades. 3 La Importancia de la Interoperabilidad entre los Procesos La concreción de los principios enunciados en el párrafo anterior conlleva la necesidad de establecer vías de comunicación concretas y seguras, entre los diferentes actores partícipes de la solución a los problemas planteados. La interoperabilidad entre procesos gubernamentales resulta fundamental para GE, tal como se menciona en el Libro Blanco de Interoperabilidad de Gobierno Electrónico para América Latina y el Caribe [7], donde se mencionan algunos ejemplos bastantes destacados tales como que los gobiernos controlen que no se paguen pensiones de jubilación a personas fallecidas o que se utilicen fraudulentamente sus números de identidad para hacerlos aparecer como votantes en las elecciones generales, prácticas muy comunes en gobiernos inmersos en grandes niveles de corrupción. La interoperabilidad permite a las agencias que recaudan el dinero de los impuestos impedir, por ejemplo, que algunas personas declaren ingresos correspondientes a estratos socioeconómicos bajos, y que posean casas de lujo sin declarar; o a los que contando con antecedentes penales sean contratados como maestros en las escuelas a las que asisten nuestros hijos. En estos ejemplos se puede observar la importancia de la interoperabilidad entre procesos para alcanzar un grado de eficiencia óptimo en los sistemas informáticos de la administración pública. Por ello es necesario comprender el concepto de interoperabilidad, el cual es definido por la Comisión Europea [8] como la habilidad de los sistemas TIC, y de los procesos de negocios que ellas soportan, de intercambiar datos y posibilitar compartir información y conocimiento, lo cual marcan las pautas de lo que una solución de GE debe cumplir. La interoperabilidad se apoya en las aplicaciones transversales [9], las cuales son sistemas de información utilizados por diferentes entidades públicas, en donde los 1385
117 procesos de gestión que intervienen están regulados por los mismos sistemas transversales. Se busca la unificación de datos en las aplicaciones transversales por diferentes razones, principalmente para lograr la integración de la información, la aplicación del concepto de dato único, la utilización compartida de información en una única base de datos, la independencia de datos de las aplicaciones y la alta disponibilidad de datos. 4 La Necesidad de Formalizar el Proceso de GE Tal como se afirma en el trabajo Diseño y desarrollo de una herramienta para automatizar el proceso de Gobierno Electrónico [10], no existe un proceso formal estándar de incorporación de las TIC en el ámbito gubernamental, de tal manera que indique los pasos y procedimientos necesarios a seguir; sin embargo establecer un único modelo de aplicación de GE para todas las instituciones públicas resulta imposible de realizar; no obstante esto es necesario establecer una metodología concreta y efectiva que permita modelar las soluciones a los problemas planteados y que asegure la calidad en la implementación del proceso de GE. Es por ello, que fruto de un trabajo de investigación anterior se elaboró una metodología para sistematizar el proceso de GE [11], de tal manera que permite administrar y controlar el proceso de incorporación de tecnología al ámbito de la Administración Pública, haciendo énfasis en la necesidad de disponer de un método formal que evite los inconvenientes que, supone, incorporar las TIC en el sector público; contribuyendo, de ese modo, a la modernización del estado, ya que se establecen requisitos mínimos, estándares y la participación efectiva de la sociedad en procesos importantes como, por ejemplo, la determinación de los servicios que brinda el Estado a sus ciudadanos. De acuerdo con los lineamientos establecidos en la citada metodología, se desarrolló metodologi@egov [2], una herramienta web de extensión libre y de código abierto para administrar proyectos de gobierno electrónico y que permite automatizar el proceso y tiene, como gran ventaja, una gran adecuación a las necesidades del proyecto a desarrollar, siendo fácilmente modificable y adaptable. 5 MDA - Model Driven Architecture En la actualidad el desarrollo de software, sobre todo aquel que tiene gran porcentaje de trabajo artesanal, requiere un gran despliegue de recursos en tiempo y costos, superando un sin fin de problemas, tales como la urgencia en que el software debe estar en pleno funcionamiento, el nivel complejidad en el desarrollo y evolución constante de los sistemas. En vistas de estos inconvenientes, existen técnicas modernas, promovidas por OMG (Object Management Group), tales como la arquitectura dirigida por modelos (Model Driven Architecture MDA), que propone la construcción de software mediante la trasformación sucesiva de modelos, desde un alto nivel de abstracción hasta el nivel de implementación en una plataforma concreta [12]. Dichos modelos van a permitir una alta flexibilidad en la implementación, 1386
118 integración, mantenimiento, prueba y simulación de sistemas, reduciendo esfuerzos y sobre todo costos. La tecnología MDA se ha convertido en una realidad, y a utilizar, por varias empresas desarrolladoras de software; sobre todo por centrarse en la funcionalidad y el comportamiento de una aplicación distribuida o sistema, no siendo influenciado por una plataforma o plataformas tecnológicas en las que se llevarán, a cabo, el desarrollo del sistema. De esta forma, MDA separa claramente detalles de la implementación de las funciones de negocio [13]. Tener presente un modelo de la arquitectura, en etapas tempranas, permitirá contar con un modelo de alto nivel de la alternativa de solución a los requerimientos planteados, que en sucesivos refinamientos conducirán al producto final, donde se propone mecanismos de transformación. MDA es especialmente utilizada para sistemas altamente conectados y muy cambiantes, tanto en reglas de negocio como en tecnología; proponiendo un marco de trabajo para una arquitectura que asegura: Portabilidad, Interoperabilidad entre plataformas, Independencia de plataforma, Especificidad del dominio y Productividad [14]. En el ciclo de vida de un desarrollo MDA, a diferencia del enfoque tradicional, incluye que la comunicación entre las etapas de desarrollo se hace mediante modelos que la computadora puede interpretar fácilmente. La arquitectura MDA especifica tres puntos de vista, en un sistema: Independiente de cómputo: El punto de vista independiente de cómputo se enfoca en el contexto y los requisitos del sistema, sin considerar su estructura o procesamiento. Independiente de plataforma: El punto de vista independiente de plataforma se enfoca en las capacidades operacionales del sistema fuera del contexto de una plataforma específica, mostrando sólo aquellas partes de la especificación completa que pueden ser abstraídas de la plataforma. Específico de plataforma: El punto de vista dependiente de plataforma agrega al punto de vista independiente, los detalles relacionados con la plataforma específica. Los clientes de una plataforma hacen uso de ella sin importarles los detalles de implementación. Estas plataformas pueden ser sistemas operativos, lenguajes de programación, bases de datos, interfaces de usuario, soluciones de middleware, etc. MDA, propone que los modelos conducen todo el proceso de desarrollo de software, desde los modelos independientes de la plataforma (CIM y PIM) hasta los modelos dependientes de la plataforma (PSM) y la generación automática de código a partir de los mismos. Para llevar adelante este pasaje entre modelos propone mecanismos de transformación [15]. 5.1 Tipos de Modelos El proceso de desarrollo MDA distingue cuatro clases de modelos [16] (Fig. 1): Modelo independiente de la computación (Computation Independent Model o CIM): describe los requerimientos del sistema y los procesos de negocio que debe resolver sin tener en cuenta aspectos computacionales, es decir son visiones de los sistemas desde el punto de vista del problema a resolver. 1387
: describe un sistema en términos de una plataforma de implementación particular.")
119 Modelo independiente de la plataforma (Platform Independent Model o PIM): es un modelo computacional independiente de las características específicas a una plataforma de desarrollo, como por ejemplo.net, J2EE o relacional. Modelo específico a la plataforma (Platform Specific Model o PSM): describe un sistema en términos de una plataforma de implementación particular. Modelo específico a la implementación (Implementation Specific Model o ISM): se refiere a componentes y aplicaciones que usan lenguajes de programación específicos, lo que implica que la generación de código se realiza automáticamente a partir de cada PSM. Fig. 1. Modelos MDA Algunas ventajas de la aplicación de MDA son las siguientes: Separación de responsabilidades: Separar la especificación de la funcionalidad del sistema de su implementación sobre una plataforma en particular Productividad: Controlar la evolución desde modelos abstractos a implementaciones, tendiendo a aumentar el grado de automatización. Portabilidad: Se logra enfocando el desarrollo en el PIM. Al ser un modelo independiente de cualquier tecnología, todo lo definido en él es totalmente portable Mantenimiento y documentación: a partir del PIM se generan los PSM y a partir de estos el código. Básicamente el PIM desempeña el papel de la documentación de alto nivel. La trazabilidad está asegurada debido a que los cambios en el PIM se reflejan regenerando PSM y código. 5.2 Transformación En MDA se contemplan dos tipos fundamentales de transformaciones (Ver Fig. 2): La transformación de un PIM en un PSM. La transformación de un PSM en el código fuente de la aplicación. 1388
120 Fig. 2. Transformación El proceso de transformación recibe como entrada un conjunto de modelos independientes de la plataforma (PIM) y un conjunto de reglas de transformación. Como producto de un proceso de transformación se obtiene un modelo específico a la plataforma (PSM). Esta estructura se denomina Patrón MDA [17]. 6 Conclusiones Como se anticipó el proceso de implementación de soluciones de GE no es una tarea sencilla, debido a inconvenientes tales como políticas burócratas, la brecha digital, la interoperabilidad entre los sistemas y sobretodo la falta de métodos formales estándar para la incorporación de TIC en soluciones de GE. En diversos trabajos, desarrollados por el grupo de investigación, se abordaron estos problemas, obteniéndose una metodología para la automatización y estandarización del proceso de GE y que incluye cinco etapas a saber: Estudio, Análisis, Diseño, Implementación y pruebas y Monitoreo y evaluación. En base a ella se desarrollaron herramientas tales como metodologí@egov, también utilizando otras basadas en SOA que aplican Web Services como SOAP y REST, tratando de optimizar los procesos de servicios para el uso y facilidad del ciudadano. Siguiendo esta línea de pensamiento y de acción, la aplicación de arquitecturas MDA para desarrollar el software que soporte todo el proceso de implementación de soluciones de GE promete grandes ventajas competitivas, en especial en lo que respecta a productividad, portabilidad, mantenimiento y documentación, independencia de plataformas, especificidad del dominio, etc. Por otro lado, la doble transformación automática PIM-PSM y PSM-Código Fuente, permite que MDA centre el objetivo en los modelos de alto nivel, asegurando la regeneración de los otros modelos de manera sencilla. También es importante considerar el aspecto tecnológico, debido a que se podrían presentar posibles modificaciones en los requisitos tecnológicos de las aplicaciones, en tal sentido se tendrían que ajustar las transformaciones, sin grandes afectaciones a la documentación de alto nivel presente en los PIM. 1389
121 Referencias [1] Jefatura de Gabinete de Ministros: Plan Nacional de Gobierno Electrónico, disponible en Última visita Junio de [2] Castro M., Sánchez Rivero D., Farfán J, Castro D., Cándido A, Vargas A, Aramayo V.: una herramienta para administrar proyectos de gobierno electrónico. XIV Workshop de Investigadores en Ciencias de la Computación. Posadas. Argentina, (2012). [3] Sánchez Rivero D., Castro M., Reinoso E., Aparicio M., Aragón F., Cazón L., Zapana J.: Aplicando SOA en Gobierno Electrónico, Actas de las VIII Jornadas de Ciencia y Tecnología de Facultades de Ingeniería del NOA, 2012 (ISSN ), (2012). [4] Castro M., Sánchez Rivero D., Farfán J., Castro d., Cándido A., Vargas A.: Aplicación de Servicios Web SOAP y REST para funcionalidades existentes en sistemas informáticos provincials, VII SIE y 42 JAIIO, SADIO, Facultad de Matemática, Astronomía y Física de la Universidad Nacional de Córdoba, Córdoba, Córdoba, Argentina, (ISSN: ), (2013). [5] Gobierno de Chile: Carta Iberoamericana de Gobierno Electrónico, CLAD (2007). [6] Castro M, Sánchez Rivero D, Farfán J, Castro D, Cándido A, Vargas A, Reinoso E, Aparicio M, Aragón F, Cazón L.: Gobierno Electrónico en el proceso de regionalización. 40JAIIO - SIE Córdoba. Argentina, (2011). [7] CEPAL: Libro blanco de interoperabilidad de gobierno electrónico para América Latina y el Caribe. Versión 3.0, (2007). [8] Comisión Europea, Tarabanis K, Archmann, S.: Study on Interoperability at Local and Regional Level Interoperability Study Final Version Executive Summary, (2006). [9] Castro M, Farfán J, Sánchez Rivero D, Cándido A.: Las aplicaciones transversales en Gobierno Electrónico. V Jornadas de Ciencia y Tecnología de las Facultades de Ingeniería del NOA. Salta. Argentina, (2009). [10] Castro M, Sánchez Rivero D, Farfán J, Castro D, Cándido A, Vargas A, Reinoso E, Aparicio M, Aragón F, Cazón L.: Diseño y Desarrollo de una herramienta para automatizar el proceso de gobierno electrónico. XIII Workshop de Investigadores en Ciencias de la Computación. Rosario. Argentina, (2011). [11] Castro M, Farfán J, Sánchez Rivero D, Castro D., Cándido A, Lombardo D.: Tic: sistematizando el proceso de gobierno electrónico. 38 JAIIO. Mar del Plata. Argentina, (2009). [12] Meaurio V., Schmieder E.: La Arquitectura de Software en el Proceso de Desarrollo: Integrando MDA al Ciclo de Vida en Espiral, Escuela de Posgrado, Facultad Regional Buenos Aires, Universidad Tecnológica Nacional, disponible en: Última visita: junio de (2014). [13] Inga Aguilera F., Sarabia Maldonado N.: Aplicación de la Arquitectura Dirigida Por Modelos a las Líneas de Producción de Software, Trabajo de Tesis, Facultad de Ingeniería de Sistemas, Escuela Politécnica Nacional, Quito, (2013). [14] Fernández Sáez P.: Un Análisis Crítico de la Aproximación Model-Driven Architecture, Máster en Investigación en Informática, Facultad de Informática, Universidad Complutense de Madrid, Curso académico: (2008/2009). [15] Amaya Barbosa P., González Contreras C., Murillo Rodríguez. J.: Aspect MDA: Hacia un desarrollo incremental consistente integrando MDA y Orientación a Aspectos, Paper, Universidad de Extremadura, disponible en Última visita: junio de (2014). [16] Martínez L.: Componentes MDA para patrones de diseño, Tesis, Universidad Nacional de La Plata, (2008). [17] Miller J., Mukerji J.: MDA Guide Version , Object Management Group, (2003). 1390
122 Las TICs como herramienta de inclusión de alumnos con discapacidad visual en el nivel universitario Héctor Tarifa 1, Nilda M. Pérez-Otero 1, Marcelo Pérez-Ibarra 1 1 Grupo de Investigación y Desarrollo en Informática Aplicada, Facultad de Ingeniería, Universidad Nacional de Jujuy, Ítalo Palanca , S. S. de Jujuy, Argentina hart969@hotmail.com, nilperez@gmail.com, cmperezi@gmail.com Resumen. En este artículo se presenta una propuesta educativa que pretende integrar TICs y estrategias de educación inclusiva para formular un espacio virtual de aprendizaje accesible a personas con discapacidad visual en la Universidad Nacional de Jujuy. Para fundamentar esta propuesta se describe el contexto en el que se realiza, presentando estado actual de las TICs como herramientas de apoyo al proceso de enseñanza-aprendizaje en la UNJu y estableciendo la situación actual de la educación inclusiva en las Universidades Nacionales en general, y en la UNJu en particular. Palabras Clave: TICs, Moodle, discapacidad visual, UNJuProdis, e-learning. 1 Introducción En los últimos años, el uso de las tecnologías de la información y la comunicación (TICs) extendió su ámbito de aplicación más allá de las ciencias informáticas; abarcando áreas como la administración, la economía y la educación, entre otras. En el campo educativo, las TICs proporcionan una herramienta poderosa para la implementación de sistemas de educación a distancia y un sólido soporte para la educación. Estos sistemas, basados en web, permiten una mayor difusión del conocimiento y la comunicación entre profesores y alumnos. Sin embargo, la mayoría de estos sistemas no contemplan criterios que faciliten el acceso a personas con discapacidades. Mejorar esto se hace prioritario debido al ingreso cada vez mayor de alumnos con discapacidades a los distintos niveles educativos. Por ello en este trabajo se presenta una propuesta tendiente a capacitar al cuerpo docente para organizar los contenidos de sus asignaturas en formatos accesibles para alumnos con discapacidad visual y configurar un entorno virtual de aprendizaje adecuado a las necesidades de estos alumnos. El presente documento se estructura como sigue: en los apartados 2, 3 y 4 se presentan conceptos básicos y antecedentes que dan soporte a la propuesta: una clasificación de los entornos virtuales de aprendizaje, recursos que se aplican en la educación de personas con discapacidad visual, y un resumen de los esfuerzos para lograr una educación superior inclusiva en Argentina; en el apartado 5 expone la propuesta junto a un análisis la situación actual de la Universidad Nacional de Jujuy (UNJu) en lo que respecta a la educación mediada y la inclusión de alumnos con discapacidades y, en el apartado 6 se presentan las conclusiones y trabajos futuros. 1391
123 2 Entornos virtuales de aprendizaje Un entorno mediado de aprendizaje puede entenderse como un lugar, espacio, comunidad o sucesión de hechos que promueven el aprendizaje. Es decir, un espacio compuesto por cuatro dimensiones: social, física, técnica y didáctica. En ocasiones, el entorno de aprendizaje se define como el espacio y las convenciones establecidas, pero es la dimensión didáctica la que convierte al entorno en un entorno de aprendizaje [1]. En esta definición se encuadran los Sistemas de Gestión de Contenidos (Content Management System: CMS), Sistema de Gestión de Aprendizaje (Learning Management System: LMS), Sistema de Gestión de Contenido de Aprendizaje (Learning Content Management System: LCMS) y Entornos Virtuales de Aprendizaje (EVA) [2][3][4]. CMS. Son sistemas que proveen una estructura de soporte para la creación y administración de contenidos, es decir, aplicaciones destinadas a administrar los contenidos de un sitio web. Permiten que los usuarios actúen como webmasters, creando y quitando noticias, subiendo imágenes, vídeos o documentos. LMS o plataformas de e-learning. Registran usuarios, organizan catálogos de cursos, almacenan datos de los usuarios y proveen informes para la gestión. Incluyen herramientas de comunicación de los participantes de los cursos. Existen LMS con diversos recursos y funcionalidades; aunque no garantizan los medios para la creación y generación adaptada de cursos online, siendo su principal desventaja actuar simplemente como plataforma de distribución. LCMS. Combinan los CMS y los LMS. Se convierten en una entidad editora, con autosuficiencia en la publicación de contenido de una forma sencilla, rápida y eficiente, resolviendo los inconvenientes de las anteriores plataformas. Ofrecen facilidad en la generación de los materiales, flexibilidad, adaptabilidad a los cambios, control del aprendizaje y un mantenimiento actualizado del conocimiento. EVA. Constituyen un método pedagógico al que se puede recurrir para responder de manera efectiva a los retos emergentes que plantea la sociedad del conocimiento. Actualmente existen multitud de plataformas de e-learning. Cada plataforma posee características que a su vez se configuran como un valor añadido para que profesores y/o responsables de teleformación opten por la utilización de una u otra. 3 Tiflotecnologías Las tiflotecnologías se refieren al conjunto de técnicas, conocimientos y recursos que brindan a las personas con discapacidad visual, los medios que les permitan la correcta utilización de la tecnología. En otras palabras, las tiflotecnologías proporcionan los instrumentos auxiliares, ayudas o adaptaciones tecnológicas, creadas 1392
124 o adaptadas específicamente para posibilitar a las personas con ceguera, discapacidad visual o sordoceguera la correcta utilización de la tecnología, contribuyendo a su autonomía personal y plena integración social, laboral y educativa [5]. 3.1 Dispositivos tiflotécnicos Según su función, pueden clasificarse de forma general en: Dispositivos electrónicos de lectura y acceso a información Dispositivos de lectura de pantalla: permiten acceder a la información presentada en la pantalla de una computadora a través de la magnificación de íconos y ventanas o su descripción en formato de audio o Braille. Dispositivos de lectura de textos impresos: programas o dispositivos (lupatv, scanners, OCRs, lectores ópticos) que magnifican la información contenida en un texto o la convierten a formato de audio o Braille. Dispositivos autónomos de almacenamiento y proceso de información: dispositivos que permiten almacenar y editar la información ingresada a través de un teclado Braille y recuperar ésta en formato de audio (Braille n Speak y Sonobraille). Pueden conectarse a impresoras o computadoras. Máquinas de escribir e impresoras Braille: impresoras que conectadas a una computadora u otro dispositivo (Braille'n Speak, Sonobraille, PC) imprimen la información en Braille. Grabadores y reproductores de sonido: dispositivos que registran información en formato de audio, regulando la velocidad de grabación o reproducción. Material educativo informatizado: un sistema informático que pone al alcance de personas con discapacidades visuales información de tipo enciclopédico. Calculadoras científicas y programas de cálculo: emiten respuesta oral sobre todas las pulsaciones del teclado y permiten oír el contenido de la visualización en cualquier momento [6]. 3.2 Tiflotecnología en Argentina En Argentina existen numerosos proyectos dedicados al desarrollo de tiflotecnología. Entre ellos, resulta interesante mencionar el proyecto realizado por estudiantes de la Universidad Tecnológica Nacional en Concepción del Uruguay (Entre Ríos) de la carrera de Ingeniería en Sistemas de la Información, quienes desarrollaron un prototipo similar a una tableta que facilitará el uso de la computadora para personas ciegas. El prototipo, denominado Incendilumen (encender la luz), traduce al sistema Braille, la información presentada en la pantalla de una computadora y permite el control por parte del usuario. Incendilumen tiene una superficie cubierta de unos dos mil puntos en relieve que suben y bajan para representar información como gráficos, botones y ventanas. Al tocar la pantalla, los usuarios pueden leer el contenido personas-ciegas 1393
125 4 Discapacidad y educación universitaria en Argentina En los últimos años, entidades gubernamentales y sociales de distintos países latinoamericanos encausaron sus esfuerzos hacia la inclusión de personas con discapacidad en los diferentes niveles de educación 2. La legislación de educación argentina (Ley Nacional N ) contempla esta situación y promueve la educación inclusiva para todos los niveles de formación, impulsando políticas que motiven a más personas con discapacidad a realizar no sólo estudios primarios y secundarios, sino también a emprender y completar carreras universitarias. Ante esta realidad, las universidades y centros de formación superior debieron concretar acciones que permitieran la inclusión, adaptación y permanencia de alumnos discapacitados en el nivel superior. En pos de alcanzar este objetivo varias universidades nacionales formularon planes de acción tendientes a lograr la educación inclusiva. Por cuestiones de espacio y considerando que todas ellas comparten objetivos se presentan las propuestas desarrolladas en algunas de las universidades más reconocidas. 4.1 Universidad de Buenos Aires: Programa Universidad y Discapacidad En 2007, la Universidad de Buenos Aires creó este programa asignándole las siguientes funciones: a) promover los estudios que favorezcan la inclusión plena de las personas con discapacidad y promover medidas para eliminar todas las formas de discriminación; b) lograr la plena accesibilidad física, comunicacional, cultural y pedagógica en todos los ámbitos de la universidad; y c) favorecer la concientización de todos los miembros de la comunidad universitaria, en relación a los derechos y necesidades de las personas con discapacidad y lograr así su plena integración en la vida académica Universidad Nacional de Córdoba: Oficina de Inclusión Educativa La Universidad Nacional de Córdoba (UNC) creó esta oficina con la misión de transversalizar la perspectiva de la accesibilidad y de la heterogeneidad en las políticas, planes, programas y proyectos que se adopten en las funciones de docencia, investigación y extensión de la UNC. Entre sus objetivos específicos se destacan: a) asesorar, programar y coordinar acciones orientadas a la inclusión educativa de personas en situación de discapacidad en las carreras de grado y posgrado; b) canalizar demandas, consultas, sugerencias de la comunidad universitaria y actores extra institucionales; c) fortalecer y coordinar las iniciativas existentes en las unidades académicas; d) preservar y consolidar la lógica de abordaje multiactoral e integrada de la temática, a partir de la articulación permanente con las diferentes dependencias de la Casa de Trejo; e) favorecer el establecimiento de acuerdos y convenios de trabajo (asesoramiento, capacitación, asistencia técnica especializada) con
126 organizaciones de la sociedad civil y dependencias del Estado provincial y municipal; y f) consolidar la participación institucional en la Comisión Interuniversitaria de Discapacidad y Derechos Humanos de Argentina Universidad Nacional de La Plata: Comisión Universitaria sobre Discapacidad Esta comisión realizó una serie de propuestas para la inclusión de la temática de la diversidad y la discapacidad, en el seno de la reflexión, la investigación y la docencia universitaria. Sus objetivos son: a) promover la inclusión expresa de la misión enunciada en los estatutos universitarios; b) propiciar en el ámbito de cada universidad acciones tendientes a la integración, evitando y eliminando las barreras físicas, de acceso a la información, académicas y actitudinales; c) promover la incorporación de la problemática de la discapacidad en la currícula de las carreras de pre-grado, grado y post-grado; d) desarrollar proyectos de docencia, investigación y extensión sobre diferentes aspectos de la discapacidad; e) promover la creación de un área para la discapacidad en cada casa de altos estudios, propiciando la formación de equipos interdisciplinarios; y f) promover el desarrollo de un sistema de información sobre discapacidad y equiparación de oportunidades Universidad Nacional de Tucumán: Programa de Discapacidad e Inclusión Social La Universidad Nacional de Tucumán creó este programa (ProDIS) con objetivos tales como el diseño y el desarrollo de medidas integrales y progresivas de acción directa a fin de posibilitar a personas con discapacidad, el acceso y permanencia a la educación superior en igualdad de oportunidades. El programa promueve la eliminación de barreras comunicacionales, garantizando la accesibilidad a los contenidos impartidos en clases y propuestos por las cátedras, así como los extracurriculares. Para ello el equipo de trabajo del ProDIS adapta el material escrito a formato audio y braille y coordina el servicio de interpretación en lengua de señas para los estudiantes. Además, se proporciona capacitación extraprogramática como herramienta fundamental para el desenvolvimiento de los estudiantes en el ámbito académico y laboral a través de cursos en inglés, informática y lecto-escritura braille. Fomenta la eliminación de las barreras físicas, transformando los espacios edilicios de la universidad para hacerlos accesibles, cómodos y seguros Área de Integración e Inclusión para Personas con Discapacidad de la UNR El Área de Integración e Inclusión para Personas con Discapacidad de la Universidad Nacional de Rosario tiene la misión de integrar e incluir a las personas con
127 discapacidad al ámbito de la universidad pública y a la sociedad en su conjunto. Siendo sus principales objetivos: a) promover el acceso, contención e ingreso a la educación superior, capacitando a toda la comunidad sobre la atención de las personas con discapacidad; y b) dar cumplimiento a las legislaciones y normativas universitarias que abordan los derechos de las personas con discapacidad. El área impulsó la creación de la Comisión Universitaria de Discapacidad que es una apuesta a futuro en pos del fortalecimiento y la consolidación de la integración de personas con discapacidad a nivel universitario 7. 5 La propuesta y el contexto de trabajo Siguiendo los lineamientos de trabajo con personas discapacitadas que siguen las principales Universidades Nacionales, el Grupo de Investigación y Desarrollo en Informática Aplicada (GIDIA) de la UNJu está trabajando en un proyecto dirigido a capacitar al cuerpo docente en la organización de los contenidos en formatos accesibles para alumnos con discapacidad visual y al mismo tiempo configurar un entorno virtual de aprendizaje adecuado a las necesidades de estos alumnos. En la primera instancia del proyecto se realizó en la UNJu un relevamiento respecto de los entornos virtuales de aprendizaje y la inclusión de personas discapacitadas. En los siguientes subapartados se muestra los resultados obtenidos. 5.1 UNJu Digital El proyecto UNJu Digital se inició en el año 2010 con el objetivo de implementar las TICs en la UNJu, así como capacitar y sensibilizar los centros que dependen de la universidad en materia de TICs. El proceso de capacitación de los docentes de las unidades académicas se llevó a cabo en forma gratuita y se organizó por cohortes alcanzando a la fecha casi la totalidad de docentes de la universidad. La capacitación se dividió en nivel inicial y avanzado. En el nivel inicial se presentó la plataforma Moodle (funcionalidades básicas), y se profundizó en la puesta en práctica del trabajo colaborativo y la realización de tareas virtuales en el rol alumno. El segundo nivel, rol docente, apuntó a integrar a la práctica docente los recursos provistos por Moodle de modo que la visión clásica del proceso de enseñanza-aprendizaje debió adaptarse a un entorno en el que la interacción no estaba limitada al aula sino que la comunicación entre docente-alumno y alumno-alumno se extendía en el tiempo y el espacio 8. Aunque actualmente no se contempla el dictado de materias a distancia, en agosto de 2013, la UNJu ingresó en la Red Universitaria de Educación a Distancia Argentina que a su vez forma parte del Consejo Interuniversitario Nacional a fin de conectarse con todas las universidades nacionales para mantenerse al tanto sobre normativas, proyectos y la demanda de la comunidad académica. Un aspecto importante a considerar acerca de UNJu Digital es que la plataforma Moodle no cumple con todas las características de accesibilidad definidas por la W3C
128 [7], lo que limita el potencial de este entorno de aprendizaje en lo que refiere a personas con discapacidad. Teniendo en cuenta que este tipo de entorno no se desarrolló específicamente para alumnos con discapacidad visual, existen varios trabajos que proponen recomendaciones para mejorar la accesibilidad de los contenidos presentados en estos espacios [7][8][9][10][11]. 5.2 Programa para la Discapacidad de la UNJu En septiembre de 2011, la UNJu lanzó el programa UNJu ProDis (Programa para la Discapacidad de la UNJu) para la atención y apoyo de estudiantes con discapacidad motora, auditiva y visual, en todas las unidades académicas de la UNJu, Escuela de Minas Dr. Horacio Carrillo y campus de recreación y deportes. El programa tiene como objetivos: a) eliminar las barreras culturales, actitudinales, normativas, edilicias y de acceso a la tecnología asistiva, y b) brindar accesibilidad para una educación inclusiva, sin segregaciones y reconociendo a las personas con discapacidad como sujetos con derecho a una formación plena, en igualdad de oportunidades. A fin de alcanzar estos objetivos el equipo de UNJu Prodis cuenta con especialistas en pedagogía, psicología, informática, bibliotecología, educación física, asistencia social, arquitectura y lengua de señas que prestan soporte no sólo al alumno con discapacidad sino que también colaboran con los docentes proporcionando recursos pedagógicos y técnicos para la inclusión del alumno Propuesta de trabajo En virtud de la información relevada el GIDIA propone combinar los recursos del campus virtual de la universidad (UNJu Digital), los desarrollos tiflotecnológicos disponibles y los planes de acción y equipo de trabajo de UNJu Prodis para: 1) capacitar al cuerpo docente para organizar los contenidos de sus asignaturas en formatos accesibles para alumnos con discapacidad visual y 2) configurar un entorno virtual de aprendizaje adecuado a las necesidades de estos alumnos. A fin de concretar estos objetivos el GIDIA no sólo cuenta con un equipo de trabajo conformado por profesionales del área de Educación, Informática y Ciencias Sociales sino también inició acciones para aunar esfuerzos con el personal de UNJuProdis. 6 Conclusiones y trabajos futuros En este trabajo se presenta la situación actual de la Facultad de Ingeniería (FI) de la Universidad Nacional de Jujuy (UNJu) respecto a la implementación de la educación apoyada en espacios virtuales. Asimismo, se comenta cómo distintas universidades de Argentina abordan la inclusión de alumnos con discapacidad visual en el ciclo de educación superior, en particular, el proyecto UNJuProdis de la UNJu. En este contexto también se describen las tiflotecnologías que dan soporte al proceso de
129 enseñanza-aprendizaje de personas con discapacidad visual. Finalmente se presenta una clasificación general de entornos mediados de aprendizaje y se mencionan las principales características de éstos indicando que tales entornos no se desarrollaron específicamente para personas con discapacidad visual, pero que existen varias propuestas para mejorar su accesibilidad. Finalmente se delineó el proyecto del GIDIA cuya concreción fomentará no sólo la iniciación de las personas con discapacidad visual en el nivel de educación superior sino también la finalización exitosa de sus estudios. Referencias 1. Pirttiniemi, E. y A. Rouvari (s.f) Dimensión didáctica del entrono de aprendizaje, en: Consultado el 19/10/10. (2010) 2. Bravo Reyes, C. Moodle a un lado y las redes sociales a otro? 27 Noviembre Disponible en: (2012) 3. Gisbert, M., Adell, J., Anaya, L. y Rallo R. Entornos de Formación Presencial Virtual y a Distancia. Grupo Tecnología Educativa. Universidad de Sevilla. (2002). 4. López Guzmán, C. Repositorios de Objetos de Aprendizaje como soporte a un entorno e- learning. (Consultado el 27 Noviembre 2013) Universidad de Salamanca. Disponible en: (2005) 5. Lafuente de Frutos, A.; Guil Torres, R.; Martínez Monasterio-Huelin, M.; Allidem Caluza, M. A.; Luna Lombardi, R.; Espinosa Rabanal, J. A. Educación Inclusiva: Personas con Discapacidad Visual. Módulo 10: Tiflotecnología. ISBN: (2011) 6. Morales Torres, M.; Berrocal Arjona, M. Tiflotectnología y Material Tiflotécnico. I Congreso Virtual INTEREDVISUAL sobre Intervención Educativa y Discapacidad Visual. Disponible en: icv/tiflotecnologia_y_material_tiflotecnico_mym.pdf (2003) 7. Calvo-Martin, R.; Iglesias, A.; Moreno, L. Is Moodle Accessible for Visually Impaired People?, Web Information Systems and Technologies - 7th International Conference, WEBIST 2011 (Revised Selected Papers), May, 2011, Lecture Notes in Business Information Processing, ISBN: , Volumen: 101, Número: 3, Páginas: (2011) 8. Litovicius, P. E-Learning para invidentes: Propuesta de evaluación para plataformas de e- learning para invidentes. EAE. ISBN 13: ISBN 10: (2014) 9. Rebaque-Rivas, P. Diseño universal y personalización en entornos virtuales de aprendizaje para estudiantes con discapacidad visual. Departamento de aplicaciones para la comunidad. Área de tecnología educative. Universitat Oberta de Catalunya. (2014) 10. Bejarano Salazar, A. G.; Gamboa Villalobos, Y. Accesibilidad de la plataforma virtual Moodle de la UNED de Costa Rica, una perspectiva de los estudiantes con discapacidad visual. Programa de Aprendiza en Línea. Universidad Estatal a Distancia de Costa Rica. Disponible en plataforma_virtual_moodle_de_la_uned_de_costa_rica,_una_perspectiva_de_los_estudi antes_con_discapacidad_visual.pdf (2012) 11. ONCE. Pautas para el diseño de entornos educativos accesibles para personas con discapacidad visual. ONCE Dirección de Educación. Grupo de Accesibilidad Plataformas Educativas. Disponible en: saludable/infovisual/ss-edpautasdediseno2005.pdf (2005) 1398
130 Una revisión del cómputo paralelo aplicado al procesamiento de imágenes Nilda M. Pérez-Otero 1, Marcelo Pérez-Ibarra 1 y Sandra A. Méndez 1 1 Grupo de Investigación y Desarrollo en Informática Aplicada Facultad de Ingeniería, Universidad Nacional de Jujuy 4600, S. S. de Jujuy, Argentina smendez.fi.unju@gmail.com, nilperez@gmail.com, cmperezi@gmail.com Resumen. En este trabajo se presenta un resumen del estado del arte del procesamiento distribuído de imágenes tanto en entornos paralelos convencionales, clusters y grid, como mediante el paradigma Map Reduce del framework Hadoop. Tras un análisis de las últimas publicaciones se concluye que aún es incipiente la investigación sobre el uso de Hadoop para el procesamiento de imágenes y que la línea correspondiente a la restauración de imágenes es un aspecto que merece ser explotado más en profundidad. Palabras Clave: En esta sección se recomienda listar las palabras claves del trabajo. 1 Introducción El Cómputo de Altas Prestaciones (HPC, High Performance Computing) que en sus inicios fue de uso exclusivo de grandes centros de investigación y desarrollo militar, en la actualidad, extendió su campo de aplicación a otros ámbitos de la actividad humana como la economía, la medicina, el entretenimiento, la producción, entre otros. Su popularización se debió principalmente al avance tecnológico de los últimos años que permitió diseñar arquitecturas que dan soporte al cómputo paralelo. Entre éstas pueden mencionarse los clusters de computadoras, las tecnologías grid y la computación cloud. El tratamiento digital de imágenes es un campo en el que HPC despertó gran interés. Actualmente, muchos sistemas que realizan procesamiento de imágenes aplican transformaciones basadas en operaciones complejas (reconocimiento de imágenes, restauración de imágenes, etc.) o almacenan importantes cantidades de información (facebook, googlemaps, etc.) lo que demanda un importante poder computacional. Esta situación impulsó muchos proyectos que desarrollaron herramientas para dar soporte al procesamiento y almacenamiento de imágenes a gran escala. En este artículo se presenta una revisión del estado actual del HPC y su aplicación al tratamiento digital de imágenes, en particular, se comentan estudios realizados sobre el framework Hadoop que proponen adaptarlo para tareas de procesamiento de imágenes. 1399
131 El documento se organiza como sigue: en el apartado 2 se hace mención de las arquitecturas paralelas cluster, grid y cloud; en el apartado 3 se presenta el framework Hadoop; en el aparatado 4 se realiza una breve descripción del área de procesamiento digital de imágenes; en el apartado 5 se comentan trabajos que aplican procesamiento paralelo al tratamiento de imágenes, particularmente, las propuestas que utilizan Hadoop; y finalmente en el apartado 6 se presentan las conclusiones. 2 Arquitecturas de Cluster, Grid y Cloud Los avances tecnológicos de los últimos años dieron lugar a que el HPC, originalmente llevado a cabo por supercomputadoras en grandes centros de investigación, migrara a arquitecturas más sencillas y accesibles para toda comunidad científica. Esto revolucionó distintas áreas del conocimiento humano, ya que pudieron abordarse problemas cuya complejidad excedía las capacidades computacionales de los equipos personales. Fue así que se hicieron grandes avances en medicina, climatología, simulación, procesos de producción, entre otros. En este escenario se desarrollaron en un primer momento las arquitecturas cluster, luego las grid y actualmente las cloud. Éstas últimas proporcionan recursos de cálculo y de almacenamiento que, además, resultan especialmente aptos para la explotación comercial de las grandes capacidades de cómputo de proveedores de servicios en Internet [1]. A continuación se describen brevemente dichas arquitecturas: Clusters. Un cluster es un sistema de procesamiento paralelo compuesto por un conjunto de computadoras interconectadas vía algún tipo de red, las cuales cooperan configurando un recurso que se ve como único e integrado, más allá de la distribución física de sus componentes. Cada procesador puede tener diferente hardware y sistema operativo, e incluso puede ser un multiprocesador [2]. Cuando se conectan dos o más clusters sobre una red tipo LAN o WAN, se tiene un multicluster [3]. La configuración más simple a considerar es la conexión de clusters homogéneos sobre una red LAN o WAN, utilizando un sistema operativo común [4]. Grid. Un Grid es un tipo de sistema distribuido que permite seleccionar, compartir e integrar recursos autónomos geográficamente distribuidos [4]. Un Grid es una configuración colaborativa que se puede adaptar dinámicamente según lo requerido por el usuario, la disponibilidad y potencia de cómputo de los recursos conectados. El Grid puede verse como un entorno de procesamiento virtual, donde el usuario tiene la visión de un sistema de procesamiento único aunque trabaja con recursos dispersos geográficamente [5]. Cloud. Las arquitecturas tipo Cloud se presentan como una evolución natural del concepto de Clusters y Grids, integrando grandes conjuntos de recursos virtuales (hardware, plataformas de desarrollo y/o servicios), fácilmente accesibles y utilizables por usuarios distribuidos, vía WEB. Estos recursos pueden ser dinámicamente reconfigurados para adaptarse a una carga variable, permitiendo optimizar su uso 1400
132 [6][7][8][9]. 3 Hadoop Hadoop es un framework open-source desarrollado en Java para el procesamiento y consulta de grandes cantidades de datos sobre un grupo de computadores 1. Hadoop fue creado por Doug Cutting, y fue desarrollado como parte del proyecto del buscador open-source Apache Nutch. En 2007, Hadoop llegó a ser un proyecto por sí mismo y tras la publicación de las especificaciones del sistema de ficheros Google (Google File System, GFS) se creó Nutch Distributed File System (NDFS) lo que permitió crear una plataforma distribuida. Luego en 2008, Hadoop ya corría en un cluster de cores en la compañía Yahoo!. Actualmente Hadoop es utilizado por empresas como Facebook, Yahoo!, Microsoft, Last.fm o LinkedIn. Entre sus características más importantes pueden mencionarse: es accesible (puede ejecutarse en clusters de miles de nodos), es robusto (puede ejecutarse con la asunción de fallos de hardware), es escalable (escala horizontal y fácilmente añadiendo más nodos para procesar grandes volúmenes de datos) y sencillo (permite crear fácilmente código paralelizable). La estructura del framework Hadoop se compone del Sistema de Archivos Distribuidos HDFS (Hadoop Distributed File System) y el modelo de programación MapReduce. Y su funcionamiento se sustenta en una serie de daemons que distribuyen las unidades de trabajo entre los nodos del cluster, gestionan el cómputo y sus estados, y administran el sistema de archivos gestionando los datos y repartiéndolos entre los nodos [10] [11]. 3.1 HDFS El sistema de archivos HDFS está diseñado para almacenar de forma fiable archivos muy grandes a través de las máquinas en un cluster; y está inspirado en el sistema de archivos de Google. Los principales procesos vinculados a HDFS son NameNode (mantiene los metadatos de los ficheros que residen en el HDFS), DataNode (mantiene los datos y se encargan de su replicación) y Secondary NameNode (mantiene los checkpoints del Namenode). HDFS almacena cada archivo como una secuencia de bloques (en la actualidad 64 MB por defecto) donde todos los bloques de un archivo son del mismo tamaño, excepto el último bloque. Los bloques que pertenecen a un archivo se replican para tolerancia a fallos. El tamaño del bloque y el factor de replicación pueden configurarse por archivo. Los archivos en HDFS son de una sola escritura y pueden tener sólo un escritor en un momento dado [12] [13]
133 3.2 MapReduce MapReduce es un modelo de programación para el procesamiento distribuido y paralelo de grandes volúmenes de datos. Al utilizar MapReduce es preciso escribir programas que involucren las siguientes tres fases: mapeo (map), mezcla (suffle) y reducción (reduce). Además, MapReduce realiza automáticamente la comunicación entre procesos map y reduce y lo que mantiene el equilibrio de carga de los procesos. A continuación se describen las fases asociadas a MapReduce: Map. La función Map toma pares clave-valor <K, V> como entrada y genera uno o múltiples pares <K, V > como salida intermedia. Shuffle. Luego que la fase de Map produce los pares clave-valor intermedios, éstos son eficiente y automáticamente agrupados por clave para ser utilizados en la fase Reduce. Reduce. La función Reduce toma como entrada el par <K, LISTA V >, dónde LISTA V es una lista de todos los valores V que están asociados con una clave K dada. La función Reduce produce un para clave-valor adicional como salida. La combinación de múltiples procesos Map y Reduce permite completar tareas complejas que no pueden ser realizadas por la ejecución de un simple proceso Map y Reduce [13]. Entre otras, Hadoop se utilizó con éxito en las siguientes aplicaciones [12]: En Google: construcción de índices para el buscador (pagerank) clustering de artículos en Google News búsqueda de rutas en Google Maps traducción estadística En Facebook: minería de datos optimización de ads detección de spam gestión de logs En I+D+I: análisis astronómico bioinformática física de partículas simulación climática procesamiento del lenguaje natural 1402
134 4 Procesamiento Digital de Imágenes El campo del procesamiento digital de imágenes abarca las técnicas, algoritmos, métodos y procedimientos que manipulan una imagen digital cualquiera con el fin de evaluar su contenido, mejorar su apariencia, recuperar información perdida por degradación, comprimir la información para su almacenamiento o transmisión, detectar las características de los objetos presentes en la imagen, o interpretar su contenido para llevar a cabo una serie de procesos informáticos, como el aprendizaje de patrones y objetos, reconocimiento de caracteres escritos, reconocimiento facial, reconstrucción tridimensional de imágenes bidimensionales, detección de movimiento y clasificación de imágenes, entre otros [14]. Considerando esto, el procesamiento digital de imágenes puede resultar computacionalmente costoso y más aún si se procesa un volumen de imágenes que puede rondar el orden de los GB. Es por ello que trabajar sobre una única computadora resultaría poco práctico por restricciones de memoria y tiempo. Lógicamente, esto deriva en el uso de plataformas de procesamiento masivo y escalable de datos [15]. 5 HPC y procesamiento de imágenes Como ya se mencionó los algoritmos utilizados para procesar imágenes son, en general, de alta complejidad computacional por la cantidad de datos que procesan y la multiplicidad de operaciones que realizan sobre ellos. Esta situación hace que los ambientes de cómputo masivo sean ideales para el tratamiento digital de imágenes. Desde los 90 se vienen realizando trabajos de investigación que presentan propuestas que aplican HPC, con resultados satisfactorios, al tratamiento de imágenes: Procesamiento de imágenes satelitales. En [16] se presentan varias técnicas y métodos (fusión de imágenes, clasificación de imágenes, mosaico de imágenes y procesamiento de imágenes hiperespectrales) que pueden aplicarse al análisis y procesamiento de imágenes satelitales utilizando los recursos de un sistema HPC. Evaluación de estrategías de scheduling y particionamiento. En [17] se realiza un estudio teórico y experimental que evalúa 2 estrategias de scheduling y particionamiento al momento de procesar de imágenes de gran tamaño en un ambiente distribuido Restauración de imágenes. En [18] se presenta una aplicación paralela para la restauración de imágenes que se basa en el paralelismo de datos realizado mediante la descomposición adaptativa del dominio espacial de la imagen para una clase de funciones de degradación. Un framework para el procesamiento de imágenes. En [19] se presenta un marco 1403
135 de trabajo para el procesamiento de imágenes que se evalúa sobre un cluster de computadoras heterogéneo. Estos trabajos, en su mayoría, se desarrollaron en entornos cluster o multiprocesador implementando los programas de tratamiento de imágenes de acuerdo a un paradigma de programación paralelo. Esto requiere, de parte de los desarrolladores, un conocimiento profundo del software y el hardware del sistema distribuido. Una alternativa atractiva y que implementa el procesamiento paralelo de forma sencilla es el framework Hadoop. 5.1 Hadoop y procesamiento de imágenes En años recientes se llevaron a cabo varios trabajos que proponen Hadoop como herramienta para el procesamiento digital de imágenes en entornos paralelos. Entre los trabajos realizados pueden mencionarse: Edición masiva de imágenes en la Cloud. En [20] se implementa en Hadoop técnicas de dominio gradiente para ensamblar grandes imágenes a partir de imágenes más pequeñas. Se utiliza la nube como una posible alternativa a la aplicación tradicional del procesamiento distribuido masivo de imágenes. Se introduce un nuevo método basado en mosaicos para resolver un sistema de Poisson para aplicaciones de imágenes que capta las tendencias a gran escala y no requiere de grandes recursos de memoria. Se extiende este método a la nube y lo que se necesita considerar para asegurar una aplicación eficiente. Finalmente, se presenta el primer programa de solución de sistemas Poisson para la edición de imágenes implementado en MapReduce. Detección de paredes de células. En [15] se presenta la implementación en Hadoop de un programa distribuido que permite encontrar las paredes de células epiteliales de plantas del tipo Arabidopsis Thaiana captadas en imágenes con interferencia diferencial de contraste mediante la implementación de un algoritmo detector de estructuras curvilíneas en un programa distribuido a partir de sus clases en C++. Reconocimento facial. En [21] se realiza la implementación de un módulo para la búsqueda de personas en una base de datos de rostros por medio del reconocimiento facial. Para el desarrollo se utiliza el procesamiento distribuido proporcionado por el modelo de programación MapReduce e implementado en la plataforma Hadoop. Procesamiento de fotogramas de video. En [13] se presenta el procesamiento de secuencias de fotogramas de vídeo con MapReduce para crear imágenes en escala de grises y extraer algunas de las características de las imágenes de vídeo. En el proceso de creación de las imágenes en escala de grises, cada fotograma de vídeo se divide en múltiples partes. En la extracción, los números de trama se utilizan como los números de clave para extraer algunas de las características de las imágenes de vídeo 1404
136 6 Conclusiones En este trabajo se presenta el estado del arte del procesamiento distribuido de imágenes en entornos paralelos, en general, y utilizando el framework Hadoop, en particular. Un análisis de los trabajos realizados respecto a la aplicabilidad de Hadoop a diferentes clases de problemas evidencia que este framework no es solo una plataforma reservada para el procesamiento masivo de archivos de texto, sino que también puede utilizarse con resultados satisfactorios en el procesamiento masivo de imágenes. En los últimos 5 años recién comenzó a explotarse el potencial de esta plataforma para el tratamiento de imágenes, sin embargo, los trabajos realizados hasta ahora apuntan a problemas muy específicos, dejando abiertas varias líneas de investigación, entre ellas la restauración de imágenes. Es en este campo que está comenzando a trabajar el Grupo de Investigación y Desarrollo en Informática Aplicada de la Facultad de Ingeniería de la Universidad Nacional de Jujuy. Referencias 1. Urueña, Alberto, Ferrari, Annie, Blanco, David y Elena Valdecasa. El Estudio Cloud Computing. Retos y Oportunidades. ONTSI. España. (2012) 2. Zoltan J., Kacsuk P., Kranzlmuller D., Distributedand Parallel Systems: Cluster and Grid Computing. The International Series in Engineering and Computer Science. Springer; 1st ed., (2004). 3. Bertogna M. L. Planificación dinámica sobre entornos Grid. Ph.D. thesis, Universidad Nacional de La Plata, La Plata, Argentina, (2010). 4. Grid Computing and Distributed Systems (GRIDS) Laboratory - Department of Computer Science and Software Engineering (University of Melbourne). Cluster and Grid Computing. oz.au/678/. (2007) 5. Grid Computing Infocentre: computing.com/ 6. Foster I. There's Grid in them thar Clouds. 2 de Enero, blog/ 2008/01/theresgrid-in.html. Noviembre, (2010). 7. Dikaikos M. et al. Distributed InterNet Computing for IT and Scientific Research. Internet Computing IEEE. Vol 13, Nro. 5, pp Ardissono L., Goy A., Petrone G., Segnan M. From Service Clouds to User-centric Personal Clouds. IEEE Second International Conference on Cloud Computing. (2009). 9. Hemsoth N. Outsourcing Versus Federation: Ian Foster on Grid and Cloud. 15 de Junio, Grid-and-Cloud html. Noviembre. (2010). 10. White, T. Hadoop. The Definitive Guide. 3rd Edition. O Reilly. ISBN: (2012) 11. Gutiérrez Millá, A. Análisis Bioinformáticos sobre la tecnología Hadoop. Memoria del proyecto de Ingeniería Técnica en Informática de Sistemas. Universidad Autónoma de Barcelona. España. (2011) 12. Nieto, D. Análisis de Hadoop y MapReduce. Benchmark en el SVGD. Centro de Supercomputación de Galicia. Informe técnico. (2013). 13. Yamamoto M. and Kaneko K. Parallel image database processing with mapreduce and performance evaluation in pseudo distributed mode. International Journal of Electronic Commerce Studies. Vol.3, No.2, pp (2012) 1405
137 14. Fernández Muñoz, J. A. Estudio Comparativo de las Técnicas de Procesamiento Digital de Imágenes. Tesis de Fin de Máster en Ingeniería del Software. Facultad de Informática. Universidad Politécnica de Madrid. (1999) 15. Cali Mena, G. I. y Moreno Quinde, E R. Utilización de la plataforma Hadoop para implementar un programa distribuido que permita encontrar las paredes de células de la epidermis de plantas modificadas genéticamente. Informe de materia de graduación. Facultad de Ingeniería en Electricidad y Computación. Escuela Superior Politécnica del Litoral. Guayaquil. Ecuador. (2010) 16. Bhojne M., Chakravarti, A., Pallav, A., Sivakumar V. High Performance Computing for Satellite Image Processing and Analyzing A Review. International Journal of Computer Applications Technology and Research. Volume 2 Issue 4, (2013) 17. Li, X.L.; Veeravalli, B. and C.C. Ko,. Distributed image processing on a network of workstations. International Journal of Computers and Applications, Vol. 25, No. 2. (2003) 18. A. Bevilacqua, E. Loli Piccolomini. Parallel image restoration on parallel and distributed computers. Parallel Computing. (2000) 19. Chalermwat, P., Alexandridis, N.; Piamsa-Nga, P. and Malachy O'Connell. Parallel image processing in heterogeneous computing network systems. Proceedings., International Conference on Volume 1. ISBN (1996) 20. Summa, B., Vo, H. T., Pascucci, V. and C. Silva. Massive image editing on the cloud. Proceedings of the IASTED International Conference on Computational Photography, Vancouver, BC, Canada, June 1 3. (2011) 21. Ángel Merchan, Juan Plaza y Juan Moreno. Implementación de un módulo de búsqueda de personas dentro de una base de datos de rostros en un ambiente distribuido usando Hadoop y los Servicios Web de Amazon (AWS). (2011) 1406
138 Cálculo de factibilidad y zonas primarias de despliegue en redes rurales de banda ancha con radios cognitivas Darío M. Goussal 1 1 Grupo de Telecomunicaciones Rurales (GTR) Facultad de Ingeniería, Universidad Nacional del Nordeste, Av. Las Heras 727 (3500) Resistencia, Argentina Resumen. Este artículo describe criterios y resultados para la evaluación de factibilidad de implantación de Redes Inalámbricas de Área Regional (WRAN) en planes de expansión para accesos rurales en banda ancha, con eventual uso de bandas de espectro de espacio blanco y radios cognitivas. Expone métodos y criterios para la determinación de áreas primarias de despliegue con nuevas premisas de adopción y cobertura, en referencia a áreas rurales de Argentina. Palabras Clave: Banda ancha rural Radios cognitivas Factibilidad WRAN 1 Introducción El concepto de red de área regional inalámbrica (WRAN) nació de la búsqueda de alternativas tecnológicas más adecuadas para accesos rurales de banda ancha. El uso potencial de radios cognitivas y sistemas de coexistencia en canales vacantes de la TV abierta se afirmó en 2004 con la formalización de un grupo de trabajo para desarrollar un nuevo estándar internacional: IEEE El concepto de radios cognitivas se basa en la idea originalmente propuesta por Joseph Mitola (1999). IEEE plantea el uso subsidiario de canales de TV- DTV en zonas u horarios vacantes mediante técnicas de geolocalización y baliza, sensado inteligente de RF, selección dinámica de frecuencias y autolimitación de la potencia radiada aparente. Procura el aprovechamiento residual de espacios blancos de VHF-UHF entre 54 y 862 Mhz, donde la distribución de última milla mediante macroceldas puede alcanzar distancias considerables. Técnicamente exitosas, las pruebas de campo de algunos productos comerciales en 2013 y 2014 en EE.UU. y Japón enfrentan sin embargo, la cautela de fabricantes y operadores hacia la evolución de expectativas de mercado y cambios regulatorios antes de planificar decisiones de inversión. Las oportunidades de expansión rural de la conectividad en ambientes de coexistencia requieren nuevos criterios de factibilidad en la ingeniería de planeamiento, con el cambio tecnológico obligando a continuas mudanzas y ajustes de modelos. Es importante remarcar el carácter subsidiario de los sistemas de coexistencia para los planes de conectividad en banda ancha en áreas rurales. La alternativa WRAN no se adecua bien a áreas urbanas y tampoco a las semi-rurales con densidades normales de abonados, ó relativamente cerca de la cobertura de otros servicios. Para zonas rurales vecinas a ciudades ó con 1407
139 topologías de racimos de abonados existen opciones más baratas, fáciles y mejor adaptadas técnicamente. Las zonas candidatas para conectividad en espacio blanco son las que permanecen sin servicio por estar fuera del interés de proveedores ó de programas de banda ancha del gobierno debido a su baja densidad de abonados, tasas de adopción, ingresos ó aislamiento geográfico. Contraintuitivamente, WRAN en bandas de espacio blanco deberían considerarse como una opción de conectividad limitada por densidades máximas de abonados y por máximas tasas de adopción. Nuestro análisis se centrará justamente en la aplicación de la tecnología WRAN con radios cognitivas a tales áreas rurales duras. La mayor parte de los modelos de factibilidad de implantación para redes de banda ancha rural de área regional (WRAN) se elaboraron antes de aprobada la versión final de la norma: Simancas (2006); Wright (2007); Calabrese & Rose (2008); Nekovee (2009); Goussal (2010); Da Silva (2010); Omar et al (2010) y Fitch et al (2011). Sin embargo, en Latinoamérica la variedad de relieves geográficos, tipos de clima, patrones demográficos y de ingreso, y las diferencias en los niveles de conectividad aun dentro de un mismo país hacían poco realista el cómputo de estimaciones de cobertura aplicando directamente las premisas originales, por lo que desde 2009 en la UNNE se ensayaron diversas modificaciones sobre el mismo (Goussal, 2011). 2. Reelaboración del modelo de factibilidad El umbral de operación viable nace de la interacción entre densidades de población y tasas esperadas de adopción del servicio. Cuanto menor fuera el número de viviendas en el área -o de personas por vivienda-, mayor debería ser la esperanza mínima de adopción. Las premisas de factibilidad de implantación de WRAN fueron planteadas originalmente en El modelo de capacidad adoptado en la norma IEEE suponía una macrocelda circular genérica de 30,7 Km (2.960 Km2), correspondiente al alcance teórico máximo de una estación base operando en una frecuencia de 617 Mhz (Canal 38 UHF), con una altura de antena de 75 m. irradiando a la potencia límite (4 W, PIRE= 98,3 W). La distribución de densidades de abonado decrecía radialmente del centro hacia el borde de celda con rendimientos espectrales progresivamente menores, desde 5 hasta 1 Bit/Hz. (Fig. 1). Luego, un canal de 6 Mhz vacante del espectro de ATV ó DTV habilitaría 18 Mhz para la distribución, en tanto la eficiencia espectral mantuviera un promedio de 3 Bit/ Hz. Ello permitiría acomodar hasta 600 abonados rurales por canal de TV en la celda, con similares capacidad y calidad de servicio a una conexión ADSL urbana (384 Kbs de subida y 1,5 Mbs de bajada con una concentración de tráfico de 50:1). Utilizando 3 canales de 6 Mhz vacantes del espacio blanco para tráfico de bajada y 1 para subida, la macrocelda podría servir hasta habitantes (1.800 abonados en áreas con 2,5 habitantes por vivienda), arrojando una densidad límite de 1,5 Hab/Km2. para celdas de 30,7 Km. En el modelo de factibilidad de David Wright (2007), el ancho de banda promedio teóricamente disponible por canal de TV (18 Mbps), se reducía a 13,5 Mbps netos una vez detraído el tráfico interno de gestión (supuesto un 25%). Esa estimación llevaba a una capacidad máxima de 358 abonados por celda, bien por sobre el umbral de factibilidad de 90 clientes por radiobase considerado por el IEEE para operación 1408
140 económica. Mantenía sin embargo las mismas premisas de adopción inicial (5 %) con 2,5 personas por vivienda, y una única relación de concentración de tráfico de 50:1, reflejando un intermedio entre los usuales para ADSL (40:1) y cablemodem (80:1). Wright adoptaba en cambio, una celda circular tipo de 17 Km de radio (908 Km2), que para la misma adopción inicial exigía una densidad mínima de 5 Habitantes por Km2, muy por debajo de la premisa de 60 por Km2 usual en accesos DSL urbanos. Nosotros concebimos un modelo más pesimista pero de menor costo, limitando a la mitad la altura de antena de la base y con ello, reduciendo el alcance máximo de celda en zonas de llanura (37,5m /23 Km). Adoptamos densidades de vivienda en lugar de densidades de población con distribución uniforme (y no, radialmente decreciente del centro al borde de celda como en el modelo de Wright). Usando celdas hexagonales de 17 Km perfectamente centradas y uniformemente distribuidas, la zona de servicio macro sin solapamiento alcanzaría 751 Km2. Con distribución irregular de abonados radiobases imperfectamente centradas y solapamiento 25%, el área de cobertura neta se degradaría hasta 563 Km2. Para radios de 11, 14, 20 y 23 Km., alcanzaría 236, 382, 779 y 1031 Km2. Obviamente, en zonas de relieve montañoso podrían desplegarse celdas de 30,7 Km y mayores, aprovechando cerros o alturas naturales. Al aprobarse la versión final de la norma (2011), recalculamos con 4 niveles de eficiencia espectral (desde 3,03 hasta 0,76 Bit/Hz), con dos topologías de WRAN -respectivamente, con y sin una localidad rural en el sitio base. En vez del único coeficiente de concentración (50:1), supusimos que éste pudiera reducirse en áreas con abonados de uso intensivo, explotaciones agrarias, escuelas rurales, puestos sanitarios y telecentros comunitarios, ó bien ampliarse para zonas de familias rurales pequeñas y usuarios ocasionales. Radio Teórico Máximo de Celda vs. Altura de Antena en Radiobase Radio Teórico Máximo de Celda (Km) m 75 m 150 m 300 m 0 1,0 10,0 100,0 PIRE de Radiobase (Watts) 1409
.")
141 Modelo propuesto de celda WRAN Para determinar la ubicación más conveniente de una radiobase WRAN, nuestro modelo considera dos casos típicos en áreas rurales vacantes: I. Zonas con al menos un aglomerado poblado adecuado para alojar la radiobase. II. Zonas sin aglomerados (únicamente población rural dispersa). Para celdas tipo I, supusimos que no habrá abonados WRAN en el área contigua a la radiobase pues no tendría sentido a tan poca distancia compitiendo con tecnologías más sencillas de corto alcance (Wi-Fi) (Fig. 2). Incluso, también deberían excluirse los del segundo hexágono, en WRAN de pequeño radio. Los umbrales de factibilidad, recalculados con la versión 2011 de la norma y manteniendo la misma premisa de tasa de adopción inicial (5 %) serían así: las celdas de tipo I, excluyendo el hexágono urbano central retendrían 96,8 % del área total con los abonados rurales allí ubicados. Los abonados del 36 % de probables usuarios situados en el hexágono exterior podrían funcionar con eficiencia espectral mínima (0,76 Bit/Hz modulando en QPSK 1/2). Luego, las del hexágono 4, representando 28 % del área total, podrían funcionar a 1,26 Bit/Hz con modulación QPSK 3/4. En el hexágono interior 3, representando el 20 % del total podrían alcanzar 2,27 Bit/Hz modulando en 16-QAM 3/4; y en el segundo, con 12,8 % del área lo harían a 3,03 Bit/Hz con modulación 64- QAM 2/3. La celda I tipo podría servir hasta 64 usuarios en el hexágono exterior, 50 en el 4º, 35 en el 3º y 23 en el 2º. El total de 172 abonados estaría bien por debajo del rango originalmente adoptado como premisa de cobertura en las recomendaciones de instalación iniciales (Chouinard, 2005). 1410
142 Al ensayar umbrales de viabilidad de WRANs con distintas opciones de calidad de servicio (concentraciones de tráfico desde 50:1 hasta 10:1), la celda típica permitiría atender hasta 172, 138, 103, 69 y 34 abonados, respectivamente. Para celdas de 11 Km de radio, la máxima densidad de abonados con el coeficiente de concentración más alto sería de 0,47 por Km2 en áreas del Caso I y 0,50 por Km2 en el Caso II, pero el umbral de viabilidad podría llegar a ser tan bajo como 0,031 por Km2 para celdas de 30,7 Km. trabajando con la máxima calidad de servicio (21:1) El Caso II reflejaría áreas de servicio rurales puras, es decir donde todavía no hay población aglomerada (aldeas ó pequeños pueblos). La estación base puede entonces estar en cualquier ubicación, siendo conveniente ubicarla en alturas naturales o compartiendo infraestructura común (torres, contenedores, energía y enlaces a la red troncal). Alternativamente, para reducir las inversiones y costos de explotación, la radiobase podría ubicarse en el sitio de un abonado intensivo (telecentro, biblioteca ó escuela rural). Al no haber áreas de exclusión en el área de la base la capacidad de servicio sería casi igual con topes ligeramente mayores -desde 53 hasta 190 abonados, con concentraciones de tráfico desde 10:1 hasta 50:1-. Estos nuevos resultados para los Casos I y II arrojan un umbral de 26:1 como concentración mínima permitida para operación viable en zonas de servicio del Caso I, y 21:1 para las del Caso II, tomando siempre como límite el umbral original de 90 abonados con adopción inicial de 5%. Sin embargo, para cálculos ejemplificativos en Argentina usamos una adopción 20%, al estimar su elasticidad acceso como más parecida a la de zonas duras de Canadá como la Península Acadiana, alcanzando 26,4:1 en el primer año (Wright, 2007). 3 Áreas primarias de despliegue en la Provincia del Chaco La estimación de áreas de primarias de despliegue necesita computar valores y tendencias demográficas con desagregación de micronivel. La cobertura de banda ancha requiere además, estimaciones de viviendas rurales dispersas, habitantes por vivienda y densidades, incluyendo el factor de ocupación. Los radios censales serían la unidad correcta, pero ese nivel de detalle supone datos a menudo difíciles de hallar u obsoletos cuando se obtienen. Por ello, nosotros utilizamos una combinación de fuentes censales (decenales) y electorales (bienales). La Tabla 1 enlista las densidades de viviendas rurales dispersas y totales ocupadas (incluyendo centros ó aglomerados), para los 26 departamentos de la provincia del Chaco. También, el número de centros con población aglomerada, adecuados para implantación de bases WRAN. Se notan las diferencias en densidad mínima y habitantes por vivienda respecto al modelo de Wright. Naturalmente, las prioridades de despliegue a nivel de departamento deberán intersectarse con tendencias intercensales y datos bienales de fuentes alternativas. La meta primaria de cobertura ideal en la provincia serían unos abonados (20% de las viviendas rurales), pero sólo 3 departamentos presentan densidades promedio de más de 1 vivienda por Km2. Las tablas 2-3 detallan posibles áreas de despliegue de celdas WRAN factibles para los Casos I y II, estimadas para adopción inicial de 20%. Ese valor refleja la inclusión de abonados rurales supuestos de baja elasticidad-acceso (viviendas con comercios en pueblos rurales y cascos de explotaciones agropecuarias de pequeños productores). 1411
143 Tabla 1 Departamento Viviendas Rurales Dispersas Viviendas Rurales (Total) Habitantes por Vivienda Densidad V.R Total Ocupadas Centros Rurales Quitilipi ,11 1,42 1 Bermejo ,66 1,23 5 Comandante Fernández ,86 1,18 Libertad ,91 0,96 3 O Higgins ,02 0,87 Sargento Cabral ,88 0,82 2 Chacabuco ,80 0,72 Maipú ,13 0,69 Independencia ,3 0, de Mayo ,31 0, de Julio ,83 0,64 General San Martín ,89 0,59 5 General Donovan ,76 0,59 1 San Lorenzo ,90 0,53 1 Santa María de Oro ,78 0, de Octubre ,83 0, de Abril ,67 0,46 1 1º de Mayo ,66 0,41 1 General Belgrano ,08 0,42 San Fernando ,77 0,44 2 Mayor Fontana ,80 0,42 1 Presidencia de la Plaza ,91 0,34 Tapenagá ,67 0,18 5 General Güemes ,14 0,21 6 Almirante Brown ,24 0,09 1 Totales ,41 43 La estimación, aún muy gruesa se obtuvo desde registros de votantes en escuelas rurales de elecciones (2013) y del Mapa Educativo Nacional. Las localidades de la Tabla 2 son pequeños municipios y las de la Tabla 3 son escuelas rurales que podrían albergar a priori, bases WRAN en topologías I y II respectivamente, ya que ambos tipos de área primaria de despliegue superan el umbral de factibilidad inicial de 90 abonados por celda. Ese umbral podría ser menor si por ejemplo, la infraestructura de la radiobase se abarata aprovechando sitios con alojamiento, energía y estructuras de antena existentes. Pero también podría aumentar, si el nivel de ingresos rural en el área primaria de despliegue determinara la fijación obligada de tarifas más bajas. Si el capital requerido para WISPs de tecnología tradicional es ya demasiado alto, por ejemplo por falta de vínculo con la red troncal ( backhaul ), la alternativa WRAN será afectada por la misma restricción. Este cálculo estimativo arroja metas de abonados para cobertura primaria en celdas WRAN tipo I y 882 en las de tipo II. 1412
144 Tabla 2 Departamento Area Rural Caso I Estimación Viviendas Viviendas Rural Agl. 20 % TA (Aglom) 20% TA (Total) 25 de Mayo Colonia Aborigen Bermejo Isla del Cerrito Sta Maria De Oro Chorotis El Espinillo Gral Güemes Fuerte Esperanza Zaparinqui Gral San Martin Laguna Limpia Pampa Almiron Quitilipi Villa El Palmar San Lorenzo Samuhu Sargento Cabral Capitán Solari Tapenagá Cote Lai Charadai Tabla 3 Departamento Area Rural Caso II Latitud Longitud Est.Viv. 20 % TA 25 de Mayo Colonia Aborigen de Mayo Colonia Tres Palmas C. Fernandez Colonia Bajo Hondo C. Fernandez Pampa Aguado Gral. San Martin Campo Bermejo Quitilipi Colonia El Paraisal Quitilipi Colonia General Paz Quitilipi El Zanjón Conclusiones Desde el punto de vista de la expansión de la infraestructura de banda ancha, las áreas sin conectividad son una oportunidad comercial y al mismo tiempo una señal de alerta para la factibilidad. Un plan de conectividad sin zonas oscuras, pero consciente en costos requiere una mezcla de tecnologías desplegadas conjuntamente (Wi-Fi ó sistemas de corto alcance para los aglomerados y WRAN para el área rural exterior. Tal es el camino seguido en los ensayos pioneros de productos comerciales en Japón y EE.UU. en Cuando la tasa de adopción o los potenciales clientes son escasos -aun incluyendo el pueblo rural y todas sus áreas circundantes-, el problema de factibilidad permanecerá irresuelto, sin importar la tecnología adoptada. Si la falta de operadores en el pueblo obedece sólo a limitaciones de cobertura, ése es el nicho correcto para el despliegue de celdas WRAN. La evaluación estimativa bajo nuevas premisas en zonas piloto ha permitido detectar zonas y condiciones para el despliegue de celdas WRAN de espacio blanco, calcular metas de cobertura primaria y prioridades de despliegue. También se ha evaluado el uso de fuentes alternativas de información demográfica para refinar la selección de las mismas. 1413
145 Referencias 1. Calabrese, M. & Rose, G. The economics of auctioning DTV white space spectrum Wireless Future Program, Working Paper 22. New America Foundation, USA (2008) 2. Chouinard, G. Recommended Practice for Installation of IEEE Wireless RAN. Doc. IEEE /0002r13 (2005) 3. Da Silva E. & Alencar, M A study of IEEE as an alternative to the Brazilian Digital Television Return Channel Proc. 9th. International Information and Telecommunications Technologies Symposium Rio de Janeiro, Brasil (2010) 4. Fitch, M.; Nekovee, M.; Kawade, S.; Briggs, K. & MacKenzie, R. Wireless service provision in TV white space with cognitive radio technology: a telecom operator s perspective and experience -IEEE Communications Magazine Vol. 49, Issue 3 ((2011). 5. Goussal, D. M. Planeamiento de sistemas de banda ancha rural inalámbrica basados en redes de coexistencia y radios cognitivas en ambiente IEEE XXII Conferencia Latinoamericana de Energía y Telecomunicaciones Rurales (CLER). Buenos Aires, (2010) 6. Goussal, D.M. Feasibility and strategic planning aspects of the deployment of rural wireless broadband networks based in white space spectrum technologies and cognitive radios. Proc. ITS Conference Telecommunications and Investment: the Road Ahead in honor of Professor Emeritus Lester D. Taylor. International Telecommunications Society (ITS). Jackson Hole, Wyoming (USA) (2011). 7. IEEE Standard for Information Technology- Telecommunications and information exchange between systems -Wireless Regional Area Networks (WRAN) Specific requirements Part 22: Cognitive Wireless RAN Medium Access Control and Physical Layer Specifications: Policies and Procedures for Operation in the TV Bands IEEE TM IEEE Computer Society, N York USA (2011) 7. Mitola, J. Software Radios: Wireless Architecture for the 21st Century John Wiley & Sons, New York, NY, USA. (1999) 8. Nekovee, M. A Survey of Cognitive Radio Access to TV White Spaces International Journal of Digital Multimedia Broadcasting, Vol. 1 (2010). 9. Omar, M; Hassan,S. & Shabli,A. Feasibility Study of Using IEEE Wireless Regional Area Network (WRAN) in Malaysia. Proc. Second International Conference on Network Applications,Protocols and Services. IEEE Computer Society, pp (2010) 10. Simancas, E. Análisis del estándar IEEE (WRAN)) y su posible implementación en Ecuador. Escuela Politécnica Nacional, Quito. (2006). 11. Wright, D. Dynamic spectrum access in the IEEE Wireless Regional Area Network Proc. II International Conference on Access Networks (Access- Nets) Ottawa, Canada (2007) 1414
146 La Impedancia en los Sistemas Informáticos para la comunicación de Datos interna, externa y las Acreditaciones Institucionales. Su importancia. Sebastian Seeligmann 1 1 Facultad de Bioquímica, Química y Farmacia, UNT,Argentina. sseeligmann@fbqf.unt.edu.ar Resumen. El corazón de un Sistema Informático es la Estructura de Datos que contiene los núcleos y objetos de información en los que se incluyen personas, actividades y bienes materiales de la institución. Se espera que el analista la diseñe mediante cálculos o intuitivamente, con la entropía óptima acorde a los objetivos de comunicación de los usuarios. Si esto no fuera así se producirá ruido (información no deseable porque no habrá máxima transferencia) que se puede eliminar, si no es muy grande, complicando la programación. Este problema es más difícil de resolver cuando existen pedidos de información externa (centros evaluadores), donde la adaptación de entropías debe acordarse necesariamente entre fuente, canales y destino para evitar confusiones y resultados equívocos. El objetivo de este trabajo es ofrecer herramientas intuitivas, mediante ejemplos, para optimizar los sistemas con la teoría de la información sin tener que utilizar sus complicadas fórmulas. Palabras Clave: información, sistema, ruido, entropía. 1 Introducción Para la primera autoevaluación institucional de la UNT en 1995 y la primera evaluación institucional externa en 1998, la Facultad de Bioquímica Química y Farmacia contaba con una informatización integrada que comprendía datos de personal, alumnos, infraestructura y parte del equipamiento de uso científico. Los estudios de adaptación de impedancias de la información entre áreas, que fue realizada por un grupo de investigadores pertenecientes a un proyecto financiado por Ciencia y Técnica, permitieron un fluido manejo de datos que se procesaban en un centro de información y cómputos de la facultad. Fueron muy escasos los datos requeridos a áreas o personas individuales, lo que dio como resultado una información precisa, rápida y controlada. No pasó lo mismo con la información enviada desde las unidades académicas a la comisión central de auto-evaluación del rectorado. Los problemas fueron solucionados parcialmente por los investigadores de Bioquímica a pedido del Sr. Rector. Por qué relatar este hecho? En el modelo de Shannon de la comunicación el ruido es un factor determinante para que la información que sale de la fuente llegue de manera adecuada al destino y esto, en un sistema informático, dependerá de las políticas de información y de los recursos humanos y tecnológicos de la institución. Se pueden deducir del relato las políticas y 1415
147 los recursos en cada caso para ese momento pero, por esta vez, el enfoque se hará sobre los recursos tecnológicos y precisamente sobre la producción del software. 2 Breve reseña sobre entropía e impedancia de la información. 2.1 Definiciones básicas. Según Shannon la entropía H está directamente relacionada con la cantidad de información I de un mensaje (símbolo) que se la expresa de la siguiente manera: y como la entropía es el valor medio de las I de todos los mensajes, entonces : donde P i es la probabilidad de un mensaje o símbolo. Se puede notar que cada mensaje contribuye con su frecuencia de aparición a la entropía. La unidad de medida de I y de H es el bit si se mantiene el logaritmo con base dos. La entropía, como se conoce normalmente en termodinámica, puede tomar valores positivos desde cero. Para el valor cero, como caso particular en información, significa que existe un mensaje con probabilidad uno -es decir la certeza- que indica ausencia de información (ver (1)). Por ejemplo para una fuente, en una base de datos para alumnos, si se le ocurre a alguien utilizar un bit para indicar si un alumno es una persona o no, este bit estará desperdiciado porque el destinatario ya sabe que todos los alumnos son personas. Un mensaje con dos casos posibles equiprobables tiene un bit de información y es la máxima entropía para esta situación. Por ejemplo, si un alumno es masculino o femenino y la probabilidad es la misma, no habrá razón para pensar que existe más información implícita que la referida al sexo. Pero se sabe que este mensaje no siempre tendrá posibilidades equiprobables, porque en varios casos dependerá del grupo étnico, de la carrera y de otras cuestiones que influyan en la decisión de una persona según su sexo, y que contribuirá al aumento de entropía y por lo tanto a la incertidumbre, pero también a la información del mensaje. De esta manera se puede calcular la información de cada mensaje para finalmente calcular la entropía de la base de datos fuente mediante la fórmula (2). (1) (2) 2.2 El ruido en el modelo de Shannon Si ahora se quiere enviar información a un destino, según el modelo de Shannon de la comunicación (ver Figura 1), aparecen la fuente, el receptor o destino, el canal de información, el codificador, el decodificador y el ruido externo. Ya se analizó parte de la fuente y se puede apreciar lo importante de estudiar la entropía con el fin de optimizar su estructura. Cuando esta fuente debe enviar información, donde el destino puede ser una persona, un área de la misma institución u otra institución, es de esperar que llegue con el mismo contenido que salió. El ruido será el encargado de modificar 1416
148 la información aumentándola inútilmente, retaceándola o tapándola hasta tal punto de poder anularla por lo que se debe tratar de evitarlo. Fig. 1. Modelo de Shannon de la comunicación. Este efecto puede iniciarse en la misma fuente como un problema de redundancia, que a veces aumenta y otras disminuye la incertidumbre del sistema sin beneficio alguno. Un caso típico de aumento de incertidumbre es el mensaje de las fechas de exámenes que en general, por reglamento, existe una relación estrecha entre las de inscripción y cierre para tipos de examen y día del examen para distintos turnos. Si se registran todas las fechas en una base de datos, es totalmente redundante porque hubiera bastado una sola fecha y un algoritmo para calcular todas las demás. También puede ser el caso de registrar la edad del alumno en cada ciclo lectivo. Otro caso de redundancia, pero con disminución de entropía y por lo tanto de la información, se produce si se utiliza una sola base de datos para toda la información de un alumno. Cada vez que cambie la situación del estudiante deberá utilizarse un nuevo registro con toda la información, por ejemplo cuando rinde y aprueba un examen. En los dos casos, además de que la utilización de bytes extras para guardar la información es muy grande, aparecerá el ruido o equivocación, tanto con la redundancia como con el algoritmo para evitarla. La diferencia reside que cuando hay redundancia el ruido es aleatorio y difícil de eliminar, en cambio con el algoritmo es sistemático, por lo tanto rápidamente localizable y eliminable. Es raro que un buen analista estructure un sistema ruidoso de un área. Entre áreas o instituciones al ruido se lo analiza con dos relaciones entre el conjunto de mensajes enviados (X) y el conjunto de mensajes recibidos (Y). Las dos relaciones dan como resultado la información neta transmitida (T). T = H(X) H(X/Y). (3) T = H(Y) H(Y/X). (4) En la (3) la expresión H(X/Y) es lo que se llama equivocación que resulta de una probabilidad condicional cuando no se conoce X pero si se conoce Y. En la (4) la expresión H(Y/X) es lo que se llama ruido que resulta de una probabilidad condicional cuando no se conoce Y pero si se conoce X. 1417
149 Como la equivocación puede también producir ruido, ambos son ruidos y no se entrará en detalles sobre los cálculos. 2.3 Impedancia y máxima transferencia La impedancia generalizada se define como la mayor o menor oposición a un flujo y está íntimamente relacionada con la entropía. En electricidad, en general, los mejores conductores tienen una mayor entropía/mol o sea un mayor grado de libertad. En los sistemas de información, al tener una entropía las estructuras de datos, se presenta una impedancia al flujo de información y cuando se acoplan dos estructuras siguen las reglas de máxima transferencia. Es decir que una condición óptima de transferencia de información se logra cuando las impedancias de las estructuras son iguales, y esto implica que las entropías tienen que ser iguales o lo más parecida posible. Puede resultar obvio afirmar que no basta que dos elementos tengan la misma entropía o impedancia para lograr un flujo entre ellos. Los dos elementos y el flujo además deben manejar los mismos códigos o tipo de mensajes. Por más que un amplificador de audio tenga la misma impedancia que un timbre no se logrará mucho conectándolos. Lo mismo sucederá si se trata de enviar información desde una base de datos personales a una base de exámenes de un mismo sistema, por más que tengan igual entropía. 3 El análisis intuitivo basado en la teoría de la Comunicación. 3.1 El análisis de la fuente En primer lugar se debe eliminar toda posibilidad de ruido en la misma fuente. Al respecto no es mucho lo que se le puede aconsejar hoy a un programador o analista porque puede quedar como un atrevimiento. Pero si vale hacer notar algunos aspectos desde la teoría de la comunicación. Cuando se estructura la información separando en bases o tablas para eliminar la redundancia, no perder de vista que se está aumentando la entropía del sistema y por ende la libertad de mensajes y la riqueza de información. Esto también aumenta la probabilidad de errores (ruido) y también llega un momento en el que la redundancia vuelve con el consecuente aumento de memoria ocupada, por lo que se sabe que existe un límite a partir del cual ya no conviene separar más. En lo posible, toda información que se pueda obtener por cálculo de otra, que no forme parte de la estructura de datos (redundancia). El primer contacto con el exterior de la estructura, que está codificada, es el usuario. El decodificador y adaptador de impedancias es el programa que lleva la información a la pantalla. La estructura pertenece al mundo del analista con una cierta impedancia, la pantalla pertenece al mundo del usuario con otra impedancia. No contemplar esta situación produce una enorme fuente de ruido. 1418
150 3.2 Interacción de la fuente con otras fuentes de información. Dentro de una institución universitaria como una unidad académica, las principales áreas que pueden interactuar son Personal, Alumnos, Biblioteca, Cátedras, Mesa de Entradas, Concursos, Decanato, Consejo, Comisión de Autoevaluación y un área virtual de infraestructura y otra de equipamiento científico. Desde el punto de vista del ruido lo peor para un canal de comunicación es el papel impreso y lo mejor un centro de información y cómputos, que interconecte y coordine mediante algoritmos las distintas áreas, sin afectar a ninguna estructura y atendiendo las necesidades de la institución. Se debe tener en cuenta que si se conectan cátedras con dirección alumnos, los mensajes son semejantes por lo que se debe cuidar la adaptación de impedancias. El intercambio de información con instituciones evaluadoras o centrales recolectoras de información es más complicado, aunque no imposible, porque las estructuras fueron creadas con distinto criterio. En esos casos se hace imprescindible la coordinación entre analistas y autoridades para solucionar las diferencias de impedancia. 3.3 Algunos ejemplos de ruidos evitables. De las formas que se pueden enviar datos se destacan los datos sin procesar y los procesados. La ventaja de la primera forma es que el ruido es mínimo y prácticamente solo depende del destinatario cuando los procese. Esto se da generalmente en los casos de comunicación interna entre áreas de una misma institución, y el que decodifica la información en el receptor puede ser el responsable de todo el sistema. Cuando el envío es hacia fuera de la institución hay necesariamente una doble comunicación. Antes tuvo que existir un pedido de la información, donde en ese momento el destinatario fue fuente, en donde se explicitan los datos requeridos. Por ejemplo que se envíe una base de datos que registre los cargos docentes del ciclo básico y la base que registre los alumnos inscriptos por materia en el ciclo básico en el presente año lectivo, sin datos personales. El mensaje recibido no es ambiguo (no tiene ruido) siempre y cuando alguien, por ignorancia, no interprete que la dedicación no se pide, porque la categoría y la dedicación están incluidas en la palabra cargo. Será entonces una transferencia directa de determinados datos con un mínimo de ruido. Envíe la relación alumnos/docentes por materia del ciclo básico en el presente ciclo lectivo sería un ejemplo para un pedido de datos procesados. Este es un caso típico de generación de ruido, ya que las respuestas pueden ser muy variadas al ser las impedancias muy diferentes entre un mensaje procedural y un sistema relacional. Algunos interpretarán que los docentes son personas, otros que son cargos puesto que un docente puede tener varios cargos, otros que son horas docentes y otros si se deben poner solamente los cargos reales y no los interinos por conversión. Lo mismo sucede si una señal electromagnética se encuentra con una impedancia diferente generando un desparramo de frecuencias. Al menos que previamente exista, en la fuente que va a enviar la información, un algoritmo acordado con el destinatario que haga las veces de adaptador de impedancias. 1419
151 4 Conclusiones. La introducción en este trabajo de la teoría de la comunicación de Shannon es sólo a título de muestra de que la información se mide y existe la forma de calcularla y está hecha con el convencimiento de que muchos analistas del medio lo aplican. Para aquellos que no lo hacen, el tener una idea intuitiva de lo que sucede o puede suceder, en la interacción de sistemas, con sólo una mirada de las estructuras de datos con el concepto de impedancia, lo que puede lograr es muchísimo. Hace poco un profesional difundía por correo electrónico un pedido de un instrumento de determinadas características. Ya debería ser cotidiano entrar al sistema universitario y ubicar exactamente donde se encuentra ese y otros instrumentos, o que en una reunión de consejo los miembros tengan acceso directo por computadora a toda la información de la institución a la que pertenecen, como por ejemplo con cuántas aulas y laboratorios se cuenta, o los metros cuadrados, o datos de docentes y alumnos etc. Lo mismo necesita un decano si necesita tomar una decisión estratégica antes de difundirla. Avanzar en la conexión de sistemas universitarios es un gran desafío, no solo para los analistas sino que exige profundizar más en las políticas de información. Referencias 1. W. Hartman: Manual de los Sistemas de Información, Ed. Paraninfo (1989) 2. Santiago Montes: Teoría de la Información - - Pablo del Río,Editor (1976) 3. Bateson Birdwhistell: La nueva Comunicación - -Editorial Kairós (1984) 4. M. Ferreyra: Data_Mining_basado_Teoria_Informacion_Marcelo_Ferreyra.pdf (2007) 5. Enrico Fermi: Termodinámica - Manuales EUDEBA 6. H.Haken: Synergetics An Introduction - Springer-Verlag Berlin Heidelberg New York (1978) 7. J.L. Jolley; Ciencia de la Información;; Ediciones Guadarrama, S.A (1968). 8. Norbert Wiener; Cibernética;; Ed. Metatemas (1998) 9. Sebastian Seeligmann: Política de Información Universitaria. 4 Encuentro Nacional y Latinoamericano La Universidad como Objeto de Estudio (2005) 1420
152 Análisis del grado de cumplimiento de Pautas de Accesibilidad al Contenido Web a través de la medición y evaluación de Calidad Cecilia Gallardo 1, Oscar Quinteros 1 1 Departamento de Informática, Facultad de Tecnologías y Ciencias Aplicadas, Universidad Nacional de Catamarca ceciliagallardo@tecno.unca.edu.ar, oequinteros@tecno.unca.edu.ar Resumen. La calidad del software, es una compleja combinación de factores que se evalúa por medio de la cuantificación de conceptos de abstracción de bajo nivel. El estándar ISO [1] define dentro del modelo de Calidad de Producto Software la sub-característica Accesibilidad, la cual mide el grado en que un sistema puede ser utilizado por personas independientemente de sus capacidades en un contexto de uso especificado. Por otra parte, la Iniciativa de Accesibilidad Web, desarrolló las Pautas de Accesibilidad para el Contenido Web (WCAG 2.0) [2], detallando cómo hacer el Contenido Web más accesible a las personas con discapacidad. En este trabajo proponemos la construcción de un modelo de calidad basado en las WCAG 2.0, cuyos atributos puedan ser cuantificados mediante el diseño de métricas e indicadores que permitan evaluar la Accesibilidad de una Aplicación Web, siguiendo las especificaciones de la Estrategia Integrada de Medición y Evaluación de Calidad GOCAME [3]. Palabras Clave: accesibilidad web, calidad del software, métricas, indicadores. 1 Introducción El principal objetivo de la ingeniería del software es obtener una aplicación o producto de alta calidad, con esto en mente, deben emplearse métodos y herramientas efectivas dentro del contexto de un proceso maduro de desarrollo del software [4]. La calidad del software podría definirse como: una relación abstracta entre los atributos de una categoría de entidad y una necesidad de información específica, que se puede constatar en diferentes niveles organizacionales [5] Dada la complejidad interna que un concepto de calidad implica, es necesario definir un modelo para especificar los requisitos de calidad. Mediante estándares como ISO :2001 [6] y 25010:2011 [1] se han tratado de determinar y categorizar los factores que afectan a la calidad del software proponiendo un modelo de calidad de 3 vistas: Calidad Interna, Calidad Externa y Calidad en Uso [7]. Por otra parte, el estándar ISO 25010:2011 define el conjunto de características y relaciones entre ellas que sirven de base para la especificación de requisitos de calidad 1421
153 y evaluación de la calidad, proponiendo 2 modelos de calidad: Calidad en Uso y Calidad de Producto Sistema/Software. El modelo de Calidad de Producto Sistema/Software, el cual es objeto de estudio de este trabajo, define entre otras, a la sub-característica Accesibilidad, la cual mide el grado en que un producto o sistema puede ser utilizado por personas con la más amplia gama de características y capacidades para lograr un objetivo determinado en un contexto de uso especificado [1]. Desde otro contexto, la Iniciativa de Accesibilidad Web (WAI) [8], donde se desarrollan estrategias, pautas y recursos para ayudar a hacer la Web accesible para personas con discapacidad, afirma que la Accesibilidad Web significa que también las personas con discapacidad puedan percibir, entender, navegar e interactuar con la Web, y así también contribuir a la Web [9]. Uno de los desarrollos de la WAI, que son considerados estándares internacionales para la accesibilidad Web, son las Pautas de Accesibilidad para el Contenido Web (WCAG) [10], cuyos documentos explican cómo hacer el contenido Web más accesible a las personas con discapacidad. La última versión técnica estable de WCAG es la 2.0 [2] y cuenta con 12 pautas que se organizan bajo 4 principios. A su vez, para cada pauta, existen criterios de éxito comprobables, en tres niveles: A, AA y AAA. Consideramos en este trabajo que es posible llevar a cabo un conjunto de actividades para la especificación, recolección y uso de métricas e indicadores que permitan medir y evaluar las características de Accesibilidad que posee una Aplicación Web. Sin embargo, es necesario contar con una estrategia de seguimiento y evaluación de calidad que considere a la vez tres capacidades: una especificación del proceso de Medición y Evaluación (M&E); un marco conceptual de M&E y claras especificaciones de métodos y herramientas, para lograr un análisis y proceso de toma de decisiones más robusto [11]. Es por eso, que hemos seleccionado para llevar a cabo este trabajo, la estrategia integrada de M&E GOCAME (Goal-Oriented Context- Aware Measurement and Evaluation), la cual soporta las 3 capacidades mencionadas anteriormente. El presente trabajo se centrará en el diseño de métricas e indicadores que permitan evaluar la Calidad Externa de una Aplicación Web, planteando un subconjunto de características y atributos de la Sub-Característica Accesibilidad del modelo de Calidad de Producto Sistema/Software estandarizado en ISO Para realizar esto, se utilizará la estrategia GOCAME para las tareas de medición y evaluación. También para el diseño de los requerimientos no funcionales y métricas referidas a la accesibilidad, se tendrán en cuenta algunos Criterios de Conformidad Nivel A de WCAG 2.0. A modo de ejemplo, se documentarán las definiciones de atributos y diseño de métricas e indicadores para un grupo reducido del árbol de requerimientos planteado. En la etapa de Implementación de la medición y evaluación, se tomará a modo ejemplificativo un formulario de la Aplicación Web de la ciudad de Buenos Aires para determinar el grado de cumplimiento de las características y atributos definidos en el árbol de requerimientos no funcionales para accesibilidad. 1422
154 2 Estrategia GOCAME GOCAME es una estrategia integrada de M&E que sigue un enfoque orientado a objetivos, sensible al contexto y centrada en la necesidad de información de una organización. Soporta de manera simultánea tres capacidades [11]: 1) Un marco conceptual centrado en una base terminológica y estructurado en seis componentes denominado C-INCAMI (Contextual-Information Need, Concept model, Attribute, Metric and Indicator) que permite especificar los datos y metadatos utilizados en las actividades y artefactos del proceso. 2) Especificaciones de proceso de M&E desde diferentes puntos de vista, es decir, perspectivas funcionales, organizacionales, de comportamiento y de información. Se compone de seis actividades principales: definir los requisitos no funcionales; diseñar la medición; implementar la medición; diseñar la evaluación; implementar la Evaluación, y analizar y recomendar. 3) La metodología WebQEM (Web Quality Evaluation), que proporciona el cómo implementar los requerimientos, la medición, evaluación, análisis y actividades de recomendación. 3 Pautas de Accesibilidad para el Contenido Web La organización W3C [12], con el objeto de guiar la Web hacia su máximo potencial, incluye la promoción de un alto grado de usabilidad para personas con discapacidad. La Iniciativa de Accesibilidad Web (WAI) [8] desarrolla su trabajo reuniendo a un grupo variado de gente para desarrollar pautas y recursos para ayudar a hacer la Web accesible para las personas con discapacidades auditivas, cognitivas, neurológicas, físicas, y visual. Una de las guías desarrolladas por WAI se denomina Pautas de Accesibilidad para el Contenido Web (WCAG), donde se define cómo crear contenido web más accesible para las personas con discapacidad y son consideradas como estándares internacionales de accesibilidad Web. Estas pautas también ayudan a que el contenido sea más usable para las personas mayores y mejoran la usabilidad para los usuarios en general. La última versión estable de las WCAG es la 2.0 [2], las cuales se basan en las WCAG versión 1.0, y proporcionan varios niveles de orientación: principios, pautas, criterios de conformidad y técnicas suficientes y recomendables que actúan en conjunto para proporcionar una orientación sobre cómo crear un contenido más accesible. 4 Desarrollo de la M&E en el Caso de Estudio 4.1 Actividad 1: Definición de Requerimientos no funcionales 1423
155 Se debe establecer aquí la Necesidad de Información, la cual se define para el caso de estudio, como sigue: Definición de Necesidad de Información. Para este caso de estudio se plantea comprender y mejorar la Calidad Externa del sub-concepto Accesibilidad de la Aplicación Web de la ciudad de Buenos Aires. Propósito: comprender y mejorar. Punto de vista de usuario: diseñadores y desarrolladores web. Concepto Calculable: calidad externa del sub-concepto Accesibilidad del Modelo de Calidad de Producto Sistema/Software de ISO Categoría de entidad: Aplicación Web (Sistema). Ente: formularios de la Aplicación Web de la ciudad de Buenos Aires ( Selección de un Modelo de Conceptos. En este trabajo se definió un modelo que extienda al modelo de Calidad de Producto Sistema/Software de ISO 25010, para cumplir con la necesidad de información planteada. Para la elaboración del modelo se realizó una correlación entre sub-conceptos y atributos del modelo de conceptos y las pautas, principios, criterios de conformidad nivel A y técnicas suficientes de HTML de las WCAG 2.0. Cabe destacar que para ejemplificar el análisis, solo se definieron los atributos para el sub-concepto Asistencia en el ingreso de datos en formularios, el cual permite evaluar el Ente definido en la Necesidad de Información. El modelo de conceptos o árbol de requerimientos resultante es el siguiente: Principio Perceptible 1. Accesibilidad 1.1. Perceptibilidad de la información y componentes de IU Principio Operable 1.2. Operabilidad de componentes de IU y de navegación Pauta 3.3 de WCAG 2.0 Criterios de Conformidad Nivel A de WCAG Comprensibilidad de la Información y del manejo de IU Principio Comprensible Asistencia en el ingreso de datos en formularios Identificación de errores apropiada Uso de notificación textual de error para campos obligatorios Notificación textual de error apropiada para campos con determinado formato Identificación de componentes de formularios apropiada Representatividad de texto de etiquetas Identificación adecuada de controles de formulario con determinado formato Identificación adecuada de campos obligatorios Asociación adecuada de etiquetas con controles de formularios Etiquetas de texto de controles de formularios ubicadas adecuadamente 1.4. Robustez del contenido Principio Robusto Fig. 1. Árbol de requerimientos para evaluar la Accesibilidad de una Aplicación Web 1424
156 Definiciones de conceptos, sub-conceptos y atributos del árbol de requerimientos. Por razones de espacio y simplicidad, a partir de aquí se tomará el atributo para ejemplificar la implementación del caso de estudio. Definición del Atributo (Uso de notificación textual de error para campos obligatorios) Cuando el sistema presenta un formulario para el ingreso de datos y el mismo contiene campos obligatorios, se debe informar al usuario mediante una descripción de texto en el caso de que no se hayan completado dichos campos obligatorios para identificar cuál o cuáles campos se omitieron. Es importante que exista una notificación textual para que sea accesible a todos los usuarios y tecnologías de asistencia. Objetivo: Encontrar el grado en que el sistema, para todos los formularios del caso de estudio, notifica al usuario mediante una descripción de texto, sobre un error producido cuando dicho usuario envía los datos de un formulario sin haber completado cada campo indicado como obligatorio. 4.2 Actividad 2: Diseño de la Medición Para el presente caso de estudio, fue necesario definir y acordar cada una de las métricas utilizadas. Una muestra de las mismas se puede ver en la tabla 1: Tabla 1. Métricas para el atributo Uso de notificación textual de error para campos obligatorios Tipo / Nombre Metrica Indirecta - Porcentaje de notificación textual de error para campos obligatorios (%NTCO) Métricas relacionadas: 1) Numero de notificaciones textuales de campos obligatorios (#NTCO) 2) Total de campos obligatorios (#CO) Directa - Numero de notificaciones textuales de campos obligatorios (#NTCO) Atributo: Cantidad Objetivo Determinar el porcentaje entre el número de notificaciones de error para campos obligatorios que no han sido completados y el número total de campos obligatorios, sobre el total de formularios del sistema. Determinar el número de notificaciones textuales de error que se emiten para campos Método de Cálculo Medición Especificación de Fórmula: n=número de formularios que intervienen en el estudio Si = 0 => = 1 ya que no se considera como una situación de incumplimiento sino de inexistencia de campos obligatorios. Especificación: en un formulario, dejar todos los campos en blanco y pulsar el botón para enviarlo. Agregar 1 (uno) por cada notificación mediante o Escala Numérica Representación: Continua Tipo de valor: Real Tipo de escala: Proporción Unidad: Porcentaje Acrónimo: % Representación: Discreta Tipo de valor: Entero Tipo de escala: Absoluta 1425
157 de notificaciones textuales de error para campos obligatorios Directa Total de campos obligatorios (#CO) Atributo: Cantidad de campos obligatorios de un formulario obligatorios que descripción de texto que no han sido identifica un campo obligatorio completados que no se completó. correspondientes a La notificación puede provenir un formulario. del lado del cliente y/o del servidor. Tipo: objetivo Determinar el Especificación: en un número de formulario, dejar todos los campos indicados como obligatorios correspondientes a un formulario. campos en blanco y pulsar el botón para enviarlo. Agregar 1 (uno) por cada campo que le sistema notifique de alguna manera que debe ser completado. Tipo: objetivo Unidad: Notificación textual Representación: Discreta Tipo de valor: Entero Tipo de escala: Absoluta Unidad: Campo obligatorio 4.3. Actividad 3: Diseño de la Evaluación Se deben identificar aquí dos tipos de indicadores: Elemental, el cual interpreta el valor de un atributo mediante el uso de un modelo elemental, e Indicador Global, que permite evaluar un concepto de alto nivel de abstracción y su valor se deriva de otros indicadores haciendo uso de un modelo global. Identificación de Indicadores elementales. Para el presente caso de estudio, se diseñará un solo Indicador Elemental para evaluar de igual manera todas las métricas resultantes. Los valores obtenidos a partir del modelo elemental del indicador planteado, serán números entre 0 y 100, debido a que el tipo de escala será numérica y su unidad será porcentaje. Por otra parte, el mapeo será directo, es decir, el mismo valor obtenido de cada métrica por medio de la medición será el valor del indicador. A continuación, se muestra la definición genérica del indicador: Tabla 2. Definición del Indicador Elemental Nombre Indicador Elemental GCA: Grado de cumplimiento del Atributo(j) j = atributos del árbol de requerimientos Especificación Modelo Elemental GCA(j) = Valor Metrica(j) j = atributos del árbol de requerimientos Criterio de Decisión Niveles de aceptabilidad: Insatisfactorio. Indica que acciones de cambio deben tomarse con una alta prioridad. Rango: 0 GCA(j) 60 Regular. Indica una necesidad de acciones de mejora. Rango: 60 < GCA(j) 95 Satisfactorio. Indica una calidad satisfactoria de la Escala Numérica Representación: Continua Tipo de valor: Real Tipo de escala: Proporción Unidad: Porcentaje Acrónimo: % 1426
158 característica analizada. Rango: 95 < GCA(j) 100 Identificación de Indicadores globales. El Modelo Parcial/Global utilizado para todos los indicadores globales y parciales será representado por la función: IG = (W1 * I1 + W2 * I Wj * Ij ) (1) Donde IG representa el indicador parcial o global a ser calculado; I i son los valores entre 0 y 100 de los indicadores del nivel más bajo; W i representa los pesos correspondientes a los atributos y subconceptos los cuales se consideran que son equivalentes por tener igual importancia todos los atributos en un mismo nivel del árbol. El Criterio de decisión a utilizar será el mismo que el definido para los indicadores elementales Actividad 4: Implementación de la Medición y Evaluación Para ejemplificar estas tareas, hemos consideramos el formulario Saca tu turno de la Aplicación Web de la ciudad de Buenos Aires ( Cabe aclarar que para obtener una conformidad con las WCAG 2.0, se deben considerar en el análisis todas las páginas y sus elementos pertenecientes al sitio o aplicación web. A continuación se muestran los valores obtenidos para las métricas de los atributos y el valor de indicadores, considerando el formulario mencionado anteriormente. Tabla 3. Valores de Indicadores y Métricas para el formulario Saca tu Turno Concepto/Subconcepto/Atributo Métrica Indicador Elemental Ind. parcial / global Asistencia en el ingreso de datos en formularios 70% Identificación de errores apropiada 100% Uso de notificación textual de error 100% 100% para campos obligatorios Notificación textual de error apropiada 100% 100% para campos con determinado formato Identificación de componentes de 40% formularios apropiada Representatividad de texto de etiquetas 100% 100% Identificación adecuada de controles 0% 0% de formulario con determinado formato Identificación adecuada de campos 0% 0% obligatorios Asociación adecuada de etiquetas con 0% 0% controles de formularios Etiquetas de texto de controles de formularios ubicadas adecuadamente 100% 100% 1427

159 4.5. Actividad 5: Análisis y Recomendación De acuerdo a los resultados, observamos que el grado de cumplimiento del subconcepto Asistencia en el ingreso de datos en formularios es del 70%, es decir que según el criterio de decisión definido para el indicador global, es necesario que se implementen acciones de mejora. Los atributos que tienen un grado cero de cumplimiento son aquellos referidos a la identificación de los campos ya sean obligatorios o con un formato requerido y la asociación de las etiquetas con los controles de formularios. Como se observa en la figura 2, no existe ninguna indicación de requerimientos para estos campos, pero si existen notificaciones de error en el caso de no completarlos o de ingresar un valor incorrecto como en el caso del campo N de documento que acepta solo valores numéricos, sin guiones. Fig. 2. Visualización de notificaciones textuales de error por campos requeridos o que requieren un formato particular 5 CONCLUSIONES En este trabajo, hemos analizado las Pautas de Accesibilidad al Contenido Web 2.0, las cuales consideramos que constituyen una muy buena orientación para plantear finalmente un modelo de calidad general, mediante la construcción de un árbol de requerimientos no funcionales, determinando las características y sub-características necesarias para poder calcular el nivel o grado de la Accesibilidad de una Aplicación Web. Por cada Pauta y Criterio de Conformidad de las WCAG 2.0 hay asociadas Técnicas Suficientes para satisfacer los Criterios de Conformidad según el nivel de accesibilidad requerido. A su vez, generalmente cada Técnica Suficiente se relaciona con un ítem y/o evento de bajo nivel de la Aplicación Web, que en este trabajo fue traducido como uno o varios atributos del árbol de requerimientos no 1428
160 funcionales. Cabe aclarar, que para el desarrollo del trabajo, solo se definieron un conjunto limitado de atributos que permiten evaluar el cumplimiento del nivel A (el nivel más bajo) de una de las pautas de WCAG 2.0: Pauta 3.3 Entrada de datos asistida, tomando en cuenta las técnicas suficientes para la tecnología HTML. La cuantificación los atributos se realizó mediante el diseño e implementación de métricas e indicadores, conforme a la estrategia de medición y evaluación de calidad GOCAME, la cual posee un robusto conjunto de especificaciones de métodos, procesos y marco conceptual que consideramos apropiados para aplicar en este contexto de análisis. En futuros trabajos se puede concluir con la definición del resto de los atributos y el diseño de sus métricas e indicadores para evaluar finalmente la Accesibilidad en su totalidad. Así también, se podrían considerar las herramientas disponibles para evaluar la accesibilidad de Aplicaciones Web, de acuerdo al cumplimiento de las WCAG 2.0, de modo que sean de ayuda al momento de implementar las métricas para medir un atributo en particular. Referencias 1. ISO/IEC Systems and software engineering Systems and software product Quality Requirements and Evaluation (SQuaRE) System and software quality models (2011) 2. Web Content Accessibility Guidelines (WCAG) 2.0, Recomendación del W3C, Diciembre de 2008, Disponible en: Fecha consulta: Mayo de Papa, F.: Aseguramiento de Calidad de Software. Estudio Comparativo de Estrategias de Medición y Evaluación, Tesis de Magister, La Plata (2011) 4. González Doria, H.: Las Métricas de Software y su Uso en la Región, Tesis de Grado, México (2001) 5. Olsina, L., Papa, F. y Molina, H.: How to Measure and Evaluate Web Applications in a Consistent Way. En G. Rossi et al. (Eds.), Web Engineering: Modeling and Implementing Web Applications (pp ). London: Springer. (2008) 6. ISO/IEC :2001. Software Engineering - Software Product Quality - Part 1: Quality Model, Int l Org. For Standardization, Geneva (2001) 7. Estayno, M., Dapozo, G., Cuenca Pletsch, L., Greiner, C.: Modelos y Métricas para evaluar Calidad de Software, XI Workshop de Investigadores en Ciencias de la Computación, Red de Universidades con Carreras en Informática (RedUNCI), Mayo de Disponible en: =1, Fecha consulta: Mayo de Web Accessibility Initiative (WAI), Página Oficial disponible en: Fecha consulta: Mayo de Introduction to Web Accessibility, Disponible en: Fecha consulta: Mayo de Web Content Accessibility Guidelines (WCAG) Overview, Disponible en: Fecha consulta: Mayo de Becker, P., Papa, F., Olsina, L.: Enhancing the Conceptual Framework Capability for a Measurement and Evaluation Strategy, Titulo Libro: Current Trends in Web Engineering, Editores: Quan Z. Sheng, Jesper Kjeldskov, pp , DOI / _11 (2013) 12. The World Wide Web Consortium (W3C), Página Oficial disponible en: Fecha de consulta: Mayo de
161 Visualizador de Estructuras de un Sistema Operativo Real con Fines Educativos Graciela De Luca 1, Martín Cortina 1, Nicanor Casas 1, Esteban Carnuccio 1, Sebastián Barillaro 1, Sergio Martín 1, Gerardo Puyo 1 1 Universidad Nacionald de La Matanza, San Justo, Buenos Aires Argentina {gdeluca, mcortina, ncasas, ecarnuccio, sbarillaro, smartin, gpuyo}@ing.unlam.edu.ar Resumen. El presente trabajo se centra en los avances relativos al desarrollo de una interfaz de depuración remota. Si bien el desarrollo de la interfaz y el graficador es genérico, inicialmente se basará en el sistema operativo S.O.D.I.U.M 1, del cual tenemos completo conocimiento y control. Para asegurar la interoperabilidad de nuestro desarrollo con el depurador GDB 2, se está analizando e incorporando un módulo remoto denominado gdbstub, que resuelve la comunicación a nivel lógico, implementando el protocolo RSP. Se analizan también las técnicas utilizadas por los depuradores modernos en cuanto a la implementación del mecanismo de breakpoints y el soporte que la arquitectura IA32 provee para facilitar dicha tarea. En función de esto estudiaremos también las responsabilidades que debe tener un manejador de excepciones de depuración por hardware. Palabras Clave: Visualizador - Sistema Operativo Educativo S.O.D.I.U.M. - Breakpoints - Gdbstub - Comunicación Serial 1 Introducción S.O.D.I.U.M. es un sistema operativo realizado con propósitos didácticos, que permite durante su ejecución la reconfiguración, cambiando los algoritmos utilizados por los administradores del sistema. Esto tiene como propósito didáctico permitir la comprensión y el análisis del funcionamiento interno del sistema operativo, pudiendo de esta manera adquirir competencias en la evaluación de los algoritmos y la elección de los sistemas operativos comerciales estableciendo rendimientos y comportamientos de acuerdo al entorno en el que se realiza la ejecución. Para esto la investigación se centra en la construcción de una aplicación con fines didácticos que permita la visualización gráfica del funcionamiento interno, estructuras de datos del sistema, valores de las variables, estados de los procesos en S.O.D.I.U.M., con el fin de modificar mínimamente la ejecución del sistema, se decidió realizar esta visualización en otra máquina, estudiando para este propósito los diferentes protocolos utilizados a tal fin. La enseñanza teórica tradicional de un sistema 1 Sistema Operativo del Departamento de Ingeniería de La Universidad de La Matanza 2 GNU Project Debugger 1430
162 operativo se basa principalmente en el estudio de una gran cantidad de bibliografía relacionada con el tema. La forma tradicional de la enseñanza universitaria está basada en proporcionar conocimientos teóricos y luego pasar a la práctica para aplicar la teoría aprendida, con esta propuesta se podrá estudiar distintos casos propuestos por el docente, analizando el comportamiento interno del sistema operativo, sin interferir prácticamente en su ejecución. En consecuencia, el desarrollo de una herramienta que permita visualizar el funcionamiento de un sistema operativo facilitará la enseñanza de los profesores a sus alumnos, dado que se podrá analizar el comportamiento de los distintos módulos del mismo en menor cantidad de tiempo. Otro de los beneficios, es que podrán visualizarse gráficamente los mecanismos utilizados por un sistema operativo real al momento de resolver problemas específicos. De esta forma el alumno podrá aprender más rápidamente su funcionamiento, pudiendo ver el estado del sistema en un determinado momento. La enseñanza tradicional de un sistema operativo se basa en tres pilares, los estudiantes modifican o amplían parte de un sistema operativo; ellos escriben código para demostrar aspectos de la tecnología en un sistema operativo comercial; además ejecutan código que simulan partes de la tecnología de un sistema operativo. El sistema operativo S.O.D.I.U.M. se construyó siguiendo la primera premisa. Como consecuencia a cada grupo se les asignó una investigación y el desarrollo de una sección determinada de este sistema operativo, con lo que su complejidad fue aumentando a medida que fueron pasando los años. A su vez, se fue incrementando la necesidad de poder visualizar gráficamente el funcionamiento, para apreciar el esfuerzo de tanto tiempo de trabajo y que luego éste pueda ser utilizado por otras instituciones educativas. Por lo tanto la investigación en curso se dispone a desarrollar un visualizador que permita la observación de su comportamiento 2 Estado del arte Las actuales aplicaciones que permiten visualizar el comportamiento de sistemas complejos, se diferencian en la manera en que estos han sido implementados, debido a que se desarrollan de acuerdo al entorno en el que van a ser utilizados. Simulación de máquina. Software que simula todos los componentes Hardware que constituyen una computadora con la finalidad de poder ejecutar un sistema. Gracias a esto se puede acceder totalmente al Hardware, en forma no intrusiva, y al estado del software utilizando simulaciones. Instrumentación en Tiempo Real: Otros sistemas usan el detalle del Hardware físico, Firmware e instrucciones de Software para observar el rendimiento de los sistemas en Tiempo Real. Los Sistemas de visualización descriptos en [2], [3] y [4] simulan una parte del funcionamiento de un sistema operativo para su enseñanza y aprendizaje. Esto trae como desventaja que el alumno puede no llegar adquirir los conocimientos necesarios sobre el funcionamiento completo de un sistema operativo. Dado que solo se estudia determinadas funcionalidades de dicha plataforma. Además, no se estaría trabajando con Hardware real, ya se emplean en entornos simulados. 1431
163 Por otra parte se encuentra el Sistema Rivet [1], que si bien trabaja con hardware físico en tiempo real y permite la creación rápida de prototipos para mostrar datos puntuales, no está orientado al ámbito educativo sino más bien al análisis de rendimiento de Sistemas. En consecuencia a lo anteriormente mencionado, se pretende que el Visualizador del sistema operativo S.O.D.I.U.M. sea una aplicación destinada para el estudio educativo sobre el funcionamiento completo de un sistema operativo tradicional. Por lo que se procurará representar gráficamente las características más importantes que el sistema ya posee. El cual además, incorporará las funcionalidades más significativas de los visualizadores previamente descriptos. Para ello, se procura que pueda ser utilizado tanto en entornos simulados como reales, brindando de esta forma mayor libertad a los usuarios, ya que se estará otorgando la posibilidad de que dicho visualizador pueda ser ejecutado tanto en la misma terminal en donde se estará ejecutando S.O.D.I.U.M. como en otra distinta. De esta forma se obtiene una gran diferencia con respecto de los visualizadores existentes, ya que se estaría trabajando tanto en un entorno real como simulado, pudiendo visualizar el completo funcionamiento de un sistema operativo real. Cabe mencionar, que para poder efectuar la comunicación entre la maquina servidor, donde se estará ejecutando S.O.D.I.U.M. y la maquina cliente, donde se estará ejecutando el visualizador del sistema, se desarrollaron distintos mecanismos de comunicación serial. Los cuales permiten el intercambio de datos entre programa visualizador y el sistema que se desea graficar. 3 Visualizador del Sistema Operativo S.O.D.I.U.M. En el escrito [5], se describe de qué forma se planea construir la aplicación del Visualizador del S.O.D.I.U.M.. En él se plantea que dicho software sea desarrollado de manera tal que pueda ser utilizado por los usuarios de dos formas distintas: a.- Ejecutando S.O.D.I.U.M. en una máquina virtual b.- Ejecutado S.O.D.I.U.M. en una máquina física. Utilizando la primera alternativa mencionada, el alumno podrá ejecutar una imagen del sistema operativo en una máquina virtual dentro de una misma plataforma, y al mismo tiempo interactuar con este utilizando el programa visualizador. Seguidamente, en la figura 1 se muestra como se implementaría la aplicación en la misma terminal. Si bien un entorno simulado no presenta, en su totalidad, las mismas características que una maquina real, se determinó que era conveniente desarrollar esta opción para el caso en particular en que los educadores y estudiantes no posean dos terminales en donde realizar las pruebas pertinentes con el Visualizador de S.O.D.I.U.M. En consecuencia, los usuarios podrán ejecutar el paquete completo del Visualizador en la misma terminal, utilizando la máquina virtual Bochs para poder ejecutar una imagen compilada de S.O.D.I.U.M. dentro de un entorno de trabajo bajo Linux. Esto es importante debido a que la utilización de dicha VM permite trabajar emulando casi en su totalidad las mismas prestaciones que ofrece el hardware de una máquina real en una computadora totalmente distinta. 1432

![4 Conexión entre terminales Como se mencionó en [5], con el objeto de conseguir la comunicación entre visualizador y sistema operativo, se desarrolló un driver que permite el intercambio de datos a](/docs-images/18/814221/images/164-0.jpg "través de los puertos serie.")
164 Por otra parte se está desarrollando la posibilidad de ejecutar S.O.D.I.U.M. en una máquina real conectada a otra terminal en donde se estará ejecutando el Visualizador. Por dicho motivo, en la figura 2 se podrá observar esta situación en particular. Fig. 1. Representación gráfica de la ejecución del visualizador y S.O.D.I.U.M. en la misma terminal Fig. 2. Representación gráfica de la ejecución del visualizador y SODIUM en dos terminales. 4 Conexión entre terminales Como se mencionó en [5], con el objeto de conseguir la comunicación entre visualizador y sistema operativo, se desarrolló un driver que permite el intercambio de datos a través de los puertos serie. Por consiguiente, se consideró necesario establecer un contrato en la configuración de dicha conexión entre la aplicación cliente y servidor, con la finalidad de conseguir correctamente la transferencia de información. Utilizándose inicialmente una transmisión con el formato estándar 8N1, a una velocidad de transferencia de 9600 bps y utilizando un cable Null-Modem con conectores RS-232. Este acuerdo fue necesario dado que la rapidez de la transacción de datos depende fundamentalmente de factores físicos, tales como el modelo del chip UART utilizado y la longitud del cable serial. En consecuencia, se están realizando distintas pruebas utilizando un hardware determinado, con el objetivo de poder ir aumentando gradualmente la velocidad de transferencia de información. Intentando ver, la factibilidad de alcanzar la máxima velocidad posible de transferencia de bps a través de medios seriales. 1433
165 5 Visualización de Estructuras del Sistema Operativo Según [1], cualquier sistema visualizador debe ser capaz de gestionar grandes cantidades de datos, manipulándolos y realizando cálculos que permitan generar rápidamente prototipos para que el usuario pueda observar y comprender la información obtenida. Por consiguiente, se pretende que el visualizador reciba información sobre los componentes y estructuras del sistema operativo durante su ejecución, de forma que al recibir estos datos la aplicación generé automáticamente gráficos comprensibles por el estudiante. La interacción entre el usuario y el visualizador es la característica fundamental en el diseño de todo visualizador de un sistema complejo, dado que de esta manera el alumnado puede llegar a entender más rápido los conceptos. Por consiguiente, como el visualizador es un aplicación externa, se determinó que era conveniente investigar la forma de implementar un mecanismo que permita al usuario controlar la ejecución del sistema operativo remotamente. Así, el visualizador ofrecerá la posibilidad de detener las operaciones que realiza S.O.D.I.U.M. y ver el estado de sus componentes en el momento en que se desee. La primera parte del análisis, consistió en comprender el funcionamiento básico de los mecanismos utilizados por los debuggers para controlar la ejecución de cualquier programa. 6 Análisis de técnicas utilizadas por los Debuggers La tarea principal es detener la ejecución de los programas en determinados momentos establecidos por los usuarios, donde se podrá analizar su estado y el del procesador en ese instante, lo que se pretende realizar en S.O.D.I.U.M. imitando la esencia de dicho comportamiento. El corazón de todo depurador es el breakpoint, también conocido como punto de parada. Los cuales pueden ser clasificados según el mecanismo utilizado durante su desarrollo [6]. Los Breakpoints desarrollados por software son los más utilizados por los debuggers existentes. Esto es debido a su simplicidad y alcance durante su implementación. Si bien estos no presentan las mismas utilidades que los que ofrecen los desarrollados por Hardware, presentan el beneficio de poder ser utilizados en gran cantidad, mientras que los otros se limitan a utilizar únicamente cuatro puntos de paradas, como consecuencia de que dicha cantidad es determinada por los registros de la CPU DR 0, 1, 2 y 3. Otra diferencia destacable, es que para su implementación solo es necesario reemplazar un solo byte en la dirección de inicio de la instrucción donde se desea detener la ejecución, por el Opcode de la instrucción assembler Int3. Mientras que para la utilización de los breakpoint por hardware, es indispensable indicar en los registros DR0-DR3 la dirección en donde se desea detener la ejecución, e indicar además las condiciones que deberán cumplir esas direcciones en el registro DR7. Gracias al empleo del último registro nombrado, los HW Breakpoints pueden 1434
166 ser utilizados para detener la ejecución de un programa al momento de ejecutar una instrucción. Así como también, cuando se lean o escriban datos en una dirección particular de memoria. Esta característica puede llegar a ser provechosa, para la situación especial en que se desea detener la ejecución de S.O.D.I.U.M. cuando se escriban o lean datos en las direcciones asignadas a los puertos COM durante la comunicación con el Visualizador. En consecuencia, algunos debuggers solamente implementan breakpoints por Software. Sin embargo, también existen depuradores que utilizan ambas clases de puntos de paradas, como por ejemplo GDB. 6.1 Ejecución de Breakpoints implementados por Software Esto se puede realizar en el código del programa de dos formas distintas. La primera de ellas es insertando en el código fuente la instrucción assembler INT 3, pero este mecanismo únicamente puede ser utilizado antes de la compilación de la aplicación. La segunda posibilidad es la que llevan a cabo los debuggers, comentada en el punto anterior, que es reemplazar el Opcode de la instrucción a detener por el de Int3 (0xCC) durante la ejecución [7][8]. Por lo que después que se produce dicha sustitución, el sistema operativo deberá retroceder el registro EIP en un byte con la finalidad de ejecutar dicha instrucción. Una vez que se produce la ejecución de dicho comando, de cualquiera de las dos formas antes descriptas, se producirá una excepción 3, siendo capturado por el handler del sistema operativo luego de este evento. 6.2 Ejecución de Breakpoints implementados por Hardware Una vez configurados, los registros de parada, el procesador compara la dirección de la instrucción en ejecución con el valor contenido en los registros DR0-DR3, y si existe coincidencia posteriormente evaluará las condiciones de debug declaradas en el registro DR7. En el caso de las comparaciones sean satisfactorias, la CPU emitirá una excepción 1, la que deberá ser capturada por el handler en el Kernel del sistema operativo. Hasta el momento en las pruebas iniciales en la investigación en curso, se consiguió capturar dichos sucesos desarrollando los handlers correspondientes, de forma tal, que pudieron ser invocados utilizando la inserción de la instrucción INT en el código fuente de los programas utilizados en S.O.D.I.U.M. Actualmente, se está analizando la factibilidad de implementar la segunda posibilidad para la ejecución de los SW Breakpoints, que es la inserción del Opcode de la instrucción INT 3 durante la ejecución del sistema operativo, además se está determinando si es viable el desarrollo de los HW Breakpoints configurando los registros de la CPU. 1435
167 7 Análisis de Gdbstub GDB ofrece un módulo denominado Gdbstub [9] que permite analizar el funcionamiento de programas en entornos remotos. Esto es particularmente deseable donde estos entornos, por sus características de implementación (escases de recursos, ausencia de consola local, problemas de accesibilidad, etc.), no son capaces de darle al desarrollador la posibilidad de trabajar localmente. Este módulo se provee en forma de código fuente en lenguaje C como parte del kit de desarrollo del depurador GDB, del cual además se disponen varias implementaciones, cada una especializada para interactuar con una arquitectura de procesador en particular. El equipo desde donde se efectúa el control del programa principal es llamado host (huésped), mientras que la computadora donde está funcionando la aplicación a analizar es conocida como target (objetivo). Cabe mencionar, que entre ambas terminales se establece un vínculo por medio de una conexión serie. El propósito concreto de este módulo es el de implementar la capa lógica de comunicación entre el depurador GDB que se ejecuta en el equipo host y el programa o sistema a ser depurado en el target. Para ello se utiliza el protocolo RSP, que ya fue comentado en [5]. Al aislar al implementador de la necesidad de resolver el desarrollo de la capa lógica de este protocolo de comunicación, se gana estabilidad y robustez en la solución, permitiendo además enfocar el esfuerzo sobre la interacción específica de este módulo con el sistema operativo en sí mismo. Esta aislación se logra presentando al desarrollador una interfaz clara (contrato) donde se define una serie de métodos cuyas responsabilidades el mismo deberá implementar para facilitar al módulo gdbstub la obtención de información del sistema. Estas rutinas son las que permiten atender y responder los mensajes recibidos por el vínculo serial, Gdbstub implementa un handle-exception que toma el control cuando se detiene la ejecución del proceso, por ejemplo, en un breakpoint. En ese momento, handleexception se comunica con GDB en la máquina host. Handle-exception actúa como un representante de GDB en la máquina target. Comienza por enviar un resumen de información del estado del proceso. Luego, continúa la ejecución, recibiendo y transmitiendo cualquier información que GDB necesita. Cuando GDB ordena resumir la ejecución normalmente, Handle-exception devuelve el control al propio código de la aplicación en la máquina target. Cada vez que handle-exception es llamada, ésta tiene la oportunidad de tomar el control. Esto puede suceder todo el tiempo, inclusive cuando se reciben caracteres por la comunicación serial. De todas formas, se puede forzar la interrupción llamando a la función breakpoint. 1436
168 8 CONCLUSIONES Hasta la fecha en la investigación en curso, se consiguió establecer la base inicial de una de las funcionalidades esenciales que deberá ofrecer el visualizador de S.O.D.I.U.M. en cuanto a la interacción con el estudiante. A partir del handler desarrollado, se buscará que el usuario pueda detener la ejecución del sistema operativo en forma remota desde el visualizador. Posteriormente podrá observar detalladamente el estado del sistema en ese instante. En consecuencia, como se mencionó anteriormente, se está evaluando la factibilidad de desarrollar breakpoints por software y/o hardware así como también complementar las funcionalidades del handler construido con las que ofrece el módulo de Gdbstub. De esta manera, se está construyendo una de las partes fundamentales que tendrá el visualizador de estructuras de un sistema operativo con fines educativos. Referencias 1. Robert P. Bosch Jr., Using Visualization to Understand The Behavior of Computer System, Agosto Farzaneh Zareie y Mahsa Najaf-Zadeh OSLab: A Hand-on Educational Software for Operating System Concepts Teaching and Learning, Research WebPub, Septiembre Besim Mustafa, Visualizing the Modern Operating System: Simulation Experiments Supporting Enhanced Learning, Edge Hill University, SIGITE 11, Año Ali Alharbi, Frans Henskens, and Michael Hannaford, Integrated Standard Environment for the Teaching and Learning of Operating Systems Algorithms Using Visualizations, The University of Newcastle, Australia, IEEE, Año Graciela De Luca, Martín Cortina, Nicanor Casas, Esteban Carnuccio, Sergio Martín, Mecanismos de visualización de estructuras de un sistema operativo en ejecución a través de la comunicación serial, Universidad Nacional de La Matanza, Congreso WICC 2014, Ushuaia, Tierra del Fuego. 6. Intel, Intel 64 and IA-32 Architectures Software Developer s Manual, Mayo Debugging in AMD64 64-bit Mode in Theory, 8. How debuggers work: Part 2 Breakpoints, 9. Debuging Remote Program:, Debugging.html#Remote-Debugging 1437
169 Nodos para aplicaciones domóticas: requerimientos y funciones Daniel Villagrán 1, Paola Beltramini 1, Sergio Gallina 1, Juan P. Moreno 1, Marcos Aranda 1, Matias Ferraro 1 1 Facultad de Tecnología y Ciencias Aplicadas de la Universidad Nacional de Catamarca. Maximio Victoria 55 - San Fernando del Valle Catamarca Catamarca (4700) Tel: (0383) s: pbeltramini@tecno.unca.edu.ar, sgallina@tecno.unca.edu.ar, juanpablomoreno@gmail.com, marcos_dario_1@hotmail.com, matiasferraro@yhoo.com.ar, Resumen. En los últimos años se ha considerado el desarrollo de nuevas tecnologías de la comunicación e información para aplicar en la construcción de hogares o edificios inteligentes, a los que podemos llamar Edificios de alta tecnología. En base a esto han surgido desarrollos nuevos como el internet de las cosas IoT (Internet of Things), donde los objetos físicos están integrados en la red de información y son participantes activos de los procesos de control y la negociación de las distintas actividades del hogar inteligente. A estos objetos físicos, a los que nos referiremos como Nodos, se conectan cada uno de los elementos que dan funcionalidad al hogar. Si a ellos les damos un contexto de estandarización aplicando la Norma IEEE 1451.x tendremos Nodos inteligentes interoperables que pueden manejar cualquier objeto físico. En resumen, este trabajo define los requerimientos y funcionalidades que deben cumplir los Nodos aplicando la Norma IEEE para aplicaciones domoticas (Vivienda Inteligente). Palabras Clave: Nodo funciones - estandarización. 1 Introducción La presente publicación surge en continuidad al avance del proyecto Desarrollo de una Plataforma de Control de Entornos Residenciales, para el cual se han definido en varios de nuestros trabajos y publicaciones la forma de comunicación entre nodos, eligiendo como protocolo de comunicación el Internet 0, que nos permite compatibilizar la aplicación con internet IPV4 e IPV6 [1]. Asimismo, se estableció la estandarización de cada nodo a partir de la aplicación de la Norma IEEE 1451, desarrollando en nuestro caso el STIM y la comunicación con los sensores y actuadores, como así también la comunicación entre el STIM y el NCAP del Nodo [2]. Para poder continuar con la elaboración de la plataforma de control residencial, debemos desarrollar la aplicación que se implementará en cada nodo, por lo que, a 1438
170 través del presente trabajo, se pretenden definir las funciones que deben realizar los nodos en el control de una vivienda residencial. 2 Arquitectura de Red de Nodos Las comunicaciones son uno de los principales elementos de las redes de nodos (sensores, actuadores) y que más las caracterizan. Por otra parte son uno de los componentes clave de los sistemas domóticos ya que fijan la integración y la compatibilidad de los sistemas. Los siguientes párrafos profundizan un poco más en las características de este atributo de las redes de nodos. Todos los aspectos relacionados con las redes de nodos están diseñados y pensados para ofrecer un bajo consumo y siempre teniendo en cuenta las limitaciones de procesamiento y capacidad de los propios nodos. Además hay que tener en cuenta otras características propias de las mismas como son la no necesidad de una infraestructura predefinida o que los datos finalmente se redirigen a un nodo destino (o varios) en el que se envía la información a un nivel superior. La arquitectura de comunicaciones suele presentar una distribución por capas o niveles típicos de las redes de comunicaciones: un nivel físico, un nivel de acceso al medio y un nivel de enrutamiento o red, ejecutándose por encima del mismo las aplicaciones. El nivel físico suele presentar varias alternativas, alámbrica ya sea utilizando la red de alimentación, o cableado propio en la estructura de la misma (por ejemplo par trenzado); o inalámbrica como las implementadas con WiFi (IEEE ), Bluetooth (IEEE ), ZigBee (IEEE ), RFID (Radio Frequency Identification), etc., todos ellas contempladas en los estándares de la Norma IEEE Sobre el nivel físico se definen los protocolos de acceso al medio y transmisión básica de datos que constituyen el nivel 2 que son niveles OSI de comunicaciones (y cuya principal misión en permitir la comunicación entre dos dispositivos). Sobre esta última capa se definen una serie de protocolos que permiten el enrutamiento de paquetes y arquitecturas de red, y finalmente la aplicación que usa los servicios ofrecidos por el nivel inferior. A modo de resumen este nivel se encarga de funciones como el descubrimiento de vecinos, el mantener una topología de red, el enrutamiento de paquetes, está preparado para preservar la energía de los nodos, y otros servicios adicionales como la autenticación y encriptación, servicios de aplicación adicionales, etc. Una red de nodos puede adoptar tres topologías distintas: Estrella, en la que un existe un nodo central que está asociado con todos los demás nodos de la red y por el que pasan todos los mensajes. Árbol, en la que existe un nodo superior y del cual cuelga una estructura de ramas y hojas. Para alcanzar su destino, un mensaje viaja arriba o abajo a través de la jerarquía hasta lograrlo. Malla, que es similar a una estructura en árbol, pero en la que algunas hojas están directamente asociadas. Por otra parte vamos a definir tres tipos distintos de nodos en una red: 1439
171 Coordinador, encargado de arrancar la red, seleccionar el canal de comunicaciones y permitir la conexión de otros nodos. En una configuración en estrella es el nodo central y en las topologías de árbol y malla es el nodo más alto de la jerarquía. Nodo Final, que envía y recibe mensajes. Está optimizado para una bajo consumo y generalmente está dormido a no ser que tenga que trasmitir o recibir información. Son los nodos extremos en una topología de estrella y las hojas en la topología en árbol y malla. Nodo enrutador, que redirecciona mensajes de un nodo a otro y permite conectarse a sus hijos. Una topología en estrella no necesita nodos enrutadores, en una topología en árbol suelen estar situados de forma que se permitan el paso de los mensajes de arriba abajo (y viceversa) y en una topología en malla en cualquier lugar donde es preciso el paso de mensajes. Estos estándares de comunicaciones que hemos definido anteriomente permiten que dispositivos creados por distintos fabricantes puedan interrelacionarse. En el ámbito de este documento y de su aplicabilidad a la domótica o al control de edificios es además un elemento prioritario. En nuestro diseño al considerar que tenemos un red inteligente hay varios niveles de coordinadores, que estarán identificados por zona y por prioridad, pero sólo puede haber un coordinador general que será el de mayor prioridad activo. Una red domótica es inteligente cuando una vez automatizada, es dotada de sistema que contiene aplicación de alto nivel que gestiona dicha automatización, en base a lo hablado de la topología se considera que la mejor elección para la implementación de la plataforma es el nivel de arquitectura distribuida compuesto por nodos, cada uno de los cuales debe ser diseñado de forma tal de que puedan cumplir las funciones que se centran en cuatro objetivos básicos: energía, seguridad, confort y comunicación. 3 Nodo Inteligente Cada una de nuestras unidades funcionales (Nodo) están compuestas por: un Network Capable Application Processor (NCAP), un Smart Transducer Interface Module (STIM) y transductores (Sensor Actuador) [3]. Esta unidad se denomina nodo inteligente, siendo inteligente por ser autónomo y tener la capacidad suficiente para realizar una aplicación específica independiente de la red pero, simultáneamente, forma parte de una red compuesta por otros nodos inteligentes, y posee la capacidad para interactuar con ellos y constituir de esta manera un sistema. 1440

172 Fig. 1: Estructura de un nodo inteligente basado en el estándar IEEE Funciones del Nodo La mayoría de los sistemas domóticos se estructuran en tres grandes apartados. El primero es la comunicación con el exterior, que permite la gestión remota del sistema y que suele disponer de un elemento que enlaza esa parte exterior con los sistemas internos. El segundo es una red interna, local o doméstica que permite la conexión de todos los equipos y sistemas involucrados entre sí. El tercero son los propios equipos o métodos que proporcionan los servicios y funcionalidades necesarias. La gama de aplicaciones y servicios ofrecidos por este tipo de sistemas son muy amplias: seguridad, control de accesos, gestión de la energía (iluminación, climatización, aguas y riegos, etc.), monitorización y control (avisos y alarmas, monitorización de la salud, automatización de tareas domésticas, etc.), ocio y entretenimiento (equipos multimedia, cultura, etc.), comunicación con sistemas y servidores externos, operación y mantenimiento de las propias instalaciones, etc., tal como lo muesta la Figura 2. Fig 2 Implementación de nodos en una vivienda 1441
173 La introducción de todos estos sistemas y tecnologías en el hogar aún no es una realidad, salvo en muy contadas ocasiones, pero si hay muchas implementaciones de dispositivos (catalizadores) que ayudarán a que ello se realice rápidamente. Por una parte, cada vez existen más dispositivos electrónicos en el hogar, y eso provoca una necesidad real de comunicar unos con otros. En el momento de definir las funciones de los nodos algo que hay que tener en cuenta al evaluar la tecnología y los sistemas más adecuados para satisfacer sus necesidades que, fundamentalmente, se dirigen a hacer más amigable su relación con el entorno en el que pasa la mayor parte de su tiempo. En un sistema domótico, cada uno de los nodos que integran la red debe ser diseñado para cumplir con las funciones de ahorro de energía, seguridad, confort y comunicaciones [4]. Estas funciones pueden particularizarse de la siguiente manera: * Energía (ahorro): 1. Encendido y apagado automático de luces interiores/exteriores mediante la sensibilización de luminosidad y horarios. 2. Persianas automáticas para proveer mayor luminosidad. 3. Riego automático: por horario o por humedad; total o sectorizado. 4. Gestión eléctrica: gestión de consumo de energía, gestión de tarifa, tele-lectura de medidor. * Seguridad: 1. Simulación de presencia. 2. Alarmas: de intrusión, técnicas (incendio, humo, etc.) personal, video vigilancia. 3. Llamadas automáticas por teléfono ante anomalías. 4. Sistema anti-incendios. 5. Detección de gases tóxicos. 6. Detección de presencia. 7. Detección de fuga de agua. 8. Controles de acceso (Edificios) 9. seguridad eléctrica (desactivar enchufes). * Confort: 1. Temperatura ambiente: de confort o de economía, antihelada. Zonificación día/noche, norte/sur. 2. Climatización piscina. 3. Automatización de electrodomésticos. 4. Domoportero (posibilidad del uso de aparatos telefónicos pre-instalados como portero eléctrico). 5. Música ambiental. 6. Despertador. 7. Formación cultura y entretenimiento: TV, Equipo de música. 8. Posibilidad de consultar y controlar el sistema desde PC remota. 9. Sensor de viento (en nuestro caso tierra, jaja). 10. Monitorización de salud. 11. Operación y mantenimiento de las instalaciones. 12. Cuidado de mascotas 1442
174 * Comunicación: 1. Encendido o apagado de equipos mediante voz. 2. La forma como se comunica con la nube. También en una forma más detallada a la que hemos definido anteriormente, en base a las funciones que cumpla cada nodo podemos clasificarlos en: - Nodos de control estándar: controlan los parámetros de cada estancia. Cada uno soporta dos circuitos independientes de conmutación y dos entradas extra para sensores. - Nodos de supervisión: realizan la interfaz con el usuario. Cada función que el usuario necesita para supervisar y controlar el sistema está implementada en el correspondiente nodo. - Nodos exteriores: en este tipo se agrupan aquellos nodos que, si bien tienen una función especifica, se instalan en el exterior de la vivienda (sirena de alarma, iluminación exterior, riego). - Nodos de comunicaciones: se dedican específicamente a soportar la red de comunicaciones de la vivienda. Se pueden destacar un Nodo repetidor, en caso de necesidad de extender en longitud la red de comunicaciones de la vivienda (si supera los 1000 m), y un Nodo Router que se encarga de adaptar física y lógicamente medios de transmisión diferentes. 4 Instalación Consiste en la colocación de cada uno de los Nodos en su lugar correspondiente teniendo en cuenta las pautas que la topología del sistema de control requiera. Hay que examinar con detenimiento su ubicación, elegir un lugar desde donde se mida bien el valor o puedan actuar de forma correcta y que esté alejado de fenómenos externos que le puedan afectar. De acuerdo a sus funciones se muestra unas recomendaciones a la hora de realizar la instalación. Recomendaciones de instalación de sensores: Gas: A una distancia no superior a 1,5 m del aparato de gas doméstico más utilizado. Lejos de ventanas y extractores. En posición vertical. Los de gas natural o ciudad por encima del nivel de la posible fuga a 30 cm del techo. Los de gas butano o propano por debajo del nivel de la posible fuga a 30 cm del suelo. Alejado de humedades, calor, corrientes, grasa, polvo, etc.. Termostato: El de ambiente se centrará en la pared enfrente de la fuente de calor, a 1,5 m del suelo, en un lugar accesible. Lejos de Corrientes de aire. Sin incidencia directa del sol. Lejos de electrodomésticos. De temperatura: Igual que los termostatos. Las sondas de exterior se instalarán en la zona norte de la vivienda, sin incidencia directa del sol. Las sondas de suelo en el interior de tubos. Las sondas de contacto en tuberías, alejadas 1,5 m de la fuente de calor. 1443
175 Incendios: Los detectores de humo de tipo iónico u óptico no deben instalarse en la cocina. Deben instalarse en el techo de la estancia, centrados y a una distancia mínima de 50 cm de la pared. Humedad/agua: La sonda quedará en contacto directo con el suelo, evitando falsas detecciones. En cuartos de baño se seguirán recomendaciones del Reglamento Electrotécnico de Baja Tensión. Receptor de radiofrecuencia: En aplicaciones de alarmas técnicas, deben asegurar el alcance de la señal en toda la vivienda. De intrusión: Se colocarán en las esquinas de las estancias y en la parte superior, alejados de fuentes de calor. Se recomiendan los de tipo infrarrojo. La parte de imantada colocada en puertas o ventanas de los detectores perimetrales con contactos magnéticos se colocara en los marcos, en la parte contraria a las bisagras. 5 Automatización de las funciones de los nodos El diseño de nuevos sistemas domóticos, se basa en la descentralización de funciones. En otras palabras, desaparece el concepto genérico de central de gestión, para convertirse en la suma de módulos de funciones especializadas, que se interconectan a través de un bus doméstico de comunicaciones (en algunos sistemas, uno de estos módulos actúa como central de gestión, que controla al resto de módulos). Una de las virtudes de este tipo de sistemas es permitir una mayor modularidad y ampliabilidad del sistema. A voluntad del usuario, el sistema domótico podía crecer mediante la adición de nuevos módulos, cubriendo nuevas aplicaciones deseadas por el usuario, los cuales eran reprogramados (algunos de ellos) para permitir estas nuevas funciones. Además, el entorno residencial propuesto ya no sólo incluye Sistemas de Domótica, sino que también comprende Sistemas de Seguridad, Multimedia, Comunicación y Pasarelas Residenciales. Así pues, no se limitan solamente al ámbito de la domótica, sino que van más allá, llevando el concepto de digitalización a todos los subsistemas y aplicaciones del hogar y de los edificios. 6 Conclusiones Las necesidades de los dispositivos domésticos actuales muestran la tendencia natural de los sistemas domóticos. La estandarización y apertura de los protocolos hace que cada vez existan más productos y que los principales fabricantes quieran proclamarse como el estándar universal en ese tipo de aplicaciones. Hoy en día tenemos ya muchas redes en el hogar (redes multimedia, Internet, etc.) y dispositivos con una capacidad de procesamiento cada vez mayor (teléfonos, televisores, vídeos, etc.) y muchos de ellos con capacidad de comunicación, pero con sus propios controles y protocolos. Existen tendencias para la interoperabilidad de 1444
176 protocolos y cada fabricante suele ofrecer gateway a los principales sistemas. Esto implica necesidades de integración, pero sobre todo una integración de servicios. Nuestra propuesta que es la utilización de los nodos estandarizado en la Norma IEEE 1451 implementados en una red de comunicación I0 (Internet Cero), permiten contemplar esta posibilidad de un sistema de control residencial abierto, nos permitiría actualizar los nodos a las nuevos productos hogareños que salen al mercado y de la inhalación modular de los mismos. Con este estudio de la funcionalidades de los nodos, con los otros desarrollados de comunicación del nodos con los transconductores y con la forma de comunicación entre ellos, nos permite en el progreso de nuestro proyecto, avanzar hacia el desarrollo del RTOS (Sistema Operativo en Tiempo Real) y de la aplicación, para terminar de diseñar la Red con Nodos Inteligentes. Referencias [1] Gallina, S.H.; Beltramini, P.; Villagran, D.; Peretti, G.; Felissia, S.F.. Internet Cero: Domótica Con Nodos Inteligentes Producción Científica de la F.T.y C.A. III. Paginas 159 a 164. (2012) [2] Gallina, S.H.; Beltramini, P.; Villagran, D.; Ferraro, M.; Arjona, L.; Lobos, D. Diseño De Un Nodo Con Capacidad Plug & Play ; IV Congreso de microelectrónica aplicada. Universidad Tecnológica Nacional- Facultad Regional Bahía Blanca. (2013). [3] IEEE Draft Standard for a Smart Transducer Interface for Sensors and Actuators Common Functions, Communication Protocols, and Transducer Electronic Data Sheet (TEDS) Formats. (January 2007). [4] Tiscoria, E.. Domotica: la vida inteligente Fac. de Ingeniería, Universidad de Palermo (2014). [5] Redes de Sensores: Aplicaciones para Control Automático de Edificios. Observatorio Industrial del Sector de la Electrónica, Tecnologías de la Información y Telecomunicaciones raci%c3%b3n%20de%20entidades%20de%20innovaci%c3%b3n%20y%20tecnolog%c3 %ADa/FEDIT%20RedesSensoresEdificios.pdf. (2014). [6] Pacific Northwest National Laboratory Advanced Sensors and Controls for Building Applications [7] Estudio MINTCASADOMO: Sistemas de Domótica y Seguridad en Viviendas de Nueva Promoción (2008) [8] Quinteiro González, J.M., Lamas Graziani, J., Sandoval González, D.: Sistemas de Control para Viviendas y Edificios: domótica. (2014). [9] CEDOM: Cuaderno de Divulgación Domótica. [10] Romero, C., Vázquez, F.: Domótica e Inmótica [11] Rodríguez, A.: Instalaciones Automatizadas en Viviendas y Edificios. Editorial: Marcombo S.A. [12 6th European Conference WSN Wireless Sensor Network [13] Phoenix Contact Soluciones Inteligentes para la Automatización de Edificios [14] Dietrich, I., Falko Dressler: On the Lifetime of Wireless Sensor Networks 1445
177 Enfoque de Control Multimodal Inteligente para un caso de Producción por Lotes Mariano De Paula 1,3, Gerardo Acosta 1,3, Sergio Gallina 2, Carlos Sanchez Reinoso 1,2 1 Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET). csanchezreinoso@santafe-conicet.gov.ar 2 Departamento de Electrónica, Facultad de Tecnología y Ciencias Aplicadas, Universidad Nacional de Catamarca. 3 INTELYMEC, Facultad de Ingeniería, Universidad Nacional del Centro de la Provincia de Buenos Aires. mariano.depaula@fio.unicen.edu.ar Resumen: La utilización de métodos de control del tipo multimodal en sistemas dinámicos de producción por lotes es una variante interesante para resolver tareas de control de procesos. La idea es reunir diferentes estrategias de control con objetivos parciales empleando autómatas de Lebesgue. Mediante simulaciones, dichos autómatas permiten identificar secuencias óptimas de control para los modos. En una secuencia de modos, cada uno comprende una ley de control por retroalimentación y condiciones relevantes de terminación. El presente paper utiliza un enfoque basado en aprendizaje por refuerzos (RL) para obtener las secuencias óptimas de control que permitan conseguir la máxima productividad en un sistema buffer compuesto de dos tanques. Palabras clave: Inteligencia Artificial - Procesos - Control 1. Introducción En muchos de los sistemas de producción en las plantas químicas existen sistemas con dinámicas híbridas [1-2]. Estos aparecen en los sectores donde es necesario acoplar operaciones por lotes como reactores o cristalizadores con otra continua como los trenes de separación u operaciones de secado [3]. La función de integración entre estas distintas formas de operación se realiza por medio inventarios intermedios o tanques buffer, cuya manipulación es crucial para no limitar innecesariamente la productividad del proceso en conjunto. Un sistema dinámico multi-modal es un sistema controlado cuya dinámica alterna entre un conjunto finito de posibilidades con vista a desplegar un dado comportamiento o alcanzar un objetivo de interés. Estos cambios del comportamiento pueden ser el resultado de un evento específico o una decisión planificada. La estrategia de control se resume en implementar un programa óptimo de modos que permita alcanzar un determinado objetivo derivado del estado deseado para un sistema o proceso a pesar de las perturbaciones que alteran el curso y resultado 1446
178 de cada modo aplicado. Uno cualquiera de estos programas de control ( ) consiste en una dada secuencia finita de modos ( i), donde cada uno de estos modos está compuesto de una ley de control i(x) y sus condiciones relevantes de terminación i(x,t). Ver referencias [4-5] para más detalles. En este trabajo se presenta un algoritmo de RL [6] que permite identificar la secuencia óptima de modos usando simulaciones del sistema estudiado. 2. Programas de control multimodal Un Supóngase que la dinámica del estado x responde a: dx f ( x, u( t), z( t)), n x X R, u U R m (1) dt de donde z(t) es una perturbación medible que evoluciona en el tiempo según: dz g( z, t), d z Z R (2) dt Si en un determinado momento, en el que el estado del sistema es x( ) y la perturbación es z( ), el sistema recibe una secuencia de modos 1, 1 ),, q, q )}se desencadena la transición de estados: (, x( ), z( )) x( ) f ( x( t), u( t), z( t) dt f ( x( t), u( t), z( t) dt q 0 q 1 (3) Si la secuencia de modos posee una longitud acotada, sólo será posible alcanzar un conjunto finito de estados. Por tanto la aplicación de programas de control con una longitud máxima N, resulta en una cuantización de los estados del sistema. De acuerdo con esto se obtiene una discretización finita del espacio de estados, conocido como Lebesgue-sampled ~ state machine,,, ~ x, ~ 0 z ) [4-5][7], donde Q corresponde a los valores de función de la ( X Q N 0 valor o utilidad [6], mientras que la función de transición de estados ~ es: ~ x ~ ( ~ x, ~ z, ) (, x( ), z( )), k 0,1,2,... x x ), z z( ), (4) k 1 k k k 0 0 Q 0 ( El espacio de estados discreto X N está dado por el conjunto de todos los estados que pueden alcanzarse desde 0 ( x0, z0) y para una dada evolución del vector de perturbaciones z(t) cuando se implementa una secuencia de modos de longitud menor o igual que N. El objetivo de este trabajo es encontrar una secuencia de modos tal que maximice la acumulación de rewards obtenidos en las transiciones de estado del autómata híbrido de Lebesgue. De Q acuerdo con la discretización multi-modal X N del espacio de estados y la dinámica de transición del autómata híbrido de Lebesgue, es posible utilizar RL para estimar los Q-values correspondientes a la función de premios (castigos) relacionada con el objetivo de control [6]. Es ventajoso que los estados explorados y los escenarios de perturbación sean utilizados para Q descubrir cuál es el mejor modo * para cada par X N.En el algoritmo representado en la Q Fig.3, inicialmente la discretización del espacio estado-perturbación X N se asume desconocida. El proceso de aprendizaje consiste en, partiendo desde un dado par estadoperturbación ~ ( ~, ~ 0 x0 z0), simular las posibles transiciones hacia todos los estados alcanzables usando los distintos modos que son factibles de aplicar en el estado inicial. En cada 1447

179 iteración del proceso de aprendizaje un par estado-perturbación se elige aleatoriamente del conjunto de estados-perturbaciones visitados. Luego se aplica uno de los modos de control ' del conjunto de modos posibles, lo cual genera la transición al siguiente estado ~ x. En dicha transición se obtiene un premio o reward r( ~ ', i) que se consigue una vez finalizada la ejecución del modo i, momento en el cual i =1. Fig. 1: Autómata híbrido con muestreo de Lebesgue 1.- : { ~, ( ~ 0 0, )}; step ( ~ 0 ) :=0; ~ 2.-step ( ~ 0, ) :=1; 3.-k:=1; index for counting visits to state-disturbance pairs 4.-Q ~ k (, ): const,, repeat 5.- k=k ( ~ ): rand( step( ) N ) 7.- : rand( ) 8.- ~ ~ ': ( ~, ) 9.- if ~ ' then 10.- step ( ~ ') step( ~ ) : ~ ' 12.- Q ~ k ( ', ): const,, end if 12.- Q ~ ~ ~ k 1( ', ): Q k ( ', ) k ( ', ) max [ ( ~ ', ') ( ~ ' Q k 1 Qk 1, )] until mod( k, L) 0 and ~ ~ Q Q k (, ) Q k L (, ),, X ; N Fig. 2: Multi-modal Q-learning control En el algoritmo, la función step( ~ x ) representa la longitud del programa de control más corto, ' necesario para alcanzar un estado ~ x a partir de un estado inicial ~ x 0. De esta forma, únicamente son explorados los estados resultantes de aplicar una secuencia de modos de longitud menor o igual que N, esto garantiza que ~ Q x' ~ ' X N. En cada transición a un nuevo ' estado ~ x, es necesario determinar si este estado pertenece o no al conjunto de estados visitados previamente. En el caso de que ~ ' no pertenezca al espacio de estados debe incorporarse al mismo, incrementando step( ~ x ) en 1; una nueva entrada se agrega la tabla Q. En las situaciones que ~ ' pertenece al entorno de un estado visitado previamente, es actualizado el Q-value del estado que define el entorno en cuestión. La exploración de estadoperturbación continúa de esta forma hasta que se estabilicen las entradas de la Q-table y no aparecen nuevos estados. Las condiciones de stop del bucle principal se imponen de tal suerte que las combinaciones de estados-perturbaciones sean visitados una suficiente cantidad de veces, y además que todos los modos sean ensayados repetidas veces para lograr una adecuada convergencia de las entradas en tabla Q. En las situaciones que ~ ' pertenece al entorno de un estado visitado previamente, es actualizado el Q-value del estado que define el entorno en cuestión. La exploración de estado-perturbación continúa de esta forma hasta que se estabilicen las entradas de la Q-table y no aparecen nuevos estados. Las condiciones de stop del bucle principal se imponen de tal suerte que las combinaciones de estados-perturbaciones 1448
180 sean visitados una suficiente cantidad de veces, y además que todos los modos sean ensayados repetidas veces para lograr una adecuada convergencia de las entradas en tabla Q. 3. Caso de estudio 3.1 Descripción general En diversos procesos de la industria química tales como manufactura de PVC o la industria azucarera existen dispositivos de almacenamiento temporario o buffers que se emplean con el fin de acoplar sin pérdida de productividad operaciones discontinuas o por lotes como reactores o cristalizadores con operaciones de naturaleza continua como secaderos, trenes de destilación, etc. [8-9].A modo de ejemplo sencillo consideraremos un conjunto de n reactores, descargando en paralelo a un tanque buffer cuya salida alimenta el proceso aguas abajo (Fig.(4)). La gestión adecuada de la capacidad de estos tanques no es un problema de fácil solución, sujeto a las restricciones operativas de cada proceso en particular y de la variabilidad del scheduling de descarga desde los reactores. El objetivo que se persigue es maximizar la productividad del proceso en conjunto buscando que el caudal volumétrico enviado hacia la sección continua sea el máximo posible en todo momento, a la vez que se evita rebalsar o secar el tanque buffer. Pensando el problema desde el punto de vista del control clásico, la variable manipulada sería, por ejemplo, el flujo de salida del tanque buffer (F out (t)). En este sentido, resulta necesario definir una variable de referencia o set point, para lo cual se podría tomar un determinado nivel del tanque como una referencia a seguir, por caso la altura media del tanque. Operado de esta manera, es muy posible que la variable manipulada (F out (t)) deba experimentar cambios abruptos teniendo en cuenta la discontinuidad de la descarga de los reactores. A efectos prácticos, esta situación no es deseable debido a que atenta con la productividad y continuidad operativa del conjunto. En la situación expuesta en este trabajo no se recurrirá a una referencia o set point determinado para ninguna de las variables de estado, sino que se enfatizará en la productividad del conjunto evitando eventos inadmisibles como que el tanque buffer rebalse o se seque. Concomitante con lo anterior se aspira a variar suavemente el flujo de descarga (F out (t)) durante períodos de tiempo considerables y sólo admitiendo unas pocas variaciones sensibles, de forma de obtener la mayor descarga posible. La variable manipulada para el control multimodal será entonces el flujo de salida del buffer tanque (F out (t)), cuya magnitud y variación se controla mediante leyes de retroalimentación que deben estar en función de las variables de estado disponibles en el sistema para cada modo de control. Hasta aquí, con el problema así definido, no se identifican en el sistema variables de estado para los flujos de entrada, que cumplan con la condición de Markov [6], de tal forma que sea posible aplicar las técnicas de Q-Learning antes descriptas. Con el fin de conseguir variables de estado Markovianas para el flujo total de entrada, se propone una modificación de las condiciones de diseño del sistema buffer (veáse Fig. 4). Esto es, en lugar de utilizar un solo tanque buffer, es posible usar dos tanques en serie, dispuestos de forma que los n reactores descarguen directamente al primero de ellos (de aquí en adelante se llamará como tanque suavizador ) y este descargue directamente al segundo ( tanque controlado ), según la ley de Torricelli. De esta manera, se tiene un sistema abierto en el que el que el tanque superior se comporta como un filtro de baja frecuencia generando una salida continua que alimenta al tanque buffer inferior. Con esta configuración se consiguen dos variables de estado genuinas que resumen la información del estado del sistema en todo momento. La primera de ellas es la altura del tanque suavizador (x 1 (t)) y la segunda es la altura del tanque controlado (x 2 (t)). Las variables x 1 (t) y x 2 (t) son variables de estados markovianas, dado que en su valor presente refleja toda la historia previa reciente. Por otra parte, el estado del tanque suavizador depende 1449
181 sólo del patrón de descarga de los reactores, con lo cual constituyen una adecuada representación del cronograma (schedule) de producción. Lógicamente sí el patrón de variación de los flujos cambia, el patrón de variación de x 1 (t) también va a cambiar y, consecuentemente, deberá cambiar el control de x 2 (t). En los procesos de producción por lotes (procesos batch) los n reactores trabajan respetando un determinado programa de producción (schedule), con lo cual el patrón de descarga del conjunto de reactores, está directamente vinculado con la estructura de dicho programa de producción. Así, el flujo de salida del tanque suavizador está directamente relacionado con el patrón de variación del schedule de las descargas. Este flujo pasa directamente al tanque controlado, cuya salida (F out (t)) será manipulada en función de las variables de estado del sistema para conseguir los objetivos propuestos anteriormente. La idea de aplicar las técnicas de control multimodal en este caso de estudio, consiste en encontrar una secuencia de modos (π) que permitan cumplir los objetivos mencionados para toda la campaña de producción. Como se explicó anteriormente, los modos se definen mediante una serie de leyes de control ( i ) y sus respectivas condiciones de terminación ( i ). Estas leyes y condiciones de terminación actúan directamente sobre las variables de estado del sistema para manipular la variable de control F out (t). Fig. 3: Tanque buffer: interfaz entre las secciones discontinuas y continuas de una planta híbrida Fig. 4: Sistema con dos tanques 3.1 Caso particular Como caso particular para ilustrar cuantitativamente el enfoque propuesto, se considera un sistema constituido por cuatro reactores, los cuales descargan en paralelo a un suavizador y este al tanque controlado, o buffer propiamente dicho. De esta configuración se pueden tener innumerables patrones de producción. En este caso se analizará uno en particular, pero el mismo análisis puede realizarse de forma similar para otros programas de producción. Algunas consideraciones a tener en cuenta, antes de aplicar la técnica para obtener el programa de control, son las relacionadas con aspectos técnicos de diseños de los equipos. El tanque al que descargan los reactores debe estar diseñado para drenar según la ley de Torricelli, en donde el flujo de descarga (f) es: f h (5) además dicho tanque deberá tener un volumen suficiente para soportar el patrón de descarga de los reactores, de manera de que no se produzcan desbordes en el suavizador. Para simplificar el problema se asume que los todos los reactores durante su correspondiente fase de descarga, drenan el mismo caudal de forma intermitente según dicta el schedule. En las siguientes subsecciones se detallarán las características del sistema de dos tanques y seguidamente se 1450
182 proporcionaran detalles de la implementación de la técnica de control multimodal para el schedule de variación de los flujos desde los reactores Especificaciones El tanque suavizador es un recipiente cilíndrico de 1.5 m 3 de volumen y con 1.5 m de altura útil, que descarga según (3) con =1; en tanto el tanque controlado posee un volumen de 1 m 3 con una altura máxima de 1.0 m. Las leyes de control en los distintos modos se definen con las metas parciales de aumentar (acumular) o disminuir (drenar) la altura promedio del tanque controlado. Las condiciones de parada comunes a todos los modos consisten en detenerlos cuando se exceda el nivel máximo del tanque controlado (H 2 ) o cuando se llegue a un nivel cercano a cero, es decir cuando se rebalsa o se seca el buffer. Para el caso de los modos cuya meta parcial sea lograr una tendencia creciente de la evolución de la altura promedio, la condición de parada del modo se corresponde en detener cuando la imposibilidad práctica de incrementar o disminuir la altura promedio indica la futilidad de continuar la ejecución. A modo de ejemplo, para los modos cuyo objetivo es lograr un decrecimiento en la tendencia de evolución de la altura del tanque, los mismos se detendrán cuando la tendencia de dicha evolución sea creciente. Para lograr un comportamiento suave de F out (t), las leyes de control actúan sobre un valor suavizado de la altura instantánea del tanque controlado, de acuerdo al conocido criterio de ajuste exponencial, con un coeficiente de ajuste α= Aplicación del algoritmo En primer lugar se define un estado inicial x 0 a un tiempo t 0, en el cual se empiezan a aplicar las acciones de control. Dicho estado se puede establecer arbitrariamente como el par (x 1 (t 0 ), x 2 (t 0 )), para el cual x 2 (t 0 ) alcanza un cierto porcentaje de la altura máxima del tanque inferior, en este ejemplo se establece en un 20% de H 2. Tanto para los modos cuya meta es lograr una tendencia positiva en la evolución de la altura como para los que tienen como meta una evolución con tendencia decreciente, las leyes de control siguen la forma indicada en la Fig. 5. Los modos 1 y 3 se comportan según la ley de la recta sólida, en tanto que los modos 2 y 4 lo hacen según la recta de trazos. En todos los casos los modos se detienen cuando se seca el tanque controlado o cuando el nivel de líquido excede su altura máxima posible (H 2 ), esto es i =0 i= 1 sí h 2 (t) ó h 2 (t) H 2. Por otra parte los modos 1 y 2 tienen el objetivo de generar un incremento en la altura del tanque controlado. Para simplificar el ejemplo, dicha tendencia se vincula directamente con la pendiente de la recta de ajuste lineal de los últimos cinco valores de altura suavizada, interrumpiendo la ejecución del modo cuando la misma es negativa. Análogamente, los modos 2 y 4 se detienen cuando el valor de la pendiente de la recta de ajuste sea positivo. Las formas de las leyes han sido definidas para responder a rangos de especificación del proceso por un lado, y por el otro variar suavemente el flujo de salida del tanque inferior. En línea con el objetivo planteado, la función de rewards se define como el volumen descargado durante la aplicación del modo, siempre y cuando no se seque ni rebalse el tanque. En este último caso al reward se le asigna un valor negativo de -5. De esta forma resulta: t r F t out t dt x 2 (t) < H 2 x 2 (t) > 0; r=-5 x 2 (t) H 2 x 2 (t) (6) Otra cuestión a definir respecto al punto 9 del algoritmo definido en la sección 2, es el criterio de similitud entre los estados visitados, para determinar si un estado pertenece o no al espacio de estados explorado hasta el momento cuando se utiliza el algoritmo de la Fig. 2. En este trabajo se acepta que un estado s t pertenece al espacio de estados previamente visitados 1451
183 ( ) si se cumple que con referencia a uno cualquiera s i de los estados previamente visitados el estado s t dista menos de una cierta fracción ( ) de la altura total del tanque controlado H 2, esto es cuando se satisface: s t s i / s t - s i. H 2 (7) En el estudio realizado, la fracción se fijó en un valor de Fig. 5: Leyes de retroalimentación Resultados El ejemplo analizado es de un programa de producción intermitente, para diez bachadas consecutivas de cada uno de los cuatros reactores. Se analizarán los resultados de controlar el sistema durante los primeros tres mil minutos aproximadamente, dado que constituye la parte más representativa en relación con el schedule de producción. El patrón del flujo de descarga del tanque suavizador, resultante de un dado schedule de producción, es el que se representa en la Fig.6. Fig. 6: Flujo de carga al tanque controlado Fig. 7: Evolución de la altura en el tanque controlado El programa de control resultante, genera una variación de la altura del tanque como el que se indica en la Fig.7. La descarga aguas abajo del tanque controlado sigue la evolución indicada en la Fig.8, la cual está directamente vinculada con la secuencia de modos (Fig. 10) y la variación de la altura x 2 (t) indicada en la Fig.7. Finalmente la secuencia de modos encontrada sigue el comportamiento representado en la Fig.9. Es para destacar que, según se observa en Fig.7, el sistema trata en todo momento de elegir los modos que generan una mayor salida aguas abajo del proceso. 1452
184 Fig. 8: Flujo de descarga aguas abajo Fig. 9: Secuencia óptima de modos 5. Conclusiones Como puede observarse en las gráficas anteriores, la cuestión más importante a resaltar de la aplicación del control multimodal surge al comparar la variación del flujo de entrada al tanque controlado (Fig.6.) con la variación en la descarga del mismo (Fig.8.). Se puede apreciar que uno de los objetivos planteados se cumple satisfactoriamente: la salida promedio se mantiene elevada a la par que se evitan que los cambios bruscos a la entrada del tanque controlado se trasladen directamente a la salida del mismo. Si bien se observan variaciones en el caudal de descarga, ésta se comporta de manera suave durante períodos prolongados de tiempo y la frecuencia y magnitud de los cambios de caudal de descarga es baja. 6. Referencias 1 Barton, Paul I., Cha Kun Lee, y Mehmet Yunt «Optimization of hybrid systems». Computers & Chemical Engineering 30 (10 12) (septiembre 12): Engell, S., S. Kowalewski, C. Schulz, y O. Stursberg «Continuous-discrete Interactions in Chemical Processing Plants». Proceedings of the IEEE 88 (7): Peirce, R, y S Crisafulli «Surge tank control in a cane raw sugar factory». Journal of Process Control (9): Mehta, Tejas, y Magnus Egerstedt «Learning multi-modal control programs». En Hybrid Systems: Computation and Control, editado por Manfred Morari y Lothar Thiele, 3414: Lecture Notes in Computer Science. Springer Berlin. 5 Mehta, Tejas R., y Magnus Egerstedt «Multi-modal control using adaptive motion description languages». Automatica 44 (7) (julio): Sutton, Richard S., y Andrew G. Barto Reinforcement learning: An introduction. MIT Press. 7 Aström, K J, y B M Bernhardsson «Comparison of Riemann and Lebesgue sampling for first order stochastic systems» 2: Geist, Stephanie, Dmitry Gromov, y Jörg Raisch «Timed discrete event control of parallel production lines with continuous outputs». Discrete Event Dynamic Systems 18 (2) (junio): Simeonova, Ilyana «On-line periodic scheduling of hybrid chemical plants with parallel production lines and shared resources». Belgium: Université catholique de Louvain. 1453
185 Localización de servicios georreferenciados y optimización de recorridos José Zapana 1, Elsa Ramirez 1, Maria Aybar 1, Felipe Mullicundo 1, Mariela Rodriguez 1, Jorge Mamani 1, Victor López 1, José Farfan 1 1 Facultad de Ingeniería, Universidad Nacional de Jujuy. jose@josezapana.com Resumen. Google maps y Google Earth son herramientas que nos brindan excelentes imágenes y permiten georreferenciar de forma gráfica, navegar virtualmente por el mundo, conocer caminos tomando datos de referencia como nombre de calles o marcar un camino o ruta. Ya no se trata solamente de geodatos limitados a los especialistas de las geociencias y SIG. La propuesta del presente proyecto muestra cómo aplicar la georreferenciación, con el fin de lograr un modelo georreferencial genérico aplicable a N tipos de servicios tales como salud, seguridad, educación, etc. También se pretende implementar un módulo para aplicaciones móviles y finalmente investigar e implementar un modelo matemático que permita determinar caminos más cortos entre dos puntos seleccionados en un mapa. Palabras Clave: servicios georreferenciados, google maps, camino más corto, primefaces. 1 Introducción Luego de analizar las tendencias tecnológicas actuales, se decidió la incursión en un área en la cual no se ha avanzado en el ámbito académico, se trata del Desarrollo de aplicaciones web y mobile con la implementación de georreferenciación. La georreferenciación[1], en primer lugar, posee una definición tecnocientífica aplicada a la existencia de las cosas en un espacio físico, mediante el establecimiento de relaciones entre las imágenes de raster o vector sobre una proyección geográfica o sistemas de coordenadas. Consiste en asignar mediante cualquier medio técnico apropiado, una serie de coordenadas geográficas procedentes de una imagen de referencia conocida, a una imagen digital de destino. Por ello la georreferenciación se convierte en central para los modelados de datos realizados por los Sistemas de Información geográfica (SIG). 1454
186 2 Objetivos Implementar una API para el manejo de mapas en el desarrollo de la aplicación Web y Mobile. Creación de un prototipo funcional de una aplicación Web y Mobile para la localización de servicios de salud, seguridad, educación, y de otras áreas. Determinar e implementar un modelo matemático eficiente para calcular el camino más corto con un grado mínimo de error para la búsqueda a un punto específico del mapa. Incorporar un modelo de Integración Continua para lograr, entre otras cosas, una monitorización continua de las métricas de calidad del proyecto. 3 Fundamento Teórico Social: El modelo realizado podrá ser aplicado para brindar servicios a ciudadanos de una determinada localidad, ya que permitirá realizar consultas en forma sencilla de diferentes servicios tales como emergencias, estaciones de servicio, hospitales, transporte, etc. Los usuarios podrán NO solamente buscar un lugar en el mapa, sino también visualizar los caminos de acceso más cortos para acceder al servicio. Tecnológico La aplicación se desarrolla utilizando una arquitectura robusta incluyendo diversos frameworks que permiten aplicar patrones de diseño tales como MVC, DAO, IoC, DTO, etc. e integrarlos con tecnologías de georreferenciación mediante un diseño de N capas que permitirán lograr una arquitectura robusta y aplicable a otras aplicaciones que hagan uso de la georreferenciación y que puedan ser aplicados a dispositivos móviles. Académico En la actualidad la facultad de ingeniería de la UNJu NO cuenta con cátedras en las carreras de informática, con contenidos relacionados a la implementación de sistemas georreferenciados. Se considera que la inclusión de estos temas, en forma progresiva, brindará un gran avance hacia las nuevas tendencias de los sistemas de información actuales en el mundo. Los conocimientos adquiridos podrán ser trasladados, tanto a los alumnos como a los docentes de la facultad de ingeniería, en forma práctica y con resultados respaldatorios probados. 1455
187 4 Alcance El desarrollo del mencionado proyecto llegará hasta la implementación de un Prototipo Funcional para una aplicación web y móvil con las siguientes características: - Interfaz gráfica restringida a una ciudad o municipio a determinar. - Contará con un módulo de Administración, que permitirá configurar los diferentes servicios implementados en el prototipo (Gestión de puntos y trayectorias en el mapa). 5 Metodología de Desarrollo El desarrollo del proyecto se realiza siguiendo las pautas de la metodología scrum, aprovechando las capacidades que nos brinda esta metodología, seleccionando los elementos necesarios y adecuados para este proyecto. Se considera que esta metodología es la más adecuada para este proyecto ya que, entre otras ventajas, permite trabajar en forma incremental y controlada, permitiendo realizar cambios y revisiones cuando se considere necesario. 6 Diseño El diseño de la aplicación se realiza en base a un modelo de capas definido para aplicaciones JEE basado en el patrón de diseño Model View Controller (MVC). El patrón de diseño MVC es el patrón de arquitectura más usado en la ingeniería del software, y nos permitió definir las 3 capas principales [2] de la aplicación: 6.1 Capa de la vista Incluye los artefactos necesarios para mostrar las diferentes interfaces de usuario. Para la arquitectura diseñada se definieron Java Server Faces como tecnología base, y Prime Faces para lograr una interfaz con componentes ricos. En esta capa se definió una subcapa denominada "Servicios googlemaps" que nos permitió acceder a la vista basada en mapas de la aplicación. 6.2 Capa del modelo En esta capa se definieron los componentes necesarios para el modelo de la aplicación. El mismo fue pensado para que pueda ser consumido por diferentes tipos de tecnologías en la capa de la vista, de este modo es posible utilizar el modelo para tecnologías Web o móviles. Básicamente se definieron: 1456
188 Servicios: está formado por un grupo de componentes organizados por categorías según las funcionalidades requeridas, básicamente consumen los servicios brindados por la capa DAO y devuelve los datos que fueron solicitados por el controlador. DAO: esta capa tiene como objetivo realizar las transacciones con la base datos, mediante el uso del framework de persistencia de mapeo objeto relacional hibernate. Utilidades: conformada con clases para el tratamiento de fechas, números, acceso a archivos de texto, etc. Entidades: en esta capa se encuentra la definición del dominio de la aplicación 6.3 Capa del controlador Esta capa es la encargada de responder a los eventos que sucedan en la capa de la vista, en cada petición del usuario realiza la correspondiente solicitud de información al modelo para luego devolver la información en el formato que la vista pueda interpretar. Aquí se definieron todos los ManagedBeans que son los encargados de trasladar la petición de la vista a la capa de servicios y luego brindar la respuesta nuevamente a la capa de la vista. 7 Tecnologías y Herramientas Seleccionadas 7.1 Tecnologías seleccionadas JSF[3]: nos permite desarrollar rápidamente aplicaciones de negocio dinámicas en las que toda la lógica de negocio se implementa en java, creando páginas para la vista con formato xhtml. La principal función del controlador JSF es asociar a las pantallas, clases java que recogen la información introducida y que disponen de métodos que responden a las acciones del usuario. JSF nos resuelve de manera muy sencilla y automática muchas tareas por medio de los managed beans que se encuentran asociados a los formularios de la vista. Primefaces: Es una librería de componentes para JSF de código abierto con varias extensiones entre las que se utilizaron la versión mobile. API Google Maps: en la arquitectura se definió una capa especial que se capaz de interactuar con los servicios de esta API. Spring framework: necesario para implementar el patrón de diseño Inversion of Control (IoC) que nos permitió, entre otras cosas, resolver la inyección de dependencias. Posee un gran número de módulos que ofrecen una diversidad de servicios de los cuales se implementaron: 1457
189 Contenedor de inversión de control: que cumple la función de una bean factory administrando el ciclo de vida de los objetos que necesita la aplicación a través de la inyección de dependencias. Programación orientada a aspectos: que permitió definir los escenarios de en los cuales se controlarán las transacciones a la base de datos. Acceso a datos con RDBMS: utilizando Java Database Connectivty (JDBC) que permite la ejecución de operaciones sobre la base de datos. Modelo Vista controlador: que facilitó la configuración de la aplicación en relación a la organización de los beans que son consumidos por la aplicación. Hibernate [4]: para facilitar el mapeo de atributos entre la base de datos relacional y los objetos del dominio de la aplicación. 8 Herramientas Utilizadas IDE de desarrollo: Eclipse versión Juno elegida por su versatilidad para integrarse con todas las tecnologías seleccionadas, además de ser un entorno liviano y de código abierto [5]. Servidor: con el fin de configurar el entorno de desarrollo del grupo de investigación, fue necesario la configuración de un servidor en un hosting dedicado, el mismo fue instalado un sistema operativo CENTOS 5.5. Subversion: utilizada para el versionamiento del código mediante un repositorio centralizado creado en el servidor del grupo de investigación. Mantis: Herramienta de gestión de proyecto utilizada para el control y asignación de tareas 9 Oracle Spatial Oracle Spatial proporciona un esquema SQL y funciones que facilitan el almacenamiento, recuperación, actualización y consultas de grupos de características espaciales en el SGBD de Oracle. Oracle Spatial tiene los siguientes componentes: Un esquema (MDSYS): determina el almacenamiento, sintaxis y semántica de los tipos de datos geométricos soportados. Un mecanismo de indización espacial. Operadores y funciones para realizar consultas sobre áreas de interés, consultas sobre relaciones espaciales y otras operaciones espaciales. Utilidades administrativas. Oracle Spatial soporta diversos tipos de elementos geométricos, tanto simples como compuestos. Entre los diferentes tipos de elementos que se pueden 1458
190 implementar están los siguientes elementos de dos dimensiones: Point, Line String, Polygon, Rectangle, Circle, etc. Los puntos de dos dimensiones son elementos compuestos por dos coordenadas X e Y, que a menudo corresponden con la longitud y la latitud. Las líneas están compuestas por uno o más pares de puntos que definen segmentos que pueden ser rectos o arcos. Los polígonos están compuestos por líneas conectadas que forman un anillo cerrado, el área de los polígonos está implícita. Para la representación de este sistema de coordenadas, se usa el tipo de dato SDO_GEOMETRY. 10 Tipo de dato SDO_GEOMETRY Con Oracle Spatial, la descripción de los objetos espaciales es guardada en una fila simple, en una columna de tipo SDO_GEOMETRY de una tabla definida por el usuario. Cualquier tabla que tenga columnas del tipo SDO_GEOMETRY debe tener otra columna, o conjunto de columnas, que definan una única clave primaria para la tabla. Las tablas de este tipo algunas veces son llamadas tablas espaciales o tablas geométricas espaciales. 11 Prototipo La fig. 1 presenta una de las pantallas del prototipo diseñado, en la misma se muestra el resultado de una consulta. 1459
191 Fig. 1 Resultado de la búsqueda de un centro de salud 12 Resultados El prototipo logrado es el resultado de la investigación e implementación de las tecnologías citadas en el presente documento, donde se destacan los siguientes los siguientes logros: Implementación de las tecnologías seleccionadas en la arquitectura diseñada, con lo cual se puede afirmar que las mismas son una buena solución para trabajar con este tipo de aplicaciones basadas en MVC y mapas. Se lograron muy buenos resultados con la metodología seleccionada ya que la misma permitió realizar varios prototipos funcionales incrementales, y realizar cambios a medida que se iba avanzando en la investigación. Las daily scrum y las sprint retrospective resultaron muy valiosas ya que permitieron detectar errores a tiempo y plantear soluciones que eviten la reaparición de los mismos. Se logró una buena performance de respuesta a las consultas realizadas con la interfaz de mapas, gracias a que en la capa del modelo se combinaron tecnologías de muy buena respuesta, tales como Spring Framework e Hibernate 13 Grado de Avance El prototipo se encuentra en un 60% de avance, se está trabajando en la implementación del modelo matemático para determinar camino más corto y en la implementación con dispositivos móviles. 14 Conclusiones y Trabajo a Futuro El desarrollo del presente proyecto permitió conocer y aplicar todos los aspectos necesarios para el modelado y programación de una aplicación Web integrado con una API para mapas. Se encontraron varios inconvenientes a la hora de implementar las diferentes capas de la aplicación, tales como: La implementación de los tipos de datos SDO_GEOMETRY con el framework Hibernate en la capa del modelo La integración de Primefaces con la API de mapas en la capa de la vista en la aplicación tanto móbil como web Se experimentaron con diferentes alternativas hasta encontrar un modelo de capas robusto, flexible y fácil de mantener, ya que separa en forma clara la lógica de negocio de la vista a implementar. La capa del modelo también presenta una gran flexibilidad 1460
192 respecto del motor de base de datos ya que es posible configurar la conexión de cualquier otro tipo de base de datos Como trabajo a futuro, se espera ampliar el alcance del alcance del prototipo a otras ciudades o provincias donde. 15 REFERENCIAS Cagatay. Cagatay Civici Primefaces user s guide 3.2. s.f. Chuck Chuck Murray. Oracle Spatial Developer's Guide, 11g. Junio Georreferencion, Mayo de Modelo Vista Controlador y algunas variantes. Mayo de Tutorial de JavaServer Faces (s.f.). Junio de Definición de Hibernate. QFjAB&url=http%3A%2F%2Fwww.unife.edu.pe%2Fing%2Fdesarrollo.doc&ei=RVqGT _b4otlqtgf_4ojnbw&usg=afqjcneywsgakuvbmr9zxzx3x- PwfI78IQ&sig2=slx7dOUOgEdwu8vDimg8Kg, Junio de Eclipse (Software). de 2012 (Ref6): Base de datos espacial, Abril de
193 Arquitectura de Alta Disponibilidad en Sistemas de Emergencia Mariela Rodriguez 1, Jose Farfan 1, José Zapana 1, Jorge Mamani 1, Victor López 1 Maria Aybar 1, Elsa Ramirez 1 y Felipe Mullicundo 1 (1) Facultad de Ingeniería, Universidad Nacional de Jujuy. 1 maru972@gmail.com Resumen. El grupo de investigación tiene como búsqueda la optimización de sistemas que integran tecnología VoIP que causan gran impacto en la sociedad, un caso particular son los sistemas de emergencia y es el en el que se basa el estudio actual. Los Sistemas de Emergencias son un área crítica, de cual puede depender la vida de las personas, es por ello la importancia de mejorar el servicio y disponer de una buena arquitectura. En este trabajo se analiza la Arquitectura necesaria para implementar un servicio de emergencia y que la misma se encuentre disponible todo el día, es decir que sea tolerante a fallos, requisito fundamental para este tipo de sistemas. Se analizará la central telefónica a utilizar, la integración con la red PSTN, la disponibilidad de las líneas PSTN y por último la disponibilidad de los datos. Palabras Clave: VoIP, PBX, Asterik, Failover, FXO, DRDB. 1 Introducción El servicio de emergencia es un organismo que asiste los llamados de emergencia de una comunidad. Se encuentra formado por sistemas que integran recursos humanos, administrativos, materiales, informáticos, entre otros, tienen como característica principal que se encuentran disponibles las 24 horas del día y como finalidad dar respuesta inmediata a la población en caso de pedido de auxilio o ante situaciones de riesgo. En consecuencia es importante que este tipo de sistema cuente con personal calificado para su atención, siendo este uno de los factores que influyen fuertemente en la eficiencia del sistema. Otro de los factores es la tecnología adecuada para gestionar este servicio, la evolución de las tecnologías permite la integración de sistemas informáticos con la telefonía a través de la Telefonía IP o VoIP. En un sistema de emergencia la telefonía IP y el software que gestionan las llamadas son de vital importancia y debe estar disponible todo el día. Este trabajo aborda la importancia de la arquitectura hardware en un servicio de emergencias y tiene como estudio un sistema de emergencias para la provincia de Jujuy. 1462
194 2 Objetivo Optimizar los requerimientos hardware y software para llevar un sistema de emergencia a tener Alta Disponibilidad con una central telefónica Asterisk. 3 La Central Telefónica En un sistema de emergencia reviste gran importancia la central telefónica que se utilice y las funcionalidades que se brindan. Luego de un análisis profundo de nuestro grupo de investigación sobre software base de PBX (Private Branch Exchange o dispositivo de ramificación de la red primaria pública de teléfonos), en este proyecto se optó por Asterisk como software base de PBX ya que el mismo presenta las siguientes ventajas: Es un software Gratuito y dispone del código fuente. Trabaja con cualquier tarjeta telefónica compatible y de cualquier marca. En la etapa del prototipo del proyecto se utilizó una tarjeta Openvox (la cual es una marca sumamente utilizada para este tipo de tarea). Para el usuario final la interfaz es de fácil uso, ya que tiene aplicaciones que hacen amigable la administración de la central telefónica, un ejemplo es el software Freepbx es un administrador de central, que facilita la interoperabilidad del usuario con el sistema VoIP Asterik y es el que por las amplias disponibilidades que brinda se utilizó en el proyecto. Se puede contar con una gran cantidad de terminales sin costo, con la implementación de softphone (software o aplicación multimedia que trabaja junto a las tecnologías VoIP brindando la posibilidad de hacer llamadas directamente desde su PC o notebook) o webphone (utiliza solo un navegador de internet y un diadema con micrófono). Si se utiliza componentes ofrecidos por el canal oficial, Digium (el cual es el software oficial de Asterik) garantiza el funcionamiento de Asterisk. Es más seguro que los sistemas de comunicaciones comerciales, ya que al ser software libre y de código abierto, las fallas de seguridad son rápidamente publicadas y su solución aparece en cuestión de horas. La instalación de Asterisk es libre para cualquier usuario a diferencia de otros fabricantes de centrales comerciales que únicamente dejan distribuir sus equipos a aquellas empresas que realizan un curso y un examen de certificación.[2] Se debe tener en cuenta que la comunidad de Asterisk crece día a día y los problemas que se presentan en código y utilización son resueltos por comunidades de desarrolladores y usuarios.[6] 1463
195 3.1 Análisis de Software basados en Asterik Habiendo optado por Asterik como software para PBX nuestro grupo de investigación analizó diferentes softwares basados en el mismo, fruto de dicha indagación se estudió: A. Tribox: es una central telefónica basada en Asterisk desarrollada en el Sistema Operativo gnu/linux CentOs. El paquete trixbox se encuentra armado con características que permite las funcionalidades de una central paga. [8] B. Elastix: es un software aplicativo que integra las mejores herramientas disponibles para PBXs basados en Asterisk en una interfaz simple y fácil de usar. Además añade su propio conjunto de utilidades y permite la creación de módulos de terceros para hacer de este el mejor paquete de software disponible para la telefonía de código abierto. En una primera instancia de desarrollo del proyecto se instaló una central en Trixbox, brindando la misma facilidad en lo referente a su instalación y configuración, es decir en unos sencillos pasos se logró hacer funcionar la central. El inconveniente que presenta el uso de la misma es a la hora de configurar e integrar con la aplicación software en desarrollo surgiendo errores difíciles de seguir, distinguir y de corregir. De acuerdo a las situaciones planteadas y las necesidades para el sistema de emergencia se eligió utilizar Asterisk puro y realizar las configuraciones necesarias para su uso. Muchas veces las distribuciones como Trixbox o Elastix se utilizan porque permiten montar un sistema rápido y pre armado. Tanto Trixbox como Elastix vienen configurado y con las librerías necesarias para su funcionamiento. Estas distribuciones ejecutan macros para realizar los distintos comandos, esto sobrecarga el sistema sumada a la complejidad de corregir los errores. Debido a esto se optó por la utilización de Asterisk puro ya que es más eficaz, funcional y de fácil depuración; permite programar el dialplan o Plan de Marcación, el cual es la columna vertebral del sistema, parecido a un lenguaje script en el que funciones, aplicaciones y recursos se van intercalando para formar algo parecido a "procedimientos" y "programas"; también admite editar el archivo extensions.conf, pudiendo las fallas o el mal funcionamiento visualizarse en el CLI y obviamente corregir los errores. Como conclusión de este análisis se determinó que Asterisk es una solución muy económica, fiable y robusta. 4 Arquitectura necesaria para la integración con la telefonía tradicional Para la integración del sistema informático de emergencias es necesario que las llamadas que se reciben se puedan grabar y asociar a la emergencia, es decir, pasar de la red de telefonía analógica a la central digital. Esto se puede lograr integrando a la red un Gateway (o puerta de enlace o de acceso a otra red) que permita el ingreso de las líneas telefónicas y se conecte a la red Lan interna. Otro modo de integración es utilizando una tarjeta analógica PCI con puertos FXO, los cuales en la Interfaz de la Central son los puertos del terminal que recibe la línea analógica PSTN (Public Switched Telephone Network o red telefónica pública conmutada ), es el enchufe del teléfono o el enlace de su centralita telefónica analógica que envía hacia la red una indicación de colgado/descolgado, conectados al 1464
196 servidor Asterisk (la cual es la solución elegida). El driver que instala es dahdi, que es una interfaz de kernel que permite acceder a las tarjetas de comunicaciones. En la figura se muestra la arquitectura necesaria para la integración con la red de telefónica. Fig. 1. Arquitectura básica necesaria. 5 Alta disponibilidad del sistema Para garantizar la alta disponibilidad y asegurar un cierto nivel de continuidad operacional del sistema en cuestión se propone la instalación de un clúster de dos nodos centrales, uno configurado como maestro y el otro como esclavo. Ambos nodos tanto el maestro como el esclavo van a ser idénticos, es decir van a contener los mismos componentes y aplicaciones de software de tal manera de conseguir una recuperación ante fallos en una mínima cantidad de tiempo. El servidor maestro es el que estará operativo inicialmente y el servidor esclavo estará en modo standby, en caso de fallo del servidor maestro, el servidor esclavo toma el control de los servicios, el almacenamiento de datos y las comunicaciones. El sistema de Clúster HA (alta disponibilidad) consiste en la prestación, en paralelo, de todos los servicios. Provee un mecanismo de sincronización de almacenamiento de datos a través de un mecanismo integrado por software y hardware que permite mantener constante coherencia entre los datos del sistema que se almacenan en ambos nodos, Finalmente el Clúster proporciona un mecanismo de control y monitoreo de los servicios que se prestan y la disponibilidad de datos para poder detectar una contingencia y actuar en consecuencia.[8] A continuación se presenta el esquema de alta disponibilidad propuesto: 1465

197 Fig. 2. Arquitectura de alta disponibilidad con Hearbeat. Cuando cae el nodo maestro es necesario que el servidor esclavo tome el control y brinde los servicios que brindaba el maestro. Este proceso se llama failover. Para el proyecto se pretende tener dos equipos que proporcionan un servicio a pesar de que uno de ellos falle, esto se denomina clúster. Es necesario definir un nivel de protección en el caso de que falle la central telefónica. El fallo podría ocurrir cuando no exista personal técnico que verifique el estado de la central telefónica, fin de semana o noche, esto provocaría problemas de accesibilidad de los usuarios. El objetivo principal de la Institución es brindar seguridad a la comunidad y el medio de comunicación asiduo entre ambos es el 101, de ahí radica la importancia de tener alta disponibilidad del servicio. La solución a esta situación es redundar los servicios que contiene el servidor maestro, entre ellos la central telefónica asterisk, la base de datos, la aplicación web, Apache Tomcat y el resto del software implementado entre otros formando un clúster de sistemas idénticos que se sincronicen y mantengan un estado de activo-pasivo. Para ello se utilizará la solución heartbeat del proyecto Linux-HA, de manera que se ofrezca a los usuarios una dirección IP virtual, compartida entre ambos. Heartbeat es un demonio que proporciona servicios de infraestructura de clúster (comunicación y pertenencia) a sus clientes. Esto permite tener conocimiento de la presencia (o desaparición) de los procesos en otras máquinas e intercambiar fácilmente mensajes entre ellos. Heartbeat necesita emplearse en combinación con un gestor de recursos del clúster CRM, el cual posee la tarea de iniciar y parar los servicios (Direcciones IP, servidores web...) a los cuales el clúster aportará alta disponibilidad. Pacemaker es el gestor de recursos de clúster preferido para los clústeres basados en Heartbeat. En la Error! No se encuentra el origen de la referencia.2 se muestra la arquitectura de alta disponibilidad. Heartbeat para brindar este servicio necesita de la red privada entre los servidores clúster, la red que se dispondrá será una privada tipo C que es /24 y para ello la interfaz de la placa de red en ambos servidores eth1. La placa de red necesaria es de 1 GB de velocidad. La red privada necesaria para el funcionamiento del sistema será la /24 y en ambos servidores se configuraran por la interfaz eth0. Aunque ambos tienen asignadas IP fijas es necesaria una IP virtual que representará al sistema , es decir, cada terminal para acceder al servidor maestro se direccionara a la IP virtual. Finalmente la disponibilidad de los datos se provee mediante un sistema de sincronización de discos DRDB el cual se refiere a los dispositivos de bloque concebido como una edificación en bloque, agrupados para formar un clúster de HA. 1466

198 Esto se hace por medio del reflejo completo de un dispositivo de bloque asignado a través de una red. 6 Sincronización de base de datos Hasta este momento la solución brindada da una alta disponibilidad al sistema. Si cae el servidor maestro se levantará el esclavo en su lugar, ocurrirá en ese momento que los operadores del sistema querrán dar gestión a una emergencia o de la dependencia se querrá asignar los recursos y cuando el servidor esclavo esté funcionando no tendrá la información para hacerlo. Este problema se podrá resolver replicando la base de datos en tiempo real desde el servidor maestro al esclavo. Esta replicación se puede hacer con DRBD (Distributed Replicated Block Device) con el cual se puede crear un RAID sobre una red entre discos conectados en una red, sin olvidar en ningún momento que se realiza en tiempo real. Usando el Protocolo C de almacenamiento los datos se escriben primero en el dispositivo de almacenamiento del servidor esclavo y luego en el maestro, de esta forma se garantiza que en caso de fallo los datos del sistema se encuentran garantizados en el servidor que asumirá la prestación de los servicios. La replicación permite que el servidor maestro registre los cambios en las bases de datos en los logs binarios. Para esto se debe activar el log binario en el servidor maestro. El servidor esclavo recibirá las actualizaciones guardadas en su log binario del maestro, de forma que el esclavo puede ejecutar las mismas actualizaciones en su copia de los datos. El servidor maestro y el esclavo se sincronizaran desde el momento que se inicializa el sistema. Heartbeat será el encargado de monitorizar al maestro para que cuando falle traspase el mando al servidor esclavo.[5] Fig. 3. Alta Disponibilidad con Heartbeat y DRDB. 7 Sistema redundante para las líneas telefónicas Una vez configurado el clúster de servidores, se cuenta con una alta disponibilidad de la central telefónica, la aplicación web, la base de datos y demás servicios contenidos en el servidor, el problema que se presenta a resolver ahora, es que no se puede duplicar las líneas telefónicas analógicas. Se debe encontrar el modo que las líneas telefónicas pasen de un servidor a otro cuando el primero deje de funcionar. Entre varias soluciones que existen en el mercado para solucionar esta situación, se ha 1467

199 seleccionado la que brinda la empresa creadora de Asterisk; Digium. Digium ofrece un Failover Serie R 800, que permite cambiar las líneas telefónicas analógicas de un servidor a otro cuando el principal o maestro falla. Este dispositivo se encuentra conectado al dispositivo principal o maestro y conectara las líneas a los puertos de las tarjetas. Si el servidor maestro deja de funcionar, el Failover dejará de recibir la información y automáticamente conectará las líneas al servidor esclavo, para ello se necesita que cada servidor tenga la tarjeta telefónica instalada.[4] El failover R 800 soporta 8 líneas telefónicas se puede optar por otro modelo si es necesaria más líneas telefónicas. La señal Watchdog informa que el servidor maestro está funcionando correctamente, viaja por USB. El mismo puerto USB que envía la señal Watchdog, se encarga de alimentar el Failover. Para el funcionamiento del servicio de Failover se debe contar con tarjetas de telefonía en cada servidor. Con estas tres soluciones que se describieron se obtiene una alta disponibilidad del proyecto que incluye la central telefónica, sistema y base de datos, esto permitirá que el usuario no se dé cuenta que el servidor maestro sufrió desperfectos. Fig. 4. Alta Disponibilidad con Heartbeat, DRDB y Failover R Conclusiones 1468
200 El trabajo de investigación desarrollado brinda las bases para dar soporte a un servicio critico en cualquier comunidad, como es un sistema de emergencias, donde se presentan situaciones que puedan presentar riesgo de vida, cuestiones de seguridad entre otros de vital importancia Las comunicaciones actualmente han dado un gran salto tecnológico, por lo cual un sistema de este tipo debe estar a la altura de la circunstancia. El trabajo permitió hacer un estudio de los recursos necesarios para garantizar la disponibilidad de un sistema de emergencias, mediante recursos hardware y software a los que se pueden acceder de manera directa sin grandes inversiones. Referencias 1. [VEGA GARCIA, 2008] Rodrigo Vega García, Sistema de comunicación con niveles de servicio basado en SIP para ambientes heterogéneos. Centro de Investigación y de Estudios Avanzados del Instituto Politécnico Nacional [MEGGELEN y OTROS, 2007] Meggelen, Jim Van; Madsen, Leif and Smith, Jared. Asterisk - The future of Telephony. 3. [SPENCER, 2007] Mark Spencer. Asterisk for Dummies. Wiley Publishing, Inc. Sitios [4] Consultada el 4/06/2014 [5] Consultado el 7/06/2014 [6] Consultado el 3/03/2014 [7] Consultado el 4/03/2014 [8]
201 Red de nodos inteligentes basados en las normas IEEE 1451 como una estructura de información Ferraro Matías 1 ; Gallina Sergio H 2 ; Villagran Luis D. 3 ; Beltramini Paola 4 ; Moreno Juan P. 5 ; Aranda Marcos 6 1,2,3,4 Departamento de Electrónica, 5,6 Departamento Informática Facultad de Tecnología y Ciencias Aplicadas, Universidad Nacional de Catamarca 1 matiasferraro@yhoo.com.ar ; 2 sgallina@tecno.unca.edu.ar ; 3 dvillagran@tecno.unca.edu.ar, 4 pbeltramini@tecno.unca.edu.ar ; 5 juanpablomoreno@gmail.com Abstract. El presente trabajo describe el desarrollo de una red de nodos basada en una estructura lógica de lista, con la explicación correspondiente de la selección de esta estructura entre otras. Además son considerados, el protocolo de comunicación a usar en la red y las funciones básicas que brinda la capa de red a la capa de aplicación del nodo. Finalmente, se resume las ventajas de esta red. El objetivo que se busca es el establecimiento de una red de información que permita la interacción de nodos, caracterizada por no requerir altas velocidades ni gran ancho de banda, con una cantidad acotada de nodos y de fácil instalación. Los resultados indican que la combinación de Internet 0, que facilita el internet sobre cualquier medio y la abstracción de pensar a un nodo como una unidad de información, identificada por una dirección, permiten el desarrollo de esta red apta para permitir que nodos independientes interactúen, con un mínimo de recurso de hardware y de software. Palabras Clave: Red de Nodos, Listas, Internet 0, IEEE Introducción Para la implementación de una red de nodos, se ha desarrollado un nodo inteligente [1] basado en los estándares IEEE Cada nodo contiene los datos y los procedimientos necesarios para el control de uno o varios dispositivos, lo que les permite funcionar como un sistema distribuido sin depender de servidores centrales, no obstante estos nodos pueden interactuar entre sí, mediante la implementación de una red de baja velocidad a los efectos de reducir costos y simplificar la infraestructura física. Por ello nos proponemos determinar una estructura de red simple con baja carga de software para la transferencia de información entre los nodos. Entre los protocolos posibles de implementar, que cumplen con las condiciones de diseño que han sido establecidas, se ha optado por Internet 0 [2] [5] sobre una red cableada de dos hilos. El internet 0 se diferencia de otros protocolos por la duración de un bit y su velocidad de propagación, basándose en que: si un bit es menor que el tamaño de una red, entonces es necesario adaptar impedancias para eliminar los reflejos, por otro lado, si un bit es de mayor tamaño que la red, los transmisores y receptores se pueden construir de manera más sencilla y económica. 1470
202 Siguiendo con este planteo, analizamos las estructuras lógicas conocidas, que nos permiten la búsqueda de información. La lista doblemente enlazada resulto la más conveniente y por el contrario, la menos conveniente resulto la estructura de Árbol, ya que la misma contempla la utilización de un nodo raíz, que debe estar representado por un servidor. Nuestro estudio se fundamenta en la consideración de diferentes aspectos. El marco teórico está integrado por: Estructura de Información, Nodos Inteligentes e Internet 0. 2 Estructura de información. Listas Entre los diferentes tipos de estructura de la información, podemos mencionar los árboles, las pilas, las colas y las listas, entre otras. De estas estructuras nos centraremos en las listas y dentro de ellas en las listas doblemente enlazadas (figura 1). Estas nos interesan particularmente porque tienen un enlace con el elemento siguiente y con el anterior, característica que permite recorrer la lista en ambos sentidos, ya sea para efectuar una operación con cada elemento o para insertar, actualizar y borrar. Fig. 1. Estructura de una lista doblemente enlazada Una lista es una estructura secuencial de datos. A la vez, un elemento de la lista o nodo es básicamente un elemento de información con sus enlaces hacia los nodos anterior y posterior. Así se conforma una lista enlazada que además es dinámica, es decir que su tamaño puede cambiar durante la operación. Otra de sus ventajas fundamentales es que es flexible a la hora de reorganizar sus elementos, a cambio se a de pagar una mayor lentitud a la hora de acceder a cualquier elemento. En la lista de la figura 1 se puede observar que hay tres elementos de información, x, y, z. Supongamos que queremos añadir un nuevo nodo, con la información p, para hacerlo basta con crear ese nodo, introducir la información p, y establecer los enlaces hacia los nodos siguiente y anterior. Resultan también simples los mecanismos de quitar un nodo o realizar la búsqueda de información dentro de la lista. 3 Nodos inteligentes El diagrama de la figura 2, muestra una unidad funcional compuesta por: el network capable application processor (NCAP), el Smart transducer interface module (STIM) y los transductores (Sensor Actuador) [3]. Esta unidad se denomina nodo inteligente, siendo inteligente por ser autónomo y tener la capacidad suficiente para realizar una aplicación específica independiente de la red pero, simultáneamente, 1471
203 forma parte de una red compuesta por otros nodos inteligentes, y posee la capacidad para interactuar con ellos y constituir de esta manera un sistema. Si hacemos una abstracción podemos pensar que esta unidad funcional, constituye una unidad de información donde no es interpretada como un conjunto de hardware y software sino como un conjunto de datos. Por ejemplo si el nodo inteligente tiene un actuador y un sensor, siendo el actuador implementado por un relé que enciende y apaga una lámpara, y el sensor, representa un sensor de humedad, el dato que contiene el nodo inteligente visto como una unidad de información, es una palabra binaria de dos byte, donde el byte menos significativo representa el estado de la lámpara (01h la lámpara está encendida y 00h apagada) y el byte más significativo indica el porcentaje de humedad ( 00h indica 0% y 64h indica 100%). Se puede así abstraer aún más el nodo inteligente y que es pensado como el bloque que se muestra en la figura 3, donde se observa como vemos un nodo como un elemento de una lista. Fig. 2. Estructura de un nodo inteligente basado en el estándar IEEE 1451 En la visión del nodo, de la figura 3, se simboliza un nodo que posee la dirección 100, este nodo apunta a otro nodo con dirección 115 y es a la vez apuntado por su antecesor. Conteniendo además como información dos byte, uno que representa el estado de la lámpara y otro que contiene el valor de la humedad ambiente, como ya se mencionó anteriormente. Fig. 3. Visión de un nodo inteligente como una estructura de dato 1472
204 4 Capa de Red La capa de red contiene las funciones de red que brindan soporte a la aplicación y las funciones del protocolo Internet 0 que controlan la codificación y el envío y la recepción de bits. 4.1 Driver de Internet 0 Como método de codificación utilizamos el método I0, el cual codifica un bit simple dividiéndolo en dos intervalos de tiempo. Si el impulso de reloj ocurre en el centro del primer intervalo entonces es codificado como un 1, y si ocurre en el centro del segundo intervalo es codificado como un 0. Cualquier otro impulso puede ser rechazado como ruido. Existe cierta similitud entre la codificación I0 y las técnicas de codificación bifase. Este esquema asegura que todos los bits presentan una transición en la parte media, proporcionando así un excelente sincronismo entre el receptor y el transmisor. Una desventaja de este tipo de transmisión es que se necesita el doble del ancho de banda para la misma información que en el método convencional. Dos ventajas significativas son: Sincronización: debido a la transición que siempre ocurre durante el intervalo de duración correspondiente a un bit, el receptor puede sincronizarse usando dicha transición. Debido a esta característica, los códigos bifase se denominan auto-sincronizados. Detección de errores: se pueden detectar errores si se detecta una ausencia de la transición esperada en la mitad del intervalo. Para que el ruido produjera un error no detectado tendría que intervenir la señal antes y después de la transición. Esta capa provee los drivers de transmisión y recepción de bits, estos realizan además la codificación para Internet 0: Void I0Codifica(Trama, Sentido): Nos permitirá codificar el mensaje bajo el protocolo Internet 0, recibiendo como parámetro la trama armada por la capa de red. Inicio Fin Si Sentido = 0 Habiolitar transmisión derecha Si Sentido = 1 Habiolitar transmisiónizquierda Mientras no sea FindeTrama Leer byte Desde i = 0 hasta i = 7 Si bit ==1 Transmite 10 sino Transmite 01 FinSi DisDesde FinMientras 1473

205 Char I0Decodifica(mensaje): Decodifica el Internet 0. Inicio Fin Inicio recepción de byte Mientras i <= 15 Leer bit n, bit n+1 Si bit n ==1 & bit n+1 == 0 Recibido recibido + 1 sino Si bit n ==0 & bit n+1 == 1 Recibido recibido + 0 sino Error en recepción FinSi FinMientras 4.2 Funciones de red La estructura de la figura 4 es un ejemplo de una estructura de red basada en una estructura lógica de lista, la red puede estar interconectada de cualquier forma entre los nodos inteligentes y poseer cualquier número de nodos. Fig. 4. Estructura de un sistema basado en nodos inteligentes Para tener definida una estructura de lista enlazada, es necesario tener definida la estructura de información de cada nodo, los punteros a los nodos siguiente y anterior y las funciones de red tales como: transmisión, recepción, control de errores y armado de cabeceras. En cada nodo se debe realizar una declaración del tipo: struct lista_doble { float dato; lista_doble *siguiente; lista_doble *anterior; }; Donde dato representa la información contenida en el nodo, que puede ser de cualquier tipo. En este ejemplo se trataría de datos de tipo numérico de punto flotante; *siguiente, se trata de un puntero al siguiente elemento de la lista y *anterior, es un 1474
206 puntero al elemento anterior de la lista. Este puntero enlaza con el elemento predecesor de la lista y permite recorrerla en sentido inverso. Nuestra lista tendrá una serie operaciones básicas definidas como funciones de biblioteca de la capa de red, que nos permiten el manejo del sistema, siendo alguna de ellas, el armado de la trama, validación de mensajes recibidos, transmisión y recepción. Int IdentificarDestino(Mensaje): Nos permitirá determinar la dirección del nodo destino a partir del conocimiento del canal transductor donde se dirige el mensaje. Devuelve el número del nodo destino Inicio Fin IDTrCh ExtraerNrocanal_transductor(mensaje) IDNodoDestino Nodos(IDTrCh) Int CalculaLargo(mensaje): Calcula el largo de la trama constituida por la dirección del nodo destino, el nodo emisor, el mensaje. Inicio Fin Desde i=0 hasta fin_de_mensaje Largo_mje = largo_mje + 1 Fin-desde Cadena ArmarTrama(IDNodoDestino, IDNodoOrigen, Largo, Mensaje): Esta función recibe como parámetros los elementos que constituyen la trama, agrega el número de secuencia y el checksum y devuelve la trama a transmitir. Inicio Fin String Trama[] Int i, j NroSecuencia Calcular_Nro_Secuencia Desde i = 0 hasta 7 Trama[i] = IDNodoDestino[i] Trama[i+8] = IDNodoOrigen[i] Trama[i+16] = Largo[i] Trama[i+24] = NroSecuencia[i] Fin-desde Desde j = 0 hasta largo Trama[j+32] =Mensaje[j] Fin-desde CkSum Calculo-Check-Sum(Trama) Trama = Trama & CkSum & fintrama Void EnviarTrama(Trama): Colocar sobre la red física la cadena de bits del mensaje, no devuelve ningún valor. Como se puede observar requiere de una función para determinar si el mensaje será enviado hacia la izquierda o derecha. El algoritmo utilizado es el más simple y se tomara la dirección izquierda si IDNodoDestino < IDNodoOrigen y dirección derecha en caso contrario. Inicio Sentido SentidoDeTransmision(IDNodoDestino, IDNodoOrigen) 1475
207 Fin I0Codifica(Trama, Sentido) Cadena RecibirTrama(): Lee el canal de ingreso y arma la trama recibida, Devuelve una cadena de caracteres, guardándola en un buffer intermedio de recepción. Inicio Fin Carácter I0Decodifica() Mientras Carácter fin_de_trama Trama = trama + Carácter Carácter I0Decodifica() Fin-mientras Boolean ValidaDireccion(Trama): Identifica si el mensaje recibido es para este nodo o debe ser retransmitido. Devuelve un booleano identificando como verdadero un mensaje valido para este nodo y como falso un mensaje a ser retransmitido. Verifica además si el mensaje recibido fue enviado por quien recibe, en este caso destruye el mensaje Inicio Fin IDNodoDestino Extraer número nodo Destino IDNodoOrigen Extraer número de nodo Origen NroSecuencia Extraer número de secuencia Si IDNodoDestino == ID de este nodo MjeValido verdadero Sino MjeValido Falso Fin-si Si IDNodoOrigen == ID de este nodo DestruirMensaje(NroSecuencia) Fin-si A estas funciones las complementan otras funciones adicionales tales como: cálculo del checksum, Verificación del checksum, Leer buffer de salida, escribir buffer de entrada, entre otras. 5 Implementación de la red de nodos La red propuesta en la figura 5, es un ejemplo, implementado con ocho nodos, se emplean multiplexores para transmitir y demultiplexores para recibir, con esto se consigue direccionar los mensajes hacia adelante y hacia atrás de un nodo específico; por simplicidad no se dibujan las líneas de selección de los multiplexores y de los demultiplexores. 1476

208 Fig. 5. Red de nodos La comunicación entre nodos es por dos hilos y se detalla con precisión en el artículo Internet 0 en Entornos Residenciales presentado en el Congreso Argentino de Ingeniería 2012 [2] [5] Mediante la implementación de un algoritmo, los nodos pueden transmitir hacia adelante y hacia atrás independientemente de la posición en que se encuentren. La precisión en este algoritmo es fundamental a la hora de analizar la velocidad y la carga de la red. De la misma manera, la información recibida puede provenir del nodo anterior o posterior, la identificación de la ruta activa se realiza por hardware, Ante la llegada de dos mensajes simultáneos, el nodo en función de sus prioridades abortara una de las comunicaciones y continuara con la otra. 6 Transmisión de datos La utilización del protocolo Internet 0 implica la reducción del número de capas, respecto de Internet común (Figura 6). Esto redunda en una reducción del código, lo cual posibilita disminuir los tiempos de procesamiento computacional. En la figura 6 se muestra el grafico comparativo del protocolo I0 versus Internet, en el mismo se aprecia la eliminación de las capas de transporte, Sesión y Presentación. Fig. 6: Internet Vs. Internet 0 La capa de aplicación genera el mensaje del usuario constituyendo así la unidad de datos de protocolo (PDU a los efectos de mantener la nomenclatura) y le añade 1477

209 una cabecera, que contiene la dirección de canal transductor destino, constituyendo así la unidad de datos de interfaz (IDU). La IDU se transfiere a la capa de red y a través del enlace físico, a la capa de red del nodo destino, y se procesa el mensaje. Para ello ha sido necesario todo este proceso: 1. La PDU se prepara en la capa de aplicación del emisor. 2. Antes de entregar la PDU a la capa de red se le añade la correspondiente cabecera con la dirección del canal transductor que será el destinatario y se transformaría así en una Unidad de datos de interfaz (IDU). 3. La capa de red recibe la IDU, le añade la información de control consistente en: Dirección del nodo destino donde se encuentra el transductor destino, Su propia dirección de nodo emisor, largo total del mensaje y checksum. 4. Al llegar al nivel físico se envían los datos que son recibidos por la capa de red del receptor. 5. En el receptor la capa de red controla la integridad del mensaje (checksum). Identifica el nodo destino y acepta o retransmite el mensaje. 6. El receptor que acepta el mensaje, extrae la cabecera y traslada el mensaje a la capa de aplicación, la cual lo procesará. Fig. 5: Estructura de datos del mensaje y de la trama La transferencia de información entre la capa de aplicación y la capa de red, del NCAP, se realiza mediante dos buffers intermedios, uno de mensajes salientes y otro de mensajes entrantes. Estos buffers posen una capacidad inicial de 80 bytes y pueden ser modificados en forma dinámica. El almacenamiento dentro de los buffers es de tipo big endian. 7 CONSIDERACIONES FINALES Basados en las consideraciones precedentes y en modelo simulado, podemos enunciar nuestra propuesta con la estructura considerada apta para el armado de una red de nodos inteligentes, partiendo de las siguientes premisas: no se requiere alta veloci- 1478
Elementos requeridos para crearlos (ejemplo: el compilador)
") Generalidades A lo largo del ciclo de vida del proceso de software, los productos de software evolucionan. Desde la concepción del producto y la captura de requisitos inicial hasta la puesta en producción
Generalidades A lo largo del ciclo de vida del proceso de software, los productos de software evolucionan. Desde la concepción del producto y la captura de requisitos inicial hasta la puesta en producción
Enginyeria del Software III
 Enginyeria del Software III Sessió 3. L estàndard ISO/IEC 15504 Antònia Mas Pichaco 1 Introducción El proyecto SPICE representa el mayor marco de colaboración internacional establecido con la finalidad
Enginyeria del Software III Sessió 3. L estàndard ISO/IEC 15504 Antònia Mas Pichaco 1 Introducción El proyecto SPICE representa el mayor marco de colaboración internacional establecido con la finalidad
forma de entrenar a la nuerona en su aprendizaje.
 Sistemas expertos e Inteligencia Artificial,Guía5 1 Facultad : Ingeniería Escuela : Computación Asignatura: Sistemas expertos e Inteligencia Artificial Tema: SISTEMAS BASADOS EN CONOCIMIENTO. Objetivo
Sistemas expertos e Inteligencia Artificial,Guía5 1 Facultad : Ingeniería Escuela : Computación Asignatura: Sistemas expertos e Inteligencia Artificial Tema: SISTEMAS BASADOS EN CONOCIMIENTO. Objetivo
DE VIDA PARA EL DESARROLLO DE SISTEMAS
 MÉTODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS 1. METODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS CICLO DE VIDA CLÁSICO DEL DESARROLLO DE SISTEMAS. El desarrollo de Sistemas, un proceso
MÉTODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS 1. METODO DEL CICLO DE VIDA PARA EL DESARROLLO DE SISTEMAS CICLO DE VIDA CLÁSICO DEL DESARROLLO DE SISTEMAS. El desarrollo de Sistemas, un proceso
Estas visiones de la información, denominadas vistas, se pueden identificar de varias formas.
 El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los
El Proceso Unificado de Desarrollo de Software
 El Proceso de Desarrollo de Software Ciclos de vida Métodos de desarrollo de software El Proceso Unificado de Desarrollo de Software 1 Fases principales del desarrollo de software Captura de requisitos:
El Proceso de Desarrollo de Software Ciclos de vida Métodos de desarrollo de software El Proceso Unificado de Desarrollo de Software 1 Fases principales del desarrollo de software Captura de requisitos:
 Introducción En los años 60 s y 70 s cuando se comenzaron a utilizar recursos de tecnología de información, no existía la computación personal, sino que en grandes centros de cómputo se realizaban todas
Introducción En los años 60 s y 70 s cuando se comenzaron a utilizar recursos de tecnología de información, no existía la computación personal, sino que en grandes centros de cómputo se realizaban todas
K2BIM Plan de Investigación - Comparación de herramientas para la parametrización asistida de ERP Versión 1.2
 K2BIM Plan de Investigación - Comparación de herramientas para la parametrización asistida de ERP Versión 1.2 Historia de revisiones Fecha VersiónDescripción Autor 08/10/2009 1.0 Creación del documento.
K2BIM Plan de Investigación - Comparación de herramientas para la parametrización asistida de ERP Versión 1.2 Historia de revisiones Fecha VersiónDescripción Autor 08/10/2009 1.0 Creación del documento.
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología
 Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
Ciclo de vida y Metodologías para el desarrollo de SW Definición de la metodología La metodología para el desarrollo de software es un modo sistemático de realizar, gestionar y administrar un proyecto
http://www.informatizate.net
 http://www.informatizate.net Metodologías De Desarrollo De Software María A. Mendoza Sanchez Ing. Informático - UNT Microsoft Certified Professional - MCP Analísta y Desarrolladora - TeamSoft Perú S.A.C.
http://www.informatizate.net Metodologías De Desarrollo De Software María A. Mendoza Sanchez Ing. Informático - UNT Microsoft Certified Professional - MCP Analísta y Desarrolladora - TeamSoft Perú S.A.C.
Gestión y Desarrollo de Requisitos en Proyectos Software
 Gestión y Desarrollo de Requisitos en Proyectos Software Ponente: María Jesús Anciano Martín Objetivo Objetivo Definir un conjunto articulado y bien balanceado de métodos para el flujo de trabajo de Ingeniería
Gestión y Desarrollo de Requisitos en Proyectos Software Ponente: María Jesús Anciano Martín Objetivo Objetivo Definir un conjunto articulado y bien balanceado de métodos para el flujo de trabajo de Ingeniería
Metodologías de diseño de hardware
 Capítulo 2 Metodologías de diseño de hardware Las metodologías de diseño de hardware denominadas Top-Down, basadas en la utilización de lenguajes de descripción de hardware, han posibilitado la reducción
Capítulo 2 Metodologías de diseño de hardware Las metodologías de diseño de hardware denominadas Top-Down, basadas en la utilización de lenguajes de descripción de hardware, han posibilitado la reducción
Diseño orientado al flujo de datos
 Diseño orientado al flujo de datos Recordemos que el diseño es una actividad que consta de una serie de pasos, en los que partiendo de la especificación del sistema (de los propios requerimientos), obtenemos
Diseño orientado al flujo de datos Recordemos que el diseño es una actividad que consta de una serie de pasos, en los que partiendo de la especificación del sistema (de los propios requerimientos), obtenemos
Unidad 1. Fundamentos en Gestión de Riesgos
 1.1 Gestión de Proyectos Unidad 1. Fundamentos en Gestión de Riesgos La gestión de proyectos es una disciplina con la cual se integran los procesos propios de la gerencia o administración de proyectos.
1.1 Gestión de Proyectos Unidad 1. Fundamentos en Gestión de Riesgos La gestión de proyectos es una disciplina con la cual se integran los procesos propios de la gerencia o administración de proyectos.
Ingeniería del Software I Clase de Testing Funcional 2do. Cuatrimestre de 2007
 Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
Enunciado Se desea efectuar el testing funcional de un programa que ejecuta transferencias entre cuentas bancarias. El programa recibe como parámetros la cuenta de origen, la de cuenta de destino y el
App para realizar consultas al Sistema de Información Estadística de Castilla y León
 App para realizar consultas al Sistema de Información Estadística de Castilla y León Jesús M. Rodríguez Rodríguez rodrodje@jcyl.es Dirección General de Presupuestos y Estadística Consejería de Hacienda
App para realizar consultas al Sistema de Información Estadística de Castilla y León Jesús M. Rodríguez Rodríguez rodrodje@jcyl.es Dirección General de Presupuestos y Estadística Consejería de Hacienda
PRODUCTIVIDAD DE PROYECTOS DE DESARROLLO DE SOFTWARE: FACTORES DETERMINANTES E INDICADORES
 PRODUCTIVIDAD DE PROYECTOS DE DESARROLLO DE SOFTWARE: FACTORES DETERMINANTES E INDICADORES Raúl Palma G. y Guillermo Bustos R. Escuela de Ingeniería Industrial Universidad Católica de Valparaíso Casilla
PRODUCTIVIDAD DE PROYECTOS DE DESARROLLO DE SOFTWARE: FACTORES DETERMINANTES E INDICADORES Raúl Palma G. y Guillermo Bustos R. Escuela de Ingeniería Industrial Universidad Católica de Valparaíso Casilla
INGENIERÍA DEL SOFTWARE
 INGENIERÍA DEL SOFTWARE Sesión No. 2 Nombre: Procesos de ingeniería del software INGENIERÍA DEL SOFTWARE 1 Contextualización La ingeniería de software actualmente es muy importante, pues con los avances
INGENIERÍA DEL SOFTWARE Sesión No. 2 Nombre: Procesos de ingeniería del software INGENIERÍA DEL SOFTWARE 1 Contextualización La ingeniería de software actualmente es muy importante, pues con los avances
1. INTRODUCCIÓN 1.1 INGENIERÍA
 1. INTRODUCCIÓN 1.1 INGENIERÍA Es difícil dar una explicación de ingeniería en pocas palabras, pues se puede decir que la ingeniería comenzó con el hombre mismo, pero se puede intentar dar un bosquejo
1. INTRODUCCIÓN 1.1 INGENIERÍA Es difícil dar una explicación de ingeniería en pocas palabras, pues se puede decir que la ingeniería comenzó con el hombre mismo, pero se puede intentar dar un bosquejo
Introducción. Metadatos
 Introducción La red crece por momentos las necesidades que parecían cubiertas hace relativamente poco tiempo empiezan a quedarse obsoletas. Deben buscarse nuevas soluciones que dinamicen los sistemas de
Introducción La red crece por momentos las necesidades que parecían cubiertas hace relativamente poco tiempo empiezan a quedarse obsoletas. Deben buscarse nuevas soluciones que dinamicen los sistemas de
CAPITULO III A. GENERALIDADES
 CAPITULO III INVESTIGACION DE CAMPO SOBRE EL DISEÑO DE UN SISTEMA AUTOMATIZADO DE CONTROL INVENTARIO Y EXPEDIENTES DE MENORES DE EDAD PARA EL CENTRO DE DESARROLLO INTEGRAL LA TIENDONA EN LA ZONA METROPOLITANA
CAPITULO III INVESTIGACION DE CAMPO SOBRE EL DISEÑO DE UN SISTEMA AUTOMATIZADO DE CONTROL INVENTARIO Y EXPEDIENTES DE MENORES DE EDAD PARA EL CENTRO DE DESARROLLO INTEGRAL LA TIENDONA EN LA ZONA METROPOLITANA
PRUEBAS DE SOFTWARE TECNICAS DE PRUEBA DE SOFTWARE
 PRUEBAS DE SOFTWARE La prueba del software es un elemento crítico para la garantía de la calidad del software. El objetivo de la etapa de pruebas es garantizar la calidad del producto desarrollado. Además,
PRUEBAS DE SOFTWARE La prueba del software es un elemento crítico para la garantía de la calidad del software. El objetivo de la etapa de pruebas es garantizar la calidad del producto desarrollado. Además,
Política de Seguridad y Salud Ocupacional. Recursos. Humanos. Abril 2006
 Endesa Chile Políticas de Índice 1. PRINCIPIOS 2. LINEAMIENTOS GENERALES 2.1 Organización 2.2 Identificación de Peligros y Evaluación de Riesgos 2.3 Planificación Preventiva 2.4 Control de la acción preventiva
Endesa Chile Políticas de Índice 1. PRINCIPIOS 2. LINEAMIENTOS GENERALES 2.1 Organización 2.2 Identificación de Peligros y Evaluación de Riesgos 2.3 Planificación Preventiva 2.4 Control de la acción preventiva
Alumna: Adriana Elizabeth Mendoza Martínez. Grupo: 303. P.S.P. Miriam De La Rosa Díaz. Carrera: PTB. en Informática 3er Semestre.
 Alumna: Adriana Elizabeth Mendoza Martínez. Grupo: 303. P.S.P. Miriam De La Rosa Díaz. Carrera: PTB. en Informática 3er Semestre. Tema: Sistemas Subtema: Base de Datos. Materia: Manejo de aplicaciones
Alumna: Adriana Elizabeth Mendoza Martínez. Grupo: 303. P.S.P. Miriam De La Rosa Díaz. Carrera: PTB. en Informática 3er Semestre. Tema: Sistemas Subtema: Base de Datos. Materia: Manejo de aplicaciones
SÍNTESIS Y PERSPECTIVAS
 SÍNTESIS Y PERSPECTIVAS Los invitamos a observar, a identificar problemas, pero al mismo tiempo a buscar oportunidades de mejoras en sus empresas. REVISIÓN DE CONCEPTOS. Esta es la última clase del curso.
SÍNTESIS Y PERSPECTIVAS Los invitamos a observar, a identificar problemas, pero al mismo tiempo a buscar oportunidades de mejoras en sus empresas. REVISIÓN DE CONCEPTOS. Esta es la última clase del curso.
Capítulo 4. Requisitos del modelo para la mejora de la calidad de código fuente
 Capítulo 4. Requisitos del modelo para la mejora de la calidad de código fuente En este capítulo definimos los requisitos del modelo para un sistema centrado en la mejora de la calidad del código fuente.
Capítulo 4. Requisitos del modelo para la mejora de la calidad de código fuente En este capítulo definimos los requisitos del modelo para un sistema centrado en la mejora de la calidad del código fuente.
Parte I: Introducción
 Parte I: Introducción Introducción al Data Mining: su Aplicación a la Empresa Cursada 2007 POR QUÉ? Las empresas de todos los tamaños necesitan aprender de sus datos para crear una relación one-to-one
Parte I: Introducción Introducción al Data Mining: su Aplicación a la Empresa Cursada 2007 POR QUÉ? Las empresas de todos los tamaños necesitan aprender de sus datos para crear una relación one-to-one
Fundamentos del diseño 3ª edición (2002)
") Unidades temáticas de Ingeniería del Software Fundamentos del diseño 3ª edición (2002) Facultad de Informática necesidad del diseño Las actividades de diseño afectan al éxito de la realización del software
Unidades temáticas de Ingeniería del Software Fundamentos del diseño 3ª edición (2002) Facultad de Informática necesidad del diseño Las actividades de diseño afectan al éxito de la realización del software
DATA MINING EN LA BASE DE DATOS DE LA OMS KNOWLEDGE DETECTION (DETECCIÓN DEL CONOCIMIENTO) Q.F.B. JUANA LETICIA RODRÍGUEZ Y BETANCOURT
 Q.F.B. JUANA LETICIA RODRÍGUEZ Y BETANCOURT") DATA MINING EN LA BASE DE DATOS DE LA OMS KNOWLEDGE DETECTION (DETECCIÓN DEL CONOCIMIENTO) Q.F.B. JUANA LETICIA RODRÍGUEZ Y BETANCOURT REACCIONES ADVERSAS DE LOS MEDICAMENTOS Los fármacos por naturaleza
DATA MINING EN LA BASE DE DATOS DE LA OMS KNOWLEDGE DETECTION (DETECCIÓN DEL CONOCIMIENTO) Q.F.B. JUANA LETICIA RODRÍGUEZ Y BETANCOURT REACCIONES ADVERSAS DE LOS MEDICAMENTOS Los fármacos por naturaleza
Plan de estudios Maestría en Sistemas de Información y Tecnologías de Gestión de Datos
 Plan de estudios Maestría en Sistemas de Información y Tecnologías de Gestión de Datos Antecedentes y Fundamentación Un Sistema de Información es un conjunto de componentes que interactúan entre sí, orientado
Plan de estudios Maestría en Sistemas de Información y Tecnologías de Gestión de Datos Antecedentes y Fundamentación Un Sistema de Información es un conjunto de componentes que interactúan entre sí, orientado
La Necesidad de Modelar. Diseño de Software Avanzado Departamento de Informática
 La Necesidad de Modelar Analogía Arquitectónica Tiene sentido poner ladrillos sin hacer antes los planos? El modelo, los planos, ayuda a afrontar la complejidad del proyecto. Cuál es el lenguaje adecuado
La Necesidad de Modelar Analogía Arquitectónica Tiene sentido poner ladrillos sin hacer antes los planos? El modelo, los planos, ayuda a afrontar la complejidad del proyecto. Cuál es el lenguaje adecuado
Decisión: Indican puntos en que se toman decisiones: sí o no, o se verifica una actividad del flujo grama.
 Diagrama de Flujo La presentación gráfica de un sistema es una forma ampliamente utilizada como herramienta de análisis, ya que permite identificar aspectos relevantes de una manera rápida y simple. El
Diagrama de Flujo La presentación gráfica de un sistema es una forma ampliamente utilizada como herramienta de análisis, ya que permite identificar aspectos relevantes de una manera rápida y simple. El
Equipos de medición. Intervalos de calibración e interpretación de Certificados de Calibración
 Equipos de medición. Intervalos de calibración e interpretación de Certificados de Calibración Equipos de Medición. Intervalos de calibración e interpretación de Certificados de Calibración Disertante:
Equipos de medición. Intervalos de calibración e interpretación de Certificados de Calibración Equipos de Medición. Intervalos de calibración e interpretación de Certificados de Calibración Disertante:
GUÍA TÉCNICA PARA LA DEFINICIÓN DE COMPROMISOS DE CALIDAD Y SUS INDICADORES
 GUÍA TÉCNICA PARA LA DEFINICIÓN DE COMPROMISOS DE CALIDAD Y SUS INDICADORES Tema: Cartas de Servicios Primera versión: 2008 Datos de contacto: Evaluación y Calidad. Gobierno de Navarra. evaluacionycalidad@navarra.es
GUÍA TÉCNICA PARA LA DEFINICIÓN DE COMPROMISOS DE CALIDAD Y SUS INDICADORES Tema: Cartas de Servicios Primera versión: 2008 Datos de contacto: Evaluación y Calidad. Gobierno de Navarra. evaluacionycalidad@navarra.es
5.4. Manual de usuario
 5.4. Manual de usuario En esta sección se procederá a explicar cada una de las posibles acciones que puede realizar un usuario, de forma que pueda utilizar todas las funcionalidades del simulador, sin
5.4. Manual de usuario En esta sección se procederá a explicar cada una de las posibles acciones que puede realizar un usuario, de forma que pueda utilizar todas las funcionalidades del simulador, sin
Actividades para mejoras. Actividades donde se evalúa constantemente todo el proceso del proyecto para evitar errores y eficientar los procesos.
 Apéndice C. Glosario A Actividades de coordinación entre grupos. Son dinámicas y canales de comunicación cuyo objetivo es facilitar el trabajo entre los distintos equipos del proyecto. Actividades integradas
Apéndice C. Glosario A Actividades de coordinación entre grupos. Son dinámicas y canales de comunicación cuyo objetivo es facilitar el trabajo entre los distintos equipos del proyecto. Actividades integradas
Estándares para planes de calidad de software. Escuela de Ingeniería de Sistemas y Computación Desarrollo de Software II Agosto Diciembre 2008
 Estándares para planes de calidad de software Escuela de Ingeniería de Sistemas y Computación Desarrollo de Software II Agosto Diciembre 2008 DIFERENCIA ENTRE PRODUCIR UNA FUNCION Y PRODUCIR UNA FUNCION
Estándares para planes de calidad de software Escuela de Ingeniería de Sistemas y Computación Desarrollo de Software II Agosto Diciembre 2008 DIFERENCIA ENTRE PRODUCIR UNA FUNCION Y PRODUCIR UNA FUNCION
SISTEMAS Y MANUALES DE LA CALIDAD
 SISTEMAS Y MANUALES DE LA CALIDAD NORMATIVAS SOBRE SISTEMAS DE CALIDAD Introducción La experiencia de algunos sectores industriales que por las características particulares de sus productos tenían necesidad
SISTEMAS Y MANUALES DE LA CALIDAD NORMATIVAS SOBRE SISTEMAS DE CALIDAD Introducción La experiencia de algunos sectores industriales que por las características particulares de sus productos tenían necesidad
PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación. II MODELOS y HERRAMIENTAS UML. II.2 UML: Modelado de casos de uso
 PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación II MODELOS y HERRAMIENTAS UML 1 1 Modelado de casos de uso (I) Un caso de uso es una técnica de modelado usada para describir lo que debería hacer
PROGRAMACIÓN ORIENTADA A OBJETOS Master de Computación II MODELOS y HERRAMIENTAS UML 1 1 Modelado de casos de uso (I) Un caso de uso es una técnica de modelado usada para describir lo que debería hacer
UNIDAD 2: Abstracción del Mundo real Al Paradigma Orientado a Objetos
 2.1. Principios básicos del Modelado de Objetos UNIDAD 2: Abstracción del Mundo real Al Paradigma Orientado a Objetos Hoy en día muchos de los procesos que intervienen en un negocio o empresa y que resuelven
2.1. Principios básicos del Modelado de Objetos UNIDAD 2: Abstracción del Mundo real Al Paradigma Orientado a Objetos Hoy en día muchos de los procesos que intervienen en un negocio o empresa y que resuelven
CAPÍTUL07 SISTEMAS DE FILOSOFÍA HÍBRIDA EN BIOMEDICINA. Alejandro Pazos, Nieves Pedreira, Ana B. Porto, María D. López-Seijo
 CAPÍTUL07 SISTEMAS DE FILOSOFÍA HÍBRIDA EN BIOMEDICINA Alejandro Pazos, Nieves Pedreira, Ana B. Porto, María D. López-Seijo Laboratorio de Redes de Neuronas Artificiales y Sistemas Adaptativos Universidade
CAPÍTUL07 SISTEMAS DE FILOSOFÍA HÍBRIDA EN BIOMEDICINA Alejandro Pazos, Nieves Pedreira, Ana B. Porto, María D. López-Seijo Laboratorio de Redes de Neuronas Artificiales y Sistemas Adaptativos Universidade
4 Pruebas y análisis del software
 4 Pruebas y análisis del software En este capítulo se presentan una serie de simulaciones donde se analiza el desempeño de ambos sistemas programados en cuanto a exactitud con otros softwares que se encuentran
4 Pruebas y análisis del software En este capítulo se presentan una serie de simulaciones donde se analiza el desempeño de ambos sistemas programados en cuanto a exactitud con otros softwares que se encuentran
GANTT, PERT y CPM. Figura 5.3: Carta GANTT 3.
 GANTT, PERT y CPM Características Conseguir una buena programación es un reto, no obstante es razonable y alcanzable. Ella debe tener el compromiso del equipo al completo, para lo cual se recomienda que
GANTT, PERT y CPM Características Conseguir una buena programación es un reto, no obstante es razonable y alcanzable. Ella debe tener el compromiso del equipo al completo, para lo cual se recomienda que
"Diseño, construcción e implementación de modelos matemáticos para el control automatizado de inventarios
 "Diseño, construcción e implementación de modelos matemáticos para el control automatizado de inventarios Miguel Alfonso Flores Sánchez 1, Fernando Sandoya Sanchez 2 Resumen En el presente artículo se
"Diseño, construcción e implementación de modelos matemáticos para el control automatizado de inventarios Miguel Alfonso Flores Sánchez 1, Fernando Sandoya Sanchez 2 Resumen En el presente artículo se
Propuesta Matriz de Actividades para un Ciclo de Vida de Explotación de Datos
 Propuesta Matriz de Actividades para un Ciclo de Vida de Explotación de Datos Britos, P. 1,2 ; Fernández, E. 2,1 ; García Martínez, R 1,2 1 Centro de Ingeniería del Software e Ingeniería del Conocimiento.
Propuesta Matriz de Actividades para un Ciclo de Vida de Explotación de Datos Britos, P. 1,2 ; Fernández, E. 2,1 ; García Martínez, R 1,2 1 Centro de Ingeniería del Software e Ingeniería del Conocimiento.
Modificación y parametrización del modulo de Solicitudes (Request) en el ERP/CRM Compiere.
 en el ERP/CRM Compiere.") UNIVERSIDAD DE CARABOBO FACULTAD DE CIENCIA Y TECNOLOGÍA DIRECCION DE EXTENSION COORDINACION DE PASANTIAS Modificación y parametrización del modulo de Solicitudes (Request) en el ERP/CRM Compiere. Pasante:
UNIVERSIDAD DE CARABOBO FACULTAD DE CIENCIA Y TECNOLOGÍA DIRECCION DE EXTENSION COORDINACION DE PASANTIAS Modificación y parametrización del modulo de Solicitudes (Request) en el ERP/CRM Compiere. Pasante:
Introducción. Ciclo de vida de los Sistemas de Información. Diseño Conceptual
 Introducción Algunas de las personas que trabajan con SGBD relacionales parecen preguntarse porqué deberían preocuparse del diseño de las bases de datos que utilizan. Después de todo, la mayoría de los
Introducción Algunas de las personas que trabajan con SGBD relacionales parecen preguntarse porqué deberían preocuparse del diseño de las bases de datos que utilizan. Después de todo, la mayoría de los
PROCESOS SOFTWARE. Según esta estrategia, todo proceso debe planificarse, implantarse y evaluarse, para luego actuar sobre él.
 PROCESOS SOFTWARE MOTIVACIÓN? Con independencia de la metodología o modelo implementado, es común la estrategia para la mejora continua de la calidad, basada en el Círculo de Deming o Plan, Do, Check,
PROCESOS SOFTWARE MOTIVACIÓN? Con independencia de la metodología o modelo implementado, es común la estrategia para la mejora continua de la calidad, basada en el Círculo de Deming o Plan, Do, Check,
TECNÓLOGO EN INFORMÁTICA PLAN DE ESTUDIOS
 Administración Nacional de Universidad de la República Educación Pública Facultad de Ingenieria CF Res..0.07 Consejo Directivo Central Consejo Directivo Central Res..05.07 Res. 17.0.07 TECNÓLOGO EN INFORMÁTICA
Administración Nacional de Universidad de la República Educación Pública Facultad de Ingenieria CF Res..0.07 Consejo Directivo Central Consejo Directivo Central Res..05.07 Res. 17.0.07 TECNÓLOGO EN INFORMÁTICA
Capítulo 5: METODOLOGÍA APLICABLE A LAS NORMAS NE AI
 Capítulo 5: METODOLOGÍA APLICABLE A LAS NORMAS NE AI La segunda fase del NIPE corresponde con la adecuación de las intervenciones de enfermería del sistema de clasificación N.I.C. (Nursing Intervention
Capítulo 5: METODOLOGÍA APLICABLE A LAS NORMAS NE AI La segunda fase del NIPE corresponde con la adecuación de las intervenciones de enfermería del sistema de clasificación N.I.C. (Nursing Intervention
Realización de Auditoría en Sistemas Informáticos. Auditoría Informática
 Realización de Auditoría en Sistemas Informáticos Auditoría Informática Índice Introducción Definiciones Objetivos Antecedentes Etapas Ejemplo Práctico Conclusiones Introducción Actualmente, las empresas
Realización de Auditoría en Sistemas Informáticos Auditoría Informática Índice Introducción Definiciones Objetivos Antecedentes Etapas Ejemplo Práctico Conclusiones Introducción Actualmente, las empresas
Centro de Investigación y Desarrollo en Ingeniería en Sistemas de Información (CIDISI)
") Centro de Investigación y Desarrollo en Ingeniería en Sistemas de Información (CIDISI) OFERTAS TECNOLÓGICAS 1) GESTIÓN ORGANIZACIONAL Y LOGÍSTICA INTEGRADA: TÉCNICAS Y SISTEMAS DE INFORMACIÓN 2) GESTIÓN
Centro de Investigación y Desarrollo en Ingeniería en Sistemas de Información (CIDISI) OFERTAS TECNOLÓGICAS 1) GESTIÓN ORGANIZACIONAL Y LOGÍSTICA INTEGRADA: TÉCNICAS Y SISTEMAS DE INFORMACIÓN 2) GESTIÓN
Escenarios. Diapositiva 1. Ingeniería de Requerimientos: Escenarios
 Escenarios Diapositiva 1. Ingeniería de Requerimientos: Escenarios Diapositiva 2. Uso de lenguaje natural Debido a que uno de los objetivos de la Ingeniería de Requisitos es aumentar el conocimiento del
Escenarios Diapositiva 1. Ingeniería de Requerimientos: Escenarios Diapositiva 2. Uso de lenguaje natural Debido a que uno de los objetivos de la Ingeniería de Requisitos es aumentar el conocimiento del
Instalación de Sistemas de Automatización y Datos
 UNIVERSIDADE DE VIGO E. T. S. Ingenieros Industriales 5º Curso Orientación Instalaciones y Construcción Instalación de Sistemas de Automatización y Datos José Ignacio Armesto Quiroga http://www www.disa.uvigo.es/
UNIVERSIDADE DE VIGO E. T. S. Ingenieros Industriales 5º Curso Orientación Instalaciones y Construcción Instalación de Sistemas de Automatización y Datos José Ignacio Armesto Quiroga http://www www.disa.uvigo.es/
Jornada informativa Nueva ISO 9001:2008
 Jornada informativa Nueva www.agedum.com www.promalagaqualifica.es 1.1 Generalidades 1.2 Aplicación Nuevo en Modificado en No aparece en a) necesita demostrar su capacidad para proporcionar regularmente
Jornada informativa Nueva www.agedum.com www.promalagaqualifica.es 1.1 Generalidades 1.2 Aplicación Nuevo en Modificado en No aparece en a) necesita demostrar su capacidad para proporcionar regularmente
Sistemas de Gestión de Calidad. Control documental
 4 Sistemas de Gestión de Calidad. Control documental ÍNDICE: 4.1 Requisitos Generales 4.2 Requisitos de la documentación 4.2.1 Generalidades 4.2.2 Manual de la Calidad 4.2.3 Control de los documentos 4.2.4
4 Sistemas de Gestión de Calidad. Control documental ÍNDICE: 4.1 Requisitos Generales 4.2 Requisitos de la documentación 4.2.1 Generalidades 4.2.2 Manual de la Calidad 4.2.3 Control de los documentos 4.2.4
PONENCIA: PLAN DE AUTOPROTECCIÓN Y SIMULACROS DE EMERGENCIA
 PONENCIA: PLAN DE AUTOPROTECCIÓN Y SIMULACROS DE EMERGENCIA Luis Carmena Servert Fundación Fuego para la Seguridad contra Incendios y Emergencias Lisboa, 3-28008 Madrid Tel.: 91 323 97 28 - www.fundacionfuego.org
PONENCIA: PLAN DE AUTOPROTECCIÓN Y SIMULACROS DE EMERGENCIA Luis Carmena Servert Fundación Fuego para la Seguridad contra Incendios y Emergencias Lisboa, 3-28008 Madrid Tel.: 91 323 97 28 - www.fundacionfuego.org
Proceso Unificado de Rational PROCESO UNIFICADO DE RATIONAL (RUP) El proceso de desarrollo de software tiene cuatro roles importantes:
 El proceso de desarrollo de software tiene cuatro roles importantes:") PROCESO UNIFICADO DE RATIONAL (RUP) El proceso de desarrollo de software tiene cuatro roles importantes: 1. Proporcionar una guía de actividades para el trabajo en equipo. (Guía detallada para el desarrollo
PROCESO UNIFICADO DE RATIONAL (RUP) El proceso de desarrollo de software tiene cuatro roles importantes: 1. Proporcionar una guía de actividades para el trabajo en equipo. (Guía detallada para el desarrollo
Aproximación local. Plano tangente. Derivadas parciales.
 Univ. de Alcalá de Henares Ingeniería de Telecomunicación Cálculo. Segundo parcial. Curso 004-005 Aproximación local. Plano tangente. Derivadas parciales. 1. Plano tangente 1.1. El problema de la aproximación
Univ. de Alcalá de Henares Ingeniería de Telecomunicación Cálculo. Segundo parcial. Curso 004-005 Aproximación local. Plano tangente. Derivadas parciales. 1. Plano tangente 1.1. El problema de la aproximación
Diseño orientado a los objetos
 Diseño orientado a los objetos El Diseño Orientado a los Objetos (DOO) crea una representación del problema del mundo real y la hace corresponder con el ámbito de la solución, que es el software. A diferencia
Diseño orientado a los objetos El Diseño Orientado a los Objetos (DOO) crea una representación del problema del mundo real y la hace corresponder con el ámbito de la solución, que es el software. A diferencia
CICLO DE VIDA DEL SOFTWARE
 CICLO DE VIDA DEL SOFTWARE 1. Concepto de Ciclo de Vida 2. Procesos del Ciclo de Vida del Software 3. Modelo en cascada 4. Modelo incremental 5. Modelo en espiral 6. Prototipado 7. La reutilización en
CICLO DE VIDA DEL SOFTWARE 1. Concepto de Ciclo de Vida 2. Procesos del Ciclo de Vida del Software 3. Modelo en cascada 4. Modelo incremental 5. Modelo en espiral 6. Prototipado 7. La reutilización en
Gestión de la Configuración
 Gestión de la ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 1 ESTUDIO DE VIABILIDAD DEL SISTEMA... 2 ACTIVIDAD EVS-GC 1: DEFINICIÓN DE LOS REQUISITOS DE GESTIÓN DE CONFIGURACIÓN... 2 Tarea EVS-GC 1.1: Definición de
Gestión de la ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 1 ESTUDIO DE VIABILIDAD DEL SISTEMA... 2 ACTIVIDAD EVS-GC 1: DEFINICIÓN DE LOS REQUISITOS DE GESTIÓN DE CONFIGURACIÓN... 2 Tarea EVS-GC 1.1: Definición de
Universidad acional Experimental Del Táchira Decanato de Docencia Departamento de Ingeniería en Informática
 Universidad acional Experimental Del Táchira Decanato de Docencia Departamento de Ingeniería en Informática Metodología Evolutiva Incremental Mediante Prototipo y Técnicas Orientada a Objeto (MEI/P-OO)
Universidad acional Experimental Del Táchira Decanato de Docencia Departamento de Ingeniería en Informática Metodología Evolutiva Incremental Mediante Prototipo y Técnicas Orientada a Objeto (MEI/P-OO)
Usos de los Mapas Conceptuales en Educación
 Usos de los Mapas Conceptuales en Educación Carmen M. Collado & Alberto J. Cañas Introducción Los mapas conceptuales son una poderosa herramienta de enseñanza-aprendizaje. Su utilización en (y fuera de)
Usos de los Mapas Conceptuales en Educación Carmen M. Collado & Alberto J. Cañas Introducción Los mapas conceptuales son una poderosa herramienta de enseñanza-aprendizaje. Su utilización en (y fuera de)
activuspaper Text Mining and BI Abstract
 Text Mining and BI Abstract Los recientes avances en lingüística computacional, así como la tecnología de la información en general, permiten que la inserción de datos no estructurados en una infraestructura
Text Mining and BI Abstract Los recientes avances en lingüística computacional, así como la tecnología de la información en general, permiten que la inserción de datos no estructurados en una infraestructura
PROPUESTA METODOLOGICA PARA LA EDUCCIÓN DE REQUISITOS EN PROYECTOS DE EXPLOTACIÓN DE INFORMACIÓN
 PROPUESTA METODOLOGICA PARA LA EDUCCIÓN DE REQUISITOS EN PROYECTOS DE EXPLOTACIÓN DE INFORMACIÓN Paola Britos 1,2, Enrique Fernandez 1,2, Ramón García-Martinez 1,2 Centro de Ingeniería del Software e Ingeniería
PROPUESTA METODOLOGICA PARA LA EDUCCIÓN DE REQUISITOS EN PROYECTOS DE EXPLOTACIÓN DE INFORMACIÓN Paola Britos 1,2, Enrique Fernandez 1,2, Ramón García-Martinez 1,2 Centro de Ingeniería del Software e Ingeniería
Experiencias de la Televisión Digital Interactiva en Colombia - ARTICA
 Experiencias de la Televisión Digital Interactiva en Colombia - ARTICA JUAN CARLOS MONTOYA Departamento de Ingeniería de Sistemas, Universidad EAFIT - Centro de Excelencia en ETI - ARTICA Medellín, Colombia
Experiencias de la Televisión Digital Interactiva en Colombia - ARTICA JUAN CARLOS MONTOYA Departamento de Ingeniería de Sistemas, Universidad EAFIT - Centro de Excelencia en ETI - ARTICA Medellín, Colombia
La explicación la haré con un ejemplo de cobro por $100.00 más el I.V.A. $16.00
 La mayor parte de las dependencias no habían manejado el IVA en los recibos oficiales, que era el documento de facturación de nuestra Universidad, actualmente ya es formalmente un CFD pero para el fin
La mayor parte de las dependencias no habían manejado el IVA en los recibos oficiales, que era el documento de facturación de nuestra Universidad, actualmente ya es formalmente un CFD pero para el fin
LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN
 LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN Tabla de Contenidos LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN... 1 Tabla de Contenidos... 1 General... 2 Uso de los Lineamientos Estándares...
LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN Tabla de Contenidos LINEAMIENTOS ESTÁNDARES APLICATIVOS DE VIRTUALIZACIÓN... 1 Tabla de Contenidos... 1 General... 2 Uso de los Lineamientos Estándares...
Administración del conocimiento y aprendizaje organizacional.
 Capítulo 2 Administración del conocimiento y aprendizaje organizacional. 2.1 La Importancia Del Aprendizaje En Las Organizaciones El aprendizaje ha sido una de las grandes necesidades básicas del ser humano,
Capítulo 2 Administración del conocimiento y aprendizaje organizacional. 2.1 La Importancia Del Aprendizaje En Las Organizaciones El aprendizaje ha sido una de las grandes necesidades básicas del ser humano,
<Generador de exámenes> Visión preliminar
 1. Introducción Proyecto Final del curso Técnicas de Producción de Sistemas Visión preliminar Para la evaluación de algunos temas de las materias que se imparten en diferentes niveles,
1. Introducción Proyecto Final del curso Técnicas de Producción de Sistemas Visión preliminar Para la evaluación de algunos temas de las materias que se imparten en diferentes niveles,
Procesos Críticos en el Desarrollo de Software
 Metodología Procesos Críticos en el Desarrollo de Software Pablo Straub AgileShift Imagine una organización de desarrollo de software que consistentemente cumple los compromisos con sus clientes. Imagine
Metodología Procesos Críticos en el Desarrollo de Software Pablo Straub AgileShift Imagine una organización de desarrollo de software que consistentemente cumple los compromisos con sus clientes. Imagine
Educación y capacitación virtual, algo más que una moda
 Éxito Empresarial Publicación No.12 marzo 2004 Educación y capacitación virtual, algo más que una moda I Introducción Últimamente se ha escuchado la posibilidad de realizar nuestra educación formal y capacitación
Éxito Empresarial Publicación No.12 marzo 2004 Educación y capacitación virtual, algo más que una moda I Introducción Últimamente se ha escuchado la posibilidad de realizar nuestra educación formal y capacitación
Cómo organizar un Plan de Emergencias
 Cómo organizar un Plan de Emergencias Las emergencias pueden aparecer en cualquier momento, situaciones que ponen en jaque la integridad de las personas y los bienes de una empresa. Este artículo presenta
Cómo organizar un Plan de Emergencias Las emergencias pueden aparecer en cualquier momento, situaciones que ponen en jaque la integridad de las personas y los bienes de una empresa. Este artículo presenta
INFORME DE ANÁLISIS DE ENCUESTAS DE SATISFACCIÓN DE USUARIOS PERÍODO 2009-2010
 INFORME DE ANÁLISIS DE ENCUESTAS DE SATISFACCIÓN DE USUARIOS PERÍODO 2009-2010 UNIDAD FUNCIONAL DE TÉCNICOS DE LABORATORIOS DOCENTES UNIVERSIDAD PABLO DE OLAVIDE. SEVILLA Sevilla, Diciembre de 2010 1 1.
INFORME DE ANÁLISIS DE ENCUESTAS DE SATISFACCIÓN DE USUARIOS PERÍODO 2009-2010 UNIDAD FUNCIONAL DE TÉCNICOS DE LABORATORIOS DOCENTES UNIVERSIDAD PABLO DE OLAVIDE. SEVILLA Sevilla, Diciembre de 2010 1 1.
Adaptación al NPGC. Introducción. NPGC.doc. Qué cambios hay en el NPGC? Telf.: 93.410.92.92 Fax.: 93.419.86.49 e-mail:atcliente@websie.
 Adaptación al NPGC Introducción Nexus 620, ya recoge el Nuevo Plan General Contable, que entrará en vigor el 1 de Enero de 2008. Este documento mostrará que debemos hacer a partir de esa fecha, según nuestra
Adaptación al NPGC Introducción Nexus 620, ya recoge el Nuevo Plan General Contable, que entrará en vigor el 1 de Enero de 2008. Este documento mostrará que debemos hacer a partir de esa fecha, según nuestra
Capítulo IV. Manejo de Problemas
 Manejo de Problemas Manejo de problemas Tabla de contenido 1.- En qué consiste el manejo de problemas?...57 1.1.- Ventajas...58 1.2.- Barreras...59 2.- Actividades...59 2.1.- Control de problemas...60
Manejo de Problemas Manejo de problemas Tabla de contenido 1.- En qué consiste el manejo de problemas?...57 1.1.- Ventajas...58 1.2.- Barreras...59 2.- Actividades...59 2.1.- Control de problemas...60
Trabajo lean (1): A que podemos llamar trabajo lean?
: A que podemos llamar trabajo lean?") Trabajo lean (1): A que podemos llamar trabajo lean? Jordi Olivella Nadal Director de Comunicación del Instituto Lean Management Este escrito inicia una serie de artículos sobre la organización en trabajo
Trabajo lean (1): A que podemos llamar trabajo lean? Jordi Olivella Nadal Director de Comunicación del Instituto Lean Management Este escrito inicia una serie de artículos sobre la organización en trabajo
Hacer Realidad BPM en su Organización ADOPTAR BPM A PARTIR DE UN PROYECTO O NECESIDAD DE AUTOMATIZACIÓN
 ADOPTAR BPM A PARTIR DE UN PROYECTO O NECESIDAD DE AUTOMATIZACIÓN OBJETIVOS GENERALES 1. Identificar, diseñar, automatizar y habilitar la mejora continua de los procesos relacionados a la necesidad o proyecto
ADOPTAR BPM A PARTIR DE UN PROYECTO O NECESIDAD DE AUTOMATIZACIÓN OBJETIVOS GENERALES 1. Identificar, diseñar, automatizar y habilitar la mejora continua de los procesos relacionados a la necesidad o proyecto
INSTRODUCCION. Toda organización puede mejorar su manera de trabajar, lo cual significa un
 INSTRODUCCION Toda organización puede mejorar su manera de trabajar, lo cual significa un incremento de sus clientes y gestionar el riesgo de la mejor manera posible, reduciendo costes y mejorando la calidad
INSTRODUCCION Toda organización puede mejorar su manera de trabajar, lo cual significa un incremento de sus clientes y gestionar el riesgo de la mejor manera posible, reduciendo costes y mejorando la calidad
Guía de los cursos. Equipo docente:
 Guía de los cursos Equipo docente: Dra. Bertha Patricia Legorreta Cortés Dr. Eduardo Habacúc López Acevedo Introducción Las organizaciones internacionales, las administraciones públicas y privadas así
Guía de los cursos Equipo docente: Dra. Bertha Patricia Legorreta Cortés Dr. Eduardo Habacúc López Acevedo Introducción Las organizaciones internacionales, las administraciones públicas y privadas así
Ventajas del software del SIGOB para las instituciones
 Ventajas del software del SIGOB para las instituciones Podemos afirmar que además de la metodología y los enfoques de trabajo que provee el proyecto, el software, eenn ssi i mi issmoo, resulta un gran
Ventajas del software del SIGOB para las instituciones Podemos afirmar que además de la metodología y los enfoques de trabajo que provee el proyecto, el software, eenn ssi i mi issmoo, resulta un gran
4.4.1 Servicio de Prevención Propio.
 1 Si se trata de una empresa entre 250 y 500 trabajadores que desarrolla actividades incluidas en el Anexo I del Reglamento de los Servicios de Prevención, o de una empresa de más de 500 trabajadores con
1 Si se trata de una empresa entre 250 y 500 trabajadores que desarrolla actividades incluidas en el Anexo I del Reglamento de los Servicios de Prevención, o de una empresa de más de 500 trabajadores con
CAPITULO 4 FLUIDIZACIÓN EMPLEANDO VAPOR SOBRECALENTADO. Potter [10], ha demostrado en una planta piloto que materiales sensibles a la
![CAPITULO 4 FLUIDIZACIÓN EMPLEANDO VAPOR SOBRECALENTADO. Potter [10], ha demostrado en una planta piloto que materiales sensibles a la](/thumbs/26/7800050.jpg "CAPITULO 4 FLUIDIZACIÓN EMPLEANDO VAPOR SOBRECALENTADO. Potter [10], ha demostrado en una planta piloto que materiales sensibles a la") 34 CAPITULO 4 FLUIDIZACIÓN EMPLEANDO VAPOR SOBRECALENTADO 4.1 Lecho fluidizado con vapor sobrecalentado Potter [10], ha demostrado en una planta piloto que materiales sensibles a la temperatura pueden
34 CAPITULO 4 FLUIDIZACIÓN EMPLEANDO VAPOR SOBRECALENTADO 4.1 Lecho fluidizado con vapor sobrecalentado Potter [10], ha demostrado en una planta piloto que materiales sensibles a la temperatura pueden
ITBA - UPM MAGISTER EN INGENIERIA DEL SOFTWARE ANTEPROYECTO DE TESIS
 ITBA - UPM MAGISTER EN INGENIERIA DEL SOFTWARE ANTEPROYECTO DE TESIS TÍTULO: TEMA: Sistema generador del mapa de actividades de un proyecto de desarrollo de software. Sistema basado en conocimientos para
ITBA - UPM MAGISTER EN INGENIERIA DEL SOFTWARE ANTEPROYECTO DE TESIS TÍTULO: TEMA: Sistema generador del mapa de actividades de un proyecto de desarrollo de software. Sistema basado en conocimientos para
MANUAL DE USUARIO APLICACIÓN SYSACTIVOS
 MANUAL DE USUARIO APLICACIÓN SYSACTIVOS Autor Edwar Orlando Amaya Diaz Analista de Desarrollo y Soporte Produce Sistemas y Soluciones Integradas S.A.S Versión 1.0 Fecha de Publicación 19 Diciembre 2014
MANUAL DE USUARIO APLICACIÓN SYSACTIVOS Autor Edwar Orlando Amaya Diaz Analista de Desarrollo y Soporte Produce Sistemas y Soluciones Integradas S.A.S Versión 1.0 Fecha de Publicación 19 Diciembre 2014
Mantenimiento de Sistemas de Información
 de Sistemas de Información ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 1 ACTIVIDAD MSI 1: REGISTRO DE LA PETICIÓN...4 Tarea MSI 1.1: Registro de la Petición... 4 Tarea MSI 1.2: Asignación de la Petición... 5 ACTIVIDAD
de Sistemas de Información ÍNDICE DESCRIPCIÓN Y OBJETIVOS... 1 ACTIVIDAD MSI 1: REGISTRO DE LA PETICIÓN...4 Tarea MSI 1.1: Registro de la Petición... 4 Tarea MSI 1.2: Asignación de la Petición... 5 ACTIVIDAD
Test de Idioma Francés. Manual del evaluador
 Test de Idioma Francés Manual del evaluador 1 CONTENIDO Introducción Qué mide el Test de idioma francés? Qué obtienen el examinado y el examinador? Descripción de los factores Propiedades psicométricas
Test de Idioma Francés Manual del evaluador 1 CONTENIDO Introducción Qué mide el Test de idioma francés? Qué obtienen el examinado y el examinador? Descripción de los factores Propiedades psicométricas
Anteproyecto Fin de Carrera
 Universidad de Castilla-La Mancha Escuela Superior de Informática Anteproyecto Fin de Carrera DIMITRI (Desarrollo e Implantación de Metodologías y Tecnologías de Testing) Dirige: Macario Polo Usaola Presenta:
Universidad de Castilla-La Mancha Escuela Superior de Informática Anteproyecto Fin de Carrera DIMITRI (Desarrollo e Implantación de Metodologías y Tecnologías de Testing) Dirige: Macario Polo Usaola Presenta:
Resumen de la solución SAP SAP Technology SAP Afaria. Gestión de la movilidad empresarial para mayor ventaja competitiva
 de la solución SAP SAP Technology SAP Afaria Gestión de la movilidad empresarial para mayor ventaja competitiva Simplificar la gestión de dispositivos y aplicaciones Simplificar la gestión de dispositivos
de la solución SAP SAP Technology SAP Afaria Gestión de la movilidad empresarial para mayor ventaja competitiva Simplificar la gestión de dispositivos y aplicaciones Simplificar la gestión de dispositivos
Observatorio Bancario
 México Observatorio Bancario 2 junio Fuentes de Financiamiento de las Empresas Encuesta Trimestral de Banco de México Fco. Javier Morales E. fj.morales@bbva.bancomer.com La Encuesta Trimestral de Fuentes
México Observatorio Bancario 2 junio Fuentes de Financiamiento de las Empresas Encuesta Trimestral de Banco de México Fco. Javier Morales E. fj.morales@bbva.bancomer.com La Encuesta Trimestral de Fuentes
+ Cómo ahorrar dinero con Software Quality
 + Cómo ahorrar dinero con Software Quality Qué es Software Quality Assurance? Porqué facilita el ahorro de dinero? Introducción El objetivo de este documento es explicar qué es Software Quality Assurance,
+ Cómo ahorrar dinero con Software Quality Qué es Software Quality Assurance? Porqué facilita el ahorro de dinero? Introducción El objetivo de este documento es explicar qué es Software Quality Assurance,
Maxpho Commerce 11. Gestión CSV. Fecha: 20 Septiembre 2011 Versión : 1.1 Autor: Maxpho Ltd
 Maxpho Commerce 11 Gestión CSV Fecha: 20 Septiembre 2011 Versión : 1.1 Autor: Maxpho Ltd Índice general 1 - Introducción... 3 1.1 - El archivo CSV... 3 1.2 - Módulo CSV en Maxpho... 3 1.3 - Módulo CSV
Maxpho Commerce 11 Gestión CSV Fecha: 20 Septiembre 2011 Versión : 1.1 Autor: Maxpho Ltd Índice general 1 - Introducción... 3 1.1 - El archivo CSV... 3 1.2 - Módulo CSV en Maxpho... 3 1.3 - Módulo CSV
Integración de la prevención de riesgos laborales
 Carlos Muñoz Ruiz Técnico de Prevención. INSL Junio 2012 39 Integración de la prevención de riesgos laborales Base legal y conceptos básicos Ley 31/1995, de Prevención de Riesgos Laborales: Artículo 14.
Carlos Muñoz Ruiz Técnico de Prevención. INSL Junio 2012 39 Integración de la prevención de riesgos laborales Base legal y conceptos básicos Ley 31/1995, de Prevención de Riesgos Laborales: Artículo 14.
El Cliente y El Ingeniero de Software
 El Cliente y El Ingeniero de Software Juan Sebastián López Restrepo Abstract. The continuing evolution of technologies have made the software technology used more and more increasing, this trend has created
El Cliente y El Ingeniero de Software Juan Sebastián López Restrepo Abstract. The continuing evolution of technologies have made the software technology used more and more increasing, this trend has created
E-learning: E-learning:
 E-learning: E-learning: capacitar capacitar a a su su equipo equipo con con menos menos tiempo tiempo y y 1 E-learning: capacitar a su equipo con menos tiempo y Si bien, no todas las empresas cuentan con
E-learning: E-learning: capacitar capacitar a a su su equipo equipo con con menos menos tiempo tiempo y y 1 E-learning: capacitar a su equipo con menos tiempo y Si bien, no todas las empresas cuentan con
Funcionalidades Software PROYECTOS GotelGest.Net Software para la gestión de Proyectos GotelGest.Net
 2012 Funcionalidades Software PROYECTOS GotelGest.Net Software para la gestión de Proyectos GotelGest.Net Servinet Sistemas y Comunicación S.L. www.softwaregestionproyectos.com Última Revisión: Febrero
2012 Funcionalidades Software PROYECTOS GotelGest.Net Software para la gestión de Proyectos GotelGest.Net Servinet Sistemas y Comunicación S.L. www.softwaregestionproyectos.com Última Revisión: Febrero
El objetivo principal del presente curso es proporcionar a sus alumnos los conocimientos y las herramientas básicas para la gestión de proyectos.
 Gestión de proyectos Duración: 45 horas Objetivos: El objetivo principal del presente curso es proporcionar a sus alumnos los conocimientos y las herramientas básicas para la gestión de proyectos. Contenidos:
Gestión de proyectos Duración: 45 horas Objetivos: El objetivo principal del presente curso es proporcionar a sus alumnos los conocimientos y las herramientas básicas para la gestión de proyectos. Contenidos:
Gestión de proyectos
 Gestión de proyectos Horas: 45 El objetivo principal del presente curso es proporcionar a sus alumnos los conocimientos y las herramientas básicas para la gestión de proyectos. Gestión de proyectos El
Gestión de proyectos Horas: 45 El objetivo principal del presente curso es proporcionar a sus alumnos los conocimientos y las herramientas básicas para la gestión de proyectos. Gestión de proyectos El